Embed Size (px)
Citation preview

COEFICIENTE DE CORRELACIÓN SEMIPARCIAL
1.- Introducción ........................................................................................................................... 2 2.- Correlación semiparcial ......................................................................................................... 2 3.- Contribución específica de las distintas variables al modelo de Regresión Múltiple............ 3 4.- Correlación semiparcial de orden superior ............................................................................ 4 5.- Correlación semiparcial múltiple ........................................................................................... 5 6.- Aplicación práctica con SPSS ............................................................................................... 7 7.- Correlación semiparcial como correlación de Y con puntuaciones residuales.................... 12
Carlos Camacho
Universidad de Sevilla

2
1.- Introducción Una de las cuestiones fundamentales en el análisis de la regresión consiste en determinar la importancia relativa que tienen sobre la variable dependiente cada una de las variables explicativas. Hasta ahora, el tema de la regresión múltiple se ha centrado fundamentalmente en el cálculo de R2, su significación y los coeficientes b asociados, pero nada se ha dicho de la contribución particular de cada una de las variables términos de proporción de variación explicada. En este sentido, en las próximas páginas se ofrecen una herramienta conceptual extraordinariamente útil -correlación semiparcial- que permite determinar el papel real representado por cada una de las variables al margen de su protagonismo aparente. Las correlaciones semiparciales tienen interés igualmente dentro de lo que se puede llamar control estadístico de variables, por cuanto permite conocer las distintas fuentes de variación que determinan la variable dependiente investigada, y por tanto, permite, de acuerdo con el modelo concebido, asignar causalidad a ciertas variables explicativas. En este sentido, este tema puede considerarse como un preludio de los modelos causales que serán estudiados más adelante. 2.- Correlación semiparcial Como se ha indicado, en el cuadrado de la correlación múltiple queda reflejada la proporción de variación explicada por el conjunto de regresores, pero nada se dice de la contribución específica de cada uno de ellos. Por otro lado, las correlaciones simples (al cuadrado) de cada una de las variables explicativas podrían ser , en principio, un indicador de dichas contribuciones, pero , como se verá, frecuentemente las distintas variables explicativas, están a su vez, correlacionadas entre sí, compartiendo variabilidad, y por tanto, elementos comunes, no siendo siempre fácil atribuir la fuente original de tales elementos compartidos. Tengamos, en este sentido, las variables X1, X2 e Y, cuyas correlaciones son las siguientes: Una primera ojeada puede hacernos pensar que la variable 𝑋1 contribuye en la variabilidad de Y en una proporción de 0.72=0.49 y que la variable 𝑋2 contribuye en una proporción de 0.62=0.36. No obstante, se sabe por la correlación múltiple que la proporción de variación explicada es de 0.82=0.64. El total de ambas contribuciones no es igual a la suma, luego está claro que ambas variables explicativas no son fuentes independientes de variabilidad, sino que comparten una cierta cantidad de la misma. Existe, pues, redundancia entre ambas variables. El siguiente diagrama de Venn ilustra lo que queremos decir:
8.06.07.0 12.21 === yyy Rrr
ab
c
d
ab
c
d
Y
X1 X2
ab
c
d
ab
c
d
Y
X1 X2

3
El campo de variación de las distintas variables queda reflejada en los diferentes círculos (de área total, la unidad), de tal manera que la contribución de 𝑋1 en Y es a+b, y la de 𝑋2, b+c . La contribución total de 𝑋1 y 𝑋2 será a+b+c. Queda una parte -d- que es la variabilidad que no logran explicar entre 𝑋1 y 𝑋2. La proporción de variación explicada por la variable 𝑋1 será precisamente la intersección del círculo correspondiente a 𝑋1 y del círculo indicado por Y. Así pues: Y la proporción de variación explicada por X2: Como entre ambas variables explican una proporción de 0.64, es evidente que la contribución adicional de 𝑋1 sobre la que explica 𝑋2 será: Esto es, lo que añade 𝑋1 a 𝑋2 es una proporción de variación explicada de 0.28. La raíz cuadrada de este valor se expresa como Ry(1.2) y se define como coeficiente de correlación semiparcial. Así:
Por otro lado, lo que añade 𝑋2 a 𝑋1 será: Es decir, la inclusión de X2 supone un incremento sobre la proporción de variación explicada por 𝑋1 de 0.15 puntos. Su coeficiente de correlación semiparcial será: 3.- Contribución específica de las distintas variables al modelo de Regresión Múltiple Las correlaciones semiparciales tienen especial interés para conocer el reparto de las contribuciones de las variables X sobre la variable Y. Frecuentemente las variables explicativas están solapadas y hay que utilizar algún criterio que permita asignar las zonas compartidas a variables específicas. A este respecto, ha de establecerse una jerarquía entre tales variables de forma que las de mayor orden jerárquico tienen prioridad respecto a su variabilidad compartida, a las que se les adjudica. Así, cuando el orden es 1º 𝑋1 y 2º 𝑋2 las contribuciones observadas por las distintas variables serán:
49.021 =+= baRy
36.022 =+= cbRy
aRRR yyy ⇒=−=−= 28.036.064.022
212.
2)2.1(
529.028.0)2.1( ==yR
cRRR yyy ⇒=−=−= 15.049.064.021
212.
2)1.2(
387.015.0)1.2( ==yR
64.015.049.02)1.2(
21
212. =+=+= yyy RRR

4
Por el contrario, cuando el orden de entrada es 1º X2 y 2º X1 entonces: Se observa la importancia del orden de entrada; de esta forma, cuando la variable 𝑋1 entra en primer lugar explica una proporción de 0.49 y deja tan sólo un resto de 0.15 para 𝑋2. Cuando 𝑋2 es la variable de mayor rango en el modelo, explica una proporción de 0.36 y deja para 𝑋1 una proporción explicada de 0.28. Es importante destacar que los mismos datos, según el acento que se ponga en cada una de las variables llevará al investigador a conclusiones muy diferentes respecto a su participación en el modelo. La siguiente tabla ilustra lo que estamos comentando: Var. Explicativa Orden Incremento Orden Incremento X1 1 0.49 2 0.28
X2 2 0.15 1 0.36
R2y.12 0.64 0.64
Así pues, la contribución específica de las distintas variables depende de su orden de entrada. Cuanto más intercorrelacionadas estén y más tarde se introduzcan menos explicarán. En cierto sentido, la importancia relativa concedida a cada una de las variables, cuando existe redundancia, es subjetiva y depende en gran parte del juicio del investigador y del dominio que tenga de la materia. No existen reglas que especifiquen claramente el orden de entrada. No obstante, se suele utilizar el criterio de maximizar progresivamente la variación explicada de la variable dependiente, por lo que se introducen las variables en orden de mayor a menor proporción de variación explicada. 4.- Correlación semiparcial de orden superior Las correlaciones expuestas del tipo 𝑅𝑦(1.2) o 𝑅𝑦(2.1)se denominan correlaciones semiparciales de primer orden porque es una variable cuya influencia se elimina. No obstante, puede interesar eliminar la influencia de más variables, por ejemplo, 𝑅𝑦(1.23) expresa que la variable Y es relacionada con la variable 𝑋1 eliminando de ésta la influencia de 𝑋2 y 𝑋3. Se trata de una correlación semiparcial de orden dos. Una correlación de orden tres sería 𝑅𝑦(1.234) donde se relaciona Y con X1 eliminado la influencia de 𝑋2, 𝑋3 y 𝑋4. En general una correlación semiparcial del tipo 𝑅𝑦(1.2…(𝑖)....𝑘) es una correlación semiparcial de orden k-1 que indica la correlación entre Y y Xi eliminado de ésta la influencia de las restantes variables explicativas. El procedimiento para calcular las correlaciones semiparciales de orden superior es equivalente al ya expuesto para correlaciones de primer orden. A este efecto, resulta de nuevo ilustrativo recurrir a los diagramas de Venn. Supongamos, ahora, que disponemos de cuatro variables: Y, 𝑋1, 𝑋2 y 𝑋3, y deseamos calcular 𝑅𝑦(3.12)
2 :
64.028.036.02)2.1(
22
212. =+=+= yyy RRR

5
Y
X1 X2
Y
X1
X3
Está claro que la contribución específica de 𝑋3 será: Si deseamos recomponer la aportación de cada una de las variables suponiendo que el orden de entrada sea 𝑋1, 𝑋2, y 𝑋3: Pero si el orden de entrada fuera X3, X2, y X1, entonces: 5.- Correlación semiparcial múltiple Todas las correlaciones estudiadas anteriormente han sido siempre entre dos variables, la variable dependiente Y y una variable explicativa Xi, eliminando la influencia, bien de una variable (correlación semiparcial simple de primer orden) o de un conjunto de k variables (correlación semiparcial simple de orden k). La correlación semiparcial múltiple hace referencia a la correlación entre una variable dependiente y un conjunto de variables explicativas eliminado la influencia de una o varias variables del conjunto de variables explicativas. Está claro que las correlaciones semiparciales múltiples pueden ser a su vez, de primer orden o de orden superior. En términos de proporción de variación, el cuadrado del coeficiente de correlación semiparcial múltiple expresa la contribución que de la variación de la variable dependiente suponen una serie de variables explicativas eliminado la influencia de otras. De esta forma, Ry(12.3) indica la correlación semiparcial de Y con las variables 𝑋1 y 𝑋2 eliminando la influencia de 𝑋3. En términos de proporción de variación se calculará de la siguiente manera:
𝑅𝑦(12.3)2 = 𝑅𝑦.123
2 − 𝑅𝑦32
212.
2123.
2)12.3( yyy RRR −=
2)12.3(
2)1.2(
21
2123. yyyy RRRR ++=
2)23.1(
2)3.2(
23
2123. yyyy RRRR ++=

6
Si por ejemplo, deseamos calcular 𝑅𝑦(12.34)2 :
𝑅𝑦(12.34)2 = 𝑅𝑦.1234
2 − 𝑅𝑦.342
Obsérvese que en el cálculo de las correlaciones semiparciales (al cuadrado), sea simple o múltiple, de primer orden o de orden superior, siempre se calcula de la misma manera. Se trata de una diferencia entre dos elementos, donde el primero de ellos hace referencia a la correlación múltiple (al cuadrado) de la variable Y con todas las variables explicativas consideradas, y donde el segundo elemento indica la correlación (al cuadrado) de la variable Y con las variables explicativas a eliminar. Ejemplo 1.- Estudiamos el efecto de las variables ejercicio, edad y grasas sobre el colesterol:
1.- Calcular 𝑅𝑦(2.1)
2 , 𝑅𝑦(23.1)2 y 𝑅𝑦(3.21)
2
2.- Suponiendo que el orden de entrada sea: 1º) ejercicio, 2º) edad y 3º) grasas, determinar las contribuciones de las diferentes variables en la R múltiple global ( 2
123.yR ). SOL: 1.- Calculemos en primer lugar los valores de R cuadrado de los distintos modelos:
082.0103385.200
8478.40421 ==yR
141.0103385.20014618.1292
12. ==yR
477.0103385.20049275.9422
123. ==yR

7
Así pues: 𝑅𝑦(2.1)2 = 𝑅𝑦.12
2 − 𝑅𝑦12 = 0.141 − 0.082 = 0.059 𝑅𝑦(23.1)2 = 𝑅𝑦.123
2 − 𝑅𝑦12 = 0.477 − 0.082 = 0.395 𝑅𝑦(3.21)2 = 𝑅𝑦.123
2 − 𝑅𝑦.122 = 0.477 − 0.141 = 0.336
Las contribuciones de las distintas variables según el orden de entrada establecido será: 2
)12.3(2
)1.2.(21
2123. yyyy RRRR ++=
donde: 2
)1.2.(yR = 212.yR - 2
1yR = 0.141 − 0.082 = 0.059
336.0141.0477.0212.
2123.
2)12.3( =−=−= yyy RRR
Por tanto:
477.0336.0059.0082.02)12.3(
2)1.2.(
21
2123. =++=++= yyyy RRRR
6.- Aplicación práctica con SPSS. Supongamos que deseamos estudiar el efecto que tiene sobre la Calificación de una determinada asignatura (Y) las siguientes variables: Inteligencia (𝑋1) Horas de estudio (𝑋2) y Nivel social (X3). A este respecto disponemos de las siguientes puntuaciones obtenidas por 20 estudiantes: X1 X2 X3 Y X1 X2 X3 Y ********************** ************************* 109 10 3 4.1 132 16 5 7.8 120 8 4 4.3 140 18 5 9.3 112 21 2 6.4 111 9 4 5.2 115 14 2 4.5 109 25 3 6.5 98 18 1 4.2 95 16 3 5.2 101 23 3 5.5 88 10 2 2.1 100 21 2 6.0 106 14 4 4.8 105 12 2 5.1 123 12 3 5.6 130 21 5 8.8 120 20 2 7.2 121 19 4 7.5 102 22 2 6.3
1.- Calcular 𝑅𝑦(3.12)
2 y 𝑅𝑦(12.3)2
2.- Determinar las contribuciones de las distintas variables suponiendo que el orden de entrada sea: 1º 𝑋1, 2º 𝑋2 y 3º 𝑋3. SOL: 1a.- En relación a la primera pregunta nos piden:
𝑅𝑦(12.3)2 = 𝑅𝑦(3.12)
2 − 𝑅𝑦.122

8
Calculamos en primer lugar la R cuadrado múltiple con todas las variables:
Tenemos el resultado justamente en el primer recuadro:
Tenemos ya 𝑅𝑦.1232 . Ahora hacemos lo mismo pero con las 2 primeras variables y obtendremos 𝑅𝑦.12
2 :

9
En consecuencia: 𝑅𝑦(3.12)2 = 𝑅𝑦.123
2 − 𝑅𝑦.122 = 0.902 − 0.882 = 0.02
1b.- Y en relación a 𝑅𝑦(12.3)2 :
𝑅𝑦(12.3)2 = 𝑅𝑦.123
2 − 𝑅𝑦32
El primer sumando es el mismo de antes, y en relación al segundo sumando:
Por tanto: 𝑅𝑦(12.3)2 = 𝑅𝑦.123
2 − 𝑅𝑦32 = 0.902 − 0.311 = 0.591 Ambos coeficientes (𝑅𝑦(3.12)
2 y 𝑅𝑦(12.3)2 ) podemos resolverlos mediante el SPSS de una manera más
efectiva. Para ello hemos de proceder a la regresión por bloques que nos permite realizar la regresión contemplando distintos paquetes de variables y comparando las distintas contribuciones de tales bloques. Por ejemplo, en relación a 𝑅𝑦(3.12)
2 introducimos en primer lugar conjuntamente las variables 𝑋1 y 𝑋2 y luego la 𝑋3. De esta forma, el primer bloque será:
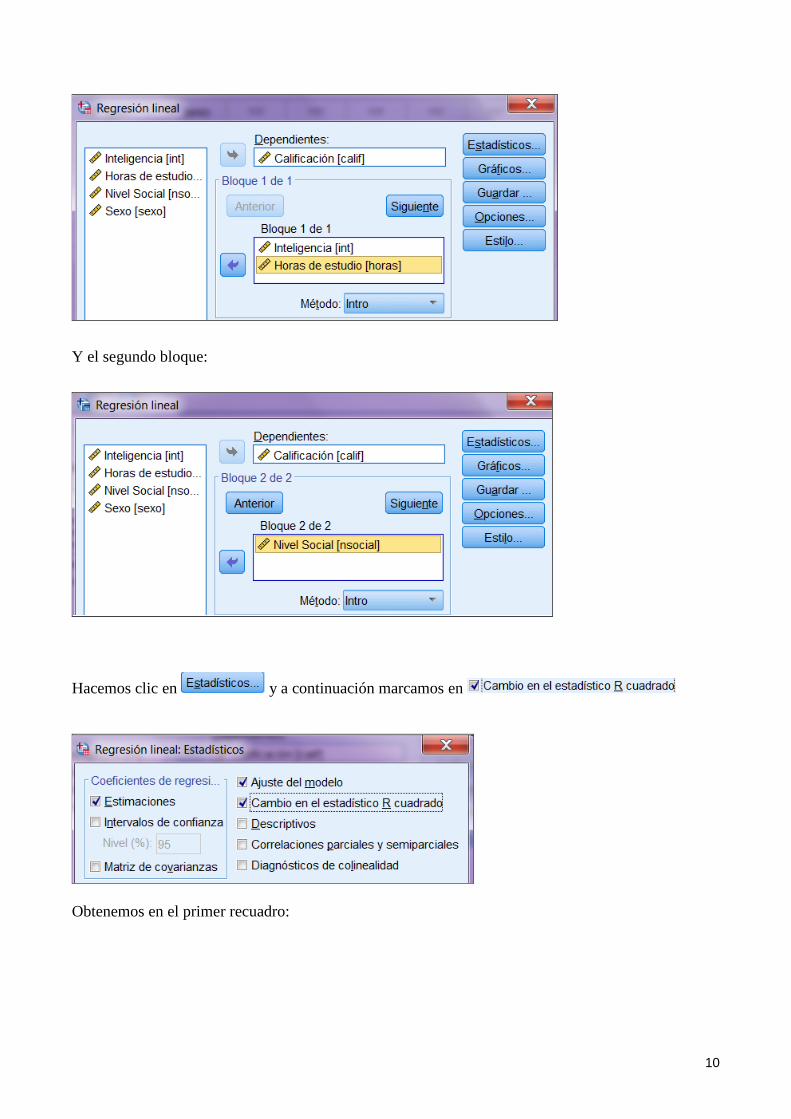
10
Y el segundo bloque:
Hacemos clic en y a continuación marcamos en
Obtenemos en el primer recuadro:
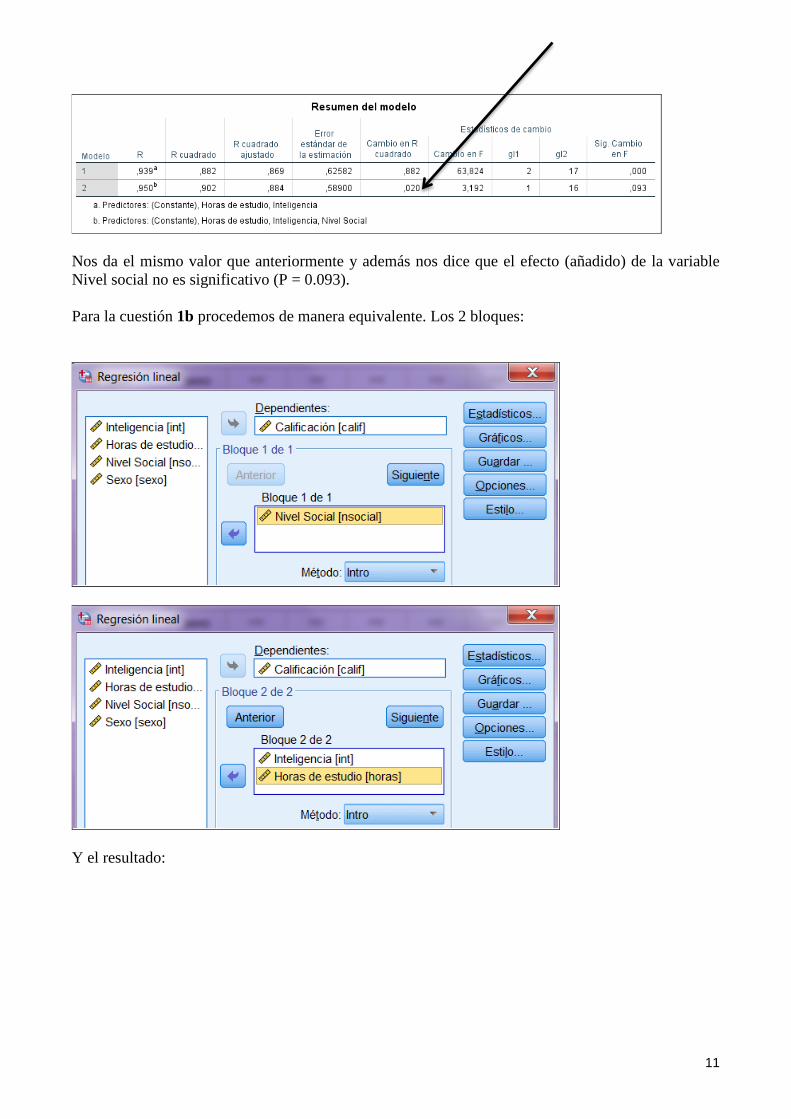
11
Nos da el mismo valor que anteriormente y además nos dice que el efecto (añadido) de la variable Nivel social no es significativo (P = 0.093). Para la cuestión 1b procedemos de manera equivalente. Los 2 bloques:
Y el resultado:

12
Igual que anteriormente y además con un efecto muy significativo. 7.- Correlación semiparcial como correlación de la variable Y con puntuaciones residuales. Otra alternativa, cuando deseamos eliminar la influencia de una determinada variable de un conjunto de ellas, consiste en restarle in situ a las puntuaciones de tales variables el efecto de la variable que deseamos suprimir. Tengamos, de nuevo, X1, X2 e Y, donde deseamos estudiar el efecto de X2 sobre Y una vez que hemos eliminado de X2 el efecto de X1. En ese sentido, calcularemos primeramente la ecuación de regresión que liga X1 con X2: Si a las puntuaciones originales de X2 les restamos 2X̂ , que son precisamente las puntuaciones de X2 que debe a X1, obtendremos, entonces, las puntuaciones de X2 libre de X1. Si a continuación calculamos la correlación entre Y con )ˆ( 22 XX − , habremos obtenido la correlación semiparcial de Y
con X2 eliminado la influencia de X1 sobre X2, esto es, )1.2(yr . Así pues, esta correlación semiparcial puede plantearse como: Ejemplo 2.- Tomando como referencia los datos del ejemplo 1, calcular mediante las puntuaciones residuales, la correlación de Inteligencia y Calificación, eliminando toda influencia del Nivel social. SOL: Calculemos en primer lugar la ecuación de regresión que liga la variable X1 (Inteligencia) con X3 (Nivel social). Resulta ser: En términos de SPSS:
)ˆ()1.2( 22 XXYY rr−
=
12ˆ bXaX +=
31 7.872X87.840ˆ +=X

13
A continuación restemos a la Inteligencia los valores de la Inteligencia explicados por Nivel social. En términos de SPSS simplemente son los residuales de esta ecuación (lo que queda de la inteligencia que no logra explicar el nivel social. Marcamos “Guardar” en el anterior modelo de regresión:
Y a continuación clic en “Residuos no estandarizados”:
1ˆ11 eXX ⇒−
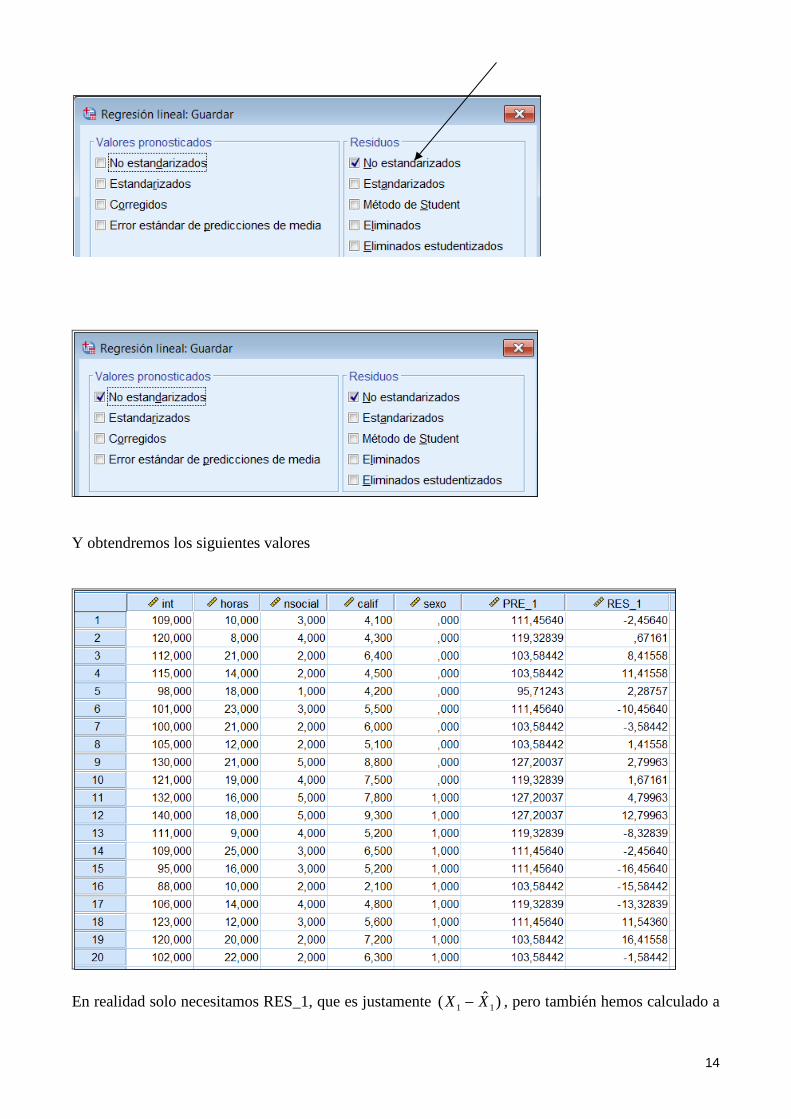
14
Y obtendremos los siguientes valores
En realidad solo necesitamos RES_1, que es justamente )ˆ( 11 XX − , pero también hemos calculado a

15
efectos puramente ilustrativos PRE_1 para que se vea exactamente que el residual es justamente la diferencia entre la puntuación real y la predicha. Por ejemplo, para el primer sujeto su puntuación en Inteligencia es 109 y el Nivel social predice 111.4564, con un residual (o error de pronóstico) de −2.4564. Pues bien, si calculásemos la relación entre estas variables:
La correlación es 0.517 y su cuadrado 0.5172 = 0.267, lo que nos indica que la inteligencia explica un 26.7% de la calificación cuando elimnamos de la Inteligencia el Nivel social, esto es:
𝑅𝑌(1.3)2 = 0.267
Lo podemos comprobar en una regresión por bloques, donde introducimos primero el Nivel social y luego La inteligencia y le indicamos que nos calcule el incremento de R cuadrado de la Inteligencia sobre el Nivel social. Primeramente:
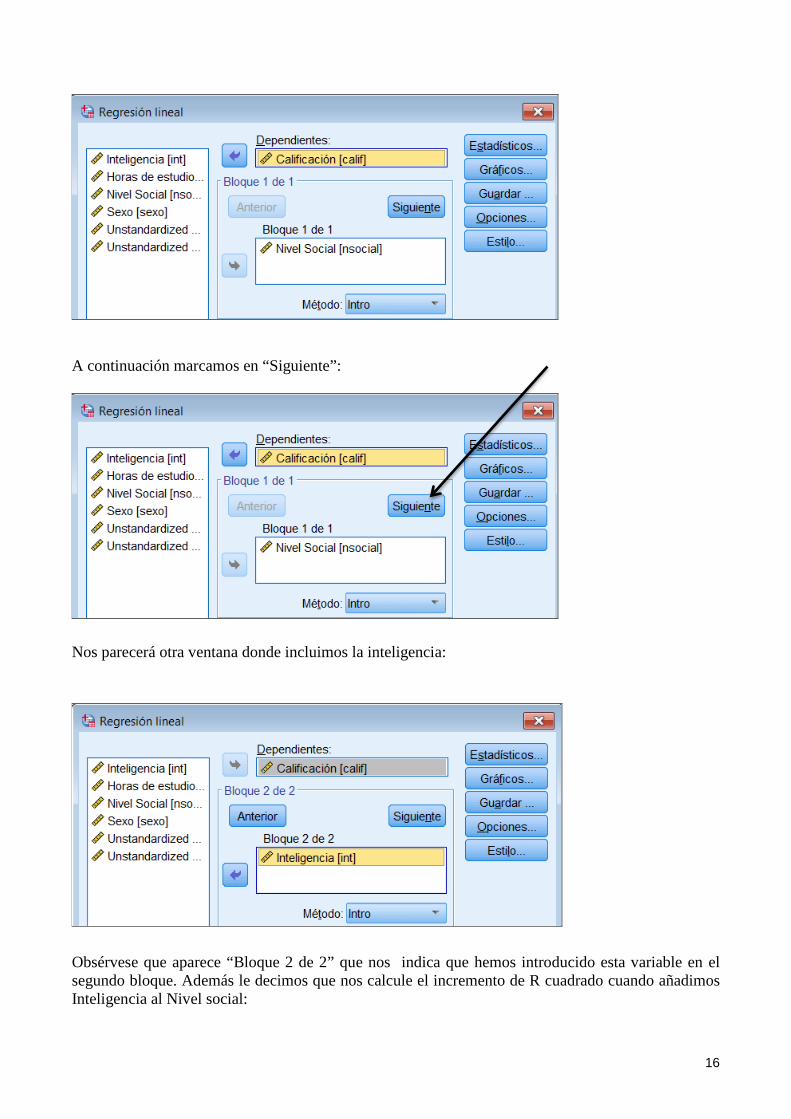
16
A continuación marcamos en “Siguiente”:
Nos parecerá otra ventana donde incluimos la inteligencia:
Obsérvese que aparece “Bloque 2 de 2” que nos indica que hemos introducido esta variable en el segundo bloque. Además le decimos que nos calcule el incremento de R cuadrado cuando añadimos Inteligencia al Nivel social:
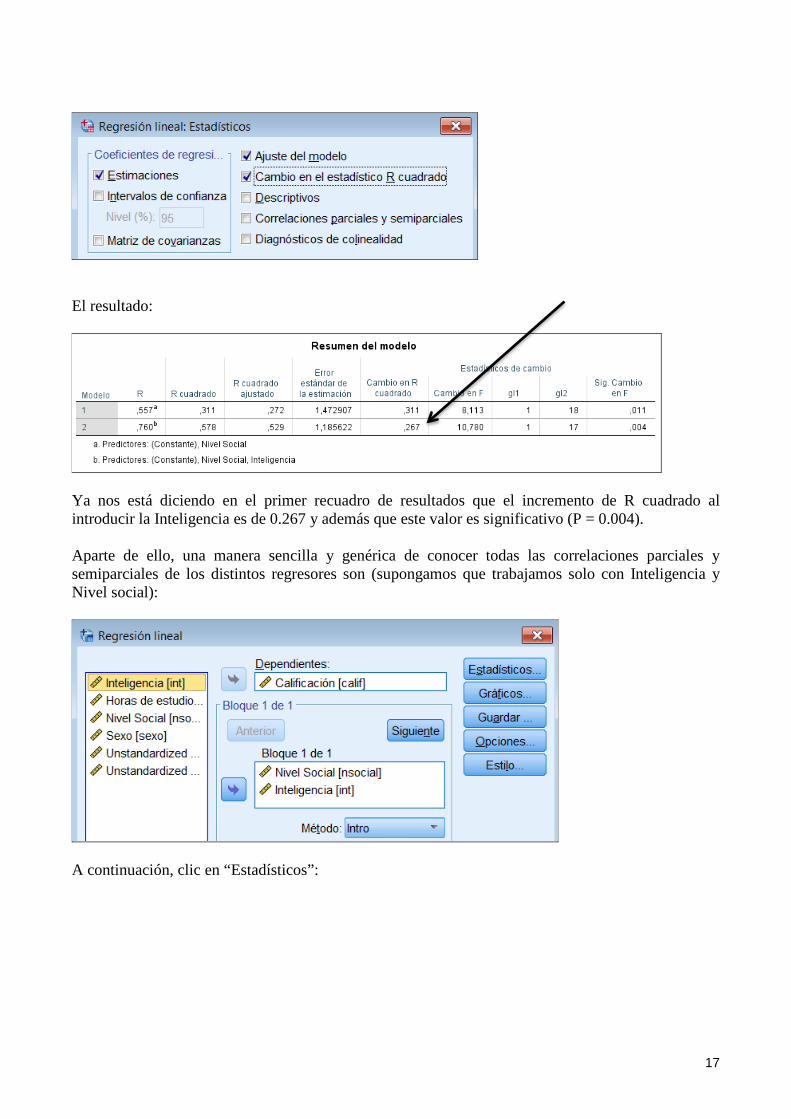
17
El resultado:
Ya nos está diciendo en el primer recuadro de resultados que el incremento de R cuadrado al introducir la Inteligencia es de 0.267 y además que este valor es significativo (P = 0.004). Aparte de ello, una manera sencilla y genérica de conocer todas las correlaciones parciales y semiparciales de los distintos regresores son (supongamos que trabajamos solo con Inteligencia y Nivel social):
A continuación, clic en “Estadísticos”:
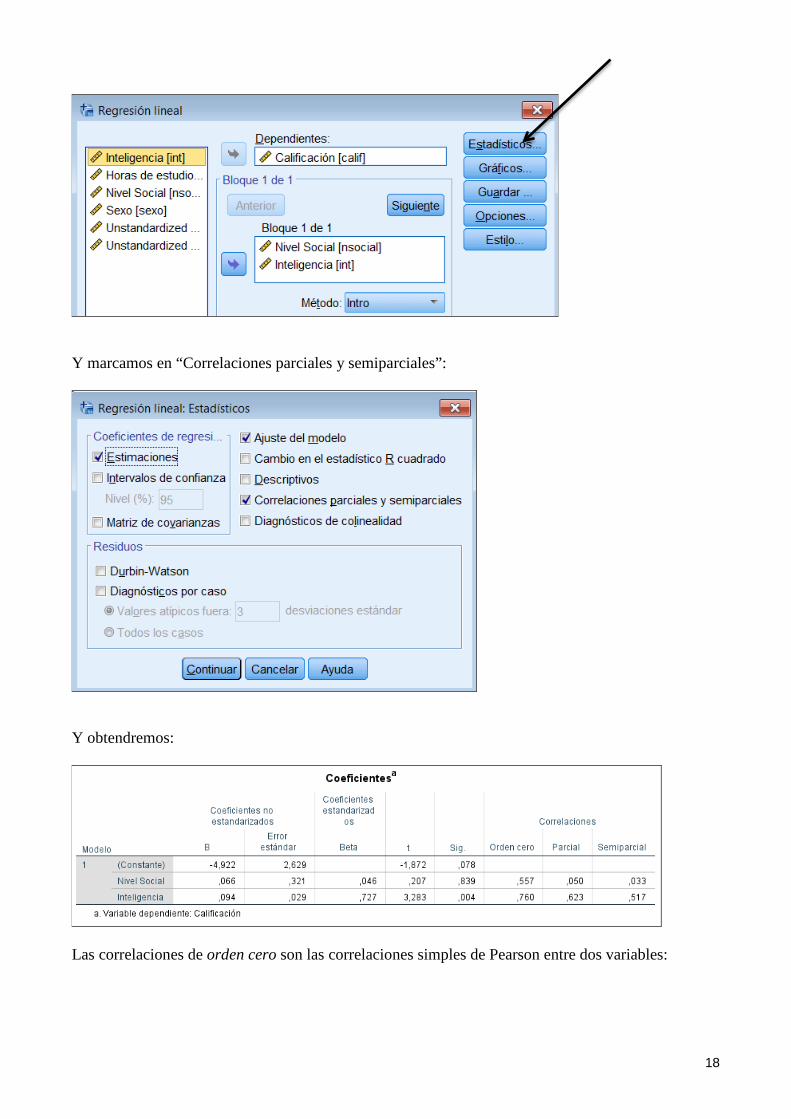
18
Y marcamos en “Correlaciones parciales y semiparciales”:
Y obtendremos:
Las correlaciones de orden cero son las correlaciones simples de Pearson entre dos variables:
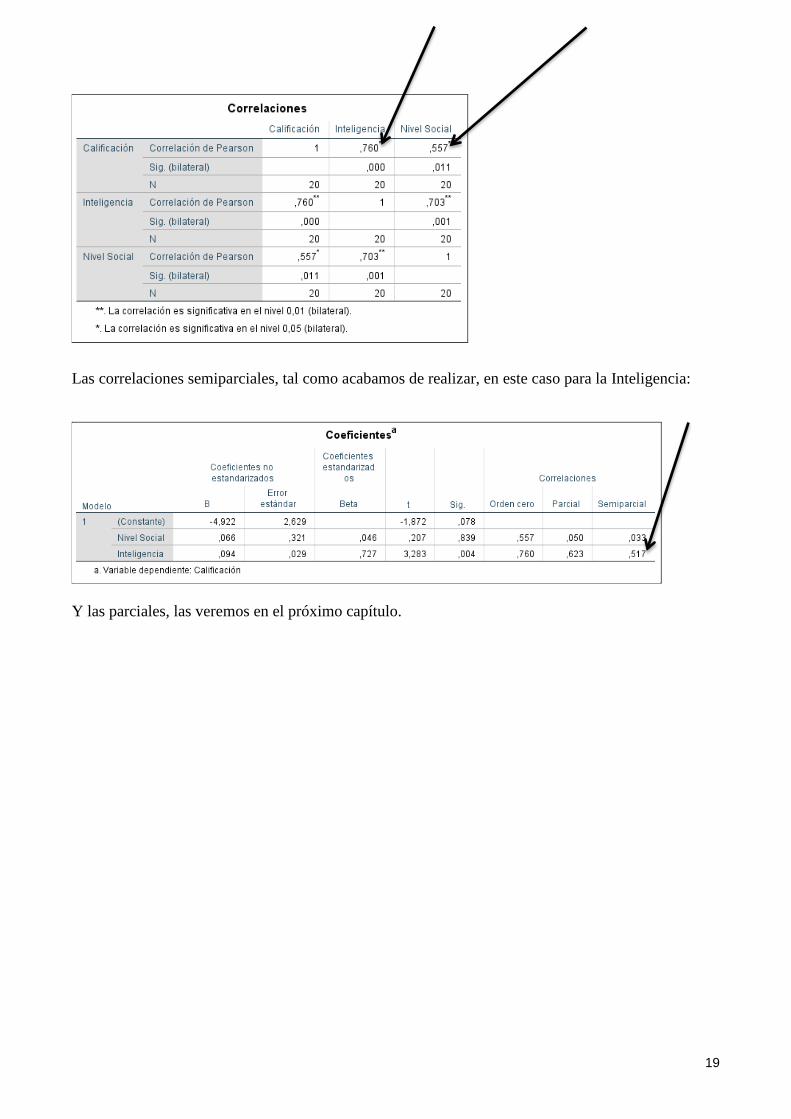
19
Las correlaciones semiparciales, tal como acabamos de realizar, en este caso para la Inteligencia:
Y las parciales, las veremos en el próximo capítulo.



![Tema3 [Modo de compatibilidad] · 2.- COVARIACIÓN Y CORRELACIÓN Objetivo: definir unas medidas estadísticas (covarianza y coeficiente de correlación lineal) que pongan de manifiesto](https://img.dokumen.tips/doc/110x75/5f1bed3afd911425cb429236/tema3-modo-de-compatibilidad-2-covariacin-y-correlacin-objetivo-definir.jpg)

























