Embed Size (px)
Citation preview

CS61C:GreatIdeasinComputerArchitecture
Lecture13:Pipelining
KrsteAsanović &RandyKatz
http://inst.eecs.berkeley.edu/~cs61c/fa17

Agenda• RISC-V Pipeline• PipelineControl• Hazards
− Structural− Data
§ R-typeinstructions§ Load
− Control• SuperscalarprocessorsCS61c Lecture13:Pipelining 2

Recap:PipeliningwithRISC-V
CS61c 3
addt0,t1,t2
ort3,t4,t5
sll t6,t0,t3tcycle
instructionsequence
tinstruction
Single Cycle PipeliningTiming tstep =100…200ps tcycle =200ps
Register accessonly100ps AllcyclessamelengthInstruction time,tinstruction =tcycle =800ps 1000psClockrate,fs 1/800ps =1.25GHz 1/200 ps =5GHzRelativespeed 1x 4x

RISC-VPipelineaddt0,t1,t2
ort3,t4,t5
slt t6,t0,t3
tcycle=200ps
instructionsequence
tinstruction =1000ps
sw t0,4(t3)
lw t0,8(t3)
addi t2,t2,1
Resourceuseofinstructionovertime
Resourceuseinaparticulartimeslot
CS61c Lecture13:Pipelining 4

Single-CycleRISC-VRV32IDatapath
CS61c 5
IMEMALU
Imm.Gen
+4
DMEMBranchComp.
Reg[]
AddrAAddrB
DataAAddrD
DataB
DataD
Addr
DataWDataR
10
0121
0 pc01
inst[11:7]
inst[19:15]
inst[24:20]
inst[31:7]
pc+4alu
mem
wb
alu
pc+4
Reg[rs1]
pc
imm[31:0]
Reg[rs2]
inst[31:0] ImmSel RegWEn BrUnBrEq BrLT ASelBSel ALUSel MemRW WBSelPCSel
wb

PipeliningRISC-VRV32IDatapath
CS61c 6
IMEMALU
Imm.Gen
+4
DMEMBranchComp.
Reg[]
AddrAAddrB
DataAAddrD
DataB
DataD
Addr
DataWDataR
10
0121
0 pc01
inst[11:7]
inst[19:15]
inst[24:20]
inst[31:7]
pc+4alu
mem
wb
alu
pc+4
Reg[rs1]
pc
imm[31:0]
Reg[rs2]
wb
InstructionFetch(F)
InstructionDecode/RegisterRead
(D)
ALUExecute(X)
MemoryAccess(M)
WriteBack(W)

PipelinedRISC-VRV32IDatapath
CS61c7
IMEM
ALU
+4
DMEMBranchComp.
Reg[]
AddrA
AddrB
DataAAddrD
DataB
DataD
Addr
DataWDataR
10
aluX
pcF+4
+4pcDpcFpcX pcM
instD
instX
rs1X
rs2X
aluM
rs2MimmXImm.
RecalculatePC+4inMstagetoavoidsendingbothPCandPC+4downpipeline
instM instW
Mustpipelineinstructionalongwithdata,socontroloperatescorrectlyineachstage

Eachstageoperatesondifferentinstruction
CS61c8
IMEM
ALU
+4
DMEMBranchComp.
Reg[]
AddrA
AddrB
DataAAddrD
DataB
DataD
Addr
DataWDataR
10
aluX
pcF+4
+4pcDpcFpcX pcM
instD
instX
rs1X
rs2X
aluM
rs2MimmXImm.instM instW
addt0,t1,t2
ort3,t4,t5slt t6,t0,t3sw t0,4(t3)lw t0,8(t3)
Pipelineregistersseparatestages,holddataforeachinstructioninflight

Agenda• RISC-V Pipeline• PipelineControl• Hazards
− Structural− Data
§ R-typeinstructions§ Load
− Control• SuperscalarprocessorsCS61c Lecture13:Pipelining 9

PipelinedControl• Controlsignalsderivedfrominstruction
− Asinsingle-cycleimplementation− Informationisstoredinpipelineregistersforusebylaterstages
CS61c 10

HazardsAhead
CS61c Lecture13:Pipelining 11

Agenda• RISC-V Pipeline• PipelineControl• Hazards
− Structural− Data
§ R-typeinstructions§ Load
− Control• SuperscalarprocessorsCS61c Lecture13:Pipelining 12

StructuralHazard• Problem:Twoormoreinstructionsinthepipelinecompeteforaccesstoasinglephysicalresource• Solution1:Instructionstakeitinturnstouseresource,someinstructionshavetostall• Solution2:Addmorehardwaretomachine• Canalwayssolveastructuralhazardbyaddingmorehardware
CS61c Lecture13:Pipelining 13

Regfile StructuralHazards• Eachinstruction:
− canreaduptotwooperandsindecodestage− canwriteonevalueinwriteback stage
• Avoidstructuralhazardbyhavingseparate“ports”− twoindependentreadportsandoneindependentwriteport
• Threeaccessespercyclecanhappensimultaneously
CS61c Lecture13:Pipelining 14

StructuralHazard:MemoryAccess
addt0,t1,t2
ort3,t4,t5
slt t6,t0,t3
instructionsequence
sw t0,4(t3)
lw t0,8(t3)
• Instructionanddatamemoryusedsimultaneously
ü Usetwoseparatememories
CS61c Lecture13:Pipelining 15

InstructionandDataCaches
16CS61c Lecture13:Pipelining
Processor
Control
DatapathPC
RegistersArithmetic&LogicUnit
(ALU)
Memory(DRAM)
Bytes
Program
Data
InstructionCache
DataCache
Caches:smallandfast“buffer”memories

Lecture13:Pipelining
StructuralHazards– Summary• Conflictforuseofaresource• InRISC-Vpipelinewithasinglememory
− Load/storerequiresdataaccess− Withoutseparatememories,instructionfetchwouldhavetostallforthatcycle§ Allotheroperationsinpipelinewouldhavetowait
• Pipelineddatapaths requireseparateinstruction/datamemories− Orseparateinstruction/datacaches
• RISCISAs(includingRISC-V)designedtoavoidstructuralhazards− e.g.atmostonememoryaccess/instruction
17

Agenda• RISC-V Pipeline• PipelineControl• Hazards
− Structural− Data
§ R-typeinstructions§ Load
− Control• SuperscalarprocessorsCS61c Lecture13:Pipelining 18

DataHazard:RegisterAccess
addt0,t1,t2
ort3,t4,t5
slt t6,t0,t3
instructionsequence
sw t0,4(t3)
lw t0,8(t3)
• Separateports,butwhatifwritetosamevalueasread?• Doessw intheexamplefetchtheoldornewvalue?
CS61c Lecture13:Pipelining 19

RegisterAccessPolicy
addt0,t1,t2
ort3,t4,t5
slt t6,t0,t3
instructionsequence sw t0,4(t3)
lw t0,8(t3)
• Exploithighspeedofregisterfile(100ps)
1) WBupdatesvalue2) IDreadsnewvalue
• Indicatedindiagrambyshading
CS61c Lecture13:Pipelining 20
Mightnotalwaysbepossibletowritethenreadinsamecycle,especiallyinhigh-frequencydesigns.Checkassumptionsinanyquestion.

DataHazard:ALUResult
adds0,t0,t1
subt2,s0,t0
ort6,s0,t3
instructionsequence
xor t5,t1,s0
sw s0,8(t3)
5 5 5 5 5/9 9 9 9 9Valueofs0
Withoutsomefix,sub andor willcalculatewrongresult!CS61c Lecture13:Pipelining 21

DataHazard:ALUResult
adds0,t1,t2
subt2,s0,t5
ort6,s0,t3
instructionsequence
xor t5,t1,s0
sw s0,8(t3)
5Valueofs0
Withoutsomefix,sub andor willcalculatewrongresult!CS61c Lecture13:Pipelining 22
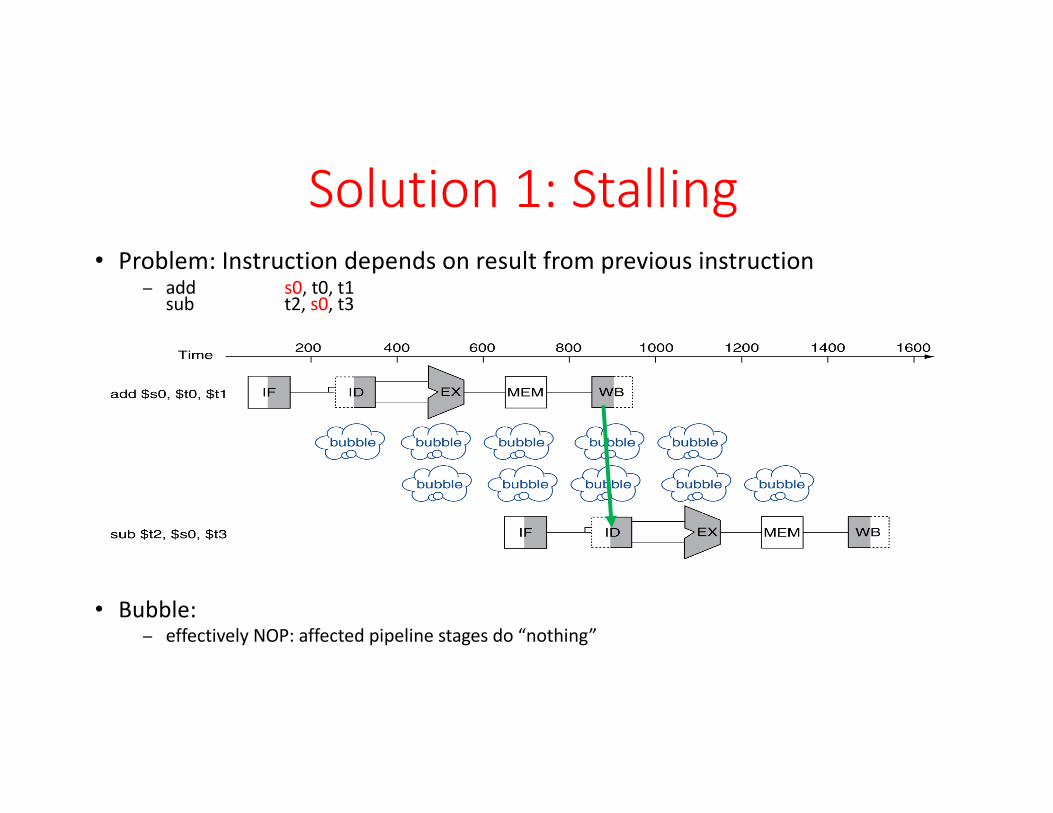
Solution1: Stalling• Problem:Instructiondependsonresultfrompreviousinstruction
− add s0,t0,t1sub t2,s0,t3
• Bubble:− effectivelyNOP:affectedpipelinestagesdo“nothing”

StallsandPerformance
• Stallsreduceperformance− Butstallsarerequiredtogetcorrectresults
• Compilercanarrangecodetoavoidhazardsandstalls− Requiresknowledgeofthepipelinestructure
CS61c 24

Solution2:Forwarding
addt0,t1,t2
ort3,t0,t5
subt6,t0,t3
instructionsequence
xor t5,t1,t0
sw t0,8(t3)
5 5 5 5 5/9 9 9 9 9Valueoft0
Forwarding:graboperandfrompipelinestage,ratherthanregisterfileCS61c 25
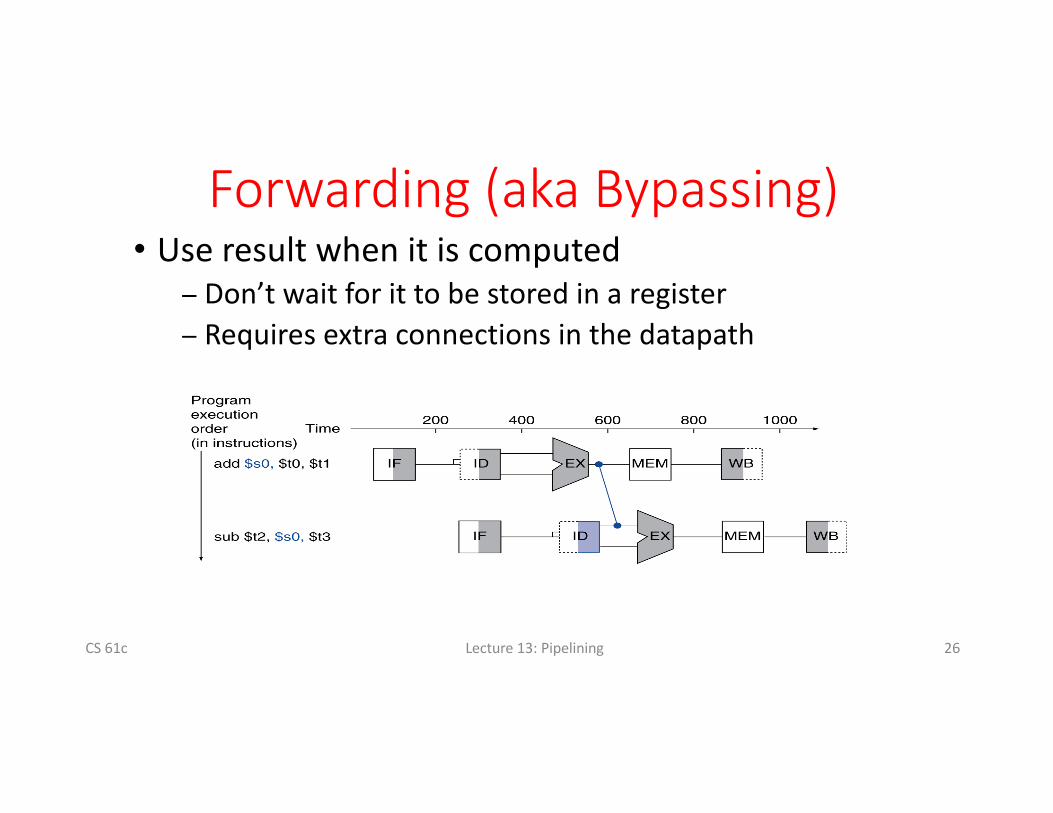
Forwarding(akaBypassing)• Useresultwhenitiscomputed
− Don’twaitforittobestoredinaregister− Requiresextraconnectionsinthedatapath
CS61c 26Lecture13:Pipelining

1)DetectNeedforForwarding(example)
addt0,t1,t2
ort3,t0,t5
subt6,t0,t3
X M WD
instX.rd
instD.rs1
CS61c 27
Comparedestinationofolderinstructionsinpipelinewithsourcesofnewinstructionindecodestage.Mustignorewritestox0!

ForwardingPath
CS61c28
IMEM
ALU
+4
DMEMBranchComp.
Reg[]
AddrA
AddrB
DataAAddrD
DataB
DataD
Addr
DataWDataR
10
aluX
pcF+4
+4pcDpcFpcX pcM
instD
instX
rs1X
rs2X
aluM
rs2MimmXImm.instM instW
ForwardingControlLogic

Administrivia
CS61c Lecture13:Pipelining 29
• Project1Part2duenextMonday• ProjectPartythisWednesday7-9pminCory293
• HW3willbereleasedbyFriday• Midterm1regradesduetonight• GuerrillaSessiontonight7-9pminCory293

Agenda• RISC-V Pipeline• PipelineControl• Hazards
− Structural− Data
§ R-typeinstructions§ Load
− Control• SuperscalarprocessorsCS61c Lecture13:Pipelining 30

LoadDataHazard
1cyclestallunavoidable
CS61c 31
forward
unaffected
Lecture13:Pipelining
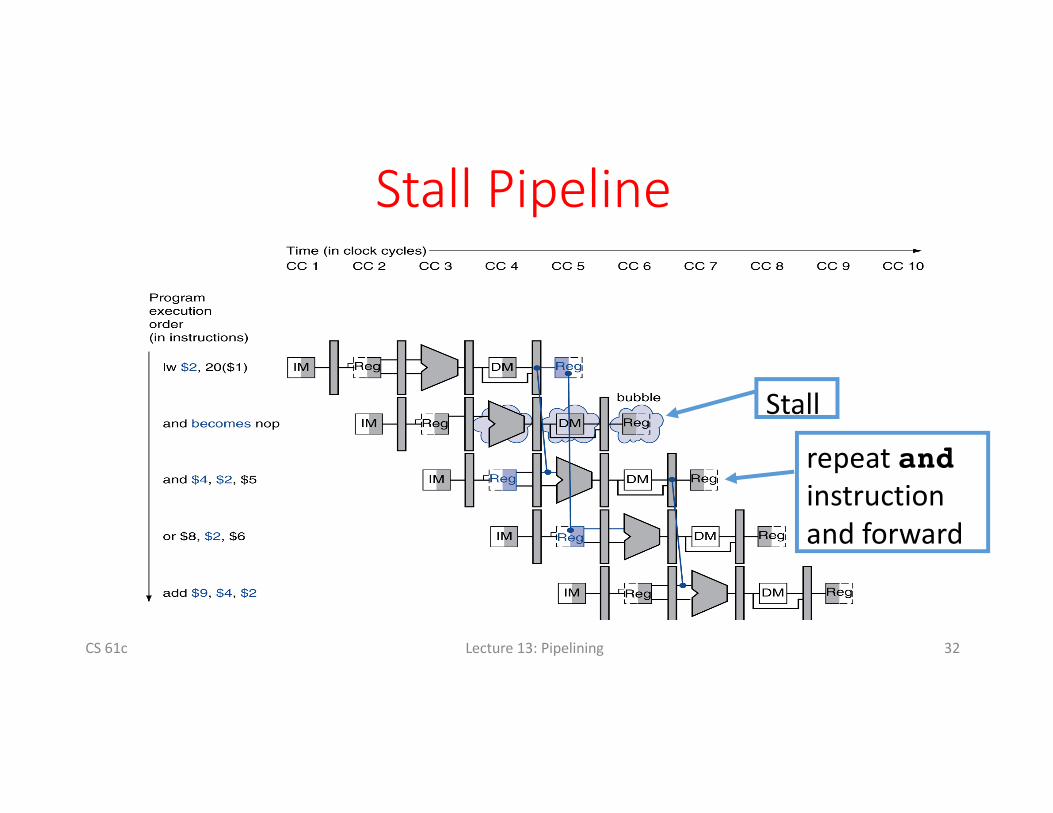
StallPipeline
Stall
CS61c 32
repeatandinstructionandforward
Lecture13:Pipelining

lw DataHazard• Slotafteraloadiscalledaloaddelayslot
− Ifthatinstructionusestheresultoftheload,thenthehardwarewillstallforonecycle
− Equivalenttoinsertinganexplicitnop intheslot§ exceptthelatterusesmorecodespace
− Performanceloss• Idea:
− Putunrelatedinstructionintoloaddelayslot− Noperformanceloss!
33CS61c Lecture13:Pipelining

CodeSchedulingtoAvoidStalls• Reordercodetoavoiduseofloadresultinthenextinstruction!• RISC-VcodeforD=A+B; E=A+C;
34
Original Order:lw t1, 0(t0)
lw t2, 4(t0)
add t3, t1, t2
sw t3, 12(t0)
lw t4, 8(t0)
add t5, t1, t4
sw t5, 16(t0)
Alternative:lw t1, 0(t0)
lw t2, 4(t0)
lw t4, 8(t0)
add t3, t1, t2
sw t3, 12(t0)
add t5, t1, t4
sw t5, 16(t0)
Stall!
Stall!
13cycles11cyclesCS61c Lecture13:Pipelining

Agenda• RISC-V Pipeline• PipelineControl• Hazards
− Structural− Data
§ R-typeinstructions§ Load
− Control• SuperscalarprocessorsCS61c Lecture13:Pipelining 35

ControlHazards
beq t0,t1,label
subt2,s0,t5
ort6,s0,t3
xor t5,t1,s0
sw s0,8(t3)
executedregardlessofbranchoutcome!
executedregardlessofbranchoutcome!!!
PCupdatedreflectingbranchoutcome
CS61c Lecture13:Pipelining 36

Observation• Ifbranchnottaken,theninstructionsfetchedsequentiallyafterbrancharecorrect• Ifbranchorjumptaken,thenneedtoflushincorrectinstructionsfrompipelinebyconvertingtoNOPs
CS61c Lecture13:Pipelining 37

KillInstructionsafterBranchifTaken
beq t0,t1,label
subt2,s0,t5
ort6,s0,t3
label:xxxxxx PCupdatedreflectingbranchoutcome
CS61c Lecture13:Pipelining 38
Takenbranch
ConverttoNOP
ConverttoNOP

ReducingBranchPenalties• Everytakenbranchinsimplepipelinecosts2deadcycles• Toimproveperformance,use“branchprediction”toguesswhichwaybranchwillgoearlierinpipeline• Onlyflushpipelineifbranchpredictionwasincorrect
CS61c Lecture13:Pipelining 39

BranchPrediction
beq t0,t1,label
label:…..
…..
CS61c Lecture13:Pipelining 40
Takenbranch
GuessnextPC!
Checkguesscorrect

Agenda• RISC-V Pipeline• PipelineControl• Hazards
− Structural− Data
§ R-typeinstructions§ Load
− Control• SuperscalarprocessorsCS61c Lecture13:Pipelining 41

IncreasingProcessorPerformance1. Clockrate
− Limitedbytechnologyandpowerdissipation2. Pipelining
− “Overlap”instructionexecution− Deeperpipeline:5=>10=>15stages
§ Less work perstageà shorter clock cycle§ Butmorepotentialforhazards (CPI>1)
3. Multi-issue”super-scalar”processor− Multipleexecutionunits(ALUs)
§ Severalinstructionsexecutedsimultaneously§ CPI<1(ideally)
CS61c Lecture13:Pipelining 42

SuperscalarProcessor
CS61c Lecture13:Pipelining 43
P&Hp.340

Benchmark:CPIofIntelCorei7
CS61c Lecture13:Pipelining 44
CPI=1
P&Hp.350

InConclusion• Pipeliningincreasesthroughputbyoverlappingexecutionofmultipleinstructions• Allpipelinestageshavesameduration
− Choosepartitionthataccommodatesthisconstraint• Hazardspotentiallylimitperformance
− Maximizingperformancerequiresprogrammer/compilerassistance− E.g.LoadandBranchdelayslots
• Superscalarprocessorsusemultipleexecutionunitsforadditionalinstructionlevelparallelism− Performancebenefithighlycodedependent
45CS61c Lecture13:Pipelining

ExtraSlides
CS61c Lecture13:Pipelining 46

Lecture13:Pipelining
PipeliningandISADesign• RISC-VISAdesignedforpipelining
− Allinstructionsare32-bits§ Easytofetchanddecodeinonecycle§ Versusx86:1- to15-byteinstructions
− Fewandregularinstructionformats§ Decodeandreadregistersinonestep
− Load/storeaddressing§ Calculateaddressin3rd stage,accessmemoryin4th stage
− Alignmentofmemoryoperands§ Memoryaccesstakesonlyonecycle
CS61c 47

SuperscalarProcessor• Multipleissue“superscalar”
− ReplicatepipelinestagesÞmultiplepipelines− Startmultipleinstructionsperclockcycle− CPI<1,souseInstructionsPerCycle(IPC)− E.g.,4GHz4-waymultiple-issue
§ 16BIPS,peakCPI=0.25,peakIPC=4− Dependenciesreducethisinpractice
• “Out-of-Order”execution− Reorderinstructionsdynamicallyinhardwaretoreduceimpactofhazards
• CS152discussesthesetechniques!CS61c Lecture13:Pipelining 48





























