Embed Size (px)
Citation preview

Challenges in Designing Data Cyberinfrastructure
Strategies
Fillia Makedon
Office of CyberinfrastructureThe National Science Foundation
on leave fromThe Dartmouth Experimental Visualization Laboratory (DEVLAB)
Department of Computer Science, Dartmouth College, USA

The decade of data
• Ubiquitous digital environments • Every scientific community has data & needs data
– Many new complex problems from all sciences– Massive data applications driving research
• Semantic heterogeneity – Few Integrative approaches– Model both raw and processed data– Model dynamic data streams generated by remote
instruments– Simultaneous modeling for (data + instruments +
processes + user/usage) – Model wide range of tools
• From capturing, analysis, modeling, storing, and preservation, to making data more easily accessible for a wider user base.

The tyranny of data: examples from neuroscience
19
Semantic Activation: Category Function Task
P<0.005, k=0
Controls
Alzheimer17
Figure 1: Human brain data example. PET (left) andMRI (right) images
Resting Brain Glucose Metabolism(FDG)Corresponding T1 Weighted Anatomic MRIAtlas Scan
Resting Brain Glucose Metabolism(FDG)Corresponding T1 Weighted Anatomic MRIAtlas Scan
18
fMRI Motor Mapping
Need to model Data and Methods;Need to model Data and Methods; MultispectralMultispectral (MRI, PET, SPECT, Methods, fMRI); (MRI, PET, SPECT, Methods, fMRI); VoluminousVoluminous :50 MB of raw scanner data per 5 minute :50 MB of raw scanner data per 5 minute scan;Hundreds of MB of processed data per subjectscan;Hundreds of MB of processed data per subject

• Sequencing of human genome = 3 billion nucleotides!– How does code translate into
structure & function?
– What parts of the code are switched “on” or “off” and when?
– Algorithms to interpret the information of microarrays describing gene expression
• Discovery process: – virtual, distributed scientific
collaborations across disciplines
– Going from phenotype to genomics and back you need tons of samples!
– Massive data
– Seamless access and sharing
84
Outline
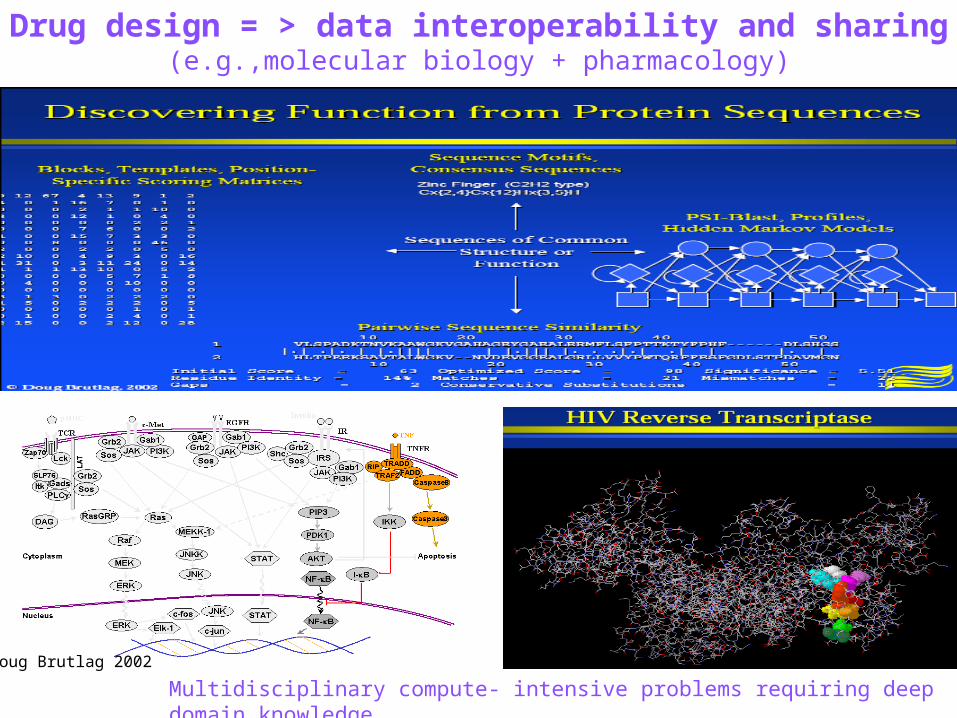
Drug design = > data interoperability and sharing(e.g.,molecular biology + pharmacology)
Multidisciplinary compute- intensive problems requiring deep domain knowledgeDoug Brutlag 2002

The case of lost Data• ‘data’ - everything you store in your hard drive
• Raw / processed data, metadata, spatiotemporal, animations, microdata, sensor data, and interpretations of these. Methods and tools that produced or analyzed data, Documentation and Instruments that generate data…
• Thousands of funded data collections lost each year
• PI loses funding • Lack of a built-in plan of how to preserve them • Loss translates to a real cost
» NSF accelerator, solar observatories, drilling ships, deep submersibles, etc.
• Lost data prevents acceleration of discovery • Need support for unexpected discoveries • Support birth of new disciplines and types of data
» GENETICS+ROBOTICS or ROBOTICS + MEDICAL IMAGING
• “Trickle down” of research

Stewardship of data collections• Scientific data = a publicly funded resource
– Instrumental in enabling discoveries & improved usage of natural resources
– Catalysts and vehicles to solving urgent world problems.
• Scientific collections require stewardship and long-term maintenance– Maintain efficiency, reliability, security, interfaces standards and
convenience (access data without any difficulty)
• Policies in place to answer complex questions:– “when is it important to make private data public?”
– “When are data confidential and who has access?”
– “What data security mechanisms are feasible?”
– “What interoperability standards are practical?”
• Flexible and able to handle change….

Handling change • Changing technologies
– New ways to capture more and more data; – New instruments - microscopes– Teragrid storage facilities – Computing hardware going obsolete
• Changing standards – NASA moon data saved on tapes-no documentation to interpret
• Emergence of new standards– Audio - MP3; – New standards for images; – Varying scientific data standards
• Emerging CI needs • Changing user base and Changing needs of user base
– New problems => new uses of data– “user support” for non-specialist users– …..

A broader and changing user base• Users who expect implicit (invisible) computation• Distributed applications (personal digital devices)• Virtual collaboration teams• Modeling user and usage• Build-in and enforce policies• Automate knowledge / pattern extraction for
decision making

NSF Office of CyberInfrastructure (OCI)• New Office of CyberInfrastructure (OCI) in Office of the Director• New Office Director: Dan Atkins (Prof. U. Michigan)• Office deals with Cyberinfrastructure (CI)
• supercomputers, data management systems, high capacity networks, digitally-enabled observatories and scientific instruments
• software and middleware services • Fiscal Year 2006 budget of $127 mil; FY2007 request for $182.42• Strategic plans for the Vision for 21st Century Discovery http://www.
nsf.gov/od/oci/ci_v5.pdf– High Performance Computing– Data, Analysis and Visualization– Collaboratories, Observatories and Virtual Organizations– Education and the Workforce– International collaboration
• Thrusts and new programs TBA• Very interested in your input ([email protected])

Data Priorities of OCI• Sustainable Data Cyberinfrastructure (CI) strategies • Stability and long-term data preservation • Management of scientific data collections• Economies of scale
– Coordination among disciplines and stakeholders – Data and tools used across disciplines
• Promote innovation: – Make data more accessible and in new ways– Elicit new methods of data organization,
integration, fusion, correlation, etc., for scientific discovery and innovation.

Outline
1. Introduction
2. Data CI challenges
3. Recommendations

Challenges in all areas of computation
• HPC• Networks• E-research• Data management : data analysis and visualization• Databases and DBMS• Security• Users • Access policies• Software• Data collection• Data fusion and synthesis

High performance computing vision NSF blue-ribbon committee http://www.arl.org/forum04
• Large numbers of teraflop computing systems and petabyte data stores, augmented by instruments (colliders and telescopes and vast collections of sensors).
• Lots of highly distributed small processors, sensors, and data stores with highly variable network requirements.
• A high-speed network, carrying petabits per second in its core, to connect systems, services, and tools.

Networks• Ubiquitous, unpredictable complex behavior & dynamics
– HPC mechanisms for discovering and negotiating access to remote resources.– Enabling distributed collaborators to share resources on unprecedented scale
• Implies…– Virtualization of massively large-scale computation and data resources
through high-level abstractions.– Dynamic and adaptive systems.– Context-aware and user-intention-aware resource management.– Algorithms and protocols for collaborative processing.– Group management and control of mobility.– Integration of heterogeneous administrative domains.– Management/control of distributed environments and connected
resources.– Rapidly deployable, self-organizing, self-configuring, and self-healing
systems. – Interoperability, usability, scalability, and robustness of future mega-
scale autonomous systems.

E-research environments• Collaborative and user-centered
– Solution to a science problem => distributed use of resources.– http://www.cra.org/CRN/articles/may03/freeman.landweber.html
• Associated services – Computational, data acquisition and management services– Available through high-performance networks– Metrics for Data quality:
• Data source; uniqueness; persistence; noise, and other
• Automated data modeling– Automated feature extraction from data at their source– Modeling unorthodox data (e.g. weblogs)– Intelligent user/data collection interfaces:
• combine workflow, security, feature extraction, error identification.
• Analysis tools to pre-process high-volume data – E.g., stream mining (still at theoretical phase)– **Data interoperability problems

Data Analysis and Visualization
• Integrate Data analysis and visualization into data processing
• However, data analysis varies and depends on • multimodality, data sensitivity, whether data is static
or dynamic, whether to process fast or insist on accuracy, etc.
• Also: Visualization not always intuitive• Need: Seamless connection between data analysis &
visualization tools• E.g., “How is time-critical information best
displayed? “(http://dimacs.rutgers.
edu/Workshops/Streaming/announcement.html)

Data management• Automated metadata generation: hard problem
– Not one process: different algorithms for different types of data– Difficult to automate (e.g., for images it is unsolved vision problem) – Multiple metadata layers to manage along with original data. – Common Ontologies and performance analysis
• Cross-domain access: data/applications driven– Technical and cultural barriers– Unresolved issues of common data representation – Multi-version access of data collections– Seamless searching across databases– Special data collection management
• Real time processing : data analyzed as it arrives– Rather than off-line, after being stored in a central database – continuously operating, heterogeneous sources make Analysis of
massive amounts of data generated very hard.

Real time data processing• Real time models important for decision-making
• emergency care (bioscience and medicine); • monitoring bridges (structural sensors); • environmental sensors
• Algorithms to compile, discover patterns & synthesize knowledge from data
• Data stream mining – Representing heterogeneous data streams-open – How should we preserve such data?
• Capture, represent, correlate with scientific data, transactional data– purchases, recruitments, debates, transportation data,
micro-activities

Database research needed• Traditional databases not interoperable - organized by
• organization of servers• organization of data- Relational, Object, Spatial & Temporal Databases • processing of data- Metadata dbs, XML, Scientific and statistical, On-line
Analytical Processing Databases (OLAP) • security features-Trustworthy databases; Resilient databases
• Instead, need..• Integration of Text, Data, Code and Streams
– tools for different types of data (Images, bio-data…, non structured data) • Integration over different enterprises, often on an ad hoc basis
– Fast, pervasive access to and response from databases– Powerful for search, retrieval, and mining– Query optimization for streams and for semi-structured data
• Sensor Data and Sensor Networks– execute queries over large sets of sensors nodes and integrate results
• Personalization - query results based on a ‘personal profile’• Enhanced Decision Logic• User Interfaces - semantic web• Multimedia Queries--’find scene where Superman first kisses Lois’

Current DBMS not sufficient• Awkward
• First define a relational schema, make data conform to that schema, and then load it in the system.
– Once data in DBMS, data can only be accessed through SQL interface
• Painful to use• Relational databases do not lend themselves to large data objects or to
certain methods of analysis • majority of scientists use file systems or do management "by hand”
• Not always able to address emerging applications (emergency response)
• Not network aware - only rudimentary support for distributed data. • Lacking DBMS for massively distributed data among
autonomous heterogeneous sites • Manage data in formats dictated by scientists, not by DBMS• Data consumers focus on what they want to discover from the data-not on
details • Self-tuning and self-configuring DBMS that any scientist can use

Integration of databases• Emergency response systems:
– federation of data and tools vital to predicting or forecasting emergencies
• Example: linking in a seamless way ambulance, hospital, telecom with scientific phenomena and environmental databases can monitor for emergency response to disasters.
• Federated databases: – Of greater use if documented and maintained for 5-10 years at a time
– data documentation should not be dependent only on the individual researcher/lab/institution
– A culture of accountability with real enforcements must be provided, similar to the library systems.

Security research• Flawed: Security considered as a stand-alone component
of an architecture, where a separate module is added to provide security
• Security must be integrated into every component- insecure components are points of attack [www.cs.purdue.edu/people/bb#colloquia].
• Privacy : mining aggregate data must protect privacy of individual records
• Proper access control and Separation of duties • Selective encryption of stored data • Management of encryption keys• Encryption for data at rest and for data moving between applications &
database
• Privacy-preserving data dissemination • Idea: make data and metadata a bundle with a self-destruction
mechanism• Policies enforced with obligations - Control who gets what data
• Tradeoffs: Privacy vs access• Data confidentiality vs. data quality

A user-centered CI• More access => more risks
– Make institutional data collections more available to individuals who want to do research with them
– Consider the scientist-legislator: Should she rely on Google to obtain a scattering of meaningless links needed to solve a problem?
• Means policies of access, storage, dissemination to be built into the data.
– NIH has policies regarding what and when and by whom data is made public
• Access policies• Who has access to this data collection, when and for how long?• When do metadata produced from public data become sensitive
or stay private?• Who pays 15 years down the road? • What happens when laws change, e.g., about data access rights

Software challenges• How do we maintain open source software? • How to promote software breakthroughs? • Current software engineering inadequate
• Most software still created by people with little or no knowledge of proven SE approaches with high costs of modification and repair.
• Need better software "building blocks"
• Need software breakthroughs for recording and correlating human actions with scientific data
• Efficient and automatic technologies to record, annotate and store human speech and action
• Extract meaning from massive amounts of video, audio, etc.• Record and correlate with GIS data
– integration of diverse data with GIS is vital to the analysis and extraction of knowledge from spatiotemporal events or data that impact vital decision making.
• Apply tools developed for one set of data to another set of data • examples: linear programming, statistical methods, retrieval, nonlinear
analysis methods, simulations, data analysis, and other

Advanced (integrative) data collection tools
• Automate and integrate data modeling, storage, data flow, mining, security, etc. – common collection standards across scientific disciplines
• Multi-source data analysis– Process data from multiple sources (e.g. multi-sensor data) and then
analyze the integrated data.
– real-time data analysis, e.g., streaming data. • Tool evaluation
– standards for user scientists to choose best tool for application
• Tools for data comparison, evaluation and measurement – enable scientists to detect similarities / differences among vast
amounts of heterogeneous data, not possible to process by a human. – incorporate functions of prediction and measurement of data noise
• Tools to link data across collections

Example: "cyber-enabled chemistry" • Hugely data-intensive applications distributed by
“collaboratories”.– Requires substantial network & computing resources. – Is problem-centered and has problems too complex to solve with any
single method
• Examples: • Molecular design of new drugs, molecular materials, and catalysts• Electrochemistry problems such as molecular structure of double
layers, and active chemical species at an electrode surface• Influence of complex environments on chemical reactions,
understanding and predicting environmental contaminant flows• Chemistry of electronically excited states and harnessing light
energy
• Need tools to allow researchers to focus on the problems themselves by freeing them from simulation details.

Data fusion and synthesisNew ways to organize disparate information
• Fuse scientific data with unrelated data and tools for policy making:
– Surveys, lab and field experiments, census results, archeological findings, speech, weblog data, maps, income accounts, ….. and other.
– Help manage collaboration in fused research environments• Huge impact to political decision making, use of natural resources,
collecting human interactions (e.g., microdata) and promoting scientific discovery
• Collect and integrate machine readable versions
– gather and correlate multimodal sensor data that record biological, remote sensing, environmental, observational, transactional and other types of data.
• Ability to collect mobile types of data (cell phones, PDAs)
– manage them as well as mine them - emergency response systems

“Intelligent” data collection• From the scanner to the database
• Integrate heterogeneous data processing– extract info directly from images– verify compatibility with existing images
• Workflow management– Show current tasks and assign tasks to users - no messages– Overview of available data and status of each item– Combine & visualize results from different analyses– Allow users to select what data to work with
• separate good from bad data• combine appropriate items for analyses• rapid testing: try different sets
• Quality assurance: notification and alerts• detect outliers- define criteria for “normal”• alert operator - Notify when data available, problems with data• control access• security alerts

Outline
1. Introduction: CI importance and benefits
2. Data challenges
3. Recommendations

Recommendations• Importance of small science research (data analysis)• Ability to handle change
• Able to capture more and more data and new instruments • Able to absorb emerging new standards• Services a changing user needs
• International cooperation and scientific exchanges• Leveraging collected data for new information or for services• Connecting to social / world problems
• Virtual collaboration• Advanced HCI techniques for the user
– Integrate views of resources and provide tools for data management
• **Incentives for data sharing** • Built-in conflict resolution / Negotiation mechanisms• Ensure production of freely available data, tools and services • Brokering of different data versions and secure formats

Prepare for the future
• Virtual collaboration: large-scale virtual labs with federated facilities – Conduct virtual, distributed experiments, not
possible in one laboratory, with thousands of physically-distributed people.
– large number of people within and outside national boundaries
• Higher diversity of information. • Enable smaller/alternative institutions/alternative
users to develop and contribute to research

Access through negotiation• Universal sharing: Sharing data, tools and services
– Sharing across databases• The Secure Content Exchange Negotiation System
(SCENS) • Requirements
– Establish User preferences (conditions)– Use Metadata to protect primary data – Use Negotiation to reach agreement on conditions of
primary data exchange– Collaborate through“intelligent” data collection and
common workspaces • built-in authentication, authorization, security alerts, privacy
choices, search personalization, incentives

Interoperability via community efforts• How can we enforce community interaction to enable
consensus and result in interoperability solutions?– Are there sustainable models for stewardship and
long-term maintenance?– How can we ensure every community makes its data
reusable in other contexts and for other purposes from when produced?
• Community driven open standards – Common ontologies and common user interfaces for
usage of data across disciplines.– Common strategies for identity management, access
control, data security and protection, and reliable author attribution.

Specific Interoperability Aims• Uniformly model data, instruments, processes and usage
across communities• Reuse/correlate/fuse/manage data beyond the original
purpose that produced them• Service a broader user base that expects fast, accurate and
implicit computation without deep knowledge of each domain• Secure virtual collaboration among large teams of
physically distributed interdisciplinary scientists• Knowledge synthesis for discovery of patterns across
domains• Resource sharing policies and international collaboration• Provide real-time answers, prediction analysis and simulations
across communities• Security and privacy for real users in real life

Evolving and critical role of libraries• Challenge to universities and academic community
how to preserve knowledge
• Academic libraries at the center – The data of a publication as important as the publication itself. – A publication is metadata, to help find and understand the
underlying data – so long as publication and data can be linked. – => Solutions for preserving digital publications must not be
undertaken in isolation from those for preserving digital scientific data.
• Infrastructure Issues – Role of academic libraries in digital data preservation– Partnerships/coalitions : academic libraries and with other sectors – How to ensure that the research challenges can be met– Test sustainable models for digital data preservation

Sustainable business models
• NSF very interested in this• Financially feasible schemes to provide long-term
stewardship• From data to discovery :
– must have full understanding of data from different domains
• Frameworks for cross-disciplinary collaborations• Unresolved policy standards for sharing & collaboration• Constraints of intellectual property• International and / or cultural differences
• Implicit access policies for different users/usage• Who has access to this data collection, when and for how
long?
• Access policies: Not one easy solution

Need business, library and other expertise to manage diverse data and users
• New law: If public policy is derived from scientific data, then these data must be maintained and documented for as long as they are of use and need
• Issues: • Data (including tools) ownership must be clearly defined • Policies for inter-institutional sharing, conversion to public
versions, legal expertise, copyrights, etc. • Resolve non interoperable database access policies• Make common the criteria and facilities to manage data
ownership, copyrights, evaluation/devaluation, data ranking, data sensitivity
• Mechanisms to update Data periodically (ranking, obsoleteness, updates)
• Controlling access must include – (a) law changes, (b) the need to knowledge, (c) level of security

Technological solutions not enough• Institutional changes needed
– New institutional structures to manage long term data guarantee (over 200 years) stewardship of data.
– Institutions to work with libraries and e-journals on common data maintenance.
– Researchers to archive & report their data to a central library institution
– be rewarded for this service - tenure changes
• Committee of data standards to oversee effort.– Efforts like ICPSR U. Michigan extended through a central
mechanism.– Enforcement of usage violations similar to libraries.– Tracking of data usage, an aspect of this enforcement
• Mechanisms of bartering, negotiation for data sharing and mediation – provided by supporting business ventures – maintenance needs - extend current library model.

Some references
1. CHE Cyber Chemistry Workshop, Washington DC, Oct. 3-5, 2004 http://bioeng.berkeley.edu/faculty/cyber_workshop/index.html
2. Peter A. Freeman and Lawrence L. Landweber. "Cyberinfrastructure: Challenges for Computer Science and Engineering Research". Computing Research News, Vol. 15/No. 3, pp. 5, 9, May 2003. http://www.cra.org/CRN/articles/may03/freeman.landweber.html
3. Social Networks and Cyberinfrastructure (SNAC) conference, NCSA, Urbana, IL, Nov. 3-5, 2005. The SCAC resources page has a list of cyberinfrastructure publications and reports: http://www.ncsa.uiuc.edu/Conferences/SNAC/resources.html




![Makedon Dent Tetovomakedondent.synthasite.com/resources/brosura.pdf · 2011. 2. 8. · Makedon Dent Tetovo 08.02.2011 22:41:13] Make a Free Website with Yola. 05 - My Love.mp3 Designed](https://img.dokumen.tips/doc/110x75/5fc9139f14ef0f43a247ff07/makedon-dent-2011-2-8-makedon-dent-tetovo-08022011-224113-make-a-free.jpg)
























