Embed Size (px)
Citation preview

DAMA Day NYCApril 19, 2016
Innovations in Data Governance, Architecture and Analytics
Robert Quinn

q Introductionq Big Data definedq Context of Big Data ‘Hype Cycle’q Challenges – created by Big Dataq Opportunities – introduced by Big Data solutionsq Case studiesq Conclusions
What are we covering

tl;dr
q Graphsq Streamingq Schema on Read
Ø DGØ DQØ Analysis
q Cognitive Computing

Big Data – Common Definition
q The 3 VsØ Volume - amount of dataØ Velocity - speed of data in and outØ Variety - range of data types and sources
“Big Data” is about the capacity to aggregate, cross-reference, utilize and manage complexity.
Variety is the primary ‘complicator’ for business’s facing big data challenges.

Big Data – ‘Original’ Definition
A cultural, technological, and scholarly phenomenon that rests on the interplay of:
q Technology: maximizing computation power and algorithmic accuracy to gather, analyze, link, and compare large and diverse data sets.
q Analysis: drawing on large data sets to identify patterns in order to make economic, social, technical, and legal claims.
q Mythology: the widespread belief that large data sets offer a higher form of intelligence and knowledge that can generate insights that were previously impossible, with the aura of truth, objectivity, and accuracy.
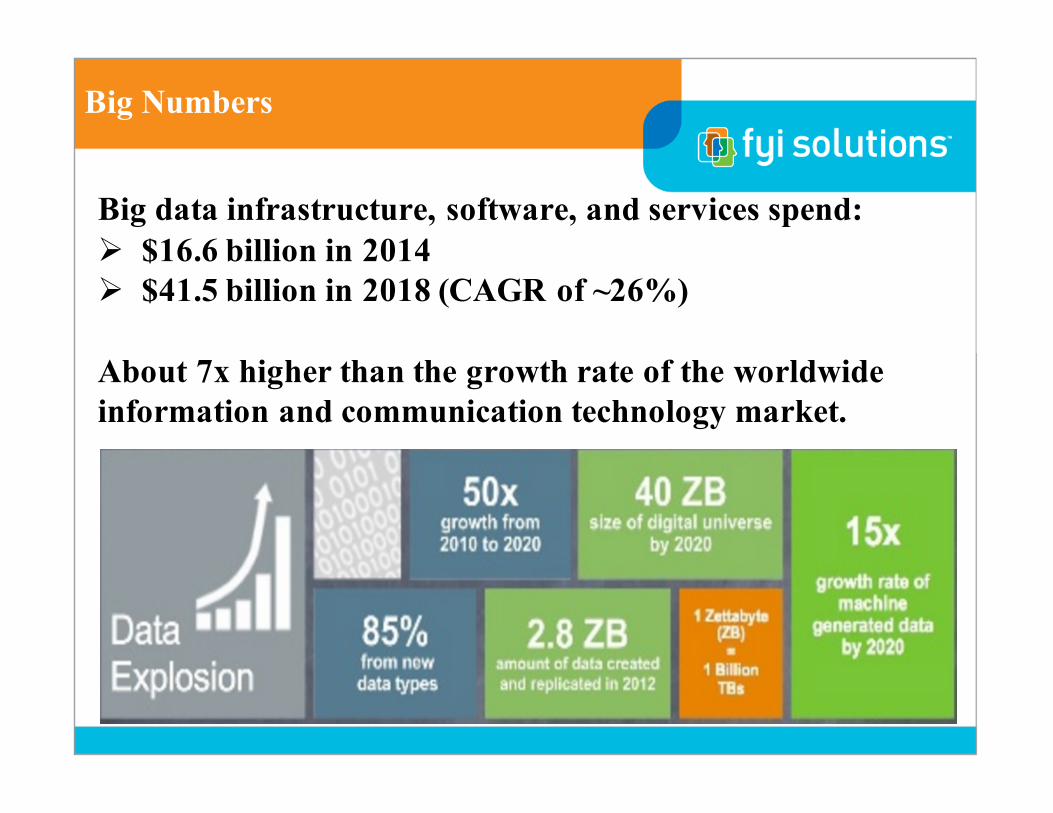
Big Numbers
Big data infrastructure, software, and services spend:Ø $16.6 billion in 2014Ø $41.5 billion in 2018 (CAGR of ~26%)
About 7x higher than the growth rate of the worldwide information and communication technology market.
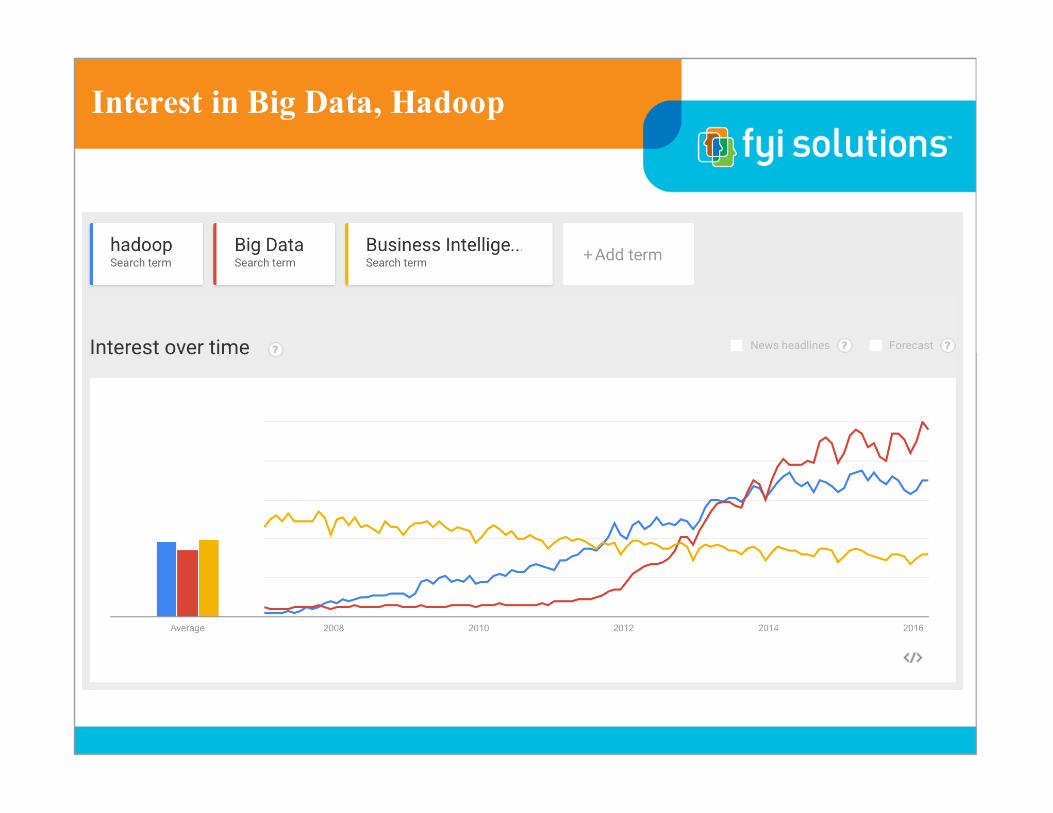
Interest in Big Data, Hadoop
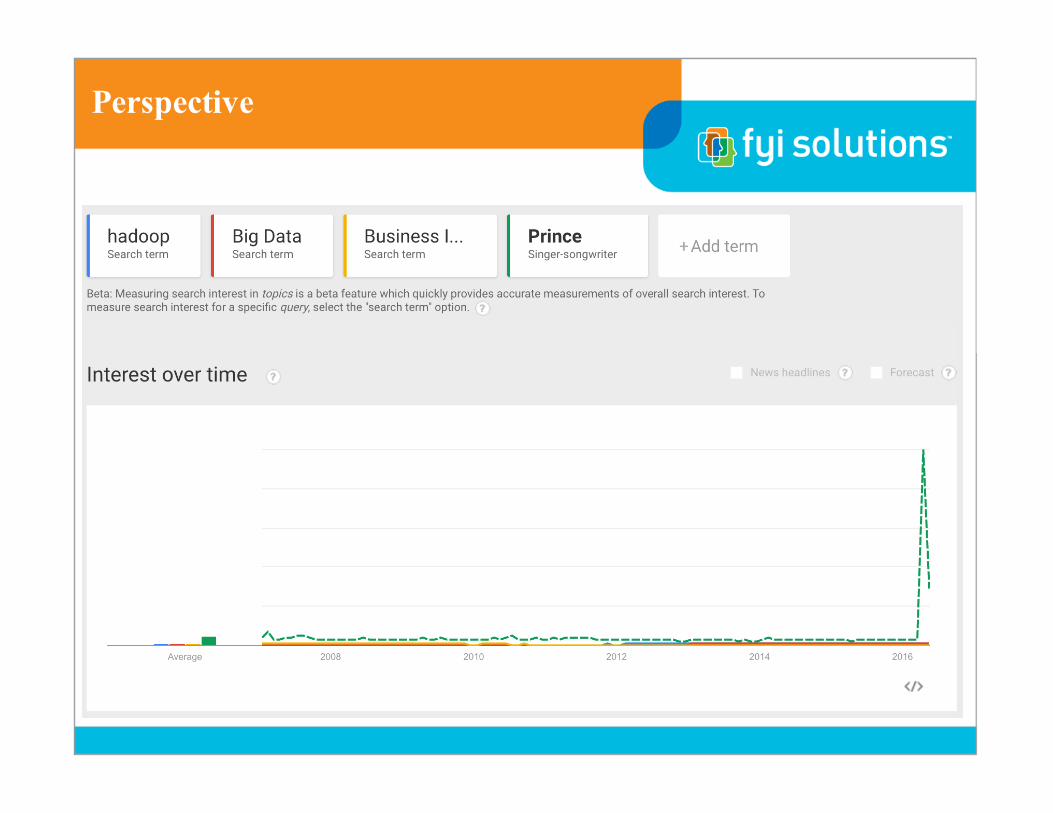
Perspective

Context
What else is happening in parallel to the Big Data craze:q Open Data Movement and Data Monetizationq Cloud Computing, Open Source, Software as a Serviceq Increased Risk awareness (Global Financial crisis)q Security, Data breachesq Ubiquitous Broad-bandq Advances in Machine Learning and AI

Challenges to existing DM approach
q Relational database management systems and desktop statistics and visualization packages often have difficulty handling big data.
q IT, DG, DQ "paradigms" have difficulty coping Ø Enterprise Data Warehouses - struggle with varietyØ ETL based architectures "limitations" have become
more widely understoodØ Centralized DG and DQ - struggle with velocity
and variety

Challenges - continued
q Existing User Tools/ApproachesØ Desktop Solution (i.e. Excel) - struggle with volumeØ Manual data cleanse - struggle with volume and varietyØ High risk of data loss
q Availability of capable/experienced resourcesq Technical solutions have shorter and shorter half lives q Project Funding (Dev -> Test -> Production model)
Ø Analytics is by nature often throw-away, experiments

Opportunities (Technologies)
q AlternativesØ Relational data model (No-SQL) Ø Embedded SQL engine (Data Processing Engines)Ø ETL architectures (Wrangling, Streaming)
q Main-stream availability of clustering and in-memory hardware/software solutions
q Availability of algorithms for dealing with text and other "unstructured" data has increase dramatically
q Products & Services that provide "out of box" Machine Learning capabilities
q Products & Services that provide "out of box" support for combining Analytics and Operational Capabilities
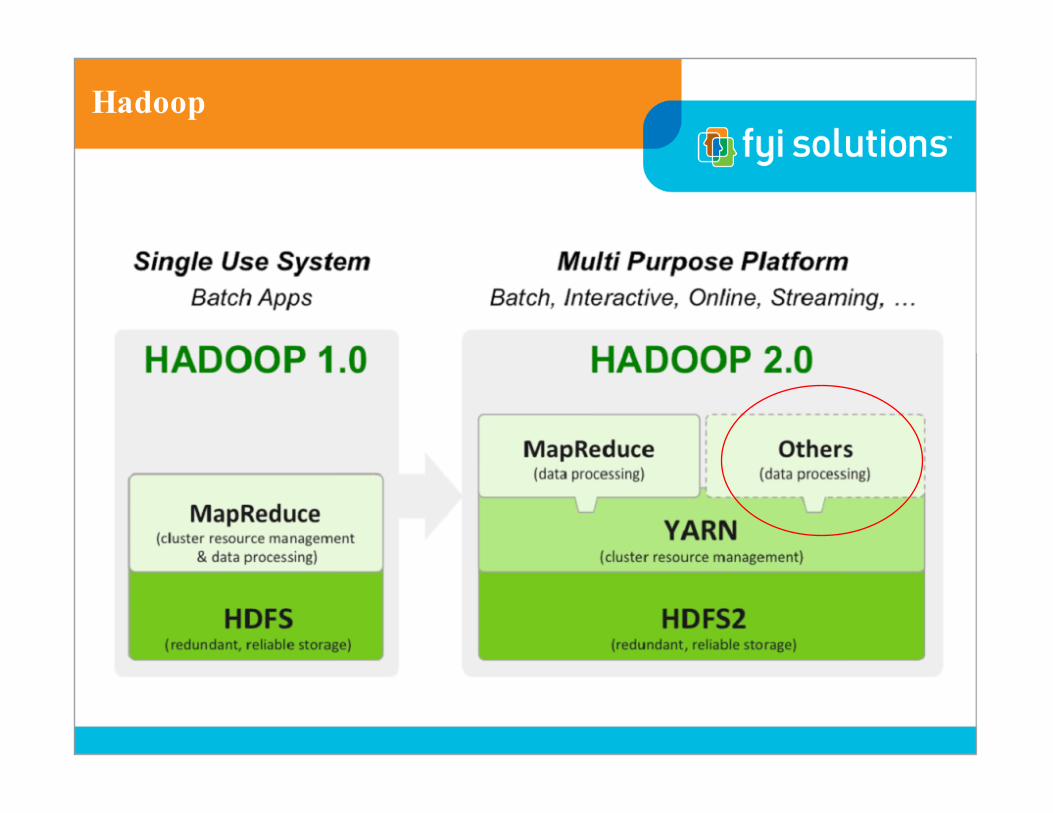
Hadoop
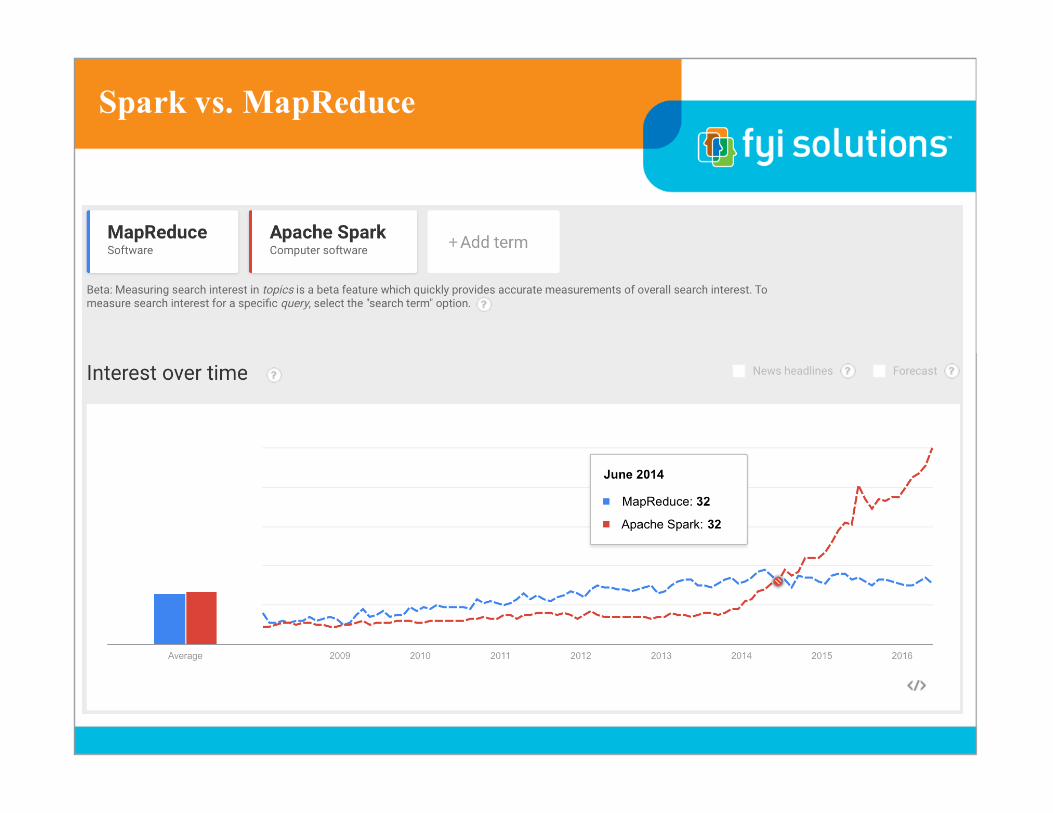
Spark vs. MapReduce
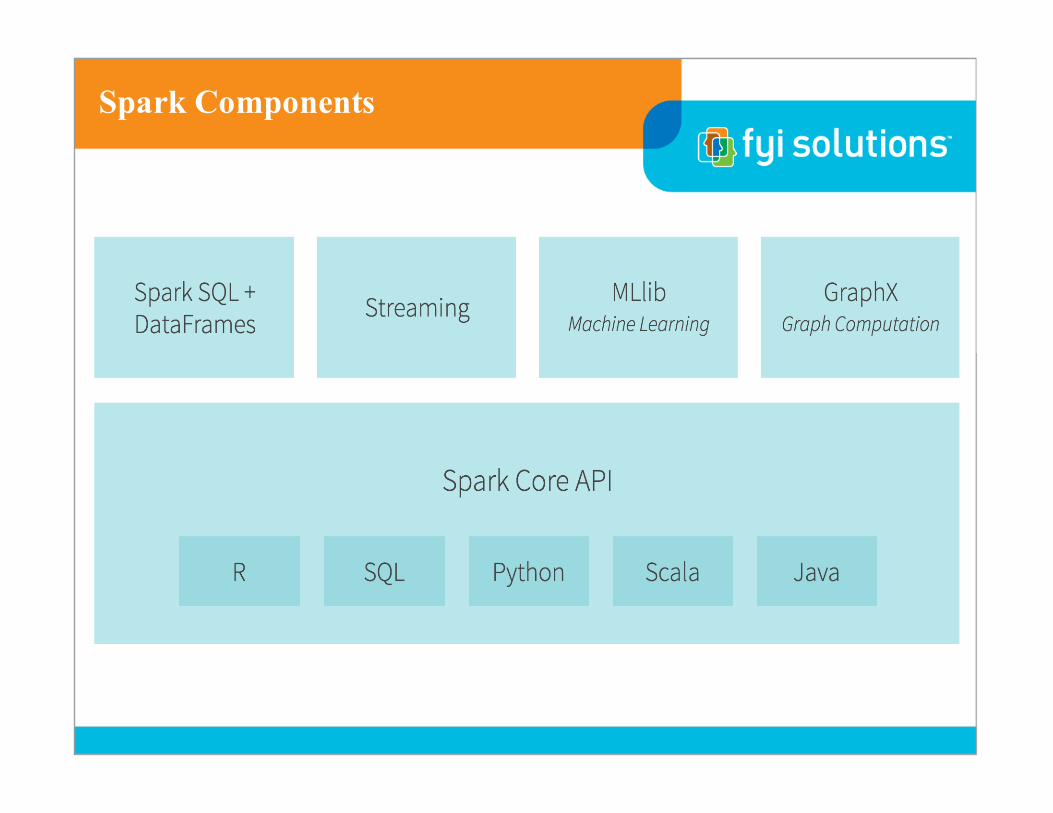
Spark Components

Spark Connectors
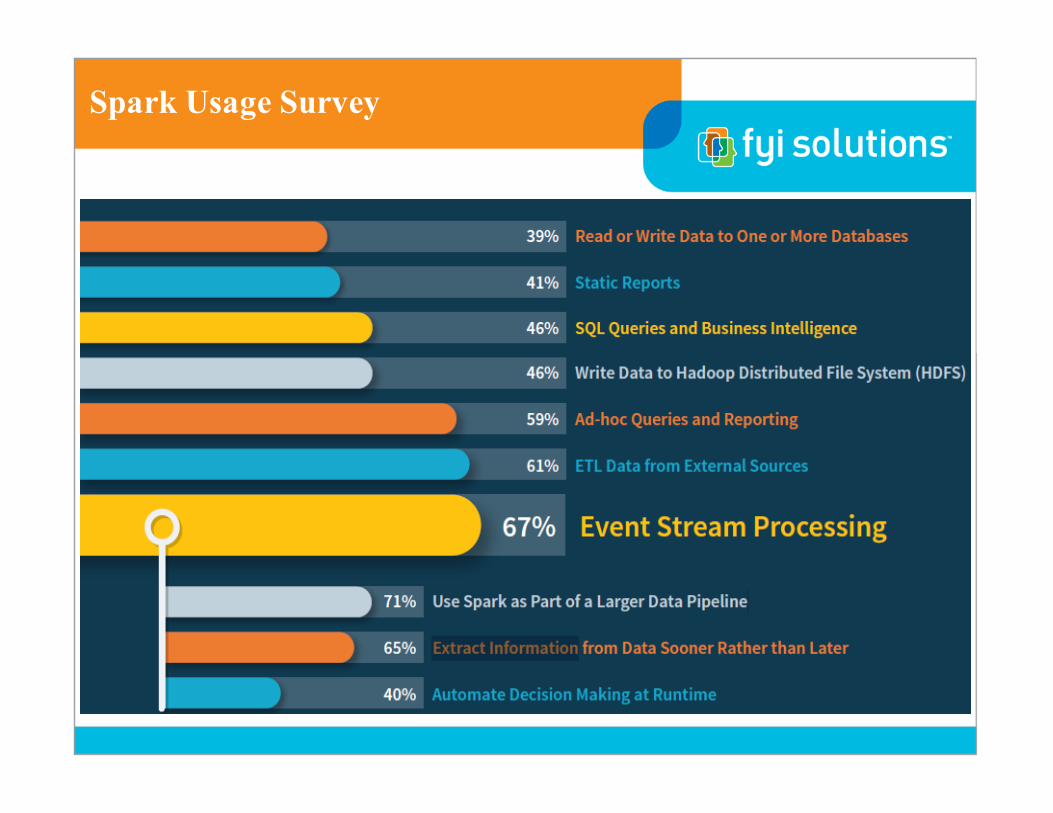
Spark Usage Survey

Machine Learning
Cognitive computing; leverages machine learning and artificial intelligence to infer and predict; offers tremendous potential to augment human expertise.
q ML development processØ Goal determination (requirements, outcomes)Ø Data analysis (discovery and wrangling)Ø Model trainingØ EvaluationØ Deployment and Monitoring

Opportunities (Process / Approaches)
q Collaboration capabilities appearing in Analytics / MDMq API services for data quality, data enhancementq Crowd Sourcing services q Data as a serviceq Explosion of research, books and courseware targeting
analytics, big data architecture and solutions

q Analyst Driven Data Sourcing (Self Service Data Prep)q Data Catalogsq Transparent/repeatable sourcing and analysisq Collaborative Governance (aka ‘Expert Sourcing’)q Crowd Sourcing, Consensus based DQq DQ based machine learning (aka ‘Data Curation’)
Opportunities (DG and DQ)
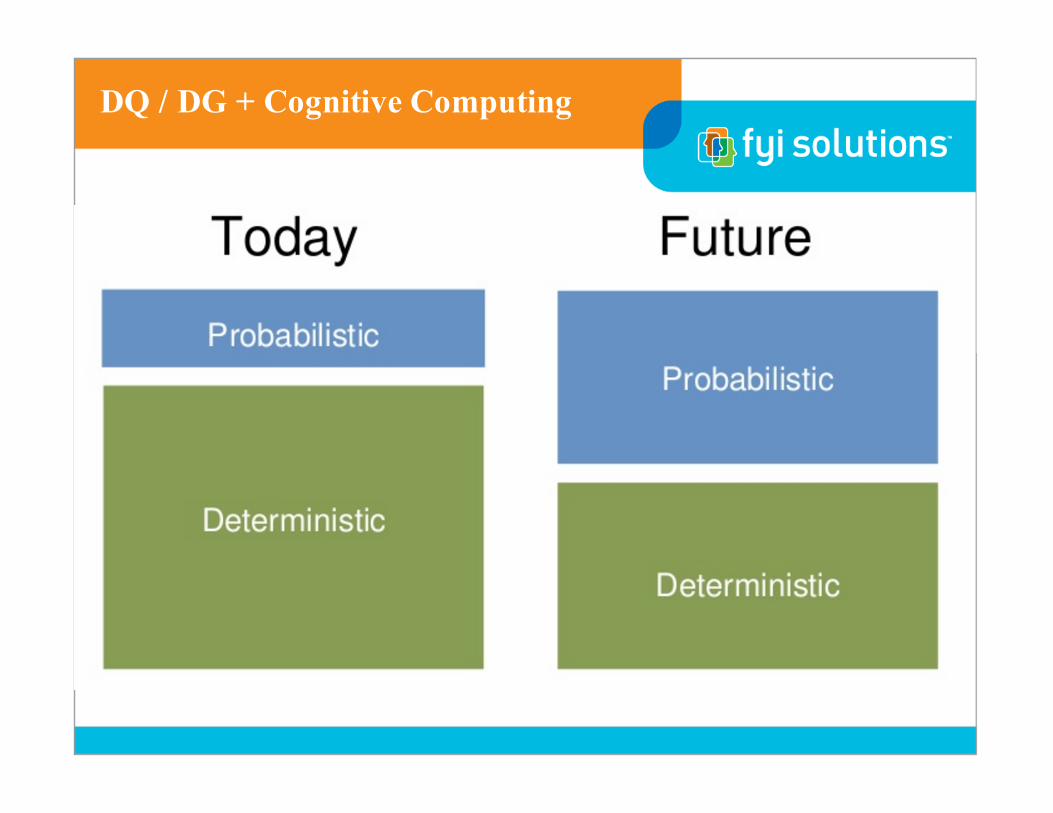
DQ / DG + Cognitive Computing
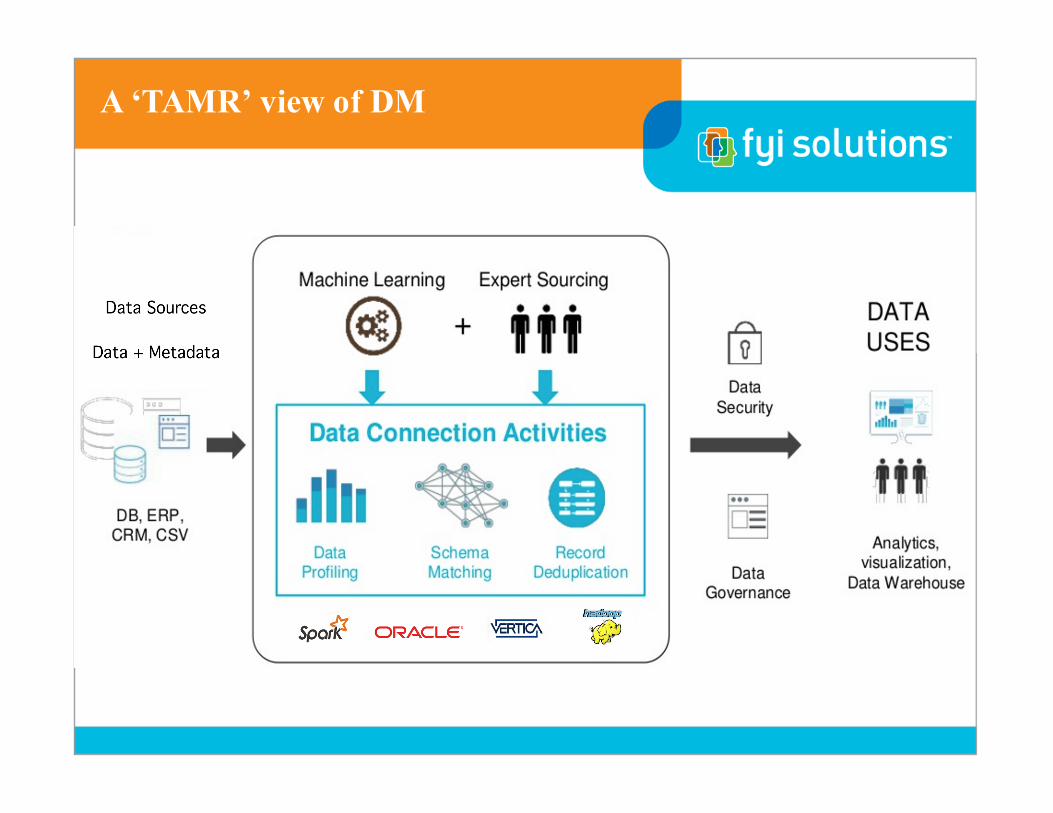
A ‘TAMR’ view of DM

Data Wrangling / Data Prep
“Data preparation tools have emerged as a vital method for analysts to quickly source, blend, and wrangle data independent of enterprise architecture’s (EA) data management processes.” Forrester
q Features / BenefitsØ Agility (build and validate in a single process)Ø Repeatability / TransparencyØ Easy to use, with many ‘advanced’ featuresØ CollaborationØ Discovery, Cleaning, Enrichment, Publishing, ...

q Massive increase in data volume q Machine Learning - Member Retentionq Sentiment Analysis - Improving Survey analysisq Crowd Sourcing - Initial Match Evaluation and Merge
Case Studies

Conclusion
q Separate Mythology from the technology and approachesq Leverage the Hype of Big Data to make improvementsq Understand which of the 3Vs you want to focus onq The most important aspects are still
Ø Business GoalsØ CultureØ People
q LeverageØ Open Source Ø Cloud Computing Ø SAAS

Messaging and Streaming Frameworks
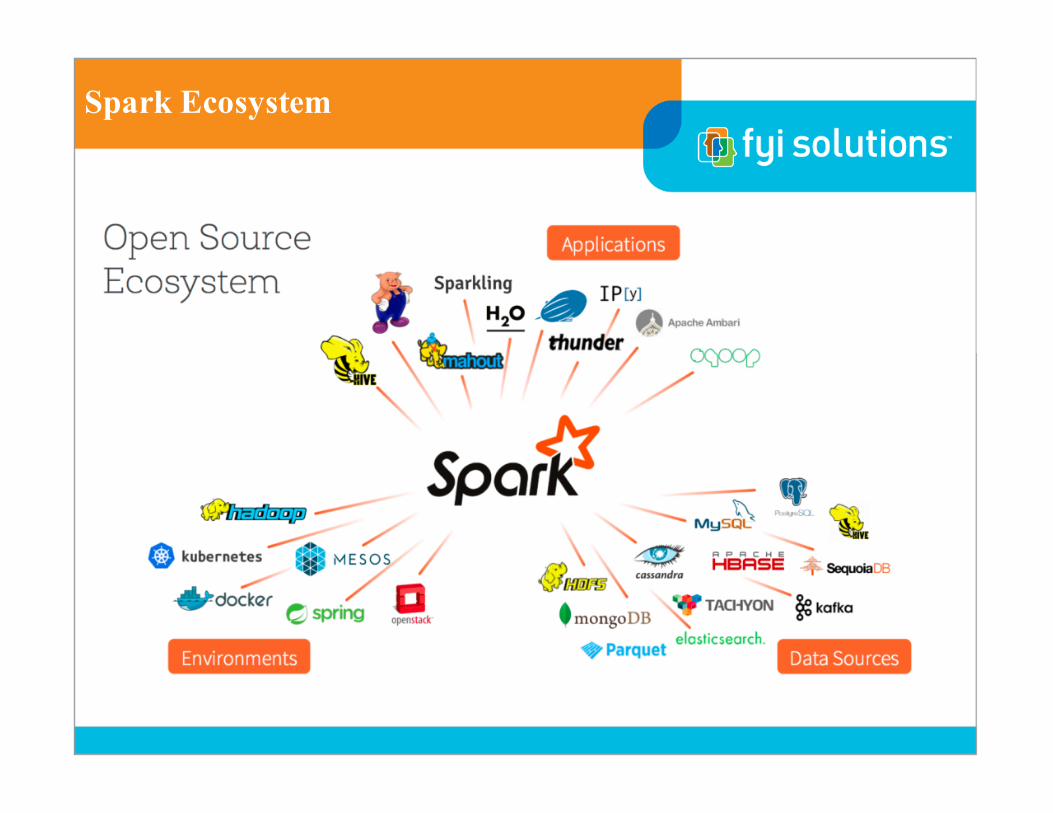
Spark Ecosystem
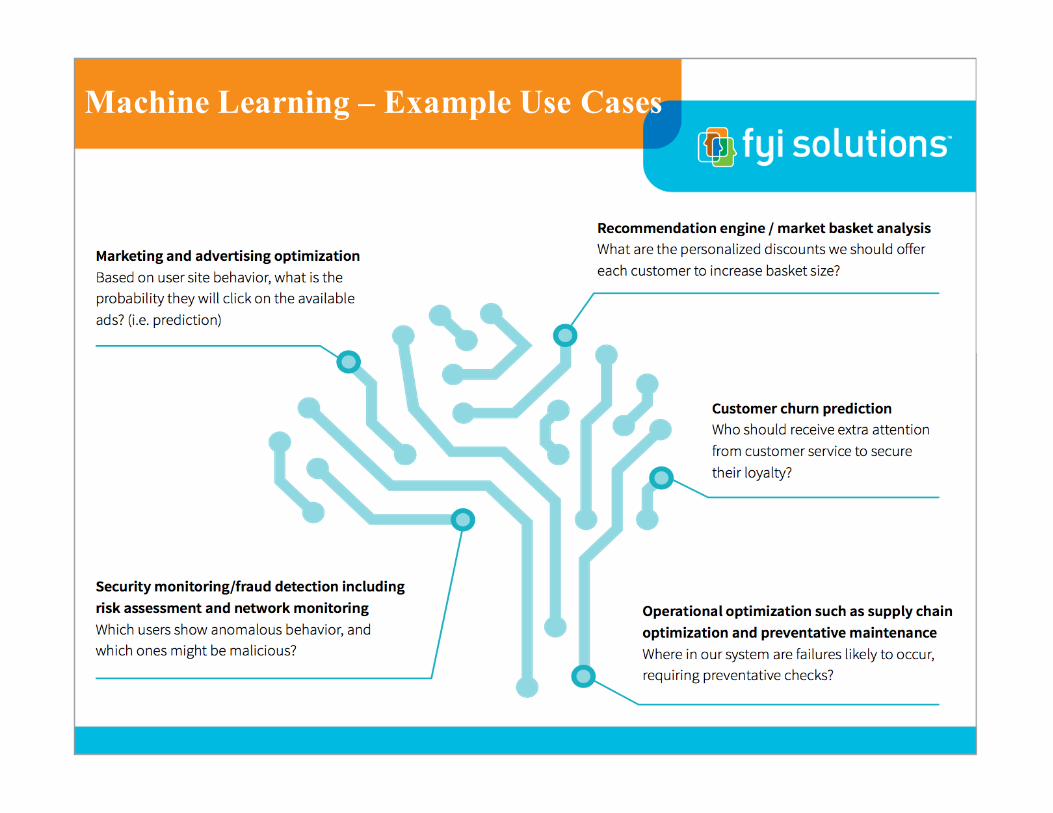
Machine Learning – Example Use Cases






























