Embed Size (px)
Citation preview

WHITE PAPER Building the Next-Generation Data Center | February 2011
building the next-generation data center – a detailed guide
Birendra Gosai CA Technologies, Virtualization Management

Building the Next-Generation Data Center
Table of Contents Executive summary 3
Virtualization maturity lifecycle 4 Purpose, target audience, and assumptions 4
Server consolidation 5 Migrate with confidence 5
Infrastructure optimization 10 Gain visibility and control 10
Automation and orchestration 14 Control VM sprawl 14
Dynamic data center 18 Agility made possible 18
Implementation methodology 22
How CA Technologies can help 23
References 23
About the Author 24
– 2 –

Building the Next-Generation Data Center
Executive summary
Challenge Server virtualization promotes flexible utilization of IT resources, reduced capital and operating costs, high energy efficiency, highly-available applications, and improved business continuity. However, virtualization brings along with it a unique set of challenges around management of the virtual infrastructure. These challenges are not just limited to technology, but include the lack of virtualization expertise—they result in roadblocks (or ‘tipping points’) during the virtualization journey, and prevent customers from advancing their virtualization implementations.
Opportunity Traditional management software vendors with long-standing expertise in mainframe and distributed environments are now delivering products and specialized services to manage the virtual environment. The virtualization management offerings by some of these vendors are mature, offer robust features, and have well defined roadmaps. These vendors bring decades of enterprise IT expertise into virtualization management—expertise which is essential to overcome ‘tipping points’ in the virtualization journey and accelerate adoption of this emerging technology within the enterprise.
Benefits IT organizations can now enjoy a consistent framework to manage and secure physical, virtual and cloud environments—thus gaining the same level of visibility, control, and security in the virtual environments that they are accustomed to in the physical ones. With these robust virtualization management capabilities, IT organizations can advance along the virtualization maturity lifecycle with confidence, better realize the capital expenditure (CapEx) and operating expense (OpEx) savings promised by this emerging technology, and operate an agile data center—thus serving as a true business partner instead of a cost center.
– 3 –

Building the Next-Generation Data Center
Virtualization maturity lifecycle Virtualization has the power to transform the way business runs IT, and it is the most important transition happening in IT today. It promotes flexible utilization of IT resources, reduced capital and operating costs, high energy efficiency, highly available applications, and better business continuity. However, the virtualization journey can be long and difficult as virtualization brings with it a unique set of challenges around the management and security of the virtual infrastructure. Most organizations struggle, sooner or later, with workload migrations, visibility and control, virtual machine (VM) sprawl, and the lack of data center agility.
Working with customers, industry analysts and other experts, CA Technologies has devised a simple 4-staged model, shown in Figure 1, to describe the progression from an entry-level virtualization project to a mature dynamic data center and private cloud strategy. These stages include server consolidation, infrastructure optimization, automation and orchestration, and dynamic data center.
+ +Figure 1.
Customer virtualization maturity cycle 1
+ +
Purpose, target audience, and assumptions Most organizations face one (or more) clear ‘tipping points’ during the virtualization journey where virtualization deployment stalls as IT stops to deal with new challenges. This ‘VM stall’ tends to coincide with different stages in the virtualization maturity lifecycle—such as the transition from tier 2/tier 3 server consolidation to the consolidation of mission-critical tier 1 applications; or from basic provisioning automation to a dynamic data center approach. This paper provides guidance on
– 4 –

Building the Next-Generation Data Center
the combination of people, process and technology needed to overcome virtualization roadblocks and promote success at each of the four distinct stages of the virtualization maturity lifecycle. For each of the four phases, we will discuss:
A definition of the phase and challenges associated with it
A high-level project plan for a sample implementation
The target audience of this paper is the director/VP of Operations/Infrastructure at IT organizations in mid-sized companies and departmental IT owner at large companies. This paper assumes that the IT organization has:
Deployed x86 server virtualization hypervisor(s), along with the requisite compute, network and storage virtualization resources, and related management software
Incorporated Intrusion Detection Systems (IDS)/Intrusion Prevention Systems (IPS)/firewall/vulnerability management software to secure the virtual and related physical systems components
Ensured virtual network segmentation using Virtual LANs (VLANs)/other technologies to meet internal best practices or compliance requirements
The tasks and timelines for sample project plans described in this paper will vary depending upon the size and scope of the project, available resources, number and complexity of candidate applications, and other parameters.
Server consolidation Server consolidation (using virtualization) is an approach that makes efficient use of available compute resources and reduces the total number of physical servers in the data center; it is one of the main drivers of virtualization adoption today. There are significant savings in hardware, facilities, operations and energy costs associated with server consolidation—hence it is being widely adopted within enterprises today.
Migrate with confidence The bottom line for IT professionals undertaking initial server consolidation is that any failure at this stage could potentially stall or end the virtualization journey. Organizations undergoing server consolidation face key challenges with:
Gaining insight into application configuration, dependency, and capacity requirements
Quick and accurate workload migrations in a multi-hypervisor environment
Ensuring application performance after the workload migration
The lack of virtualization expertise
– 5 –

Building the Next-Generation Data Center
The following section discusses the tasks and capabilities required to overcome these and other challenges, and migrate with confidence.
Project plan
A high-level project plan for a department-level server consolidation project within a mid-sized organization is presented here. It details some of the key tasks necessary for a successful server consolidation project. The timelines and tasks mentioned in Table 1 present a broad outline for a tier 2/tier 3 departmental server consolidation project that targets converting approximately 200 production and non-production physical windows and Linux servers onto about 40 virtual server hosts—the 2-3 person implementation team suggested for the project is expected to be proficient in project management, virtualization design and deployment, and systems management.
A successful server consolidation project necessitates a structured approach which should consist of the following high-level tasks. For each of these tasks we will discuss the key objectives and possible challenges, articulate a successful outcome, and more.
+ +Table 1.
Server consolidation project plan
+ +
# Tasks Weeks 1 2 3 4 5 6 7 8
Server consolidation workshop a
Application and system discovery/profiling b
Capacity analysis and planning c
Workload migration d
VM configuration testing e
Production testing and final deliverables f
Resources Weeks 1 2 3 4 5 6 7 8
a Project Manager and Architect
b Virtualization Analyst(s)
c Application and Systems Consultant(s)
d All of the above
– 6 –

Building the Next-Generation Data Center
Server consolidation workshop
A server consolidation workshop should identify issues within the environment that may limit the organization’s ability to successfully achieve expected results, and provide a project plan that details tasks, resources, and costs associated with the project. A well-defined checklist should be used to identify potential challenges with resources like servers, network, and storage. For example, the checklist should ensure that:
The destination servers are installed and a physical rack placement diagram is available that depicts the targeted location of equipment in the rack space provided
Highly available and high-bandwidth network paths are available between the virtual servers and the core network to support both application and management traffic
An optimum data store and connectivity to it is available for the virtual machine disks
The workshop should draw a complete picture of the potential challenges with the proposed server consolidation, and include concrete strategies and recommendations on moving forward with the project. It should result in the creation of a comprehensive project plan that clearly divides tasks among the implementation teams/individuals, defines timelines, contingency plans, etc., and is approved by all the key management and IT stakeholders.
Application and system discovery/profiling
Migrating physical workloads necessitates in-depth knowledge of the applications supported by them. Discovery and dependency mapping is one of the most important tasks during server consolidation as not knowing details of the environment can jeopardize the entire project. Although many vendors provide free tools for light discovery, these don’t dig deep enough to collect information necessary for successful server consolidation. The lack of detailed discovery and application/system dependency will result in problems during migration almost all of the time.
During the application discovery and profiling process, application and systems consultants should use a configuration management tool to store configuration and dependency details of the applications supported by the target workloads. These tools discover and snapshot application/system components to provide a comprehensive, cross-platform inventory of applications at a granular level, including directories, files, registries, database tables, and configuration parameters—thus allowing for greater success during workload migration.
Capacity analysis and planning
Once organizations have profiled the candidate applications/systems for consolidation, they will need to determine what host hardware configuration and VM configuration will support optimal performance and scalability over time. Comprehensive capacity analysis and planning is essential to determine the optimal resource requirements in the target virtual infrastructure, and allows IT organizations to plan additional capacity purchases (server/storage hardware, bandwidth, etc.) prior to starting the migration process.
– 7 –

Building the Next-Generation Data Center
Here too, there are free tools available, but they are generally very ‘services heavy’. In addition, they do not include important factors necessary for comprehensive capacity planning such as power consumption, service level requirements, organizational resource pools, security restrictions, and other non-technical factors. These tools also lack critical features such as what-if analysis, etc.
Capacity planning becomes even more important with critical applications. For instance, combining applications that have similar peak transaction times could have serious consequences, resulting in unnecessary downtime, missed SLAs and consequent credibility issues with internal customers. To avoid such issues, historical performance data from the applications should be utilized during the capacity planning process.
Workload migration
The workload migration process is easily the most complex component of an organization’s virtualization endeavor. The migration process refers to the “copying” of an entire server/application stack. IT organizations face several many challenges during workload migration—most end up migrating only 80-85% of target workloads successfully, and that too with considerable problems. Some of the challenges include:
Migration in a multi-hypervisor environment, and possible V2P and V2V scenarios
The flexibility of working with either full snapshots or performing granular data migration
In-depth migration support for critical applications like AD, Exchange, SharePoint, etc.
Application/system downtime during the migration process
There are free tools for migration available from some hypervisor vendors, but these don’t work well and require system shutdown for several hours for the conversion. They might also limit the amount of data supported or require running tests on storage to uncover and address bad storage blocks in advance. Backup, High Availability (HA) and IP based replication tools serve as a very good option for successful workload migrations as they not only help overcome/mitigate the abovementioned challenges, but can also be used for comprehensive BCDR (Business Continuity and Disaster Recovery) capabilities (discussed in section 2 of this paper).
From a process standpoint, ensure that the migrations are performed per a pre-defined schedule and include acceptance testing and sign-off steps to complete the process. Ensure contingency plans, and factor in a modest amount of troubleshooting time to work out minor issues in real-time and complete the migration of that workload at that time rather than rescheduling downtime again later.
– 8 –

Building the Next-Generation Data Center
VM configuration testing
Configuration error is the root cause of a large percentage of application performance problems—post migration VM configuration testing prevents performance and availability problems due to configuration error. Another key post-migration challenge is preventing configuration drift; maintaining various disparate VM/OS/application base templates can be very challenging—and IT organizations can significantly ease configuration challenges by using a few well-defined gold standard templates. Post migration, application/systems consultants should use change and configuration management tools to:
Compare to validated configurations (stored during the discover/profiling task) after migration
Detect and remediate deviations from the post-migration configuration or gold standard templates
These and related actions are essential to enable a successful migration, debug post-migration issues if any, and prevent configuration drift.
Production testing and final deliverables
The breadth and depth of post-migration testing will vary according to the importance of the migrated workload—less critical workloads might require only basic acceptance tests, while critical ones might necessitate comprehensive QA tests. In addition, this task should include follow up on any changes that the migration teams should have applied to a VM but are unable to perform due to timing or need for additional change management approval. All such post-migration recommendations should be noted, as appropriate, within the post-test delivery document/s.
This final stage of the implementation process should include delivery of documentation on the conversion and migration workflow and procedures for all workloads. Doing so will remove dependency on acquired tribal knowledge and allow staffing resources to be relatively interchangeable. These artifacts and related best practices documents will also allow continuation of the migration process for additional workloads in an autonomous fashion in the future if desired.
– 9 –

Building the Next-Generation Data Center
Infrastructure optimization IT organizations today are experiencing pressure to not only adopt new and emerging technologies like virtualization, but also reduce costs and do more with fewer resources (thus reducing CapEx)—all while delivering assurance of capacity and performance to the business. However, organizations that have successfully consolidated their server environment and are progressing on their virtualization journey, often find it difficult to virtualize tier 1 workloads. They also face significant challenges in utilizing the hosts at higher capacity. This happens because they lack the confidence to move critical application onto the virtual environment, or utilize servers to capacity.
A mature and optimized infrastructure is essential for IT organizations to virtualize tier 1 workloads and achieve increased capacity utilization on the virtual hosts—thus helping reap the true CapEx savings promised by virtualization.
Gain visibility and control Organizations face significant challenges in trying to achieve the visibility and control necessary to optimize their virtual infrastructure. These include:
Providing performance and Service Level Agreement (SLA) assurance to the business
Deploying and maintaining capacity on an automated basis
Securing access to the virtual environment and facilitating compliance
Providing business continuity in the event of a failure
The following section discusses the tasks and capabilities required to optimize the infrastructure and gain visibility and control into the availability and performance of the virtual environment.
Project plan
A high-level plan for an infrastructure optimization project is presented here. The timelines and tasks mentioned in Table 2 present a broad outline for a tier 1 infrastructure optimization project that targets setting up an optimized infrastructure and adding approximately 10 critical production workloads to about 40 virtual server hosts (with existing workloads)—thus resulting in a 80-90% capacity utilization on those servers. The 3-4 person implementation team suggested for the project is expected to proficient in project management, virtualization design and deployment, and systems management.
A successful infrastructure optimization project necessitates a structured approach which should consist of the following high-level tasks. For each of these tasks we will discuss the key objectives and possible challenges, articulate a successful outcome, and more. Since workload migration and production testing were discussed in the previous section, they are not repeated here.
– 10 –

Building the Next-Generation Data Center
+ +Table 2.
Infrastructure Optimization project plan
+ +
Performance and fault monitoring
Prior to moving critical workloads onto the virtual environment, IT operations teams need to ensure that they have clear visibility and control into the availability and performance of the virtual environment. To foster this visibility and control, application/systems consultants should use performance management tools to:
Discover the virtual environment and create an aggregate view of the virtual infrastructure: This discovery should be dynamic and not static—i.e. the aggregate view should automatically reflect changes in the virtual environment that result from actions such as vMotion. In addition, this discovery should not only reflect the virtual environment, but also components surrounding the virtual network.
Setup event correlation: In a production environment where hundreds of events may be generated every second by the various components, event correlation is extremely essential to navigate through the noise and narrow down the root cause of active or potential problems.
# Tasks Weeks 1 2 3 4 5 6 7 8
a Performance and fault monitoring
b Continuous capacity management
c Change and configuration mgmt
d Workload migration
e Privileged user mgmt and system hardening
f Business continuity and disaster recovery
g Production testing, and final deliverables
Resources Weeks 1 2 3 4 5 6 7 8
a Virtualization Analyst(s)
b Application and Systems Consultant(s)
c All of the above
Enable real-time performance monitoring and historical trending: The performance monitoring should go beyond the basic metrics like CPU/memory consumption and provide insight into the traffic responsiveness across hosts. Trending capabilities are also essential to monitor and be cognizant of historical performance.
Capabilities like the ones mentioned above provide IT administrators and business/application owners the confidence to move critical production applications into the virtual environment.
– 11 –

Building the Next-Generation Data Center
Continuous capacity management
Critical applications depend on multiple components in the virtual environment. Given the dynamic nature of the virtual environment and high volume of workloads processed by virtual servers, it is almost impossible for administrators to create and manage capacity plans on a project by project basis. Therefore, managing critical workloads requires automating the manual steps of capacity management, thus enabling continuous capacity management. A continuous capacity management environment should:
Collect and correlate data from multiple data sources, update dashboards with the current state of utilization across virtual and physical infrastructure, and publish reports on the efficiency of resource utilization for each application/business service
Highlight opportunities for optimization, solve resource constraints, update baselines in predictive models, utilize the predictive model to produce interactive illustrations of future conditions
Integrate with provisioning solutions for intelligent automation, and eco-governance solutions to help maintain compliance with environmental mandates
The level of continuous capacity management described above, along with comprehensive analytic and simulation modeling capabilities, will allow the IT administrator to effectively manage the capacity of critical applications/services on an ongoing basis.
Change and Configuration Management (CCM)
Pre/post migration configuration discovery and testing is essential to enable successful server consolidation. However, IT organizations that support tier 1 workloads cannot afford to perform these activities on a one-time project basis. Optimized infrastructures need continuous CCM not only for the workloads, but also for the infrastructure itself. In a highly dynamic environment, erroneous virtual infrastructure configuration can have drastic effects on VM performance. Comprehensive CCM involves:
Providing ongoing configuration compliance with system hardening guidelines from the Center for Internet Security (CIS), hypervisor vendors, etc.
Tracking virtual machines, infrastructure components, applications, and the dependencies between them on a continuous basis
Monitoring virtual infrastructure configuration and its association with workload performance
Implementing comprehensive CCM for the virtual environment will not only help avoid configuration drift and its impact to workload performance, but also facilitate compliance with vendor license agreements and regulatory mandates like Payment Card Industry Data Security Standards (PCI DSS), Health Insurance Portability and Accountability Act (HIPAA), Sarbanes-Oxley Act (SOX), etc.
– 12 –

Building the Next-Generation Data Center
Privileged user management and system hardening
Privileged users enjoy much more leverage in the virtual environment as they have access to most virtual machines running on a host—hence tight control of privileged user entitlements is essential. This task should ensure that:
Access to critical system passwords is only available to authorized users and programs
Passwords are stored in a secure password vault, and not shared among users or hardcoded in program scripts
Privileged user actions are audited and the audit-logs are stored in a tamper-proof location
In addition to privileged user management which protects from internal threats, IT organizations need to ensure that their servers are secure from malicious external threats. This includes installing antivirus/antimalware software to protect against these external threats, and making sure that the systems conform to the comprehensive system hardening guidelines provided by the hypervisor vendors.
Business continuity and disaster recovery (BCDR)
BCDR has long been an essential requirement for critical applications and services—this includes backup, high availability and disaster recovery capabilities. However, server virtualization has changed the way modern IT organizations view BCDR. Instead of the traditional methods of installing and maintaining backup agents on each virtual machine, IT organizations should utilize tools that integrate with snapshot and off-host backup capabilities provided by most hypervisor vendors—thus enabling backups without disrupting operations on the VM and offloading workload from production servers to proxy ones. Activities within this task should ensure that:
Machines are backed up according to a pre-defined schedule, and granular restores using push button failback are possible
Critical applications and systems are highly available, and use automated V2V or V2P failover for individual systems/clusters
Non disruptive recovery testing capabilities are available for the administrators, etc.
The one week timeline scheduled for this task assumes the existence of comprehensive BCDR plans for the physical workloads, which then only need to be translated into the virtual environment.
– 13 –

Building the Next-Generation Data Center
Automation and orchestration IT organizations that have successfully consolidated and optimized their virtual infrastructures face a unique set of virtualization management challenges. Server provisioning that used to take weeks can now be achieved in minutes, and results in increased virtualization adoption within the business. This increased adoption results in 'VM sprawl’ (the problem of uncontrolled workloads), increased provisioning and configuration errors, and the lack of a detailed audit trail—all of which significantly increase the risk of service downtime.
Organizations that try to tackle this problem with increase in manpower will fail to get their hands around the problem. In addition, IT managers/CIOs don't want expensive IT staff to do mundane repetitive tasks, but focus their time on important strategic initiatives. Automation and Orchestration capabilities are extremely essential to tackle VM sprawl, reduce provisioning errors, improve audit capabilities, and achieve the significant savings in OpEx promised by server virtualization.
Control VM sprawl Organizations face multiple challenges when trying to automate and orchestrate their virtual environments and obtain the reduction in OpEx achievable by server virtualization. These include:
Faster provisioning of standardized servers/applications into heterogeneous virtual and cloud environments
Process integration across heterogeneous platforms, applications and IT groups
Standardized configuration and compliance
The following section discusses the tasks and capabilities required to incorporate automation and orchestration capabilities within the virtual environment, thus helping control VM sprawl and reduce OpEx.
Project plan
A high-level plan for a sample project to automate application provisioning and build associated orchestrations is presented here. The timelines and tasks mentioned in Table 3 present a broad outline for a lab management project with approval orchestration, showback, and the ability to test composite applications spanning multiple VMs. Other sample projects could be an automated self-service reservation management system, production/staging environment management, demos on demand capability, educational labs, etc. The IT capabilities required for these projects are almost similar, but the design and workflows required will be different. The 3-4 person implementation team suggested for the project is expected to proficient in project management, virtualization design and deployment, and systems management.
– 14 –

Building the Next-Generation Data Center
A successful automation and orchestration project necessitates a structured approach which should consist of the following high-level tasks. For each of these tasks we will discuss the key objectives and possible challenges, articulate a successful outcome, and more.
+ +Table 3.
+ +
# Tasks Weeks 1 2 3 4 5 6 Automation and orchestration project plan
a System design
b Resource pool deployment
c VM template and lifecycle management
d Workflow orchestration
e Showback configuration
f Monitoring, production testing, and final deliverables
Resources Weeks 1 2 3 4 5 6
a Project Manager and Architect
b Virtualization Analyst(s)
c Application and Systems consultant(s)
d All of the above
System design
A lab management system enables IT organizations to provide a web-based self-service reservation system so that users can reserve and deploy customized server and virtual machine instances without administrator intervention. The system design begins with application/systems consultants interviewing IT administrators and users to better understand the business requirements and workflows. The requirements should be captured, analyzed, and refined over multiple interviews and/or white-boarding sessions, and result in the development of comprehensive workflows. A well-defined checklist should be used to identify important details such as:
Usage characteristics, roles and access entitlements of the various users
Operating system/other software needs and system maintenance requirements
Approval workflows, reporting needs, HA/DR requirements, etc.
The system design phase should result in the creation of a comprehensive project plan that clearly details the deliverables, defines timelines, contingency plans, etc., and is approved by all the key business and IT stakeholders.
– 15 –

Building the Next-Generation Data Center
Resource pool deployment
The lab management system will be required to serve several departments within the organization—each of which might have different availability requirements. Resource pools are a very easy and convenient way for IT administrators to manage departmental requirements. Setting up resource pools involves:
Defining resource pools to better manage and administer the system for different departments/organizations. Resource pool definitions should consider service level/Quality of Service (QoS) requirements of the applications supported by the resource pools, HA and BCDR requirements, etc.
Attaching appropriate compute, network and storage resources to the resource pool
Integrating with performance monitoring products to consume data on usage thresholds and perform dynamic balancing of the resource pools
Careful planning during resource pool design and deployment will significantly reduce manual administration requirements and helpdesk calls during regular operations.
VM template and lifecycle management
Template based provisioning capabilities are present in all automation products. This task involves creating VM templates, defining a default lifecycle for provisioning and de-provisioning VMs, etc. Careful consideration should be given to the following during this phase:
Software license requirements and integration with Asset Management products if necessary
Integration with identity management products to import user and role information and providing a personalized experience to the users
Setting up template availability rules for different user roles, and orchestrating workflow if necessary
A properly configured VM lifecycle significantly improves the user experience, reduces helpdesk calls, and helps control/arrest virtual sprawl.
Workflow orchestration
Workflow orchestration goes hand in hand with the automation system—allowing organizations to design, deploy and administer the automation of manual, resource-intensive and often inconsistent IT operational procedures. For the lab management system discussed here, workflow orchestration will incorporate:
Design of essential workflows such as reservation/access approvals, system availability, change notifications, etc.
Integration with relevant enterprise systems—such as email, identity management/LDAP, asset management, etc.—to enable the workflow
– 16 –

Building the Next-Generation Data Center
Execution of the workflow while maintaining insight into the process, audit records, and other details for administration and compliance
A good orchestration engine will speed the delivery of IT services while helping to remove manual errors—by defining, automating and orchestrating processes across organizational silos that use disparate systems, it helps improve productivity while also enforcing standards.
Showback configuration
Showback is essential to inform users about the cost of their system reservation and report on their usage. It is different from chargeback, which integrates with financial systems to provide a comprehensive bill to the business units requesting resources. Showback provides users with a comprehensive view of their costs depending upon the reservation options, duration/time of reservation, etc. It also allows administrators to generate detailed usage reports by Lines of Business (LOB), geographical location, asset type, etc.
During the showback configuration task, reservation options should be evaluated and costs assigned to the different options and services offered in the lab management system. The system should either be orchestrated to get these details from other financial/asset management software or approximate values should be derived from previous metrics available within the IT organization.
Monitoring, production testing, and final deliverables
The monitoring and production testing details for this project will be similar to the ones discussed in the previous sections. In addition, this final deliverable should document the system design, deployment, testing and orchestration details for knowledge transfer. It should include
An architecture and design guide that will document client business requirements combined with best practices guidelines
An assembly, configuration and testing guide that will enable building the system in accordance to the abovementioned architecture and design guide
Formal user focused training customized to above architecture will facilitate knowledge transfer of final design and usage policies/procedures as well as level set knowledge base amongst the entire user group.
– 17 –

Building the Next-Generation Data Center
Dynamic data center A dynamic data center is an IT environment that not only supports the business, but at times, is part of the product delivered by the business. It is an agile IT environment, built on top of an optimized and automated virtual infrastructure (discussed in the previous two sections), that is:
Service oriented – delivering on-demand, standardized services to the business (internal customers, partners, etc.)
Scalable – with the ability to span heterogeneous physical, virtual and cloud environments
Secure – providing security as a service to internal/external customers
Agility made possible The dynamic data center is neither a one-size-fits-all solution, nor an endless pit where CIOs should invest money and resources to obtain capabilities not needed for their business. However, IT organizations trying to build a dynamic data center face some fundamental challenges such as:
Delivering a standard set of tiered-services (with well-defined SLAs) that are consumable by business users
Service oriented automation and orchestration that spans heterogeneous physical, virtual and cloud environments
Ensuring security, compliance and QoS for the entire service
Providing a comprehensive service interface that serves as a visual communication tool between IT and the business
The following section discusses the basic tasks and capabilities required to build and maintain a dynamic data center that allows IT departments to serve as an agile service provider and drive competitive differentiation for the business.
Project plan
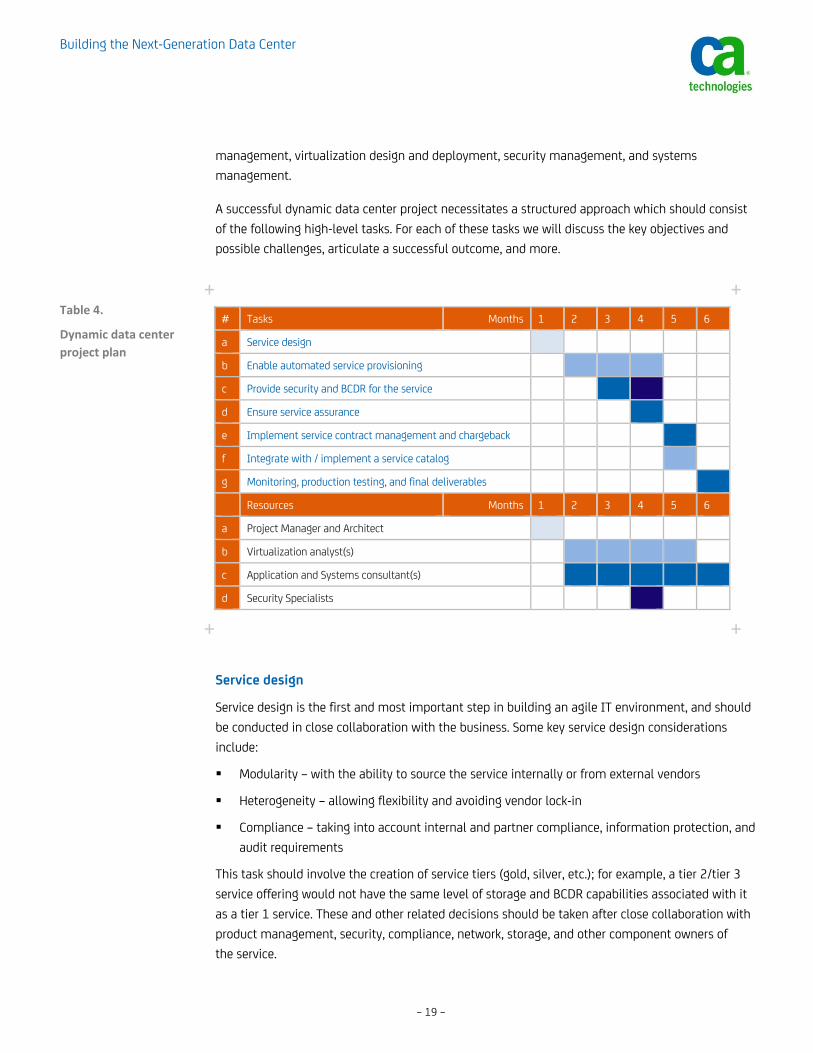
A high-level project plan for a sample scenario that would be part of achieving dynamic data center is presented here. The timelines and tasks mentioned in Table 4 present a broad outline for a mid-tier IT project that is focused on supporting expanding business initiatives with agility. Forward Inc has identified a lucrative opportunity in offering one of its internal services (e.g. billing, shipping, order management, Electronic Medical Records, etc.) to a host of new local and international partners. This would not only allow Forward Inc to profit from its IT investments, but also provide valuable services to its partners—thus helping improve partner retention/expansion.
The project assumes the availability of an optimized infrastructure with comprehensive automation and orchestration capabilities (as discussed in the previous two sections of this paper). The 4-6 person implementation team suggested for the project is expected to proficient in project
– 18 –
Building the Next-Generation Data Center
management, virtualization design and deployment, security management, and systems management.
A successful dynamic data center project necessitates a structured approach which should consist of the following high-level tasks. For each of these tasks we will discuss the key objectives and possible challenges, articulate a successful outcome, and more.
+ +Table 4.
Dynamic data center project plan
+ +
Service design
Service design is the first and most important step in building an agile IT environment, and should be conducted in close collaboration with the business. Some key service design considerations include:
Modularity – with the ability to source the service internally or from external vendors
Heterogeneity – allowing flexibility and avoiding vendor lock-in
Compliance – taking into account internal and partner compliance, information protection, and audit requirements
This task should involve the creation of service tiers (gold, silver, etc.); for example, a tier 2/tier 3 service offering would not have the same level of storage and BCDR capabilities associated with it as a tier 1 service. These and other related decisions should be taken after close collaboration with product management, security, compliance, network, storage, and other component owners of the service.
# Tasks Months 1 2 3 4 5 6
a Service design
b Enable automated service provisioning
c Provide security and BCDR for the service
d Ensure service assurance
e Implement service contract management and chargeback
f Integrate with / implement a service catalog
g Monitoring, production testing, and final deliverables
Resources Months 1 2 3 4 5 6
a Project Manager and Architect
b Virtualization analyst(s)
c Application and Systems consultant(s)
d Security Specialists
– 19 –

Building the Next-Generation Data Center
Enable automated service provisioning
Automated service provisioning is the ability to provision, on demand, an instance of the service in a private, public or hybrid cloud. Some of the tasks involved in this process include:
Performing workload migrations, if necessary, of service components (servers, applications, databases, etc.)
Automating provisioning of the entire service infrastructure using template-based provisioning capabilities offered by next-generation automation tools
Orchestrating integrations between the service components, including approval workflows, integration with change and configuration management systems, helpdesk software, etc.
With the ability to provision across multiple platforms, IT organizations will retain the flexibility to in-source/outsource the entire service/components of it, to public or private data centers.
Provide security and BCDR for the service
The security in context here builds on the already optimized and automated infrastructure discussed in the previous sections (which includes IDS, IPS, Firewall, VLAN and PUPM capabilities). The capabilities discussed below are necessary considering the dynamic nature of service in context, and include
Installing security policies on the VMs associated with the service, and providing for the appropriate policy to be in place irrespective of the VM location (i.e. within an internal production/staging cloud, or external cloud)
Implementing Web Access Management software to permit only authenticated and authorized users to have access to critical resources within the service
Using identity federation technologies to maintain a clear distinction between the identity provider (partner) and the service provider (business)
Providing for backup and high-availability of the service
Security is one of the top concerns in the minds of the business as any major breach can not only cause financial damage but also affect customer loyalty and brand image. In addition to securing the service, the abovementioned capabilities also allow IT to leverage security services for business enablement.
Ensure service assurance
The modular and scalable nature of the service, coupled with the dynamic nature of the virtual environment, necessitates service-centric assurance—the ability to monitor the availability and performance of the service (application plus the underlying infrastructure) as a whole. This task involves:
Building and maintaining an end-to-end model of the infrastructure supporting the service
– 20 –

Building the Next-Generation Data Center
Real-time monitoring of events and notifications from the service components
Providing a dashboard for customers to view service availability/quality status
Serving data to SLA management tools regarding service availability, performance, etc.
Monitoring of service components in silos is not only cumbersome, but can fail to detect critical inter-dependent errors. Service-centric assurance significantly reduces management costs by providing a single portal for administration, improving service quality and reducing risk.
Implement service contract management and chargeback
In today’s competitive business environment, accountability and transparency are essential to maintain customer satisfaction. To do so, IT organizations need to define, manage, monitor and report on their SLAs in a timely manner. To enable this, IT analysts should:
Define easy-to-understand SLAs; this definition should include metrics such as system availability, helpdesk response times, Mean Time To Repair (MTTR) for reported problems, etc.
Aggregate service-level information from disparate operational systems (network monitoring solutions, application monitoring solutions, helpdesk systems, etc.), and compare it to performance objectives for each customer
Report on these SLAs in a scheduled manner, and tie them back to the chargeback system
Performing these tasks manually or on a project basis will not be sustainable over the long run—automated service contract management and chargeback capabilities are essential to allow the end customer track, on demand, the responsiveness of IT services. In addition, chargeback capabilities should be linked to contract management, thus ensuring customer satisfaction with service delivery, and easing the burden of financial accounting.
Integrate with/implement a service catalog
A service catalog serves as a front end for IT to interface with business users. It is a perfect portal for publishing role-based services to internal/external users—allowing them to subscribe to services delivered by IT. Organizations that have already implemented a service catalog should look to publish this service within the existing catalog implementation. Since the end consumer for the service is most probably a business user, it is essential to ensure that the service is easily described in business terms instead of technical jargon.
Service desk integration is also essential as there is generally a learning curve involved with new services—a good service desk and related knowledge base implementation prevents IT from being inundated with individual requests.
– 21 –

Building the Next-Generation Data Center
Monitoring, production testing, and final deliverables
The monitoring and production testing requirements for this project will be similar to the ones discussed in the previous sections. In addition, the large scope of the project might necessitate a structured beta program with a controlled group before the service is rolled out to a large audience of partners.
Implementation methodology Virtualization is a relatively new technology, and not all IT organizations have strong in-house expertise or experience with virtualization implementations. The Virtual Infrastructure Lifecycle Methodology (described in Figure 2) from CA Technologies is an excellent example of leveraging enterprise experiences and industry best practices to carefully navigate each stage of virtualization adoption. It helps ensure that the key aspects of virtualization are accounted for and addressed, thus enabling a smooth deployment without the remediation delays that are common to many virtualization initiatives. The Virtual Infrastructure Lifecycle Methodology is based upon actual practical experience gained from the delivery of virtual infrastructure to many Fortune 500 enterprise environments, and is widely adopted by CA Services teams and partner organizations.
+ +Figure 2.
Virtual Infrastructure Lifecycle Methodology from CA Technologies2
+ +
Analyze – Define the business objectives for adopting virtualization along with TCO/ROI analysis. Execute a broad assessment of the environment including existing people, process, and technologies to identify potential gaps that will impact adoption. Create a
go-forward strategy supported by actionable steps to ensure success.
Design – Consider implementation and support requirements by developing staffing and training plans. Identify and document functional and non-functional requirements that will shape the design. Create a detailed architectural design and plan for the
implementation.
Implement – Institute a program portal or other medium for communicating key content like policy, project status, etc. Start adapting existing operational processes to support the virtualization and cloud infrastructure. Install and configure the solution as specified by the plan and blueprints.
Optimize – Identify and develop areas to drive more efficiency in the virtual infrastructure based on experiences to this point. Implement means to monitor the usage of resources and harvest capacity through reclamation. Perform financial tracking of usage to rationalize growth while adding continuity and leveraging external clouds.
– 22 –

Building the Next-Generation Data Center
How CA Technologies can help People, process and technology are three key ingredients to achieve the reduction in CapEx/OpEx, and improved data center agility with virtualization. Figure 3 summarizes the key capabilities required by IT organizations at each phase of the virtualization maturity lifecycle to overcome ‘tipping points’ in the virtualization journey and gain the same level of visibility, control, and security in the virtual environments, that they’ve been accustomed to in the physical ones.
CA Technologies recently introduced CA Virtual, a comprehensive portfolio of products to provision, control, manage, secure and assure heterogeneous virtual environments. Products in the CA Virtual portfolio are not only quick to deploy and easy to use, but also provide an on-ramp to manage heterogeneous physical, virtual, and cloud environments. For further information, please visit ca.com/virtual or ca.com/virtualization.
+ +Figure 3.
Overcoming virtualization 'tipping points'
+ +
References 1. CA Technologies virtualization maturity lifecycle: ca.com/virtual or ca.com/virtualization
2. CA Technologies (ex 4Base) Virtual Infrastructure Lifecycle Methodology: ca.com/4base
– 23 –

Building the Next-Generation Data Center
– 24 –
About the Author
Birendra Gosai has a Masters degree in Computer Science and over ten years of experience in the enterprise software industry. He has worked extensively on data warehousing, network and systems management, and security management technologies. At present, he works in the virtualization management business at CA Technologies.
+ +
CA Technologies is an IT management software and solutions company with expertise across all IT environments—from mainframe and distributed, to virtual and cloud. CA Technologies manages and secures IT environments and enables customers to deliver more flexible IT services. CA Technologies innovative products and services provide the insight and control essential for IT organizations to power business agility. The majority of the Global Fortune 500 rely on CA Technologies to manage their evolving IT ecosystems. For additional information, visit CA Technologies at ca.com.
+ +
Copyright ©2011 CA. All rights reserved. Exchange and SharePoint are registered trademarks of Microsoft Corporation in the U.S. and/or other countries. Linux is the registered trademark of Linus Torvalds in the U.S. and other countries. All trademarks, trade names, service marks and logos referenced herein belong to their respective companies. This document is for your informational purposes only. CA assumes no responsibility for the accuracy or completeness of the information. To the extent permitted by applicable law, CA provides this document “as is” without warranty of any kind, including, without limitation, any implied warranties of merchantability, fitness for a particular purpose, or noninfringement. In no event will CA be liable for any loss or damage, direct or indirect, from the use of this document, including, without limitation, lost profits, business interruption, goodwill, or lost data, even if CA is expressly advised in advance of the possibility of such damages. CS0414_0211





























