Embed Size (px)
Citation preview

Artikel til JDoc, nov 2012Foreløbig planlagt til publ. primo 2014
Hans Jørn Nielsen and Birger Hjørland
Curating research data: The potential roles of libraries and information professionals
Abstract:Purpose – A big issue in the literature about research libraries is their potential role managing research data. The present article studies the arguments for and against this task for libraries and information professionals and presents the many competitors to libraries in this field. It will not, however, analyse or evaluate specific tools or services of data management. Design/methodology/approach – The article considers the nature of data and discusses data typologies, kinds of data in databases and considers the implications of the criticism raised against the data-information-knowledge (DIK) hierarchy. It outlines the many competing agencies in data curating and describes their relations to different kinds of data. Findings – Many data are organically connected to the activities of large domain-specific organizations for which reason it seems difficult for research libraries to take over the tasks involved in the curating of their data. It seems more likely that the qualifications of information professionals become needed in such organizations and that the functions of research libraries may migrate to the producers of research data. In some cases, however, research libraries may be the best place to select, keep, organize and facilitate the use of research data. In order to be prepared for this task, research libraries should be actively involved in domain-analytic studies of their respective domains. Originality/value –The paper offers a theoretical analysis and clarification of the problems of data curating from the perspective of research libraries.
IntroductionIn the literature is has been suggested that libraries should take on the role to manage research data. Actually this theme seems to be growing in the research literature to a level in which it can be characterized as a big issue. In 2007 the Association of Research Libraries (ARL) thus made aware that e-science created opportunity for research libraries to take a leading part in management and preservation of scientific data (Meyer et al. 2010:84). Some have made the point that research libraries traditionally have made access to research as kinds of published documentation, and that it will be a natural prolonging of that library function to make access to kinds of research data (Lewis
1

2010; Shearer & Argáez 2010; Heller et al. 2011). In his book Facilitating Access to the Web of Data, David Stuart states the argument of the book in this way:
…as this book will show, library and information professionals are ideally positioned to bridge the gap between users and the wide range of data that is being made available from a host of different organizations1 (Stuart 2011: XI)
A working group attached to the Danish DEFF (Danmarks Elektroniske Fag- og Forskningsbibliotek / Denmark’s Electronic Research Library) recommends in a report that research libraries (e.g. university libraries) become leading operators in data curation2. Their vision is a combination of local curation by research libraries and national management rules, securing possibilities of aggregation on a national level.
Integration of and access to big datasets with the purpose of identification, retrieval, sharing, and recycling require description, organization, and consistent control and treatment according to harmonized rules, formats, and protocols. This is precisely what research libraries do today in relation to documents (Heller et al. 2011:2. Our translation)
In relation to harmonization of common rules and protocols the DEFF group points at the making of national centres, e.g. in Australia (ANDS, Australian National Data Service) and UK (DCC, Digital Curation Centre). The purpose of DDC is described on the homepage of the centre: “The Digital Curation Centre provides expert advice and practical help to anyone in UK higher education and research wanting to store, manage, protect and share digital research data.”
An opposite argument is that even if research data are publicized data they cannot be equalized with printed documents. It has, for example, been argued that while printed documents are copies of a well-defined object, research data often are complex datasets of very different kinds, dependent of domain, context and provenance (Weber et al. 2012). The maintaining of such datasets requires scientific knowledge of the domain and technological advanced knowledge in order to store and organize the data with the purpose of reuse and preserving. Do academic librarians possess the necessary qualifications for this task? Are there principal differences between managing data versus documents? If yes: what kind of educational programs may support data management activities?
The scholarly communication system is radically changing and a main point in Borgman’s book (2007) is that we have a traditional and very stable infrastructure of scholarly communication in print culture. But:
1 Notice, however, that Stuart underlines the competences of “library and information professionals”. In fact they may execute their work in other contexts than a research library.2 Digital curation is the selection, preservation, maintenance, collection and archiving of digital assets.
2

While capturing and managing the ”data deluge” is a major driver for scholarly infrastructure developments, no social framework for data exists that is comparable to that for publishing (Borgman 2007: xviii Preface)
Many, among others Anna Gold, points to the growing importance of research data:
Where standards and practices for publishing research results in textual form are well-established and supported, managing access to data has the feel of a vast frontier with pockets of homesteaders and small settlements, and a few well-supplied and well-guarded nodes. And yet, data is the currency of science, even if publications are still the currency of tenure. To be able to exchange data, communicate it, mine it, reuse it, and review it is essential to scientific productivity, collaboration, and to discovery itself (Gold 2007).
The present article studies the arguments for and against this task for libraries and information professionals. First it considers the nature of “data” and the difference between indexing “documents” and “data”. It illuminates the problem whether data curation is a natural extension of the traditional roles of research libraries or should be considered a principal different task. Is data curation a task that put others and new demands and principles compared to library tasks in relation to document management? Is data-curation in libraries a problematic idea that will show itself to be impossible to realize in a meaningful way? Second it provides a broader look at the many different agents and ways in which research data have been managed or could be managed in the future as competing service agencies to the libraries. Examples are data sets published by scholarly journals, the data archives movement, data based on (digitalized) collections and data sets developed outside science, but used by science. This article examines these issues and tries to help establishing a theoretical frame for the further consideration of the problems involved in data curation. Our primary research question is: To what degree is data curation a natural extension of the traditional roles of research libraries?
What are data? “Data” is a concept much used in information science, in which “database”, “data archive”, “data mining”, “descriptive data” and “data” itself, among others, are core terms. Besides, computer science is in Denmark termed “datalogi” which means “the science of data” and which is associated with “data processing”.
Data has been discussed in information science in relation to other terms under the label data, information and knowledge hierarchy. Data are often comprehended as the raw material of information processing and knowledge acquisition. It has consequently been proposed that there is a hierarchy of data, information, knowledge and wisdom (DIKW). Among the first presentations of this hierarchy was Ackoff (1989).
3

Figure 1: Data, information, knowledge, wisdom hierarchy
However, although this view has been extremely popular in information science, computer science, knowledge management and other fields, the criticism raised against is has been harsh. Among the important critics are Frické (2009) and Ma (2012). Lai Ma wrote:
” the DIKW model depicts a theory of knowledge, echoing a tradition of empiricism and metaphorically relying upon an data processing, rather than a communicative model for shaping its concept of information. The DIKW model relies heavily on sense perception and the collection of data as the initial stages in the production of knowledge. It shares the assumption of an empiricist epistemology that sense perceptions are the source for human understanding. In brief, while the DIKW model may well model the machine processing of data, in terms of human understanding it remains epistemologically grounded in a version of empiricism with a technical metaphor added on. If we remove the technical metaphor, the resulting conception of information would to bypass research into language, communication, and learning in human beings in the past three centuries” (Ma, 2012, p. 721). And: “It is argued that the epistemological assumptions have led to the negligence of the cultural and social aspects of the constitution of information (i.e., how something is considered to be and not to be information) and the unquestioned nature of science in research methodologies.” (Ma, 2012, p. 716).
The same conclusion has also been made by Rafael Capurro:
"Data are (or datum is) an abstraction. I mean, the concept of 'data' or 'datum' suggests that there is something there that is purely given and that can be known as such. The last one hundred years of (late) philosophic discussion and, of course, many hundred years
4

before, have shown that there is nothing like 'the given' or 'naked facts' but that every (human) experience/knowledge is biased. This is the 'theory-laden' theorem that is shared today by such different philosophic schools as Popper's critical rationalism (and his followers and critics such as Kuhn or Feyerabend), analytic philosophy (Quine, for instance), hermeneutics (Gadamer), etc. Modern philosophy (Kant) is very acquainted with this question: experience ("Erfahrung") is a product of 'sensory data' within the framework of perception ("Anschauung") and the categories of reason ("Verstand") ("perception without concepts is blind, concepts without perception are void"). Pure sensory data are as unknowable as "things in themselves"." (Capurro in Zins, 2007, page 481).
Capurro here expresses a general scepticism concerning the concept of “data” and relates it to a mislead philosophy His line of criticism supports Frické (2009) and Ma (2012). Another critic, Fritz Machlup, wrote:
"The use and misuse of the term data is due, in part, to linguistic ignorance. Many users do not know that this is a Latin word: dare means "to give"; datum, "the given" (singular); and data, "the givens" (plural). Data are the things given to the analyst, investigator, or problem-solver; they may be numbers, words, sentences, records, assumptions― just anything given, no matter in what form and of what origin. This used to be well known to scholars in most fields: Some wanted the word data to refer to facts, especially to instrument-readings; others to assumptions. Scholars with a hypothetico-deductive bent wanted data to mean the given set of assumptions; those with an empirical bent wanted data to mean the records, or protocol statements, representing the findings of observation, qualitative or quantitative...
One can probably find quotations supporting all possible combinations of the three terms [data, information, knowledge] or of the concepts they are supposed to denote. Each is said to be a specific type of each of the others, or an input for producing each of the others, or an output of processing each of the others.
Now, data from the point of view of the programmers, operators, and users of the computer, need not be data in any other sense" (Machlup, 1984, s. 646-647).
Machlup’s contribution is to consider “data” is a relative concept. What is data for somebody is not necessarily also data for somebody else, data is relative to a given process in which something is considered “given”.
In accordance with Frické, Ma and Capurro we find that the nature of “data” is fundamentally a problem in the philosophy of science. The issues discussed by, for example, Bogen’s (2009) article theory and observation in science is a proper context for understanding the concept of data. Borgen finds: “that counterparts to Kuhnian questions about theory loading and its epistemic significance arise in connection with the analysis and interpretation of observational evidence [i.e. data]. For the most part, such questions must be answered by appeal to details that vary from case to case.” We
5

interpret this quote that the usefulness of data in other theoretical contexts than the one in which they were produced “must be answered by appeal to details that vary from case to case”. In other words: there is a need for specific expertise on how to manage research date in all domains (for which information specialists may play an important role). However, the general goal of collecting all data in libraries is problematic because there is an organic connection between producing and using data that cannot be broken.
Although the mentioned authors have questioned our every-day understanding of “data” no positive definition of “data” has so far been given based on an alternative to empiricism. Max Kaase suggested the following definition:
“Data is information on properties of units of analysis” (Kaase, 2001, p. 3251)
If we accept that different research project have different units of analysis and also have varying degrees of relevance for information about different properties, then this definition seems to be sufficient broad and relativistic to serve as a general definition of data. Properties are thus not just measures, but are any kind of characteristics about an object of investigation. It is implicit in this definition that data are always recorded on the basis of some interests, perspectives, technologies and situated practices, which determines their meaning and usefulness in different contexts. Therefore, we suggest that Kaase’s definition should be accepted and used as the point of departure.
The conclusion of this section is that a connection has been found between the traditional understanding of “data” and the philosophical positions of empiricism and positivism. Knowledge about the problems in these philosophies puts an entirely new perspective on what data are, and by implication: what is needed in order to manage them. Types and typologies of data There are in the literature suggestions on how to classify data. The following quote suggests such definitions:
“[Data are] the primary inputs into research, as well as the first order results of that research” (Blue Ribbon Task Force on Sustainable Economics for a Digital Planet 2010:56).
This definition suggests that data may be of two kinds 1) data produced outside a given research project as input 2) data produced within a given field of research as, for example, 1) observational, 2) computational, and 3) experimental data as distinguished in a report from National Science Foundation (National Science Board, 2005: 19). To these three types of research data Borgman (2007, p. 120) adds 4) data of records, i.e. records of government, business, and public and private life. Borgman notices that these four categories “tend to obscure the many kinds of data that may be collected in any given scholarly endeavor” (Borgman 2010: 3). One could therefore also suggest 5)
6

data from works of art and literature and artefacts from cultural heritage as studied by the humanities.
Category 4 and 5 are not data produced within research itself, but are data used as input in research processes (but this does not make them less relevant for investigations of research infrastructures). We can also say that the last two categories blur the differences between data and documents, a problem we will consider later in this article. Finally we can say that not just the humanities, but also the sciences depends on data derived from collections of preserved objects (or “documents”3), e.g. herbaria. We discuss these three issues further in a section below: “Data based on (digitalized) collections”.
The above classification of research data seems, however, to underplay the organic interaction between research and data so that science use data as input to produce a new output used as new input. It is also unclear what the implication of this classification is: Do the National Science Board and Borgman suggest that different kinds of policies, systems and services are needed for each of these kinds of data? The National Science Board (2005, p. 19) suggests that the distinction between observational, computational, or experimental data is crucial to choices made for archiving and preservation in that observational data are historical records that cannot be recollected, an thus “are usually archived indefinitely” (i.e. should be archived indefinitely) thereby suggesting that observational data should automatically have priority compared to the other kinds of data in future infrastructures. But is this not simply a problematic empiricist doctrine? Can we – a priory – say that one such kind of data should always have priority in all domains? Are observations and other kinds of data not organic related? And if we cannot a priory give priority to observational data, what is the value of this classification? How does it serve our priorities in the conservation of data?
Based on these points of criticism we think that the above described classification should be given up and replaced by a perspective in which data are understood from the perspective of the human activities of which they form parts. Humans conduct a lot of different activities such as sport activities, learning activities, religious activities, business activities, health activities, legal activities, cultural activities and research activities. Data are produced in relation to all kinds of activities. In sports, for example, data are produced about human performances (who won The Wimbledon Championships 2012? how fast has the marathon been run?); in institutions data are produced about employees (e.g. their salaries and telephone numbers), in police work data are produced about crimes, crime scenes, criminals etc. (e.g. fingerprints). In business data are produced about commodities (such as their prices). Data about populations are important for governments, why statistical agencies are created and maintained. In the humanities data are produced about, for example works of art and objects from cultural heritage4. In libraries data are
3 As discussed later in this article were also physical objects, including animals in a Zoo, considered “documents” by the classical documentalists such as Briet (1951). 4 Humanistic data (about for example objects of cultural heritage) may be less “data-like” in that they are more difficult to categorize in specific fields in databases. Input data, output data and analytic frameworks may be harder to distinguish in much research in the humanities. In other words: the hypothetical-deductive method is less explicable in the humanities.
7

produced about books and other documents (bibliographic data or metadata). Each human activity implies not just the production of some data, but also systems for organization of such data for future use in relation to these activities. Each human activity system makes experiences on how to improve data production and data organization, and uses new technologies, media and genres to do so5. It is the activity that determines which data are relevant and how data should best be produced, described and organized.
Research is both a kind of human activity in its own right (producing its own data) as well as a transversing activity depending on data from other activities. For example, we have sports scientists producing data about sports, but also using sport data produced outside research. In information science bibliometric data are important in the study of bibliographical databases. In a section below we shall consider how meteorological research is closely interacting with meteorological data produced for the purpose of daily whether forecasts. All kinds of data can hypothetically be of interest to research: we cannot exclude any kind of data as not being potential relevant for research activities and thus for research libraries or data repositories. Not all data are equally relevant in relation to on-going research or to predictions/anticipations about developments in research activities. The relevance of a given set of data (or the need for other sets of data) is determined by the specific research questions raised – and the theoretical perspectives from which questions are formulated. For example, a feminist historian, a black historian, a Marxist historian, a positivist historian and so on each has different perspectives on human history and each have different needs in relation to data collection, preservation and organization. And as new hypothesis evolves during a research process, new perspectives and new needs follows.
When the question is to provide infrastructures for research, we will argue that we have to take our point of departure in models of research activities in different disciplines such as the updated UNISIST-model (Fjordback Søndergaard; Andersen & Hjørland, 2003). A general classification of data from the point of view of research infrastructures is:
Input (data) from natural information sources (corresponding to observational data in the domain).
Input (data) from information sources produced in own discipline (corresponding to computational data, experimental data, data obtained from (digitalized) collections, including scientific and scholarly literatures as well as metadata on items in collections of cultural artefact, natural objects and scientific literatures).
Input (data) produced in other disciplines Input (data) produced in mass-media, cultural sources and everyday information sources
Our conclusion of this section is that the needs for different kinds of data need to be considered from a domain-specific perspective. Priorities in preserving data cannot be made on a priori
5 This is also the case in the humanities. Given our definition of data as “information on properties of units of analysis”, the data of a literary scholar are information about the properties of the literary works they produce by studying those works, e.g. their genre classification and data about their reception.
8

categories, but have to take into consideration 1) the current scientific estimates regarding the future value of a given set of recorded data 2) considerations about the resources spend on establishing the data (and whether an equivalent set of data can be established at a reasonable cost). In making such priorities it is always important to consider that new perspectives may reevaluate former judgments. The priorities, considerations and estimates from a domain-specific perspective require in depth competences from data managers and curators. At the home page of the Data Curation Centre of UK it is put this way:
“Curation requires a significant amount of domain knowledge; data scientists and data curators may add value to the original data. Users, custodians and reusers of the data and the funding bodies have curation responsibilities. There is currently a shortage of experienced data scientists and curators with digital preservation experience” (Data Curation Centre http://www.dcc.ac.uk/about-us/dcc-charter/dcc-charter-and-statement-principles ).
Kinds of data indexed in databasesThe influential database host “Dialog” (owned by Thomson Reuters) classify its databases in the following categories:
Full Text databases Bibliographic databases Directories Numeric databases (Combinations of these four kinds)
Full text databases contain documents (which again contain data), whereas bibliographical databases contain data about documents, directories contain data about people, companies, institutions etc. Numeric databases contain numerical data such as statistics, measurements, financial data etc.
When research libraries are today considering “data” as a new kind of objects to be selected, described, stored and communicated to users this must necessarily be understood as a contrast to what libraries have always done: selected, described, stored and communicated documents. It should be considered, however, that many documents are in themselves purely data collections and that such data collections have always been parts of the focus of research libraries (whether in printed or in digital form). Many “data handbooks” and statistical documents, for example, consist of data, but have been considered documents (also when they are purely digital databases).
There has been a tendency in information science to consider documents as containers of “the real thing:” data or information. By implication the goal is not “document retrieval systems” but “data retrieval systems,” “fact retrieval systems” or “information retrieval systems.” Sparck Jones (1987, p. 9), for instance, claimed that ‘we are concerned with access and, more materially, indirect access
9

to the information the user wants: he wants the information in the documents, but the system only gives him the documents’. This statement represents a rather ordinary view with roots back to the foundation of documentation and information science. A fine criticism of this view was given by Henning Spang-Hanssen:
Information about some physical property of a material is actually incomplete without information about the precision of the data and about the conditions under which these data were obtained. Moreover, various investigations of a property have often led to different results that cannot be compared and evaluated apart from information about their background. An empirical fact always has a history and a perhaps not too certain future. This history and future can be known only through information from particular documents, i.e. by document retrieval.
The so-called fact retrieval centers seem to me to be just information centers that keep their information sources – i.e. their documents – exclusively to themselves. (Spang-Hanssen, 2001, pp. 128-129)
With a rewording of Spang-Hanssen one could say that data always need to be described and that the most obvious description of data are the scientific documents in which they are first presented together with the methodology which has been used to obtain them as well as the arguments for their usefulness and qualities. Data from several documents may be combined in a meta-analysis but that requires a new document to describe and argue for the specific combination made and it’s methodology in each case.
The concept of “analytical entry” in library cataloguing suggests that not just documents, but also part of documents may be described and made searchable in library catalogues or bibliographical databases. In principle tables, figures appendixes etc. may be indexed (although in practice this is seldom, if ever, done). If the principle of analysis of data contained in documents were broadly utilized by research libraries, “data” would not be a new object for them. To understand why research libraries have mostly abstained from providing such analytic entries of data in documents could provide some relevant insight into whether this is like to be an activity in the future. The main reason is probably that this activity is better done by centralized bibliographical services compared to being done parallel by many research libraries.
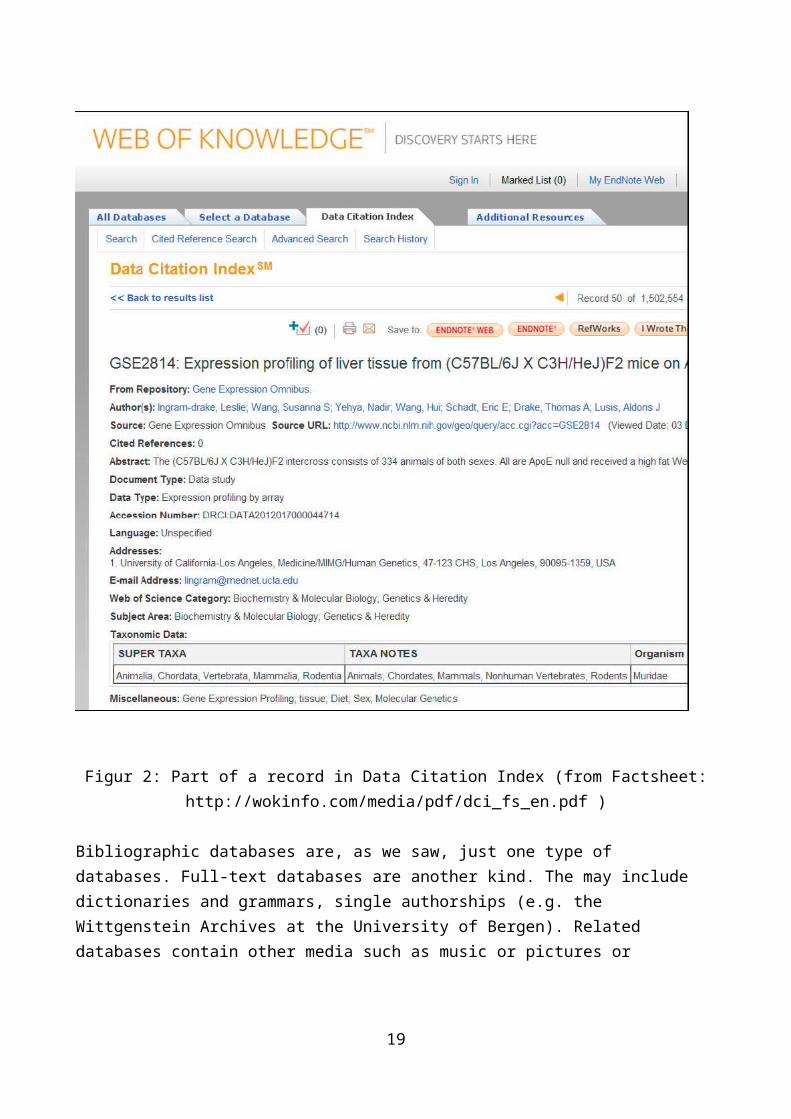
October 2012 Thomson Reuter launched a new citation database Data Citation Index on its platform Web of Knowledge (Thomson Reuter, 2012). It seems that this new index is concentrating solely on digital web based resources. What is being selected and indexed are data repositories 6
6 “Data repository: a database or collection comprising data studies, and data sets which stores and providesaccess to the raw data. Constituent data studies, and sometimes individual data sets, are marked up withmetadata providing a context for the available raw data.” http://wokinfo.com/media/pdf/DCI_selection_essay.pdf
10

which are databases or collections comprising data studies 7 and data sets 8 which stores and provides access to the raw data. Constituent data studies, and sometimes individual data sets, are marked up with metadata providing a context for the available raw data.
According to the view developed by the documentation movement the concept of “document” is understood as “any concrete or symbolic indication, preserved or recorded, for reconstructing or for proving a phenomenon, whether physical or mental (Briet, 1951/2006, 7; here quoted from Buckland, 1991). The data repositories, data studies and data sets which are indexed by the Data Citation Index should therefore be considered documents and we can observe that data are being accompanied with information needed to interpret them (as Spang-Hanssen demanded, cf. quote above)9. If a data set is cited, it should be understood as one document citing another. As such the indexing of “data” is here fully in line with the bibliographical tradition of information science10.
The Data Citation Index is interdisciplinary (i.e. general or universal). Just as there are general bibliographies versus disciplinary bibliographies, the description of data repositories, data studies and data sets should of course also be described in subject specific databases, for example, in medicine. It has always been the job of academic librarians to know about relevant databases, to advice users in their use, and to include them in the bibliographic guides/portals/libguides. It is therefore unfruitful to consider the registration of “data” as principally different from the registration of “documents” as far as they are identified by such attributes as authors, publishers/research institutions, publication years, and physical addresses.
7 “Data study: description of studies or experiments held in repositories with the associated data which havebeen used in the data study. (Includes serial or longitudinal studies over time). Data studies can be a citableobject in the literature and may have cited references attached in their metadata, together with informationon such aspects as the principal investigators, funding information, subject terms, geographic coverage etc.The level of metadata provided varies between repositories.” http://wokinfo.com/media/pdf/DCI_selection_essay.pdf8 “Data set: a single or coherent set of data or a data file provided by the repository, as part of a collection, datastudy or experiment. Data sets may exist in a number of file formats and media types: they may be numberbased files such as spreadsheets, images, video, audio, databases etc. Data sets can be a citable object in theliterature and may include cited references attached in their metadata, but more commonly they inherit themetadata of the overall study in which they are used.” http://wokinfo.com/media/pdf/DCI_selection_essay.pdf9 Consider in figure 2 that there is a field termed “document type” thus recognizing that what is being indexed are documents. 10 Unfortunately, this tradition has been weakened within information science in recent years, cf. Hjørland (2007).
11

Figur 2: Part of a record in Data Citation Index (from Factsheet: http://wokinfo.com/media/pdf/dci_fs_en.pdf )
Bibliographic databases are, as we saw, just one type of databases. Full-text databases are another kind. The may include dictionaries and grammars, single authorships (e.g. the Wittgenstein Archives at the University of Bergen). Related databases contain other media such as music or pictures or representations of physical objects (see also the section below: Data based on (digitalized) collections).
12

Factual databases includes the ones produced by statistical agencies (see Martin et al. 2000), which are well established institutions with a long history and are established in most countries of the world.
“`Government statistics' means factual information that is reported upon for statistical purposes by a unit of government. Some countries also use the term `official statistics.' In this articles, `statistics' and `data' are used interchangeably to mean factual information, and the terms are not restricted to quantitative information” (Straf, 2001, p. 6314).
There are three points to be about such statistical agencies: 1) Many data produced by them are publications in their own right which are included in libraries and indexed in bibliographic databases. 2) It would be a strange suggestion to have such statistical institutions to be parts of libraries: that would be the tail wagging the dog. 3) Statistical agencies sometimes preserve statistical data from other research institutions. In some cases they are more natural partners to do so compared to research libraries. Among the kinds of data collected are censuses (see Anderson, 2001) and survey data (see Mohler, 2001 for descriptions of some important national centers for survey research).
The construction or maintenance of such factual databases has so far been outside the roles of research libraries. The idea that libraries should be the curator of such data seems problematic as a general principle, but of course there may be local circumstances in which that could be a good solution. The databases themselves are, however, documents, which are of vital interest for scientific documentation and research libraries. They should therefore be described, evaluated, indexed and communicated to potential users in the domains of potential interest.
Data sets in scholarly journalsElectronic journals do not have the same limitations in relation to data storage as the printed journals have. Therefore there is a development towards more data in digital journals. Sometimes, for example, the digital versions have figures in colours, while the printed journals only have black-and-white figures. Also electronic versions may make tables interactive and – most relevant for the present article – they may provide access to digital data sets, which are not available in printed journals. Clifford Lynch has stated: Data and software will become integral parts of the scientific record:
With the arrival of the data-intensive computing paradigm, the scientific record and the supporting system of communication and publication have reached a Janus moment where we are looking both backward and forward. It has become clear that data and software must be integral parts of the record—a set of first-class objects that require systematic management and curation in their own right (Lynch 2009: 181).
13

It is important to remember that one of the basic design principles for scientific articles have always been to bring enough details in order to allow other scientist to repeat experiments and to confirm the data and conclusions made. But at the same time, the printed document is characterized by a scarcity of space, not leaving room for too many research data. This premise disappears in the digital context and the publishing of full datasets becomes possible. Concerning documents cited or referred to, copyright issues seems to be the limiting factor for full inclusion.
Scholarly journals are important in relation to data curation because they often have explicit rules not just for codifying the scientific style, including rules for documenting citations and scientific claims, but also for developing policies regarding researchers’ storage of primary data and of access to those data. Together with the major grant-giving institutions such as the National Science Foundation (NSF) in USA, and leading universities such as Oxford11 and Edinburgh12, scholarly journals are important actors in demanding data-sharing based on explicit norms. Various scientific journals have differing policies regarding how much of their data and methods scientists are required to store in a public archive, and what is actually archived varies widely between different disciplines. In a few fields, all of the data necessary to replicate the work is already available in the journal article. In other fields (e.g. drug development), a great deal of data is generated and must be archived so researchers can verify that the published reports (e.g. from the drug companies) accurately reflect the data.
Journals such as The American Naturalist, Journal of Heredity, Molecular Ecology, Nature and Science all have policies that data must be archived in an appropriate public archive. Nature, for example demands:
“A condition of publication in a Nature journal is that authors are required to make materials, data and associated protocols promptly available to others without undue qualifications. […]For biological materials such as mutant strains and cell lines, the Nature journals require authors to use established public repositories when one exists (for example, Jackson Laboratory, the European Mouse Mutant Archive (EMMA), the European Conditional Mouse Mutagenesis Program (EUCOMM), the Knockout Mouse Project (KOMP), Addgene, RIKEN Bioresource Centre, the Mutant Mouse Regional Resource Centers, American Type Culture Collection (Americas), American Type Culture Collection (Asia/Europe), UK Stem Cell Bank), and provide accession numbers in the manuscript”.
Other journals such as Economics (http://www.economics-ejournal.org/ ) goes a step further and provide archive options for of data sets (using The Dataverse Network), which is an application to publish, share, reference, extract and analyze research data, which was designed by the Institute for Quantitative Social Science beginning in 2006 and developed in collaboration with, among others, the Harvard University Library. Economics is an Open-Access e-journal, which provides direct
11 Oxford University:Research Data Management: Retrieved from: http://www.admin.ox.ac.uk/rdm/ 12 Edinburgh University Data Library Research Data Management Handbook, v.1.0 (Aug. 2011). Retrieved from: http://www.docs.is.ed.ac.uk/docs/data-library/EUDL_RDM_Handbook.pdf
14

access to all data sets in the journal: “Please click on the following link to get all papers of the E-Journal Economics with data sets archived in Dataverse: http://dvn.iq.harvard.edu/dvn/dv/economics “
John Mackenzie Owen found, however, that such data in journals are rare:
Only 17 (9%) journals in our sample allow for inclusion of data resources. But even in these cases, articles containing data resources are relatively rare […] Most of the journal with embedded or linked data resources are found in the sciences … (Owen, 2007, p. 145).
Owens findings suggest that there may not be a great number of datasets around just waiting for an opportunity to get saved in a library. This seems especially to be the case outside scientific fields such as molecular chemistry, but more research is needed on this issue.
The data archives movementThe term “data archive” has been used both in science and in social science. In natural science data center seems to be the most used term although Borgman (2007, p. 18) writes that “collections of primary data, such as that generated by satellites or networks of embedded sensors, are more often referred to as data archives or repositories”. An example of an institution is CISL Research Data Archive (see also Wikipedia: Scientific data archiving).
In the social sciences data archives are professional institutions for the acquisition, preparation, preservation, and dissemination of data, which evolved in the 1950s and has been perceived as an international movement:
“By 1964 the International Social Science Council (ISSC) had sponsored a second conference on Social Science Data Archives and had a standing Committee on Social Science Data, both of which stimulated the data archives movement. By the beginning of the twenty-first century, most developed countries and some developing countries had organized formal and well-functioning national data archives. In addition, college and university campuses often have `data libraries' that make data available to their faculty, staff, and students; most of these bear minimal archival responsibility, relying for that function on a national institution” (Rockwell, 2001, p. 3227).
The arguments seem rather similar to many arguments which today are considered in relation to the curation of data in research libraries:
“Both natural and social scientists have long recognized the value of sharing data with their contemporaries and of preserving data for their successors. Records of
15

astronomical observations have been kept for several thousand years. During the 1957 International Geophysical Year, the natural sciences established a system of World Data Centers that still exists today. Historical parish, census, and tax records, although not originally designed as scientific data collections, were nevertheless a foundation for the development of actuarial science and demography in the eighteenth century. From the nineteenth century onwards, cultural anthropologists carefully documented and preserved their observations, some of which were incorporated into the Human Relations Area Files” (Rockwell, 2001, p. 3227).
Data archives have been criticized, for example, by information scientist Michael Brittain:
"The simple conclusion to be drawn is that data is not knowledge. However, those who support experimentation and controlled observation are sometimes difficult to persuade otherwise. The libraries of the world are full of documents containing unprocessed, and unusable data. The databank movement in the social sciences has perpetuated the mistaken belief that mountains of data are worthwhile, and that if enough is collected, analysed, and stored, benefits will result and the social sciences will progress. This belief is mistaken: it is characteristic of alchemists, or mystics, rather than scientists." (Brittain, 1989, 99-100).
Brittain’s criticism is relevant in relation to early expectations on the roles of data archives, and we fully support Brittain’s criticism of the idea of mechanical collection and piling up of endless numbers of data from ill-conceived social scientific research. However, because data archives certainly fulfil certain important functions, Brittain fails to provide guidelines for the possible roles for data archives, which are less extreme inductivist based.
Today libraries try to get a foothold in the business of data curation. An example is the Royal Library in Copenhagen is intended to keep data from the Kepler Asteroseismic Investigation, as announced in a scientific article (Kjeldsen et al., 2010; preprint version from 2006) and in the Danish media (Dreehsen, 2009; Cotta Schønberg, 2009, p. 17).13 This example is surprising: Is the management of these data just a technical problem? If not, does the Royal Library have the necessary subject knowledge in this field?
In Denmark we also have Dansk Data Arkiv (Danish Data Archives, DDA) which at the moment has limited functions as a research data centre of parts of the social sciences and health science. DDA is a part of The Danish State Archives and therefore not part of the library system. DDA also has researchers and a peer reviewed scholarly journal (Metode og Forskningsdesign, i.e. method
13 About the actual stage of the Kepler-data project the Royal Library has informed: “We expect to receive all data during the fall in that Kepler Science Operations Center (KASOC) by University of Aarhus will be doubled by us. This is of course only the first step and data are thus not described in our catalog […] It are these data, which will be doubled at the Royal Library, among other reasons for security and curation” (email July 10, 2012 from Bertil Dorch on the behalf of project owner Birte Christensen-Dalsgaard).
16

and research design) affiliated to it. Researchers in the Danish context thus have among their options to have their data stored and managed by DDA.
DDA keeps at the moment quantitative data14 – is seems therefore most appropriate for the university library [i.e. The Royal Library in Copenhagen] primarily to aim at the keeping of qualitative data – and perhaps on quantitative data which, for one reason or another, not are interesting for DDA or which are primarily interesting in relation to teaching or students theses. A data archive for students exist at the Institute of Sociology, but there seems to be a need for something similar at other social science institutions (Barfort et al., 2010, p. 22, here translated from Danish).
DDA is organizational a part of the Danish State Archives, which are collecting, selecting, and storing documents from local and national governmental institutions, church books, private archives, business archives etc. with the purpose of preserving sources for historic studies, private or professional. The sources are primarily for future research and study, and may be regarded as historical and cultural heritage. One could ask, whether the research data of DDA are of a different kind? These are data produced from research processes, and may be recycled into other, contemporary research projects: they are publicized data and may be considered on a par with scholarly published documents. Is DDA more related to research libraries that to archives? Would it be more natural to organize such archives with research libraries?
The example demonstrates that archives have already occupied a niche of the functions that research libraries are now trying to get hold on. Again it is an example that many different institutions are competing on the same “market”. Perhaps it could be argued that the work of DDA is closer related to that of research libraries that to the work of traditional archives? But with media converge both libraries and archives are changed in fundamental ways and perhaps some kinds of libraries and archives will be merged in the future?
In this section we have demonstrated that the current interest in data curation is not new, but that historical experiences from the data archives exist. This fact makes the need for research libraries less obvious. Are there unfulfilled needs to be managed by libraries? If yes: why have they not already been served by the data archives?
Our conclusion is that research data today are stored in several ways (individual PCs, institutional servers or repositories, national archives, national and international subject repositories etc.), and that no institution yet has been selected as a common, national institution for storing of research data, and probably never will or should be. Research libraries must (as suggested by Barfort et al., 2010) identify unfulfilled needs which is in accordance with their interests and goals. As for the role of information professionals the needed competencies seems to converge: 14 An ironic example from the conclusion by Barfort et al (2010) is that DDA stores and curate quantitative data which might make a room for research libraries to store and preserve qualitative data. However, when you look in the DDA journal Metode og Forskningsdesign, the latest issues have several articles about DDA as an archive of qualitative data too.
17

“As data archives developed, a specialized profession of data librarian/archivist emerged, blending knowledge and skills from information technology, librarianship, statistics, and the social sciences. These professionals staff most national and many campus data archives. The International Association for Social Science Information Service and Technology (IASSIST) is their central professional organization. Among the organization's goals are the promotion of archiving and the development of standards for the preservation of data” (Rockwell, 2001, p. 3226).
Such blending of knowledge and skills seems necessary whether we speak of research libraries or independent data archives.
Data based on (digitalized) collections Data used in research may also come, although indirectly, from collections such as herbaria, zoological museums, geological museums, medical/anatomical collections and collections of fossils. Also collections of living plants and animals (botanical and zoological gardens) and less tangible things such as models of ecosystems, natural centres, centres for preserving plant and animal species are examples of what might be understood as museum institutions developed in order to support natural science. In the humanities and social sciences many different kinds of cultural collections and museums also have developed in order to serve scholarship. Examples are art museums, book and manuscript collections, media collections, military museums, museums of musical instruments etc. etc.
Such collections may increasingly consist of “digital born” materials. The content of such collections cannot in itself be considered data. Important data arises, however, by the study of items in collections. After the data have been collected the collection is maintained and may at a later time serve the production of new data, for example, motivated by new methods, by new theoretical points of view, or simple to control former studies.
Museums, archives and libraries have traditionally been considered different kinds of memory institutions although they are overlapping15). These different kinds of institutions have developed different kinds of standards and principles on how to describe, represent and organize their collections in order to serve their functions. The Internet has, however, changed the conditions for the description and organization of information objects (or documents in the wide sense of the word) and the tendency to media convergence demands the development of new principles and standards, of which the semantic web and linked data are among the theoretical most ambitious (see also Lee, 2000).
Many collections are being digitalized. This is both the case with book collections where we have projects such as European Digital Library Project, Google’s Print for Libraries, and Project
15 Many libraries contain for example also archives and museums and from certain point of view such as book-binding, many library collections should be understood as museums.
18
Gutenberg. But it is also the case with many other kinds of collections such as herbaria16. Sometimes digitalized collections will substitute the non-digital collections and often the digitalized and none digital collections will continue to exist side-by side (perhaps at a later point of time research may have a need for an improved digitalization or for different kinds of digitalization). The Swedish library and information scholar Mats Dahlström (2010) has quoined the term critical digitization (corresponding to critical editions) as opposed to mass digitalization in order to indicate the need for quality digitalization based on scholarly qualifications.
Collections have been seen as representing products in the collecting stage of the development of a scientific field from natural history to theoretical science. Battalio (1998) (based on Killingsworth & Palmer, 1992) suggests, for example, that zoology has developed in the following stages
1) Observing in the field (extreme natural history); 2) Collecting specimens; 3) Observing and measuring in the field; 4) Manipulating in the field; 5) Manipulating in semi-natural conditions; 6) Bringing systems into the lab, and finally 7) Theoretical systems, manipulation with numbers and computer models (the extreme of
theoretical science).
We have no indication however, that collections are no longer necessary for many sciences. Rather than understanding the use of collections as an obsolete epistemological stage, we consider different epistemologies as competing ideals in which systematic comparison of species in collections may still serve scientific purposes (perhaps theoretical science would tend to become superficial and short-sighted without a basis in such collections?)
The collections discussed in this section should be considered parts of science and scholarship themselves, although they are a kind of service institutions for science with some relative independence. They are also important parts of the existing infrastructure of scholarship that should be taken into account. There is no indication that such institutions should not continue to be so. To consider collections to be based on an obsolete epistemology is in our opinion wrong and reductionist. We do not imagine that other kinds of collections are taken over by libraries; on the contrary: libraries seem to be the most endangered species among the memory institutions. We do imagine, however, that information specialists will play important roles in the managing, digitalization and developing metadata systems of collections for scientific purposes. This was well understood by the founders of the documentation movement, who, as we have seen saw the term “document” as the central term covering all kinds of informative objects. Therefore the content of archives and museums is part of the sciences of documentation and information. The internet and its technologies will of course be the backbone in this development towards integration of different kinds of “documents”.
16 For example: University of Idaho Stillinger Herbarium: Digitizing the Herbarium: http://www.uidaho.edu/herbarium/about/digitizingtheherbarium
19

The organic interaction between science and data collections (case: meteorology, DMI)In this section we will demonstrate the organic interaction between science, data and other human activities in order to argue that huge amount of data probably is out of the reach for libraries.
Meteorological research depends on measures of climate developed as a practical means to make whether forecasts. The Danish Meteorological Institute (DMI) was founded in 1872 and has today a widespread number of measurement stations (see: http://www.dmi.dk/eng/cpt6.pdf ). The Data Processing Department is responsible for ensuring that information and prognoses are available to the meteorologists round the clock every day. The Department is responsible for providing computing services to other DMI departments and external customers, as well as for national and international data exchange. The meteorological information is stored in DMI’s climate database.
The Weather and Climate Information Division provides climate information daily to insurance companies, the police, lawyers, contractors, the agricultural sector, county and municipal authorities and the general public. In all, the Division handles approx. 5,000 telephone enquiries and 2,000 written enquiries each year. Climate data are used to prepare diagrams and tables and for the customer’s own analyses. Observations and climate data are made available on discs, CD or magnetic tape or via direct Internet access to the database (some of which is fee-based, a problem to be discussed below).
Can libraries – or information professionals in the information division – play a role in the further selection, curation and organization in relation to research activities such as climate changes or perhaps wind energy? Should libraries prepare meteorological data to be used for (further) computer simulations and calculations for researchers at DMI as well as for researchers in an international context? It is important in this connection to consider that DMI have research activities as an integrated part of their activities:
Applied research, development and exploitation of new knowledge within DMI's field of activity are preconditions if DMI is to be able to maintain rational production and to fulfill its obligations to the Danish society. (DMI 2008; http://www.dmi.dk/eng/index/research_and_development.htm )
The data collected by DMI are therefore also used in research and development, not the least in order to improve the quality of future weather forecasts. It is unthinkable that such data could be collected and organized just in order to fulfill the needs of research because that would not be economically possible. Research is in integrated activity and the development of measurement stations, satellites and computer and communication systems, forecasts and research are mutual depending processes. If research shows that new data could improve forecasts, then such data might be obtained and used for both daily activities as well as for further research.
20

The question is therefore: Which knowledge has been used so far by DMI to construe their databases in order to make them useful to normal operational activities as well as to research activities? (Have information specialists played a role in addition to meteorologists and computer scientists?) In what way (if any) could we - as information specialists - offer relevant knowledge in order to improve the organization and utilization of information from the collected data?
In the literature researchers and organizations (e.g. ARL) have argued that data curation is a task for research libraries. Some have made the point that research data might be used more effectively if they are organized in connected data bases, just like research articles and papers (Ruusalep 2008; van de Sompel & Lagoze 2009). Raivo Ruusalep wrote:
In the longer term, however, there is a need to produce and adopt universal rules for data description, to define minimum data curation services, and to identify rules for data security that are designed for use across different disciplines (Ruusalep, 2008, p. 5).
DMI has a library, but to consider data curation, data management and related functions the role of the library is probably absurd in this case. Nor is it probably fruitful to claim that the preservation and organization of meteorological data specifically for research purposes has such a special character, that there is a need for special library services to maintain that function. The reason for that is first and foremost the organic, integrated and interdependent nature of research activities, professional meteorological activities and data collection activities. To have the library organizing the data would again be the tail wagging the dog. The question is, of course, whether this example is representative for other domains as well?17 This question can be turned round: If, one case shows that research libraries cannot expect to be the place where data are managed, then we have shown that libraries cannot in general count on this function. If there are domains in which libraries can handle this, it has to be showed from domain to domain.
ConclusionLibraries (as well as archives and museums) has traditionally worked with documents (and only secondarily with data). One of the findings in this paper is that when “data” are recorded and given metadata they should be considered kinds of documents (as in the Data Citation Index) and thus included in the sphere of interest of research libraries. Instead of asking: Should libraries select, conserve, maintain, organize and communicate data, the question should rather be: How should libraries decide and make priorities between different kinds of documents? Among the new conditions for libraries is in particular that they are increasingly dependent on documents they do not owe but just provide access to (hence the saying: “from collections to connections”).
17 A reviewer of this paper commended: “I agree, that many examples can be found, where there is a very close link between the research process and the subsequent data handling; however my claim is, that there is also examples, where this link might be better exploited by introducing experts with e.g. classification knowledge – or with a very good knowledge of building ontologies to stimulate the cross discipline uptake of results. Therefore ONE example really shows nothing – unless it is argued how this example is representative – and for what.”
21

The discussion of data selection and management is thus by principle just part of the general discussion of document collection, indexing and preservation in libraries and other kinds of “memory institutions”, including digital repositories. Before the digital revolution there was a rough division of labour in that libraries have mainly been responsible for collecting published texts (produced in many copies), archives have mainly been responsible for collecting unique unpublished texts and museums have mainly been responsible for collecting unique non-textual objects. But these lines of division have never been sharp, and with media-convergence these lines are going to be more blurred (if not to disappear altogether).
Different kinds of libraries have used very different criteria for document collection and for collections management. National libraries have tried to preserve copies of all published documents in their respective countries. The International Federation of Library Associations and Institutions (IFLA) developed important principles (in 1982) about the Universal Availability of Publications. It is generally considered very important that scholars and everybody else all over the world have access to study and further develop the cumulated corpus of knowledge which has been documented and published. The principles of collecting materials in national libraries have traditionally been based on formal criteria (rather than criteria of relevance), in opposition to public libraries and research libraries, where criteria of user demands and relevance for research and education have traditionally dominated the selection of materials and the maintenance of collections. In principle, the collection of the kinds of documents termed “data” in research libraries should be based on the same principles of estimating relevance for future research activities as have been applied to the selection of other kinds of documents.
A diffusion of functions will probably evolve. Academic libraries will in some cases be important both in relation to creation of digital data and data collections and to data curation. But many other players will be on the ground, so academic libraries will perhaps not often be first choice. Information specialists will be embedded in many places, not necessarily as librarians but, but as specialists in scientific documentation, as IKD specialists: information, knowledge, and data specialists.
The design of research infrastructures is both a technological issue, an issue of determining disciplinary research needs and a policy issue. As a policy issue research infrastructures are closely related to overall research policy. We shall here focus on the disciplinary research needs and suggest that each domain is given a voice about its own needs in relation to research infrastructures. Such a project is closely related to studies of domains in other fields of metascience (such as the sociology of science, the theory of science and scientometrics). It is closely related to what has traditionally been the job of research librarians, documentalists and information specialists: to overview knowledge production in order to provide access to information needed by the users (which can be compared with maintaining a part of the research infrastructure). A traditional job has
22

also been to produce guides to information sources to users in different domains18. This work is as much needed in the future as in the past and needs to be based in proper studies of scholarly fields.
The difference between on the one hand to describing and select information sources in a given domain for the researchers and on the other hand to produce input about what data are important for research in that domain seems just in principle to be a small one. We suggest that information specialists who are also domain specialists could be important partners in providing information about research needs for data in different domains. Information specialists should help researchers articulate their needs for research infrastructures and data curating. This activity should be research-based, and the kind of research should be domain-analytic studies (Hjørland, 2002; Weber et al., 2012).
LiteratureAckoff, R. L. (1989). From data to wisdom, Journal of Applied Systems Analysis, 16(1), 3–9.
Anderson, M. (2001). Censuses: History and Methods; IN: Smelser, N. J. & Baltes, P. B. (eds.) International Encyclopedia of the Social and Behavioral Sciences (Vol. 3 , pp. 1605-1610). Amsterdam: Elsevier.
Attwood, T. K., Kell, D. B., McDermott, P., Marsh, J., Pettifer, S. R., & Thorne, D. (2010). Utopia documents: linking scholarly literature with research data. Bioinformatics. 26(18): i568-i574. http://dx.doi.org/10.1093/bioinformatics/btq383
Barfort, S. et al. (2010). Samfundsvidenskabelige Primærdata (Primary Data of Social Sciences). KUBIS Videncenter for Videnskabelig Kommunikation, Det Kongelige Bibliotek / Københavns Universitets Biblioteks og Informationsservice. Localized 8 May 2012 on http://hprints.org/docs/00/45/10/00/PDF/KUBIS-rapport_om_samfundsvidenskabelige_primaerdata_2009_Barfort_et_al.pdf
Battalio, J.T. (1998). The rhetoric of science in the evolution of American ornithological discourse. London : Ablex Publishing Corporation.
Blue Ribbon Task Force on Sustainable Economics for a Digital Planet (2010) Sustainable Economics for a Digital Planet. Ensuring Long-Term Access to Digital Information. http://brtf.sdsc.edu/biblio/BRTF_Final_Report.pdf
Bogen, Jim (2009). Theory and Observation in Science. In: Stanford Encyclopedia of Philosophy. http://plato.stanford.edu/entries/science-theory-observation/
18 As Bottle (1997, p. 213) wrote: "Probably the first distinct information science literature type was the literature guide. An early example was W. Ostwald's Die chemische Literatur und die Organisation der Wissenschaft (Leipzig, 1919)".
23

Borgman, Christine L. (2007) Scholarship in the Digital Age: Information, Infrastructure, and the Internet. MIT Press
Borgman, C.L (2010). Research Data: Who will share what with whom, when, and why. Fifth China – North America Library Conference. 8-12 September 2010. Beijing
Bottle, R. T. (1997). Information science. I: Feather, J. & Sturges, P. (Eds.). International encyclopedia of library and information science. London & New York : Routledge. (pp. 212-214).
Briet, Suzanne (1951). Qu'est-ce que la documentation? Paris: Editions Documentaires Industrielle et Techniques. [English translation by Ronald E. Day and Laurent Martinet in 2006 as What is Documentation? English Translation of the Classic French Text. Lanham, MD: Scarecrow Press.]
Briet, S. (2006). What is documentation? (R.E. Day & L. Martinet, with H.G.B. Anghelescu, Trans. and Eds.). Lanham, MD: Scarecrow Press. (Original: Qu’est-ce que la documentation? Paris, EDIT, published 1951)
Buckland, M. (1991). Information and information systems. New York: Greenwood Press.
Brittain, J. M. (1989). Knowledge in the social sciences. International Journal of Information and Library Research, 1(2), 93-105.
Buckland, M. (1991). Information and information systems. New York: Greenwood Press.
Campbell, R. T. (2001). Databases, Core: Sociology. IN: Smelser, N. J. & Baltes, P. B. (eds.) International Encyclopedia of the Social and Behavioral Sciences (Vol. 5, pp. 3255-3260). Amsterdam: Elsevier.
Cotta Schønberg, M. (2009). En refleksion over universitetsbibliotekets fremtidsperspektiv anno 2009. Dansk Biblioteksforskning, 5(2/3), 5-19. Retrieved 2011-05-05 from: http://www.danskbiblioteksforskning.dk/2009/nr2-3/cotta-Schoenberg.pdf
Dahlstrom, Mats (2010). Critical editing and critical digitization. I: E. Thoutenhoofd, A. van der Weel & W. Th. van Peursen (Eds.), Text comparison and digital creativity: the production of presence and meaning in digital text scholarship. Amsterdam: Brill, pp. 79-97.
Dreehsen, L.L. (2009). NASA: Jagten sættes ind på Jordens tvilling. Berlingske Tidende, 7. marts 2009, 1. sektion, s.6, Retrieved 2009-10-09 from: http://www.berlingske.dk/article/20090307/viden/703060102/
24

Fjordback Søndergaard, T.; Andersen, J. & Hjørland, B. (2003). Documents and the communication of scientific and scholarly information. Revising and updating the UNISIST model. Journal of Documentation, 59(3), s. 278-320.
Frické, Martin (2009). The knowledge pyramid. A critique of the DIKW hierarchy. Journal of information science, 35(2), 131-142.
Frohmann, B. (2004). Deflating information. From science studies to documentation. Toronto: University of Toronto Press.
Furner, J. (2004). Information studies without information. Library Trends, 52(3), 427-446.
Gold, A. (2007). Cyberinfrastructure, Data, And Libraries, Part 1. A Cyberinfrastructure Primer for Librarians. D-Lib Magazine, vol. 13, Number 9/10
Gold, M. K. (ed.) (2012). Debates in the Digital Humanities. Minneapolis, London: University of Minnesota press
Heller, Alfred et al. (2011). Forskningsdata og Open Access. Et deff-projekt. Lokaliseret 18-8-11 på http://forskningsdata.deff.wikispaces.net/file/view/Forskningsdata+og+Open+Accetss+Slutrapport.pdf
Hjørland, B. (2000). Documents, memory institutions, and information science. Journal of Documentation, 56(1), 27-41.
Hjørland, B. (2002). Domain analysis in information science: eleven approaches–traditional as well as innovative. Journal of Documentation, 58(4), 422-462.
Hjørland, B. (2007). Arguments for 'the bibliographical paradigm'. Some thoughts inspired by the new English edition of the UDC. Information Research, 12(4) paper colis06. Available at http://InformationR.net/ir/12-4/colis/colis06.html
Juster, F. T. (2001). Microdatabases: Economic. IN: Smelser, N. J. & Baltes, P. B. (eds.) International Encyclopedia of the Social and Behavioral Sciences (Vol. 14, pp. 9770-9777). Amsterdam: Elsevier.
Kaase, M. (2001). Databases, Core: Political Science and Political Behavior. IN: Smelser, N. J. & Baltes, P. B. (eds.) International Encyclopedia of the Social and Behavioral Sciences (Vol. 5, pp. 3251-3255). Amsterdam: Elsevier.
Killingsworth, M. J. & Palmer, J.S. (1992). Ecospeak. Rhetoric and environmental politics in America. Carbondale and Edwardsville : Southern Illinois University Press.
25

Kjeldsen, H.; Christensen-Dalsgaard, J.; Handberg, R.; Brown, T.M.; Gilliland, R.L.; Borucki, W.J. & Koch, D. (2010).The Kepler Asteroseismic Investigation: Scientific goals and the first results. Astronomische Nachrichten, 331(9-10), 966–971. Preprint version obtained from: http://arxiv.org/pdf/1007.1816.pdf
Lee, Hur-Li (2000). What is a collection? Journal of the American Society for Information Science. 51(12), 1106-1113. http://comminfo.rutgers.edu/~tefko/Courses/Zadar/Readings/HurliLeeJASIS.pdf
Lewis, Martin (2010). Libraries and the Management of Research Data. In: McKnight, Sue (ed.): Envisioning future academic library services. London: Facet Publishing. http://eprints.whiterose.ac.uk/11171/1/LEWIS_Chapter_v10.pdf
Lund, N. W. (2004). Documentation in a complementary perspective.In W. B. Rayward, J. Hansson, & V. Suominen (Eds.), Aware and responsible: Papers of the Nordic-International Colloquium on Social and Cultural Awareness and Responsibility in Library, Information and Documentation Studies (pp. 93–102). Lanham, MD: Scarecrow Press, Inc.
Lynch, Clifford A. (2009) "Jim Gray's Fourth Paradigm and the Construction of the Scientific Record", The Fourth Paradigm: Data-Intensive Scientific Discovery, Tony Hey, Stewart Tansley, and Kirstin Tolle (Eds.), (Redmond, WA: Microsoft Research, 2009), pp 177-183http://research.microsoft.com/en-us/collaboration/fourthparadigm/4th_paradigm_book_part4_lynch.pdf
Ma, L. (2012). Meanings of Information: The Assumptions and Research Consequences of Three Foundational LIS Theories. Journal of the American Society for Information Science and Technology, 63(4), 716–723.
Machlup, F. (1984). Semantic quirks in studies of information. In: Machlup, Fritz & Una Mansfield. The study of information: Interdisciplinary messages. NY : Wiley. (pp. 641-671).
Martin, M. E.; Straf, M. L. & Citro, C. F. (2001). Principles and Practices for a Federal Statistical Agency. Second Edition. National Academy Press, Washington, DC
Meyer, Eric T., Madsen, Christine, and Fry, Jenny (2010). ”Digital Resources and the Future og Libraries”. I: Dotton, William H. & Jeffreys, Paul W. (ed.) World Wide Research. Reshaping the Sciences and Humanities. Cambridge, London: The MIT Press.
Mohler, P. P. (2001). Survey Research: National Centers. IN: Smelser, N. J. & Baltes, P. B. (eds.) International Encyclopedia of the Social and Behavioral Sciences (Vol. 22, pp. 15311- 15314). Amsterdam: Elsevier.
26

National Science Board (2005). Long-Lived Digital Data Collections: Enabling Research and Education in the 21st Century. National Science Foundation. US. http://www.nsf.gov/pubs/2005/nsb0540/
Ørom, A. (2007). The concept of information versus the concept of document. In R. Skare, N. W. Lund, & A. Vårheim (Eds.), Document (re)turn. Contributions from a research field in transition (pp. 53-72). Frankfurt am Main: Peter Lang.
Ostwald, W (1919). Die chemische Literatur und die Organisation der Wissenschaft. Leipzig : W. Ostwald & C. Drucker.
Owen, J. M. (2007). The scientific article in the age of digitalization. Dordrecht: Springer.
Rockwell, R. C. (2001). Data Archives: International. IN: Smelser, N. J. & Baltes, P. B. (eds.) International Encyclopedia of the Social and Behavioral Sciences (vol. 5, pp. 3225- 3230). Amsterdam: Elsevier. Ruusalep, R. (2008) Infrastructure Planning and Data Curation: A Comparative Study of International Approaches to Enabling the Sharing of Research Data. JISC, Nov. 30, 2008. Lokaliseret på www 30-11-11 http://www.dcc.ac.uk/sites/default/files/documents/publications/reports/Data-Sharing-Report.pdf
Shearer, K and Argáez, D. (2010). Addressing the Research Data Gap: A Review of Novel Services for Libraries. Canadian Association of Research Libraries.
Spang-Hanssen, H. (2001).: How to teach about information as related to documentation. Human IT. (1), 125-143. http://www.hb.se/bhs/ith/1-01/hsh.htm [written 1970].
Sparck Jones, K. (1987). Architecture problems in the construction of expert systems for document retrieval. In: Wormell, I., ed. Knowledge engineering: expert systems and information retrieval. London: Taylor Graham, 7–33.
Straf, M. (2001). Government Statistics. IN: Smelser, N. J. & Baltes, P. B. (eds.) International Encyclopedia of the Social and Behavioral Sciences (Vol. 9, pp. 6314- 6321). Amsterdam: Elsevier.
Stuart, D. (2011). Facilitating Access to the Web of Data: A guide for librarians. London: Facet Publishing.
27

Thomson Reuter (2012). Repository evaluation, selection, and coverage policies for the Data Cittaion IndexSM within Thomson Reuters Web of KnowledgeSM. Retrieved 2012-11-25 from: http://wokinfo.com/media/pdf/DCI_selection_essay.pdf
Van de Sompel, H. & Lagoze, C. (2009) All Aboard: Toward a Machine-Friendly Scholarly Communication System. The Fourth Paradigm: Data-Intensive Scientific Discovery, Tony Hey, Stewart Tansley, and Kirstin Tolle (Eds.), (Redmond, WA: Microsoft Research), pp 193-199http://research.microsoft.com/en-us/collaboration/fourthparadigm/4th_paradigm_book_part4_sompel_lagoze.pdf
Weber, Nicholas M. , Karen S. Baker, Andrea K. Thomer, Tiffany C. Chao and Carole L. Palmer (2012): Value and Context in Data Use: Domain Analysis Revisited. ASIST 2012 Annual Meeting Baltimore, MD, October 26-30, 2012, in press
White, H. D. (2010). Relevance in theory. In M. J. Bates & M. N. Maack (Eds.), Encyclopedia of library and information sciences (3rd ed.; Vol 6; pp. 4498-4511). New York: Taylor & Francis.
Zins, C. (2007). Conceptual approaches for defining data, information, and knowledge. Journal of the American Society for Information Science and Technology. 58(4), 479-493.
28










![Frei-journal.net/jdoc/apc_4.pdf · 2018. 6. 9. · самоуправления) в современном демократическом государстве [2, с. 33]; как](https://img.dokumen.tips/doc/110x75/600c964fd9a36d05d97ff6bd/frei-2018-6-9-f-.jpg)


















