Embed Size (px)
Citation preview

Autonomous Replication for High Availability in Unstructured P2P Systems
Francisco Matias Cuenca-Acuna,
Richard P. Martin,
Thu D. Nguyen
Department of Computer Science,
Rutgers University
April, 2003

Content
Introduction Background: PlanetP Autonomous Replication Performance Evaluation Conclusions

Introduction (1)
Peer-to-peer (p2p) computing becomes a powerful paradigm sharing information across the internet
Problem of providing high availability for shared data Recent measurements suggest
– Members of p2p communities may be offline more than they are online
Providing practical availability, say 99-99.9% would be– Expensive storage-wise using traditional replication methods– Expensive bandwidth-wise as peers leave and rejoin the
community

Introduction (2)
Question: Is it possible to place replicas of shared files in such a way that
– Files are highly available– Without requiring the continual movement of replicas to
members currently online
Propose a distributed replication algorithm– Decisions are made entirely autonomously by individual
members– Only need a small amount of loosely synchronized global
state

Introduction (3)
Assumption– Files are replicated in their entirety only when a member
hoards that file for disconnected operation– Otherwise, files are replicated using an erasure code– Study a very weakly structured system because tight
coordination is difficult and costly in dynamic environment

Background: PlanetP (1)
PlanetP is a publish/subscribe system– Support content-based search, rank and retrieval
Members publish documents when they wish to share
Publication of a document– Give PlanetP a XML snippet containing a pointer to the file– PlanetP indexes the XML snippet and the file– Local index is used to support content search

Background: PlanetP (2)
Two major components to enable community-wide sharing
– An gossiping layer Periodically gossip about changes to keep shared data weakly
consistent
– Content search, rank and retrieval service Two data structures to be replicated on every peer
– Membership directory: Contains names and addresses of all current members
– Global content index: Contains term-to-peer mapping

Background: PlanetP (3)
To locate content– Users pose queries at a specific node– Identify the subset of target peers from the local copy of
global content index– Query is passed to these target peers– The targets evaluate the query against their local indexes
and return results (URLs for relevant documents)
Results have shown that PlanetP can easily scale to sizes of several thousands

Autonomous Replication (1)
Member’s hoard set– Members hoard some subset of the shared files entirely on
their local storage– Members take responsibility for ensuring the availability
Replicator– Member is trying to replicate an erasure-coded fragment of
a file Target
– Peer that the replicator is asking to store the fragment Replicator store
– Excess storage space contributed by each member for replication

Autonomous Replication (2)
Each file is identified by a unique ID Overall algorithm
– Advertises the file IDs in its hoard set and the fragments in its replication store to the global index
– Periodically estimates the availability of its hoarded files and the fragments (Estimating Availability)
– Every Tr time units, increase the availability of a file that is not at a target availability (Randomized Replication)
– The target peer saves the incoming fragment (Replacement Scheme)

Estimating Files Availability (1)
Replicated in two manners– Entire copies– Erasure-coded file fragments
H(f): set of peers hoarding a file f F(f): set of peers containing a fragment f A(f): availability of f
– All nodes in H(f) are simultaneously offline– At least n-m+1 of the nodes in F(f) are offline
)( fFn

Estimating Files Availability (2)
H(f) and F(f) do not intersect– Peer adds a file for which it is storing a fragment to its hoard
set, it ejects the fragment immediately A(f) does not account for the possibility of duplicate
fragments– n >> m

Randomized Replication (1)
Erasure codes (Reed Solomon) provide data redundancy– Divide a file into m fragment and recode them into n fragment (m <
n) Generate all n fragments => detect and regenerate specific lost
fragments Disadvantages for highly dynamic environment
– Member availability changes over time Necessary to change n => re-fragmenting and replication of some files
– Peers leaving Accurate accounting of which peer is storing which fragment => regenerate
fragment loss
– Peers temporarily going offline Introducing duplicate fragments

Randomized Replication (2)
Choose n >> m but do not generate all n fragments To increase the availability of a file
– RANDOMLY generate an additional fragment from the set of n possible fragments
Chance of having duplicate fragments is small if n is very large
Not having any peer coordination

Replacement (1)
A target peer receives a replication request If its store is full
– Decide whether to accept the incoming fragment, OR– select other fragments to evict from its store
Choose the fragments with the highest availability to make space
– Deterministic algorithm => victimize fragments of the same file => drastic changes in the file’s availability
Propose Weighted Random Selection Process

Replacement (2)
Policy– Compute the average number of nines in the availability of
the fragments– Incoming fragment’s number of nines > 10% of this average
=> reject incoming fragment– Lottery scheduling to select victim fragments
Divide tickets into two subsets with 80:20 Each fragment is assigned an equal share of the smaller subset Fragments with availability above 10% of the average are given a
portion of the larger subset

Replacement (3)
Example– Target node has 3 fragments with availability 0.99, 0.9, 0.5– Number of nines => 2, 1, 0.3– Average availability in nines + 10% = 0.76– If we have 100 tickets
First fragment=67+6.6, Second fragment=13+6.6, Third fragment=0+6.6
– Chances of each fragment to be evicted First fragment=0.74, Second fragment=0.2, Third fragment=0.06
Use number of nines rather than the availability– It linearizes the differences between values

Replicators (1)
Select fragment to replicate Similar to replacement, lottery scheduling is used
– Favoring files with low availability
Find target peer– Select a target randomly– If the target does not have sufficient space, select another
target– Repeat this process for five times– If not success, randomly choose from these five targets

Experimental Environment (1)
Event driven simulator Assumption
– Members replicate files at synchronous intervals– Not simulate the detail timing of message transfers– Not simulate the full PlanetP gossiping protocol
To account for the data staleness, reestimate file availability only once every 10 minutes
– Use Reed Solomon code and m=10
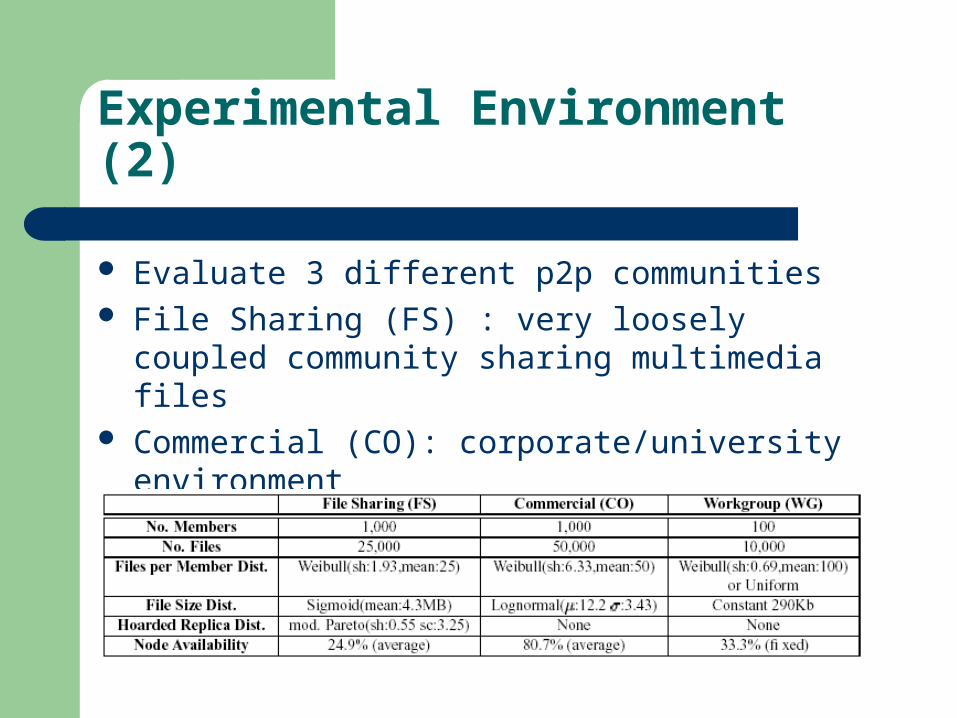
Experimental Environment (2)
Evaluate 3 different p2p communities File Sharing (FS) : very loosely coupled community
sharing multimedia files Commercial (CO): corporate/university environment Worgroup (WG): distributed development group

Experimental Environment (3)
Parameters– Per peer mean uptime and downtime– Peer arrival to and exit from the community as exponential
arrival process– Number of file per node– Number of hoarded replicas per file– Amount of excess space on each node– File sizes
BASE: nodes pushing and accepting replicas in the complete absences of information on file availability
OMNI: replication is driven by a central agent to maximize the minimum file availability
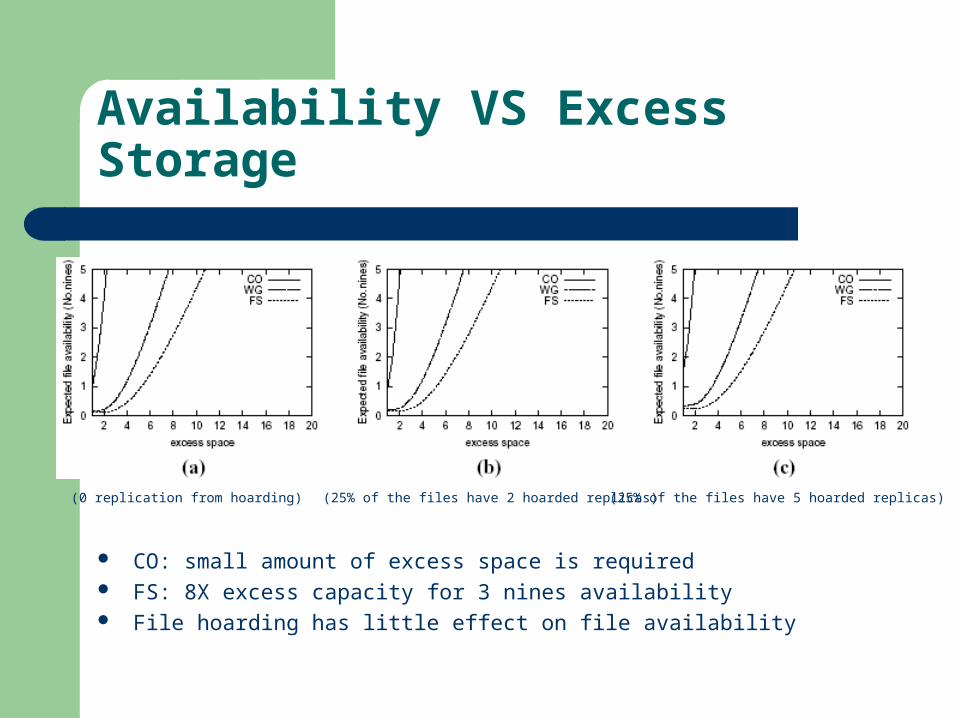
Availability VS Excess Storage
CO: small amount of excess space is required FS: 8X excess capacity for 3 nines availability File hoarding has little effect on file availability
(0 replication from hoarding) (25% of the files have 2 hoarded replicas) (25% of the files have 5 hoarded replicas)

Overall Availability (CDF)
(CO with 1X, 1.5X and 2X) (FS with 1X, 3X and 6X) (WG with 9X)
CO: 2X excess storage, over 99% of files with 3 nines availability FS: around 6X excess storage for 3 nines availability WG: performs better if files and excess storage are uniformly distributed
– Non-uniform => not easy for replicators to find free space on the subset of peers– Peers with the most files to replicate have the most excess storage

Against BASE
(CDF: Availability for FS with 3X) (BASE: number of fragments) (REP: number of fragments)
BASE: about 16% of files < a single nine availability Replacement policy can increase fairness BASE’s FIFO favors peers who are frequently online
– They push their files to less available peers even if the latter’s content should be replicated more

Bandwidth Usage
CO– REP: excess space from 1X to 2X => average number of
files replicated per hour from 10 to 0
FS– REP: excess space from 1X to 3X => average number of
files replicated per hour from 241 to 0– BASE: 3X excess space => replicate 816 files per hour

Conclusions
Address the question of increasing the availability of shared files
Study a decentralized algorithm under a very loosely coordinated environment
Achieve practical availability (99.9%) in a completely decentralized system with low individual availability
Such availability levels do not require– Sophisticated data structures– Complex replication schemes– Excessive bandwidth





























