Embed Size (px)
Citation preview

CS621 : Seminar-2008
DEEP WEB
Shubhangi Agrawal (08305044)
Jayalekshmy S. Nair (08305056)

Introduction
Deep Web : The part of web which does not
come under surface web.
Surface Web : That part of the World Wide Web
which is crawled and indexed by conventional
search engines.
Deep Web consists of 91,000 terabytes of data
whereas surface web contains only 167
terabytes.

Contextual View Of The Deep Web

What Constitutes Deep Web
Dynamic content : dynamic pages which are
returned in response to a submitted query.
Unlinked content : pages which are not linked to
other pages.
Private Web : sites that require registration and
login.

What Constitutes Deep Web
Limited access content : sites that limit access
to their pages in a technical way.
Scripted content : pages that are only
accessible through links produced by
JavaScript.
Non-HTML/text content : textual content
encoded in multimedia (image or video) files or
specific file formats not handled by search
engines.

Why Is The Information Not
Accessible Conventional search engines use programs
called spiders or crawlers.
When a search engine reaches a page, it will
capture the text on that page, indexes it and
crawls to any pages that may have static
hyperlinks to it.
Cannot crawl and index information in
databases because they don't have a static
URL.

Why Use The Deep Web
Very vast : 550 times that of surface web
Quality of content / higher level of authority
Comprehensiveness
Focused
Timeliness
The material isn’t available elsewhere on the
Web

How To Access Contents Of Deep
Web
Manually search all the databases
Human Crawlers (Web Harvesting)
Federated Search

Web Harvesting
Web Harvesting is an implementation of a Web
crawler uses human expertise or machine
guidance to direct the crawler to URLs which
compose a specialized collection or set of
knowledge. Web harvesting can be thought of as
focused or directed Web crawling.

Process Identifying and specifying as input to a computer program
a list of URLs that defines a specialized collection or a set
of knowledge
The computer program then begins to download this list of
URLs.
Crawl depth can be defined , crawling need not be
recursive
The downloaded content is then indexed by the search
engine application and offered to information customers as
a searchable Web application.

Limitations
Amount of human intervention needed is high.
Some sites are very slow, particularly during
busy periods, so getting all the information
needed within a limited time window may be
impossible.

Federated Search
Simultaneous search of multiple online
databases
User enters the query in a single interface
Query is sent to different databases associated
with the search engine.
Results are presented in a manner suitable to
the user

Process
Transforming a query and
broadcasting it to a group of
databases with the appropriate
syntax
Merging the results collected from
the databases
Presenting them in a unified format
with minimal duplication
Providing a means, performed
either automatically or by the portal
user, to sort the merged result set.

Federated Search contd...
Advantage : They are as current as the
information sources as the sources are searched
in real time
Eg : WorldWideScience
Contains 40 information sources several of them
are federated search portals themselves

Limitations
Scalability
Vast amount of info coming can be a problem
All the databases cannot be covered
Either it searches the entire database or User
intervention is required
Results depend on user supplying the correct
keywords

Automatic Information Discovery
From The Invisible Web
Database of specialized search engines
Automatic search engine selection
Data mining for better query specification and search
Automatic Information Discovery
From The Invisible WebA system that maintains information about the specialized
search engines in the invisible web. When a query arrives, the
system not only finds the most appropriate specialized engines,
but also redirects the query automatically so that the user can
directly receive the appropriate query results.
Characteristics
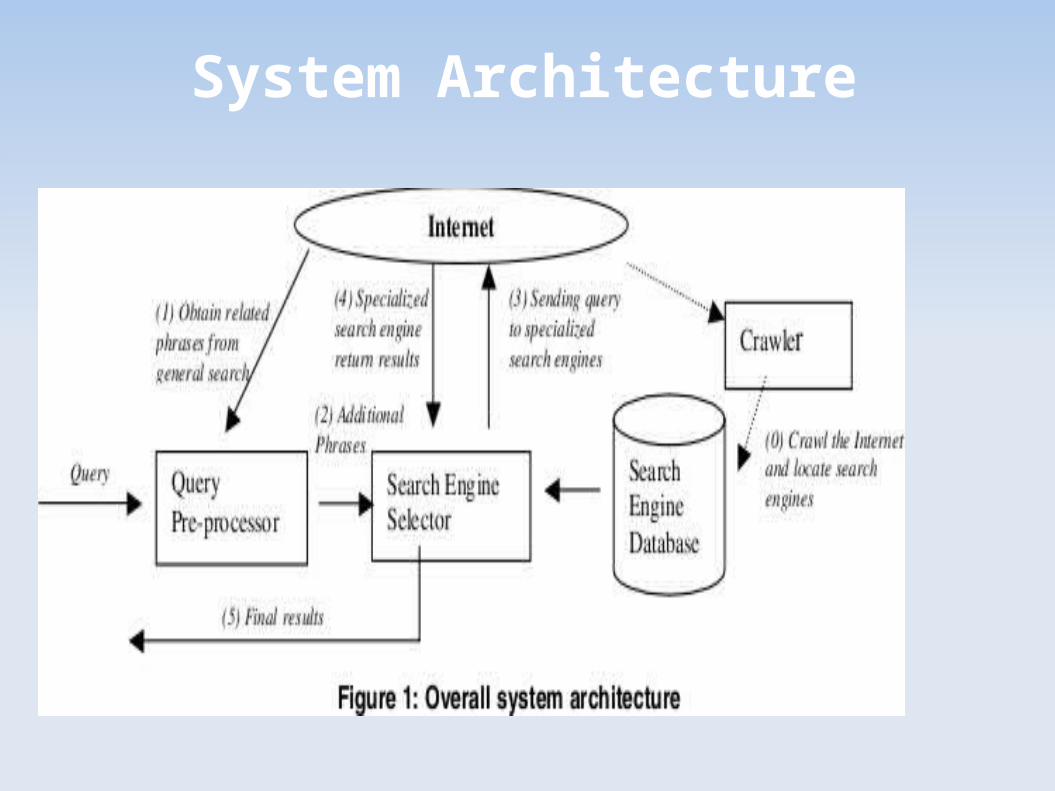
System Architecture

System Overview
Crawlers identify search engines using form tags
Along with the URL , an engine description is also stored
in the database
1.Populate the search engine database
2.Query pre-processing
Send the keywords to some general search engines for a
query and return the top results.
Based on the results, find words and phrases that appear
often with the search keywords.

System Overview
Each keyword/phrase generated from the pre-processing step
is matched with the search engine description of database
3.Engine selection
4.Query execution and result post-processing
After the search engines are selected, the system
automatically sends the query to all the search engines and
awaits the results to return.
Based on the information stored in the database, the system
can automatically generate the query string and send the
appropriate query to the websites

Conclusion
Deep Web constitutes a large repository of information which
is getting deeper and bigger all the time. There are various
possible ways in which the information in it can be accessed.
There has been continuous improvement in this field , still
there is need of more efficient methods to be commercially
implemented.

References
Bergman, M.K. (2001). The deep web: Surfacing hidden value.
The Journal of Electronic Publishing, 7(1). Retrieved from
http://www.press.umich. edu/jep/07-01/bergman.html
King-Ip Lin, Hui Chen, "Automatic Information Discovery from
the "Invisible Web"," itcc,pp.0332, International Conference on
Information Technology: Coding and Computing, 2002
www.wikipedia.com
http://worldwidescience.org/
http://science.gov/

Queries ???














