Embed Size (px)
Citation preview

Prof. Hui Jiang
Department of Computer Science
York University, Toronto, Ontario, Canada
Email: [email protected]
Confidence Measures:how much we can trust our
speech recognizers

Outline
• Speech recognition in multimedia communications
• Confidence Measures: overviews
• Confidence Measure as Utterance Verification
• The conventional method: “anti-models”
• Our proposed approaches:– Approach 1: to use accurate competing models– Approach 2: nested neighborhood in HMM model space
• Conclusions

Speech Recognition in Multimedia Communications (I): server side
The Internet(IP)
TelephoneNetworks
(3G)
Desktops
Laptops
PDA
Telephone
Mobilephone
Multimedia servers
Communication servers
Server side
Multimedia Content Analysis:• Audio/Video Segmentation• Speech Transcription• Text Understanding• Speaker/Topic Identification• Speech/Audio/Video Indexing• Audio Mining

Multimedia Content Analysisfor Information retrieval
Multimedia
stream(documents)
MediaSeparation
Audio
Video
AudioSegmentation
SpeechRecognition
Language Understanding
speech
Video Processing Synchronization
and Indexing
Index for information retrieval
SpeakerIdentification
Text
speechA
udioText
Video
Content
Semantics
Speaker ID

Speech Recognition in Multimedia Communications (II): client side
The Internet(IP)
TelephoneNetworks
(3G)
Desktops
Laptops
PDA
Telephone
Mobilephone
Multimedia servers
Communication servers
End User Side(client side)
Natural User Interface:• Speech input/output• Multi-modal interface• Dialog systems• Intelligent agent
Intelligent Agent

Intelligent Agent
Key Issues:• Robust speech recognition• Spoken language understanding• Dialogue modeling
DialogueManager
LanguageUnderstanding
Speech Recognition
ResponseGeneration
ContextTracking
Text-to-speechSynthesis
Users
Speech Input
TextInput
TextOutput
SpeechOutput
Multimedia servers
Domain Knowledge

Speech Recognition: state-of-the-art
• The technology allows us to easily build a state-of -the-art speech system for a variety of applications.
• Not an issue to build a system if given:– Large training corpus (in-house, LDC for public, et c.)– Software tools (HTK, etc.)
• There exist many demo systems; few practically used in-field– Most speech recognition systems are not usable in p ractice
• Reasons: – vulnerable to various interferences (noises, accent , etc.)– not stable– not reliable– Not friendly to non-expert users

A Few Examples from the DARPA Communicator system
User:User: my starting location is Fort-Wayne Indiana
Recognizer:Recognizer: my starting location is four morning Indiana
User: do they have a flight that leaves earlier in the da y
Recognizer: in have flight that is earlier mid-day
User: i cannot continue this conversation
Recognizer: i not continue this comfort-inn

Improve Usability of Speech Recognition Systems
• Robust Speech Recognition– Make the system more robust in practical applicatio ns
• Confidence Measures– Attach each recognized word a score to indicate its reliability in
recognition
– Focus on words with high scores; discard low-score words
– Detect and correct recognition errors
– Reject out-of-vocabulary words used by non-expert u sers
– Selectively interpret recognition results

Previous Examples with confidence measure attached
User:User: my starting location is Fort-Wayne Indiana
Recognizer:Recognizer: my(0.74) starting(0.92) location(0.83) is(0.78) four(0.31) morning(0.06) Indiana(0.90)
User: do they have a flight that leaves earlier in the da y
Recognizer: in (0.43) have (0.65) flight (0.83) that (0.34) is (0.27) earlier (0.76) mid-day (0.12)
User: i cannot continue this conversation
Recognizer: i (0.91) not (0.69) continue (0.87) this (0.79) comfort-inn (0.16)

How to calculate confidence measures (CM) for speech recognition
• CM as a combination of predictor features
• CM as a posterior probability
• CM as utterance verification

Speech & Audio Processing
Feature Extraction (Linear Prediction, Filter Bank)
waveform
Feature vectors
sliding window
Audio Segmentation Speech Recognition
speech/music/noise words
Audio/speech coding
bit stream for transmission

W)Pr(),|Pr(maxarg
) = |Pr(maxarg
WWPX
XWWW
⋅=
=
AcousticMatching
LanguageMatching
Acoustic Models
Hidden Markov Models (HMM’s)
LanguageModels
Markov Chain(N-gram)
speechfeature vectors
X P
phoneme sequence
h W @ r y U
wordsequence
W
How are you?
Automatic Speech Recognition
)Pr(
)Pr()|Pr(maxarg
X
WWX
W
⋅
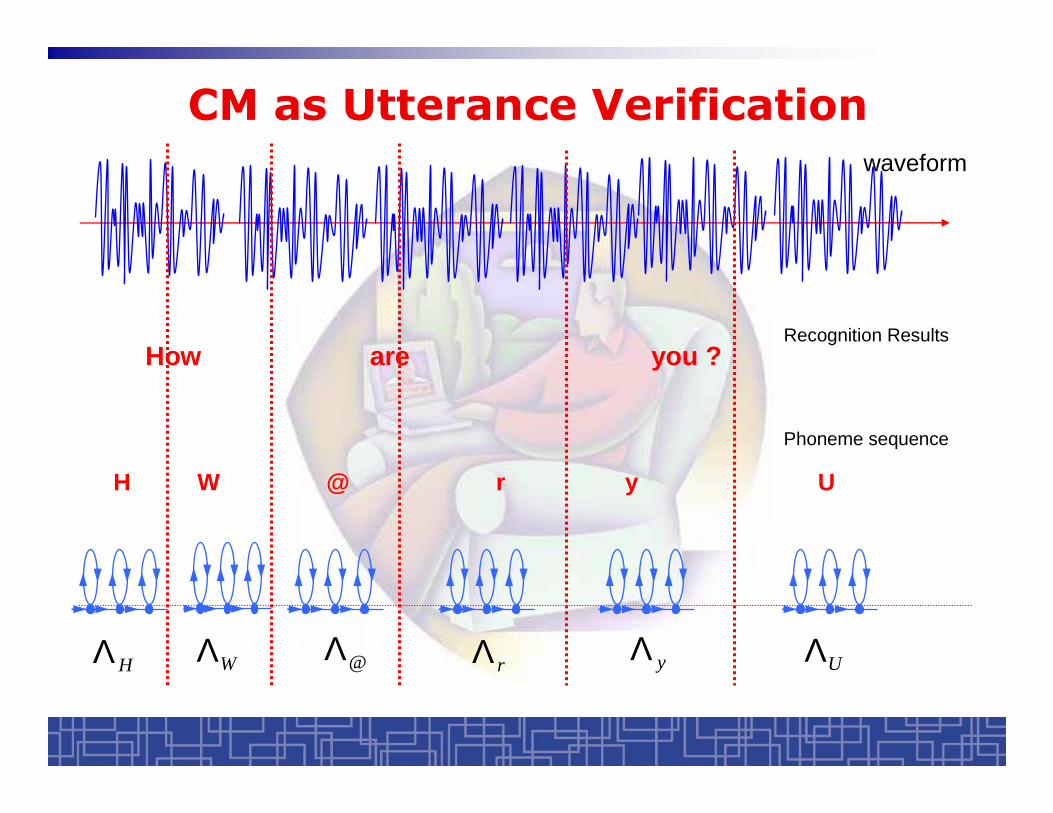
CM as Utterance Verificationwaveform
Recognition ResultsHow are you ?
HΛ WΛ @ΛrΛ yΛ UΛ
H W @ r y U
Phoneme sequence

Verify every phoneme segment
• Assume one speech segment X i is recognized as phoneme @, represented by HMM @Λ
phoneme @
@Λ
• Verify the decision under the framework of statisti cal hypothesis testing
HH00: Xi is truly from model @ HH11: Xi is not from model @VS.
η>=)|Pr(
)|Pr( LR
1
0
HX
HX
i
iSolution is Likelihood Ratio (LR) Testing:

Problem: how to calculate the denominator
• For the numerator in LR testing:
• What about the denominator?
– H1 is not easy to model, is a composite hypothesis which includes so many possibilities:
a) Xi from another phoneme rather than @
b) Xi is speech sound not in the phoneme set
c) Xi is a non-speech noise
d) None of the above
)|()H|Pr( @0 Λ⇒ ii XlX

The conventional method:using “anti-models”
• For each phoneme aa, estimate an “anti-model” using all training data which are not from the phoneme.
– The anti-model is a HMM having the same structure a s
• Every phoneme aa has two models:
– Regular recognition model
– An anti-model
• In previous example:
• LR i can be used as a confidence measure for this speech segment.
aΛ
aΛaΛ
aΛ
η>ΛΛ
=)|(
)|(
@
@
i
ii Xl
XlLR

• If we can’t enumerate and model all situations in H 1, approximate it with only the most significant one.
• In most cases, especially when X i was misrecognized, the probability in the case a.1) dominates the total pr obability in H 1, i.e., .
New verification method based on accurate competing models (I)
a. Xi from another phoneme rather than @
1) Xi from competing models of @
2) Xi from non-competing models of @
b. Xi is speech sound not in the phoneme set
c. Xi is a non-speech noise
d. None of the above
)|Pr( 1HX i

How to formulate the competing models
• Competing tokens of a HMM @ is defined as all data segments (in training set) which are mis-recognized as @ during recognition.
• For any HMM , we have two sets:
– The true token set: SSt( )
– The competing token set: SSc( )
Given the decision: data X is recognized as
HH00: X is truly from model HH11: X is not from model VS.
H’0: H’1: )(Λ∈ tSX )(Λ∈ cSX
)|(
)|(
))(Pr(
))(Pr(
)H|Pr(X
)H|Pr(XLR
1
0
c
t
c
t
Xp
Xp
SX
SX
λλ=
Λ∈Λ∈== Competing
model

t
A word-ending active path
search beam
Time
Sta
te
InIn--Search Data Selection methodSearch Data Selection method
a-b+c
Reference Segmentation
$-b-u b-u-k u-k+T k-T+i T-i+s i-s+T s-T+r T-r+i r-i+p i-p+$
Token Selection
phone a-b+c phone a-b+c
True TokenTrue TokenSetsSets
CompetingCompetingToken SetsToken Sets
phone a’-b’+c’ phone a’-b’+c’

Original model
HMM Model Space
New Verification method based on nested neighborhood in model space
Competing model
Other models
Tight Neighborhood 1
Medium Neighborhood 2
Large Neighborhood 3
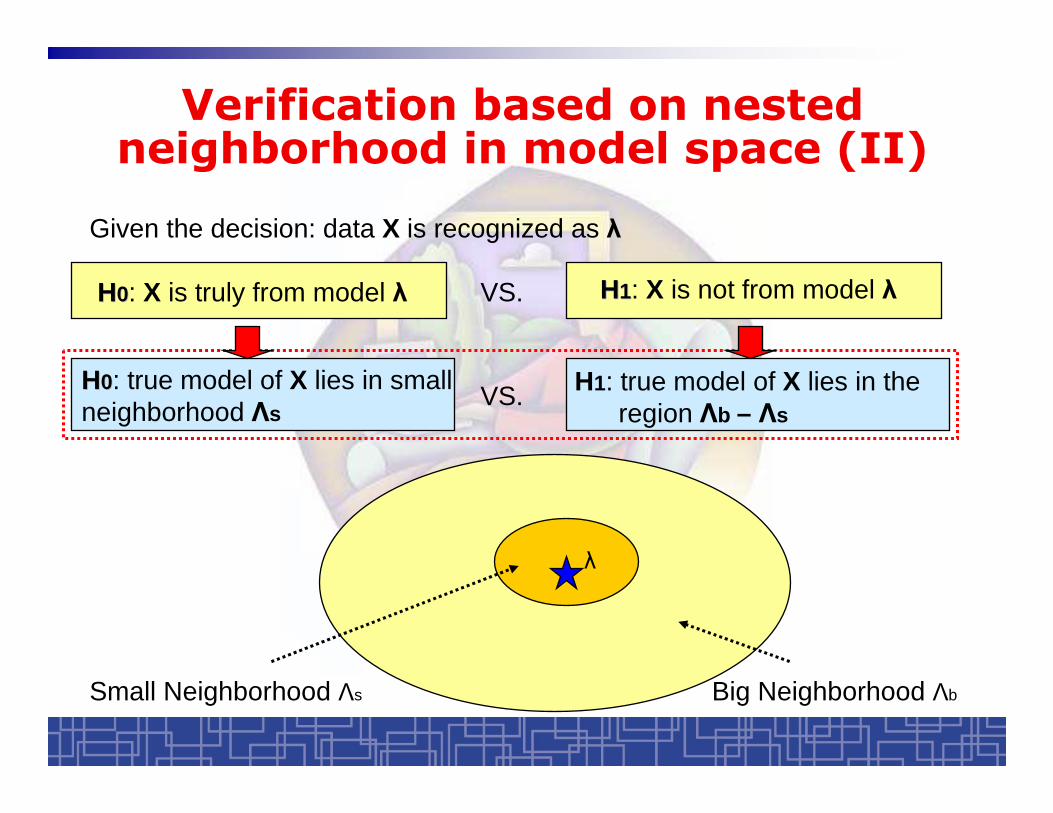
Verification based on nested neighborhood in model space (II)
Given the decision: data X is recognized as
Small Neighborhood s Big Neighborhood b
HH00: X is truly from model HH11: X is not from model VS.
HH00: true model of X lies in small neighborhood s
VS. H1: true model of X lies in the region b – s

Verification based on nested neighborhood in model space (III)
• Bayes factors: the tool to implement the verificatio n
• Model is viewed as random variable in model space
• l(X| ) is the likelihood function of any speech data X
• s( ) is the prior distribution of inside neighborhood s
• b( ) is the prior distribution of in the region b— s
ηλλρλ
λλρλ>
⋅
⋅=∫
∫
Λ−Λ
Λ
Sb
S
b
s
Xl
Xl
d)()|(
d)()|(BF

Specify Neighborhoodsand Priors (I)
• Use a small (C 1, 1) for small neighborhood s
– Same for all Gaussian components in all HMMs
• Use a large (C 2, 2) for big neighborhood b
– Same for all Gaussian components in all HMMs
• Priors: constrained uniform pdf in neighborhood
• Tune C1, 1, C2, 2 (C1<C2, 1< 2) for best performance
}|{)( 1*1**),(
dikd
dikdc CdmmCdm ρρλλρ
−− +≤≤−=Λ
A parametric neighborhood: (C, ) neighborhood:

Λ
*λ
51λ
2λ
3λ
4λ
λ
Specify Neighborhoodsand Priors (II)
A non-parametric neighborhood: Define -function priors:
)(1
)( i
iN
λλδλρλ
−= ∑Λ∈
Λ
BF calculation is simplified:
bi
si
NXl
NXl
b
s
/)|(
/)|(BF
i
i
∑∑
Λ∈
Λ∈=λ
λ
λ
λ

Experiments
• Tested on Bell Labs Communicator system for the DAP AR communicator project. (a travel reservation task)
• Use confidence measure to detect recognition errors from the recognition results given by our best recognizer.
• The best recognition performance: 15.8% word error rate
• Verify correctly recognized words vs. mis-recognize d words
• For each utterance, calculate confidence measure fo r every recognized phoneme, then combine for each word.
• Baseline: Likelihood Ratio Testing based on anti-mo dels
• New approach 1: Likelihood Ratio Testing based on c ompeting models
• New Approach 2: Bayes factors based on nested neigh borhoods
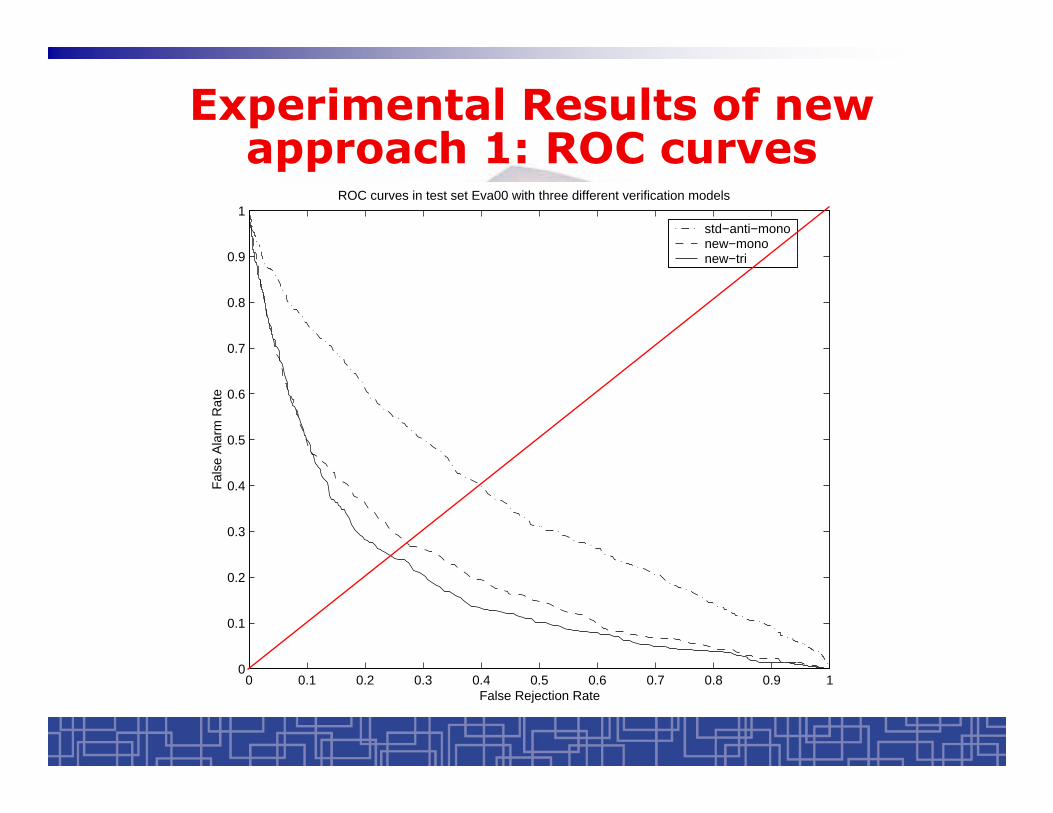
Experimental Results of new approach 1: ROC curves
0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 10
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1ROC curves in test set Eva00 with three different verification models
False Rejection Rate
Fal
se A
larm
Rat
estd−anti−mononew−mononew−tri

Experimental results of new approach 1: equal error rate (EER)
24.6%New Approach 1
(tri-phone model)
27.3%New Approach 1
(mono-phone model)
40.0%baseline
Equal Error Rate
(EER)
Method

Experimental results of new approach 2: ROC curves
0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 10
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1Comparison of ROC curves
False Rejection
Fals
e Ac
cept
ance
Baseline (Anti−models)(C,p) neighborgoodDelta Neighborgood (N=1500)Dist2C neighborhood

Experimental results of new approach 2: equal error rate (EER)
31.0%Non-parametric neighborhood
(case B)
31.5%Non-parametric neighborhood
(case A)
32.4%Parametric neighborhood
(state-dependent)
36.7%Parametric neighborhood
(global)
40.0%baseline
Equal Error Rate
(EER)
Method

Conclusions• Reliable confidence measures (CM) play a key role i n building a successful
speech recognition system.
• Utterance verification is a good framework to calcu late confidence measures (CM).
• We proposed two new approaches for CM calculation
– By using accurate competing models
– Based on neighborhood information in HMM space and Bayes factors.
• The new approaches are proved to outperform the con ventional method based on “anti-models”.
• Future works:
– How to interpret H1 in other ways
– In approach 2, how to define a good neighborhood qu antitatively in high-dimension HMM model space


ERROR: undefinedOFFENDING COMMAND: ��
STACK:

![Calibration of Confidence Measures in Speech Recognition · 2018-01-04 · strategies or to inform users what can be trusted and what ... [14][15], boosting [16], and maximum entropy](https://img.dokumen.tips/doc/110x75/5f035f777e708231d408e47e/calibration-of-confidence-measures-in-speech-recognition-2018-01-04-strategies.jpg)



























