Embed Size (px)
Citation preview

Automatic Generation of Efficient
Accelerator Designs for
Reconfigurable Hardware
Stanford University
ISCA 2016
David Koeplinger Raghu Prabhakar Yaqi Zhang
Christina Delimitrou Christos Kozyrakis Kunle Olukotun

FPGAs in Data Centers
Increasing interest in use of FPGAs as application accelerators in data centers
2
Key advantage: Performance/Watt

Problem: Large Design Spaces
Design spaces grow exponentially with the number of parameters
Even relatively small designs can have very large spaces
Parameters can change runtime by orders of magnitude
Parameters typically aren’t independent
Manual exploration is tedious, may result in suboptimal designs
3

Key
DRAM
A
B
Design Space Example: Dot Product
4
FPGA
+ ×
Tile B
Tile A
Algorithm: Dot Product of Vectors A and B
Small and simple, but slow!
acc
Scratchpad
Reg op

DRAM
A
B
Important Parameters: Tile Sizes
Increases length of DRAM accesses Runtime
Increases exploited spatial locality Runtime
Increases local memory sizes Area
5
FPGA
+ ×
Tile B
Tile A
Algorithm: Dot Product of Vectors A and B
acc
Key
Scratchpad
Reg op

DRAM
A
B
FPGA
Stage 2
Stage 1
+ ×
Tile B
Tile A
Important Parameters: Pipelining
6
Algorithm: Dot Product of Vectors A and B
Overlaps memory and compute Runtime
Increases local memory sizes Area
Adds synchronization logic Area
acc
Key
Double
Reg op
Buffer

DRAM
Important Parameters: Parallelization
7
FPGA
+
×
Algorithm: Dot Product of Vectors A and B
×
×
Tile A
Tile B
+ +
Improves element throughput Runtime
Duplicates compute resources Area
A
B
acc
Key
Scratchpad
Reg op

Language/Tool Requirements
8
VHDL Verilog
LegUp Vivado HLS OpenCL SDK
Aladdin
DHDL
Targets FPGAs Enables pipelining at arbitrary loop levels
Exposes design parameters to the compiler Evaluates designs prior to synthesis
Explores design space automatically
Generates synthesizable code

Delite Hardware Definition Language Includes a variety parameterized templates
Parallel patterns with implicit parallelization factors
Pipeline constructs for pipelining at arbitrary levels
Explicit size parameters for loop step size and buffer sizes
All parameters are exposed to compiler
Compiler includes latency and area models for quick design evaluation
Compiler automatically explores design space
Generates synthesizable MaxJ HGL after exploration
9

DRAM
Dot Product DHDL Diagram
10
Tile B
Tile A
×
+
Inner Reduce
Outer Reduce
Parallelism factor #1 Pipelining toggle
Tile Size (B)
Parallelism factor #2
Parallelism factor #3
A
B
out out
+

Dot Product in DHDL
11
val output = Reg[Float]
val vectorA = OffChipMem[Float](N)
val vectorB = OffChipMem[Float](N)
Reduce(N by B)(output){ i =>
val tileA = Scratchpad[Float](B)
val tileB = Scratchpad[Float](B)
val acc = Reg[Float]
tileA load vectorA(i :: i+B)
tileB load vectorB(i :: i+B)
Reduce(B by 1)(acc){ j =>
tileA(j) * tileB(j)
}{a, b => a + b}
}{a, b => a + b}
Parallelism factor #1 Pipelining toggle
Tile Size (B)
Parallelism factor #2
Parallelism factor #3
1
2
MaxCompiler + Altera Toolchain
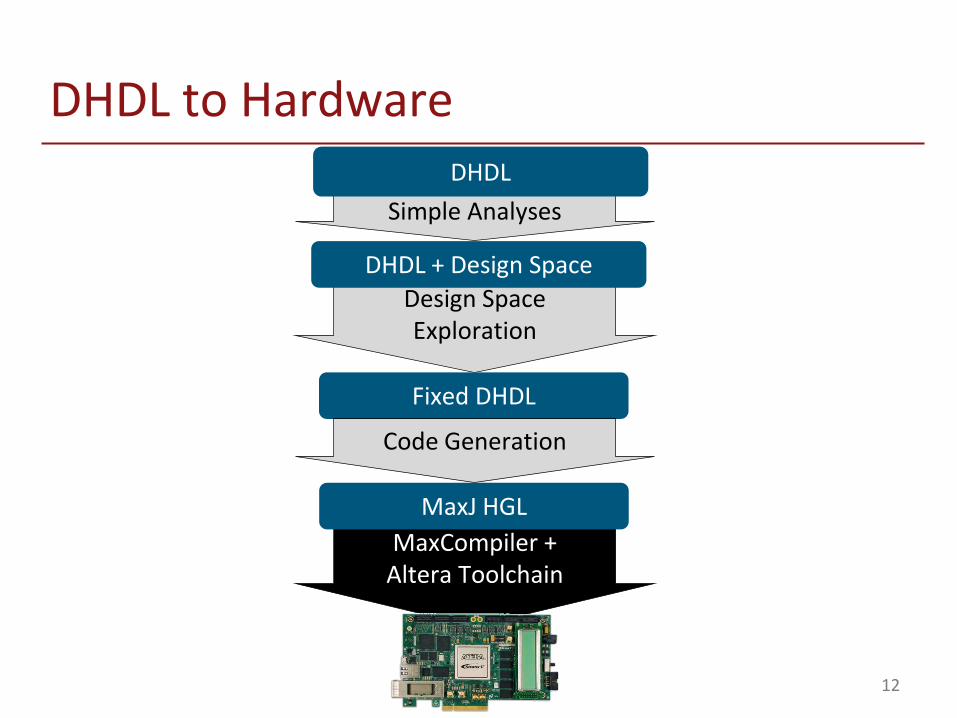
Design Space Exploration
DHDL to Hardware
12
Simple Analyses
MaxJ HGL
DHDL + Design Space
DHDL
Fixed DHDL
Code Generation

DHDL Enables Fast DSE
13
DHDL Program
Simple Linear Models
Concise IR
Parameterized Templates
Easily Derived Space Constraints
Space Pruning
Fast Design Space Exploration
Fast Estimation No Unrolling
No Scheduling Smaller Spaces

Latency Modeling
Analytical model
Uses depth-first search to get critical path of pipelines
Accurate estimation requires data size annotations
Main-memory model
Mathematical model fit to observed runtimes
Parameterized by:
Number of contending readers/writers
Number of commands issued in sequence
Command length
14

Area Modeling
Analytical model
Simple summation of area of each template
Includes estimates for delay lines, banked memories
Neural network models
Models routing costs and memory duplication
Simple, 3 layer networks suffice here (we use 11-6-1)
Trained on about set of 200 characterization designs
Total area = analytical area + neural net area
15

Evaluation
16
Accuracy: How accurate are the models, compared to observations?
Speed: How fast are the predictions, compared to commercial tools?
Space: Do the design parameters help capture an interesting space?
Performance: How good is the best generated design?

Model
Synthesized
Results: Model Accuracy (Area)
17
Area models follow important trends and are accurate enough to drive
automatic design space exploration
100%
60%
20%
ALMs
BRAMs
DSPs
Re
sou
rce
Usa
ge (
%)
dotproduct outerprod tpchq6 blackscholes gda kmeans gemm

Results: Model Accuracy (Latency)
18
Latency models follow important trends and are accurate enough to drive
automatic design space exploration
2.8% 1.3%
3.1% 3.4%
6.7% 7%
18.4%
0%
5%
10%
15%
20%
dotproduct outerprod tpchq6 blackscholes gda kmeans gemm
Ave
rage
Err
or
(%)

Results: Prediction Speed
19
Benchmark Designs Search Time
Dot Product 5,426 5.3 ms / design
Outer Product 1,702 30 ms / design
TPCHQ6 5,426 8.2 ms / design
Blackscholes 572 27 ms / design
Matrix Multiply 70,740 11 ms / design
K-Means 75,200 20 ms / design
GDA 42,800 17 ms / design
Designs Search Time
GDA 250 1.85 min / design
Vivado HLS:
6533x Speedup
Over HLS!
DHDL:

20% 60% 100% 20% 60% 100% 20% 60% 100% ALMs DSPs BRAMs Resource Usage (% of maximum)
Cyc
les
(Lo
g Sc
ale
)
Results: GDA Design Space
20
1010 109 108
107
Valid design point Pareto-optimal design Invalid design point Synthesized pareto design point
Performance limited by available BRAMs
Space for GDA spans four orders of magnitude

Evaluation: Multi-Core Comparison
21
FPGA
Altera Stratix V (28 nm)
150 MHz clock
Peak main memory bandwidth of 37.5 GB/sec
Multi-core CPU
Intel Xeon E5-2630 (32nm)
2.3 GHz
Peak main memory bandwidth of 42.6 GB/sec
6 cores, 6 threads
Multi-threaded C++ code generated from Delite
Execution time = FPGA execution time
Does not include CPU FPGA communication or configuration time

Results: Comparison with Multi-Core
22
1.07 2.42
1.11
16.73
4.55
1.15 0.1
0
5
10
15
20
dotproduct outerprod tpchq6 blackscholes gda kmeans gemm
Spe
ed
up
Memory-bound Compute-bound
Gemm uses multi-threaded OpenBLAS on CPU

Summary
DHDL exposes large design spaces to the compiler
Parameterized templates enable fast, accurate estimators
Fast estimators enable rapid automated DSE
Up to 6533x faster estimation compared to Vivado HLS
Up to 16.7x speedup over 6-core CPU
23

24

20% 60% 100% 20% 60% 100% 20% 60% 100% ALMs DSPs BRAMs Resource Usage (% of maximum)
Cyc
les
(Lo
g Sc
ale
)
Results: TPCHQ6 Design Space
25
108
107
106
Valid design point Pareto-optimal design Invalid design point Synthesized pareto design point
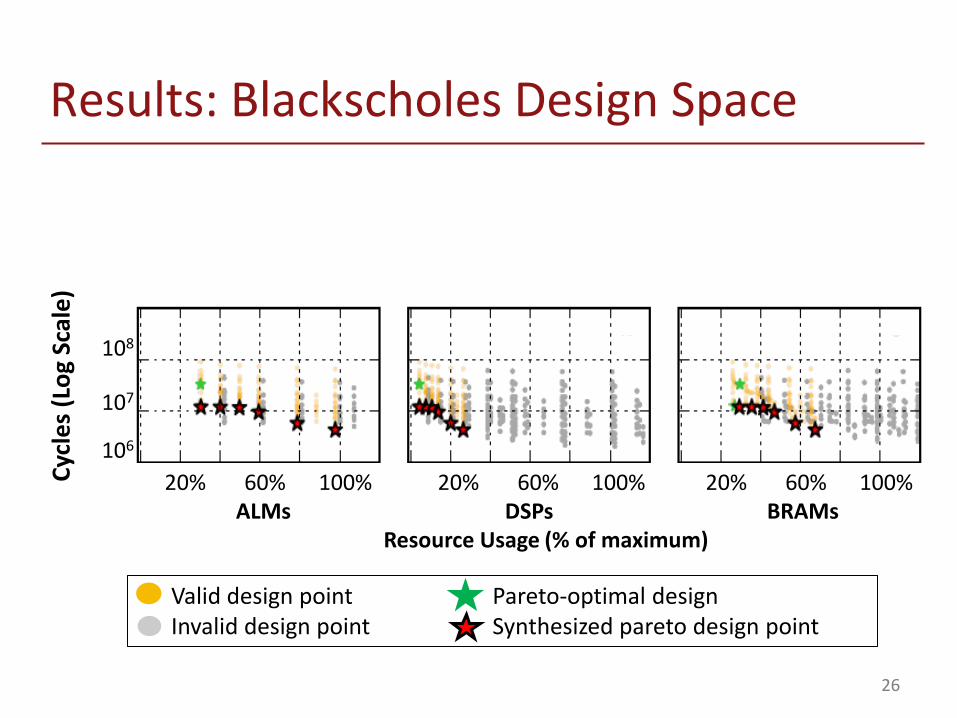
108
107
106
20% 60% 100% 20% 60% 100% 20% 60% 100% ALMs DSPs BRAMs Resource Usage (% of maximum)
Cyc
les
(Lo
g Sc
ale
)
Results: Blackscholes Design Space
26
Valid design point Pareto-optimal design Invalid design point Synthesized pareto design point





























