Embed Size (px)
Citation preview

上海交通大学硕士研究生公共课
生物数学(一)
课程名称 : 生物数学(一)
学生专业 : 生命科学, 医学, 生物科学, 农学院
教师姓名 : 林建忠 副教授
助教姓名 : 王磊 硕士生
开课院(系): 理学院数学系
2007年9月–2008年1月

课程教学内容简介
一、概况
1. 开课学院(系)和学科:理学院数学系应用数学教研室
2. 课程代码:
3. 课程名称:生物数学(一)
4. 学时/学分:45学时/2学分
5. 预修课程:中学初等数学,如果学习过部分《高等数学》、《线性代数》、《概率
统计》则更好
6.课程主要内容:生物统计学,试验数据分析,流行病研究中的统计和分析技术,
临床科学分析,微分方程模型
7. 适应专业学科:全校大生命学科各类研究生中数学起点低的部分同学(指本
科阶段数学学习得较少的同学)
8. 教材/教学参考书:徐克学,《生物数学》科学出版社2002
伯纳德o罗斯纳,《生物统计学基础》(原书第5版)孙尚洪译,科学出版社
2004 曾照芳等,《医用生物数学》(第2版)重庆大学出版社1999
王松桂等,《线性统计模型》高等教育出版社2000年
二、课程的性质和任务
本课程是面向全校大生命学科专业数学基础较低的同学开设的。
自然科学的发展经历由定性研究到定量研究的过程。生命科学的各个领域的发
展也是如此。生物数学是从数量上研究生物学中带有普遍性、深刻性和客观性规律的
一门应用交叉学科。从生物学的应用去划分,有数量分类学,数量遗传学,数量生态
学和生物力学等。这些分支是数学与生物学不同领域相结合的产物,在生物学中有明
确的研究范围。从使用的数学方法划分,生物数学又可分为生物统计学,生物此系统
ii

上海交通大学硕士研究生公共课—-生物数学(一)—-林建忠编
论,生物控制论,生物信息学和生物方程等。这些分支与前者不同,它们没有明确的
生物研究对象,只研究那些涉及生物学应用有关的数学方法与理论。
具备用数学工具对生物研究对象进行定量分析的能力,是现代生命学科的科学
研究、工程技术和管理人员必须具备的基本素养之一。本课程为训练这类能力打下一
定的基础。
由于受到学时数较少,以及受到相当多数研究生本科阶段数学基础的限制,本课
程的内容主要局限在生物统计学与试验数据分析方面。通过该门课程的学习,要求
学生能理解统计地描述实验数据的思想,掌握基本而常用的计算法,能运用多元统
计分析方法,对复杂数据作主成分,判别,聚类等分析,能认识和理解生物系统演化
的Markov模型和微分方程模型,并会进行简单的正交试验设计和结果分析。通过练
习和学生自己收集实际问题,开阔视野,理论联系实际,提高学生的数学素质,加强
学生开展科研工作和解决实际问题的能力。鼓励学有余力的学生在掌握上述基本方
法的同时,进一步提高自己在生物数学方面的水平和能力。
日期: 2007年9月28日
– iii –

上海交通大学硕士研究生公共课—-生物数学(一)—-林建忠编
– iv –

目录
第一章 概论 2
1.1 学科界说 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2
第二章 生物统计数学模型 3
2.1 简单的统计数学方法 . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3
2.1.1 χ2分布 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3
2.1.2 t 分布(学生分布) . . . . . . . . . . . . . . . . . . . . . . . . . . 6
2.1.3 F 分布 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 8
2.2 回归预测数学模型 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 10
2.2.1 一元线性回归模型 . . . . . . . . . . . . . . . . . . . . . . . . . 10
2.2.2 多元线性回归模型 . . . . . . . . . . . . . . . . . . . . . . . . . 12
2.2.3 原始数据的中心化和标准化 . . . . . . . . . . . . . . . . . . . . 13
2.2.4 误差项方差 σ2的估计 . . . . . . . . . . . . . . . . . . . . . . . 15
2.2.5 回归方程的显著性检验 . . . . . . . . . . . . . . . . . . . . . . . 16
2.2.6 判别系数(复相关系数) . . . . . . . . . . . . . . . . . . . . . . . 17
2.2.7 非线性回归方程的一些处理方法 . . . . . . . . . . . . . . . . . 18
2.2.8 逐步回归 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 19
2.3 判别分析数学模型 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 21
2.3.1 Fisher 的判别分析法 . . . . . . . . . . . . . . . . . . . . . . . . 21
2.3.2 多类群时的Bayes 判别法 . . . . . . . . . . . . . . . . . . . . . . 28
2.4 主成分分析 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 31
1

上海交通大学硕士研究生公共课—-生物数学(一)—-林建忠编
2.4.1 线性回归模型的主成分估计 . . . . . . . . . . . . . . . . . . . . 31
2.4.2 主成分分析(principal component analysis)原始数值矩阵 . . . . 34
2.4.3 主成分的计算与实际意义 . . . . . . . . . . . . . . . . . . . . . 36
2.4.4 主成分分析作图 . . . . . . . . . . . . . . . . . . . . . . . . . . . 36
2.4.5 主成分分析方法解决分析单位作图(Q分析) . . . . . . . . . . . . 38
第三章 生物分类的数学模型 39
3.1 分类的基本概念和原始数据的获得 . . . . . . . . . . . . . . . . . . . . 39
3.1.1 分类的基本概念 . . . . . . . . . . . . . . . . . . . . . . . . . . . 39
3.1.2 性状的种类 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 40
3.2 数据变换和数据标准化 . . . . . . . . . . . . . . . . . . . . . . . . . . . 42
3.3 相似性概念的数量化 . . . . . . . . . . . . . . . . . . . . . . . . . . . . 42
3.3.1 距离系数 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 43
3.3.2 相关系数与角余弦系数 . . . . . . . . . . . . . . . . . . . . . . . 46
3.3.3 联合系数 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 47
3.4 表征分类的分类运算 . . . . . . . . . . . . . . . . . . . . . . . . . . . . 49
第四章 生物演化的数学模型 50
4.1 演化集合及其基本定理 . . . . . . . . . . . . . . . . . . . . . . . . . . . 50
4.2 分支性状与编码 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 57
4.3 演化的定量表示与俭约性公理 . . . . . . . . . . . . . . . . . . . . . . . 62
4.4 性状演化的和谐性与和谐性分析方法 . . . . . . . . . . . . . . . . . . . 67
4.5 生物演化历史的重构 . . . . . . . . . . . . . . . . . . . . . . . . . . . . 72
第五章 马尔柯夫链数学模型 74
5.1 马尔柯夫链的基本概念及其表示 . . . . . . . . . . . . . . . . . . . . . . 74
5.2 正则马尔柯夫链 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 78
5.3 吸收马尔柯夫链 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 84
– 2 –

上海交通大学硕士研究生公共课—-生物数学(一)—-林建忠编
第六章 微分方程数学模型 96
6.1 单一种群生态数学模型 . . . . . . . . . . . . . . . . . . . . . . . . . . . 96
6.2 Lotka-Volterra生态数学模型 . . . . . . . . . . . . . . . . . . . . . . . . 101
第七章 方差分析模型与正交试验设计 107
7.1 单因素方差分析 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 107
7.2 两因素方差分析 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 116
7.3 正交试验设计与方差分析 . . . . . . . . . . . . . . . . . . . . . . . . . 125
– 3 –

第一章 概论
1.1 学科界说
自学内容
4

第二章 生物统计数学模型
2.1 简单的统计数学方法
2.1.1 χ2 分布
定义 若 X1, · · · , Xn相互独立, 都服从正态分布 N(0, 1) , 则称统计量
X = X21 + · · ·+ X2
n
为具有自由度为 n的 χ2分布.
这里N(0, 1)表示标准正态随机变量的分布密度函数
f(x) =1√2π
e−x2/2, ∀ x ∈ R
性质 若 X1, · · · , Xn 相互独立, 都服从正态分布 N(µ, σ2) , 作变换 Xi−µσ
, 则统计
量
Y =1
σ2
n∑i=1
(Xi − µ)2
为具有自由度为 n的 χ2n分布.
性质 统计量
χ2n−1 =
1
σ2
n∑i=1
(Xi − X)2
是具有自由度为 n− 1的 χ2分布.
χ2 分布的密度函数
f(x) =
1
Γ(n2 )2
n2e−
x2 x
n2−1, if x > 0
0, if x ≤ 0
5

上海交通大学硕士研究生公共课—-生物数学(一)—-林建忠编
这里, 伽玛函数
Γ(p) =
∫ ∞
0
tp−1e−tdt.
柯赫伦(Cochran)定理 若 X1, · · · , Xn 相互独立, 都服从正态分布 N(µ, σ2) , 记
样本均值统计量
X =1
n
n∑i=1
Xi
和样本方差统计量
s2 =1
n− 1
n∑i=1
(Xi − X)2
则
(a) X ∼ N(µ, σ2/n) , 即 X−µσ
√n ∼ N(0, 1) ,
(b) (n− 1)S2/σ2 ∼ χ2n−1,
(c)X 与S2 独立.
分布假设检验—-皮尔逊(K.Pearson)的 χ2 检验(拟合优度检验)
假设母体分布是只有有限多项的离散分布, 假设它的分布是已知的. 用式子表示,
设 A1, A2, · · · , Al是两两不相容的事件完备组, 既l⋃
i=1
Ai = Ω, AiAj = φ . 作
假设H0: P (Ai) = pi, i = 1, 2, · · · , l
其中 p1, p2, · · · , pl是已知数.
现做n 次独立重复试验, 各事件 Ai出现的实际频数分布为
事件 A1, A2, · · · , Al
实际频数 m1,m2, · · · ,ml
而l∑
i=1
mi = n . 用这个子样检验上面的假设. 再看理论频数分布
然后考察子样的实际频数mi对理论频数 npi偏差的加权平方和
χ2 =l∑
i=1
(mi − npi)2
npi
– 6 –

上海交通大学硕士研究生公共课—-生物数学(一)—-林建忠编
事件 A1, A2, · · · , Al
理论频数 np1, np2, · · · , npl
这里 χ2值的大小刻划子样实际频数对理论频数的拟合程度. 它的渐近分布由下面定
理给出.
皮尔逊(K.Pearson)定理 设 P (Ai) = pi , i = 1, 2, · · · , l , 其中 p1, p2, · · · , pl是已
知数. 若 χ2由上式给出, 则
limn→∞
Pχ2 ≤ x =
1
Γ( l−12 )2
l−12
e−x2 x
l−32 , if x > 0
0, if x ≤ 0
即当 n →∞时 χ2按分布收敛到自由度为 l − 1的 χ2分布.
例. 孟德尔碗豆杂交实验
使用种子黄色,圆粒的自交系与种子绿色,皱粒的自交系进行杂交.
黄色Y与绿色y是一对等位基因; 圆粒R与皱粒r是另一对等位基因. 杂交以后共获
得 4× 4 = 16种基因型, 由于杂交基因型只表现显性, 因此杂交的后代只表现出黄圆,
黄皱, 绿圆,绿皱 4 种结果. 如果孟德尔的遗传规则成立, 黄圆, 黄皱, 绿圆,绿皱四种
结果的出现比例为 9 : 3 : 3 : 1 .
表 2.1: 碗豆杂交基因型表
YR Yr yR yr
YR YYRR黄圆 YYRr黄圆 YyRR黄圆 YyRr黄圆
Yr YYRr黄圆 YYrr黄皱 YyRr黄圆 Yyrr黄皱
yR YyRR黄圆 YyRr黄圆 yyRR绿圆 yyRr绿圆
yr YyRr黄圆 Yyrr黄皱 yyRr绿圆 yyrr绿皱
孟德尔实验获得的杂交后代有黄圆315颗, 黄皱101颗, 绿圆108颗,绿皱32颗,共
计556颗. 检验孟德尔的遗传规则是否成立, 等价于检验假设
H0 : 杂交的后代黄圆, 黄皱, 绿圆,绿皱 4 种结果出现的比例为 9 : 3 : 3 : 1 .
如果 H0成立, 按此比例比例分配黄圆, 黄皱, 绿圆,绿皱理论预期值应分别为313,
– 7 –

上海交通大学硕士研究生公共课—-生物数学(一)—-林建忠编
104, 104, 35颗. 作 χ2统计量
χ2 =(315− 313)2
313+
(101− 104)2
104+
(108− 104)2
104+
(32− 35)2
35= 0.51031
此例自由度= n−1 = 4−1 = 3 ,查表 χ3(0.01)2 = 11.345 ,说明P (χ23 > 11.345) = 0.01
, 而 0.51031 < 11.345 , 因而在显著性水平 α = 0.01之下, 接受原假设 H0 , 杂交的后
代遵从上述预期比例. 孟德尔遗传定律获得支持
2.1.2 t 分布(学生分布)
定义 若 X 服从正态分布 N(0, 1) , 且与 χ2n独立, 则称统计量
t =X√χ2
n/n
为具有自由度为 n的 t分布.
性质 若 X1, · · · , Xn相互独立, 都服从正态分布 N(µ, σ2) , 则统计量
t =X − µ
s
√n
是具有自由度为 n− 1的 t分布.
t分布的密度函数
f(x) =1√
nB(
12, n
2
) 1(1 + x2
n
)n+12
=Γ
(n+1
2
)√
nπΓ(
n2
) 1(1 + x2
n
)n+12
这里, 贝塔函数
B(p, q) =
∫ 1
0
tp−1(1− t)q−1dt.
注意上面用到了关系式
B(p, q) =Γ(p)Γ(q)
Γ(p + q), Γ(1
2) =
√π.
性质 当 n →∞时, 中心 t(n)分布收敛于 N(0, 1) .
– 8 –

上海交通大学硕士研究生公共课—-生物数学(一)—-林建忠编
例 在医学中, 以中药青木香治疗高血压, 50个临床治疗病例, 治疗前后舒张压数
据之差x 为随机变量, 平均值 x = −16.28 , 标准差 s = 10.58 , 问疗效是否显著?
解 如果 X ∼ N(µ, σ) , 疗效的检验成为检验 µ是否大于0. 假设 H0 : µ = 0 , 建
立t 统计量
t =x− 0
s
√n =
−16.28
10.58
√50 = −10.88
这是自由度 = n − 1 = 50 − 1 = 49 的学生分布. 显著性水平 α = 0.01 , 查表
t49(0.01) = −2.41 , 说明 P (t < −2.41) = 0.01 , 而 t = −10.86 < −2.41 , 因而在显著性
水平之下, 拒绝原假设 H0 , 即疗效显著.
对x 的置信区间进行估计, 在置信度 1 − α = 0.95 , 查表 t0.025 = 2.01 , 说明
P (|t| < 2.01) = 0.95
t =|x− µ|
s
√n < 2.01
即
x− 2.01√n
s < µ < x +2.01√
ns
−16.28− 2.01√50× 10.58 < µ < −16.28 +
2.01√50× 10.58
−19.29 < µ < −13.27
最后结果说明在置信度0.95 之下,舒张压平均下降 13.27 ∼ 19.29 .
检验正态母体平均树(方差未知)
设有两个分别服从正态分布 N(µ1, σ) , N(µ2, σ)的母体. 分别从该母体独立取出
n1 和 n2 个子样, 样本均值分别为 X 和 Y , 标准差分别为和 s1 和和 s2 , 试检验假设
和 H0 : µ1 = µ2 .
解 首先
X − Y ∼ N
(0,
√n1 + n2
n1n2
σ
).
故
U =X − Y√
n1+n2
n1n2σ∼ N(0, 1)
– 9 –

上海交通大学硕士研究生公共课—-生物数学(一)—-林建忠编
又因为n1∑i=1
(xi − x
σ
)2
∼ χ2n1
n2∑i=1
(yi − y
σ
)2
∼ χ2n2
它们的和服从自由度为 n1 + n2 − 2的 χ2分布. 根据t 分布的定义可得,
t =x− y√
(n1 − 1)s21 + (n2 − 1)s2
2
√n1n2(n1 + n2 − 2)
n1 + n2
∼ tn1+n2−2
例 某种植物原料经处理后含脂率的变化如下: 试检验处理对含脂率的下降是否
表 2.2: 某种植物原料处理前后含脂率数据
处理前 0.19 0.18 0.21 0.30 0.66 0.42 0.08 0.12 0.30 0.27
处理后 0.15 0.13 0.00 0.07 0.24 0.24 0.19 0.04 0.08 0.20 0.12
有效?
解
处理前: n1 = 10 , x = 0.273 , s21 = 0.02811 ,
处理后: n1 = 11 , x = 0.133 , s22 = 0.00642 .
代入t 统计量公式得,
t =0.237− 0.133√
9× 0.02811 + 10× 0.00642
√10× 11× 19
10 + 11= 2.48
原假设 H0 : µ1 ≤ µ2 为单边假设检验. 在显著性水平 α下应根据 P (|t| > t2α) = 2α .
取显著性水平 α = 0.05 , 查表 t19(0.1) = 1.729 , 而 t = 2.48 > t19(0.1) , 因而在显著性
水平之下, 拒绝原假设 H0 , 即结果说明含脂率的下降.
2.1.3 F 分布
定义 若X 和 Y 分别服从自由度为 n1 , n2的 χ2n分布, 且X 和 Y 相互独立, 则称
统计量
F =X/n1
Y/n2
– 10 –

上海交通大学硕士研究生公共课—-生物数学(一)—-林建忠编
为具有第一自由度为 n1 , 第二自由度为 n2的 F 分布. 记为 F (n1, n2)
F 分布的密度函数
f(x) =
Γ(n1+n22 )
Γ(n12 )Γ(n2
2 )
(n1
n2
) (n1
n2x)n1
2−1 (
1 + n1
n2x)−n1+n2
2
, if x > 0
0, if x ≤ 0
– 11 –

上海交通大学硕士研究生公共课—-生物数学(一)—-林建忠编
2.2 回归预测数学模型
2.2.1 一元线性回归模型
例:在畜牧业中,需要通过猪的长度了解猪的体重.现获得北方猪的一批数据:
表 2.3: 北方猪的长度与体重关系数据
体长(cm) 体重(kg)
136.6 161.9
157.5 200.0
139.0 176.5
144.0 205.0
138.6 180.2
138.6 113.0
141.9 148.0
149.7 180.3
134.6 133.8
一元线性回归模型:
设原始数据是 (xi, yi)(i = 1, 2, · · · , n) , 其中 xi代表体长, 称为自变量, 其中 yi代
表体重, 称为因变量. 根据散点图, 可假设
y = b0 + b1x + e
其中, b0和 b1是待定常数, e是观测误差. 此方程称为一元线性回归方程.
问题:如何根据自变量和因变量的观测数据估计 b0 和 b1 ?
最小二乘法
构造偏差和函数
Q =n∑
i=1
(yi − b0 − b1xi)2
– 12 –

上海交通大学硕士研究生公共课—-生物数学(一)—-林建忠编
依据多元函数达到极值的条件有
∂Q
∂b0
= −2n∑
i=1
(yi − b0 − b1xi) = 0
∂Q
∂b1
= −2n∑
i=1
(yi − b0 − b1xi)xi = 0
移项整理得
b0n + b1
n∑i=1
xi =n∑
i=1
yi
b0
n∑i=1
xi + b1
n∑i=1
x2i =
n∑i=1
xiyi
解线性方程组得
b1 =
∑ni=1 xiyi − 1
n
∑ni=1 xi
∑ni=1 yi∑n
i=1 x2i − 1
n(∑n
i=1 xi)2
b0 =1
n
n∑i=1
yi − b11
n
n∑i=1
xi
记样本平均值 x = 1n
∑ni=1 xi和 x = 1
n
∑ni=1 yi ,上式可写为:
b1 =
∑ni=1 xiyi − nxy∑ni=1 x2
i − nx2
b0 = y − b1x
这样一来,我们获得了经验线性回归方程
y = b0 + b1x
算例:北方猪的长度与体重回归关系式算例
首先计算
n∑i=1
xi = 1280.5,n∑
i=1
yi = 1497.7
n∑i=1
x2i = 182605.59,
n∑i=1
y2i = 256944.43
n∑i=1
xiyi = 214308.15.
x =1
91280.5, y =
1
91497.7 = 166.5222
– 13 –

上海交通大学硕士研究生公共课—-生物数学(一)—-林建忠编
带入公式
b1 =214308.15− 142.2778× 166.5222/9
182605.59− (142.2778)2/9= 2.5697
b0 = 166.5222− 2.5697× 142.2778 = −199.0919
得经验线性回归方程
y = −199.0919 + 2.5697x
2.2.2 多元线性回归模型
假设影响因变量 Y 的自变量有 p− 1个: X1, X2, · · · , Xp−1 ,并且它们之间有如下
线性关系
Y = β0 + β1X1 + β2X2 + · · ·+ βp−1Xp−1 + e,
其中 e是误差项(试验或测量误差). β0, β1, · · · , βp−1是待估计的未知参数
现我们有因变量 Y 和自变量 X1, X2, · · · , Xp−1的 n组观测值
(xi1, · · · , xi,p−1, yi), i = 1, 2, · · · , n,
它们满足
yi = β0 + β1xi1 + β2xi2 + · · ·+ βp−1xip−1 + ei
误差项 ei, i = 1, 2, · · · , n满足如下Gauss-Markov假设
(a)E(ei) = 0
(b)V ar(ei) = σ2,
(c)Cov(ei, ej) = 0, i 6= j.
写成矩阵形式
y1
y2
...
yn
=
1 x11 · · · x1,p−1
1 x21 · · · x2,p−1
......
......
1 xn1 · · · xn,p−1
β1
β2
...
βp−1
+
e1
e2
...
en
– 14 –

上海交通大学硕士研究生公共课—-生物数学(一)—-林建忠编
等价地
y = Xβ + e, E(e) = 0, Cov(e) = σ2In
问题:如何根据自变量和因变量的观测数据估计参数向量 β ?
最小二乘法
构造偏差向量函数
Q(β) = ‖y −Xβ‖2 = (y −Xβ)′(y −Xβ)
将此式展开
Q(β) = y′y − 2y′Xβ + β′X′Xβ
对求偏导数, 并令其为零,得正则方程组
X′Xβ = X′y
若X′X的秩为 p , 则得唯一解
β = (X′X)−1
X′y
记 β = (β0, β1, · · · , βp−1)′ , 代入回归方程, 并去掉误差项, 得到
Y = β0 + β1X1 + · · ·+ βp−1Xp−1,
此方程称为经验线性回归方程.
2.2.3 原始数据的中心化和标准化
原始数据的中心化 记第j个回归自变量n次观测值的平均值为
xj =1
n
n∑i=1
xij, j = 1, · · · , p− 1
这样一来,可改写为
yi = α + (xi1 − x1)β1 + · · ·+ (xi,p−1 − xp−1)βp−1 + ei
– 15 –

上海交通大学硕士研究生公共课—-生物数学(一)—-林建忠编
这里, α与式中的 β0有如下关系式
α = β0 + x1β1 + · · ·+ xp−1βp−1.
在中, 我们把每个回归自变量减去了它们的平均值, 此过程称为中心化. 若记
Xc =
x11 − x1 x12 − x2 · · · x1,p−1 − xp−1
x21 − x1 x22 − x2 · · · x2,p−1 − xp−1
......
......
xn1 − x1 xn1 − x2 · · · xn,p−1 − xp−1
则可改写为
y = α1n + Xβ + e
这里 1n = (1, · · · , 1)′ , β′ = (β1, · · · , βp−1)′ . 中心化设计矩阵Xc满足
1′Xc = 0
正则方程变形为
n 0
0 X′cXcβ
α
β
=
1′y
X′cy
最小二乘估计为,
α = y,
β = (X′cXc)
−1X′
cy
原始数据的标准化
记
s2j =
n∑i=1
(xij − xj)2, j = 1, · · · , p− 1,
zij =xij − xj
sj
.
– 16 –

上海交通大学硕士研究生公共课—-生物数学(一)—-林建忠编
命 Z = (zij) , 则 Z 有性质:
(a) 1′Z = 0
(b) Rdef= Z′Z = (rij)
rij =
n∑k=1
(xki − xi)(xkj − xj)
sisj
, i, j = 1, · · · , p− 1.
即 R = Z′Z的第 (i, j)元正是回归自变量 Xi 与 Xj 的样本相关系数, 因此 R是
回归自变量的相关阵, 于是对一切i, rii = 1
好处: (1) 用R可以分析回归自变量之间的相关关系;
(2) 在一些问题中, 诸回归自变量所用的单位可能不相同, 取值范围大小也不相同, 经
过标准化, 消去了单位和取值范围的差异, 这便于对回归系数估计值的统计分析.
标准化后的回归模型为
yi = α +
(xi1 − x1
s1
)β1 + · · ·+
(xip−1 − x1
sp−1
)β1 + ei
这里的 α当然不同于前面的 α , 回归方程的矩阵形式为
y = α1n + Zcβ + e
2.2.4 误差项方差 σ2 的估计
误差向量 e = y −Xβ , 它是一不可观测的随机向量. 用最小二乘估计 β 代替其
中 β的, 得到
e = y −Xβ
称为残差向量. 若用 x′i表示设计矩阵X的第i行, 则上式分量形式为
ei = yi − x′iβ, i = 1, · · · , n
称为第i次试验或观测误差.
自然地用
RSS = e′e =n∑
i=1
e2i
来衡量 σ2的大小,这里RSS是残差平方和(Residual Sum of Squares).
– 17 –

上海交通大学硕士研究生公共课—-生物数学(一)—-林建忠编
定理2.1.
(a) RSS = y′(I−X(X′X)−1X′)y
(b) σ2 =RSS
n− p
是 σ2的无偏估计.
2.2.5 回归方程的显著性检验
考虑正态回归模型
yi = β0 + xi1β1 + · · ·+ xi,p−1βp−1 + ei, ei ∼ N(0, σ2), i = 1, · · · , n
检验
H : β1 = · · · = βp−1 = 0.
将假设代入模型,得简约模型
yi = β0 + ei, i = 1, · · · , n
β0的最小二乘估计为 β∗0 = y , 于是相应的残差平方和
RSSH = y′y − β∗01′y =
n∑i=1
(yi − y)2
这个特殊的残差平方和称为总平方和(Total Sum of Squares, 简记为TSS).
对于原来的模型, 我们知道残差平方和
RSS = y′y − βX′y
于是
RSSH −RSS = βX′y − β∗01′y = β′cX
′cy
它是由于在模型中引人回归自变量之后所引起的残差平方和的减少量, 称为回归平方
和(Regression Sum of Squares, 简记为 SSR ).这样, 有关系式
TSS = RSS + SSR
– 18 –

上海交通大学硕士研究生公共课—-生物数学(一)—-林建忠编
构造检验统计量
FR =SSR/(p− 1)
RSS/(n− p).
当原假设成立时, FR ∼ Fp−1,n−p . 对给定的置信水平 α , 当 FR > Fp−1,n−p(α)时, 我
们拒绝原假设H.
表 2.4: 表: 方差分析表
方差源 平方和 自由度 均方 F 比 P (F > FR)
回归 SSR p− 1 SSR/(p− 1) FR
误差 RSS n− p RSS/(n− p)
总计 TSS n-1
其中,
TSS =n∑
i=1
(yi − y)2
SSR =n∑
i=1
(yi − y)2
RSS =n∑
i=1
(yi − yi)2
2.2.6 判别系数(复相关系数)
定义判别系数
R2 =SSR
TSS
它度量了回归自变量X1, · · · , Xp−1对因变量 Y 的拟合程度的好坏. 显然, 0 ≤ R2 ≤ 1
. 它的值愈大, 表明Y与诸X有较大的相依关系.
在一元回归模型中, R2就是因变量 Y 与自变量 X 的样本相关系数的平方.
R2 =[∑n
i=1(yi − y)(xi − x)]2
∑ni=1(yi − y)2
∑ni=1(xi − x)2
因此, R2 的值愈大, 表明回归方程与数据拟合得愈好.
– 19 –

上海交通大学硕士研究生公共课—-生物数学(一)—-林建忠编
算例 通过大量的统计资料的分析, 已确定反映中国猪种经济性状的主要指标是
猪体长( x1 cm), 背膘厚( x2 cm)和乳头对数( x3对), 把猪体重(y kg)定为预测变量. 设
多元回归方程为
Y = b0 + b1X1 + b2X2 + b3X3 + e,
此数据 p = 3, n = 48 . 先计算平均值
x1 = 118.4, x2 = 4.49, x3 = 13.3, x4 = 99.9,
解正则方程得方程得
b1 = 2.3836, b2 = −1.4440, b3 = −1.3536
将变量平均值代入回归方程得
b0 = −156.1709
回归方程是
Y = −156.1709 + 2.3836X1 − 1.444X2 + 1.3536X3,
最后进行显著检验
TSS = 81769.3969 nT = 48− 1 = 47
SSR = 68706.3435 nReg = 3
RSS = 12849.87324 nR = 48− 3− 1 = 44
F =68706.3435× 44
12849.87324× 3= 78.4205 > F3,44(0.01) = 4.26
R =
√68706.3435
81769.3936= 0.91665
这说明回归检验是显著的.
2.2.7 非线性回归方程的一些处理方法
对于非线性回归方程
1
y= b0 + b1x1 + b2x
22 + b3x
33
– 20 –

上海交通大学硕士研究生公共课—-生物数学(一)—-林建忠编
作变换
t1 = x1, t2 = x22, t3 = x2
3, z =1
y
可得线性回归方程
z = b0 + b1t1 + b2t2 + b3t3
2.2.8 逐步回归
在多元线性回归问题中, 一方面, 把种种影响预测值的因素都考虑在内,自变量的
个数取得十分大, 希望获得较好的回归效果. 另一方面,自变量的个数取得很大, 增加
了计算量, 而且有些自变量的不准确性会导致回归方程的不稳定.
因此理想的回归不在于自变量取得多, 而是要把对因变量有显著联系的自变量
选取在内. 把关系甚微的自变量剔除掉.
逐步回归设计成多次循环的运算步骤, 自变量被逐个选入回归方程, 同时把不合
格的自变量剔除, 直到获得一组稳定的自变量.
1. 计算相关系数
x11 x12 · · · x1p−1 y1
x21 x22 · · · x2p−1 y2
· · · · · · · · · · · · · · ·xn1 xn2 · · · xnp−1 yn
⇒
r11 r12 · · · r1p−1 r1y
r21 r22 · · · r2p−1 r2y
· · · · · · · · · · · · · · ·rp1 rp2 · · · rp−1p−1 rpy
ry1 ry2 · · · ryp−1 ryy
相关系数计算公式为
rij =
∑nk=1 xkixkj − 1
n
∑nk=1 xki
∑nk=1 xkj√[∑n
k=1 x2ki − 1
n(∑n
k=1 xki)2] [∑n
k=1 x2kj − 1
n(∑n
k=1 xkj)2] , (i, j = 1, 2, · · · , p− 1)
2. 对未选中自变量作增加检验
以 G表示已被选自变量标号集合, 设已有 g个自变量被选取. 作统计量
M =r2ky
rkk
= maxi∈G
r2iy
rii
F =M(n− g − 2)
ryy −M
– 21 –

上海交通大学硕士研究生公共课—-生物数学(一)—-林建忠编
若 F ≥ F ∗ , 则将第 k自变量选入, 否则不增加自变量.
3. 对已选中自变量作删除检验
作统计量
m =r2ky
rkk
= mini∈G
r2iy
rii
F =m(n− g − 2)
ryy
若 F < F ∗ , 则将第 k自变量删除, 否则不删除.
5. 计算回归系数
当没有自变量增加, 被选中自变量也不被删除时, 根据最后获得的工作矩阵, 对
被选中的 g个自变量计算回归系数:
bi = riy
(ryy
rii
) 12
, i ∈ G
b0 = y −∑i∈G
bixi
– 22 –

上海交通大学硕士研究生公共课—-生物数学(一)—-林建忠编
2.3 判别分析数学模型
2.3.1 Fisher 的判别分析法
植物中许多临近种类的鉴别成为困惑分析专家的难题. 现以重要药用人参和西洋
参为例, 这两种植物极为相似. 我们选取小叶片长度和小叶前部宽度两个指标讨论这
两个种的鉴别问题.
如图, 为了进行判别分析收集了西洋参32组, 人参43组对小叶片长度和小叶前部
宽度的度量数据. 取小叶片长l为横坐标, 小叶前部宽度d纵坐标,作出散点图.
从总体上看, 点的分布具有一定的规律性, 西洋参和人参在平面中各占据一定的
区域. 虽然区域的界限不清, 我们会很自然地设想在平面中作出两个区域的明确分界
限, 把整个平面划分为两个部分. 假如另有一个待鉴定的标本, 度量了相应的叶片长
度l和叶前部宽度d, 在坐标图中描点P (l, d), 若P落在西洋参区域, 就可以作出该标本
是西洋参的判断; 否则就是人参. 于是获得一个利用作图进行判别鉴定的方法.
作图法的定量化
假设该分界线是一条直线, 其方程为
G(l, d) = Al + Bd + C = 0
其中A, B和C都是常数. 在分界线上点P (l, d)满足方程, 有G(l, d) = 0. 整个平面被该
直线划分为两个部分, 直线的一边使方程G(l, d) > 0, 另一边G(l, d) < 0, 于是我们从
直线方程, 获得定量化的判别方法.
实际上还可以作函数
F (l, d) = C −G(l, d) = −Al −Bd,
相应于G(l, d) > 0或G(l, d) < 0分别就是函数F (l, d) < C或F (l, d) > C. 把F (l, d)称为
判别函数, C称为判别值. 将待鉴别的值(l, d)代入F (l, d), 根据函数值F (l, d)是大于或
小于判别值C就可以作出鉴别.
如果判别的依据是n个指标, 被鉴别的单位在n个指标下以n维向量X表示:
X(x1, x2, · · · , xn),
– 23 –

上海交通大学硕士研究生公共课—-生物数学(一)—-林建忠编
被鉴别的两个类分别称为类群I和类群II, 两个类群分别提供了p和q组数据, 这些数
据按类群分别排列如下: 其中类群I第i组数据的向量是
指 标
1 2 · · · n
1 x(1)11 x
(1)12 · · · x
(1)1n
2 x(1)21 x
(1)22 · · · x
(1)2n
类群I... · · · · · · · · · · · ·p x
(1)p1 x
(1)p2 · · · x
(1)pn
1 x(2)11 x
(2)12 · · · x
(2)1n
2 x(2)21 x
(2)22 · · · x
(2)2n
类群II... · · · · · · · · · · · ·q x
(2)q1 x
(2)q2 · · · x
(2)qn
X(1)i (x
(1)i1 , x
(1)i2 , · · · , x
(1)in ), (i = 1, 2, · · · , p)
其中类群II第i组数据的向量是
X(2)i (x
(2)i1 , x
(2)i2 , · · · , x
(2)in ), (i = 1, 2, · · · , q)
这里n个指标构成n维空间, 每一组数据的n维向量对应于此n维空间中的一个点. 上
述类群I和类群II的数据构成n维空间中p和q个点, 划分类群I和类群II为两个区域的
分界是n维空间中的一个平面. 这里的判别函数是
F (x1, x2, · · · , xn) = C1x1 + C2x2 + · · ·+ Cnxn
其中Ci(i = 1, 2, · · · , n)是常数. 如果判别值是C,对于任何待鉴定的数据组X(x1, x2, · · · , xn),
将这组数据代入判别函数, 依据判别函数值与判别值C的比较, 可以判断待鉴定的数
据X属于哪一类群.
先将原始数据中的每一组数据代入判别函数, 类群I和类群II分别以y(1)i 和y
(2)i 表
示其值:
Category I y(1)i = C1x
(1)i1 + C2x
(1)i2 + · · ·+ Cnx
(1)in (i = 1, 2, · · · , p)
Category II y(2)i = C1x
(2)i1 + C2x
(2)i2 + · · ·+ Cnx
(2)in (i = 1, 2, · · · , q)
– 24 –

上海交通大学硕士研究生公共课—-生物数学(一)—-林建忠编
再计算每个指标在类群中的平均值, 类群I和类群II分别以x(1)i 和x
(2)i 表示
Category I x(1)i = 1
p
p∑k=1
x(1)ki (i = 1, 2, · · · , n)
Category II x(2)i = 1
q
q∑k=1
x(2)ki (i = 1, 2, · · · , n)
同时计算y(1)i (i = 1, 2, · · · , p)和y
(2)i (i = 1, 2, · · · , q)的平均值
y(1) =1
p
p∑i=1
y(1)i y(2) =
1
q
q∑i=1
y(2)i
这些平均值代入判别方程满足以下关系
y(1) = C1x(1)1 + C2x
(1)2 + · · ·+ Cnx
(1)n
y(2) = C1x(2)1 + C2x
(2)2 + · · ·+ Cnx
(2)n
值A = (y(1) − y(2))2能反映上述两组数据间的差距. 较好的判别函数应使 A 愈
大愈好. 在同类群中, 也应使y(1)i 和y
(2)i (i = 1, 2, · · · , n)与其平均值的离差较小, 即
使B =p∑
i=1
(y(1)i − y(1))2 +
q∑i=1
(y(2)i − y(2))2愈小愈好. 由这两方面的要求, 构造函数I, 使
其尽可能大.
I =A
B=
(y(1) − y(2))2
p∑i=1
(y(1)i − y(1))2 +
q∑i=1
(y(2)i − y(2))2
问题: 将I视作C1, C2, · · · , Cn的函数, 如何选择一组C1, C2, · · · , Cn的恰当值使I达到
极大, 从而得到理想的判别函数.
先对I实行对数变换
lnI = lnA− lnB
由对 lnI 取极值的必要条件
1
I
∂I
∂Ci
=1
A
∂A
∂Ci
− 1
B
∂B
∂Ci
, (i = 1, 2, · · · , n)
得条件
1
I
∂A
∂Ci
=∂B
∂Ci
(i = 1, 2, · · · , n)
– 25 –

上海交通大学硕士研究生公共课—-生物数学(一)—-林建忠编
其中
A = (y(1) − y(2))2
=
[n∑
k=1
Ck(x(1)i − x
(2)k )2
]2
B =
p∑i=1
(y(1)i − y(1))2 +
q∑i=1
(y(2)i − y(2))2
=
p∑i=1
[n∑
k=1
Ck(x(1)ik − x
(1)k )
]2
+
q∑i=1
[n∑
k=1
Ck(x(2)ik − x
(2)k )
]2
等式的左边
1
I
∂A
∂Ci
=2
I(y(1) − y(2))(x
(1)i − x
(2)i ),
右边有
∂B
∂Ci
= 2
p∑
k=1
(y(1)k − y(1))(x
(1)ki − x
(1)i ) + 2
q∑
k=1
(y(2)k − y(2))(x
(2)ki − x
(2)i )
= 2n∑
j=1
SijCj
其中
Sij =
p∑
k=1
(x(1)ki − x
(1)i )(x
(1)kj − x
(1)j ) +
q∑
k=1
(x(2)ki − x
(2)i )(x
(2)kj − x
(2)j )
将上面的计算结果代入等式的左右两边, 让 i跑遍所有 n个指标, 得 C1, C2, · · · , Cn的
线性方程组
S11C1 + S12C2 + · · ·+ S1nCn =1
I(y(1) − y(2))(x
(1)1 − x
(2)1 )
S21C1 + S22C2 + · · ·+ S2nCn =1
I(y(1) − y(2))(x
(1)2 − x
(2)2 )
· · · · · · · · · · · · · · · · · · · · · · · · · · · · · · · · · · · · · · · · · · · · · · · · · · · · · ·
Sn1C1 + Sn2C2 + · · ·+ SnnCn =1
I(y(1) − y(2))(x(1)
n − x(2)n )
– 26 –

上海交通大学硕士研究生公共课—-生物数学(一)—-林建忠编
相应的矩阵形式
S11 S12 · · · S1n
S21 S22 · · · S2n
· · · · · · · · · · · ·Sn1 Sn2 · · · Snn
C1
C2
...
Cn
=
x(1)1 − x
(2)1
x(1)2 − x
(2)2
· · · · · ·x
(1)n − x
(2)n
运算步骤
1.先对原始数据分别计算以下求和以及平均值:
p∑
k=1
x(1)ki ,
q∑k=1
x(2)ki , x
(1)i = 1
p
p∑k=1
x(1)ki , x
(2)i = 1
q
q∑k=1
x(2)ki , (i = 1, 2, · · · , n)
p∑
k=1
x(1)ki x
(1)kj
q∑k=1
x(2)ki x
(2)kj , (i, j = 1, 2, · · · , n)
2. 再计算
di = x(1)i − x
(2)i , (i = 1, 2, · · · , n)
Sij =
p∑
k=1
(x(1)ki − x
(1)i )(x
(1)kj − x
(1)j ) +
q∑
k=1
(x(2)ki − x
(2)i )(x
(2)kj − x
(2)j )
注意对称性Sij = Sji.
3. 解线性代数方程组
S11 S12 · · · S1n
S21 S22 · · · S2n
· · · · · · · · · · · ·Sn1 Sn2 · · · Snn
C1
C2
...
Cn
=
d1
d2
...
dn
如果方程有解, 得判别函数
F (x1, x2, · · · , xn) = C1x1 + C2x2 + · · ·+ Cnxn
4. 将平均值代入判别函数, 计算判别值
y(1) = C1x(1)1 + C2x
(1)2 + · · ·+ Cnx
(1)n
y(2) = C1x(2)1 + C2x
(2)2 + · · ·+ Cnx
(2)n
– 27 –

上海交通大学硕士研究生公共课—-生物数学(一)—-林建忠编
判别值
C =py(1) + qy(2)
p + q
5. 最后将判别组数据代入判别函数, 进行鉴别
y = C1x1 + C2x2 + · · ·+ Cnxn
若y(1) > y(2) 当y > C, X属于类群I
当y < C, X属于类群II
若y(1) < y(2) 当y > C, X属于类群II
当y < C X属于类群I
算例: 西洋参与人参依据小叶长与宽进行鉴别问题
类群I, 西洋参, 指标n = 2, 原始数据p = 32组;
类群II, 人参, 指标n = 2, 原始数据p = 43组;
第1步, 算以下求和以及平均值:
∑x
(1)k1 = 2668,
∑x
(1)k2 = 1392,
x(1)1 =
1
322668 = 83.375, x
(1)2 = 1
321392 = 43.5,
∑x
(1)k1 x
(1)k1 = 225956,
∑x
(1)k2 x
(1)k2 = 63002,
∑x
(1)k1 x
(1)k2 = 118478,
∑x
(2)k1 = 4136,
∑x
(2)k2 = 1491,
x(2)1 =
1
434136 = 96.186, x
(2)2 = 1
431491 = 34.67442,
∑x
(2)k1 x
(2)k1 = 413824,
∑x
(2)k2 x
(2)k2 = 53927,
∑x
(2)k1 x
(2)k2 = 146544
第2步, 再计算 Sij(i, j = 1, 2)和 di(i = 1, 2)
– 28 –

上海交通大学硕士研究生公共课—-生物数学(一)—-林建忠编
依两个类群将 Sij 分解为两个部分, 即 Sij = S(1)ij + S
(2)ij
S(1)11 = 225956− 1
32(2668)2 = 3511.5,
S(1)22 = 63002− 1
32(1392)2 = 2450,
S(1)12 = S
(1)21 = 118478− 1
32× 2668× 1392 = 2420
S(2)11 = 413824− 1
43(4136)2 = 15998.5116,
S(2)22 = 53927− 1
43(1491)2 = 2227.4419
S(2)12 = S
(2)21 = 146544− 1
43× 4136× 1491 = 3130.6047
S11 = S(1)11 + S
(2)11 = 19510.0116,
S22 = S(1)22 + S
(2)22 = 4677.4419,
S12 = S21 = S(1)12 + S
(2)12 = 5550.6047,
d1 = x(1)1 − x
(2)1 = −12.8110
d2 = x(1)2 − x
(2)2 = 8.8256
第3步, 解线性代数方程组
19510.0117C1 + 5550.6047 = −12.8110
5550.6047C1 + 4677.4419C2 = 8.8256
C1 =1
4
∣∣∣∣∣∣−12.8110 5550.6047
8.8256 4677.4419
∣∣∣∣∣∣= −108910/4
C2 =1
4
∣∣∣∣∣∣19510.0117 −12.8110
5550.6047 8.8256
∣∣∣∣∣∣= 243296/4
其中 4代表行列式∣∣∣∣∣∣
19510.0117 5550.6047
5550.6047 4677.4419
∣∣∣∣∣∣, 对它的运算可以身略, 直接取 C1 =
−1089 , C2 = 2433 , 得判别方程
F (x1, x2) = −1089x1 + 2433x2
– 29 –

上海交通大学硕士研究生公共课—-生物数学(一)—-林建忠编
第4步, 将平均值代入判别方程, 再求判别值
y(1) = −1089x(1)1 + 2433x
(1)2 = 15040.125
y(2) = −1089x(2)1 + 2433x
(2)2 = −20383.69
判别值
C =32× y(1) + 43y(2)
32 + 43= −5269.53
第5步, 进行判别
试就3 分标本数据 (110, 44) , (88, 34)和 (86, 41)进行鉴定.
(110,44) y = −1089× 110 + 2433× 44 = −12738 < C 属于人参
(88,34) y = −1089× 88 + 2433× 34 = −13110 < C 属于人参
(86,41) y = −1089× 86 + 2433× 41 = 13398 > C 属于西洋参
2.3.2 多类群时的Bayes 判别法
对于多个类群的归属鉴别, 如果仍采用Fisher 判别法, 就需要把多个类群归并成
两大类群, 利用Fisher 判别法, 判得属于某一类群. 取出该类群, 再划分为两大类群,
再利用Fisher 判别法, 如此逐级做下去,最后获得属于某一不能再划分的类群, 判别鉴
定属于该类群即是.
当类群特别多时, Fisher 的逐级判别法太累赘. 现介绍距离法, 它是Bayes 判别法
的一种特殊情形.
考虑具有n 个性状的实体, 组成m 个类群, 每个类群具有 tl(l = 1, 2, · · · ,m)个实
体, 全部数据如下:
x(1)11 x
(1)12 · · · x
(1)1n
x(1)21 x
(1)22 · · · x
(1)2n
· · · · · · · · · · · ·x
(1)t11 x
(2)t12 · · · x
(1)t1n
x(2)11 x
(2)12 · · · x
(2)1n
x(2)21 x
(2)22 · · · x
(2)2n
· · · · · · · · · · · ·x
(2)t21 x
(2)t22 · · · x
(2)t2n
· · ·
x(m)11 x
(m)12 · · · x
(m)1n
x(m)21 x
(m)22 · · · x
(m)2n
· · · · · · · · · · · ·x
(m)tm1 x
(m)tm2 · · · x
(m)tmn
另有 X(x1, x2, · · · , xn)实体, 问属于哪个类群?
– 30 –
上海交通大学硕士研究生公共课—-生物数学(一)—-林建忠编
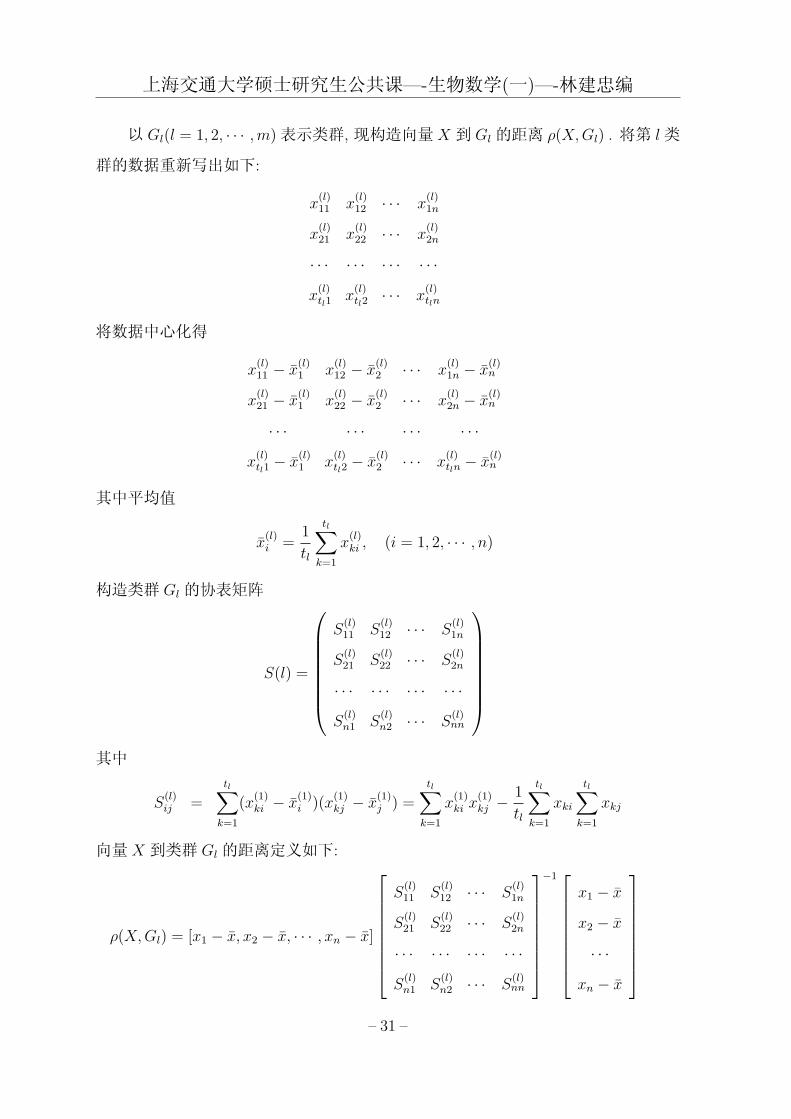
以 Gl(l = 1, 2, · · · ,m)表示类群, 现构造向量X 到 Gl的距离 ρ(X,Gl) . 将第 l类
群的数据重新写出如下:
x(l)11 x
(l)12 · · · x
(l)1n
x(l)21 x
(l)22 · · · x
(l)2n
· · · · · · · · · · · ·x
(l)tl1
x(l)tl2
· · · x(l)tln
将数据中心化得
x(l)11 − x
(l)1 x
(l)12 − x
(l)2 · · · x
(l)1n − x
(l)n
x(l)21 − x
(l)1 x
(l)22 − x
(l)2 · · · x
(l)2n − x
(l)n
· · · · · · · · · · · ·x
(l)tl1− x
(l)1 x
(l)tl2− x
(l)2 · · · x
(l)tln− x
(l)n
其中平均值
x(l)i =
1
tl
tl∑
k=1
x(l)ki , (i = 1, 2, · · · , n)
构造类群 Gl的协表矩阵
S(l) =
S(l)11 S
(l)12 · · · S
(l)1n
S(l)21 S
(l)22 · · · S
(l)2n
· · · · · · · · · · · ·S
(l)n1 S
(l)n2 · · · S
(l)nn
其中
S(l)ij =
tl∑
k=1
(x(1)ki − x
(1)i )(x
(1)kj − x
(1)j ) =
tl∑
k=1
x(1)ki x
(1)kj −
1
tl
tl∑
k=1
xki
tl∑
k=1
xkj
向量 X 到类群 Gl的距离定义如下:
ρ(X,Gl) = [x1 − x, x2 − x, · · · , xn − x]
S(l)11 S
(l)12 · · · S
(l)1n
S(l)21 S
(l)22 · · · S
(l)2n
· · · · · · · · · · · ·S
(l)n1 S
(l)n2 · · · S
(l)nn
−1
x1 − x
x2 − x
· · ·xn − x
– 31 –

上海交通大学硕士研究生公共课—-生物数学(一)—-林建忠编
其中平均值
x =1
n
n∑i=1
xi
如果引进平均值向量 X , 向量 X 和平均值向量 X 写成矩阵形式
X =
x1
x2
· · ·xn
, X =
x
x
...
x
X 到 Gl的距离可写成更简单的形式
ρ(X,Gl) = (X − X)T S(l)−1(X − X)
取距离系数最小者
ρ(X,Gi) = minρ(X,Gl)|l = 1, 2, · · · ,m
– 32 –

上海交通大学硕士研究生公共课—-生物数学(一)—-林建忠编
2.4 主成分分析
2.4.1 线性回归模型的主成分估计
考虑一般的线性回归模型
y = α01 + Xβ + e, E(e) = 0, Cov(e) = σ2I
假设设计阵X已中心化, 且矩阵的第i 行向量和第j 列向量分别记作
Xi = [xi1, xi2, · · · , xi,p−1], Xj =
x1j
x2j
...
xnj
于是常数项 α0 的最小二乘估计 α0 = y , 记 λ1 ≥ · · · ≥ λp−1 为 X′X的特征根,
ϕ1, · · · , ϕp−1为对应的标准正交化特征向量, 而
Φdef= (ϕ1, · · · , ϕp)
def=
ϕ11 ϕ12 · · · ϕ1p−1
ϕ21 ϕ22 · · · ϕ2p−1
· · · · · · · · · · · ·ϕp−11 ϕp−12 · · · ϕp−1p−1
是一个 (p− 1)× (p− 1)正交阵, 再记 Z = XΦ , α = Φ′β则模型可变形为
y = α01 + Zα + e, E(e) = 0, Cov(e) = σ2I
这是线性回归典则形式. 称α为典则参数. 在模型中,新的设计阵Z = (z(1), · · · , z(p−1)) =
(Xϕ1, · · · ,Xϕp−1) , 即
z(1) = Xϕ1, · · · , z(p−1) = Xϕp−1,
于是 Z的第i 列 z(i) 是原来p-1 个自变量的线性组合, 其组合系数为 X′X的第i 个特
征根对应的特征向量 ϕi . 因此, Z 的p-1 个列就对应于p-1 个以原来变量的特殊线
性组合(即以 X′X 的特征向量为组合系数)构成的新变量. 在统计学上, 称这些新变
量为主成分.
– 33 –

上海交通大学硕士研究生公共课—-生物数学(一)—-林建忠编
排在第1 列的新变量对应于 X′X的最大特征根, 称为第一主成分, 排在第2 列的
就称为第二主成分,依次类推. 因为X是中心化的,即 1′X = 0 ,于是 1′Z = 1′XΦ = 0
. 所以 Z也是中心化的. 因而 Z的各列元的平均值
z(j) =1
n
n∑i=1
zij = 0, j = 1, · · · , p− 1
由此定义的主成分有以下性质
(1) z(i) · z(j) = z′(i)z(j) = 0, (i 6= j; i, j = 1, 2, · · · , p− 1),
(2) ‖z(i)‖ = z′(i)z(i) = ϕ′iX′Xϕi = λi, (i = 1, 2, · · · , p− 1)
(3) Xi = ϕi1z(1) + ϕi2z(2) + · · ·+ ϕip−1z(p−1)
(4) z(i) = ϕ1iX1 + ϕ2iX2 + · · ·+ ϕp−1iXp−1, (i = 1, 2, · · · , p− 1)
结合知
n∑i=1
(zij − zj)2 = z′(i)z(i) = λi, i = 1, 2, · · · , p− 1.
于是 X′X 的第i 个特征根 λi 就度量了第i 个主成分取值变动大小. 若假设
λr+1, · · · , λp − 1 ≈ 0 . 这时后面的 p − r − 1 个主成分取值变动就很小, 再结
合(即它们的均值都为零), 因而这些主成分取值近似为零. 因此, 在用主成分作为新
的回归自变量时, 这后面的 p − r − 1 个对因变量的影响就可以忽略掉, 故可将它们
从回归模型中剔除. 用最小二乘法(LSE)做剩下的r 个主成分的回归, 然后再回到原
来的自变量, 就得到了主成分回归.
上述思想的具体化
记 Λ = diag(λ1, · · · , λn) , 对 Λ ,α, Z和 Φ做分块:
Λ =
Λ1 0
0 Λ2
,
其中 Λ1为 r × r矩阵,
α =
α1
α2
,
– 34 –

上海交通大学硕士研究生公共课—-生物数学(一)—-林建忠编
其中 α1为 r × 1向量,
Z = (Z1...Z2)
其中 Z1为 n× r矩阵,
Φ = (Φ1...Φ2)
其中 Φ1为 (p− 1)× r矩阵, 代入并剔除 Z2α2项得到回归模型
y = α01 + Z1α1 + e, E(e) = 0, Cov(e) = σ2I
应用最小二乘法(LSE), 得到 α0和 α1的最小二乘估计:
α0 = y =1
n
n∑i=1
yi,
α1 = (Z′1Z1)−1
Z′1y = Λ−11 Z′1y.
由于我们从模型中剔除了后面 p− r − 1个主成分, 这相当于用 α2 = 0去估计 α2 = 0.
利用关系 β = Φα , 可以获得原来参数 β 的估计
β = Φ
α1
α2
= (Φ1, Φ2)
α1
0
= Φ1Λ−11 Z′1y = Φ1Λ
−11 Φ′
1X′y
这就是 β的主成分估计.
主成分估计方法归纳
(a) 做正交变换 Z = XΦ , 获得新的自变量, 称为主成分.
(b) 做回归自变量选择: 剔除对应的特征值比较小的那些主成分.
(c) 将剩余的主成分对 Y 做最小二乘回归,再返回到原来的参数, 便得到的因变量
对原始自变量的主成分回归.
主成分估计的两个性质
(a) 主成分估计是有偏估计. 这是因为
E(β) = (Φ1, Φ2)
α1
0
= Φ1α1,
– 35 –

上海交通大学硕士研究生公共课—-生物数学(一)—-林建忠编
但
β = Φα = Φ1α1 + Φ2α2
一般说来 E(β) 6= β .
(b) 适当选择保留的主成分个数可致主成分估计比最小二乘估计有较小的均方
误差, 即
MSE(β) < MSE(β), MSE(β) = E‖β − β‖2
被剔除的主成分个数的选择
选择 r , 使得r∑
i=1
λi 与全部 p − 1个特征值之和p−1∑i=1
λi 的比值(称为主成分的贡献
率)达到预先给定值, 譬如 75%或 80%等.
说明: 主成分作为原来自变量的线性组合, 是一种”人造变量”, 一般不具有任何
实际含义, 特别当回归自变量具有不同度量单位时更是如此. 例如在研究农作物产量
与气候条件,生产条件的关系问题中, 假定 X1和 X2分别表示该作物生长期内日平均
气温和降雨量, 它们的度量单位分别是 1C (摄氏度)和mm (毫米),而 X3表示单位面
积上化学肥料的施用量, 单位是kg (公斤). 这时主成分作为这些变量的线性组合, 它
们的单位就什么都不是了, 更谈不上其实际意义.
2.4.2 主成分分析(principal component analysis)原始数值矩阵
如果一个被研究的生物学问题具有多个(个)性状,特征或指标, 另一方面又具有
多个(个)单位,品种或实体. 通过调查,实验得到这个事物的数据, 该数据可以表示成一
个矩阵(行列), 即主成分分析原始数值矩阵. 其相应的中心化或标准化矩阵记为, 上
p 个指标
n个单位
y11 y12 · · · y1p
y21 y22 · · · y20
· · · · · · · · · · · ·yn1 yn2 · · · ynp
– 36 –

上海交通大学硕士研究生公共课—-生物数学(一)—-林建忠编
p 个指标
n个单位
x11 x12 · · · x1p
x21 x22 · · · x20
· · · · · · · · · · · ·xn1 xn2 · · · xnp
面讨论的主成分构造原理可以平行移到这一原始数值矩阵来. 在这一模型下, 由上小
节的性质有,
Xi = ϕi1z(1) + ϕi2z(2) + · · ·+ ϕipz(p), (i = 1, 2, · · · , p)
设 r ≤ p , 记
Xi = ϕi1z(1) + ϕi2z(2) + · · ·+ ϕirz(r), (i = 1, 2, · · · , p)
X(r+1,p)i = ϕirz(r) + ϕir+2z(r+2) + · · ·+ ϕipz(p), (i = 1, 2, · · · , p)
由主成分向量的正交性, 有p∑
i=1
‖X(r+1,p)i ‖2 =
p∑i=1
(X(r+1,p)i )T · (X(r+1,p)
i )
=
p∑i=1
(ϕ2
i,r+1zT(r+1)z(r+1) + · · ·+ ϕ2
i,pzT(p)z(p)
)
=
p∑i=1
ϕ2i,r+1λr+1 + · · ·+
p∑i=1
ϕ2i,pλp
= ‖Φr+1‖2λr+1 + · · ·+ ‖Φp‖2λp
=
p∑j=r+1
λj
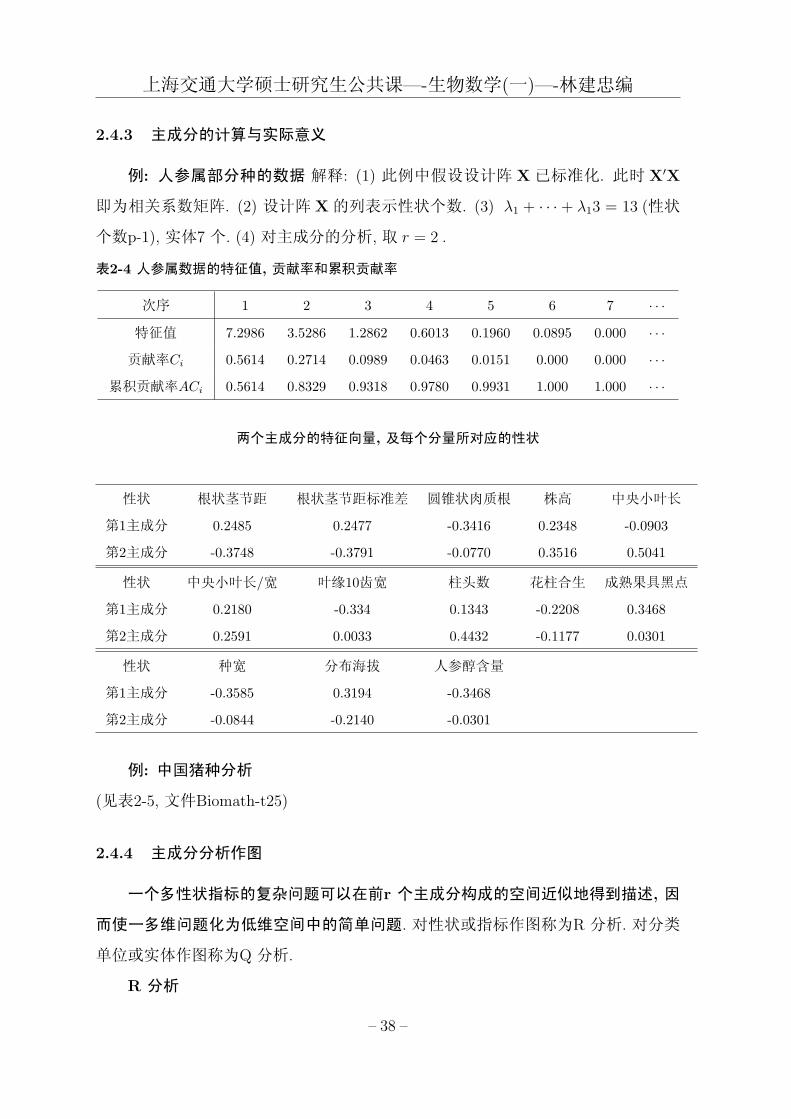
这样一来我们可以获得 ‖Xi − Xi‖的整体估计,
p∑i=1
‖Xi − Xi‖2 =
p∑i=1
‖X(r+1,p)i ‖2 =
p∑j=r+1
λj.
这个结果也从一个侧面告诉我们, 只要选取r 充分大使得累积贡献率∑r
j=1 λj∑pj=1 λj
充分大, 就可以使 Xi充分逼近 Xi .
– 37 –
上海交通大学硕士研究生公共课—-生物数学(一)—-林建忠编
2.4.3 主成分的计算与实际意义
例: 人参属部分种的数据 解释: (1) 此例中假设设计阵 X已标准化. 此时 X′X
即为相关系数矩阵. (2) 设计阵 X的列表示性状个数. (3) λ1 + · · · + λ13 = 13 (性状
个数p-1), 实体7 个. (4) 对主成分的分析, 取 r = 2 .
表2-4 人参属数据的特征值, 贡献率和累积贡献率
次序 1 2 3 4 5 6 7 · · ·特征值 7.2986 3.5286 1.2862 0.6013 0.1960 0.0895 0.000 · · ·贡献率Ci 0.5614 0.2714 0.0989 0.0463 0.0151 0.000 0.000 · · ·
累积贡献率ACi 0.5614 0.8329 0.9318 0.9780 0.9931 1.000 1.000 · · ·
两个主成分的特征向量, 及每个分量所对应的性状
性状 根状茎节距 根状茎节距标准差 圆锥状肉质根 株高 中央小叶长
第1主成分 0.2485 0.2477 -0.3416 0.2348 -0.0903
第2主成分 -0.3748 -0.3791 -0.0770 0.3516 0.5041
性状 中央小叶长/宽 叶缘10齿宽 柱头数 花柱合生 成熟果具黑点
第1主成分 0.2180 -0.334 0.1343 -0.2208 0.3468
第2主成分 0.2591 0.0033 0.4432 -0.1177 0.0301
性状 种宽 分布海拔 人参醇含量
第1主成分 -0.3585 0.3194 -0.3468
第2主成分 -0.0844 -0.2140 -0.0301
例: 中国猪种分析
(见表2-5, 文件Biomath-t25)
2.4.4 主成分分析作图
一个多性状指标的复杂问题可以在前r 个主成分构成的空间近似地得到描述, 因
而使一多维问题化为低维空间中的简单问题. 对性状或指标作图称为R 分析. 对分类
单位或实体作图称为Q 分析.
R 分析
– 38 –

上海交通大学硕士研究生公共课—-生物数学(一)—-林建忠编
依据主成分向量的性质, 可将性状向量表示为主成分向量的线性组合:
Xi = ϕi1z(1) + ϕi2z(2) + · · ·+ ϕip−1z(p−1), (i = 1, 2, · · · , p− 1)
定义单位向量
ei = z(i)/‖z(i)‖ = z(i)/√
λi, (i = 1, 2, · · · , p− 1)
如果 λi = 0 ,则剔除相应的 z(i) .于是相应的线性表示为
Xi = ϕi1
√λ1e1 + ϕi2
√λ2e2 + · · ·+ ϕip−1
√λp−1ep−1, (i = 1, 2, · · · , p− 1)
只要前个r 主成分的累积贡献率充分大, 则可以用以下 Xi近似代表Xi .
Xi = ϕi1
√λ1e1 + ϕi2
√λ2e2 + · · ·+ ϕir
√λrer, (i = 1, 2, · · · , p− 1)
在前个r 主成分所构成的 r维空间中, Xi的坐标就是 (ϕi1
√λ1, · · · , ϕir
√λr) , 因此研
究性状的作图问题被简化成研究在 r 维空间中点 Pi(ϕi1
√λ1, · · · , ϕir
√λr)的作图问
题. 一般取 r = 1, 2或 3 , 这是三维以下空间中点集合的作图问题.
点 Pi的第 j 分量有以下关系:
ϕij
√λj = ‖Xi‖
XTi · z(j)
‖Xi‖ · ‖z(j)‖ = ‖Xi‖ cos ∠(Xi, z(j))
因此, 点 Pi 的第 j 个坐标 ϕij
√λj , 称为第 j 个主成分对第 i个性状指标的因子负
荷(factor loading).
画出 Pi 在空间中的位置, 每一点代表一个性状, 全部 p − 1个性状构成空间中
p− 1个点的图形, 它们显示出性状之间的关系, 相距靠近者表示关系密切, 远离者表
示关系疏远.
算列: 人参属小型数据 前两个因子负荷计算如下:
P1 : ϕ11
√λ1 = 0.2485×
√7.2988 = 0.6713
ϕ12
√λ2 = −0.3748×
√3.5285 = −0.7040
P2 : ϕ21
√λ1 = 0.2477×
√7.2986 = 0.6691
ϕ22
√λ2 = −0.3791×
√3.5285 = −0.7122
性状坐标图如图2-6(文件Biomath-g26)
– 39 –

上海交通大学硕士研究生公共课—-生物数学(一)—-林建忠编
人参属数据R 分析坐标值
1 0.6713 -0.7040
2 0.6691 -0.7122
3 -0.9230 -0.1447
4 0.6343 0.6605
5 -0.2440 0.9468
6 0.5890 0.4866
7 -0.9024 0.0062
8 0.3628 0.8326
9 -0.5965 -0.2211
10 0.9368 0.0566
11 -0.9685 -0.1585
12 0.8629 -0.4019
13 -0.9368 -0.0566
2.4.5 主成分分析方法解决分析单位作图(Q分析)
依据主成分向量的性质X = ZΦ′ , 可将单位向量表示为主成分向量的线性组合:
Xi = z(i1)ΦT1 + z(i2)Φ2 + · · ·+ z(ip−1)Φ
Tp−1, (i = 1, 2, · · · , n)
其中 ΦTi = [ϕ1i, · · · , ϕp−1i] . 由于是正交矩阵, 故
ΦTi · Φj =
0 i 6= j (i, j = 1, 2, · · · , p− 1)
1 i = j
同理, 选择累积贡献率充分大的r, 就可以用
Xi = z(i1)ΦT1 + z(i2)Φ2 + · · ·+ z(ir)Φ
Tr , (i = 1, 2, · · · , n)
来代替 X .
因此研究分析单位的作图问题被简化成研究在 r 维空间中代表 Xi 的点
Qi(zi1, · · · , zir)的作图问题. 作出全部n 个点 Qi(i = 1, 2, · · · , n) . Qi点集合的空间结
构近似地显示出分析单位之间的分析关系.
算列: 人参属小型数据
人参属数据Q分析坐标图如图2-6(文件Biomath-g26)
– 40 –

第三章 生物分类的数学模型
3.1 分类的基本概念和原始数据的获得
3.1.1 分类的基本概念
分类有两个要素,
(1) 被分类的对象, 分类对象由许多被分类的实体所组成, 3个以上的实体构成一
个基本分类对象. 被分类的实体, 就是被分类的基本单位, 在数量分类学中称为运算
分类单位(operational taxonomic unit, OTU). 全部被分类的分类单位构成的集合称
为被分类群.
(2)分类的依据,分类依据取决于被类群中分类单位的性状,所谓性状(character)是
一个分类单位区分于其他分类单位的性质,特征或属性.一个分类单位对某个性状所呈
现的状态, 称为该性状的性状状态(character state), 简称状态(state).
分类 就是将被分类群中所有的分类单位, 依据它们的性状状态, 遵从一定的原则
作出划分或聚合, 得到一组新的分类单位集合. 通过分类获得的这个分类单位集合称
为分类群(taxon).
生物分类学中的分类:
(1) 表征分类(phenetic classification): 依据生物表现性状相似性全面比较而建立
的系统分类.
(2) 分支分类(cladistic classification): 遵从生物演化的谱系关系而建立的系统分
类.
本章研究表征分类.
定义 如果 A是被考虑的一个分类群, 又有分类单位 x ∈ A , 且分类单位 y ∈ A ,
41

上海交通大学硕士研究生公共课—-生物数学(一)—-林建忠编
则认为 x与 y之间建立起同属于一个分类群的联系, 称作分类单 x与 y共分类群, 记
作
xϕy
分类单位共分类群的性质(等价关系(equivalence relation))
性质1. 自反性(reflexivity), 即 xϕx ;
性质2. 对称性(symmetry), 若 xϕy , 则 yϕx ;
性质3. 传递性(transitivity), 若 xϕy且 yϕz , 则 xϕz ;
具有等价关系的集合, 可以依据等价关系将集合分类, 得等价集合类.这是集合论
中的一个重要结论. 数量分类学中的定量分类方法正是依靠这一结论解决分类问题
的. 等价关系下的等价集合类成为表征分类方法的理论依据.
当被分类群一经确定, 合适的性状也被挑选出来,生物学工作者就要对调查,观
察,测量,实验得到的数据进行整理, 获得有关分类单位和性状的原始记录.当原始记录
的形式不能直接进行数学运算时, 需要对原始记录进行性状编码.
3.1.2 性状的种类
1. 数值性状 以整数或实数所表示的性状称为数值性状(numerical character). 例
如:生物形态的各种度量,长度,面积,重量等.数值性状本身已是数值,无需编码.
2. 二元性状 表现为对立二种状态的性状称为二元性状(binary character). 例如:
动物是脊椎动物还是无脊椎动物, 两个状态分别以”0”和”1”表示.
3. 有序多态性状 表现为三个状态以上, 能排列成一定次序, 次序具有分类意义
的性状称为有序多态性状(ordered multistate character). 例如被毛的性状编码如下:
性状状态 无毛 微具毛 具毛 多毛 密毛
编码 0 1 2 3 4
4. 无序多态性状 表现为三个状态以上, 不能排列成具有分类意义的一条序列的
性状称为无序多态性状(disordered multistate character). 例如:种子植物的花序有总
状, 头状,伞状,伞房,穗状.
– 42 –

上海交通大学硕士研究生公共课—-生物数学(一)—-林建忠编
无序多态性状的编码比较复杂, 有以下三种方法:
4.1 分解法 分解法就是将原性状分成多个新性状, 再进行编码.
例如: 植物被毛的种类, 有短毛, 长毛, 硬毛, 软毛, 单一毛, 二歧分支毛, 多歧星
状毛和腺毛等.
毛的长短性, 二元性状. 短, 0; 长, 1.
毛的质地, 二元性状. 软, 0; 硬, 1.
毛的分歧程度, 有序多态性状. 单一毛, 0; 二歧分支毛, 1; 星状毛, 2.
毛端是否具腺状点,二元性状. 非腺毛, 0; 腺毛, 1.
4.2 综合评分法 在编码之前确定评分的标准, 规定合适的综合计算方法, 并要求
评分者深明性状的分类学意义.
例如: 猪品种的分类中, 猪耳的形态学性状具有重要意义.
耳大小: 耳小, 0; 一般, 1; 耳大, 2; 特大, 3; 特大遮眼, 4.
耳下垂: 耳直立, 0; 耳平伸, 1; 耳下垂, 2.
从这两个方面评出分数, 再将这两分数相加得综合评分编码.
例如: 焦溪猪, 耳特大遮眼, 下垂, 评分编码值 6 = 4 + 2 .
4.3 演化分析法 生物分类的某些无序多态性状, 性状自身呈现出树状的演化过
程, 可画出其演化关系–树.
有向树图概念解释: 状态顶点, 称为演化起源. 演化终点. 演化方向. 主通路. (如
图3-1)
例: (见文件Biomathg31) 其实, 演化分析的编码方法也是性状分解法, 它的分解
是依据性状的演化关系.
经过编码以后的原始数据, 如果有 t个, n个性状, 数据可列成表格记录如下:
性状
1 2 · · · n
1 y11 y12 · · · y1n
分类单位 2 y21 y22 · · · y2n
... · · · · · · · · · · · ·t yt1 yt2 · · · ytn
– 43 –

上海交通大学硕士研究生公共课—-生物数学(一)—-林建忠编
3.2 数据变换和数据标准化
平移变换:
x′i = xi − c, (i = 1, 2, · · · , t)
数乘变换:
x′i = xi · c, (i = 1, 2, · · · , t)
m次幂乘变换:
x′i = xmi , (i = 1, 2, · · · , t)
初等函数变换:
x′i = sinxmi ,
x′i = arcsinxi,
x′i = axi ,
x′i = logbxi.
极差标准化变换:
xij =yij −min
kykj
maxk
ykj −mink
ykj
, (i = 1, 2, · · · , t), (j = 1, 2, · · · , n)
统计标准化变换(前面已介绍).
例:(见文件Biomatht31, Biomatht32, Biomatht33)
3.3 相似性概念的数量化
亲缘关系是生物学中的重要概念, 生物学中的分类需要引进比亲缘关系更广泛
的概念, 即相似性概念. 由表现性状差异所决定的, 分类单位之间的相似性关系称为
相似性(similarity). 两个分类单位, 性状表现比较一致,相似性就大; 反之相似性就小.
因此, 相似性概念是表征生物分类学中的基本分类度量.
– 44 –

上海交通大学硕士研究生公共课—-生物数学(一)—-林建忠编
相似性程度用数值来表示, 该数值称为相似性系数(similarity coefficient). 相似
性系数有以下几个主要类型, 即距离系数, 相关系数, 联合系数, 信息系数和模糊系数.
按数值大小与其反映的相似性程度是否一致, 可将相似性系数分为相异系数和相
亲系数两大类.
相异系数(dissimilarity coefficient)系数值愈小, 表示的相似性程度愈高; 反之, 值
愈大, 愈不相似. 距离系数是最常见的相异系数.
相亲系数(similarity coefficient)系数值愈大, 表示的相似性程度愈高; 反之, 值愈
小, 愈不相似.
3.3.1 距离系数
现考虑一简单情形, 三个性状之下讨论两个分类单位之间的关系, 性状状态数据
如下 建立坐标系如图(文件Biomathg32).
性状
1 2 3
分类单位A x1 x2 x3
分类单位B y1 y2 y3
距离 dAB 可取为
dAB =√
(x1 − y1)2 + (x2 − y2)2 + (x3 − y3)2
对于 n个性状, 可取 n维欧氏距离系数(Euclidean distance coefficient)
dAB =
√√√√n∑
i=1
(xi − yi)2
距离系数具有以下三个性质:
(1) dAB ≥ 0 , 当且仅当 A = B时, 等式成立.
(2) dAB = dBA .
(3) dAB ≤ dAC + dCB 这里 C 是 A和 B之外的另一个任意的分类单位.
– 45 –

上海交通大学硕士研究生公共课—-生物数学(一)—-林建忠编
第三条性质是几何学中的三角不等式, 有时这一性质被改换成其他形式, 如:
(3′) dAB ≤ maxdAC , dBC
这条性质比原来的三角不等式要求更强, 因为
maxdAC , dBC ≤ dAC + dBC
距离系数的前两条性质保证了共分类群等价条件的自反性和对称性成立. 但是三角
不等式不能保证传递性的成立. 而性质 (3)′ 能做到这一点.这是因为如果把距离系数
作为共分类群关系的判别系数, 亦即对于任意 d0 > 0如果有
dAB ≤ d0 ⇔ OTUAϕOTUB
由此从性质 (3)′ 可导出等价性的传递条件成立. 但绝大多数的距离系数不能满足如
此苛刻的要求. 这是距离系数作为相似性系数的重大缺陷.
常见的距离系数
如果我们需要比较分类单位和而建立距离系数, 从已标准化原始数值矩阵取出分
类单位向量
OTUi Xi = [xi1, xi2, · · · , xin],
OTUj Xj = [xj1, xj2, · · · , xjn].
则通常有如下常见的距离系数:
平均欧氏距离系数(mean Euclidean distance coefficient):
dij =
[1
n
n∑
k=1
(xik − xjk)2
] 12
平均绝对距离系数(mean absolute distance coefficient):
dij =1
n
n∑
k=1
|xik − xjk|
Minkowski 距离系数:
dij =
[1
n
n∑
k=1
(xik − xjk)r
] 1r
– 46 –

上海交通大学硕士研究生公共课—-生物数学(一)—-林建忠编
其中常数 r > 0 . 当 r充分小时Minkowski 距离系数对较小的差异十分敏感, 在化学
分类中常被使用.
Chebyshev 距离系数:
dij = max1≤k≤n
|xik − xjk|
Mahalanobis 距离系数—-欧氏距离系数的推广形式:
dij =
[n∑
k,l=1
mkl(xik − xjk)(xil − xjl)
]
其中mkl(k, l = 1, 2, · · · , n)是参数.若记
Xi −Xj =
xi1 − xj1
xi2 − xj2
· · ·xin − xjn
则Mahalanobis 距离系数也有向量表示
dij = (Xi −Xj)′M(Xi −Xj)
其中常数矩阵M = [mkl]n×n . 当M = E 时, Mahalanobis 距离系数既是欧氏距离系
数.
Canberra 距离系数:
dij =n∑
k=1
|xik − xjk|xik + xjk
在此要求 xij ≥ 0 . 不然的话, 应将公式稍加改变为:
dij =n∑
k=1
|xik − xjk||xik|+ |xjk|
分离距离系数:
dij =
[1
n
n∑
k=1
(xik − xjk
xik + xjk
)2] 1
2
– 47 –

上海交通大学硕士研究生公共课—-生物数学(一)—-林建忠编
C.R.L.距离系数:
当分类单位取样不止一个, 相似性可按下面计算.
dij =
1
n
n∑
k=1
(xik − xjk)2
s2ik
mi+
x2jk
mj
12
− 2
n
其中mi和mj 分别表示分类单位 i和分类单位 j 的取样个数.
3.3.2 相关系数与角余弦系数
本节介绍两个相亲系数, 即相关系数与角余弦系数
如果数据来自已标准化的原始数据, 两个分类单位 i 与 j 之间的相关系
数(correlation coefficient)定义为:
rij =
n∑k=1
(xik − xi)(xjk − xj)
[n∑
k=1
(xik − xi)2n∑
k=1
(xjk − xj)2
] 12
其中 xi = 1n
n∑k=1
xik , xj = 1n
n∑k=1
xjk .
角余弦系数(coefficient of cosine of included angle)定义为:
aij =
n∑k=1
xikxjk
[n∑
k=1
x2ik
n∑k=1
x2jk
] 12
角余弦系数具有明显的几何意义, 把两个分类单位向量 Xi和 Xj 之间的夹角记作 θ ,
则
cosθ =Xi ·XT
j
‖Xi‖‖Xj‖这两个相亲系数系数值越大, 相似性程度越大. 它们具有以下两条基本性质:
(1) −1 ≤ rij ≤ 1 , 当且仅当 xik = cxjk ( c 6= 0 )时, rij = 1(c > 0)或 rij = −1(c <
0)
(2) rij = rji .
这两条性质保证了共分类群等价性的自反性和对称性要求. 但是传递性未能被
满足要求.
例:(见文件Biomatht34,Biomatht36)
– 48 –

上海交通大学硕士研究生公共课—-生物数学(一)—-林建忠编
3.3.3 联合系数
联合系数是在整个二元性状或多态性状数据上, 一对之间一致性度量的配对函
数.
本节考虑二元性状的联合系数. 假设两个分类单位 OTUi和 OTUj , 待比较其相
似性, 从原始数值矩阵中提取相应的第 i个和第 j 个分类单位向量
OTUi Yi = [yi1, yi2, · · · , yin],
OTUj Yj = [yj1, yj2, · · · , yjn].
其中的分量 yik和 yjk(k = 1, 2, · · · , n)取值 0或 1 .当对比 OTUi和 OTUj 的相似性时,
两组数据的匹配有四种情况. 即 OTUi和 OTUj 分别为 1− 1 , 1− 0 , 0− 1 , 0− 0 .
计数这四种情形, 汇总列表如下:
OTUj
1 0
1 a b
OTUi 0 c d
这里 n = a + b + c + d , a , b , c和 d称为 OTUi和 OTUj 的匹配数值.
例:现有两个被比较的分类单位, 32个性状状态记录如下:
OTUi 111 100 111 011 010 001 001 001 110 110 11
OTUj 110 010 110 111 100 001 110 101 001 110 10
OTUj
1 0
1 11 8
OTUi 0 7 6
这时 n = 11 + 8 + 7 + 6 = 32 .
– 49 –

上海交通大学硕士研究生公共课—-生物数学(一)—-林建忠编
将获得的匹配值代入下马将要介绍的联合系数公式, 就可以得到反映 OTUi 和
OTUj 之间相似性的系数值.
简单的联合系数考虑计算匹配一致的性状个数占总性状个数的百分比值. 其公式
为:
SSM =a + d
n=
17
32= 0.53125.
常见的联合系数列表于3-8(文件Biomatht38, ).
此外, 还有两种系数分别是如下两个超越方程的解:
(a + c)s
a + b + c+
(a + b)s
a + b + c= 1.
怎样从众多的联合系数中挑选合适的公式
采取分类分析, 利用桔梗科6个种的二元数据, 对每一个联合系数公式, 计算全部
种之间的系数值(共有 C26 = 15个数值), 把 23个联合系数当作 OTU , 种间的 15个系
数值当作性状, 作分类运算, 得树谱图(文件Biomathg36).
二元数据的某些计算机技术
为节省计算机资源和提高计算机工作效率, 可将二元数据进行分组, 每组由三个
连续的二元数字组成, 如此一组二进位数转换成从 0到 7的普通十进位数, 表示如下:
二元数据 000 001 010 011 100 101 110 111
十进位数 0 1 2 3 4 5 6 7
将转换后的十进位数 0 7代替二元数据, 将节省存储空间. 例如, 两组32位的二元
数据处理过程如下:
二元数据依次分成3个数字一组:
OTUi 111 100 111 011 010 001 001 001 110 110 11
OTUj 110 010 110 111 100 001 110 101 001 110 10
转换成十进位数 0 7
– 50 –

上海交通大学硕士研究生公共课—-生物数学(一)—-林建忠编
OTUi 7 4 7 3, 2 1 1 1, 6 6 6
OTUj 6 2 6 7, 4 1 6 5, 1 6 4
(数据结尾如果不足一组时, 以 0补充直到凑足 3个一组.)
以下内容见文件(Biomatht39, Biomatht310)
联合系数的两个普遍公式(可根据自身需求进行自学)
3.4 表征分类的分类运算
见文件(Biomatht311, Biomathg38, Biomathg314)
– 51 –

第四章 生物演化的数学模型
4.1 演化集合及其基本定理
定义: 在分支分类中代表生物演化的实体或单位称为分支分类单位(cladistic
taxonomic unit, 简称分支单位CTU). 分支单位可以代表个体, 居群, 种, 属, 科等等,
也可以是分支分类学中的分类单位(OTU)或假设分类单位(HTU). 它是研究物演化的
最基本单位.
分支单位也称为分支点(cladistic point),所有分支点集合记作X = x1, x2, · · · , xi, · · · . 两个分支单位 x和 y如果完全相同, 表为 x = y ; 如果不相同, 表为 x 6= y ; 如果具
有演化关系, 比如分支单位 x是 y的祖先, 表为 x ≤ y (或者 y ≥ x ). x是 y的祖先,
也称 y是 x的后裔. x ≤ y也可表为 x → y .
定义4.1 分支单位集合 X , 在 X 的部分分支单位间建立的演化关系如果满足以
下四条性质, 则称该分支单位集合 X 为演化集合.
性质1 任何分支单位 x是其自身的祖先, 即 x ≤ x (自反性);
性质2 三个分支单位 x , y与 z , 若 x ≤ y , 且 y ≤ z , 则 x ≤ z (传递性);
性质3 如果分支单位满足 x0 ≤ x1 ≤ x2 = x0 , 则 x0 = x1 (反对称性);
性质4 任意两个分支单位 x与 y , 若存在分支单位 z ∈ X 使 x ≤ z , y ≤ z , 则 x
与 y可比较, 即要么 x ≤ y或者 y ≤ x (可比较性);
说明1: 性质3的结果如果不成立, 即, 将得到如图4-1(文件Biomathg41)所示循环
逆转的演化关系. 自然界不可能存在这种关系. 性质3的一般形式为
性质3(附) 演化集合中多个分支点若满足
x0 ≤ x1 ≤ x2 ≤ · · · ≤ xn = x0,
52

上海交通大学硕士研究生公共课—-生物数学(一)—-林建忠编
则
x0 = x1 = x2 = · · · = xn,
说明2: 性质4反映了生物演化的分支性, 它说明生物演化过程中不可能出现融
合, 而产生网状进化. 因为性质4如果不成立, 将出现两个不可比较的分支点 x与 y ,
z是它们共同的后裔.
定义 演化集合 X 的任一子集 Y , 如果在集 Y 上仍然保留 X 中的演化关系, 显
然在 Y 集上所有演化关系的4条性质亦保持正确, 故 Y 亦是一个演化集合. 称 Y 为X
的演化子集(evolutionary subset), 记作 X ⊇ Y 或 Y ⊆ X .
说明3: 把树图的顶点视作分支单位, 有向树可以看作在共祖条件下的演化集
合; 反过来, 演化集合虽是一个有向图, 但并不一定能看作有向树. 后面将指出演化
集合与有向树图可以建立同构关系. 因此演化集合有时也被称为演化图(evolutionary
graph), 演化集合中的分支单位有时被称为分支点(cladistic point). 图中的弧有时也
被称为分支线(cladistic line)或分支边(cladistic edge).
例1: n + 1个非负整数 N(n) = 0, 1, 2, · · · , n , 在通常不等式意义下, 把普通不
等式符号 ” ≤ ”看作演化关系, 集合 N(n)构成演化集合.
例2: 图4-2(文件Biomathg41)所示有向树图, 顶点集合 a, b, c, d, e, f, g, h在图示的方向上, 如果从一个顶点 x可以到达另一个顶点 y , 规定演化关系 x ≤ y , 则该顶
点集合构成演化集合.
例3: 桔梗科6个种的演化关系(文件Biomathg42).
例4: 有向树图 T , 把图 T 的所有顶点视作分支点, 如果两个顶点 x和 y , 从 x可
以到达 y , 则规定演化关系 x ≤ y , 于是图 T 的所有分支点构成演化集合. 可以验证,
如此确定的演化关系满足演化关系4条基本性质, 故图 T 是演化集合.
例5: 以如下集合 e , f , g , h , e, f , g, h , e, f, g, h为元素构成的集合类, 并规定演化关系:如果 A ⊆ B作为 B ≤ A , 则该集合类构成演化集合.
例6: 一个集合的一切子集类 G , 除去空集, 且满足条件: 若 A⋂
B 6= ∅ , 则要么
A ⊇ B要么B ⊇ A . 把子集合看作分支单位,并定义演化关系若A ⊆ B ,作为B ≤ A
, 则该子集类构成演化集.
– 53 –

上海交通大学硕士研究生公共课—-生物数学(一)—-林建忠编
证明: 仅证性质4. 假如集合类 G中两集合 A与 B , 又存在集合 C ∈ G , 有关系
A ≤ C , B ≤ C 即 C ⊆ A , C ⊆ B . 无空集, C 非空, 故 A⋂
B 6= ∅ . 由已知条件得,
要么 A ≤ B要么 B ≤ A .
分支分类的基本原理:
作为数学模型的抽象的演化集合并不是真实的, 能够反映生物演化真实历史的演
化集合称作真实演化集合(true evolutionary set). 如何从众多的具有可能性的演
化集合中, 把真实演化集合区别出来呢? 如何把真实演化集合以容易理解的形式显示
给生物学家呢?这是分支分类所需要解决的问题.
我们首先需要一些基本原则, 它是从生物演化实际现象中把那些最本质的因素作
为公理提炼出来, 作为研究分支分类和重构生物演化历史的根本依据. 分支分类的基
本公理如下:
公理1: 对任意一个生物类群, 在生物实际演化关系下, 存在把该类群包含在内的
一个基本演化集, 使该类群在此基本演化集上共祖且类群的实际演化关系在基本演化
集上得到表达.
公理2: 生物真实演化集合到分支性状状态集合的映象是演化保序的.
公理3: 生物真实演化集合的演化图中, 同一演化路径上表示演化关系的演化系
数满足可加性;
公理4: 生物真实演化集合其加权演化图的演化长度, 取可能达到的最小值.
定义4.2 在演化集合 X 中, 有这样一种分支单位 x , 除 x外不存在另一个分支单
位 y ∈ X , y是 x的祖先,即 y < x ,则称如此分支单位 x为演化集合的祖源(ancestral
source). 又若除 x外不存在另一个分支单位 y ∈ X , x是 y的祖先, 即 x < y , 则称 x
为演化集合的终裔(end of descendent). 即是祖源又是终裔的分支单位称为孤立分支
单位(isolated cladistic unit)简称孤立单位.
定理4.1 有限演化集合必定存在祖源与终裔.
定义4.3 演化集合 X 中, 两个分支单位 x与 y , 若存在 z ∈ X , 有 z ≤ x且 z ≤ y
则称 x与 y在 X 中共祖(coancestral), z是 x与 y的共同祖先(common ancestor). 又
若在演化集合 X 中, z 是 x与 y的共同祖先, 不再有另一个共同祖先 z′ , z′ 6= z , 且
z < z′ , 则称 z是 x与 y的最近共同祖先(nearest common ancestor), 记作 z = x ∧ y .
– 54 –

上海交通大学硕士研究生公共课—-生物数学(一)—-林建忠编
易知, 若 x ≤ y , 则 x = x ∧ y .
定理4.2 演化集合中两个共祖分支单位必存在唯一最近共同祖先.
定理4.3 在演化集合 X 中, x1与 x2共祖, x2又与 x3共祖, 则 x1与 x3共祖.
共祖关系是等价关系
(1) 任意分支单位与自身共祖(自反性).
(2) 若 x与 y共祖, 则 y与 x共祖(对称性).
(3) 若 x与 y共祖, 且 y与 z共祖, 则 x与 z共祖(传递性).
现将共祖及最近共祖的概念推广到集合上.
定义4.4 对于演化集 X 有演化子集 Y ⊆ X , 若存在分支单位 x ∈ X , 使得任何
y ∈ Y 都以 x为祖先, 即 x ≤ y , 则称 Y 在 X 上共祖, x是 Y 的共同祖先. 特殊情形,
当 Y = X 时, 称演化集X 自身共祖, 简称作演化集X 共祖. 如果 x是 Y 的共同祖先,
在 X 中不存在另一个共同祖先 x′ , x′ 6= x , 且 x < x′ , 则称 x是 Y 在 X 上的最近共
同祖先.
定理4.4 演化集合 X 的子集合 Y , 若 Y 在 X 上共祖, 必存在唯一的最近共同祖
先 ∧Y .
定理4.5 演化集合 X 的子集 Y , Y 在 X 上共祖的充分必要条件为 Y 中的分支
单位在 X 上两两共祖.
定理4.6 自身共祖的演化集合 X 存在唯一的祖源, 就是最近共同祖先 ∧X .
定理4.7 基本定理(分解定理) 凡演化集合 X 可分解为 m个 (1 ≤ m)演化子集
Xi , 并且有以下性质:
性质1, X =m⋃
i=1
Xi , 其中 Xi
⋂Xj = ∅(i 6= j) ;
性质2 演化子集 Xi(i = 1, 2, · · · ,m)无论在演化子集 X 上或对自身都共祖, 且有
唯一的祖源 Si(i = 1, 2, · · · ,m) ;
性质3 不同演化子集的分支单位在 X 上非共祖.
数 m称为演化集合的分支数(cladistic number). Xi(i = 1, 2, · · · ,m)称为 X 的
分支演化集合(cladistic evolutionary set).
对于 X 的演化子集 Xi和 Xj , 如果不存在 x ∈ Xi与 y ∈ Xj 使 x与 y在 X 上共
祖, 则称 Xi与 Xj 在 X 上非共祖.
– 55 –

上海交通大学硕士研究生公共课—-生物数学(一)—-林建忠编
基本定理的证明
如果 X = (x1, x2, · · · , xn) , 先把演化子集 Xi构造出来.
Xi = x|x ∈ X, 且 x与 xi在 X 上共祖 (*)
考虑到共祖的传递性, Xi无论在 X 上或者对自身都是共祖的, 根据共祖的三条
等价关系, 如果 xi与 xj 共祖, 集合 Xi与 Xj 包含的分支单位相同, 视为等价, 凡等价
者归并于同一个集合类, 全部 Xi 可归属于有限个( m个)等价集合类. 从每一集合类
取出一个演化子集为代表, m个演化子集不妨就是
X1, X2, · · · , Xm,
这些演化子集彼此都非共祖, 性质3真. 因为彼此非共祖, 显然有 Xi
⋂Xj = ∅ , 当
i 6= j . X 中的任意分支点 x , 依(*)属于该点的演化子集, 该子集又属于某等价集合
类. 存在某一演化子集 Xi , x ∈ Xi , 因而有 X =m⋃
i=1
Xi , 性质1亦真. 至于性质2的真
确性, 考虑 Xi的构造, 知 Xi共祖, 再利用定理4.6, 祖源的存在性与唯一性立即可得.
最近共祖符号 ” ∧ ”的基本性质
性质1 x = x ∧ x ;
性质2 若 x与 y共祖, 则 x ∧ y = y ∧ x ;
性质3 若 x , y和 z互相共祖, 则
x ∧ (y ∧ z) = y ∧ (z ∧ x) = z ∧ (x ∧ y) = ∧x, y, z
对于 n个分支单位间的运算 ∧ , 与运算的排列次序无关. 形式为
x1 ∧ (x2 ∧ · · · ∧ (xn−2 ∧ (xn−1 ∧ xn)) · · · )
的运算可写成∧ni=1xi并且运算结果就是 x1, x2, · · · , xn的最近共同祖先∧x1, x2, · · · , xn
,
∧ni=1xi = ∧x1, x2, · · · , xn.
分支分类问题, 就是把生物演化的真实过程重新显示出来, 从而认识当今生物类
群的谱系关系.这需要把所提的问题具体化, 以数学语言对问题进行描述并说明解决
问题的途径.
– 56 –

上海交通大学硕士研究生公共课—-生物数学(一)—-林建忠编
如果有 t(3 ≤ t)个分类单位 xi(i = 1, 2, · · · , t)构成一个分类单位集合, 记作 O ,
全部分支分类工作从集合O开始. 分支分类的目的就是找到一个包含集合O在内的
演化集合, 通过它认识与分类单位有关的生物演化真实过程.
除集合O中的分类单位以外, 某些分支单位所代表的生物种类可能已经灭绝; 但
是为了展示整个演化过程, 应该把这些生物种类当作假设分类单位予以恢复, 置于演
化集合中.
如果 x与 y是分类单位集合 O中的任意两个元素, 作为分支单位其最近共同祖
先 x ∧ y可以看作前述的假设分类单位, 它不一定在分类单位集合 O中, 可是为了说
明 x与 y的演化历史, 应该把 x ∧ y作为假设分类单位包括在演化集合中. 根据最近
共同祖先的存在性与唯一性定理, 为了得到 x ∧ y , 必须要求 x ∧ y 在某演化集合下
共祖. 这等价于要求存在某一演化集合, 在该集合下 O中每一对OTU是共祖的.由定
理4.5, 即要求存在一个演化集合, 使分类单位集合O在其上共祖.
对于任意分类单位集合 O 是否存在充分大的演化集合 U , 集合 O 在 U 上
共祖. 如此集 U 称为集 O 的基本演化集(fundamental evolutionary set). (参见文
件Biomathg44)
我们以公理的形式来说明基本演化集的客观存在.
公理1 对于任意一个生物类群, 在生物实际演化关系下, 存在把该类群包含在内
的一个基本演化集, 使该类群在此基本演化集上共祖且类群的实际演化关系在基本演
化集上得到表达.
定义4.5 对于分类单位集合 O , 依据公理1存在基本演化集 U , 因为 O在 U上
共祖, 对任意 x1和 x2 ∈ O , 存在 x ∈ U有 x = x1 ∧ x2 , 称 x1与 x2的最近共同祖先 x
为分支分类问题的假设分类单位(hypothetical taxonomic unit),简称假设单位(HTU).
假设分类单位构成的集合
H = x|x = x1 ∧ x2, 对于任意x1, x2 ∈ O
称为假设分类单位集合(hypothetical taxonomic unit set). 集合H与O的并集
X = O ∪H
称为分类单位集合 O的导出集(induced set). 如果将基本演化集 U中的所有演化
– 57 –

上海交通大学硕士研究生公共课—-生物数学(一)—-林建忠编
关系都引入导出集中, 获得一个新的演化集合, 称为分类单位集合 O的导出演化集
合(induced evolutionary set), 亦简称导出集.
定理4.8 导出演化集无论对基本演化集或对自身都共祖.
推论 导出演化集存在唯一的祖源.
定义4.6 对于演化集 X 中的任一分支单位 x , 如下演化子集
R(x) = y|x ≤ y, y 6= x, y ∈ X
称为 x的演化可达集(evolutionary reachable set), 演化可达集 R(x)的分支数称为分
支单位 x的分歧数(branch number), 记作 BN(x) .
当 x是X 的终裔时, 演化可达集是空集, 规定 BN(x) = 0 . 演化集中的分支单位
x是终裔的充分必要条件是 BN(x) = 0 .
按照分歧数的多少定义以下集合
B(i) = x|BN(x) = i, x ∈ X (i = 0, 1, 2, · · · )
B(i)称为分歧数为 i的集合. 显然, 分歧数为 0的集合 B(0)就是演化集合 X 的一切
终裔集合.
说明: 对于 B(1)点集, 每点的分支数为1, 它所代表的生物类群如果与我们的研
究内容没多大关系, 一般情形我们都把这样的分支点的后续分支点从演化图中删除,
删除之后也不影响整个演化图的基本结构.
定义 对于一个分支分类问题, 导出演化集的 B(0) 与 B(1) 之并称为产生
集(product set), 表示如下:
P (O) = y|BN(y) ≤ 1, y ∈ O 的导出演化集
定理4.9 对于一个分支分类问题, 分类单位集合O的产生集 P (O)是分类单位集
合O的子集合. 即
P (O) ⊆ O
– 58 –

上海交通大学硕士研究生公共课—-生物数学(一)—-林建忠编
4.2 分支性状与编码
如果 Y 表示被研究的分类单位集合,此集合属于演化集合,如果对于 Y 中的分支
单位 y , 依据性状映象M 都有一个状态 x = M(y) , 集合 X = x|x = M(y), y ∈ Y 是状态集合. 于是代表性状的映象M 把集合 Y 映象到性状状态集合 X 上. 其关系表
示如下:
YM−→ X
定义4.7 从代表生物演化的演化集合 Y 到性状状态集合 X 上的一个性状映象M , 如
果 X 对自身是共祖演化集, 则称映象M 为 Y 的分支性状(cladistic character).
例(见文件Biomathg45)
说明: 演化保序性和演化同构性.
M2(鸟)=翅肢
M2(鱼)=鳍
在演化集合 Y 里, 鱼类居鸟类之先. 因而在性状状态集 X2 , 鳍应在翅肢之
先. 在性状状态集合中, 两个性状状态互相比较, 演化关系在先的称为祖先性状
状态(ancestral character state), 或者简称祖征; 在后的称为衍生性状状态(derived
character state), 或者简称衍征. 例如: 鳍与翅肢比较, 鳍是祖先性状状态, 翅肢是衍
生性状状态.
定义性状状态集合中,状态之间祖先与衍生的次序关系称为演化极性(evolutionary
polarity).
状态集合应保持与生物演化集合有相同的演化次序. 例如:
鱼类 ≤鸟类⇒鳍 ≤翅肢
由此引入
定义4.8 从演化集合 Y 到演化集合 X 的映象M , 对于任意两个分支单位 y1 ,
y2 ∈ Y 有 x1 = M(y1) , x2 = M(y2) , 其中 x1 , x2 ∈ X , 如果能够从 y1 ≤ y2 导出
x1 ≤ x2则称映象M 演化保序(evolutionary isotone)
– 59 –

上海交通大学硕士研究生公共课—-生物数学(一)—-林建忠编
公理2 生物真实演化集合到分支性状状态集合上的分支性状映象是演化保序的.
映象的演化性是可以传递的. 如果M 是一个从 X 到 Y 的映象, N 是一个从 Y
到 Z 的映象,
XM−→ Y
N−→ Z
连续两次映象确定了一个从 X 到 Z 的映象 NM :
XNM−→ Z
该映象称为映象M 对映象 N 的乘积. 也可写成
NM(X) = N(M(X)) = N(Y ) = Z
保序的传递性是指如果映象M 与 N 是保序的, 则映象的乘积 NM 也同样是保序的.
例 在前例中, 考虑再建立一个映象M3 , 把生殖方式从祖征到衍征三个状态分别
映象到0, 1 和2整数集 0, 1, 2 .
定义4.9 两演化集合X 与 Y , 若存在从X 到 Y 上的一一对应映象M , 对于任意
x1 , x2 ∈ X 如果 x1 ≤ x2成立的充分必要条件是
M(x1) ≤ M(x2)
则称演化集 X 与演化集 Y 演化同构(isomorphism of evolution). 表为:
X ∼= Y
定义4.10 演化集 X , 对于 x ∈ X , 集合
A(x) = y|y ≤ x, y ∈ X
称为分支单位 x的祖集合(ancestral set of x).
定理4.10 演化集 X , 对于 x ∈ X , 祖集合 A(x)存在唯一的祖源, 亦即 X 的祖
源, 存在唯一的终裔, 即 x .
定理4.11 祖集合 A(x)中的所有分支单位可排成演化次序:
x0 = x1 < x2 < · · · < xn = x
– 60 –

上海交通大学硕士研究生公共课—-生物数学(一)—-林建忠编
其中 x0是 A(x)的祖源.
推论 共祖演化集与其祖集合有共同祖源.
任给一棵有向树 T (X,L) , 其中X 代表树的顶点集合, L表示弧集合. 对于X 中
的部分顶点, 例如 x与 y , 如果从 x可到达 y , 包括 x = y在内, 则规定关系
x ≤ y
在 X 上确立的上述关系, 有
定理4.12 有向树 T (X,L) , 在部分顶点间依可到达所确立的上述关系下, 顶点集
合 X 是演化集合.
推论 与有向树对应的演化集合共祖, 祖源是树的根.
与演化集合相对应的有向图的构造 对于演化集合 X , 两不同分支单位 x 与
y ∈ X , 如果 x < y , 且于 X 中不存在第三个分支单位 z(z 6= x, z 6= y)使得
x < z < y
成立, 则把两有序的分支单位确立为有向图的弧 l = (x, y) . 所有如此构造的弧组成
集合 L , 把 X 中的分支单位当作顶点, 于是集合 X 与集合 L构成一个由演化集合
X 产生的有向图 T (X,L) , 称为与演化集合相对应的有向图(corresponding directed
graph)
定理4.13 共祖演化集合 X , 与其对应的有向图是一棵有向树 T (X,L) .
定理4.14 共祖演化集合 X , T (X,L)为相对应的有向树. 对于任意 x与 y ∈ X ,
x ≤ y成立的充分必要条件是在 T (X,L)中从 x可到达 y .
分支分类的定量分析 (见文件Biomathg46, Biomathg47)
分支性状的状态集合是一个共祖的演化集合, 如果状态集合能排成下面的演化次
序
x0 ≤ x1 ≤ · · · ≤ xn,
就可移状态符号” xi ”的下标 i , 建立从 xi到整数 i(i = 0, 1, 2, · · · , n)的映象. 该映象
构成从性状状态集合到整数演化集合 Rn = 0, 1, 2, · · · , n的一一对应关系. 易知该
性状状态集合与整数演化集合 Rn演化同构.
– 61 –

上海交通大学硕士研究生公共课—-生物数学(一)—-林建忠编
定理4.15 不共祖或者具有两个以上终裔的演化集不可能与整数演化集合
Rn = 0, 1, 2, · · · , n演化同构.
定义 如果 x是演化集X 的终裔则祖集合 A(x)称为演化集X 关于终裔 x的单位
演化集(unit of evolutionary set), 记作 I(X, x) . 单位演化集与某一整数演化集合同
构.
如果某一演化集 X 有 l 个终裔 xi(i = 0, 1, 2, · · · , l) , 相应地有 l 个单位演化集
I(X, xi)(i = 0, 1, 2, · · · , l) . 把这 l个单位演化集视为演化集 X 的分解. 另有
定理4.16 演化集是其所有单位演化集之并. 即
l⋃i=1
I(X, xi)
其中 xi(i = 0, 1, 2, · · · , l)是 X 的全部 l个终裔; I(X, xi)是关于 xi的单位演化集.
利用此定理可以进行分支性状的分解与编码. 现阐述其具体做法.
某被研究的生物分支单位集合记作 Y , 依据公理1在某一充分大的基本演化集
下, Y 是共祖的. 如果分支性状M , 把 Y 映象到状态集合 X 上, X 是演化集, 按照
公理2的条件, 映象 YM−→ X 是保序的. 如果 X 具有 l个终裔, 得到 l个单位演化集
I(X, xi)(i = 0, 1, 2, · · · , l) . 第 i个单位演化集合表示如下:
x0 < xi1 < xi2 < · · ·xini, (i = 0, 1, 2, · · · , l)
分支性状状态集合X 是共祖演化集, 对任意 x ∈ X , x∧ xi ≤ xi , 有 x∧ xi ∈ A(xi) =
I(X, xi) , 因而存在某个状态 xik = x ∧ xi . 这样得到一个从 X 到 I(X, xi)的映象
Ti : Ti(x) = x ∧ xi = xik , x ∈ X . 可以证明映象是保序的. 假如有分支单位 x′ 和
x′′ ∈ X ,
x′ ≤ x′′
则有
x′ ∧ xi ≤ x′′ ∧ xi
得保序的结论
Ti(x′) ≤ Ti(x
′′)
– 62 –

上海交通大学硕士研究生公共课—-生物数学(一)—-林建忠编
最后得到映象Mi = TiM , 该映象把生物分支单位集合 Y 映象到 I(X, xi)上, 它也
是保序的. 把由单位演化集 I(X, xi)确定的性状Mi称为单位分支性状(unit cladistic
character). 又单位分支性状的状态集合 I(X, xi)与整数演化集合 Rn同构, 从而利用
单位分支性状解决了分支分类中分支性状的合理编码问题. 它们的关系如下:
YM−→ X
Ti−→ I(X, xi) ∼= Rni
得
YMi=TiM−→ I(X, xi) ∼= Rni
分支性状的编码处理方法总结:
分支分类的分类单位集合如果是 Z = z1, z2, · · · , zt , 某一分支性状M 把 Z 映
象到该性状的状态集合 X 上.
ZM−→ X
对于性状状态集合 X , 如果有 l个终裔分支单位 xi(i = 0, 1, 2, · · · , l) , 对应于每个终
裔有一个单位演化集合 I(X, xi) , 该单位演化集合构成一条演化路径:
I(X, xi) : x0 = xi0 < xi1 < xi2 < · · · < xini= xi,
对 X 中任一分类单位 x , 如果 xik = x ∧ xi , 把 xik 确定为 x在单位演化集合 I(X, xi)
所确定的单位分支性状下的状态, 由此得到保序映象 Ti , 使
Ti(X) = I(X, xi)
即对于 x ∈ X , 有 Ti(x) = x ∧ xi ∈ I(X, xi) , 也就得到分类单位集合 Z 到单位分支性
状的映象Mi = TiM , 把映象 Z 映象到 I(X, xi) ,
Mi(Y ) = Ti(M(Y )) = Ti(X) = I(X, xi)
不失一般性, 从一开始就可以认为所有的性状Mj 已处理成单位性状,
ZMj−→ I (j = 1, 2, · · · , n)
– 63 –

上海交通大学硕士研究生公共课—-生物数学(一)—-林建忠编
其中第 j 个性状具有mj + 1个状态:
Ij : xj0 < xj1 < xj2 < · · · < xjmi, (j = 1, 2, · · · , n)
对任意分类单位 zi ∈ Z , 如果第 j 个性状的映象是 xjk ,
Mj(zi) = xjk
即第 i分类单位第 j 个性状的编码值 yij 确定为整数 k(0 ≤ k ≤ mj) :
yij = k
让 i 跑遍所有的分类单位编号 (i = 1, 2, · · · , t) ; j 跑遍所有的性状编号 (j =
1, 2, · · · , n) , 得到矩阵:
Y =
y11 y12 · · · y1n
y21 y22 · · · y2n
· · · · · · · · · · · ·yt1 yt2 · · · ytn
该矩阵就是分支分类的原始数值矩阵. 行代表分类单位, 列代表性状. 每个性状的取
值介于 0到mj 之间的整数, 0值表示该性状最原始的状态. mj 表示该性状最高演化
状态.
例: 脊椎动物肢趾类型性状编码 参见文件biomatht41
例: 桔梗科6个种分支分类试验数据
参见文件biomatht42
4.3 演化的定量表示与俭约性公理
演化关系的数值表示称为演化系数(evolutionary coefficients). 若以相异性距离
系数 d(x, y)表示两分类单位 x与 y间的演化关系, 下面两个要求是必要的:
(1) d(x, y) ≥ 0 , 当且仅当 x = y时, 等式成立.
(2) d(x, y) = d(y, x) .
在纯数学的度量空间中有三角不等式的要求,
– 64 –

上海交通大学硕士研究生公共课—-生物数学(一)—-林建忠编
1. 茎的类型 直立 −→缠绕,
2. 株高 短矮型 −→长高型,
3. 叶序 互生 −→对生 −→轮生,
4. 叶缘 全缘或波状 −→锯齿 −→重锯齿,
5. 花序 单生 −→总状或疏圆锤花 −→复总状或圆锤花序,
6. 子房室数 3室 −→ 4室 −→ 5室,
7. 果开裂方式 侧壁开裂 −→顶端开裂 −→室背开裂,
8. 种子 不具翼 −→具翼.
(3) d(x, y) ≤ d(x, z) + d(z, y) , 这里 z是 x和 y之外的另一个任意的分类单位. 在
表征分类中, 为保证传递性, 要求 d(x, y) ≤ maxd(x, z), d(z, y) . 在分支分类中, 演
化系数还需要怎样的要求呢?
公理3 生物真实演化集合的演化图中, 同一演化路径上表示演化关系的演化系数
满足可加性.
定义 演化路径上三个分支单位 x , y与 z , 如果 x ≤ y ≤ z , 令 d表示演化系数,
可加性是指下面等式成立:
d(x, z) = d(x, y) + d(y, z)
如果有 n + 1个分支单位, 它们构成一个演化路径:
x = x0 ≤ x1 ≤ · · · ≤ xn = y
则
d(x, y) =n∑
i=1
d(xi−1, xi)
绝对距离系数满足可加性条件.
证明: 如果三个分支单位满足
xi ≤ xh ≤ xj
– 65 –

上海交通大学硕士研究生公共课—-生物数学(一)—-林建忠编
从性状编码的规定, 第 k个相应的编码应有不等式 xik ≤ xhk ≤ xjk(k = 1, 2, · · · , n) ,
因而有
|xik − xjk| = xjk − xhk + xhk − xik
= |xjk − xhk|+ |xhk − xik|
最后得
n∑
k=1
|xik − xjk| =n∑
k=1
|xjk − xhk|+n∑
k=1
|xhk − xik|
因此我们取绝对距离系数作为分支分类的演化系数
定义4.11 分支分类中的绝对距离系数又称曼哈顿系数(Manhattan coefficient),
因为属于距离系数也称为演化距离(evolutionary distance). 两个分支单位 CTUi 和
CTUj , 它们的分支单位向量分别是
xi = [xi1, xi2, · · · , xin]
xj = [xj1, xj2, · · · , xjn]
分支单位 i与 j 之间曼哈顿演化系数计算公式为
d(i, j) =n∑
k=1
|xik − xjk|
定义4.12 把演化集合视作有向图, 对于分支线(弧) l = (x, y) , 可以把距离 d(x, y)定
为分支线的长度(length of evolutionary line), 记作
d(l) = d(x, y)
把分支线的长度视作分支线的赋权值, 该演化图成为赋权图, 称为赋权演化
图(weighted evolutionary graph). 赋权演化图所有分支线的长度的总和称为该演化图
的演化长度(evolutionary length).
在一条演化路径 L : x = x0 ≤ x1 ≤ · · · ≤ xm = y中, 所有分支线的长度的总和称
为该演化路径的长度, 由于在同一条演化路径中演化距离是可以相加的, 因而演化路
径的长度等于起点与终点间的距离, 即
d(L) =m∑
k=1
|xi−1 − xi| = d(x, y)
– 66 –

上海交通大学硕士研究生公共课—-生物数学(一)—-林建忠编
公理4(生物进化俭约性公理, Edward 和Cavall-Sforza) 代表生物演化真实过
程的演化图符合俭约性原则, 即演化图取其长度可能达到的最小者.
定义4.13 三个数值除去最大, 最小值以外剩下的值称为中位值(mean value).
三个分支点 A , B与 C 关于 n个性状的向量坐标表示为
A = [a1, a2, · · · , an], B = [b1, b2, · · · , bn], C = [c1, c2, · · · , cn]
定义4.14 以三个分支点相应性状分量 ai , bi和 ci的中位值mi为性状分量的分
支点M = [m1,m2, · · · ,mn] , 称为分支点 A , B 与 C 的中位分支点(median cladistic
point), 简称中位点.
定理4.17 (Farris 中位值定理) 为分支分类问题而构造的演化图, 图中三个分支
点 A , B与 C 靠一个分支点W 与其连接(即在三个分支点中, 从其中之一点经W 演
化到其余两分支点), 则以下两结论成立:
(1) W 取 A , B 与 C 的中位点时, 从W 连向 A , B 与 C 的演化路径总长度达
到最小;
(2) A , B与 C 的中位点M 到各点的演化距离有以下关系:
d(A,M) =1
2[d(B, A) + d(C, A)− d(B, C)]
d(B, M) =1
2[d(C, B) + d(A,B)− d(C, A)]
d(C, M) =1
2[d(A,C) + d(B, C)− d(A,B)]
推论1 符合俭约性原则为分支分类问题而构造的演化图中, 与三个分支点 A , B
与 C 相邻接的分支点必取 A , B与 C 的中位点.
在三个分支点 A , B 与 C 中, 若已知 C 是祖先, A与 B 是后裔, 这时中位点M
的性状分量将是 A与 B相应性状分量的最小值.
mi = minai, bi (i = 1, 2, · · · , n)
满足这个关系的分支点M 称为 A与 B 的最小值点(minimal value point). 这是因为,
由 ci ≤ ai , ci ≤ bi得:
ci = minai, bi, ci ≤ minai, bi ≤ maxai, bi, ci = maxai, bi
– 67 –

上海交通大学硕士研究生公共课—-生物数学(一)—-林建忠编
此式说明 A与 B的最小值点就是 A , B与 C 的中位值点.
推论2 在中位值定理及其推论1中, 当 C 是 A与 B的祖先时, 将 A , B与 C 的中
位值点改为 A与 B的最小值点, 结论正确.
推论3 为分支分类问题而构造且符合俭约性原则的演化图, 任何分支点的性状分
量是所有可演化到达分支点相应性状分量的最小值, 亦是所有可演化到达的终裔点相
应性状分量的最小值.
如果两个待结合分支单位的向量表示是:
Xp[xp1, xp2, · · · , xpn]
Xq[xq1, xq2, · · · , xqn]
二者的最近共同祖先为假设分类单位 Xr , 其每个性状分量应该满足:
xri = minxpi, xqi (i = 1, 2, · · · , n)
从而获得 Xr 的向量表示
Xr[xr1, xr2, · · · , xrn]
定义4.15 共祖分支单位在相同性状上出现相同性状状态的进化, 称为平行进化.
性质 没有平行进化的演化图, 其演化图的长度 L等于所有被考虑单位分支性状
其状态进化次数mi(i = 1, 2, · · · , n)的总和. 即
Lmin =n∑
i=1
mi
定义4.16凡构造的演化图,其演化长度取到 Lmin时,称为最俭约演化图,值 Lmin
称为最俭约演化长度, 简称最俭长度.
定理4.18 分支分类问题获得最俭约演化图的充分必要条件是演化图无平行进化.
一般地说, 我们所构造的演化图其长度 L应满足:
Lmin =n∑
i=1
mi ≤ L ≤ Lmax =t∑
i=1
n∑j=1
xij
实际构造的演化图未必能达到最俭约目标, 我们用俭约系数来衡量演化图俭约性程
度, 其定义为:
CL =L− Lmin
Lmax − Lmin
– 68 –

上海交通大学硕士研究生公共课—-生物数学(一)—-林建忠编
易知 0 ≤ CL ≤ 1 , 当 CL = 1 时, 演化图长度呈现出最大程度的浪费(见文
件Biomathg49), 当 CL = 0时, 演化图达到最大程度的俭约.
4.4 性状演化的和谐性与和谐性分析方法
设分类单位集合为 O , 取出任一性状记作M , 状态集合为 S , 分支性状的状态
集合 S 是一共祖的演化集合. 先建立起一个 O 的导出演化集, 要求该演化集仅仅反
映单一性状M 的演化关系.
导出演化集的构造: 与演化集 S 相应的有向树图 S 中任取一个分支点 s , 分以下
两种情形处理:
若分类单位集合中仅有唯一的分类单位 y ∈ O , 使 s = M(y) , 则规定 y = s . 若
存在两个以上的分类单位 yi ∈ O , s = M(yi)(i = 1, 2, · · · ,m) , 则在原有有向树图 S
中补充以新的分支点 yi和弧 li = (s, yi)(i = 1, 2, · · · ,m) .
对 S中每一分支点 s都做上述处理, 最后得 S扩展图, 记作 S∗ . 该图保持着一棵
有向树图. 所有的分支点构成演化集合, 从 S∗ 的构造过程知 O ⊆ S∗ , 并且 O在 S∗
上共祖. 又把M 亦看作 O到 S∗的映象, 显然M 是保序的, 说明 S∗当作演化集合符
合公理2保序性要求. 如果把 S∗看作基本演化集合, 作出 O的导出演化集X . 此时导
出演化集 X 与基本演化集 S∗ 相同. 把如此获得的导出演化集称为分类单位集合 O
对性状M 的性状演化集合.
定义4.17 集合的非空子集构成集合类, 以集合为元素, 集合之间的包含关系
B ⊆ A确定为演化关系 A ≤ B , 在如此演化关系之下, 如果该集合类构成演化集, 则
称为演化类.
定义4.18 两集合 A与 B若 A ∩ B = ∅ , 或者当 A ∩ B 6= ∅时, A与 B存在包含
关系 A ⊆ B或 A ⊇ B , 则称两集合 A与 B和谐.
定义4.19 集合 X 的两个子集类 G与 H , 对任意集合 A ∈ G , B ∈ H , A与 B
是和谐的, 则称集合类 G与 H 是和谐的. 特殊情形, 若集合类与自身是和谐的, 称该
集合类自身是和谐的.
集合与集合类的和谐性具有对称性(若 A与 B 和谐, 则 B 与 A亦和谐), 但不满
足传递性.
– 69 –

上海交通大学硕士研究生公共课—-生物数学(一)—-林建忠编
反例: 集合 A = a, b, c与 C = c集合和谐, B = c, d, e, f与 C 也和谐, 但
是 A与 B不和谐.
三个集合类, G = [a, b, c, b, c, a, b, c] , H = [a, b, c, a, b, c]和F = [a, b, c, a, b, a, b, c] , 易验证 G与 H 和谐, H 与 F 和谐, 但 G与 F 不
和谐.
定理4.19 不存在空集的和谐的集合类是演化类.
注 演化类未必都一定是自身和谐的.
反例: 集合类
G = [Xa, b, Y b, c, Zd, Ub, c, d, V a, b, c, d]
按集合包含关系确立的演化关系(即若 A ⊆ B则 B ≤ A)构成演化类(图参见文
件Biomathg410), 但 X 与 Y 不和谐.
定理4.20 包含所有单个元素的集合, 又不含空集的集合类, 构成演化类的充分必
要条件是自身和谐.
定义4.20 在导出演化集 X 中, 对任意 x ∈ X , 先定义与 x对应的集合:
C(x) = y|x ≤ y, y ∈ O
此集合称为分支单位 x的演化对应集(evolutionary corresponding set), 简作对应
集. 然后引入演化对应类的概念.
G(X) = C(x)|x ∈ X
称为演化集 X 的演化对应类(evolutionary corresponding class), 简作对应类.
演化对应类 G(X)正是我们需要建立的与演化集合 X 同构的集合. 为说明这一
点需设立下面一系列定理.
定理4.21 演化对应集非空集合.
定理4.22 在导出演化集 X 中, 若分支点 x1 6= x2 , 则相应的演化对应集
C(x1) 6= C(x2) .
定理4.23 在导出演化集 X 中, 分支点 x1 ≤ x2的充分必要条件是演化对应集有
C(x1) ⊇ C(x2)
– 70 –

上海交通大学硕士研究生公共课—-生物数学(一)—-林建忠编
定理4.24 在导出演化集 X 中, 分支点 x1与 x2不可比较的充分必要条件是相应
的演化对应集 C(x1) ∩ C(x2) = Ø .
定理4.25 演化对应类是和谐的, 亦属演化类.
定理4.26 导出演化集中任意分支点 x是其演化对应集 C(x)的最近共同祖先,
即:
x = ∧C(x)
定理4.27(集合同构基本定理) 导出演化集合与其演化对应类演化同构.
对于任意 x ∈ X , 定义4.20中对应集的表达式可以写成:
C(x) = y|x ≤ y, y ∈ B(0) ∪B(1)
这样我们找到了与一个共祖演化集合 X 演化同构的另一个演化集合 G(X) , 其
中一个演化关系被揭示, 另一个演化关系也被知晓.
定义4.21 确立在分类单位集合 O上的两个分支性状M1与M2其性状演化集合
分别是 X1 与 X2 , 如果其对应类 G(X1)与 G(X2)和谐, 则称性状M1 与M2 演化和
谐(evolution compatible), 或简称和谐(compatible).
现设分类单位集合是 O = y1, y2, · · · , yt , 附有 n个单位性状, Mj 表示第 j 个
性状的映象, Ij 是该性状的状态集合,单位性状的状态集合与Rmj= 0, 1, 2, · · · ,mj
演化同构. 不妨设 Ij = 0, 1, 2, · · · ,mj . 映象Mj 把导出演化集X 保序映象到 Ij 上.
定义
D(i, j) = y|Mj(y) ≥ i, y ∈ O (0 ≤ i ≤ mj; j = 1, 2, · · · , n)
在性状 j 的性状演化集合上让 aij 表示 D(i, j)的最近共同祖先:
aij = ∧D(i, j)
作 aij 的演化对应集 C(aij) = y|aij ≤ y, y ∈ O .
定理4.28 分类单位第 j 性状 (1 ≤ j ≤ n)编码值大于等于 i(0 ≤ i ≤ mj)的集合
D(i, j)就是对应集 C(aij)(aij = ∧D(i, j)) . 即:
D(i, j) = C(aij)
– 71 –

上海交通大学硕士研究生公共课—-生物数学(一)—-林建忠编
对固定的 j , 根据定理4.28获得的分类单位集合 Bj = a0j, a1j, · · · , amjj , Bj 的对应
类 G(Bj)实际上就是第 j性状演化集合Xj 的对应类 G(Xj) . 因而为了检验性状之间
的和谐性, 只需检验 G(Bj)(j = 1, 2, · · · , n)的和谐性. 又 O = C(a0j) = D(0, j)与任
何子集合和谐, 故可以从中除 i = 0项, 令
Aj = a1j, a2j, · · · , amjj (j = 1, 2, · · · , n)
得 Aj 的对应类
G(Aj) = [C(a1j), C(a2j), · · · , C(amjj)] (j = 1, 2, · · · , n)
即
G(Aj) = [D(1, j), D(2, j), · · · , D(mj, j)] (j = 1, 2, · · · , n) (∗)
我们只需对检验性状之间的和谐性.
例: 桔梗科6个种分支分类试验数据 下面以行为分类单位, 列为性状, 桔梗科6个
种分支分类原始数据矩阵表示如下(由表4-2得):
Y =
1 1 1 0 0 1 2 0
0 0 0 1 0 2 1 0
0 0 2 1 2 0 0 0
0 0 0 2 1 0 0 0
1 1 1 0 0 1 2 1
0 0 0 1 2 0 0 0
OTU
以性状3的数据 [102010]为例. 按照 (∗)式, 演化对应类 G(A3)中的对应集合有以下两
个:
i = 1, D(1, 3) = 1, 3, 5
i = 2, D(2, 3) = 3
性状3的演化对应类 G(A3)是:
G(A3) = [1, 3, 5, 3]
– 72 –

上海交通大学硕士研究生公共课—-生物数学(一)—-林建忠编
表 4.1: 表4-5 桔梗科试验数据性状的对应集和对应类
性状 对应类 对应集
1 G(A1) 1, 52 G(A2) 1, 53 G(A3) 1, 3, 5 , 34 G(A4) 2, 3, 4, 6 , 45 G(A5) 3, 4, 6 , 3, 66 G(A6) 1, 2, 5 , 27 G(A7) 1, 2, 5 , 1, 58 G(A8) 5
Kexue 和谐性分析方法(性状比较)
设待比较对应类如下:
G(Ai) = [D(1, i), D(2, i), · · · , D(mi, i)]
G(Aj) = [D(1, j), D(2, j), · · · , D(mj, j)]
定义4.22 为了表示两性状的和谐性程度, 定义性状 i与性状 j 的科学不和谐数:
K(i, j) =
1 当性状i与性状j不和谐
0 否则
再定义性状 i不和谐数
K(i) =n∑
j=1
K(i, j)
以及性状 i不和谐系数
C(i) =1
n− 1K(i)
对整个数据和谐性的评估值有性状不和谐总数:
K =n∑
i=1
K(i)
– 73 –

上海交通大学硕士研究生公共课—-生物数学(一)—-林建忠编
以及性状不和谐总系数
C =K
n(n− 1)
例: 桔梗科试验数据Kexue和谐性分析 参见文件Biomatht46
4.5 生物演化历史的重构
设被分类研究的 t个分类单位构成分类单位集合
O : x1, x2, · · · , xt
分类的依据是 n个性状: C1, C2, · · · , Cn . 原始数值矩阵:
性状
OTU
x11 x12 · · · x1n
x21 x22 · · · x2n
· · · · · · · · · · · ·xt1 xt2 · · · xtn
其中第 i个OTU向量 Xi = [xi1, xi2, · · · , xin] .
如果采取聚合的分支分类运算, 两个分支单位 CTUp与 CTUq 结合成 CTUr , 依
据中位值定理推论1, 分支单位 CTUr 向量的分量为
xrk = minxpk, xqk (k = 1, 2, · · · , n)
第 j 性状状态最大值由mj 表示,
mj = max1≤k≤t
xkj
Lmin =n∑
j=1
mj
Lmax =t∑
i=1
n∑j=1
xij
– 74 –

上海交通大学硕士研究生公共课—-生物数学(一)—-林建忠编
分支分类问题的解就是构造出导出演化集 X = O ∪H . X 以加权有向图的形式
表示. 记演化图长度为 L , 一切解的下确界记作:
Linf = infL
定义4.24 分支分类问题解的演化图长度 L取到 Linf 时, 该解称为分支分类问题
的最优解. 若演化图长度取到 Lmin时, 称为分支分类问题的理想解.
定理4.29 分支分类问题具有理想解的充分必要条件是原分支分类问题和谐.
定义4.25 一个分支分类方法, 若对于和谐的分支分类问题获得理想解, 则称该分
支分类方法是合理方法; 反之, 不能保证获得理想解, 称为不合理方法. 一个分支分类
方法, 若对任何分支分类问题均能达到最优解, 则称该分支分类方法为最优方法.
最大同步分支分类法 参见文件Biomatht49
最小平行进化分支分类法 参见文件Biomathg412
– 75 –

第五章 马尔柯夫链数学模型
5.1 马尔柯夫链的基本概念及其表示
定义 一个随机过程就是一族随机变量 X(t), t ∈ T , 其中参数 t在指标集 T 中
变化. 若 T = 0,±1,±2, · · · 或 T = 0, 1, 2, · · · , 称随机过程为离散参数过程; 若
T = t : −∞ < t < ∞或 T = t : t ≥ 0 , 称随机过程为连续参数过程.
对所有整数 n和 T 中任意 n个点 t1 , t2 , · · · , tn , 规定 n个随机变量 X(t1) ,
· · · , X(tn)的联合概率分布函数为:
FX(t1),··· ,X(tn)(x1, · · · , xn) = P [X(t1) ≤ x1, · · · , X(tn) ≤ xn].
定义 称一个离散参数随机过程 X(t), t = 0, 1, 2, · · · ,或连续参数过程 X(t), t ≥ 0
, 为马尔柯夫过程, 如果对于过程的指标集中任意 n个时刻 t1 < t2 < · · · < tn , 当给
定X(t1) , · · · , X(tn−1)时, X(tn)的条件分布只依赖于最邻近的已知值X(tn−1) . 即
对任意实数 x1 , · · · , xn ,
P [X(tn) ≤ xn|X(t1) = x1, · · · , X(tn−1) = xn−1] = P [X(tn) ≤ xn|X(tn−1) = xn−1].
马尔柯夫过程的这一性质也称为无后效性.
称实数 x为随机过程 X(t), t ∈ T 的一个可能值或状态, 如果存在 T 中的一个时
刻 t , 使得对一切 h > 0 , 概率 P [x− h < X(t) < x + h]恒为正值. 随机过程的所有可
能值的集合称做它的状态空间. 状态空间称为离散的, 如果它包含有限个或可数无穷
多个状态. 非离散状态空间称为连续的. 具有离散状态空间的马尔柯夫过程称为马尔
柯夫链. 譬如具有 n个状态, 其状态空间可以记作
U = u1, u2, · · · , un
76

上海交通大学硕士研究生公共课—-生物数学(一)—-林建忠编
也可记作
U = 1, 2, · · · , n
马尔柯夫链通常用转移概率函数来描述. 当在时间 t0 , 状态 X(t0)取状态 i , 之
后当时刻 t0 + t(t ≥ 0) , 状态 X(t0 + t)到达 j 的概率记作 pij(t0, t0 + t) . 如果此概率
与所处的时间 t0 无关, 而只与状态 i , j 和时间间隔 t有关, 则称此随机过程关于时
间为齐性的, 即时齐性, 此概率可记作 pij(t) . 特别地, pij(1)称为一步转移概率(one
step transition probability), 相应的转移概率矩阵为
P =
p11 p12 · · · p1n
p21 p22 · · · p2n
· · · · · · · · · · · ·pn1 pn2 · · · pnn
马尔柯夫过程的实际例子 参见文件Biomathg51
马尔柯夫链转移矩阵的性质
(1) pij ≥ 0 (i, j = 1, 2, · · · , n)
(2)n∑
k=1
pik = 1 (i = 1, 2, · · · , n)
定义 若向量的分量非负, 且所有分量值之和为1, 则该向量称为随机向
量(stochastic vector), 行向量皆是随机向量的矩阵称为随机矩阵(stochastic matrix).
性质 随机向量与随机矩阵的乘积仍然是随机向量.
证明: 设 X = [x1, x2, · · · , xn]为随机向量, P = [pij]为随机矩阵, 作乘积
Y = XP
向量 Y 其分量非负显然, 且n∑
i=1
yi =n∑
i=1
n∑
k=1
xkpki
=n∑
k=1
(xk
n∑i=1
pki
)
=n∑
k=1
xk note thatn∑
i=1
pki = 1
= 1 ¤
– 77 –

上海交通大学硕士研究生公共课—-生物数学(一)—-林建忠编
性质 随机矩阵与随机矩阵的乘积仍然是随机矩阵.
性质 任何马尔柯夫链, 都存在一个随机矩阵作为转移矩阵, 对该马尔柯夫链进行
描述.
除转移矩阵外, 还可以用赋权有向图来研究马尔柯夫链, 其赋权值就是相应
的转移概率, 当然也应符合条件 pij ≥ 0 (i, j = 1, 2, · · · , n) 和n∑
k=1
pik = 1 (i =
1, 2, · · · , n) . 满足该条件的赋权有向图又称为马尔柯夫链的转移图(transition
digraph).
定义 赋权值非负, 且从任意顶点到所有其它顶点弧的赋权值之和为1的赋权有向
图称之为随机图(stochastic digraphs). 转移图亦是随机图.
例 在例3的杂交试验中, 如果在杂交试验之前, 一个群体按基因型 AA , Aa和 aa
的分配比率分别是 x1 , x2和 x3 , 基因型状态分配比率构成的向量 X = [x1, x2, x3]显
然是随机向量, 经过与基因型为 Aa的个体进行杂交, 杂交后基因型的分配比率如下
表:
状态 AA Aa aa
由状态 AA与 Aa杂交后得 x1 × 12
x1 × 12
x1 × 0
由状态 Aa与 Aa杂交后得 x2 × 14
x2 × 12
x2 × 14
由状态 aa与 Aa杂交后得 x3 × 0 x3 × 12
x3 × 12
杂交后基因型分配比率 x1
2+ x2
4x1
2+ x2
4+ x3
2x2
4+ x3
2
X(1) =[x1
2+
x2
4,x1
2+
x2
4+
x3
2,x2
4+
x3
2
]
在此向量 X(1)表示第1代杂交基因型分配比率, 易见
X(1) = XP = [x1, x2, x3]
12
12
0
14
12
14
0 12
12
让第1代杂交后代继续与基因型 Aa杂交, 获得第2代杂交后代, 其基因型分配比率
X(2)应有
X(2) = X(1)P = (XP )P = XP 2
– 78 –

上海交通大学硕士研究生公共课—-生物数学(一)—-林建忠编
如果令 X(k)表示第k代与基因型 Aa杂交获得的基因型分配比率, 则类推有
X(k) = XP k
定理5.1 若 P 是马尔柯夫链的转移矩阵, 经k 步从状态i 转移到状态j 的转移概率
则是矩阵乘积 P k 的第i 行j 例元素值.
证明 (1) 当 k = 1时, 命题显然成立.
(2) 设 k = m(m ≥ 1)时命题成立, 令 p(m)ij 表示经过m步从状态i转移到状态j的转
移概率, 则
p(m+1)ij =
n∑
k=1
pik · p(m)kj
= (P · Pm)ij
= (Pm+1)ij ¤
推论 若 P 是马尔柯夫链的转移矩阵, 状态分配比率为随机向量 X 的事物, 经
过k步转移后, 新的状态分配比率向量 X(k) = XP k .
例 在例3的杂交试验中, 如果一个群体基因型 AA , Aa 和 aa 的个体数分别
是40, 60和100, 个体总数200, 基因型分配比率分别是 0.2 , 0.3和 0.5 , 以随机向量
X = [0.2, 0.3, 0.5]表示基因型3个状态的分配比率, 通过与 Aa杂交后, 基因型的分配
比率向量为:
X(1) = XP = [0.2, 0.3, 0.5]
0.5 0.5 0
0.25 0.5 0.25
0 0.5 0.5
= [0.175, 0.5, 0.325]
继续与基因型 Aa杂交, 获得第2代杂交后代的基因型分配比率为
X(2) = XP 2 = [0.2, 0.3, 0.5]
0.375 0.5 0.125
0.25 0.5 0.25
0.125 0.5 0.375
= [0.2125, 0.5, 0.2875]
如此杂交下去, 基因型分配比率将趋向极限, 这是因为矩阵 P 所代表的马尔柯夫
链是正则马尔柯夫链.
– 79 –

上海交通大学硕士研究生公共课—-生物数学(一)—-林建忠编
5.2 正则马尔柯夫链
定义5.2 对于马尔柯夫链, 若存在正整数k使其转移矩阵乘幂 P k 的所有元素值皆
大于0, 则称该马尔柯夫链是正则的(regular).
引理 对于随机矩阵 P , 若 P 中的最小元素是 ∈ (∈> 0) , 又对于 n维向量 X , 其
最小和最大分量分别是m0和M0 , 向量 PX 的最小和最大分量分别是m1和M1 , 则
有
(1) m0 ≤ m1 ≤ M1 ≤ M0
(2) M1 −m1 ≤ (1− 2 ∈)(M0 −m0)
证明 如果向量 X 的第 j 分量取到最小值, xj = m .
X =
x1
x2
...
xj = m0
...
xn
将向量 X 中除最小分量 x0以外, 所有分量都更换以M0 , 得向量
Y =
M0
M0
...
M0
m0
M0
...
M0
显然有不等式
X ≤ Y
– 80 –

上海交通大学硕士研究生公共课—-生物数学(一)—-林建忠编
又 P ≥ 0 , 故
PX ≤ PY
PY 的第i分量取为
pijm0 + M0
∑
k 6=j
pik = pijm0 + M0(1− pij)
= M0 − pij(M0 −m0)
≤ M0− ∈ (M0 −m0)
因为 PX 的每个分量都小于等于 PY 的相应分量, 当然也都小于等于 M0− ∈(M0 −m0) , 特别当取到 PX 的最大分量M1时, 有不等式
M1 ≤ M0− ∈ (M0 −m0) ≤ M0 (∗)
类似上面的步骤, 将向量 X 中除其中一个最大分量M0 以外, 所有的分量都更换成
m0 , 得向量
Z =
m0
m0
...
m0
M0
m0
...
m0
与前面类似的推导, 得不等式
m1 ≥ m0+ ∈ (M0 −m0) ≥ m0 (∗∗)
联合前面两个获得的不等式(*)与(**), 引理的结论(1)成立. 再将两不等式相减得不等
式
M1 −m1 ≤ M0 −m0 − 2 ∈ (M0 −m0)
– 81 –

上海交通大学硕士研究生公共课—-生物数学(一)—-林建忠编
即
M1 −m1 ≤ (1− 2 ∈)(M0 −m0). ¤
定理5.2 对于正则马尔柯夫链的转移矩阵 P , 有以下结论,
(1) 当 t →∞时, P t → W (随机矩阵);
(2) W 的每一行向量均相同;
(3) W 的所有分量都大于 0 .
证明 不妨设一开始 P 的每个元素都大于 0 , 若 ∈ (∈> 0)是其最小值. 再设矩阵
P t的第 j 列向量的最小和最大分量分别是mt和Mt(t = 1, 2, · · · ) . 考虑等式
P t = PP t−1 (t ≥ 2)
取其中矩阵 P t和 P t−1的第 j 列向量, 多次引用引理可得下面一系列不等式:
Mt −mt ≤ (1− 2 ∈)(Mt−1 −mt−1)
Mt−1 −mt−1 ≤ (1− 2 ∈)(Mt−2 −mt−2)
· · · · · · · · · · · · · · · · · · · · · · · ·
M2 −m2 ≤ (1− 2 ∈)(M1 −m1)
这样
0 ≤ Mt −mt ≤ (1− 2 ∈)t−1(M1 −m1) (∗)
考虑到 ∈是矩阵 P 的最小元素值, 又注意矩阵 P 的随机性, 故
0 < ∈≤ 1
2
−1 ≤ −2 ∈< 0
0 ≤ 1− 2 ∈< 1
在不等式(*)的右边, 令 t →∞时就得到
Mt −mt → 0, as t →∞ (∗∗)
– 82 –

上海交通大学硕士研究生公共课—-生物数学(一)—-林建忠编
由引理还应有不等式
m1 ≤ m2 ≤ · · · ≤ mt ≤ Mt ≤ · · · ≤ M2 ≤ M1 < 1
其中m1 , m2 , · · · 和M1 , M2 , · · · 分别是有界单调递增和递减序列, 必存在极限
limt→∞
mt, and limt→∞
Mt
再由(**)得
limt→∞
mt = limt→∞
Mtdef= vj
这样令 V = [v1, v2, · · · , vn] , W 是一个行向量都是 V 的矩阵. 即
W =
v1 v2 · · · vn
v1 v2 · · · vn
· · · · · · · · · · · ·v1 v2 · · · vn
这样就有
P t → W, as t →∞
由于 P t 始终是随机矩阵, W 也必是随机矩阵. 又 m1 是 P 中的元素, 且 mk(k =
1, 2, · · · )是递增序列, 应满足不等式
0 <∈≤ m1 ≤ vi (i = 1, 2, · · · , n), ¤
推论 若 P 是正则马尔柯夫链的转移矩阵, 且 P t → W (t → ∞) , V =
[v1, v2, · · · , vn]是矩阵W 的行向量, 则有
(1) 对于任意随机向量 X = [x1, x2, · · · , xn] , XP t → V (t →∞) ;
(2) 存在唯一的随机向量 V 使 V P = V , 向量 V 亦称为随机矩阵 P 的不动点向
量(stationary vector).
证明: 利用定理2, 取 P t的极限有
XP t → XW (t →∞)
– 83 –

上海交通大学硕士研究生公共课—-生物数学(一)—-林建忠编
考虑到向量 X 的随机性条件, XW 的第 i分量计算如下
x1vi + x2vi + · · ·+ xnvi = (x1 + x2 + · · ·+ xn)vi
得
XW = V
获极限
XP t → V (t →∞)
结论(1)获证.
利用等式
P t+1 = P t−1P
令 t →∞ , 等式两边取极限得矩阵
W = WP
亦是向量
V = V P
结论(2)的存在性已证, 再证唯一性. 若另有随机向量 Z , ZP = Z 成立, 则
ZP t = (ZP )P t−1
= ZP t−1
以此类推
ZP t = ZP t−1 = · · · = ZP 2 = ZP = Z
有极限
ZP t → Z
– 84 –

上海交通大学硕士研究生公共课—-生物数学(一)—-林建忠编
但是根据已证结论(1)又有
ZP t → V (t →∞)
因此 Z = V , 唯一性得证. ¤ .
说明: 如果把随机向量 X 设置成初始状态的分配比率, XP t 就是经过 t步以后
状态分配的比率, 此分配比率将趋向一稳定的向量 V , 而且此向量与反映初始状态
的向量 X 无关.
不动点向量求解方法 利用等式
V P = V
可写出求解不动点向量的线性代数方程组:
v1p11 + v2p21 + · · ·+ vnpn1 = v1
v1p12 + v2p22 + · · ·+ vnpn2 = v2
· · · · · · · · · · · · · · · · · · · · · · · ·
v1p1n + v2p2n + · · ·+ vnpnn = vn
其中 v1 , v2 , · · · , vn是方程中的未知变量, 再依据向量随机性约束条件
v1 + v2 + · · ·+ vn = 1
可求解不动点向量.
例(续前节例3与基因型 Aa的杂交试验)
此马尔柯夫链的转移矩阵的二次乘幂
P 2 =
38
12
18
14
12
14
18
12
38
矩阵 P 2的所有元素皆大于 0 . 对 P 的乘幂 P t计算结果如下:
P 2 =
0.375 0.5 0.125
0.25 0.5 0.25
0.125 0.5 0.375
P 3 =
0.3125 0.5 0.1875
0.25 0.5 0.25
0.1875 0.5 0.3125
– 85 –

上海交通大学硕士研究生公共课—-生物数学(一)—-林建忠编
P 4 =
0.28125 0.5 0.28175
0.25 0.5 0.25
0.28175 0.5 0.28125
P 5 =
0.265625 0.5 0.234375
0.25 0.5 0.25
0.234375 0.5 0.265625
P 10 =
0.250488 0.5 0.249512
0.25 0.5 0.25
0.249512 0.5 0.250488
P 19 =
0.250001 0.5 0.24999
0.25 0.5 0.25
0.249999 0.5 0.250001
实际演算也验证了定理5.2中 P t → W 的情况, 矩阵W 中的行向量就是不动点向量
[0.25, 0.5, 0.25] .
现利用不动点向量求解方法求解, 不动点向量 [v1, v2, v3]满足
[v1, v2, v3]
12
12
0
14
12
14
0 12
12
= [v1, v2, v3]
求解不动点向量的线性代数方程组:
v1
2+ v2
4= v1
v1
2+ v2
2+ v3
2= v2
v2
4+ v3
2= v3
v1 + v2 + v3 = v4
得解
v1 =1
4, v2 = 1
2, v3 =
1
4,
不动点向量为 V = [14, 1
2, 1
4] . 它说明多次与基因型 Aa杂交, 最后基因型 [AA,Aa, aa]
的分配比率将趋向稳定的向量 [14, 1
2, 1
4] .
5.3 吸收马尔柯夫链
定义5.3 马尔柯夫链中状态若转移概率满足以下两条件:
(1) pii = 1
(2) pik = 0, k 6= i.
– 86 –

上海交通大学硕士研究生公共课—-生物数学(一)—-林建忠编
则称该状态为吸收状态(absorbing state).
定义5.4 满足以下两条件的马尔柯夫链, 称为吸收马尔柯夫链(absorbing Markov
chain).
(1) 至少存在一个吸收状态;
(2) 从任何状态经有限步终可到达一个吸收状态.
吸收马尔柯夫链中的非吸收状态称为转移状态(transient state).
例 除例3是正则马尔柯夫链外, 其余的都属于吸收马尔柯夫链. 但图5-8中的例中
虽有吸收状态, 但不构成吸收马尔柯夫链. (文件Biomathg58)
吸收马尔柯夫链的例 参见文件Biomathg58
定理5.3 对于吸收马尔柯夫链, 从任何状态出发最终进入吸收状态的概率为 1 .
证明: 设开始时处于转移状态. 如果从某一转移状态 ui开始, 根据吸收马尔柯夫
链的定义, 存在最少步数, 记作 ri步, 使之达到吸收状态, 其概率非 0 , 记作 pi(pi > 0)
. 如果转移状态集合记作 T , 对 T 中所有转移状态作上述步骤, 可以获得一系列的转
移步数 ri与概率值 pi(pi > 0) , 取相应的最小值, 分别记作:
r = maxri|ui ∈ T
p = minpi|ui ∈ T
其中整数步数 r ≥ 1 , 概率值 p > 0 . 然后有下列一系列的论断.
首先从 T 中任意状态 ui开始,经 ri步不能到达吸收状态的概率是 1−p1 ,如果必
要让其继续到 r步 r ≥ ri , 其不能到达吸收状态的概率将小于或等于前述概率 1− pi
, 由于 p ≤ pi , 这些概率值都有 1− pi ≤ 1− p . 于是有
从 T 中状态 ui开始, 经 r步不能达到吸收状态的概率 ≤ 1− pi ≤ 1− p . 由于 ui
在 T 中的任意性又有
从 T 中任意状态开始, 经 r步不能到达吸收状态的概率 ≤ 1− p .
然后经连续 2r步, 考虑到前 r步与后 r步是相互独立事件, 将有
从 T 中任意状态开始, 经 2r步不能到达吸收状态的概率 ≤ (1− p)2 .
· · ·从 T 中任意状态开始, 经 kr 步不能到达吸收状态的概率 ≤ (1 − p)k . 又
limk→∞
(1− p)k = 0 , 结论证毕.
– 87 –

上海交通大学硕士研究生公共课—-生物数学(一)—-林建忠编
转移矩阵的典范式(canonical form)
P =
E O
R Q
r个吸收状态
k个转移状态
r个吸收状态 k个转移状态
其中
E −−− r × r方阵, 因为从吸收状态到自身的转移概率为1, 其余为0, 故是单位
矩阵.
O −−− r × k矩阵, 因为从吸收状态到转移状态的转移概率皆为0, 故是零矩阵.
R−−− k × r矩阵, 表示从转移状态一步就到达吸收状态的概率.
Q−−− k × k矩阵, 表示从一个转移状态转入新的(包括自身)转移状态的概率.
公式 典范式转移矩阵的乘幂为
P t =
E O
Rt Qt
其中 Rt = (E + Q + Q2 + · · ·+ Qt−1)R .
证明: (1) 当 t = 2时,
P 2 =
E O
R Q
2
=
E O
(R + Q)R Q2
(2) 设当 t = l时公式成立, 则
P l+1 = P lP =
E O
Rl Ql
E O
R Q
=
E O
Rl + QlR Ql+1
从当 t = l时公式成立有
Rl = (E + Q + Q2 + · · ·+ Ql−1)R
– 88 –

上海交通大学硕士研究生公共课—-生物数学(一)—-林建忠编
代入前式右边
Rl+1 = Rl + QlR
= (E + Q + Q2 + · · ·+ Ql−1)R + QlR
= (E + Q + Q2 + · · ·+ Q(l+1)−1)R ¤
定理5.4 吸收马尔柯夫链取典范式的转移矩阵
E O
R Q
, 有以下结论:
(1) 当 t →∞时, Qt → O ,
(2) 矩阵 E −Q可逆,
(3) N = (E −Q)−1 = E + Q + Q2 + · · · ,
其中 N 是 k阶方阵, 称为该吸收马尔柯夫链的基本矩阵.
证明: 因
P t =
E O
Rt Qt
由定理5.3可知, 当 t →∞时, Qt → O . 结论(1)得证.
因为
(E −Q)(E + Q + Q2 + · · ·+ Qt−1) = (E −Q) + (Q−Q2) + · · ·+ (Qt−1 −Qt)
= E −Qt (∗)
故
det(E −Q) · det(E + Q + Q2 + · · ·+ Qt−1) = det(E −Qt) (∗∗)
令 t →∞ , 由于 Qt → O , 故存在极限
limt→∞
det(E −Qt) = detE = 1
从而存在充分大的T ,使 t > T 以后, det(E−Qt) > 12. 由等式(**)可知 det(E−Q) 6= 0
, 这样 E −Q可逆获证.
由于 E −Q可逆, 式(*)可改写成
E + Q + Q2 + · · ·+ Qt−1 = (E −Q)−1(E −Qt)
– 89 –

上海交通大学硕士研究生公共课—-生物数学(一)—-林建忠编
上式两边取极限, 右边为
limt→∞
(E −Q)−1(E −Qt) = (E −Q)−1 limt→∞
(E −Qt)
= (E −Q)−1(E − limt→∞
Qt)
= (E −Q)−1
结论(3)得证. ¤
现重新注明典范矩阵的书写格式:
1, 2, · · · , r;r + 1, r + 2, · · · , r + k
1
2
...
r
r+1
r+2
...
r+k
E O
R Q
如果在 P 中设第 i1 = r + i行, 第 j1 = r + j 列元素, 也就是矩阵 Q中的第 i行,
第 j 列元素; 在 P 中设第 i1 = r + i行, 第 j 列元素, 也就是矩阵 R中的第 i行, 第 j
列元素.
定理5.5 具有 r 个吸收状态的吸收马尔柯夫链, 从转移状态 i1 = r + i 开始,
到达吸收状态之前, 进入转移状态 j1 = r + j 的次数的数学期望值是基本矩阵
N = (E −Q)−1的第 i行, 第 j 列元素之值.
证明: 为计数进入转移状态 j1的次数, 定义计数值
c(S) =
1
0
从转移状态 i1开始, 第 S 步进入 j1状态时
否则
这里当 S = 0 时, 如果从一开始状态 i1 就取在状态 j1 规定 C(0) = 1 ; 否则
– 90 –

上海交通大学硕士研究生公共课—-生物数学(一)—-林建忠编
C(0) = 0 .于是从状态 i1开始, 到达吸收状态之前进入转移状态 j1的总次数是:
∞∑S=0
C(S)
则
E[C(S)] = p(S)i1j1
· 1 + (1− p(S)i1j1
) · 0
= p(S)i1j1
这里当 S = 0时, 根据 C(0)的取值规定
p(S)i1j1
=
1
0
当 i1 = j1时
否则
QS 的第 i行, 第 j 列元素记作 q(S)ij , 则
p(S)i1j1
= q(S)ij (S = 1, 2, · · · )
再规定 q(0)ij = p
(0)i1j1
, 利用定理5.4中结论(3), 知级数 E + Q + Q2 + · · · 收敛, 其第 i行,
第 j 列元素, 即
∞∑S=0
p(S)i1j1
=∞∑
S=0
q(S)ij
亦收敛, 其收敛值正是基本矩阵 N 的第 i行, 第 j 列元素之值 nij . 这样
E
[ ∞∑S=0
C(S)
]=
∞∑S=0
M [C(S)]
=∞∑
S=0
p(S)i1j1
=∞∑
S=0
q(S)ij
= nij ¤
推论 具有 r个吸收状态的吸收马尔柯夫链, 从转移状态 i1 = r + i开始, 到达吸
收状态之前, 在所有转移状态之间传递步数的数学期望值是基本矩阵 N = (E −Q)−1
的第 i行元素值之和.
– 91 –

上海交通大学硕士研究生公共课—-生物数学(一)—-林建忠编
算例: 在前面例4中, 考虑与纯显性基因型AA杂交的情况, 此时典范式的转移矩
阵是
P =
1 0 0
12
12
0
0 1 0
Q =
12
0
1 0
P 的乘幂计算结果为
P 2 =
1 0 0
0.75 0.25 0
0.5 0.5 0
Q2 =
0.25 0
0.5 0
P 3 =
1 0 0
0.875 0.125 0
0.75 0.25 0
Q3 =
0.125 0
0.25 0
P 4 =
1 0 0
0.9375 0.0625 0
0.875 0.125 0
Q4 =
0.0625 0
0.125 0
P 5 =
1 0 0
0.96875 0.03125 0
0.9375 0.0625 0
Q5 =
0.03125 0
0.0625 0
· · · · · · · · · · · · · · · · · ·
P 10 =
1 0 0
0.99902 0.00098 0
0.998055 0.00195 0
– 92 –

上海交通大学硕士研究生公共课—-生物数学(一)—-林建忠编
从以上计算结果可见, Qt → O , 这正是定理5.4中的结论(1). 它说明, 多次与基因
型AA杂交, 最后必将落入吸收状态AA.
按照定理5.4中的结论(2)和(3), 求矩阵
E −Q =
12
0
−1 1
的逆矩阵, 即基本矩阵
N = (E −Q)−1 =
2 0
2 1
基本矩阵行的状态位置与矩阵 Q在典范式中的位置相同
状态 Aa aa 停留总次数
开始状态Aa 2 0 2+0=2
开始状态aa 2 1 2+1=3
例1: 属于吸收马尔柯夫链, 死亡是唯一的吸收状态, 典范式转移矩阵如下:
死亡健康患病
死亡
健康
患病
1 0 0
0 0.99 0.01
0.01 0.9 0.09
其中
Q =
0.99 0.01
0.9 0.09
E −Q =
0.01 −0.01
−0.9 0.91
基本矩阵
N = (E −Q)−1 =
9100 100
9000 100
– 93 –

上海交通大学硕士研究生公共课—-生物数学(一)—-林建忠编
基本矩阵第 1行之和, 就是开始从健康状态出发寿命的估计值 9100 + 100 = 9200
(日). 第 2行之和, 就是开始从患病状态出发寿命的估计值 9000 + 100 = 9200 (日).
例7: 是一流行病问题, 属于吸收马尔柯夫链, 典范式转移矩阵的 Q矩阵如下:
Q =
0.89 0.1 0
0 0.1 0.8
0 0 0.99
E −Q =
0.11 −0.1 0
0 0.9 −0.8
0 0 0.01
基本矩阵
非免疫, 患病, 免疫
非免疫
患病
免疫
9.0909 1.0101 80.8080
0 1.1111 88.8888
0 0 100
将基本矩阵 N 中第1行求和
3∑i=1
n1i = 90.909
就是动物从初始非免疫状态出发到达死亡吸收状态的生存时间. 动物的寿命预计
在90.91岁.
定理5.6 具有 r(r > 1)个吸收状态的吸收马尔柯夫链, 从转移状态 i1 = r + i开
始, 最终进入第 j 吸收状态的概率正是矩阵 B = NR的第 i行, 第 j 列元素之值.
证明: 首先
P t =
E O
Rt Qt
其中
Rt = (E + Q + Q2 + · · ·+ Qt−1)R
– 94 –

上海交通大学硕士研究生公共课—-生物数学(一)—-林建忠编
由定理5.4有
Rt → NR (t →∞)
因而
P t =
E O
Rt Qt
→
E O
NR O
(t →∞)
这里当 t → ∞时, 从 P t 的极限矩阵说明吸收马尔柯夫链最终都将以吸收状态为结
果, 且从转移状态到达吸收状态的转移概率取极限值于矩阵 B = NR . 即从转移状态
i1 = r + i开始到达吸收状态 j的转移概率 p(t)i1j 取极限值于矩阵 B = NR的第 i行, 第
j 列元素之值,
p(t)i1j → bij (t →∞)¤
例9: 是具有3个吸收状态的吸收马尔柯夫链, 因
P t =
E O
Rt Qt
现列出 P t中一系列 Rt和 Qt的计算结果
P 2 =
0.001889 0.002 0.01 0.877321 0.00989 0.0989
0.0007 0.22 0 0.6923 0.017 0.07
0.0008 0 0.01 0.7912 0.008 0.09
P 10 =
0.008598 0.017126 0.085632 0.790606 0.008913 0.089125
0.005994 0.233980 0.058788 0.623875 0.007033 0.070329
0.006851 0.013437 0.178298 0.713000 0.008038 0.080377
P 100 =
0.050798 0.112270 0.561352 0.245176 0.002764 0.027639
0.039295 0.309059 0.434184 0.193471 0.002181 0.021810
0.044908 0.099241 0.607322 0.221110 0.002493 0.024926
– 95 –

上海交通大学硕士研究生公共课—-生物数学(一)—-林建忠编
P 600 =
0.069739 0.154975 0.774874 0.000367 0.000004 0.000041
0.054241 0.342757 0.602676 0.000290 0.000003 0.000033
0.061990 0.137755 0.799884 0.000331 0.000004 0.000037
在该例中, P t 极限收敛十分缓慢, 100步以后 Qt 矩阵块值才开始大量减少, Rt 矩阵
块值开始向稳定值逼近.
现把 R600的数及所现实的关系列表如下:
状态 其他死亡 呼吸病死亡 循环病死亡
健康 0.0697 0.1550 0.7749
呼吸病 0.0542 0.3428 0.6027
循环病 0.0620 0.1378 0.7999
以下根据定理5.6的结论进行计算. 本例典范式转移矩阵 P =
E O
R Q
中,
Q =
0.889 0.01 0.1
0.7 0.1 0
0.8 0 0.1
R =
0.001 0 0
0 0.2 0
0 0 0.1
E −Q =
0.111 −0.01 −0.1
−0.7 0.9 0
−0.8 0 0.9
基本矩阵计算得
N = [E −Q]−1 =
69.768 0.775 7.752
54.264 1.714 6.029
62.016 0.689 8.002
矩阵 B = NR计算得
B = NR =
0.0698 0.1550 0.7752
0.0543 0.3428 0.6029
0.0620 0.1378 0.8002
– 96 –

上海交通大学硕士研究生公共课—-生物数学(一)—-林建忠编
该矩阵按原典范式转移矩阵行与列的排列位置, 显示矩阵 B = NR所对应的状
态如下
状态 其他死亡 呼吸病死亡 循环病死亡
健康 0.0698 0.1550 0.7752
呼吸病 0.0543 0.3428 0.6029
循环病 0.0620 0.1378 0.8012
由于健康状态是转移的开始状态 (i1 = r + i = 3 + 1 = 4) , 依定理5.6, 矩阵
B = NR的第 i行 i = 1
[0.0698 0.1550 0.7752
]
该向量各分量值应该是最终到达各吸收状态的概率值. 因而人口死亡原因的分配比例
是
其他死亡 6.98%
呼吸系统疾病死亡 15.5%
循环系统疾病死亡 77.52%
该数据说明循环系统疾病是造成人口死亡的主要因素.
又由定理5.7, 基本矩阵 N 的第 i(i = 1)行各元素值之和
3∑i=1
n1i = 69.768 + 0.775 + 7.752
= 78.295(year)
为人口寿命的分析结果.
– 97 –

第六章 微分方程数学模型
6.1 单一种群生态数学模型
Malthusian种群增长模型
表6-1给出了美国人口增长的部分记录. 在1790年至1800年10年间
人口平均增长率 = 5.308−3.9291800−1790
× 106 = 0.1379× 106 人/年
人口平均相对增长率 = 5.308−3.9293.929(1800−1790)
= 0.03510 /年
表 6.1: 美国人口调查数据
年 人口(千) 年 人口(千)
1790 3929 1900 75995
1800 5308 1910 91972
1810 7240 1920 105711
1820 9638 1930 122775
1830 12866 1940 131669
1840 17069 1950 150697
1850 23192 1960 179323
1860 31443 1970 203185
1870 38558 1980 226500
1880 50156
1890 62948
对一般的种群增长, 若以连续函数 N(t) 表示 t 时刻的种群数量, 则在时间段
[t, t +4t]内,
98

上海交通大学硕士研究生公共课—-生物数学(一)—-林建忠编
平均种群增长速率 = N(t+4t)−N(t)4t
= 4N4t
平均种群相对增长速率 = N(t+4t)−N(t)N(t)4t
= 4NN4t
令4t → 0 , 则在 t时刻
种群增长速率 lim4t→0
4N4t
= dNdt
种群相对增长速率 lim4t→0
4NN4t
= 1N
dNdt
在一定条件下, 种群相对增长速率与种群大小无关, 是一个正常数 r , 称为自然
增长率. 于是我们就获得一个描述种群增长规律的数学模型(称为Malthusian模型)
1
N
dN
dt= r
求解该方程
∫dN
dt=
∫rdt
lnN = rt + C
其中 C 是积分常数. 如果当 t = t0时种群 N = N0 , 有
lnN0 = rt0 + C
由上面两等式得
r(t− t0) = lnN
N0
或
N = N0er(t−t0)
Logistic种群增长模型
在前面的美国人口增长例子中, 从1790年至1800年10年间的相对增长速率可以通
过更为合理的方式计算出来, 此值是 r = 0.031 , 相应地
N(t) = 3.929× 106e0.031(t−1790)
– 99 –

上海交通大学硕士研究生公共课—-生物数学(一)—-林建忠编
这个方程所表示的结果与1790-1860年的实际调查人口数据十分吻合, 当
从1860年以后出现较大误差. 实际人口数比计算的数据小; 随着时间推移, 误差
愈大. 它说明人口相对增长速率不可能一直保持在原有水平.
实际生活中种群不可能无限增大, 当种群达到一定大小, 种群的增长受到种种约
束, 种群的生活空间有限, 生存条件有限. 因此需对Malthusian模型进行修正.
如果在有限生存资源条件下, 能够维持种群生存的最大数量记作 N , 此值称为饱
和种群量. 种群未饱和程度可以用比值 (N − N)/N 表示. 以 r N−NN来代替 r表示种
群相对增长速率, 得到Logistic方程:
1
N
dN
dt= r
(1− N
N
)
现求解该方程
rdt =NdN
N(N −N)
=
(1
N+
1
N −N
)dN
两边积分
rt + C =
∫ (1
N+
1
N −N
)dN
= lnN − ln(N −N)
= lnN
N −N
初值条件 t = t0时, N = N0 , 代入上式得
rt0 + C = lnN0
N −N0
上面两式相减消去常数 C 得
r(t− t0) = lnN
N −N/
N0
N −N0
= ln
(N
N0
N −N0
N −N
)
最后得Logistic方程的解为
r(t− t0) = lnN
N0
− lnN −N
N −N0
(∗)
– 100 –

上海交通大学硕士研究生公共课—-生物数学(一)—-林建忠编
N(t)的表达式为
N(t) =N
1 + (N/N0 − 1)e−r(t−t0)
Logistic方程解的图形见图6-1(文件Biomathg61)
求 N 的二阶导数. 二阶导数为 0的条件是 N = 0 (无意义), N = N (饱和值, 不
讨论)或者 N = N2
. 当 N = N2时, 方程曲线出现拐点
N =N
2
在该点种群增长速率达到极大值 dNdt
= 14rN . 如果把初始条件选在该点, 即 t = t0时,
N0 = N2
, 这时Logistic方程的解成为简单的形式(Bartlett形式),
N(t) =N
1 + e−r(t−t0)
特别地取 r = 1 , N = ab
Logistic方程和它的解分别为
dN
dt= aN − bN2
和
N(t) =a/b
1 + e−a(t−t0)
Logistic方程参数的估计
Logistic曲线有两个基本参数, 即饱和种群量 N 和相对增长速率 r . 现介绍估计
这两个参数的等时间间隔四点法及等时间间隔三点法
设有时间间隔 t0 , t1 , t2和 t3 , 要求 t3 − t2 = t1 − t0 , 相应的种群大小已知分别
是 A , B , C 和 D . 即 N(t0) = A , N(t1) = B , N(t2) = C , N(t3) = D.
由等式 (∗)可得
r(t− t0) = ln
[(N
N −N
) (N −N0
N0
)]
将 t0 , t1和 t2和 t3两组数据分别代入前式, 得
r(t− t0) = ln
[(B
N −B
) (N − A
A
)]
– 101 –

上海交通大学硕士研究生公共课—-生物数学(一)—-林建忠编
r(t3 − t2) = ln
[(D
N −D
) (N − C
C
)]
因为 t3 − t2 = t1 − t0 , 得
B
N −B
N − A
A=
D
N −D
N − C
C
然后把 N 看作未知变量, 求解可得 N = 0 (无意义)和
N =AD(B + C)−BC(A + D)
AD −BC
如果让 t1 = t2 , 此时前面时间间隔四点变为等时间间隔三点, 且 B = C , 上面的计算
公式改为
N =B[2AD −B(A + D)]
AD −B2
如果数据较多, 应将所有可能组合的数据都进行计算, 然后取平均值作为饱和种群量
的估计值.
有了饱和种群量 N , 现计算相对增长速率 r . 如果有m + 1个数据, 对应的时间
为 t0 , t1 , · · · , tm . 先计算
yi = lnN(ti)
N −N(ti)(i = 0, 1, · · · ,m)
根据Logistic方程的积分结果 rt + C = ln NN−N
, 知 yi和 ti呈线性关系. 然后从 yi与 ti
的m + 1组数据, 回归 r值得
r =
m∑i=0
yiti − 1m+1
m∑i=0
yi
m∑i=0
ti
m∑i=0
t2i − 1m+1
(m∑
i=0
ti
)2
例: 美国人口统计1790-1910年数据, 计算得饱和种群量 N = 197.274 × 106 和
相对增长速率 r = 0.031 . 获得Logistic 函数如下
N(t) =197.274× 106
1 +(
197.2743.929
− 1)e−0.031(t−1790)
它比Malthusian模型获得的增长公式要好, 在更长的时间范围(1790-1950年), 它
与实际人口数据吻合得很好. 但自20世纪60年代以后, 实际人口调查数据大于模型预
期的数值. 实际上, 随着时间的推移, 饱和种群量亦在变化.
– 102 –

上海交通大学硕士研究生公共课—-生物数学(一)—-林建忠编
一种扩展的Logistic方程(崔启武)
1
N
dN
dt= r
(1− N
N
)/
(1− N
¯N
)
此模型在Logistic方程的基础上增加一项(1− N
¯N
), 并引入新的常数 ¯N . 现求解该方
程
rdt =
(1− N
¯N
)N
N(N −N)dN
=
(1
N+
1
N −N− N
¯N
1
N −N
)dN
两边积分
rt + C = lnN − ln(N −N) +N¯N
ln(N −N)
初值条件 t = t0时, N = N0 , 代入上式, 消去常数 C 得方程的解为
r(t− t0) = lnN
N0
− lnN −N
N −N0
+N¯N
lnN −N
N −N0
(5∗)
上式第一项右边属于方程Malthusian方程的解, 前两项属于Logistic方程的解, 新方程
又补充了最后一项.
第一项表示种群自身的自然增长量, 第二项表示种群的相对增长受有限生存资
源的限制量. 在第三项中, 比例参数 N¯N在0与1之间, 表示生存资源对种群影响的程
度, 或者指种群对环境利用的程度. 如果 N¯N
= 0 , 表示生存资源对种群的影响最大, 等
式 (5∗)体现为Logistic方程的解; 当 N¯N
= 1时, 表示生存资源对种群的影响最小, 等式
(5∗)体现为Malthusian方程的解. 扩展后的新模型成为介于Malthusian与Logistic的中
间类型.
6.2 Lotka-Volterra生态数学模型
本节讨论捕食与被捕食两个种群的生态学关系.
设一生态系统包括捕食与被捕食两个种群的生态系统. 捕食者靠被捕食者而生
存, 系统与外界无种群交换关系. 以 N1(t)和 N2(t)表示被捕食与捕食种群量.
– 103 –

上海交通大学硕士研究生公共课—-生物数学(一)—-林建忠编
先考虑被捕食种群量的变化速率 dN1(t)dt
, 该种群的自然增殖与自身的多少成正比,
如果比例常数为 a1 > 0 , 因而有 a1N1 项; 如果被捕食种群的死亡率与两个种群个体
相遇的机率成比例, 因而有 −b1N1N2项, 其中比例常数 b1 > 0 . 这样一来, 被捕食种
群的微分方程为
dN1
dt= a1N1 − b1N1N2.
对于捕食种群量的变化速率 dN2(t)dt
, 捕食种群的增殖不仅与自身的种群大小有关, 还
与被捕食种群能够提供食饵的多少也有关系. 如果这些关系都以正比例的形式出现,
比例常数为 b2 > 0 , 捕食种群的增殖速率应该是 b2N1N2 ; 捕食种群的死亡速率如果
与自身的多少成正比, 比例常数为 a2 > 0 , 种群的变化应包括 −a2N2 项. 这样一来,
捕食种群的微分方程为
dN2
dt= −a2N2 + b2N1N2.
最后, 我们获得了描述捕食与被捕食两个种群生态系统的数学模型
dN1
dt= a1N1 − b1N1N2.
dN2
dt= −a2N2 + b2N1N2. (∗)
其中常数 a1 , a2 , b1和 b2 > 0 . 此方程称为Lotka-Volterra方程.
现求解该方程. 首先根据方程有
dN1
dN2
=(a1 − b1N2)N1
(−a2 + b2N1)N2
.
进行分离变量, 将变量 N1都置等式左边, 变量 N2都置等式右边.
−a2 + b2N1
N1
dN1 =a1 − b1N2
N2
dN2
等式两边分别积分得
−a2lnN1 + b2N1 + C = a1lnN2 − b1N2
最后得方程的通解
a1lnN2 + a2lnN1 − b1N2 − b2N1 = C
– 104 –

上海交通大学硕士研究生公共课—-生物数学(一)—-林建忠编
其中 C 是积分常数. 不同的 C 值获得一组曲线簇.
定性分析方法: 对于一个复杂的数学模型, 在尚未得到解析答案, 亦未进行大量
数值计算之前, 凭借一定的数学关系分析模型中变量变化的过程, 从中总结出一定的
规律, 这种研究数学模型的方法称为定性分析方法.
以 N1和 N2变量为直角坐标系的两坐标轴, 在该坐标系下, 任何时刻种群量 N1 ,
N2代表在该坐标系下一点 P (N1, N2) . 随着时间的推移, 种群量的变化将描绘出一定
的轨迹. 定性分析往往从轨迹构成的图形分析种群变化的规律性.
平衡点: 所谓平衡即变化的速率为0, 两个种群达到平衡的条件是,
dN1
dt= 0,
dN2
dt= 0
考察方程 (∗)的右端, 令其等于零, 得两个直线方程
L1 : a1 − b1N2 = 0
L2 : −a2 + b2N1 = 0
如图6-2所示(参见文件Biomathg62), 两直线的交点(
a2
b2, a1
b1
)满足平衡条件, 该点称为
平衡点.
因 N1 , N2 > 0 , 直线 L1和 L2把第一象限的区域划分为四个部分I, II, III和IV.
在直线 L1的下半部分, 直线方程 a1 − b1N2 > 0 , 因而有 dN1
dt> 0 ; 在直线 L1的
上半部分, 直线方程 a1 − b1N2 < 0 , 有 dN1
dt> 0 ; 以向右或左的箭头分别表示导数
dN1
dt> 0或 < 0 , 说明 N1的变化分别是增加或减少.
完全类似的方式对直线 L2 进行讨论, 如图6-2所示. 于是在每个区域从 dN1
dt> 0
和 dN2
dt> 0所呈现的符号, 确定了该区域种群变化的倾向性. 综合这四个区域的变化
情况, 种群的移动轨迹是一条逆时针方向沿平衡点转动的封闭曲线.
例1: 加拿大哈德逊公司山猫与野兔毛皮收购数据(图6-3, 文件Biomathg63)
把坐标原点移到平衡点(
a2
b2, a1
b1
), 并引入新的变量 N
′1和 N
′2 , 作坐标变换,
N′1 = N1 − a2
b2
N′2 = N2 − a1
b1
– 105 –

上海交通大学硕士研究生公共课—-生物数学(一)—-林建忠编
即
N1 = N′1 + a2
b2
N2 = N′2 + a1
b1
将后一个变换代入 (∗)整理后得方程
dN′1
dt= − b1a2
b2N
′2 − b1N
′1N
′2
dN′2
dt= b2a1
b1N
′1 + b2N
′1N
′2
在平衡点附近, N′1和 N
′2都比较小, N
′1N
′2项作为高阶项被略去, 得
dN′1
dt= − b1a2
b2N
′2 (∗∗)
dN′2
dt= b2a1
b1N
′1 (∗∗)
dN′1
dN′2
=dN
′1
dt/dN
′2
dt
= −b21a2
b22a1
N′2
N′1
有方程
b22a1N
′1dN
′1 + a2b
21N
′2dN
′2 = 0
积分上式得方程
b22a1N
′21 + a2b
21N
′22 = C (∗ ∗ ∗)
其中 C 是积分常数. 该方程是椭圆方程, 它说明在平衡点附近种群的变化呈现近似的
椭圆轨道.
作变换将坐标改换成极坐标
N′1 = b1
√a2rcosθ (4∗)
N′2 = b2
√a1rsinθ (4∗)
代入方程 (∗ ∗ ∗)得
a1a2b21b
22r
2 = C
r =
√C
b1b2√
a1a2
– 106 –

上海交通大学硕士研究生公共课—-生物数学(一)—-林建忠编
对 (4∗)求导dN
′1
dt= −b1
√a2rsinθ
dθ
dt
又直接从 (∗∗)有dN
′1
dt= −b1a2
√a1rsinθ
联合以上两等式
dθ
dt=
√a1a2
θ = θ0 +√
a1a2t
将 r与 θ的结果代入 (4∗) , 得参数方程
N′1 =
1
b2
√C
a1
cos(θ0 +√
a1a2t)
N′2 =
1
b1
√C
a2
sin(θ0 +√
a1a2t)
其中常数 C 和 θ0由初始条件决定.
由此可见种群呈周期性变化, 周期 T = 2π√a1a2
. 在一个周期内种群 N′1 的平均大
小为
1
T
∫ t0+T
t0
N′1dt =
1
Tb2
√C
a1
∫ t0+T
t0
cos(θ0 +√
a1a2t)dt = 0
即原来的变量 N1 = N′1 + a2
b2, 知被捕食种群量的平均大小为 a2
b2. 类似地, 捕食种群
N2 的平均大小为a1
b1. 平均种群量恰好取在平衡点上.
另外, 被捕食种群变化的振幅为
N1 =2
b2
√C
a1
捕食种群变化的振幅为
N2 =2
b1
√C
a2
例2: 一战时期, 意大利生物学家D. Ancona 对海洋捕捞鱼类的调查发现, 战
时捕鱼业的下降导至非肉食性鱼类的减少而肉食性鱼类却明显增加. 意大利数学
– 107 –

上海交通大学硕士研究生公共课—-生物数学(一)—-林建忠编
家V.Volterra 成功地解释了这一捕鱼比例的变化. 设海洋鱼类捕捞率为 c , 考虑捕捞
的影响, Lotka-Volterra方程中只须增加 cN1和 cN2项. 得新的方程
dN1
dt= (a1 − c− b1N2)N1
dN2
dt= (−a2 − c + b2N1)N2
上式中 N1和 N2的平均大小应分别是
N1 =a2 + c
b2
, N2 =a1 − c
b1
消去 c得 N1和 N2满足的直线方程称为平衡直线.
N1b2 + N2b1 = a1 + a2
战时捕捞率 c(0 < c ≤ a1)的下降, 将使平衡点在平衡直线从右向左移动(图6-4, 文
件Biomathg64). 结果 N1 减少, 而 N2 增加. 也就是说非肉食性鱼类的减少而肉食性
鱼类却明显增加.
– 108 –

第七章 方差分析模型与正交试验设计
7.1 单因素方差分析
问题的背景 假设某个农业试验引进了 a种小麦品种, 在进行大面积种植之前, 先
进行小范围的试验种植, 以便从中挑选出最合适本地区的优良品种.
将一块大田划分为面积相等的几个小块, 其中 n1块种植第 1种小麦, n2块种植
第 2种小麦, n1 + · · ·+ na = n . 我们感兴趣的只是小麦品种这一个因素. 所有其它因
素, 例如施肥量, 浇水等对这块田都控制在相同状态下.
小麦品种中的每个具体的品种, 称为小麦品种这个因素的一个”水平”. 现在有 a
个不同品种. 于是小麦品种这个因素一共有 a个水平. 因此这是单因素 a个水平的问
题.
表 7.1: 单因素方差分析问题
水平 总体 样本
1 N(µ1, σ2) y11, y12, · · · , y1n1
2 N(µ2, σ2) y21, y22, · · · , y2n2
......
......
...
a N(µa, σ2) ya1, ya2, · · · , yana
记 yij 为种植第 i个品种的小麦的第 j 块田的产量, i = 1, · · · , a ; j = 1, · · · , ni .
对固定的 i , yi1 , yi2 , · · · , yini分别是种植第 i种小麦的 ni块田的产量. 因为除了
一些随机误差之外, 这 ni块田的一切生产条件完全一样, 因此它们可以看作来自一个
正态总体的随机样本, 这个正态总体的均值只与 i有关, 记这个均值为 µi (如表7.1所
109

上海交通大学硕士研究生公共课—-生物数学(一)—-林建忠编
示), 也就是说 yi1 , · · · , yini都相互独立, 且
yij ∼ N(µi, σ2), j = 1, · · · , ni (7.1)
因此比较 a个小麦品种的问题就归结为比较 a个正态总体的均值 µ1 , · · · , µa 的问
题.
考虑一般的单因素方差分析问题, 我们称所考虑的因素为因素 A , 假定它有 a个
水平, 我们的目的是比较这 a个水平的差异. 假设对第 i个水平, 我们感兴趣的指标观
测值如表(7.1). 将其改写成如下形式:
yij = µi + eij, i = 1, · · · , a,
eij ∼ N(0, σ2), j = 1, · · · , ni (7.2)
其中 µi是第 i个总体的均值, eij 是相应的试验误差, 比较因素 A的 a个水平的差异
归结为比较这 a个总体的均值. 记
µ =1
n
a∑i=1
niµi, n =a∑
i=1
ni,
αi = µi − µ
这里 µ为所有样本均值 E(yij)的总平均. αi为第 i个水平对指标 Y 的效应, 反映第 i
个水平下的均值与总平均的差异. 易证a∑
i=1
niαi = 0 . 因为 µi = µ + αi , 于是(7.2)可以
写成
yij = µ + αi + eij,
eij ∼ N(0, σ2),a∑
i=1
niαi = 0,
(7.3)
这就是单因素方差分析模型. 其矩阵形式即为
Y = Xβ + e,
e ∼ N(0, σ2In),
h′β = 0,
(7.4)
其中
yn×1 = (y11, · · · , y1n1 , y21, · · · , y2n2 , · · · , yana)′,
– 110 –

上海交通大学硕士研究生公共课—-生物数学(一)—-林建忠编
Xn×(a+1) =
1 1
......
1 1
1 1
......
1 1
.... . .
1 1
......
1 1
n1 行
n2 行
... 行
na 行
β(a+1)×1 = (µ, α1, α2, · · · , αa)′,
en×1 = (e11, · · · , e1n1 , e21, · · · , e2n2 , · · · , eana)′,
h(a+1)×1 = (0, n1, n2, · · · , na)′,
可见, 单因素方差分析模型是一个带约束条件 h′β = 0的线性模型.
对此模型检验因素 A的 a个水平下的均值是否有显著差异, 即检验假设
H0 : µ1 = µ2 = · · · = µa,
这等价于检验
H0 : α1 = α2 = · · · = αa = 0,
如果 H0被拒绝, 则说明因素 A的各水平的效应之间有显著的差异. 在小麦品种的例
子中, 就是 a种小麦品种之间有显著差异. 下面将导出 H0的检验统计量.
以 y表示所有 yij 的总平均值, 即
y =1
n
a∑i=1
ni∑j=1
yij.
– 111 –

上海交通大学硕士研究生公共课—-生物数学(一)—-林建忠编
考虑统计量
SST =a∑
i=1
ni∑j=1
(yij − y)2.
称 SST 为总的离差平方和, 简称为总平方和. 它反映全部试验数据之间的差异. 对其
进行分解:
SST =a∑
i=1
ni∑j=1
(yij − y)2
=a∑
i=1
ni∑j=1
(yij − yi· + yi· − y)2
=a∑
i=1
ni∑j=1
[(yij − yi·)2 + 2(yij − yi·)(yi· − y) + (yi· − y)2]
其中 yi· = 1ni
ni∑j=1
yij , 为第 i水平下的样本均值. 由于
ni∑j=1
(yij − yi·)(yi· − y) = 0,
所以有
SST =a∑
i=1
ni∑j=1
(yij − yi·)2 +a∑
i=1
ni∑j=1
(yi· − y)2
= SSE + SSA, (7.5)
该式称为平方和分解公式, 其中
SSE =a∑
i=1
ni∑j=1
(yij − yi·)2 (7.6)
SSA =a∑
i=1
ni∑j=1
(yi· − y)2. (7.7)
这里 SSE 表示了随机误差的影响. 通常称为误差平方和或组内平方和.
将 SSA改写为
SSA =a∑
i=1
ni(yi· − y)2. (7.8)
因为 yi·为第 i个总体的样本均值, 它是第 i个总体均值 µi的估计, 因此 a个总体均值
µ1 , · · · , µa之间的差异愈大, 这些样本均值 y1· , · · · , ya·之间的差异也就愈倾向于
– 112 –

上海交通大学硕士研究生公共课—-生物数学(一)—-林建忠编
大. SSA正是 a个总体均值 µ1 , · · · , µa差异大小的度量, 通常称为组间平方和或因
素 A的平方和.
从(7.1)知
S2i =
ni∑j=1
(yij − yi·)2/(ni − 1). (7.9)
是来自第 i个总体 N(µi, σ2)的样本 yi1 , · · · , yini
的样本方差, 因而, 它是 σ2的一个
无偏估计, 即
ES2i = σ2. (7.10)
于是
E(SSE) =a∑
i=1
E
ni∑j=1
(yij − yi·)2
=a∑
i=1
(ni − 1)σ2
= (n− a)σ2
此式表明 SSE/(n− a)是 σ2的一个无偏估计.
另一方面
E(SSA) = E
[a∑
i=1
ni(yi· − y)2
]
= E
[a∑
i=1
ni(yi· − y − αi + αi)2
]
=a∑
i=1
ni
[E(yi· − y − αi)
2 + α2i
]
=a∑
i=1
ni
(σ2
ni
− σ2
n
)+
a∑i=1
niα2i
= (a− 1)σ2 +a∑
i=1
niα2i
所以有
E
(SSA
a− 1
)= σ2 +
1
a
a∑i=1
niα2i
– 113 –

上海交通大学硕士研究生公共课—-生物数学(一)—-林建忠编
由这个式子也可以看出, SSA/(a − 1) 反映了各水平效应的影响. 当 H0 成立时,
SSA/(a− 1)是 σ2的一个无偏估计. 所以, 从直观上看, 若 H0为真, 则比值
SSA/(a− 1)
SSE/(n− a)
将接近于 1 ; 而当 H0 不成立时, 它将倾向于比较大. 这就启发我们通过比较 SSA 与
SSE 的大小来检验 H0 . 记统计量
F =SSA/(a− 1)
SSE/(n− a)
下面导出当 H0成立时 F 的分布.
首先, 因为
ni∑i=1
(yij − yi·)2/σ2 ∼ χ2ni−1, i = 1, · · · , a.
又由样本 yij 的独立性知, 此 a项平方和独立, 故
SSE/σ2 =a∑
i=1
ni∑j=1
(yij − yi·)2/σ2 ∼ χ2a∑
i=1(ni−1)
= χ2n−a, i = 1, · · · , a. (7.11)
应用著名的Cochran定理可以证明, 当 H0成立时, SSA/σ2 ∼ χ2a−1 , 并且与 SSE 相互
独立. 因此, 当 H0成立时,
F =SSA/(a− 1)
SSE/(n− a)∼ Fa−1,n−a (7.12)
于是 F 可以作为 H0的检验统计量. 对于给定的显著性水平 α , 若 F > Fa−1,n−a(α) ,
拒绝原假设, 认为因素 A的 a个水平效应有显著差异. 相反, 若 F ≤ Fa−1,n−a(α) , 接
受原假设, 认为因素 A的 a个水平效应没有显著差异. 方差分析表如表7.2
表 7.2: 单因素方差分析表
方差来源 平方和 自由度 均方 F比
因素A SSA a− 1 MSA = SSA
a−1
误差 SSE n− a MSE = SSE
n−aF = MSA
MSE
总和 SST n− 1
例7.1 设有三个小麦品种, 经试种得每公倾产量数据如表7.3(单位 kg/hm2 )
– 114 –

上海交通大学硕士研究生公共课—-生物数学(一)—-林建忠编
表 7.3: 小麦品种试验数据
品种\试验号 1 2 3 4 5
1 4350 4650 4080 4275
2 4125 3720 3810 3960 3930
3 4695 4245 4620
问:不同品种的小麦产量之间有无显著差异?
解: 因素只有一个, 即”品种”, 它取3个不同的水平. 利用表7.3中的数据计算可得
全部数据的总平均值 y = 4205 ,
三个品种各自数据的平均值
y1· = 4339, n1 = 4,
y2· = 3909, n2 = 5,
y3· = 4520, n3 = 3,
总平方和 SST = 1186800.00 , 其自由度 n− a = 12− 3 = 9 .
因素平方和 SSA = 807311.25 ,
误差平方和 SSE = 379488.75 ,
均方值
MSA = 807311.25/2 = 403655.62,
MSE = 379488.75/9 = 42165.42,
F = 403655.62/42165.42 = 9.57
将计算结果填入方差分析表7.4
查表得 F2,9(0.05) = 4.26 , F2,9(0.01) = 8.02 , 由于 9.57 > 8.02 . 可认为品种效应
具有显著的差异.
如果 F 检验的结论是拒绝原假设, 则表明 µ1 , · · · , µa 不完全相同. 这时, 我们
还需要对每一对 µi 和 µj 之间的差异程度作出估计. 这就要对效应之差 µi − µj 作区
间估计.
– 115 –

上海交通大学硕士研究生公共课—-生物数学(一)—-林建忠编
表 7.4: 小麦品种的方差分析表
方差来源 平方和 自由度 均方 F比
因素A 807311.25 2 403655.62 9.57
误差 379488.75 9 42165.42,
总和 1186800.00 11
由假设(7.1)可推知
yi· ∼ N
(µi,
σ2
ni
), i = 1, · · · , a,
并且 yi·与 yj·(i 6= j)相互独立. 这样易证
yi· − yj· ∼ N
(µi − µj,
(1
ni
+1
nj
)σ2
), (7.13)
因而
U =(yi· − yj·)− (µi − µj)
σ√
1ni
+ 1nj
∼ N(0, 1). (7.14)
记
σ2 =SSE
n− a,
由(7.11)知
(n− a)σ2
σ2=
SSE
σ2∼ χ2
n−a. (7.15)
再由正态总体样本均值与样本方差的独立性可推出, U 和 σ2 相互独立. 因此根据 t
分布的定义, 从(7.14)和(7.15)可得
(yi· − yj·)− (µi − µj)
σ√
1ni
+ 1nj
∼ tn−a.
对给定的 α , 随机事件∣∣∣∣∣∣(yi· − yj·)− (µi − µj)
σ√
1ni
+ 1nj
∣∣∣∣∣∣≤ tn−a
(α
2
).
– 116 –

上海交通大学硕士研究生公共课—-生物数学(一)—-林建忠编
发生的概率为 1−α , 其中 tn−a
(α2
)为自由度为 n− a的 t分布的上侧 α
2分位点. 因此
对固定的 i , j , µi − µj 的置信系数 1− α的置信区间为[(yi· − yj·)− σ
√1
ni
+1
nj
tn−a
(α
2
), (yi· − yj·) + σ
√1
ni
+1
nj
tn−a
(α
2
)]. (7.16)
如果这个区间包括零, 则表明我们可以以概率 1− α断言 µi 与 µj 没有显著差异. 如
果整个区间落在零的左边, 则我们以概率 1− α 断言 µi 小于 µj . 相反, 如果整个区
间落在零的右边, 则我们以概率 1− α断言 µi 大于 µj .
例7.2(续例7.1)
利用公式(7.16), 取水平 α = 0.05 , 查表得 tn−a
(α2
)= t9(0.025) = 2.262 . 得到
µi − µj 的置信区间分别为
µ1 − µ2 ∈ [118.17, 741.34],
µ1 − µ3 ∈ [−536.01, 173.51],
µ2 − µ3 ∈ [−950.21,−271.79].
可见第一个区间整个在零点的右边, 所以我们以概率 95%断言 µ1大于 µ2 . 第二个区
间包括零点, 从点估计上看 µ3 大于 µ1 . 第三个区间整个在零点的左边, 所以我们以
概率 95%断言 µ3大于 µ2 .
同时(联合,一致)置信区间
对于每一个固定的 i , j . 用(7.16)构造出置信系数为 1− α的置信区间. 但对于
多个这样的置信区间, 它们联合起来的置信系数就不再是 1− α .为说明这个问题, 现
介绍Bonferroni不等式.
假设 Ei , i = 1, · · · ,m为m个随机事件, P (Ei) = 1− α , i = 1, · · · ,m , 则
P
(m⋂
i=1
Ei
)= 1− P
(m⋂
i=1
Ei
)= 1− P
(m⋃
i=1
Ei
)≥ 1−
m∑i=1
P (Ei) = 1−mα,
即得著名的Bonferroni不等式
P
(m⋂
i=1
Ei
)≥ 1−mα
这个不等式说明, m个事件若每个单独发生的概率为 1− α , 那么它们同时发生的概
率不再是 1− α , 而是大于或等于 1−mα , 为了使它们同时发生的概率不低于 1− α ,
– 117 –

上海交通大学硕士研究生公共课—-生物数学(一)—-林建忠编
一个办法是把每个事件发生的概率提高到 1− αm
, 即 P (Ei) = 1− αm
, 此时我们有
P
(m⋂
i=1
Ei
)≥ 1− α
应用这个思想, 我们可以构造m个形如 µi − µj 的效应之差的同时置信区间. 事实上,
对每个 µi − µj 应用(7.16)构造置信系数 1− αm的置信区间
[(yi· − yj·)− σ
√1
ni
+1
nj
tn−a
( α
2m
), (yi· − yj·) + σ
√1
ni
+1
nj
tn−a
( α
2m
)]. (7.17)
那么这m个 µi − µj 同时分别落在这m个置信区间的置信系数为 1− α .
例7.3(续例7.2)
利用公式(7.17), 取水平 α = 0.05 , 计算出 µi − µj 的置信系数为 1− α的同时置
信区间为
µ1 − µ2 ∈ [25.691, 833.809],
µ1 − µ3 ∈ [−641.291, 278.791],
µ2 − µ3 ∈ [−1050.883,−171.117].
即我们以概率 95%的概率说明上面三个等式同时成立. 从同时置信区间及前面的点
估计的结果看, 品种3应视为最好, 品种1其次.
7.2 两因素方差分析
问题的背景 在上节小麦品种农业试验中, 除考虑小麦品种这一因素外, 如果我们
还考虑”土质”这一因素对小麦产量的影响, 从而导致两因素试验问题.
解决这一问题的方法是采用所谓区组设计. 其做法是, 先把一块田分成若干块,
譬如 b块, 使得每块田的土质肥沃程度基本上保持一样. 在试验设计中, 称这种块为
区组, 然后把每一个区组又分成若干小块, 称为试验单元. 现在有 a种小麦品种, 方便
的方法是把每个区组分成 a个试验单元. 在每一个试验单元上种植一种小麦. 若用
yij 表示第 j 个区组中种植第 i种小麦的那个试验单元的产量, 则 yij 就可表为
yij = µ + αi + βj + eij, i = 1, · · · , a, j = 1, · · · , b (7.18)
– 118 –

上海交通大学硕士研究生公共课—-生物数学(一)—-林建忠编
这里 µ称为总平均, αi 为第 i种小麦品种的效应, βj 为第 j 个区组的效应, eij 为随
机误差.
考虑一般的两因素试验问题, 将这两个因素分别记为 A和 B . 假设因素 A有 a
个不同的水平, 记为 A1 , · · · , Aa , 而因素 B 有 b个不同的水平, 记为 B1 , · · · , Bb
. 在因素 A和 B 的各个水平组合下做 c次试验. 设 yijk 为在水平组合 (Ai, Bj)下第 k
次试验的指标值. 对固定的 i和 j , yij1 , yij2 , · · · , yijc都是在水平组合 (Ai, Bj)下
的指标观测值, 我们可以把它们看成来自一个正态总体的样本, 这个正态总体的均值
只与 i和 j 有关, 记这个均值为 µij . 于是 yij1 , yij2 , · · · , yijc都相互独立, 且
yijk ∼ N(µij, σ2), k = 1, · · · , c. (7.19)
将这些数据列成表, 如表7.5
表 7.5: 两因素方差分析问题数据
因素A各水平\因素B各水平 B1 B2 · · · Bb
A1 y111y112 · · · y11c y121y122 · · · y12c · · · y1b1y1b2 · · · y1bc
A2 y211y212 · · · y21c y221y222 · · · y22c · · · y2b1y2b2 · · · y2bc
......
... · · · ...
Aa ya11ya12 · · · ya1c ya21ya22 · · · ya2c · · · yab1yab2 · · · yabc
我们可以将(7.19)改写成以下形式:
yijk = µij + eijk,
eijk ∼ N(0, σ2),
i = 1, · · · , a, j = 1, · · · , b, k = 1, · · · , c,
(7.20)
– 119 –

上海交通大学硕士研究生公共课—-生物数学(一)—-林建忠编
为了做统计分析, 我们需要将均值 µij 做恰当的分解, 为此引入
µ =1
ab
a∑i=1
b∑j=1
µij,
µi· =1
b
b∑j=1
µij,
µ·j =1
a
a∑i=1
µij,
αi = µi· − µ, i = 1, · · · , a,
βj = µ·j − µ, j = 1, · · · , b,
γij = µij − µi· − µ·j + µ,
其中 µ为总平均, αi为因素 A的水平 Ai的效应, βj 为因素 B的水平 Bj 的效应. γij
的意义不是很明显, 我们把它改写为
γij = µij − (µi· − µ)− (µ·j − µ)− µ
= (µij − µ)− αi − βj,
其中 µij − µ 反映了水平组合 (Ai, Bj) 对指标值的效应. 在许多情况下, 水平组合
(Ai, Bj)的这种效应并不等于水平 Ai的效应 αi和 Bj 的效应 βj 之和. 称 γij 为 Ai和
Bj 的交互效应. 通常将因素 A和 B 对试验指标的交互效应设想为某一因素的效应.
称这个因素为 A与 B的交互作用, 记为 A×B , 易证
a∑i=1
αi = 0,b∑
j=1
βj = 0,a∑
i=1
b∑j=1
γij = 0.
引入上述记号之后, 就有 µij = µ + αi + βj + γij , 于是改写(7.20)为
yijk = µ + αi + βj + γij + eijk,
eijk ∼ N(0, σ2), i.i.d.a∑
i=1
αi = 0,b∑
j=1
βj = 0,a∑
i=1
b∑j=1
γij = 0,
i = 1, · · · , a, j = 1, · · · , b, k = 1, · · · , c,
(7.21)
这就是两因素方差分析模型.
– 120 –

上海交通大学硕士研究生公共课—-生物数学(一)—-林建忠编
一, 无交互效应的情形
假设 γij = 0 , i = 1, 2, · · · , a , j = 1, 2, · · · , b , 即不存在交互效应. 现假定每种组
合下试验次数 c = 1 .于是
µij = µ + αi + βj, i = 1, · · · , a, j = 1, · · · , b.
此时, 模型(7.21)可写为
yij = µ + αi + βj + eij,
eij ∼ N(0, σ2), i.i.d.a∑
i=1
αi = 0,b∑
j=1
βj = 0,
i = 1, · · · , a, j = 1, · · · , b,
(7.22)
这就是无交互效应的两因素方差分析模型. 我们的目的是要考查或各水平对指标的
影响有无显著差异, 这归结为假设
H1 : α1 = α2 = · · · = αa = 0
或
H2 : β1 = β2 = · · · = βa = 0
的检验.
现导出检验统计量, 记
y =1
ab
a∑i=1
b∑j=1
yij ,
yi· =1
b
b∑j=1
yj ,
y·j =1
a
a∑i=1
yij ,
SST =a∑
i=1
b∑j=1
(yij − y)2 ,
– 121 –

上海交通大学硕士研究生公共课—-生物数学(一)—-林建忠编
其中 SST 为全部试验数据的总变差, 称为总平方和, 对其进行分解
SST =a∑
i=1
b∑j=1
(yij − y)2
=a∑
i=1
b∑j=1
(yij − yi· − y·j + y + yi· − y + y·j − y)2
=a∑
i=1
b∑j=1
(yij − yi· − y·j + y)2 +a∑
i=1
b(yi· − y)2 +b∑
j=1
a(y·j − y)2
= SSE + SSA + SSB,
可以验证, 在上述平方和分解中交叉项均为 0 . 其中
SSE =a∑
i=1
b∑j=1
(yij − yi· − y·j + y)2,
SSA =a∑
i=1
b(yi· − y)2,
SSB =b∑
j=1
a(y·j − y)2,
SSA 称为因素 A的平方和, SSB 称为因素 B 的平方和. 至于 SSE 可以这样来理解:
因为
SSE = SST − SSA − SSB, (7.23)
在我们所考虑的两因素问题中, 除了因素 A与 B之外, 剩余的再没有其它系统性因素
的影响, 因此从总平方和中减去 SSA 和 SSB 之后, 剩下的数据变差只能归于随机误
差, 故 SSE 反映了试验的随机误差.
有了总平方和的分解式
SST = SSE + SSA + SSB,
即知, 假设 H1 (或 H2 )的检验统计量应取为 SSA (或 SSB )与 SSE 的比.
可以证明, 当 H1 成立时, SSA/σ2 ∼ χ2a−1 , 并且与 SSE 相互独立, 而 SSE/σ2 ∼
χ2(a−1)(b−1) . 于是当 H1成立时
FA =SSA/(a− 1)
SSE/(a− 1)(b− 1)∼ Fa−1,(a−1)(b−1) (7.24)
– 122 –
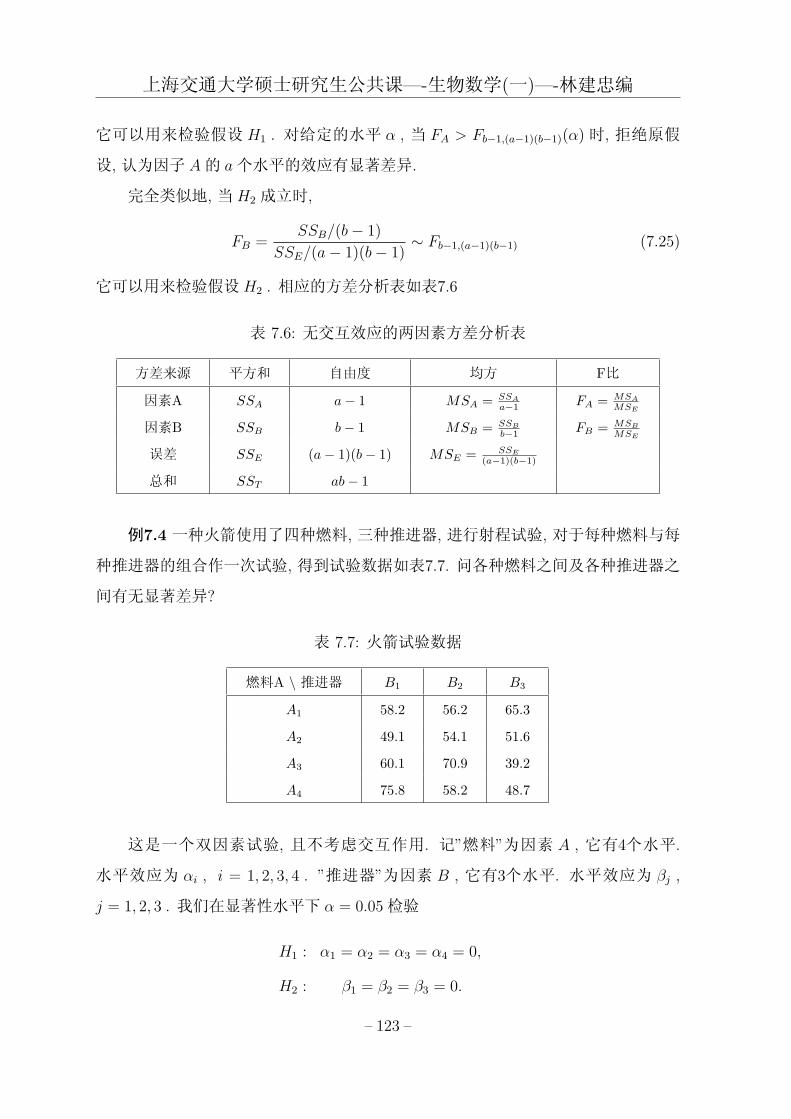
上海交通大学硕士研究生公共课—-生物数学(一)—-林建忠编
它可以用来检验假设 H1 . 对给定的水平 α , 当 FA > Fb−1,(a−1)(b−1)(α)时, 拒绝原假
设, 认为因子 A的 a个水平的效应有显著差异.
完全类似地, 当 H2成立时,
FB =SSB/(b− 1)
SSE/(a− 1)(b− 1)∼ Fb−1,(a−1)(b−1) (7.25)
它可以用来检验假设 H2 . 相应的方差分析表如表7.6
表 7.6: 无交互效应的两因素方差分析表
方差来源 平方和 自由度 均方 F比
因素A SSA a− 1 MSA = SSA
a−1FA = MSA
MSE
因素B SSB b− 1 MSB = SSB
b−1FB = MSB
MSE
误差 SSE (a− 1)(b− 1) MSE = SSE
(a−1)(b−1)
总和 SST ab− 1
例7.4 一种火箭使用了四种燃料, 三种推进器, 进行射程试验, 对于每种燃料与每
种推进器的组合作一次试验, 得到试验数据如表7.7. 问各种燃料之间及各种推进器之
间有无显著差异?
表 7.7: 火箭试验数据
燃料A \ 推进器 B1 B2 B3
A1 58.2 56.2 65.3
A2 49.1 54.1 51.6
A3 60.1 70.9 39.2
A4 75.8 58.2 48.7
这是一个双因素试验, 且不考虑交互作用. 记”燃料”为因素 A , 它有4个水平.
水平效应为 αi , i = 1, 2, 3, 4 . ”推进器”为因素 B , 它有3个水平. 水平效应为 βj ,
j = 1, 2, 3 . 我们在显著性水平下 α = 0.05检验
H1 : α1 = α2 = α3 = α4 = 0,
H2 : β1 = β2 = β3 = 0.
– 123 –

上海交通大学硕士研究生公共课—-生物数学(一)—-林建忠编
由表中数据计算可得
y = 54;
y1· = 59.9, y2· = 51.6, y3· = 56.7, y4· = 60.9,
y·1 = 60.8, y·2 = 59.9, y·3 = 51.2.
SST = 1113.42; SSA = 157.59, SSB = 223.85, SSE = 731.96
将计算结果填入方差分析表7.8
表 7.8: 火箭试验的方差分析表
方差来源 平方和 自由度 均方 F比
因素A 157.59 3 52.53 FA = 0.4306
因素B 223.85 2 111.93 FB = 0.9175
误差 731.98 6 122.00
总和 1113.42 11
因为 F3,6(0.05) = 4.76 > FA = 0.4306 , 所以接受 H1 . 又因为 F2,6(0.05) = 5.14 >
FB = 0.9175 , 所以接受 H2 . 即各种燃料之间及各种推进器之间无显著差异.
如果经 FA检验, H1被拒绝, 那么我们认为因素 A的 a个水平效应 α1 , · · · , αa
不完全相同. 此时要做 [αi, αt]的区间估计.
因为 yij ∼ N(µ + αi + βj, σ2) , 利用
∑bj=1 βj = 0及正态分布的性质, 可以证明
yi· ∼ N
(µ + αi,
σ2
b
), i = 1, · · · , a,
于是
yi· − yt· ∼ N
(αi − αt,
2σ2
b
), (7.26)
用
σ2 =SSE
(a− 1)(b− 1)
– 124 –

上海交通大学硕士研究生公共课—-生物数学(一)—-林建忠编
作为 σ2的估计, 可以得到对固定的 i , t , αi − αt的置信系数 1− α的置信区间为
[(yi· − yt·)− σ
√2
bt(a−1)(b−1)
(α
2
), (yi· − yt·) + σ
√2
bt(a−1)(b−1)
(α
2
)]. (7.27)
如果这个区间包括零, 则表明我们可以以概率 1− α断言 αi 与 αj 没有显著差异. 如
果整个区间落在零的左边, 则我们以概率 1− α 断言 αi 小于 αj . 相反, 如果整个区
间落在零的右边, 则我们以概率 1− α断言 αi 大于 αj .
m个效应之差 αi − αt的置信系数为 1− α的同时置信区间为
[(yi· − yt·)− σ
√2
bt(a−1)(b−1)
( α
2m
), (yi· − yt·) + σ
√2
bt(a−1)(b−1)
( α
2m
)]. (7.28)
如果经 FB 检验, H2被拒绝, 用与上面完全类似的方法, βi − βq 的置信系数 1− α的
置信区间
[(y·j − y·q)− σ
√2
at(a−1)(b−1)
(α
2
), (y·j − y·q) + σ
√2
at(a−1)(b−1)
(α
2
)]. (7.29)
m个效应之差 βi − βq 的置信系数为 1− α的同时置信区间为
[(y·j − y·q)− σ
√2
at(a−1)(b−1)
( α
2m
), (y·j − y·q) + σ
√2
at(a−1)(b−1)
( α
2m
)].
二, 关于交互效应的检验
当考虑因素 A , B间的交互作用 A× B时, 在各水平组合下需要做重复试验, 设
每种组合下试验次数均为 c(c > 1) . 此时对应的模型就是(7.21). 在这样的模型中, 效
应 αi并不能反映水平 Ai的优劣. 这是因为在交互效应存在的情况下, 因子水平 Ai的
优劣还与因子 B 的水平有关系. 对不同的 Bj , Ai 的优劣也不相同. 因此, 对这样的
模型, 检验 α1 = · · · = αa = 0与检验 β1 = · · · = βb = 0没有实际意义. 然而一个重要
的检验问题是交互效应是否存在的检验, 即检验
H3 : γij = 0, i = 1, 2 · · · , a j = 1, · · · , b
– 125 –

上海交通大学硕士研究生公共课—-生物数学(一)—-林建忠编
现导出检验统计量, 记
y =1
abc
a∑i=1
b∑j=1
c∑
k=1
yijk,
yij· =1
c
c∑
k=1
yijk,
yi·· =1
bc
b∑j=1
c∑
k=1
yijk,
y·j· =1
ac
a∑i=1
c∑
k=1
yijk,
SST =a∑
i=1
b∑j=1
c∑
k=1
(yijk − y)2 ,
其中 SST 为全部试验数据的总变差, 称为总平方和, 对其进行分解
SST =a∑
i=1
b∑j=1
c∑
k=1
(yijk − y)2
=a∑
i=1
b∑j=1
c∑
k=1
(yijk − yij· + yi·· − y + y·j· − y + yij· − yi·· − y·j· + y)2
=a∑
i=1
b∑j=1
c∑
k=1
(yijk − yij·)2 + bca∑
i=1
(yi·· − y)2
+acb∑
j=1
(y·j· − y)2 + ca∑
i=1
b∑j=1
(yij· − yi·· − y·j· + y)2
= SSE + SSA + SSB + SSA×B,
可以验证, 在上述平方和分解中交叉项均为 0 . 其中
SSE =a∑
i=1
b∑j=1
c∑
k=1
(yijk − yij·)2,
SSA = bca∑
i=1
(yi·· − y)2,
SSB = acb∑
j=1
(y·j· − y)2,
SSA×B = ca∑
i=1
b∑j=1
(yij· − yi·· − y·j· + y)2,
– 126 –
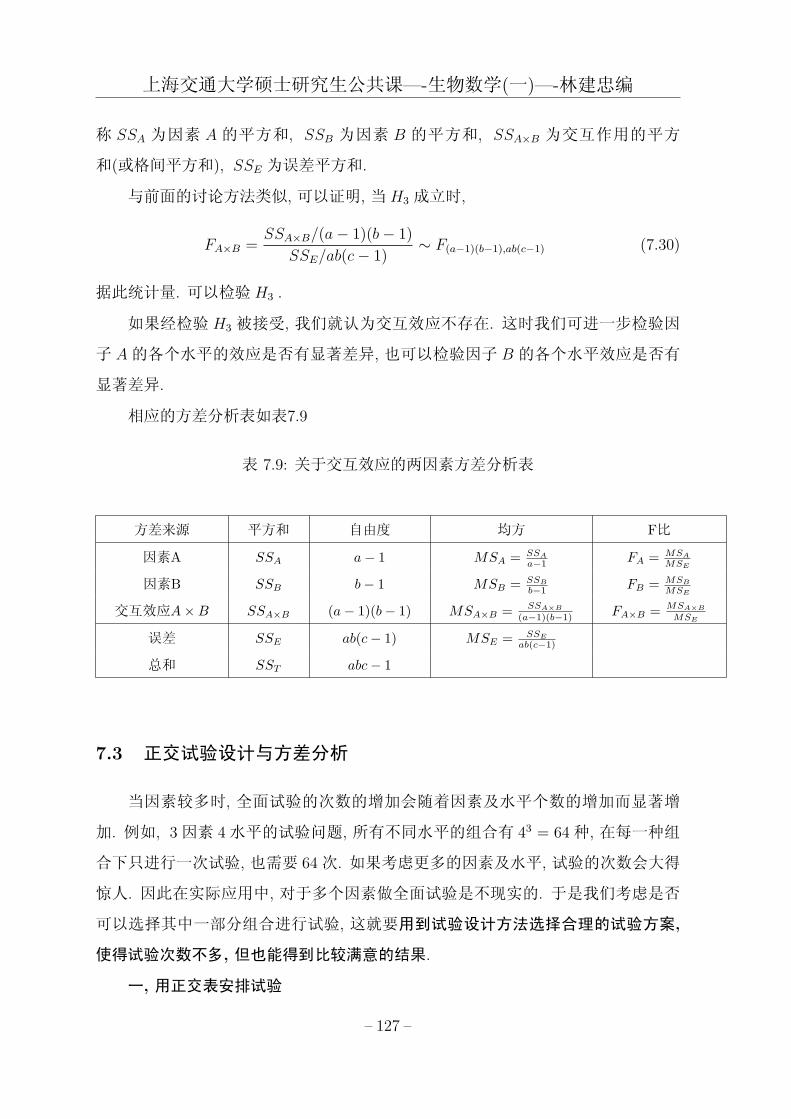
上海交通大学硕士研究生公共课—-生物数学(一)—-林建忠编
称 SSA 为因素 A的平方和, SSB 为因素 B 的平方和, SSA×B 为交互作用的平方
和(或格间平方和), SSE 为误差平方和.
与前面的讨论方法类似, 可以证明, 当 H3成立时,
FA×B =SSA×B/(a− 1)(b− 1)
SSE/ab(c− 1)∼ F(a−1)(b−1),ab(c−1) (7.30)
据此统计量. 可以检验 H3 .
如果经检验 H3 被接受, 我们就认为交互效应不存在. 这时我们可进一步检验因
子 A的各个水平的效应是否有显著差异, 也可以检验因子 B 的各个水平效应是否有
显著差异.
相应的方差分析表如表7.9
表 7.9: 关于交互效应的两因素方差分析表
方差来源 平方和 自由度 均方 F比
因素A SSA a− 1 MSA = SSA
a−1FA = MSA
MSE
因素B SSB b− 1 MSB = SSB
b−1FB = MSB
MSE
交互效应A×B SSA×B (a− 1)(b− 1) MSA×B = SSA×B
(a−1)(b−1)FA×B = MSA×B
MSE
误差 SSE ab(c− 1) MSE = SSE
ab(c−1)
总和 SST abc− 1
7.3 正交试验设计与方差分析
当因素较多时, 全面试验的次数的增加会随着因素及水平个数的增加而显著增
加. 例如, 3因素 4水平的试验问题, 所有不同水平的组合有 43 = 64种, 在每一种组
合下只进行一次试验, 也需要 64次. 如果考虑更多的因素及水平, 试验的次数会大得
惊人. 因此在实际应用中, 对于多个因素做全面试验是不现实的. 于是我们考虑是否
可以选择其中一部分组合进行试验, 这就要用到试验设计方法选择合理的试验方案,
使得试验次数不多, 但也能得到比较满意的结果.
一, 用正交表安排试验
– 127 –
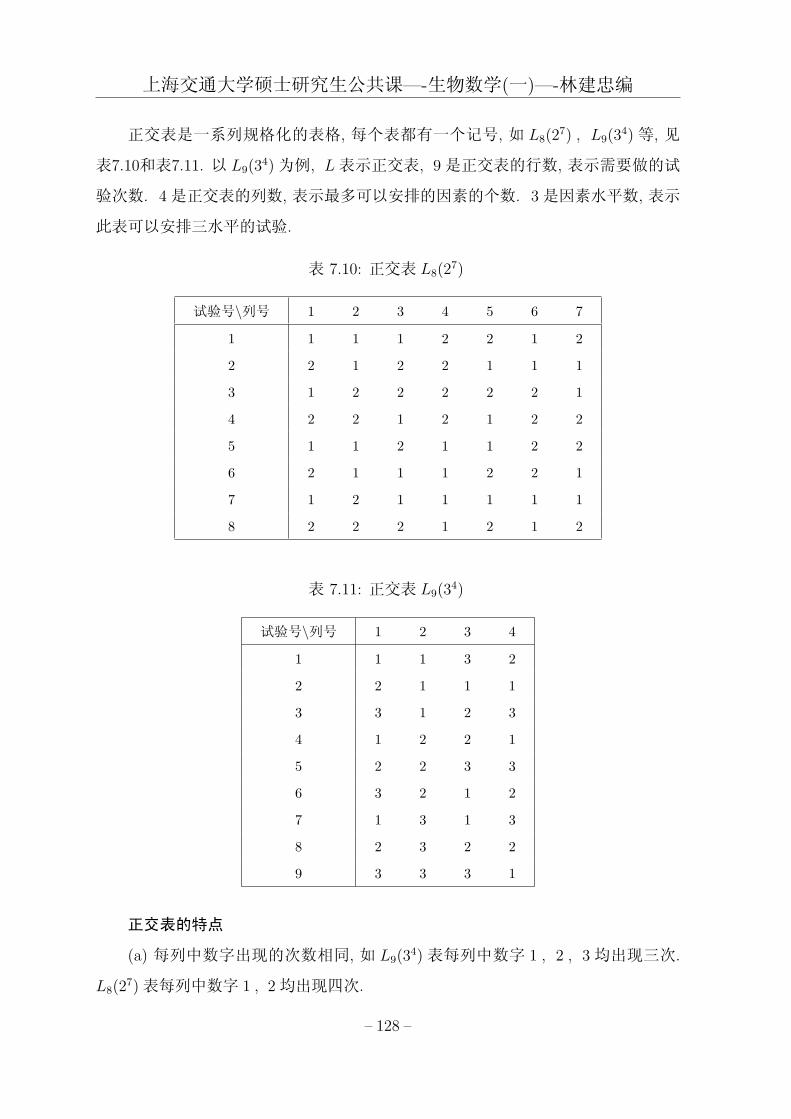
上海交通大学硕士研究生公共课—-生物数学(一)—-林建忠编
正交表是一系列规格化的表格, 每个表都有一个记号, 如 L8(27) , L9(3
4)等, 见
表7.10和表7.11. 以 L9(34)为例, L表示正交表, 9是正交表的行数, 表示需要做的试
验次数. 4是正交表的列数, 表示最多可以安排的因素的个数. 3是因素水平数, 表示
此表可以安排三水平的试验.
表 7.10: 正交表 L8(27)
试验号\列号 1 2 3 4 5 6 7
1 1 1 1 2 2 1 2
2 2 1 2 2 1 1 1
3 1 2 2 2 2 2 1
4 2 2 1 2 1 2 2
5 1 1 2 1 1 2 2
6 2 1 1 1 2 2 1
7 1 2 1 1 1 1 1
8 2 2 2 1 2 1 2
表 7.11: 正交表 L9(34)
试验号\列号 1 2 3 4
1 1 1 3 2
2 2 1 1 1
3 3 1 2 3
4 1 2 2 1
5 2 2 3 3
6 3 2 1 2
7 1 3 1 3
8 2 3 2 2
9 3 3 3 1
正交表的特点
(a) 每列中数字出现的次数相同, 如 L9(34)表每列中数字 1 , 2 , 3均出现三次.
L8(27)表每列中数字 1 , 2均出现四次.
– 128 –

上海交通大学硕士研究生公共课—-生物数学(一)—-林建忠编
(b) 任取两列数字的搭配是均衡的, 如 L9(34)表里每两列中 (1, 1) , (1, 2) , · · · ,
(3, 3) , 九种组合各出现一次. L8(27)表里每两列中 (1, 1) , (1, 2) , (2, 1)和 (2, 2) ,各
出现两次.
这种均衡性使得根据正交表安排的试验, 其试验结果具有很好的可比性, 易于进
行统计分析.
例7.5 为提高某种化学产品的转化率(%), 考虑三个有关因素; 反应温度 A(0C) ,
反应时间 B(min)和催化剂的含量 C(%) . 各因素选取三个水平, 如表7.12
表 7.12: 转化率试验因素水平表
水平\因素 温度 A 时间 B 催化剂含量 C
1 80 90 5
2 85 120 6
3 90 150 7
如果做全面试验, 则需要 33 = 27次. 若用正交表 L9(34) , 仅做 9次试验. 将三个
因素 A , B , C 分别放在 L9(34)表的任意三列上, 如将 A , B分别放在第 2 , 3列上,
C 放在第 4列上. 将表中 A , B , C 所在的三列上的数字 1 , 2 , 3分别用相应的因素
水平去代替, 得 9次试验方案. 以上工作称为表头设计. 再将 9次试验结果转化率数
据列于表上(见表7.13), 并在表上进行计算.
表中各列的 K1 , K2 , K3值分别是对应因素第一,二,三水平的试验指标值之和.
如因素A , K1 = 31+53+57 = 141 ,它是在九次试验中,所有A在第一水平(即 800C
)时试验所得转化率之和. 类似地K2 = 54 + 49 + 62 = 165和K3 = 38 + 42 + 64 = 144
分别是 A所有在第二水平(即 850C )和在第三水平(即 900C )时试验所得转化率之和.
各列的 k1 , k2 , k3分别是本列的 K1 , K2 , K3分别除以 3得到的平均转化率. 如对
A有 k1 = 141/3 = 47 , k2 = 165/3 = 55 , k3 = 144/3 = 48 .
在这个试验中, 指标转化率是愈高愈好, 经过直观比较各因素的 k1 , k2和 k3 , 水
平组合 (A2, B3, C1) = (850C, 150min, 5%)应是最好的试验条件. 需要注意的是, 这个
试验水平的组合, 是已经做过的九次试验中没有出现过的. 它是否真正符合客观实际,
还需要通过试验或生产实际来检验.
– 129 –

上海交通大学硕士研究生公共课—-生物数学(一)—-林建忠编
表 7.13: 转化率试验的正交表
试验号\因素 反应温度 A 反应时间 B 催化剂含量 C 转化率
1 80(1) 90(1) 6(2) 31
2 85(2) 90(1) 5(1) 54
3 90(3) 90(1) 7(3) 38
4 80(1) 120(2) 5(1) 53
5 85(2) 120(2) 7(3) 49
6 90(3) 120(2) 6(2) 42
7 80(1) 150(3) 7(3) 57
8 85(2) 150(3) 6(2) 62
9 90(3) 150(3) 5(1) 64
K1 141 123 171
K2 165 144 135
K3 144 183 144
k1 47 41 57
k2 55 48 45
k3 48 61 48
二, 正交试验的方差分析
以上正交试验数据也可以用线性模型来描述. 以 ai , bj , ck 分别表示 Ai , Bj ,
Ck 水平的效应, µ为总平均, yi为第 i次试验结果, 则例7.5可以用下面的线性模型来
– 130 –

上海交通大学硕士研究生公共课—-生物数学(一)—-林建忠编
描述:
y1 = µ + a1 + b1 + c2 + ε1,
y2 = µ + a2 + b1 + c1 + ε2,
y3 = µ + a3 + b1 + c3 + ε3,
y4 = µ + a1 + b2 + c1 + ε4,
y5 = µ + a2 + b2 + c3 + ε5,
y6 = µ + a3 + b2 + c2 + ε6,
y7 = µ + a1 + b3 + c3 + ε7,
y8 = µ + a2 + b3 + c2 + ε8,
y9 = µ + a3 + b3 + c1 + ε9,
εi ∼ N(0, σ2), i.i.d., i = 1, · · · , 9,∑3
i=1 ai = 0,∑3
j=1 bj = 0,∑3
k=1 ck = 0,
(7.31)
对此模型考虑如下三种假设的检验问题:
H1 : a1 = a2 = a3 = 0, (7.32)
H2 : b1 = b2 = b3 = 0, (7.33)
H3 : c1 = c2 = c3 = 0. (7.34)
若 H1成立, 则说明因素 A的三个水平对指标 y的影响无显著差异. 若 H2 (或 H3 )成
立, 则说明因素 B (或 C )的三个水平对指标 y的影响无显著差异.
若在正交表中总的试验次数为 n , n次试验的结果分别记为 y1 , y2 , · · · , yn .
设因素有 m个, 每个因素取 a个水平, 每个水平作了 r次试验, 则 n = ra , 总平方和
为
SST =n∑
i=1
(yi − y)2 =n∑
i=1
y2i − ny2. (7.35)
记 y = 1n
∑ni=1 yi , 为试验数据的总平均. 与前面两节讨论相似, 可将 SST 分解为
SST = SSE + SS1 + SS2 + · · ·+ SSm, (7.36)
其中 SSE 为误差平方和, SSi 为第 i个因素的平方和. 下面给出分解式(7.36)中各平
方和的具体计算公式.
– 131 –

上海交通大学硕士研究生公共课—-生物数学(一)—-林建忠编
例如计算因素 A的平方和, 设将因素 A安排在正交表的第 `列上, 此时将试验
看作单因素 A的试验. 用 yij 表示因素 A的第 j 水平的第 i个试验值, i = 1, · · · , r ,
j = 1, · · · , a , 则
r∑i=1
a∑j=1
yij =n∑
i=1
yi.
于是由单因素方差分析知
SSA = ra∑
j=1
(KAj − y)2, (7.37)
其中KAj 表示因素 A的第 j 水平的试验值之和(从正交表的第 `列上可以算出).
在(7.37)中的 A代表所考虑的任何一个因素. 如前所设共有m个这样的因素, 所
以我们可得到m个平方和 SS1 , SS2 , · · · , SSm . 而
SSE = SST −m∑
i=1
SSi
记 fT 和 fE 分别为总平方和及误差平方和的自由度, 而用 fi表示第 i个因子平方和的
自由度. 则各平方和的自由度分别为
fT = 总试验次数−1 = n− 1 ,
fi = 因素水平数−1 = a− 1, i = 1, · · · ,m
fE = fT−各因素自由度之和= fT −
m∑i=1
fi = n−m(a− 1)− 1
可以证明, 当第 i个因素的各水平效应相等时
Fi =SSi/fi
SSE/fE
∼ Fa−1,n−m(a−1)−1
于是 Fi可以用作检验第 i个因素诸水平对试验指标 y的影响有无显著差异的统计量.
其方差分析表如下,
例7.6(续例7.5) 对正交试验进行方差分析
– 132 –

上海交通大学硕士研究生公共课—-生物数学(一)—-林建忠编
表 7.14: 正交试验设计的方差分析表
方差来源 平方和 自由度 均方 F比
因素1 SS1 a− 1 MS1 = SS1a−1
F1 = MS1MSE
因素2 SS2 a− 1 MS2 = SS2a−1
FB = MS2MSE
......
......
...
因素m SSm a− 1 MSm = SSm
a−1FB = MSm
MSE
误差 SSE n−m(a− 1)− 1 MSE = SSE
n−m(a−1)−1
总和 SST n− 1
总平方和
SST =9∑
i=1
y2i − 9× y2,
9∑i=1
y2i = 312 + 542 + · · ·+ 642 = 23484,
y =1
9(31 + 54 + · · ·+ 64) =
1
9× 450 = 50.
各平方和分别为
SST = 23484− 9× 502 = 984,
SSA =1
3(1412 + 1652 + 1442)− 1
9× 4502 = 114
SSB =1
3(1232 + 1442 + 1832)− 1
9× 4502 = 618
SSC =1
3(1712 + 1352 + 1442)− 1
9× 4502 = 234
SSE = 984− 114− 618− 234 = 18
各平方和相应的自由度分别为
fT = 9− 1 = 8, fA = fB = fC = 3− 1 = 2,
fE = 9− 3(3− 1)− 1 = 2.
将计算结果列于方差分析表
– 133 –

上海交通大学硕士研究生公共课—-生物数学(一)—-林建忠编
表 7.15: 转化率试验方差分析表
方差来源 平方和 自由度 均方 F比
A 114 2 57 6.33
B 618 2 309 34.33
C 234 2 117 13.00
误差 18 2 9
总和 984 8
查 F 分布表得临界值, F2,2(0.05) = 19 , F2,2(0.1) = 9 . 可见因素 B , C 的各水
平对指标值 y的影响有显著差异, 而因素 A的各水平对 y的影响无显著差异.
– 134 –





























