Embed Size (px)
Citation preview

Winter 2012-2013Compiler Principles
Syntax Analysis (Parsing) – Part 1Mayer Goldberg and Roman Manevich
Ben-Gurion University

2
BooksCompilersPrinciples, Techniques, and ToolsAlfred V. Aho, Ravi Sethi, Jeffrey D. Ullman
Advanced Compiler Design and ImplementationSteven Muchnik
Modern Compiler DesignD. Grune, H. Bal, C. Jacobs, K. Langendoen
Modern Compiler Implementation in JavaAndrew W. Appel

3
Today
• Understand role of syntax analysis• Context-free grammars– Basic definitions– Ambiguities
• Top-down parsing– Predictive parsing
• Next time: bottom-up parsing method

4
The bigger picture
• Compilers include different kinds of program analyses each further constrains the set of legal programs– Lexical constraints
– Syntax constraints
– Semantic constraints
– “Logical” constraints(Verifying Compiler grand challenge)
Program consists of legal tokens
Program included in a given context-free language
Type checking, legal inheritance graph, variables initialized before used
Memory safety: null dereference, array-out-of-bounds access, data races, assertion violation
5
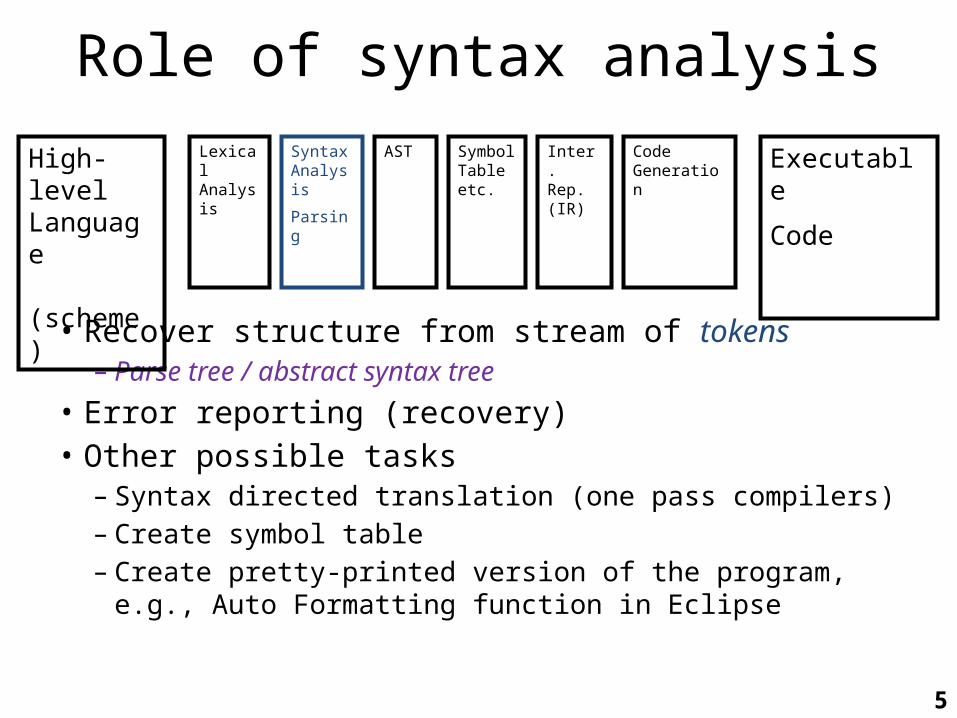
Role of syntax analysis
• Recover structure from stream of tokens– Parse tree / abstract syntax tree
• Error reporting (recovery)• Other possible tasks
– Syntax directed translation (one pass compilers)– Create symbol table– Create pretty-printed version of the program, e.g., Auto
Formatting function in Eclipse
High-levelLanguage
(scheme)
Executable
Code
LexicalAnalysis
Syntax Analysis
Parsing
AST SymbolTableetc.
Inter.Rep.(IR)
CodeGeneration

From tokens to abstract syntax trees5 + (7 * x)
) id * num ( + num
Lexical Analyzer
program text
token stream
Parser
Grammar:E id E numE E + EE E * EE ( E ) +
num
num id
*
Abstract Syntax Tree
validsyntaxerror
6
Regular expressionsFinite automata
Context-free grammarsPush-down automata

Example grammar
shorthand for Statement
shorthand for Expression
shorthand for List(of expressions)
7
S S ; SS id := E S print (L)E idE numE E + EL EL L, E

CFG terminology
8
Symbols: Terminals (tokens): ; := ( ) id num printNon-terminals: S E L
Start non-terminal: SConvention: the non-terminal appearingin the first derivation rule
Grammar productions (rules)N α
S S ; SS id := E S print (L)E idE numE E + EL EL L, E

9
Language of a CFG
• A sentence ω is in L(G) (valid program) if– There exists a corresponding derivation– There exists a corresponding parse tree

Derivations • Show that a sentence ω is in a grammar G– Start with the start symbol– Repeatedly replace one of the non-terminals by a
right-hand side of a production– Stop when the sentence contains only terminals
• Given a sentence αNβ and rule NµαNβ => αµβ
• ω is in L(G) if S =>* ω– Rightmost derivation– Leftmost derivation
10

Leftmost derivation
11
S
=> S ; S
=> id := E ; S
=> id := num ; S
=> id := num ; id := E
=> id := num ; id := E + E
=> id := num ; id := num + E
=> id := num ; id := num + num
a := 56 ; b := 7 + 3
id := num ; id := num + num
S S ; SS id := E S print (L)E idE numE E + EL EL L, E

Rightmost derivation
12
S
=> S ; S
=> S ; id := E
=> S ; id := E + E
=> S ; id := E + num
=> S ; id := num + num
=> id := E ; id := num + num
=> id := num ; id := num + num
a := 56 ; b := 7 + 3
id := num ; id := num + num
S S ; SS id := E S print (L)E idE numE E + EL EL L, E

Parse trees• Tree nodes are symbols, children ordered left-to-right• Each internal node is non-terminal and its children
correspond to one of its productions
N µ1 … µk
• Root is start non-terminal• Leaves are tokens• Yield of parse tree: left-to-right walk over leaves
13
µ1 µk
N
…

Parse tree example
14
S S ; SS id := E S print (L)E idE numE E + EL EL L, E id := num ; id := num num+
Draw parse tree for expression

Parse tree example
15
id := num ; id := num num+
E E E
S E
S
S
Order-independent representation
S S ; SS id := E S print (L)E idE numE E + EL EL L, E
(S(Sa := (E56)E)S ; (Sb := (E(E7)E + (E3)E)E)S)SEquivalently add parentheses labeled by non-terminal names

16
Capabilities and limitations of CFGs
• CFGs naturally express– Hierarchical structure
• A program is a list of classes,A Class is a list of definition,A definition is either…
– Beginning-end type of constraints• Balanced parentheses S (S)S | ε
• Cannot express– Correlations between unbounded strings (identifiers)– Variables are declared before use: ω S ω– Handled by semantic analysis
p. 173

Sometimes there are two parse trees
Leftmost derivationEE + Enum + Enum + E + Enum + num + Enum + num + num
num(1)
E
E E
+
E E
+num(2) num(3)
Rightmost derivationEE + EE + numE + E + numE + num + numnum + num + num
+ num(3)+num(1) num(2)
Arithmetic expressions:E id E numE E + EE E * EE ( E )
1 + 2 + 3
E
E E
E
E
1 + (2 + 3) (1 + 2) + 3
17

Is ambiguity a problem?
Leftmost derivationEE + Enum + Enum + E + Enum + num + Enum + num + num
num(1)
E
E E
+
E E
+num(2) num(3)
Rightmost derivationEE + EE + numE + E + numE + num + numnum + num + num
+ num(3)+num(1) num(2)
Arithmetic expressions:E id E numE E + EE E * EE ( E )
1 + 2 + 3
E
E E
E
E
= 6 = 6
1 + (2 + 3) (1 + 2) + 3Depends on semantics
18

Problematic ambiguity example
Leftmost derivationEE + Enum + Enum + E * Enum + num * Enum + num * num
num(1)
E
E E
+
E E
*num(2) num(3)
Rightmost derivationEE * EE * numE + E * numE + num * numnum + num * num
* num(3)+num(1) num(2)
Arithmetic expressions:E id E numE E + EE E * EE ( E )
1 + 2 * 3
This is what we usually want: * has precedence over +
E
E E
E
E
= 7 = 9
1 + (2 * 3) (1 + 2) * 3
19

20
Ambiguous grammars
• A grammar is ambiguous if there exists a sentence for which there are– Two different leftmost derivations– Two different rightmost derivations– Two different parse trees
• Property of grammars, not languages• Some languages are inherently ambiguous – no
unambiguous grammars exist• No algorithm to detect whether arbitrary
grammar is ambiguous

21
Drawbacks of ambiguous grammars
• Ambiguous semantics• Parsing complexity• May affect other phases• Solutions– Transform grammar into non-ambiguous– Handle as part of parsing method• Using special form of “precedence”• Wait for bottom-up parsing lecture

Transforming ambiguous grammars to non-ambiguous by layering
Ambiguous grammarE E + EE E * EE id E numE ( E )
Unambiguous grammarE E + TE TT T * FT FF idF numF ( E )
Layer 1
Layer 2
Layer 3
Let’s derive 1 + 2 * 3
Each layer takes care of one way of composing sub-strings to form a string:1: by +2: by *3: atoms
22

Transformed grammar: * precedes +
Ambiguous grammarE E + EE E * EE id E numE ( E )
Unambiguous grammarE E + TE TT T * FT FF idF numF ( E )
Derivation E=> E + T=> T + T=> F + T=> 1 + T=> 1 + T * F=> 1 + F * F=> 1 + 2 * F=> 1 + 2 * 3
+ * 321
F F F
T
TE
T
E
Parse tree
23

Transformed grammar: + precedes *
Ambiguous grammarE E + EE E * EE id E numE ( E )
Unambiguous grammarE E * TE TT T + FT FF idF numF ( E )
+ * 321
Derivation E=> E * T=> T * T=> T + F * T=> F + F * T=> 1 + F * T=> 1 + 2 * T=> 1 + 2 * F=> 1 + 2 * 3
F F F
T
T
E
T
E
Parse tree
24
25
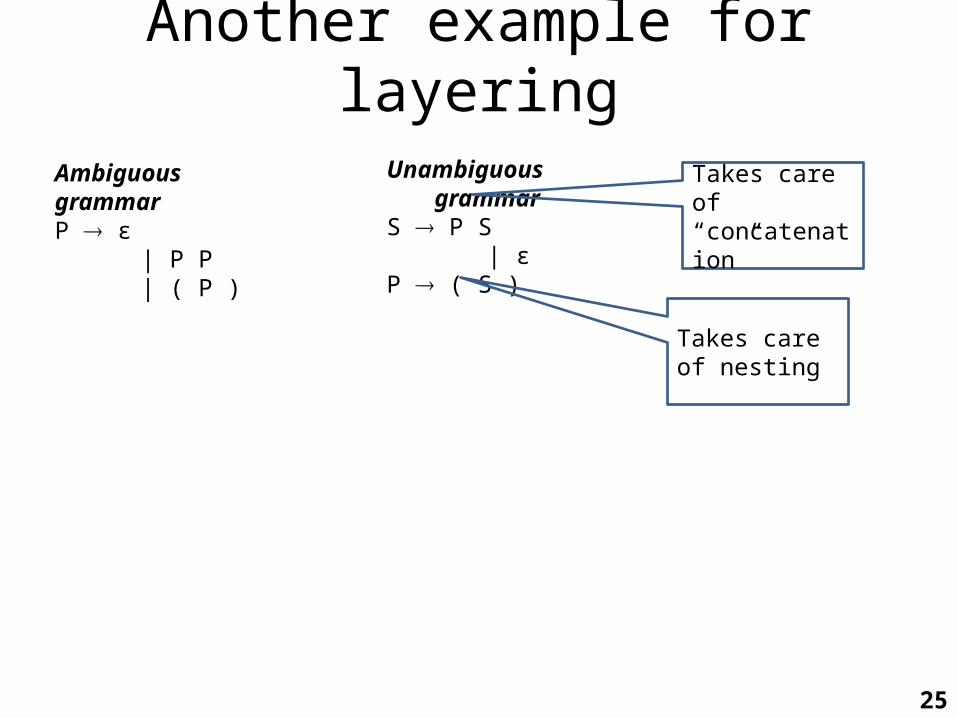
Another example for layering
Ambiguous grammarP ε | P P | ( P )
Unambiguous grammarS P S | εP ( S )
Takes care of “concatenation”
Takes care of nesting
26
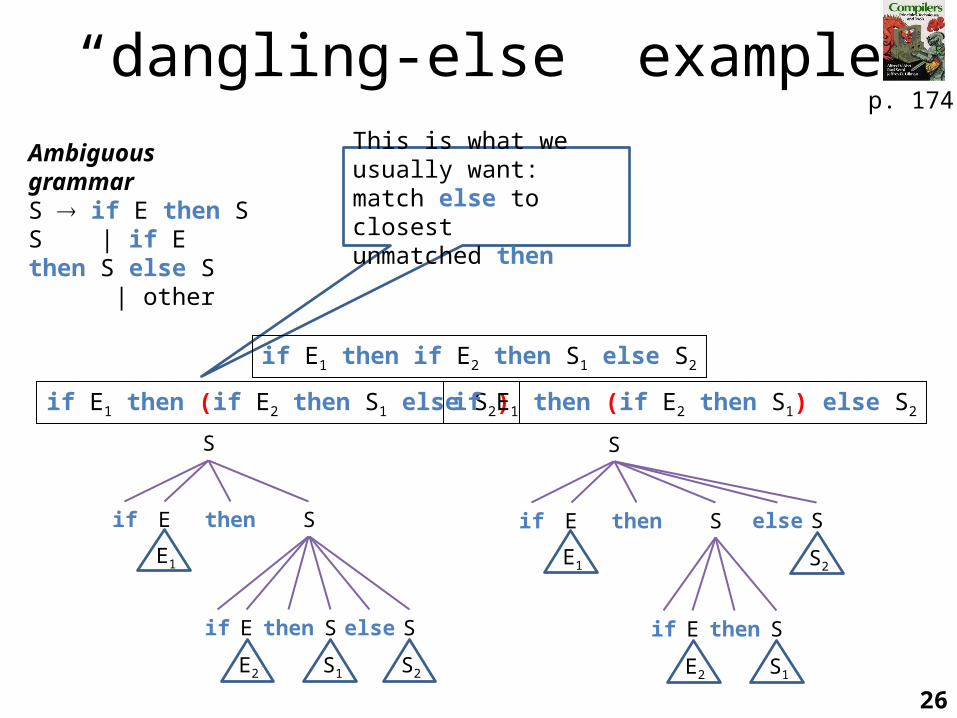
“dangling-else” exampleAmbiguous grammar S if E then S S | if E then S else S | other
if
S
Sthen
thenif elseE S S
E
E1
E2 S1 S2
if
S
Sthen
thenif
else
E S
SE
E1
E2 S1
S2
if E1 then (if E2 then S1 else S2) if E1 then (if E2 then S1) else S2
This is what we usually want: match else to closest
unmatched then
if E1 then if E2 then S1 else S2
p. 174

27
“dangling-else” example
if
S
Sthen
thenif else
Ambiguous grammar S if E then S S | if E then S else S | other
E S S
E
E1
E2 S1 S2
if
S
Sthen
thenif
else
E S
SE
E1
E2 S1
S2
if E1 then (if E2 then S1 else S2) if E1 then (if E2 then S1) else S2
Unambiguous grammar S M | UM if E then M else M | otherU if E then S | if E then M else U
if E1 then if E2 then S1 else S2
Matched statements
Unmatched statements
p. 174

Broad kinds of parsers • Parsers for arbitrary grammars
– Earley’s method, CYK method O(n3)– Not used in practice
• Top-Down– Construct parse tree in a top-down matter– Find the leftmost derivation– Predictive: for every non-terminal and k-tokens predict the next
production LL(k)– Preorder tree traversal
• Bottom-Up– Construct parse tree in a bottom-up manner– Find the rightmost derivation in a reverse order– For every potential right hand side and k-tokens decide when a
production is found LR(k)– Postorder tree traversal
28

29
Top-down vs. bottom-up
• Top-down parsing– Beginning with the start symbol, try to guess the
productions to apply to end up at the user's program
• Bottom-up parsing– Beginning with the user's program, try to apply
productions in reverse to convert the program back into the start symbol

30
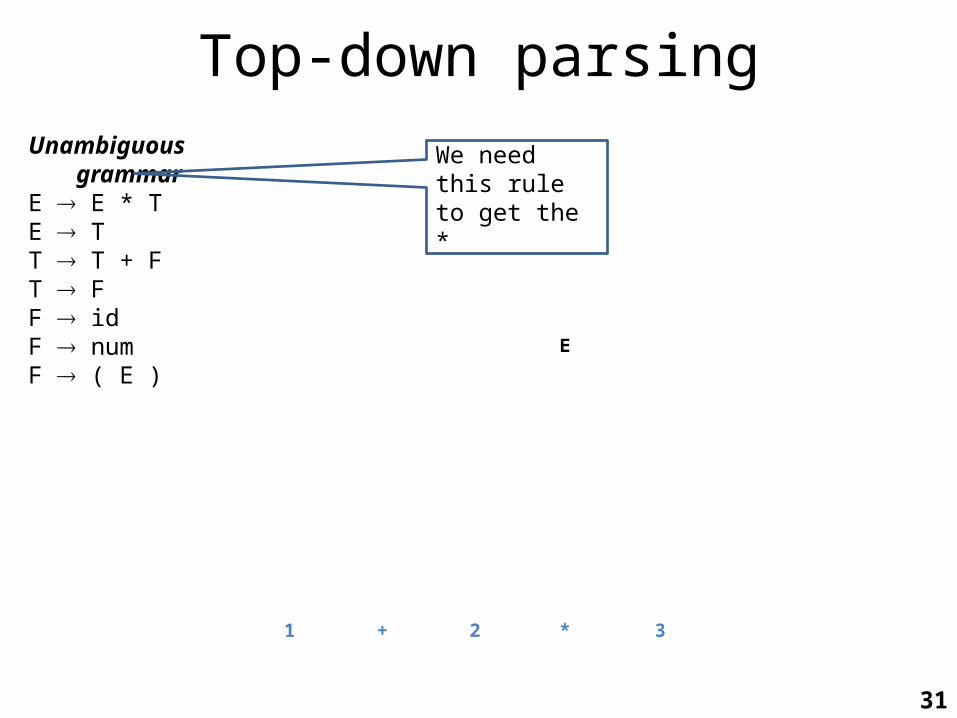
Top-down parsingUnambiguous grammarE E * TE TT T + FT FF idF numF ( E )
+ * 321
F F F
T
T
E
T
E
31
Top-down parsingUnambiguous grammarE E * TE TT T + FT FF idF numF ( E )
We need this rule to get the *
+ * 321
E

32
Top-down parsingUnambiguous grammarE E * TE TT T + FT FF idF numF ( E )
+ * 321
E
T
E

33
Top-down parsingUnambiguous grammarE E * TE TT T + FT FF idF numF ( E )
+ * 321
F
T
E
T
E

34
Top-down parsingUnambiguous grammarE E * TE TT T + FT FF idF numF ( E )
+ * 321
F F
T
T
E
T
E

35
Top-down parsingUnambiguous grammarE E * TE TT T + FT FF idF numF ( E )
+ * 321
F F F
T
T
E
T
E

36
Top-down parsingUnambiguous grammarE E * TE TT T + FT FF idF numF ( E )
+ * 321
F F F
T
T
E
T
E

37
Bottom-up parsingUnambiguous grammarE E * TE TT T + FT FF idF numF ( E )
+ * 321

38
Bottom-up parsingUnambiguous grammarE E * TE TT T + FT FF idF numF ( E )
+ * 321
F

39
Bottom-up parsingUnambiguous grammarE E * TE TT T + FT FF idF numF ( E )
+ * 321
F F

40
Bottom-up parsingUnambiguous grammarE E * TE TT T + FT FF idF numF ( E )
+ * 321
F F
T

41
Bottom-up parsingUnambiguous grammarE E * TE TT T + FT FF idF numF ( E )
+ * 321
F F
T
F

42
Bottom-up parsingUnambiguous grammarE E * TE TT T + FT FF idF numF ( E )
+ * 321
F F
T
F
T

43
Bottom-up parsingUnambiguous grammarE E * TE TT T + FT FF idF numF ( E )
+ * 321
F F
T
F
T
T

44
Bottom-up parsingUnambiguous grammarE E * TE TT T + FT FF idF numF ( E )
+ * 321
F F
T
F
T
T
E

45
Bottom-up parsingUnambiguous grammarE E * TE TT T + FT FF idF numF ( E )
+ * 321
F F
T
F
T
T
E
E

46
Challenges in top-down parsing• Top-down parsing begins with virtually no• information– Begins with just the start symbol, which matches every
program• How can we know which productions to apply?• In general, we can‘t– There are some grammars for which the best we can do is
guess and backtrack if we're wrong• If we have to guess, how do we do it?– Parsing as a search algorithm– Too expensive in theory (exponential worst-case time) and
practice

47
Predictive parsing
• Given a grammar G and a word w attempt to derive w using G
• Idea– Apply production to leftmost nonterminal– Pick production rule based on next input token
• General grammar– More than one option for choosing the next production
based on a token• Restricted grammars (LL)– Know exactly which single rule to apply– May require some lookahead to decide

48
Boolean expressions example
not ( not true or false )
E => not E => not ( E OP E ) =>not ( not E OP E ) =>not ( not LIT OP E ) =>not ( not true OP E ) =>not ( not true or E ) =>not ( not true or LIT ) =>not ( not true or false )
not E
E
( E OP E )
not LIT or LIT
true false
production to apply known from next token
E LIT | (E OP E) | not ELIT true | falseOP and | or | xor

49
Recursive descent parsing
• Define a function for every nonterminal• Every function work as follows– Find applicable production rule– Terminal function checks match with next input
token– Nonterminal function calls (recursively) other
functions• If there are several applicable productions for
a nonterminal, use lookahead

50
Matching tokens
• Variable current holds the current input token
match(token t) { if (current == t) current = next_token() else error}
E LIT | (E OP E) | not ELIT true | falseOP and | or | xor

51
Functions for nonterminals
E() { if (current {TRUE, FALSE}) // E LIT LIT(); else if (current == LPAREN) // E ( E OP E ) match(LPAREN); E(); OP(); E(); match(RPAREN); else if (current == NOT) // E not E match(NOT); E(); else error;}
LIT() { if (current == TRUE) match(TRUE); else if (current == FALSE) match(FALSE); else error;}
E LIT | (E OP E) | not ELIT true | falseOP and | or | xor
52
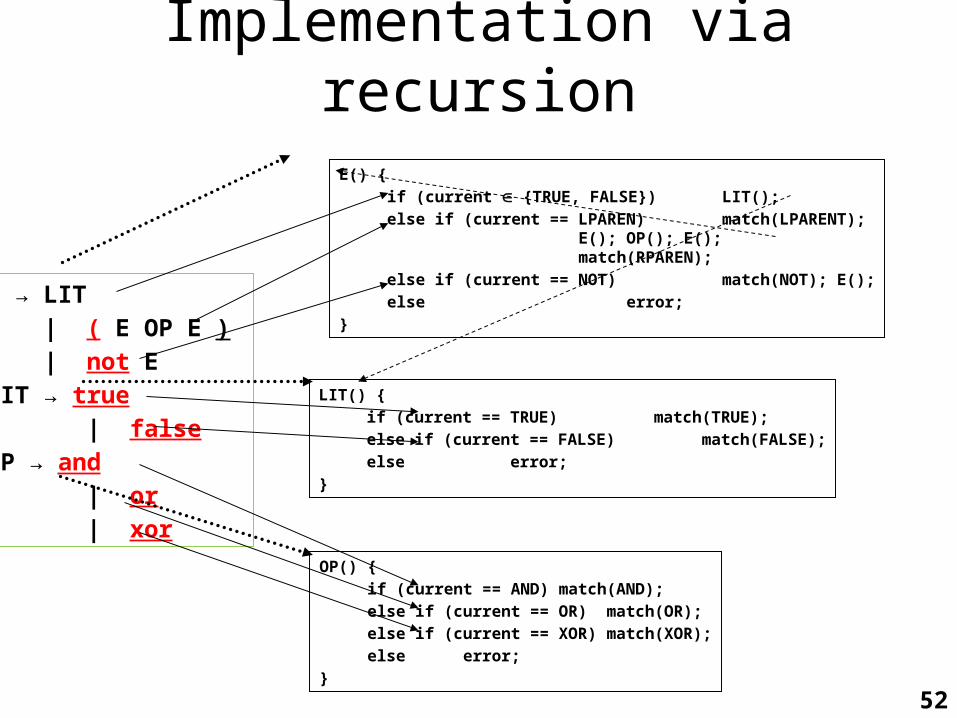
Implementation via recursion
E → LIT | ( E OP E ) | not ELIT → true | falseOP → and | or | xor
E() {if (current {TRUE, FALSE}) LIT();else if (current == LPAREN) match(LPARENT);
E(); OP(); E();match(RPAREN);
else if (current == NOT) match(NOT); E();else error;
}
LIT() {if (current == TRUE) match(TRUE);else if (current == FALSE) match(FALSE);else error;
}
OP() {if (current == AND) match(AND);else if (current == OR) match(OR);else if (current == XOR) match(XOR);else error;
}

53
Adding semantic actions
• Can add an action to perform on each production rule
• Can build the parse tree– Every function returns an object of type Node– Every Node maintains a list of children– Function calls can add new children

54
Building the parse tree
Node E() { result = new Node(); result.name = “E”; if (current {TRUE, FALSE}) // E LIT result.addChild(LIT()); else if (current == LPAREN) // E ( E OP E ) result.addChild(match(LPAREN)); result.addChild(E()); result.addChild(OP()); result.addChild(E()); result.addChild(match(RPAREN)); else if (current == NOT) // E not E result.addChild(match(NOT)); result.addChild(E()); else error; return result;}

55
Recursive descent
• How do you pick the right A-production?• Generally – try them all and use
backtracking• In our case – use lookahead
void A() { choose an A-production, A X1X2…Xk; for (i=1; i≤ k; i++) { if (Xi is a nonterminal) call procedure Xi(); elseif (Xi == current) advance input; else
report error; }}

56
• The function for indexed_elem will never be tried… – What happens for input of the form ID[expr]
term ID | indexed_elemindexed_elem ID [ expr ]
Problem 1: productions with common prefix

57
Problem 2: null productions
int S() { return A() && match(token(‘a’)) && match(token(‘b’));}int A() { return match(token(‘a’)) || 1;}
S A a bA a |
What happens for input “ab”? What happens if you flip order of alternatives and try “aab”?

58
Problem 3: left recursion
int E() { return E() && match(token(‘-’)) && term();}
E E - term | term
What happens with this procedure? Recursive descent parsers cannot handle left-recursive grammars
p. 127

59
FIRST sets• For every production rule Aα
– FIRST(α) = all terminals that α can start with – Every token that can appear as first in α under some derivation for α
• In our Boolean expressions example– FIRST( LIT ) = { true, false }– FIRST( ( E OP E ) ) = { ‘(‘ }– FIRST( not E ) = { not }
• No intersection between FIRST sets => can always pick a single rule
• If the FIRST sets intersect, may need longer lookahead– LL(k) = class of grammars in which production rule can be
determined using a lookahead of k tokens– LL(1) is an important and useful class

60
Computing FIRST sets
• Assume no null productions A 1. Initially, for all nonterminals A, set
FIRST(A) = { t | A tω for some ω }2. Repeat the following until no changes occur:
for each nonterminal A for each production A Bω set FIRST(A) = FIRST(A) FIRST(B)∪
• This is known a fixed-point

61
FIRST sets computation example
STMT if EXPR then STMT | while EXPR do STMT | EXPR ;EXPR TERM -> id | zero? TERM | not EXPR | ++ id | -- idTERM id | constant
TERM EXPR STMT

62
1. Initialization
STMT if EXPR then STMT | while EXPR do STMT | EXPR ;EXPR TERM -> id | zero? TERM | not EXPR | ++ id | -- idTERM id | constant
TERM EXPR STMT
idconstant
zero?Not++--
ifwhile

63
2. Iterate 1
STMT if EXPR then STMT | while EXPR do STMT | EXPR ;EXPR TERM -> id | zero? TERM | not EXPR | ++ id | -- idTERM id | constant
TERM EXPR STMT
idconstant
zero?Not++--
ifwhile
zero?Not++--
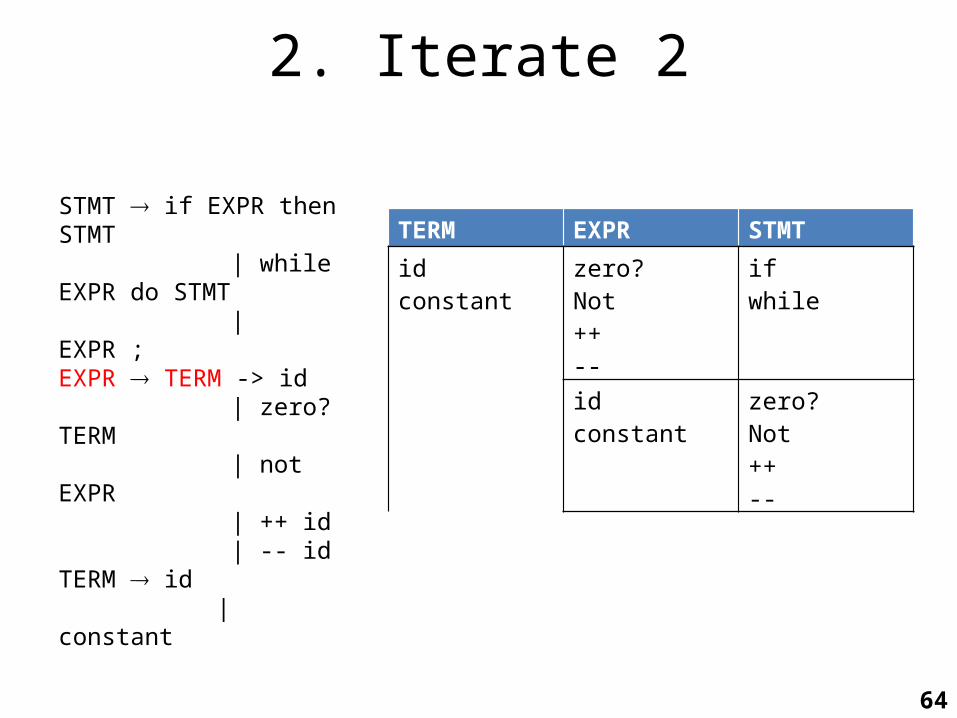
64
2. Iterate 2
STMT if EXPR then STMT | while EXPR do STMT | EXPR ;EXPR TERM -> id | zero? TERM | not EXPR | ++ id | -- idTERM id | constant
TERM EXPR STMT
idconstant
zero?Not++--
ifwhile
idconstant
zero?Not++--

65
2. Iterate 3 – fixed-point
STMT if EXPR then STMT | while EXPR do STMT | EXPR ;EXPR TERM -> id | zero? TERM | not EXPR | ++ id | -- idTERM id | constant
TERM EXPR STMT
idconstant
zero?Not++--
ifwhile
idconstant
zero?Not++--
idconstant

FOLLOW sets
• What do we do with nullable () productions?– AB C D B C – Use what comes afterwards to predict the right
production• For every production rule Aα – FOLLOW(A) = set of tokens that can immediately
follow A
• Can predict the alternative Ak for a non-terminal N when the lookahead token is in the set– FIRST(Ak) (if Ak is nullable then FOLLOW(N))
p. 189
66

LL(k) grammars
• A grammar is in the class LL(K) when it can be derived via:– Top-down derivation– Scanning the input from left to right (L)– Producing the leftmost derivation (L)– With lookahead of k tokens (k)– For every two productions Aα and Aβ we have
FIRST(α) ∩ FIRST(β) = {}and FIRST(A) ∩ FOLLOW(A) = {}
• A language is said to be LL(k) when it has an LL(k) grammar
67

Back to problem 1
• FIRST(term) = { ID }• FIRST(indexed_elem) = { ID }
• FIRST/FIRST conflict
term ID | indexed_elemindexed_elem ID [ expr ]
68

Solution: left factoring
• Rewrite the grammar to be in LL(1)
Intuition: just like factoring x*y + x*z into x*(y+z)
term ID | indexed_elemindexed_elem ID [ expr ]
term ID after_IDAfter_ID [ expr ] |
69

S if E then S else S | if E then S | T
S if E then S S’ | TS’ else S |
Left factoring – another example
70

Back to problem 2
• FIRST(S) = { a } FOLLOW(S) = { } • FIRST(A) = { a } FOLLOW(A) = { a }
• FIRST/FOLLOW conflict
S A a bA a |
71

Solution: substitution
S A a bA a |
S a a b | a b
Substitute A in S
S a after_A after_A a b | b
Left factoring
72

Back to problem 3
• Left recursion cannot be handled with a bounded lookahead
• What can we do?
E E - term | term
73

Left recursion removal
• L(G1) = β, βα, βαα, βααα, …
• L(G2) = same
N Nα | β N βN’ N’ αN’ |
G1 G2
E E - term | term E term TE | termTE - term TE |
For our 3rd example:
p. 130
Can be done algorithmically.Problem: grammar becomes mangled beyond recognition
74

LL(k) Parsers
• Recursive Descent– Manual construction– Uses recursion
• Wanted– A parser that can be generated automatically– Does not use recursion
75

• Pushdown automaton uses– Prediction stack– Input stream– Transition table• nonterminals x tokens -> production alternative• Entry indexed by nonterminal N and token t contains
the alternative of N that must be predicated when current input starts with t
LL(k) parsing via pushdown automata
76

77
LL(k) parsing via pushdown automata
• Two possible moves– Prediction
• When top of stack is nonterminal N, pop N, lookup table[N,t]. If table[N,t] is not empty, push table[N,t] on prediction stack, otherwise – syntax error
– Match• When top of prediction stack is a terminal T, must be equal
to next input token t. If (t == T), pop T and consume t. If (t ≠ T) syntax error
• Parsing terminates when prediction stack is empty– If input is empty at that point, success. Otherwise,
syntax error

78
Model of non-recursivepredictive parser
Predictive Parsing program
Parsing Table
X
Y
Z
$
Stack
$ b + a
Output

( ) not true false and or xor $
E 2 3 1 1LIT 4 5OP 6 7 8
(1) E → LIT(2) E → ( E OP E ) (3) E → not E(4) LIT → true(5) LIT → false(6) OP → and(7) OP → or(8) OP → xor
Non
term
inal
s
Input tokens
Which rule should be used
Example transition table
79

a b c
A A aAb A c
A aAb | caacbb$
Input suffix Stack content Move
aacbb$ A$ predict(A,a) = A aAbaacbb$ aAb$ match(a,a)
acbb$ Ab$ predict(A,a) = A aAbacbb$ aAbb$ match(a,a)
cbb$ Abb$ predict(A,c) = A ccbb$ cbb$ match(c,c)
bb$ bb$ match(b,b)
b$ b$ match(b,b)
$ $ match($,$) – success
Running parser example
80

a b c
A A aAb A c
A aAb | cabcbb$
Input suffix Stack content Move
abcbb$ A$ predict(A,a) = A aAbabcbb$ aAb$ match(a,a)
bcbb$ Ab$ predict(A,b) = ERROR
Illegal input example
81

Error handling and recovery
x = a * (p+q * ( -b * (r-s);
Where should we report the error?
The valid prefix property
Recovery is tricky Heuristics for dropping tokens, skipping to
semicolon, etc.82

Error handling in LL parsers
• Now what?– Predict b S anyway “missing token b inserted in line XXX”
S a c | b Sc$
a b c
S S a c S b S
Input suffix Stack content Move
c$ S$ predict(S,c) = ERROR
83

Error handling in LL parsers
• Result: infinite loop
S a c | b Sc$
a b c
S S a c S b S
Input suffix Stack content Move
bc$ S$ predict(b,c) = S bSbc$ bS$ match(b,b)
c$ S$ Looks familiar?
84

Error handling
• Requires more systematic treatment• Enrichment– Acceptable-set method– Not part of course material
85

Summary
• Parsing– Top-down or bottom-up
• Top-down parsing– Recursive descent– LL(k) grammars– LL(k) parsing with pushdown automata
• LL(K) parsers– Cannot deal with left recursion– Left-recursion removal might result with
complicated grammar
86

See you next time





























