Embed Size (px)
Citation preview

CERN CERN 18 December 2013 18 December 2013GenèveGenève
Scientific collaboration with CERNScientific collaboration with CERNScientific collaboration with CERNScientific collaboration with CERNJ. ChaskalovicJ. Chaskalovic
Institut Jean le Rond d’AlembertInstitut Jean le Rond d’Alembert
University Pierre and Marie CurieUniversity Pierre and Marie Curie
F. AssousF. AssousMathematics DepartmentMathematics Department
Bar Ilan Ariel UniversityBar Ilan Ariel University

AgendaAgenda
The teamThe team
Theoretical and numerical approaches Theoretical and numerical approaches for charged particle beamsfor charged particle beams
Actual itemsActual items
Our future projectsOur future projects
Data Mining for the CERNData Mining for the CERN

The teamThe team

Joel Chaskalovic: Dual expertiseJoel Chaskalovic: Dual expertise– PhD in Theoretical Mechanics (UniversityPhD in Theoretical Mechanics (University Pierre & Marie Curie) Pierre & Marie Curie)
and and EngineerEngineer of « Ecole Nationale des Ponts & Chaussées ». of « Ecole Nationale des Ponts & Chaussées ».– Associate Professor in Associate Professor in MathematicalMathematical ModelingModeling appliedapplied to to
Engineering Sciences, (Engineering Sciences, (UniversityUniversity Pierre & Marie Curie). Pierre & Marie Curie). – DirectorDirector of Data Mining and Media of Data Mining and Media Research, Research, Publicis Group, Publicis Group,
(1993-2007)(1993-2007)..
Franck Assous: Academic and industrial experimentFranck Assous: Academic and industrial experiment– PhD in Applied Mathematics (Dauphine UniversityPhD in Applied Mathematics (Dauphine University, Paris 9)., Paris 9).– Associate Professor in Associate Professor in AppliedApplied MathematicsMathematics, , Bar Ilan Ariel Bar Ilan Ariel UniversityUniversity, ,
((IsraelIsrael). ). – Scientific ConsultantScientific Consultant, , CEA, (FranceCEA, (France), (1990-2002).), (1990-2002).
The teamThe team

Theoretical and numerical Theoretical and numerical approaches for particles acceleratorsapproaches for particles accelerators

Actual itemsActual items
A new method to evaluate asymptotic A new method to evaluate asymptotic numerical models by Data Mining techniquesnumerical models by Data Mining techniques
On a new paraxial modelOn a new paraxial model
Data Mining: a tool to evaluate the quality Data Mining: a tool to evaluate the quality of modelsof models

A new method to evaluate asymptotic numerical models
by Data Mining techniques

The physical problemThe physical problem
• Physical frameworks: collisionless charged particles Physical frameworks: collisionless charged particles beams (Accelerators, F.E.L, …)beams (Accelerators, F.E.L, …)

The mathematical modelThe mathematical model

Approximate modelsApproximate models
Poisson modelPoisson model Neglect the time derivative Neglect the time derivative
Magneto-static modelMagneto-static model Neglect the time derivative Neglect the time derivative
Darwin modelDarwin model Neglect the transverse part ofNeglect the transverse part of
Paraxial modelParaxial model Use the paraxial propertyUse the paraxial property
Exploit given physical/experimental assumptions:Exploit given physical/experimental assumptions:

How we derive a paraxial modelHow we derive a paraxial model
1.1. Write the equations in the beam frame.Write the equations in the beam frame.
2.2. Introduce a scaling of the equations.Introduce a scaling of the equations.
3.3. Define a small parameter.Define a small parameter.
4.4. Use expansion techniques and retains the first orders.Use expansion techniques and retains the first orders.
5.5. Build an Build an ad hocad hoc discretization. discretization.
6.6. Simulations with numerical results.Simulations with numerical results.

The asymptotic expansionsThe asymptotic expansions

• Second order:Second order:
The first paraxial model The first paraxial model (axisymmetric case)(axisymmetric case)
• First order:First order:
• Zero order:Zero order:

Numerical ResultsNumerical Results

But…fundamental questionsBut…fundamental questions
Despite a theoretical result (controlled accuracy)…Despite a theoretical result (controlled accuracy)…How many terms to retain in the asymptotic expansion How many terms to retain in the asymptotic expansion to get a “precise” model ?to get a “precise” model ?
How to compare the different orders of approximation:How to compare the different orders of approximation:- What each order of the asymptotic expansion brings to the What each order of the asymptotic expansion brings to the
numerical results ?numerical results ?- Which variables are responsible of the improvement between Which variables are responsible of the improvement between
models Mmodels Mii and M and Mi+1i+1 ? ?
Use of Data Mining MethodologyUse of Data Mining MethodologyUse of Data Mining MethodologyUse of Data Mining Methodology

Data processingData processing
100 time steps1250 space nodes
125 000 rows26 columns

The DatabaseThe Database

1,21,2 is around 1is around 1:: equivalence of numerical results equivalence of numerical results
obtained between the two models Mobtained between the two models M11 and M and M22 for for the calculation of X.the calculation of X.
1,21,2 is either very small or very great compared to 1is either very small or very great compared to 1::
the numerical results between Mthe numerical results between M11 and M and M22 are are significantly different. significantly different.
Data Data ModelingModeling

EEzz(2)(2) is the most discriminate predictor. is the most discriminate predictor.
(Expected because E(Expected because Ezz(1) (1) = 0).= 0).
The second most important predictor is EThe second most important predictor is Err(2)(2)..
(Non expected because E(Non expected because Err(1) (1) 0). 0).
BBzz(2)(2) appears as a non significant predictor. appears as a non significant predictor.
(Non expected because B(Non expected because Bzz(1)(1) = 0). = 0).
Data Mining ExplorationData Mining ExplorationSignificant differences between VSignificant differences between Vrr (1) (1) andand VVrr (2)(2)
(F. Assous and J. Chaskalovic, J. Comput. Phys., 2011)(F. Assous and J. Chaskalovic, J. Comput. Phys., 2011)

Future Future developmentsdevelopments
Which is the best asymptotic expansion?Which is the best asymptotic expansion?
GloballyGlobally the second order is better than the the second order is better than the first order. first order. But But locallylocally, could we status when and where , could we status when and where the first one could be better ?the first one could be better ?
Data ExperimentsData Experimentsandand
Data MiningData Mining
Data ExperimentsData Experimentsandand
Data MiningData Mining

On a new paraxial modelOn a new paraxial model

Revisiting the scalingRevisiting the scaling
The characteristic longitudinal dimension The characteristic longitudinal dimension LLzz is chosen is chosen different from the characteristic transverse dimension different from the characteristic transverse dimension LLrr..
Z = Z = LLzz Z’, r = Z’, r = LLrr r’, ( r’, (LLzz LLrr))
LLzz
LLrr

The new paraxial modelThe new paraxial model(axisymmetric case)(axisymmetric case)
(F. Assous and J. Chaskalovic, CRAS, 2012)(F. Assous and J. Chaskalovic, CRAS, 2012)
• Zero order:Zero order:
• First order:First order:

Future developmentsFuture developments
Numerical simulations.Numerical simulations.
Validation and characterization by Data Mining Validation and characterization by Data Mining techniques of significant differences between the techniques of significant differences between the two asymptotic modelstwo asymptotic models ((LLz z = = LLrr)) and and ((LLzz LLrr))..
Comparison with experimental data.Comparison with experimental data.

Data Mining Data Mining a tool to evaluate the quality of modelsa tool to evaluate the quality of models

The four sources of errorThe four sources of error
Error sourcesError sources
The The modelingmodeling errorerror
The The approximation errorapproximation error
The The discretization errordiscretization error
TheThe parameterization error parameterization error

The famous theorems of calculusThe famous theorems of calculus
Rolle’s theoremRolle’s theorem
Lagrange’s theoremLagrange’s theorem
Taylor’s theoremTaylor’s theorem

The The discretization errordiscretization error is the error which corresponds to the is the error which corresponds to the difference of order between two numerical models (MNdifference of order between two numerical models (MN11) and (MN) and (MN22) )
from a given family of approximations methods. from a given family of approximations methods.
Suppose we solve a given mathematical model (E) with finite Suppose we solve a given mathematical model (E) with finite elements Pelements P11 and P and P22. .
The The discretizationdiscretization error error
Bramble-HilbertBramble-Hilbert theorem claims: theorem claims:

The discretization errorThe discretization error
PP11 - P - P22 finite elements method for numerical finite elements method for numerical
approximation to Vlasov-Maxwell equationsapproximation to Vlasov-Maxwell equations

The PThe P11 – P – P22 finite elements finite elements Database Database

““surprising surprising ” rows w.r.t Bramble ” rows w.r.t Bramble Hilbert Hilbert theoremtheorem
If |ErIf |Er22-Er-Er11| | ≤≤ 0.65 (5% of Max |Er 0.65 (5% of Max |Er22-Er-Er11|)|)
PP11 vsvs P P22 = = Same orderSame order
Same order Same order 14 % of the Dataset 14 % of the DatasetSame order Same order 14 % of the Dataset 14 % of the Dataset

Kohonen’ cardsKohonen’ cards
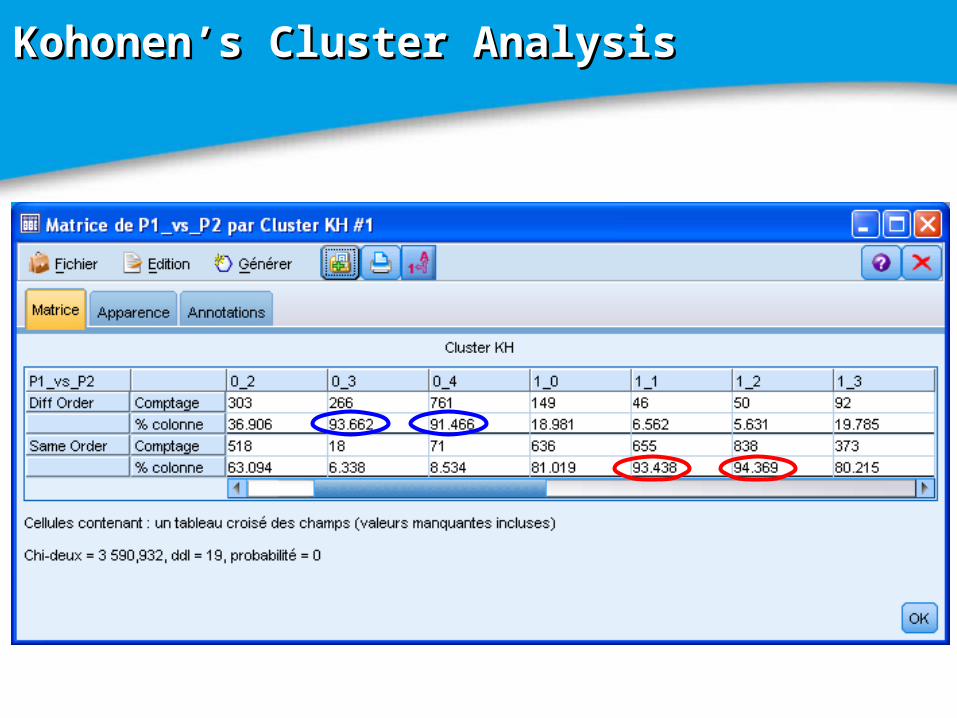
Kohonen’s Cluster AnalysisKohonen’s Cluster Analysis

P1 P1 vsvs P2 P2
Rules of Cluster “PRules of Cluster “P11 – P – P22 same order” same order”
P1 P1 vsvs P2 P2

EErr(1) (1) and Eand Err
(2)(2) are equivalent on are equivalent on 14%14% elements of elements of the data.the data.
Data Mining techniques identified the number of Data Mining techniques identified the number of time stepstime steps t tnn as the most discriminate predictor. as the most discriminate predictor.
The critical computed threshold of tThe critical computed threshold of tnn is equal to is equal to 4242 on on 100100 time stepstime steps..
An example : An example : Equivalent results between PEquivalent results between P11 andand PP22 finite finite elementselements
PP2 2 finite elements overqualified finite elements overqualified
at the beginning of the propagationat the beginning of the propagation
PP2 2 finite elements overqualified finite elements overqualified
at the beginning of the propagationat the beginning of the propagation

Future developmentsFuture developments
Physical interpretations of the above results : The Physical interpretations of the above results : The threshold tthreshold tnn = 42. = 42.
Robustness of the results: comparison with other Robustness of the results: comparison with other data technologies, (Neural Networks, Kohonen data technologies, (Neural Networks, Kohonen Cards, etc.).Cards, etc.).
Extensions to other physical unknowns.Extensions to other physical unknowns.
Sensibility regarding the Data.Sensibility regarding the Data.
Coupling errors.Coupling errors.
Data MiningData MiningData MiningData Mining

Data Mining for the CERNData Mining for the CERN

« Les expériences du « Les expériences du Large Hadron Collider représentent représentent environ 150 millions de capteurs délivrant des données 40 environ 150 millions de capteurs délivrant des données 40 millions de fois par seconde. millions de fois par seconde.
Il y a autour de 600 millions de collisions par seconde, et Il y a autour de 600 millions de collisions par seconde, et après filtrage, il reste 100 collisions d’intérêt par seconde. après filtrage, il reste 100 collisions d’intérêt par seconde.
En conséquence, il y a 25 Po de données à stocker chaque En conséquence, il y a 25 Po de données à stocker chaque année. » année. » ((source : Wikipédiasource : Wikipédia) )
The CERN and the Data MiningThe CERN and the Data Mining

Project ManagementProject Management
BusinessBusinessExpertiseExpertise
SoftwareSoftwareEngineeringEngineering
Data ExplorationData Exploration
• •
•
•
Data Mining : les clefs pour une Data Mining : les clefs pour une exploitation pertinente des exploitation pertinente des donnéesdonnées

Data ScanData Scan : inventory of potential and : inventory of potential and explicative variables.explicative variables.
Data ManagementData Management : collection, : collection, arrangement and presentation of the Data arrangement and presentation of the Data in the right way for mining.in the right way for mining.
Data Modeling Data Modeling :: LearningLearning ClusteringClustering ForecastingForecasting
The Data Mining is a discovery process
Data Mining and not Data Analysis

Supervised Data MiningSupervised Data Mining : One or more : One or more targettarget variables variables must must be explained in terms of a set of be explained in terms of a set of predictorpredictor variables. variables.
Data Mining PrinciplesData Mining Principles
Non supervised Data MiningNon supervised Data Mining : No variable to : No variable to explain, explain, all available variables are considered to all available variables are considered to create groups create groups of individuals with homogeneous of individuals with homogeneous behavior.behavior.
Segmentation by Decision Tree, Neural Networks, etc.Segmentation by Decision Tree, Neural Networks, etc.
Typology by Kohonen’s cards, Clustering, etc.Typology by Kohonen’s cards, Clustering, etc.

Future developmentsFuture developmentsAccuracy comparison of asymptotic models.Accuracy comparison of asymptotic models.
Choice of a given order accuracy.Choice of a given order accuracy.
Accuracy comparison of numerical methods.Accuracy comparison of numerical methods.
Curvature of the trajectories.Curvature of the trajectories.
Non relativistic beams.Non relativistic beams.
Etc.Etc.
OutlooksOutlooks
Data Mining with CERNData Mining with CERNData Mining with CERNData Mining with CERN

Merci !Merci !





























