Embed Size (px)
Citation preview

Coarrays in GNU Fortran
Alessandro Fanfarillo
June 24th, 2014
Alessandro Fanfarillo Coarrays in GFortran June 24th, 2014 1 / 50

Introduction
Coarray Fortran (also known as CAF) is a syntactic extension of Fortran95/2003 which has been included in the Fortran 2008 standard.
The main goal is to allow Fortran users to realize parallel programswithout the burden of explicitly invoke communication functions ordirectives (MPI, OpenMP).
The secondary goal is to express parallelism in a “platform-agnostic” way(no explicit shared or distributed paradigm).
Coarrays are based on the Partitioned Global Address Space model(PGAS).
Compilers which support Coarrays:
Cray Compiler (Gold standard - Commercial)
Intel Compiler (Commercial)
Rice Compiler (Free - Rice University)
OpenUH (Free - University of Houston)
G95 (Coarray support not totally free - Not up to date)
Alessandro Fanfarillo Coarrays in GFortran June 24th, 2014 2 / 50

PGAS Languages
The PGAS model assumes a global memory address space that is logicallypartitioned and a portion of it is local to each process or thread.
It means that a process can directly access a memory portion owned byanother process.
The model attempts to combine the advantages of a SPMD programmingstyle for distributed memory systems (as employed by MPI) with the datareferencing semantics of shared memory systems.
Coarray Fortran.
UPC (upc.gwu.edu).
Titanium (titanium.cs.berkeley.edu).
Chapel (Cray).
X10 (IBM).
Alessandro Fanfarillo Coarrays in GFortran June 24th, 2014 3 / 50

Coarray concepts
A program is treated as if it were replicated at the start of execution,each replication is called an image.
Each image executes asynchronously.
An image has an image index, that is a number between one and thenumber of images, inclusive.
A Coarray is indicated by trailing [ ].
A Coarray could be a scalar or array, static or dynamic, and ofintrinsic or derived type.
A data object without trailing [ ] is local.
Explicit synchronization statements are used to maintain programcorrectness.
Alessandro Fanfarillo Coarrays in GFortran June 24th, 2014 4 / 50

Coarray example
real , dimension (10), codimension [*] :: x, y
integer :: num_img , me
num_img = num_images ()
me = this_image ()
! Some code here
x(2) = x(3)[7] ! get value from image 7
x(6)[4] = x(1) ! put value on image 4
x(:)[2] = y(:) ! put array on image 2
sync all
x(1:10:2) = y(1:10:2)[4] ! strided get from image 4
sync images (*)
Alessandro Fanfarillo Coarrays in GFortran June 24th, 2014 5 / 50

Coarray support
The most mature, efficient and complete implementation is providedby Cray.
Cray runs on proprietary architecture.
Intel provides a CAF implementation but it works only on Linux andWindows.
Intel CAF has two modes: shared and distributed. For the distributedmode the Intel Cluster Toolkit is required.
Alessandro Fanfarillo Coarrays in GFortran June 24th, 2014 6 / 50

GNU Fortran Libcaf
GFortran uses an external library to support Coarrays (libcaf).
Currently there are three libcaf implementations:
MPI Based
GASNet Based
ARMCI Based (not updated)
The idea is to provide the MPI version as default and the GASNet/ARMCIas “expert version”.
Alessandro Fanfarillo Coarrays in GFortran June 24th, 2014 7 / 50

GASNet
GASNet (Global Address Space Networking) provided by UC Berkeley.
Efficient Remote Memory Access operations.
Native network communication interfaces.
Useful features like Active Messages and Strided Transfers.
Main issue: GASNet requires an explicit declaration of the total amountof remote memory to use (allocatable coarrays?).
Secondary issue: GASNet requires a non-trivial configuration during theinstallation and before the usage.
The GASNet version of Libcaf has not been deeply studied yet.
Alessandro Fanfarillo Coarrays in GFortran June 24th, 2014 8 / 50

MPI Version - Current status
Supported Features:
Coarray scalar and array transfers (efficient strided transfers)
Synchronization
Collectives
Vector subscripts
Unsupported Features:
Derived type coarrays with non-coarray allocatable components
Atomics
Critical
Error handling
Alessandro Fanfarillo Coarrays in GFortran June 24th, 2014 9 / 50

Hardware
Eurora: Linux Cluster, 16 cores per node, Infiniband QDR QLogic(CINECA).
PLX: IBM Dataplex, 12 cores per node, Infiniband QDR QLogic(CINECA).
Yellowstone/Caldera: IBM Dataplex, 16 cores per node, InfinibandMellanox (NCAR).
Janus: Dell, 12 cores per node, Infiniband Mellanox (CU-Boulder).
Hopper: Cray XE6, 24 cores per node, 3-D Torus Cray Gemini(NERSC).
Edison: Cray XC30, 24 cores per node, Cray Aries (NERSC).
Only Yellowstone and Hopper used for this presentation.
Alessandro Fanfarillo Coarrays in GFortran June 24th, 2014 10 / 50

Software
On Hopper:
Cray: Cray (CCE) 8.2.1
GFortran: GCC-4.10 experimental (gcc branch) + Mpich/6.0.1
On Yellowstone:
Intel: Intel 14.0.2 + IntelMPI 4.0.3
GFortran: GCC-4.10 experimental (gcc branch) + MPICH IBM opt.Mellanox IB
For Intel CAF, every coarray program runs in CAF Distributed Mode.
Alessandro Fanfarillo Coarrays in GFortran June 24th, 2014 11 / 50

Test Suite Description
CAF Psnap (Dan Nagle)
It is a network noise analyzer. It can be useful for a statistical study ofthe communication between processes.
EPCC CAF Micro-benchmark suite (Edinburgh University)
It measures a set of basic parallel operations (get, put, strided get,strided put, sync, halo exchange).
Burgers Solver (Damian Rouson)
It has nice scaling properties: it has a 87% weak scaling efficiency on16384 cores and linear scaling (sometimes super-linear).
CAF Himeno (Prof. Ryutaro Himeno - Bill Long - Dan Nagle)
It is a 3-D Poisson relaxation.
Distributed Transpose (Bob Rogallo).
It is a 3-D Distributed Transpose.
Dense matrix-vector multiplication (MxV).
Alessandro Fanfarillo Coarrays in GFortran June 24th, 2014 12 / 50

Tests execution
Every test has been run on Yellowstone/Caldera and Hopper.
On Yellowstone we are able to run only Intel and GFortran.
On Hopper we are able to run only GFortran and Cray.
GFortran runs with whatever MPI implementation is available.
On GFortran we used only the -Ofast flag.
On Intel we used the following flags: -Ofast -coarray -switchno launch
On Cray we used the -O3 flag. We also loaded craype-hugepages2Mand set XT SYMMETRIC HEAP SIZE properly.
Alessandro Fanfarillo Coarrays in GFortran June 24th, 2014 13 / 50

CAF Psnap - Yellowstone 32 cores
This test shows the performance of the communication layer underthe Coarrays interface.
Psnap sends several times a single integer between “peer” processes(0-16, 1-17, ..).
Using Intel CAF (and thus IntelMPI) transferring a single integertakes on average 1.018 msecs.
Using GFortran/MPI (and thus IBM MPI) transferring a singleinteger takes on average 1.442 msecs.
The time distribution is different (Gamma for Intel, Normal for IBMMPI).
Alessandro Fanfarillo Coarrays in GFortran June 24th, 2014 14 / 50

CAF Psnap - Hopper 48 cores
Using Cray transferring a single integer takes on average 1.021 msecs.
Using GFortran/MPI transferring a single integer takes on average2.996 msecs.
Both distributions look like heavy-tail.
Alessandro Fanfarillo Coarrays in GFortran June 24th, 2014 15 / 50

EPCC CAF Micro-benchmark suite
Single point-to-point: image 1 interacts with image n.
Put, Get, Strided Put, Strided Get.
Multiple point-to-point: image i interacts with image i+n/2.
Put, Get, Strided Put, Strided Get.
Synchronization: several pattern of synchronization. (Not shown)
Sync all, sync images.
Halo swap: exchange of the six external faces of a 3D array. (Notshown)
Alessandro Fanfarillo Coarrays in GFortran June 24th, 2014 16 / 50

Latency/Bw Single Put 16 cores Yellowstone (Small)
0
2e-05
4e-05
6e-05
8e-05
0.0001
0.00012
1 2 4 8 16 32 64
Tim
e (
sec)
Block size (byte)
Latency put 16 cores (no network)
GFor/MPIIntel
0
5
10
15
20
25
30
35
40
1 2 4 8 16 32 64
MB
/sec
Block size (byte)
Bandwidth put 16 cores (no network)
GFor/MPIIntel
Latency: lower is better - Bandwidth: higher is better
Alessandro Fanfarillo Coarrays in GFortran June 24th, 2014 17 / 50

Latency/Bw Single Put 16 cores Yellowstone (Big)
1e-05
0.0001
0.001
0.01
0.1
1
10
128
256
512
1024
2048
4096
8192
16384
32768
65536
131072
262144
524288
1048576
2097152
4194304
Tim
e (
sec)
Block size (byte)
Latency put 16 cores (no network)
GFor/MPIIntel
1
10
100
1000
10000
128
256
512
1024
2048
4096
8192
16384
32768
65536
131072
262144
524288
1048576
2097152
4194304
MB
/sec
Block size (byte)
Bandwidth put 16 cores (no network)
GFor/MPIIntel
Latency: lower is better - Bandwidth: higher is better
Alessandro Fanfarillo Coarrays in GFortran June 24th, 2014 18 / 50

Bw Multi Put 16 cores Yellowstone
0.1
1
10
100
1000
10000
1 2 4 8 16
32
64
128
256
512
1024
2048
4096
8192
16384
32768
65536
131072
262144
524288
1048576
2097152
4194304
MB
/sec
Block size (byte)
Bandwidth multi put Yellowstone 16 cores (no network)
GFor/MPIIntel
Alessandro Fanfarillo Coarrays in GFortran June 24th, 2014 19 / 50

Bw Difference Single/Multi Put 16 cores Yellowstone
0.1
1
10
100
1000
10000
1 2 4 8 16
32
64
128
256
512
1024
2048
4096
8192
16384
32768
65536
131072
262144
524288
1048576
2097152
4194304
MB
/sec
Block size (byte)
Bw difference put Yellowstone 16 cores single/multi (no network)
Diff_GFor/MPIDiff_Intel
A constant trend means that the network contention does not impact (toomuch) the performance.
Alessandro Fanfarillo Coarrays in GFortran June 24th, 2014 20 / 50

Bw Single Strided Put 16 cores Yellowstone
1
10
100
1000
10000
1 2 4 8 16 32 64 128
MB
/se
c
Stride size (byte)
Bandwidth strided put 16 cores (no network)
GFor/MPIIntel
GFor/MPI_NS
Alessandro Fanfarillo Coarrays in GFortran June 24th, 2014 21 / 50
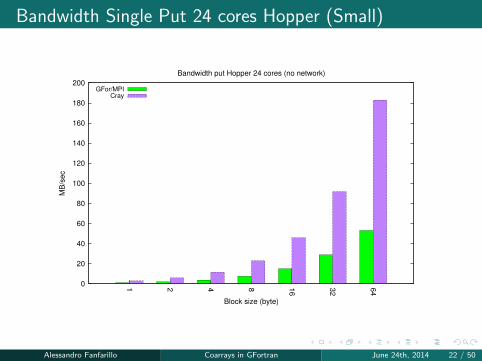
Bandwidth Single Put 24 cores Hopper (Small)
0
20
40
60
80
100
120
140
160
180
200
1 2 4 8 16
32
64
MB
/sec
Block size (byte)
Bandwidth put Hopper 24 cores (no network)
GFor/MPICray
Alessandro Fanfarillo Coarrays in GFortran June 24th, 2014 22 / 50

Bandwidth Single Put 24 cores Hopper (Big)
0
500
1000
1500
2000
2500
3000
3500
128
256
512
1024
2048
4096
8192
16384
32768
65536
131072
262144
524288
1048576
2097152
4194304
MB
/sec
Block size (byte)
Bandwidth put Hopper 24 cores (no network)
GFor/MPICray
Alessandro Fanfarillo Coarrays in GFortran June 24th, 2014 23 / 50

Bw Multi Put 24 cores Hopper
0.1
1
10
100
1000
10000
1 2 4 8 16
32
64
128
256
512
1024
2048
4096
8192
16384
32768
65536
131072
262144
524288
1048576
2097152
4194304
MB
/sec
Block size (byte)
Bandwidth multi put 24 cores Hopper (no network)
GFor/MPICray
Alessandro Fanfarillo Coarrays in GFortran June 24th, 2014 24 / 50

Bw Difference Single/Multi Put 24 cores Hopper
0.1
1
10
100
1000
10000
1 2 4 8 16
32
64
128
256
512
1024
2048
4096
8192
16384
32768
65536
131072
262144
524288
1048576
2097152
4194304
MB
/sec
Block size (byte)
Bw difference single/multi put 24 cores Hopper (no network)
Diff_GFor/MPIDiff_Cray
Alessandro Fanfarillo Coarrays in GFortran June 24th, 2014 25 / 50

Bw Single Strided Put 24 cores Hopper
10
100
1000
10000
1 2 4 8 16 32 64 128
MB
/se
c
Stride size (byte)
Bandwidth strided put 24 cores Hopper (no network)
GFor/MPICray
Alessandro Fanfarillo Coarrays in GFortran June 24th, 2014 26 / 50

Latency/Bw Single Put 32 cores Yellowstone
1e-05
0.0001
0.001
0.01
0.1
1
10
100
1000
1 2 4 8 16 32 64 128 256 512
Tim
e (
sec)
Block size (byte)
Latency put 32 cores
GFor/MPIIntel
1e-06
1e-05
0.0001
0.001
0.01
0.1
1
10
100
1000
1 2 4 8 16 32 64 128 256 512
MB
/sec
Block size (byte)
Bandwidth put 32 cores
GFor/MPIIntel
Latency: lower is better - Bandwidth: higher is better
Note: Latency is expressed in seconds and Bw in MB/Sec.
Alessandro Fanfarillo Coarrays in GFortran June 24th, 2014 27 / 50

Latency/Bw Intel 32 cores Yellowstone
With 2 nodes we have a weird behavior from the Intel compiler.The benchmark gets an internal error during the subput test for everyconfiguration of nodes.
blksize (Bytes) latency (sec) bwidth (MB/s)
1 0.837 0.9133E-05
2 1.67 0.9178E-05
4 3.35 0.9157E-05
8 6.66 0.9159E-05
16 13.4 0.9156E-05
32 26.8 0.9155E-05
64 53.4 0.9148E-05
128 107. 0.9150E-05
256 214. 0.9149E-05
512 428. 0.9141E-05
Alessandro Fanfarillo Coarrays in GFortran June 24th, 2014 28 / 50
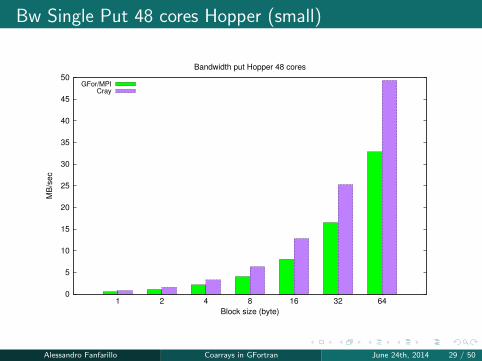
Bw Single Put 48 cores Hopper (small)
0
5
10
15
20
25
30
35
40
45
50
1 2 4 8 16 32 64
MB
/sec
Block size (byte)
Bandwidth put Hopper 48 cores
GFor/MPICray
Alessandro Fanfarillo Coarrays in GFortran June 24th, 2014 29 / 50
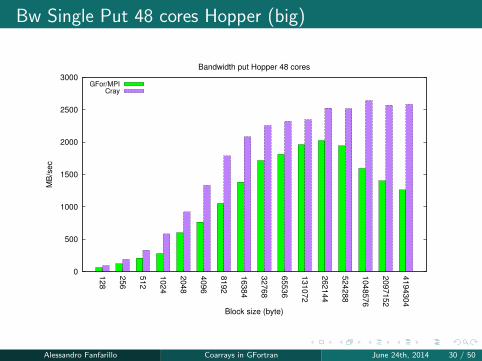
Bw Single Put 48 cores Hopper (big)
0
500
1000
1500
2000
2500
3000
128
256
512
1024
2048
4096
8192
16384
32768
65536
13107
2
26214
4
52428
8
10485
76
20971
52
41943
04
MB
/sec
Block size (byte)
Bandwidth put Hopper 48 cores
GFor/MPICray
Alessandro Fanfarillo Coarrays in GFortran June 24th, 2014 30 / 50

Bw Single Strided Get 48 cores Hopper
10
100
1000
10000
1 2 4 8 16 32 64 128
MB
/se
c
Stride size (byte)
Bandwidth strided get 48 cores Hopper
GFor/MPICray
Alessandro Fanfarillo Coarrays in GFortran June 24th, 2014 31 / 50

Bw Single Strided Put 48 cores Hopper (2)
During a strided transfer Cray sends a predefined amount of data(perhaps elem-by-elem).
GFortran uses the MPI Derived Data Types.
Only the bandwidth is not enough for a fair comparison.
Derived data types require a lot of memory (a Yellowstone’s computenode does not have enough memory for running the entirebenchmark).
A good way to compare the two CAF implementation is through aTime/Memory trade-off.
We plan to improve the strided transfer very soon.
Alessandro Fanfarillo Coarrays in GFortran June 24th, 2014 32 / 50

BurgersCAF
It uses Coarrays mainly for scalar transfers.
It communicates with neighbour images which are usually placed onthe same node.
The nature of the algorithm influences the performance a lot.
Alessandro Fanfarillo Coarrays in GFortran June 24th, 2014 33 / 50

BurgersCAF - Yellowstone
00:00
00:15
00:30
00:45
01:00
01:15
01:30
01:45
02:00
02:15
02:30
02:45
03:00
16 32 64 128 256
Tim
e (
min
:sec)
# Cores
BurgersCAF on Yellowstone
GFor/MPIIntelCAF
(Lower is better)Alessandro Fanfarillo Coarrays in GFortran June 24th, 2014 34 / 50

BurgersCAF - Hopper
00:00
00:30
01:00
01:30
02:00
02:30
03:00
03:30
04:00
04:30
24 48 192 384
Tim
e (
min
:sec)
# Cores
BurgersCAF on Hopper
GFor/MPICray
Alessandro Fanfarillo Coarrays in GFortran June 24th, 2014 35 / 50

CAF Himeno
It uses the Jacobi method for a 3D Poisson relaxation.
Intel requires more than 30 minutes to complete the test with 64cores.
Cray requires several tuning arrangements in order to run (the 32cores test has been run with 8 images on each node).
GFortran was the easiest to run.
Alessandro Fanfarillo Coarrays in GFortran June 24th, 2014 36 / 50

CAF Himeno - Yellowstone
0
5000
10000
15000
20000
25000
30000
16 32
MF
LO
PS
Cores
Performance CAFHimeno Yellowstone
GFor/MPI
Intel
Alessandro Fanfarillo Coarrays in GFortran June 24th, 2014 37 / 50

CAF Himeno - Hopper
0
5000
10000
15000
20000
25000
30000
16 32
MF
LO
PS
Cores
Performance CAFHimeno Hopper
GFor/MPICray
Alessandro Fanfarillo Coarrays in GFortran June 24th, 2014 38 / 50

Distributed Transpose
3-D Distributed Transpose.
It is performed sending element-by-element.
The problem size has been fixed at 1024,1024,256.
It is a good communication test case.
Alessandro Fanfarillo Coarrays in GFortran June 24th, 2014 39 / 50

Distributed Transpose - Yellowstone
0
10
20
30
40
50
60
70
16 32 64
Tim
e (
sec)
Cores
Performance Distributed Transpose Yellowstone
GFor/MPIIntel
Alessandro Fanfarillo Coarrays in GFortran June 24th, 2014 40 / 50

Distributed Transpose - Hopper
0.5
1
1.5
2
2.5
3
3.5
16 32 64
Tim
e (
sec)
Cores
Performance Distributed Transpose Hopper
GFor/MPICray
Alessandro Fanfarillo Coarrays in GFortran June 24th, 2014 41 / 50

Distributed MxV
A group of rows is sent to each image.
The usual array syntax has been used (it implies strided arraytransfer).
The bottleneck is communication (broadcast and gather).
With a single MxV the computational part is too small for gettingbenefits from a parallel approach.
Alessandro Fanfarillo Coarrays in GFortran June 24th, 2014 42 / 50

Distributed MxV - Executions
Yellowstone 16 cores (single node)
GFor/MPI Intel
0:40 (m:s) 5:09 (m:s)
Hopper 16 cores (single node)
GFor/MPI Cray
1:54 (m:s) 0:08 (m:s)
Alessandro Fanfarillo Coarrays in GFortran June 24th, 2014 43 / 50

Conclusions - GFortran vs. Intel
Intel shows better performance than GFortran only during scalartransfers within the same node.
Intel pays a huge penalty when it uses the network (multi node).
GFortran shows better performance than Intel on array transferswithin the same node.
GFortran shows better performance than Intel in every configurationwhich involves the network.
Alessandro Fanfarillo Coarrays in GFortran June 24th, 2014 44 / 50

Conclusions - GFortran vs. Cray
Cray has better performance than GFortran within the same node.
Cray has better performance than GFortran during contiguous arraytransfer on multi node (using the network).
GFortran has better performance than Cray for strided transfers onmulti node. (!!!)
Cray requires some tuning (env vars and modules).
Alessandro Fanfarillo Coarrays in GFortran June 24th, 2014 45 / 50

Conclusions
GFortran provides a stable, easy to use and efficient implementationof Coarrays.
GFortran provides a valid and free alternative to commercialcompilers.
Coarrays in GFortran can be used on any architecture able to compileGCC and a standard MPI implementation.
Alessandro Fanfarillo Coarrays in GFortran June 24th, 2014 46 / 50

Future developments
On the compiler side the multi image Coarray support is already onGCC 4.10 trunk (It also supports OpenMPv4).
On the library side we plan to release the MPI version very soon.
Improve the strided transfer support and add all the missing featuresexpected by the standard.
Improve the experimental GASNet version.
Alessandro Fanfarillo Coarrays in GFortran June 24th, 2014 47 / 50

The Team
Development Team:
Tobias Burnus
Alessandro Fanfarillo
Support Team:
Valeria Cardellini
Salvatore Filippone
Dan Nagle
Damian Rouson
Alessandro Fanfarillo Coarrays in GFortran June 24th, 2014 48 / 50

Acknowledgment
CINECA (Grant HyPSBLAS)
Google (Project GSoC 2014)
UCAR/NCAR
NERSC (Grant OpenCoarrays)
Alessandro Fanfarillo Coarrays in GFortran June 24th, 2014 49 / 50
Thanks
Suggestions/Feedback/Questions?
Alessandro Fanfarillo Coarrays in GFortran June 24th, 2014 50 / 50





























