Embed Size (px)
Citation preview

CSE 326: Data StructuresLecture #21Graphs II.5
Alon Halevy
Spring Quarter 2001

Outline
• Dijkstra’s algorithm (finally!!)• Algorithms for minimum spanning trees.• Search huge graphs.

Single Source, Shortest Path
Given a graph G = (V, E) and a vertex s V, find the shortest path from s to every vertex in V
Many variations:– weighted vs. unweighted– cyclic vs. acyclic– positive weights only vs. negative weights allowed– multiple weight types to optimize

Dijkstra’s Algorithm for Single Source Shortest Path
• Classic algorithm for solving shortest path in weighted graphs without negative weights
• A greedy algorithm (irrevocably makes decisions without considering future consequences)
• Intuition:– shortest path from source vertex to itself is 0
– cost of going to adjacent nodes is at most edge weights
– cheapest of these must be shortest path to that node
– update paths for new node and continue picking cheapest path

Dijkstra’s Pseudocode(actually, our pseudocode for Dijkstra’s algorithm)
Initialize the cost of each node to Initialize the cost of the source to 0
While there are unknown nodes left in the graphSelect the unknown node with the lowest cost: n
Mark n as known
For each node a which is adjacent to n
a’s cost = min(a’s old cost, n’s cost + cost of (n, a))
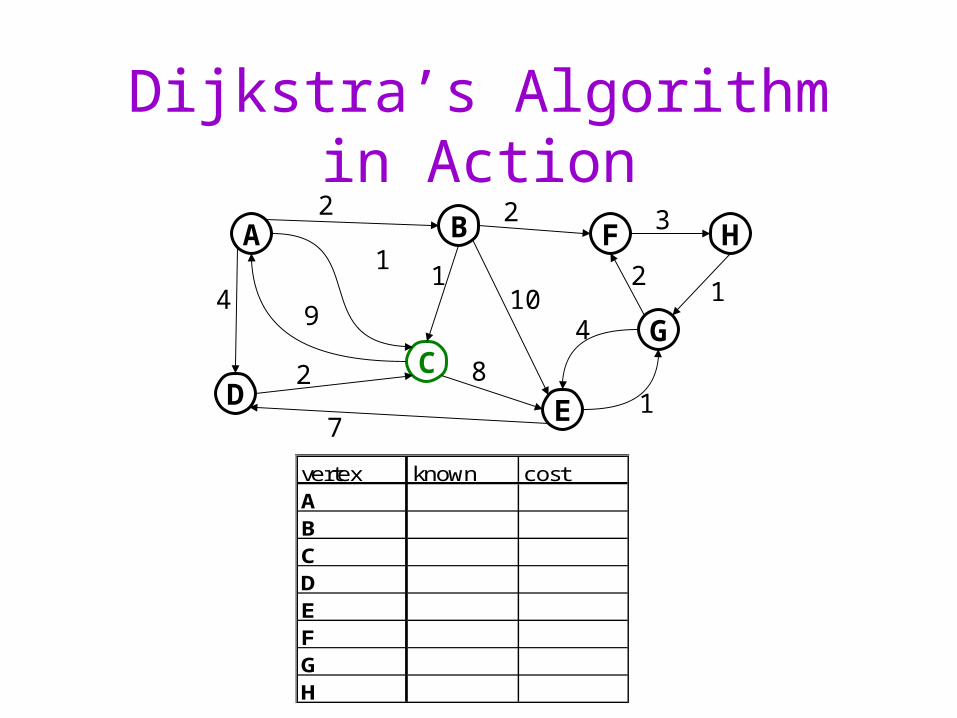
Dijkstra’s Algorithm in Action
A
C
B
D
F H
G
E
2 2 3
21
1
410
8
11
94
2
7
vertex known costABCDEFGH
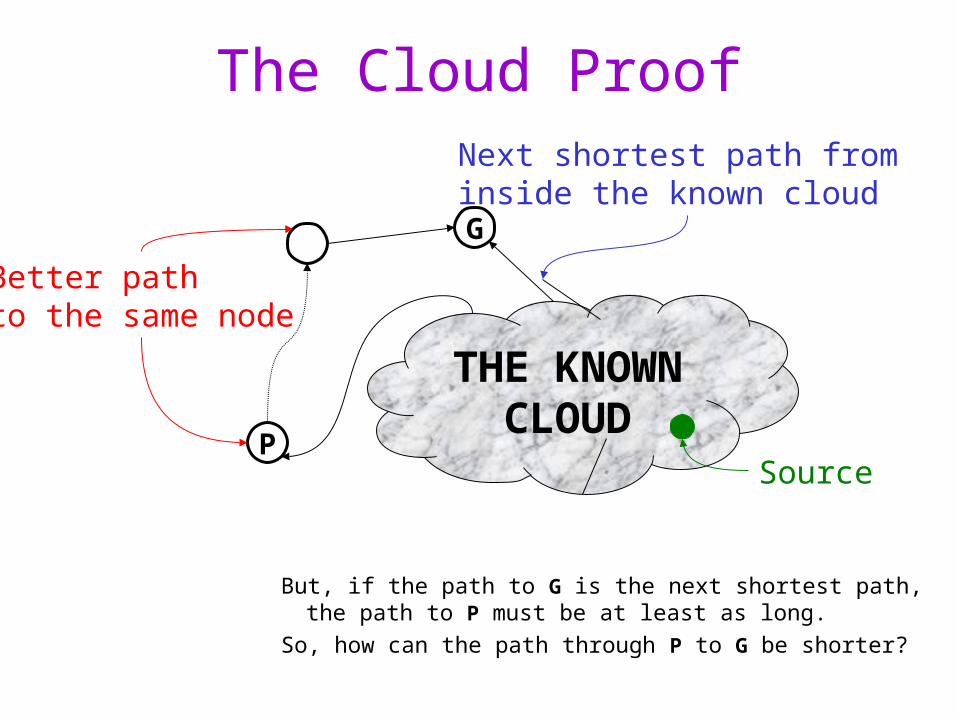
THE KNOWNCLOUD
G
Next shortest path from inside the known cloud
P
Better pathto the same node
The Cloud Proof
But, if the path to G is the next shortest path, the path to P must be at least as long.
So, how can the path through P to G be shorter?
Source

Inside the Cloud (Proof)
Everything inside the cloud has the correct shortest path
Proof is by induction on the # of nodes in the cloud:– initial cloud is just the source with shortest path 0
– inductive step: once we prove the shortest path to G is correct, we add it to the cloud
Negative weights blow this proof away!

Revenge of the Dijkstra Pseudocode
Initialize the cost of each node to s.cost = 0;
heap.insert(s);
While (! heap.empty)
n = heap.deleteMin()
For (each node a which is adjacent to n)
if (n.cost + edge[n,a].cost < a.cost) then
a.cost = n.cost + edge[n,a].cost
a.path = n;
if (a is in the heap) then heap.decreaseKey(a)
else heap.insert(a)

Data Structures for Dijkstra’s Algorithm
Select the unknown node with the lowest cost
findMin/deleteMin
a’s cost = min(a’s old cost, …)
decreaseKey
find by name
|V| times:
|E| times:
runtime:
O(log |V|)
O(log |V|)
O(1)

Single Source & Goal
• Suppose we only care about shortest path from source to a particular vertex g– Run Dijkstra to completion
– Stop early? When?• When g is added to the priority queue
• When g is removed from the priority queue
• When the priority queue is empty

Key Idea
• Once g is removed from the priority queue, its shortest path is known
• Otherwise, even if it has been seen, a shorter path may yet be found
• Easy generalization: find the shortest paths from source to any of a set of goal nodes g1, g2, …

Spanning tree: a subset of the edges from a connected graph that……touches all vertices in the graph (spans the graph)
…forms a tree (is connected and contains no cycles)
Minimum spanning tree: the spanning tree with the least total edge cost.
Spanning Trees
4 7
1 5
9
2

Applications of Minimal Spanning Trees
• Communication networks
• VLSI design
• Transportation systems
• Good approximation to some NP-hard problems (more later)

Kruskal’s Algorithm for Minimum Spanning Trees
A greedy algorithm:
Initialize all vertices to unconnected
While there are still unmarked edgesPick a lowest cost edge e = (u, v) and mark it
If u and v are not already connected, add e to the minimum spanning tree and connect u and v

Kruskal’s Algorithm in Action (1/5)
A
C
B
D
F H
G
E
2 2 3
21
4
10
8
194
2
7

Kruskal’s Algorithm in Action (2/5)
A
C
B
D
F H
G
E
2 2 3
21
4
10
8
194
2
7

Kruskal’s Algorithm in Action (3/5)
A
C
B
D
F H
G
E
2 2 3
21
4
10
8
194
2
7

Kruskal’s Algorithm in Action (4/5)
A
C
B
D
F H
G
E
2 2 3
21
4
10
8
194
2
7
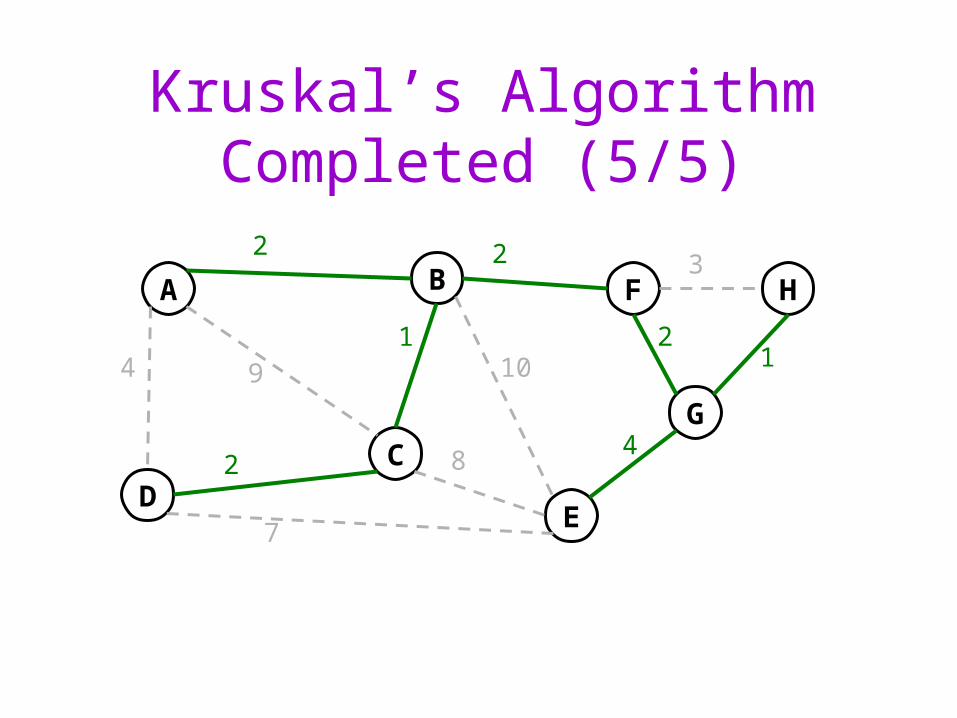
Kruskal’s Algorithm Completed (5/5)
A
C
B
D
F H
G
E
2 2 3
21
4
10
8
194
2
7

Why Greediness Works
The algorithm produces a spanning tree. Why?
Proof by contradiction that Kruskal’s finds the minimum:Assume another spanning tree has lower cost than Kruskal’s
Pick an edge e1 = (u, v) in that tree that’s not in Kruskal’s
Kruskal’s alg. connects u’s and v’s sets with another edge e2
But, e2 must have at most the same cost as e1!
So, swap e2 for e1 (at worst keeping the cost the same)
Repeat until the tree is identical to Kruskal’s: contradiction!
QED: Kruskal’s algorithm finds a minimum spanning tree.
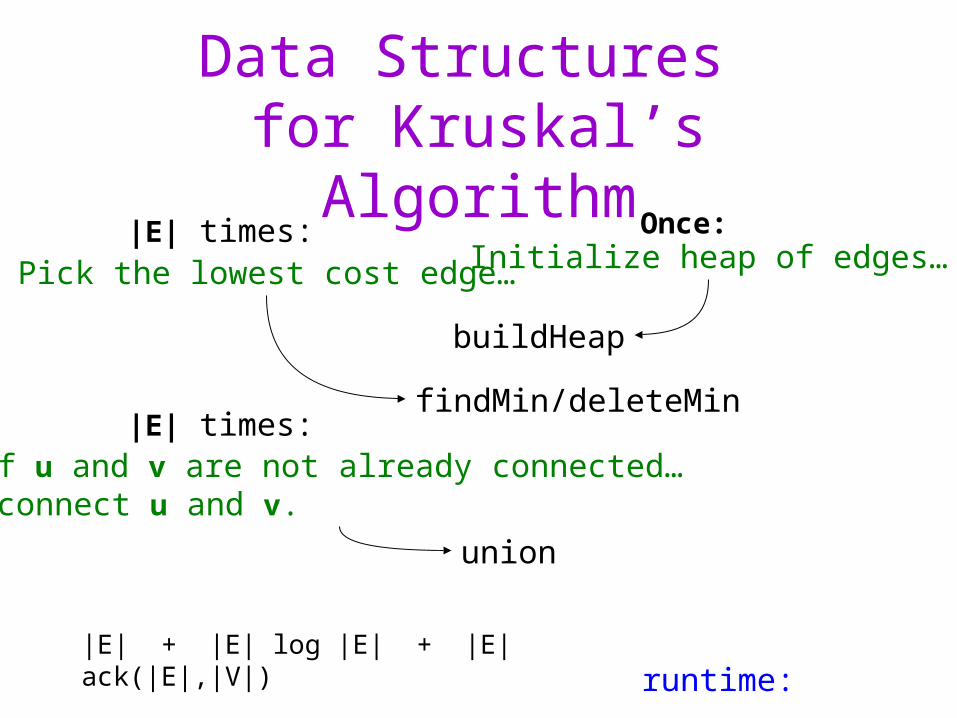
Data Structures for Kruskal’s Algorithm
Pick the lowest cost edge…
findMin/deleteMin
If u and v are not already connected… …connect u and v.
union
|E| times:
|E| times:
runtime:
Once:Initialize heap of edges…
buildHeap
|E| + |E| log |E| + |E| ack(|E|,|V|)

Prim’s Algorithm
• Can also find Minimum Spanning Trees using a variation of Dijkstra’s algorithm:
Pick a initial nodeUntil graph is connected:
Choose edge (u,v) which is of minimum cost among edges where u is in tree but v is notAdd (u,v) to the tree
• Same “greedy” proof, same asymptotic complexity

Does Greedy Always Work?
• Consider the following problem:– Given a graph G = (V,E) and a designed subset of
vertices S, find a minimum cost tree that includes all of S
• Exactly the same as a minimum spanning tree, except that it doesn’t have to include ALL the vertices – only the specified subset of vertices.– Does Kruskal or Prim work?

Nope!
• Greedy can fail to be optimal– because different solutions may contain different “non-
designed” vertices, proof that you can covert one to the other doesn’t go through
• This Minimum Steiner Tree problem has no known solution of O(nk) for any fixed k
– NP-complete problems strike again!– Finding a spanning tree and then pruning it a pretty
good approximation

Huge Graphs• Consider some really huge graphs…
– All cities and towns in the World Atlas
– All stars in the Galaxy
– All ways 10 blocks can be stacked
Huh???
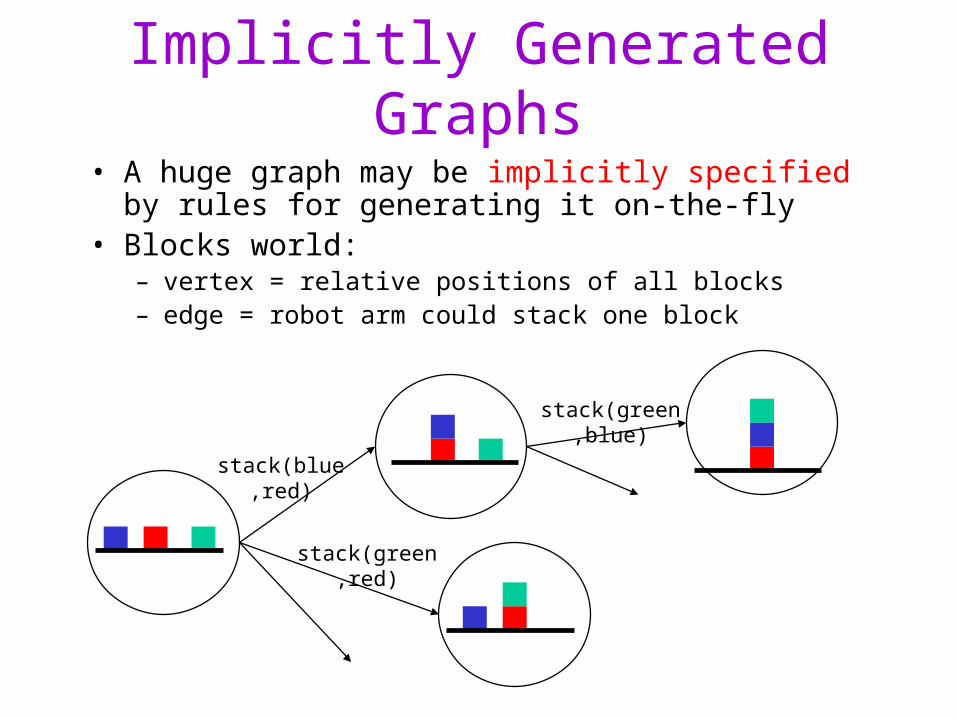
Implicitly Generated Graphs
• A huge graph may be implicitly specified by rules for generating it on-the-fly
• Blocks world: – vertex = relative positions of all blocks– edge = robot arm could stack one block
stack(blue,red)
stack(green,red)
stack(green,blue)

Blocks World
• Source = initial state of the blocks• Goal = desired state of the blocks• Path from source to goal = sequence of actions
(program) for robot arm!• n blocks nn states• 10 blocks 10 billion states

Problem: Branching Factor
• Cannot search such huge graphs exhaustively. Suppose we know that goal is only d steps away.
• Dijkstra’s algorithm is basically breadth-first search (modulo arc weights)
• If out-degree of each node is 10, potentially visits 10d vertices– 10 step plan = 10 billion vertices!

An Easier Case
• Suppose you live in Manhattan; what do you do?
52nd St
51st St
50th St
10th A
ve
9th A
ve
8th A
ve
7th A
ve
6th A
ve
5th A
ve
4th A
ve
3rd A
ve
2nd A
ve
S
G

Best-First Search
• The Manhattan distance ( x+ y) is an estimate of the distance to the goal– a heuristic value
• Best-First Search– Order nodes in priority to minimize estimated distance
to the goal
• Compare: Dijkstra– Order nodes in priority to minimize distance from the
start

Best First in Action
• Suppose you live in Manhattan; what do you do?
52nd St
51st St
50th St
10th A
ve
9th A
ve
8th A
ve
7th A
ve
6th A
ve
5th A
ve
4th A
ve
3rd A
ve
2nd A
ve
S
G

Problem 1: Led Astray
• Led astray – eventually will expand vertex to get back on the right track
52nd St
51st St
50th St
10th A
ve
9th A
ve
8th A
ve
7th A
ve
6th A
ve
5th A
ve
4th A
ve
3rd A
ve
2nd A
ve
S G

Problem 2: Optimality
• With Best-First Search, are you guaranteed a shortest path is found when– goal is first seen?
– when goal is removed from priority queue?
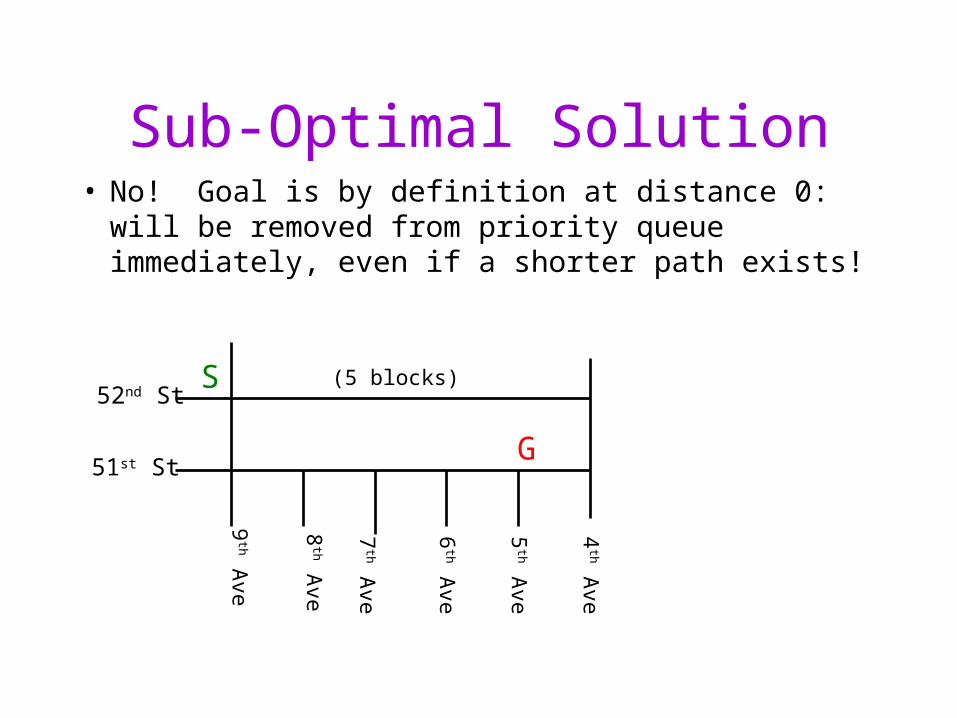
Sub-Optimal Solution• No! Goal is by definition at distance 0: will be
removed from priority queue immediately, even if a shorter path exists!
52nd St
51st St
9th A
ve
8th A
ve
7th A
ve
6th A
ve
5th A
ve
4th A
veS
G
(5 blocks)

Synergy?
• Dijkstra / Breadth First guaranteed to find optimal solution
• Best First often visits far fewer vertices, but may not provide optimal solution
– Can we get the best of both?

A*
• Order vertices in priority queue to minimize
(distance from start) + (estimated distance to goal)
f(n) = g(n) + h(n)
f(n) = priority of a node
g(n) = true distance from start
h(n) = heuristic distance to goal

Optimality
• Suppose the estimated distance (h) is the true distance to the goal– (heuristic is a lower bound)
• Then: when the goal is removed from the priority queue, we are guaranteed to have found a shortest path!

Problem 2 Revisited
52nd St
51st St
9th A
ve
8th A
ve
7th A
ve
6th A
ve
5th A
ve
4th A
veS
G
(5 blocks) 5+2=6
1+4=5
Dijkstra would have
visited these guys!
50th St

Revised Cloud Proof• Suppose have found a path of cost c to G which is not optimal
– priority(G) = f(G) = g(G) + h(G) = c + 0 = c
• Say N is the last vertex on an optimal path P to G which has been added to the queue but not yet dequeued.– There must be such an N, otherwise the optimal path would have been found.– priority(N) = f(N) = g(N) + h(N) g(N) + actual cost N to G
= cost of path P < c
• So N will be dequeued before G is dequeued• Repeat argument to show entire optimal path will be expanded before G is
dequeued.
SN
Gc

A Little History
• A* invented by Nils Nilsson & colleagues in 1968– or maybe some guy in Operations Research?
• Cornerstone of artificial intelligence– still a hot research topic!
– iterative deepening A*, automatically generating heuristic functions, …
• Method of choice for search large (even infinite) graphs when a good heuristic function can be found
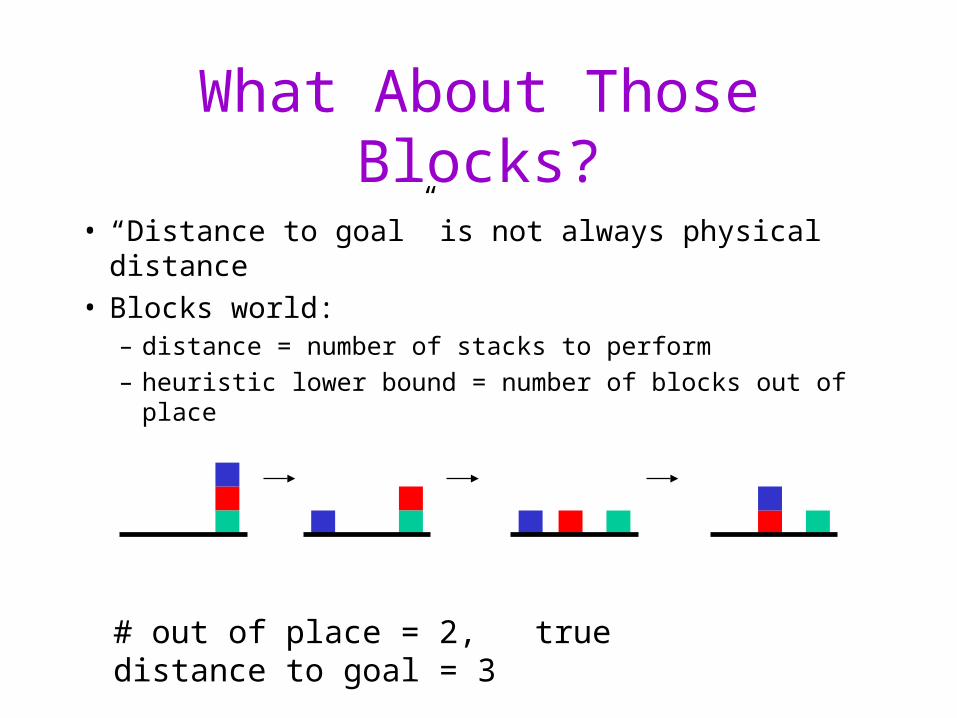
What About Those Blocks?
• “Distance to goal” is not always physical distance• Blocks world:
– distance = number of stacks to perform
– heuristic lower bound = number of blocks out of place
# out of place = 2, true distance to goal = 3

Other Examples
• Simplifying Integrals– vertex = formula
– goal = closed form formula without integrals
– arcs = mathematical transformations
– heuristic = number of integrals remaining in formula
1
1
nn x
x dxn

DNA Sequencing
• Problem: given chopped up DNA, reassemble• Vertex = set of pieces• Arc = stick two pieces together• Goal = only one piece left• Heuristic = number of pieces remaining - 1

Solving Simultaneous Equations
• Input: set of equations• Vertex = assignment of values to some of the
variables• Edge = Assign a value to one more variable• Goal = Assignment that simultaneously satisfies
all the equations• Heuristic = Number of equations not yet satisfied

What ISN’T A*?
essentially, nothing.












![Hazem Elmeleegy Jayant Madhavan Alon Halevy [EMH09] Juri CastellaniEmma Coradduzza Daniela Moschetto Gruppo 17 :](https://img.dokumen.tips/doc/110x75/5542eb66497959361e8d207d/hazem-elmeleegy-jayant-madhavan-alon-halevy-emh09-juri-castellaniemma-coradduzza-daniela-moschetto-gruppo-17-.jpg)
















