Embed Size (px)
Citation preview

Formation ML – Palaiseau – 24/01/17 - 1
Classification supervisée
Exemple des « Support Vector Machines »
24/01/2017
S. Herbin
DTIM/PSR

Formation ML – Palaiseau – 24/01/17 - 2
La chaîne d’interprétation de données
capteur
Prétraitement
extraction de
caractéristiques
Algorithme
de
décision
KssS ,...1
sources
NRI
mesures, images
dRx
caractéristiques
LaaAy ,...1
décision/action
Maintenant
)(xDy
Formation ML – Palaiseau – 24/01/17 - 3
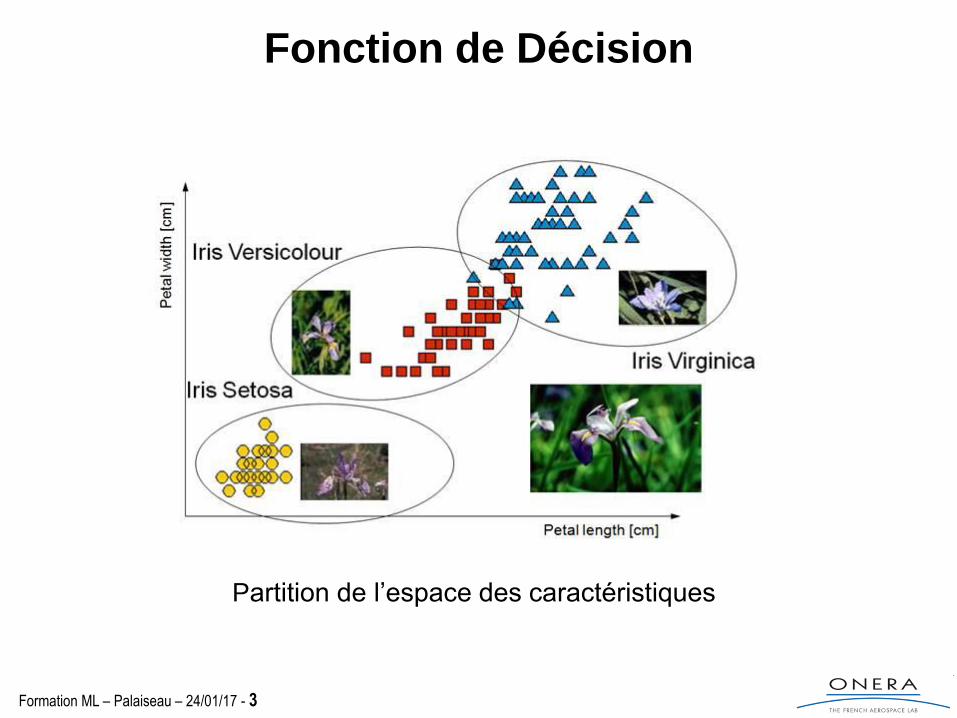
Fonction de Décision
Partition de l’espace des caractéristiques

Formation ML – Palaiseau – 24/01/17 - 4
Apprentissage et test
Ensemble d’apprentissage
(observé)
Distribution
sous jacente
(non observée)
Ensemble de test
(non observé)
Données disponibles
(hors ligne)
Données à traiter
(en ligne)

Formation ML – Palaiseau – 24/01/17 - 5
Différents types de classification
• Binaire
• Multi classe
• Détection
• Caractérisation des données:
• Rejet
• Anomalie
1,1A
L...2,1A
inconnu,ambigu,...2,1 LA
4...2,1 RL A

Formation ML – Palaiseau – 24/01/17 - 6
Apprentissage supervisé
• On veut construire une fonction de décision D à partir d’exemples
• On dispose d’un ensemble d’apprentissage L sous la forme de paires
{xi,yi} où xi est la donnée à classer et yi est la vraie valeur (classe):
• L’apprentissage consiste à trouver cette fonction de classification dans
un certain espace paramétrique W optimisant un certain critère E:
• On l’applique ensuite à de nouvelles données de test:
)ˆ;( wxDy
N
iii y1
,
xL
),maxargˆ www
E(LW

Formation ML – Palaiseau – 24/01/17 - 7
Différentes manières de classer (cas binaire)
• Par calcul d’un score ou d’un rapport de vraisemblance puis seuil:
• Par comparaison de similarité (plus proche voisin, prototypes…)
• Par maximisation d’une fonction de compatibilité
• …
• Il y a (presque) toujours comme intermédiaire une ou des fonctions
à valeurs réelles à calculer Régression
1)( yS x
),1(),,1(maxarg* xx CCy
),(),(,tq)(* jii SSjyy xxxxx

Formation ML – Palaiseau – 24/01/17 - 8
Un exemple « paradigmatique »:
la régression polynomiale
• La courbe verte est la véritable fonction à estimer (non polynomiale)
• Les données sont uniformément échantillonnées en x mais bruitées en y.
• L’erreur de régression est mesurée par la distance au carré entre les points vrais et le polynôme estimé.
from Bishop

Formation ML – Palaiseau – 24/01/17 - 9
Quelles sont les meilleures régressions?
from Bishop

Formation ML – Palaiseau – 24/01/17 - 10
Une approche simple pour contrôler la
complexité
Si on pénalise les grandes valeurs des coefficients du polynôme, on obtient une fonction moins « zigzagante »
2
1
||||}),({)(2
2
2
1wwxw
ii tD
N
i
E
Paramètre de
régularisation
Valeur vraie
au point xi
Fonction de
coût
from Bishop

Formation ML – Palaiseau – 24/01/17 - 11
Regularisation: vs.
2
2
1
RMS }),({)(1
ii tDN
i
wxwE
)ln(RMSE
Sur apprentissage
= « Overfitting »
Classifieur
pas assez expressif Bon régime

Formation ML – Palaiseau – 24/01/17 - 12
Deux types d’approches:
génératives vs. discriminatives
Objectif = modéliser les
distributions de données
puis les exploiter
Objectif = construire les
meilleures frontières
𝑦 = 𝐷(𝒙)
On estime directement
On calcule la frontière à
partir des modèles

Formation ML – Palaiseau – 24/01/17 - 13
Critères statistiques pour la classification
• Risque ou erreur empirique
• Erreur de généralisation (ou de test, ou idéale…)
• Critère à optimiser (fonction objectif):
}),({),(1
1
train iiNyD
N
i
wxw LE
yDE Y ),()( ,test wxw XE
)()),,((),(Loss1
1wwxw ryDl iiN
N
i
L
Adéquation aux données Régularisation

Formation ML – Palaiseau – 24/01/17 - 14
Problématiques de l’apprentissage supervisé
• A distribution de données d’entrée fixée…
• Maîtriser:
• Le choix de l’espace des classifieurs (structure et paramètres)
• Le critère empirique à optimiser
• La stratégie d’optimisation
• L’évaluation de la solution
• A situer dans une démarche de conception plus globale:
• Choix des caractéristiques
• Temps de calcul
• Nature de la classification
• Performances attendues…

Formation ML – Palaiseau – 24/01/17 - 15
Garanties théoriques (exemple)
Où N = nombre de données
h = indicateur de complexité des classifieurs (VC dimension)
p = probabilité que la borne soit fausse
En jouant sur la complexité des classes de classifieurs, on peut optimiser la borne d’erreur d’estimation.
Cette borne est plutôt lâche
En pratique, la démarche est plutôt « experte », et repose sur un certain savoir faire et une connaissance des données.
2
1
)4/log()/2log(
N
phNhhtraintest EE
Les données disponibles Les données cachées

Formation ML – Palaiseau – 24/01/17 - 16
Validation croisée
• Permet d’estimer l’erreur de généralisation à partir des données
d’apprentissage (« astuce »)
• Principe:
• Division des données en k sous ensembles (« fold »)
• Choix d’une partie comme ensemble de test fictif, les autres comme train
• Apprentissage sur l’ensemble train
• Estimation des erreurs sur test
• On fait tourner l’ensemble de test sur chacune des parties
• L’erreur de généralisation estimée est la moyenne des erreurs sur chaque
ensemble de test

Formation ML – Palaiseau – 24/01/17 - 17
Stratégies de partitionnement
• k-fold
Train Test
Données
• Leave-one-out

Formation ML – Palaiseau – 24/01/17 - 18
Quelques approches discriminatives
d’apprentissage supervisé en vision
106 examples
Nearest neighbor
Shakhnarovich, Viola, Darrell 2003
Berg, Berg, Malik 2005...
Neural networks (Deep Learning)
LeCun, Bottou, Bengio, Haffner 1998
Rowley, Baluja, Kanade 1998
…
Support Vector Machines Conditional Random Fields
McCallum, Freitag, Pereira
2000; Kumar, Hebert 2003
…
Guyon, Vapnik
Heisele, Serre, Poggio, 2001,…
Boosting
Viola, Jones 2001,
Torralba et al. 2004,
Opelt et al. 2006,…

Formation ML – Palaiseau – 24/01/17 - 19
Références
• K. Fukunaga, Introduction to Statistical Pattern Recognition (Second Edition),
Academic Press, New York, 1990.
• P.A. Devijver and J. Kittler, Pattern Recognition, a Statistical Approach, Prentice
Hall, Englewood Cliffs, 1982)
• R.O. Duda and P.E. Hart, Pattern classification and scene analysis, John Wiley &
Sons, New York, 1973.
• L. Breiman, J.H. Friedman, R.A. Olshen, and C.J. Stone, Classification and
regression trees, Wadsworth, 1984.
• L. Devroye, L. Györfi and G. Lugosi, A Probabilistic Theory of Pattern Recognition,
(Springer-Verlag 1996)
• S. Haykin, Neural Networks, a Comprehensive Foundation. (Macmillan, New York,
NY., 1994)
• V. N. Vapnik, The nature of statistical learning theory (Springer-Verlag, 1995)
• C. Bishop, Pattern Recognition and Machine Learning, (Springer-Verlag, 2006).
• Jerome H. Friedman, Robert Tibshirani et Trevor Hastie, The Elements of Statistical
Learning: Data Mining, Inference, and Prediction (Springer-Verlag 2009).
• Ian Goodfellow and Yoshua Bengio and Aaron Courville, Deep Learning, An MIT
Press book (http://www.deeplearningbook.org)

Formation ML – Palaiseau – 24/01/17 - 20
Support Vector Machines
• Historique
• Principe: maximiser la marge de séparation d’un hyperplan
• Le cas séparable
• Le cas non séparable: les fonctions de perte (« hinge loss »)
• L’extension au cas non linéaire: les noyaux
• Le calcul effectif
• Les paramètres de contrôle

Formation ML – Palaiseau – 24/01/17 - 21
Historique du Machine Learning

Formation ML – Palaiseau – 24/01/17 - 22
Modèles linéaires de décision
Hypothèse = les données sont linéairement séparables.
• En 2D, par une droite
• En ND, par un hyperplan.
m
j
j
j xwb1
0
m
j
j
j xwb1
0
m
j
j
j xwb1
0

Formation ML – Palaiseau – 24/01/17 - 23
Classifieur linéaire
• Equation de l’hyperplan séparateur
• Expression du classifieur linéaire (pour yi valant -1 et 1)
• Erreur
).(sign);( xwwx bD
N
i
iitest byN 1
0).(sign.1
),( xww LE
0. xwb

Formation ML – Palaiseau – 24/01/17 - 24
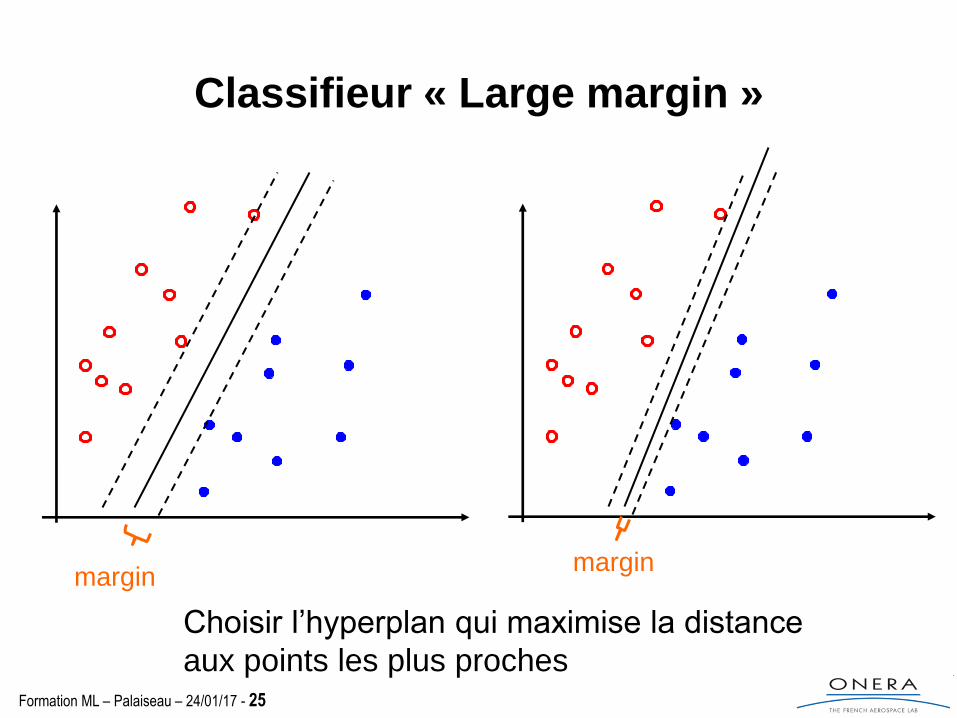
Quel hyperplan choisir?
Formation ML – Palaiseau – 24/01/17 - 25
Classifieur « Large margin »
Choisir l’hyperplan qui maximise la distance
aux points les plus proches
margin margin

Formation ML – Palaiseau – 24/01/17 - 26
Support Vector Machines
• On cherche l’hyperplan qui maximise la marge.
1:1)(négatif
1:1)( positif
by
by
iii
iii
wxx
wxx
Margin M Support vectors
Pour les vecteurs de
support,
1 bi wx
Distance entre point et
hyperplan: ||||
||
w
wx bi
www
211
M
ww
xw 1
bΤ
Pour les « support vectors »:

Formation ML – Palaiseau – 24/01/17 - 27
Principe du SVM (Large Margin)
• Maximiser la marge = distance des vecteurs à l’hyperplan
séparateur des vecteurs de supports
• Sous contraintes
• Les vecteurs de support vérifiant:
iby ii 1)( xw
1)( by ii xw
2
1max
w
Le 1 est conventionnel.
N’importe quelle
constante >0 est valable.

Formation ML – Palaiseau – 24/01/17 - 28
Formulation du SVM
ibxwy ii 1)(
Tel que:
2
, min wbw
Si les données sont séparables
Problème d’optimisation quadratique
Avec contraintes linéaires
Grand nombre de manières de l’optimiser!

Formation ML – Palaiseau – 24/01/17 - 29
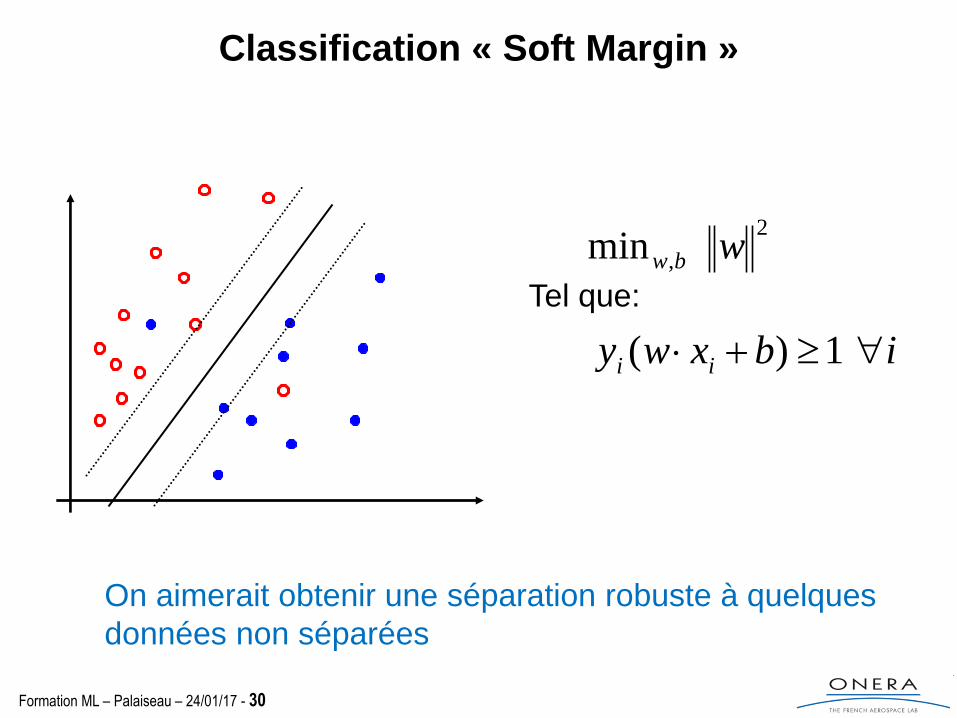
Classification « Soft Margin »
Comment traiter le cas non linéairement séparable?
ibxwy ii 1)(
Tel que:
2
, min wbw
Formation ML – Palaiseau – 24/01/17 - 30
Classification « Soft Margin »
On aimerait obtenir une séparation robuste à quelques
données non séparées
ibxwy ii 1)(
Tel que:
2
, min wbw

Formation ML – Palaiseau – 24/01/17 - 31
Idée: « Slack variables »
ibxwy ii 1)(
tq:
2
, min wbw
ibxwy iii 1)(
tq:
i ibw Cw
2
, min
0i
slack variables
(une par exemple)
Permet de relacher la
contrainte de
séparabilité pour
chaque exemple.

Formation ML – Palaiseau – 24/01/17 - 32
« Slack variables »
ibxwy iii 1)(
Tel que:
i ibw Cw
2
, min
0i
Relâchement de la contrainte
Formation ML – Palaiseau – 24/01/17 - 33
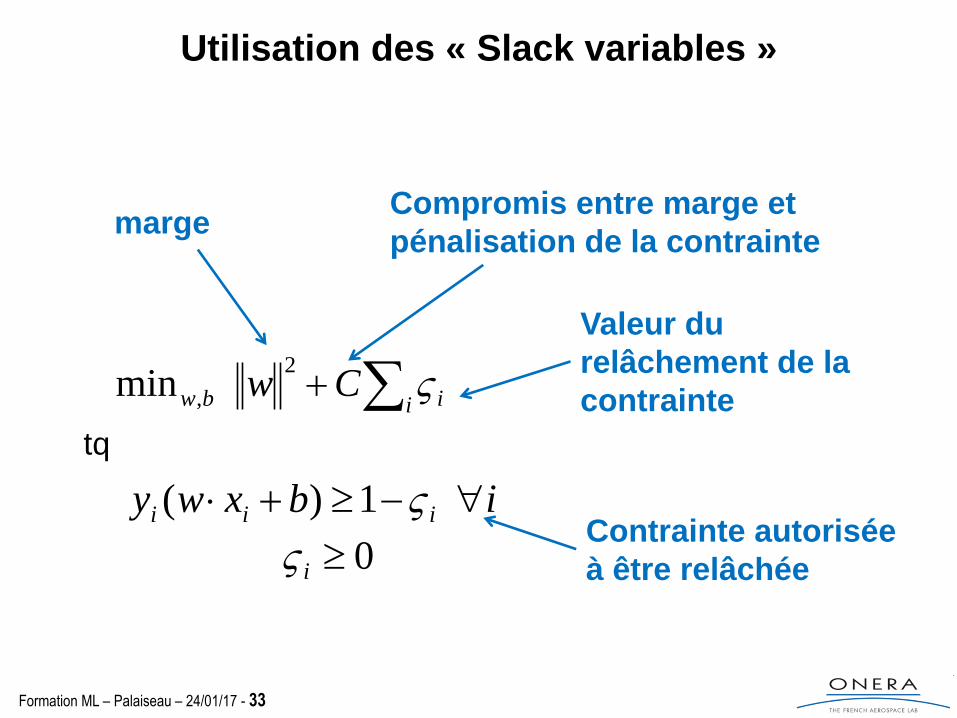
Utilisation des « Slack variables »
ibxwy iii 1)(
tq
i ibw Cw
2
, min
0iContrainte autorisée
à être relâchée
Valeur du
relâchement de la
contrainte
Compromis entre marge et
pénalisation de la contrainte marge

Formation ML – Palaiseau – 24/01/17 - 34
Soft margin SVM
On garde un problème quadratique!
ibxwy iii 1)(
Tel que
i ibw Cw
2
, min
0i

Formation ML – Palaiseau – 24/01/17 - 35
Autre formulation
ibxwy iii 1)( tq:
i ibw Cw
2
, min
0i
))(1,0max( bxwy iii
i iibw bxwyCw ))(1,0max( min
2
,
Problème d’optimisation non contraint
Autres méthodes d’optimisation (descente de gradient)

Formation ML – Palaiseau – 24/01/17 - 36
Interprétation du « Soft Margin SVM »
On retrouve la formulation:
)()),,((),(Loss1
1wwxw ryDl iiN
N
i
L
i iibw bxwyCw ))(1,0max( min
2
,
)).(1,0max()),,(( byyDl iiii xwwx
21)( ww
Cr
Avec
Le SVM est un cas particulier du formalisme:
« erreur empirique + régularisation »
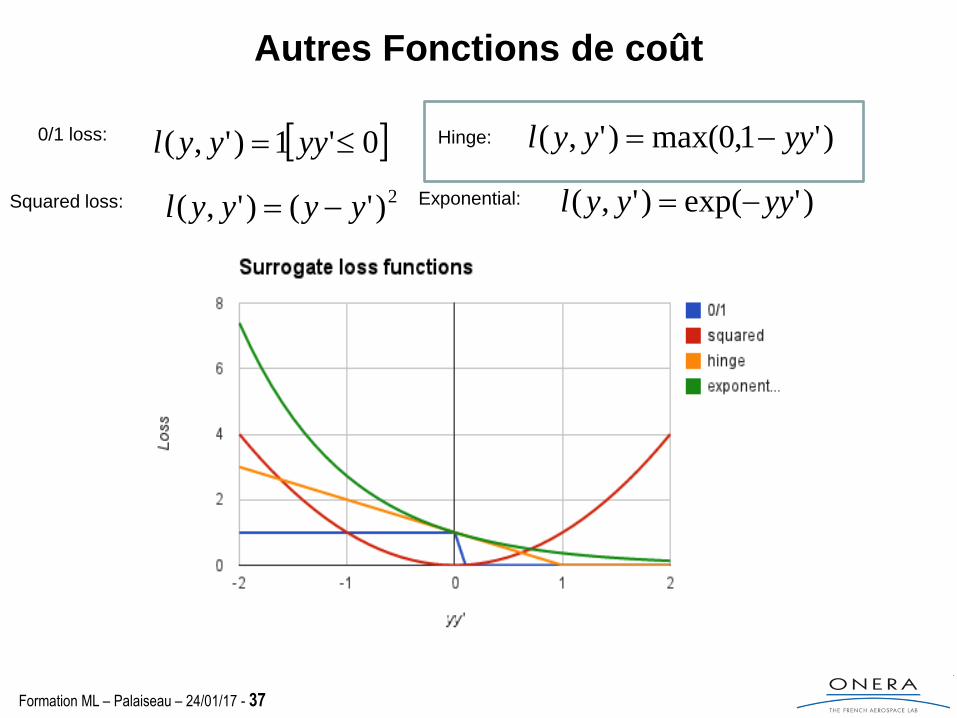
Formation ML – Palaiseau – 24/01/17 - 37
Autres Fonctions de coût
0'1)',( yyyyl0/1 loss:
Squared loss: 2)'()',( yyyyl
Hinge: )'1,0max()',( yyyyl
Exponential: )'exp()',( yyyyl

Formation ML – Palaiseau – 24/01/17 - 38
Forme duale du SVM
• Problème d’optimisation sous contrainte
𝑠. 𝑡. ∀𝑖, 𝑦𝑖(𝒘. 𝒙𝑖+𝑏) ≥ 1 − 𝜉𝑖
argmin𝐰𝒘 2
2+ 𝐶 𝜉𝑖
𝑖
𝜉𝑖 ≥ 0
Primal
𝛼𝑖
𝛽𝑖
Multiplicateurs de Lagrange
Dual (Lagrangien)
𝐿 𝒘, 𝝃, 𝜶, 𝜷
=𝒘 2
2+ 𝐶𝜉𝑖 − 𝛼𝑖 𝑦𝑖(𝒘. 𝒙𝑖+𝑏) − 1 + 𝜉𝑖 − 𝛽𝑖𝜉𝑖𝑖
𝑠. 𝑡. ∀𝑖, 𝛼𝑖 ≥ 0, 𝛽𝑖 ≥ 0
Pour simplifier l’expression des calculs

Formation ML – Palaiseau – 24/01/17 - 39
Forme duale du SVM
• Lagrangien
𝑠. 𝑡. ∀𝑖, 0 ≤ 𝛼𝑖 ≤ 𝐶
𝐿 𝛼 = 𝛼𝑖𝑖
−1
2 𝛼𝑖𝛼𝑗𝑦𝑖𝑦𝑗𝒙𝑗 . 𝒙𝑗𝑖,𝑗
On garde un
pb. quadratique
Solution optimale (conditions de Kuhn-Tucker): 𝛼𝑖 𝑦𝑖𝑤𝑇𝑥𝑖 − 1 + 𝜉𝑖 = 0
Dual des contraintes « slack »
Interprétation: 𝛼𝑖 = 0 si la contrainte est satisfaite (bonne classification)
𝛼𝑖 > 0 si la contrainte n’est pas satisfaite (mauvaise
classification)
Maximisation dans le dual!

Formation ML – Palaiseau – 24/01/17 - 40
Sparsité du SVM
• Seuls certains 𝛼 sont non nuls = autre manière de définir
les vecteurs de support.
Y
X
𝑤𝑇𝑥 + 𝑏 = 0
Contraintes Inactives
Contraintes actives
𝛼 > 0
= « Support vector »
Ne contribuent pas au
calcul de l’hyperplan
𝛼 = 0
Direction de l’hyperplan séparateur 𝒘 = 𝛼𝑖𝑦𝑖𝒙𝑖𝑖
Optimalité = 𝜶𝒊 𝒚𝒊𝒘𝑻𝒙𝒊 − 𝟏 + 𝝃𝒊 = 𝟎

Formation ML – Palaiseau – 24/01/17 - 41
Données non linéairement séparables
• Transformation non linéaire 𝜙(𝒙) pour séparer linéairement les
données d’origine
𝑥1 𝑥1
𝑥2 = 𝑥12
𝜙(𝒙) = Transformation polynomiale
𝑥2

Formation ML – Palaiseau – 24/01/17 - 42
Données non linéairement séparables
• Transformation non linéaire 𝜙(𝒙) pour séparer linéairement les
données d’origine
𝜙(𝒙) = Transformation polaire
𝑥1
𝑥2 Coordonnées polaires
𝑟
𝜃

Formation ML – Palaiseau – 24/01/17 - 43
Retour sur la formulation duale du SVM
tq ∀𝑖, 0 ≤ 𝛼𝑖 ≤ 𝐶
max𝛼 𝛼𝑖𝑖
−1
2 𝛼𝑖𝛼𝑗𝑦𝑖𝑦𝑗𝒙𝑖𝒙𝑗𝑖,𝑗
Produit scalaire
uniquement
Lagrangien

Formation ML – Palaiseau – 24/01/17 - 44
max𝛼 𝛼𝑖𝑖
−1
2 𝛼𝑖𝛼𝑗𝑦𝑖𝑦𝑗𝐾(𝒙𝑖 , 𝒙𝑗)
𝑖,𝑗
« Kernel trick »
tq ∀𝑖, 0 ≤ 𝛼𝑖 ≤ 𝐶 Noyau
Le noyau 𝐾 est un produit scalaire dans l’espace
transformé:
𝐾 𝒙𝑖 , 𝒙𝑗 = 𝜙 𝒙𝑖𝑇𝜙(𝒙𝑗)
Il est uniquement nécessaire de connaître la similarité
entre données pour introduire la non linéarité dans le
problème (avec des conditions…)

Formation ML – Palaiseau – 24/01/17 - 45
Utilisation de noyaux dans les SVM
• Permet d’introduire des mesures de similarités propres au domaine
étudié et sans avoir à gérer la complexité de la transformation
• Permet de séparer modélisation = noyau de la classification et SVM
(optimisation)
• Définit la fonction de classification à partir de noyaux « centrés » sur
les vecteurs de support
D 𝒙,𝒘 = 𝑏 + 𝛼𝑖𝑦𝑖𝑲(𝒙𝑖 , 𝒙)
𝑖

Formation ML – Palaiseau – 24/01/17 - 46
Noyaux courants
• Polynômes de degrés supérieurs à d
𝐾 𝒙, 𝒚 = 𝒙. 𝒚 + 1 𝑑
• Noyau gaussien
𝐾 𝒙, 𝒚 = exp −𝒙 − 𝒚 𝑇 𝒙 − 𝒚
2𝜎2
• Intersection d’histogrammes
𝐾 𝒙, 𝒚 = min (𝑥𝑖 , 𝑦𝑖)
𝑖
Paramètres à définir
= degré de liberté
supplémentaire

Formation ML – Palaiseau – 24/01/17 - 47
Intérêt de la formalisation par noyaux
• Noyaux = partie « métier »
• Connaissance du sens à donner à la similarité
• Choix expert des espaces de représentation et des caractéristiques
informatives
• Classification/Optimisation = partie « ML »
• Utilisation d’optimiseurs génériques
• Certaine optimalité à représentation du problème donnée
• Utilisation des SVM à noyaux.
• Représentations multi dimensionnelles (mais pas trop…)
• Données de volume raisonnable
• mais passage à l’échelle plus délicat (on se restreint alors en général
aux noyaux linéaires)
• « Deep Learning » montrera que ce peut être sous-optimal…

Formation ML – Palaiseau – 24/01/17 - 48
Codes
• LibSVM + LibLinear (nombreuses interfaces)
https://www.csie.ntu.edu.tw/~cjlin/libsvm/
https://www.csie.ntu.edu.tw/~cjlin/liblinear/
• Scikit-Learn (Python)
https://www.csie.ntu.edu.tw/~cjlin/liblinear/
• Matlab

Formation ML – Palaiseau – 24/01/17 - 49
Résumé sur SVM
• Une formulation optimale quadratique du problème de classification
binaire:
• Primal: optimisation d’un critère empirique + régularisation
• Dual: permet d’introduire sparsité et « kernel trick »
plusieurs manières d’optimiser
• Les solutions s’expriment comme des combinaisons linéaires
éparses de noyaux:
D 𝒙,𝒘 = 𝑏 + 𝛼𝑖𝑦𝑖𝑲(𝒙𝑖 , 𝒙)
𝑖
où 𝛼𝑖>0 seulement pour les vecteurs de support, 0 sinon.
• En pratique, ce qu’il faut régler:
• Le coefficient de régularisation: C
• Le type de noyau et ses caractéristiques
• Les paramètres de l’optimiseur

Formation ML – Palaiseau – 24/01/17 - 50
Résumé
• Apprentissage supervisé
• Un problème ancien, avec un corpus théorique solide (statistique) et
des outils pratiques (optimiseurs, environnements logiciels)
• Mais rien ne vaut une bonne modélisation du problème (quoique DL)
• SVM
• Une démarche assez générique et solide théoriquement
• Performances plutôt bonnes pour jeux de données modestes, et faibles
dimensions de représentation
• Il y a d’autres approches (arbres de décision, boosting, bagging,
random forrest…) qui ont d’autres qualités (espaces de
caractéristiques et de décision structurés ou plus complexes,
gestion des données manquantes, incrémentalité…)




























