Embed Size (px)
Citation preview

Chapter 8:
Part-of-Speech Tagging (POS Tagging)

2
Overview
•Task
•Brill-tagger (rule based)
•HMM tagger (statistical)

3
Goal of Part-of-Speech Tagging
•Determine in a simple way the
grammatical function of a word

4
Brown corpus tag
•The Brown Corpus Tag-set.htm

5
Goal of Part-of-Speech Tagging
•Examples of tags: Tag Description Example
CC Coordinating
Conjunction
and, but, or
CD Cardinal number one, two, three
DT Determiner a. the
JJ Adjective yellow
NN Noun, sing. or mass province
NNS Noun in plural houses, apples
IN Preposition in
VB Verb, base form eat
VBD Verb, past tense ate
… … …
The representative put chairs on the table .
DT NN VBD NNS IN DT NN .

6
Goal of Part-of-Speech Tagging
One more example sentence Next you flour the pan .
JJ PRP VB DT NN .
More examples of ambiguous words:
play: NN (“a new play”)
VBP (“to play”)
bear: NN (“the bear”)
VB (“to bear”)

7
How difficult is the task
•Roughly 10% of the token (running words)
are ambiguous.
the is also an OOV problem!

8
Applications of Tagging
•Partial parsing: syntactic analysis
•Information Extraction: tagging and partial parsing help identify useful terms and relationships between them.
•Information Retrieval: noun phrase recognition and query-document matching based on meaningful units rather than individual terms.
•Question Answering: analyzing a query to understand what type of entity the user is looking for and how it is related to other noun phrases mentioned in the question.

9
Brill-Tagger:
Transformation based
learning (TBL)

10
Transformation-Based Tagging (Brill
Tagging)
•Idea: •Assign each word the most likely tag
•Learn rules how to correct errors
•Combination of rule-based and machine-
learning approach
•Example •The bear
•Most likely tags: DT VB
•Transformation rule •VB NN if previous tag is DT
•Corrected tags: DT NN

11
Rule Learning
•Problem: Could apply transformations ad infinitum! •Constrain the set of transformations with “templates”:
•Replace tag X with tag Y, provided tag Z or word Z’ appears in some position
•Rules are learned in ordered sequence •Rules may interact. •Rules are compact and can be inspected by humans

12
Brill Tagger
•Types of rules •Tag triggered
•Word triggers
•Morphology triggered (unknown words!)
•Tagging-Algorithms •Assign default tag
•For each rule •For all positions in text
•If rule is applicable: change tag accordingly

13
Most likely tags
thanksgiving NN
Thanks NNS UH
thanks NNS VBZ VB UH
thank VB VBP
the DT VBD VBP NN|DT IN JJ NN NNP PDT
•See LEXICON

14
TBL: Rule Learning
•2 parts to a rule •Triggering environment
•Rewrite rule
•The range of triggering environments of
templates (from Manning & Schutze 1999:363)
Schema ti-3 ti-2 ti-1 ti ti+1 ti+2 ti+3
1 *
2 *
3 *
4 *
5 *
6 *
7 *
8 *
9 *

15
Templates for TBL
See CONTEXTUALRULEFILE

16
Using Morphological Information

17
Training of the Brill Tagger
C0 := corpus tagged with most likely tag k:=0 Do {
V:= the transformation ui that minimizes E(ui(Ck)) If ( E(Ck) - E(v(Ck)) ) < then break Ck+1 = v(Ck) k+1 = v k++
} print 1, 2, … k

18
Accuracy vs. Transformation Number

19
See it running
brilltagger/RULE_BASED_TAGGER_V1.14/Bin_and_Data

20
TBL: Problems
•First 100 rules achieve 96.8% accuracy
•First 200 rules achieve 97.0% accuracy
•Execution Speed: TBL tagger is slower than
HMM approach
•Learning Speed: Brill’s implementation over a
day (600k tokens)
BUT … (1) Learns small number of simple, non-
stochastic rules
(2) Can be made to work faster with FST
(3) Best performing algorithm on unknown
words

21
Download the Tagger
•http://www.cs.jhu.ed
u/~brill

22
Hidden Markov Model
(HMM) based Taggers

23
Part-Of-Speech Tagging
Sentence: Next you flour the pan .
Tags: JJ PRP VBP DT NN .
Intuitive idea of HMM:
use statistics of co-occurences
24
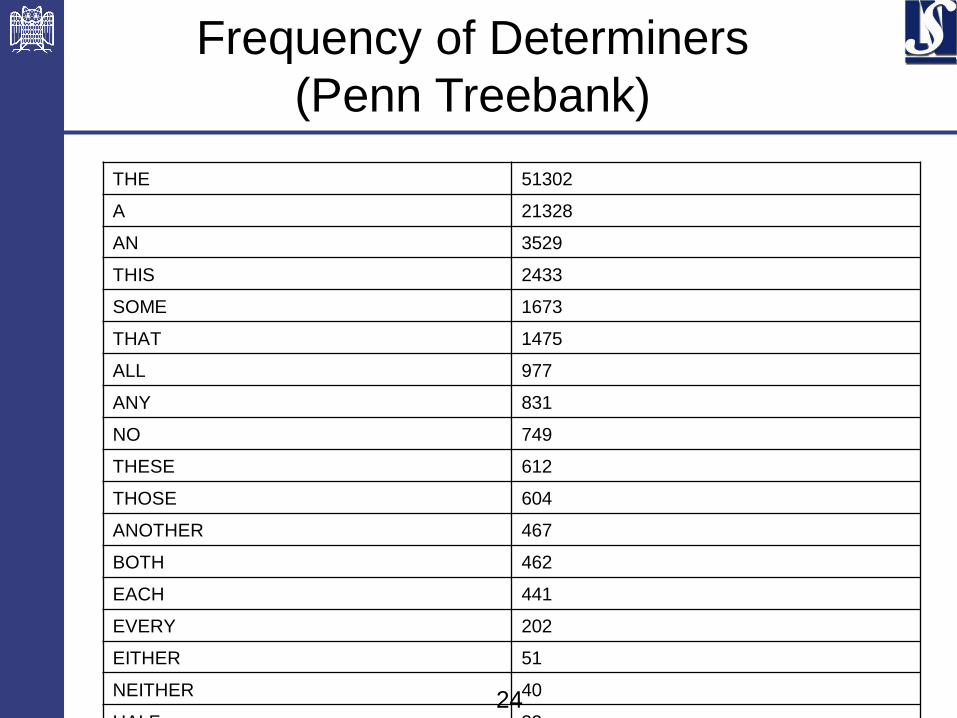
Frequency of Determiners
(Penn Treebank)
THE 51302
A 21328
AN 3529
THIS 2433
SOME 1673
THAT 1475
ALL 977
ANY 831
NO 749
THESE 612
THOSE 604
ANOTHER 467
BOTH 462
EACH 441
EVERY 202
EITHER 51
NEITHER 40
HALF 33
MANY 14

25
Most frequent continuations of DT
•DT: overall 87232 occurrences
DT NN 39302
DT JJ 19085
DT NNP 9529
DT NNS 6269
DT CD 2787
DT NN-POS 2174
DT RB 878
DT IN 843
DT JJS 800

26
Most frequent continuations of DT NN
DT NN IN 11926
DT NN NN 4799
DT NN , 4067
DT NN . 3384
DT NN VBD 2559
DT NN VBZ 2462
DT NN TO 1612
DT NN RB 1138
DT NN CC 1095

27
Most frequent continuations of
DT NN IN
DT NN IN DT 3698
DT NN IN NNP 1601
DT NN IN NN 1557
DT NN IN JJ 1306
DT NN IN NNS 933
DT NN IN CD 714
DT NN IN PRP 480
… …
Reliable statistics available
How to use it?

28
•Remember Bayes classifier from WSD
Can the POS-tagging problem be cast
as a Bayes classifier?

29
HMMs as a Bayes Classifier
•Consider the complete sequence of tags
as the class to be assigned

30
HMMs as a Bayes Classifier
•Rewrite
How many classes are there?

31
Estimation of Emission probabilities
•Assume –Each word only depends on its tag
–Words are statistically independent

32
Estimate Transition Probabilities
Use definition of conditional probabilities to rewrite
Too many parameters to be estimated!

33
Markov property: only immediate predecessors matter
Bigram:
Trigram:
Simplifying assumptions

34
Bigram Tagger

35
Trigram Tagger

36
Estimate Probabilities
•Maximum likelihood estimate would give:
•C(): count on training corpus
•In case of unseen events: use your favorite
smoothing technique (see chapter 4)

37
Handling of Unknown Words
•Guess the POS: •plunking
•resuciation verb (VBG) (“to plunk”?)
noun (NN)

38
Statistical properties of unknown
words
Feature Value NNP NN NNS VBG VBZ
Unk. word yes 0.05 0.02 0.02 0.005 0.005
no 0.95 0.98 0.98 0.995 0.995
Captialized yes 0.95 0.10 0.10 0.005 0.005
no 0.05 0.90 0.90 0.995 0.995
ending -s 0.05 0.01 0.98 0.00 0.99
-ing 0.01 0.01 0.00 1.00 0.00
-tion 0.05 0.10 0.00 0.00 0.00
other 0.89 0.88 0.02 0.00 0.01

39
Estimate Emission Probabilities use
Decomposition
About 80% of the unknown words can be tagged
correctly using that model

40
Finding the Best Tag Sequence
•Suppose sentence has N words •Tag set has T tags
TN possible tag sequences
e.g. N=14, T=50 1023 hypothesis to check
(106 hypothesis per second 3 171 000 000 CPU years; about the age of Earth)

41
Finding the best path:
Viterbi Algorithm (Bigram)
•See wikipedia or other lectures

42
Summary
•Assign grammatical labels to words
•Two well established approaches •Brill tagger
•Hidden Markov model





























