Embed Size (px)
Citation preview

CSM06 Information RetrievalLecture 8: Video Retrieval, and Learning Associations between Visual Features & Words
Dr Andrew Salway [email protected]

Recap…
• Image retrieval exercise…

Recap…
• The challenges of image retrieval (many possible index words, sensory/semantic gaps) are also challenges for video retrieval
• Likewise, the same kinds of approaches used for image retrieval have been applied to video retrieval (manual indexing, visual features, words extracted from collateral text)

Lecture 8: OVERVIEW
• BACKDROP: Think about how approaches are more/less applicable for different kinds of image/video collections (general or specialist) and for different kinds of users (public or domain expert)
• Three approaches to the indexing-retrieval of videos:– Manual indexing– Content-based Image Retrieval (visual similarity;
query-by-example), e.g. VideoQ– Automatic selection of keywords from text related to
images, e.g. Informedia, Google Video, BlinkxTV
• The potential for systems to learn associations between words and visual features (based on large quantities of text-image data from the web), e.g. for automatic image/video indexing

Three Approaches to Video Indexing-Retrieval
1. Index by manually attaching keywords to videos – query by keywords
2. Index by automatically extracting visual features from video data – query by visual example
3. Index by automatically extracting keywords from text already connected to videos – query by keywords

1. Manual Video Indexing
• The same advantages / disadvantages of manual image indexing
• Must also consider how to model the video data, e.g. attach keywords to the whole video file, or to intervals within it

2. Indexing-Retrieval based on Visual Features
• Same idea as content-based image retrieval, but with video data there is also the feature of motion
• For example, the VideoQ system developed at Columbia University

VideoQ: Columbia University, New York
• Indexing based on automatically extracted visual features, including colour, shape and motion: these features are generated for regions/objects in sequences within video data streams.
• Sketch-based queries can specify colour and shape are specified as well as motion over a number of frames and spatial relationships with other objects/regions.
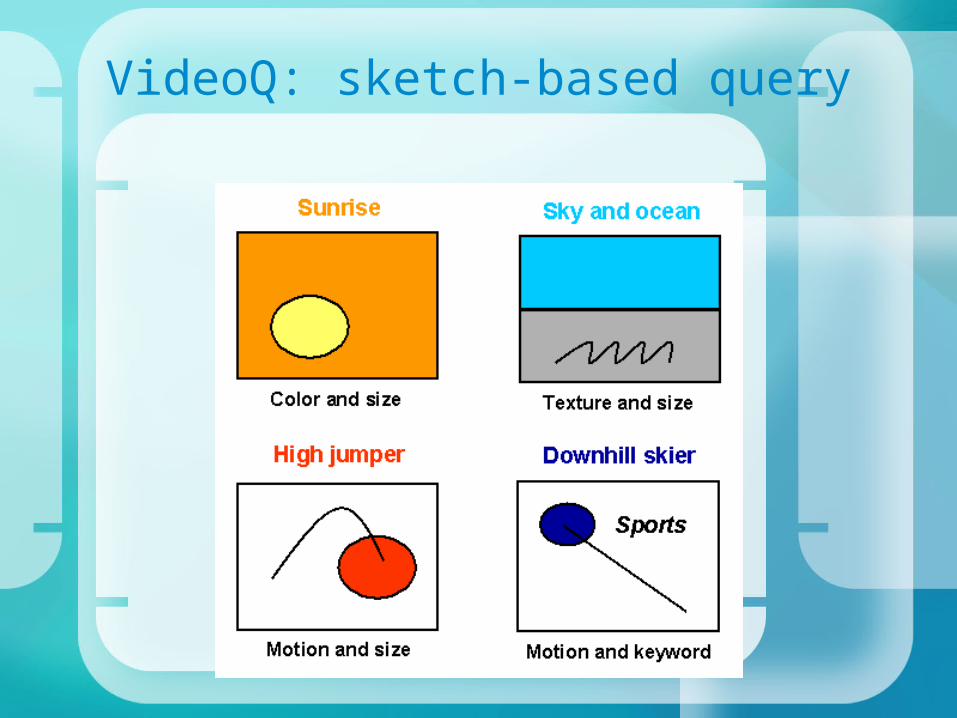
VideoQ: sketch-based query

VideoQ: sketch-based query
Success depends on how well information needs can be expressed as visual features – may not capture
all the ‘semantics’ of a video sequence

3. Extracting keywords from text already associated with videos…
• As with image retrieval, systems may need to extract words for collateral text in order to index video in terms of the meanings it conveys to humans
• Example collateral texts include: speech / closed captions, film scripts and audio description

Informedia: Carnegie Mellon University
• Indexing based on keywords extracted from the audio stream and/or subtitles of news and documentary programmes.
• Also combines visual and linguistic features to classify video segments


Informedia: Carnegie Mellon University
Success depends on how closely the spoken words of
the presenters relates to what can be seen

Fusing visual and linguistic information: ‘INFORMEDIA’
Visual information processing: detects indoors / outdoors; single person / crowd
Linguistic information processing: detect political speech / news report
Political speech + outdoors = rallyPolitical speech + indoors = conference

Audio Description: a ‘new’ kind of collateral text?

Audio Description Script[11.43] Hanna passes Jan some banknotes.
[11.55] Laughing, Jan falls back into her seat as the jeep overtakes the lorries.
[12.01] An explosion on the road ahead.
[12.08] The jeep has hit a mine.
[12.09] Hanna jumps from the lorry.
[12.20] Desperately she runs towards the mangled jeep.
[12.27] Soldiers try to stop her.
[12.31] She struggles with the soldier who grabs hold of her firmly.
[12.35] He lifts her bodily from the ground, holding her tightly in his arms.

Extracting Information about Emotions in Films
• A ‘narrative’ representation of a film should include characters’ changing mental states
• Audio Description does not comment on characters’ mental states explicitly, but does indicate emotions with visible manifestation
[1.15] She is resting peacefully…
[5.12] She peers anxiously…

Extracting Information about Emotions in Films
METHOD• Using classification of 22 emotion types from
Ortony, Clore and Collins (1988)• Created lists of 600+ ‘emotion tokens’ using
WordNet on all grammatical variants of type names
FEAR: nervously, desperately, terrified…
JOY: joy, contented, cheerful, delighted…
HOPE: hope, expectation…
Visualise and analyse distribution of emotion tokens as a machine-executable
representation of film content

Plot of ‘Emotion Tokens’ in Audio Description for Captain Correlli’s Mandolin

Plot of ‘Emotion Tokens’ in Audio Description for Captain Correlli’s Mandolin
52 tokens of 8 emotion types15-20 minutes: Pelagria’s betrothal to Madras20-30 minutes: invasion of the island68-74 minutes: Pelagria and Correlli’s growing relationship92-95 minutes: German soldiers disarm Italians

Plot of ‘Emotion Tokens’ in Audio Description for The Postman

Extracting Information about Emotions in Films
Potential applications…• Video Retrieval by Story Similarity• Video Summarisation by Dramatic
Sequences• Video Browsing by Cause-Effect
Relationships
TIWO Project (Television in Words), Department of Computing, University of Surrey.

Learning Associations between Words and Visual Features
• Some researchers view the web as an opportunity to train systems to understand image content – there are 100,000,000’s of images and many have some text description. This has been a major research theme in recent years
• Maybe this is a way to close the Semantic Gap between the visual features that a machine can analyse from an image, and the meanings that humans understand in an image
• One recent example of this is the work of Yanai (2003)

“Generic Image Classification Using Visual Knowledge on the Web” (Yanai 2003)
What problem does this word address?
• The aim is for generic image classification, i.e. classification of an unconstrained set of images like on the Web
• (Typically computer vision systems have been developed to recognise specific kinds of images, e.g. medical images, or traffic images)

“Generic Image Classification Using Visual Knowledge on the Web” (Yanai 2003)
What is the approach?• The approach is to develop a
system that learns associations between keywords (connected with a class of images) and the visual features of those images
• The co-occurrence of images and keywords on web pages is used to give ‘training data’ for the system

“Generic Image Classification Using Visual Knowledge on the Web” (Yanai 2003)
How does it work?Three modules…• Image Gathering Module • Image Learning Module• Image Classification Module

“Generic Image Classification Using Visual Knowledge on the Web” (Yanai 2003)
Image Gathering Module • “gathers images related to given class
keywords from the Web automatically”• A ‘scoring algorithm’ is used to measure the
strength of the relationship between a keyword and an image– For example, the score gets higher if the
keyword appears in the “SRC IMG” tag and the ALT field; also if it appears in the TITLE of the webpage and “H1 --- H6” tags
• (Previous work had used image collections with manually annotated keywords – not
representative of the Web)

“Generic Image Classification Using Visual Knowledge on the Web” (Yanai 2003)
Image Learning Module• “extracts image features from
gathered images and associates them with each class”
• Image Features represented as vectors based on colours in blocks and regions of the image

“Generic Image Classification Using Visual Knowledge on the Web” (Yanai 2003)
Image Classification Module • “classifies an unknown image into
one of the classes … using the association between image features and classes”
• Calculate image features for the new image and work out which class of images it is closest to (based on similarity of colour features)

“Generic Image Classification Using Visual Knowledge on the Web” (Yanai 2003)
How has it been evaluated?• 10 Classes of animals (bear, cat,
dog, etc.) – about 37,000 images gathered from the web
• Encouraging results for some image classes, e.g. ‘whale’ – better when training images were manually filtered
• Some classes more difficult, e.g. ‘house’ - **is it ever possible to specify what a house is only in terms of visual features?**

“Generic Image Classification Using Visual Knowledge on the Web” (Yanai 2003)
What is the applicability for the Web?• There certainly is a need for generic image
classification on the web, but there are still challenges to overcome
• Maybe need more research to find out what are the most appropriate image features and text features to associate, and what training method
• Also need to recognise that when text occurs with an image it is not always giving a straightforward description of image content ( a variety of image-text relationships)
These issues are challenges for all the researchers who build systems to learn associations between
images and words on the Web.

Set Reading
Yanai (2003), “Generic Image Classification Using Visual Knowledge on the Web”, Procs ACM Multimedia 2003.
***Only Section 1 and Section 5 are essential

Further Reading (Video Retrieval)
• More on VideoQ at:http://www.ctr.columbia.edu/videoq/.index.html
• Informedia Research project:http://www.informedia.cs.cmu.edu/
• More on TIWO at:www.computing.surrey.ac.uk/personal/pg/A.Salway/tiwo/TIWO.htm
Salway and Graham (2003), Extracting Information about Emotions in Films. Procs. 11th ACM Conference on Multimedia 2003, 4th-6th Nov. 2003, pp. 299-302.

Further Reading (Learning visual-text feature association)
• Barnard et al (2003), “Matching Words and Pictures”, Journal of Machine Learning Research, Volume 3, pp. 1107-1135.
• Wang, Ma and Li (2004), “Data-driven approach for Bridging the Cognitive Gap in Image Retrieval”, Procs. IEEE Conference on Multimedia and Expo, ICME 2004.

Lecture 8: LEARNING OUTCOMES
You should be able to:- Describe, critique and compare three different
approaches to indexing-retrieving images with reference to example systems, and with reference to different kinds of video collections and users
- Explain the approach taken in Yanai (2003), i.e. the aim of the work, the method and the results
- Discuss to what extent, in your opinion, systems that learn to associate words and visual features can solve the problem of the semantic gap, with reference to work such as Yanai (2003)

Revising Set Reading
• I suggest that you use the lecture notes to guide you through the Set Reading, i.e. use the set reading to give you a deeper understanding of what was in the lecture.
• It might not be helpful to try and remember every detail from the set reading, especially if we didn’t cover it in the lecture

Another note about REVISION
• For the depth of understanding required for a topic, consider (as a rough guide):– The amount of lecture time spent
on it; did it feature in more than one lecture?
– Were there any in-class / set exercises
– Was there any related set reading

Preparing Presentations for Next Week
• The aim is to get feedback from the class and from me
• Each group should present for 10-15 minutes; I suggest maximum 10 slides
• Suggested structure:– Brief explanation (from literature) of the idea that
you are investigating– A statement of your aim, i.e. what you are trying
to find out / test– A description of your method / implementation for
getting data– A presentation and discussion of your results
and what you have found out• Either, bring your own laptop, or email me your
slides BEFORE Tuesday morning





























