Embed Size (px)
Citation preview

Ch 8. Graphical ModelsCh 8. Graphical Models
Pattern Recognition and Machine Learning, Pattern Recognition and Machine Learning, C. M. Bishop, 2006.C. M. Bishop, 2006.
Summarized by
B.-H. Kim
Biointelligence Laboratory, Seoul National University
http://bi.snu.ac.kr/

2 (C) 2007, SNU Biointelligence La
b, http://bi.snu.ac.kr/
ContentsContents
8.3 Markov Random Field 8.3.1 Conditional independence properties 8.3.2 Factorization properties 8.3.3 Illustration: Image de-noising 8.3.4 Relation to directed graphs
8.4 Inference in Graphical Models 8.4.1 Inference on a chain 8.4.2 Trees 8.4.3 Factor graphs 8.4.4 The sum-product algorithm 8.4.5 The max-sum algorithm 8.4.6 Exact Inference in general graphs 8.4.7 Loopy belief propagation 8.4.8 Learning the graph structure

3 (C) 2007, SNU Biointelligence La
b, http://bi.snu.ac.kr/
Directed graph vs. undirected graphDirected graph vs. undirected graph
Both graphical model Specify a factorization (how to express the joint distribution) Define a set of conditional independence properties
Parent - childLocal conditional distribution
Maximal cliquePotential function
• Chain graphs: graphs that include both directed and undirected links

4 (C) 2007, SNU Biointelligence La
b, http://bi.snu.ac.kr/
8.3.1 Conditional independence properties8.3.1 Conditional independence properties
In directed graphs ‘D-separation’ test: if the paths connecting two sets of nodes are
‘blocked’ Subtle case: ‘head-to-head’ nodes
In undirected graphs Simple graph separation (simpler than in directed graphs) Checking all the paths btw A and B
if all the paths are blocked by C or not After removing C, if there is any path remaining
Markov blanket for an undirected graph
Shaded circle:evidence, i.e.observed variables
5 (C) 2007, SNU Biointelligence La
b, http://bi.snu.ac.kr/
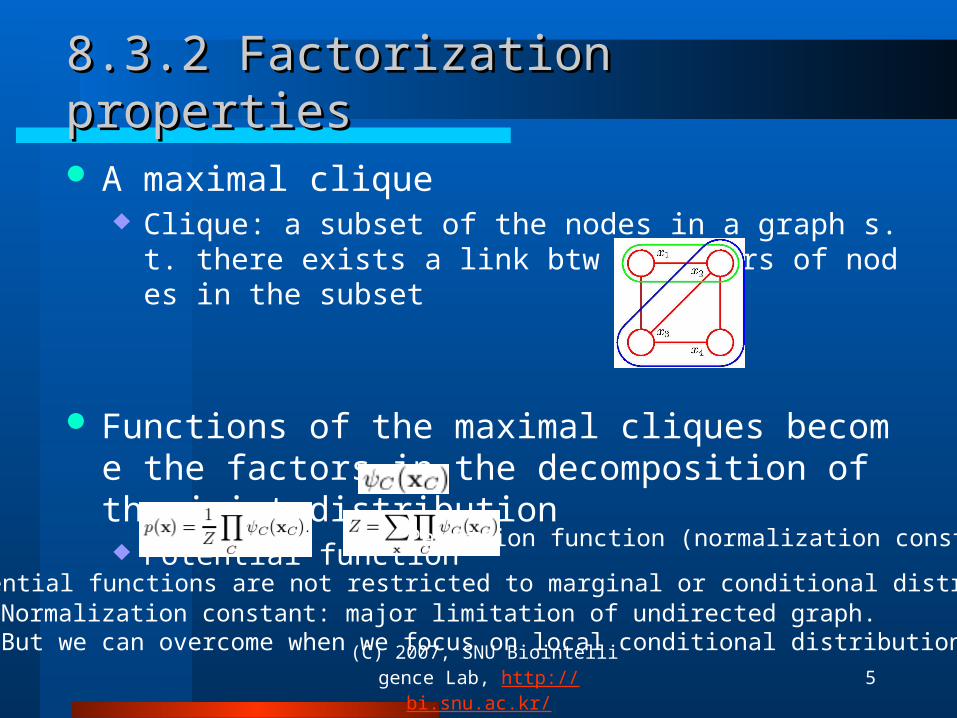
8.3.2 Factorization properties8.3.2 Factorization properties
A maximal clique Clique: a subset of the nodes in a graph s.t. there exists a link bt
w all pairs of nodes in the subset
Functions of the maximal cliques become the factors in the decomposition of the joint distribution Potential function
Partition function (normalization constant)
• Potential functions are not restricted to marginal or conditional distributions• Normalization constant: major limitation of undirected graph. But we can overcome when we focus on local conditional distribution

6 (C) 2007, SNU Biointelligence La
b, http://bi.snu.ac.kr/
and are identical
8.3.2 Factorization properties8.3.2 Factorization properties
Considering formal connection btw conditional independence and factorization Restriction: should be strictly positive
Hammersley-Clifford theorem
Expressing potential functions in exponential form
(a graphical model as a filter)
: energy function( )CE x
Boltzmann distribution

7 (C) 2007, SNU Biointelligence La
b, http://bi.snu.ac.kr/
8.3.3 Illustration: Image de-noising (1)8.3.3 Illustration: Image de-noising (1)
Setting Image as a set of ‘binary pixel values’ {-1, +1} In the observed noisy image In the unknown noise-free image Noise: randomly flipping the sign of pixels with some small
probability
Goal: to recover the original noise-free image
{ 1, 1}iy { 1, 1}ix
(Original image) (noisy-image: 10% noise)

8 (C) 2007, SNU Biointelligence La
b, http://bi.snu.ac.kr/
8.3.3 Illustration: Image de-noising (2)8.3.3 Illustration: Image de-noising (2)
Prior knowledge (when the noise level is small) Strong correlation between and Strong correlation between neighboring pixels and
Corresponding Markov random field A simple energy function for the cliques
form : form :
Bias (preference of one particular sign) : The complete energy function for the model / joint distribution :
ix iy
ix jx
jxix
{ , }i ix y i ix y{ , }i jx x i jx x
ihx
Ising model

9 (C) 2007, SNU Biointelligence La
b, http://bi.snu.ac.kr/
8.3.3 Illustration: Image de-noising (3)8.3.3 Illustration: Image de-noising (3)
Image restoration results Iterated conditional modes (ICM)
Coordinate-wise gradient ascent Initialization: for all I Take one node, evaluate the total energy, change the state of the no
de if it results in lower energy Repeat till some stopping criterion is satisfied
Graph-cut algorithm Guaranteed to find
the global maximum in Ising model
i ix y original 10% noise
Restored by ICM
Restored by graph-cut

10 (C) 2007, SNU Biointelligence La
b, http://bi.snu.ac.kr/
8.3.4 Relation to directed graphs (1)8.3.4 Relation to directed graphs (1)
Converting a directed graph to un undirected graph Case 1: straight line
In this case, the partition function Z=1

11 (C) 2007, SNU Biointelligence La
b, http://bi.snu.ac.kr/
8.3.4 Relation to directed graphs (2)8.3.4 Relation to directed graphs (2)
Converting a directed graph to un undirected graph Case 2: general case. Moralization, ‘marrying the parents’
Add additional undirected links btw all pairs of parents Drop the arrows
Result in the moral graph Fully connected -> no conditional independence properties, in
contrast to the original directed graph We should add the fewest extra links to retain the maximum
number of independence properties
Usage example:Exact inference algorithmEx) junction tree alg.

12 (C) 2007, SNU Biointelligence La
b, http://bi.snu.ac.kr/
8.3.4 Relation to directed graphs (3)8.3.4 Relation to directed graphs (3)
Directed and undirected graphs can express different conditional independence properties
specific view:graphical model as a filter (map)
D map
I map
Perfect map =both I&D map
filtered
Ex) completely disconnected graph is a trivial D map for any distribution
Ex) fully connected graph is a trivial I map for any distribution

13 (C) 2007, SNU Biointelligence La
b, http://bi.snu.ac.kr/
8.3.4 Relation to directed graphs (4)8.3.4 Relation to directed graphs (4)
D: the set of distributions that can be represented as a perfect map using a directed graph
U: ~ using a undirected graph

14 (C) 2007, SNU Biointelligence La
b, http://bi.snu.ac.kr/
ContentsContents
8.3 Markov Random Field 8.3.1 Conditional independence properties 8.3.2 Factorization properties 8.3.3 Illustration: Image de-noising 8.3.4 Relation to directed graphs
8.4 Inference in Graphical Models 8.4.1 Inference on a chain 8.4.2 Trees 8.4.3 Factor graphs 8.4.4 The sum-product algorithm 8.4.5 The max-sum algorithm 8.4.6 Exact Inference in general graphs 8.4.7 Loopy belief propagation 8.4.8 Learning the graph structure

15 (C) 2007, SNU Biointelligence La
b, http://bi.snu.ac.kr/
Introduction / GuidelinesIntroduction / Guidelines
Inference in graphical models Given evidences (some nodes are clamped to observed values) Wish to compute the posterior distributions of other nodes
Inference algorithms in graphical structures Main idea: propagation of local messages Exact inference: section 8.4
Sum-product algorithm, max-product algorithm, junction tree algorithm
Approximate inference: chapter 10, 11 Loopy belief propagation + message passing schedule (8.4.7) Variational methods, sampling methods (Monte Carlo methods)
A
B D
C E
ABD
BCD
CDE

16 (C) 2007, SNU Biointelligence La
b, http://bi.snu.ac.kr/
Graphical interpretation of Bayes’ theoremGraphical interpretation of Bayes’ theorem
Given structure: We observe the value of y Goal: infer the posterior distribution over x,
Marginal distribution : a prior over the latent variable x We can evaluate the marginal distribution
By Bayes’ theorem we can calculate
( , ) ( ) ( | )p x y p x p y x
( | )p x y
( )p x
( )p y
'
( ) ( | ') ( ')x
p y p y x p x
( | ) ( )( | )
( )
p y x p xp x y
p y
(a)
(b)
(c)

17 (C) 2007, SNU Biointelligence La
b, http://bi.snu.ac.kr/
8.4.1 Inference on a chain (1)8.4.1 Inference on a chain (1)
Specific setting N nodes, each discrete node has K states => each potential function: K by K table, total (N-1)K2 parameters
Problem: inference the marginal distribution
Naïve implementation first evaluate the joint distribution and then perform the summations
explicitly => KN values for x, exponential growth with N
Efficient algorithm: exploiting the conditional independence Each summation effectively removes a variable from the distribution
( )np x
`

18 (C) 2007, SNU Biointelligence La
b, http://bi.snu.ac.kr/
8.4.1 Inference on a chain (2)8.4.1 Inference on a chain (2)
The desired marginal is expressed as following
Key concept of the underlying idea multiplication is distributive over addition
The computational cost is linear in the length of a chain
3 op. 2 op.

19 (C) 2007, SNU Biointelligence La
b, http://bi.snu.ac.kr/
8.4.1 Inference on a chain (3)8.4.1 Inference on a chain (3)
Powerful interpretation of (8.52) passing of local messages around on the graph
Recursive evaluation of message
A message passed forwards
A message passed backwards

20 (C) 2007, SNU Biointelligence La
b, http://bi.snu.ac.kr/
8.4.1 Inference on a chain (4)8.4.1 Inference on a chain (4)
Evaluation of the marginals for every node in the chain
If some of the nodes in the graph are observed Corresponding variables are clamped => no summation The joint distribution is multiplied by
Calculating the joint distribution for two neighbouring nodes
One by one separately=> wasteful, duplicated
Storing all of the intermediate messages along the way
2( )O N NK
2(2 )O NK

21 (C) 2007, SNU Biointelligence La
b, http://bi.snu.ac.kr/
8.4.2 Trees8.4.2 Trees
Efficient exact inference using local message passing In case of a chain: linear time in the number of nodes More general case: trees
Sum-product algorithm
A tree in an undirected graph There is one, and only one, path btw any pair of nodes
A tree in a directed graph Root: single node which has no parents All other nodes have one parent Conversion to an undirected graph =>
undirected tree with no more links added during the moralization step
Polytree A directed graph that have more than one parent, but there is still only one path btw any two nodes

22 (C) 2007, SNU Biointelligence La
b, http://bi.snu.ac.kr/
8.4.3 Factor graphs (1)8.4.3 Factor graphs (1)
Factor graphs Introducing additional nodes for the factors themselves Explicit decomposition /factorization Joint distribution in the form of a product of factors Factors in directed/undirected graphs
example
factor(Factor graphs are bipartite)

23 (C) 2007, SNU Biointelligence La
b, http://bi.snu.ac.kr/
8.4.3 Factor graphs (2)8.4.3 Factor graphs (2)
Conversion An undirected graph => factor graph
A directed graph => factor graph
There can be multiple factor graphs all of which correspond to the same undirected/directed graph

24 (C) 2007, SNU Biointelligence La
b, http://bi.snu.ac.kr/
8.4.3 Factor graphs (3)8.4.3 Factor graphs (3)
Converting directed/undirected tree to a factor graph The result is again a tree (no loops, one and only one path connecting any two
nodes)
In the case of a directed polytree To undirected: results in loops due to the moralization step To factor graphs: we can avoid loops

25 (C) 2007, SNU Biointelligence La
b, http://bi.snu.ac.kr/
8.4.3 Factor graphs (4)8.4.3 Factor graphs (4)
Local cycles in a directed graph can be removed on conversion to a factor graph
Factor graphs are more specific about the precise form of the factorization
No corresponding conditional
independence properties

26 (C) 2007, SNU Biointelligence La
b, http://bi.snu.ac.kr/
8.4.4 The sum-product algorithm (0)8.4.4 The sum-product algorithm (0)
The sum-product algorithm allows us to take a joint distribution p(x) expressed as a factor g
raph and efficiently find marginals over the component variables
Exact inference algorithm that are applicable to tree-structured graphs
The max-sum algorithm A technique to find the most probable state

27 (C) 2007, SNU Biointelligence La
b, http://bi.snu.ac.kr/
8.4.4 The sum-product algorithm (1)8.4.4 The sum-product algorithm (1)
Basic setting Suppose that all of the variables are discrete, and so marginaliza
tion corresponds to performing sums
(the framework is equally applicable to linear-Gaussian models)
The original graph is un undirected tree or a directed tree or polytree => corresponding factor graph has a tree structure
Goal: exact inference for finding marginals

28 (C) 2007, SNU Biointelligence La
b, http://bi.snu.ac.kr/
8.4.4 The sum-product algorithm (2)8.4.4 The sum-product algorithm (2)
Two distinct kinds of message From factor nodes to variable nodes: From variable nodes to factor nodes:
Factorization:
View x as the root

29 (C) 2007, SNU Biointelligence La
b, http://bi.snu.ac.kr/
8.4.4 The sum-product algorithm (3)8.4.4 The sum-product algorithm (3)
…
Recursive computation of messages
Two cases in leaf nodes
• Each node can send a message towards the root once it has received messages from all of its other neighbours• Once the root node has received messages from all of its neighbours, the required marginal can be evaluated

30 (C) 2007, SNU Biointelligence La
b, http://bi.snu.ac.kr/
8.4.4 The sum-product algorithm (4)8.4.4 The sum-product algorithm (4)
To find the marginals for every variable node in the graph Running the algorithm for each node => wasteful Efficient procedure: by ‘overlaying’ multiple message passing
Step 1: arbitrarily pick any node, designate it as the root Step 2: propagate messages from the leaves to the root Step 3: now, the root node received messages from all of its neighb
ours=>send out messages outwards all the way to the leaves
By now, a message have passed in both directions across every link, and every node received a message from all of its neighbours
We can readily calculate the marginal distribution for every variable in the graph

31 (C) 2007, SNU Biointelligence La
b, http://bi.snu.ac.kr/
8.4.4 The sum-product algorithm (5)8.4.4 The sum-product algorithm (5)
Issue of normalization If the factor graph was derived from a directed graph
The joint distribution is already correctly normalized
If from un undirected graph Unknown normalization coefficient 1/Z We first run the sum-product algorithm to find the corresponding u
nnormalized marginals => obtain 1/Z after then

32 (C) 2007, SNU Biointelligence La
b, http://bi.snu.ac.kr/
8.4.4 The sum-product algorithm (6-1)8.4.4 The sum-product algorithm (6-1)
A simple example to illustrate the operation of the sum-product algorithm
Designate node x3 as the root.Then leaf nodes are x1 and x4

33 (C) 2007, SNU Biointelligence La
b, http://bi.snu.ac.kr/
8.4.4 The sum-product algorithm (6-2)8.4.4 The sum-product algorithm (6-2)
A simple example to illustrate the operation of the sum-product algorithm (cont’d)
• From leaves to the root
• From the root to leaves

34 (C) 2007, SNU Biointelligence La
b, http://bi.snu.ac.kr/
8.4.4 The sum-product algorithm (6-3)8.4.4 The sum-product algorithm (6-3)
A simple example to illustrate the operation of the sum-product algorithm (cont’d)
Sum-product algorithm applied to a graph of linear-Gaussian variables=> Linear dynamical systems (LDS) in chapter 13

35 (C) 2007, SNU Biointelligence La
b, http://bi.snu.ac.kr/
8.4.5 The max-sum algorithm (1)8.4.5 The max-sum algorithm (1)
Goal of the algorithm To find a setting of the variables that has the larges probability To find the value of that probability An application of dynamic programming in the context of graphical
models
Problem description
Exchanging the max and product operators results in a much more efficient computation

36 (C) 2007, SNU Biointelligence La
b, http://bi.snu.ac.kr/
8.4.5 The max-sum algorithm (2)8.4.5 The max-sum algorithm (2)
In practice, to prevent numerical underflow in products of small probabilities, we take logarithm Logarithm is a monotonic function The distributive property is preserved
max-sum algorithm

37 (C) 2007, SNU Biointelligence La
b, http://bi.snu.ac.kr/
8.4.5 The max-sum algorithm (3)8.4.5 The max-sum algorithm (3)
Finding the configuration of the variables for which the joint distribution attains its maximum value We need a rather different kind of message passing
keeping track of which values of the variables gave rise to the maximum state of each variable
• For each state of a given variable, there is a unique state of the previous variable that maximizes the probability => indicated by the lines connecting the nodes• by back-tracking we can build a globally consistent maximizing configuration

38 (C) 2007, SNU Biointelligence La
b, http://bi.snu.ac.kr/
8.4.5 The max-sum algorithm (4)8.4.5 The max-sum algorithm (4)
The max-sum algorithm, with back-tracking, gives an exact maximizing configuration for the variables provided the factor graph is a tree Important application: the Viterbi algorithm in HMM (ch. 13)
For many practical applications, we have to deal with graphs having loops Generalization of the message passing framework to arbitrary gr
aph topology => junction tree algorithm

39 (C) 2007, SNU Biointelligence La
b, http://bi.snu.ac.kr/
8.4.6 Exact Inference in general graphs8.4.6 Exact Inference in general graphs
Junction tree algorithm Refer explanation in the textbook At its heart is the simple idea that we have used already of
exploiting the factorization properties of the distribution to allow sum and products to be interchanged So that partial summations can be performed, avoiding having to
work directly with the joint distribution

40 (C) 2007, SNU Biointelligence La
b, http://bi.snu.ac.kr/
8.4.7 Loopy belief propagation8.4.7 Loopy belief propagation
For many problems of practical interests, we use approximation methods Variational methods => Ch. 10 Sampling methods, also called Monte Carlo methods => Ch. 11
One simple approach to approximate inference in graphs with loops Simply apply the sum-product algorithm even though there is n
o guarantee that it will yield good results: loopy belief propagation
We need to define a message passing schedule Flooding schedule, serial schedules, pending messages

41 (C) 2007, SNU Biointelligence La
b, http://bi.snu.ac.kr/
8.4.8 Learning the graph structure8.4.8 Learning the graph structure
Learning the graph structure itself from data requires A space of possible structures A measure that can be used to score each structure
From a Bayesian viewpoint
Tough points Marginalization over latent variables => challenging computational
problem Exploring the space of structures can also be problematic
The # of different graph structures grows exponentially with the # of nodes
Usually we resort to heuristics
: score for each model





























