Embed Size (px)
Citation preview

機器學習法應用於企業信用評等之預測
Machine learning method applied to the prediction
of corporate credit rating
摘要
本研究針對台灣電子業上市櫃公司,依其財務及公司治理資訊來當作變數,透過支
援向量機、類神經網路、樸素貝氏分類器及深度學習之間的比較來建立一個準確率高的
信用評等預測模型,由於一般投資人、債權人取得信用評等資訊需要花費成本,透過此
模型能夠降低取得評等資訊的成本。
過去的文獻中較常使用支援向量機及類神經網路,本研究再加入最近較新興的機器
學習法—深度學習來作探討,以及較少人研究的樸素貝氏分類器,實證結果發現類神經
網路的的模型效度最佳,其準確率達 82.381%。可看出在台灣電子業上市櫃公司的信用
評等預測以類神經網路的機器學習法來執行效果較佳。
關鍵字:信用評等、台灣電子業、機器學習法、財務大數據

1
壹、前言
信用評等的目的是為了顯示受評者及時履行其財務義務的能力與意願,可以降低資
訊不對稱,提供予債權人或投資人作參考。信用評等在金融市場有著重要的影響,投資
人、債權人、發行人與政府都高度關注他們的信評活動,投資人把信評結果作為投資決
定的重要資訊,作為是否願意承受風險的依據。過去發生過美國安隆案、世界通訊等弊
案以及 2008 年的金融風暴,大眾對於信用評等也愈加重視,相關單位也不斷地在檢討
信用評等機構在評級上所發生的潛在問題。
目前國際上具權威的信用評等機構,為標準普爾(Standard & Poor’s)、穆迪(Moody’
s)、惠譽國際(Fitch Rating)三家公司,國內信用評等制度的發展較國外來的晚,國內第
一家信用評等機構為中華信用評等公司,是由財政部輔導於民國 86 年 5 月 29 日正式成
立,其結合全球性信用評等機構-標準普爾(Standard & Poor’s)與熟知台灣金融環境的國
內股東共同成立。
在預測信用評等模型的方法上面,Zhong, Miao, Shen, and Feng (2014)為了克服統計
方法的缺點,人工智慧(AI)技術已被研究用於信用評級。過去很多信用評等預測常用的
人工智慧方法為支援向量機(Support Vector Machines , SVM)和類神經網路(Artificial
Neural Network , ANN),Huang, Chen, Hsu, Chen, and Wu (2004)測試對於美國和台灣市場
的二值神經網路(Binary Neural Network, BNN)和SVM方法獲得了約80%的預測準確度。
Guo, Zhu, and Shi (2012)過去基於人工智慧應用於信用評等預測的技術中,類神經網路因
從訓練樣本中的學習能力而被應用於金融領域。而且,就過度擬合等人工神經網絡的缺
陷而言,支持向量機因為它比傳統方法 ANN 具有更好的性能,因此被認為是解決這些
問題的流行替代解決方案之一。除了這兩種方法外,本研究再加入最近較新興的機器學
習法—深度學習來作探討,以及較少人研究的樸素貝氏分類器,Luo, Wu, and Wu (2017)
認為使用深度信念網路(Deep Belief Network, DBN)的信用風險評估研究很少,且實證結
果發現以 DBN 來預測信用評等性能是好的。吳陳和張明華(2012)認為樸素貝氏分類器是
最簡單的貝氏網絡分類器,具有高效率和良好的泛化能力,同時也具有確定的結構,只
根據訓練數據來估計參數。
信用評等機構在做評等意見時,通常都是基於經驗豐富的專業人士以及分析師團隊
的分析,且一般投資人、債權人如要取得信用評等資訊都需要支付費用,綜上所述,本
研究期望能提供相關內部人及外部投資人一個高準確率且低成本的企業信用評等預測
模型。
貳、文獻探討
信用評等的目的是顯示受評對象違約風險的大小,惠譽國際(Fitch Rating)對信用評
等的定義是一個受評個體履行其財務承諾的相對能力所發佈之意見,所謂財務承諾包括
利息、特別股股利、本金償付、保險理賠、或相對人債務。投資人將評等視為是否可能

2
依照議定投資條款收回投資金額的指標。標準普爾(Standard & Poor's)對信用評等的定義
是關於信用風險的意見,他們的評等表達了他們對發行人(例如公司或州或市政府)全面
及按時履行其財務義務的能力和意願的看法。表 1 有整理出三間國際信用評等公司以及
台灣中華信用評等公司的信用評等等級。
一、信用評等服務機構
目前全球有三大信用評等機構,為標準普爾(Standard & Poor's)、穆迪(Moody’s)、惠
譽國際(Fitch Rating);在國內的信用評等機構有中華信用評等公司以及台灣經濟新報
社。
(一) 標準普爾(Standard & Poor's)
標準普爾(Standard & Poor's)是一家世界權威金融分析機構,總部位於美國紐約市,
在 26 個國家有據點。由 Mr .Henry Varnum Poor 於 1860 年時以“投資者有知情權”為
宗旨建立了金融資訊業。透過分析師從已發布的報告中獲取信息,以及從與發行人管理
層的訪談和討論中獲取信息。他們使用該信息並應用其分析判斷來評估實體的財務狀況,
經營業績,政策和風險管理策略。
(二) 穆迪(Moody’s)
穆迪(Moody’s)是全球資本市場的重要組成部分,提供信用評級、研究、工具和
分析,這些都可以歸功於透明和綜合的金融市場。穆迪公司(紐約證券交易所股票代碼:
MCO)是穆迪投資者服務公司的母公司,該公司提供債務工具和證券的信用評級和研
究,以及穆迪公司的分析,提供領先的軟體、諮詢服務和信貸與經濟分析和金融研究。
(三) 惠譽國際(Fitch Rating)
惠譽國際(Fitch Rating)提供前瞻性信用評級,評級報告提供個別發行人的信用狀況
的完整分析,包括關鍵評級驅動因素,評級敏感度,調整後的財務狀況以及同行。評級
報告每年更新或由事件驅動。
(四) 中華信用評等公司 (Taiwan Ratings)
中華信用評等公司(中華信評)為台灣金融市場資訊的主要提供者,為第一家在台
成立的信評公司,中華信評並透過與標普全球評級(S&P Global Ratings)的關係,向全
球市場傳送品質最佳的金融訊息與分析報告。
(五) 台灣經濟新報社 (Taiwan Economic Journal, TEJ)
台灣經濟新報社(TEJ)在民國 80 年開始建置信用風險指標機制,稱為目前其評等範
圍是公開發行公司,不含金融、證券、投資、建經仲介以及媒體,不同於一般傳統外部
的信用評等機構,他們是以財務報告為依據,數量方法為底,並輔以人工判讀,產生
TCRI 等級結果,1 到 4 等級為低風險;5 和 6 等級為中度風險;7 到 9 等級為高風險。
二、變數選取之探討

3
過去很多的文獻在做信用評等的預測都會以財務比率做為輸入變數,黃劭彥、李超
雄、洪光宏和吳東憲 (2006)以償債能力、財務結構、獲利能力、經營能力以及現金流量
等構面的財務比率來建置一個電子業財務危機的預警模型;羅玉惠 (2007)以財務比率的
五力分析,收益力、安全力、活動力、成長力及生產力來做為選取財務變數的構面來建
構信用評等預測模型;高惠松 (2012)在信用評等預測模型的變數當中以獲利能力、安全
性、活動力以及規模等構面來選擇財務比率。
從上述的文獻可看出每一篇的財務比率選擇上都不盡相同,本研究依據過去與信用評等
以及財務危機相關的文獻匯總出以下表 1 的財務比率。

4
表 1 過去財務比率變數文獻整理
財務比率
黃劭彥
et al.
(2006)
羅玉惠
(2007)
高惠松
(2012)
薛立言和
張志向
(2004)
Zhong et
al. (2014)
Zan
et al.
(2004)
Lee
(2007)
Kim and
Ahn
(2012)
Hajek,
and
Michalak
(2013)
Guo et al.
(2012)
每股盈餘
淨值報酬率(%)
銷貨毛利率(%)
營業利益率(%)
稅後淨利率(%)
總資產報酬率(%)
流動比率(%)
速動比率(%)
利息支出率(%)
負債比率(%)
利息保障倍數
長期資金適合率(%)
借款依存度(%)
現金再投資比率(%)
存貨周轉率(次)
應收帳款週轉率(次)
總資產周轉率(次)

5
固定資產周轉率(次)
淨值周轉率(次)
總資產成長率(%)
淨值成長率(%)
營收成長率(%)
營業毛利成長率(%)
營業利益成長率(%)
稅後淨利成長率(%)
每人營收
每人營業利益
固定比率
存貨佔流動資產比率(%)
現金流量佔總資產比率
(%)
營運活動之現金流量
現金對流動負債比率(%)
現金對銷貨淨額比率(%)
總負債
總資產
流動負債比率(%)
現金流量比率(%)

6
信用評等主要是信用評估機構針對企業公開的財務資訊來進行評估,但仍有其他影
響信用評等評估的要素。所以輸入變數方面除了考慮財務比率之外,也考慮了公司治理
的相關變數。古永嘉、李在僑和羅玉惠 (2009)實證分析的結果顯示,在最佳演化代數及
基因選取組合下,基因演算法篩選出之九個關鍵變數中,公司治理指標佔有五個。換言
之,公司治理變數佔全體關鍵變數組合接近一半甚至以上之比例,顯示出公司治理的確
是評估企業風險上不可忽視之警訊指標;高惠松 (2012)發現融入公司治理因素的信用評
等模型可以讓整個模型更加完整。由上述可看出公司治理機制對企業信用評等是有影響
的。本研究將根據呂素蓮等人(2014)所提出的董事會結構、所有權結構與資訊揭露三大
構面探討公司治理對公司評等之影響。
(一) 董事會結構
董事會成員是由股東選出並代表股東監督管理階層,為公司的內部監理,具
有連繫公司治理與管理績效的功能。
1.董事會規模
古永嘉等人(2009)實證分析出董事會規模越大,代表企業的信用評等
預測結果屬於較低風險類別的可能性是比較高。呂素蓮等人 (2014)實證結
果發現從他們研究的六個產業中約有半數產業支持董事會規模會影響企
業信用評等。
2.董事長是否兼任總經理
Patton and Baker (1987)認為總經理若兼具雙重角色,則會因自身利益
而干擾董事會議事之進行與董事會監督之機制。但亦有些學者認為,董事
長兼任總經理,有可能消除資訊不對稱的問題,並基於自身之利益,而盡
心於公司經營績效。Daily and Dalton (1993)發現董事長兼任總經理的企業,
有較佳之經營績效。
而呂素蓮等人(2014)認為公司績效與信用評等息息相關,其實證結果
發現就電子業而言,董事長是否兼任總經理對企業信用評等是有顯著影
響。
3.董事會之獨立性
王秀珍和歐進士 (2006)認為外部董事可降低管理階層與股東之間的
代理問題,而且可減少股東財富被管理階層透過財務報表詐欺剝削的可能
性。Beasley(1998)對於外部董事的任期及股權關係,比較詐欺公司與無
詐欺公司董事會的組成與任期發現,相較於有詐欺公司,無詐欺公司有較
多外部董事,也發現詐欺較非詐欺公司的外部董事平均任期較短。呂素蓮
等人(2014)實證結果發現大多數的產業支持獨立董事的比例越高,企業信
用評等也越好。

7
4.是否設立審計委員會
審計委員會是在董事會之下成立的單位,其成員大部分由不執行業務
之董事組成,須具備相關法律、準則及閱讀報表的能力。王秀珍 和歐進
士 (2006)在公司治理機制下審計委員會扮演著監督財務報導、內部控制結
構及審計功能的角色,可見審計委員會的設立是會影響財報品質,進而影
響到信用評等之意見。
(二) 所有權結構
高惠松(2012)認為信用評等與公司治理之間的關聯是以代理理論為基礎。有
關所有權結構所衍生的代理理論有兩個假說,一個是利益掠奪或侵占
(entrenchment),此假說主張如果股權都集中在管理者手中,管理者會為了自身的
利益進而侵害到小股東的權益或做出對於整體公司不利的行為;另一個是利益收
斂說(interest-alignment),Berle and Means(1932) ; Jensenand Meckling (1976)主張當
公司主權集中在管理者手上,管理者會以公司利益最大為決策依據,以提升公司
整體價值。Beasley(1998)比較詐欺與無詐欺公司董事會的組成與任期發現,相
較於有發生詐欺公司,無詐欺公司外部董事擁有較大股權比例。所以當外部董事
會擁有的股權比例越高,該企業財務報表發生詐欺的機會較低。林美鳳、金成隆
和林良楓 (2009)實證結果發現董監事持股質押比率與信用風險為正相關,因為公
司的財務風險會增加進而造成信用風險的增加。呂素蓮等人(2014)實證結果發現
機構投資人持股比例越高,企業信用評等越佳,也認為管理者持股比例越高,企
業信用評等越佳,根據因為會使企業的利益和成本產生收斂效應,公司的經營績
效會越好。
(三) 資訊揭露與透明度
邱琬婷 (2011)研究結果發現良好的審計品質相對的信用評等也會較高,因企
業會願意支付較高的審計公費給審計品質較為高的會計事務所,使能提供更為正
確的資訊給投資人。呂素蓮等人 (2014)選用四大會計師事務所對企業信用評等有
正面顯著影響,因此會計師之信譽確實有利於公司資訊揭露與提升透明度,進而
提升信用評等。綜上所述可見所選擇的會計事務所為資訊透明度的一個重要因素,
此外,高蘭芬、陳振遠和李焮慈 (2006)以國內證基會之評分標準外,同時考慮到
財報的品質,再加入財報是否重編的項目來衡量。
三、人工智慧評等方法
80 年代後期陸續有人工智慧方法導入信用評等領域,Guo et al. (2012)通過使用模糊
聚類算法的數據預處理,僅選擇邊界數據點作為訓練樣本,以實現支持向量域規範,從
而降低計算成本並獲得更好的性能。Hájek (2012)使用基於模糊規則的系統對信用評級
的分析,結合遺傳算法的濾波器作為搜索方法來選擇特徵,由此產生的特徵子集證實了
評級過程是行業特定的假設。Yuan, Lau, Wong, and Li (2018)獲取社交媒體上的公眾情緒
來預測信用評等風險,以隨機森林作為分類器來建構信用評等模型。表 4 為整理出過去
對於機器學習法應用在信用評等預測的文獻,大多以支援向量機和類神經網路為大多

8
數。
(一) 監督式學習
監督式方法的特徵是採取教師或主管的概念,在他人的監督下進行學習,
有人會判斷是否正確。監督學習的訓練集要求包括輸入和輸出,也可以說是
特徵和目標。訓練集中的目標是由人標註的,可以由訓練資料中建立一個模
型(learning model),並依照此模型推測新的資料。常見的監督學習算法包括
回歸分析和統計分類。
1.支援向量機(Support Vector Machine)
簡稱為 SVM,又名支援向量網路,是在分類與迴歸分析中分析資料
的監督式學習模型與相關的學習演算法。給定一組訓練例項,每個訓練例
項被標記為屬於兩個類別中的一個或另一個,SVM 訓練演算法建立一個
將新的例項分配給兩個類別之一的模型,使其成為非機率二元線性分類器。
SVM 模型是將例項表示為空間中的點,這樣對映就使得單獨類別的例項
被儘可能寬的明顯的間隔分開。然後,將新的例項對映到同一空間,並基
於它們落在間隔的哪一側來預測所屬類別。Lee (2007)將支持向量機(SVM)
應用於企業信用評級問題試圖建議一個具有更好解釋力和穩定性的新模
型,為了達到這個的,研究人員使用網格搜索技術,使用 5 倍交叉驗證來
找出 RBF內核的最佳參數值 SVM 的功能。
2.類神經網路(Artificial Neural Network)
簡稱為 ANN,是一種模仿生物神經網路(動物的中樞神經系統,特
別是大腦)的結構和功能的數學模型或計算模型,用於對函式進行估計或
近似。神經網路由大量的人工神經元聯結進行計算。大多數情況下人工神
經網路能在外界資訊的基礎上改變內部結構,是一種自適應系統。古永嘉
等人(2009)整合人工智慧方法中之基因演算與類神經網路建構預測模型,
目的在檢驗公司治理指標對信用評等結果的預測能力。Zhong et al. (2014)
對由企業信用評級的真實財務數據組成的數據集上的四種學習算法(即
BP,ELM,I-ELM 和 SVM)的有效性進行了全面的實驗對比研究,在信
用評級問題上,ELM 和 BP 的表現優於 I-ELM 和 SVM,但考慮到計算複
雜性,ELM 比 BP 更具吸引力。
3.樸素貝氏分類器(Naive Bayes)
樸素貝氏分類器是一系列以假設特徵之間強獨立下運用貝氏定理為
基礎的簡單機率分類器。吳陳和張明華(2012)提到其分類器以高效率和良
好的泛化能力著稱。
樸素貝氏分類器的一個優勢在於只需要根據少量的訓練資料估計出

9
必要的參數(變數的均值和變異數)。Hu and Ansell (2009)在做美國零售市
場的違約預測模型,將四種標準的信用評分技術:樸素貝氏分類器、邏輯迴
歸分析、遞迴區分和類神經網路來與序列最小優化算法來做比較,發現外
部大環境的變數使用樸素貝氏分類器是有較好的效果。吳陳和張明華
(2012)利用最優樸素貝氏分類器運用在個人信用評等的預測上,並與支持
向量機預測結果進行對比,結果發現其預測準確率高於支援向量機。
(二) 非監督式學習
非監督式機器學習為給定事先無標記的訓練樣本,也就是訓練樣本無標準答
案,故機器在學習時不知其分類結果是否正確。這種分法沒有監督者,因此會有
絕對誤差量值。
深度信念網路(Deep Belief Network)
簡稱為 DBN,由 Geoffrey Hinton 在 2006 年提出。它是一種生成模型,通
過訓練其神經元間的權重,可以讓整個神經網絡按照最大機率來生成訓練數據。
不僅可以使用 DBN 識別特徵、分類數據,還可以用它來生成數據。DBN 由多
層神經元構成,這些神經元又分為顯性神經元和隱性神經元顯性神經元用於接受
輸入,隱性神經元用於提取特徵。因此隱性神經元也有個別名,叫特徵檢測器
(feature detectors)。最頂上的兩層間的連接是無向的,組成聯合內存 (associative
memory)。較低的其他層之間有連接上下的有向連接。最底層代表了數據向量
(data vectors),每一個神經元代表數據向量的一維。DBN 的組成元件是受限玻爾
茲曼機 (Restricted Boltzmann Machines, RBM)。訓練 DBN 的過程是一層一層地
進行的。在每一層中,用數據向量來推斷隱層,再把這一隱層當作下一層 (高一
層) 的數據向量。Luo et al. (2017)研究了應用於 CDS 數據集的信用評分模型的性
能。對具有受限玻爾茲曼機器的深度置信網絡等深度學習算法的分類性能進行了
評估,並與一些流行的信用評分模型進行了比較,如邏輯回歸,多層感知器和支
持向量機。使用分類精度和接收器操作特性曲線下的面積來評估性能,發現 DBN
產生最佳性能。
參、研究方法
一、資料來源與養本選取
本研究以民國 97 年到 106 年之電子業的上市櫃公司為研究對象,本研究來源為台
灣證券交易所公開資訊觀測站及台灣經濟新報社資料庫的公司相關財務數據、公司治理
及信用評等等級之資料。其中,以民國 97 年到 104 年資料 4,666 筆資料,作為建構模型
之訓練樣本,並同樣以其民國 105 年到 106 年筆 1,130 筆資料作為測試樣本,以評估模
型之效度。
二、 變數定義與衡量

10
本研究以台灣經濟新報社公開發佈之企業信用風險指標(TCRI)為輸出變數。評等
結果共分 9 級,等級愈低表信用狀況愈佳,為實證分析之所需,在表 2 中本研究將此 9
等級分類成三種、四種以及六種等級的信用品質作為輸出變數。
表 2 本研究信用評等等級
三
等級
信用品質 低度風險 中度風險 高度風險
本研究設
計代碼 A B C
四
等級
信用品質
最高的財
務履行能
力
高的財務
履行能力
適當的財
務履行能
力
投機級
本研究設
計代碼 A B C D
六
等級
信用品質
最高的財
務履行能
力
很高的財
務履行能
力
高的財務
履行能力
適當的財
務履行能
力
可能違
約性
高違
約性
本研究設
計代碼 A B C D E F
輸入變數的部分分為兩類,分別為財務變數以及公司治理變數,財務變數是來自各
企業的財務報表,下面表 3 是從前一章的表 1 中整理出過去文獻出現兩次以上的財務變
數。
表 3 財務比率變數
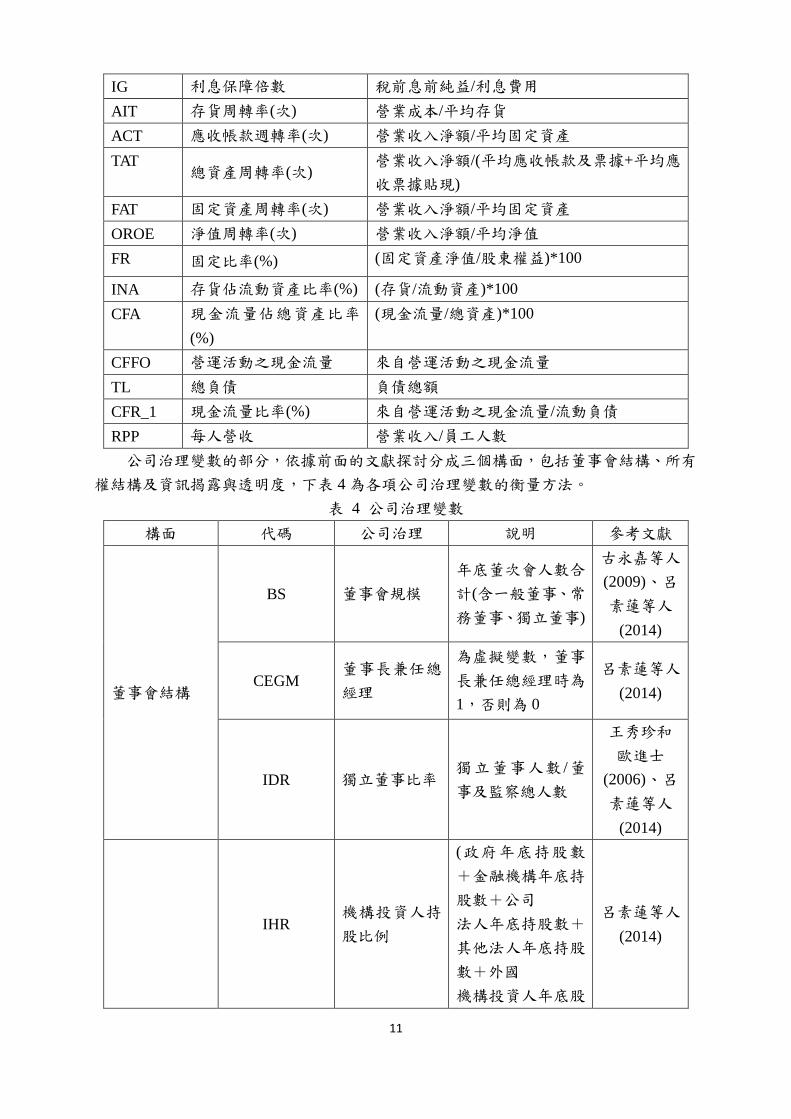
代碼 財務比率 說明
EPS 每股盈餘 稅後淨利/流動在外的普通股加權股數
ROE 淨值報酬率(%) (稅後淨利/股東權益)*100
GP 銷貨毛利率(%) (銷貨毛利/銷貨淨額)*100
OP 營業利益率(%) (營業利益/營業收入)*100
PM 稅後淨利率(%) (稅後淨利/營業收入淨額)*100
ROA 總資產報酬率(%) (稅後息前利益/平均資產)*100
CR 流動比率(%) (流動資產/流動負債)*100
QR 速動比率(%)
(流動資產-存貨-預付款項-其他流動資產)/流
動負債*100
INT 利息支出率(%) (利息支出/營業收入)*100
DA 負債比率(%) (負債總額/資產總額)*100
LFA 長期資金適合率(%) (淨值+長期負債)/固定資產*100
DE 借款依存度(%) (長短期借款/股東權益)*100
CFR 現金再投資比率(%)
(營業活動淨現金-現金股利)/(固定資產毛額+
長期投資+其他資產+營運資金)*100
11
IG 利息保障倍數 稅前息前純益/利息費用
AIT 存貨周轉率(次) 營業成本/平均存貨
ACT 應收帳款週轉率(次) 營業收入淨額/平均固定資產
TAT 總資產周轉率(次)
營業收入淨額/(平均應收帳款及票據+平均應
收票據貼現)
FAT 固定資產周轉率(次) 營業收入淨額/平均固定資產
OROE 淨值周轉率(次) 營業收入淨額/平均淨值
FR 固定比率(%) (固定資產淨值/股東權益)*100
INA 存貨佔流動資產比率(%) (存貨/流動資產)*100
CFA 現金流量佔總資產比率
(%)
(現金流量/總資產)*100
CFFO 營運活動之現金流量 來自營運活動之現金流量
TL 總負債 負債總額
CFR_1 現金流量比率(%) 來自營運活動之現金流量/流動負債
RPP 每人營收 營業收入/員工人數
公司治理變數的部分,依據前面的文獻探討分成三個構面,包括董事會結構、所有
權結構及資訊揭露與透明度,下表 4 為各項公司治理變數的衡量方法。
表 4 公司治理變數
構面 代碼 公司治理 說明 參考文獻
董事會結構
BS 董事會規模
年底董次會人數合
計(含一般董事、常
務董事、獨立董事)
古永嘉等人
(2009)、呂
素蓮等人
(2014)
CEGM 董事長兼任總
經理
為虛擬變數,董事
長兼任總經理時為
1,否則為 0
呂素蓮等人
(2014)
IDR 獨立董事比率 獨立董事人數 /董
事及監察總人數
王秀珍和
歐進士
(2006)、呂
素蓮等人
(2014)
IHR 機構投資人持
股比例
(政府年底持股數
+金融機構年底持
股數+公司
法人年底持股數+
其他法人年底持股
數+外國
機構投資人年底股
呂素蓮等人
(2014)

12
所有權結構
所有權結構
數)/年底流通在外
股數
DHR 董監持股比例
(董事年底持股總
數+監察人年底持
股總數)/年底流通
在外股數
Beasley
(1998)、
Berle and
Means
(1932) 、
Jensenand
Meckling
(1976)
MHR 經理人持
股比例
經理人(總經理、副
總經理、重要部門
經理及協理 )年底
持股總數 /年底流
通在外股數
Berle and
Means
(1932)、
Jensenand
Meckling
(1976)
IHR_1 內部人持股比
例
董監持股比例+經
理人持股比例
Berle and
Means
(1932)、
Jensenand
Meckling
(1976)
DPR 董監持股質押
比例
董監質押數 /董監
持有股數
林美鳳等人
(2009)
資訊揭露與透
明度 RES 財報是否重編
為虛擬變數,財報
曾經重編為 1,反
之為 0
高蘭芬等人
(2006)
三、 研究方法
本研究將會用 WEKA 軟體分析支援向量機、類神經網路、樸素貝氏分類器及深度
學習,WEKA是紐西蘭懷卡託大學用 JAVA開發的開放軟體,有提供資料預處理、分類、
迴歸、聚類、關聯規則以及可視化等功能。
(一) 支援向量機(Support Vector Machine)
在 WEKA 中的支援向量機演算法是由 J. Platt(1998)、S.S. Keerthi, S.K.
Shevade, C. Bhattacharyya, K.R.K. Murthy (2001)以及 Trevor Hastie, Robert
Tibshirani(1998)所提出。

13
支援向量機可以在線性與非線性的情況下使用,在許多不同的領域中都有很
高的效能。
探討一個想要分類的特徵向量資料集:
𝑋 = {�̅�1, �̅�2, … , �̅�𝑛} 其中 �̅�𝑖 ∈ ℝ𝑚
為了簡化,我們假設它屬於二元分類,並將分類標籤設為-1 與 1:
𝑌 = {𝑦1, 𝑦2, … , 𝑦𝑛} 其中 𝑦𝑛 ∈ {−1,1}
目標是找出最佳分隔超平面,其方程式為:
�̅�𝑇�̅� + b = 0 其中 �̅� = (𝑤1
⋮𝑤𝑚
) 且 �̅� = (𝑥1⋮
𝑥𝑚)
(二) 類神經網路(Artificial Neural Network)
類神經網路是一種定向結構,它會將輸入層連接至輸出層。一般來說,所有
的操作是可區分的,且整體的向量函數可簡單寫成:
�̅� = 𝑓(�̅�)
在此:
�̅� = (𝑥1, 𝑥2, … , 𝑥𝑛)且 �̅� = (𝑦1, 𝑦2, … , 𝑦𝑚)
(三) 樸素貝氏分類器(Naive Bayes)
在WEKA中樸素貝氏分類器的演算法是由George H. John, Pat Langley(1995)
提出,樸素貝氏是一種強大且容易訓練的分類器族群,它使用貝氏定理,根據一
組條件來決定某個輸出的機率,貝氏定理是考慮兩個機率事件 A 與 B,可以用乘
積法來建立臨界機率 P(A)與 P(B)與條件機率 P 與 P(𝐵|𝐴)之間的關係。
𝑃(𝐴 ∩ 𝐵) = 𝑃(𝐴|𝐵)𝑃(𝐵)
𝑃(𝐵 ∩ 𝐴) = 𝑃(𝐵|𝐴)𝑃(𝐴)
考慮交集是可交換的,第一組成員是相等的,所以可以導出貝氏定理:
𝑃(𝐴|𝐵) =𝑃(𝐵|𝐴)𝑃(𝐴)
𝑃(𝐵)
依據貝氏定理,可以延伸推導至樸素貝氏機率模型如下:
P(𝑐|𝑥) =𝑃(x|𝑐)𝑃(𝑐)
𝑃(𝑥)
(四) 深度信念網路(Deep Belief Network)
DBN 是深度信念網絡,每一層是一個 RBM(受限玻爾茲曼機),整個網絡可
以視為 RBM 堆疊得到,彼此構建 DBN。如下圖所示,第一個 RBM 的隱藏層被
視為第二個 RBM 的可見層,這第二個 RBM 將學習第一個隱藏層的特徵分佈
RBM。第一個 RBM 的輸入層是整個輸入層網絡,隨著層堆疊,網絡從原始數據
學習越來越複雜的特徵組合。
肆、實證結果與分析
在測試分類器的準確率時,資料集方面分成兩種資料集進行測試,一為正規化後的
資料集,另一為剔除離群值後的資料集,接著各分為兩個形式來進行,第一個形式為以
14
10 折交叉驗證的方式,由系統進行訓練及測試,第二個形式為自行將所有資料以 8:2 的
比例拆成訓練集及測試集,先以訓練集進行建構模型,再以測試集進行模型的準確率測
試。
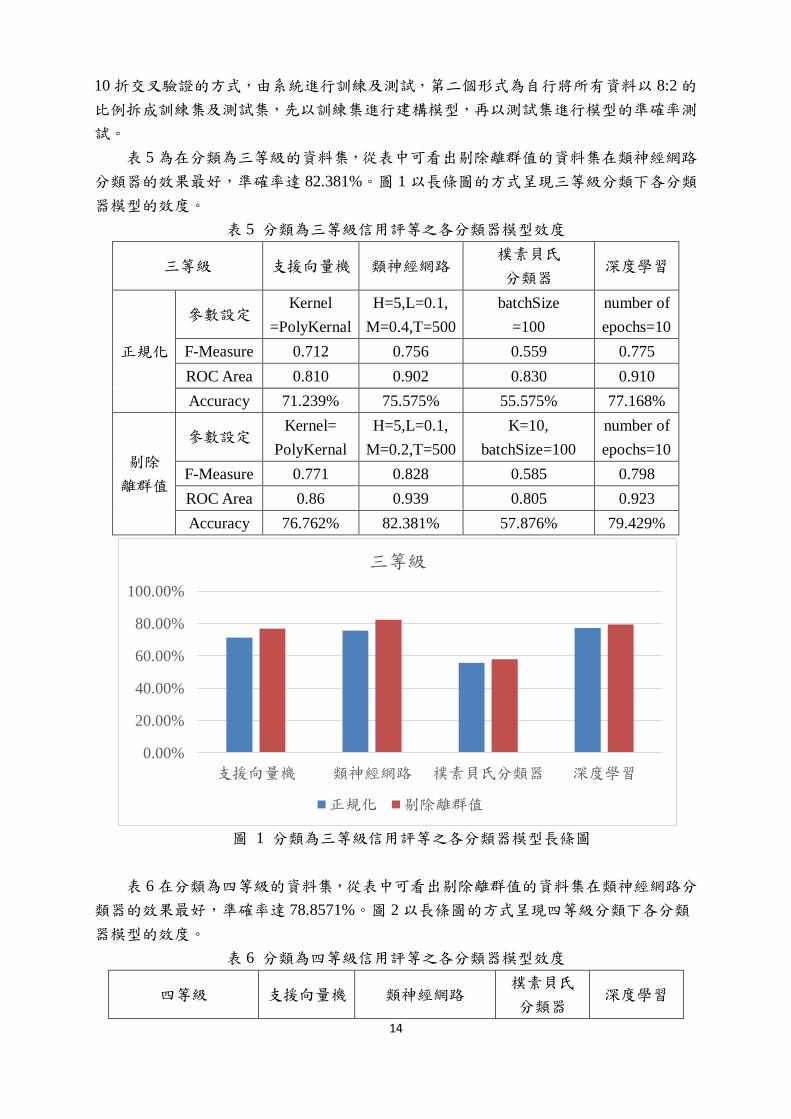
表 5 為在分類為三等級的資料集,從表中可看出剔除離群值的資料集在類神經網路
分類器的效果最好,準確率達 82.381%。圖 1 以長條圖的方式呈現三等級分類下各分類
器模型的效度。
表 5 分類為三等級信用評等之各分類器模型效度
三等級 支援向量機 類神經網路 樸素貝氏
分類器 深度學習
正規化
參數設定 Kernel
=PolyKernal
H=5,L=0.1,
M=0.4,T=500
batchSize
=100
number of
epochs=10
F-Measure 0.712 0.756 0.559 0.775
ROC Area 0.810 0.902 0.830 0.910
Accuracy 71.239% 75.575% 55.575% 77.168%
剔除
離群值
參數設定 Kernel=
PolyKernal
H=5,L=0.1,
M=0.2,T=500
K=10,
batchSize=100
number of
epochs=10
F-Measure 0.771 0.828 0.585 0.798
ROC Area 0.86 0.939 0.805 0.923
Accuracy 76.762% 82.381% 57.876% 79.429%
圖 1 分類為三等級信用評等之各分類器模型長條圖
表 6 在分類為四等級的資料集,從表中可看出剔除離群值的資料集在類神經網路分
類器的效果最好,準確率達 78.8571%。圖 2 以長條圖的方式呈現四等級分類下各分類
器模型的效度。
表 6 分類為四等級信用評等之各分類器模型效度
四等級 支援向量機 類神經網路 樸素貝氏
分類器 深度學習
0.00%
20.00%
40.00%
60.00%
80.00%
100.00%
支援向量機 類神經網路 樸素貝氏分類器 深度學習
三等級
正規化 剔除離群值

15
正規化
參數設定 Kernel
=PolyKernal
H=5,L=0.1,
M=0.2,T=500
BatchSize
=100
number of
epochs=10
F-Measure 0.572 0.713 0.502 0.673
ROC Area 0.674 0.906 0.844 0.914
Accuracy 65.166% 74.779% 47.434% 73.274%
剔除
離群值
參數設定
K=10
Kernel
=PolyKernal
H=5,L=0.1,
M=0.2,T=500
K=10,
batchSize
=100
number of
epochs=10
F-Measure - 0.929 0.663 0.685
ROC Area 0.766 0.907 0.866 0.917
Accuracy 72.381% 78.857% 69.524% 73.905%
圖 2 分類為四等級信用評等之各分類器模型長條圖
表 7 在分類為六等級的資料集,從表中可看出正規化的資料集在類神經網路分類器
的效果最好,準確率達 59.9115%。圖 3 以長條圖的方式呈現六等級分類下各分類器模
型的效度。
表 7 分類為六等級信用評等之各分類器模型效度
六等級 支援向量機 類神經網路 樸素貝氏
分類器 深度學習
正規化
參數設定
K=10
Kernel
=PolyKernal
H=10,L=0.1,
M=0.4,T=500 batchSize=100
number of
epochs=10
F-Measure - 0.577 0.324 0.528
ROC Area 0.738 0.866 0.787 0.854
Accuracy 48.965% 59.912% 35.929% 56.637%
剔除 參數設定 K=10 H=10,L=0.3, K=10, number of
0.00%
20.00%
40.00%
60.00%
80.00%
100.00%
支援向量機 類神經網路 樸素貝氏分類器 深度學習
四等級
正規化 剔除離群值

16
離群值 Kernel=
PolyKernal
M=0.2,T=500 batchSize=100 epochs=10
F-Measure - 0.643 0.358 0.542
ROC Area 0.807 0.888 0.785 0.860
Accuracy 55.061% 64.191% 40.095% 57.333%
圖 3 分類為六等級信用評等之各分類器模型長條圖
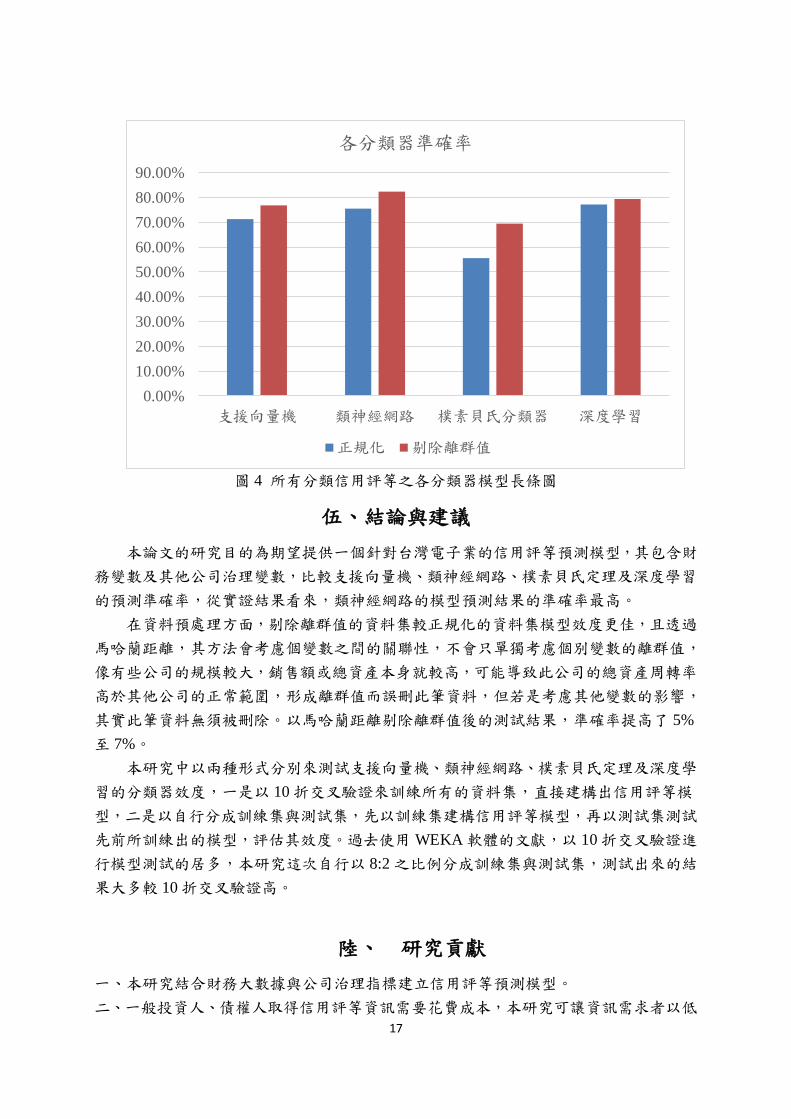
表 8 整理出在各種分類器中,模型效度最好的分類等級、資料預處理方式及參數設
定,從測試結果可看出在類神經網路分類器的準確率為最高。圖 4 以長條圖的方式呈現
在所有等級分類下各分類器模型的效度。
表 8 各分類器模型效度
支援向量機 類神經網路 樸素貝氏
分類器 深度學習
正規化
分類等級 三等級 三等級 三等級 三等級
參數設定 Kernel
=PolyKernal
H=5,L=0.1,
M=0.4,T=500
batchSize
=100
number of
epochs=10
F-Measure 0.712 0.756 0.559 0.775
ROC Area 0.810 0.902 0.830 0.910
Accuracy 71.239% 75.575% 55.575% 77.168%
剔除
離群值
分類等級 三等級 三等級 四等級 三等級
參數設定 Kernel
=PolyKernal
H=5,L=0.3,
M=0.4,T=500
K=10,
batchSize
=100
number of
epochs=10
F-Measure 0.771 0.828 0.663 0.798
ROC Area 0.86 0.939 0.866 0.923
Accuracy 76.762% 82.381% 69.524% 79.429%
0.00%
10.00%
20.00%
30.00%
40.00%
50.00%
60.00%
70.00%
支援向量機 類神經網路 樸素貝氏分類器 深度學習
六等級
正規化 剔除離群值
17
圖 4 所有分類信用評等之各分類器模型長條圖
伍、結論與建議
本論文的研究目的為期望提供一個針對台灣電子業的信用評等預測模型,其包含財
務變數及其他公司治理變數,比較支援向量機、類神經網路、樸素貝氏定理及深度學習
的預測準確率,從實證結果看來,類神經網路的模型預測結果的準確率最高。
在資料預處理方面,剔除離群值的資料集較正規化的資料集模型效度更佳,且透過
馬哈蘭距離,其方法會考慮個變數之間的關聯性,不會只單獨考慮個別變數的離群值,
像有些公司的規模較大,銷售額或總資產本身就較高,可能導致此公司的總資產周轉率
高於其他公司的正常範圍,形成離群值而誤刪此筆資料,但若是考慮其他變數的影響,
其實此筆資料無須被刪除。以馬哈蘭距離剔除離群值後的測試結果,準確率提高了 5%
至 7%。
本研究中以兩種形式分別來測試支援向量機、類神經網路、樸素貝氏定理及深度學
習的分類器效度,一是以 10 折交叉驗證來訓練所有的資料集,直接建構出信用評等模
型,二是以自行分成訓練集與測試集,先以訓練集建構信用評等模型,再以測試集測試
先前所訓練出的模型,評估其效度。過去使用 WEKA軟體的文獻,以 10 折交叉驗證進
行模型測試的居多,本研究這次自行以 8:2 之比例分成訓練集與測試集,測試出來的結
果大多較 10 折交叉驗證高。
陸、 研究貢獻
一、本研究結合財務大數據與公司治理指標建立信用評等預測模型。
二、一般投資人、債權人取得信用評等資訊需要花費成本,本研究可讓資訊需求者以低
0.00%
10.00%
20.00%
30.00%
40.00%
50.00%
60.00%
70.00%
80.00%
90.00%
支援向量機 類神經網路 樸素貝氏分類器 深度學習
各分類器準確率
正規化 剔除離群值

18
成本的方式來獲取資訊。
柒、 研究限制與建議
一、本研究只針對台灣上市櫃電子業公司來做研究,未來可分別針對台灣的各產業上市
櫃公司做信用評等的預測;也可以再針對外國各產業的上市櫃公司來做為研究對
象。
二、只針對支援向量機、類神經網路、樸素貝氏分類器及深度學習四種機器學習法來做
比較,可再多研究其他種的機器學習法的成效。
三、深度學習需要大量的樣本量,測試結果才會較為準確,未來可再增加樣本量以提升
準確率。
捌、 參考文獻
中文部分
葉銀華、李存修、柯承恩,(2002),公司治理與平等系統,商智文化出版社。
廖芝嫻、王大維,(2015),再探公司治理對經營績效與財務報導品質之影響:因素分析
與類神經網路之應用,中華會計學刊,第 11 卷第 2 期,頁 169-201。
王秀珍、歐進士. (2006). 公司治理機制架構(上)─財務報表詐欺之預防與偵測. 會計
研究月刊(249), 94-103.
古永嘉、李在僑、羅玉惠. (2009). 加入公司治理指標建構信用評等預測模型之研究. 當
代會計, 10(2), 131-162.
吳陳、張明華 (2012). 基於最優樸素貝氏分類器的個人信用預測.. 江蘇科技大學學報
(自然科學版), 26(4), 376-380.
呂素蓮、李國榮、謝聖涵. (2014). 公司治理對企業信用評等之影響與預測.. 東吳經濟商
學學報(87), 97-133.
林美鳳、金成隆、林良楓. (2009). 股權結構、會計保守性與信用評等關係之研究.. 臺大
管理論叢, 20(1), 289-329.
邱琬婷. (2011). 企業社會責任、審計品質對信用評等之關聯性. (碩士), 國防大學管理學
院, 桃園縣.
高惠松. (2012). 融合公司治理的信用評等模型:Cubist 迴歸樹模型之應用. 當代會計,
13(2), 117-159.
高蘭芬、陳振遠、李焮慈. (2006). 資訊透明度及席次控制權與現金流量權偏離對公司績
效之影響-以台灣電子業為例.. 台灣管理學刊, 6(2), 81-104.
黃劭彥、李超雄、洪光宏、吳東憲. (2006). 以經營效率觀點建立台灣資訊電子業財務危
機預警模型.. 文大商管學報, 11(2), 1-20.
廖芝嫻、王大維. (2015). 再探公司治理對經營績效與財務報導品質之影響:因素分析與
類神經網路之應用. 中華會計學刊, 11(2), 169-201.
薛立言、張志向. (2004). 信用評等:期間與產業差異分析.. 中山管理評論, 12(2), 307-336.
羅玉惠. (2007). 整合財務比率與公司治理指標建構信用評等預測模型-區別分析與類神

19
經網路之應用. (碩士), 國立臺北大學, 新北市.
林萍珍, 柯博昌, & 游俊忠. (2010). 演化式多重組合羅吉斯迴歸模型-應用於信用評等.
資訊管理學報, 17(2), 115-139.
陳冠宇, & 蘇志雄. (2009). 應用資料採礦技術建置台灣中小企業電子業信用評等模型.
Journal of Data Analysis, 4(5), 23-53.
鄭宇庭, 蔡紋琦, 鄧家駒, & 林孟寬. (2013). 企業信用評等模型-以營造業為例. Journal
of Data Analysis, 8(3), 71-90.
英文部分
Luo, Luo, C., & Wu, D. (2017). A deep learning approach for credit scoring using credit
default swaps. Engineering applications of artificial intelligence, 65, 465-470.
Patton, A., J. C. Backer .(1987). Why won't Directors Rock the Boat. Harvard Business
Review 65(6): 10-18.
Daily, C. M., D. R. Dalton .(1993). Board of directors leadership and structure: Control and
performanceimplications. Entrepreneurship: Theory and Practice 17(3): 65-81.
Beasley, M.S. (1998). Boards of directors and fraud. The CPA Journal. 56-58.
Hsu, Feng-Jui, Chen, Mu-Yen, Chen, Yu-Cheng. (2018). The human-like intelligence with
bio-inspired computing approach for credit ratings prediction. Neurocomputing
(Amsterdam) 279: 11-18.
Guo, X., Zhu, Z., & Shi, J. (2012). A Corporate Credit Rating Model Using Support Vector
Domain Combined with Fuzzy Clustering Algorithm. Mathematical Problems in
Engineering, 2012, 20.
Hajek, Hajek, P., & Michalak, K. (2013). Feature selection in corporate credit rating
prediction. Knowledge-based systems, 51, 72-84.
Hájek, & Hájek, P. (2012). Credit rating analysis using adaptive fuzzy rule-based systems: an
industry-specific approach. Central European Journal of Operations Research, 20(3),
421-434.
Hsu, Hsu, F.-J., Chen, M.-Y., & Chen, Y.-C. (2018). The human-like intelligence with
bio-inspired computing approach for credit ratings prediction. Neurocomputing
(Amsterdam), 279, 11-18.
Kim, K.-j., & Ahn, H. (2012). A corporate credit rating model using multi-class Support
Vector Machines with an ordinal pairwise partitioning approach. Computers &
Operations Research, 39(8), 1800-1811.
Lee, & Lee, Y.-C. (2007). Application of Support Vector Machines to corporate credit rating
prediction. Expert systems with applications, 33(1), 67-74.
Luo, Luo, C., & Wu, D. (2017). A deep learning approach for credit scoring using credit
default swaps. Engineering applications of artificial intelligence, 65, 465-470.
Yu-Chiang, H., & Ansell, J. (2009). Retail default prediction by using sequential minimal
optimization technique. Journal of Forecasting, 28(8), 651-666.
Zan, H., Hsinchun, C., Chia-Jung, H., Wun-Hwa, C., & Soushan, W. (2004). Credit rating
analysis with Support Vector Machines and neural networks: a market comparative study.
Decision Support Systems, 37(4), 543-558.
Zhong, Zhong, H., Miao, C., Shen, Z., & Feng, Y. (2014). Comparing the learning
effectiveness of BP, ELM, I-ELM, and SVM for corporate credit ratings.
Neurocomputing (Amsterdam), 128(C), 285-295.

20
J. Platt(1998)Fast Training of Support Vector Machines using Sequential Minimal
Optimization. In B. Schoelkopf and C. Burges and A. Smola, editors, Advances in Kernel
Methods - Support Vector Learning.
S.S. Keerthi, S.K. Shevade, C. Bhattacharyya, K.R.K. Murthy (2001). Improvements to Platt's
SMO Algorithm for SVM Classifier Design. Neural Computation. 13(3):637-649.
Trevor Hastie, Robert Tibshirani(1998).Classification by Pairwise Coupling. In: Advances in
Neural Information Processing Systems.
George H. John, Pat Langley(1995).Estimating Continuous Distributions in Bayesian
Classifiers. In Eleventh Conference on Uncertainty in Artificial Intelligence, San Mateo,
338-345.
Drobetz, Drobetz, W., Schillhofer, A., & Zimmermann, H. (2004). Corporate Governance and
Expected Stock Returns: Evidence from Germany. European Financial Management,
10(2), 267-293.
Jensen, M. C., & Meckling, W. H. (1976). Theory of the firm: Managerial behavior, agency
costs and ownership structure. Journal of Financial Economics, 3(4), 305-360.
Lang, S., Bravo-Marquez, F., Beckham, C., Hall, M., & Frank, E. (2019).
WekaDeeplearning4j: A deep learning package for Weka based on Deeplearning4j.
Knowledge-based systems, 178, 48-50.
Hirk, R., Hornik, K., & Vana, L. (2018). Multivariate ordinal regression models: an analysis
of corporate credit ratings. Statistical Methods & Applications.
Yuan, H., Lau, R. Y. K., Wong, M. C. S., & Li, C. (2018). Mining Emotions of the Public
from Social Media for Enhancing Corporate Credit Rating.2018 IEEE 15th International
Conference on e-Business Engineering (ICEBE).





























