Embed Size (px)
Citation preview

A White Paper
Breaking Big: When Big Data Goes BadThe Importance of Data Quality Management in Big Data Environments
WebFOCUS iWay Software Omni

1 Introduction
3 Big Data, Big Problems
3 Volume and Data Quality
3 Variety and Data Quality
4 Velocity and Data Quality
4 Veracity and Data Quality
5 Addressing Big Data Quality Problems
5 Data Quality for Big Data Is Different
5 Big Data Can Be Unstructured and Have No Schema
6 Use Real-Time Capabilities
6 Take Advantage of Big Data Computation for Cleansing
7 Best Practices in Big Data Quality Management
7 Don’t Hoard Big Data Just Because You Can
7 Establish Baseline Metrics With Data Profiling and Cleansing
7 Consider Master Data Management
8 Big Data Governance
9 Breaking Bad Data With Information Builders Solutions
9 Assess Your Data Using the Data Profiler Dashboard
9 A Comprehensive Data Quality Management Solution
10 Conclusion
Table of Contents

Information Builders1
Introduction
The big data boom has largely been fueled by a simple calculation:
Big Data + Analytics = Actionable Insights
The reality, of course, is far different. While big data technology has improved the ability to store large volumes of disparate information in real time, getting the analytics right is not as straightforward. Sometimes, big data can go bad.
A classic example of bad analytics in action comes from Harvard University Professor Gary King, as told in a recent CSO article.1 A big data project designed to predict the U.S. unemployment rate was using Twitter feeds and social media posts to monitor key words like “unemployment”, “jobs”, and “classifieds”. Leveraging these key words with sentiment analysis, the group collected tweets and other social media content to see if there was a correlation between an increase or decrease in the use of these words and the monthly unemployment rate.
While a correlation was obvious, the researchers noticed a significant spike in the number of tweets containing one of those key words. But as Professor King discovered, this spike had nothing to do with unemployment. Tweets containing the word “jobs” increased for a completely different reason. “What they had not noticed was Steve Jobs had passed,” he said. Outside of the tragedy of Jobs’ untimely passing, this kind of story demonstrates the challenge of relying on big data to guide decisions.
A recent post in the New York Times based on IDC data predicts that there will be a whopping 40 trillion gigabytes of global production data by 2020.2 To remain competitive, businesses need to learn how to exploit this information and use it strategically.
The new equation for Big Data success: Big Data + Data Quality + Analytics = Actionable Insight.
1 Armerding, Taylor. “Big Data Without Good Analytics Can Lead to Bad Decisions,” CSO, August 2013.2 “Big Data Will Get Bigger,” The New York Times, June 2013.
Images
HTML
E-mailSocial
Databases
Sensor data
Clickstream
Big Data+Data Quality+Predictive Analytics=Actionable Intelligence
Predictive Analytics
Big Data
Data Quality
Actionable Intelligence
�

Breaking Big: When Big Data Goes Bad2
But with all the hype around big data analytics, not enough attention is being given to data quality. Accurate, complete, and consistent information must form the foundation of the models on which the data is built. The reality is, algorithms are only as good as the data with which their modelers work. When the data is suspect, the negative impact will spread far and wide.
In a recent survey by Oracle, business executives were asked to grade themselves on their ability to cope with and take advantage of the data deluge within their industry.3 Approximately 40 percent of respondents in healthcare gave themselves a D or an F, while large numbers of respondents in utilities (39 percent), airlines (31 percent), retail (30 percent), and financial services (25 percent) also gave themselves failing grades.
More organizations are collecting big data – that combination of high-volume, high-velocity, high-variety, structured and unstructured information. As data flows in from mobile devices, social networks, and other new and emerging sources, the ability to truly leverage it to boost business performance will require a different calculation:
Big Data + Data Quality + Analytics = Actionable Insights
In this paper, we’ll discuss the differences between big data and conventional data, and how those differences put big data environments at a greater risk of data quality problems. We’ll also highlight the importance of implementing effective and broad-reaching data quality management in big data scenarios, and share solutions and best practices for doing so.
3 “Evans, Bob. “The Deadly Cost of Ignoring Big Data: $71.2 Million per Year,” The Innovation Advantage, July 2012.

Information Builders3
Big data, and its benefits, are often defined by three primary characteristics – variety, velocity, and volume. More than a decade after the introduction of these concepts, many businesses still struggle to take advantage of them. This is because there is a fourth V – veracity – which must serve as the foundation of the other three. Veracity is the hardest to achieve.
Volume and Data QualityCleansing and scrubbing data sets that reach petabytes in size, to the same degree as smaller data sets, is an unrealistic and unattainable goal. Consider also that many data quality issues in smaller, structured data sets are man-made, while most information in big data scenarios is machine-generated, such as log files, GPS data, or click-through data.
It would seem that because big data is not subject to human errors or mistakes, it is therefore cleaner. But the reality is that large volumes of big data are being aggregated across many industries, and this has serious data quality ramifications.
In retail, for example, more companies have begun to aggregate large amounts of big data related to consumer shopping preferences. They gather information about what types of products they buy, how much they are looking to spend, which sales channel they used, etc. In healthcare, organizations use aggregated big data to improve care and increase the likelihood of finding cures for deadly diseases through research, pharmacological enhancements, and wellness programs. Government agencies use aggregated big data for law enforcement purposes, and financial services firms use it to spot market trends and identify key indicators for growth among investment opportunities.
Variety and Data Quality Much of today’s big data is acquired through data harvesting. This involves such activities as collecting competitive pricing information from multiple travel or shopping websites, gathering customer sentiment from blogs or social media sites, or grabbing part descriptions from manufacturer or vendor web pages.
But no true analytics can be performed until the acquired unstructured and/or semi-structured data has been identified, parsed, and cleansed.
For example, when applying sentiment analysis to product reviews, carefully tuned language processing is needed to ensure accuracy. Sentiment is not defined solely by the definition of words and phrases, but also by the context in which those words and phrases are used. The word “sick” might have negative connotations for a restaurant chain (“The food made me sick!”), but may indicate positive feelings for a concert, opera, or other performance (“That soprano’s voice was sick!”). Some flavor of data quality filtering must be applied to these raw feeds in order to turn the variety of big data into actionable intelligence.
Big Data, Big Problems

Breaking Big: When Big Data Goes Bad4
Velocity and Data QualityBusinesses need to harness data velocity to stay competitive.
In the retail sector, for example, companies must respond in seconds if they hope to connect with customers who visit their sites. They must immediately use all customer data available – past purchase history, social networking activity, recent customer support interactions, etc. – to generate customized and compelling messages for their consumers on the fly. But for this scenario to work, the data must be accurate. Amazon’s recommendation engine is so powerful because it makes relevant suggestions at the precise moment a customer is ready to purchase a product. But that requires complete, accurate data.
Veracity and Data QualityVeracity is the most important “V”; it serves as the foundation of data quality in big data scenarios. Veracity refers to the data that is being stored, and its relevance to the problem being analyzed. Big data veracity is based on:
■n Data validity – The accuracy of the data for its intended use. Clearly valid data is critical to effective decision-making
■n Data volatility – How long is data valid and how long should it be stored? In a real-time data world, organizations must determine when data is no longer relevant to an analysis initiative
The former Three Vs of Big Data must now make room for the Fourth V: Veracity.
Veracity
Big Data
Actionable Intelligence
�
Variety
�
�
Volume
�
Velocity�

Information Builders5
One of the key goals of big data management is to ensure a high level of quality and accessibility, so trusted and timely data can be leveraged strategically through business intelligence (BI) and big data analytics applications and tools. Everything and everyone who uses big data is directly impacted by its quality. Consequently, the value of big data lies not only in its ability to be harnessed by analytics, but also in its trustworthiness.
There are countless data quality solutions on the market today but, unfortunately, few of them are equipped to promote information integrity in big data environments. To truly maintain optimum data quality across all big data sources, organizations must consider the following:
Data Quality for Big Data Is DifferentMany data quality management tools can only process relational data. Big data is distinctly different from traditional relational data in terms of data types, data access, and data queries. Data quality tools built to natively support big data understand these differences and are optimized to cleanse the information accordingly. To ensure information integrity in big data scenarios, the tools in use must also be able to access, correlate, cleanse, standardize, and enrich sources like IBM Netezza, Oracle Exadata, SAP HANA, Teradata and Teradata’s Aster Data, EMC Greenplum, HP Vertica, 1010data, ParAccel, and Kognitio, as well as MapReduce databases such as Hadoop, MongoDB, Cloudera, and MapR.
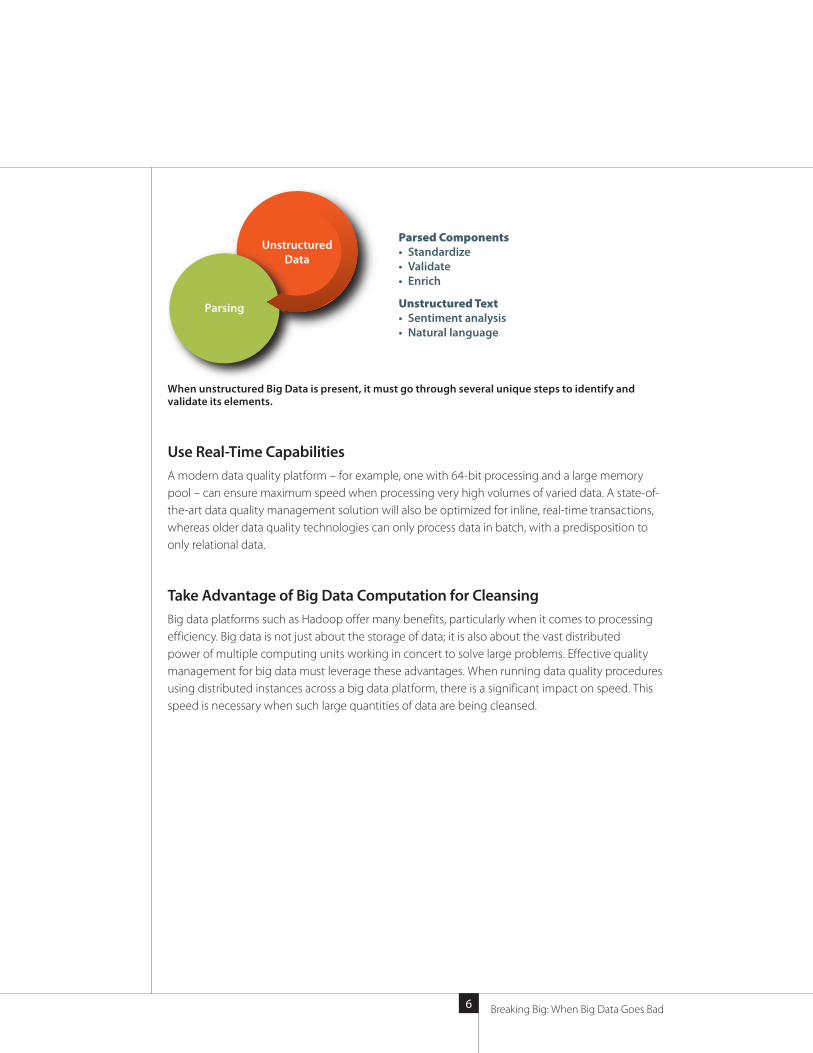
Big Data Can Be Unstructured and Have No SchemaBig data environments are highly diverse. In addition to structured data from enterprise resource planning (ERP), customer relationship management (CRM), legacy, and other systems, they can also include blog posts, social media streams, cloud-based information, or sensor data, such as RFID or UPC scans and utility gauge readings. In many cases, data without a schema is present. Because of this lack of structure and schema, a number of distinct steps are required to identify and validate the data elements. First, the data quality management tool must be able to parse that data, which automatically breaks down large, unstructured fields into identifiable elements.
For instance, an address written in a single line may have constituent parts identified, such as house number, street name, apartment, city, state, zip code, and country. From there, relevant data will be standardized, validated, and enriched when necessary. Such address errors can be corrected to conform to the appropriate country’s address standards, while also filling in missing information such as a zip code.
Text analytics capabilities can also be very useful when the data schema is unknown. They provide the ability to determine context, such as sentiment, when examining free-form text. This ability across large swaths of data provides insight into how customers feel about a company or its products.
Addressing Big Data Quality Problems
Breaking Big: When Big Data Goes Bad6
When unstructured Big Data is present, it must go through several unique steps to identify and validate its elements.
Use Real-Time CapabilitiesA modern data quality platform – for example, one with 64-bit processing and a large memory pool – can ensure maximum speed when processing very high volumes of varied data. A state-of-the-art data quality management solution will also be optimized for inline, real-time transactions, whereas older data quality technologies can only process data in batch, with a predisposition to only relational data.
Take Advantage of Big Data Computation for CleansingBig data platforms such as Hadoop offer many benefits, particularly when it comes to processing efficiency. Big data is not just about the storage of data; it is also about the vast distributed power of multiple computing units working in concert to solve large problems. Effective quality management for big data must leverage these advantages. When running data quality procedures using distributed instances across a big data platform, there is a significant impact on speed. This speed is necessary when such large quantities of data are being cleansed.
Parsing
Parsed Components• Standardize• Validate• Enrich
Unstructured Text• Sentiment analysis• Natural language
UnstructuredData

Information Builders7
To successfully manage quality in big data environments, organizations need more than just a solution. They need a solid strategy. For example, they must consider where the data is coming from, how it will be used, who will be consuming it, and what decisions it will support before deciding on a plan of action.
Some best practices for ensuring the integrity of big data include:
Don’t Hoard Big Data Just Because You CanIt isn’t practical to attempt to manage quality across an entire big data store. Users will consume only a fraction of the data collected, so running quality checks and processes on all of it will just waste a tremendous amount of time and resources.
Predictive analytics can help here, allowing organizations to determine which data sets are most likely to be used, and therefore should be targeted. Smart extract, transform, and load (ETL) processes can then be used to collect that data – for example, customers most likely to buy a certain product – and move it to a repository for cleansing and analysis.
Establish Baseline Metrics With Data Profiling and CleansingData profiling tools should be employed, to understand the current state of data, as well as where and what types of quality problems exist. Data quality management can then be applied to dynamically cleanse any inaccurate or invalid information uncovered during the profiling process.
Another important component of effective big data cleansing is proactive, real-time detection of bad information. Once invalid or corrupt information has entered a big data environment, it may be too late to prevent widespread damage. A data quality management solution must be able to block dirty information as it is being generated, before it enters the environment in the first place. This concept is known as a data-quality firewall and is essential for any intraday reliance on operational data.
Consider Master Data ManagementData quality is a very important factor for big data. When it comes to the integrity of information, data quality projects yield themselves to master data management (MDM) initiatives.
What is MDM and why consider it?
Data quality applied to big data ensures the integrity of each individual record and its constituent fields. Master data management furthers the integrity of this data by creating a unified view across disparate, conflicting, and duplicated records. For instance, data quality ensures that all the customer information is correct. MDM helps answer questions like: How many customers are there? How many times have various divisions and departments communicated with John Smith?
Best Practices in Big Data Quality Management

Breaking Big: When Big Data Goes Bad8
In big data scenarios, it is particularly important to ensure consistency and uniformity across all data assets, and to create a single “golden record” for key business entities. MDM solutions help organizations harness their big data by creating and maintaining a single, unified view of products, customers, employees, and vendors.
Furthermore, social media analytics is a growing space where MDM applied to customer information is essential. Customers utilize channels such as Facebook and Twitter – in addition to traditional phone and e-mail – to communicate with companies. While data quality can ensure that these various touch points are complete, there is a void in understanding the relationship between these interactions. A person who calls a contact center may talk to an agent whom has no knowledge of the issues discussed between that same customer and the Twitter customer support rep.
An integrated profile of each customer, consistent across these touch points, provides better service and a competitive advantage. Master data management accomplishes this by consolidating data across different sources to create a single, complete customer view.
Big Data GovernanceData governance is a critical component of any data quality management strategy. But governance is even more vital in big data environments, where the variety, velocity, and volume of information that is created and maintained increase the risk of integrity issues. Because big data offers distinct challenges – for example, it is more fluid and undefined – it requires more attention than traditional sources. Data governance strategies offer a strong framework to apply to these large volumes of unstructured data.
Companies must remain extra-vigilant when managing big data, and should clearly define ownership and rules or policies for overseeing their information assets. Policies must be in place to effectively deal with the stewardship of different types of big data. It is imperative to coordinate among business units and users to ensure consistent usage and quality of big data.

Information Builders9
The iWay Data Quality Suite (DQS) from Information Builders is designed to ensure data’s “fourth V” – veracity – across even the biggest and most diverse information environments. No matter where data resides, what format it is in, or how much of it there is, iWay can seamlessly cleanse and enrich it, in real time or in batch, to ensure a trusted, complete view from every interaction point.
Assess Your Data Using the Data Profiler DashboardData profiling, the first step in any data quality initiative, enables users to assess and understand data through basic analysis. The Data Profiler dashboard provides advanced, built-in, in-depth reports and profiling information, so data can be efficiently assessed, and quality improvements can be tracked over time. Pre-built metrics and customizable business rules also help users to monitor data and perform offline analytics in batch or real time.
A Comprehensive Data Quality Management SolutionThe DQS is a comprehensive, unified solution designed to profile, cleanse, and enrich data to drive better planning and decision-making by ensuring the consistency, accuracy, and completeness of enterprise information. This state-of-the-art solution is also designed to optimize information integrity throughout its lifecycle. It leverages fully customizable business rules and a portfolio of localized dictionaries, as well as advanced unification, validation, cleansing, and enrichment techniques, to not only identify and correct bad data, but also to proactively prevent it from entering the environment in the first place.
The DQS can also be easily extended to master data to create a single version of the truth for key business entities, such as customers, vendors, employees, or products. The iWay Master Data Suite (MDS) consolidates millions of records, and makes unified and validated master data instantly available to a wide range of enterprise applications and systems. Extensive capabilities from the Data Quality Suite are included in this master data management solution to allow for the most comprehensive data integrity solution available. Organizations can also facilitate data governance across all big data sources using an integrated data stewardship portal with customizable workflows for insight and remediation.
Breaking Bad Data With Information Builders Solutions
Breaking Big: When Big Data Goes Bad10
In a recent Forbes Market Insight survey, 92 percent of companies polled indicated that by making sufficient use of their big data, they were able to meet or exceed their goals.4
But how accurate is that big data?
Big data is complex, and highly prone to widespread quality problems. Big data’s “Three Vs” – volume, variety, and velocity – must make room for a “Fourth V”: Veracity. Delivering that most elusive characteristic begins by ensuring that big data has the highest possible integrity. The best way to do that is to clean data where it lives – as transactions flow into systems, as the user clicks “OK” on a website, or as an RSS feed indicates that a new blog post is live.
Information Builders provides comprehensive data quality management, including master data management and data governance. With Information Builders, organizations can optimize the quality of big data before it spreads into other parts of the enterprise. The result is better operational processes, better business intelligence, and better correlated and managed big data analytics.
Conclusion
4 “Rubin, James Peter. “The Big Potential for Big Data: A Field Guide for CMOs,” Forbes Insights, October 2013.

Worldwide Offices
Corporate HeadquartersTwo Penn Plaza New York, NY 10121-2898 (212) 736-4433 (800) 969-4636
United StatesAtlanta, GA* (770) 395-9913
Boston, MA* (781) 224-7660
Channels (770) 677-9923
Chicago, IL* (630) 971-6700
Cincinnati, OH* (513) 891-2338
Dallas, TX* (972) 398-4100
Denver, CO* (303) 770-4440
Detroit, MI* (248) 641-8820
Federal Systems, D.C.* (703) 276-9006
Florham Park, NJ (973) 593-0022
Houston, TX* (713) 952-4800
Los Angeles, CA* (310) 615-0735
Minneapolis, MN* (651) 602-9100
New York, NY* (212) 736-4433
Philadelphia, PA* (610) 940-0790
Pittsburgh, PA (412) 494-9699
San Jose, CA* (408) 453-7600
Seattle, WA (206) 624-9055
St. Louis, MO* (636) 519-1411, ext. 321
Tampa, FL (813) 639-4251
Washington, D.C.* (703) 276-9006
InternationalAustralia* Melbourne 61-3-9631-7900 Sydney 61-2-8223-0600
Austria Raffeisen Informatik Consulting GmbH Wien 43-1-211-36-3344
Brazil São Paulo 55-11-2847-4519
Canada Calgary (403) 718-9828 Montreal* (514) 421-1555 Ottawa (416) 364-2760 Toronto* (416) 364-2760 Vancouver (604) 688-2499
China Beijing 86-10-5128-9680
Estonia InfoBuild Estonia ÖÜ Tallinn 372-618-1585
Finland InfoBuild Oy Espoo 358-207-580-840
France* Puteaux +33 (0)1-49-00-66-00
Germany Eschborn* 49-6196-775-76-0
Greece Applied Science Ltd. Athens 30-210-699-8225
Guatemala IDS de Centroamerica Guatemala City (502) 2412-4212
India* InfoBuild India Chennai 91-44-42177082
Israel SRL Software Products Ltd. Petah-Tikva 972-3-9787273
Italy Agrate Brianza 39-039-596620
Japan KK Ashisuto Tokyo 81-3-5276-5863
Latvia InfoBuild Lithuania, UAB Vilnius 370-5-268-3327
Lithuania InfoBuild Lithuania, UAB Vilnius 370-5-268-3327
Mexico Mexico City 52-55-5062-0660
Middle East Innovative Corner Est. Riyadh 966-1-2939007 n Iraq n Lebanon n Oman n Saudi Arabia n United Arab Emirates (UAE)
Netherlands* Amstelveen 31 (0)20-4563333 n Belgium n Luxembourg
Nigeria InfoBuild Nigeria Garki-Abuja 234-9-290-2621
Norway InfoBuild Norge AS c/o Okonor Tynset 358-0-207-580-840
Portugal Lisboa 351-217-217-400
Singapore Automatic Identification Technology Ltd. Singapore 65-69080191/92
South Africa InfoBuild (Pty) Ltd. Johannesburg 27-11-510-0070
South Korea UVANSYS, Inc. Seoul 82-2-832-0705
Southeast Asia Singapore 60-172980912 n Bangladesh n Brunei n Burma n Cambodia n Indonesia n Malaysia n Papua New Guinea n Thailand n The Philippines n Vietnam
Spain Barcelona 34-93-452-63-85 Bilbao 34-94-400-88-05 Madrid* 34-91-710-22-75
Sweden InfoBuild AB Stockholm 46-8-76-46-000
Switzerland Dietlikon 41-44-839-49-49
Taiwan Galaxy Software Services, Inc. Taipei (866) 2-2586-7890, ext. 114
United Kingdom* Uxbridge Middlesex 0845-658-8484
Venezuela InfoServices Consulting Caracas 58212-763-1653
* Training facilities are located at these offices.
Corporate Headquarters Two Penn Plaza, New York, NY 10121-2898 (212) 736-4433 Fax (212) 967-6406 DN7507726.0514Connect With Us informationbuilders.com [email protected]
Copyright © 2014 by Information Builders. All rights reserved. [117] All products and product names mentioned in this publication are trademarks or registered trademarks of their respective companies.




























![Big Band - As Time Goes by {[Rocha Sousa]](https://img.dokumen.tips/doc/110x75/552bad6e550346690f8b4574/big-band-as-time-goes-by-rocha-sousa.jpg)
