Embed Size (px)
Citation preview

Asynchronous Datapath Design• Adders• Comparators• Multipliers• Registers• Completion Detection• Bus• Pipeline•….. Read Reading 3:
Delay-Insensitive Adders

Asynchronous Adder Design
• Motivation• Background: Sync and Async adders• Delay-insensitive carry-lookahead adders• Complexity Analysis• Conclusions

Motivation
• Integer addition is one of the most important operations in digital computer systems
• Statistics shows that in a prototypical RISC
machine (DLX) 72% of the instructions perform additions(or subtractions) in the datapath.
• In ARM processors it even reaches 80%.
• The performance of processors is significantly influenced by the speed of their adders.

Background
• Adders: synchronous or asynchronous synchronous adders: worst case performance asynchronous adders: average case performance
• For example:
Ripple-Carry Adders(synchronous): O(n) Carry-Completion Sensing Adders(asynchronous): O(log n)

Background: Binary Addition
• Worst case 00000001 + 11111111 ---------------------- S 00000000 C 11111111 ---------------------- 100000000
• Adders can perform average case behavior
• Best case 00000000 + 00000000 ---------------------- S 00000000 C 00000000 ---------------------- 000000000

Background
• Ripple-Carry Adders:
• One-stage full adder:• Logic complexity: O(n)• Time complexity: O(n)

Background
• Carry-Sensing Completion Detection Adders: (asynchronous version of RCA)

Background
• One-stage CSCD Adder:
• Carry-Sensing Completion Detection Adders:
Logic complexity: O(n) Time complexity: O(log n)

Background
• Delay-Insensitive Ripple-Carry Adders: (DI version of RCA):
Background
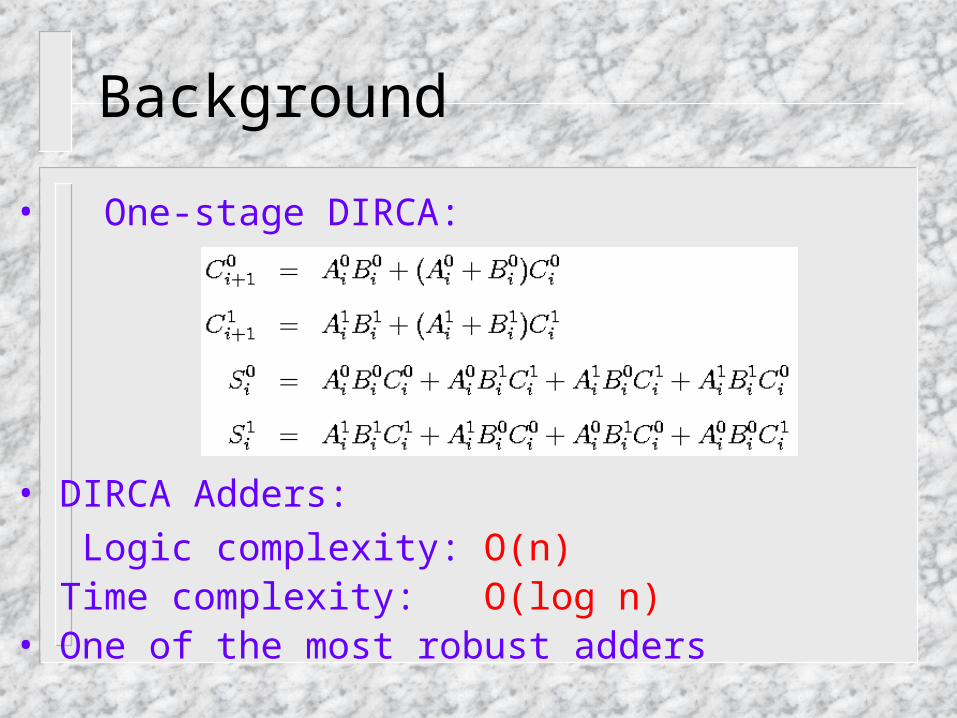
• One-stage DIRCA:
• DIRCA Adders:
Logic complexity: O(n) Time complexity: O(log n)• One of the most robust adders

Background
• Completion detection for asynchronous adders:

Background
• DI adder VS Bundling Constraint adder:

Carry-Lookahead Adders
• RCA requires n stage-propagation delays. • For high speed processors, this scheme is undesirable. • One way to improve adder performance is to use parallel processing in computing the carries. • That is why Carry-Lookahead Adders (CLA) are introduced.
• CLAs:
Logic complexity: O(n) Time complexity: O(log n)

Carry-Lookahead Adders

Carry-Lookahead Adders
• A module:
• B module:

DI Carry-Lookahead Adders
• Delay-Insensitive Carry-Lookahead Adders (DICLA) may be implemented by using delay-insensitive code.
1. dual-rail signaling: inputs, sums, and carry bits
2. one-hot code: internal signals
A1=0A0=0
A1=0A0=1
A1=1A0=0
A1=1A0=1
a. No data b. valid 0 c. valid 1 d. illegal
a. No data: 000b. 001c. 010d. 100

QDI Carry-Lookahead Adders
• DI C module: 1. internal signals: one-hot code, k, g, p
2. input and sum bits: dual-rail signals
CLA A module

QDI Carry-Lookahead Adders
• DI D module: 1. Internal signals: one-hot code, K, G, P 2. Carry bits: dual-rail signals
CLA B module

DI Carry-Lookahead Adders

DI Carry-Lookahead Adders
If A3=B3 thenC3 is carry kill or generate
k3,g3

DI Carry-Lookahead Adders
G3,2, K3,2
can be used tospeed up the carry computation too.
k3,g3
K3,2, G3,2

Speeding Up DICLA
• Idea: Send the carry-generate’s and carry-kill’s to any possible stages which needs these information to compute carries immediately.• D module with speed-up circuitry

Speeding Up DICLA
• General form:• D module with speed-up circuitry
for carry-kill
for carry-generate
= gj-1+gj-2Pj-1+…+g0p1p2…pj-1
This is in fact the full carry-lookahead scheme.

Speeding Up DICLA
• Problem of full carry-lookahead scheme • practical limitations on fan-in and fan-out, irregular structure, and many long wire.• logic complexity increases more than linearly
• Solution: use the properties of tree-like structure• New speed-up circuitry:

• SP focuses on the root node of a subtree.• All leftmost root node of its right subtree

Power of Speed-up Circuitry
x : carry chainx’ in r subtreex-x’ in l subtree

Power of Speed-up Circuitry
Without Speed-up circuitry
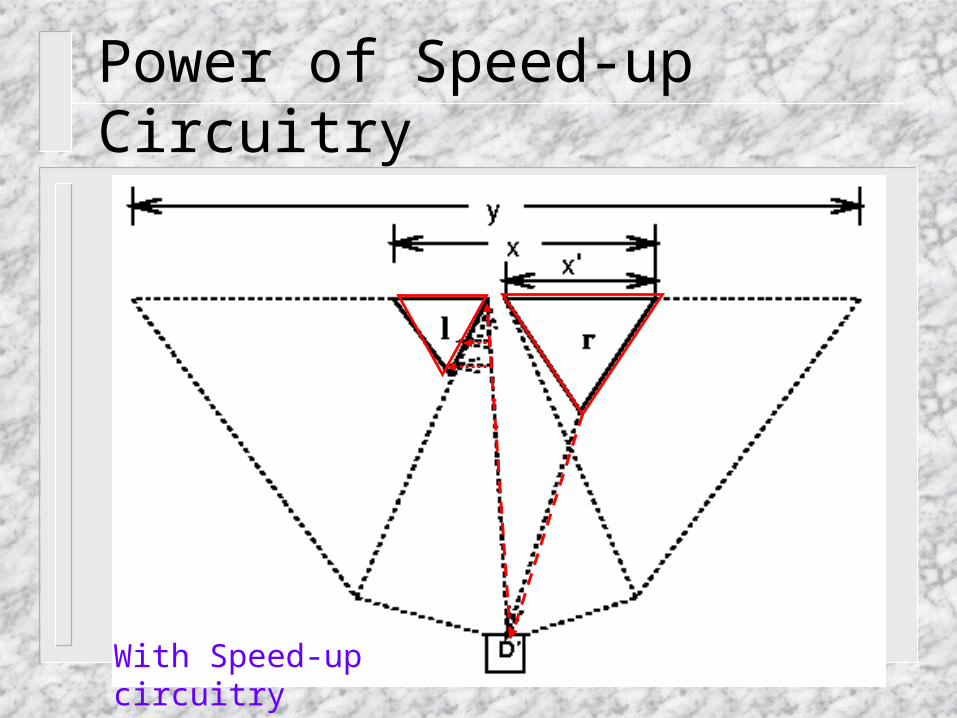
Power of Speed-up Circuitry
With Speed-up circuitry

Optimization:
• Simplified D module • Simplified D’ module
• Better logic complexity• Delay-Insensitive again


Complexity Analysis
• DICLASP
• Logic Complexity: (n)• Time Complexity: (log log n)• Best area-time efficiency: (n log log n)

Complexity Analysis

CMOS: C module
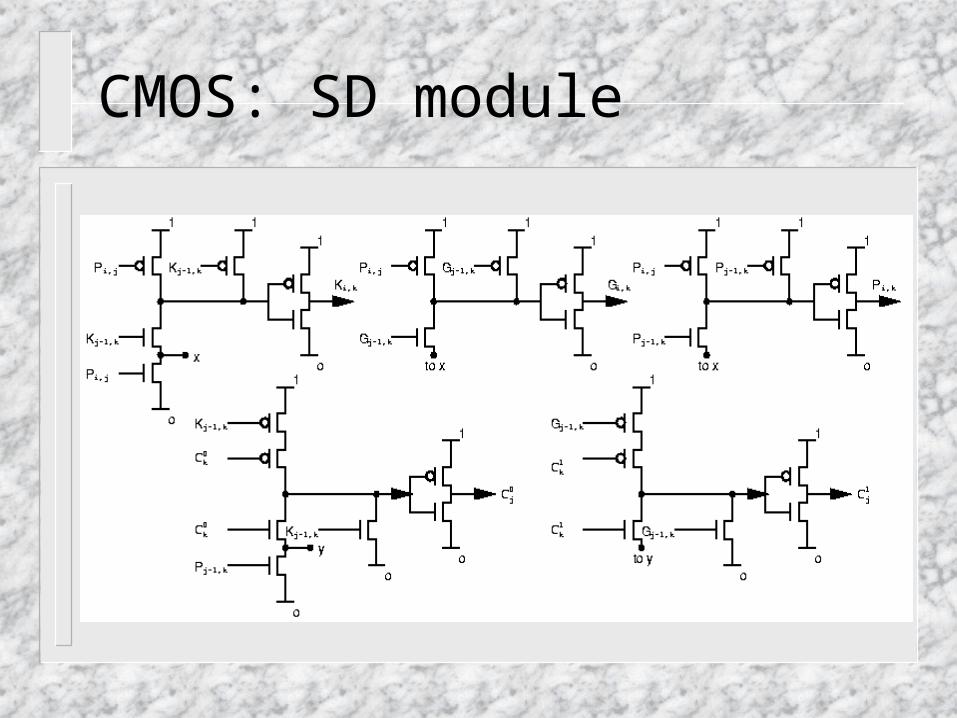
CMOS: SD module

CMOS: SD’ module

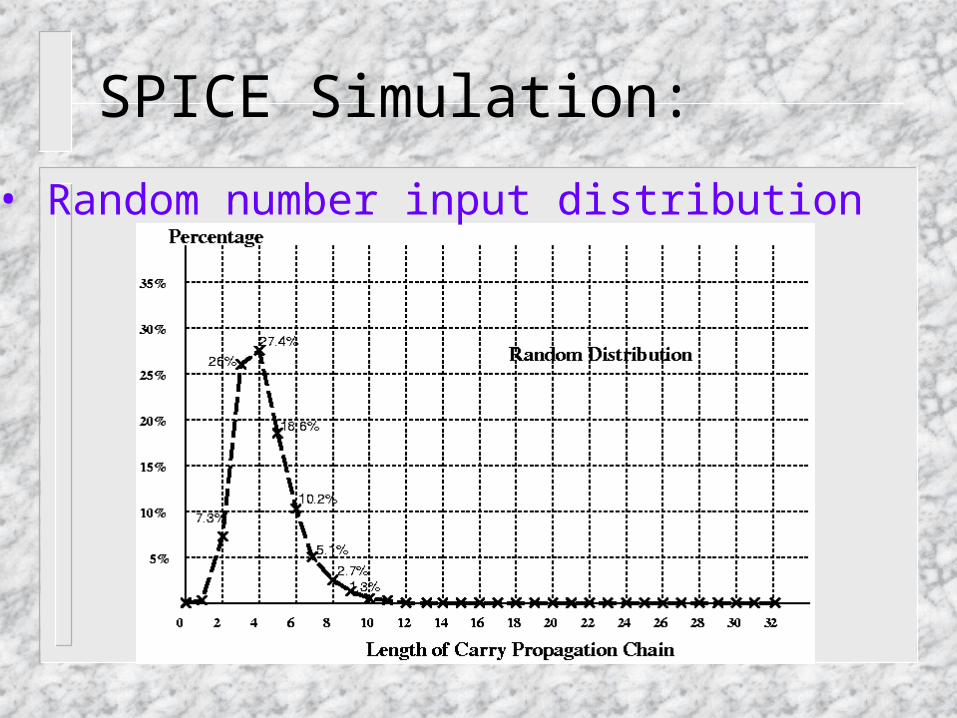
SPICE Simulation:
SPICE Simulation contains two parts:• Random number inputs: 10000 random generated input pairs• Statistical data: running examples on a 32-bit ARM emulator
SPICE Simulation:
• Random number input distribution

SPICE Simulation:
• SPICE simulation results: random number inputs
• Speedup: DIRCA vs RCA: 6.39 DICLASP vs CLA: 2.64

SPICE Simulation:
• Breakdown of addition/subtraction operations: by runing three benchmark programs: Dhrystone f1, Dhrystone f2 and Espresso dc2 on a 32-bit ARM simulator

SPICE Simulation:dynamic traces

SPICE Simulation:
• dynamic traces• 83.92% instructions: |carry chain| <17

SPICE Simulation:
• SPICE simulation results: dynamic traces• Average computation time:
DIRCA 9.61ns DICALSP 5.25ns• Speedup: DIRCA vs RCA: 4.1
DICLASP vs CLA: 2.2

Conclusion
• DICLASP Best area-time efficiency: (n log log n)
Correctness: No adder is more robust than
DICLASP
Cost(Logic Complexity):No parallel adder is
cheaper than DICLASP ((n)). Speed(Time Complexity):No adder is better
than DICLASP ((log log n)). Suitable for VLSI implementation.





























