Embed Size (px)
Citation preview

1
Compilation 0368-3133 (Semester A, 2013/14)
Lecture 6b: Context Analysis(aka Semantic Analysis)
Noam RinetzkySlides credit: Mooly Sagiv and Eran Yahav
Attribute Grammar

2
Conceptual Structure of a Compiler
Executable
code
exe
Source
text
txt
Semantic
Representation
Backend
CompilerFrontend
LexicalAnalysi
s
Syntax Analysi
s
Parsing
Semantic
Analysis
IntermediateRepresentati
on
(IR)
Code
Generation

You are here…
3
Executable
code
exe
Source
text
txtLexical
AnalysisSem.
AnalysisProcess
text input
characters SyntaxAnalysistokens AST
Intermediate code
generation
Annotated AST
Intermediate code
optimization
IR CodegenerationIR
Target code optimization
Symbolic Instructions
SI Machine code generation
Write executable
output
MI
Back End

4
Abstract Syntax Tree
• AST is a simplification of the parse tree
• Can be built by traversing the parse tree– E.g., using visitors
• Can be built directly during parsing– Add an action to perform on each production rule– Similarly to the way a parse tree is constructed

5
Building a Parse Tree
Node E() { result = new Node(); result.name = “E”; if (current {TRUE, FALSE}) // E LIT result.addChild(LIT()); else if (current == LPAREN) // E ( E OP E ) result.addChild(match(LPAREN)); result.addChild(E()); result.addChild(OP()); result.addChild(E()); result.addChild(match(RPAREN)); else if (current == NOT) // E not E result.addChild(match(NOT)); result.addChild(E()); else error; return result;}

6
Building an AST
Node E() { if (current {TRUE, FALSE}) // E LIT result = new LitNode(current); else if (current == LPAREN) // E ( E OP E ) result = new BinNode(); match(LPAREN); result.left = E(); result.op = OP(); result.right = E(); match(RPAREN); else if (current == NOT) // E not E result = new NotNode(); match(NOT)); result.expr = E(); else error; return result;}

7
Abstract Syntax Tree
• The interface between the parser and the rest of the compiler– Separation of concerns– Reusable, modular and extensible
• The AST is defined by a context free grammar– The CFG of the AST can be ambiguous!
• Is this a problem?
• Keep syntactic information– Why?

What we want
symbol kind type propertiesx var ?tomato var ?potato var Potatocarrot var Carrot
8
Lexical analyzer
Potato potato;Carrot carrot;x = tomato + potato + carrot
…<id,tomato>,<PLUS>,<id,potato>,<PLUS>,<id,carrot>,EOF
Parser
‘tomato’ is undefined ‘potato’ used before initialized Cannot add Potato and Carrot
LocationExprid=tomato
AddExprleft right
AddExprleft right
LocationExprid=potato id=carrot
LocationExpr

9
Context Analysis• Check properties contexts of in which
constructs occur– Properties that cannot be formulated via CFG
• Type checking• Declare before use
– Identifying the same word “w” re-appearing – wbw • Initialization • …
– Properties that are hard to formulate via CFG• “break” only appears inside a loop • …
• Processing of the AST

10
Context Analysis
• Identification– Gather information about each named item in
the program– e.g., what is the declaration for each usage
• Context checking– Type checking– e.g., the condition in an if-statement is a
Boolean

11
Identification
month : integer RANGE [1..12];month := 1;while (month <= 12) { print(month_name[month]); month : = month + 1;}

12
Identification
• Forward references?• Languages that don’t require declarations?
month : integer RANGE [1..12];month := 1;while (month <= 12) { print(month_name[month]); month : = month + 1;}

13
Symbol table
• A table containing information about identifiers in the program
• Single entry for each named item
name pos type …
month 1 RANGE[1..12]
month_name … …
…
month : integer RANGE [1..12];…month := 1;while (month <= 12) { print(month_name[month]); month : = month + 1;}

14
Not so fast…
struct one_int { int i;} i;
main() { i.i = 42; int t = i.i; printf(“%d”,t);}
A struct field named i
A struct variable named i
Assignment to the “i” field of struct “i”
Reading the “i” field of struct “i”

15
Not so fast…
struct one_int { int i;} i;
main() { i.i = 42; int t = i.i; printf(“%d”,t); { int i = 73; printf(“%d”,i); }}
A struct field named i
A struct variable named i
int variable named “i”
Assignment to the “i” field of struct “i”
Reading the “i” field of struct “i”

16
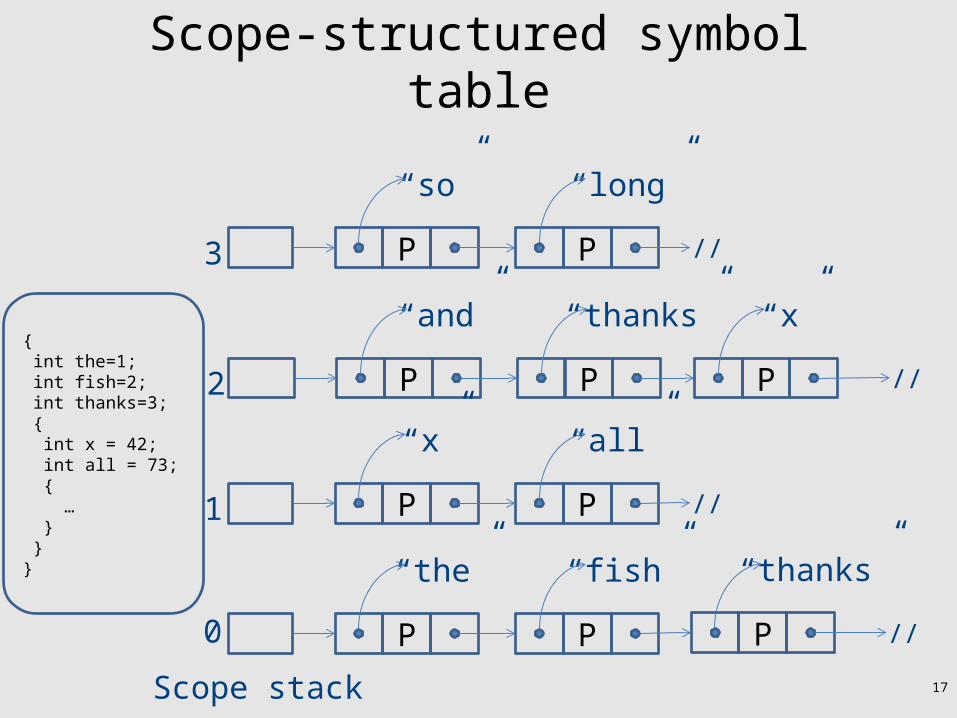
Scopes
• Typically stack structured scopes
• Scope entry– push new empty scope element
• Scope exit– pop scope element and discard its content
• Identifier declaration– identifier created inside top scope
• Identifier Lookup– Search for identifier top-down in scope stack
17
Scope-structured symbol table
Scope stack
0
3 P
“so”
P
“long”
//
2 P
“and”
P
“thanks”
1 P
“x”
P
“all”
//
P
“the”
P
“fish”
P
“thanks”
//
P
“x”
//
{ int the=1; int fish=2; int thanks=3; { int x = 42; int all = 73; { … } }}

18
Scope and symbol table
• Scope x Identifier -> properties – Expensive lookup
• A better solution – hash table over identifiers
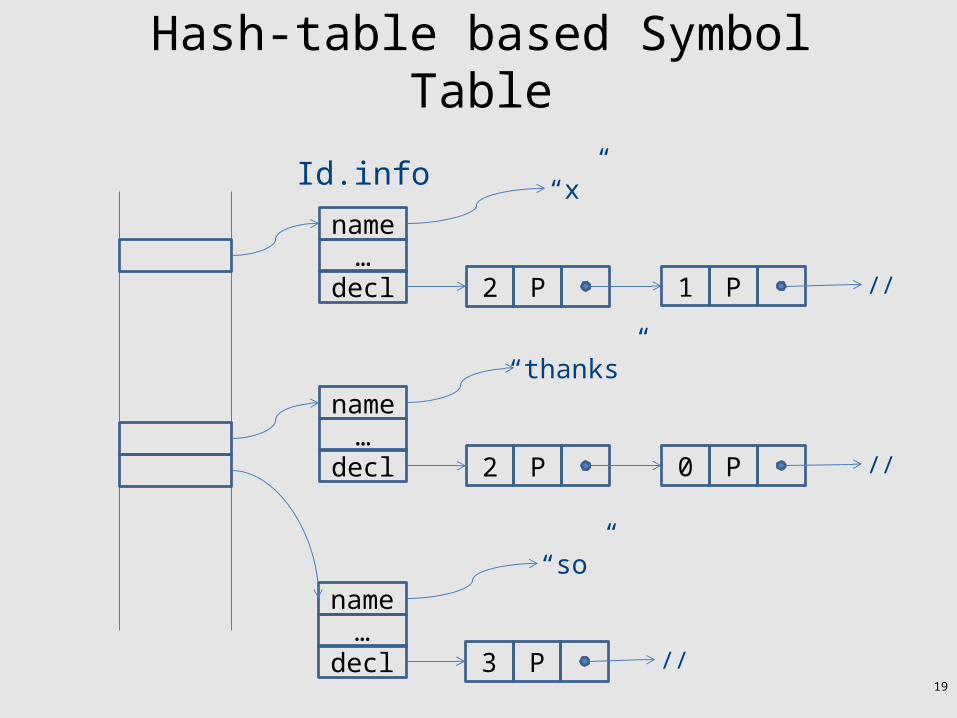
Hash-table based Symbol Table
19
name…
decl 2 P
“x”
1 P //
name…
decl 2 P
“thanks”
0 P //
name…
decl 3 P
“so”
//
Id.info
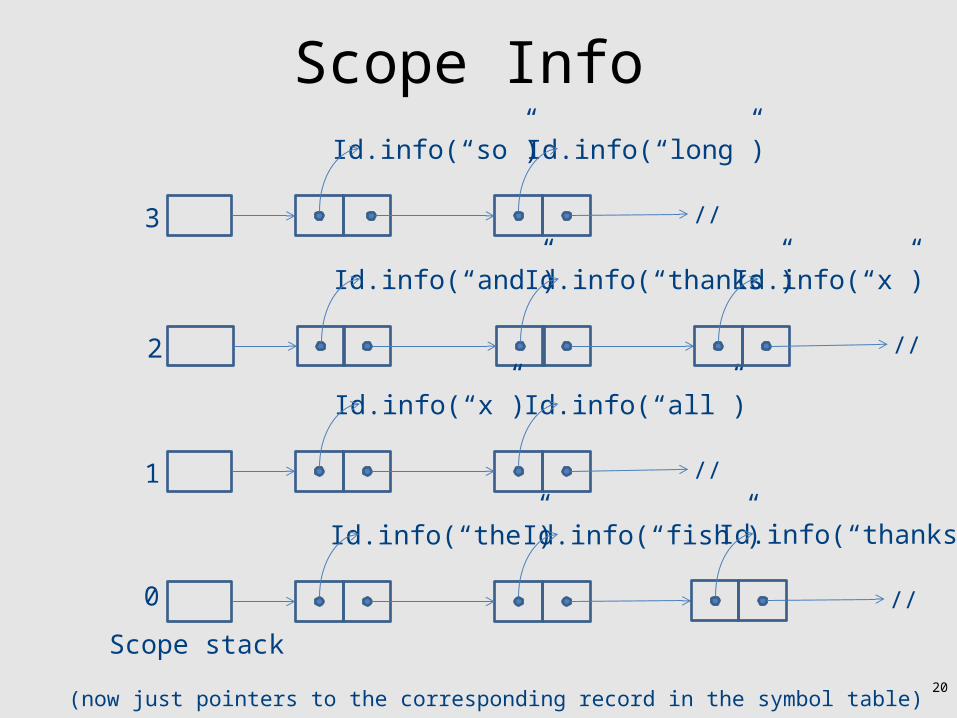
Scope Info
20
Scope stack
0
3
Id.info(“so”) Id.info(“long”)
//
2
Id.info(“and”) Id.info(“thanks”)
1
Id.info(“x”) Id.info(“all”)
//
Id.info(“the”) Id.info(“fish”) Id.info(“thanks”)
//
Id.info(“x”)
//
(now just pointers to the corresponding record in the symbol table)

21
Symbol table
• A table containing information about identifiers in the program
• Single entry for each named item
name pos type …
month 1 RANGE[1..12]
month_name … …
…
month : integer RANGE [1..12];…month := 1;while (month <= 12) { print(month_name[month]); month : = month + 1;}

22
Semantic Checks
• Scope rules– Use symbol table to check that
Identifiers defined before used No multiple definition of same identifier …
Type checking Check that types in the program are consistent
How? Why?

23
Types
• What is a type?– Simplest answer: a set of values + allowed operations– Integers, real numbers, booleans, …
• Why do we care?– Code generation: $1 := $1 + $2– Safety
• Guarantee that certain errors cannot occur at runtime– Abstraction
• Hide implementation details – Documentation– Optimization

24
Type System (textbook definition)
“A type system is a tractable syntactic method for proving the absence of certain program behaviors by classifying phrases according to the kinds of values they compute”
-- Types and Programming Languages / Benjamin C. Pierce

25
Type System
• A type system of a programming language is a way to define how “good” program behave– Good programs = well-typed programs– Bad programs = not well typed
• Type checking– Static typing – most checking at compile time– Dynamic typing – most checking at runtime
• Type inference– Automatically infer types for a program (or show that there is no
valid typing)

26
Static typing vs. dynamic typing
• Static type checking is conservative– Any program that is determined to be well-typed is free from
certain kinds of errors– May reject programs that cannot be statically determined as
well typed– Why?
• Dynamic type checking – May accept more programs as valid (runtime info)– Errors not caught at compile time– Runtime cost– Why?

27
Type Checking• Type rules specify
– which types can be combined with certain operator – Assignment of expression to variable– Formal and actual parameters of a method call
• Examples
“drive” + “drink” 42 + “the answer”stringstring
string
int string
ERROR

28
Type Checking Rules• Specify for each operator
– Types of operands– Type of result
• Basic Types– Building blocks for the type system (type rules)– e.g., int, boolean, (sometimes) string
• Type Expressions– Array types – Function types – Record types / Classes

29
Typing Rules
If E1 has type int and E2 has type int, then E1 + E2 has type int
E1 : int E2 : int
E1 + E2 : int

30
More Typing Rules (examples)true : boolean
E1 : int E2 : int
E1 op E2 : int
false : boolean
int-literal : int string-literal : string
op { +, -, /, *, %}
E1 : int E2 : int
E1 rop E2 : booleanrop { <=,<, >, >=}
E1 : T E2 : T
E1 rop E2 : booleanrop { ==,!=}

31
And Even More Typing Rules E1 : boolean E2 : boolean
E1 lop E2 : booleanlop { &&,|| }
E1 : int
- E1 : int
E1 : boolean
! E1 : boolean
E1 : T[]
E1.length : int
E1 : T[] E2 : int
E1[E2] : T
E1 : int
new T[E1] : T[]

32
Type Checking
• Traverse AST and assign types for AST nodes– Use typing rules to compute node types
Alternative: type-check during parsing– More complicated alternative – But naturally also more efficient

33
Example
45 > 32 && !false
BinopExpr UnopExpr
BinopExpr
…
op=AND
op=NEGop=GT
intLiteral
val=45
intLiteral
val=32
boolLiteral
val=false
: int : int
: boolean
: boolean
: boolean
: boolean
false : boolean
int-literal : int
E1 : int E2 : int
E1 rop E2 : boolean
rop { <=,<, >, >=}
E1 : boolean E2 : boolean
E1 lop E2 : boolean
lop { &&,|| }
E1 : boolean
!E1 : boolean

34
Type Declarations• So far, we ignored the fact that types can
also be declared
TYPE Int_Array = ARRAY [Integer 1..42] OF Integer;
Var a : ARRAY [Integer 1..42] OF Real;
(explicitly)
(anonymously)

35
Var a : ARRAY [Integer 1..42] OF Real;
TYPE #type01_in_line_73 = ARRAY [Integer 1..42] OF Real; Var a : #type01_in_line_73;
Type Declarations

36
Forward References
• Forward references must be resolved – A forward references added to the symbol table as forward reference, and later
updated when type declaration is met– At the end of scope, must check that all forward references have been resolved– Check must be added for circularity
TYPE Ptr_List_Entry = POINTER TO List_Entry;TYPE List_Entry =
RECORD Element : Integer;
Next : Ptr_List_Entry; END RECORD;

37
Type Table
• All types in a compilation unit are collected in a type table
• For each type, its table entry contains:– Type constructor: basic, record, array, pointer,…– Size and alignment requirements
• to be used later in code generation– Types of components (if applicable)
• e.g., types of record fields
38
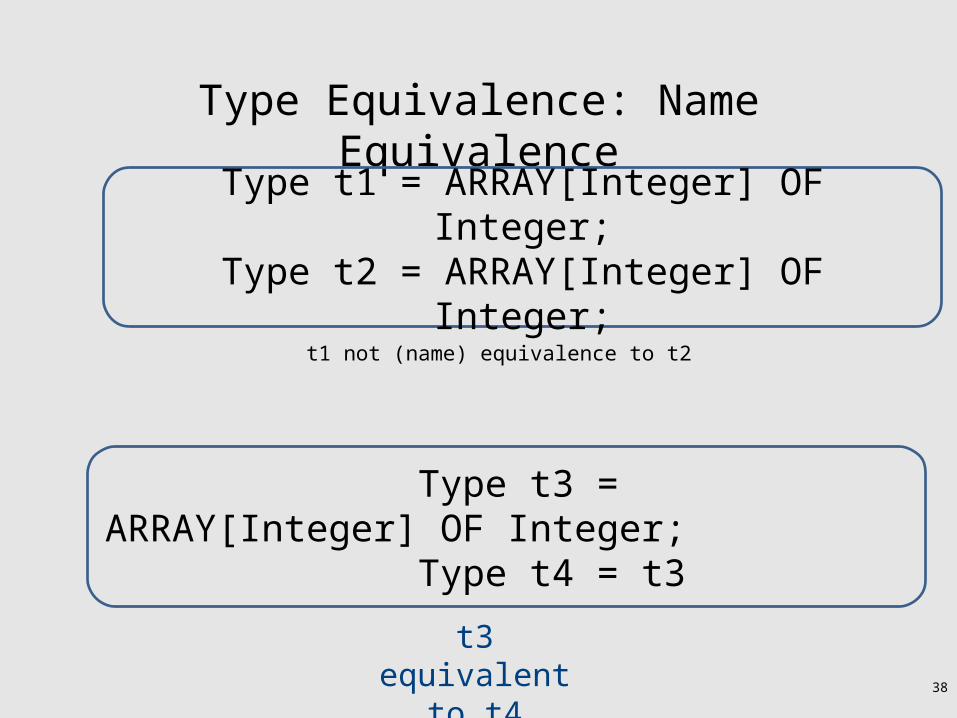
Type Equivalence: Name Equivalence
t1 not (name) equivalence to t2
Type t1 = ARRAY[Integer] OF Integer;Type t2 = ARRAY[Integer] OF Integer;
t3 equivalent to t4
Type t3 = ARRAY[Integer] OF Integer; Type t4 = t3

39
Type Equivalence: Structural Equivalence
t5, t6, t7 are all (structurally) equivalent
Type t5 = RECORD c: Integer; p: POINTER TO t5; END RECORD;Type t6 = RECORD c: Integer; p: POINTER TO t6; END RECORD;Type t7 = RECORD c: Integer; p: POINTER TO RECORD c: Integer; p: POINTER to t5; END RECORD;END RECORD;

40
In practice• Almost all modern languages use name
equivalence• why?

41
Coercions• If we expect a value of type T1 at some
point in the program, and find a value of type T2, is that acceptable?
float x = 3.141;int y = x;

42
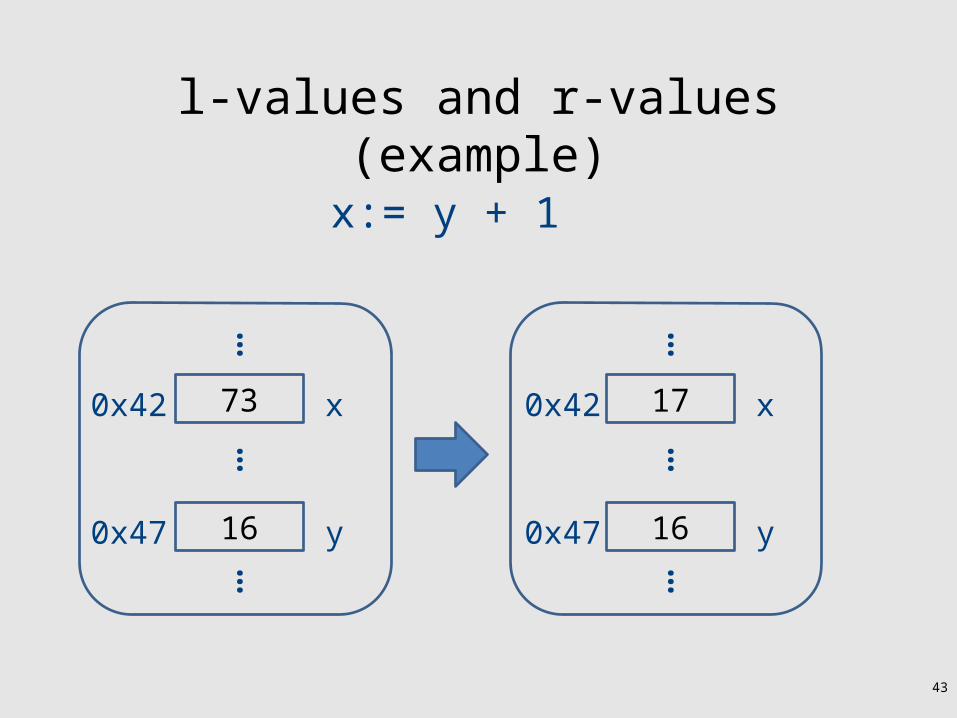
l-values and r-values
• What is dst? What is src?– dst is a memory location where the value should be
stored– src is a value
• “location” on the left of the assignment called an l-value
• “value” on the right of the assignment is called an r-value
dst := src
43
l-values and r-values (example)
x:= y + 1
730x42
160x47
x
y
……
…
170x42
160x47
x
y
……
…

44
l-values and r-values
lvalue rvaluelvalue - derefrvalue error -
expectedfo
und

45
So far…
• Static correctness checking– Identification– Type checking
• Identification matches applied occurrences of identifier to its defining occurrence– The symbol table maintains this information
• Type checking checks which type combinations are legal• Each node in the AST of an expression represents either
an l-value (location) or an r-value (value)

46
How does this magic happen?
• We probably need to go over the AST?
• how does this relate to the clean formalism of the parser?

47
Syntax Directed Translation
• Semantic attributes– Attributes attached to grammar symbols
• Semantic actions– (already mentioned when we did recursive
descent)– How to update the attributes
• Attribute grammars

48
Attribute grammars
• Attributes– Every grammar symbol has attached attributes
• Example: Expr.type
• Semantic actions– Every production rule can define how to assign
values to attributes • Example:
Expr Expr + TermExpr.type = Expr1.type when (Expr1.type == Term.type) Error otherwise

49
Indexed symbols
• Add indexes to distinguish repeated grammar symbols
• Does not affect grammar • Used in semantic actions
• Expr Expr + TermBecomesExpr Expr1 + Term

50
Example
Production Semantic Rule
D T L L.in = T.type
T int T.type = integer
T float T.type = float
L L1, id L1.in = L.in addType(id.entry,L.in)
L id addType(id.entry,L.in)
D
float
L
L id1
T
L id2
id3
float x,y,z
float float
float
float

51
Attribute Evaluation
• Build the AST• Fill attributes of terminals with values derived
from their representation• Execute evaluation rules of the nodes to
assign values until no new values can be assigned– In the right order such that
• No attribute value is used before its available• Each attribute will get a value only once

52
Dependencies
• A semantic equation a = b1,…,bm requires computation of b1,…,bm to determine the value of a
• The value of a depends on b1,…,bm– We write a bi
53
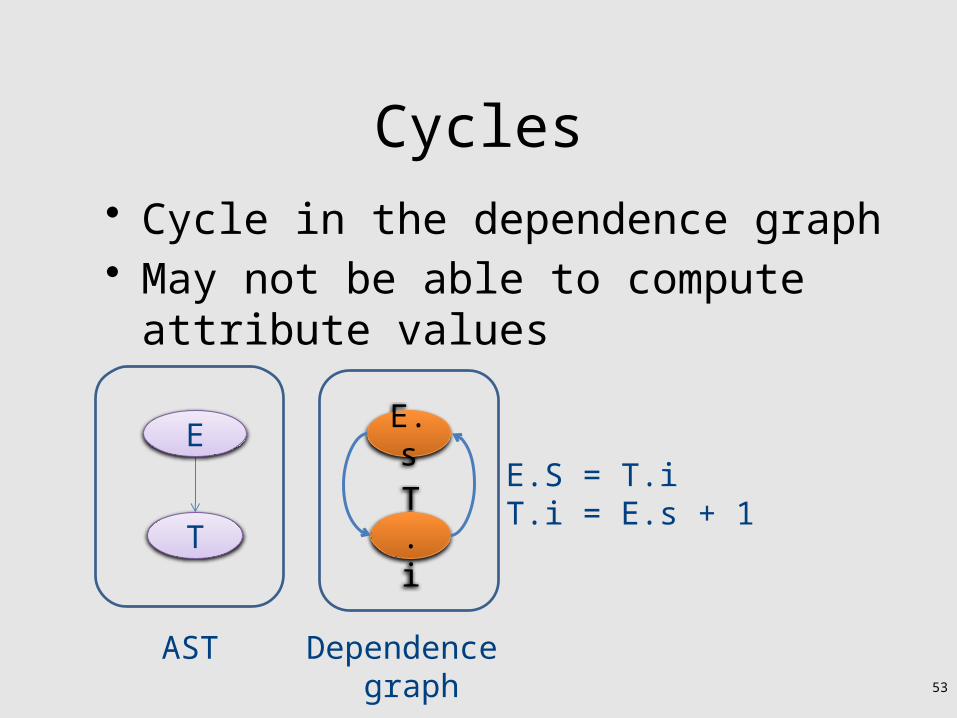
Cycles• Cycle in the dependence graph• May not be able to compute attribute
values
T
EE.S = T.iT.i = E.s + 1
T.i
E.s
AST Dependence graph

54
Attribute Evaluation
• Build the AST• Build dependency graph• Compute evaluation order using topological
ordering• Execute evaluation rules based on
topological ordering
• Works as long as there are no cycles

55
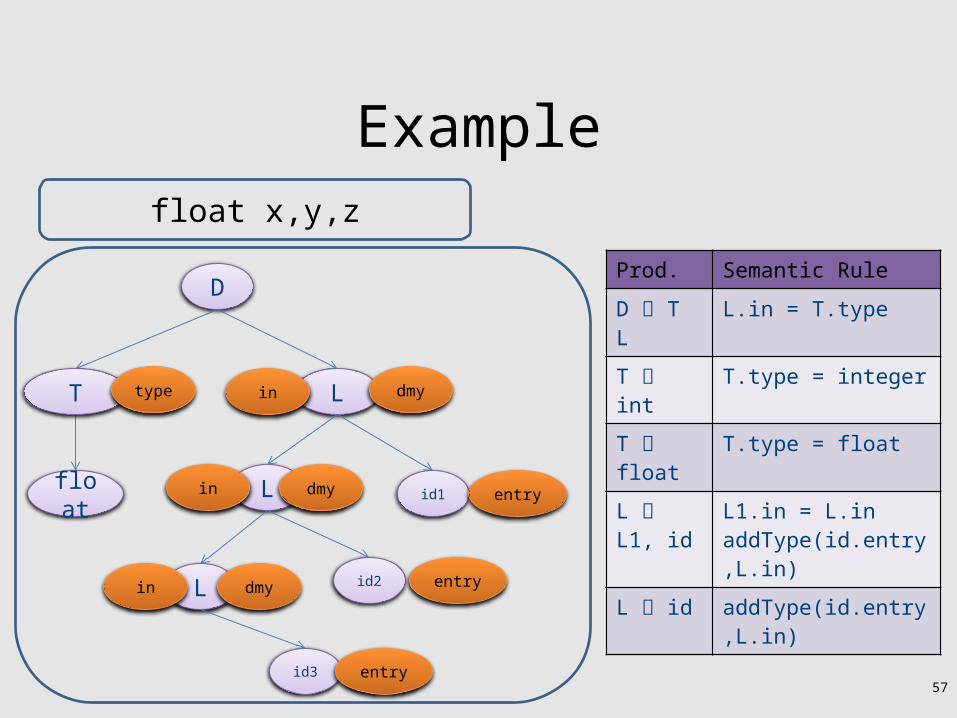
Building Dependency Graph
• All semantic equations take the form
attr1 = func1(attr1.1, attr1.2,…)attr2 = func2(attr2.1, attr2.2,…)
• Actions with side effects use a dummy attribute• Build a directed dependency graph G
– For every attribute a of a node n in the AST create a node n.a– For every node n in the AST and a semantic action of the
form b = f(c1,c2,…ck) add edges of the form (ci,b)

Example
56
Production Semantic Rule
D T L ➞ L.in = T.typeT int➞ T.type = integerT float➞ T.type = float
L L1, id ➞ L1.in = L.in addType(id.entry,L.in)
L id➞ addType(id.entry,L.in)
Production Semantic Rule
D T L ➞ L.in = T.typeT int➞ T.type = integerT float➞ T.type = float
L L1, id ➞ L1.in = L.in L.dmy = addType(id.entry,L.in)
L id➞ L.dmy = addType(id.entry,L.in)
Convention: Add dummy variables for side effects.
57
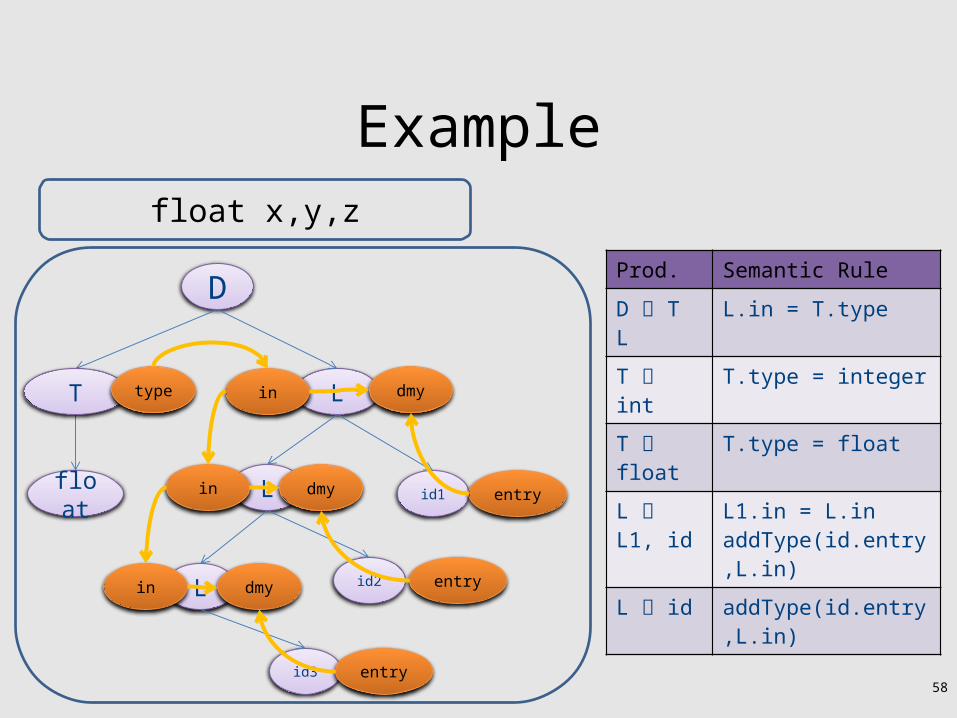
Example
Prod. Semantic Rule
D T L L.in = T.type
T int T.type = integer
T float T.type = float
L L1, id L1.in = L.in addType(id.entry,L.in)
L id addType(id.entry,L.in)
D
float
L
L id1
T
L id2
id3
float x,y,z
type in dmy
entry
entry
entry
in
in
dmy
dmy
58
Example
Prod. Semantic Rule
D T L L.in = T.type
T int T.type = integer
T float T.type = float
L L1, id L1.in = L.in addType(id.entry,L.in)
L id addType(id.entry,L.in)
D
float
L
L id1
T
L id2
id3
float x,y,z
type in dmy
entry
entry
entry
in
in
dmy
dmy
59
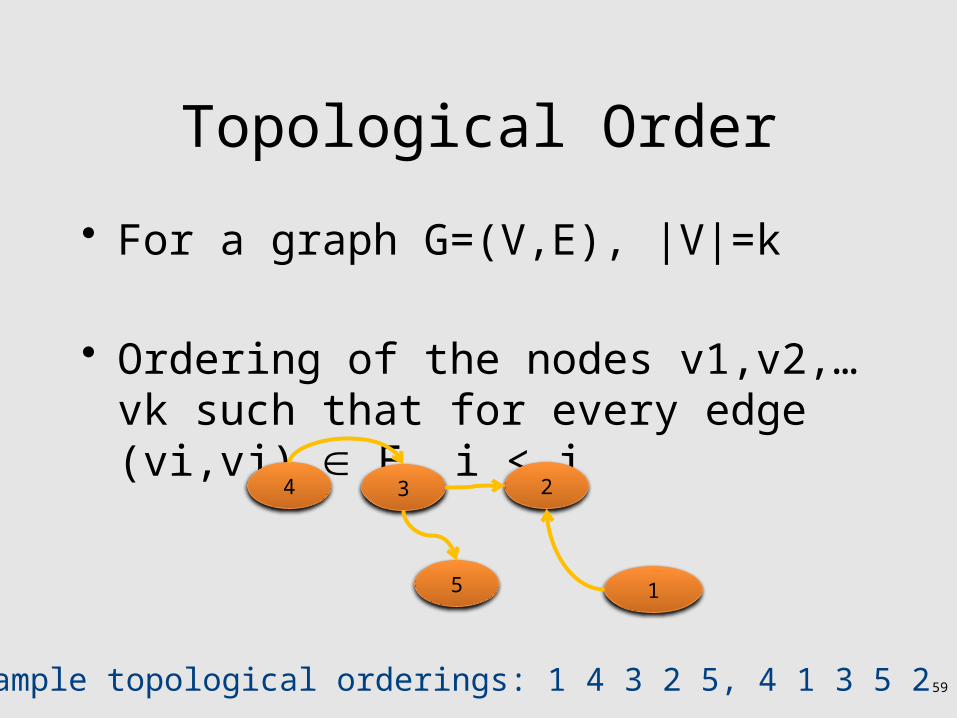
Topological Order
• For a graph G=(V,E), |V|=k
• Ordering of the nodes v1,v2,…vk such that for every edge (vi,vj) E, i < j
4 3 2
15
Example topological orderings: 1 4 3 2 5, 4 1 3 5 2
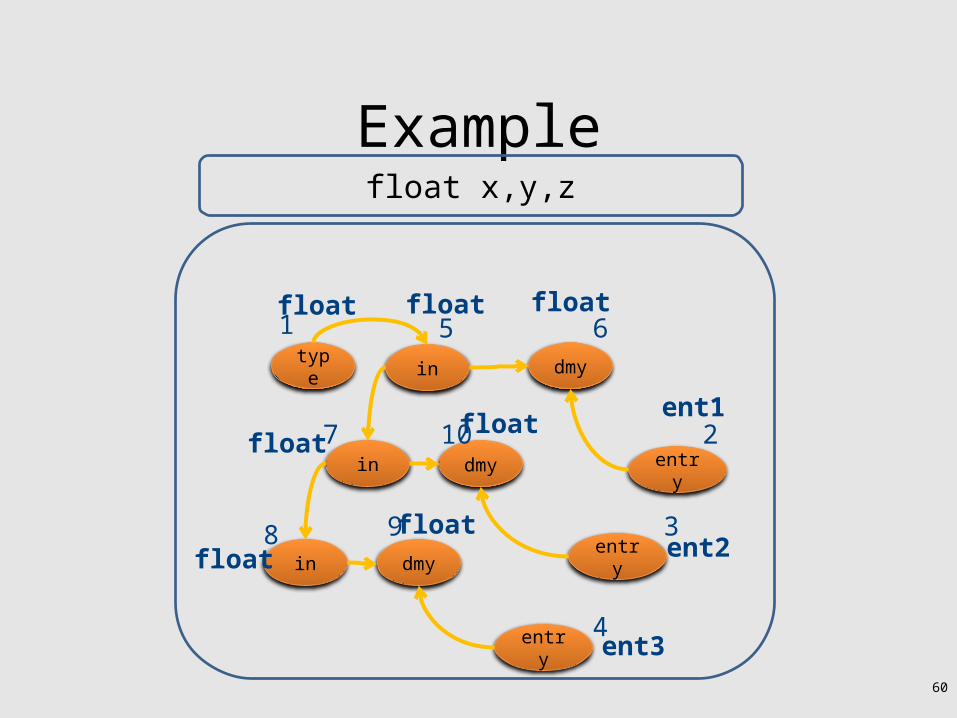
60
Examplefloat x,y,z
type in dmy
entry
entry
entry
in
in
dmy
dmy
1
2
3
4
5
7
8 9
10
6float float
ent1
ent2
ent3
float
float
floatfloat
float

61
But what about cycles?
• For a given attribute grammar hard to detect if it has cyclic dependencies– Exponential cost
• Special classes of attribute grammars– Our “usual trick”– sacrifice generality for predictable
performance

62
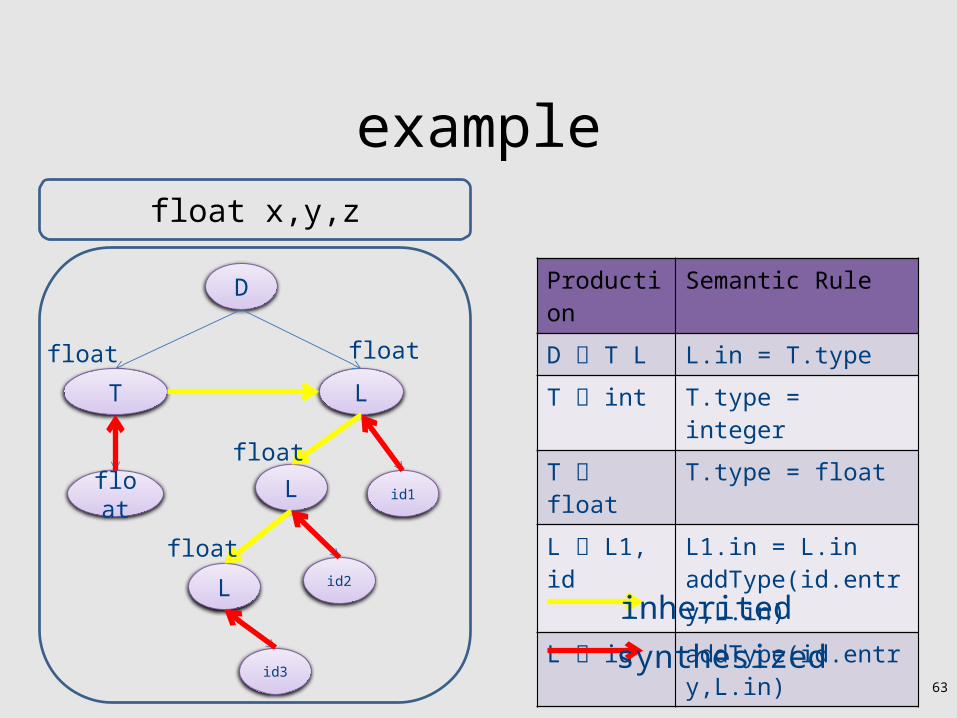
Inherited vs. Synthesized Attributes
• Synthesized attributes– Computed from children of a node
• Inherited attributes– Computed from parents and siblings of a node
• Attributes of tokens are technically considered as synthesized attributes
63
example
Production Semantic Rule
D T L L.in = T.type
T int T.type = integer
T float T.type = float
L L1, id L1.in = L.in addType(id.entry,L.in)
L id addType(id.entry,L.in)
D
float
L
L id1
T
L id2
id3
float x,y,z
float float
float
float
inherited
synthesized

64
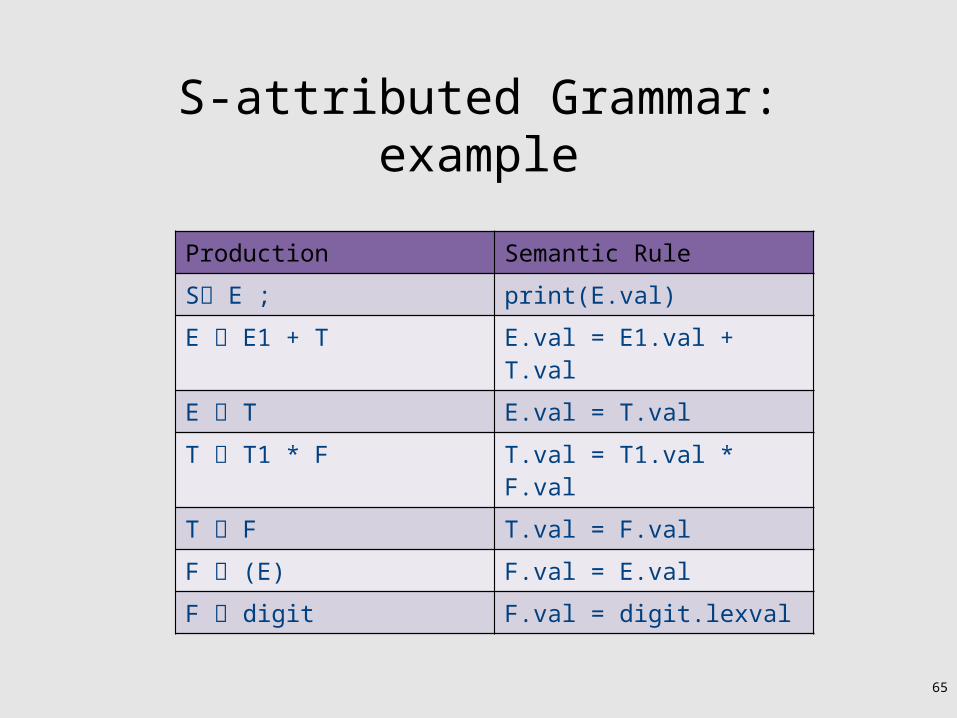
S-attributed Grammars
• Special class of attribute grammars • Only uses synthesized attributes (S-attributed)• No use of inherited attributes
• Can be computed by any bottom-up parser during parsing
• Attributes can be stored on the parsing stack• Reduce operation computes the (synthesized)
attribute from attributes of children
65
S-attributed Grammar: example
Production Semantic Rule
S E ; print(E.val)
E E1 + T E.val = E1.val + T.val
E T E.val = T.val
T T1 * F T.val = T1.val * F.val
T F T.val = F.val
F (E) F.val = E.val
F digit F.val = digit.lexval

66
example
3
F
T
E +
4
F
T
E *
7
F
T
S
Lexval=3Lexval=4Lexval=7
val=7
val=7
val=4
val=4
val=28
val=3
val=3
val=31
31

67
L-attributed grammars
• L-attributed attribute grammar when every attribute in a production A X1…Xn is– A synthesized attribute, or– An inherited attribute of Xj, 1 <= j <=n that only
depends on • Attributes of X1…Xj-1 to the left of Xj, or• Inherited attributes of A

68
Example: typesetting
• Each box is built from smaller boxes from which it gets the height and depth, and to which it sets the point size.
• pointsize (ps) – size of letters in a box. Subscript text has smaller point size of o.7p.
• height (ht) – distance from top of the box to the baseline• depth (dp) – distance from baseline to the bottom of the box.

69
Example: typesettingproduction semantic rules
S B➞ B.ps = 10
B B1 B2➞ B1.ps = B.psB2.ps = B.psB.ht = max(B1.ht,B2.ht)B.dp = max(B1.dp,B2.dp)
B B1 sub B2➞ B1.ps = B.psB2.ps = 0.7*B.psB.ht = max(B1.ht,B2.ht – 0.25*B.ps)B.dp = max(B1.dp,B2.dp– 0.25*B.ps)
B text➞ B.ht = getHt(B.ps,text.lexval)B.dp = getDp(B.ps,text.lexval)

Computing the attributes from left to right during a DFS traversal
procedure dfvisit (n: node);begin
for each child m of n, from left to right beginevaluate inherited attributes of m;dfvisit (m) end;evaluate synthesized attributes of n
end

71
Summary
• Contextual analysis can move information between nodes in the AST– Even when they are not “local”
• Attribute grammars – Attach attributes and semantic actions to grammar
• Attribute evaluation– Build dependency graph, topological sort, evaluate
• Special classes with pre-determined evaluation order: S-attributed, L-attributed

72
The End





























