Embed Size (px)
Citation preview

Day 1: Introduction 2010 - Course MT1
Basics of Supercomputing
Prof. Thomas Sterling
Pervasive Technology Institute
School of Informatics & Computing
Indiana University
Dr. Steven R. Brandt
Center for Computation & Technology
Louisiana State University
Supercomputer Architecture

Day 1: Introduction 2010 - Course MT1
Topics
• Overview of Supercomputer Architecture
• Enabling Technologies
• SMP
• Memory Hierarchy
• Commodity Clusters
• System Area Networks
2

Day 1: Introduction 2010 - Course MT1
Topics
• Overview of Supercomputer Architecture
• Enabling Technologies
• SMP
• Memory Hierarchy
• Commodity Clusters
• System Area Networks
3

Day 1: Introduction 2010 - Course MT1
New Fastest Computer in the World
DEPARTMENT OF COMPUTER SCIENCE @ LOUISIANA STATE UNIVERSITY 4

Day 1: Introduction 2010 - Course MT1
5
Supercomputing System Stack • Device technologies
– Enabling technologies for logic, memory, & communication
– Circuit design
• Computer architecture – semantics and structures
• Models of computation – governing principles
• Operating systems – Manages resources and provides virtual machine
• Compilers and runtime software – Maps application program to system resources, mechanisms, and
semantics
• Programming – languages, tools, & environments
• Algorithms – Numerical techniques
– Means of exposing parallelism
• Applications – End user problems, often in sciences and technology

Day 1: Introduction 2010 - Course MT1 6
Classes of Architecture for
High Performance Computers
• Parallel Vector Processors (PVP) – NEC Earth Simulator, SX-6
– Cray-1, 2, XMP, YMP, C90, T90, X1
– Fujitsu 5000 series
• Massively Parallel Processors (MPP) – Intel Touchstone Delta & Paragon
– TMC CM-5
– IBM SP-2 & 3, Blue Gene/Light
– Cray T3D, T3E, Red Storm/Strider
• Distributed Shared Memory (DSM) – SGI Origin
– HP Superdome
• Single Instruction stream Single Data stream (SIMD)
– Goodyear MPP, MasPar 1 & 2, TMC CM-2
• Commodity Clusters – Beowulf-class PC/Linux clusters
– Constellations
– HP Compaq SC, Linux NetworX MCR

Day 1: Introduction 2010 - Course MT1
7
Where Does Performance Come From?
• Device Technology
– Logic switching speed and device density
– Memory capacity and access time
– Communications bandwidth and latency
• Computer Architecture
– Instruction issue rate
• Execution pipelining
• Reservation stations
• Branch prediction
• Cache management
– Parallelism
• Number of operations per cycle per processor
– Instruction level parallelism (ILP)
– Vector processing
• Number of processors per node
• Number of nodes in a system
Day 1: Introduction 2010 - Course MT1
9
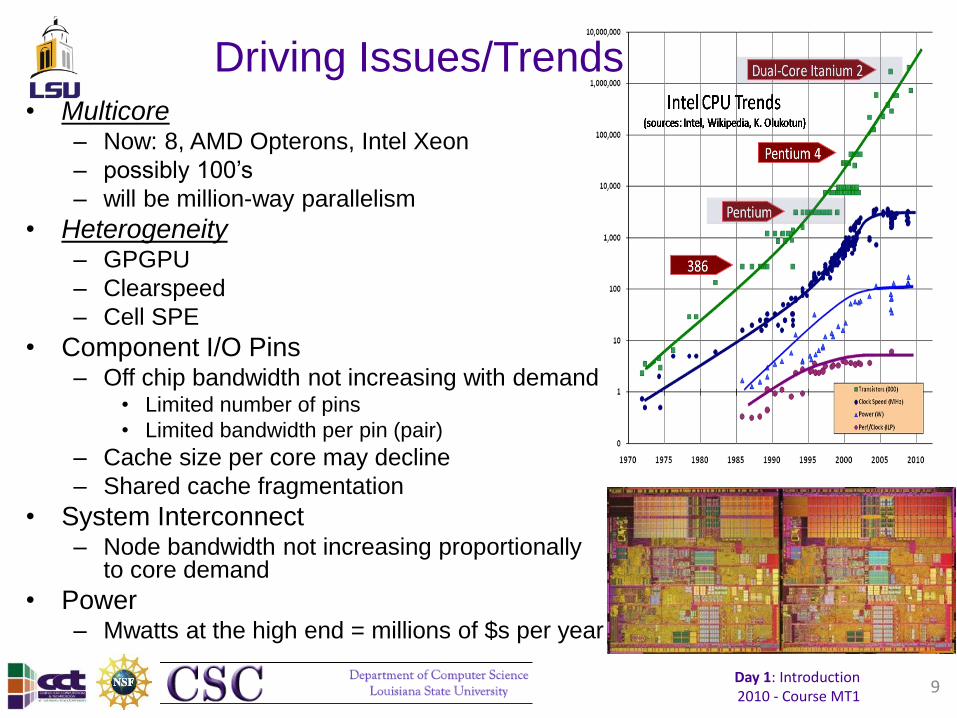
Driving Issues/Trends • Multicore
– Now: 8, AMD Opterons, Intel Xeon
– possibly 100’s
– will be million-way parallelism
• Heterogeneity – GPGPU
– Clearspeed
– Cell SPE
• Component I/O Pins – Off chip bandwidth not increasing with demand
• Limited number of pins
• Limited bandwidth per pin (pair)
– Cache size per core may decline
– Shared cache fragmentation
• System Interconnect – Node bandwidth not increasing proportionally
to core demand
• Power – Mwatts at the high end = millions of $s per year

Day 1: Introduction 2010 - Course MT1 10
Multi-Core • Motivation for Multi-Core
– Exploits improved feature-size and density
– Increases functional units per chip (spatial efficiency)
– Limits energy consumption per operation
– Constrains growth in processor complexity
• Challenges resulting from multi-core – Relies on effective exploitation of multiple-thread
parallelism • Need for parallel computing model and parallel
programming model
– Aggravates memory wall • Memory bandwidth
– Way to get data out of memory banks
– Way to get data into multi-core processor array
• Memory latency
• Fragments (shared) L3 cache
– Pins become strangle point • Rate of pin growth projected to slow and flatten
• Rate of bandwidth per pin (pair) projected to grow slowly
– Requires mechanisms for efficient inter-processor coordination
• Synchronization
• Mutual exclusion
• Context switching

Day 1: Introduction 2010 - Course MT1 11
Heterogeneous Multicore Architecture
• Combines different types of processors
– Each optimized for a different operational modality
• Performance > Nx better than other N processor types
– Synthesis favors superior performance
• For complex computation exhibiting distinct modalities
• Conventional co-processors
– Graphical processing units (GPU)
– Network controllers (NIC)
– Efforts underway to apply existing special purpose components to general applications
• Purpose-designed accelerators
– Integrated to significantly speedup some critical aspect of one or more important classes of computation
– IBM Cell architecture
– ClearSpeed SIMD attached array processor

Day 1: Introduction 2010 - Course MT1
Topics
• Overview of Supercomputer Architecture
• Enabling Technologies
• SMP
• Memory Hierarchy
• Commodity Clusters
• System Area Networks
12

Day 1: Introduction 2010 - Course MT1
Major Technology Generations (dates approximate)
• Electromechanical – 19th century through 1st half of 20th century
• Digital electronic with vacuum tubes – 1940s
• Transistors – 1947
• Core memory – 1950
• SSI & MSI RTL/DTL/TTL semiconductor – 1970
• DRAM – 1970s
• CMOS VLSI – 1990
• Multicore – 2006
13

Day 1: Introduction 2010 - Course MT1
14
Moore’s Law
Moore's Law describes a long-
term trend in the history of
computing hardware, in which
the number of transistors that
can be placed inexpensively on
an integrated circuit has doubled
approximately every two years.

Day 1: Introduction 2010 - Course MT1
15
The SIA ITRS Roadmap
19
97
19
99
20
01
20
03
20
06
20
09
20
12
Y e a r o f T e c h n o l o g y A v a i l a b i l i t y
1
1 0
1 0 0
1 , 0 0 0
1 0 , 0 0 0
1 0 0 , 0 0 0M B p e r D R A M C h i p
L o g i c T r a n s i s t o r s p e r C h i p ( M )
u P C l o c k ( M H z )

Day 1: Introduction 2010 - Course MT1
16
Impact of VLSI
• Mass produced microprocessor enabled low cost computing
– PCs and workstations
• Economy of scale
– Ensembles of multiple processors
• Microprocessor becomes building block of parallel computers
• Favors sequential process oriented computing
– Natural hardware supported execution model
– Requires locality management
• Data
• Control
– I/O channels (south bridge) provides external interface
• Coarse grained communication packets
• Suggests concurrent execution at the process boundary level
– Processes statically assigned to processors (one on one)
• Operate on local data
– Coordination by large value-oriented I/O messages
• Inter process/processor synchronization and remote data exchange

Day 1: Introduction 2010 - Course MT1
17
• Memory mats: ~ 1 Mbit each • Row Decoders • Primary Sense Amps • Secondary sense amps & “page” multiplexing • Timing, BIST, Interface • Kerf
Classical DRAM
0.000001
0.00001
0.0001
0.001
0.01
0.1
1
10
100
1000
1970 1975 1980 1985 1990 1995 2000 2005 2010 2015 2020
Gb
its p
er
ch
ip
Historical ITRS @ Production ITRS @ Introduction
0.00
0.10
0.20
0.30
0.40
0.50
0.60
0.70
0.80
0.90
1.00
1970 1980 1990 2000 2010 2020
% C
hip
Overh
ead
Historical SIA Production SIA Introduction
Density/Chip has dropped below 4X/3yrs And 45% of Die is Non-Memory

Day 1: Introduction 2010 - Course MT1
18
Microprocessors no longer realize the
full potential of VLSI technology
1e-4
1e-3
1e-2
1e-1
1e+0
1e+1
1e+2
1e+3
1e+4
1e+5
1e+6
1e+7
1980 1990 2000 2010 2020
Perf (ps/Inst)
Linear (ps/Inst)
30:1
1,000:1
30,000:1
Courtesy of Bill Dally, Nvidia

Day 1: Introduction 2010 - Course MT1
19
The Memory Wall T
ime
(
ns
)
Me
mo
ry
t
o
CP
U
Ra
tio
Memory Access Time
CPU Time
Ratio
THE WALL

Day 1: Introduction 2010 - Course MT1
20
Recap: Who Cares About the Memory Hierarchy?
µProc 60%/yr. (2X/1.5yr)
DRAM 9%/yr. (2X/10 yrs)
1
10
100
1000
19
80
19
81
19
83
19
84
19
85
19
86
19
87
19
88
19
89
19
90
19
91
19
92
19
93
19
94
19
95
19
96
19
97
19
98
19
99
20
00
DRAM
CPU
19
82
Processor-Memory Performance Gap: (grows 50% / year)
Pe
rfo
rman
ce
Time
“Moore’s Law”
Processor-DRAM Memory Gap (latency)
Copyright 2001, UCB, David Patterson

Day 1: Introduction 2010 - Course MT1
Topics
• Overview of Supercomputer Architecture
• Enabling Technologies
• SMP
• Memory Hierarchy
• Commodity Clusters
• System Area Networks
21

Day 1: Introduction 2010 - Course MT1
Shared Memory Multiple Thread
• Static or dynamic
• Fine grained
• OpenMP
• Distributed shared memory systems
• Covered on day 3
22
Network
CPU 1 CPU 2 CPU 3
Orio
n J
PL
NA
SA
memory memory memory
Network
CPU 1 CPU 2 CPU 3
memory memory memory
Symmetric Multi Processor (SMP usually cache coherent )
Distributed Shared Memory (DSM often not cache coherent)

Day 1: Introduction 2010 - Course MT1
23
SMP Context
• A standalone system
– Incorporates everything needed for computation:
• Processors
• Memory
• External I/O channels
• Local disk storage
• User interface
– Enterprise server and institutional computing market
• Exploits economy of scale for enhanced performance-to-cost
• Substantial performance
– Target for ISVs (Independent Software Vendors)
• Shared memory multiple thread programming platform
– Easier to program than distributed memory machines
– Enough parallelism to fully employ system threads (processor cores)
• Building block for ensemble supercomputers
– Commodity clusters
– MPPs

Day 1: Introduction 2010 - Course MT1
24
Major Elements of an SMP Node • Processor chip
• DRAM main memory cards
• Motherboard chip set
• On-board memory network
– North bridge
• On-board I/O network
– South bridge
• PCI industry standard interfaces
– PCI, PCI-X, PCI-express
• System Area Network controllers
– e.g. Ethernet, Myrinet, Infiniband, Quadrics, Federation Switch
• System Management network
– Usually Ethernet
– JTAG for low level maintenance
• Internal disk and disk controller
• Peripheral interfaces

Day 1: Introduction 2010 - Course MT1
25
SMP Node Diagram
MP
L1 L2
MP
L1 L2
L3
MP
L1 L2
MP
L1 L2
L3
M1 M2 Mn-1
Controller
S
S
NIC NIC USB Peripherals
JTAG
Legend : MP : MicroProcessor L1,L2,L3 : Caches M1.. : Memory Banks S : Storage NIC : Network Interface Card
Ethernet
PCI-e

Day 1: Introduction 2010 - Course MT1
26
Performance Issues for SMP
Nodes • Cache behavior
– Hit/miss rate
– Replacement strategies
• Prefetching
• Clock rate
• ILP
• Branch prediction
• Memory
– Access time
– Bandwidth
– Bank conflicts

Day 1: Introduction 2010 - Course MT1
27
Sample SMP Systems
DELL PowerEdge
HP Proliant
Intel Server System
IBM p5 595
Microway Quadputer
Day 1: Introduction 2010 - Course MT1
28
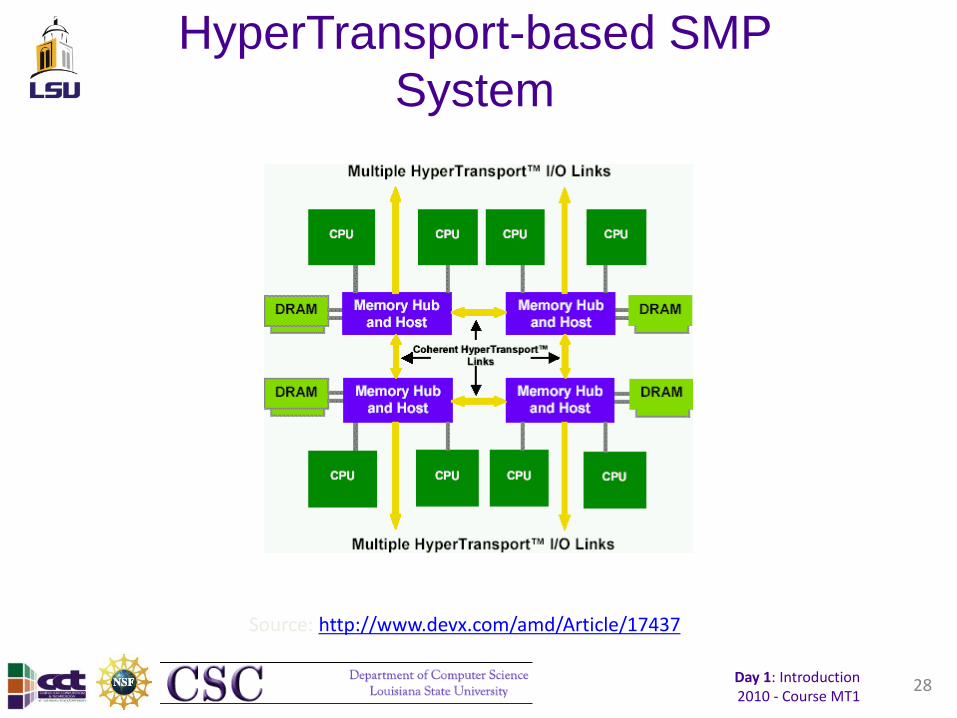
HyperTransport-based SMP
System
Source: http://www.devx.com/amd/Article/17437
Day 1: Introduction 2010 - Course MT1
29
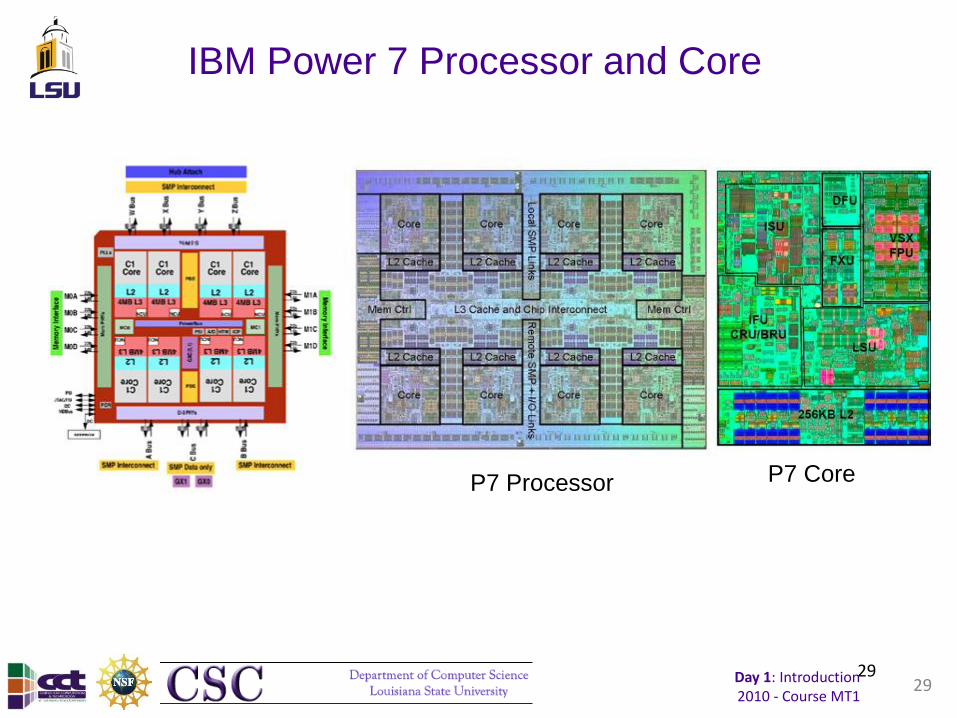
IBM Power 7 Processor and Core
29
P7 Processor P7 Core

Day 1: Introduction 2010 - Course MT1
30
Processor Core Micro Architecture
• Execution Pipeline – Stages of functionality to process issued instructions
– Hazards are conflicts with continued execution
– Forwarding supports closely associated operations exhibiting precedence constraints
• Out of Order Execution – Uses reservation stations
– hides some core latencies and provide fine grain asynchronous operation supporting concurrency
• Branch Prediction – Permits computation to proceed at a conditional branch point
prior to resolving predicate value
– Overlaps follow-on computation with predicate resolution
– Requires roll-back or equivalent to correct false guesses
– Sometimes follows both paths, and several deep

Day 1: Introduction 2010 - Course MT1
Topics
• Overview of Supercomputer Architecture
• Enabling Technologies
• SMP
• Memory Hierarchy
• Commodity Clusters
• System Area Networks
31

Day 1: Introduction 2010 - Course MT1 32
What is a cache?
• Small, fast storage used to improve average access time to slow memory.
• Exploits spatial and temporal locality
• In computer architecture, almost everything is a cache! – Registers: a cache on variables
– First-level cache: a cache on second-level cache
– Second-level cache: a cache on memory
– Memory: a cache on disk (virtual memory)
– TLB: a cache on page table
– Branch-prediction: a cache on prediction information
Proc/Regs
L1-Cache
L2-Cache
Memory
Disk, Tape, etc.
Bigger Faster
Copyright 2001, UCB, David Patterson

Day 1: Introduction 2010 - Course MT1
33
Multicore Microprocessor Component
Elements
• Multiple processor cores – One or more processors
• L1 caches – Instruction cache
– Data cache
• L2 cache – Joint instruction/data cache
– Dedicated to individual core processor
• L3 cache – Not all systems
– Shared among multiple cores
– Often off die but in same package
• Memory interface – Address translation and management (sometimes)
– North bridge
• I/O interface – South bridge

Day 1: Introduction 2010 - Course MT1
34
Levels of the Memory Hierarchy
CPU Registers 100s Bytes < 0.5 ns (typically 1 CPU cycle)
Cache L1 cache: 10s-100s K Bytes 1-5 ns $10/ Mbyte
Main Memory Few G Bytes 50ns- 150ns $0.02/ MByte
Disk 100s-1000s G Bytes 500000ns- 1500000ns $ 0.25/ GByte
Capacity Access Time Cost
Tape infinite sec-min $0.0014/ MByte
Registers
Cache
Memory
Disk
Tape
Instr. Operands
Blocks
Pages
Files
Staging Xfer Unit
prog./compiler 1-8 bytes
cache cntl 8-128 bytes
OS 512-4K bytes
user/operator Mbytes
Upper Level
Lower Level
faster
Larger
Copyright 2001, UCB, David Patterson

Day 1: Introduction 2010 - Course MT1
Performance: Locality
• Temporal Locality is a property that if a program accesses a
memory location, there is a much higher than random probability
that the same location would be accessed again.
• Spatial Locality is a property that if a program accesses a
memory location, there is a much higher than random probability
that the nearby locations would be accessed soon.
• Spatial locality is usually easier to achieve than temporal locality
• A couple of key factors affect the relationship between locality
and scheduling :
– Size of dataset being processed by each processor
– How much reuse is present in the code processing a chunk of
iterations.
35

Day 1: Introduction 2010 - Course MT1
36
Memory Hierarchy: Terminology • Hit: data appears in some block in the upper level (example:
Block X) – Hit Rate: the fraction of memory accesses found in the upper level
– Hit Time: Time to access the upper level which consists of RAM access time + Time to determine hit/miss
• Miss: data needs to be retrieved from a block in the lower level (Block Y) – Miss Rate = 1 - (Hit Rate)
– Miss Penalty: Time to replace a block in the upper level +
Time to deliver the block to the processor
• Hit Time << Miss Penalty (500 instructions on 21264!)
Lower Level
Memory Upper Level
Memory To Processor
From Processor
Blk X
Blk Y
Copyright 2001, UCB, David Patterson

Day 1: Introduction 2010 - Course MT1
Cache Performance
37
T = total execution time Tcycle = time for a single processor cycle Icount = total number of instructions IALU = number of ALU instructions (e.g. register – register) IMEM = number of memory access instructions ( e.g. load, store) CPI = average cycles per instructions CPIALU = average cycles per ALU instructions
CPIMEM = average cycles per memory instruction rmiss = cache miss rate rhit = cache hit rate CPIMEM-MISS = cycles per cache miss CPIMEM-HIT=cycles per cache hit MALU = instruction mix for ALU instructions MMEM = instruction mix for memory access instruction
T = Icount ´T = Icount ´CPI ´Tcycle
Icount = IALU + IMEM
CPI =IALU
Icount
æ
èç
ö
ø÷´CPIALU +
IMEM
Icount
æ
èç
ö
ø÷´CPIMEM MALU ´CPIALU( ) + MMEM ´ CPIMEM-HIT + rMISS ´CPIMEM-MISS( )( )é
ëùû´Tcycle

Day 1: Introduction 2010 - Course MT1
Cache Performance: Example
38
1
100
5.0
1
102
10
10
11
HITMEM
MISSMEM
cycle
ALU
MEM
count
CPI
CPI
nsT
CPI
I
I
2.010
102
8.010
8
10
108
108
11
10
11
10
10
count
MEMMEM
count
ALUALU
MEMcountALU
I
IM
I
IM
III
sec150
105))112.0()18.0((10
11100)9.01(1
9.0
1011
A
MISSMEMAMISSHITMEMAMEM
hitA
T
CPIrCPICPI
r
sec550
105))512.0()18.0((10
51100)5.01(1
5.0
1011
B
MISSMEMBMISSHITMEMBMEM
hitB
T
CPIrCPICPI
r

Day 1: Introduction 2010 - Course MT1
Performance Shared Memory (OpenMP): Key Factors
• Load Balancing :
– mapping workloads with thread scheduling
• Caches :
– Write-through
– Write-back
• Locality :
– Temporal Locality
– Spatial Locality
• How Locality affects scheduling algorithm selection
• Synchronization :
– Effect of critical sections on performance
39

Day 1: Introduction 2010 - Course MT1
Topics
• Overview of Supercomputer Architecture
• Enabling Technologies
• SMP
• Memory Hierarchy
• Commodity Clusters
• System Area Networks
40

Day 1: Introduction 2010 - Course MT1
41
What is a Commodity Cluster
• It is a distributed/parallel computing system
• It is constructed entirely from commodity subsystems
– All subcomponents can be acquired commercially and separately
– Computing elements (nodes) are employed as fully operational
standalone mainstream systems
• Two major subsystems:
– Compute nodes
– System area network (SAN)
• Employs industry standard interfaces for integration
• Uses industry standard software for majority of services
• Incorporates additional middleware for interoperability among
elements
• Uses software for coordinated programming of elements in parallel

Day 1: Introduction 2010 - Course MT1
42
Cluster System
MP L1 L2
MP L1 L2
L3
MP L1 L2
MP L1
L2
L3
M1 M2 Mn-1
Controller
S
S
NIC NIC
Resource management & scheduling subsystem
Login & Cluster Access
Co
mp
ute
N
od
es
Interco
nn
ect
Netw
ork
MP L1 L2
MP L1 L2
L3
MP L1 L2
MP L1
L2
L3
M1 M2 Mn-1
Controller
S
S
NIC NIC
MP L1 L2
MP L1 L2
L3
MP L1 L2
MP L1
L2
L3
M1 M2 Mn-1
Controller
S
S
NIC NIC
MP L1 L2
MP L1 L2
L3
MP L1 L2
MP L1
L2
L3
M1 M2 Mn-1
Controller
S
S
NIC NIC

Day 1: Introduction 2010 - Course MT1
45
UC-Berkeley NOW Project
• NOW-1 1995
• 32-40 SparcStation 10s and
20s
• originally ATM
• first large myrinet network
NOW-2 1997
100+ Ultra Sparc 170s
128 MB, 2 2GB disks, ethernet, myrinet
largest Myrinet configuration in the world
First cluster on the TOP500 list

Day 1: Introduction 2010 - Course MT1
46
Machine Parameters affecting Performance
• Peak floating point performance
• Main memory capacity
• Bi-section bandwidth
• I/O bandwidth
• Secondary storage capacity
• Organization – Class of system
– # nodes
– # processors per node
– Accelerators
– Network topology
• Control strategy – MIMD
– Vector, PVP
– SIMD
– SPMD

Day 1: Introduction 2010 - Course MT1
47
Why are Clusters so Prevalent
• Excellent performance to cost for many workloads – Exploits economy of scale
• Mass produced device types
• Mainstream standalone subsystems – Many competing vendors for similar products
• Just in place configuration – Scalable up and down
– Flexible in configuration
• Rapid tracking of technology advance – First to exploit newest component types
• Programmable – Uses industry standard programming languages and tools
• User empowerment

Day 1: Introduction 2010 - Course MT1
48
Key Parameters for Cluster
Computing • Peak floating-point performance
• Sustained floating-point performance
• Main memory capacity
• Bi-section bandwidth
• I/O bandwidth
• Secondary storage capacity
• Organization – Processor architecture
– # processors per node
– # nodes
– Accelerators
– Network topology
• Logistical Issues – Power Consumption
– HVAC / Cooling
– Floor Space (Sq. Ft)

Day 1: Introduction 2010 - Course MT1
49
Where’s the Parallelism
• Inter-node
– Multiple nodes
– Primary level for commodity clusters
– Secondary level for constellations
• Multi socket, intra-node
– Routinely 1, 2, 4, 8
– Heterogeneous computing with accelerators
• Multi-core, intra-socket
– 2, 4 cores per socket
• Multi-thread, intra-core
– None or two usually
• ILP, intra-core
– Multiple operations issued per instruction
• Out of order, reservation stations
• Prefetching
• Accelerators

Day 1: Introduction 2010 - Course MT1
Topics
• Overview of Supercomputer Architecture
• Enabling Technologies
• SMP
• Memory Hierarchy
• Commodity Clusters
• System Area Networks
50

Day 1: Introduction 2010 - Course MT1
51
Fast and Gigabit Ethernet
• Cost effective
• Lucent, 3com, Cisco, etc.
• Directly leverage LAN technology and market
• Up to 384 100 Mbps ports in one switch
• Switches can be stacked on connected with multiple gigabit links
• 100 Base-T: – Bandwidth: > 11 MB/s
– Latency: < 90 microseconds
• 1000 Base-T: – Bandwidth: ~ 50 MB/s
– Latency: < 90 microseconds
• 10 GbE: – Bandwidth: 1250 MB/s
– Latency: ~2.5 microseconds

Day 1: Introduction 2010 - Course MT1
InfiniBand
52
• High Performance: 10 - 20 Gbps
• Low latency: 1.2 microseconds
• Copper interconnects
• High availability - IEEE 802.3ad Link Aggregation / Channel Bonding
http://www.hpcwire.com/hpc/1342206.html

Day 1: Introduction 2010 - Course MT1
Network Interconnect Topologies
54
TORUS
FAT-TREE (CLOS)

Day 1: Introduction 2010 - Course MT1
55
Example: 320-host Clos topology
of 16-port switches
64 hosts 64 hosts 64 hosts 64 hosts 64 hosts
(From Myricom)



































