Embed Size (px)
Citation preview

[email protected] 2017 1
The CPU
Computer Architecture
1DT016 distanceFall 2017
http://xyx.se/1DT016/index.php
Per FoyerMail: [email protected]
1

[email protected] 2017 2
Where in the machine now?
2
Level 0
Level 1
Level 2
Level 3
Level 4
Level 5
Digital Logic Level
Microprogramminglevel
Conventionalmachine level
Problem-orientedlanguage level
Operating systemmachine level
Assembly languagelevel
addmul: addi $r1, $zero, 2 mul $r1, $r1, 2 jr $ra
int addmul( int t ){ return (t + 2) * 2;}
li $v0, 4syscall
0x24020004 0x0000000c0x03E00008
110110101111010000010110000100010011111010100001
Translation (compiler)
Translation (assembler)
Partial interpretation (OS)
Interpretation(microprogram)
Executed byhardware

Intel 4004
[email protected] 2017 3
MCS-4 (chipset):i4001: ROM (256 bytes)i4002: RAM (40 bytes)i4003: Shift register (10 bits)i4004: CPU (4-bit)
4-bit
Designed by Federico Faggin

CISC – The early days
Complex Instruction Set Computer
•Primary memory was slow and expensive
•Reduce memory access The more that could be done inside the CPU, the better
•µ-code can be (quite) easily changed Enhance or reduce the ISA, fix machine level bugs
•The more machine instructions avaliable, the easier to write high-level compilers producing ”tight code”.
•Less amount of PM needed to store machine instructions
Gave: Large and writeable µ-stores, and in some cases even nano-code
Example: VAX 11/750 had 303 µ-coded assembler instructions
[email protected] 2017 9

Example: IBM 4341 mainframe
[email protected] 2017 10
1. IPL1 (hardware): Read CPU instruction set from removable media (5 ¼” floppy)
2. IPL2: Read boot firmware from removable media (5 ¼” floppy)
3. IPL3: Use firmware to boot OS loader from disk drive 0.
4. IPL4: Load OS from disk drive x.
CISC Galore!
• CPU machine instructions can be added or removed• Bugs in implementations of CPU machine instructions can be corrected
IPL = Initial Program Loader

µ-coded CISC Trivia
• It’s almost impossible to design a CPU without bugs on the hardware level (including µ-code)
• Intel had problems with the infamous FDIV (floating point divide) FPU instruction in the Pentium family.
• The affected part was defined in µ-code so the problem was fixed between CPU steppings (hardware revisions) without any hardware redesign.
• It’s so common with CPU bugs that vendors release several erratas for the same type of CPU during it’s life span (but no erratas when EOL)
[email protected] 2017 11

Flynn’s [1] taxonomy
[email protected] 2017 19
Type Instructions Datum [2] Examples
SISD 1 1 Classic vN / Harvard
SIMD 1 Multi Vector processors
MISD Multi 1 Fault tolerant systems
MIMD Multi Multi Multiprocessors
[1] Michael J. Flynn, Stanford university, 1966
[2] Datum may refer to a part of a data set, e.g. in shared memory

Intel Pentium MMX
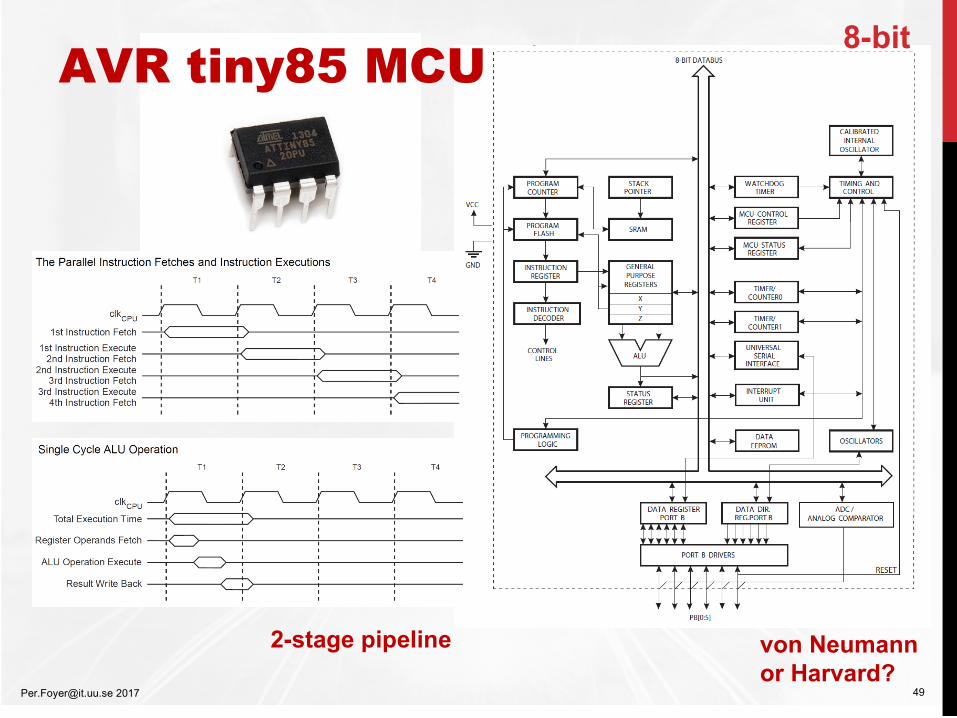
[email protected] 2017 20
MMX – SIMD3DNOW! SSE
APIC – Advanced ProgrammableInterrupt Controller
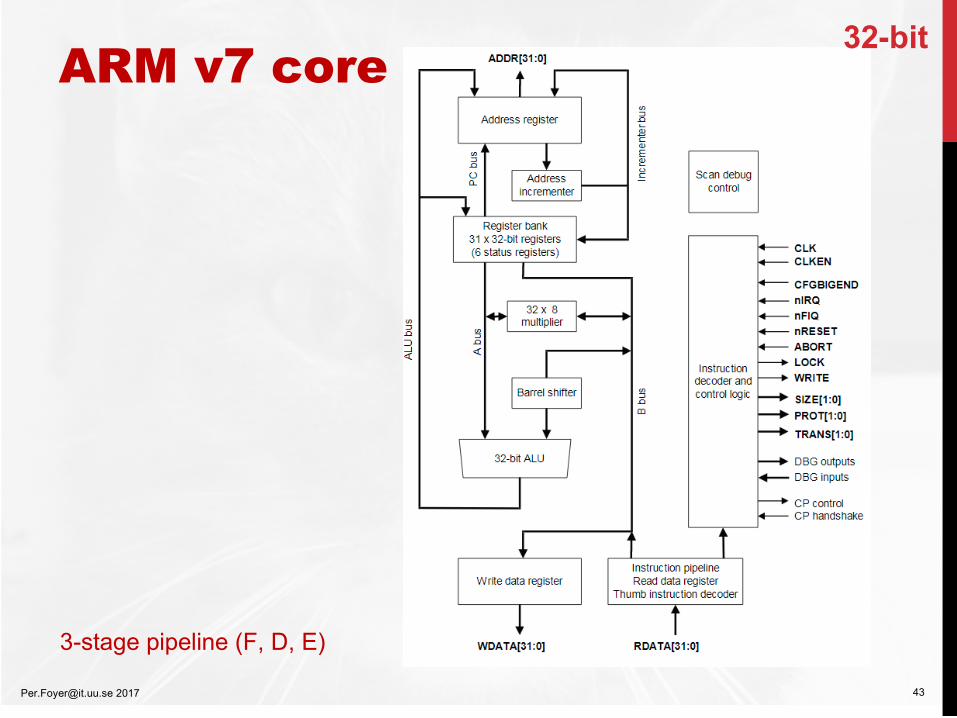
32-bit

A µ-Coded CPU in no timeWhat do we need?
•A Register bank (or a few discrete registers)
•PC and SP registers
•One or two ALUs with a set of ALUops
•A flag register: Z, P, N, C, …
•An Unidirectional MAR (Memory Address Register)
•A Bidirectional MDR (Memory Data Register)
•Outgoing control signals (MREQ, IORQ, RD, WR, …)
•An internal databus and a control bus
•A µ-coded Control Unit (CU)
…and, of course an [email protected] 2017 21

µControl Unit: Horizontal µ-code
[email protected] 2017 22
• Maximum parallelism, given the number of bits from the µROM
• Many control lines make it easier to modify the ISA
• µROM acts as a sequencer of arbitrary control signals
• Easily expanded by adding parallel ROMs
• Large ROMs costs expensive silicon die space
• Sometimes called Wide µ-code
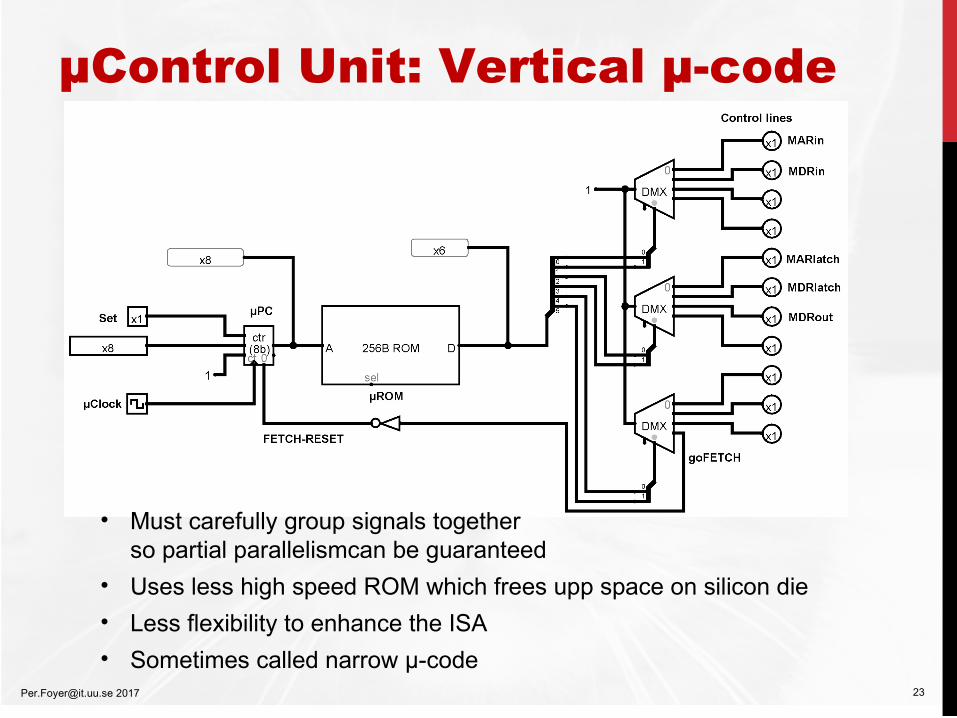
µControl Unit: Vertical µ-code
[email protected] 2017 23
• Must carefully group signals together so partial parallelismcan be guaranteed
• Uses less high speed ROM which frees upp space on silicon die
• Less flexibility to enhance the ISA
• Sometimes called narrow µ-code

µControl Unit with Lookup table
[email protected] 2017 24
• The machine instruction in IR is index to the Lookup ROM• The value in the Lookup ROM is the start address (set in µPC) for
the µ-code corresponding to the machine code in IR

µ-code: Fetch, Decode and Execute
[email protected] 2017 25
1. PCout, MARin, MARlatch, PCincr
2. MREQout, memRD, memWAIT
3. MDRin, MDRlatch, MDRout,IRin, IRlatch
1. µJTable[ IR[31:26]out ], µPCin
1. IR[20:16]out, REGBANKin, REG-RD,REGBANKout, ALU1in, IR[15:0]out, ALUin2, ALUopADD, µPCincr
2. ALUout, MARin, MARlatch, µPCincr
3. MREQout, memRD, memWAIT
4. MDRin, MDRlatch, MDRout, IR[25:21], REGBANKin, REG-WR, GotoFETCH
lw $t1, 100($t2)
Fetch
Decode
Execute

RISC – The early daysReduced Instruction Set Computer
Motives:
•CISC ISAs often overly complex
•Many CISC instructions are very seldom used
•Analyzing an arbitrary program reveals that it most often is written with just a few number of basic constructs:
• Simple variable or memory assignments• If … then … else (conditional jumps/branches)• Loops• Subroutine / function calls
•How many instructions in the Intel i7 are used less than 0.25%? Is it really worth having them on silicon? - Probably no, but there is another story to this: The need to be compatible with every earlier x86 processor ever made…
[email protected] 2017 27

RISC – The ideas
• Create a set of a few very carefully choosen machine instructions of a single fixed size
• Only Load and Store instructions refer to memory
• Create optimizing compilers that take full use of these few machine instructions
• Replace µ-code with hardwired control logic
• Reg-to-Reg-operations in one clock cycle
• Complex math instructions co-processor
• Fewer instructions means freed space on silicon that can be used for pipelines, larger register files and caches.
[email protected] 2017 28

RISC – The ideas (2)
Main goals:
•Make the datapath turnaroud time as short as possible.
•When no more instructions can be removed, the specification of the RISC ISA is finalized.
[email protected] 2017 29

Pipelining Analogy
[email protected] 2017 32
Pipelined laundry: Overlapping execution Parallelism improves performance

PipeliningDesign the CPU with the overall goal to start a new instruction every clock cycle
Use pipelines for each step of the instruction cycle:
1. Instruction fetch [IF]• Get instruction from program memory
2. Instruction decode [ID]• Translate opcode to control signals and read registers
3. Execute [EX]• Perform ALU operation, calculate branch tagets
4. Memory [MEM] (data)• Access memory if needed (Load/Store)
5. Write back [WB]• Update register file
[email protected] 2017 33
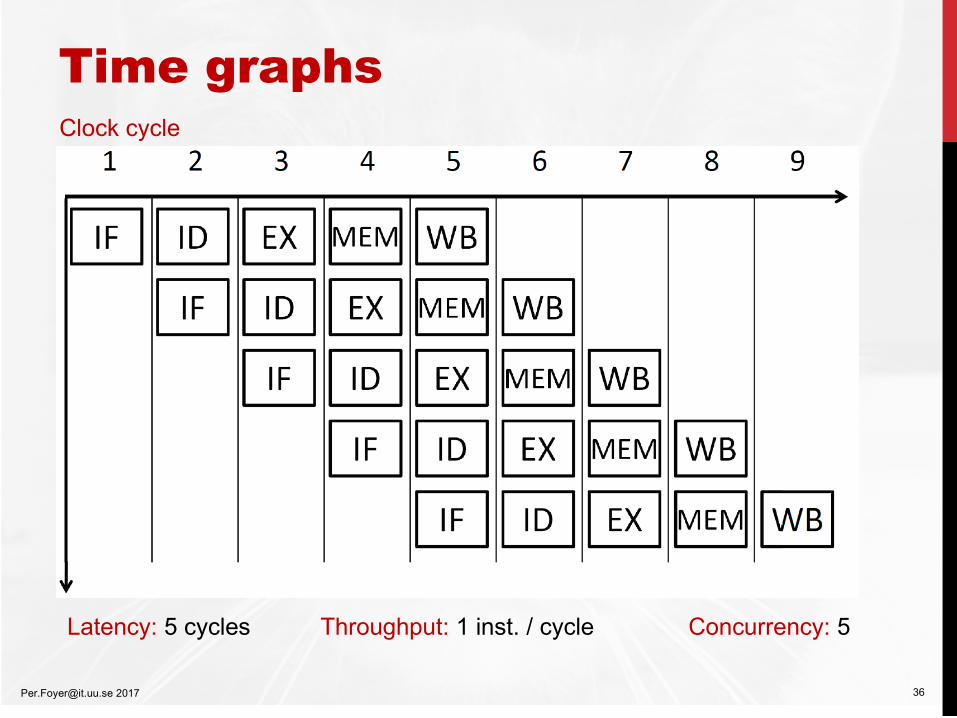
Time graphs
[email protected] 2017 36
Clock cycle
Latency: 5 cycles Throughput: 1 inst. / cycle Concurrency: 5

Pipelining: Hazards
Situations that prevent starting the next instruction in the next cycle (creating pipeline stalls):
•Structure hazards
• A required resource is busy
•Data hazard
• Need to wait for previous instruction to complete its read/writeadd $s0, $t0, $t1sub $t2, $s0, $t3
•Control hazard
• Deciding on control action depends on previous instruction
[email protected] 2017 37

Pipelining: Data Hazards
Dependencies backward in time cause hazards
Example: Instruction flow – 5 stage pipeline:
lw $1, 4($2)sub $4, $1, $5 # $1 is still in pipelineand $6, $1, $7or $8, $1, $9 # $1 available in stage 4xor $4, $1, $5
”Load-use” data hazard
•May be ”fixed” with a pipeline stall
•…or by inserting NOPs
•…or reordering instructions
[email protected] 2017 38

Pipelining: Structure hazards
• Conflict for use of a resource
• In MIPS pipeline with single memory:
• Load/store requires data access• Instruction fetch would have to stall for that cycle
Would cause a pipeline ”bubble”
• Hence, pipelined datapaths require separate instruction/data memories
• …or separate instruction/data caches
[email protected] 2017 39

Pipelining: Control Hazards
• When the flow of instruction addresses is not sequential (i.e. not PC = PC + 4), due to change of instruction flow
• Unconditional branches (j, jal, jr)• Conditional branches (beq, bne,…)• Exceptions (internal or external interrupts)
• Possible approaches
• Stall (impacts CPI – Clocks Per Instruction)• Move decision point as early in the pipeline as possible
thereby reducing the number of stall cycles• Delay decision (requires compiler support)
• Control hazards occur less frequently than data hazards
• Jumps are very infrequent – only 3% of the instructions ina normal program
[email protected] 2017 40

(binary executable)
Code reorder (”afterburner”)
[email protected] 2017 41
C / C++, …
gcc –S …
Assemblycode
Reorganizer
ReorderedAssembly code
gas –o …(Assembler)
Object code
ld –o …

lw $t1, 0($t0) # blw $t2, 4($t0) # elw $t4, 8($t0) # fadd $t3, $t1, $t2 # b + esw $t3, 12($t0) # a add $t5, $t1, $t4 # b + fsw $t5, 16($t0) # c
lw $t1, 0($t0) # blw $t2, 4($t0) # eadd $t3, $t1, $t2 # b + esw $t3, 12($t0) # a lw $t4, 8($t0) # fadd $t5, $t1, $t4 # b + fsw $t5, 16($t0) # c
Code scheduling to avoid stalls
• Reorder code to avoid use of load result in the next instruction
• Example: a = b + e; c = b + f;
[email protected] 2017 42
13 cycles 11 cycles
Stall
Stall
(reordered code)

Co-processors
Used to take load off main processors
•Floating Point Units (FPU)
•I/O-processors
•Crypto co-processors
•Graphical Processing Units (GPU)
Examples from the 8086 era:
•8087 FPU
•8089 I/O processor
•8288 Bus controller
[email protected] 2017 55


























![[Raivo Alla] - utkodu.ut.ee/~raivoa/cpu.pdf · RF(resume) ehk resümee.Kasutatakse koos debugginguga, et kontrollida programmi käiku peale järgnevat instruktsiooni. VM(virtual mode)](https://img.dokumen.tips/doc/110x75/5f5d109c9a5fcf60e64b32ec/raivo-alla-raivoacpupdf-rfresume-ehk-resmeekasutatakse-koos-debugginguga.jpg)