Embed Size (px)
Citation preview

1
ChaNGa: The Charm N-BodyGrAvity Solver
Filippo Gioachin¹Pritish Jetley¹Celso Mendes¹
Laxmikant Kale¹Thomas Quinn²
¹ University of Illinois at Urbana-Champaign² University of Washington

Parallel Programming Laboratory @ UIUC 04/23/072
Outline
● Motivations● Algorithm overview● Scalability● Load balancer● Multistepping

Parallel Programming Laboratory @ UIUC 04/23/073
Motivations
● Need for simulations of the evolution of the universe
● Current parallel codes:– PKDGRAV– Gadget
● Scalability problems:– load imbalance– expensive domain decomposition– limit to 128 processors

Parallel Programming Laboratory @ UIUC 04/23/074
ChaNGa: main characteristics
● Simulator of cosmological interaction– Newtonian gravity– Periodic boundary conditions– Multiple timestepping
● Particle based (Lagrangian)– high resolution where needed– based on tree structures
● Implemented in Charm++– work divided among chares called TreePieces– processor-level optimization using a Charm++ group
called CacheManager

Parallel Programming Laboratory @ UIUC 04/23/075
Space decomposition
TreePiece 1 TreePiece 2 TreePiece 3 ...

Parallel Programming Laboratory @ UIUC 04/23/076
Basic algorithm ...
● Newtonian gravity interaction– Each particle is influenced by all others: O(n²) algorithm
● Barnes-Hut approximation: O(nlogn)– Influence from distant particles combined into center of
mass

Parallel Programming Laboratory @ UIUC 04/23/077
... in parallel
● Remote data– need to fetch from other processors
● Data reusage– same data needed by more than one particle
Parallel Programming Laboratory @ UIUC 04/23/078
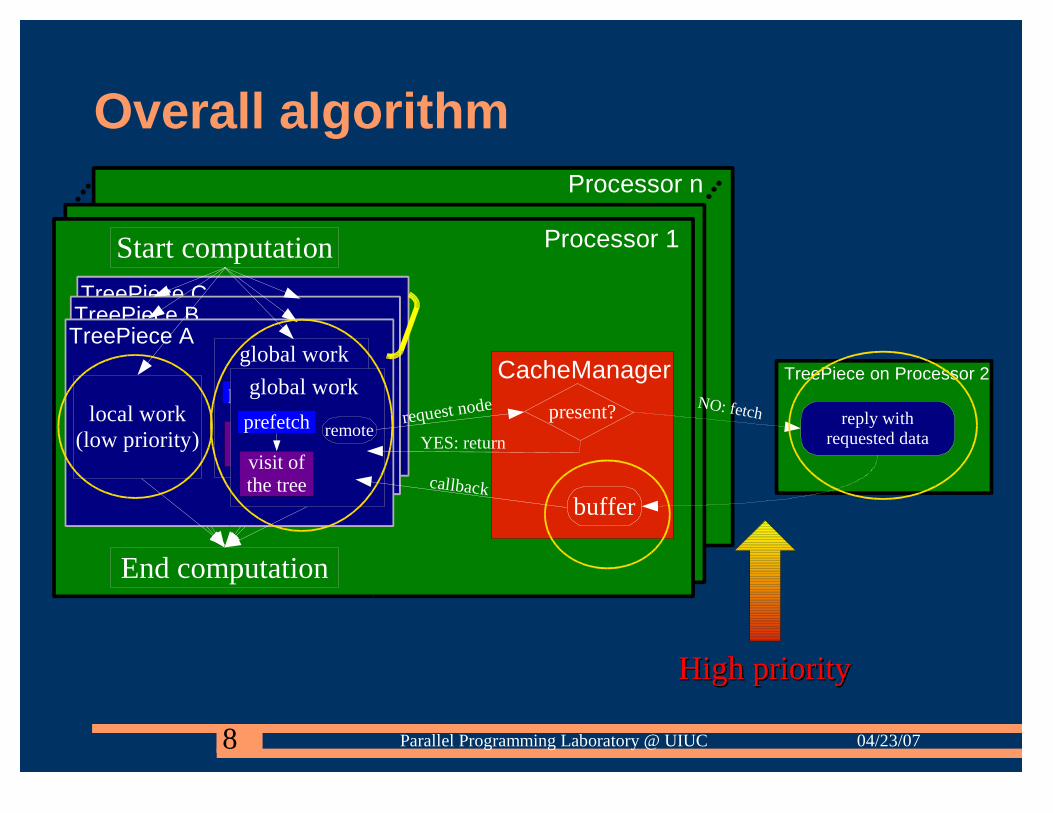
Overall algorithm
Processor 1
local work(low priority)
remotework
miss
TreePiece C
local work(low priority)
remotework
TreePiece B
global work
prefetch
visit ofthe tree
TreePiece A
local work(low priority)
Start computation
End computation
global work
remotepresent?request node
CacheManager
YES: return
Processor n
reply withrequested data
NO: fetch
callback
TreePiece on Processor 2
buffer
High priorityHigh priority
prefetch
visit ofthe tree

Parallel Programming Laboratory @ UIUC 04/23/0710
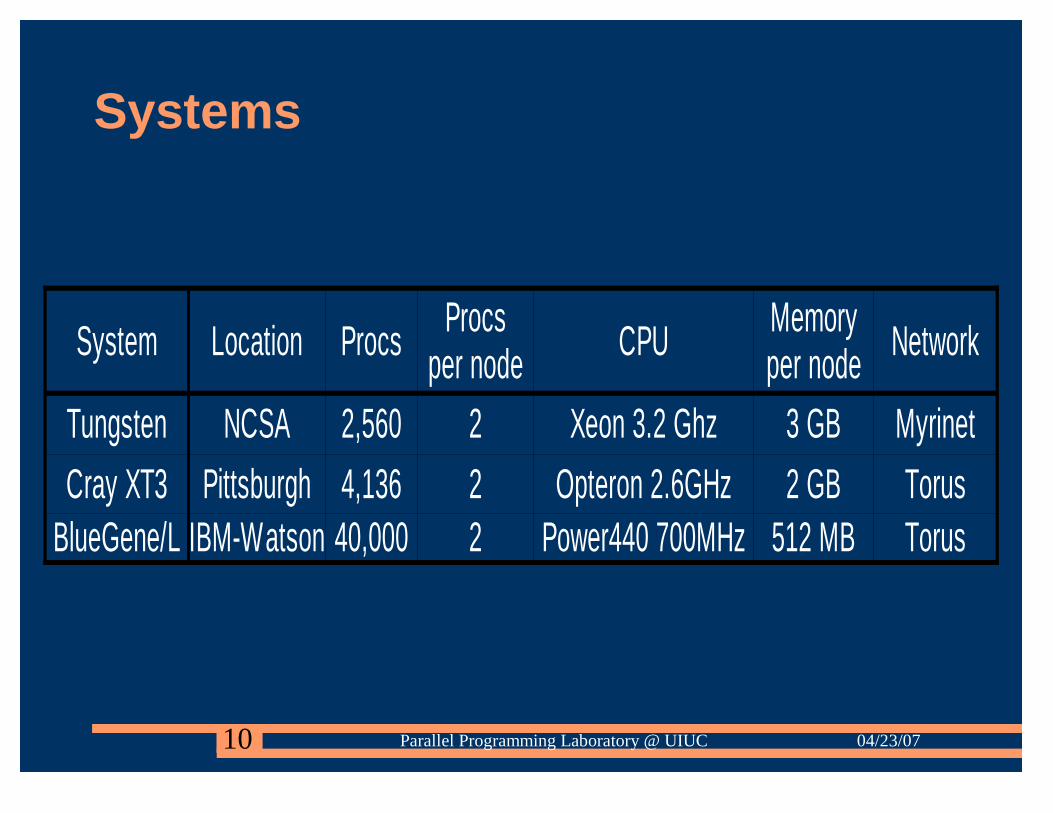
Systems
System Location Procs CPU Network
Tungsten NCSA 2,560 2 Xeon 3.2 Ghz 3 GB Myrinet
Cray XT3 Pittsburgh 4,136 2 Opteron 2.6GHz 2 GB TorusBlueGene/L IBM-Watson 40,000 2 Power440 700MHz 512 MB Torus
Procsper node
Memoryper node
Parallel Programming Laboratory @ UIUC 04/23/0711
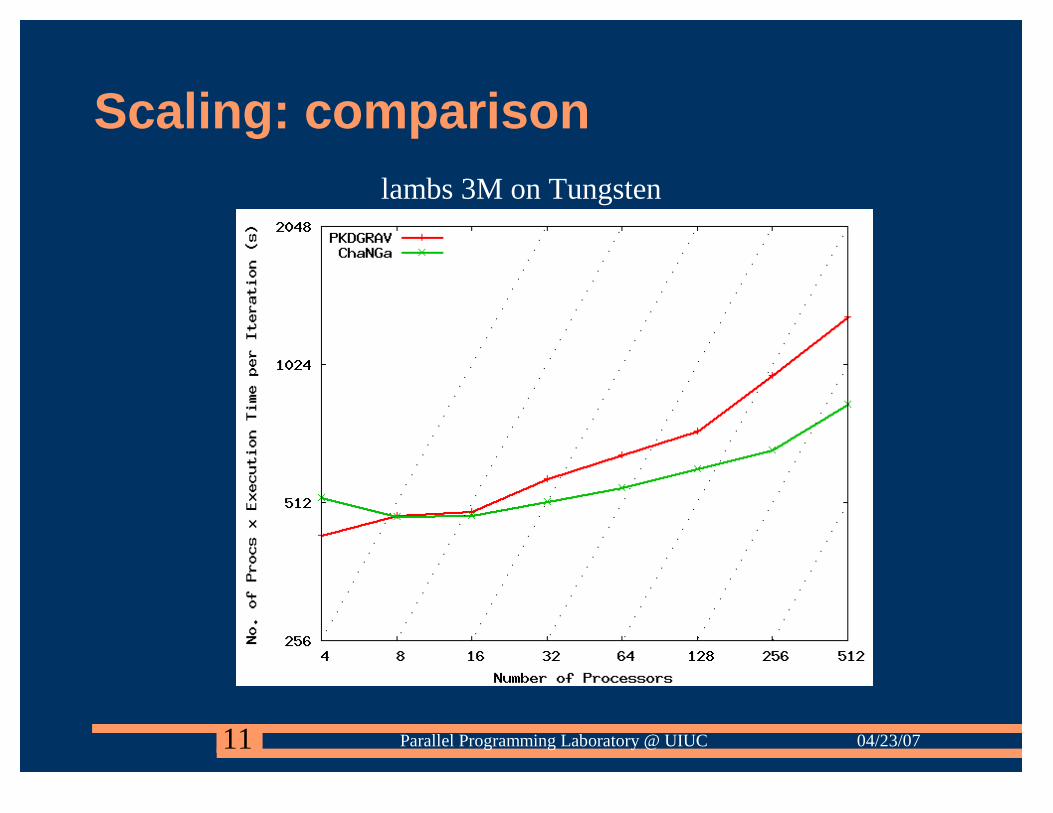
Scaling: comparisonlambs 3M on Tungsten

Parallel Programming Laboratory @ UIUC 04/23/0712
Scaling: IBM BlueGene/L

Parallel Programming Laboratory @ UIUC 04/23/0713
Scaling: Cray XT3


Parallel Programming Laboratory @ UIUC 04/23/0715
Load balancing with OrbLBlambs 5M on 1,024 BlueGene/L processors
white is good
proc
ess
ors
time


Parallel Programming Laboratory @ UIUC 04/23/0717
Scaling with load balancing
Nu
mbe
r of
Pro
cess
ors
x E
xecu
tion
Tim
e pe
r Ite
ratio
n (
s)

Parallel Programming Laboratory @ UIUC 04/23/0718
Multistepping
● Particles with higher accelerations require smaller integration timesteps to be accurately predicted.
● Compute particles with highest accelerations every step, and particles with lower accelerations every few steps.
● Steps become different in terms of load.

Parallel Programming Laboratory @ UIUC 04/23/0719
ChaNGa scalability - multisteppingdwarf 5M on Tungsten

Parallel Programming Laboratory @ UIUC 04/23/0720
ChaNGa scalability - multistepping

Parallel Programming Laboratory @ UIUC 04/23/0721
Future work
● Adding new physics– Smoothed Particle Hydrodynamics
● More load balancer / scalability– Reducing overhead of communication
– Load balancing without increasing communication volume
– Multiphase for multistepping
– Other phases of the computation

Parallel Programming Laboratory @ UIUC 04/23/0722
Questions?
Thank you

Parallel Programming Laboratory @ UIUC 04/23/0723
Decomposition types
● OCT– Contiguous cubic volume of space to each TreePiece
● SFC – Morton and Peano-Hilbert– Space Filling Curve imposes total ordering of particles– Segment of this line to each TreePiece
● ORB– Space divided by Orthogonal Recursive Bisection on
the number of particles– Contiguous non-cubic volume of space to each
TreePiece– Due to the shapes of the decomposition, requires more
computation to produce correct results

Parallel Programming Laboratory @ UIUC 04/23/0724
Serial performance
Execution Time on Tungsten (in seconds)
SimulatorLambs datasets
30,000 300,000 1,000,000 3,000,000
PKDGRAV 0.8 12.0 48.5 170.0
ChaNGa 0.8 13.2 53.6 180.6
Time difference 0.00% 9.09% 9.51% 5.87%

Parallel Programming Laboratory @ UIUC 04/23/0725
CacheManager importance
Number of Processors4 8 16 32 64
No Cache 48,723 59,115 59,116 68,937 78,086
With Cache 72 115 169 265 397
Time (seconds)No Cache 730.7 453.9 289.1 67.4 42.1
With Cache 39.0 20.4 11.3 6.0 3.3
Speedup 18.74 22.25 25.58 11.23 12.76
Number of messages(in thousand)
1 million lambs dataset on HPCx

Parallel Programming Laboratory @ UIUC 04/23/0726
Prefetching
1) explicit● before force computation, data is requested for preload
2) implicit in the cache● computation performed with tree walks● after visiting a node, its children will likely be visited● while fetching remote nodes, the cache prefetches
some of its children

Parallel Programming Laboratory @ UIUC 04/23/0727
Cache implicit prefetching
0 1 2 3 4 5 6 7 8 9 10 11 12 13 147.5
7.55
7.6
7.65
7.7
7.75
7.8
7.85
7.9
7.95
8
8.05
0
5
10
15
20
25
30
35
40
45
50
55
60
65
lambs dataset on 64 processors of Tungsten
TimeMemory
Cache Prefetch Depth
Exe
cutio
n T
ime
(in s
econ
ds)
Mem
ory
Con
sum
ptio
n (in
MB
)
0
1
2
3


Parallel Programming Laboratory @ UIUC 04/23/0729
Charm++ Overview
● work decomposed into objects called chares
● message driven
User view
System view
P 1 P 3P 2
● mapping of objects to processors transparent to user
● automatic load balancing● communication optimization

Parallel Programming Laboratory @ UIUC 04/23/0730
Tree decomposition
TreePiece 1 TreePiece 3TreePiece 2
● Exclusive● Shared● Remote

Parallel Programming Laboratory @ UIUC 04/23/0731
Space decomposition
TreePiece 1 TreePiece 2 TreePiece 3 ...

Parallel Programming Laboratory @ UIUC 04/23/0732
Overall algorithm
Processor 1
local work(low priority)
remotework
miss
TreePiece C
local work(low priority)
remotework
TreePiece BTreePiece A
local work(low priority)
globalwork
Start computation
End computation
remote present?request node
CacheManager
YES: return
Processor n
reply withrequested data
NO: fetch
callback
TreePiece on Processor 2
buffer
Parallel Programming Laboratory @ UIUC 04/23/0733
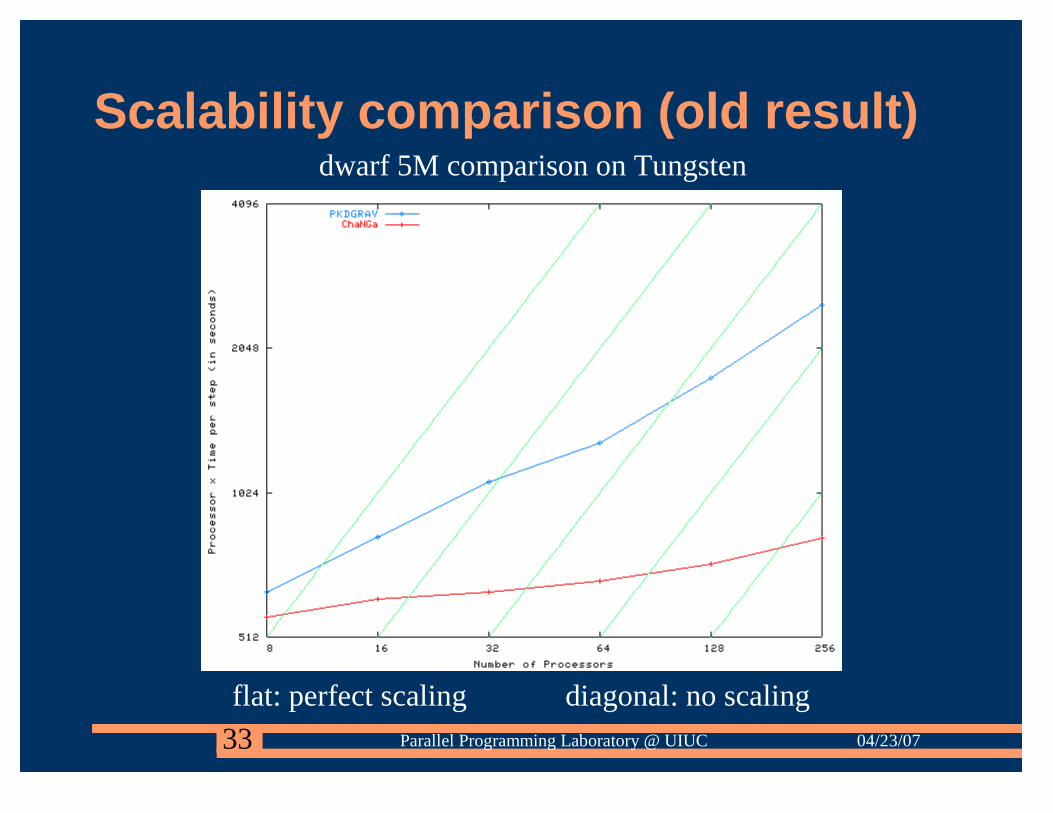
Scalability comparison (old result)dwarf 5M comparison on Tungsten
flat: perfect scaling diagonal: no scaling

Parallel Programming Laboratory @ UIUC 04/23/0734
ChaNGa scalability (old results)
flat: perfect scaling diagonal: no scaling
results on BlueGene/L

Parallel Programming Laboratory @ UIUC 04/23/0735
Interaction list
X •
TreePiece A

Parallel Programming Laboratory @ UIUC 04/23/0736
Interaction lists
Node X
•
opening criteriacut-off
node X is undecided
node X is accepted
node X is opened

Parallel Programming Laboratory @ UIUC 04/23/0737
Interaction list
Interaction ListCheck List
Interaction ListCheck List
Interaction ListCheck List
Interaction List Interaction List
Interaction List
Interaction ListCheck List
•Node X
Node X
Node X
Node X
Interaction ListCheck List
Children of X
Double simultaneouswalk in two copiesof the tree:1) force computation2) exploit this observation
walk 2)

Parallel Programming Laboratory @ UIUC 04/23/0738
Interaction list: results
Number of checks for opening criteria, in millions
lambs 1M dwarf 5M
Original code 120 1,108
Interaction list 66 440
● 10% average performance improvement
32 64 128 256 5120%
10%
20%
30%
40%
50%
60%
70%
80%
90%
100%
dwarf 5M on HPCx
OriginalInteraction lists
Number of processors
Rel
ativ
e tim
e


Parallel Programming Laboratory @ UIUC 04/23/0740
Load balancer
dwarf 5M dataset on BlueGene/L
improvementbetween 15%and 35%
flat lines goodraising lines bad
Parallel Programming Laboratory @ UIUC 04/23/0741
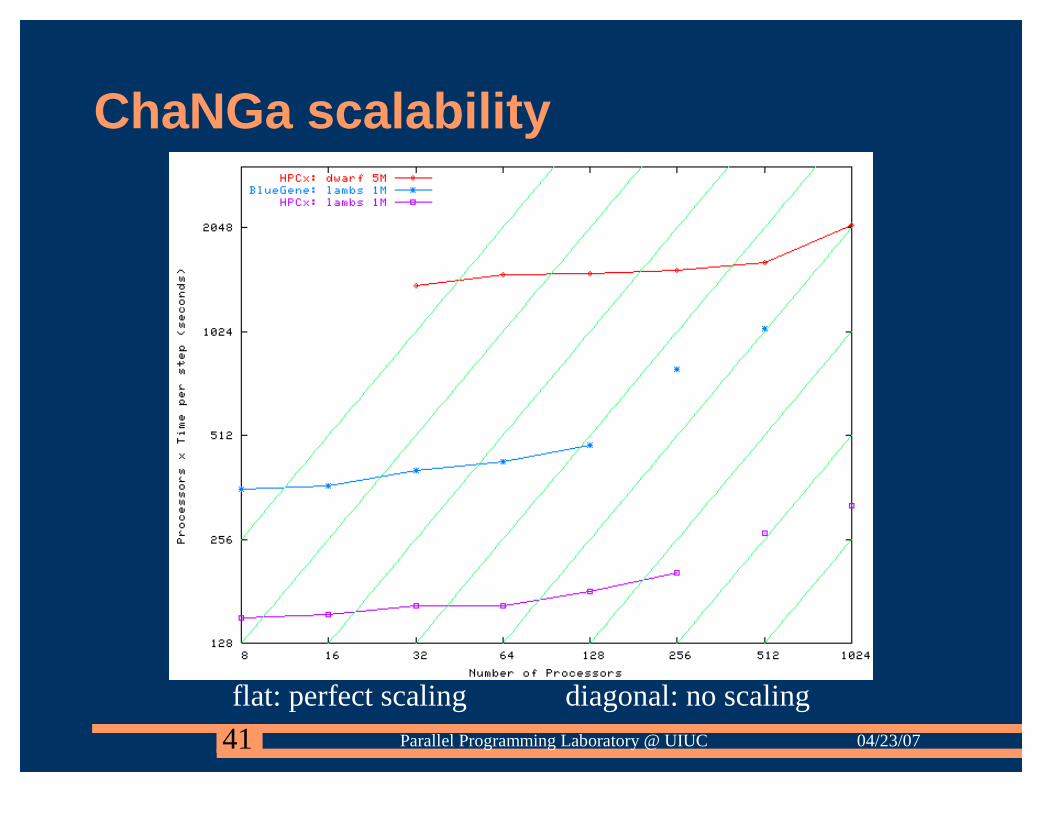
ChaNGa scalability
flat: perfect scaling diagonal: no scaling





























