Embed Size (px)
DESCRIPTION
A Distributed Storage System for Structured Data
Citation preview

Bigtable: A Distributed Storage System for Structured Data
student prof.
Nenu Anda-Roxana Ciprian Dobre

Problem … data (lots of it)● data size
● latency requirements
Solution … Bigtable● what is it?
● works for Google
● data model
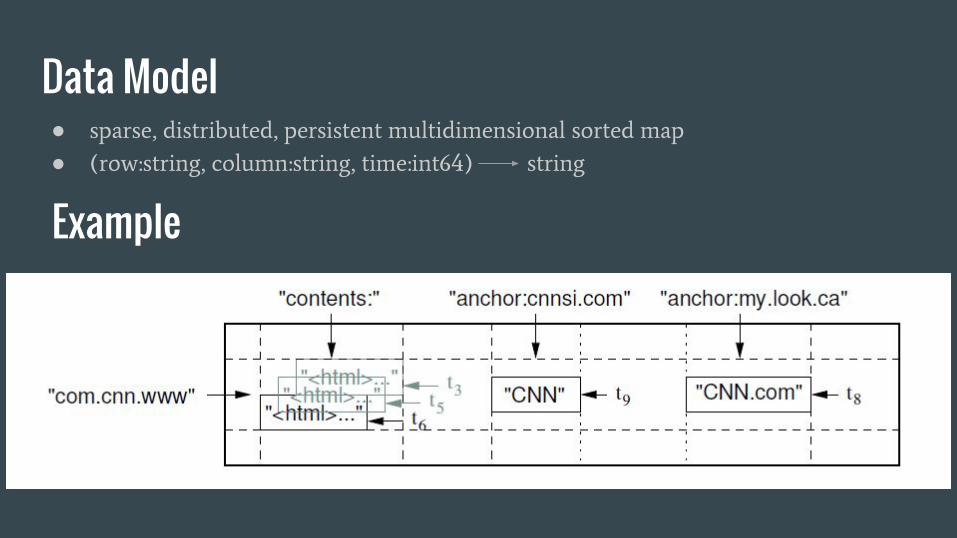
Data Model● sparse, distributed, persistent multidimensional sorted map
● (row:string, column:string, time:int64) string
Example
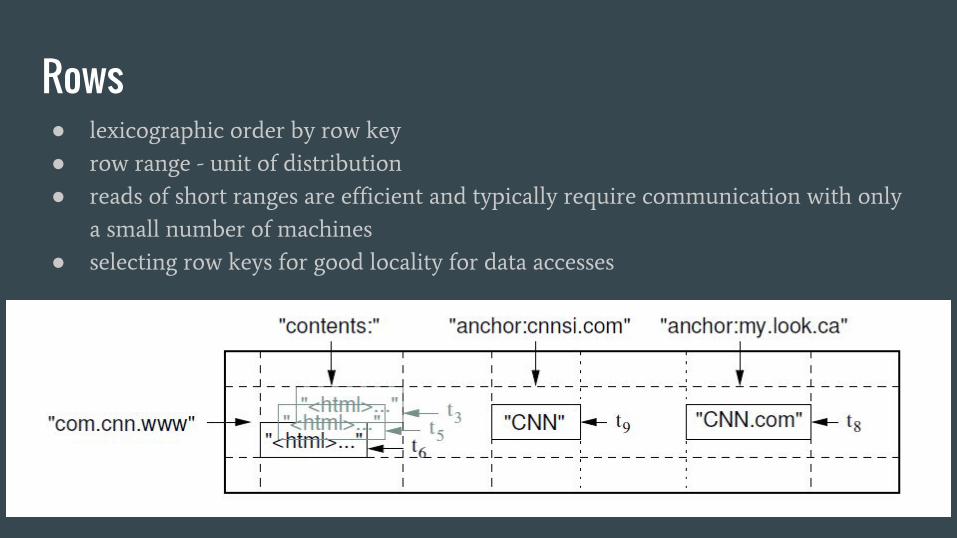
Rows● lexicographic order by row key
● row range - unit of distribution
● reads of short ranges are efficient and typically require communication with only
a small number of machines
● selecting row keys for good locality for data accesses
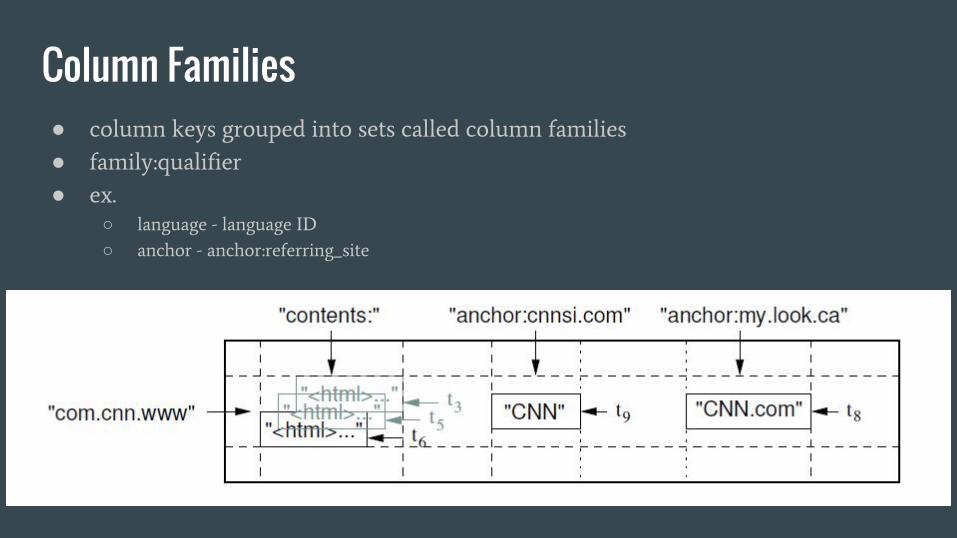
Column Families● column keys grouped into sets called column families
● family:qualifier
● ex.
○ language - language ID
○ anchor - anchor:referring_site
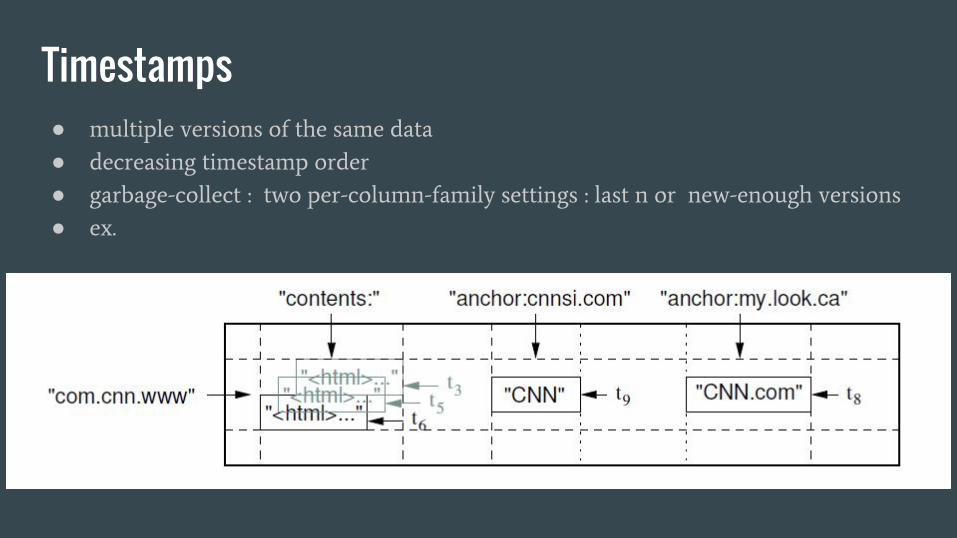
Timestamps● multiple versions of the same data
● decreasing timestamp order
● garbage-collect : two per-column-family settings : last n or new-enough versions
● ex.

Building BlocksBigtable is build on other pieces of Google infrastructure:
● GFS to store log and data files
● Google SSTable file format to store Bigtable data
● Chubby : distributed lock service

Implementation● a library linked into every client
● master server
● many tablet servers
Master server● assigning tablets to tablet servers
● add/remove tablet servers
● garbage collection
● schema changes - table and column family creations

Table server● manages a set of tables
● read and write requests
● splits tablets that have grow too large
Client data● does not move through the master
● clients communicate directly with tablet servers for read and writes

Table Assignment (I)● Each tablet is assigned to one tablet server at a time.
● When a tablet is unassigned, and a tablet server with sufcient room for the tablet
is available, the master assigns the tablet by sending a tablet load request to the
tablet server.
● The master is responsible for detecting when a tablet server is no longer serving
its tablets, and for reassigning those tablets as soon as possible
● Uses Chubby to keep track of table servers

Table Assignment (II)● When a tablet server starts, it creates, and acquires an exclusive lock on, a
uniquely-named file in a specific Chubby directory.
● The master monitors this directory to discover tablet servers.
● A tablet server can lose its lock eg. due to a network partition that caused the
server to lose its Chubby session.
● A tablet server will attempt to reacquire an exclusive lock on its file as long as the
file still exists. If the file no longer exists, then the tablet server will never be able
to serve again, so it kills itself.
● If tablet server terminates, it attempts to release its lock so that the master will
reassign its tablets more quickly.

Table Assignment (III)● To detect when a tablet server is no longer serving its tablets, the master
periodically asks each tablet server for the status of its lock.
● If problem (?), then the master attempts to acquire an exclusive lock on the
server's file.
● If the master is able to acquire the lock, then Chubby is live and the tablet server
is either dead or having trouble reaching Chubby, so the master ensures that the
tablet server can never serve again by deleting its server file.
● Move all the tablets that were previously assigned to that server into the set of
unassigned tablets.

WhyBigtable? Other projects : Oracle's Real Application Cluster, IBM's DB2 Parallel Edition
Difference : relational database
● The key-value pair model provided by distributed B-trees or distributed hash
tables is too limiting.
● Key-value pairs are a useful building block, but they should not be the only
building block one provides to developers.
● Bigtable : it is still simple enough that it lends itself to a very efficient at-file
representation, and it is transparent enough (via locality groups) to allow users to
tune important behaviors of the system.




















![Distributed Systems [Fall 2012] - Columbia Universitydu/ds/assets/lectures/...Bigtable: A Distributed Storage System for Structured Data Fay Chang, Jeffrey Dean, Sanjay Ghemawat, Wilson](https://img.dokumen.tips/doc/110x75/5e2e872fd0713b44e47eb0c1/distributed-systems-fall-2012-columbia-university-dudsassetslectures.jpg)








