Embed Size (px)
Citation preview

Softw Syst ModelDOI 10.1007/s10270-013-0350-8
REGULAR PAPER
AuRUS: explaining the validation of UML/OCL conceptualschemas
Guillem Rull · Carles Farré · Anna Queralt ·Ernest Teniente · Toni Urpí
Received: 30 December 2011 / Revised: 10 April 2013 / Accepted: 8 May 2013© Springer-Verlag Berlin Heidelberg 2013
Abstract The validation and the verification of concep-tual schemas have attracted a lot of interest during the lastyears, and several tools have been developed to automate thisprocess as much as possible. This is achieved, in general,by assessing whether the schema satisfies different kinds ofdesirable properties which ensure that the schema is correct.In this paper we describe AuRUS, a tool we have developedto analyze UML/OCL conceptual schemas and to explaintheir (in)correctness. When a property is satisfied, AuRUSprovides a sample instantiation of the schema showing a par-ticular situation where the property holds. When it is not,AuRUS provides an explanation for such unsatisfiability, i.e.,a set of integrity constraints which is in contradiction withthe property.
Keywords Validation · Conceptual modeling · UML ·OCL · Automated reasoning · Explanation
Communicated by Prof. Tony Clark.
G. Rull · C. Farré · E. Teniente (B) · T. UrpíUniversitat Politècnica de Catalunya, BarcelonaTech,Barcelona, Spaine-mail: [email protected]
G. Rulle-mail: [email protected]
C. Farrée-mail: [email protected]
T. Urpíe-mail: [email protected]
A. QueraltBarcelona Supercomputing Center, Barcelona, Spaine-mail: [email protected]
1 Introduction
Assessing the correctness of a conceptual schema is a veryrelevant task, since the mistakes made in the conceptual mod-eling phase are propagated throughout the whole softwaredevelopment cycle, thus affecting the quality and correctnessof the final product. The correctness of a conceptual schemacan be assessed from two different perspectives. On the onehand, the schema must be verified in order to check that itsdefinition is correct according to a set of well-known prop-erties. On the other hand, the schema must also be validatedin order to assess that it complies with the requirements ofthe domain.
The Unified Modeling Language (UML) [23] has becomea de facto standard in conceptual modeling. In UML, a con-ceptual schema is represented by means of a class diagram,with its graphical constraints, together with a set of user-defined constraints (i.e., textual constraints), which are usu-ally specified in OCL [24].
Validation and verification of UML/OCL conceptualschemas have attracted a lot of interest during the last years,and several techniques have been proposed for this purpose(see [26] for a detailed comparison of the most relevant ones).Moreover, several tools have been developed for assisting thedesigner to perform this task (see for instance [6,8,11,16]).
The following example illustrates the difficulty of man-ually checking the correctness of a UML/OCL conceptualschema, which in turn makes clear the need to provide thedesigner with a set of tools that assist him during this process.
The UML class diagram in Fig. 1 states informationabout hiking events. It consists of six classes (HikingEvent, TrailSection,Person, the association classes Registra-tion and HikedSection and its subclass DangerousSection),together with their attributes, and five associations (Has-Section, Organizes, HasCompanion and, again, Registration
123

G. Rull et al.
Fig. 1 A UML schema for thedomain of hiking events
andHikedSection). This diagram allows specifying the infor-mation regarding hiking events, the trail sections they con-sist of, people organizing and registering at the events andthe sections hiked by these people. Note that when a sectionhiked is a dangerous one, it must also have an accompanyingregistration for the sake of security.
The OCL constraints in Fig. 2 provide the class dia-gram with additional semantics. There are three primarykey constraints (PersonKey, HikingEventKey and Trail-SectionClass), one for each class. The constraint NoSec-tionEasierThanMinLevel states that the minimum levelrequired by the hiking event is lower or equal than the diffi-culty of all its trail sections, and SomeSectionSuitableToAll-Parts states that there is at least one section whose diffi-culty is exactly the minimal level required by the hikingevent. The constraint HikedSectionsBelongToEvent ensuresthat all sections hiked by each registration are part of thehiking event of the registration, while ParticipantLevel-MustReachMinRequired states that the expertise level ofthe participant is higher than the minimum level requiredby the hiking event. The next constraint, DifficultSection-sAreDangerous, establishes that all hiked sections with a dif-ficulty level higher than seven must be dangerous sections,while SectionDifficultyNoHigherThanHikerLevel guaranteesthat nobody hikes a section if he is not qualified to do it.Finally, there are four constraints restricting properties ofdangerous sections: DangerousSectionMinDifficulty speci-fies that the minimum difficulty of a dangerous section is 7;CompanionMustHikeSameTrailSect guarantees that both thehiker and the companion are hiking the same section whileCompanionCannotBeSelf states that they both are differentpeople; and OneCannotAccompanyMoreThanOnePersonIn-SameTrailSection ensures that nobody can accompany twopeople at the same trail section.
The above UML/OCL conceptual schema contains plentyof classes and associations plus a lot of integrity constraints.So, How can we manually assess its correctness? How canwe verify whether all classes and associations in the schemamay contain at least one instance? How can we ensure thatall constraints are strictly necessary? How can we validatethat the schema is compliant with the requirements of thedomain being modeled? It is important to know the answerto all these questions if we want to assess the quality of aninformation system before it is built.
The previous example clearly illustrates that we need toprovide the designer with automatic tools that support him inthis difficult and relevant task. This is, in fact, the main goal ofthis paper: to describe the AuRUS (Automated Reasoning onUML/OCL conceptual Schemas) tool. AuRUS is able both toverify and to validate a UML/OCL conceptual schema. Veri-fication consists in determining whether the schema satisfiesa set of well-known desirable properties such as class live-liness or non-redundancy of integrity constraints. Validationconsists in allowing the user to perform queries about reach-able states (non-standard properties) of the schema. Knowingwhether a state is reachable will allow the designer to deter-mine whether the schema satisfies the requirements or not.
The answer that AuRUS provides when checking bothkinds of properties is not just whether or not a given propertyholds. If a property is satisfied, then it also provides a sampleinstantiation of the schema proving the property. If it is not,then AuRUS gives an explanation of why the tested propertydoes not hold. An explanation is a set of constraints thatmakes impossible to satisfy the property.
The initial explanation provided by AuRUS is approxi-mated in the sense that it may be not minimal, i.e., a subsetof its constraints might also be an explanation. However,AuRUS may convert this initial explanation into a minimal
123

UML/OCL conceptual schemas
Fig. 2 Textual integrity constraints of the schema in Fig. 1, expressed in OCL
one by removing some of its constraints. Moreover, all mini-mal explanations for a given test can be computed by AuRUS,if required by the designer.
The work reported here extends our previous work in sev-eral directions. The methodology we follow in AuRUS toassess the (in)correctness of a UML/OCL conceptual schemaand some theoretical background were presented in [26]. Weprovide here, however, a complete and practical implementa-tion of the approach, where additional properties have beentaken into account, and which is able to validate schemasspecified by means of ArgoUML, an open source CASE tool[2]. A preliminary version of the method used in AuRUSto check the properties and to compute the explanationswas sketched in [29]. These ideas are further developed andformalized in this paper, with additional features as far ascomputing the explanations is concerned. Some initial ideasregarding the AuRUS tool were outlined in [25].
The rest of this paper is organized as follows. Section 2describes the functionalities provided by AuRUS and itsinternal architecture. Section 3 presents the reasoning engineused by AuRUS, which provides an approximated explana-tion. Section 4 discusses how to refine the explanation pro-vided by the reasoning engine, and how to find all the otherpossible explanations. Section 5 reviews current tools forchecking the correctness of a UML/OCL conceptual schema
and related work on computing explanations. Finally, Sect. 6presents our conclusions and points out future work.
2 The AuRUS tool1
AuRUS is a standalone application which allows verify-ing and validating UML/OCL conceptual schemas speci-fied in ArgoUML. The current version of ArgoUML (0.34)is based directly on the UML 1.4 specification. Further-more, it provides an extensive support for OCL and XMI(XML Model Interchange format). ArgoUML is available forfree and can be used in commercial settings [2]. The com-munication between ArgoUML and AuRUS is performedthrough the .xmi file of the schema, automatically generatedby ArgoUML, which is the input to be uploaded to AuRUS.AuRUS is publicly available as a web application at http://folre.essi.upc.edu.
Without loss of generality, the only graphical constraintswe consider as such in the UML schema are cardinalitiesof associations and disjointness and covering constraints inhierarchies, due to their widespread use. We assume that other
1 Available at http://folre.essi.upc.edu/aurus.
123

G. Rull et al.
Fig. 3 AuRUS main window, after loading the UML/OCL conceptual schema
graphical constraints (such as subset or xor) are expressedtextually, following the ideas in [15].
As far as OCL is concerned, the operations AuRUScan handle are: and, or, implies, includes,excludes, includesAll, excludesAll,isEmpty,notEmpty,oclIsTypeOf, oclAsType,exists, forAll, one, isUnique, select,reject, arithmetic comparisons and size(with an arithmetic comparison). Note that all these oper-ations either evaluate to a Boolean value or can be expressedin terms of Boolean predicates. That is, the OCL con-straints admitted by AuRUS can be defined by arbitrary OCLexpressions built by combining the previous operations. Thisexcludes operations such assum, and also operations definedin classes, as well as datatypes. The reason for this syntacticallimitation is the logic representation we use as a target for ourreasoning engine and which will be explained in Sect. 3.2.
Once the schema is loaded in AuRUS, the user is pre-sented with the main window (Fig. 3). The schema is rep-resented hierarchically on the left, featuring all the informa-tion defined in the UML class diagram and the OCL con-straints. When clicking on a class, for instance, its attributesappear below; for associations, the type and cardinality oftheir participants are shown; and for constraints, their cor-responding OCL expressions appear (as it is shown in thefigure).
As seen in the previous figure, AuRUS provides twodifferent tabs to analyze the quality of the schema: Is theschema right? and Is it the right schema? The first one isrelated to verification of the schema while the second one isrelated to its validation. We explain the functionalities pro-
vided by AuRUS to perform these tasks in Sects. 2.1 and2.2, respectively. The architecture of the tool is described inSect. 2.3.
It is important to note that our tool does not check whethera particular instance, usually provided by the designer, sat-isfies a certain property as it happens with tools like [16]or [11]. On the contrary, AuRUS reasons directly from theschema alone. For this reason, the answers we get showwhether a property is satisfied by at least one of the pos-sible instances of the schema. The sample instance given asa result is automatically generated by AuRUS and showsthat the property is satisfied with this particular content ofthe schema.
2.1 Verifying a UML/OCL conceptual schema with AuRUS
Verification is aimed at assessing whether the schema is right,mainly in the sense that it does not include contradictoryinformation. AuRUS provides several properties for this pur-pose:
– Are all classes and associations lively? A class or asso-ciation is lively if it can contain at least one non-emptyinstance that satisfies all the integrity constraints. Clearly,if a class is not lively, then the schema is not correct sinceit does not make sense to have a concept which will nevercontain information.
– Are all constraints non-redundant? A constraint is redun-dant if it is only violated when some other constraint isalso violated. The presence of a redundant constraint in aschema does not necessarily entail that it is incorrect, but
123

UML/OCL conceptual schemas
Fig. 4 Verifying our running example
it is important to detect these situations in order to keepthe schema simpler while preserving its semantics.
– Are minimum cardinalities correct? A minimum cardi-nality constraint is incorrect when all instances at theother end of the association where the cardinality isdefined will always be associated to a greater numberof instances than the ones stated by the lower bound. Inthis case, the constraint is not restricting anything in prac-tice when taking the possible instantiations of the schemainto account. This property entails that the schema is notcorrect in the sense that the cardinality constraint is notstating what is happening in practice.
– Are maximum cardinalities correct? Similarly, to theminimum cardinality constraints, it shows whether theupper bound of a cardinality constraint may be reachedin practice.
– Are incomplete hierarchies correct? An incomplete hier-archy is incorrect when every instance of the superclassalways belongs also to at least one of the subclasses.Again, the schema is incorrect when this happens sinceeither something else is wrong or the hierarchy shouldhave been defined as complete.
– Are overlapping hierarchies correct? An overlappinghierarchy is incorrect when no instance of the superclassmay belong to more than one subclass simultaneously.The schema is also wrong in this case either because thehierarchy should have been restricted by a disjoint con-straint or because some other constraint prevents over-lapping instances.
We show in Fig. 4 the result of checking all these propertiesin our running example. As shown in the figure, all of themcan be checked at once just by clicking on the correspondingbutton. The figure also shows that all classes of the schema arelively that minimum and maximum cardinalities are correctas well as incomplete and overlapping hierarchies. However,some redundant constraint has been found as stated by theNo in red at the top right of the screen. The figure also showsthat the nine tests required to check this redundancy havebeen performed in 8,547 ms, i.e., about eight seconds and ahalf.
The tabs in the bottom part of the screen contain the resultsfor each test. In particular, the selected “Non-redundancy” tabdisplays, for each constraint, whether it is redundant or not.In this example, we have that the constraint OneCannotAc-companyMoreThanOnePersonInSameTrailSection is redun-dant while the rest of the constraints are non-redundant. Wecan now further analyze these results by selecting one of theconstraints and clicking the button Show result. If the cho-sen constraint is non-redundant, then AuRUS will provide uswith a sample instantiation which shows how the constraintcan be violated without violating any other constraint. Oth-erwise, the constraint is redundant, and we will obtain the setof constraints which cause the contradiction. The two kindsof feedback provided by AuRUS are shown in Fig. 5.
The left part of Fig. 5 displays the eleven instancesrequired to prove that the constraint ConstraintCompan-ionCannotBeSelf is not redundant while the right part ofthe figure states that the constraint OneCannotAccompany-
123

G. Rull et al.
Fig. 5 Providing feedback to the designer
MoreThanOnePersonInSameTrailSection is redundant withthe 0 . . . 1 cardinality constraint of the role accompanies inthe association HasCompanion. We say that this right part ofFig. 5 provides an explanation for the “failure” of the non-redundancy property.
We use the term explanation to refer to a set of integrityconstraints that prevents the satisfaction of the tested prop-erty. An explanation is minimal if no proper subset is alsoan explanation. Note that AuRUS firstly provides an expla-nation that is not guaranteed to be minimal. The user canrequest a minimal explanation by pressing the button Com-pute a minimal explanation in the right part of Fig. 5. Sinceminimal explanations are not unique, AuRUS allows the userto request the computations of all the minimal explanationsby pressing the button Compute all minimal explanationsalso shown in the right part of Fig. 5.
So, summarizing the verification, AuRUS has shown usthat our UML/OCL schema is correct except for one con-straint which is redundant. So, this constraint can be removedwithout changing the semantics of the schema.
2.2 Validating a UML/OCL conceptual schemawith AuRUS
The goal of validation is determining whether the informa-tion represented by the schema corresponds to the require-ments of the application being built. Two kinds of propertiescan be checked by AuRUS in order to validate a concep-tual schema: predefined properties and interactive properties.Checking predefined validation properties is similar to veri-fying the schema. That is, we have identified some propertieswhich illustrate common situations where the schema maynot be compliant with the requirements. The intervention ofthe designer is required in all cases only to determine whetherthe schema is correct in light of the results of checking theseproperties. The properties considered are the following:
– Is some identifier missing? An important aspect of UMLschemas is that primary keys of classes must be textually
defined by means of OCL. So, the designer might easilyforget defining one such constraint, especially when theschema has a huge number of classes. Note, however,that a class without a primary key may make sense in anobject-oriented schema. Then, the fact that some identi-fier is missing does not necessarily mean that the schemais incorrect. The designer should confirm whether this isthe case.
– Is some irreflexive constraint missing? Recursive associa-tions often require the definition of a constraint to preventlinking an instance to itself.
– Is some path inclusion missing? Whenever we have morethan one association linking the same two classes, it isrequired in many domains that the set of instances of oneof the associations is included in the other. When thishappens, a textual constraint must be specified to ensureit. So, it is important to check this property to guaranteethat we have not forgotten one such constraint.
– Is some path exclusion missing? This property is analo-gous to the previous one, but is applicable to those caseswhere the instances of two associations must be disjoint.
Figure 6 shows the result of predefined validation for ourschema. Note that there is no identifier or irreflexive con-straint missing, but we need additional feedback from thedesigner to make sure if there are some path inclusion orexclusion constraints missing. Moreover, as shown at the bot-tom of the figure, no inclusion constraint has been definedamong the associations Organizes and Registration. Click-ing at the Path exclusion tab AuRUS would also show us thatthese two associations are not disjoint. The designer shoulddecide whether this is correct according to the domain andadd the appropriate constraints if necessary. These four testshave been performed in 1.5 s.
The Interactive validation tab allows the designer to freelycheck for all properties he may find relevant to assess com-pliance with the requirements. For instance, he might wonderwhether the schema accepts a hiked section whose trail has
123

UML/OCL conceptual schemas
Fig. 6 Predefined validation
Fig. 7 Defining ad-hoc properties of the schema
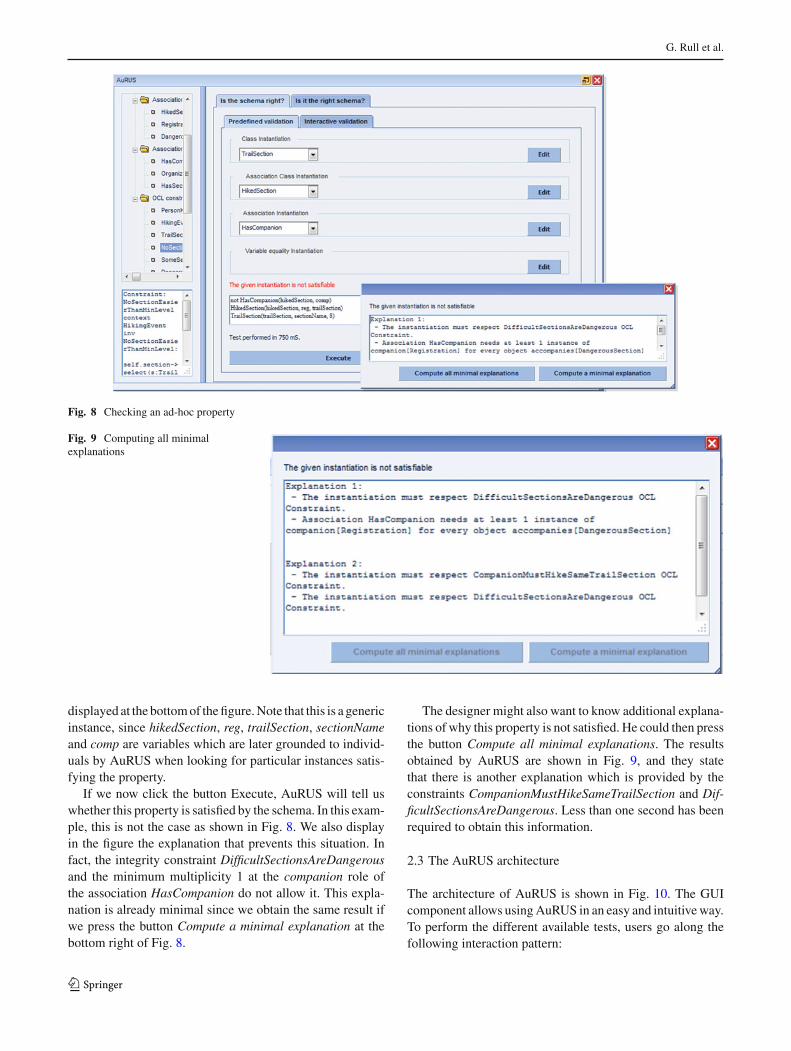
a difficulty of 8 that does not have a companion, since thissituation is clearly contradictory with the requirements ofthe domain. Intuitively, this property holds whether there is asample instantiation of the schema that contains the instancesHikedSection(hikedSection, reg, trailSection) and TrailSec-
tion(trailSection, sectionName, 8), but does not contain theinstance HasCompanion(hikedSection, comp). AuRUS pro-vides a means to query such kind of properties as shown inFig. 7. Editing the instantiation of classes, association classesand associations, we may define the instance of the schema
123
G. Rull et al.
Fig. 8 Checking an ad-hoc property
Fig. 9 Computing all minimalexplanations
displayed at the bottom of the figure. Note that this is a genericinstance, since hikedSection, reg, trailSection, sectionNameand comp are variables which are later grounded to individ-uals by AuRUS when looking for particular instances satis-fying the property.
If we now click the button Execute, AuRUS will tell uswhether this property is satisfied by the schema. In this exam-ple, this is not the case as shown in Fig. 8. We also displayin the figure the explanation that prevents this situation. Infact, the integrity constraint DifficultSectionsAreDangerousand the minimum multiplicity 1 at the companion role ofthe association HasCompanion do not allow it. This expla-nation is already minimal since we obtain the same result ifwe press the button Compute a minimal explanation at thebottom right of Fig. 8.
The designer might also want to know additional explana-tions of why this property is not satisfied. He could then pressthe button Compute all minimal explanations. The resultsobtained by AuRUS are shown in Fig. 9, and they statethat there is another explanation which is provided by theconstraints CompanionMustHikeSameTrailSection and Dif-ficultSectionsAreDangerous. Less than one second has beenrequired to obtain this information.
2.3 The AuRUS architecture
The architecture of AuRUS is shown in Fig. 10. The GUIcomponent allows using AuRUS in an easy and intuitive way.To perform the different available tests, users go along thefollowing interaction pattern:
123

UML/OCL conceptual schemas
Fig. 10 AuRUS architecture
1. Load a UML/OCL conceptual schema.2. Select one of the available desirable property tests.3. Enter the test parameters (if required).4. Execute the test.5. Obtain the test result and its feedback, which can be in
the form of example schema instances, or in the formof an explanation stating which schema constraints areresponsible for the test result.
The main goal of the UML-OCL Schema Loader is to loadthe XMI file containing the schema into a Java library [13]that implements the UML and OCL metamodels. Since aconceptual schema is an instance of these metamodels, the setof Java classes and primitives in this library allows creatingand manipulating a model.
However, the AuRUS reasoning functions do not oper-ate directly on that UML/OCL model, but on a semanticallyequivalent internal first-order-logic representation, the In-memory Logic Encoding. Consequently, a Logic translatoris required to transform the loaded UML/OCL model into itscorresponding internal logic representation.
It is well-known that the problem of automatically rea-soning with integrity constraints in their full generality isundecidable. Since AuRUS admits arbitrary constraints forwhich decidability is not guaranteed a priori, the Termina-tion Analyzer checks and informs the user whether the loadedschema satisfies certain sufficient conditions that, when ful-filled, assure that all the tests to be performed will terminatein finite time.
The Test Controller processes the commands provided byusers through the GUI. It expresses the selected tests as aninput for the C QCE Method Engine, and transfers back theobtained results.
The C QCE Method Engine is the core reasoning engine ofAuRUS. It implements the automated reasoning we need toperform the tasks required by the tests demanded by the TestController. The CQCE method will be explained in detail inthe next section.
Users, via the Test Controller, and depending on the testedproperty and on the test result, can obtain different feed-backs. Such a feedback can be in the form of sample syn-thetic schema instances, or in the form of an explanation.In this latter case, users may ask the Explanation Engine tocheck whether a given explanation provided by the CQCEMethod Engine is minimal or not, and to find the other possi-ble minimal explanations (if any). Explanations are translatedto a natural-language representation and shown to the userthrough the GUI.
All the components of AuRUS have been implemented inJava, except for the C QCE Method Engine, which is imple-mented in C# using Microsoft Visual Studio as a developmenttool. The source input normally used in AuRUS, i.e., the con-ceptual schema to be evaluated, is a plain ArgoUML XMIexport file. The current version of ArgoUML (0.32) is baseddirectly on the UML 1.4 specification. Furthermore, it pro-vides an extensive support for OCL and XMI (XML ModelInterchange format). ArgoUML is available for free and canbe used in commercial settings.
3 A reasoning engine that provides explanations:the CQCE method
AuRUS reformulates each test into a query satisfiability prob-lem, which is then solved by an underlying reasoning engine.This engine, called the CQCE method, does not only returna Boolean answer indicating if the tested query is satisfiable,but also provides additional feedback to help understand thetest’s result. This feedback has two possible forms:
(1) An instance of the conceptual schema that exemplifiesthe satisfiability of the query, i.e., an instance in whichthe query has a non-empty answer.
(2) A subset of the integrity constraints that is preventingthe query from returning a non-empty answer (typically,due to a contradiction between these constraints and thequery’s definition).
The CQCE extends the previous Constructive Query Con-tainment (CQC) method [14] by adding the computation ofexplanations2 [i.e., point (2) above]. That is the reason whyin this paper we focus mainly on this kind of feedback.
2 CQCE stands for CQC with explanations. Note that although the CQCmethod was initially designed for query containment, it reformulatedcontainment in terms of query satisfiability. So, it is essentially a querysatisfiability checking method.
123

G. Rull et al.
It is necessary to remark that the subset of constraintspinpointed by the CQCE may not be minimal. Intuitively,the reason for this is that the CQCE returns the subset ofconstraints that led it to a contradiction when trying to finda solution, which may not be the shortest possible path. Itis also worth noting that additional explanations to the onereturned may exist, i.e., there may be more than one sub-set of constraints that causes the query to be unsatisfiable.Actually, in the general case, there may be an exponentialnumber of explanations for a single query satisfiability test.The reason why the CQCE returns only one is that the rea-soning ends as soon as it finds a contradiction. In a sense,the explanation that is found “hides” the other explanations.If the user requires a more precise explanation or wants allthe possible explanations, he can ask the AuRUS tool forthem. AuRUS implements the techniques for minimizing anexplanation and for finding all the additional ones that aredescribed in [28]. We will explain these techniques in Sect. 4and show how they can be combined with the CQCE.
The CQCE method reasons on a first-order logic represen-tation of the conceptual schema. This representation encodesboth the graphical constraints of the UML schema and thetextual OCL constraints, and we refer to it as logic schema.Each test is encoded as a query to be checked for satisfiabilityover this logic schema.
To solve a query satisfiability test, the CQCE follows aconstructive approach. That is, it tries to build an instancein which the query has a non-empty answer and that, atthe same time, satisfies all the integrity constraints on theschema.
In the next subsections, we introduce the basic concepts oflogic schemas and query satisfiability, comment on the first-logic encoding of the conceptual schema and reformulationof the tests, and detail how the CQCE method computes anexplanation.
3.1 Logic schemas and query satisfiability
In this section, we summarize some basic concepts and nota-tion of logic programming and databases that we will use inthe paper (see [1] and [34] for more details on these topics).
Throughout the paper, a, b, c. . . (lower-case terms) areconstants. The symbols X, Y, Z . . .(upper-case terms) denotevariables. Lists of constants are denoted by a, b, c . . . andX , Y , Z . . . denote lists of variables. Predicate symbols arep, q, r . . . A term is either a variable or a constant. If p is an-ary predicate and T1, . . ., Tn are terms, then p(T1, . . ., Tn)
is an atom, which can also be written as p(T ) when n isknown from the context. An atom is ground if every Ti is aconstant. An ordinary literal is defined as either an atom ora negated atom, i.e., ¬p
(T
). A built-in literal has the form
of A1 ω A2, where A1 and A2 are terms. Operator ω is either<,≤,>,≥,=, or �=.
A normal clause has the form
A← L1 ∧ · · · ∧ Lm with m ≥ 0
where A is an atom and each Li is a literal, either ordinaryor built-in. All the variables occurring in A, as well as ineach Li , are assumed to be universally quantified over thewhole formula. A is the head and L1 ∧ · · · ∧ Lm is the bodyof the clause. A normal clause is safe [34] if each variablein the head appears in some positive ordinary literal in thebody and each variable in a negative ordinary literal appearsin a positive ordinary literal. Depending on its form, a nor-mal clause can correspond to a fact, a deductive rule or acondition, which are defined as follows.
A fact is a normal clause of the form: p(a)← (or, simply,p(a)), where p(a) is a ground atom.
A deductive rule is a normal clause of the form:
p(T )← L1 ∧ · · · ∧ Lm with m ≥ 1
where p is the derived predicate defined by the deductiverule. The definition of a predicate symbol p is the set of allthe deductive rules that have p in their head. We refer topredicates that are not derived as base predicates. We referto literals whose predicate is base/derived as base/derivedliterals.
An integrity constraint is a formula of the (denial) form:
← L1 ∧ · · · ∧ Lm with m ≥ 1
which states a situation that cannot hold. More general con-ditions can be transformed into denial form in a finite numberof steps by using the procedure described by Lloyd and Topor[20].
A logic schema S is a tuple (DR, IC) where DR is a finiteset of deductive rules, and IC is a finite set of integrity con-straints. Literals occurring in the body of deductive rules andintegrity constraints in S are either ordinary or built-in.
For a schema S = (DR, I C), an instance D is a setof ground facts about base predicates. DR(E) denotes thewhole set of ground facts about base and derived predicatesthat are inferred from an instance D, i.e., it corresponds tothe fix-point model of DR
⋃D. We use I DB(D) to denote
the set of facts about derived predicates in DR(D). We saythat an instance D of schema S = (DR, I C) is consistent ifD satisfies all integrity constraints in IC.
A query Q is a set of deductive rules with a same predicateq in its head. The answer to a query Q on an instance D,denoted AQ(D), is the set of facts about predicate q that areinferred from D, i.e., AQ (D) = {q (a) ∈ I DB (D)}. QueryQ is satisfiable on schema S if and only if exists a consistentinstance D of S such that AQ (D) �= ∅.
A set E of integrity constraints—E ⊆ I C—is an expla-nation for the unsatisfiability of a query Q on schemaS = (DR, I C) if Q is unsatisfiable on the schema (DR, E).
123

UML/OCL conceptual schemas
Explanation E is minimal if no proper subset of E is anexplanation.
A substitution θ is a set of the form {X1 → t1, . . . , Xn →tn}, where X1, . . ., Xn are distinct variables, and t1, . . ., tn areterms. A substitution is said to be ground when t1, . . ., tn areconstants. The result of the application of a substitution θ to afirst-order logic expression E , denoted E θ, is the expressionobtained from E by simultaneously replacing each occur-rence of each variable Xi by the corresponding term ti . Aunifier of two expressions E1 and E2 is a substitution σ suchthat E1 σ = E2 σ. Substitution σ is a most general unifier forE1 and E2 if for all other unifier σ′ there is a substitution θ
such that σ′ = σ θ (i.e., σ′ is the composition of σ and θ).For the sake of uniformity when dealing with deductive
rules and constraints, we associate an inconsistency predicateI ci to each integrity constraint. Then, an instance violates aconstraint
I ci ← L1 ∧ · · · ∧ Lk
if predicate I ci is true in that instance, i.e., if there issome ground substitution σ that makes (L1 ∧ · · · ∧ Lk) σ
true.
3.2 First-order logic encoding of conceptual schemasand tests
We translate the given UML/OCL conceptual schema andeach test into a logic schema using the encoding specified in[26]. In this section, we briefly review the main ideas of thisencoding, which is automatically performed by AuRUS forboth the UML class diagram and the OCL constraints.
3.2.1 Encoding of the conceptual schema
Each class, association and association class in the concep-tual schema is encoded as a base predicate. A class C isencoded as predicate C(oid). An association Assoc betweenclasses C1 and C2 is encoded as predicate Assoc(oidC1,oidC2). An association class AC is encoded in the same wayas an association with an additional oidAC attribute, denotingthe oid of the association class. For instance, in our runningexample, we get the following predicates:
HikingEvent (oidHE)Person (oidP)TrailSection (oidTS)HasSection (oiHE, oidTS)Organizes (oidP, oidHE)Registration (oidR, oidP, oidHE)HikedSection (oidHS, oidR, oidTS)DangerousSection (oidDS)HasCompanion (oidDS, oidP)
The attributes of a class are encoded as binary associationsthat relate the oid of an object of that class with the value ofthe attribute. In our example
HikingEventName (oidHE, name)HikingEventMinLevelRequired (oidHE, minLevelRequired)PersonName (oidP, name)PersonExpertiseLevel (oidP, espertiseLevel)TrailSectionName (oidTS, name)TrailSectionDifficulty (oidTS, difficulty),
both graphical and textual constraints are encoded as denialconstraints in the logic schema. For example, the maximumand minim cardinality constraints in the Person’s end of asso-ciation Organizes are encoded into the denials:
← Organizes (oid P1, oid H E)
∧Organizes (oid P2, oid H E) ∧ oid P1 �= oid P2
← HikingEvent (oid H E)
∧¬∃oid P Organizes (oid P, oid H E)
which state that a hiking event cannot have two differentorganizers and that a hiking event must have an organizer,respectively. In order to keep the logic expressions safe withrespect to negation (see Sect. 3.1), we fold the negated literalabove into an auxiliary derived predicate:
← HikingEvent (oid H E) ∧ ¬hasOrganizer (oid H E)
where
hasOrganizer (oid H E)← Organizes (oid P, oid H E)
As an example of the encoding of a textual OCL constraint,PersonKey is encoded into the denial:
← Person (oid P1) ∧ Person (oid P2) ∧ oid P1 �= oid P2
∧PersonName (oid P1, name)
∧PersonName (oid P2, name)
which states that there cannot be two different Person objectswith the same value on attribute name.
In addition to graphical and textual constraints, the logicschema also encodes implicit constraints of UML schemas,such as the following:
← Organizes (oid P, oid H E)
∧¬HikingEvent (oid H E)
which states that whenever association Organizes relatesoids oidP and oidHE, then oidHE must be the oid of aHikingEvent object. There is an implicit constraint like theone above for each association end in the schema.
123

G. Rull et al.
3.2.2 Encoding of the tests
Each test is encoded as a query to be checked for satisfiabil-ity on the logic schema resulting from the encoding of theconceptual schema.
As an example, assume we want to verify whether classPerson is lively. We reformulate this property in terms ofquery satisfiability by defining a query isPersonLively withthe following deductive rule:
is PersonLively (oid P)← Person (oid P)
It is easy to see that isPersonLively is satisfiable if and onlyif exists some instance of the schema in which class Personhas at least one object.
As a second example, assume that now we want to testwhether OCL constraint
context DangerousSection inv OneCannot
AccompanyMoreThanOneInSameTrail
Section :DangerousSection.allInstances()
− > forAll(ds1,ds2 |ds1 <> ds2implies
ds1.hikedTrailSection <> ds2.hikedTrail
Sectionandds1.companion
<> ds2.companion))
is redundant with respect to the other OCL constraints. Wereformulate this test by defining a query that intends to returnthose persons that accompany more than one other person,i.e., the query returns those objects that violate the constraint,and by checking the satisfiability of this query on a copy of thelogic schema that does not include the tested OCL constraint.The deductive rule of this query is the following:
is − OneCannot AccompanyMoreT hanOneI nSame
T railSection − Reduntant (oid DS1, oid DS2)←DangerousSection (oid DS1)
∧DangerousSection (oid DS2) ∧ oid DS1 �= oid DS2
∧Hiked Section (oid DS1, oid R1, oidT S1)
∧Hiked Section (oid DS2, oid R2, oidT S2)
∧oidT S1 = oidT S2
∧HasCompanion (oid DS1, oid P1)
∧HasCompanion (oid DS2, oid P2) ∧ oid P1 = oid P2
Note that the body of the above deductive rule corresponds tothe negation of the OCL constraint. Recall that query satisfia-bility implies the existence of a consistent instance; therefore,if a consistent instance can be found in which the query hasa non-empty answer, which means it is possible to violatethe tested constraint while satisfying the other constraints,i.e., the tested constraint is not redundant. In other words,
the OCL constraint is redundant if and only if the query isnot satisfiable.
We will not detail here the encoding of each test and referthe interested reader to [26] for a detailed description.
3.3 Computing explanations with the CQCE method
The CQCE is a constructive method, which means that it triesto construct an instance that exemplifies the satisfiability ofthe tested query. Since the number of consistent instances fora given schema is infinite, the CQCE reduces the search toa finite set of canonical instances. Intuitively, each canon-ical instance represents a fraction of the infinite space ofinstances, in the sense that the query will provide an emptyanswer on the canonical instance if and only if it providesan empty answer on all the instances in that fraction of thespace. Therefore, the tested query will be satisfiable if andonly of there is at least one canonical instance on which ithas a non-empty answer.
The CQCE method explores a tree-shaped solution spacein which each branch either constructs a canonical instance orreaches a contradiction. We refer to this tree as the C QCE −tree and to each branch as a C QCE -derivation.
Each node in the CQCE-tree is a tuple (Gi , Di , Fi , Ci ,
Ki ), where:
• Gi is a conjunction of literals, which represent the goalto attain;• Di is the instance under construction;• Fi is a set of constraints to enforce, which contains con-
straints that are to be checked on Di ;• Ci is the set of constraints to maintain, which keeps record
of all the constraints that may need to be checked in thefuture; and• Ki is the set of constants used so far during the construc-
tion of Di .
Assuming that we want to check the satisfiability of query Qon schema S = (DR, I C), the root of the CQCE-tree is thenode (G0, D0, F0, C0, K0), where
• G0 = q(X), being q the derived predicate of Q;• D0 = ∅ , since we have not yet started the construction
of any canonical instance;• F0 = ∅, since there is no need to check any constraint
on the empty instance;• C0 = IC; and• Ki contains the constants that appear in the deductive
rule(s) of Q, in the constraints in IC, or in the deductiverules in DR.
A CQCE-derivation is successful if it reaches a node(Gs, Ds, Fs, Cs, Ks), where
123

UML/OCL conceptual schemas
• Gs is the empty conjunction of literals, meaning that thereis no further goal to attain (we have already reached thesolution);• Fs is empty; and• Ds satisfies the constraints in Cs .
In this case, Dn is a canonical instance that exemplifies thesatisfiability of query Q.
A CQCE-derivation is failed if it reaches a node (G f , D f ,
F f , C f , K f ), where
• D f contains a constraint I ci that is violated by D f andthat cannot be repaired by means of adding new tuples toD f (i.e., I ci has no negated literal in its body).
In this case, instance D f is not a consistent instance andcannot be turned into one.
The tested query Q is satisfiable if and only if there is atleast one successful CQCE-derivation. Whenever the queryis satisfiable, the CQCE returns Ds as feedback. When Qis unsatisfiable, then the CQCE returns the explanation forthe failure of the CQCE-tree which, roughly speaking, isthe union of explanations for the failure of each CQCE-derivation.
Intuitively, the explanation for the failure of a particularCQCE-derivation is the set of constraints that were violatedat some point during the construction of the correspondingD f . Note that this includes the constraints that were repairedand that ultimately led the CQCE to an irreparable violation.
To illustrate this, assume that we want to check the satisfi-ability of the following query on the logic schema that resultsfrom the encoding of our running example—let us refer to itas S = (DR, IC); the query asks for TrailSection objects witha difficulty of 8 and no companions:
noComp (ts)← T railSection (ts)
∧T railSectionDi f f iculty (ts, 8)
∧Hiked Section (hs, r, ts) ∧ ¬aux (hs)
where
aux (hs)← HasCompanion (hs, p)
A CQCE-derivation for the satisfiability check of querynoComp would be as follows. First, we start with the rootnode.
Node 0 (root)G0 = noComp (ts)D0 = ∅; F0 = ∅;C0 = I C; K0 = {8}
We want to reach the goal, i.e., construct an instance in whichG0 is true. In this case, G0 has only one literal which isderived. The first step is thus to unfold the derived literal
with its definition. This results in a new node, namely node1, which is a child of node 0 (below, we omit the node’scomponents that remain unchanged). Note that the new liter-als are decorated with the node responsible for its addition3
(shown as a superscript). We will need this information laterfor computing the explanations.
Node 1 (unfold derived literal)G1 = T railSection (ts)0 ∧ T railSectionDi f f iculty(ts, 8)0 ∧ Hiked Section (hs, r, ts)0 ∧ ¬aux (hs)0
It is worth noting that, in this example, the derived pred-icate noComp has only one deductive rule. In the gen-eral case, however, a derived predicate may have manydeductive rules. In that case, since there is more than oneway of unfolding the derived literal, the current derivationwould choose one and produce the corresponding child nodefor node 0. Other derivations would choose other unfold-ings, resulting in several branches going out from the root(recall that the solution space explored by the CQCE is tree-shaped).
Continuing with the example, since now the literals inthe goal are base, we can make them true by instantiatingtheir variables and adding the resultant facts to the instanceunder construction. We do this in several steps. Instantiatinga variable takes one step. Adding a fact to the instance takesanother step. Each step produces a new child node. Let usillustrate the first two steps.
Node 2 (instantiate variable ts with fresh constant, e.g.,0)G2 = T railSection
(01
)0 ∧ T railSectionDi f f iculty(01, 8
)0∧Hiked Section(hs, r, 01
)0∧¬aux (hs)0 K2={8, 0}
In this case, the current derivation instantiates variable tswith a fresh constant. Another possibility would be to reusea constant from K1. The different possible instantiations aredetermined by the application of a Variable Instantiation Pat-tern (VIP). A few VIPs were defined by the original CQCmethod in [14], but the most common one consists in tryingto instantiate a variable with either a fresh constant or a pre-viously used constant. The application of one VIP or anotherdepends on the syntactic properties of the logic expressions.The advantage of the VIPs is that they guarantee that if oneexplores the finite set of possible ways of instantiating thevariables with the corresponding VIP and does find a solu-tion for the query satisfiability check, then it means than nosolution exists.
3 We consider that if a literal appears in node i+1 as a consequence ofan unfolding, then the node that caused the appearance of the literal isthe parent node i .
123

G. Rull et al.
While the current derivation chooses to instantiate ts witha fresh constant, another derivation branching from node 2would choose to reuse a constant; in that way, the CQCE-treeexplores all the instantiations provided by the VIPs.
Note that the new occurrences of the constant used toinstantiate the variable are decorated with the parent node(the responsible of the appearance of these new occurrences).
Now that the goal has ground literals, we can make themtrue by adding them to the instance under construction (oneat a time).
Node 3 (add fact to the instance under construction)G3 = T railSectionDi f f iculty(01, 8)0 ∧ HikedSection(hs, r, 01)0 ∧ ¬aux(hs)0
D3 = {T railSection(01)2}F3 = all the integrity constrains involving TrailSection
Note that, when we add a new fact to the instance, we maybe causing the violation of some integrity constraints. Wemust therefore add to the set of constraints to enforce all theconstraints that may be violated, so they can be checked later.Note also that the new fact is decorated with the parent node.
The derivation continues adding a new fact for TrailSec-tionDifficulty, instantiating variable hs (with another freshconstant, e.g., 1), instantiating variable r (fresh constant 2)and adding a new fact for HikedSection.
Node 7G7 = ¬aux(14)0
D7 = {T railSection(01)2, T railSectionDi f f iculty(01, 8)3, Hiked Section(14, 25, 01)6}F7 = F3∪ all the constraints involving TrailSectionDif-ficulty∪ all the constraints involving HikedSectionK7 = {8, 0, 1, 2}
At this point, the goal contains one negated ground literal.The semantics here are that our goal is to prevent aux(14)
from being true. The way the CQCE deals with this is byintroducing a new integrity constraint I c7
a ← aux(14). Notethat the CQCE handles integrity constraints as if they weredeductive rules with an inconsistency predicate in its head(see Sect. 3.1). Note also that the new constraint is decoratedwith the node responsible for its introduction (shown as asuperscript of the inconsistency predicate).
The new constraint is added both to the set of constraintsto maintain (it may have to be rechecked in the future) andto the set of constraints to enforce (we must check that weare not already violating it).
Node 8 (negated literal turned into integrity constraint)G8 = trueF8 = F7 ∪ {I c7
a ← aux(14)}C8 = C0 ∪ {I c7
a ← aux(14)}
The current derivation has already reached the goal, but it stillhas to check whether the instance constructed is consistent,i.e., it has to check the constraints to enforce. If D8 wereto satisfy all the constraints in F8, we would be done, andD8 would be an example for the satisfiability of noComp.However, that is not the case here. The derivation must chooseone of the violations and try to repair it. In particular, thecurrent derivation selects the following violation of the OCLconstraint Difficult-SectionsAreDangerous.
I cDi f f icult Sections AreDangerous ← T railSection(01)2
∧Hiked Section(14, 25, 01)6
∧T railSectionDi f f iculty(01, 8)3
∧8 > 7 ∧ ¬DangerousSection(14)
The selected violation is repairable, since it has a negatedliteral. That is, we can avoid its violation by makingDangerousSection(14) true. This will make the negatedliteral false and prevent the inconsistency predicateI cDi f f icult Sections AreDangerous from being true. The way theCQCE handles this situation is by adding the literal that wewant to make true to the goal. The selected violation is thenremoved from the constraints to enforce (as it has alreadybeen dealt with).
Node 9 (repaired DifficultSectionsAreDangerous)G9 = DangerousSection(14)8
F9 = F8 − {I cDi f f icult Sections AreDangerous ← . . .}
Node 10 (add fact to the instance under construction)G10 = trueD10 = D7
⋃{DangerousSection(14)9}F10 = F9
⋃all constraints that involve DangerousSec-
tion
A new violation is selected:
I cMinCardinali t yO f RoleCompanion
← DangerousSection(14)9
∧¬aux HasCompanion(14)
where
aux HasCompanion(ds)← HasCompanion(ds, p)
Node 11 (repairedmincardinali t yo f rolecompanion)G11 = aux HasCompanion(14)10
F11 = F10 − {I cMinCardinali t yO f RoleCompanion ← . . .}
The derived literal is unfolded, variable p is instantiated withfresh constant 3, and the fact is added to the instance underconstruction.
123

UML/OCL conceptual schemas
Node 14G14 = trueD14 = D10
⋃{HasCompanion(14, 312)13}F14 = F11
⋃all constraints that involve HasCompanion
K14 = K7⋃{3}
The constraint added in node 8 is now violated:
I c7a ← HasCompanion(14, 312)13
Since the violated constraint has no negated literals, it can-not be repaired by adding new tuples. Therefore, the currentderivation fails.
The explanation for the failure of this derivation consists ofthe irreparable constraint I ca and all those other constraintsthat have been previously repaired in the derivation: mincardinality of role companion and DifficultSectionsAreDangerous. Note that the repair of these two con-straints led the derivation to the irreparable violation. Ifwe translate the explanation back in terms of the con-ceptual schema, we see that the failure of the deriva-tion was due to a contradiction among (1) the testedquery Q, which requires that no companion exists for theselected trail section of difficulty 8, (2) the OCL constraintDifficultSectionsAreDangerous, which statesthat trail sections with difficulty greater than 7 are dangeroussections, and (3) the minimum cardinality of role companion,which requires that each dangerous section has a companion.
However, in the general case, an explanation that includesall constraints previously repaired during the derivation isan explanation with many unnecessary constraints, for anarbitrary derivation may not necessarily choose the path thatleads directly to the contradiction. For instance, let us con-sider an alternative derivation that makes the same choicesas the one above until node 10, i.e., this alternative deriva-tion is like the one above until node 10 (inclusive), but thenchooses a different violation to be repaired in node 11. For thesake of clarity, we will number the new nodes of this alter-native derivation as 15, 16, . . . so node 15 takes the placeof node 11 in this alternative derivation. Let us assume thatthis node 15 repairs the violation of the minimum cardinal-ity of role event, which requires that a trail section mustbe part of a hiking event. That will cause the addition of aHasSection fact. Assume that it then repairs the cardinalityof role companion and finds the contradiction. If we com-pute now the explanation for this alternative derivation in theway explained above, we get that it consists of {constraintI ca , min cardinality of role companion, min cardinality ofrole event and DifficultSectionsAreDangerous}.Obviously, min cardinality of role event is unnecessary.
The same technique can be applied repeatedly to showthat it is possible to have derivations with a large numberof unnecessary constraints in its explanation (if the expla-
nation is computed in the way explained above). To addressthis, the CQCE analyses the contradiction that caused thefailure of the derivation and, using the decorations added tothe literals, constant occurrences and constraints, determineswhich of the constraints repaired during the derivation arereally necessary to reach the contradiction. The explanationfor the failure of the derivation consists of these necessaryconstraints.
The analysis begins with the irreparable violation. In ouralternative derivation (where nodes 19–22 are equivalent tonodes 11–14 from the first derivation), that is,
I c7a ← HasCompanion
(14, 320
)21
which corresponds to the constraint
I c7a ← aux
(14
)
aux (hs)← HasCompanion (hs, p)
In order to determine which repaired constraints are respon-sible for reaching this violation, we have to consider all thepossible choices where the derivation could have deviatedavoiding to reach this point. We do that by looking at thedecorations.
We could think of choosing a different value for the firstattribute of HasCompanion (the oid of the HikedSectionobject) in node 4 (recall that the decoration in constant occur-rence 14 points to the node in which the choice of instantiat-ing this attribute with constant 1 was made). In that way, thefact about HasCompanion could not be unified with the con-straint, which requires a HikedSection’s oid of 1. However,as we notice that both occurrences of constant 1—the one inthe violation and the one in the constraint—have the samedecoration, i.e., 4, we realize that they are not two differentoccurrences of the same constant, but the same occurrencethat was propagated from node 4 both to the constraint andto the violation. Therefore, changing its value from 1 to anyother value would not avoid the unification, since it wouldchange on both the violation and the constraint.
Another possibility would be to try to avoid the additionof the HasCompanion fact entirely. The decoration 21 onthe fact indicates that node 21 was the responsible for thisinsertion.
Node 21G21 = HasCompanion(14, 320)19
By looking at node 21, we see that it added the fact in order tosatisfy its goal. The only way to avoid that would be that theHasCompanion literal in G21 would not be there. The dec-oration 19 in this literal indicates that it appeared as a resultof the unfolding of a derived literal in node 19. Therefore,we could avoid the appearance of the literal by choosing adifferent unfolding (if there is any).
123

G. Rull et al.
Node 19 (repaired min cardinality of role companion)G19 = aux HasCompanion(14)18
Unfortunately, node 19 was unfolding derived predicateauxHasCompanion, which has only one deductive rule, so noalternative unfolding can be chosen. By transitivity, we couldavoid the appearance of the HasCompanion literal in node21 by avoiding the appearance of literal auxHasCompanionin node 19. Again, the decoration 18 in the latter literal tellsus that node 18 was the responsible for its appearance.
Node 18G18 = trueF18 = {I cMinCardinali t yO f RoleCompanion ←DangerousSection(14)9∧¬aux HasCompanion(14),
. . .}
where the violation in F18 corresponds to the constraint
I cMinCardinali t yO f RoleCompanion
← DangerousSection(ds)
∧¬aux HasCompanion(ds)
aux HasCompanion(ds)← HasCompanion(ds, p)
The only way we could avoid the repair of min cardinalityof role companion is by avoiding the addition of the factDangerousSection(14)9. The decoration tells us that it wasadded by node 9.
Node 9 (repaired DifficultSectionsAreDangerous)G9 = DangerousSection(14)8
Again, to avoid the addition of the fact, we must avoid theappearance of the literal in G9. The decoration points us tonode 8.
Node 8G8 = trueF8 = {I cDi f f icult Sections AreDangerous ←T railSection(01)2 ∧ Hiked Section(14, 25, 01)6
∧T railSectionDi f f iculty(01, 8)3
∧ 8 > 7 ∧ ¬DangerousSection(14), . . .}
where the violation in F8 corresponds to the constraint
I cDi f f icult Sections AreDangerous ← T railSection(ts)
∧Hiked Section(hs, r, ts)
∧T railSectionDi f f iculty(ts, d)
∧d > 7 ∧ ¬DangerousSection(hs)
Since constant occurrence 8 has no decoration, it meansthat it is not the result of any choice made during the deriva-
tion, so we cannot avoid the satisfaction of the comparisonthat way. We can, however, try to avoid the addition of any ofthe three facts required to trigger the constraint. In all threecases, the result of the analysis will be the same: the facts wereadded due to some literals in the goal that all appeared due tothe unfolding of the tested query, which has only one deduc-tive rule, so no alternative unfolding is possible. The conclu-sion is thus that the HasCompanion fact in node 21 that wewanted to avoid (because it triggered the irreparable violationof Ica) is unavoidable, and that the chain of constraints thatcauses its addition is the one we have been tracing back dur-ing the analysis:DifficultSectionsAreDangerousand min cardinality of role companion.
The analysis of the violation is not over yet. Going backto the irreparable violation
I c7a ← HasCompanion(14, 320)21,
we could still try a final way of avoiding it: preventing con-straint I ca from being created during the derivation. The dec-oration 7 in the inconsistency predicate reveals that the con-straint was created by node 7, which did that in order to dealwith the negated literal in the body of the tested query, whichas we have already discussed has no alternative unfoldingthat would avoid the presence of this negated literal. There-fore, the creation of I ca cannot be avoided. Note that, in thiscase, the analysis does not pinpoint any additional constraintas required in order to reach the irreparable violation, buttells us that I ca is not really a constraint from the schemabut a constraint induced by the goal. This means that I ca hasno real translation back in terms of the conceptual schema,other than the simple indication that the goal of the test con-tradicts the integrity constraints (which is always true whena test fails).
The final result of the analysis is thus that the explana-tion for the failure of the alternative derivation is the setof constraints {DifficultSectionsAreDangerous,min cardinality of role companion}.
By applying this analysis to each branch in a failed CQCE-tree, we get the explanation for the failure of each of thesebranches. Intuitively, the entire tree fails because all itsbranches fail; therefore, the explanation for the failure ofthe entire tree will be the union of the explanations of thebranches.
In the next subsection, we provide a more detailed descrip-tion of the violation analysis and of the CQCE method ingeneral.
3.3.1 Detailed description of the C QCE method
Let S = (DR, I C) be a database schema, G0 = L1∧· · ·∧Ln
a goal, and F0 ⊆ IC a set of constraints to enforce, whereG0 and F0 characterize a certain query satisfiability test. ACQCE-node is a 5-tuple of the form (Gi , Fi , Di , Ci , Ki ),
123

UML/OCL conceptual schemas
where Gi is a goal to attain; Fi is a set of conditions to enforce;Di is a set of facts, i.e., an instance under construction; Ci isthe whole set of conditions that must be maintained; and Ki
is the set of constants appearing in DR, G0, F0 and Di .A CQCE-tree is inductively defined as follows:
1. The tree consisting of the single CQCE-node (G0, F0,
∅, F0, K ) is a CQCE-tree.2. Let T be a CQCE-tree, and (Gn, Fn, Dn, Cn, Kn) a leaf
CQCE-node of T such that Gn �= [] or Fn �= ∅. Then, thetree obtained from T by appending one or more descen-dant CQCE-nodes according to a CQCE-expansion ruleapplicable to (Gn, Fn, Dn, Cn, Kn) is again a CQCE-tree.
It may happen that the application of a CQCE-expansionrule on a leaf CQCE-node (Gn, Fn, Dn, Cn, Kn) does notobtain any new descendant CQCE-node to be appended tothe CQCE-tree because some necessary constraint defined onthe CQCE-expansion rule is not satisfied. In such a case, wesay that (Gn, Fn, Dn, Cn, Kn) is a failed CQCE-node. Eachbranch in a CQCE-tree is a CQCE-derivation consisting of a(finite or infinite) sequence (G0, F0, D0, C0, K0), (G1, F1,
D1, C1, K1), . . . of CQCE-nodes. A CQCE-derivation is suc-cessful if it is finite, and its last (leaf) CQCE-node has theform ([], ∅, Dn, Cn, Kn). A CQCE-derivation is failed if it isfinite, and its last (leaf) CQCE-node is failed. A CQCE-treeis successful when at least one of its branches is a successfulCQCE-derivation. A CQCE-tree is finitely failed when eachone of its branches is a failed CQCE-derivation.
Figure 11 shows the formalization of the CQCE-treeexploration process. ExpandNode(T, N ) is the main algo-rithm, which generates and explores the subtree of T thatis rooted at N . The CQCE method starts with a call toExpandNode(T, Nroot ) where T contains only the initialnode Nroot = (G0, F0, ∅, F0, K ). If the CQCE methodconstructs a successful derivation, ExpandNode (T, Nroot )
returns “trueA” and solution (T ) pinpoints its leaf CQCE-node. On the contrary, if the CQCE-tree is finitely failed,ExpandNode (T, Nroot ) returns “false” and explanations(Nroot ) ⊆ F0 is an explanation for the unsatisfiability of thetested query.
Regarding notation, we use explanation(N ) and repairs(N )to denote the explanation and the set of repairs attachedto CQCE-node N . We assume that every CQCE-nodehas a unique identifier. When it is necessary, we write(Gi , Fi , Di , Ci , Ki )
id to indicate that id is the identifier ofthe node. Similarly, constants, literals and constraints mayhave labels attached to them. We write I label when we needto refer the label of I . The expansion rules attach these labels.Constants, literals and constraints in the initial CQCE-nodeNroot are unlabeled.
We assume the bodies of the constraints in Nroot are nor-malized. We say that a conjunction of literals is normalized if
it satisfies the following syntactic requirements: (1) there isno constant appearing in a positive ordinary literal, (2) thereare no repeated variables in the positive ordinary literals and(3) there is no variable appearing in more than one positiveordinary literal. We consider normalized constraints becausethat simplifies the violation analysis process.
Figure 12 shows the CQCE-expansion rules used byExpandNode. The Variable Instantiation Patterns (VIPs)used by expansion rule A2.1 are those defined in [14]. TheNormalize function used by rules A3 and B1 returns thenormalized version of the given conjunction of literals.
The application of a CQCE-expansion rule to a givenCQCE-node (Gi , Fi , Di , Ci , Ki ) may result in none, oneor several alternative (branching) descendant CQCE-nodesdepending on the selected literal L , which can be either fromthe goal Gi or from any of the conditions in Fi . LiteralL is selected according to a safe computation rule, whichselects negative and built-in literals only when they are fullygrounded. If the selected literal is a ground negative literalfrom a condition, we assume all positive literals in the bodyof the condition have already been selected along the CQCE-derivation.
In each CQCE-expansion rule, the part above the horizon-tal line presents the CQCE-node to which the rule is applied.Below the horizontal line is the description of the resultingdescendant CQCE-nodes. Vertical bars separate alternativescorresponding to different descendants. Some rules such asA4, B2 and B4 include also an “only if” condition that con-strains the circumstances under which the expansion is pos-sible. If such a condition is evaluated false, the CQCE-nodeto which the rule is applied becomes a failed CQCE-node. Inother words, the CQCE-derivation fails because either a built-in literal in the goal or a constraint in the set of conditions toenforce is violated.
Figure 13 shows the formalization of the violation analy-sis process, which is aimed to determine the set of repairsfor a failed CQCE-node. A repair denotes a CQCE-node thatis relevant for the violation. RepairsOfGoalComparisonand RepairsOfIc return the corresponding set of repairs forthe case in which the violation is in the goal and in a condi-tion to enforce, respectively. AvoidLiteral (AvoidIc) returnsthe nodes that are responsible for the presence of the givenliteral (constraint) in the goal (set of conditions to main-tain). Finally, ChangeConstants returns the nodes in whichthe labeled constants that appear in the given comparisonwere used to instantiate certain variables.
4 Minimizing an explanation and finding all minimalexplanations
The CQCE returns an explanation that, in general, may notbe minimal. That is, the explanation may include integrity
123

G. Rull et al.
Fig. 11 CQCE-tree explorationprocess
constraints that are not actually involved in the contradic-tion that caused the failure of the query satisfiability check.This is due to the fact that (1) the explanation provided bythe CQCE is the union of the explanations for the failure ofthe branches in the CQCE-tree and (2) not all branches faildue to an actual contradiction between the query’s definitionand the integrity constraints; some fail due to a bad choicemade during the derivation, e.g., choosing at some point toinstantiate an object’s attribute with constant 5 and later real-izing that this causes the violation of an OCL constraintwhich states that the attribute should have a value greaterthan 5.
Even though the approximated explanation provided bythe CQCE may be enough in many cases to understand theproblem and fix it, the user may want to know the exact (i.e.,minimal) explanation (minimal in the sense that no propersubset of it is also an explanation) or, even more, the usermay want to know all the other possible minimal explana-tions (recall that a single query satisfiability test may havemany possible minimal explanations, which essentially indi-
cate that the query is unsatisfiable due to a number of differentcauses).
We combine the techniques presented in [28] with theCQCE to minimize the approximated explanation returned bythe method and find all the additional minimal explanations(if any).
4.1 Minimizing an explanation
Given the approximated explanation returned by the CQCE,the aim of this technique is to remove from the explanationthose constraints that are not involved in the contradiction.We say that a constraint is involved in the contradiction ifthe removal of this constraint from the schema causes thetested query to become satisfiable. The resulting explanationis minimal in the sense that it has no unnecessary constraints,i.e., no proper subset of it is also an explanation.
The minimization algorithm iteratively removes oneinstance from the approximated explanation. After theremoval, it checks the satisfiability of the tested query Q
123

UML/OCL conceptual schemas
Fig. 12 CQCE-expansion rules
on the subset of the schema that contains only the integrityconstraints that are still left in the approximated explanation.If Q is now satisfiable, this means the constraint that we justremoved was involved in the contradiction, i.e., it is not anunnecessary constraint. In this case, the minimization algo-rithm inserts back the constraint and tries to remove the next.Otherwise, when Q is still unsatisfiable after the removal ofthe constraint, this means the constraint is indeed unneces-sary and needed to be removed. In this case, the minimizationalgorithm simply moves on to removing the next constraint.The process ends once it has tried to remove each of the con-straints in the approximated explanation. The minimal expla-nation resulting from this process is the set of constraints thathave been inserted back during the minimization.
Note that the minimization requires performing a numberof executions of the CQCE that is linear with respect to thesize of the approximated explanation.
We can sketch the algorithm’s proof as follows. We wantto show that the resulting set of constraints is an explanationand that it is minimal. The algorithm starts with a set ofconstraints that causes the tested property to fail, and onlyremoves from this set those constraints that do not change thatfact. Therefore, at the end of the process, we are left with a(smaller) set of constraints that still causes the property tofail, i.e., we are left with an explanation. We also know that,if we remove any of the remaining constraints, the testedproperty does no longer fail. That means no proper subset ofthe explanation computed by the minimization algorithm isalso an explanation, i.e., the computed explanation is indeedminimal.
The minimization algorithm can be run on top of any querysatisfiability method. However, since the CQCE returns anapproximated explanation for each failed execution, we canslightly modify the minimization algorithm to take advantage
123

G. Rull et al.
Fig. 13 Violation analysisprocess
of this and reduce the number of iterations (note that eachiteration makes a query satisfiability test which has an expo-nential cost). The pseudo-code for the algorithm is shown inFig. 14. The idea is that when we remove a constraint fromthe approximated explanation—let us refer to it as E—andmake a query satisfiability check, if the check fails, the CQCEreturns a new approximated explanation—namely E ′—thatis a subset of the one we already have—E ′ ⊆ E . Therefore,we can safely remove from E all those constraints that arenot in E ′. For example, assume E = {I c1, I c2, I c3, I c4} andthat we remove I c1. We run the CQCE on {I c2, I c3, I c4} andit returns {E ′ = I c3, I c4}. We do not insert I c1 back to E , butalso remove I c2. Then, a new iteration of the minimizationalgorithm begins, which tries to remove I c3.
4.2 Finding all minimal explanations
The CQCE fails due to the existence of a contradictionbetween the tested query and the integrity constraints. How-ever, the unsatisfiability of the tested query may have morethan one cause, that is, there may be more than one contra-diction. Intuitively, the reason why the CQCE returns only
one explanation is because it fails as soon as it finds one ofthese contradictions; so, in a sense, the explanation found bythe CQCE is “hiding” the other explanations. In order to beable to find these other explanations, we need to “disable”the explanation we have already found and repeat the querysatisfiability check. This will allow us to find a second expla-nation. If we want to find a third explanation, we have todisable the two that we have and do the query satisfiabil-ity check again and so on. Note that disabling an explana-tion E means removing from the schema n ≥ 1 constraintsI c1, . . . , I cn ⊆ E . Note also that we have to try all the possi-ble ways of disabling the explanation, i.e., we have to try andremove each subset of E . In order to disable multiple expla-nations, we have to try all the combinations of the differentways of disabling each explanation.
The algorithm for finding all explanations can take advan-tage of the minimization algorithm from the previous section,as shown in [28], and can also take advantage of the approxi-mated explanation returned by the CQCE. The idea is to min-imize the approximated explanation provided by the CQCEand then obtain the remaining minimal explanations in twostages. In the first stage, we obtain all those explanations that
123

UML/OCL conceptual schemas
Fig. 14 Algorithm for minimizing an explanation
are disjoint to each other and to the one we already have.Then, in the second stage, we obtain the remaining expla-nations, which overlap with the ones we have found so far.The advantage of doing the computation in these two stagesis that, while the entire process requires an exponential num-ber of query satisfiability tests, the first stage does only alinear number of them (linear with respect to the number ofintegrity constraints in the schema). The user can thus decidewhether suffices to obtain a maximal set of non-overlappingexplanations or whether he also wants all the possible expla-nations. In latter case, the computation has an exponentialcost (recall that, in the worst case, there is an exponen-tial number of explanations for a single query satisfiabilitytest).
The first stage begins after we have minimized the approx-imated explanation returned by the CQCE. The process is asfollows (the pseudo-code is shown in Fig. 15). We removefrom the schema all the integrity constraints in the mini-mal explanation and repeat the query satisfiability test. Ifthe query is now satisfiable, this means there is no disjointexplanation and we can, therefore, move on to the secondstage. Otherwise, we minimize the approximated explana-tion returned by the latter execution of the CQCE, whichgives us a minimal explanation that is disjoint with the onewe have. Then, we remove the constraints of this new expla-nation from the schema and repeat the satisfiability test again.The first stage repeats this process iteratively until no newdisjoint explanation is found. At the second stage, we have toexplore all the possible ways of disabling the disjoint expla-
nations we have. The pseudo-code is shown in Fig. 16. Forexample, assume we have the disjoint explanations:
E1 = {I c1, I c2}E2 = {I c3, I c4, I c5}E3 = {I c6, I c7}There are 24 possible ways of disabling these explanations:
• Remove I c1, I c3, I c6
• Remove I c1, I c3, I c7
• Remove I c1, I c4, I c6
• . . .
• Remove I c2, I c5, I c7
• Remove I c1, I c3, I c4, I c6
• Remove I c1, I c3, I c4, I c7
• Remove I c2, I c3, I c4, I c6
• Remove I c2, I c3, I c4, I c7
• Remove I c1, I c3, I c5, I c6
• . . .
• Remove I c2, I c4, I c5, I c7
For each of these combinations, we repeat the query satis-fiability check on the remaining constraints. If the query isnow satisfiable, then the current combination does not leadus to finding any new explanation, and we simply try the nextone. Otherwise, we minimize the approximated explanationretuned by the CQCE, and we get a new minimal explanationthat overlaps with the ones we already have. Then, we extend
Fig. 15 Algorithm forcomputing disjoint minimalexplanations
123

G. Rull et al.
Fig. 16 Algorithm forcomputing overlapping minimalexplanations
the set of combinations above with the constraints in the newexplanation and repeat the process. The second stage endswhen all the combinations have been explored.
5 Related work
In this section, we review current tools for checking the cor-rectness of a UML/OCL conceptual schema and related workon computing explanations.
5.1 Tools for checking the correctness of a UML/OCLconceptual schema
There exist several tools for checking the correctness of aUML/OCL conceptual schema. We review the most relevantones in this section. It is worth mentioning that none of thesetools is able to provide the kind of explanations that we do.
One of the best-known tools to validate UML/OCL con-ceptual schemas is USE [16]. This tool allows the designer toprovide an instantiation of the schema and to check whether itsatisfies the OCL constraints. USE may also trace and debugthe validity of an expected theorem (i.e., an OCL constraint)within a given instantiation provided by the designer [7], butit does not tell the user whether there are other causes (i.e.,explanations) for the same problem as AuRUS does. USEbehaves as model checking since it may determine whether aconstraint is violated, but it is not able to invent new instancesthat could complement the given test case to make it valid ifit is not. Note that, although a scripting language for snapshotgeneration (i.e., instance generation) is defined in [16], theactual generation of schema instances requires that the userwrites a program using this language; a program that, whenexecuted, produces a schema instance. This differs from our
approach in the sense that AuRUS is able to automaticallygenerate instances given only the schema and the propertyto be tested, without the user having to provide them neithermanually nor via a script program. Regarding the supportedlanguage, AuRUS restricts the subset of OCL to expressionsbuilt using the operators indicated in Sect. 2. USE does nothave this restriction and supports full OCL.
A similar functionality is provided by the ITP/OCL tool[11], which supports automatic validation of UML class dia-grams with respect to OCL constraints. This tool is alsoable to check whether a given instantiation satisfies the OCLconstraints, but it is not able to invent new instances whenit does not. The implementation of ITP/OCL is directlybased on the equational implementation of UML/OCL classdiagrams. This tool does not restrict the supported OCLlanguage.
The UMLtoCSP tool [8] is aimed at the formal verifica-tion of UML/OCL schemas using constraint programming.This tool is able to verify typical properties such as satisfi-ability, class liveliness or non-redundancy of integrity con-straints. These properties are similar to some of the checksperformed by AuRUS in the sense that they are based onthe properties defined in [12]. A major difference betweenUMLtoCSP and AuRUS is that the former does not pro-vide any kind of explanation when the tested property doesnot hold (in the case when the property holds, both toolsprovide an instance of the schema that illustrates that fact).Moreover, completeness is not always guaranteed by UML-toCSP since it restricts the domains of the variables in orderto guarantee decidability and this may imply failing to findan existing solution. Regarding the supported OCL opera-tors, UMLtoCSP is less restrictive than AuRUS; in particu-lar, it supports arithmetic operations and comparisons whileAuRUS supports only comparisons.
123

UML/OCL conceptual schemas
The HOL-OCL system [6] is an interactive proof envi-ronment for UML and OCL. It provides several derivedproof calculi that allow the formal derivations establishingthe validity of UML/OCL formulas. This system allows theuser to reason over the schema; however, it is the user who hasto guide the construction of the corresponding proofs, whileAuRUS performs its checks automatically. It is not clear,however, how some checks that AuRUS is able to performcan be done in HOL-OCL. In particular, we do not see aneasy way to simulate AuRUS’ interactive validation check.This check is parameterized by the user with particular data,in such a way that the existence of a consistent instance ofthe schema that includes this data is tested; however, proofsin HOL-OCL refer to elements of the schema and not data.The output produced by the two systems is entirely different;while HOL-OCL produces a formal proof for the tested prop-erty, AuRUS provides either an instance of the schema thatexemplifies the satisfaction of the property or highlights theconstraints responsible for its failure. Also, it is worth notingthat a formal proof that shows the failure of a property maynot be pinpointing all the possible causes of the problem,whereas AuRUS feature of computing all minimal explana-tions does. HOL-OCL does, however, support all standardOCL operators, while AuRUS restricts them to a particularsubset.
The OCLE environment [10] is a tool for checking the con-sistency of UML models. The checks provided by this toolallow ensuring the consistency of UML models as definedby means of well-formedness rules specified in OCL. Thiskind of validation is complementary to the one we propose inthis paper since we assume that the model to validate alreadysatisfies such well-formedness rules.
Wahler et al. [35] propose consistency checking rules forconstraints patterns. A constraint pattern is a parameterizedconstraint expression that can be instantiated to produce spe-cific constraints. The check is syntax-based, and it can thusbe done in polynomial time. The user gets pairs of pat-tern instances that can potentially contradict each other, butan alternative approach is required to check whether theyare really contradictory. Wahler et al. also survey differentnotions of consistency for UML/OCL schemas. AuRUS’ testthat checks if all classes are lively corresponds to the notionof class consistency in [35].
5.2 Computing explanations
Our notion of explanation is related to that of Minimal Unsat-isfiable Subformula (MUS) in the propositional SAT field [17]and to that of axiom pinpointing in Description Logics [30].In the next subsections, we review the most relevant works inthese areas. We also review the relevant works that deal withexplanations in the field of UML/OCL conceptual schemas.
5.2.1 Explanations in propositional SAT
The explanation of contradictions inside sets of propositionalclauses has received a lot of attention during the last years. Asurvey of existing approaches to this problem can be foundin [17]. The majority of these techniques rely on the conceptof MUS in order to explain the source of infeasibility. A setof propositional clauses U is said to be a MUS of a CNF(Conjunctive Normal Form) formula F if (1) U ⊆ F , (2) Uis unsatisfiable and (3) U cannot be made smaller withoutbecoming satisfiable. Notice that what we call an explana-tion is basically the same as a MUS; the difference is thatinstead of propositional clauses we have schema constraintsand mapping assertions.
It is well known that there may be more than one MUSfor a single CNF formula. The most efficient methods for thecomputation of all MUSes are those that follow the hittingset dualization approach—see the algorithm [3] and the algo-rithms [18,19]. The hitting set dualization approach is basedon a relationship that exists between MUSes and CoMSSes,where a CoMSS is the complementary set of a MSS, and aMSS is a Maximal Satisfiable Subformula defined as follows.A set of clauses S is a MSS of a formula F if (1) S ⊆ F ,(2) S is satisfiable and (3) no clause from F can be added toS without making it unsatisfiable. The relationship betweenMUSes and CoMSSes is that they are “hitting set duals” ofone another, that is, each MUS has at least one clause incommon with all CoMSSes (and is minimal in this sense),and vice versa. For example, assume that F is an unsatisfiableCNF formula with 6 clauses (denoted c1–c6) and that it hasthe following set of MSSes and CoMSSes (example takenfrom [17]):
MSSes : {c1, c2, c3, c5, c6}, {c2, c3, c4, c6}, {c3, c4, c5},{c2, c4, c5}
CoMSSes : {c4}, {c1, c5}, {c1, c2, c6}, {c1, c3, c6}The corresponding set of MUSes would be the following:
MUSes : {c2, c3, c4, c5}, {c1, c4}, {c4, c5, c6}Notice that each MUS has indeed an element in commonwith each CoMSS, and that removing any element from aMUS would invalidate this property.
In order to find all MUSes, the algorithms that follow thehitting set dualization approach start by finding all MSSes,then compute the CoMSSes, and finally find the minimalhitting sets of these CoMSSes. The intuition of why thisapproach is more efficient than finding the MUSes directlyis the fact that, in propositional SAT, finding a satisfiablesubformula can be done in a more efficient way than find-ing an unsatisfiable one, mainly thanks to the use of incre-mental SAT solvers. Moreover, the problem of finding theminimal hitting sets is equivalent to computing all minimal
123

G. Rull et al.
transversals of a hypergraph; a well-known problem forwhich many algorithms have been developed.
The problem of applying hitting set dualization in our con-text is that, to our knowledge, there is no incremental methodfor query satisfiability checking, and, in particular, it is notclear how to make the CQC method incremental (that couldbe a topic for further research). Therefore, there is no advan-tage in going through the intermediate step of finding theMSSes, and finding the MUSes directly becomes the moreefficient solution. This intuition is confirmed by the exper-iments we have conducted [27] to compare the techniquesdiscussed in Sect. 4 with the algorithm of Bailey and Stuckey[3].
Since in the worst case the number of MUSes may be expo-nential w.r.t. the size of the formula, computing all MUSesmay be costly, especially when the number of clauses is large.In order to combat this intractability, Liffiton and Sakallah[19] propose a variation of their hitting set dualization algo-rithm that does not compute all CoMSSes neither all MUSes,but a subset of them. This goes on the same direction that thefirst stage of the algorithm for finding all minimal explanationfrom Sect. 4.2, which is more than a mere intermediate stepin the process of finding all explanations. It provides a maxi-mal set of minimal explanations with only a linear number ofcalls to the CQCE method. The idea is to relax completenessso the user can obtain more than one explanation without theexponential cost of finding all of them.
Also because of this intractability, many approaches toexplain infeasibility of Boolean clauses focus on the easiertask of finding one single MUS. The two main approaches arethe constructive [32] and the destructive [4]. The constructiveapproach considers an initial empty set of clauses F ′. It keepsadding clauses from the given formula F to the set F ′ whileF ′ is satisfiable. When F ′ becomes unsatisfiable, the lastadded clause c is identified as part of the MUS. The process isiterated with F ′−{c} as the new formula F and {c} as the newset F ′. The process ends when F ′ is already unsatisfiable atthe beginning of an iteration, which means that F ′ is a MUS.
The destructive approach considers the whole given for-mula and keeps removing clauses until the formula becomessatisfiable. When that happens, the last removed clause isidentified as part of the MUS. The process is iterated withthe identified and remaining clauses as the new initial for-mula. The process ends when no new clause is identified.
The computation of one MUS relates with the algorithmfor minimizing an explanation from Sect. 4.1, which is aimedat computing one minimal explanation (from the approxi-mated explanation provided by the CQCE). The minimiza-tion algorithm applies the destructive approach to our con-text and combines it with the CQCE method. The idea isto take advantage of the fact that the CQCE does not onlycheck whether a given query is satisfiable, but also providesan approximated explanation (i.e., not necessarily minimal)
when is not. The destructive approach is the one that is bestcombined with the CQCE since it is expected to perform a lotof satisfiability tests with negative result. Each time a con-straint is removed, and the tested query is still unsatisfiablew.r.t. the remaining constraints, the CQCE will provide anapproximated explanation in such a way that in the next iter-ation of the destructive approach we will be able to remove allremaining constraints that do not belong to the approximatedexplanation. This way, the number of calls that the minimiza-tion algorithm makes to the CQCE decreases significantly.Moreover, since the minimization algorithm is reused by thealgorithm that finds all minimal explanations (Sect. 4.2), wecan benefit from this combination of the minimization algo-rithm and CQCE not only when we are interested in com-puting one explanation, but also when computing either amaximal set of disjoint explanations or all the possible expla-nations.
Given that computing one single MUS still requires mul-tiple calls to the underlying satisfiability method, someapproaches consider the approximation of a MUS a quickerway of providing the user with some useful insight into thesource of infeasibility of the formula. Zhang and Malik [37]propose a glass-box approach that makes use of a resolutiongraph that is built during the execution of the SAT solver.The resolution graph is a directed acyclic graph in whicheach node represents a clause and the edges represent a reso-lution step. An edge from a node A to a node B indicates thatA is one of the source clauses used to infer B via resolution.The root nodes are the initial clauses, and the internal nodesare the clauses obtained via resolution. In order to obtain anapproximated MUS, the root nodes that are ancestors of theempty clause are considered. Such a MUS is approximatedsince it is not guaranteed to be minimal. The drawback ofthis approach is the size of the resolution graph, which maybe very large; actually, in most cases, the resolution graphis stored in a file on disk. Besides the storage problems, theadditional step that is required to obtain the approximatedMUS from the resolution graph may also introduce a signifi-cant cost given the necessity of exploring the file in a reverseorder.
5.2.2 Explanations in description logics
Axiom pinpointing is a technique introduced by Schlobachand Cornet [30] as a non-standard reasoning service for thedebugging of Description Logic terminologies. The idea isto identify those axioms in a given DL terminology that areresponsible for the unsatisfiability of its concepts, which issimilar to the concept of MUSes in the SAT field and toour notion of explanations. They define a MUPS (MinimalUnsatisfiability-Preserving Sub-TBox) as a subset T ′ of aterminology T such that a concept C from T is unsatisfiablein T ′, and removing any axiom from T ′ makes C satisfiable.
123

UML/OCL conceptual schemas
Schlobach and Cornet propose a glass-box approach tocalculate all the MUPSes for a given concept with respect to agiven terminology. The algorithm works for unfoldable ALCterminologies [22] (i.e., ALC terminologies whose axiomsare in the form of C � D, where C is an atomic concept andD contains no direct or indirect reference to C), althoughit has been extended to general ALC terminologies in [21].The idea is to extend the standard tableau-like procedure forconcept satisfiability checking, and decorate the constructedtableau with the axioms that are relevant for the closure ofeach branch. After the tableau has been constructed and thetested concept found unsatisfiable, an additional step is per-formed, which applies a minimization function on the tableau(it can also be applied during the construction of the tableau)and uses its result (a Boolean formula) to obtain the MUPSes.The MUPSes will be the prime implicants of the minimiza-tion function result, i.e., the smallest conjunctions of literalsthat imply the resulting formula. Comparing with the CQCE,the main difference is that the two approaches have differentgoals; while our method is aimed at providing one approxi-mated explanation without increasing the running time, thealgorithm of Schlobach and Cornet provides all the exactMUPS, but that requires and additional exponential cost.
A black-box approach to the computation of MUPSes ispresented in [31]. Since it makes use of an external DL rea-soner, it can deal with any class of terminology for whicha reasoner exists. The algorithm uses a selection function toheuristically choose subsets of axioms of increasing size fromthe given terminology. The satisfiability of the target conceptis checked against each one of these subsets. The approach issound, but, however, not complete, i.e., it does not guaranteethat all MUPSes are found. In this sense, it is similar to thefirst stage of the algorithm for finding all minimal explana-tions from Sect. 4.2, which produces an incomplete but soundset of minimal explanations.
Another way of explaining the result of the different rea-soning tasks in Description Logics is explored by Borgidaet al. [5]. Their notion of explanation is different from oursin the sense that they consider an explanation to be a formalproof, which can be presented to the user following some pre-sentation strategy (e.g., tree-shaped proofs). They proposea set of inference rules for each reasoning task commonlyperformed in DL-Lite [9]. Then, a proof can be constructedfrom the premises by means of using the corresponding setof inference rules. As future research, it would be interestingto study how these proof-like explanations can be combinedwith ours. The motivation would be that highlighting theconstraints responsible for the result of the test may not beenough to fully understand what the problem is, i.e., it maynot be clear what the precise interaction between the high-lighted elements is, especially if the constraints are complex.In this situation, providing some kind of proof that illustrateshow these elements relate might be very useful.
5.2.3 Explanations in UML/OCL schemas
Wille et al. presented in [36] an approach for automaticallychecking the consistency of an UML/OCL model (i.e., a con-ceptual schema) and determining contradiction candidates.This concept of contradiction candidate is related to ournotion of explanation since it pinpoints a small subset ofthe original schema which explains the conflict. They com-pute the contradiction candidates in two phases. First, theyfocus on the UML part of the schema. If a contradiction isfound, they provide the corresponding contradiction candi-dates. Otherwise, the OCL part of the schema is examined,and its contradiction candidates computed. They use two dif-ferent solvers, one for each phase: a Linear Integer Arithmeticsolver for the UML phase and a Bit-Vector Logic solver forthe OCL phase. Comparing with our approach, the main dif-ference is that we reason over the UML and OCL parts atthe same time. This makes a difference, since it allows usto provide explanations that relate both parts of the schema,i.e., it may be that a test fails because of a contradiction thatinvolves not only UML elements or only OCL elements butboth of them.
Soeken et al. introduce in [33] at bit-vector encoding forOCL data types, including sets and bags, which enables theverification of UML/OCL models using a SAT solver. In par-ticular, they address the verification of two properties: con-sistency of the schema (i.e., whether there is a consistentinstance of the schema), and reachability of an OCL expres-sion (i.e., whether there is an instance in which the OCLexpression is true or returns a non-empty result), but theyrestrict the number of objects in the instance of the schemato be a particular number. From the point of view of explana-tions, their approach provides a witness that exemplifies thesatisfaction of the tested property, but they do not provide anykind of explanation for the negative case (i.e., when the testedproperty does not hold). In this sense, their notion of witnesscorresponds to our notion of (counter)example provided bythe AuRUS tool, but not to our notion of explanation.
6 Conclusions and further work
The AuRUS tool is able to check the (in)correctness of aUML/OCL conceptual schema by providing the designerwith several properties both to verify and to validate theschema. AuRUS reasons directly from the schema and is ableto determine whether each one of these properties is satisfiedby at least one of the possible instances of the schema.
The conceptual schema can be specified in ArgoUML,an open source CASE tool, since the XMI file of the schemaautomatically generated by ArgoUML can be directlyuploaded to AuRUS to perform the analysis. AuRUS is avail-able as a web application at folre.essi.upc.edu.
123

G. Rull et al.
Verification properties include classical properties suchas class liveliness or non-redundancy of a constraint, butalso additional properties such as correctness of minimumand maximum cardinalities or correctness of incomplete oroverlapping hierarchies. AuRUS incorporates also some pre-defined properties for validation such as missing identifiers,missing irreflexive constraints or missing inclusion or exclu-sion path constraints. Validation may also be achieved byallowing the designer to freely check for all properties he mayfind relevant to assess compliance with the requirements. Toour knowledge, no other tool allows for such a wide spectrumof verification and validation properties.
When a property is satisfied, AuRUS also provides a sam-ple instantiation proving the property. When it is not, AuRUSdelivers an explanation for such unsatisfiability, i.e., a set ofintegrity constraints which is in contradiction with the prop-erty. This feedback is very relevant for the designer to beable to assess whether the schema actually complies withthe requirements and to fix the errors encountered during theanalysis of the schema.
Despite the theoretically high computational cost of per-forming such kind of analysis in UML/OCL conceptualschemas (due to the high expressivity of both languages),our experience shows that AuRUS behaves quite efficientlyfor conceptual schemas like the one considered in this paper,where the maximum time we have required to check someproperty is 8.5 s.
As further work, we plan to extend our techniques to val-idate not only the structural part of the schema but also itsbehavioral part, i.e., the set of operations that can be appliedto the schema and that are gathered as a result of the require-ments engineering phase.
Acknowledgments Our thanks to Lluís Munguía and Xavier Oriol,for their valuable help in the development of this tool. This work hasbeen partly supported by Ministerio de Ciencia and Tecnología underTIN2011-24747, TIN2008-00444, Grupo Consolidado, and the FEDERfunds.
References
1. Abiteboul, S., Hull, R., Vianu, V.: Foundations of Databases, vol.8. Addison-Wesley, Reading (1995)
2. ArgoUML: http://argouml.tigris.org/ (2012)3. Bailey, J., Stuckey, P.J.: Discovery of minimal unsatisfiable subsets
of constraints using hitting set dualization. Practical Aspects ofDeclarative Languages. Lecture Notes in Computer Science, vol.3350, pp. 174–186 (2005)
4. Bakker, R.R., Dikker, F., Tempelman, F., Wognum, P.M.: Diagnos-ing and solving over-determined constraint satisfaction problems.Int. Joint Conf. Artif. Intell. 13, 276–276 (1993)
5. Borgida, A., Calvanese, D., Rodriguez-Muro, M.: Explanation inthe dl-lite family of description logics. On the Move to MeaningfulInternet Systems: OTM 2008. Lecture Notes in Computer Science,vol. 5332, pp. 1440–1457 (2008)
6. Brucker, A. D., Wolff, B.: HOL-OCL: A formal proof environmentfor UML/OCL. In: Fiadeiro, J.L., Inverardi, P. (eds.) FundamentalApproaches to Software Engineering. Lecture Notes in ComputerScience, vol. 4961, pp. 97–100. Springer, Berlin, Heidelberg (2008)
7. Brüning, J., Gogolla, M., Hamann, L., Kuhlmann, M.: Evaluat-ing and debugging OCL expressions in UML models. In: Brucker,A.D., Julliand, J. (eds.) Tests and Proofs, vol. 7305, pp. 156–162.Springer, Berlin (2012)
8. Cabot, J., Clarisó, R., Riera, D.: UMLtoCSP: a tool for the for-mal verification of UML/OCL models using constraint program-ming. In: Proceedings of the Twenty-Second IEEE/ACM Interna-tional Conference on Automated Software Engineering, ASE ’07,pp. 547–548. New York, NY, USA (2007)
9. Calvanese, D., De Giacomo, G., Lembo, D., Lenzerini, M., Rosati,R.: Tractable reasoning and efficient query answering in descrip-tion logics: the DL-Lite family. J. Autom. Reason. 39(3), 385–429(2007)
10. Chiorean, D., Pasca, M., Cârcu, A., Botiza, C., Moldovan, S.:Ensuring UML models consistency using the OCL environment.Electron. Notes Theor. Comput. Sci. 102(November), 99–110(2004)
11. Clavel, M., Egea, M.: ITP/OCL: a rewriting-based validation toolfor UML+OCL static class diagrams. In: Johnson, M., Vene, V.(eds.) Algebraic Methodology and Software Technology, vol. 4019,pp. 368–373. Springer, Berlin (2006)
12. Decker, H., Teniente, E., Urpí, T.: How to tackle schema validationby view updating. In: Proceeding of the 5th International Confer-ence on Extending Database Technology (EDBT), pp. 535–549(1996)
13. EinaGMC Project: http://guifre.lsi.upc.edu/eina_GMC/ (2011)14. Farré, C., Teniente, E., Urpí, T.: Checking query containment with
the CQC method. Data Knowl. Eng. 53(2), 163–223 (2005)15. Gogolla, M., Richters, M.: Expressing UML class diagrams prop-
erties with OCL. In: Object Modeling with OCL, Lecture Notes inComputer Science, vol. 2263, pp. 85–114 (2002)
16. Gogolla, M., Bohling, J., Richters, M.: Validating UML and OCLmodels in USE by automatic snapshot generation. Softw. Syst.Model. 4(4), 386–398 (2005)
17. Grégoire, É., Mazure, B., Piette, C: On approaches to explaininginfeasibility of sets of Boolean clauses. In: 20th IEEE InternationalConference on Tools with Artificial Intelligence, 2008. ICTAI’08vol. 1, pp. 74–83 (2008)
18. Liffiton, M.H., Sakallah, K.A.: On finding all minimally unsat-isfiable subformulas. In: Theory and Applications of SatisfiabilityTesting, Lectur Notes in Computer Science, vol. 3569, pp. 173–186(2005)
19. Liffiton, M.H., Sakallah, K.A.: Algorithms for computing minimalunsatisfiable subsets of constraints. J. Autom. Reason. 40(1), 1–33(2008)
20. Lloyd, J.W., Topor, R.W.: Making prolog more expressive. J. LogicProgram. 1(3), 225–240 (1984)
21. Meyer, T., Lee, K., Booth, R., Pan, J.Z.: Finding maximally satisfi-able terminologies for the description logic ALC. In: Proceedingsof the National Conference on Artificial Intelligence, vol. 21, p.269 (2006)
22. Nebel, B.: Terminological reasoning is inherently intractable. Artif.Intell. 43(2), 235–249 (1990)
23. OMG: (2011a). http://www.omg.org/spec/UML/24. OMG: 2011b OCL http://www.omg.org/spec/OCL/25. Queralt, A., Rull, G., Teniente, E., Farré, C., Urpí, T.: AuRUS:
automated reasoning on UML/OCL schemas. In: Concep-tual Modeling—ER 2010. http://www.springerlink.com/content/x15v9q081x602204/ (2010)
26. Queralt, A., Teniente, E.: Verification and validation of UML con-ceptual schemas with OCL constraints. ACM Trans. Softw. Eng.Methodol. 21(2), 13 (2012)
123

UML/OCL conceptual schemas
27. Rull, G.: Validation of mappings between data schemas. PhD The-sis. Universitat Politècnica de Catalunya (2011). http://hdl.handle.net/10803/22679
28. Rull, G., Farré, C., Teniente, E., Urpí, T.: Computing explanationsfor unlively queries in databases. In: Proceedings of the SixteenthACM Conference on Conference on Information and, KnowledgeManagement, pp. 955–958 (2007)
29. Rull, G., Farré, C., Teniente, E., Urpí, T.: Providing explanationsfor database schema validation. In: Database and Expert SystemsApplications, pp. 660–667 (2008)
30. Schlobach, S., Cornet, R.: Non-standard reasoning services forthe debugging of description logic terminologies. In: InternationalJoint Conference on Artificial Intelligence vol. 18, pp. 355–362(2003)
31. Schlobach, S., Huang, Z., Cornet, R., van Harmelen, F.: Debug-ging incoherent terminologies. J. Autom. Reason. 39(3), 317–349(2007)
32. De Siqueira, J.L., Puget, J.F.: Explanation-based generalisation offailures. In: Proceedings of ECAI vol. 88, pp. 339–344 (1988)
33. Soeken, M., Wille, R., Drechsler, R.: Encoding OCL data typesfor SAT-based verification of UML/OCL models. In: Proceedingsof the 5th International Conference on Tests and Proofs, TAP’11.pp. 152–170. Springer-Verlag, Berlin, Heidelberg (2011)
34. Ullman, J.D.: Principles of Database and Knowledge-Base Sys-tems, vol. 2. Computer Science Press, New York (1989)
35. Wahler, M., Basin, D.A., Brucker, A.D., Koehler, J.: Efficient analy-sis of pattern-based constraint specifications. Softw. Syst. Model.9(2), 225–255 (2010)
36. Wille, R., Soeken, M., Drechsler, R.: Debugging of inconsistentUML/OCL models. In: Design, Automation Test in Europe Con-ference Exhibition (DATE) 2012, pp. 1078–1083 (2012)
37. Zhang, L., Malik, S.: Validating SAT solvers using an indepen-dent resolution-based checker: practical implementations and otherapplications. In: Design, Automation and Test in Europe (DATE).pp. 10880–10885 (2003)
Author Biographies
Guillem Rull is currently post-doc researcher at the Depart-ment of Service and Informa-tion System Engineering (ESSI)at the Universitat Politècnica deCatalunya—BarcelonaTech. Hereceived his Ph.D. degree fromthe Technical University of Cat-alonia in 2011. His currentresearch interests are involvedwith schema and mapping vali-dation.
Carles Farré is currently asso-ciate professor at the Depart-ment of Service and Informa-tion System Engineering (ESSI)at the Universitat Politècnicade Catalunya—BarcelonaTech.He received his Ph.D. degreefrom the Technical University ofCatalonia in 2003. He workedon deductive databases, querycontainment and schema val-idation. His research interestsare involved with conceptualmodeling and data and serviceintegration.
Anna Queralt received herMS degree from the Universi-tat Politècnica de Catalunya—BarcelonaTech in 2003, and herPh.D. in Computer Science fromthe same university in 2009.She was an assistant profes-sor at the Department of Ser-vice and Information SystemEngineering, where she teachedsoftware engineering, and herresearch interests focused onautomated reasoning on concep-tual schemas. Currently, she is asenior researcher at the storage
system group in the Barcelona Supercomputing Center, where sheworks on storage and big data sharing.
Ernest Teniente is a full pro-fessor at the Department ofService and Information Sys-tem Engineering at the Univer-sitat Politècnica de Catalunya—BarcelonaTech, where he teachesgraduate and undergraduatecourses on software engineeringand databases. He got his Ph.D.in Computer Science from thesame university. He was a visit-ing researcher at the Politecnicodi Milano and at the Universita’di Roma Tre, in Italy. His currentresearch interests are focused on
conceptual modeling, automated reasoning on conceptual schemas anddata integration. He is author of more than 60 refereed publications,including ones in the most prestigious international conferences andjournals in the areas of databases and software engineering. He is regu-larly invited to serve on the Program Committees of international con-ferences in these areas.
123

G. Rull et al.
Toni Urpí is currently asso-ciate professor at the Depart-ment of Service and Informa-tion System Engineering (ESSI)at the Universitat Politècnica deCatalunya—BarcelonaTech. Hereceived his Ph.D. degree fromthe same university. He workedon deductive databases, data-base updates, integrity constraintmaintenance, query containmentand schema validation. Currentresearch interests are involvedwith conceptual modelling anddata integration.
123










![UMLto[No]SQL: Mapping Conceptual Schemas to Heterogeneous ...€¦ · Index Terms—Database Design, UML, OCL, NoSQL, RDBMS, constraint, SQL, model partitioning I. INTRODUCTION The](https://img.dokumen.tips/doc/110x75/605c311db378d858b31acca7/umltonosql-mapping-conceptual-schemas-to-heterogeneous-index-termsadatabase.jpg)


















