Embed Size (px)
Citation preview

Comparazione dei modelli di reti di geni
Damiano Carne 2004

Introduzione alle reti di geniGrazie all’avvento della tecnologia dei microarray si è potuto effettuare l’analisi dell’espressione dei geni su larga scala e indagare:• Interazione tra geni.• Funzionalità dei geni.Una rete di geni consiste di un insieme di componenti molecolari (geni, proteine, ecc..) e delle loro reciproche relazioni che, globalmente, caratterizzano una funzione nella cellula.
Esiste un ampia varietà di metodologie per indagare le interazioni geniche MODELLI DI RETI DI GENI.N.B. Non è noto quanto questi metodi si sovrappongano e quali siano le loro capacità e i loro limiti.

Introduzione alle reti di geniLa tassonomia proposta dei modelli di reti di geni, consistedi sei parametri di valutazione :
1. CAPACITA’ DEDUTTIVA2. CAPACITA’ PREDITTIVA3. ROBUSTEZZA4. CONSISTENZA5. STABILITA’6. COSTO COMPUTAZIONALE

Introduzione alle reti di geniLe reti di geni sono costruite per estrarre la “matrice di regolazione del gene”, la quale ci dice :• Come i geni vengono regolati;• Come le condizioni ambientali influenzano la regolazione.Questa matrice può essere designata per dare in uscita come i geni agiscano insieme per esprimere un determinato fenotipo.Per modellare un processo genetico, si inizia solitamente con lacostruzione di un modello parametrizzato che descrive la regolazione del processo e che viene estratto dalle conoscenze biologiche circa:• Interazioni tra geni;• Degradazione del prodotto del gene;• Risposta dei geni ad input specifici.

Confronto fra i modelliIl confronto si concentra su modelli continui, cioè modelli che non richiedono discretizzazione dei dati in input prima del processo di illazione. Le reti Booleane, le reti Baesiane e i modelli qualitativi sono quindi escluse.Consideriamo tre categorie di modelli continui:• Metodi “Pair-Wise”;• Modelli di reti approssimativi “Rough Network Models”;• Reti complesse, che descrivono i prodotti intermedi, quali proteine, metaboliti, ecc…

Pair-WiseQuesti metodi costruiscono i rapporti tra i geni
basandosi unicamente sul confronto di coppie di geni. Di conseguenza non vengono considerate le interazioni dove il livello di espressione risultante di un gene sia governato dall’azione di un multiplo
diverso di geni. Vediamo di seguito due esempi di questi metodi:
Arkin-and-Ross’97: Correlation Metric Construction (CMC)
Chen, Filkov e Skiena’99: Reti di attuazione/inibizione

Pair-WiseArkin-and-Ross’97: Correlation Metric Construction (CMC) In primo luogo il metodo computa la grandezza e la posizione a cui si presenta la cross-correlazione massima. Ciò fornisce rispettivamente una misura di somiglianza e un ordinamento temporale. Viene costruita una matrice di distanza (D) : • per confronto;• per accoppiamento di geni;• per similarità con altri geni. Gli autovalori significativi della matrice di distanza costruita, danno un indicazione sulla dimensionalità intrinseca del sistema. Viene impiegato un singolo legame nel clustering gerarchico per trovare un singola unione nell’albero che unisca i geni associati. Questo diagramma di associazione è arricchito con direzionalità e informazioni sul time-lag , rivelando un ordinamento temporale.

Pair-WiseChen, Filkov e Skiena’99: Reti di attuazione/inibizioneEsprimono la regolazione basandosi sui picchi dei segnali. Dopo le operazioni iniziali di sogliatura e clustering risulta un insieme di segnali prototipo, ogni prototipo è rappresentato da una serie di picchi. Per ogni accoppiamento dei prototipi sono calcolati tre punteggi, rappresentanti rispettivamente:• una possibile attivazione;• una possibile inibizione;• un disaccoppiamento.La matrice di regolazione viene arguita prendendo il valore più alto di questi punteggi.

Rough Network ModelsQueste reti modellano direttamente gli effetti che derivano dalla combinazione dei diversi input di
geni, per mezzo di una somma pesata del loro livello di espressione.
Il termine “rough” si riferisce al fatto che l’influenza di tutti i prodotti intermedi è
ricapitolata nel rapporto lineare gene-a-gene.Questi pesi forniscono informazioni sui rapporti
fra i geni, cioè pesi nulli (pari a 0) indicano l’assenza di interazione fra i geni, peso positivo e
negativo indicano rispettivamente stimolo o repressione. Il valore assoluto di un peso corrisponde alla forza dell’interazione.

Rough Network ModelsTutti i modelli di rete possono essere rappresentati dalla seguente equazione differenziale:
Con le seguenti interpretazioni biologiche:g(•) : Funzione monotona regolazione-espressione (attivazione);xi(t),xi[t] : Espressione del gene; del gene “i” all’istante “t”;Ri : Costante stimata del gene “i”;Wi,j : Forza di controllo di “j” su “i”;uk(t),uk[t] : K-th input esterno del gene “i”;Vi,k : Influenza del K-th input esterno del gene “i”;Bi : Livello di espressione fondamentale del gene “i”;λi : costante di degradazione dell’i-th prodotto di espressione dei geni.
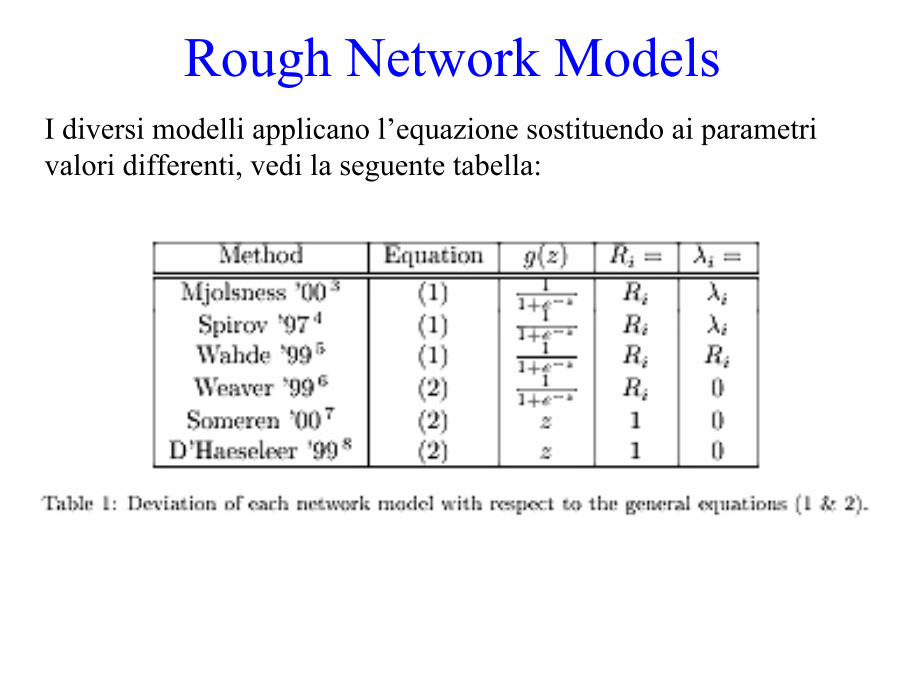
Rough Network ModelsI diversi modelli applicano l’equazione sostituendo ai parametrivalori differenti, vedi la seguente tabella:

Rough Network ModelsLa tabella che segue ricapitola invece gli algoritmi impiegati per arguire i parametri del modello da misure dei livelli di mRNA:

Complex NetworksQueste reti sono le più complesse in quanto
modellano non soltanto le interazioni fra i geni basate sulla misura dei livelli di mRNA, ma anche esplicitamente i loro prodotti intermedi, come le
proteine e i metaboliti. Di conseguenza i loro parametri non possono essere ricavati da dataset
contenenti soltanto le misure dei livelli di mRNA, poiché è necessaria la conoscenza esplicita circa i
livelli di espressione degli intermedi. Tuttavia, in questo confronto è stato impiegato il modello di Savageau. Per generare dati realistici
dell’espressione dei geni e verificare gli altri approcci modellati.

Complex NetworksSavageau’99 Il modello di rete di geni proposto da Savageau modella mRNA, proteine e i livelli di espressione del metabolita. I cambiamenti nel livello di espressione di una data specie sono modellati come segue:
Il primo termine rappresenta l’attivazione (SI= specie di attivazione) ed il secondo la degradazione (SD = specie addetta alla degradazione).La formulazione della “product power law” risulta dai livelli di espressione con comportamento non lineare, ma che rimangono facilmente interpretabili.Questo modello contiene tantissimi parametri rispetto ai due discussi in precedenza e questo rende il processo di illazione particolarmente difficile.

Valutazione dei modelliVediamo ora le caratteristiche centrali per la riuscita di un modello e quindi di riferimento per una rete di geni:
1. CAPACITA’ DEDUTTIVA2. CAPACITA’ PREDITTIVA3. ROBUSTEZZA4. CONSISTENZA5. STABILITA’6. COSTO COMPUTAZIONALE
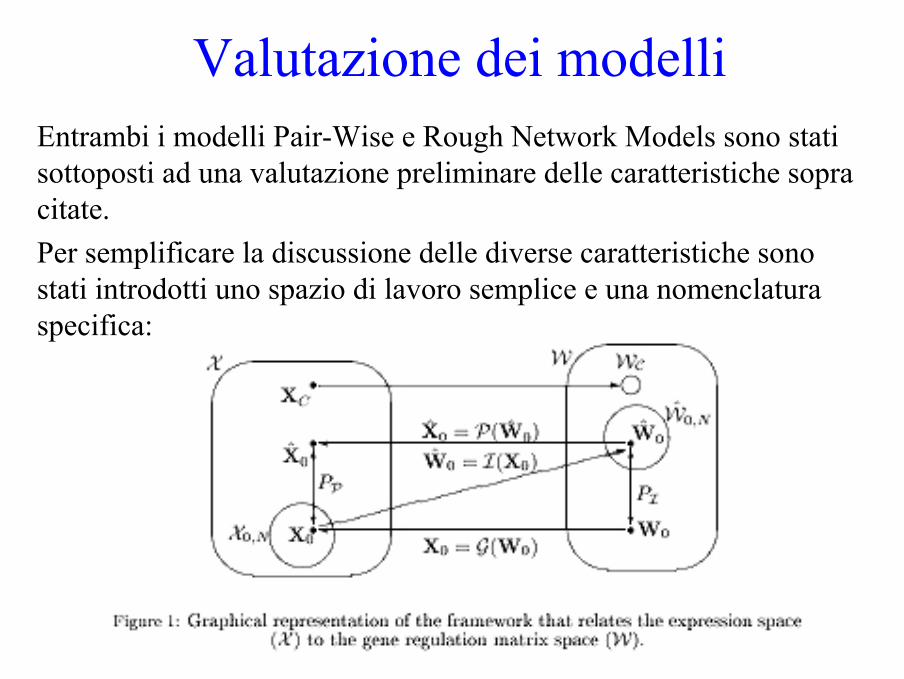
Valutazione dei modelliEntrambi i modelli Pair-Wise e Rough Network Models sono stati sottoposti ad una valutazione preliminare delle caratteristiche sopra citate.Per semplificare la discussione delle diverse caratteristiche sono stati introdotti uno spazio di lavoro semplice e una nomenclatura specifica:

Valutazione dei modelliW rappresenta lo spazio della matrice di regolazione.W rappresenta un esempio di matrice di regolazione.X rappresenta il dataset dello spazio di espressione associato a W.X rappresenta un particolare data set.Una particolare matrice W0 è stata scelta per rappresentare la “rete reale”. Basandosi su W0 (e sulle condizioni iniziali) è stato generato un dataset X0 (X0 = G(W0 )). Durante lo step di deduzione (applicando uno dei modelli descritti in precedenza) una stima di W0è stata ottenuta basandosi solamente su X0 e questa è rappresentata da Ŵ0 con Ŵ0 = I(X0 ). Ŵ0 può essere impiegato per fare una predizione dei dati di espressione dando alcune condizioni iniziali. Questo produce un approssimazione di X0, che è denotata da Χˆ0, con Χˆ0 = P(Ŵ0).N.B. Nella realtà W0 non è conosciuto ma viene arguito con algoritmi genetici. Comunque, in un esperimento sintetico, siamo liberi di scegliere W0, per permettere di verificare i risultati prodotti dall’algoritmo.

Capacità deduttiva PIPoiché i modelli di reti di geni sono in primo luogo impiegati per dedurre i modelli di interazione di regolazione da dati di espressione, è abbastanza importante che questo processo consegni una stima accurata della matrice di regolazione del gene. La capacità deduttiva è la misura di questa attitudine.DEF. Formalmente la capacità deduttiva è misurata come similarità tra la matrice di regolazione reale (W0) e arguita (Ŵ0) del gene :
PI (W0,Ŵ0) = 0.5(1+ ρ(W0,Ŵ0))
Con ρ(•) correlazione di Pearson.DistanzaDistanza EuclideaEuclidea:
raggruppa geni che hanno andamenti simili a livelli di espressione simili.Correlazione diCorrelazione di PearsonPearson:
raggruppa geni che hanno andamenti simili indipendentemente dal livello di espressione che hanno.

Capacità deduttiva PIVALUTAZIONE PRELIMINAREL’approccio Pair-Wise deduce la matrice di regolazione basandosi sulla comparazione a singole coppie. Di conseguenza le soluzionisono poco dense e sotto ottimali. Quando un gene è influenzato da più di un singolo gene si può ottenere una soluzione sbagliata. In un modello di rete questo non è tollerato, ma la matrice di regolazione può essere dedotta indirettamente minimizzando l’errore in predizione (differenza tra X0 e Χˆ0) invece che massimizzare ρ(W0, Ŵ0). Questo è fatto sotto l’assunzione che da piccoli errori in predizione risulta un accurata matrice di regolazione.

Capacità predittiva PPLa capacità predittiva si riflette nell’accuratezza prevista, come Χˆ0approssima a X0. Per i modelli di reti le matrici di regolazione sono ricavate minimizzando l’errore in predizione. Quindi è importante intuire la relazione tra PP e PI per la comparazione dei diversi modelli.DEF. Dato un dataset di espressione, X0, e la sua predizione approssimata Χˆ0, la capacità predittiva è espressa come:
PP = 1/(1+ EMSE)
Con la media dei quadrati degli errori data da:
EMSE(X0,Χˆ0) = 1/TN ∑ i,t(X 0(i,t) - Χˆ0(i,t))2

Capacità predittiva PPVALUTAZIONE PRELIMINAREQuesto aspetto è più adatto a modelli complessi, come un modellodi rete contenente non-linearità o un grande set di parametri. Questi modelli, infatti, hanno potenzialmente una grande capacità predittiva che un modello di rete semplice, come ,i modelli lineari proposti da D’Haeseleer e Van Someren. Comunque più il modello è complesso, più richiede dati di training (è costretto da più regolazioni) e sono richiesti algoritmi di deduzione non deterministici (come GA e SA), che non garantiscono convergenza a un minimo globale, probabilmente il valore di capacità deduttiva risulta sotto ottimale.

RobustezzaIl rumore è un fenomeno spesso presente. Le misurazioni dell’espressione dei geni sono particolarmente rumorose ed è importante conoscere con quale grado di accuratezza la matrice di regolazione del gene può essere estratta in presenza di rumore. DEF. Χ0,N ⊂ X denota un set di dati di espressione che ho ottenuto con rumore, N(0,σ)c,è aggiunto a X0 :
X0,N = {X0,σ|X0,σ = X0 + N(0,σ), σ ∈ [0, σMAX]}Ŵ0,N denota il set di dati delle matrici di regolazione che è ottenuta dalla deduzione di ogni elemento Χ0,N :
Ŵ0,N = {Ŵ0,σ | Ŵ0,σ = I(X0,σ), X0,σ∈ X0,N}La misura di robustezza PR, definita come la correlazione minima della matrice di regolazione, è dedotta da W0,N :
PR = min [{Ŵ’0,σ ,Ŵ0,σ} ∈Ŵ0,N] [0.5(1 + ρ(Ŵ0,σ ,Ŵ’0,σ))]

RobustezzaVALUTAZIONE PRELIMINARENessuna delle tecniche contiene caratteristiche esplicite per aumentare la robustezza. Comunque esistono delle caratteristiche implicite che possono migliorare la robustezza. Per esempio:
1. Diverse tecniche eseguono uno step di clustering prima dello step di deduzione che può aumentare la robustezza. Successivamente la deduzione viene attuata sui prototipi (media dei segnali nei cluster).
2. CMC in più applica un processo di mediazione (cross-correlazione), che può contribuire ad aumentare la robustezza.
3. Il metodo proposto da Chen può essere migliorato con la creazione di un filtro per i segnali, applicabile prima dello step di deduzione.

ConsistenzaUna delle proprietà più singolari dei dati di espressione disponibili è il numero decisamente grande di geni confrontati per i time-point misurati. Questa è chiamata “dimensionalità del problema” ed è un importante causa di inconsistenza nel modello di reti digeni dedotto e quindi una caratteristica importante da investigare.DEF. Un modello di reti di geni è detto inconsistente se più set di parametri possono essere dedotti da dei dati di espressione.
Formalmente per un set di dati di espressione arbitrario, XC ⊂ X il set della matrice di regolazione è definita:
Wc = {Wc|Wc = I(XC), PI(P(WC),XC) > 1 - ε}E il grado di consistenza del modello dato da:
PC = min [{WC, i ;WC,j} ∈ Wc] [0.5(1 + ρ(WC,i ,WC,j))].

ConsistenzaVALUTAZIONE PRELIMINARESenza un meccanismo principale per selezionare la matrice di regolazione più adatta a partire dall’insieme delle soluzioni, iparametri arguiti saranno inconsistenti.L’inconsistenza proviene dalla combinazione di due cause:• Il problema di dimensionalità, i dati rappresentano una incompleta descrizione del modello.• La capacità predittiva del modello eccede la complessità intrinseca dei dati.La prima causa può essere corretta mediante interpolazione; mentre per correggere la seconda è necessario controllare la capacità predittiva del modello aggiungendo delle soglie o introducendo dei vincoli appropriati.

StabilitàA causa della limitata energia e all’immagazzinamento all’interno della cellula, le concentrazioni dei prodotti di espressione dei geni quale l’mRNA, sono limitate. Tutte le reti di geni sono quindi stabili per definizione. Conseguentemente i modelli di reti di geni dovrebbero essere stabili per essere realistici.DEF. Un modello parametrizzato per una matrice di regolazione di un gene specifico, è stabile se i livelli previsti di espressione rimangono limitati lungo tutto il tempo e per tutte le condizioni. Se sono disponibili insiemi infinitamente grandi di addestramento eEMSE rimane limitato, la stabilità può essere garantita. Su insiemi di dati limitati il requisito di limitato EMSE deve essere garantito maggiormente.

Costo computazionale
I metodi che richiedono tempi computazionali molto lunghi sono ovviamente indesiderati, a meno che il tempo di attesa supplementare provochi un miglioramento sostanziale nei risultati. I metodi che non possono computare soluzioni analitiche, ma contano su metodi di soluzione iterativi, in generale, richiedono tempi di calcolo maggiori.Per ciascuno dei modelli è stata fatta una valutazione empirica per ottenere un indicazione sul tempo richiesto per raggiungere la soluzione.

Valutazione sperimentaleSono stati generati 3 set di dati differenti basandosi sulla matrice di regolazione di 5 geni senza input esterni:• D1 Un set di dati di espressioni semplici generato con il modello lineare di Van Someren.• D2 Un data set di complessità intermedia generata dal modello di Wahde.• D3 Un data set più realistico, generato dal modello piùaccurato proposto da Savageau.Sono stati prodotti 5 dataset per ogni tipo di dati, con 25 punti di campionamento (time-point) generati con condizioni iniziali casuali e differenti. Per ognuno di questi 15 dataset, 10 set addizionali sono stati generati aggiungendo una quantità di rumore variabile [1;2;…10%].

Valutazione sperimentaleSei modelli (Arkin, Chen, Wahde, Weaver, Someren e un modello di
riferimento) sono stati implementati e addestrati su ciascuno dei 165
(15 + 10x15) dataset.Il modello di riferimento restituisce una matrice di regolazione casuale
come deduzione e la media dei segnali di espressione come
predizione. La figura mostra la misura di deduzione (PI) e la capacità di
predizione (PP) come funzione del livello di rumore per tutti i modelli
esaminati sui tre tipi di gruppi di dati.

Valutazione sperimentale
CAPACITA’ DEDUTTIVA La capacità deduttiva è stata valutata sui set di dati privi di rumore. Il modello di Arkin è ragionevolmente applicabile al set di dati D1 e D2 ed è il solo modello che funziona significativamente meglio del modello di riferimento su D3. Ciò è probabilmente dovuto alla matrice di regolazione D3 che è confusa, quindi si adatta bene alle singole unioni del metodo ad albero di Arkin. Il modello di Someron è il migliore per i set di dati semplici e intermedi ma fallisce nei dati realistici. Le prestazione degli altri modelli sono indistinguibili dal modello di riferimento sui dataset D2 e D3.

Valutazione sperimentale
CAPACITA’ PREDITTIVA Anch’essa valutata a rumore 0.Sorprendentemente il modello lineare di Someren sorpassa il modello più complesso di Wahde su D1 e D2 in capacità predittiva. La buona prestazione di Someren su D3, è probabilmente dovuta al fatto che i dati non riflettono completamente la non linearità del modello di Savageau che li ha generati.Weaver è significativamente più difettoso del modello di riferimento su tutti i gruppi di datiNell’esperimento non è stato notato nessun evidente rapporto tra capacità deduttiva e capacità predittiva.

Valutazione sperimentale
ROBUSTEZZA Indichiamo la misura della robustezza come cambiamento della capacità deduttiva con l’aumento del rumore.Su D1 e D2 il metodo di Someren mostra una diminuizione della capacità deduttiva proporzionale al livello di rumore.Sorprendentemente su D1, la capacità deduttiva del modello di Weaver aumenta con l’aumentare del rumore. Ciò potrebbe essere dovuto al fatto che il rumore induce il massimo range del segnale del sigmoideo ad essere sovrastimato, inducendo il metodo a funzionare nel relativo intervallo lineare migliorando la compatibilità con il dataset lineare.Arkin mostra una robustezza notevole su tutti i gruppi di dati, probabilmente causato dall’effetto della correlazione.

Valutazione sperimentaleSTABILITA’ Le prestazioni scarse e imprevedibili di Weaver sono probabilmente dovute allo step di inversione del sigmoideo, che troviamo nel metodo, che è sensibile alle piccole variazioni di segnale, inducendo la regressione lineare a produrre matrici instabili con conseguente aumento del comportamento oscillatorio.COSTO COMPUTAZIONALE Quasi tutti i metodi hanno tempi di esecuzione similari. Per un singolo step di deduzione e previsione, i modelli di Arkin, Chen, Weaver e Someren hanno impiegato in media rispettivamente 0.6 - 1.1 - 1.3 - 3.8 secondi.In contrasto, il metodo iterativo di Wahde ha avuto bisogno spesso di almeno 15 minuti per convergere. Dato l’enorme tempo di convergenza per una rete di 5 geni, questo costo computazionale compromette severamente la scalabilità di questo approccio.

ConclusioniE’ stata proposta una tassonomia dei metodi per modellare una rete di geni, che si dividono in tre classi: Pair-Wise, approssimati e modelli di reti complesse.Sono state confrontate le caratteristiche per ogni modello di rete di geni. Ricavando che:• Il modello Pair-Wise, CMC, risulta costante e robusto realizzando le prestazioni migliori nel gruppo di dati complessi. Grazie alla loro bassa difficoltà di computazione questi modelli sono particolarmente utili per estrarre l’ipotesi iniziale della rete, che può essere ulteriormente affinata dai modelli più estesi che considerano iterazioni multiple dei geni.• I modelli lineari hanno realizzato la più alta capacità predittiva su tutti gli insieme di dati e esibito un eccellente capacità deduttiva sul gruppo di dati D1.• I modelli più complessi hanno scarsa capacità deduttiva (Weaver) e tempi computazionali proibitivi (Wahde).

ConclusioniUn tema comune a tutti i modelli di reti di geni è che la matrice di regolazione del gene viene assunta per rivelare la struttura alla base della rete di geni. Il presupposto implicito è dunque che la capacità deduttiva sia sufficientemente alta. La conclusione più significativa di questo lavoro è che la capacità deduttiva in realtà, nella maggior parte dei casi, è sorprendentemente bassa anche quando la capacità predittiva esibita è buona. In linea di principio i modelli più complessi dovrebbero stabilizzarsi su alta predizione e alta capacità deduttiva, questo a condizione che misure appropriate siano prese per abbassare la complessità del modello.Questo è un problema tuttora non risolto.

Bibliografia• L.F.A. Wessels, E.P Van Someren and M.J.T.
Reinders“A comparison of genetic network models”.
• M. A. Savageau“Rules for the evolution of gene circuitry”.
• A. Arkin, P. Shen, J. Ross “A test case of correlation metric construction of a reaction pathway from measurements”.





























