Embed Size (px)
Citation preview

Chapter 1
RESOURCE MANAGEMENT IN THE ENTROPIASYSTEM
Andrew A. Chien1, Shawn Marlin2, and Stephen T. Elbert31University of California, San Diego, 2Science Application International Corporation,3International Business Machines
Abstract Resource management for desktop grids is particularly challenging amongstGrid resource management because of the heterogeneity in system, net-work, and sharing of resources with desktop users. Desktop grids mustsupport thousands to millions of computers with low management over-head. We describe the resource management techniques used in theEntropia Internet and Enterprise desktop grids, to make the systemsmanageable, usable, and highly productive. These techniques exploit awealth of database, Internet, and traditional high performance comput-ing technologies and have demonstrated scale to hundreds of thousandsof computers. In particular, the Enterprise system includes extensivesupport for central management, failure management, and robust exe-cution.
Keywords: Desktop Grid, resource classification, resource pools, fault-tolerance,availability job scheduling, task scheduling, locality
1. INTRODUCTIONFor over five years, the largest computing systems in the world have
been based on distributed computing the assembly of large numbersof PC’s over the Internet. These Grid systems sustain multiple ter-aflops (see SETI@home, 2001) continuously by aggregating hundreds ofthousands to millions of machines and demonstrate the utility of such re-sources for solving a surprisingly wide range of large-scale computationalproblems in data mining, molecular interaction, financial modeling, etc.These systems have come to be called distributed computing systems andleverage the unused capacity of high performance desktop PC’s (up to 3GHz machines, see Brewin, 2002), high-speed local-area networks (100

2
Mbps to 1 Gbps switched), large main memories (256 MB to 1 GB),and large disks (60 to 100 GB). Such distributed computing systemsleverage installed hardware capability and are now gaining increased in-terest within enterprises to solve their largest computing problems. Fora general background of distributed computing, see Chien et al., 2003.
In this chapter, we focus on the resource management problem for En-terprise Desktop Grid computing. The focus is on very capable desktopsand laptops, which in Enterprise systems often number tens of thousandswith sufficient network bandwidth to enable a wide range of applications.For these PC grids, unlike server grids, an integral part of their func-tionality is to gather unused cycles unobtrusively. Resource managementfor desktop grids is particularly challenging because of heterogeneity insystem, network, and model of sharing between Grid computations anddesktop use. Desktop grids must exploit large numbers of resources,thousands to millions of computers, to deliver tremendous power, and doso with modest requirements for additional IT administration support.Furthermore, to achieve a high degree of utility, distributed computingmust capture a large number of valuable applications – it must be easy toput applications on the platform – and secure the application and its dataas it executes on the network. We use the terms distributed computing,high throughput computing, and desktop grids synonymously to refer tosystems that tap vast pools of desktop resources to solve large computingproblems – both to meet deadlines and increase resource availability.
The Entropia system provides novel solutions to Enterprise DesktopGrid resource management challenges. These solutions are developed intwo systems: an Internet Grid and an Enterprise Desktop Grid system.The result is a flexible, manageable system that is easily accessible tomany applications. We describe the system at three stages: the InternetGrid resource management system (Entropia 2000), where innovationsinclude large scale system management, scalable client-server interac-tion, and flexible scheduling; the Enterprise Grid resource managementsystem (Entropia DCGridTM 5.0 and 5.1), where innovations include re-source pooling, batch-style scheduling , scheduling for reliable and robustcompletion times, and basic data-locality scheduling; and finally futureresource management approaches, including the use of proactive repli-cation and more advanced data locality sensitive scheduling in network-poor environments.
The remainder of the chapter is organized as follows. First, Section2 describes the unique requirements and challenges for resource man-agement in desktop grids. Sections 3 and 4 describe the resource man-agement techniques used in the Entropia 2000 Internet Desktop Gridand then the DCGrid 5.0 Enterprise Desktop Grid systems. Section 5

3
explores future directions in resource management, in particular, exten-sions to data-intensive applications needed for bioinformatics. Finally,Sections 6 and 7 discuss the related work and a range of future directions.
2. RESOURCE MANAGEMENTREQUIREMENTS FOR DESKTOP GRIDS
Large scale distributed computing using laptop and desktop systemsface challenges unlike any other form of Grid computing. A principalsource of these challenges is the scale of unreliable, heterogeneous re-sources: hardware, software, and network, which must be combined tocreate a reliable and robust resource. Another challenge is creating asecure resource from insecure components. Finally, there is the chal-lenge of matching application requirements to the available resource inan effective manner.
2.1 Resource Management for Internet GridsA resource manager must characterize the resource environment from
hardware information (e.g. processor type, free memory, processor uti-lization, software configuration such as operating system and version).In general, all of these quantities are dynamic and must be monitoredcontinuously. The information is tagged with an Entropia network iden-tifier for each machine, because system and IP names are transient.
Network characterization is also critical, including bandwidth avail-able to each client, whether its network connection is continuous orintermittent with some pattern, what protocols can be used to com-municate, and geographic considerations. Geographic concerns may beperformance related – shared bandwidth (many clients at the end of athin pipe) or legal – (restrictions on cryptographic use, data placement,software licenses, etc.).
The resource manager not only needs to worry about the robust com-pletion of individual work assignments (tasks), but also the functionalstatus of individual clients. Malfunctioning clients must be diagnosedand removed from the list of available clients. Failure to do so can resultin sinks or “black holes” for tasks, i.e., reporting completion of largenumbers of tasks quickly without producing results. Such behavior isvery damaging to the system – preventing other nodes from completingthose tasks and resulting in the overall failure of a job.
Once the Grid resources have been characterized, the management ofthe resources begins as tasks are scheduled, monitored and completed.Tasks must be matched to appropriate clients while observing any addi-

4
tional requirements of priority and task association. To optimize networkbandwidth usage scheduling may need to be data locality aware.
Once a task is scheduled its progress is monitored to assure comple-tion. Progress monitoring responsibility is split between clients whichmonitor resource limits (memory, disk, thread counts, network activity,etc.) and the server which is responsible for rescheduling the task if theclient fails or takes too long. For performance or reliability, tasks canbe scheduled redundantly (sent to more than one client), requiring themanager to decide which result to accept and when to reassign clients.
2.2 Resource Management for Enterprise GridsThe issues faced in building a Desktop Grid in the Enterprise (e.g. a
large corporation, university, etc.) are similar to those on the Internet.Resources must be characterized and tasks must be scheduled againstthe available resources, tasks monitored and completed robustly withfailures properly diagnosed and recovered. Enterprise grids have oneadvantage in that network management tools may provide configurationand performance information. While enterprises may have slightly lesssystem heterogeneity, the reduction is generally not enough to signif-icantly simplify management. The typical case – fast machines withhigh-speed network connections – represent valuable resources, but theymay present server scaling problems.
Enterprise environments do present novel challenges. One is an evengreater demand for unobtrusiveness on the desktop and the network. Atthe same time, a higher degree of desktop control is possible. Obtrusivebehavior from applications that use large fractions of available memoryand disk may be tolerable during non-business hours.
With always-on clients, centrally initiated scheduling and applicationdata transfer is not only feasible, but also desirable. The work units canbe shorter, with corresponding increases in server load and scalabilitychallenges. In general, machines in an Enterprise environment are morereliable than those on the Internet, which is factor in scheduling forperformance as well as throughput. Pools of more reliable clients mayallow applications to exploit peer-to-peer communication without thefault tolerance concerns normally raised by this style of computing, butwith additional requirements to gang schedule the communicating nodes.
Data protection, through digests, and data privacy, through encryp-tion, concerns vary from one Enterprise to another. Accidental datatampering is as much an issue in the Enterprise as it is on the Internet,but privacy issues vary considerably. In some enterprises the value ofthe data may be such that any disclosure to unauthorized personnel is

5
unacceptable so encryption is required throughout the system. In othercases the Enterprise may elect to eliminate the overhead incurred withdata encryption (significant for some applications).
The administrative effort to manage the system (manageability) isnot only more critical in an Enterprise environment, but a Desktop Gridmust integrate well with existing Enterprise resource management sys-tems, including cost-recovering accounting systems. Central softwareconfiguration management obviates the need for clients to support theself-upgrading used in Internet grids.
3. ENTROPIA 2000: INTERNET RESOURCEMANAGEMENT
Figure 1.1. Entropia 2000 System Overview.
The Entropia 2000 system (see Figure 1.1), an Internet Grid comput-ing platform, consists of four main components; the Task Server, the FileServer, the App Server, and the Entropia Client (EC). The EC is thelocal resource manager on each client and reports machine characteris-tics to the Task Server, requests assignments, executes the applicationclient specified by an assignment, and ensures the unobtrusiveness ofthe platform on member (users donating their unused computing cy-cles) machines. The App Server decomposes an application job into itssubcomponents, called application runs, and assigns them to applica-tion clients. The Task Server is the heart of the Entropia 2000 systemscheduling and resource management capability. The Task Server’s mainresponsibilities are the registration , scheduling , and the administrationof EC’s. The Task Server database contains all of the information neces-sary to describe the EC’s and the application clients in order to enableefficient scheduling. This approach allows the grouping of online and

6
offline resources to be assigned to App Servers, eliminating the need foran EC to negotiate its assignment when it becomes available.
3.1 Resource ManagementThe system automatically characterizes each EC (memory size, disk
space, processor speed, OS type, network speed, firewall protected, ge-ographical location, and availability) to enable efficient scheduling. Anagent on the client collects information from the WindowsTM registryand other local sources and transmits the information to the Task Serverperiodically and upon startup. The one exception is the EC’s geographi-cal location, where the Task Server employs an external service to resolveIP addresses to geographical locations. Several resource attributes arecollected from the owner of the computing resource, including systemavailability, network type/speed, and firewall protected characteristics.Availability indicates when the machine may be used. To allow appli-cations to employ a custom network protocol through firewalls, proxytechnology was developed to encapsulate all communications to and fromapplication clients.
3.1.1 Advantages and Limits of Centralized Management
A key feature of the centralized database approach is the ability togroup online and offline resources into an Application Pool to be utilizedby an App Server. Because the computing resources are not dedicated,Application Pools are configured to provide sufficient compute power.
Another powerful feature is the ability for an administrator to stop,restart, or remove an EC from the platform. Administrators can easilyaccess and analyze a work history for an EC and determine if it wasstuck. Because each EC checks in with the Task Server for assignmentsthe EC can be informed to upgrade itself to a specific cached applicationclient to a newer version which is network accessible. Therefore, thecentral database approach also provides easy deployment of new versionsof the EC and application clients, enabling central version management.
3.1.2 Application Pools
Application pools (see Figure 1.2) are the key to Entropia 2000 schedul-ing. Each App Server (see Figure 1.1) is associated with an applicationpool (a list of EC’s allocated for a specific job , the number of assign-ments in the job, the number assignments completed, and the pool prior-ity). Pools can group EC’s with similar capabilities to deal with hetero-geneity. Pre-allocating EC’s supports efficient task assignment becausepolicy decisions are pre-evaluated, not done for each task assignment.

7
Figure 1.2. Application servers are associated with pools of resources (ApplicationPools).
3.2 SchedulingThe Application Pools and their priorities determine a large part of
the scheduling policy. In the normal case, an EC requests a task from theTask Server, it will find the highest priority Pool of which that machineis a member and send it the application client, the startup parametersneeded, and the connection information for the associated App Server.
Across the Internet, intermittent network connectivity is common.There are two major issues: the direction of communication and durationof assignments. Computing assignments must be “pulled” from the TaskServer with short-lived connections. If a request fails, the EC delaysand retries with random backoff. This supports system scalability. Inaddition, the amount of work per run is adjusted to fill the useful CPUtime between network connections. Choosing the parameters for suchbackoff is critical for system performance. It was shown statistically thatthe time between requests for tasks by an EC are not correlated to thelength of the computation performed, but instead correlated to machineInternet connectivity characteristics. Empirically, we found that theefficiency of an EC increases with the length of the task being assignedto the EC with diminishing returns around 12 hours. App Servers usethis observed behavior to schedule a number of application runs at eachinteraction to maximize EC efficiency.
3.3 PitfallsAmong the most challenging issues in making Entropia 2000 work
reliably are those of scale and congestion. If requests are distributedevenly in time, the system could handle one million EC’s. However, there

8
were a number of circumstances that lead to entrainment or convoys andscaling problems. Causes included: server outage, network outage, ECreconfigurations, application misconfiguration, etc. If a server outageoccurred, it caused most of the EC’s to be starved for tasks. Whenthe Task Server came up, it gets flooded by task requests from EC’s,and crashed again. This type of problem was cited for [email protected] careful design of the backoff scheme to include randomization andexponential backoff achieved stability for Entropia 2000 systems.
4. DCGRIDTM 5.0: ENTERPRISERESOURCE MANAGEMENT
The DCGridTM 5.0 software platform significantly improves uponthe Entropia 2000 platform in the areas of resource management andscheduling efficiency. The App Servers and application clients were re-placed with components providing generalized job and subjob manage-ment capabilities, simplifying both the system and applications. In DC-Grid 5.0, all scheduling and fault tolerance issues are handled generically,enabling applications to ignore most aspects of distributed computing –generic sequential applications work fine.
One of the biggest departures between Entropia 2000 and DCGridTM
5.0 was that Entropia 2000 was an Internet based platform whereasDCGridTM 5.0 is an Enterprise based platform. This eased the require-ments on resource information gathering. Because of the non –restrictivecommunications allowed in Enterprise networks, firewalls separating theserver side components and the EC’s are no longer an issue and thereforebecome an extraneous piece of information. The assumption of no fire-walls in the Enterprise network environment allows for a greater range ofapplications that assume direct connectivity, to be deployed and allowsfor a number of communication protocols which could not be deployedon the Internet.
4.1 Adapting the Internet approach (layeredscheduling)
As can be seen in Figure 1.3, the scheduling and resource manage-ment of DCGridTM 5.0 has three layers: the Job Management layer, theSubjob Management layer, and the Resource Management layer. TheResource Management layer encompasses what was previously the TaskServer and the functions performed by Application Servers and Clientsare now handled generically by the Job Management and Subjob Man-agement layers.This approach cleanly separates physical resource man-agement, job decomposition and management, and subjob scheduling.

9
Figure 1.3. DCGrid 5.0 Components.
Definitions of Work elements:Job – the original work that is to be performed by a platform user.Subjobs – a single-machine job component. Jobs are decomposed
into subjobs and distributed to the computing resources.Run – an assignment of a subjob to a specific computing resource.
There may be more than one run per subjob.Applications – the program executables used by subjobsThe Job Management layer is utilized by a platform user to submit a
specific problem for the platform to solve, and its constraints. The JobManagement layer will decompose the problem to a number of indepen-dent subjobs to be worked on by the nodes within the system. After theresults of each subjob have been acquired, the Job Management layerwill compile them into a single result an present it back to the plat-form user. The Job Management layer’s primary responsibilities includedecomposing a job description into the appropriate number of subjobdescriptions, submitting subjobs to the Subjob Management layer, andretrieval and reconstitution of subjob results into a job result. The JobManagement layer is a purely server side component with an interfacewith the Subjob Management server side components, the File Server,and the user.
The Subjob Management layer’s primary responsibilities include thereception and storage of subjob descriptions and their associated files,the assignment and execution of subjob runs on EC’s, individual resultretrieval and reporting, and the handling of subjob and systemic failureswith respect to subjob scheduling. The Subjob Management layer pro-vides a public interface for subjob submission that is utilized by the JobManagement layer, but can be used by any Job Management system aswell as provided command line submission utilities.

10
Figure 1.4. Subjob Management Layer.
As shown in Figure 1.4, the Subjob Management layer is decomposedinto its individual components; the Subjob Monitor server, the EBSservers, and App Moms. The Subjob Monitor server provides the sub-mission interface for subjobs, subjob description storage in a database,scheduling policies to route subjob runs to EBS servers, policies to han-dle subjob and EBS server failures, and subjob status reporting.
The EBS servers perform assignment of subjob runs to App Mom’s,subjob run result reporting, subjob run heartbeat indicating that thesubjob is executing, EBS server status interface, and fault tolerancepolicies to handle subjob run failures effectively. The Subjob Man-agement system provides the capability to expand the number of EBSservers within the system and distribute the App Mom’s appropriatelyacross multiple EBS servers.
The App Mom provides the local resource management capabilitiesfor a subjob run. It manages all process created by a subjob run en-suring that they do not run too long, too short, or create zombie pro-cesses. The App Mom creates the execution environment specified fora subjob run before execution begins by creating the desired sandboxdirectory structure, downloading necessary files from the File Server ,creating environment variables, and executing the startup script speci-fied by the subjob run description. The App Mom generates the subjobrun heartbeat, which allows for quicker response time to errant subjobsand non-responsive resources. At subjob run termination the App Momtransfers the desired results to the file server and cleans up the executionenvironment.

11
4.2 Resource PoolsDCGridTM extends Entropia 2000’s application pool abstraction into
pool, partition, and queue abstractions to support generalized schedul-ing. Pools are managed by the Resource Management Server and sup-port allocation EC’s to a Subjob Management system – either a generalpurpose or single application system. When a pool is allocated to ageneric Subjob Management system, each EC will instantiate the AppMom and the App Moms will be distributed amongst the EBS Servers.
Within the Subjob Management system, resources can be partitionedto support performance guarantees. For example, a user might haveexclusive access to a partition (group of resources); each a named set ofApp Moms in a pool of computing resource. Administrators organizethe resources by assigning EC’s to partitions.
Submission queues are where work is submitted. Users can submit toparticular partitions by selecting appropriate submission queues. Eachsubmission queue has an associated priority and partition. These at-tributes drive scheduling policies. Queues also have default values fortime to live (in an EBS server), max time to run, and min time to runassociated with them in case they are not specified during submission.
4.3 Scheduling for Robust Execution andPerformance
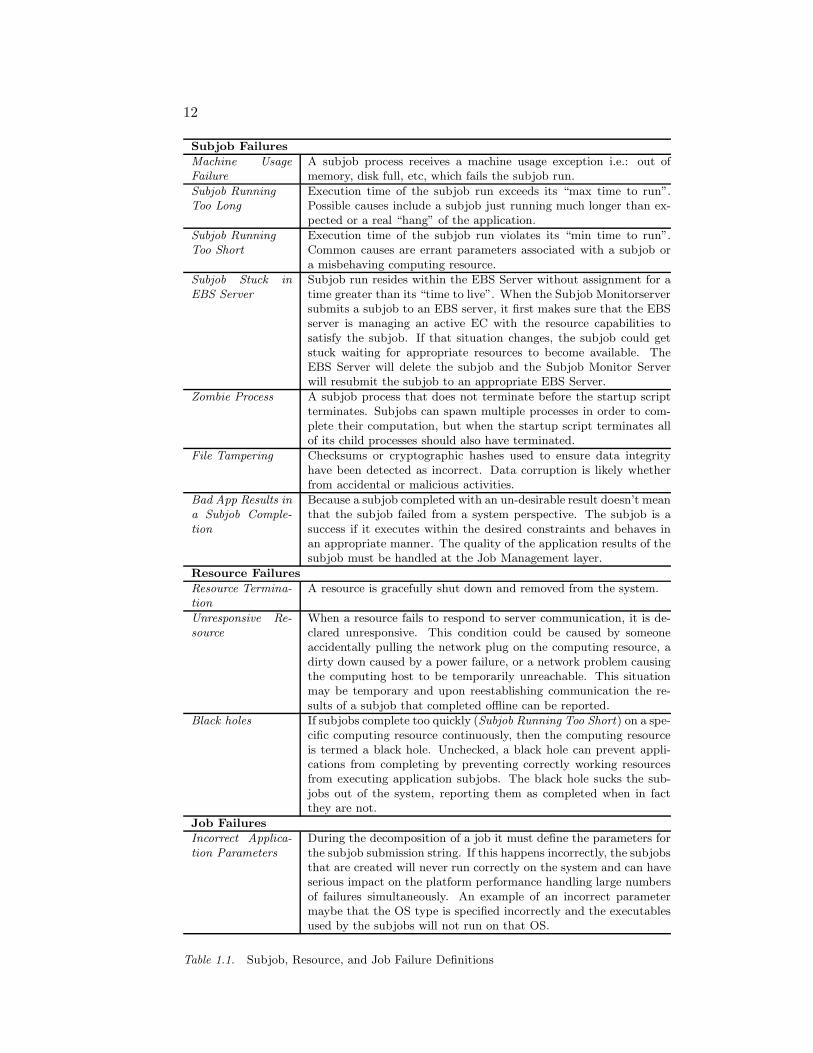
Tables 1.1 and 1.2 describe the failure modes of applications and thesystem, as well as the algorithms that handle them. We discuss a rangeof failures, organizing by the subsystem that handles the failure mode.The generic handling of subjob failures is one of the biggest improve-ments between Entropia 2000 and DCGridTM 5.0. Scheduling in theDCGridTM 5.0 platform is performed at each layer of the system: Re-source Layer, Subjob Layer, and Job Layer. Errors are handled by theirassociated subsystem with the exception of systemic failures, which re-quire a coordinated effort to handle them.
4.3.1 Subjob Scheduling
Subjob scheduling in the “go-path” starts with the Subjob Monitorserver finding the capacity of each EBS server and the capabilities ofthe ir associated computing resources. The capabilities of the EC’s arebinned; the Subjob Monitor defines the bins. The Subjob Monitor firstfinds all of the third retry subjobs (subjobs that have previously beensubmitted twice to an EBS Server without successfully completing) inthe highest priority queue and assigns them to an EBS server. The mon-
12
Subjob Failures
Machine UsageFailure
A subjob process receives a machine usage exception i.e.: out ofmemory, disk full, etc, which fails the subjob run.
Subjob RunningToo Long
Execution time of the subjob run exceeds its “max time to run”.Possible causes include a subjob just running much longer than ex-pected or a real “hang” of the application.
Subjob RunningToo Short
Execution time of the subjob run violates its “min time to run”.Common causes are errant parameters associated with a subjob ora misbehaving computing resource.
Subjob Stuck inEBS Server
Subjob run resides within the EBS Server without assignment for atime greater than its “time to live”. When the Subjob Monitorserversubmits a subjob to an EBS server, it first makes sure that the EBSserver is managing an active EC with the resource capabilities tosatisfy the subjob. If that situation changes, the subjob could getstuck waiting for appropriate resources to become available. TheEBS Server will delete the subjob and the Subjob Monitor Serverwill resubmit the subjob to an appropriate EBS Server.
Zombie Process A subjob process that does not terminate before the startup scriptterminates. Subjobs can spawn multiple processes in order to com-plete their computation, but when the startup script terminates allof its child processes should also have terminated.
File Tampering Checksums or cryptographic hashes used to ensure data integrityhave been detected as incorrect. Data corruption is likely whetherfrom accidental or malicious activities.
Bad App Results ina Subjob Comple-tion
Because a subjob completed with an un-desirable result doesn’t meanthat the subjob failed from a system perspective. The subjob is asuccess if it executes within the desired constraints and behaves inan appropriate manner. The quality of the application results of thesubjob must be handled at the Job Management layer.
Resource Failures
Resource Termina-tion
A resource is gracefully shut down and removed from the system.
Unresponsive Re-source
When a resource fails to respond to server communication, it is de-clared unresponsive. This condition could be caused by someoneaccidentally pulling the network plug on the computing resource, adirty down caused by a power failure, or a network problem causingthe computing host to be temporarily unreachable. This situationmay be temporary and upon reestablishing communication the re-sults of a subjob that completed offline can be reported.
Black holes If subjobs complete too quickly (Subjob Running Too Short) on a spe-cific computing resource continuously, then the computing resourceis termed a black hole. Unchecked, a black hole can prevent appli-cations from completing by preventing correctly working resourcesfrom executing application subjobs. The black hole sucks the sub-jobs out of the system, reporting them as completed when in factthey are not.
Job Failures
Incorrect Applica-tion Parameters
During the decomposition of a job it must define the parameters forthe subjob submission string. If this happens incorrectly, the subjobsthat are created will never run correctly on the system and can haveserious impact on the platform performance handling large numbersof failures simultaneously. An example of an incorrect parametermaybe that the OS type is specified incorrectly and the executablesused by the subjobs will not run on that OS.
Table 1.1. Subjob, Resource, and Job Failure Definitions

13
System Failures
Network Segmen-tation
With large networks a router or switch failure could cause wholesubnets to become disconnected.
Power Outages Power outages could cause server side components to fail and/ormany EC’s, and conversely App Mom’s, to become unresponsiveand executing subjob runs to fail.
EBS Server Fail-ure
In the event of an EBS Server failure subjobs runs may become staleand timeout as well as App Mom’s to go unused during the failure.
Table 1.2. System Failure Definitions
itor chooses a server with appropriate capacity and capabilities but alsoconsiders load balancing. The Subjob Monitor does the same for secondretry subjobs and then first try subjobs. Subjob runs that complete suc-cessfully are flagged complete to the submitter and subjobs that havethree failed runs are reported failed.
Within an EBS server, subjob runs are handled in FIFO with pri-ority for third retry subjobs, then second retry subjobs (subjobs thathave previously been submitted only once to an EBS Server withoutsuccessfully completing), and so on. Subjob run assignments are doneperiodically. The subjob run at the top of the list is assigned to theleast capable available client that can run the subjob. Subjob runs aresubmitted to the least capable available client to allow for maximumusage of client in a fully loaded system. When no available App Mom’scan satisfy a run, it is saved in the queue for the next scheduling period.When a run completes the App Mom reports this to the EBS Server,thereby becoming available. The EBS server in turn reports the subjobstatus to the Subjob Monitor server.
Priorities are only enforced on a submission queue basis; subjobs sub-mitted to high priority queue are sent to an EBS server before others.However, subjobs submitted to a high priority queue will not necessar-ily be assigned to a client. This is subject to the scheduling policy. Inthe EBS server, scheduling depends on the subjobs ahead of it in theassignment list, the length of time to run of the subjobs ahead of it, andthe clients capable of satisfying the request.
Subjob failures affect scheduling through time to live. Once thissubjob timeout is reached, the subjob run is failed to the Subjob Monitorand relevant state removed.
4.3.2 Resource Scheduling
Resources are assigned to Subjob Management systems in units ofpools. These resources are initially declared “Up”. When the ResourceManagement server has received a heartbeat from an EC for a longperiod of time, it declares the computing resource “Disconnected”. If

14
the EC does not communicate with the resource management server forsome time after being declared “Disconnected” the computing resourceis declared “Down” and removed from the system.
When a subjob runtime is too short, meaning that its computing timewas less than its minimum computing time allowed, an error is signaledand the App Mom notifies the local EC . If the EC has three consecu-tive subjobs terminating with runtime too short, the EC declares itselfa black hole and notifies the resource management server, which thenremoves the computing resource from the Subjob Management system.
4.3.3 Job Scheduling
The Job Management system submits jobs , adjusts their attributes,can choose which queues to submit them to, and if appropriate deletesubjobs. Thus, the Job Management system can mediate the accessof multiple jobs to a set of resources. The Job Management systemperiodically checks subjob status to monitor progress. For example, theJob Manager looks for a large number of failed runs for a job. Thisusually indicates that the subjobs were malformed. In this case, the JobManager deletes the remaining subjobs and reports an error to the user.
4.3.4 More Aggressive Techniques
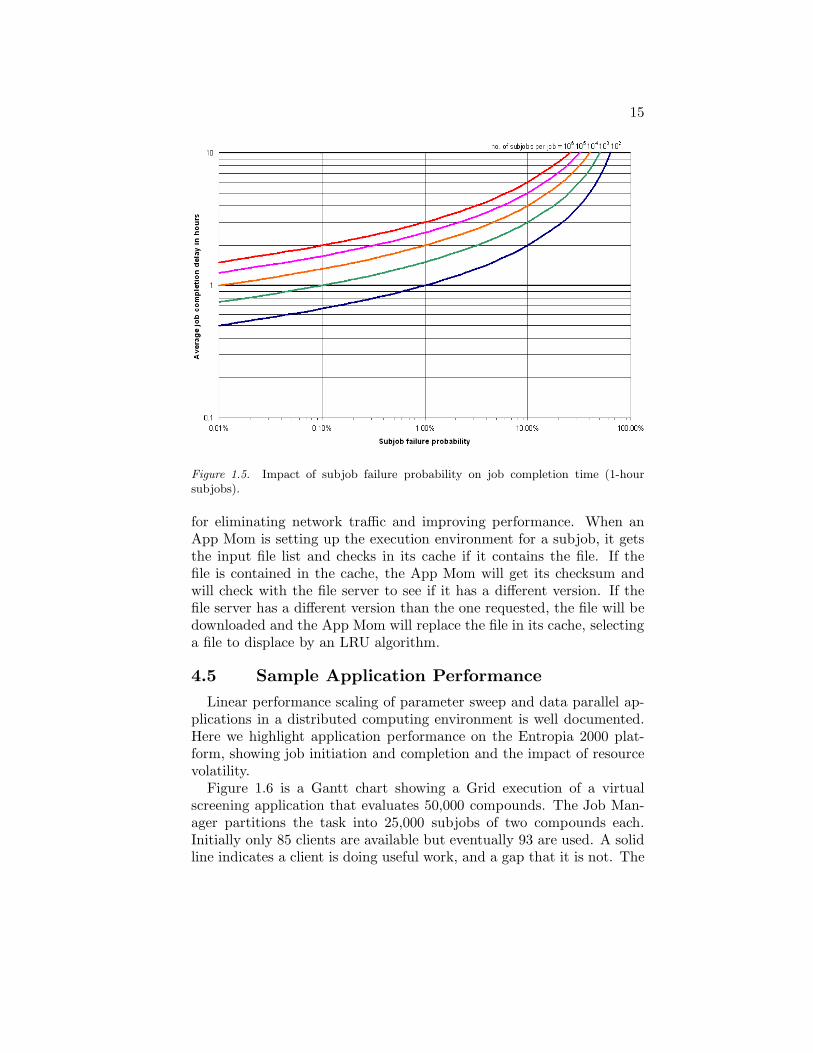
In enterprises, an important capability is timely job completion. How-ever, desktop grids are known to have unpredictable subjob failures,due to machine shutdowns, network disconnects, etc. Empirical datafrom Enterprise desktop grids at several Fortune 500 companies usingDCGridTM 5.0 shows subjob failure rates below one-tenth of one per-cent. For example, in one 25,000 subjobs job, only 25 failed. Figure 1.5shows that rerunning failed subjobs produces good job completion timesgiven the observed failure rates. This works well because all retries arerapidly assigned. Over-scheduling , assigning the same subjob to mul-tiple clients, wastes resources, reducing throughput with little benefit(see Kondo et al., 2002). A better strategy is to schedule subjob retriesagainst the fastest clients available as necessary.
4.4 Scheduling for Network BandwidthManagement
A major concern for enterprises deploying distributed computing isthe system’s network usage. The major network usage occurs whendownloading files (executables and data) from the File Server for eachsubjob execution by the Subjob Management layer. Often, these filesare used repeatedly by subjobs making file caching an important feature
15
Figure 1.5. Impact of subjob failure probability on job completion time (1-hoursubjobs).
for eliminating network traffic and improving performance. When anApp Mom is setting up the execution environment for a subjob, it getsthe input file list and checks in its cache if it contains the file. If thefile is contained in the cache, the App Mom will get its checksum andwill check with the file server to see if it has a different version. If thefile server has a different version than the one requested, the file will bedownloaded and the App Mom will replace the file in its cache, selectinga file to displace by an LRU algorithm.
4.5 Sample Application PerformanceLinear performance scaling of parameter sweep and data parallel ap-
plications in a distributed computing environment is well documented.Here we highlight application performance on the Entropia 2000 plat-form, showing job initiation and completion and the impact of resourcevolatility.
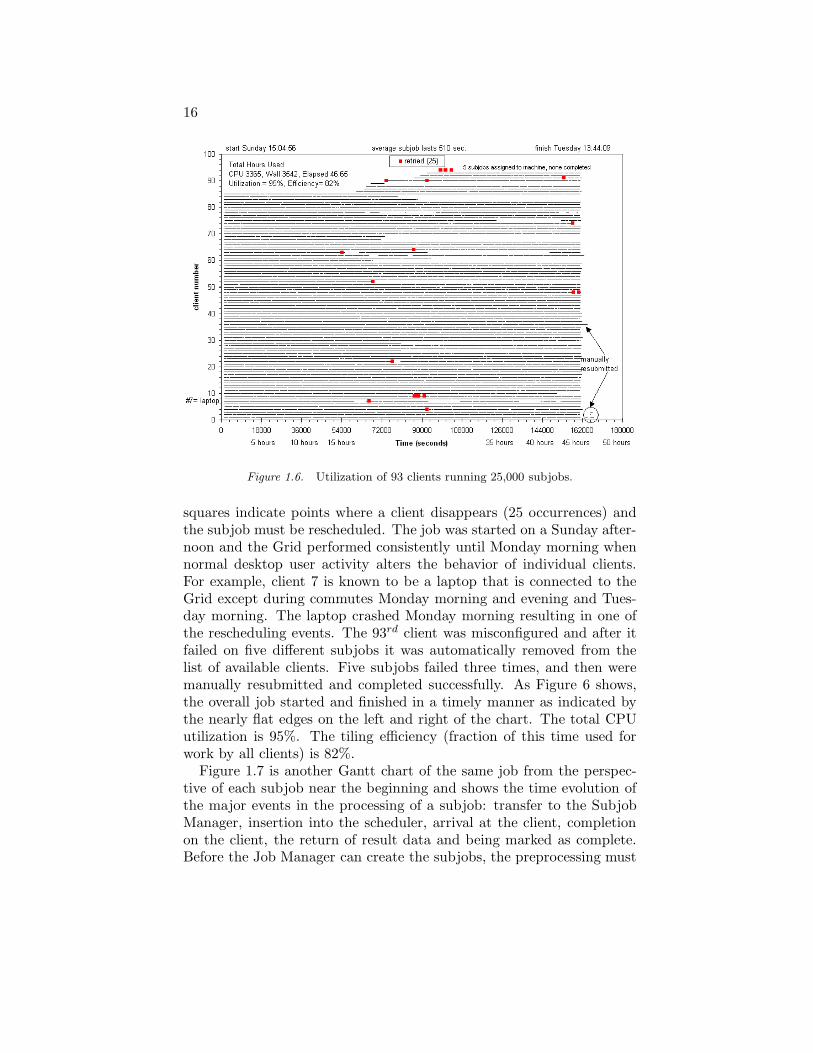
Figure 1.6 is a Gantt chart showing a Grid execution of a virtualscreening application that evaluates 50,000 compounds. The Job Man-ager partitions the task into 25,000 subjobs of two compounds each.Initially only 85 clients are available but eventually 93 are used. A solidline indicates a client is doing useful work, and a gap that it is not. The
16
Figure 1.6. Utilization of 93 clients running 25,000 subjobs.
squares indicate points where a client disappears (25 occurrences) andthe subjob must be rescheduled. The job was started on a Sunday after-noon and the Grid performed consistently until Monday morning whennormal desktop user activity alters the behavior of individual clients.For example, client 7 is known to be a laptop that is connected to theGrid except during commutes Monday morning and evening and Tues-day morning. The laptop crashed Monday morning resulting in one ofthe rescheduling events. The 93rd client was misconfigured and after itfailed on five different subjobs it was automatically removed from thelist of available clients. Five subjobs failed three times, and then weremanually resubmitted and completed successfully. As Figure 6 shows,the overall job started and finished in a timely manner as indicated bythe nearly flat edges on the left and right of the chart. The total CPUutilization is 95%. The tiling efficiency (fraction of this time used forwork by all clients) is 82%.
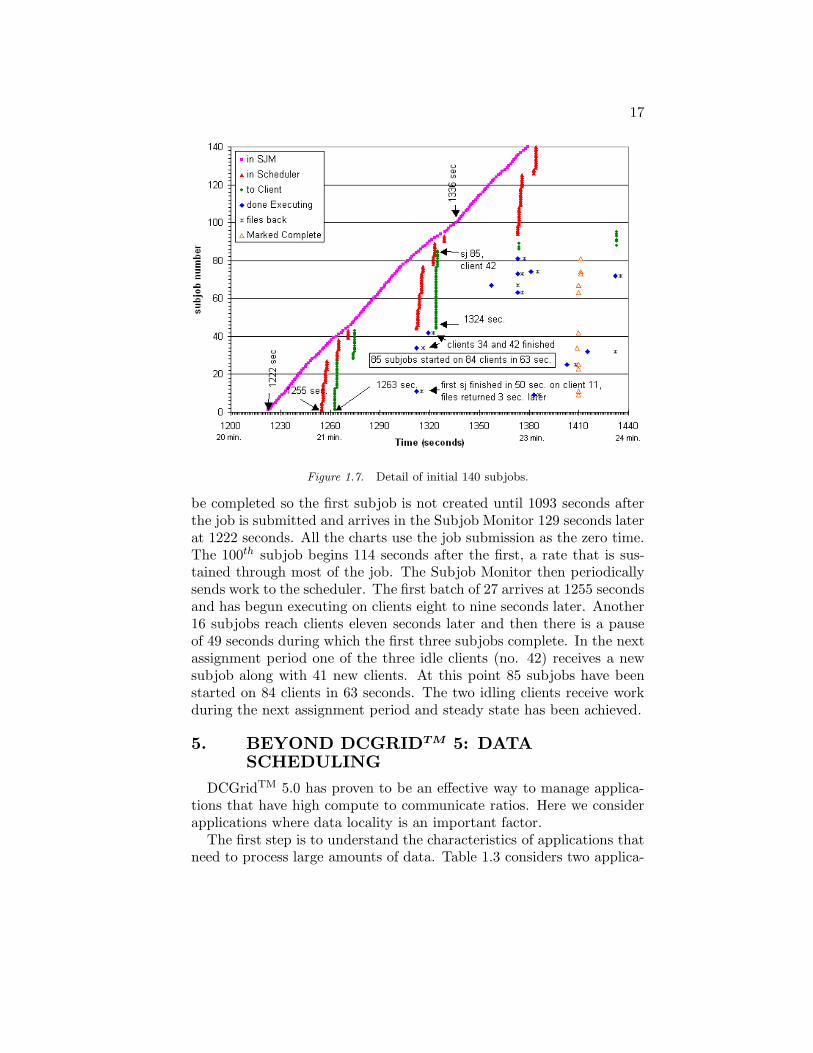
Figure 1.7 is another Gantt chart of the same job from the perspec-tive of each subjob near the beginning and shows the time evolution ofthe major events in the processing of a subjob: transfer to the SubjobManager, insertion into the scheduler, arrival at the client, completionon the client, the return of result data and being marked as complete.Before the Job Manager can create the subjobs, the preprocessing must
17
Figure 1.7. Detail of initial 140 subjobs.
be completed so the first subjob is not created until 1093 seconds afterthe job is submitted and arrives in the Subjob Monitor 129 seconds laterat 1222 seconds. All the charts use the job submission as the zero time.The 100th subjob begins 114 seconds after the first, a rate that is sus-tained through most of the job. The Subjob Monitor then periodicallysends work to the scheduler. The first batch of 27 arrives at 1255 secondsand has begun executing on clients eight to nine seconds later. Another16 subjobs reach clients eleven seconds later and then there is a pauseof 49 seconds during which the first three subjobs complete. In the nextassignment period one of the three idle clients (no. 42) receives a newsubjob along with 41 new clients. At this point 85 subjobs have beenstarted on 84 clients in 63 seconds. The two idling clients receive workduring the next assignment period and steady state has been achieved.
5. BEYOND DCGRIDTM 5: DATASCHEDULING
DCGridTM 5.0 has proven to be an effective way to manage applica-tions that have high compute to communicate ratios. Here we considerapplications where data locality is an important factor.
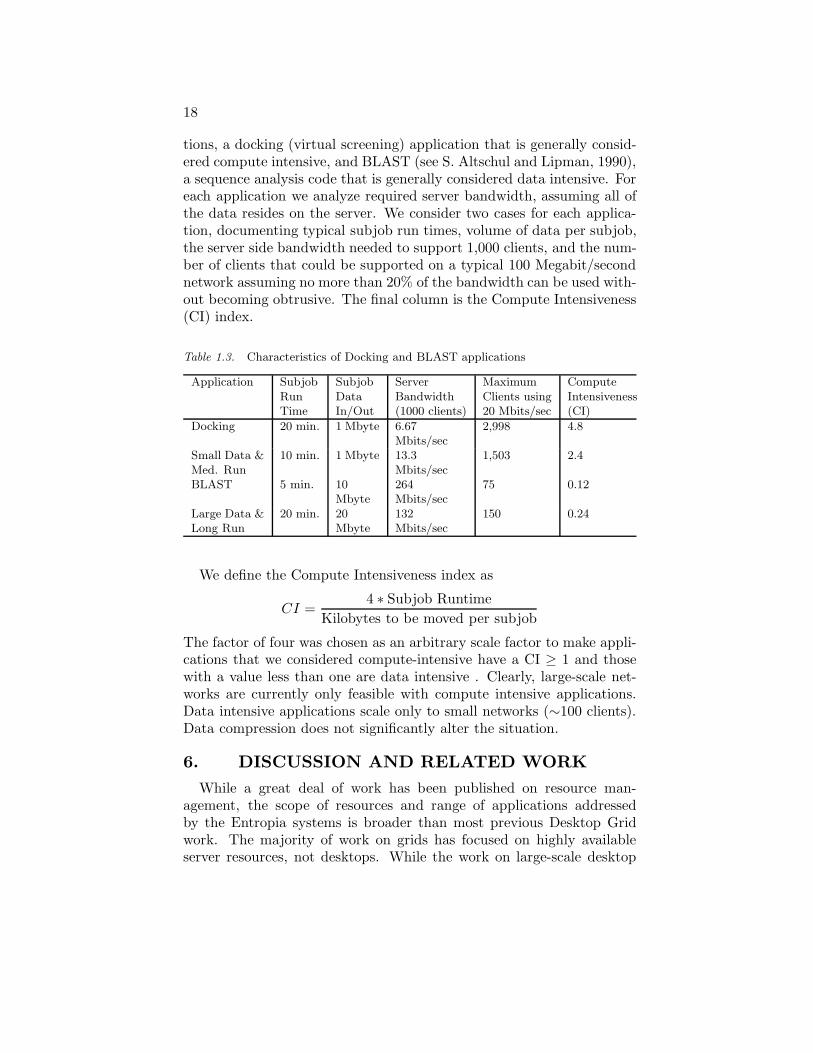
The first step is to understand the characteristics of applications thatneed to process large amounts of data. Table 1.3 considers two applica-
18
tions, a docking (virtual screening) application that is generally consid-ered compute intensive, and BLAST (see S. Altschul and Lipman, 1990),a sequence analysis code that is generally considered data intensive. Foreach application we analyze required server bandwidth, assuming all ofthe data resides on the server. We consider two cases for each applica-tion, documenting typical subjob run times, volume of data per subjob,the server side bandwidth needed to support 1,000 clients, and the num-ber of clients that could be supported on a typical 100 Megabit/secondnetwork assuming no more than 20% of the bandwidth can be used with-out becoming obtrusive. The final column is the Compute Intensiveness(CI) index.
Table 1.3. Characteristics of Docking and BLAST applications
Application SubjobRunTime
SubjobDataIn/Out
ServerBandwidth(1000 clients)
MaximumClients using20 Mbits/sec
ComputeIntensiveness(CI)
Docking 20 min. 1 Mbyte 6.67Mbits/sec
2,998 4.8
Small Data &Med. Run
10 min. 1 Mbyte 13.3Mbits/sec
1,503 2.4
BLAST 5 min. 10Mbyte
264Mbits/sec
75 0.12
Large Data &Long Run
20 min. 20Mbyte
132Mbits/sec
150 0.24
We define the Compute Intensiveness index as
CI =4 ∗ Subjob Runtime
Kilobytes to be moved per subjob
The factor of four was chosen as an arbitrary scale factor to make appli-cations that we considered compute-intensive have a CI ≥ 1 and thosewith a value less than one are data intensive . Clearly, large-scale net-works are currently only feasible with compute intensive applications.Data intensive applications scale only to small networks (∼100 clients).Data compression does not significantly alter the situation.
6. DISCUSSION AND RELATED WORKWhile a great deal of work has been published on resource man-
agement, the scope of resources and range of applications addressedby the Entropia systems is broader than most previous Desktop Gridwork. The majority of work on grids has focused on highly availableserver resources, not desktops. While the work on large-scale desktop

19
grids has largely focused on single application systems, the Entropiasystems described in this paper combine large-scale heterogeneous unre-liable desktop resources with complex multi-application workloads. Keynovel resource management techniques aspects of these two systems in-clude scheduling for intermittent connectivity, resource pooling, innova-tive failure management, and data management.
The idea of distributed computing has been pursued for nearly as longas networks have connected computers. However, most Desktop Gridsystems employed simple scheduling systems as they supported only asingle application or were not operated as resources for extended peri-ods of time. Systems falling into this category include: crack, GIMPS,SETI@home, United Devices (see United Devices, 2003), Parabon Com-putation (see Parabon, 2002), BOINC (see BOINC, 2001), etc. Thesesystems provide only rudimentary resource management, collecting re-source capability information and using it only to gather statistics forthe aggregate “distributed supercomputer”. In practice, scheduling ofwork units is done naively to all the resources in the system, with repli-cation/retry for lost units. Since there is only one application (forwhich many pieces are available), there is no incentive to do more so-phisticated scheduling. This tradition is continued in new open sourceinfrastructures such as BOINC. These projects have all been single-application systems, difficult to program and deploy, and very sensitiveto the communication-to-computation ratio. A simple programming er-ror could cause network links to be saturated and servers to be over-loaded.
Another important body of related work involves batch schedulers fordedicated resources such as clusters, supercomputers, and mainframes.Typically homogeneous resources, or nearly so, and include PBS (seeNitzberg, 2003), Maui Scheduler (see Maui, 2003) and its grid exten-sion Silver (see ??), Turbo Linux system (see Turbolinux, 2002), andLoad-leveler. Because the resources managed by these systems are typ-ically highly reliable (and available), and have limited heterogeneity,these systems do little complex resource management, and deal with re-source unavailability in simple ways (as it rarely happens). The resourcemanagement (and coordination approaches) typically assumes continu-ous connection to resources, and don’t deal systematically with taskfailure other than signaling it. Systems supporting heterogeneous re-source management for complex mixed workloads include Condor. TheMatchmaking (see Basney and Livny, 1999) system in Condor managescomplex heterogeneous resources, and jobs can specify a “class ad” in-dicating their resource requirements and priorities (see ??). However,the resource assignment does not have the same detailed control and op-

20
timization possible in a central database system, and has no high levelunderstanding of collections of jobs and their relationship to application(and user) progress.
Several commercial products address the Enterprise Desktop Gridmarket, including UD’s MetaProcessor and Platform’s ActiveCluster(see Platform Computing, 2002). Because of the difficulty in obtainingaccurate information about commercial product capabilities and short-comings, we omit a comparison of the Entropia system to these othercommercial systems.
Grid technologies developed in the research community have focusedon issues of security, interoperation, scheduling, communication, andstorage. In all cases, these efforts have focused on Unix servers. For ex-ample, the vast majority of Globus (see Foster and Kesselman, 1997) andLegion (see Natrajan et al., 2001) activity has been done on Unix servers.Such systems differ significantly from ones developed by Entropia, asthey do not address issues that arise in a desktop environment, includ-ing dynamic naming, intermittent connection, untrusted users, etc. Fur-ther, they do not address a range of challenges unique to the Windowsenvironment, whose five major variants are the predominant desktopoperating system.
7. SUMMARY AND FUTURESResource management for desktop grids is particularly challenging be-
cause of the heterogeneity in system, network, and model of use allowedfor grid computations. We describe the resource management techniquesused in the Entropia Internet and Enterprise desktop grids, to make thesystems manageable, usable, and highly productive. These techniquesexploit a wealth of database, Internet, and more traditional high per-formance computing technologies and have demonstrated scale to hun-dreds of thousands of systems. Building on the capabilities of these sys-tems, future systems will include more advanced resource classification,and particularly the management of data movement and locality-basedscheduling to optimize network resource consumption.
AcknowledgmentsWe gratefully acknowledge the contributions of the talented engineers
and architects at Entropia to the Entropia system. We specifically ac-knowledge Kenjiro Taura, Scott Kurowski, Brad Calder, and WayneSchroeder for contributions to the resource management system.

21
ReferencesBasney, J. and Livny, M. (1999). Improviong Goodput by Co-scheduling
CPU and Network Capacity. International Journal of High Perfor-mance Computing Applications, 13.
BOINC (2001). The Berkeley Open Infrastructure for Network Comput-ing (BOINC). http://www.isi.edu/nsnam/ns.
Brewin, B. (14 November 2002). Intel Introduces 3Ghz Desktop Chip.Comnputerworld.
Chien, Andrew, Calder, Bradley, Elbert, Stephen, and Bhatia, Karan(2003). Entropia: Architecture and Performance of an Enterprise Desk-top Grid System. Journal of Parallel and Distributed Computing.
Foster, I. and Kesselman, C. (1997). Globus: A Metacomputing Infras-tructure Toolkit. IJSA.
Kondo, D., Casanova, H., Wing, E., and Berman, F. (2002). Models andScheduling Mechanisms for Global Computing Applications. In Proc.of the International Parallel and Distributed Processing Symposium(IPDPS), Fort Lauderdale, Florida.
Maui (2003). The Maui Scheduler. http://mauischeduler.sourceforge.net/.Natrajan, A., Crowley, M., Wilkins-Diehr, N., Humphrey, M., Fox, A.,
and Grimshaw, A. (2001). Studying Protein Folding on the Grid: Ex-periences using CHARM on NPACI Resources under Legion. In Pro-ceedings of the Tenth IEEE International Symposium on High Perfor-mance Distributed Computing (HPDC-10).
Nitzberg, B. (2003). the Portable Batch System.Parabon (2002). The Parabon Distributed Frontier Distributed Com-
puting System.Platform Computing (2002). The Platform ActiveCluster Desktop Com-
puting System. http://www.platform.com/products/wm/ActiveCluster/.S. Altschul, W. Gish, W. Miller E. Myers and Lipman, D. (1990). Basic
Local Alignment Search Tool. Journal of Molecular Biology.SETI@home (2001). http://setiathome.ssl.berkeley.edu.Turbolinux (2002). The Enfuzion System. http://www.turbolinux.com/.United Devices (2003). The United Devices MetaProcessor Platform.
http://www.ud.com/.





























