Embed Size (px)
Citation preview

Automatic Spoken Document Processing for Retrieval and Browsing
Zahra Ahmadi

Outline
• Motivation • Typical speech retrieval system• Works done• Dealing with OOV • Improvements
2

Motivation
• Ever-increasing computing power and connectivity bandwidth, together with falling storage costs resulting in an overwhelming amount of data of various types
• Information search and retrieval is a key application area • Less attention to speech search
• As data availability increases, lack of adequate technology for processing spoken documents becomes the limiting factor to large-scale access to spoken content
• Automatic approaches for indexing and searching spoken document collections are very desirable
3

Typical Speech Retrieval System
• Two primary processing stage: ▫ Offline process of audio content to generate index▫ Query searches via interface and system’s retrieval based
on indexes • ASR is the core component of speech retrieval system
4

SDR Challenges
• Primary difficulties due to limitations of ASR technology:▫ Highly spontaneous, unprepared speech▫ Topic-specific or person-specific vocabulary & language
usage▫ Unknown content and topics potentially lacking support in
general language model▫ Wide variety of accents and speaking styles▫ OOVs in queries▫ Infrequent query terms, which are most useful for retrieval
5

Prominent Approaches
• Many of prominent research efforts: SDR-TREC in 1999-2000
• Significant recent contributions on wide variety of speech sources: ▫ SpeechBot: audio from public web sites▫ SCANMail: voice mail▫ Oral history interviews▫ SpeechFind: National Gallery of the Spoken Word (NGSW)
consisting of speeches, news broadcasts, and recordings that are of significant historical content
6

TREC-SDR: A Success Story
• About 550 hours of broadcast news • Segmented manually into 21,574 stories of 250 words on
average• Evaluation of ASR systems tuned to broadcast news domain:
15-20% WER• Preexisting approximate manual transcriptions had WER of
14.5% for video and 7.5% for radio broadcasts • Accuracy evaluation: by human assessors search queries
• Retrieval performance was flat with respect to ASR WER (1-best) variations in the range of 15-30% (robust to recognition errors)
• No severe degradation in retrieval performance when evaluating with ASR outputs in comparison with approximate manual transcriptions
7

TREC-SDR Robustness Results
8

Shortcomings of TREC-SDR
• Speech recognizers tuned heavily for domain:▫ Lead to very good ASR performance▫ Unrealistic to expect 10–15% WER especially when
decoding speech is mismatched to the training data▫ Common to observe WER of 30-50%
• Very low OOV rates: ▫ Typically below 1%▫ Query-side OOV (Q-OOV) was very low as well
By Q-OOV rate close to 15%, severe degradation in MAP performance (50% relative, from 44 to 22) occurs
9

Dealing with OOV Query Words
• Most common: represent both query and spoken document using subword units:▫ Linguistically:
Phone: completely solves OOV problem, low performance Syllable: stable acoustically, poor language model Morpheme: hard to distinguish acoustically Stem-ending: acceptable OOV, distinguishable segment
(agglutinative lang.)
▫ Data driven: Multigram: non-overlapping, variable-length, phone
subsequences with some predefined maximum length Particle: found greedy to max. leave-one-out likelihood of
bigram LM Morph: based on minimum description length
10

Dealing with OOV Query Words (cont)
• Advocates tighter integration of ASR and IR:▫ Index phone n-grams appearing in ASR N-best lists▫ Focused on broadcast news thus benefiting from good ASR
performance
• Combination of word and subword level indexing: ▫ word-level indexing and querying is still more accurate▫ abundance of word-spotting false-positives in subword
retrieval▫ somewhat masked by the MAP measure
11
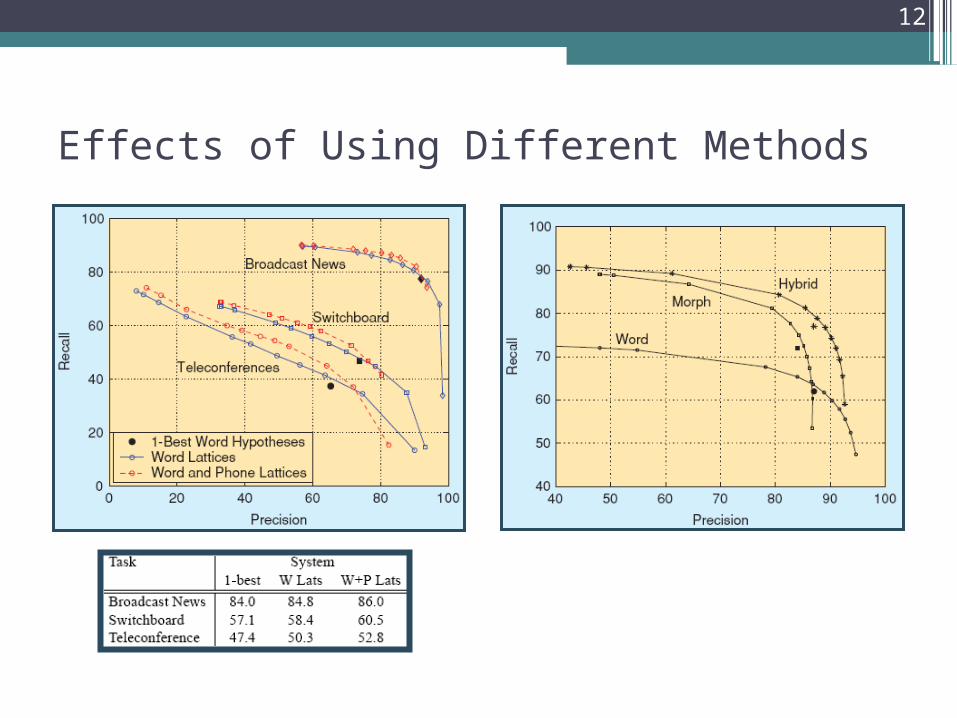
Effects of Using Different Methods
12

Dealing with OOV Query Words (cont)
• Building inverted index from ASR lattice:▫ Storing full connectivity information in lattice ▫ Retrieval is performed by looking up strings of units▫ Allows for exact calculation of n-gram expected counts but
more general proximity information is hard to calculate
• Query expansion: ▫ Expand to similar in-vocabulary phrases▫ Phone confusion matrix: acoustic confusion between words▫ Stemming ▫ Semantic similarity
Use of more than just one-best information (N-best lists or lattices) significantly improves retrieval accuracy
13

Long Spoken Communications
• Important to locate the relevant portion• Achievable by segmenting documents into topics and
locating topics • Spoken Utterance Retrieval (SUR): where segments are
short or when consist of short utterances• SUR goal is to find all utterances containing query• Applications: browsing broadcast news, telephone
conversations, teleconferences, and lectures• NIST STD 2006 Evaluation :
▫ Locating exact occurrence of query in large heterogeneous speech archives
▫ Notable technique with significant improvements: setting detection thresholds in a term-specific fashion to maximize ATWV metric
14

Spoken Document Understanding & Organization
Keywords in spoken document to
understand subject matters
Automatically extracting key information of
events in segmented short
paragraphsAutomatically
segmented into short
paragraphs with some
central concept
Automatically generating
summery for each
segmented short
paragraphs
Automatically generating title for each
short paragraph
Automatically analyzing subject
topics of segmented paragraphs,
clustering with topic labels, organizing
hierarchical presentation
15

Finally…
• Use of audio content and text metadata jointly can improve retrieval performance
• Conjunction of subword and word-based methods improves performance
• Need to universal ASR which controls variance in WER across narrow domains as SDR poses new challenges for the core ASR
• Cross-Language SDR: Assumes queries and target spoken documents are not in the same language ▫ Bilingual performance was lower than English monolingual run▫ However, the degree of degraded performance was shown to
depend on the translation resources used.▫ Extension of TREC collections by manually translating short
topics into five European languages: Dutch, French, German, Italian, Spanish
16
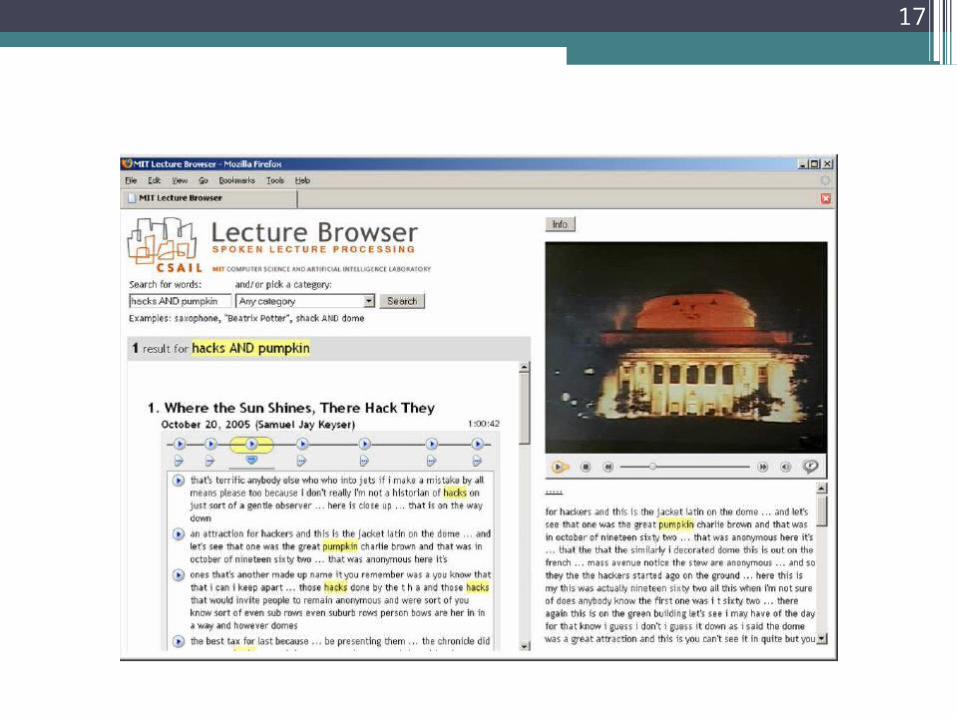
17

References
• C. Chelba, T.J. Hazen, M. Saraclar. “Retrieval and Browsing of Spoken Content”. IEEE Signal Processing Magazine, May 2008.
• L. Lee, B. Chen. “Spoken Document Understanding and Organization”. IEEE Signal Processing Magazine, September 2005.
• J. Garofolo, G. Auzanne, and E. Voorhees. “The TREC Spoken Document Retrieval Track: A Success Story”. Proc. Recherche d’Informations Assiste par Ordinateur: Content Based Multimedia Information Access Conf., 2000.
• L. Begeja, D. Gibbon, et. Al. “A System for Searching and Browsing Spoken Communications”. 2004.
• S. Parlak, M. saraclar. “Spoken Term Detection for Turkish Broadcast NEWS”. ICASSP 2008.
• N. Bertoldi, M. Federico. “Cross-Language Spoken Document Retrieval on the TREC SDR Collection”. Springer, pp.476-481, 2003.
• C. Chelba, T.J. Hazen. “Automatic Spoken Document Processing for Retrieval and Browsing”. Tutorial slides, NAACL 2006.
• …
18





























