Embed Size (px)
Citation preview

4/3/01 ©UCB April 3, 2001 CS152 / Kubiatowicz
Lec19.1
CS152Computer Architecture and Engineering
Lecture 19
Finish speculationLocality and Memory Technology
April 03, 2001
John Kubiatowicz (http.cs.berkeley.edu/~kubitron)
lecture slides: http://www-inst.eecs.berkeley.edu/~cs152/

4/3/01 ©UCB April 3, 2001 CS152 / Kubiatowicz
Lec19.2
Review: Tomasulo Organization
FP addersFP adders
Add1Add2Add3
FP multipliersFP multipliers
Mult1Mult2
From Mem FP Registers
Reservation Stations
Common Data Bus (CDB)
To Mem
FP OpQueue
Load Buffers
Store Buffers
Load1Load2Load3Load4Load5Load6

4/3/01 ©UCB April 3, 2001 CS152 / Kubiatowicz
Lec19.3
Review: Tomasulo Architecture° Reservations stations: renaming to larger set of registers + buffering
source operands• Prevents registers as bottleneck• Avoids WAR, WAW hazards of Scoreboard• Allows loop unrolling in HW
° Not limited to basic blocks (integer units gets ahead, beyond branches)
° Dynamic Scheduling:• Scoreboarding/Tomasulo• In-order issue, out-of-order execution, out-of-order commit
° Branch prediction/speculation• Regularities in program execution permit prediction of branch
directions and data values• Necessary for wide superscalar issue

4/3/01 ©UCB April 3, 2001 CS152 / Kubiatowicz
Lec19.4
Review: Independent “Fetch” unit
Instruction Fetchwith
Branch Prediction
Out-Of-OrderExecution
Unit
Correctness FeedbackOn Branch Results
Stream of InstructionsTo Execute
° Instruction fetch decoupled from execution
° Need mechanism to “undo results” when prediction wrong??? Called “Speculation”

4/3/01 ©UCB April 3, 2001 CS152 / Kubiatowicz
Lec19.5
HW support for More ILP° The fewer branches, the further ahead the fetch unit
can run on its own!° One option: conditionally executed instructions: if (x) then A = B op C else NOP
• If false, then neither store result nor cause exception• Expanded ISA of Alpha, MIPS, PowerPC, SPARC have conditional
move; PA-RISC can annul any following instr.• EPIC: 64 1-bit condition fields selected so conditional execution
In IA64, may of the embedded architectures (ARM)° Drawbacks to conditional instructions
• Still takes a clock even if “annulled”• Stall if condition evaluated late• Complex conditions reduce effectiveness;
condition becomes known late in pipeline
° Still need to predict branches for highest throughput: • puts pipelining into fetch feedback loop
4/3/01 ©UCB April 3, 2001 CS152 / Kubiatowicz
Lec19.6
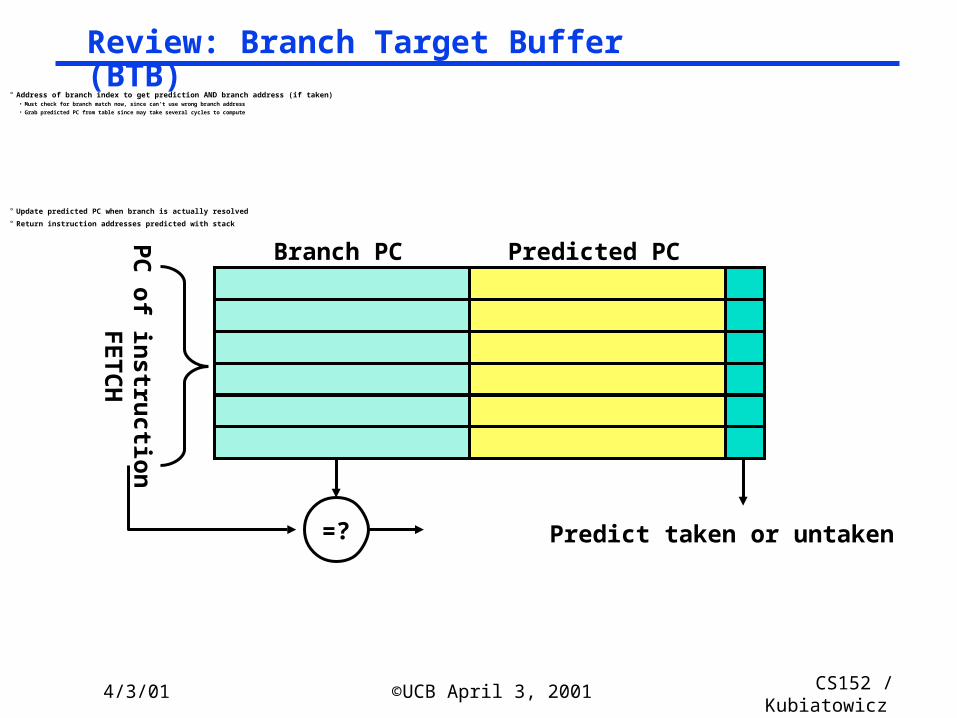
° Address of branch index to get prediction AND branch address (if taken)• Must check for branch match now, since can’t use wrong branch address
• Grab predicted PC from table since may take several cycles to compute
° Update predicted PC when branch is actually resolved
° Return instruction addresses predicted with stack
Branch PC Predicted PC
=?
PC
of in
stru
ctio
nFETC
H
Predict taken or untaken
Review: Branch Target Buffer (BTB)

4/3/01 ©UCB April 3, 2001 CS152 / Kubiatowicz
Lec19.7
° Solution: 2-bit scheme where change prediction only if get misprediction twice: (Figure 4.13, p. 264)
° Red: stop, not taken
° Green: go, taken
° Adds hysteresis to decision making process
Review: Better Dynamic Branch Prediction
T
TNT
NT
Predict Taken
Predict Not Taken
Predict Taken
Predict Not TakenT
NT
T
NT

4/3/01 ©UCB April 3, 2001 CS152 / Kubiatowicz
Lec19.8
Review: BHT Accuracy
° BHT: like branch target buffer• Table indexed by branch PC, with 2-bit counter value
° Mispredict because either:• Wrong guess for that branch
• Got branch history of wrong branch when index the table
° 4096 entry table programs vary from 1% misprediction (nasa7, tomcatv) to 18% (eqntott), with spice at 9% and gcc at 12%
° 4096 about as good as infinite table(in Alpha 211164)

4/3/01 ©UCB April 3, 2001 CS152 / Kubiatowicz
Lec19.9
Review: Something better? Correlating Branches° Hypothesis: recent branches are correlated; that is, behavior of
recently executed branches affects prediction of current branch
° Two possibilities; Current branch depends on:• Last m most recently executed branches anywhere in program
Produces a “GA” (for “global address”) in the Yeh and Patt classification (e.g. GAg)
• Last m most recent outcomes of same branch.Produces a “PA” (for “per address”) in same classification (e.g. PAg)
° Idea: record m most recently executed branches as taken or not taken, and use that pattern to select the proper branch history table entry
• A single history table shared by all branches (appends a “g” at end), indexed by history value.
• Address is used along with history to select table entry (appends a “p” at end of classification)

4/3/01 ©UCB April 3, 2001 CS152 / Kubiatowicz
Lec19.10
Correlating Branches
(2,2) GAs predictor• First 2 means that we keep two
bits of history
• Second means that we have 2 bit counters in each slot.
• Then behavior of recent branches selects between, say, four predictions of next branch, updating just that prediction
• Note that the original two-bit counter solution would be a (0,2) GAs predictor
• Note also that aliasing is possible here...
Branch address
2-bits per branch predictors
PredictionPrediction
2-bit global branch history register
° For instance, consider global history, set-indexed BHT. That gives us a GAs history table.
Each slot is2-bit counter

4/3/01 ©UCB April 3, 2001 CS152 / Kubiatowicz
Lec19.11
Accuracy of Different SchemesFre
qu
en
cy
of
Mis
pre
dic
tio
ns
0%
2%
4%
6%
8%
10%
12%
14%
16%
18%
nasa
7
matr
ix300
tom
catv
doducd
spic
e
fpppp
gcc
esp
ress
o
eqnto
tt li
0%
1%
5%
6% 6%
11%
4%
6%
5%
1%
4,096 entries: 2-bits per entry Unlimited entries: 2-bits/entry 1,024 entries (2,2)
4096 Entries 2-bit BHTUnlimited Entries 2-bit BHT1024 Entries (2,2) BHT
0%
18%
Fre
qu
ency
of
Mis
pre
dic
tio
ns

4/3/01 ©UCB April 3, 2001 CS152 / Kubiatowicz
Lec19.12
What if we predict incorrectly?
° Out-of-order commit really messes up our chance to get precise exceptions!
• When committing results out-of-order, register file contains results from later instructions while earlier ones have not completed yet.
• What if need to cause exception on one of those early instructions??
° Need to “rollback” register file to consistent state
• Remember that “precise” means that there is some PC such that: all instructions before have committed results, and none after have committed results.
° Technique for both precise interrupts/exceptions and speculation: in-order completion or commit

4/3/01 ©UCB April 3, 2001 CS152 / Kubiatowicz
Lec19.13
Review: HW support for precise exceptions/branches° Concept of Reorder Buffer (ROB):
• Holds instructions in FIFO order, exactly as they were issued
- Each ROB entry contains PC, dest reg, result, exception status
• When instructions complete, results placed into ROB
- Supplies operands to other instruction between execution complete & commit more registers like RS
- Tag results with ROB buffer number instead of reservation station
• Instructions commit values at head of ROB placed in registers
• As a result, easy to undo speculated instructions on mispredicted branches or on exceptions
ReorderBufferFP
OpQueue
FP Adder FP Adder
Res Stations Res Stations
FP Regs
Commit path

4/3/01 ©UCB April 3, 2001 CS152 / Kubiatowicz
Lec19.14
1. Issue—get instruction from FP Op Queue• If reservation station and reorder buffer slot free, issue instr & send operands
& reorder buffer no. for destination (this stage sometimes called “dispatch”)
2. Execution—operate on operands (EX)• When both operands ready then execute; if not ready, watch CDB for result;
when both in reservation station, execute; checks RAW (sometimes called “issue”)
3. Write result—finish execution (WB)• Write on Common Data Bus to all awaiting FUs & reorder buffer; mark
reservation station available.
4. Commit—update register with reorder result• When instr. at head of reorder buffer & result present, update register with
result (or store to memory) and remove instr from reorder buffer. • Mispredicted branch or interrupt flushes reorder buffer (sometimes called
“graduation”)
Four Steps of Speculative Tomasulo Algorithm

4/3/01 ©UCB April 3, 2001 CS152 / Kubiatowicz
Lec19.15
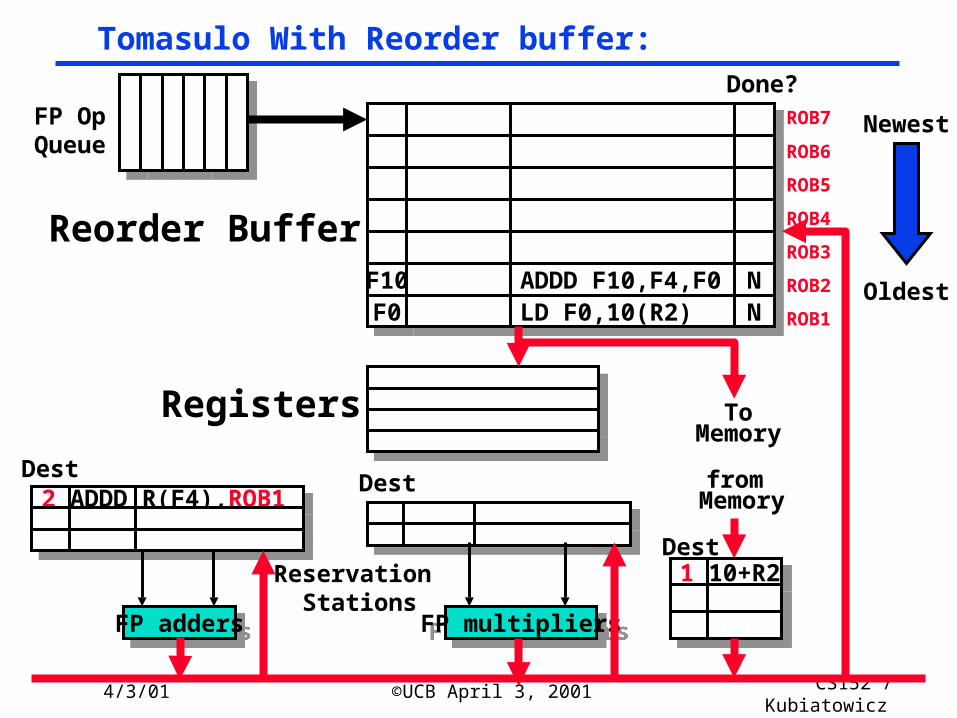
Tomasulo With Reorder buffer:
ToMemory
FP addersFP adders FP multipliersFP multipliers
Reservation Stations
FP OpQueue
ROB7
ROB6
ROB5
ROB4
ROB3
ROB2
ROB1F0F0 LD F0,10(R2)LD F0,10(R2) NN
Done?
DestDest
Oldest
Newest
from Memory
1 10+R21 10+R2Dest
Reorder Buffer
Registers
4/3/01 ©UCB April 3, 2001 CS152 / Kubiatowicz
Lec19.16
2 ADDD R(F4),ROB12 ADDD R(F4),ROB1
Tomasulo With Reorder buffer:
ToMemory
FP addersFP adders FP multipliersFP multipliers
Reservation Stations
FP OpQueue
ROB7
ROB6
ROB5
ROB4
ROB3
ROB2
ROB1
F10F10
F0F0ADDD F10,F4,F0ADDD F10,F4,F0
LD F0,10(R2)LD F0,10(R2)NN
NN
Done?
DestDest
Oldest
Newest
from Memory
1 10+R21 10+R2Dest
Reorder Buffer
Registers

4/3/01 ©UCB April 3, 2001 CS152 / Kubiatowicz
Lec19.17
3 DIVD ROB2,R(F6)3 DIVD ROB2,R(F6)2 ADDD R(F4),ROB12 ADDD R(F4),ROB16 ADDD ROB5, R(F6)6 ADDD ROB5, R(F6)
Tomasulo With Reorder buffer:
ToMemory
FP addersFP adders FP multipliersFP multipliers
Reservation Stations
FP OpQueue
ROB7
ROB6
ROB5
ROB4
ROB3
ROB2
ROB1
F0F0 ADDD F0,F4,F6ADDD F0,F4,F6 NN
F4F4 LD F4,0(R3)LD F4,0(R3) NN
---- BNE F2,<…>BNE F2,<…> NN
F2F2
F10F10
F0F0
DIVD F2,F10,F6DIVD F2,F10,F6
ADDD F10,F4,F0ADDD F10,F4,F0
LD F0,10(R2)LD F0,10(R2)
NN
NN
NN
Done?
DestDest
Oldest
Newest
from Memory
1 10+R21 10+R2Dest
Reorder Buffer
Registers
6 0+R36 0+R3

4/3/01 ©UCB April 3, 2001 CS152 / Kubiatowicz
Lec19.18
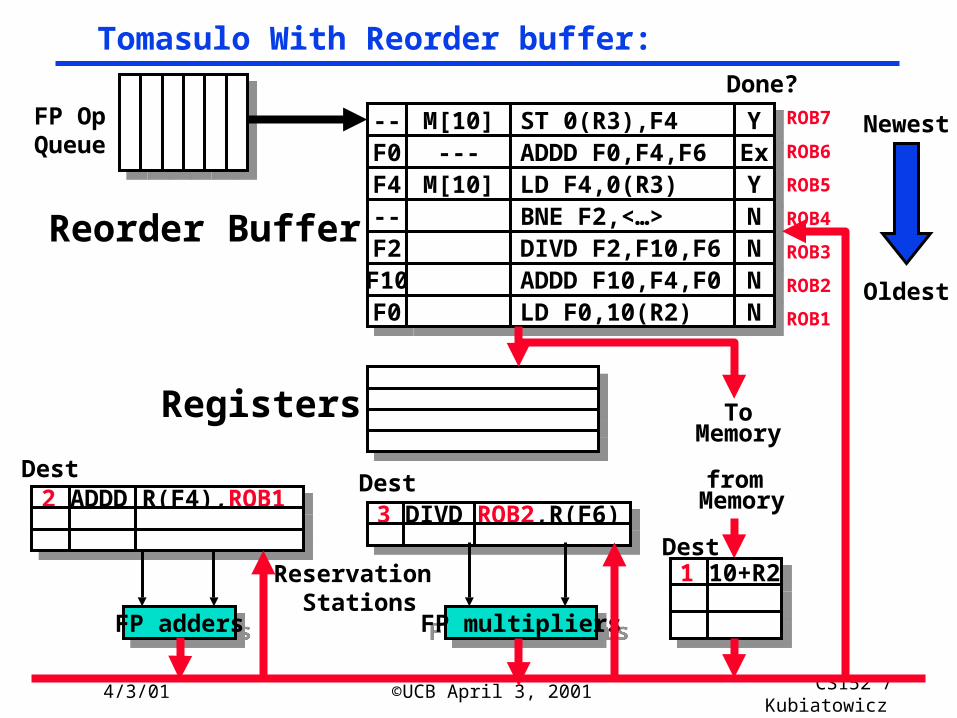
3 DIVD ROB2,R(F6)3 DIVD ROB2,R(F6)2 ADDD R(F4),ROB12 ADDD R(F4),ROB16 ADDD ROB5, R(F6)6 ADDD ROB5, R(F6)
Tomasulo With Reorder buffer:
ToMemory
FP addersFP adders FP multipliersFP multipliers
Reservation Stations
FP OpQueue
ROB7
ROB6
ROB5
ROB4
ROB3
ROB2
ROB1
----
F0F0ROB5ROB5
ST 0(R3),F4ST 0(R3),F4
ADDD F0,F4,F6ADDD F0,F4,F6NN
NN
F4F4 LD F4,0(R3)LD F4,0(R3) NN
---- BNE F2,<…>BNE F2,<…> NN
F2F2
F10F10
F0F0
DIVD F2,F10,F6DIVD F2,F10,F6
ADDD F10,F4,F0ADDD F10,F4,F0
LD F0,10(R2)LD F0,10(R2)
NN
NN
NN
Done?
DestDest
Oldest
Newest
from Memory
Dest
Reorder Buffer
Registers
1 10+R21 10+R26 0+R36 0+R3
4/3/01 ©UCB April 3, 2001 CS152 / Kubiatowicz
Lec19.19
3 DIVD ROB2,R(F6)3 DIVD ROB2,R(F6)2 ADDD R(F4),ROB12 ADDD R(F4),ROB1
Tomasulo With Reorder buffer:
ToMemory
FP addersFP adders FP multipliersFP multipliers
Reservation Stations
FP OpQueue
ROB7
ROB6
ROB5
ROB4
ROB3
ROB2
ROB1
----
F0F0M[10]M[10]
------ST 0(R3),F4ST 0(R3),F4
ADDD F0,F4,F6ADDD F0,F4,F6YY
ExEx
F4F4 M[10]M[10] LD F4,0(R3)LD F4,0(R3) YY
---- BNE F2,<…>BNE F2,<…> NN
F2F2
F10F10
F0F0
DIVD F2,F10,F6DIVD F2,F10,F6
ADDD F10,F4,F0ADDD F10,F4,F0
LD F0,10(R2)LD F0,10(R2)
NN
NN
NN
Done?
DestDest
Oldest
Newest
from Memory
1 10+R21 10+R2Dest
Reorder Buffer
Registers

4/3/01 ©UCB April 3, 2001 CS152 / Kubiatowicz
Lec19.20
----
F0F0M[10]M[10]
------ST 0(R3),F4ST 0(R3),F4
ADDD F0,F4,F6ADDD F0,F4,F6YY
ExEx
F4F4 M[10]M[10] LD F4,0(R3)LD F4,0(R3) YY
---- BNE F2,<…>BNE F2,<…> NN
3 DIVD ROB2,R(F6)3 DIVD ROB2,R(F6)2 ADDD R(F4),ROB12 ADDD R(F4),ROB1
Tomasulo With Reorder buffer:
ToMemory
FP addersFP adders FP multipliersFP multipliers
Reservation Stations
FP OpQueue
ROB7
ROB6
ROB5
ROB4
ROB3
ROB2
ROB1
F2F2
F10F10
F0F0
DIVD F2,F10,F6DIVD F2,F10,F6
ADDD F10,F4,F0ADDD F10,F4,F0
LD F0,10(R2)LD F0,10(R2)
NN
NN
NN
Done?
DestDest
Oldest
Newest
from Memory
1 10+R21 10+R2Dest
Reorder Buffer
Registers
What about memoryhazards???

4/3/01 ©UCB April 3, 2001 CS152 / Kubiatowicz
Lec19.21
Memory Disambiguation: Handling RAW Hazards in memory° Stores don’t commit until they reach head of ROB
• No WAR or WAW hazards through memory!
° Question: Given a load that follows a store in program order, are the two related?
• (Alternatively: is there a RAW hazard between the store and the load)?
Eg: st 0(R2),R5 ld R6,0(R3)
° Can we go ahead and start the load early? • Store address could be delayed for a long time by some calculation that
leads to R2 (divide?).
• We might want to issue/begin execution of both in same cycle.
° Two techiques:• No Speculation: we are not allowed to start load until we know that
address 0(R2) 0(R3)
• Speculation: We might guess at whether or not they are dependent (called “dependence speculation”) and use reorder buffer to fixup if we are wrong.

4/3/01 ©UCB April 3, 2001 CS152 / Kubiatowicz
Lec19.22
° Need buffer to keep track of all outstanding stores to memory, in program order.
• Keep track of address (when becomes available) and value (when becomes available)
• FIFO ordering: will retire stores from this buffer in program order
° When issuing a load, record current head of store queue (know which stores are ahead of you).
° When have address for load, check store queue:• If any store prior to load is waiting for its address, stall load.
• If load address matches earlier store address (associative lookup), then we have a memory-induced RAW hazard:
- store value available return value
- store value not available return ROB number of source
• Otherwise, send out request to memory
° Actual stores commit in order, so no worry about WAR/WAW hazards through memory.
Hardware Support for Memory Disambiguation

4/3/01 ©UCB April 3, 2001 CS152 / Kubiatowicz
Lec19.23
° Speculation is a form of guessing• Branch prediction, data prediction, dependence speculation
• If we speculate and are wrong, need to back up and restart execution to point at which we predicted incorrectly
• This is exactly same as precise exceptions!
° Branch prediction is a very important• Need to “take our best shot” at predicting branch direction.
• If we issue multiple instructions per cycle, lose lots of potential instructions otherwise:
- Consider 4 instructions per cycle
- If take single cycle to decide on branch, waste from 4 - 7 instruction slots!
° Technique for both precise interrupts/exceptions and speculation: in-order completion or commit
• This is why reorder buffers in all new processors
Relationship between precise interrupts and speculation:

4/3/01 ©UCB April 3, 2001 CS152 / Kubiatowicz
Lec19.24
° Start reading Chapter 7 of your book (Memory Hierarchy)
° Demonstrate your pipelines tomorrow in 119 Cory!• Everyone in your group should come to this!
° Make sure to get started on Lab 6!• This is as long or longer than Lab 5
• Tricky elements
° Second midterm 3 weeks (Thursday, April 26th)• Pipelining
- Hazards, branches, forwarding, CPI calculations
- (may include something on dynamic scheduling)
• Memory Hierarchy
• Possibly something on I/O (see where we get in lectures)
• Possibly something on power
Administrative Issues

4/3/01 ©UCB April 3, 2001 CS152 / Kubiatowicz
Lec19.25
Limits to Multi-Issue Machines
° Inherent limitations of ILP• 1 branch in 5: How to keep a 5-way superscalar busy?
• Latencies of units: many operations must be scheduled
• Need about Pipeline Depth x No. Functional Units of independent instructions to keep fully busy
• Increase ports to Register File
- VLIW example needs 7 read and 3 write for Int. Reg. & 5 read and 3 write for FP reg
• Increase ports to memory
• Current state of the art: Many hardware structures (such as issue/rename logic) has delay proportional to square of number of instructions issued/cycle

4/3/01 ©UCB April 3, 2001 CS152 / Kubiatowicz
Lec19.26
° Conflicting studies of amount• Benchmarks (vectorized Fortran FP vs. integer C programs)
• Hardware sophistication
• Compiler sophistication
° How much ILP is available using existing mechanims with increasing HW budgets?
° Do we need to invent new HW/SW mechanisms to keep on processor performance curve?
• Intel MMX
• Motorola AltaVec
• Supersparc Multimedia ops, etc.
Limits to ILP

4/3/01 ©UCB April 3, 2001 CS152 / Kubiatowicz
Lec19.27
Initial HW Model here; MIPS compilers.
Assumptions for ideal/perfect machine to start:
1. Register renaming–infinite virtual registers and all WAW & WAR hazards are avoided
2. Branch prediction–perfect; no mispredictions
3. Instruction Window–machine with an unbounded buffer of instructions available
4. Memory-address alias analysis–addresses are known & a store can be moved before a load provided addresses not equal
1 cycle latency for all instructions; unlimited number of instructions issued per clock cycle
Limits to ILP

4/3/01 ©UCB April 3, 2001 CS152 / Kubiatowicz
Lec19.28
Programs
Inst
ruct
ion
Iss
ues
per
cycl
e
0
20
40
60
80
100
120
140
160
gcc espresso li fpppp doducd tomcatv
54.862.6
17.9
75.2
118.7
150.1
Integer: 18 - 60
FP: 75 - 150
IPC
Upper Limit to ILP: Ideal Machine

4/3/01 ©UCB April 3, 2001 CS152 / Kubiatowicz
Lec19.29
Program
Instr
ucti
on
issu
es p
er
cy
cle
0
10
20
30
40
50
60
gcc espresso li fpppp doducd tomcatv
35
41
16
61
5860
9
1210
48
15
67 6
46
13
45
6 6 7
45
14
45
2 2 2
29
4
19
46
Perfect Selective predictor Standard 2-bit Static None
Change from Infinite window to examine to 2000 and maximum issue of 64 instructions per clock cycle
ProfileBHT (512)Pick Cor. or BHTPerfect No prediction
FP: 15 - 45
Integer: 6 - 12
IPC
More Realistic HW: Branch Impact
4/3/01 ©UCB April 3, 2001 CS152 / Kubiatowicz
Lec19.30
Program
Instr
ucti
on
issu
es p
er
cy
cle
0
10
20
30
40
50
60
gcc espresso li fpppp doducd tomcatv
11
15
12
29
54
10
15
12
49
16
10
1312
35
15
44
9 10 11
20
11
28
5 5 6 5 57
4 45
45 5
59
45
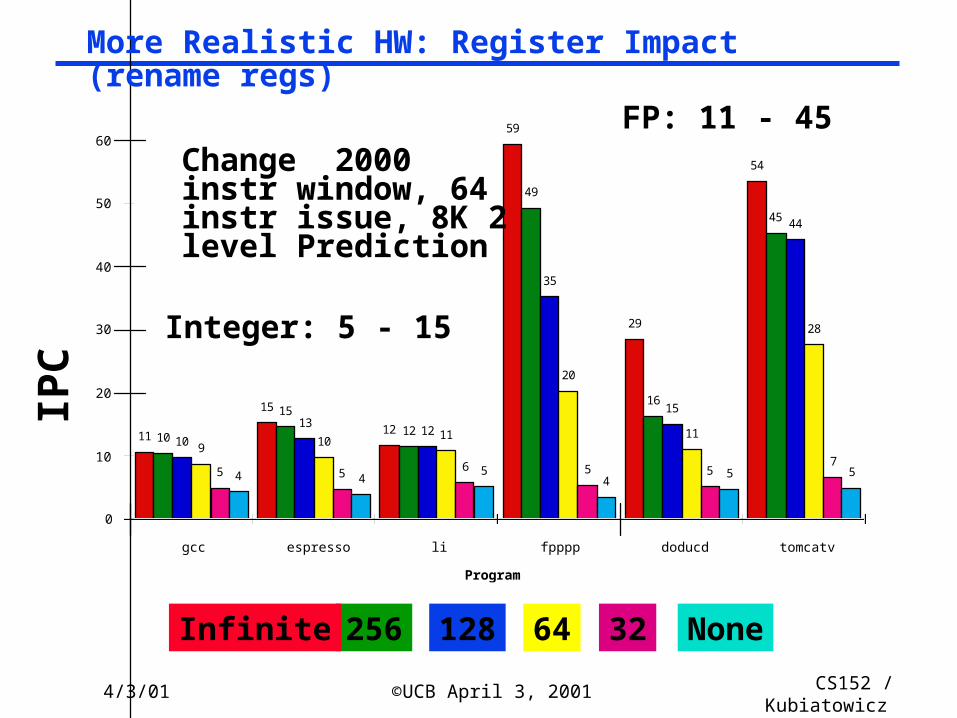
Infinite 256 128 64 32 None
Change 2000 instr window, 64 instr issue, 8K 2 level Prediction
Integer: 5 - 15
FP: 11 - 45
IPC
More Realistic HW: Register Impact (rename regs)
64 None256Infinite 32128

4/3/01 ©UCB April 3, 2001 CS152 / Kubiatowicz
Lec19.31
Program
Instr
ucti
on
issu
es p
er
cy
cle
0
5
10
15
20
25
30
35
40
45
50
gcc espresso li fpppp doducd tomcatv
10
15
12
49
16
45
7 79
49
16
45 4 4
6 53
53 3 4 4
45
Perfect Global/stack Perfect Inspection None
Change 2000 instr window, 64 instr issue, 8K 2 level Prediction, 256 renaming registers
FP: 4 - 45(Fortran,no heap)
Integer: 4 - 9
IPC
More Realistic HW: Alias Impact
NoneGlobal/Stack perf;heap conflicts
Perfect Inspec.Assem.

4/3/01 ©UCB April 3, 2001 CS152 / Kubiatowicz
Lec19.32
Program
Instr
ucti
on
issu
es p
er
cy
cle
0
10
20
30
40
50
60
gcc expresso li fpppp doducd tomcatv
10
15
12
52
17
56
10
15
12
47
16
10
1311
35
15
34
910 11
22
12
8 8 9
14
9
14
6 6 68
79
4 4 4 5 46
3 2 3 3 3 3
45
22
Infinite 256 128 64 32 16 8 4
Perfect disambiguation (HW), 1K Selective Prediction, 16 entry return, 64 registers, issue as many as window
Integer: 6 - 12
FP: 8 - 45
IPC
Realistic HW for ‘9X: Window Impact
64 16256Infinite 32128 8 4

4/3/01 ©UCB April 3, 2001 CS152 / Kubiatowicz
Lec19.33
° 8-scalar IBM Power-2 @ 71.5 MHz (5 stage pipe) vs. 2-scalar Alpha @ 200 MHz (7 stage pipe)
Benchmark
SP
EC
Ma
rks
0
100
200
300
400
500
600
700
800
900
esp
ress
o li
eqnto
tt
com
pre
ss sc gcc
spic
e
doduc
mdljdp2
wave5
tom
catv
ora
alv
inn
ear
mdljsp
2
swm
256
su2co
r
hydro
2d
nasa
fpppp
Braniac vs. Speed Demon(1993)
4/3/01 ©UCB April 3, 2001 CS152 / Kubiatowicz
Lec19.34
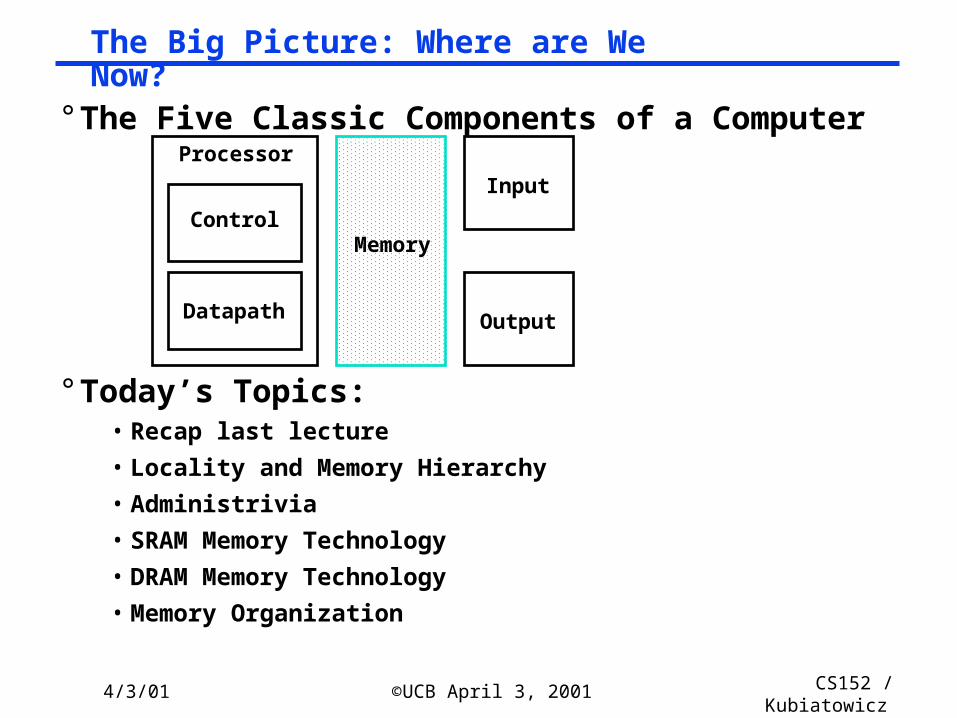
° The Five Classic Components of a Computer
° Today’s Topics: • Recap last lecture
• Locality and Memory Hierarchy
• Administrivia
• SRAM Memory Technology
• DRAM Memory Technology
• Memory Organization
The Big Picture: Where are We Now?
Control
Datapath
Memory
Processor
Input
Output

4/3/01 ©UCB April 3, 2001 CS152 / Kubiatowicz
Lec19.35
Technology Trends (from 1st lecture)
DRAM
Year Size Cycle Time
1980 64 Kb 250 ns
1983 256 Kb 220 ns
1986 1 Mb 190 ns
1989 4 Mb 165 ns
1992 16 Mb 145 ns
1995 64 Mb 120 ns
Capacity Speed (latency)
Logic: 2x in 3 years 2x in 3 years
DRAM: 4x in 3 years 2x in 10 years
Disk: 4x in 3 years 2x in 10 years
1000:1! 2:1!

4/3/01 ©UCB April 3, 2001 CS152 / Kubiatowicz
Lec19.36
µProc60%/yr.(2X/1.5yr)
DRAM9%/yr.(2X/10 yrs)1
10
100
1000
198
0198
1 198
3198
4198
5 198
6198
7198
8198
9199
0199
1 199
2199
3199
4199
5199
6199
7199
8 199
9200
0
DRAM
CPU198
2
Processor-MemoryPerformance Gap:(grows 50% / year)
Per
form
ance
Time
“Moore’s Law”
Processor-DRAM Memory Gap (latency)
Who Cares About the Memory Hierarchy?
“Less’ Law?”

4/3/01 ©UCB April 3, 2001 CS152 / Kubiatowicz
Lec19.37
Today’s Situation: Microprocessor
° Rely on caches to bridge gap
° Microprocessor-DRAM performance gap• time of a full cache miss in instructions executed
1st Alpha (7000): 340 ns/5.0 ns = 68 clks x 2 or 136 instructions
2nd Alpha (8400): 266 ns/3.3 ns = 80 clks x 4 or 320 instructions
3rd Alpha (t.b.d.): 180 ns/1.7 ns =108 clks x 6 or 648 instructions
• 1/2X latency x 3X clock rate x 3X Instr/clock 5X

4/3/01 ©UCB April 3, 2001 CS152 / Kubiatowicz
Lec19.38
Impact on Performance
° Suppose a processor executes at • Clock Rate = 200 MHz (5 ns per cycle)
• Base CPI = 1.1
• 50% arith/logic, 30% ld/st, 20% control
° Suppose that 10% of memory operations get 50 cycle miss penalty
° Suppose that 1% of instructions get same miss penalty
° CPI = base CPI + average stalls per instruction 1.1(cycles/ins) +[ 0.30 (DataMops/ins)
x 0.10 (miss/DataMop) x 50 (cycle/miss)] +[ 1 (InstMop/ins)
x 0.01 (miss/InstMop) x 50 (cycle/miss)] = (1.1 + 1.5 + .5) cycle/ins = 3.1
° 58% of the time the proc is stalled waiting for memory!
DataMiss(1.6)49%
Ideal CPI(1.1)35%
Inst Miss(0.5)16%

4/3/01 ©UCB April 3, 2001 CS152 / Kubiatowicz
Lec19.39
Impact on Performance
° Suppose a processor executes at • Clock Rate = 200 MHz (5 ns per cycle)
• Base CPI = 1.1
• 50% arith/logic, 30% ld/st, 20% control
° Suppose that 10% of memory operations get 50 cycle miss penalty
° CPI = Base CPI + average memory stalls per instruction= 1.1(cyc)+ ( 0.30 (datamops/ins)
x 0.10 (miss/datamop) x 50 (cycle/miss) )
= 1.1 cycle + 1.5 cycle = 2. 6
° 58 % of the time the processor is stalled waiting for memory!
° a 1% instruction miss rate would add an additional 0.5 cycles to the CPI!
DataMiss(1.6)49%
Ideal CPI(1.1)35%
Inst Miss(0.5)16%

4/3/01 ©UCB April 3, 2001 CS152 / Kubiatowicz
Lec19.40
The Goal: illusion of large, fast, cheap memory
° Fact: Large memories are slow
Fast memories are small
° How do we create a memory that is large, cheap and fast (most of the time)?
• Hierarchy
• Parallelism

4/3/01 ©UCB April 3, 2001 CS152 / Kubiatowicz
Lec19.41
An Expanded View of the Memory System
Control
Datapath
Memory
Processor
Mem
ory
Memory
Memory
Mem
ory
Fastest Slowest
Smallest Biggest
Highest Lowest
Speed:
Size:
Cost:

4/3/01 ©UCB April 3, 2001 CS152 / Kubiatowicz
Lec19.42
Why hierarchy works
° The Principle of Locality:• Program access a relatively small portion of the address space at
any instant of time.
Address Space0 2^n - 1
Probabilityof reference

4/3/01 ©UCB April 3, 2001 CS152 / Kubiatowicz
Lec19.43
Memory Hierarchy: How Does it Work?
° Temporal Locality (Locality in Time):=> Keep most recently accessed data items closer to the processor
° Spatial Locality (Locality in Space):=> Move blocks consists of contiguous words to the upper levels
Lower LevelMemoryUpper Level
MemoryTo Processor
From ProcessorBlk X
Blk Y

4/3/01 ©UCB April 3, 2001 CS152 / Kubiatowicz
Lec19.44
Memory Hierarchy: Terminology° Hit: data appears in some block in the upper level
(example: Block X) • Hit Rate: the fraction of memory access found in the upper level
• Hit Time: Time to access the upper level which consists of
RAM access time + Time to determine hit/miss
° Miss: data needs to be retrieve from a block in the lower level (Block Y)
• Miss Rate = 1 - (Hit Rate)
• Miss Penalty: Time to replace a block in the upper level +
Time to deliver the block the processor
° Hit Time << Miss PenaltyLower Level
MemoryUpper LevelMemory
To Processor
From ProcessorBlk X
Blk Y
4/3/01 ©UCB April 3, 2001 CS152 / Kubiatowicz
Lec19.45
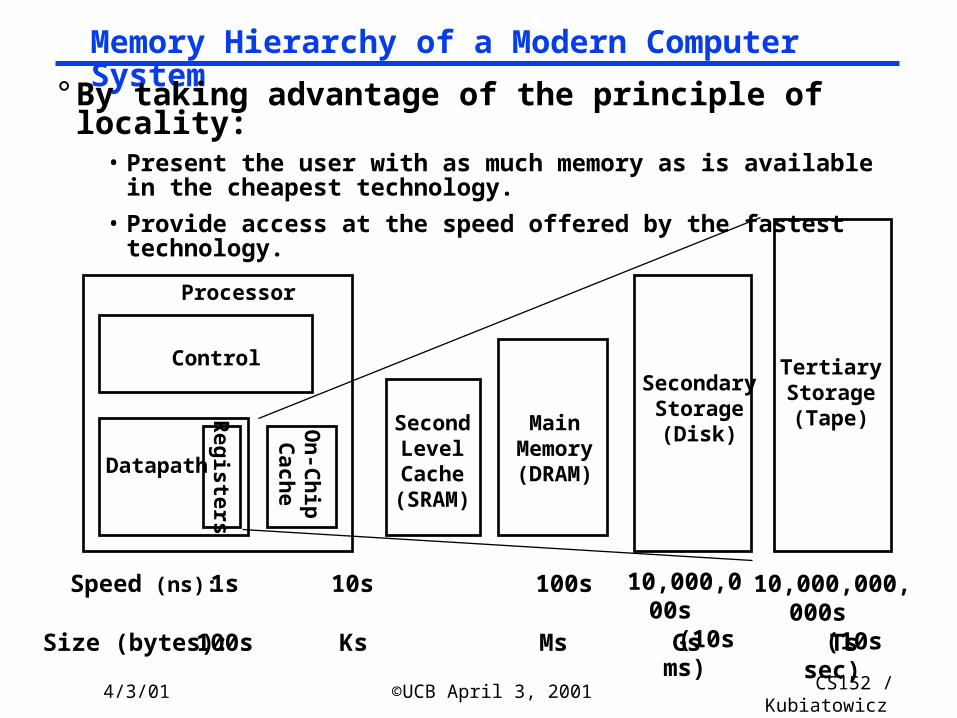
Memory Hierarchy of a Modern Computer System
° By taking advantage of the principle of locality:• Present the user with as much memory as is available in the
cheapest technology.
• Provide access at the speed offered by the fastest technology.
Control
Datapath
SecondaryStorage(Disk)
Processor
Registers
MainMemory(DRAM)
SecondLevelCache
(SRAM)
On
-Ch
ipC
ache
1s 10,000,000s
(10s ms)
Speed (ns): 10s 100s
100s GsSize (bytes): Ks Ms
TertiaryStorage(Tape)
10,000,000,000s (10s sec)
Ts

4/3/01 ©UCB April 3, 2001 CS152 / Kubiatowicz
Lec19.46
How is the hierarchy managed?
° Registers <-> Memory• by compiler (programmer?)
° cache <-> memory• by the hardware
° memory <-> disks• by the hardware and operating system (virtual memory)
• by the programmer (files)

4/3/01 ©UCB April 3, 2001 CS152 / Kubiatowicz
Lec19.47
Memory Hierarchy Technology
° Random Access:• “Random” is good: access time is the same for all locations• DRAM: Dynamic Random Access Memory
- High density, low power, cheap, slow- Dynamic: need to be “refreshed” regularly
• SRAM: Static Random Access Memory- Low density, high power, expensive, fast- Static: content will last “forever”(until lose power)
° “Non-so-random” Access Technology:• Access time varies from location to location and from time to time• Examples: Disk, CDROM, DRAM page-mode access
° Sequential Access Technology: access time linear in location (e.g.,Tape)
° The next two lectures will concentrate on random access technology• The Main Memory: DRAMs + Caches: SRAMs

4/3/01 ©UCB April 3, 2001 CS152 / Kubiatowicz
Lec19.48
Main Memory Background
° Performance of Main Memory: • Latency: Cache Miss Penalty
- Access Time: time between request and word arrives
- Cycle Time: time between requests
• Bandwidth: I/O & Large Block Miss Penalty (L2)
° Main Memory is DRAM : Dynamic Random Access Memory• Dynamic since needs to be refreshed periodically (8 ms)
• Addresses divided into 2 halves (Memory as a 2D matrix):
- RAS or Row Access Strobe
- CAS or Column Access Strobe
° Cache uses SRAM : Static Random Access Memory• No refresh (6 transistors/bit vs. 1 transistor)
Size: DRAM/SRAM 4-8 Cost/Cycle time: SRAM/DRAM 8-16

4/3/01 ©UCB April 3, 2001 CS152 / Kubiatowicz
Lec19.49
Random Access Memory (RAM) Technology
° Why do computer designers need to know about RAM technology?
• Processor performance is usually limited by memory bandwidth
• As IC densities increase, lots of memory will fit on processor chip
- Tailor on-chip memory to specific needs
- Instruction cache
- Data cache
- Write buffer
° What makes RAM different from a bunch of flip-flops?• Density: RAM is much denser

4/3/01 ©UCB April 3, 2001 CS152 / Kubiatowicz
Lec19.50
Static RAM Cell
6-Transistor SRAM Cell
bit bit
word(row select)
bit bit
word
° Write:1. Drive bit lines (bit=1, bit=0)
2.. Select row
° Read:1. Precharge bit and bit to Vdd or Vdd/2 => make sure equal!
2.. Select row
3. Cell pulls one line low
4. Sense amp on column detects difference between bit and bit
replaced with pullupto save area
10
0 1

4/3/01 ©UCB April 3, 2001 CS152 / Kubiatowicz
Lec19.51
Typical SRAM Organization: 16-word x 4-bit
SRAMCell
SRAMCell
SRAMCell
SRAMCell
SRAMCell
SRAMCell
SRAMCell
SRAMCell
SRAMCell
SRAMCell
SRAMCell
SRAMCell
- +Sense Amp - +Sense Amp - +Sense Amp - +Sense Amp
: : : :
Word 0
Word 1
Word 15
Dout 0Dout 1Dout 2Dout 3
- +Wr Driver &Precharger - +
Wr Driver &Precharger - +
Wr Driver &Precharger - +
Wr Driver &Precharger
Ad
dress D
ecoder
WrEnPrecharge
Din 0Din 1Din 2Din 3
A0
A1
A2
A3
Q: Which is longer:word line or
bit line?

4/3/01 ©UCB April 3, 2001 CS152 / Kubiatowicz
Lec19.52
° Write Enable is usually active low (WE_L)
° Din and Dout are combined to save pins:• A new control signal, output enable (OE_L) is needed
• WE_L is asserted (Low), OE_L is disasserted (High)
- D serves as the data input pin
• WE_L is disasserted (High), OE_L is asserted (Low)
- D is the data output pin
• Both WE_L and OE_L are asserted:
- Result is unknown. Don’t do that!!!
° Although could change VHDL to do what desire, must do the best with what you’ve got (vs. what you need)
A
DOE_L
2 Nwordsx M bitSRAM
N
M
WE_L
Logic Diagram of a Typical SRAM

4/3/01 ©UCB April 3, 2001 CS152 / Kubiatowicz
Lec19.53
Typical SRAM Timing
Write Timing:
D
Read Timing:
WE_L
A
WriteHold Time
Write Setup Time
A
DOE_L
2 Nwordsx M bitSRAM
N
M
WE_L
Data In
Write Address
OE_L
High Z
Read Address
Junk
Read AccessTime
Data Out
Read AccessTime
Data Out
Read Address

4/3/01 ©UCB April 3, 2001 CS152 / Kubiatowicz
Lec19.54
Problems with SRAM
° Six transistors use up a lot of area
° Consider a “Zero” is stored in the cell:• Transistor N1 will try to pull “bit” to 0
• Transistor P2 will try to pull “bit bar” to 1
° But bit lines are precharged to high: Are P1 and P2 necessary?
bit = 1 bit = 0
Select = 1
On Off
Off On
N1 N2
P1 P2
OnOn
4/3/01 ©UCB April 3, 2001 CS152 / Kubiatowicz
Lec19.55
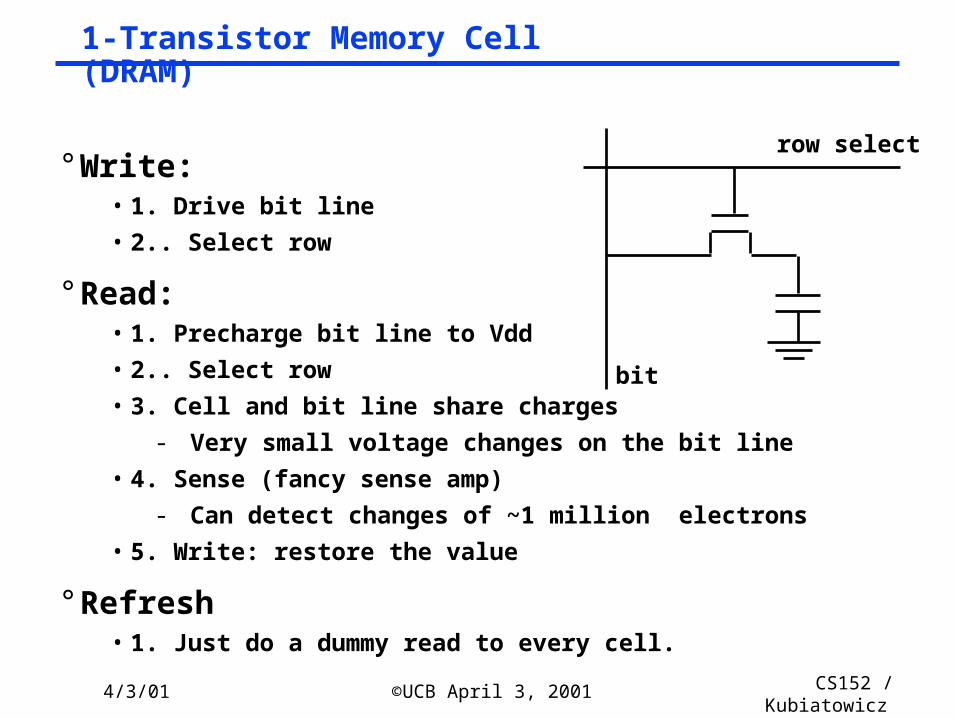
1-Transistor Memory Cell (DRAM)
° Write:• 1. Drive bit line
• 2.. Select row
° Read:• 1. Precharge bit line to Vdd
• 2.. Select row
• 3. Cell and bit line share charges
- Very small voltage changes on the bit line
• 4. Sense (fancy sense amp)
- Can detect changes of ~1 million electrons
• 5. Write: restore the value
° Refresh• 1. Just do a dummy read to every cell.
row select
bit
4/3/01 ©UCB April 3, 2001 CS152 / Kubiatowicz
Lec19.56
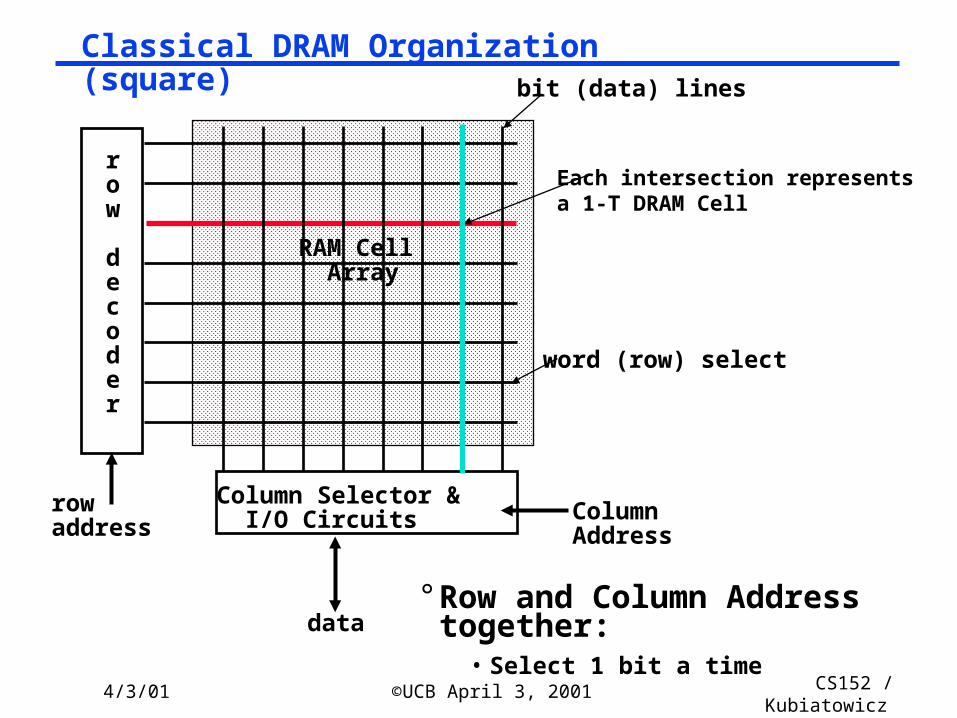
Classical DRAM Organization (square)
row
decoder
rowaddress
Column Selector & I/O Circuits Column
Address
data
RAM Cell Array
word (row) select
bit (data) lines
° Row and Column Address together:
• Select 1 bit a time
Each intersection representsa 1-T DRAM Cell

4/3/01 ©UCB April 3, 2001 CS152 / Kubiatowicz
Lec19.57
DRAM logical organization (4 Mbit)
° Square root of bits per RAS/CAS
Column Decoder
Sense Amps & I/O
Memory Array(2,048 x 2,048)
A0…A10
…
11 D
Q
Word LineStorage Cell

4/3/01 ©UCB April 3, 2001 CS152 / Kubiatowicz
Lec19.58
Block Row Dec.
9 : 512
RowBlock
Row Dec.9 : 512
Column Address
… BlockRow Dec.
9 : 512
BlockRow Dec.
9 : 512
…
Block 0 Block 3…
I/OI/O
I/OI/O
I/OI/O
I/OI/O
D
Q
Address
2
8 I/Os
8 I/Os
DRAM physical organization (4 Mbit)

4/3/01 ©UCB April 3, 2001 CS152 / Kubiatowicz
Lec19.59
DRAM2^n x 1chip
DRAMController
address
MemoryTimingController Bus Drivers
n
n/2
w
Tc = Tcycle + Tcontroller + Tdriver
Memory Systems

4/3/01 ©UCB April 3, 2001 CS152 / Kubiatowicz
Lec19.60
AD
OE_L
256K x 8DRAM9 8
WE_L
° Control Signals (RAS_L, CAS_L, WE_L, OE_L) are all active low
° Din and Dout are combined (D):• WE_L is asserted (Low), OE_L is disasserted (High)
- D serves as the data input pin
• WE_L is disasserted (High), OE_L is asserted (Low)
- D is the data output pin
° Row and column addresses share the same pins (A)• RAS_L goes low: Pins A are latched in as row address
• CAS_L goes low: Pins A are latched in as column address
• RAS/CAS edge-sensitive
CAS_LRAS_L
Logic Diagram of a Typical DRAM

4/3/01 ©UCB April 3, 2001 CS152 / Kubiatowicz
Lec19.61
° tRAC: minimum time from RAS line falling to the valid data output.
• Quoted as the speed of a DRAM
• A fast 4Mb DRAM tRAC = 60 ns
° tRC: minimum time from the start of one row access to the start of the next.
• tRC = 110 ns for a 4Mbit DRAM with a tRAC of 60 ns
° tCAC: minimum time from CAS line falling to valid data output.
• 15 ns for a 4Mbit DRAM with a tRAC of 60 ns
° tPC: minimum time from the start of one column access to the start of the next.
• 35 ns for a 4Mbit DRAM with a tRAC of 60 ns
Key DRAM Timing Parameters

4/3/01 ©UCB April 3, 2001 CS152 / Kubiatowicz
Lec19.62
° A 60 ns (tRAC) DRAM can • perform a row access only every 110 ns (tRC)
• perform column access (tCAC) in 15 ns, but time between column accesses is at least 35 ns (tPC).
- In practice, external address delays and turning around buses make it 40 to 50 ns
° These times do not include the time to drive the addresses off the microprocessor nor the memory controller overhead.
• Drive parallel DRAMs, external memory controller, bus to turn around, SIMM module, pins…
• 180 ns to 250 ns latency from processor to memory is good for a “60 ns” (tRAC) DRAM
DRAM Performance

4/3/01 ©UCB April 3, 2001 CS152 / Kubiatowicz
Lec19.63
AD
OE_L
256K x 8DRAM9 8
WE_LCAS_LRAS_L
WE_L
A Row Address
OE_L
Junk
WR Access Time WR Access Time
CAS_L
RAS_L
Col Address Row Address JunkCol Address
D Junk JunkData In Data In Junk
DRAM WR Cycle Time
Early Wr Cycle: WE_L asserted before CAS_L Late Wr Cycle: WE_L asserted after CAS_L
° Every DRAM access begins at:
• The assertion of the RAS_L
• 2 ways to write: early or late v. CAS
DRAM Write Timing
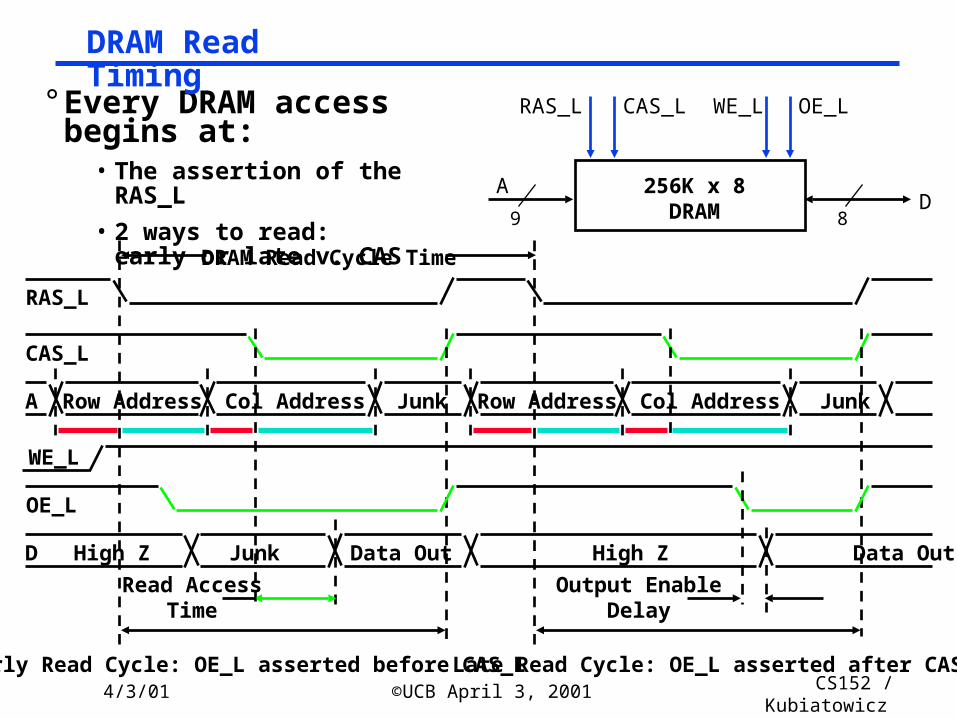
4/3/01 ©UCB April 3, 2001 CS152 / Kubiatowicz
Lec19.64
AD
OE_L
256K x 8DRAM9 8
WE_LCAS_LRAS_L
OE_L
A Row Address
WE_L
Junk
Read AccessTime
Output EnableDelay
CAS_L
RAS_L
Col Address Row Address JunkCol Address
D High Z Data Out
DRAM Read Cycle Time
Early Read Cycle: OE_L asserted before CAS_L Late Read Cycle: OE_L asserted after CAS_L
° Every DRAM access begins at:
• The assertion of the RAS_L
• 2 ways to read: early or late v. CAS
Junk Data Out High Z
DRAM Read Timing

4/3/01 ©UCB April 3, 2001 CS152 / Kubiatowicz
Lec19.65
° Simple: • CPU, Cache, Bus, Memory
same width (32 bits)
° Interleaved: • CPU, Cache, Bus 1 word:
Memory N Modules(4 Modules); example is word interleaved
° Wide: • CPU/Mux 1 word;
Mux/Cache, Bus, Memory N words (Alpha: 64 bits & 256 bits)
Main Memory Performance

4/3/01 ©UCB April 3, 2001 CS152 / Kubiatowicz
Lec19.66
° DRAM (Read/Write) Cycle Time >> DRAM (Read/Write) Access Time
• 2:1; why?
° DRAM (Read/Write) Cycle Time :• How frequent can you initiate an access?
• Analogy: A little kid can only ask his father for money on Saturday
° DRAM (Read/Write) Access Time:• How quickly will you get what you want once you initiate an access?
• Analogy: As soon as he asks, his father will give him the money
° DRAM Bandwidth Limitation analogy:• What happens if he runs out of money on Wednesday?
TimeAccess Time
Cycle Time
Main Memory Performance

4/3/01 ©UCB April 3, 2001 CS152 / Kubiatowicz
Lec19.67
Access Pattern without Interleaving:
Start Access for D1
CPU Memory
Start Access for D2
D1 available
Access Pattern with 4-way Interleaving:
Acc
ess
Ban
k 0
Access Bank 1
Access Bank 2
Access Bank 3
We can Access Bank 0 again
CPU
MemoryBank 1
MemoryBank 0
MemoryBank 3
MemoryBank 2
Increasing Bandwidth - Interleaving

4/3/01 ©UCB April 3, 2001 CS152 / Kubiatowicz
Lec19.68
° Timing model• 1 to send address,
• 4 for access time, 10 cycle time, 1 to send data
• Cache Block is 4 words
° Simple M.P. = 4 x (1+10+1) = 48° Wide M.P. = 1 + 10 + 1 = 12° Interleaved M.P. = 1+10+1 + 3 =15
address
Bank 0
048
12
address
Bank 1
159
13
address
Bank 2
26
1014
address
Bank 3
37
1115
Main Memory Performance

4/3/01 ©UCB April 3, 2001 CS152 / Kubiatowicz
Lec19.69
° How many banks?number banks number clocks to access word in bank
• For sequential accesses, otherwise will return to original bank before it has next word ready
° Increasing DRAM => fewer chips => harder to have banks
• Growth bits/chip DRAM : 50%-60%/yr
• Nathan Myrvold M/S: mature software growth (33%/yr for NT) growth MB/$ of DRAM (25%-30%/yr)
Independent Memory Banks

4/3/01 ©UCB April 3, 2001 CS152 / Kubiatowicz
Lec19.70
Fewer DRAMs/System over TimeM
inim
um
PC
Mem
ory
Siz
e
DRAM Generation‘86 ‘89 ‘92 ‘96 ‘99 ‘02 1 Mb 4 Mb 16 Mb 64 Mb 256 Mb 1 Gb
4 MB
8 MB
16 MB
32 MB
64 MB
128 MB
256 MB
32 8
16 4
8 2
4 1
8 2
4 1
8 2
Memory per System growth@ 25%-30% / year
Memory per DRAM growth@ 60% / year
(from PeteMacWilliams, Intel)
4/3/01 ©UCB April 3, 2001 CS152 / Kubiatowicz
Lec19.71
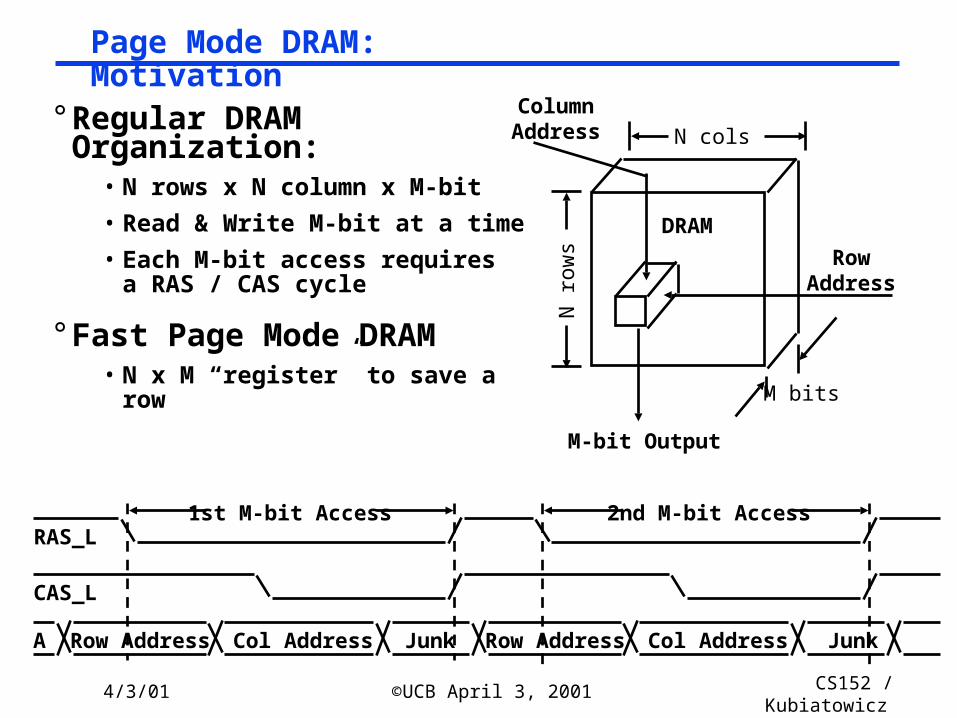
Page Mode DRAM: Motivation
° Regular DRAM Organization:• N rows x N column x M-bit
• Read & Write M-bit at a time
• Each M-bit access requiresa RAS / CAS cycle
° Fast Page Mode DRAM• N x M “register” to save a row
A Row Address Junk
CAS_L
RAS_L
Col Address Row Address JunkCol Address
1st M-bit Access 2nd M-bit Access
N r
ows
N cols
DRAM
M bits
RowAddress
ColumnAddress
M-bit Output

4/3/01 ©UCB April 3, 2001 CS152 / Kubiatowicz
Lec19.72
Fast Page Mode Operation
° Fast Page Mode DRAM• N x M “SRAM” to save a row
° After a row is read into the register
• Only CAS is needed to access other M-bit blocks on that row
• RAS_L remains asserted while CAS_L is toggled
A Row Address
CAS_L
RAS_L
Col Address Col Address
1st M-bit Access
N r
ows
N cols
DRAM
ColumnAddress
M-bit OutputM bits
N x M “SRAM”
RowAddress
Col Address Col Address
2nd M-bit 3rd M-bit 4th M-bit

4/3/01 ©UCB April 3, 2001 CS152 / Kubiatowicz
Lec19.73
Standards pinout, package, binary compatibility,refresh rate, IEEE 754, I/O buscapacity, ...
Sources Multiple Single
Figures 1) capacity, 1a) $/bit 1) SPEC speedof Merit 2) BW, 3) latency 2) cost
Improve 1) 60%, 1a) 25%, 1) 60%, Rate/year 2) 20%, 3) 7% 2) little change
DRAM v. Desktop Microprocessors Cultures

4/3/01 ©UCB April 3, 2001 CS152 / Kubiatowicz
Lec19.74
° Reduce cell size 2.5, increase die size 1.5
° Sell 10% of a single DRAM generation• 6.25 billion DRAMs sold in 1996
° 3 phases: engineering samples, first customer ship(FCS), mass production
• Fastest to FCS, mass production wins share
° Die size, testing time, yield => profit• Yield >> 60%
(redundant rows/columns to repair flaws)
DRAM Design Goals

4/3/01 ©UCB April 3, 2001 CS152 / Kubiatowicz
Lec19.75
° DRAMs: capacity +60%/yr, cost –30%/yr• 2.5X cells/area, 1.5X die size in 3 years
° ‘97 DRAM fab line costs $1B to $2B• DRAM only: density, leakage v. speed
° Rely on increasing no. of computers & memory per computer (60% market)
• SIMM or DIMM is replaceable unit => computers use any generation DRAM
° Commodity, second source industry => high volume, low profit, conservative
• Little organization innovation in 20 years page mode, EDO, Synch DRAM
° Order of importance: 1) Cost/bit 1a) Capacity• RAMBUS: 10X BW, +30% cost => little impact
DRAM History

4/3/01 ©UCB April 3, 2001 CS152 / Kubiatowicz
Lec19.76
° Commodity, second source industry high volume, low profit, conservative
• Little organization innovation (vs. processors) in 20 years: page mode, EDO, Synch DRAM
° DRAM industry at a crossroads:• Fewer DRAMs per computer over time
- Growth bits/chip DRAM : 50%-60%/yr
- Nathan Myrvold M/S: mature software growth (33%/yr for NT) growth MB/$ of DRAM (25%-30%/yr)
• Starting to question buying larger DRAMs?
Today’s Situation: DRAM
4/3/01 ©UCB April 3, 2001 CS152 / Kubiatowicz
Lec19.77
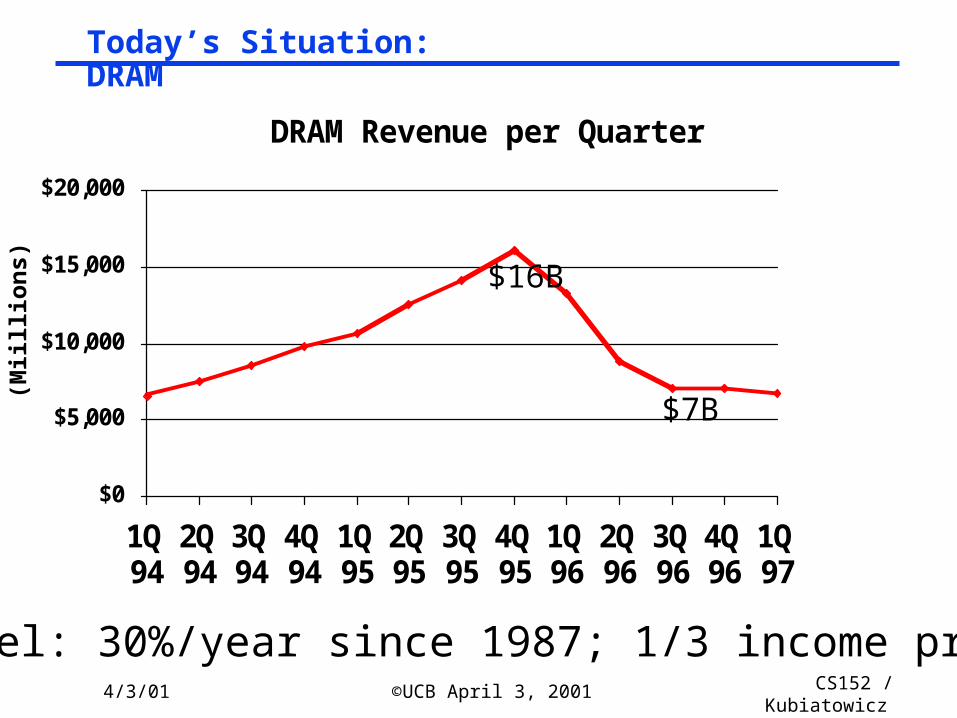
DRAM Revenue per Quarter
$0
$5,000
$10,000
$15,000
$20,000
1Q94
2Q94
3Q94
4Q94
1Q95
2Q95
3Q95
4Q95
1Q96
2Q96
3Q96
4Q96
1Q97
(Miil
lion
s)
$16B
$7B
• Intel: 30%/year since 1987; 1/3 income profit
Today’s Situation: DRAM

4/3/01 ©UCB April 3, 2001 CS152 / Kubiatowicz
Lec19.78
° Reorder Buffer:• Provides generic mechanism for unrolling computation• Instructions placed into Reorder buffer in issue order• Instructions exit in same order – providing in-order-commit• Trick: Don’t want to be unrolling too often (wasted computation)!
° Parallelism hard to get from real hardware.° Two Different Types of Locality:
• Temporal Locality (Locality in Time): If an item is referenced, it will tend to be referenced again soon.
• Spatial Locality (Locality in Space): If an item is referenced, items whose addresses are close by tend to be referenced soon.
° By taking advantage of the principle of locality:• Present the user with as much memory as is available in the cheapest technology.• Provide access at the speed offered by the fastest technology.
° DRAM is slow but cheap and dense:• Good choice for presenting the user with a BIG memory system
° SRAM is fast but expensive and not very dense:• Good choice for providing the user FAST access time.
Summary:

4/3/01 ©UCB April 3, 2001 CS152 / Kubiatowicz
Lec19.79
Processor % Area %Transistors
( cost) ( power)
° Alpha 21164 37% 77%
° StrongArm SA110 61% 94%
° Pentium Pro 64% 88%• 2 dies per package: Proc/I$/D$ + L2$
° Caches have no inherent value, only try to close performance gap
Summary: Processor-Memory Performance Gap “Tax”





























