Embed Size (px)
DESCRIPTION
Resumen de cómo se compone y computa un CPU
Citation preview

Arquitectura y organización de computadoras Página 1 de 76
Organización y Arquitectura de computadoras
Introducción:
Es a veces difícil identificar donde está la diferencia entre la arquitectura y la organización de computadores. La arquitectura se refiere a las características del sistema que son visibles al programador, o sea que el programador va a tener que tener en cuenta al momento de programar (ejemplo de esto serían los modos de direccionamiento, el conjunto de instrucciones, la cantidad de bits usados para representar los distintos tipos de datos. La organización en cambio es transparente al programador, este no se preocupa por estos temas, señales del bus de control, interfaces entre periféricos y computador, tecnología usada en memoria, cantidad de caches, etc. En general lo fabricantes de máquinas producen familias de pc con una misma arquitectura y a medida que pasa el tiempo salen nuevos modelos con la misma arquitectura, pero con una organización diferente, con lo cual logran una compatibilidad de software. Ejemplo de esto serían las PC comunes y una Macintoch, por poseer distinta arquitectura no son compatibles sus SW.
Estructura y funcionamiento: La descripción del sistema se va a ser la siguiente forma: Se comenzara con una visión muy superficial, para de a poco introducirnos en las capas más bajas en cuestión de estructura y funcionamiento.
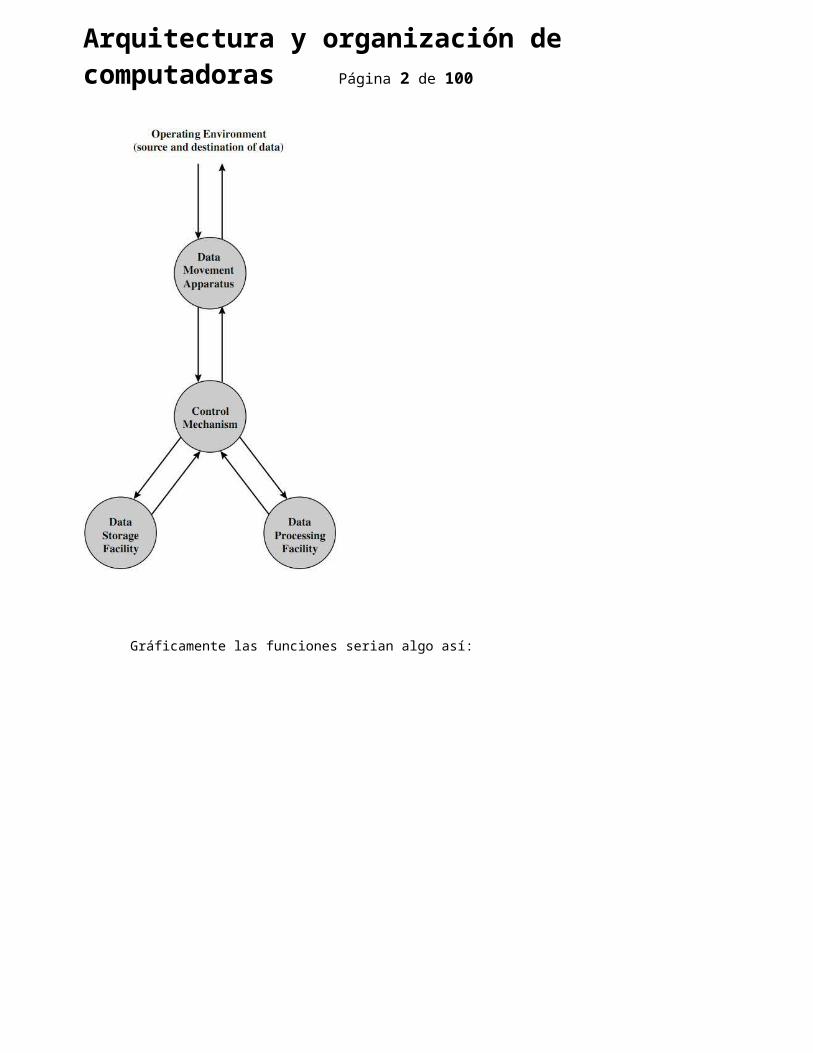
Funciones básicas de un computador:
1. Procesamiento de datos. 2. Almacenamiento de datos. 3. Trasferencia de datos. 4. Control.
Gráficamente sería así:
Arquitectura y organización de computadoras Página 2 de 76
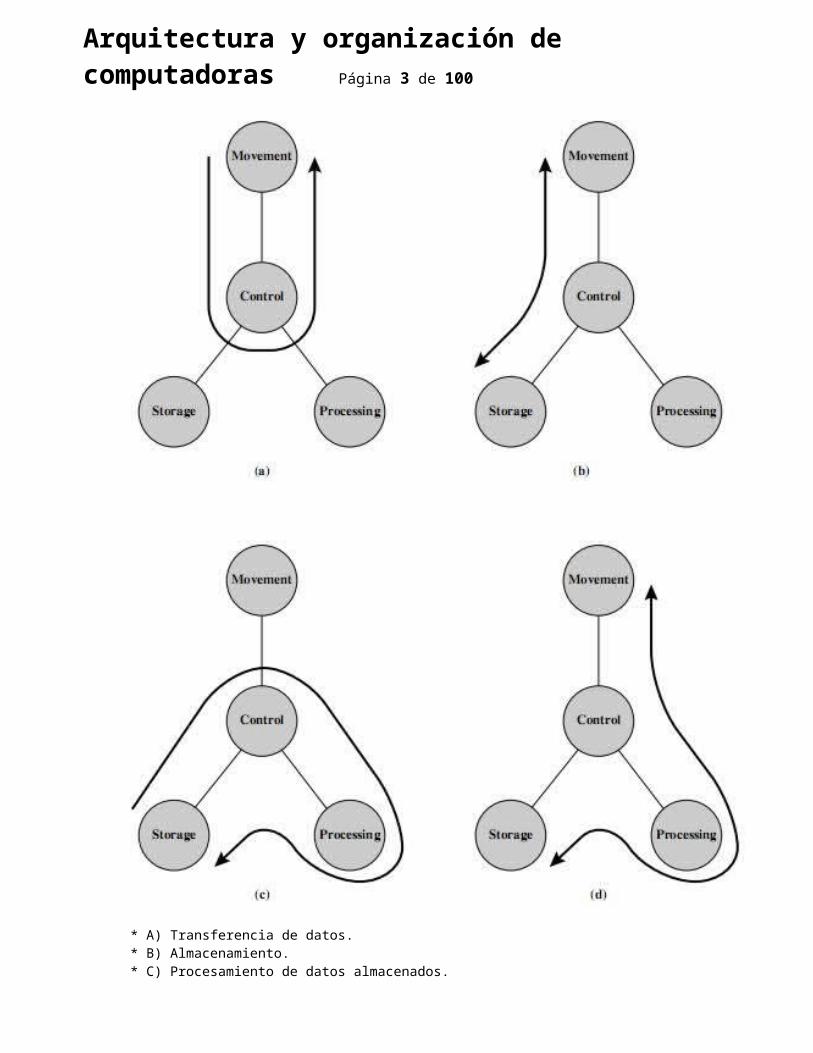
Gráficamente las funciones serian algo así:
Arquitectura y organización de computadoras Página 3 de 76
* A) Transferencia de datos. * B) Almacenamiento. * C) Procesamiento de datos almacenados. * D) Entrada o salida de datos con un procesamiento previo.

Arquitectura y organización de computadoras Página 4 de 76
Estructura del Computador
La representación más sencilla y superficial de un computador podría ser la siguiente:
Arquitectura y organización de computadoras
El computador es el que vamos a analizar más en detalle. Las formas que ésta se comunica con el entorno exterior se pueden clasificar en 2 grandes grupos:
Periféricos y
líneas de comunicación.
Computador:
Entrando un poco más en el detalle del computador, podemos distinguir 4 componentes principales:
CPU (Central Procesing Unit): Controla el funcionamiento de la computadora y se encarga del procesamiento de datos, comúnmente se lo llama procesador.
Input/Output (I/O o entrada y salida): se encarga de la transferencia de datos entre la computadora y el entorno externo.
Main Memory (Memoria principal): Almacena datos.
System Interconnection (Sistema de interconexión): Proporciona comunicación entre las tres partes.
El componente que vamos a analizar ahora más en detalle es la CPU:
Arquitectura y organización de computadoras Arquitectura y organización de computadoras

Arquitectura y organización de computadoras Página 5 de 76
Los principales componentes son los siguientes:
Registros: Proporcionan un almacenamiento interno a la CPU. ALU (Unidad Aritmético-Lógica): En ella se realizan las operaciones de procesamiento,
aritméticas (suma resta, etc.) y lógicas (AND, OR, XOR, etc.) Unidad de Control: Controla el funcionamiento de la CPU, con lo cual controla el
funcionamiento del computador. Interconexiones: Proporcionan comunicación entre los 3 componentes anteriores.
Principios de la programación En los primeros computadores se puede observar aproximadamente el siguiente funcionamiento: Al computador entraban datos, a esos datos se les daba un procesamiento, dicho procesamiento se configuraba antes de empezar por medio de cableado, y del computador salían los resultados. Como se puede apreciar el procesador era para un uso específico. Un ejemplo de esto es la famosa ENIAC, para distraerme un poco vamos a poner algo de ella:

Arquitectura y organización de computadoras Página 6 de 76
Unos datos interesantes: Trabajaba con numeración decimal. Pesaba 30 toneladas Poseía 18000 válvulas. Consumía 140 Kilovatios. Realizaba 5000 sumas por segundo.
Vídeo de YouTube
link: http://www.videos-star.com/watch.php?video=sJnMBnZElqw
ENIAC De Wikipedia, la enciclopedia libre
ENIAC
ENIAC es un acrónimo inglés de Electronic Numerical Integrator And Computer (Computador e Integrador Numérico Electrónico), utilizada por el Laboratorio de Investigación Balística del Ejército de los Estados Unidos.
Contenido

Arquitectura y organización de computadoras Página 7 de 76
1 Modalidad 2 Prestaciones 3 Las programadoras de ENIAC 4 Enlaces externos
Modalidad
No fue la primera computadora electrónica de propósito general. Ese honor se le debe al Z3 construido en el 1941. Además está relacionada con el Colossus, que fue usado para descifrar código alemán durante la Segunda Guerra Mundial y destruido tras su uso para evitar dejar pruebas, siendo recientemente restaurada para un museo británico. Era totalmente digital, es decir, que ejecutaba sus procesos y operaciones mediante instrucciones en lenguaje máquina, a diferencia de otras máquinas computadoras contemporáneas de procesos analógicos. Presentada en público el 15 de febrero de 1946.
La ENIAC fue construida en la Universidad de Pennsylvania por John Presper Eckert y John William Mauchly, ocupaba una superficie de 167 m² y operaba con un total de 17.468 válvulas electrónicas o tubos de vacío. Físicamente, la ENIAC tenía 17.468 tubos de vacío, 7.200 diodos de cristal, 1.500 relés, 70.000 resistencias, 10.000 condensadores y 5 millones de soldaduras. Pesaba 27 Tm, medía 2,4 m x 0,9 m x 30 m; utilizaba 1.500 conmutadores electromagnéticos y relés; requería la operación manual de unos 6.000 interruptores, y su programa o software, cuando requería modificaciones, tardaba semanas de instalación manual.
La ENIAC elevaba la temperatura del local a 50ºC. Para efectuar las diferentes operaciones era preciso cambiar, conectar y reconectar los cables como se hacía, en esa época, en las centrales telefónicas, de allí el concepto. Este trabajo podía demorar varios días dependiendo del cálculo a realizar.
Uno de los mitos que rodea a este aparato es que la ciudad de Filadelfia, donde se encontraba instalada, sufría de apagones cuando la ENIAC entraba en funcionamiento, pues su consumo era de 160 kW.
A las 23.45 del 2 de octubre de 1955, la ENIAC fue desactivada para siempre.
Prestaciones
La computadora podía calcular trayectorias de proyectiles, lo cual fue el objetivo primario al construirla. En 1,5 segundos era posible calcular la potencia 5000 de un número de hasta 5 cifras.
La ENIAC podía resolver 5.000 sumas y 360 multiplicaciones en 1 segundo. Pero entre las anécdotas estaba la poco promisoria cifra de un tiempo de rotura de 1 hora.
Las programadoras de ENIAC
Si bien fueron los ingenieros de ENIAC, Mauchly y Eckert, los que pasaron a la historia de la computación, hubo seis mujeres que se ocuparon de programar la ENIAC, cuya historia ha sido silenciada a lo largo de los años y recuperada en las últimas décadas. Clasificadas entonces como "sub-profesionales", posiblemente por una cuestión de género o para reducir los costos laborales, este equipo de programadoras destacaba por ser hábiles matemáticas y lógicas y trabajaron inventando la programación a medida que la realizaban. Betty Snyder Holberton, Jean Jennings Bartik, Kathleen

Arquitectura y organización de computadoras Página 8 de 76
McNulty Mauchly Antonelli, Marlyn Wescoff Meltzer, Ruth Lichterman Teitelbaum y Frances Bilas Spence prácticamente no aparecen en los libros de historia de la computación, más dedicaron largas jornadas a trabajar con la máquina utilizada principalmente para cálculos de trayectoria balística y ecuaciones diferenciales y contribuyeron al desarrollo de la programación de computadoras. Cuando la ENIAC se convirtió luego en una máquina legendaria, sus ingenieros se hicieron famosos, mientras que nunca se le otorgó crédito alguno a estas seis mujeres que se ocuparon de la programación.
Muchos registros fotográficos de la época muestran la ENIAC con mujeres de pie frente a ella. Hasta la década del 80, se dijo incluso que ellas eran sólo modelos que posaban junto a la máquina ("Refrigerator ladies" . Sin embargo, estas mujeres sentaron las bases para que la programación fuera sencilla y accesible para todos, crearon el primer set de rutinas, las primeras aplicaciones de software y las primeras clases en programación. Su trabajo modificó drásticamente la evolución de la programación entre las décadas del 40 y el 50.
-------------------------------------------------------------------------------------------------------------------------
Bueno, programar este computador para que realice una tarea determinada, consistía en cambiar las conexiones de todos esos cables que se aprecian en las imágenes.
En esta época surgió la idea de programa almacenado, que se le atribuye principalmente al matemático asesor del proyecto Eniac John Von Neumann.

Arquitectura y organización de computadoras Página 9 de 76
Las ideas del programa almacenado fue desarrollada al mismo tiempo por Turing (Recomiendo leer la historia de este genio).
Pero la primera publicación fue hecha por Neumann en 1945, proponiendo la EDVAC (Electronic Discrete Variable Computer) Ésta se empezó a diseñar en la universidad de Princeton en 1946 y fue completada en 1952.
La idea era la siguiente, en vez de tener un procesador que realiza una sola tarea, y la programación sea cableada, encontrar la forma de cambiar esas conexiones por medio de órdenes almacenadas en memoria junto a los datos. A la idea de la llamo "La máquina de Von Neumann", y es la base general de los computadores de hoy en día.
Con esto para cambiar la tarea que realizara la computadora, bastara sólo con leer otro conjunto de órdenes almacenadas en memoria, de esta manera nace el SOFTWARE.

Arquitectura y organización de computadoras Página 10 de 76
En este diagrama se ejemplifica el computador realizaba una tarea fija con los datos
En este diagrama vemos ejemplificado que por medio de instrucciones al procesador, se podía hacer que el computador sea de uso general y realizar distintas tareas.
Como se puede apreciar en la última figura, la memoria y los datos provienen de la misma memoria. La idea es la siguiente, se leía una instrucción, ésta pasaba a la unidad de control, dicha unidad realizaba las conexiones correspondientes para que la ALU realizara una tarea determinada, entraban los datos a la ALU, esta realizaba las operaciones, y el resultado salía por algún dispositivo de E/S.
Hoy en día, a grandes rasgos es similar, se lee una instrucción, se decodifica, la unidad de control manda las señales necesarias por los buses, los datos se mandan a la ALU, y se realiza la operación. Con este avance se logró tener el primer computador de propósito general, era más fácil usarlo para diversas tareas.

Arquitectura y organización de computadoras Página 11 de 76
Buses
Los buses son el mecanismo más común para la comunicación entre los dispositivos del computador.
Físicamente son conductores por donde viajan señales eléctricas.
Bueno, los buses son casi todos esos caminos que se ven en las motherboard de las imágenes anteriores.
El bus es un dispositivo en común entre dos o más dispositivos, si dos dispositivos transmiten al mismo tiempo señales las señales pueden distorsionarse y consecuentemente perder información.
Por dicho motivo existe un arbitraje para decidir quien hace uso del bus.

Arquitectura y organización de computadoras Página 12 de 76
Por cada línea se pueden trasmitir señales que representan unos y ceros, en secuencia, de a una señal por unidad de tiempo. Si se desea por ejemplo transmitir 1 byte, se deberán mandar 8 señales, una detrás de otra, en consecuencia se tardaría 8 unidades de tiempo. Para poder transmitir 1 byte en 1 sola unidad de tiempo tendríamos que usar 8 líneas al mismo tiempo.
Existen varios tipos de buses que realizan la tarea de interconexión entre las distintas partes del computador, al bus que comunica al procesador, memoria y E/S se lo denomina BUS DEL SISTEMA y que vamos a detallar ahora.
La cantidad de líneas del bus a medida que pasa el tiempo se va incrementando como uno de los métodos para incrementar la velocidad de transferencia de señales en el computador, y así incrementar el desempeño. Cada línea tiene un uso específico, y hay una gran diversidad de implementaciones, pero en general podemos distinguir 3 grandes grupos de buses.
Bus de datos: Por estas líneas se transfieren los datos, pueden ser de 8, 16, 32 o más líneas( no se realmente en cuanto andan hoy en día), lo cual nos indica cuantos datos podemos transferir al mismo tiempo, y es muy influyente en el rendimiento del sistema. Por ejemplo si el bus es de 8 líneas y las instrucciones son de 16 bits, el sistema va a tener que acceder 2 veces a memoria para poder leer la instrucción, el doble de tiempo en leer instrucciones comparado con un bus de datos de 16 líneas.
Bus de direcciones: Por estas líneas se envía la dirección a la cual se requiere hacer referencia para una lectura o escritura, si el bus es de 8 líneas por ejemplo, las combinaciones posibles para identificar una dirección irían del 00000000 al 11111111, son 256 combinaciones posibles, en

Arquitectura y organización de computadoras Página 13 de 76
consecuencia el ancho del bus de datos nos indica la cantidad de direcciones de memoria a la que podemos hacer referencia. Dentro de las direcciones posibles, en general el sistema no usa todas para hacer referencia a la memoria principal, una parte las usa para hacer referencia a los puertos de E/S.
Bus de control: Estas líneas son utilizadas para controlar el uso del bus de control y del bus de datos. Se transmiten órdenes y señales de temporización. las órdenes son muy diversas las más comunes son:
* Escritura en memoria. * Lectura de memoria. * Escritura de E/S. * Lectura de E/S. * Transferencia reconocida. * Petición del bus.
* Cesión del bus. * Petición de interrupción. * Interrupción reconocida. * Señal de reloj. * Inicio…
Las señales de temporización indican la validez de los datos que están en el bus en un momento Dado.
Todo elemento que esté conectado al bus tiene que saber reconocer si la dirección que está en el bus de datos le corresponde, tiene que reconocer algunas órdenes transmitidas por el bus de control, y puede emitir algún tipo de señal por el bus de control (señal de interrupción, señal de reconocimiento de alguna petición, etc.)En general, cuanto más dispositivos conectamos al bus, disminuye el rendimiento del sistema; las causantes de esto son varias, pero las más importantes son el tiempo de sincronización que se necesita para coordinar el uso del bus entre todos los dispositivos, y que el bus tiene una capacidad máxima, la cual puede llegar a convertirse en un cuello de botella del sistema. Una de las formas de tratar este problema es implementando jerarquía de buses.
Jerarquía de buses:
Para mejorar el rendimiento del bus, las jerarquías de buses fueron implementadas cada vez más, una primera aproximación a una jerarquía de bus básica sería la siguiente:

Arquitectura y organización de computadoras Página 14 de 76
Primero tenemos un bus local, de alta velocidad que conecta el procesador a la cache, el controlador de la cache también puede acceder al bus del sistema, con esta implementación, la mayor parte de los datos a los que va a acceder el procesador, que están en la cache, serán entregados a una alta velocidad, otro punto a destacar de esta parte es que los accesos a memoria por parte de la cache no van a interrumpir el flujo de datos entre procesador y cache. También se ve la posibilidad de conectar un dispositivo de entrada salida al bus local. Luego tenemos el bus del sistema, al cual está conectada la memoria y por debajo el bus de expansión, al cual se pueden conectar una amplia diversidad de dispositivos, entre el bus del sistema y el bus de expansión se encuentra una interfaz, que entre las principales tareas está la de adaptar las velocidades de transmisión, por ejemplo para un dispositivo muy lento conectado al bus de expansión la interfaz podría acumular una cierta cantidad de datos y luego transmitirla a través del bus del sistema. El hecho de que cada vez más salgan al mercado dispositivos que requieren más velocidad de transmisión en los buses, hizo que los fabricantes implementaran los buses de alta velocidad, el cual está muy estrechamente ligado al bus local, sólo hay un adaptador que los une. Debajo de este bus tenemos el bus de expansión, más lento conectado mediante otro adaptador.

Arquitectura y organización de computadoras Página 15 de 76
Existen varios parámetros y elementos en los buses con los cuales podemos clasificarlos.
Tipos de buses:
Una clarificación que podemos hacer es según la funcionalidad de este, los podríamos dividir en dedicados o multiplexados.
Un ejemplo común de dedicados serian el bus de datos y el bus de direcciones, cada uno se utiliza sólo para una función específica. Esta situación de bus de datos y de direcciones dedicados es lo más común, pero podría llegar a implementarse con un sólo bus multiplexado el tiempo. Esto funcionaria a grandes rasgos de la siguiente forma:
Al comienzo de la transferencia se sitúa en el bus la dirección de donde se quiere leer o a donde se desea escribir, luego se emite por el bus de datos una señal indicando que en el bus se encuentra una dirección valida.
A partir de ese momento se dispone de una unidad de tiempo para que los dispositivos identifiquen si es su dirección, luego de esto se pone en el mismo bus los datos y se realiza la transferencia en el sentido que lo indique una orden emitida por el bus de control.
Ventaja de este método es la reducción de la cantidad de líneas, lo cual ahorra espacio y costos, la desventaja son que para poder implementar es forma de operar la circuitería en cada módulo tiene que ser más compleja, y que el rendimiento del sistema será menor por no poder transmitir los datos simultáneamente, en paralelo (datos y dirección).
Otro tipo de clarificación podría ser según su dedicación física: Podríamos poner como ejemplo el

Arquitectura y organización de computadoras Página 16 de 76
bus de E/S, el cual se encarga de conectar sólo los dispositivos de E/S, este bus se conecta al bus principal mediante algún adaptador, la ventaja está en que al ser dedicado sólo a E/S, el rendimiento de este va a ser mejor, ya que sólo van a operar con el los módulos de E/S, y no va a haber tanta competencia por el bus, este ejemplo lo voy a explicar más detalladamente cuando llegue a la parte de E/S.
Método de arbitraje:
Por la razón de que en un momento dado sólo puede usar el bus un sólo dispositivo, debe existir un método para decidir quien hace uso de él. Todos los métodos que existen en general pueden ser clasificados en 2 grandes grupos:
Arbitraje centralizado: Una parte del hardware del sistema denominada controlador del bus se encarga de decidir el uso del bus en cada momento, este dispositivo puede ser un módulo separado o puede estar incorporado al procesador.
Arbitraje distribuido: En este esquema no existe un controlador centralizado, en su lugar, cada dispositivo que hace uso del bus tiene que tener incorporada la lógica necesaria para poder interactuar con los demás dispositivos y decidir quien hace uso del bus.
En cualquiera de los dos casos lo que se busca es que se decida quién va a tener la posesión del bus en un momento dado, procesador, módulo de E/S o memoria, al cual se lo denomina maestro del bus, el maestro del bus establecerá una comunicación con otro dispositivo (lectura o escritura) al cual se lo denominara esclavo.
Temporización:
La temporización clasifica al método utilizado para coordinar los eventos dentro del bus. Según la temporización usada podemos clasificar los buses en 2 grupos.
Temporización síncrona: Todos los eventos del bus se rigen a través del reloj del computador. Una de las líneas del bus transmite continuamente una señal de reloj, simplemente una secuencia de unos y ceros, la cual puede ser leída por todos los dispositivos conectados al bus.
Al intervalo transcurrido en la emisión de un uno y un cero se lo llama ciclo de reloj, todo los eventos ocurridos dentro del bus comienzan el principio del ciclo y pueden durar uno más . En este método de temporización todos van al ritmo del reloj.

Arquitectura y organización de computadoras Página 17 de 76
Bien, en el diagrama anterior podemos apreciar cómo sería en forma simplificada una lectura de datos a través del bus. Tener en cuenta que hay muchísimas más líneas que no se figuran en el gráfico, por ejemplo la línea del reloj, que sería algo más constante como el siguiente gráfico.
Las líneas sólo pueden tener uno de dos estados, uno o cero. La velocidad en el ritmo que se alterna de un uno a un cero en la línea del reloj nos da la velocidad del bus, y como todas las operaciones se van a realizar al ritmo del reloj, al aumentar la velocidad del ciclo vamos a aumentar la velocidad del sistema.
Con referencia al gráfico de un ciclo de lectura de datos, el maestro (el que tiene permiso para el uso del bus) pone en el bus de direcciones la dirección de la cual desea leer su contenido, luego de haber puesto la dirección en las líneas correspondientes, envía por una línea del bus de control una señal indicando que desea hacer una lectura, el dispositivo correspondiente a esa dirección reconoce la dirección, y pone en el bus de datos la información solicitada, tras lo cual, manda otra señal por una línea del bus de control indicando que se le ha reconocido su petición (que los datos situados en el bus de datos son válidos, son los datos solicitados)
Todo con este método de temporización empieza o finaliza rigiéndose de las señales del reloj, en

Arquitectura y organización de computadoras Página 18 de 76
general la mayoría de los eventos tiene un duración de un ciclo.
Temporización asincrónica: Acá los eventos no se rigen por la línea del reloj, en general todo evento es disparado por otro evento anterior.
El procesador pone en el bus de direcciones la dirección a ser leída y en el bus de control por la línea correspondiente señal de lectura, luego de un breve tiempo para que las señales eléctricas se estabilicen, se manda señal por la línea MSYN (sincronización del maestro) indicando que hay señales validas en el bus de dirección y de control, el módulo correspondiente reconocerá su dirección, pone el dato solicitado en el bus de datos y emite una señal (SSYN sincronización del esclavo) en bus de control indicando que las señales del bus de datos son válidas (son los datos solicitados)
La temporización síncrona es más fácil de implementar y comprobar, pero es menos flexible que la síncrona. Por ejemplo, en el caso de que hubiesen varios dispositivos conectados al bus, de distintas velocidades, todos tienen que funcionar a la velocidad del reloj, si hay uno más rápido, este tiene que bajar su velocidad: En cambio con el asíncrono, cada uno funcionaria a su velocidad, en el mismo bus se trabajaría a distintas velocidades, cada transferencia se haría con la velocidad óptima de sus dos partes (maestro-esclavo).
Anchura del bus: La anchura del bus ya lo he explicado, es simplemente la cantidad de líneas que posee, y está directamente relacionado con el rendimiento del sistema, cuanto más ancho el bus de direcciones, mayor va a ser la cantidad de direcciones posibles utilizadas para direccionar memoria y dispositivos de E/S, y cuanto más ancho el bus de datos, mayor ya a ser la cantidad de bis que se va a poder transmitir en paralelo.
Tipo de transferencia de datos:

Arquitectura y organización de computadoras Página 19 de 76
Todos los buses permiten la transferencia de datos, ya sea para escritura como para lectura.
En el gráfico tenemos ejemplificado una escritura y una lectura, en este caso el bus está multiplexado en el tiempo, primero se utiliza para transmitir la dirección y luego los datos. En el segundo diagrama se puede apreciar un periodo nombrado con "Access time", ese tiempo es el necesario para acceder al medio en donde se encuentra el dato (disco rígido, memoria principal, etc.) y ponerlo en el bus.
Para optimizar el rendimiento existen algunas operaciones combinadas en las cuales se pasa la dirección una sola vez, por ejemplo "lectura-modificación-escritura", sería la lectura del dato, se le aplica alguna modificación y luego se escribe nuevamente. Todo esto es una sola operación, nadie puede acceder al bus en el medio de la operación, se utiliza para proteger los recursos de memoria compartida en sistemas con multiprogramación para mantener la integridad de los datos. Otra instrucción es "lectura después de escritura" que serviría para comprobar el resultado. Otra operación muy común es la transferencia por bloque, se pasa al principio de la operación la dirección inicial y luego se realiza lectura o escritura a las siguientes direcciones, la cantidad de direcciones siguientes también es un parámetro que hay que pasar.

Arquitectura y organización de computadoras Página 20 de 76
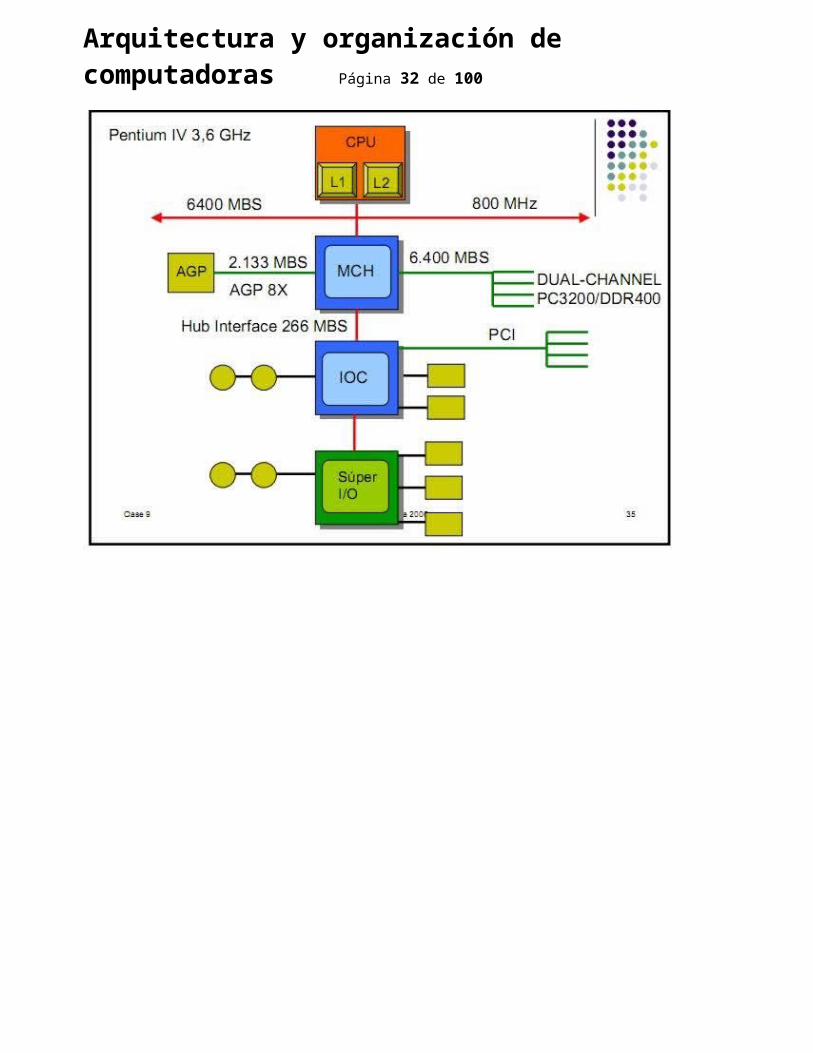
Bien, ahora tendría que enumerar algunos buses en especial, pero como tienen muchos datos técnico que pueden ser medios pesados, voy a poner algunas imágenes donde se pueden ver distintas implementaciones y velocidades. Nobleza obliga, estas diapositivas las tome de las teoría de la cátedra de Arquitectura de Computadoras de la Carrera de Licenciatura en Informática de la Universidad Nacional de La Plata.

Arquitectura y organización de computadoras Página 21 de 76

Arquitectura y organización de computadoras Página 22 de 76

Arquitectura y organización de computadoras Página 23 de 76

Arquitectura y organización de computadoras Página 24 de 76

Arquitectura y organización de computadoras Página 25 de 76
Memoria Interna
Arquitectura y organización de computadoras Página 26 de 76
La memoria interna de un computador tiene tan amplia diversidad que provoca un poco extenso estudiarla. No existe un tipo de memoria óptima para un computador, por lo cual hay que utilizar varias clases en una misma máquina en busca de la combinación lo más aceptable posible teniendo en cuenta principalmente 3 parámetros:
* Velocidad de acceso. * Capacidad. * Costo.
En está pirámide podemos observar lo siguiente: cuanto más arriba de la pirámide, más cerca (físicamente) del procesador nos encontramos. Cuanto más arriba, mayor el costo, cuanto más arriba menor la capacidad y cuanto más arriba menor el tiempo de acceso.
Entonces, tenemos que armar una jerarquía dentro de la máquina con varios de estos tipos de memoria, tratando de lograr que el costo se asemeje a los costos de las memorias de los niveles inferiores, el tiempo de acceso se asemeje a los tiempos de las memorias de los niveles superiores y las capacidades se asemejen a las de los niveles inferiores.
Esto se logra utilizando una jerarquía de memorias.
Antes de abordar las técnicas de comunicación entre los distintos tipos de memorias, debemos saber un poco más de sus características y clasificarlas según ellas.

Arquitectura y organización de computadoras Página 27 de 76
Memorias internas y externas.
Cuando hablamos de memoria interna nos referimos generalmente a la memoria principal, pero no debemos olvidar que existen otras, el procesador necesita su memoria propia (registros del procesador) y la unidad de control puede llegar a necesitar memoria propia.
Cuando decimos memoria externa, nos vamos a estar refiriendo a dispositivos periféricos a los cuales se accede a través de algún controlador de E/S (discos rígidos, lectoras de CD/DVD, pen-drivers, cintas, etc.).
Capacidad:
Las memorias internas son las más pequeñas y se miden en bytes o palabras, siendo las longitudes más comunes para las palabras las de 8, 16 y 32 bits, las memorias externas son mayores y se suelen medir en términos de bytes(Kbyte, Mbytes, Tbytes, etc.).
Unidad de transferencia:
Arquitectura y organización de computadoras Página 28 de 76
En general la unidad de transferencia es igual al número de líneas de entrada/salida de datos que posee el módulo de memoria, en general coincide a la longitud de palabra del módulo de memoria, por lo general.
Vamos a aclarar 2 términos usados comúnmente para que se aclare un poco el tema.
Palabra: Es la unidad natural en que está organizada la memoria, suele coincidir con el número de bits utilizados para representar los números y con la longitud de las instrucciones, pero como siempre hay excepciones.
Unidades direccionables: En muchos sistemas la unidad direccionable es la palabra, pero en algunos casos se puede direccionar de a nivel de byte, y no nos olvidemos que las unidades direccionables están directamente relacionadas con la anchura del bus de direcciones.
Entonces finalizando este punto, la unidad de transferencia es la cantidad de bits que se pueden leer o escribir a la vez y comúnmente coincide con la unidad de palabra o con la unidad direccionable. Para l memoria externa la unidades son más grandes y se las llaman bloques.
Métodos de acceso:
Esta otra clarificación que podemos hacer varía según la forma de acceder al dato.
Acceso secuencial: Los datos se organizan en unidades llamadas registros, el acceso se logra mediante un acceso lineal específico. Además de los datos se agrega información que permite distinguir donde comienza un registro y comienza otro y permite la escritura/lectura de los datos. La forma de acceder como su nombre lo indica es secuencial, teniendo que pasar por todos los registros intermedios, anteriores al que deseamos acceder, hasta llegar al registro deseado. El tiempo de acceso es variable dependiendo de la ubicación del registro deseado. Un ejemplo de este tipo de acceso son las cintas magnéticas.

Arquitectura y organización de computadoras Página 29 de 76
Acceso directo: Cada unidad de información en que está dividida la unidad tiene una dirección única basada en su ubicación física. El acceso es directo, pero no al dato especifico, sino a toda la vecindad, luego dentro de la vecindad se hace un acceso secuencial contando o esperando alcanzar la posición final. El tiempo de acceso es variable.
Un ejemplo de esto son los discos magnéticos.
Acceso aleatorio: Cada posición de memoria direccionable tiene un acceso directo para acceder, cableado físicamente. El tiempo de acceso a cada posición es constante y no depende de accesos anteriores. Un ejemplo de este tipo de acceso es la memoria principal y algunos sistemas de cache.

Arquitectura y organización de computadoras Página 30 de 76
Acceso asociativo: Se compara una parte de la dirección a buscar contra una parte de las palabras almacenadas en este tipo de memoria, dichas palabras además de los datos contienen información para identificar a que posición corresponden. La comparación se hace en paralelo con todas las palabras almacenadas en la memoria. Cada palabra de memoria tiene un acceso directo para acceder, cableado físicamente. El tiempo de acceso es constante y no depende de accesos anteriores. Un ejemplo de este tipo de acceso son algunos sistemas de cache.

Arquitectura y organización de computadoras Página 31 de 76
Este es un Pentium Pro a 200 MHz. El Pentium Pro fue el primer procesador de Intel diseñado específicamente para entornos de servidor. Para este cometido implementaron junto al Pentium MMX otro chip que era la memoria caché (256Kb), de ahí que tenga dos chips en un sólo procesador.
El chip de la izquierda es el procesador mientras que el de la derecha es una memoria caché (se denota por lo regular de la superficie). Muy buena imagen tomada de http://karman.homelinux.net, muchas gracias.
Tiempo de acceso: es el tiempo en que se tarda en la operación de lectura o escritura. En memorias de acceso de acceso aleatorio es el tiempo entre que se pone la dirección en el bus y el momento en que el dato ha sido guardado (escritura) o el dato se encuentra disponible (lectura). Para memorias de otro tipo de acceso, el tiempo de acceso es el tiempo que se tarda en ubicar el mecanismo de lectura/escritura en la posición deseada. Tiempo de ciclo de memoria: Es el tiempo necesario que se requiere para realizar la segunda lectura luego de haber realizado la primera. Generalmente este término se usa con las memorias de tipo aleatorio, y es requerido para que finalicen las transacciones en las líneas de controlo para regenerar los datos si se trata de lecturas destructivas.
Velocidad de transferencia: Es la velocidad a la cual se pueden transmitir datos desde o hacia memoria, para memorias de tiempo aleatorio esto equivale a la inversa del tiempo de ciclo, para los otros tipos de memoria se utiliza la siguiente relación:
Arquitectura y organización de computadoras Página 32 de 76
Estas 3 últimas características de la memoria son las más importantes desde el punto de vista del usuario junto a la capacidad.
Jerarquía de memoria:
El tema clave de toda la organización de los distintos tipos de memoria está en obtener una disminución de los accesos a las clases más lentas de memoria. La motivación principal a este tema es la siguiente: La prioridad de todo el sistema es que la CPU ejecute la mayor cantidad de instrucciones, se debe tratar de que no se detenga para esperar que lleguen las instrucciones y datos desde la memoria. El procesador es mucho más rápido que la memoria principal, en este punto para solucionar el tema entra la memoria cache, más cara, más pequeña pero más rápida. Esta memoria puede estar ubicada en distintas partes del computador, cuanto más cerca del CPU, más rápido es el acceso. Las que están ubicadas en el mismo procesador se las llama de nivel uno (un chip), también están las de nivel 2 y nivel 3, una más lejos que la otra. Antes de proseguir debemos conocer a lo que se le llama "Principio de localidad"
Principio de localidad de programas y datos • Localidad temporal: los elementos (datos o instrucciones) accedidos recientemente, también lo serán en un futuro próximo. • Localidad espacial: los elementos cuyas direcciones están cercanas tienden a ser referenciados.
Teniendo el claro este principio, podemos dar una aproximación de cómo se utilizan las cache: Cuando la CPU solicita un el contenido de una dirección, primero se busca en la primera cache (rápidamente), si no se encuentra ahí, se va a buscar el dato a memoria, cuando se accede a memoria, no se extrae sólo el contenido solicitado, sino que todo el conjunto de direcciones lo rodea, a conjunto extraído se lo llama bloque. El bloque extraído se guarda en la cache, y de ese bloque el dato solicitado se manda a la CPU. Debido al principio de localidad, hay muy altas posibilidades que se requieran otros datos que contiene el bloque guardado en cache, por lo cual cuando estos datos se requieran, el acceso va a ser muy rápido. Debido a los muy buenos algoritmos que manejan las cache, la tasa de acierto es aproximadamente del 95%. Para que quede más claro el gran beneficio de la cache Supongamos que tenemos 2 niveles de cache L1 (nivel 1) y L2(nivel 2)

Arquitectura y organización de computadoras Página 33 de 76
Estos cálculos son sólo para tener una aproximación, ya que no se tienen en cuenta muchos factores.
L1 tiene un tiempo de acceso de 0.1µs y L2 de 1µs
(0.95 + 0.1µs) + (0.05*(0.1µs + 1µs)= 0.15µs Estamos teniendo un tiempo de acceso aproximadamente de 0.15µs a cada dirección de memoria. A L2 accedemos sólo el 0.05% de las veces, agregando un nivel más L3, a L3 sólo tendríamos acceder el 0.0025 % de las veces y a la memoria principal sólo el 0.000125. La mayor parte del tiempo el procesador recibe datos e instrucciones rápidamente de la cache, por lo cual va a estar menos tiempo esperando. Más adelante voy a detallar más su funcionamiento e implementaciones.
Memoria semiconductora:
Antes de empezar con este tema aconsejo leer la muy interesante página que habla de la forma más común de almacenar información en los computadores antiguos, los núcleos de ferrita.

Arquitectura y organización de computadoras Página 34 de 76

Arquitectura y organización de computadoras Página 35 de 76
Diálogo sobre las memorias de anillos de ferrita.
Hoy en las memorias principales utilizan memoria principal, vamos a enumerarlas y dar una breve descripción. Todas los tipos de memoria que veremos acá son de acceso aleatorio, a cada palabra que las componen se la puede acceder directamente.
RAM:
La más común, (Random Access Memory), obviamente todas las memorias que vamos a ver en esta parte son Random pero a ésta se la llama así. Se puede escribir como leer rápidamente en ella, es volátil, o sea que se pierden los datos cuando se apaga el computador. Se las puede dividir en 2 grupos, estáticas y dinámicas. Las dinámicas están compuestas por celdas que conservan la carga, como un condensador, el hecho de que tenga carga o no diferencia un uno de un cero. Estas cargas disminuyen gradualmente por lo cual tienen implementadas un sistema de refresco, el cual cargara periódicamente las celdas con carga. Las RAM estáticas estas conformadas por puertas bioestables, como los Flip-Flops, que pueden mantener uno de dos estados mientras estén alimentadas, con lo cual se identifica un uno o un cero. Las RAM dinámicas son más simples y compactas, lo cual hace que sean más pequeñas y económicas.

Arquitectura y organización de computadoras Página 36 de 76

Arquitectura y organización de computadoras Página 37 de 76
ROM: Read Only Memory, sólo se pueden leer, los datos vienen grabados físicamente, como un circuito y no es volátil
PROM: Son iguales que las ROM pero estas se pueden grabar eléctricamente una vez. Podría grabarla el fabricante o el posterior comprador con un equipo especial. No es volátil.
EPROM: Memoria de sólo lectura programable y borrable ópticamente, estas memorias se pueden leer y grabar eléctricamente, el tema importante es que antes de grabarla hay que borrarla completamente, lo cual se realiza exponiendo la ventanita del chip a rayos ultravioleta, suele tardar unos cuantos minutos en borrarse. Son más costosas que las ROM y PROM, pero nos da más ventajas. No es volátil. En la imagen se puede apreciar la ventana, que viene tapada con una etiqueta para evitar borrados no intencionados.

Arquitectura y organización de computadoras Página 38 de 76
EEPROM: Memoria de sobre todo lectura programable y borrable eléctricamente, Se puede leer tanto como escribir de forma eléctricamente y sólo el o los byte direccionados. La escritura demora mucho más tiempo que la lectura, Son más costosas y menos densas, pero nos dan gran flexibilidad al poder actualizables mediante las líneas de datos, direcciones y control.

Arquitectura y organización de computadoras Página 39 de 76
Flash: Iguales que las EEPROM pero más rápidas, otra diferencia es que no permiten borrar a nivel de byte, sólo se puede borrar a nivel de bloque. Estas 3 imágenes son de memorias flash, las podemos ver comúnmente en los pen drivers. La última es de 64GB de Samsung.

Arquitectura y organización de computadoras Página 40 de 76

Arquitectura y organización de computadoras Página 41 de 76
Organización de la memoria semiconductora:
El elemento básico de la memoria semiconductora es la celda de memoria, aunque existen muchas

Arquitectura y organización de computadoras Página 42 de 76
tecnologías utilizadas para su implementación, todas compartes algunas propiedades.
* Presentan 2 estados, los cuales se utilizan para representar un uno o un cero. * Puede escribirse en ellas al menos una vez. * Pueden leerse para saber su estado.
Lo más común es que posean tres terminales, uno para seleccionar la celda para lectura o escritura, otra para indicar el tipo de operación (lectura/escritura), y otro para los datos, como salida (lectura) o entrada (escritura).
Lógica del chip de memoria:
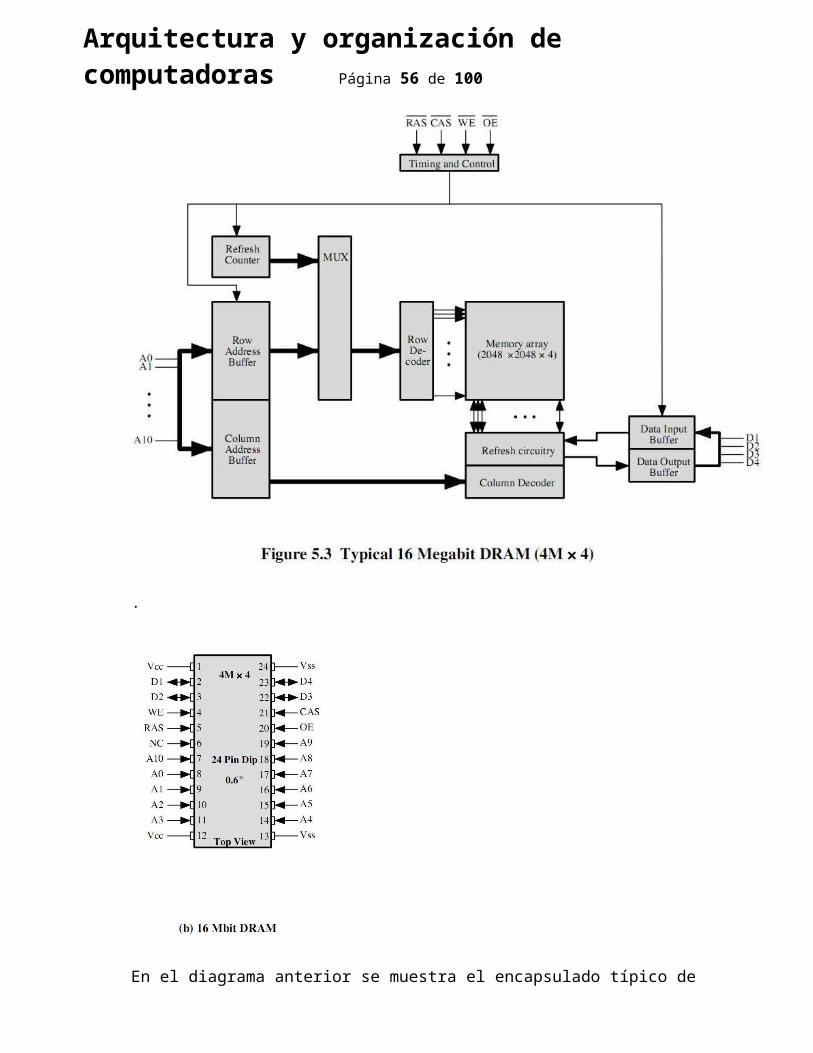
Las memorias semiconductoras vienen encapsuladas, y cada chip contiene una matriz de celdas de memoria. Una de las características más importantes de los chips de memoria, es la cantidad de bits que se pueden leer/escribir simultáneamente. Tenemos muchas formas de organizar la memoria, en un extremo tenemos una memoria en la cual la organización física es igual a la lógica (igual a como la percibe el procesador), esto sería que el chip de memoria está organizado en W palabras de B bits cada una. Por ejemplo una memoria de 16 Mbits podría estar organizada en 1Mpalabras de 16 bits cada una. En el otro extremo tenemos la estructura llamada "un bit por chip" en la cual los datos se lee/escriben por bits, y desarrollare a continuación.
Organización típica de una DRAM de 16Mbits en la que se leen/escriben de a 4 bits simultáneamente: Lógicamente la matriz está compuesta por 4 matrices cuadradas de 2048 X 2048 elementos.
Para poder seleccionar un elemento particular de cada chip de 2048 X 2048 se necesitan, para poder expresar 2048 combinaciones, necesitamos 11 líneas, por lo cual a cada chip entran 11 líneas para especificar la fila de la matriz y 11 líneas para especificar la columna de la matriz.
Como se puede ver en este gráfico, a la DRAM sólo entran 11 líneas de datos ( de A0 a A10), esto se debe a que estas líneas dedicadas a especificar la dirección están multiplexadas en el tiempo, primero se pasa la dirección que especifica la fila y luego se pasa la dirección que

Arquitectura y organización de computadoras Página 43 de 76
especifica la columna. De cada chip obtengo un elemento, los 4 de la misma posición relativa dentro de cada uno de los chips. Si el bus de datos del sistema fuera de 16 bits, tendría que tener 4 DRAM conectadas al controlador de memoria para poder leer/escribir una palabra en el bus de datos. Como comentario, el uso de matrices cuadradas y de líneas de direcciones multiplexadas provoca que con cada línea que se agrega a las líneas de direcciones la capacidad se podría cuadriplicar, por ejemplo con el caso anterior con 11 líneas se obtienen 2048 posibles combinaciones, con 12 líneas 4096, el doble, el doble de filas y el doble de columnas, o sea, el cuádruple de capacidad de direccionamiento con el sólo hecho de agregar una línea más
.

Arquitectura y organización de computadoras Página 44 de 76
En el diagrama anterior se muestra el encapsulado típico de una DRAM de 16Mbits.
Ahora, en el ejemplo anterior el chip tenía una entrada/salida de 4 bits, en cambio si cada chip tiene 1 bit de entrada/salida, claramente necesito N chips, donde N es igual a la cantidad de bits por palabra. Para ejemplificar veamos una forma de organizar un módulo de memoria de 256K palabras de 8 bits.

Arquitectura y organización de computadoras Página 45 de 76
Aclaración: El diagrama anterior tiene un error, en el chip inferior del gráfico debería decir "Chip #8"
En el diagrama podemos apreciar que las líneas de datos no se multiplexan. Cada chip posee 512 X 512 (256K) elementos de 1 bit, al momento de leer una de las 256k palabras de 8 bits, se envía la dirección y se selecciona un bit de cada chip (la misma ubicación en cada chip), cada bit seleccionado de cada chip conformara la palabra.

Arquitectura y organización de computadoras Página 46 de 76
Memoria Cache:
El objetivo de la memoria cache es obtener un tamaño grande de memoria, con una velocidad tendiendo a la de las memorias más rápidas y un costo tendiendo a las más baratas. Como ya hemos visto cuando el procesador necesita acceder a una dirección de memoria, primero se fija si está en la cache, si esta, se llama acierto o "HIT", entonces la dirección es accedido directamente de la cache, si no está en la cache, se llama fallo o "MISS", entonces se accede a la memoria principal y se extrae el conjunto próximo a la dirección buscada y se pone en la cache, para aprovechar el principio de proximidad. En esta parte tenemos dos organizaciones más comunes, una es que se pasa el bloque de memoria a cache y se pasa la dirección solicitada al procesador en paralelo, al mismo tiempo, la otra primero se pasa el bloque de palabras a la cache y luego esta, pasa la dirección solicitada a el procesador.
Este sería el diagrama del segundo caso, primero se pasa el bloque a la cache y luego se pasa la palabra al procesador.

Arquitectura y organización de computadoras Página 47 de 76
Es este diagrama podemos ver la operación de lectura, realmente no se bien a que se refiere con RA, me imagino que es Registry address, un registro donde el procesador pone la dirección a la que quiere hacer referencia. El flujo sería algo así: el procesador pone la dirección requerida en RA, se chequea si la dirección está en cache, si está se capta la palabra para luego pasarla al procesador, si no está se accede a memoria, se decide en qué lugar de la cache se va a alojar el bloque y EN PARALELO se pasa el bloque a la cache y se pasa la palabra al procesador, este sería el primer caso que hacía referencia el párrafo anterior y es la organización que se usa en general en las cache actuales.

Arquitectura y organización de computadoras Página 48 de 76
En este diagrama se ve como estaría dispuesta la cache con sus líneas de conexión, en el caso de entregar los datos primero a la cache y luego al procesador, si hay un acierto, se inhabilitan los dos buffer y el tráfico es sólo de cache a procesador, si hay un fallo, se coloca la dirección en el buffer de direcciones, y por medio del bus del sistema se accede a la memoria principal, luego se transfiere el bloque de datos a la cache para después está entregar la palabra al procesador. La cache se interpone físicamente entre la memoria y el procesador. Antes de seguir con las características de la cache vamos a ver un poco más sobre el principio de localidad. Este principio establece que las referencias a memoria tienden a formar agrupaciones, quiere decir que las referencias en un período de tiempo se hacen sobre un conjunto de palabras que están próximas físicamente, estas agrupaciones cambian, pero durante períodos cortos de tiempo el procesador hace referencia a algún conjunto en particular. El tema es que ese grupo o bloque esté en ese período de tiempo en cache, para tener un tiempo de acceso rápido. Algunas afirmaciones para ver que la localidad tiene sentido:
Excepto cuando hay instrucciones de salto, en general la ejecución de un programa es secuencial, o sea que la próxima instrucción a captar es la inmediatamente siguiente a la última captada.
Es raro tener una secuencia larga ininterrumpida de llamadas a procedimientos con sus retornos correspondientes, en general el programa queda confinado a una ventana bastante estrecha de profundidad o nivel de anidamiento de procedimientos, por lo cual, en un periodo corto de tiempo las referencias tienden a localizarse en unos pocos procedimientos.

Arquitectura y organización de computadoras Página 49 de 76
La mayoría de las instrucciones iterativas contienen pocas instrucciones, por lo cual, durante el periodo que dure la iteración, se va a hacer referencia a instrucciones contiguas, y la ventana de profundidad durante la iteración va a ser pequeña.
En muchos programas se hacen referencias a estructuras de datos como secuencia de registros o matrices, en muchos casos estas unidades de datos se encuentran en posiciones contiguas de memoria, por lo cual se va a estar haciendo referencia a un mismo bloque de datos.
Este tema es muy estudiado por su gran importancia en el rendimiento del computador.
Este gráfico se basa en las llamadas a procedimiento de un programa con su retorno correspondiente, en él se puede observar ventanas de profundidad igual a 5, se aprecia como durante un periodo apreciable de tiempo se hace referencia a llamadas que contiene una misma ventana.
Más adelante vos a ampliar esta parte, ya que hay muchos datos interesantes.
Como se verá que no hay duda de los beneficios de tener en cuenta este principio, ahora para aprovecharlo tendríamos que saber el tamaño óptimo del bloque para pasar de memoria a cache y la cantidad de bloques que tendría que alojar la cache, para eso seguiré con las características de las cache.
Estructura de la cache:
Vamos a ver algunos criterios básicos de diseño que nos van a servir para clasificarlas y poder diferenciar las distintas arquitecturas de cache.
Tamaño de la cache:
Lo ideal sería tener una cache lo suficientemente pequeña para que el costo promedio por bit se aproxime al costo de la memoria principal, y que sea lo suficientemente grande para que la velocidad de acceso promedio se aproxime a la velocidad de la memoria cache.

Arquitectura y organización de computadoras Página 50 de 76
Igualmente hay otros motivos que nos restringen a tamaños de cache grandes, uno es que cuanto más grandes las caches, mayor puertas implicadas en el direccionamiento de estas, lo cual implica que un mayor el tamaño tiende a cache más lentas. Diversos estudios han llegado a que el tamaño óptimo estaría entre 1K y 512K palabras. Como las tareas a realizar por el procesador son muy variables, y la cache depende de eso, es imposible predecir un tamaño óptimo.
Función de correspondencia:
La memoria principal consta de hasta 2 elevado a la N palabras direccionables de n bits cada una, estas palabras están agrupadas en M bloques de k palabras cada uno.La cache consta de C líneas de K palabras cada una.
En todo momento hay un subconjunto de bloques alojado en la cache, y como hay menos líneas en la cache que bloques en la memoria principal, debe haber una función de correspondencia que nos indique a que bloque de memoria principal corresponde cada línea de la cache, además que necesitamos elegir que bloque se van a almacenar en la cache.
Pueden utilizarse 3 técnicas de correspondencia:
* Directa. * Asociativa. * Asociativa por conjuntos.

Arquitectura y organización de computadoras Página 51 de 76
Para explicar las tres técnicas vamos a usar los siguientes elementos:
Cache de 64 Kbyte. Los datos se transfieren entre memoria y cache en bloques de 4 bytes, por lo cual la cache
está organizada en 16K líneas de 4 bytes cada una. Una memoria principal de 16Mbytes, direccionable de a byte, para lo cual se necesita una
dirección de 24 bits para poder hacer referencia a los 16M de direcciones. Para poder realizar la correspondencia vamos a considerar que la memoria consta de 4M bloques de 4 bytes cada uno.
Correspondencia directa:
Es la más simple, cada bloque de la memoria principal se puede alojar sólo en una línea específica de la cache.

Arquitectura y organización de computadoras Página 52 de 76
La función de correspondencia se implementa tomando la dirección de memoria y dividiéndola en tres, la parte menos significativa identifica la palabra dentro del bloque, lo que resta se divide en dos, la parte más significativa identifica la etiqueta, cada etiqueta identifica un conjunto de bloques, y el resto identifica la línea dentro de este conjunto de bloques, este número de línea se corresponde con la línea de cache.

Arquitectura y organización de computadoras Página 53 de 76
Debido a este tratamiento cuando se necesita buscar una dirección en cache, el sistema toma de la dirección la parte que identifica la línea, y va a la cache y busca en ese mismo número de línea la etiqueta, si en esa línea encuentra la etiqueta igual a la etiqueta de la dirección de memoria se ha producido un acierto, entonces recién ahí se usan los bits menos significativos de la dirección para identificar la palabra dentro de la línea de la cache.
Como se puede ver, cada posición de la memoria principal se puede alojar sólo en una posición de la cache. Es la función más fácil de implementar, por lo cual menos costosa pero tiene un problema importante.
Imaginemos que el procesador hace referencia repetidas veces a dos palabras de bloques de memoria principal diferentes, a los que les corresponde la misma línea dentro de la cache, en ese caso el sistema estaría cambiando continuamente el bloque dentro de la cache, haciendo que baje la tasa de acierto. Este problema se resuelve con la siguiente función de correspondencia.
Correspondencia asociativa:
Esta correspondencia supera la desventaja de la anterior, los bloques de la memoria principal se pueden ubicar en cualquier línea de la cache, para lo cual la lógica de la cache interpreta la dirección de memoria de la siguiente forma: los bits menos significativos sirven para identificar la palabra dentro de la línea, y al resto de los bits se lo llama etiqueta y sirve para identificar si la línea le corresponde al bloque requerido.
En la correspondencia directa la lógica de la cache se dirigía directamente a una línea en particular de la cache, porque cada bloque se podía ubicar sólo en una línea determinada de la cache, una sola comparación.
En el caso de la asociativa, como un bloque de memoria puede alojarse en cualquier línea de la cache, tendría que comparar cada etiqueta de cada línea de la cache hasta encontrar coincidencia o el final de la cache, para que la búsqueda tarde lo mismo que en la correspondencia directa, mediante circuitería extra se hace la comparación de todas las etiquetas de las líneas de la cache en paralelo, simultáneamente.
Obviamente al ser más compleja la circuitería, el costo es mayor.
La principal desventaja de esta correspondencia es la complejidad de la circuitería requerida.

Arquitectura y organización de computadoras Página 54 de 76
Correspondencia asociativa por conjuntos:
Esta correspondencia toma lo bueno de las dos anteriores, la cache se divide en conjuntos y un bloque de memoria principal puede ubicarse sólo en una posición, pero de cualquier conjunto, la lógica de la cache sólo tiene que chequear una posición de cada conjunto.
Lo más común son las cache organizadas en 2 conjuntos, y se la llama correspondencias asociativa por conjuntos de 2 vías, mejora considerablemente el rendimiento de la asociativa. Las de 4 vías

Arquitectura y organización de computadoras Página 55 de 76
producen una leve mejora y más vías producen muy poca mejora.
Como un bloque de memoria principal sólo se puede ubicar en un sólo conjunto, la etiqueta a comparar posee menos bits, y además hay que compararla contra menos posiciones de la cache, una comparación por vía.
Este gráfico ejemplifica una correspondencia asociativa por conjuntos de 2 vías, un bloque de
Arquitectura y organización de computadoras Página 56 de 76
memoria principal puede ubicarse en una sola ubicación de cualquiera de los dos conjuntos de la cache.Algoritmos de sustitución:
Ya vimos los métodos para saber que bloques están en cache, ahora tenemos que ver como decidir que bloques nos conviene que estén en la cache. Por ejemplo imaginemos que tenemos una correspondencia directa, en determinada línea X de la cache tenemos un bloque de memoria al que el procesador uso recientemente, ahora el procesador requiere otro bloque de memoria que le corresponde la línea X de la cache, a la lógica de la cache no le queda otra que sacar el bloque actual y poner el nuevo. Pero con las otras 2 correspondencias la lógica de la cache tiene varios lugares para poner ese bloque que el procesador requiere. En esta parte vamos a ver los algoritmos usados para decidir qué línea sacar de la cache para alojar el nuevo bloque requerido.
Probablemente el más efectivo el LRU (Least Recently Used) "utilizado menos recientemente". En este algoritmo se reemplaza el bloque que se ha mantenido más tiempo en la cache sin haberse referenciado. Esto es fácil de implementar en la correspondencia asociativa por conjuntos de dos vías, sólo necesitamos 1 bit extra por línea, cuando una línea es referenciada se pone ese bit extra de esa línea en 1, y el de la otra vía en 0. Cuando necesitamos guardar un nuevo bloque, es tan simple como elegir la línea que posea el bit extra en 0.
Otra posibilidad es el FIFO (First In First Out) "primero en entrar, primero en salir" En este algoritmo se reemplaza el bloque que ha estado más tiempo en la cache, esto es implementado fácilmente mediante una técnica cíclica "buffer circular".
Otra podría ser LFU (Least Frequently Used) "menos frecuentemente usado", en este caso se sustituye la línea que posee menos referencias hechas, para esto se tendría que implementar un contador.
Otra técnica no basada en el grado de utilización sería en elegir la línea aleatoriamente (al azar). Estudios realizados indican que las prestaciones de esta técnica son levemente inferiores a las descriptas anteriormente basadas en el grado de utilización.
Política de escritura:
Un problema que todavía no se ha mencionado es el tema de la validez de los datos un bloque de memoria principal respecto a la línea correspondiente en cache.
Imaginemos una línea de cache la cual ha sido modificada por el procesador, ahora el procesador requiere un bloque de memoria el cual va a ser alojado en esa línea modificada de la cache. La lógica de la cache debe actualizar el bloque de memoria principal correspondiente a la línea modificada antes de alojar el nuevo bloque.
Bien con el problema ya descripto, vamos a explicar algunas técnicas de escrituras que difieren en su prestación y costo de implementación.
Existen 2 grandes problemas a resolver. Primero, más de un dispositivo puede tener acceso a la memoria principal, por ejemplo imaginemos un módulo de E/S que accede para lectura a la memoria principal, si la dirección accedida está en cache y fue modificada, el dato que se lleva el módulo de E/S va a ser erróneo. Ahora imaginemos que el módulo de E/S va a realizar una escritura, y la dirección en cuestión está en cache y fue modificada, cual es el dato válido?, el de la cache o el del

Arquitectura y organización de computadoras Página 57 de 76
módulo de E/S?.
Una vez que una dirección se ha modificado en la cache, la dirección correspondiente de memoria deja de tener validez.
Otro problema más complejo se da en sistemas con varios procesadores en que cada uno posee su propia cache. El hecho de modificar una dirección de la cache, no sólo invalida la dirección correspondiente en la memoria principal, sino que también podría invalidad datos de las otras caches.
La técnica más sencilla es la llamada "escritura inmediata", todas las escrituras se hacen tanto en cache como en memoria principal. Para los sistemas con varias unidades procesador-cache, estos pueden monitorizar el tráfico hacia memoria y detectar modificaciones en direcciones que dichas caches contienen, para así mantener la coherencia de datos. La principal desventaja de esta técnica es que aumenta considerablemente el tráfico a través del bus, hacia la memoria principal, lo cual podría producir un cuello de botella en el sistema.
Otra técnica es la llamada "post-escritura", en la cual se minimizan las escrituras en memoria. En esta técnica la cache dispone de un bit extra por línea de cache, en el momento de modificar un bloque, esta modificación sólo se hace en la cache, además de modificar el bloque, se utiliza ese bit extra para marcar que el bloque ha sido modificado. Recién en el momento de sustituir el bloque de la cache, se chequea este bit extra para saber si se ha modificado el contenido, si se ha modificado, antes de reemplazar el bloque se actualiza la memoria principal.
Como una parte de los datos de memoria no son válidos porque todavía no se han actualizado, los accesos de los módulos de E/S deben hacerse a través de la cache para chequear primero si están ahí, y entonces usar información valida. Esto hace que la circuitería tenga que ser más compleja, y existe la posibilidad de que se genere un cuello de botella.
En sistemas con más de una unidad procesador-cache, no sólo alcanza con mantener la coherencia entre la cache modificada y la memoria principal, sino que además hay que mantener la coherencia entre la información de las cache, a un sistema que tiene en cuenta este punto se le dice que mantiene la coherencia de cache. Entre las técnicas usadas pala lograr esto se encuentran:
Vigilancia del bus con escritura inmediata:
Todas las caches monitorean las líneas de direcciones del bus, cuando una cache detecta que se ha modificado un bloque de memoria que ella posee, procede a invalidar su línea de cache.
Transparencia hardware:
Se utiliza hardware adicional, cada vez que una cache es modificada, este hardware se encarga de mantener la coherencia con la memoria principal y otras caches.
Memoria excluida de cache:
Con esta técnica sólo una porción de la memoria principal es compartida por los procesadores, esta memoria no es transferible a la cache, por lo cual cada vez que se accede a la memoria compartida por parte de un procesador, quiere decir que antes se ha producido un fallo en la cache, porque es imposible que la memoria compartida se encuentre en cache

Arquitectura y organización de computadoras Página 58 de 76
Tamaño de línea:
Cuando el procesador requiere acceder a una palabra de la memoria principal, el sistema lleva a la cache no sólo esa palabra sino también las palabras de su vecindad, lo que se llama bloque, para aprovechar el principio de localidad. Bien, ahora, cual será la cantidad óptima de palabras que deba contener ese bloque? Al ir aumentando la capacidad de palabras de la línea de cache va a ir aumentando la tasa de aciertos, por el hecho de tener más palabras próximas a la referenciada, con posibilidad de ser usadas, pero al pasar un cierto número de palabras, la proximidad se va haciendo más lejana, y así empieza a reducirse la tasa de aciertos, en ese punto sería más conveniente reemplazar la línea.
Dos factores entran en juego en este tema: Primero es que cuanto más grande sean los bloque menor será el número de estos que entren en la cache. Y el hecho de que haya menos bloques, produce que este permanezca menos tiempo en cache, por será reemplazado por otro más rápidamente, no pudiéndose aprovechar completamente el principio de localidad. Segundo, es que cuando más palabras tenga el bloque, más lejana va a ser la proximidad de las palabras extra con respecto a la requerida en consecuencia menos probable va a ser que sea requerida en corto plazo.
Es difícil establecer un número de palabras óptimo, por haber muchas variables en juego, pero parecería que un tamaño entre 4 y 8 unidades direccionables sería próximo a lo óptimo.
Número de caches:
Debido al aumento logrado en la integración de los circuitos, se ha logrado reducir considerablemente los tamaños de las caches, lo que permitió incorporarlas dentro del mismo procesador, reduciendo los tiempos de acceso hasta hacerlos casi nulos.
Luego se incorporó un segundo nivel de cache, mejorando aún más los tiempos promedio de acceso a datos e instrucciones alojados en memoria principal.
Además de incorporar 2 niveles de cache, se ha hecho normal particionar la cache y dedicar una a almacenar datos y otra a almacenar instrucciones.
Las caches unificadas presentas 2 grandes ventajas, la primera es el tema del balanceo según las necesidades, por ejemplo supongamos el caso ficticio que el procesador requiera de memoria principal sólo instrucciones, nada de datos, en el caso de cache partida, una dedicada a datos y otra a instrucciones, tendríamos la cache de datos casi sin uso, en cambio, si no estuviera particionada, el sólo uso de la cache balancea según las necesidades la cantidad de instrucciones o datos cargados en la cache. La otra ventaja más obvia es que sólo habría que diseñar e implementar una sola cache.
Pese a esto la tendencia se fue incrementando para el lado de las caches partidas, esto se debe principalmente para explotar más la técnica de ejecución de tareas en paralelo. En procesadores que se implementa segmentación de cauce "Pipelining", dentro del procesador se realizan en paralelo distintas tareas, y se pueden llegar a requerir en un mismo momento datos e instrucciones. Con la cache partida se elimina la competencia por el acceso a ella, por ejemplo el pre-captador de instrucciones podría tratar de acceder a la cache en busca de futuras instrucciones, y no podría

Arquitectura y organización de computadoras Página 59 de 76
hacerlo, porque la ALU en ese momento está haciendo uso ella para obtener operandos.
Registros:
Primero recordemos las cosas que debe poder hacer la CPU:
* Captar instrucciones: La CPU lee una instrucción de memoria. * Interpretar una instrucción: La instrucción debe ser decodificada, para saber qué acciones se deben realizar. * Procesar datos: La ejecución de una instrucción puede requerir que se realice alguna operación aritmética o lógica. * Escribir datos: La instrucción puede requiere que se escriban datos en memoria o en algún módulo de E/S.
Para realizar estas tareas, la CPU requiere de la capacidad de poder almacenar algunos datos temporales, para eso necesita de una pequeña memoria interna, la cual ya hemos nombrado, que son los registros.
Estos registros están en lo más alto de la jerarquía de memoria, por lo cual son a los que se accede más rápidamente, las más pequeñas, y las más caras. Se las dividen en 2 grupos: Registros visibles al usuario: Permiten a los programadores de bajo nivel, hacer uso de ellas. Registros de control y estado: Son usados por la unidad de control para controlar la CPU, y son también usados por programas privilegiados del sistema operativo, para controlar la ejecución de programas.
Registros visibles al usuario:

Arquitectura y organización de computadoras Página 60 de 76
Estos registros pueden ser referenciados por medio de lenguaje de máquina, y podemos clasificarlos de la siguiente forma:
* De uso general. * Datos. * Direcciones. * Código de condición.
Un registro de uso general se puede usar para cualquier cosa, este uso está estrechamente ligado al repertorio de instrucciones. Por ejemplo hay instrucciones que permiten direccionar una posición de memoria usando cualquier registro, mientras hay otras instrucciones que trabajan con registros específicos. La ventaja de un registro de uso general, es la flexibilidad en el trabajo que le da al programador, la desventaja de un registro general y a su vez ventaja de un uso específico (datos o direcciones) está en que las instrucciones no debe especificar en qué registro se encuentra el dato o dirección, el registro ya está implícito con la instrucción, ya se sabe que para determinada instrucción, hay que usar determinado registro, lo que hace a la instrucción más corta. También existen instrucciones de direccionamiento que hacen uso de un registro determinado, pero ese registro además se le puede dar otro uso, sería de uso más o menos general.
Un tema importante a tener en cuenta es la cantidad de registros de uso general, esta cantidad afectara a la longitud de las instrucciones, ya que más registros requieren más bits para poder identificarlos, por lo cual en las instrucciones necesitaran más bits en el campo del operando. También debemos tener en cuenta el tamaño del registro, Los de direcciones deben poder contener la dirección más alta, los de datos deben poder contener los valores de los distintos tipos de datos. En algunos sistemas se permite el uso de dos registros como si fuera uno sólo para aumentar su capacidad. La última clasificación de los registros visibles al usuario son los que almacenan los códigos de condición o "Flags". Estos flags son bits, que utiliza el hardware de la CPU para indicar algún tipo de información adicional al resultado de la operación que acaba de realizar, por ejemplo, si realizo una operación aritmética, los flags nos van a indicar, si hubo carry, overflow, si fue positivo, negativo, nulo, la paridad, etc. Son de mucho uso para corroborar resultados. Muchas veces también se realizan operaciones y sólo se miran los flas, por ejemplo en operaciones de salto o bucles, se toma la decisión de saltar o volver a ejecutar el bucle luego de hacer una comparación "=", en la ALU realizaríamos una resta de los 2 operandos y sólo habría que chequear el flag que nos indica si el resultado fue cero. O por ejemplo si la comparación que hiciéramos fuera un "A<B" , en la ALU haríamos A-B y sólo habría que chequear el flag que nos indica si el resultado fue negativa, en si el resultado no nos interesa. Estos registros son visibles al programador o parcialmente visibles, pero no se pueden modificar. Hay ciertas instrucciones como las de llamada a subrutina, que hacen una copia de estos registros, luego durante la ejecución de la subrutina la CPU hace uso de estos registros, y cuando se retorna al programa que llamo a la subrutina, se vuelven a poner los mismos valores en estos registros para así poder continuar con la ejecución tal cual como lo venía haciendo antes de la llamada a subrutina. En otras máquinas, cuando se llama a la subrutina, el resguardo de los flags no se hace automáticamente por la CPU, en esos casos es responsabilidad del programador.
Registros de control y estado:
Estos registros se usan para controlar el funcionamiento de la CPU, en general no son visibles al usuario, y , algunas de ellas pueden ser visibles por instrucciones de máquina ejecutadas en modo de control o de sistema operativo.

Arquitectura y organización de computadoras Página 61 de 76
Los más importantes son:
* PC - Contador del programa (Program counter): Contiene la dirección de la próxima instrucción a captar. * IR - Registro de instrucción (Instruction register) Contiene la última instrucción captada. * MAR - Registro de dirección de memoria (Memory address register) Contiene la dirección de una posición de memoria. * MBR - Registro intermedio de memoria (Memory buffer register) Contiene la palabra de datos a escribir, o la que se ha leído última.
En este gráfico podemos apreciar un poco más en detalle la estructura interna de la CPU, se pueden ver las conexiones internas, un bus interno, las conexiones de datos de los registros, y las conexiones de la unidad de control para indicarle a los registros, que operación queremos realizar (lectura o escritura) también se pueden ver los flags.
Procesador:

Arquitectura y organización de computadoras Página 62 de 76
Ciclos de una instrucción:
Como ya hemos visto la función de un computador es la ejecución de un programa, el cual está compuesto por un conjunto de instrucciones, y es el procesador el que se tiene que encargar de ejecutarlas. Dicha ejecución la voy a empezar a describir empezando por la forma más simple, en 2 etapas, captación de la instrucción y ejecución de la instrucción, entonces la ejecución de un programa consta en la repetición del proceso de captación y ejecución de instrucciones. Básicamente se capta la instrucción de memoria principal, se guarda el código de la instrucción en el registro IR, se incrementa el registro PC, la CPU interpreta la instrucción almacenada en IR y realiza las acciones necesarias para que se ejecute la acción requerida.
Como ya hemos visto anteriormente, en general las acciones que puede realizar la CPU se pueden agrupar en:
* Procesador-memoria: Transferencia de datos desde o hacia memoria. * Procesador-E/S: Transferencia de datos desde o hacia el exterior a través de un módulo de E/S. * Procesamiento de datos: Alguna operación aritmética o lógica con los datos. * Control: Por ejemplo una instrucción de salto, que lo único que requiere es que se cambie el valor del registro PC.
Unas instrucciones requieren una combinación de algunas.
Bueno, vamos a agregar algunas etapas

Arquitectura y organización de computadoras Página 63 de 76
IAC - Instruction address calculation: En general consiste en sumar 1 al registro PC, pero no siempre. Supongamos que las instrucciones tienen un largo de 16 bits y la memoria está direccionada de a 16 bits, en ese caso sumariamos 1 al PC, pero si la memoria estuviera direccionada de byte, cada instrucción ocuparía 2 posiciones de memoria, en ese caso tendríamos que sumar 2 al PC. IF - Instruction fetch: La CPU lee la instrucción desde su posición en la memoria. IOD - Instruction operation decoding: Decodifica la instrucción para saber el tipo de operación a realizar y los operandos a utilizar. OAC - Operand address calculation: Si el o los operandos se encuentran en memoria o se accede a ellos a través de E/S, se determina la dirección. OF - Operand fetch: Se capta el operando de memoria o a través de E/S. DO - Data operation: Se realiza la operación que requiere la instrucción. OS - Operand store: Se almacena el operando en memoria o a través de E/S.
En el gráfico podes observar varias cosas, las etapas están dispuestas tal que en la parte de arriba están las etapas que requieren salir del procesador, y la parte inferior están las etapas que se solucionan internamente. Otra cosa para destacar son las flechas dobles en el momento de ir a buscar un operando o al almacenarlo, esto se debe porque hay instrucciones que requieren varios operandos y hay otras que generan más de un resultado. Por último hay instrucciones que realizan una misma operación con distintos valores de un vector, por eso, al terminar de almacenar el resultado no captan la siguiente instrucción, en vez de eso, captan el próximo valor del vector realiza lo mismo con otros valores.
Interrupciones:
Para seguir con el ciclo de la instrucción voy a dar una idea de lo que es una interrupción, más adelante la veremos con más profundidad. Una interrupción es un mecanismo, con el cual un módulo de E/S puede interrumpir el procesamiento normal de la CPU.

Arquitectura y organización de computadoras Página 64 de 76
Esto sirve para mejorar el rendimiento del sistema. Este mecanismo puede llegar deshabilitarse si es necesario.
Ejemplo, ya sabemos que la mayoría de los dispositivos externos son las lentos que la CPU, imaginemos la CPU imprimiendo un documento
Procesador a 200 MHz (tiempo ciclo reloj = 5 ns; Ciclos por instrucción CPI = 2 , en promedio) • Una instrucción tarda en promedio 2 x 5 ns = 10 ns =>la computadora puede ejecutar ~100 Mips Queremos imprimir un archivo de 10 Kbytes en una impresora láser de 20 páginas por minuto • 1 página ≅ 3.000 caracteres (1 carácter = 1 byte) • La impresora imprime 60.000 caracteres por minuto = 1 Kbyte/s
Hasta hora lo único que podíamos hacer era que la CPU envíe los datos que pudiera recibir la impresora y esperar que termine de imprimir o que solicite más datos.
Sin interrupciones:
• La CPU entra en un bucle y envía un nuevo byte cada vez que la impresora está preparada para recibirlo. • La impresora tarda 10 seg en imprimir 10 Kbytes • La CPU está ocupada con la operación de E/S durante 10 seg. (en ese tiempo la CPU podría haber ejecutado 1000 millones de instrucciones)
Con el uso de interrupciones la CPU no tiene que esperar, mandaría los datos a la impresora y seguiría haciendo alguna tarea productiva.
Con interrupciones:
La impresora genera una interrupción cada vez que está preparada para recibir un nuevo byte. • Si la gestión de interrupción (ATI) tiene 10 instrucciones (salvar contexto, comprobar estado, transferir byte, restaurar contexto, rti) • Para transferir 10 Kbytes tenemos que ejecutar 10.000 veces la ATI ⇒ ejecutar 100.000 instrucciones para atender al periférico ⇒ la CPU tarda 0,001 seg. • La CPU está ocupada con la operación de E/S durante 0,001 seg. • La E/S por interrupciones reduce en 10.000 veces el tiempo que la CPU está ocupada gestionando la impresora.
Esta diferencia es tan marcada porque el periférico es realmente muy lento, con periféricos rápidos, sólo con las interrupciones no alcanza para solucionar el problema.

Arquitectura y organización de computadoras Página 65 de 76
En este gráfico se muestra el tiempo que utiliza la CPU en el periférico, la línea punteada nos marca en que se estaría utilizando el CPU. Cuando se atiende, un periférico el procesador ejecuta un programa que atiende al módulo de entrada salida, este programa se carga, prepara lo necesario para que se pueda realizar la operación requerida con el periférico, seguido a esto se ejecuta la instrucción solicitada, cuando termina el periférico su tarea, en algunos casos el programa cargado puede realizar alguna otra tarea relacionada, para el lado del periférico o para el lado de los buses, por ejemplo mandar información de algún error que se haya detectado en el periférico, para luego proseguir con la ejecución del programa original. Se puede ver, en la primera sección, que mientras está funcionando el periférico (entre los círculos 4 y 5) el CPU no hace nada, sólo espera que termine, en cambio se puede apreciar en la segunda seccione del gráfico, que luego de que el programa que atiende la E/S pone en funcionamiento el periférico, el procesador dedica su tiempo en procesar el programa original hasta que reciba una nueva interrupción, las 2 cruces identifican las interrupciones. Bien, que sucedería si ocurre una interrupción mientras se está ejecutando una interrupción? Hay 2 alternativas, la primera es que mientras se está atendiendo una interrupción se desactivan las demás, luego que se termina de atender la interrupción el procesador, antes de proseguir con la ejecución del programa principal, chequea si hay alguna interrupción pendiente, y así las va ejecutando secuencialmente. La desventaja es que no se tiene en cuenta ninguna prioridad, y es necesario porque hay peticiones que en la que es importante atenderlas rápidamente y hay otras que no. La otra alternativa es que las interrupciones tengan prioridad, entonces, si una interrupción es interrumpida por otra que posee mayor prioridad, se almacena el contexto de ejecución de la interrupción en curso, se carga el PC con la nueva dirección y se empieza a ejecutar las instrucciones del programa que atiende la nueva interrupción, al terminar se continua atendiendo la interrupción

Arquitectura y organización de computadoras Página 66 de 76
anterior, y cuando se termina de atender esta, se vuelve a la ejecución del programa principal.
En la primera parte del gráfico se muestra como sería una atención secuencial de interrupciones, y en la segunda parte muestra el procesamiento de interrupciones anidadas, una dentro de otra, obviamente la interrupción "Y" es de mayor prioridad que la "X", en caso contrario, el gráfico hubiese sido similar al de la primera parte.
Sabiendo un poco de las interrupciones ahora podemos agregar una nueva etapa al ciclo de la instrucción básico.

Arquitectura y organización de computadoras Página 67 de 76
En este gráfico podemos ver que si las interrupciones están deshabilitadas, el ciclo es igual, pero si están habilitadas antes de captar la próxima instrucción, chequea si hay alguna interrupción pendiente, si lo hay, en la etapa "Check for Interrupt" el procesador guardara el contexto (registro que contiene los flags, registro PC, etc.) cargara en el registro PC la dirección donde está el programa que atiende la interrupción, y empezara a captar y ejecutar las instrucciones del programa de atención a la interrupción.
También vamos a agregar la etapa de detección de interrupciones el gráfico más detallado:
A esto faltaría agregarle una etapa.
Las instrucciones pueden contener uno, varios o ningún operando, este operando puede pasado de distintas modos de direccionamiento, los más comunes son:
* Direccionamiento inmediato: El valor del operando se encuentra incluido en la instrucción. * Direccionamiento directo: En la instrucción se encuentra la dirección efectiva en donde se encuentra el operando o el registro donde se encuentra el operando. * Direccionamiento indirecto a través de registro: En la instrucción se hace referencia implícitamente o explícitamente al registro en donde se encuentra la dirección efectiva del operando. * Direccionamiento indirecto a través de memoria: En la instrucción se encuentra la dirección en donde se encuentra el operando, este operando contiene la dirección de donde se encuentra el valor a procesar.

Arquitectura y organización de computadoras Página 68 de 76
y otros modos y subdivisiones de cada uno, que no vienen al caso explicar ahora como, con desplazamiento, usando la pila, estos direccionamientos varían según el procesador. Sabiendo esto podemos ver que faltaría una etapa para acceder al valor del operando en los direccionamientos indirectos.
Flujo de datos:
Veamos un poco como se usan los buses en el ciclo de una instrucción:
Ciclo de captación: En el momento de captar la próxima instrucción, se toma la dirección contenida en el PC y se coloca en el MAR, luego la unidad de control manda señal de lectura por el bus de control, y entonces la memoria coloca en el bus de datos la información requerida. A continuación el
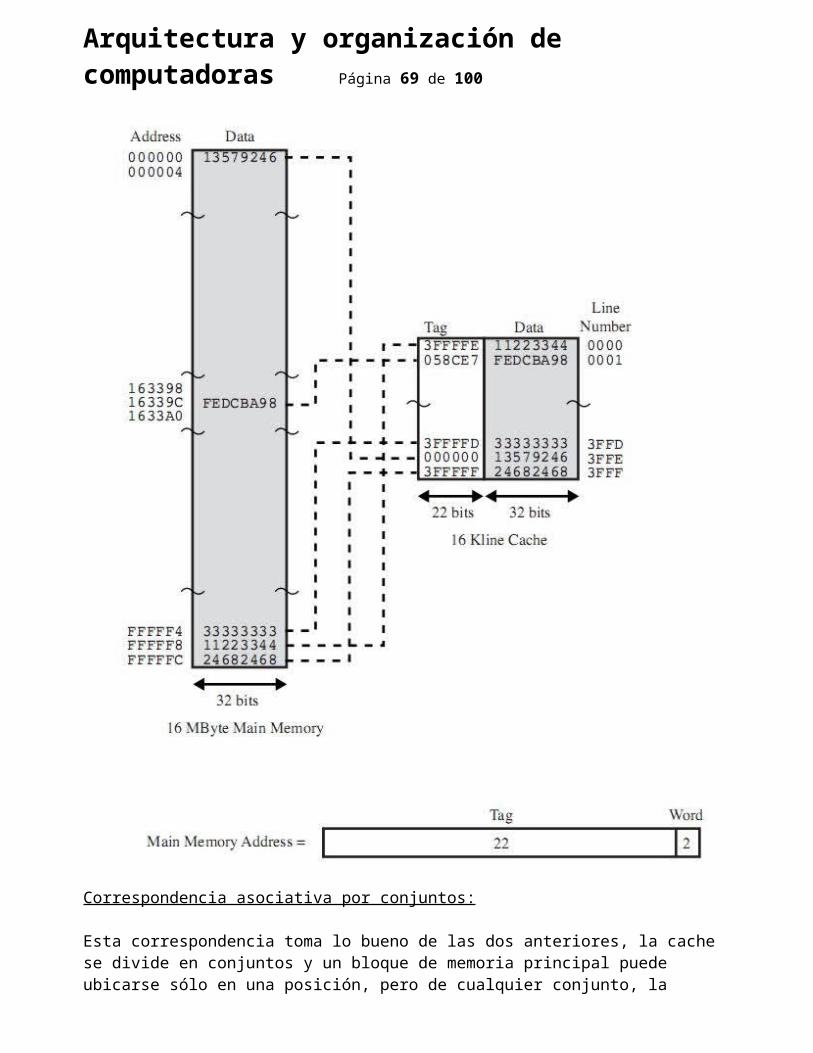
Arquitectura y organización de computadoras Página 69 de 76
MBR copia la información que se encuentra en el bus de datos al cual está conectado, y como paso final el dato contenido en MBR pasa a IR.
Ciclo indirecto: Si el operando utiliza direccionamiento indirecto, entonces se toma los N bits más a la derecha del registro MBR, los cuales corresponden a la dirección de referencia del operando, estos bits se pasan al MAR, la unidad de control manda señal de lectura, la memoria pone los datos solicitados en el bus de datos, la MBR capta la información del bus de datos
El ciclo de ejecución no tan fácil y predecible como los dos anteriores, todo depende de la instrucción que el ciclo de captación haya dejado en IR, son muchas las posibilidades de flujos posibles.
En cambio, el ciclo de interrupción es predecible como los 2 primeros.

Arquitectura y organización de computadoras Página 70 de 76
Ciclo de interrupción: Antes de atender a la subrutina que atenderá la interrupción, el contexto del CPU debe guardarse (flags y PC), para eso la unidad de control coloca en MAR la dirección en donde hace el resguardo de esos datos, podría ser la pila, luego de esto se coloca el dato a guardar en MBR, la unidad de control envía señal de escritura, la memoria detecta la señal y copia en la dirección que se encuentra en el bus de direcciones el dato que se encuentra en el bus de datos, dependiendo del tamaño del dato a guardar puede que este proceso se repita más de una vez. Luego de eso, se coloca en el PC la dirección donde comienza la subrutina de atención a la interrupción, gracias a lo que se realizó, en el próximo ciclo se empezara a captar instrucciones de la rutina de atención a la interrupción.
Segmentación de cauce:
Las técnicas de organización se fueron implementando a medida que la tecnología fue avanzando y permitieron ponerlas en práctica. La de segmentación de instrucciones es una técnica muy usada hoy en día. Que es la segmentación de instrucciones?. Para explicarlo recordemos primero el ciclo de la instrucción, abarca varias etapas, en las cuales se realizan distintas tareas, bien, como son distintas, las realizan generalmente distintas partes del procesador, por ejemplo, la parte de ejecución la va a realizar la ALU, pero en la etapa de captación la ALU no interviene, este es el punto, mientras una parte del procesador está trabajando, hay otras que no. La técnica de segmentación de cauce intenta que trabajen las distintas partes del procesador en paralelo. Por ejemplo cuando la etapa de ejecución recibe la instrucción, la etapa de captación se libera y podría empezar a captar la próxima instrucción. Es muy gráfico y simple verlo haciendo una analogía con una línea de montaje de un producto en una fábrica, en la cual el producto va pasando por distintas etapas y en cada una se le hace algo al producto, no es necesario que el producto termine de pasar por todas las etapas para poder ingresar
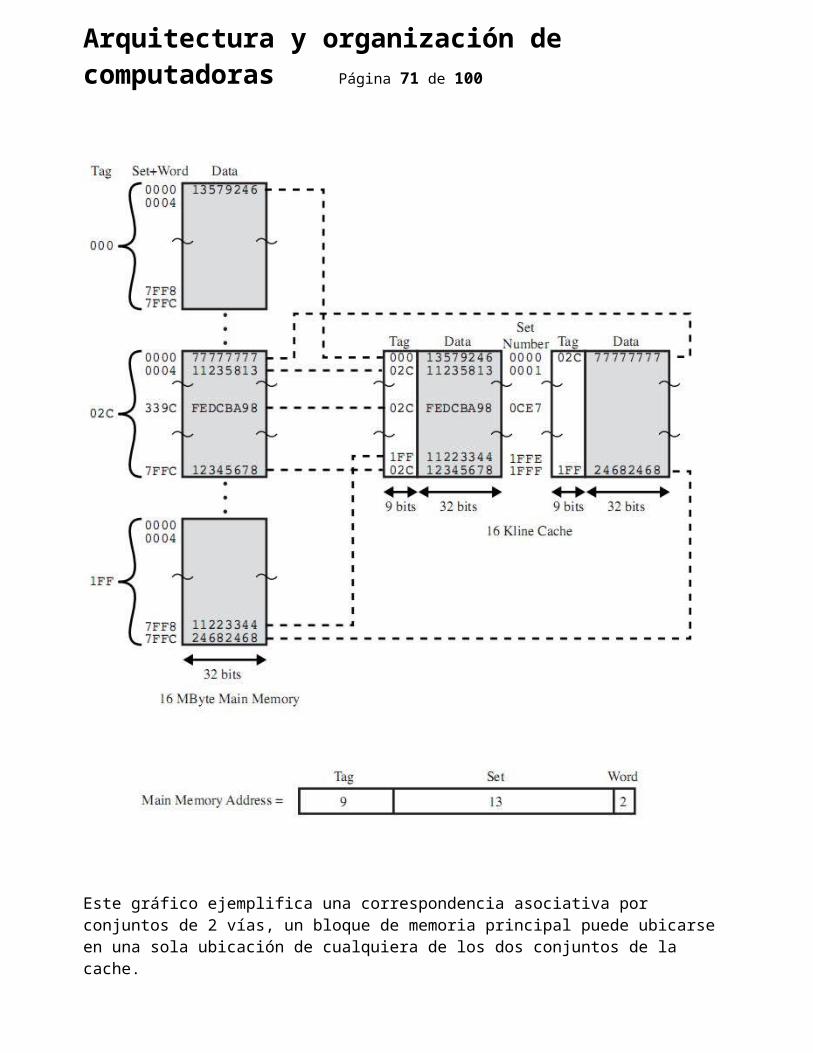
Arquitectura y organización de computadoras Página 71 de 76
un nuevo producto a la línea de montaje. Otro ejemplo podría ser un lavadero de ropa.
Lavado Secuencial
Lavado Segmentado
¡Gracias a la cátedra de arquitectura por las diapositivas que les tomo prestadas!

Arquitectura y organización de computadoras Página 72 de 76
Los dibujitos vendrían a ser las tres etapas, lavado, secado y planchado.
El tema es hacer tareas en simultáneo en las cuales no se superpongan unidades funcionales. Cuanto más se pueda sementar el ciclo de instrucción más beneficioso sería. No todas las instrucciones utilizan todas las etapas, por ejemplo un movimiento de datos no utilizaría la etapa de ejecución, ni tampoco las etapas consumen la misma cantidad de tiempo, pero para simplificar la implementación, todas las instrucciones pasan por todas las etapas y todas las etapas duran lo que tarda la etapa más lenta. Teóricamente el incremento de la productividad es proporcional al número de etapas, digo teóricamente porque el uso de segmentación trae aparejado muchos contratiempos que le van a bajar un poco ese rendimiento teórico. Otra cosa a tener en cuenta es que la instrucción va a tardar lo mismo en ejecutarse, la diferencia está en que el procesador va a ser más productivo. Bien, ahora vamos a determinar las etapas de nuestro cauce:
FI - Fetch instruction: Captar la siguiente instrucción. DI - Decode instruction: Determinar la operación a realizar, y los campos de operando. CO - Calculate operands: Se calcula la dirección efectiva de los operandos. FO - Fetch operands: Se captan los operandos de memoria, los que están en registros no son necesarios captarlos EI - Execute instruction: Realizar la operación indicada en la instrucción. WO - Write operand: Almacenar el resultado en memoria.
Esta sería una situación óptima sin ninguna complicación, 9 instrucciones de 6 etapas, que si se ejecutaran en forma secuencial consumirían 54 unidades de tiempo, pero gracias a esta segmentación se requieren sólo 14 unidades de tiempo.

Arquitectura y organización de computadoras Página 73 de 76
Bien, veamos problemas, uno de los dos más importantes serían los saltos.
No siempre la ejecución del programa es secuencial, los saltos condicionales, los saltos incondicionales, las llamadas a subrutina son un gran problema para la segmentación de cauce.
Imaginemos que en el cauce del gráfico anterior la instrucción 1 es una instrucción de salto condicional, la dirección de salto no se va a saber hasta que la instrucción pase por la etapa EI, el procesador seguirá cargando las instrucciones de forma secuencial, para cuando la instrucción 1 sabe a dónde debe saltar para seguir captando instrucciones, ya se cargaron 4 instrucciones al cauce las cuales deben descartarse.
En este caso la instrucción de salto sería la instrucción 3, y se deben descartar las instrucciones 4, 5, 6 y 7. Se desperdiciaron 4 ciclos.
Si el salto no se hubiese realizado, el gráfico sería igual al anterior.
El segundo problema es la dependencia de datos. Imaginemos que la primer instrucción es una suma, A + B=C, y la segunda es otra suma C + D=E.
La segunda instrucción no va a poder captar el operando C hasta que la primera instrucción almacene el resultado C en memoria.
En el próximo gráfico para mostrar la dependencia de datos el cauce que se toma es de 5 etapas pero mostrar la dependencia sirve, es lo mismo.

Arquitectura y organización de computadoras Página 74 de 76
El gráfico está tomado de un simulador MIPS64 (RISC), abajo pongo que se hace en cada etapa, las instrucciones LD leen un dato de memoria y lo guardan en un registro (lee el dato en la posición A de memoria y lo guarda en el registro R1), las SD al revés, toman el dato del registro y lo almacenan en memoria. Donde dice RAW es que hay dependencia de datos (read after write) lectura antes de escritura, quiere decir que se está intentando leer un dato que todavía no se escribió.
En este gráfico podemos apreciar un poquito más de detalle, se puede ver que hay buffers intermedios entre las etapas llamados registros de segmentación, además de esto hay circuitería dedicada a minimizar las dos dificultades antes mencionadas.
Según lo visto hasta ahora parecería que cuantas más etapas mejor va a ser el rendimiento, pero los diseñadores se dieron cuenta de que no era así, ¿por qué?
Primero, al agregar más etapas estamos agregando más buffer intermedios, los cuales adicionan tiempo, además que entre cada etapa ya hay una demora debido a funciones de preparación y

Arquitectura y organización de computadoras Página 75 de 76
distribución. Segundo, con cada etapa que se agrega la circuitería para controlar las dependencias y otras para optimizar el uso del cauce y aumenta enormemente la complejidad, pudiendo llegar al punto que esta circuitería sea más compleja que las etapas mismas.
Por esta razón se busca un rendimiento óptimo con una complejidad moderada.
Tratamiento de las instrucciones de salto condicional:
Los tratamientos más utilizados son:
* Flujos múltiples. * Precaptar el destino de salto. * Buffer de bucles. * Predicción de saltos. * Salto retardado.
Flujos múltiples: Esta implementación duplica la parte inicial del cauce, y en la etapa de captación, cuando se detecta una instrucción de salto, se comienza a captar por los dos cauces, en uno se capta como si el salto no se fuera a realizar, y en el otro cauce se capta como si el salto se fuera a producir. Pase lo que pase, ya están pre captadas las instrucciones de las 2 opciones posibles. Con esta alternativa tenemos 2 problemas, el primer problema es que los 2 causes compiten por el acceso a memoria y registros. El segundo problemas es el siguiente: supongamos que ingresa una instrucción de salto, a partir de ahí se empieza a captar por los dos causes simultáneamente, ahora que pasa si ingresa en ese momento otra instrucción de salto antes de que se resuelva la primera. Se necesitaría otro cauce adicional.
Precaptar destino de salto: En esta implementación además de captar la instrucción siguiente a la del salto, se pre capta y se guarda la instrucción del destino del salto, hasta que se decida si se salta o no. Si se produce el salto, el destino ya habrá sido pre captado.
Buffer de bucles: El buffer de bucles es una memoria de pequeña y muy rápida, la cual es controlada por la etapa de captación, en ella se almacenan las N últimas instrucciones captadas. Entonces en el momento que se detecta que se va a producir el salto, el hardware comprueba si la dirección de salto se encuentra en el buffer, si se encuentra, la capta del buffer rápidamente, en vez de ir a memoria a buscarla.
Este buffer tiene tres utilidades:
1. Con el uso de pre captación, el buffer se adelanta y almacena las próximas instrucciones secuencialmente delante de la última captada. Con esto se logra que la etapa de captación tome las instrucciones del buffer en vez de hacerlo de memoria, reduciendo considerablemente los tiempos de acceso.
2. Si se produce un salto con una dirección de destino próxima a la dirección actual, esta dirección va a encontrarse en el buffer.
3. Está especialmente pensado para el tratamiento de bucles, si el buffer es lo suficientemente grande, todo el bucle entrara en el buffer, por lo cual el procesador va a tener que ir a memoria a buscar las instrucciones sólo la primera vez, para las siguientes iteraciones tomará los datos del

Arquitectura y organización de computadoras Página 76 de 76
buffer.
Predicción de saltos: Existen diversas técnicas para predecir los saltos, algunas son:
* Predecir que nunca salta. * Predecir que siempre salta. * Predecir según el código de operación. * Conmutado saltar / no saltar. * Tabla de historia de saltos.
Las dos primeras son las más fáciles, en la primera se decide no saltar nunca y pre captar lo que sigue a continuación de la instrucción de salto, y si al final se salta se descarta lo pre captado. La segunda es al revés de la primera se decide saltar siempre. Estas 2 técnicas en general tienen una tasa de acierto aproximadamente del 50%.
En la técnica de predecir según el tipo de instrucción, el procesador decide si salta o no, dependiendo de la instrucción de salto, con esta técnica se logra una tasa de acierto mayor al 75%.
Estas primeras tres técnicas son estáticas, las dos últimas son dinámicas, registran algún tipo de información histórica de cuáles fueron las decisiones tomadas con anterioridad. Por ejemplo si para almacenar el historial se dispone de un sólo bit, sólo podremos almacenar la última decisión tomada en el salto (se saltó / no se saltó)
Salto retardado: Usando esta técnica, la instrucción que le sigue secuencialmente a la instrucción de salto se ejecuta siempre, se salte o no se salte, dependiendo del procesador puede ser más de una instrucción.
Queda poco legible el código utilizando esta técnica, porque después de la instrucción de salto va a ir una instrucción que normalmente estaría antes de la instrucción de salto. La ventaja es que la instrucción que se va a captar es útil, se salte o no se salte, no se va a descartar nunca.





















