Embed Size (px)
Citation preview

CS267 Dense Linear Algebra I.1 Demmel Fa 2002
CS 267 Applications of Parallel Computers
Dense Linear Algebra
James Demmel
http://www.cs.berkeley.edu/~demmel/cs267_171002.ppt

CS267 Dense Linear Algebra I.2 Demmel Fa 2002
Outline
° Motivation for Dense Linear Algebra
° Benchmarks
° Review Gaussian Elimination (GE) for solving Ax=b
° Optimizing GE for caches on sequential machines• using matrix-matrix multiplication (BLAS)
° LAPACK library overview and performance
° Data layouts on parallel machines
° Parallel Gaussian Elimination
° ScaLAPACK library overview
° Eigenvalue problems
° Open Problems

CS267 Dense Linear Algebra I.3 Demmel Fa 2002
Success Stories (with NERSC, LBNL)
Scattering in a quantum system of three charged particles
(Rescigno, Baertschy, Isaacs and McCurdy, Dec. 24, 1999).
Cosmic Microwave Background Analysis, BOOMERanG
collaboration, MADCAP code (Apr. 27, 2000).
SuperLU ScaLAPACK

CS267 Dense Linear Algebra I.4 Demmel Fa 2002
Motivation (1)
°3 Basic Linear Algebra Problems• Linear Equations: Solve Ax=b for x
• Least Squares: Find x that minimizes ri2 where
r=Ax-b
• Eigenvalues: Findand x where Ax = x
- Singular Value Decomposition: ATAx=2x
• Lots of variations depending on structure of A
- A symmetric, positive definite, banded, …

CS267 Dense Linear Algebra I.5 Demmel Fa 2002
Motivation (2)
°Why dense A, as opposed to sparse A?• Many large matrices are sparse, but …
• Dense algorithms easier to understand
• Some applications yields large dense matrices
• Benchmarking
- “How fast is your computer?” = “How fast can you solve dense Ax=b?”
• Large sparse matrix algorithms often yield smaller (but still large) dense problems

CS267 Dense Linear Algebra I.6 Demmel Fa 2002
Winner of TOPS 500 (LINPACK Benchmark), by year
Year Machine Tflops Factor faster
Peak
Tflops
Num
Procs
N
2002 Earth System Computer, NEC
35.6 4.9 40.8 5104 1.04M
2001 ASCI White, IBM SP Power 3
7.2 1.5 11.1 7424 .52M
2000 ASCI White, IBM SP Power 3
4.9 2.1 11.1 7424 .43M
1999 ASCI Red, Intel PII Xeon
2.4 1.1 3.2 9632 .36M
1998 ASCI Blue, IBM SP 604E
2.1 1.6 3.9 5808 .43M
1997 ASCI Red, Intel Ppro, 200 MHz
1.3 3.6 1.8 9152 .24M
1996 Hitachi CP-PACS
.37 1.3 .6 2048 .10M
1995 Intel Paragon XP/S MP
.28 1 .3 6768 .13M
Source: Jack Dongarra (UTK)

CS267 Dense Linear Algebra I.7 Demmel Fa 2002
Current Records for Solving Small Dense Systems
MegaflopsMachine n=100 n=1000 Peak
Intel Pentium 4 1190 2355 5060 (1 proc, 2.53 GHz)
NEC SX 5 (16 proc, 250 MHz) 45030 64000 (1 proc, 250 MHz) 856 7280 8000
www.netlib.org, click on Performance DataBase Server

CS267 Dense Linear Algebra I.8 Demmel Fa 2002
Review of Gaussian Elimination (GE) for solving Ax=b
° Add multiples of each row to later rows to make A upper triangular
° Solve resulting triangular system Ux = c by substitution
… for each column i… zero it out below the diagonal by adding multiples of row i to later rowsfor i = 1 to n-1 … for each row j below row i for j = i+1 to n … add a multiple of row i to row j for k = i to n A(j,k) = A(j,k) - (A(j,i)/A(i,i)) * A(i,k)

CS267 Dense Linear Algebra I.9 Demmel Fa 2002
Refine GE Algorithm (1)
° Initial Version
° Remove computation of constant A(j,i)/A(i,i) from inner loop
… for each column i… zero it out below the diagonal by adding multiples of row i to later rowsfor i = 1 to n-1 … for each row j below row i for j = i+1 to n … add a multiple of row i to row j for k = i to n A(j,k) = A(j,k) - (A(j,i)/A(i,i)) * A(i,k)
for i = 1 to n-1 for j = i+1 to n m = A(j,i)/A(i,i) for k = i to n A(j,k) = A(j,k) - m * A(i,k)

CS267 Dense Linear Algebra I.10 Demmel Fa 2002
Refine GE Algorithm (2)
° Last version
° Don’t compute what we already know: zeros below diagonal in column i
for i = 1 to n-1 for j = i+1 to n m = A(j,i)/A(i,i) for k = i+1 to n A(j,k) = A(j,k) - m * A(i,k)
for i = 1 to n-1 for j = i+1 to n m = A(j,i)/A(i,i) for k = i to n A(j,k) = A(j,k) - m * A(i,k)

CS267 Dense Linear Algebra I.11 Demmel Fa 2002
Refine GE Algorithm (3)
° Last version
° Store multipliers m below diagonal in zeroed entries for later use
for i = 1 to n-1 for j = i+1 to n m = A(j,i)/A(i,i) for k = i+1 to n A(j,k) = A(j,k) - m * A(i,k)
for i = 1 to n-1 for j = i+1 to n A(j,i) = A(j,i)/A(i,i) for k = i+1 to n A(j,k) = A(j,k) - A(j,i) * A(i,k)

CS267 Dense Linear Algebra I.12 Demmel Fa 2002
Refine GE Algorithm (4)
° Last version for i = 1 to n-1 for j = i+1 to n A(j,i) = A(j,i)/A(i,i) for k = i+1 to n A(j,k) = A(j,k) - A(j,i) * A(i,k)
o Split Loopfor i = 1 to n-1 for j = i+1 to n A(j,i) = A(j,i)/A(i,i) for j = i+1 to n for k = i+1 to n A(j,k) = A(j,k) - A(j,i) * A(i,k)

CS267 Dense Linear Algebra I.13 Demmel Fa 2002
Refine GE Algorithm (5)
° Last version
° Express using matrix operations (BLAS)
for i = 1 to n-1 A(i+1:n,i) = A(i+1:n,i) * ( 1 / A(i,i) ) A(i+1:n,i+1:n) = A(i+1:n , i+1:n ) - A(i+1:n , i) * A(i , i+1:n)
for i = 1 to n-1 for j = i+1 to n A(j,i) = A(j,i)/A(i,i) for j = i+1 to n for k = i+1 to n A(j,k) = A(j,k) - A(j,i) * A(i,k)

CS267 Dense Linear Algebra I.14 Demmel Fa 2002
What GE really computes
° Call the strictly lower triangular matrix of multipliers M, and let L = I+M
° Call the upper triangle of the final matrix U
° Lemma (LU Factorization): If the above algorithm terminates (does not divide by zero) then A = L*U
° Solving A*x=b using GE• Factorize A = L*U using GE (cost = 2/3 n3 flops)
• Solve L*y = b for y, using substitution (cost = n2 flops)
• Solve U*x = y for x, using substitution (cost = n2 flops)
° Thus A*x = (L*U)*x = L*(U*x) = L*y = b as desired
for i = 1 to n-1 A(i+1:n,i) = A(i+1:n,i) / A(i,i) A(i+1:n,i+1:n) = A(i+1:n , i+1:n ) - A(i+1:n , i) * A(i , i+1:n)

CS267 Dense Linear Algebra I.15 Demmel Fa 2002
Problems with basic GE algorithm
° What if some A(i,i) is zero? Or very small?• Result may not exist, or be “unstable”, so need to pivot
° Current computation all BLAS 1 or BLAS 2, but we know that BLAS 3 (matrix multiply) is fastest (earlier lectures…)
for i = 1 to n-1 A(i+1:n,i) = A(i+1:n,i) / A(i,i) … BLAS 1 (scale a vector) A(i+1:n,i+1:n) = A(i+1:n , i+1:n ) … BLAS 2 (rank-1 update) - A(i+1:n , i) * A(i , i+1:n)
PeakBLAS 3
BLAS 2
BLAS 1

CS267 Dense Linear Algebra I.16 Demmel Fa 2002
Pivoting in Gaussian Elimination° A = [ 0 1 ] fails completely because can’t divide by A(1,1)=0 [ 1 0 ]
° But solving Ax=b should be easy! ° When diagonal A(i,i) is tiny (not just zero), algorithm may complete but get completely wrong answer ° Numerical instability ° Roundoff error is cause
° Cure: Pivot (swap rows of A) so A(i,i) large

CS267 Dense Linear Algebra I.17 Demmel Fa 2002
Gaussian Elimination with Partial Pivoting (GEPP)° Partial Pivoting: swap rows so that A(i,i) is largest in column
for i = 1 to n-1
find and record k where |A(k,i)| = max{i <= j <= n} |A(j,i)| … i.e. largest entry in rest of column i if |A(k,i)| = 0 exit with a warning that A is singular, or nearly so elseif k != i swap rows i and k of A end if A(i+1:n,i) = A(i+1:n,i) / A(i,i) … each quotient lies in [-1,1] A(i+1:n,i+1:n) = A(i+1:n , i+1:n ) - A(i+1:n , i) * A(i , i+1:n)
° Lemma: This algorithm computes A = P*L*U, where P is a permutation matrix° This algorithm numerically stable in practice° For details see LAPACK code at www.netlib.org/lapack/single/sgetf2.f

CS267 Dense Linear Algebra I.18 Demmel Fa 2002
Problems with basic GE algorithm
° What if some A(i,i) is zero? Or very small?• Result may not exist, or be “unstable”, so need to pivot
° Current computation all BLAS 1 or BLAS 2, but we know that BLAS 3 (matrix multiply) is fastest (earlier lectures…)
for i = 1 to n-1 A(i+1:n,i) = A(i+1:n,i) / A(i,i) … BLAS 1 (scale a vector) A(i+1:n,i+1:n) = A(i+1:n , i+1:n ) … BLAS 2 (rank-1 update) - A(i+1:n , i) * A(i , i+1:n)
PeakBLAS 3
BLAS 2
BLAS 1

CS267 Dense Linear Algebra I.19 Demmel Fa 2002
Converting BLAS2 to BLAS3 in GEPP
° Blocking• Used to optimize matrix-multiplication
• Harder here because of data dependencies in GEPP
° Delayed Updates• Save updates to “trailing matrix” from several consecutive BLAS2
updates
• Apply many saved updates simultaneously in one BLAS3 operation
° Same idea works for much of dense linear algebra• Open questions remain
° First Approach: Need to choose a block size b• Algorithm will save and apply b updates
• b must be small enough so that active submatrix consisting of b columns of A fits in cache
• b must be large enough to make BLAS3 fast
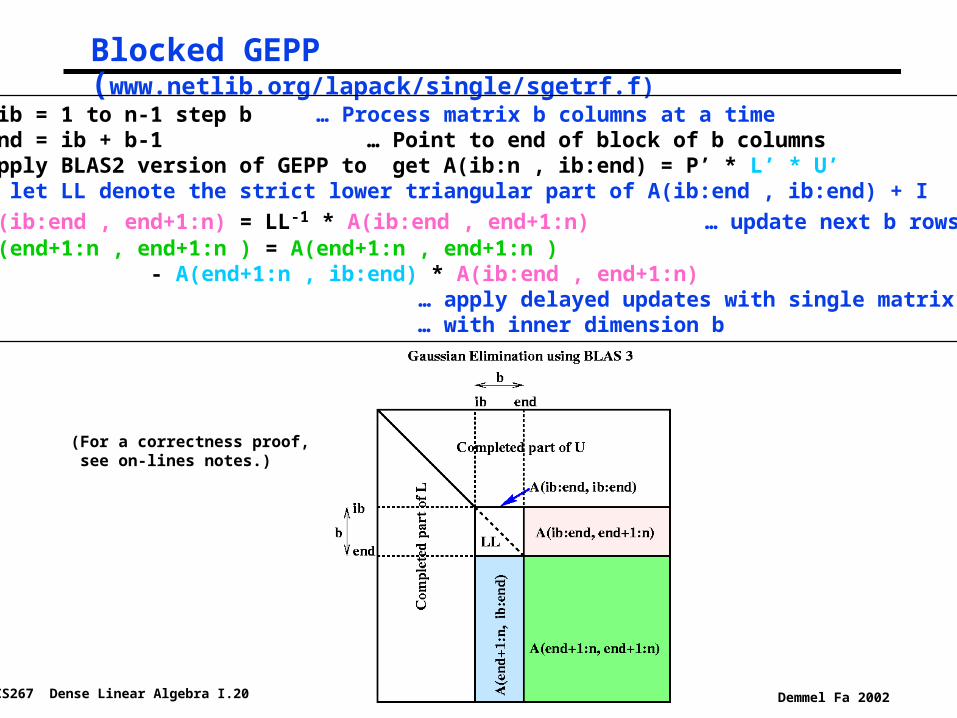
CS267 Dense Linear Algebra I.20 Demmel Fa 2002
Blocked GEPP (www.netlib.org/lapack/single/sgetrf.f)for ib = 1 to n-1 step b … Process matrix b columns at a time end = ib + b-1 … Point to end of block of b columns apply BLAS2 version of GEPP to get A(ib:n , ib:end) = P’ * L’ * U’ … let LL denote the strict lower triangular part of A(ib:end , ib:end) + I
A(ib:end , end+1:n) = LL-1 * A(ib:end , end+1:n) … update next b rows of U A(end+1:n , end+1:n ) = A(end+1:n , end+1:n ) - A(end+1:n , ib:end) * A(ib:end , end+1:n) … apply delayed updates with single matrix-multiply … with inner dimension b
(For a correctness proof, see on-lines notes.)

CS267 Dense Linear Algebra I.21 Demmel Fa 2002
Efficiency of Blocked GEPP

CS267 Dense Linear Algebra I.22 Demmel Fa 2002
Overview of LAPACK
° Standard library for dense/banded linear algebra• Linear systems: A*x=b
• Least squares problems: minx || A*x-b ||2• Eigenvalue problems: Ax =x, Ax = Bx
• Singular value decomposition (SVD): A = UVT
° Algorithms reorganized to use BLAS3 as much as possible
° Basis of math libraries on many computers, Matlab 6
° Many algorithmic innovations remain• Projects available
• Automatic optimization
• Quadtree matrix data structures for locality
• New eigenvalue algorithms

CS267 Dense Linear Algebra I.23 Demmel Fa 2002
Performance of LAPACK (n=1000)

CS267 Dense Linear Algebra I.24 Demmel Fa 2002
Performance of LAPACK (n=100)

CS267 Dense Linear Algebra I.25 Demmel Fa 2002
Recursive Algorithms
° Still uses delayed updates, but organized differently• (formulas on board)
° Can exploit recursive data layouts• 3x speedups on least squares for tall, thin matrices
° Theoretically optimal memory hierarchy performance
° See references at• http://lawra.uni-c.dk/lawra/index.html
• http://www.cs.berkeley.edu/~yelick/cs267f01/lectures/Lect14.html
• http://www.cs.umu.se/research/parallel/recursion/

CS267 Dense Linear Algebra I.26 Demmel Fa 2002
Recursive Algorithms – Limits
° Two kinds of dense matrix compositions
° One Sided • Sequence of simple operations applied on left of matrix
• Gaussian Elimination: A = L*U or A = P*L*U
- Symmetric Gaussian Elimination: A = L*D*LT
- Cholesky: A = L*LT
• QR Decomposition for Least Squares: A = Q*R
• Can be nearly 100% BLAS 3
• Susceptible to recursive algorithms
° Two Sided• Sequence of simple operations applied on both sides, alternating
• Eigenvalue algorithms, SVD
• At least ~25% BLAS 2
• Seem impervious to recursive approach?
• Some recent progress on SVD (25% vs 50% BLAS2)

CS267 Dense Linear Algebra I.27 Demmel Fa 2002
Parallelizing Gaussian Elimination
° Recall parallelization steps from earlier lecture• Decomposition: identify enough parallel work, but not too much
• Assignment: load balance work among threads
• Orchestrate: communication and synchronization
• Mapping: which processors execute which threads
° Decomposition• In BLAS 2 algorithm nearly each flop in inner loop can be done in
parallel, so with n2 processors, need 3n parallel steps
• This is too fine-grained, prefer calls to local matmuls instead
• Need to discuss parallel matrix multiplication
° Assignment• Which processors are responsible for which submatrices?
for i = 1 to n-1 A(i+1:n,i) = A(i+1:n,i) / A(i,i) … BLAS 1 (scale a vector) A(i+1:n,i+1:n) = A(i+1:n , i+1:n ) … BLAS 2 (rank-1 update) - A(i+1:n , i) * A(i , i+1:n)
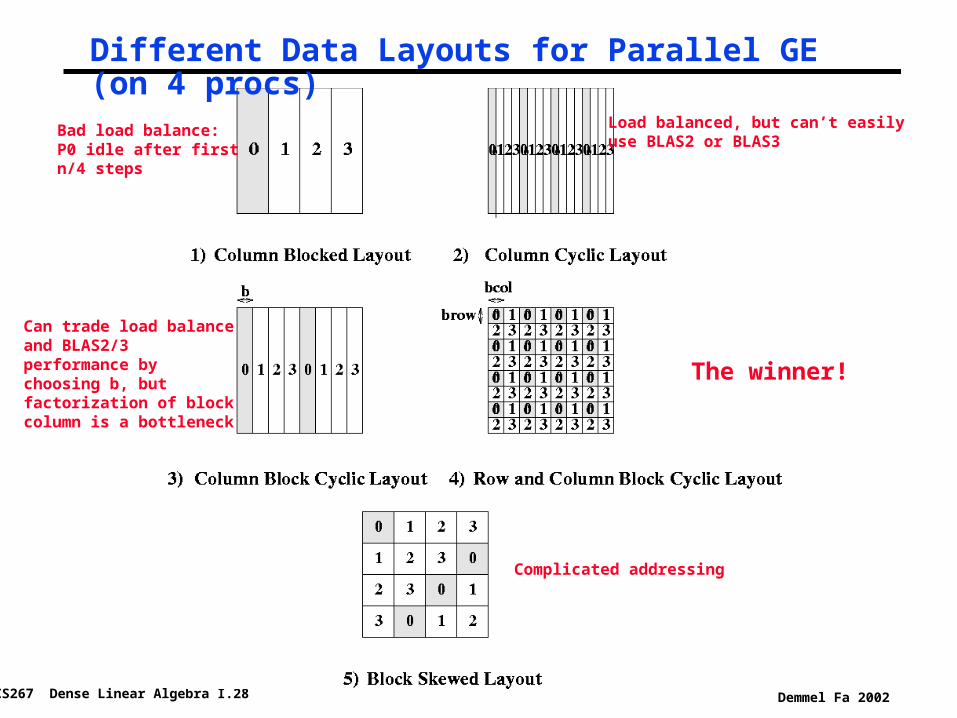
CS267 Dense Linear Algebra I.28 Demmel Fa 2002
Different Data Layouts for Parallel GE (on 4 procs)
The winner!
Bad load balance:P0 idle after firstn/4 steps
Load balanced, but can’t easilyuse BLAS2 or BLAS3
Can trade load balanceand BLAS2/3 performance by choosing b, butfactorization of blockcolumn is a bottleneck
Complicated addressing

CS267 Dense Linear Algebra I.29 Demmel Fa 2002
PDGEMM = PBLAS routine for matrix multiply
Observations: For fixed N, as P increases Mflops increases, but less than 100% efficiency For fixed P, as N increases, Mflops (efficiency) rises
DGEMM = BLAS routine for matrix multiply
Maximum speed for PDGEMM = # Procs * speed of DGEMM
Observations (same as above): Efficiency always at least 48% For fixed N, as P increases, efficiency drops For fixed P, as N increases, efficiency increases

CS267 Dense Linear Algebra I.30 Demmel Fa 2002
Review: BLAS 3 (Blocked) GEPP
for ib = 1 to n-1 step b … Process matrix b columns at a time end = ib + b-1 … Point to end of block of b columns apply BLAS2 version of GEPP to get A(ib:n , ib:end) = P’ * L’ * U’ … let LL denote the strict lower triangular part of A(ib:end , ib:end) + I
A(ib:end , end+1:n) = LL-1 * A(ib:end , end+1:n) … update next b rows of U A(end+1:n , end+1:n ) = A(end+1:n , end+1:n ) - A(end+1:n , ib:end) * A(ib:end , end+1:n) … apply delayed updates with single matrix-multiply … with inner dimension b
BLAS 3

CS267 Dense Linear Algebra I.31 Demmel Fa 2002
Review: Row and Column Block Cyclic Layout
processors and matrix blocksare distributed in a 2d array
pcol-fold parallelismin any column, and calls to the BLAS2 and BLAS3 on matrices of size brow-by-bcol
serial bottleneck is eased
need not be symmetric in rows andcolumns

CS267 Dense Linear Algebra I.32 Demmel Fa 2002
Distributed GE with a 2D Block Cyclic Layout
block size b in the algorithm and the block sizes brow and bcol in the layout satisfy b=brow=bcol.
shaded regions indicate busy processors or communication performed.
unnecessary to have a barrier between each step of the algorithm, e.g.. step 9, 10, and 11 can be pipelined

CS267 Dense Linear Algebra I.33 Demmel Fa 2002
Distributed GE with a 2D Block Cyclic Layout

CS267 Dense Linear Algebra I.34 Demmel Fa 2002
Ma
trix
mu
ltip
ly o
f
gre
en
= g
ree
n -
blu
e *
pin
k

CS267 Dense Linear Algebra I.35 Demmel Fa 2002
ScaLAPACK Performance Models (1)ScaLAPACK Operation Counts

CS267 Dense Linear Algebra I.36 Demmel Fa 2002
ScaLAPACK Performance Models (2)Compare Predictions and Measurements
(LU)
(Cholesky)

CS267 Dense Linear Algebra I.37 Demmel Fa 2002
PDGESV = ScaLAPACK parallel LU routine
Since it can run no faster than its inner loop (PDGEMM), we measure:Efficiency = Speed(PDGESV)/Speed(PDGEMM)
Observations: Efficiency well above 50% for large enough problems For fixed N, as P increases, efficiency decreases (just as for PDGEMM) For fixed P, as N increases efficiency increases (just as for PDGEMM) From bottom table, cost of solving Ax=b about half of matrix multiply for large enough matrices. From the flop counts we would
expect it to be (2*n3)/(2/3*n3) = 3 times faster, but communication makes it a little slower.

CS267 Dense Linear Algebra I.38 Demmel Fa 2002

CS267 Dense Linear Algebra I.39 Demmel Fa 2002
Parallelism in ScaLAPACK
° Level 3 BLAS block operations
• All the reduction routines
° Pipelining• QR Iteration, Triangular Solvers,
classic factorizations
° Redundant computations• Condition estimators
° Static work assignment• Bisection
° Task parallelism• Sign function eigenvalue
computations
° Divide and Conquer• Tridiagonal and band solvers,
symmetric eigenvalue problem and Sign function
° Cyclic reduction• Reduced system in the band
solver

CS267 Dense Linear Algebra I.40 Demmel Fa 2002
Scales well, nearly full machine speed

CS267 Dense Linear Algebra I.41 Demmel Fa 2002
Old version,pre 1998 Gordon Bell Prize
Still have ideas to accelerateProject Available!
Old Algorithm, plan to abandon

CS267 Dense Linear Algebra I.42 Demmel Fa 2002
The “Holy Grail” (Parlett, Dhillon, Marques) Perfect Output complexity (O(n * #vectors)), Embarrassingly parallel, Accurate
To be propagated throughout LAPACK and ScaLAPACK
Making the symmetric eigenproblem and SVD scalable
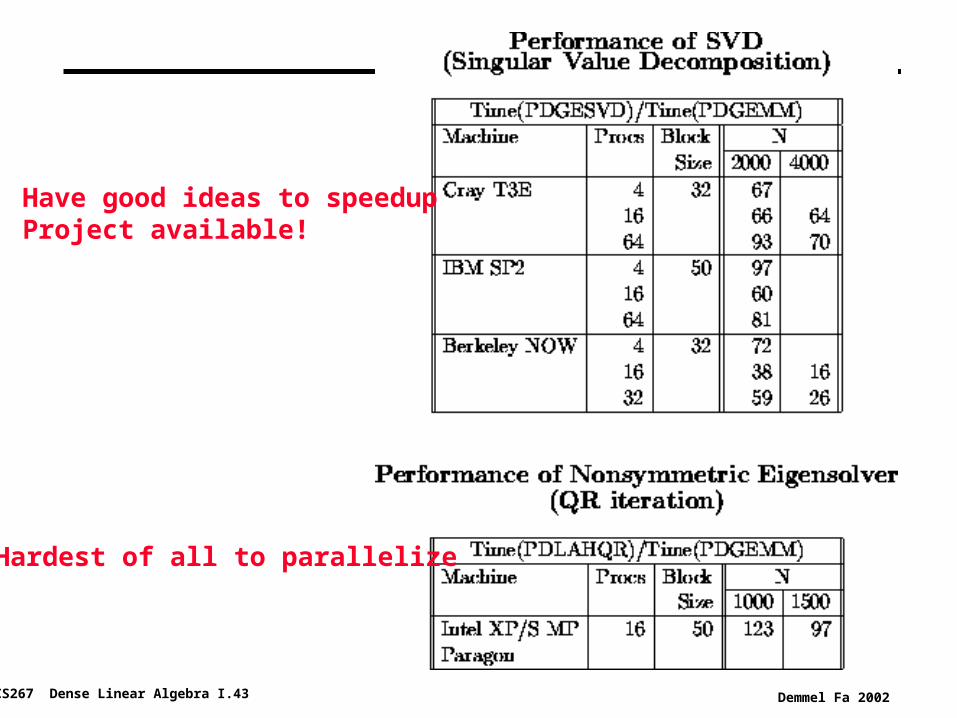
CS267 Dense Linear Algebra I.43 Demmel Fa 2002
Have good ideas to speedupProject available!
Hardest of all to parallelize

CS267 Dense Linear Algebra I.44 Demmel Fa 2002
Making the nonsymmetric eigenproblem scalable
° Axi = i xi , Schur form A = QTQT
° Parallel HQR • Henry, Watkins, Dongarra, Van de Geijn
• Now in ScaLAPACK
• Not as scalable as LU: N times as many messages
• Block-Hankel data layout better in theory, but not in ScaLAPACK
° Sign Function • Beavers, Denman, Lin, Zmijewski, Bai, Demmel, Gu, Godunov, Bulgakov,
Malyshev
• Ai+1 = (Ai + Ai-1)/2 shifted projector onto Re > 0
• Repeat on transformed A to divide-and-conquer spectrum
• Only uses inversion, so scalable
• Inverse free version exists (uses QRD)
• Very high flop count compared to HQR, less stable

CS267 Dense Linear Algebra I.45 Demmel Fa 2002
Out-of-core means matrix lives on disk; too big for main mem
Much harder to hide latency of disk
QR much easier than LU because no pivoting needed for QR

CS267 Dense Linear Algebra I.46 Demmel Fa 2002
ScaLAPACK Summary and Conclusions
° “One-sided Problems” are scalable• LU (“Linpack Benchmark”)
• Cholesky, QR
° “Two-sided Problems” are harder• Half BLAS2, not all BLAS3
• Eigenproblems, SVD (Holy Grail coming…)
• 684 Gflops on 4600 PE ASCI Red (149 Mflops/proc)
- Henry, Stanley, Sears
- Hermitian generalized eigenproblem Ax = Bx
- 2nd Place, Gordon Bell Peak Performance Award, SC98
° Narrow band problems hardest• Solving and eigenproblems
• Galois theory of parallel prefix
° www.netlib.org/scalapack

CS267 Dense Linear Algebra I.47 Demmel Fa 2002
A small software project ...

CS267 Dense Linear Algebra I.48 Demmel Fa 2002
Extra Slides

CS267 Dense Linear Algebra I.49 Demmel Fa 2002
Parallelizing Gaussian Elimination
° Recall parallelization steps from Lecture 3• Decomposition: identify enough parallel work, but not too much
• Assignment: load balance work among threads
• Orchestrate: communication and synchronization
• Mapping: which processors execute which threads
° Decomposition• In BLAS 2 algorithm nearly each flop in inner loop can be done in
parallel, so with n2 processors, need 3n parallel steps
• This is too fine-grained, prefer calls to local matmuls instead
for i = 1 to n-1 A(i+1:n,i) = A(i+1:n,i) / A(i,i) … BLAS 1 (scale a vector) A(i+1:n,i+1:n) = A(i+1:n , i+1:n ) … BLAS 2 (rank-1 update) - A(i+1:n , i) * A(i , i+1:n)

CS267 Dense Linear Algebra I.50 Demmel Fa 2002
Assignment of parallel work in GE
° Think of assigning submatrices to threads, where each thread responsible for updating submatrix it owns
• “owner computes” rule natural because of locality
° What should submatrices look like to achieve load balance?

CS267 Dense Linear Algebra I.51 Demmel Fa 2002
Different Data Layouts for Parallel GE (on 4 procs)
The winner!
Bad load balance:P0 idle after firstn/4 steps
Load balanced, but can’t easilyuse BLAS2 or BLAS3
Can trade load balanceand BLAS2/3 performance by choosing b, butfactorization of blockcolumn is a bottleneck
Complicated addressing

CS267 Dense Linear Algebra I.52 Demmel Fa 2002
The main steps in the solution process are
Fill: computing the matrix elements of A
Factor: factoring the dense matrix A
Solve: solving for one or more excitations b
Field Calc: computing the fields scattered from the object
Computational Electromagnetics (MOM)

CS267 Dense Linear Algebra I.53 Demmel Fa 2002
Analysis of MOM for Parallel Implementation
Task Work Parallelism Parallel Speed
Fill O(n**2) embarrassing low
Factor O(n**3) moderately diff. very high
Solve O(n**2) moderately diff. high
Field Calc. O(n) embarrassing high

CS267 Dense Linear Algebra I.54 Demmel Fa 2002
BLAS 3 (Blocked) GEPP, using Delayed Updates
for ib = 1 to n-1 step b … Process matrix b columns at a time end = ib + b-1 … Point to end of block of b columns apply BLAS2 version of GEPP to get A(ib:n , ib:end) = P’ * L’ * U’ … let LL denote the strict lower triangular part of A(ib:end , ib:end) + I
A(ib:end , end+1:n) = LL-1 * A(ib:end , end+1:n) … update next b rows of U A(end+1:n , end+1:n ) = A(end+1:n , end+1:n ) - A(end+1:n , ib:end) * A(ib:end , end+1:n) … apply delayed updates with single matrix-multiply … with inner dimension b
BLAS 3

CS267 Dense Linear Algebra I.55 Demmel Fa 2002
BLAS2 version of Gaussian Elimination with Partial Pivoting (GEPP)
for i = 1 to n-1
find and record k where |A(k,i)| = max{i <= j <= n} |A(j,i)| … i.e. largest entry in rest of column i if |A(k,i)| = 0 exit with a warning that A is singular, or nearly so elseif k != i swap rows i and k of A end if A(i+1:n,i) = A(i+1:n,i) / A(i,i) … each quotient lies in [-1,1] … BLAS 1 A(i+1:n,i+1:n) = A(i+1:n , i+1:n ) - A(i+1:n , i) * A(i , i+1:n) … BLAS 2, most work in this line

CS267 Dense Linear Algebra I.56 Demmel Fa 2002
How to proceed:
° Consider basic parallel matrix multiplication algorithms on simple layouts
• Performance modeling to choose best one
- Time (message) = latency + #words * time-per-word
- = + n*
° Briefly discuss block-cyclic layout
° PBLAS = Parallel BLAS

CS267 Dense Linear Algebra I.57 Demmel Fa 2002
Parallel Matrix Multiply
° Computing C=C+A*B
° Using basic algorithm: 2*n3 Flops
° Variables are:• Data layout
• Topology of machine
• Scheduling communication
° Use of performance models for algorithm design

CS267 Dense Linear Algebra I.58 Demmel Fa 2002
1D Layout
° Assume matrices are n x n and n is divisible by p
° A(i) refers to the n by n/p block column that processor i owns (similiarly for B(i) and C(i))
° B(i,j) is the n/p by n/p sublock of B(i) • in rows j*n/p through (j+1)*n/p
° Algorithm uses the formulaC(i) = C(i) + A*B(i) = C(i) + A(j)*B(j,i)
p0 p1 p2 p3 p5 p4 p6 p7
j

CS267 Dense Linear Algebra I.59 Demmel Fa 2002
Matrix Multiply: 1D Layout on Bus or Ring
° Algorithm uses the formulaC(i) = C(i) + A*B(i) = C(i) + A(j)*B(j,i)
° First consider a bus-connected machine without broadcast: only one pair of processors can communicate at a time (ethernet)
° Second consider a machine with processors on a ring: all processors may communicate with nearest neighbors simultaneously
j

CS267 Dense Linear Algebra I.60 Demmel Fa 2002
Naïve MatMul for 1D layout on Bus without Broadcast
Naïve algorithm:
C(myproc) = C(myproc) + A(myproc)*B(myproc,myproc)
for i = 0 to p-1
for j = 0 to p-1 except i
if (myproc == i) send A(i) to processor j
if (myproc == j)
receive A(i) from processor i
C(myproc) = C(myproc) + A(i)*B(i,myproc)
barrier
Cost of inner loop:
computation: 2*n*(n/p)2 = 2*n3/p2
communication: + *n2 /p

CS267 Dense Linear Algebra I.61 Demmel Fa 2002
Naïve MatMul (continued)
Cost of inner loop:
computation: 2*n*(n/p)2 = 2*n3/p2
communication: + *n2 /p … approximately
Only 1 pair of processors (i and j) are active on any iteration,
an of those, only i is doing computation
=> the algorithm is almost entirely serial
Running time: (p*(p-1) + 1)*computation + p*(p-1)*communication
~= 2*n3 + p2* + p*n2*
this is worse than the serial time and grows with p

CS267 Dense Linear Algebra I.62 Demmel Fa 2002
Better Matmul for 1D layout on a Processor Ring
° Proc i can communicate with Proc(i-1) and Proc(i+1) simultaneously for all i
Copy A(myproc) into TmpC(myproc) = C(myproc) + T*B(myproc , myproc)for j = 1 to p-1 Send Tmp to processor myproc+1 mod p Receive Tmp from processor myproc-1 mod p C(myproc) = C(myproc) + Tmp*B( myproc-j mod p , myproc)
° Same idea as for gravity in simple sharks and fish algorithm
° Time of inner loop = 2*( + *n2/p) + 2*n*(n/p)2
° Total Time = 2*n* (n/p)2 + (p-1) * Time of inner loop
~ 2*n3/p + 2*p* + 2**n2
° Optimal for 1D layout on Ring or Bus, even with with Broadcast: Perfect speedup for arithmetic A(myproc) must move to each other processor, costs at least (p-1)*cost of sending n*(n/p) words
° Parallel Efficiency = 2*n3 / (p * Total Time) = 1/(1 + * p2/(2*n3) + * p/(2*n) ) = 1/ (1 + O(p/n))
Grows to 1 as n/p increases (or and shrink)

CS267 Dense Linear Algebra I.63 Demmel Fa 2002
MatMul with 2D Layout
° Consider processors in 2D grid (physical or logical)
° Processors can communicate with 4 nearest neighbors
• Broadcast along rows and columns
p(0,0) p(0,1) p(0,2)
p(1,0) p(1,1) p(1,2)
p(2,0) p(2,1) p(2,2)

CS267 Dense Linear Algebra I.64 Demmel Fa 2002
Cannon’s Algorithm
… C(i,j) = C(i,j) + A(i,k)*B(k,j)
… assume s = sqrt(p) is an integer
forall i=0 to s-1 … “skew” A
left-circular-shift row i of A by i
… so that A(i,j) overwritten by A(i,(j+i)mod s)
forall i=0 to s-1 … “skew” B
up-circular-shift B column i of B by i
… so that B(i,j) overwritten by B((i+j)mod s), j)
for k=0 to s-1 … sequential
forall i=0 to s-1 and j=0 to s-1 … all processors in parallel
C(i,j) = C(i,j) + A(i,j)*B(i,j)
left-circular-shift each row of A by 1
up-circular-shift each row of B by 1
k

CS267 Dense Linear Algebra I.65 Demmel Fa 2002
Communication in Cannon
C(1,2) = A(1,0) * B(0,2) + A(1,1) * B(1,2) + A(1,2) * B(2,2)

CS267 Dense Linear Algebra I.66 Demmel Fa 2002
Cost of Cannon’s Algorithm
forall i=0 to s-1 … recall s = sqrt(p)
left-circular-shift row i of A by i … cost = s*( + *n2/p)
forall i=0 to s-1
up-circular-shift B column i of B by i … cost = s*( + *n2/p)
for k=0 to s-1
forall i=0 to s-1 and j=0 to s-1
C(i,j) = C(i,j) + A(i,j)*B(i,j) … cost = 2*(n/s)3 = 2*n3/p3/2
left-circular-shift each row of A by 1 … cost = + *n2/p
up-circular-shift each row of B by 1 … cost = + *n2/p
° Total Time = 2*n3/p + 4* s* + 4**n2/s ° Parallel Efficiency = 2*n3 / (p * Total Time) = 1/( 1 + * 2*(s/n)3 + * 2*(s/n) ) = 1/(1 + O(sqrt(p)/n)) ° Grows to 1 as n/s = n/sqrt(p) = sqrt(data per processor) grows° Better than 1D layout, which had Efficiency = 1/(1 + O(p/n))

CS267 Dense Linear Algebra I.67 Demmel Fa 2002
Drawbacks to Cannon
° Hard to generalize for• p not a perfect square
• A and B not square
• Dimensions of A, B not perfectly divisible by s=sqrt(p)
• A and B not “aligned” in the way they are stored on processors
• block-cyclic layouts
° Memory hog (extra copies of local matrices)

CS267 Dense Linear Algebra I.68 Demmel Fa 2002
SUMMA = Scalable Universal Matrix Multiply Algorithm
° Slightly less efficient, but simpler and easier to generalize
° Presentation from van de Geijn and Watts• www.netlib.org/lapack/lawns/lawn96.ps
• Similar ideas appeared many times
° Used in practice in PBLAS = Parallel BLAS• www.netlib.org/lapack/lawns/lawn100.ps

CS267 Dense Linear Algebra I.69 Demmel Fa 2002
SUMMA
* =C(I,J)I
J
A(I,k)
k
k
B(k,J)
° I, J represent all rows, columns owned by a processor° k is a single row or column (or a block of b rows or columns)° C(I,J) = C(I,J) + k A(I,k)*B(k,J)
° Assume a pr by pc processor grid (pr = pc = 4 above) For k=0 to n-1 … or n/b-1 where b is the block size … = # cols in A(I,k) and # rows in B(k,J)
for all I = 1 to pr … in parallel
owner of A(I,k) broadcasts it to whole processor row
for all J = 1 to pc … in parallel
owner of B(k,J) broadcasts it to whole processor column Receive A(I,k) into Acol Receive B(k,J) into Brow C( myproc , myproc ) = C( myproc , myproc) + Acol * Brow

CS267 Dense Linear Algebra I.70 Demmel Fa 2002
SUMMA performance
For k=0 to n/b-1 for all I = 1 to s … s = sqrt(p) owner of A(I,k) broadcasts it to whole processor row … time = log s *( + * b*n/s), using a tree for all J = 1 to s owner of B(k,J) broadcasts it to whole processor column … time = log s *( + * b*n/s), using a tree Receive A(I,k) into Acol Receive B(k,J) into Brow C( myproc , myproc ) = C( myproc , myproc) + Acol * Brow
… time = 2*(n/s)2*b
° Total time = 2*n3/p + * log p * n/b + * log p * n2 /s
° Parallel Efficiency = 1/(1 + * log p * p / (2*b*n2) + * log p * s/(2*n) )° ~Same term as Cannon, except for log p factor log p grows slowly so this is ok° Latency () term can be larger, depending on b When b=1, get * log p * n As b grows to n/s, term shrinks to * log p * s (log p times Cannon)° Temporary storage grows like 2*b*n/s° Can change b to tradeoff latency cost with memory

CS267 Dense Linear Algebra I.71 Demmel Fa 2002
Summary of Parallel Matrix Multiply Algorithms
° 1D Layout• Bus without broadcast - slower than serial
• Nearest neighbor communication on a ring (or bus with broadcast): Efficiency = 1/(1 + O(p/n))
° 2D Layout• Cannon
- Efficiency = 1/(1+O(p1/2 /n))
- Hard to generalize for general p, n, block cyclic, alignment
• SUMMA
- Efficiency = 1/(1 + O(log p * p / (b*n2) + log p * p1/2 /n))
- Very General
- b small => less memory, lower efficiency
- b large => more memory, high efficiency
• Gustavson et al
- Efficiency = 1/(1 + O(p1/3 /n) ) ??

CS267 Dense Linear Algebra I.72 Demmel Fa 2002
Extra Slides

CS267 Dense Linear Algebra I.73 Demmel Fa 2002
Current Records for Solving Dense Systems
Year System Size Machine # Procs Gflops (Peak)
1950's O(100) 1995 128,600 Intel Paragon 6768 281 ( 338)1996 215,000 Intel ASCI Red 7264 1068 (1453)1998 148,000 Cray T3E 1488 1127 (1786)1998 235,000 Intel ASCI Red 9152 1338 (1830) (200 MHz Ppro)
1999 374,000 SGI ASCI Blue 5040 1608 (2520)2000 362,000 Intel ASCI Red 9632 2380 (3207) (333 MHz Xeon)
2001 518,000 IBM ASCI White 8000 7226 (12000) (375 MHz Power 3) 2002 1,075,200 Earth Simulator 5120 35860 (40960)
www.netlib.org, click on Performance DataBase Server

CS267 Dense Linear Algebra I.74 Demmel Fa 2002
Computational Electromagnetics – Solve Ax=b
•Developed during 1980s, driven by defense applications
•Determine the RCS (radar cross section) of airplane
•Reduce signature of plane (stealth technology)
•Other applications are antenna design, medical equipment
•Two fundamental numerical approaches:
•MOM methods of moments ( frequency domain)
•Large dense matrices
•Finite differences (time domain)
•Even larger sparse matrices

CS267 Dense Linear Algebra I.75 Demmel Fa 2002
Computational Electromagnetics
image: NW Univ. Comp. Electromagnetics Laboratory http://nueml.ece.nwu.edu/
- Discretize surface into triangular facets using standard modeling tools
- Amplitude of currents on surface are unknowns
- Integral equation is discretized into a set of linear equations

CS267 Dense Linear Algebra I.76 Demmel Fa 2002
Computational Electromagnetics (MOM)
After discretization the integral equation
has the form
A x = b where
A is the (dense) impedance matrix,
x is the unknown vector of amplitudes, and
b is the excitation vector.
(see Cwik, Patterson, and Scott, Electromagnetic Scattering on the Intel Touchstone Delta, IEEE Supercomputing ‘92, pp 538 - 542)

CS267 Dense Linear Algebra I.77 Demmel Fa 2002
Results for Parallel Implementation on Intel Delta
Task Time (hours)
Fill (compute n2 matrix entries) 9.20
(embarrassingly parallel but slow)
Factor (Gaussian Elimination, O(n3) ) 8.25
(good parallelism with right algorithm)
Solve (O(n2)) 2 .17
(reasonable parallelism with right algorithm)
Field Calc. (O(n)) 0.12
(embarrassingly parallel and fast)
The problem solved was for a matrix of size 48,672. 2.6 Gflops for Factor - The world record in 1991.

CS267 Dense Linear Algebra I.78 Demmel Fa 2002
Computational Chemistry – Ax = x
° Seek energy levels of a molecule, crystal, etc.• Solve Schroedinger’s Equation for energy levels = eigenvalues
• Discretize to get Ax = Bx, solve for eigenvalues and eigenvectors x
• A and B large Hermitian matrices (B positive definite)
° MP-Quest (Sandia NL)• Si and sapphire crystals of up to 3072 atoms
• A and B up to n=40000, complex Hermitian
• Need all eigenvalues and eigenvectors
• Need to iterate up to 20 times (for self-consistency)
° Implemented on Intel ASCI Red• 9200 Pentium Pro 200 processors (4600 Duals, a CLUMP)
• Overall application ran at 605 Gflops (out of 1800 Gflops peak),
• Eigensolver ran at 684 Gflops
• www.cs.berkeley.edu/~stanley/gbell/index.html
• Runner-up for Gordon Bell Prize at Supercomputing 98

CS267 Dense Linear Algebra I.79 Demmel Fa 2002





























