Embed Size (px)
Citation preview

CS 4432 1
CS4432: Database Systems II
Basic indexing

CS 4432 2
Indexing : helps to retrieve data quicker for certain queries
value= 1,000,000
Select * FROM Emp WHERE salary = 1,000,000;Select * FROM Emp WHERE salary = 1,000,000;
Chapter 13
value
record

CS 4432 3
Topics
• Sequential Index Files (chap 13.1)• Secondary Indexes (chap 13.2)

CS 4432 4
Sequential File
2010
4030
6050
8070
10090
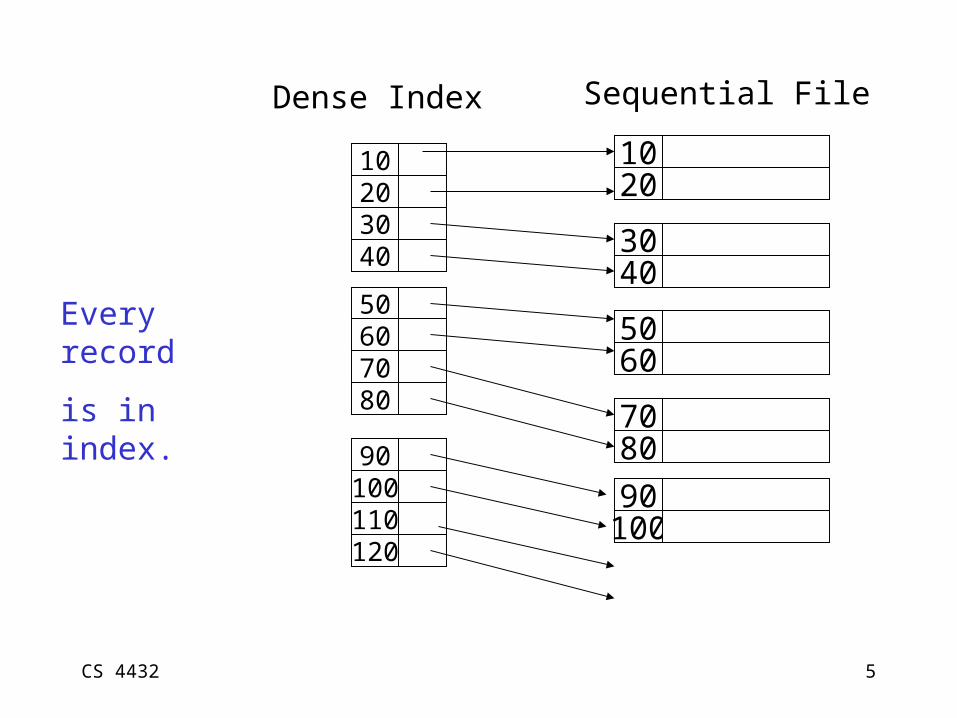
CS 4432 5
Sequential File
2010
4030
6050
8070
10090
Dense Index
10203040
50607080
90100110120
Every record
is in index.

CS 4432 6
Sequential File
2010
4030
6050
8070
10090
Sparse Index
10305070
90110130150
170190210230
Only first record
per block in index.

CS 4432 7
Sequential File
2010
4030
6050
8070
10090
Sparse 2nd level
10305070
90110130150
170190210230
1090
170250
330410490570

CS 4432 8
Note : DATA FILE or INDEX are “ordered files”.
Question:How would we lay them out on disk ?
- contiguous layout on disk ? - block-chained layout on disk ?

CS 4432 9
Questions:
• Do we want to build a dense 2nd-level index for a dense index?
• Can we even do this ?
Sequential File2010
4030
6050
8070
10090
2nd level?1030507090
110130150170190210230
1090
170250330410490570
1st level?

CS 4432 10
Notes on pointers:
(1)Block pointer (used in sparse index) can be smaller than record pointer (used in dense index)
BP
RP

CS 4432 11
K1
K3
K4
K2
R1
R2
R3
R4
say:1024 Bper block
• if we want K3 block:• get it at offset (3-1)*1024 = 2048 bytes
Note : If file is contiguous, then we can omit pointers

CS 4432 12
Sparse vs. Dense Tradeoff
• Sparse: Less index space per record can keep more of index in
memory (Later: sparse better for insertions)
• Dense: Can tell if any record exists without accessing file
(Later: dense needed for secondary indexes)

CS 4432 13
Terms
• Index sequential file• Search key ( primary key)• Primary index (on sequencing field)• Secondary index• Dense index (contains all search
key values)• Sparse index• Multi-level index

CS 4432 14
Next:
• Duplicate keys
• Deletion/Insertion
• Secondary indexes

CS 4432 15
Duplicate keys
1010
2010
3020
3030
4540

CS 4432 16
1010
2010
3020
3030
4540
1010
2010
3020
3030
4540
10101020
20303030
10101020
20303030
Dense index ! Point to each value !
Duplicate keys

CS 4432 17
1010
2010
3020
3030
4540
Dense index. Point to each distinct value!
10203040
Duplicate keys

CS 4432 18
1010
2010
3020
3030
4540
10102030
Sparse index: point to start of block !
Duplicate keys
care
ful if lookin
gfo
r 2
0 o
r 3
0!

CS 4432 19
1010
2010
3020
3030
4540
10203030
Sparse index, another way ?
Duplicate keys
– place first new key from block
shouldthis be40?

CS 4432 20
Duplicate values, primary index
• Index may point to first instance ofeach value only
File Index
Summary
aaa
b

CS 4432 21
Next:
• Duplicate keys
• Deletion/Insertion
• Secondary indexes

CS 4432 22
Deletion from sparse index
2010
4030
6050
8070
10305070
90110130150

CS 4432 23
Deletion from sparse index
2010
4030
6050
8070
10305070
90110130150
– delete record 40

CS 4432 24
Deletion from sparse index
2010
4030
6050
8070
10305070
90110130150
– delete record 30
4040

CS 4432 25
Deletion from sparse index
2010
4030
6050
8070
10305070
90110130150
– delete records 30 & 40
5070

CS 4432 lecture #8 26
Deletion from dense index
2010
4030
6050
8070
10203040
50607080

CS 4432 27
Deletion from dense index
2010
4030
6050
8070
10203040
50607080
– delete record 30
4040

CS 4432 28
Insertion, sparse index case
2010
30
5040
60
10304060

CS 4432 29
Insertion, sparse index case
2010
30
5040
60
10304060
– insert record 34
34
• our lucky day! we have free space where we need it!

CS 4432 30
Insertion, sparse index case
2010
30
5040
60
10304060
– insert record 15
15
2030
20
• Immediate reorganization• Other variations?

CS 4432 31
• Just Illustrated: -Immediate reorganization
• Now Variation:– insert new block (chained file)

CS 4432 32
Insertion, sparse index case
2010
30
5040
60
10304060
– insert record 25
25
overflow blocks(reorganize later...)

CS 4432 33
Insertion, dense index case
• Similar
• Often more expensive . . .

CS 4432 34
Next:
• Duplicate keys
• Deletion/Insertion
• Secondary indexes

CS 4432 35
Secondary indexesSequencefield
5030
7020
4080
10100
6090
Can I make a
secondary
index sparse ?

CS 4432 36
Secondary indexesSequencefield
5030
7020
4080
10100
6090
• Sparse index
302080
100
90...
does not make sense!

CS 4432 37
Secondary indexesSequencefield
5030
7020
4080
10100
6090
• Must be dense index !10203040
506070...
105090...
sparsehighlevel
allowed?

CS 4432 38
With secondary indexes:
• Lowest level is dense• Other levels are sparse
Also: Pointers are record pointers
(not block pointers; not computed)

CS 4432 39
Duplicate values & secondary indexes
1020
4020
4010
4010
4030

CS 4432 40
Duplicate values & secondary indexes
1020
4020
4010
4010
4030
10101020
20304040
4040...
one option...
Problem:excess overhead!
• disk space• search time

CS 4432 41
Duplicate values & secondary indexes
1020
4020
4010
4010
4030
10
another option...
4030
20Problem:variable sizerecords inindex!

CS 4432 42
Duplicate values & secondary indexes
1020
4020
4010
4010
4030
10203040
5060...
Another idea :Chain records with same key !
Problems:• Need to add fields to data records for each index• Need to follow chain to know records

CS 4432 43
Summary : Conventional Indexes
– Basic Ideas: sparse, dense, multi-level…
– Duplicate Keys– Deletion/Insertion– Secondary indexes

CS 4432 44
Multi-level Index StructuresSequencefield
5030
7020
4080
10100
6090
firstlevel
(dense,if non-
sequential)
10203040
506070...
105090...
highLevel
(alwayssparse)
1
2
5
43

CS 4432 45
Sequential indexes : pros/cons ?
Advantage:- Simple- Index is sequential file
good for scans - Search efficient for static data
Disadvantage:
- Inserts expensive, and/or- Lose sequentiality & balance
- Then search time unpredictable

CS 4432 46
Example Sequential Index
continuous
free space
102030
405060
708090
39313536
323834
33
overflow area(not sequential)

CS 4432 47
Another type of index
• Give up “sequentiality” of index• Predictable performance under
updates• Achieve always balance of “tree” • Automate restructuring under
updates

CS 4432 48
Root
B+Tree Example n=3
100
120
150
180
30
3 5 11
30
35
100
101
110
120
130
150
156
179
180
200

CS 4432 49
Sample non-leaf
to keys to keys to keys to keys
< 57 57 k<81 81k<95 95
57
81
95

CS 4432 50
Sample leaf node:
From non-leaf node
to next leafin
sequence5
7
81
95
To r
eco
rd
wit
h k
ey 5
7
To r
eco
rd
wit
h k
ey 8
1
To r
eco
rd
wit
h k
ey 8
5

CS 4432 51
In textbook’s notationn=3
Leaf:
Non-leaf:
30
35
30
30 35
30

CS 4432 52
Size of nodes: n+1 pointersn keys
(fixed)

CS 4432 53
Don’t want nodes to be too empty
• Use at least
Non-leaf: (n+1)/2pointers
Leaf: (n+1)/2 pointers to data

CS 4432 54
Full nodemin. node
Non-leaf
Leaf
n=3
12
01
50
18
0
30
3 5 11
30
35
counts
even if
null
Non-leaf: (n+1)/2 pointers
Leaf: (n+1)/2 pointers to data

CS 4432 55
B+tree rules tree of order n
(1) All leaves at same lowest level(balanced tree)
(2) Pointers in leaves point to records except for “sequence pointer”

CS 4432 57
Root
B+Tree Example : Searches
100
120
150
180
30
3 5 11
30
35
100
101
110
120
130
150
156
179
180
200

CS 4432 58
Insert into B+tree
(a) simple case– space available in leaf
(b) leaf overflow(c) non-leaf overflow(d) new root

CS 4432 59
(a) Insert key = 32 n=33 5 11
30
31
30
100
32

CS 4432 60
(a) Insert key = 7 n=3
3 5 11
30
31
30
100
3 5
7
7

CS 4432 61
(c) Insert key = 160 n=3
10
0
120
150
180
150
156
179
180
200
160
18
0
160
179

CS 4432 62
(d) New root, insert 45 n=3
10
20
30
1 2 3 10
12
20
25
30
32
40
40
45
40
30new root

CS 4432 63
Recap: Insert Data into B+ Tree
• Find correct leaf L. • Put data entry onto L.
– If L has enough space, done!– Else, must split L (into L and a new node L2)
• Redistribute entries evenly, copy up middle key.• Insert index entry pointing to L2 into parent of L.
• This can happen recursively– To split index node, redistribute entries evenly, but
push up middle key. (Contrast with leaf splits.)
• Splits “grow” tree; root split increases height. – Tree growth: gets wider or one level taller at top.

CS 4432 64
(a) Simple case (b) Coalesce with neighbor (sibling)
(c) Re-distribute keys(d) Cases (b) or (c) at non-leaf
Deletion from B+tree

CS 4432 65
(a) Delete key = 11 n=33 5 11
30
31
30
100

CS 4432 66
(b) Coalesce with sibling– Delete 50
10
40
100
10
20
30
40
50
n=4
40

CS 4432 67
(c) Redistribute keys– Delete 50
10
40
100
10
20
30
35
40
50
n=4
35
35

CS 4432 68
40
45
30
37
25
26
20
22
10
141 3
10
20
30
40
(d) Coalese and Non-leaf coalese– Delete 37
n=4
40
30
25
25
new root

CS 4432 69
B+tree deletions in practice
– Often, coalescing is not implemented– Too hard and not worth it!

CS 4432 70
Delete Data from B+ Tree
• Start at root, find leaf L where entry belongs.• Remove the entry.
– If L is at least half-full, done! – If L has only d-1 entries,
• Try to re-distribute, borrowing from sibling (adjacent node with same parent as L).
• If re-distribution fails, merge L and sibling.
• If merge occurred, must delete entry (pointing to L or sibling) from parent of L.
• Merge could propagate to root, decreasing height.

CS 4432 71
• Concurrency control harder in B-Trees• B-tree consumes more space• DBA does not know when to reorganize• DBA does not know how full to load pages of new index• Buffering
– B-tree: has fixed buffer requirements– Static index: must read several overflow blocks to be efficient (large & variable size
buffers needed)
Comparison: B-trees vs. static indexed sequential file

CS 4432 72
• Speaking of buffering… Is LRU a good policy for B+tree
buffers?Of course not!
Should try to keep root in memory at all times
(and perhaps some nodes from second level)

CS 4432 73
ComparisonB-tree vs. indexed seq.
file• Less space, so
lookup faster• Inserts managed
by overflow area• Requires
temporary restructuring
• Unpredictable performance
• Consumes more space, so lookup slower
•Each insert/delete potentially restructures
•Build-in restructuring
• Predictable performance

CS 4432 74
Interesting problem:
For B+tree, how large should n be?
…
n is number of keys / node

CS 4432 75
assumptions: n children per node and N records in database
(1) Time to read B-Tree node from disk is (tseek + tread*n) msec.(2) Once in main memory, use binary search to locate key, (a + b log_2 n) msec(3) Need to search (read) log_n (N) tree nodes
(4) t-search = (tseek + tread*n + (a + b*log_2(n)) * log n (N)

CS 4432 76
Can get: f(n) = time to find a record
f(n)
nopt n
FIND nopt by f’(n) = 0
What happens to nopt as:•Disk gets faster? CPU get faster? …

CS 4432 77
Bulk Loading of B+ Tree
• For large collection of records, create B+ tree.• Method 1: Repeatedly insert records slow.• Method 2: Bulk Loading more efficient.

CS 4432 78
Bulk Loading of B+ Tree
• Initialization: – Sort all data entries – Insert pointer to first (leaf) page in new (root) page.
3* 4* 6* 9* 10* 11* 12* 13* 20* 22* 23* 31* 35* 36* 38* 41* 44*
Sorted pages of data entries; not yet in B+ treeRoot

CS 443279
Bulk Loading (Contd.)
• Index entries for leaf pages always entered into right-most index page
• When this fills up, it splits.
Split may go up right-most path to root.
3* 4* 6* 9* 10*11* 12*13* 20*22* 23* 31* 35*36* 38*41* 44*
Root
Data entry pages
not yet in B+ tree3523126
10 20
3* 4* 6* 9* 10* 11* 12*13* 20*22* 23* 31* 35*36* 38*41* 44*
6
Root
10
12 23
20
35
38
not yet in B+ treeData entry pages

CS 4432 80
Summary of Bulk Loading
• Method 1: multiple inserts.– Slow.– Does not give sequential storage of leaves.
• Method 2: Bulk Loading – Has advantages for concurrency control.– Fewer I/Os during build.– Leaves will be stored sequentially (and
linked) – Can control “fill factor” on pages.














