Embed Size (px)
Citation preview

Evolution of Psychological Measurement Models and their Applications in Practical
Testing and Assessment
Greg Hurtz, Ross Brown, Nicole Tucker PSI Services LLC

12/2/2014 2
A BRIEF (AND SOMEWHAT SELECTIVE)
HISTORICAL OVERVIEW OF MEASUREMENT MODELS IN
PSYCHOLOGY

12/2/2014 3
1860
1870
1880
1890
1900
1910
1920
1930
1940
1950
1960
1970
1980
1990
2000
2010
Galton/ Pearson
Spearman
Thurstone
Likert
Stevens
Rasch Gibson, McDonald
Lord/Novick/ Birnbaum
Jöreskog
The Classics
Guttman
Fechner
More Complex/Advanced Models

12/2/2014 4
EXPLANATIONS AND RELATIONS AMONG SOME KEY
ITEM RESPONSE MODELS

Linear Regression Model Item Score = f(Test Score)
No [0,1] Constraint on P(correct) Predictions
p-values = Probability of success for the average test-taker.
Point-Biserial r = Standardized slopes. Slope = Change in probability of success for every 1-unit change in test score.

Linear Factor Model Item Score = f(Factor Score)
No [0,1] Constraint on P(correct) Predictions
Factor Loadings = r between the latent factor and item scores. Still slopes!

Nonlinear Factor Models Item Score = f(Factor Score)
[0,1] Constraint on P(correct) Predictions
Patch the factor model by knotting or bending the lines to avoid exceeding the floor (0) and ceiling (1)

“IRT” Normal Ogive Models Item Score = f(Factor Score)
[0,1] Constraint on P(correct) Predictions
Slopes are a translation of factor loadings “Ability” is the factor score
b-values = Ability where probability of a correct response reaches the .50 mark.

“Rasch” Logistic Models Item Score = f(Factor Score)
[0,1] Constraint on P(correct) Predictions
b-values = Ability where probability of a correct response reaches the .50 mark.
Slopes are held constant “Ability” is the factor score in this constrained model

All Strategies Are Pursuing the Same Basic Goal
■ “Item Response Modeling”
■ Responses are a function of the latent trait activated by the stimulus
■ Choice of model depends on purpose ■ “Constrained” models are often the most practical ■ Rasch models sit in this mid-ground
Stimulus (Item)
Organism (Trait Activation)
Response (Answer Choice)

Classical Test Theory vs. Rasch Model (Dichotomous Models)
CTT
■ Difficulty: Percent correct varies across items at a fixed ability value (test-taker mean).
■ Discrimination: Varies across items (rpb); we determine if they meet a minimum standard, then implicitly hold them constant at 1 (despite actual variability) for scoring.
■ Guessing: Uncontrolled.
■ Ceiling/Floor: Can exceed range of 0,1.
■ Scoring: Number correct.
Rasch
■ Difficulty: Requisite test-taker ability varies across items to reach a fixed percent correct value (.5).
■ Discrimination: Held constant at 1 for all items (despite actual variability); we determine if fit of this model meets a minimum standard before using items for scoring.
■ Guessing: Uncontrolled, but accounted for in model fit test.
■ Ceiling/Floor: Constrained within the range of 0,1.
■ Scoring: Maximum likelihood score (but direct nonlinear conversion to number correct is possible).
12/2/2014 11

Rasch Model vs. IRT Models (Dichotomous Models)
IRT
■ Difficulty: Same as Rasch
■ Discrimination: Can be freely estimated; varies across items to maximize fit.
■ Guessing: Can be freely estimated; varies across items to maximize fit.
■ Ceiling/Floor: Same as Rasch, but can be freely estimated in guessing and carelessness parameters.
■ Scoring: Maximum likelihood score (monotonically related to number correct, but not directly convertible).
12/2/2014 12
Rasch
■ Difficulty: Requisite test-taker ability varies across items to reach a fixed percent correct value (.5).
■ Discrimination: Held constant at 1 for all items (despite actual variability); we determine if fit of this model meets a minimum standard before using items for scoring.
■ Guessing: Uncontrolled, but accounted for in model fit test.
■ Ceiling/Floor: Constrained within the range of 0,1.
■ Scoring: Maximum likelihood score (but direct nonlinear conversion to number correct is possible).

Rasch vs. IRT: More Than Math
■ Primacy of Model vs. Data ■ IRT: Modify model to best fit the data and map item response patterns
uniquely for each item ■ Rasch: Require the data to adequately fit this same ideal model for each
item
■ Adherence to Measurement Principles ■ Rasch: Parallel curves keep the measure and objects of measurement
independent (invariant) ■ IRT: Crossing curves means properties of the measure (e.g., relative item
difficulties) depend on properties of the object of measurement (level of ability)
■ Practicality ■ IRT: More complex models map item responses in a more sophisticated
way, but require more resources ■ Rasch: Constraining parameters reduces resource requirements without
significant loss of practical value
12/2/2014 13

Concluding Remarks ■ Psychological measurement models
have evolved over the past 100+ years ■Classical methods have some basic,
rugged utility ■ Rasch models are more refined while
retaining many practical features ■ IRT models allow more sophistication in
some aspects while demanding more resources
12/2/2014 14

12/2/2014 15
MAKING THE CASE: PRACTICAL CONSIDERATIONS IN TRANSITIONING CLIENTS FROM
CTT TO RASCH MODELS

Working with testing organizations to implement mathematically complex
Rasch analyses ■ Challenges and concerns ■ Different measurement contexts
– Dichotomous applications
– Polytomous applications, i.e., many-facet Rasch (MFR) model for analysis of performance assessments and standard setting judgments
12/2/2014 16

Keys to Success ■ Thorough and ongoing education of
testing stakeholders ■ Focus on educating clients about the
application, characteristics, and benefits of these measurement models.
12/2/2014 17

Scaled scores instead of raw scores ■ “Candidates want to know, ‘I need to get
70 questions correct to pass.’ ” ■ Assumption may be that some candidates
aren’t sophisticated enough to understand scaled scores
12/2/2014 18

Scaled scores instead of raw scores ■ Reality: Commonly used for SAT, ACT ■ A little education usually convinces test
sponsors: – Measurement benefits, i.e., improve measurement precision of
equated exams while still having same scaled pass point
– Comparisons can be made: Scaled scores have the same meaning across years for equated examinations
12/2/2014 19

Communicating to candidates ■ Candidates want their raw score, raw-score
pass point – Encouraged testing organizations to only release scaled scores
– Raw score pass point and scaled score equivalents of raw scores may be different in future years.
■ Describing test analysis and model – Not present analysis and methods as an opaque black box
– Describe analysis model and criterion-referenced standards at a higher level, focusing on applications and benefits
12/2/2014 20

CTT v Rasch: Targeting item difficulties ■ Upper bound for p-values
– Items more often too easy, particularly for new testing programs
– More items for SMEs to write
– More time and money for testing organizations
■ Challenge: Get buy-in on this expenditure ■ Solution
– Explain benefits in terms of Rasch measurement from targeted items
– Track progress
– Show results
12/2/2014 21

Explaining item targeting to stakeholders
12/2/2014 22
A B

Explaining item targeting to stakeholders
12/2/2014 23
A B

Explaining item targeting to stakeholders
12/2/2014 24
A B

Explaining item targeting to
stakeholders: Wright Map
12/2/2014 25
MEASURE | MEASURE <more> --------------------- PERSONS -+- ITEMS --------------------- <rare> 9 + 9 | | | . | . | X | 8 . + XX 8 # | XXX # T|T XXXX More able candidates .##### | XXX More difficult items .##### | X .######### S| XXX ########### | XX 7 .#################### + XXXXX 7 .################ M| XXX ################# | XXX .############## |S XXXXXXXXXX Cut score .######### S| XXXXXX .###### | XXXXXXX .# | XXXXXX 6 .### T+ XXXXXXXXXX 6 # | XXXXXXXXXX . | XXXXXXXXXXXXXX . | XXXXXXXXXXXXXXX Less able candidates . |M XXXXXXXXXXXXXXX . | XXXXXXXXXXXXX . | XXXXXXXXXX 5 + XXXXXXXXXXXX 5 | XXXXXXXXXXX | XXXXXXXX | XXXXXXXXXXXXXXXXXX | XXXX |S XXXXXX | XXXXXX 4 + XXXX Easier items 4 | XX | XX | XX | XX | XXX |T XX 3 + X 3 | X | | | | | X 2 + 2 | X | | | | | 1 + 1 <less> --------------------- PERSONS -+- ITEMS ------------------<frequent>

Explaining item targeting to
stake-holders: Wright Map
12/2/2014 26
MEASURE | MEASURE <more> --------------------- PERSONS -+- ITEMS --------------------- <rare> 9 + 9 | | | | | | 8 X + XX 8 |T XXXX T| XX More able candidates | XXXXX XXXX | X XXXX | XXX XXXXXXXXXXXXX S| XXXXX More difficult items 7 XXXXXXX + XXXXX 7 XXXXXXXXXXXXX |S XXXXXXXX XXXXXXXXXXXXX | XXXXXX XXXXXXXXXXX M| XXXX XXXXXXXXXX | XXXXXXXX XXXXXXXXXX | XXXXXXX XXXXXXXX | XXXXXXXXXXXXXXX 6 XXXXXXXXX + XXXXXXXX 6 Cut score XXXXXX S| XXXXXXXXXXXXXXXXX X |M XXXXXXXXXXXXXXXXXXXXX XXXXXXXXX | XXXXXXXXX XXXX | XXXXXXXXXXXXX XXX T| XXXXXXXXXXXXXXX | XXXX 5 X + XXXXXXX 5 | XXXXXXX Less able candidates |S XXXX | XXX | XXXX Easier items | | X 4 + X 4 | X |T | XXX | X | XX | 3 + 3 | | | | | | XX 2 + 2 | | | | X | | 1 + 1 <less> --------------------- PERSONS -+- ITEMS ------------------<frequent>

Monitoring progress
12/2/2014 27
P-Value 2005 2006 2007 2008 2009 .10 – .19 1 (0.6%) 1 (0.5%) 0 1 (0.5%) 1 (.5%) .20 – .29 2 (1.1%) 5 (2.6%) 4 (2.1%) 5 (2.6%) 9 (4.6%) .30 – .39 4 (2.2%) 4 (2.1%) 6 (3.1%) 7 (3.6%) 11 (5.6%) .40 – .49 4 (2.2%) 13 (6.8%) 11 (5.7%) 16 (8.3%) 20 (10.3%) .50 – .59 14 (7.8%) 12 (6.3%) 7 (3.6%) 14 (7.3%) 21 (10.8%) .60 – .69 18 (10%) 29 (15.1%) 23 (11.9%) 30 (15.5%) 56 (28.7%) .70 – .79 32 (17.8%) 31 (16.1%) 57 (29.4%) 52 (26.9%) 43 (22.1%) .80 – .89 50 (27.8%) 65 (33.9%) 45 (23.2%) 52 (26.9%) 21 (10.8%) .90 – .99 55 (30.6%) 32 (16.7%) 41 (21.1%) 16 (8.3%) 13 (6.7%)

Showing results: Lower SEM, Greater reliability
12/2/2014
2004 2005 2006 2007 2008
Mean Score 6.79 6.65 6.49 6.48 6.52 SD 0.56 0.52 0.47 0.54 0.46 SEM 0.21 0.17 0.17 0.17 0.16 Reliability .86 .89 .88 .91 .89 Average Item Difficulty 5.00 5.98 5.99 5.99 6.04

Implications: ■ Time and money ■ Lower percent-correct to pass
12/2/2014
2005 2006 2007 2008 2009
Candidate Mean Score 6.82 6.70 6.76 6.70 6.51
SD 0.75 0.77 0.64 0.65 0.59
Candidate Score SEM 0.22 0.19 0.20 0.19 0.17
Reliability .91 .93 .90 .90 .92
Average Item Difficulty 5.00 5.30 5.28 5.51 5.77
Percent Correct to Pass 62% 47%

Implication: ■ Greater flexibility when drafting forms
12/2/2014
2005 2006 2007 2008 2009
Candidate Mean Score 6.82 6.70 6.76 6.70 6.51
SD 0.75 0.77 0.64 0.65 0.59
Candidate Score SEM 0.22 0.19 0.20 0.19 0.17
Reliability .91 .93 .90 .90 .92
Average Item Difficulty 5.00 5.30 5.28 5.51 5.77
Percent Correct to Pass 62% 47%

12/2/2014 31
BEYOND DICHOTOMIES: RATING SCALES AND THE
MANY-FACET RASCH (MFR) MODEL

Applications: ■ Performance assessments ■ Standard-setting judgments
12/2/2014

Performance Assessment Format
■ Examiners rate candidate performance on standardized protocols, i.e., hypothetical patient scenarios, using a four-point rating scale within different skill areas, such as diagnoses, treatment, prognosis, and management of complications.
■ Overlap: Multiple examiners rate the same candidates, multiple candidates are rated on the same clinical scenarios, and all candidates are rated on the same skills.
12/2/2014

Characteristics of this MFR Model Implementation
■ Examiners’ individual severity is quantified
■ Although examiners are calibrated, less emphasis on consensus and inter-rater reliability
■ As long as individual raters demonstrate internal consistency in their severity, that individual severity can be calculated and adjusted for before candidate scores are calculated.
12/2/2014

Characteristics of this MFR Model Implementation
■ Rating scale and its performance descriptors can be used to set the pass point ■ Point on scale reflecting acceptable performance
■ Facets outputs “fair average,” which can be used to determine logit equivalent
■ Initial criterion standard subject to adjustment via SEM
12/2/2014

Characteristics of this MFR Model Implementation
■ Subsequent performance assessments can be equated ■ Research shows individual examiners’ severity levels are
relatively invariant over time
■ Hold individual facet elements – individual examiners, clinical scenarios, and skills – at initial calibrations
■ Equated pass point can be applied, eliminating need for a testing organization to revisit it with each exam administration
12/2/2014

Characteristics of this MFR Model Implementation
■ Rating consistency can be monitored ■ Fit statistic represents the ratio of observed rating and
expected rating
■ Greater than 1: Unexpected variability considering ability of candidate and difficulty of other facets
■ Less than 1: Insufficient variability, tending to give the same rating to many candidates regardless of differences in ability
12/2/2014

Challenges Implementing MFR Model
■ Misfitting examiners rating barely failing candidates ■ If examiner was exhibiting unexpected variability, did the
candidate receive an unfair rating?
■ Difficult for psychometrician to recommend to a testing organization that it supersede the considered judgment of the expert practitioners invited to assess candidates – based on a statistical finding
■ More commonly, examiners not invited to return
12/2/2014

Challenges Implementing MFR Model
■ Stakeholders may have difficulties with raw-score adjustments made by the model
■ Candidate with lower raw score than another may have a higher logit score
12/2/2014

12/2/2014 40
ID Score Fair Average Scaled Score Error
60135 282 2.13 5.83 0.15 80158 299 2.10 5.73 0.17 30303 296 2.09 5.69 0.16 30370 264 2.07 5.61 0.15 30342 270 2.03 5.46 0.16 40285 280 2.03 5.45 0.15
5.28 Equated Pass Point 40301 220 1.97 5.22 0.14 80123 254 1.96 5.20 0.15 50168 291 1.89 4.95 0.16 80137 243 1.82 4.73 0.15 30354 250 1.80 4.67 0.15 80211 209 1.73 4.46 0.13 50144 203 1.33 3.58 0.13
Challenges Implementing MFR Model

12/2/2014 41
Examiner Severity
14 3.91 15 3.80 16 5.91 18 5.29 19 2.71 20 5.02 21 3.80 22 4.49
Model = ?,19,?,?,RS Examiner 19 Rating (or partial credit) scale = RS,R3,S,O -------------------------------------- |Response | DATA | |Category | Category Counts Cum.| | Name |Score Used % % | -------------------------------------- | UNACCEPTABLE| 0 2 0% 0%| | DEFICIENT | 1 18 4% 4%| | ACCEPTABLE | 2 131 29% 34%| | EXCELLENT | 3 299 66% 100%| ------------------------------------ Model = ?,16,?,?,RS Examiner 16 Rating (or partial credit) scale = RS,R3,S,O -------------------------------------- |Response | DATA | |Category | Category Counts Cum.| | Name |Score Used % % | -------------------------------------- | UNACCEPTABLE| 0 11 2% 2%| | DEFICIENT | 1 124 28% 30%| | ACCEPTABLE | 2 300 67% 97%| | EXCELLENT | 3 15 3% 100%| --------------------------------------
Challenges Implementing MFR Model

Challenges Implementing MFR Model: Ongoing Education
■ Repeat educational information at every meeting and every conference call
■ Explain how model works; its features, benefits, and requirements; and the statistics, their meaning, and acceptable parameters.
■ Eventually stakeholders (board members) become conversant with features of the model
12/2/2014

Other MFR Model Applications
■ Evaluating standard-setting ratings ■ Standard setting judgments modeled as
■ panelist severity
■ judged item difficulty
■ judged average performance level for rounds
■ judged locations of individual recommended cut scores
12/2/2014

MFR Model Application: Evaluating Standard-Setting Ratings
■ MFR analysis provided evidence of the standard setting ratings’ quality
■ Researchers examined ■ panelist severities
■ judged item difficulties
■ rounds
■ cut scores
12/2/2014

MFR Model Application: Evaluating Standard-Setting Ratings
■ Analysis provided supporting evidence of the procedure’s validity.
■ Validity evidence included: ■ large spread in panelist severity
■ lack of evidence of halo effect or inconsistency in panelist ratings
■ range of item difficulties,
■ which were moderately positively correlated with observed difficulties.
12/2/2014

12/2/2014 46
ADDITIONAL PRACTICAL CONSIDERATIONS IN
IMPLEMENTING RASCH MODELS

Practical Considerations for Test Implementation
Ultimate goal of psychometric research is to develop and select best model for the needs
of the individual testing program.
Important Considerations Reliability of Test Scores Security of Test Items
12/2/2014 47

Precision of Item Difficulty Estimate All measures of item difficulty are estimates
which include a degree of error or variability. Precision of the estimate increases with
increase in sample size of representative candidate sample.
12/2/2014 48

Precision of Item Difficulty Estimate From a practical standpoint, a key question
becomes.... what is the minimum examinee volume required to implement the Rasch model?
12/2/2014 49

Linacre, 1994 A sample of 50 well-targeted examinees is
conservative for obtaining useful, stable estimates. 30 examinees is enough for well- designed pilot studies, given a two-tailed 99% confidence interval for a ±1 logit interval estimation.
12/2/2014 50

Chen et al, 2014 Rasch analysis based on small samples (≤ 50)
identified a greater number of items with incorrectly ordered parameters than larger samples (≥ 100). However, fewer items were identified as misfitting. Results from small samples led to opposite conclusions from those based on larger samples. Rasch analysis based on small samples should be used for exploratory purposes with extreme caution.
12/2/2014 51

Empirical Exercise to Explore Variation in Difficulty Estimation by Sample Size
Using examinee response data from a pool of
items, calibrated item difficulty (Rasch Measure) for 99 items at sample sizes of 30, 50, 80, 100 and 7000.
Goal: To determine the sample size that
achieves the biggest decrease in difference of item difficulty estimate from large sample.
12/2/2014 52

• Items are four-option multiple choice
• Dichotomously scored
• Pvalue range: 0.35 to 0.95
• Point Biserial: 0.1 to 0.45
• Pooled or multiple form item administration
• Rasch item difficulty (Measure) calibrated using
Winsteps.
12/2/2014 53
Description of Item Pool

12/2/2014 54
Sample Size Average Item N
Minimum Item N
Maximum Item N
Minimum Item
Measure
Maximum Item
Measure
Mean Item Measure
7,128 3, 205 1,579 7,107 -2.070 2.010 0.000
30 14 4 30 -3.780 2.490 -0.345
50 24 11 50 -3.940 2.770 -0.146
80 28 18 80 -3.710 2.130 -0.037
100 48 22 100 -2.600 2.120 0.000
Empirical Exercise to Explore Variation in Difficulty Estimation by Sample Size

12/2/2014 55
Sample Size Number of Items
with difference less than 0.3 Logit
Number of Items with difference less
than 1 Logit
Number of Items with difference
greater than 1.5 Logit
7,128
30 27 77 13
50 47 84 5
80 55 94 3
100 64 95 1
Empirical Exercise to Explore Variation in Difficulty Estimation by Sample Size

Precision of Item Difficulty Estimate It is important to consider the Item N in addition
to the examinee volume when determining appropriateness of Rasch model for testing program.
Even for low volume testing programs there exists
a need to have multiple test forms to accommodate retakes, resulting in a lower N per item.
Research and exploratory exercise suggests a
minimum item N of 50 -100 for Rasch model. More research is needed.
12/2/2014 56

12/2/2014 57
DYNAMIC TEST CONTENT DELIVERY SUPPORTED BY RASCH MODELS

12/2/2014 58
Selecting the Optimal Test Delivery Method Historically, IRT has been implemented
using fixed test forms and Computer adaptive testing (CAT).
Linear On-The-Fly Testing using the Rasch
model offers an opportunity to take advantage of the benefits of both.

Linear On the Fly Testing (LOFT)
• Builds unique, equivalent forms for each candidate from an item bank
• Balances content & psychometric criteria • Ensures uniform item rotation – minimizes
exposure • Unique exams minimize form overlap –
improves security • Allows for monitoring and updating of items
rather than test forms • Continuous monitoring– update items rather
than test forms

60
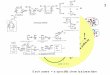
Random Selection
per Domain
Item Bank
Evaluate Test
Properties
Monte Carlo Analysis - Target Parameters
Acceptable Test Forms
Preliminary Test Form
OK?
Gibson & Weiner (1998)
1
2
3 4 5 6
FormCastTM – A System for Generating Parallel Test Forms

12/2/2014 61
LeaderAmp – An Expert System for Coaching Leaders
Computer-Adaptive Self- Assessment
• Short ~15 minutes • Android, iPhone apps • Automated, tailored content
delivered instantly • Rasch measurement: Leaders
scaled along same dimension as developmental feedback statements
• Feedback “task” recommendations selected that fall at leader’s trait level, for maximum relevance
• Multi-source ratings; MFR model adjusts for rater biases, including self-enhancement
Goal Setting & Personal
Plan
eCoaching Lessons Learned
Baseline & Re-
Assessment

12/2/2014 62
THANK YOU! QUESTIONS?
Greg Hurtz Senior Psychometrican, PSI Services LLC [email protected] Ross Brown Senior Psychometrican, PSI Services LLC [email protected] Nicole Tucker Senior Test Development Specialist, PSI Services LLC [email protected]