Embed Size (px)
DESCRIPTION
ARMOR A synchronous R ISC M icroprocess or. הטכניון - מכון טכנולוגי לישראל המעבדה למערכות ספרתיות מהירות - PowerPoint PPT Presentation
Citation preview

ARMORAsynchronous RISC Microprocessor
המעבדה למערכות ספרתיות מהירות הטכניון - מכון טכנולוגי לישראל הפקולטה להנדסת
חשמל
Submitted by: Tziki Oz-Sinay, Ori Lempel
Supervised by: Rony Mitleman
Mid-Semester Presentation

Milestones Reached• Development platform selected
– Balsa over Petrify+VHDL
• Micro-Architecture Specification (MAS) completed– functional block partition, datapath interface
defined– asynchronous handshaking protocol defined
• Detailed asynchronous pseudo-code implementation written
• Balsa code writing, dynamic simulation and synthesis started

Development Platform Selection
Two development enviornments were examined:
Balsa:• Language for
synthesising large asynchronous circuits and systems
• Compiles to a small, parametric, set of handshake components
– Balsa flow– Balsa initial flow
Petrify:• A synthesis tool for
Petri Nets and asynchronous controllers
• Reads a Petri Net and generates another Petri Net, which is simpler than the original description but behaviorally similar

Development Platform Selection
(cont.)Balsa’s Advantages
– One development environment
easier debugging and integration– Synthesis implements a delay-insensitive circuit
implementation is transparent to the developer (no need for timing analysis)
– Control channels are automatically created at compilation
– High level language easier to learn

Petrify’s Advantages– A more mature environment than Balsa– When using Petrify the core of the system is
written in VHDL
all of the tools/flows are well known and supported in the lab
– Petrify’s output is translated to Verilog, while Balsa only supports EDIF synthesis
higher level output, compatible with Altera
Development Platform Selection
(cont.)

The Balsa Environment Was Chosen
This constitutes new hardware requirements:
– A simplified design, comprising an in-order pipeline and no external memory will be synthesized on a Xilinx Spartan FPGA
– The complete design will later on be implemented on a Xilinx Vertex Pro II
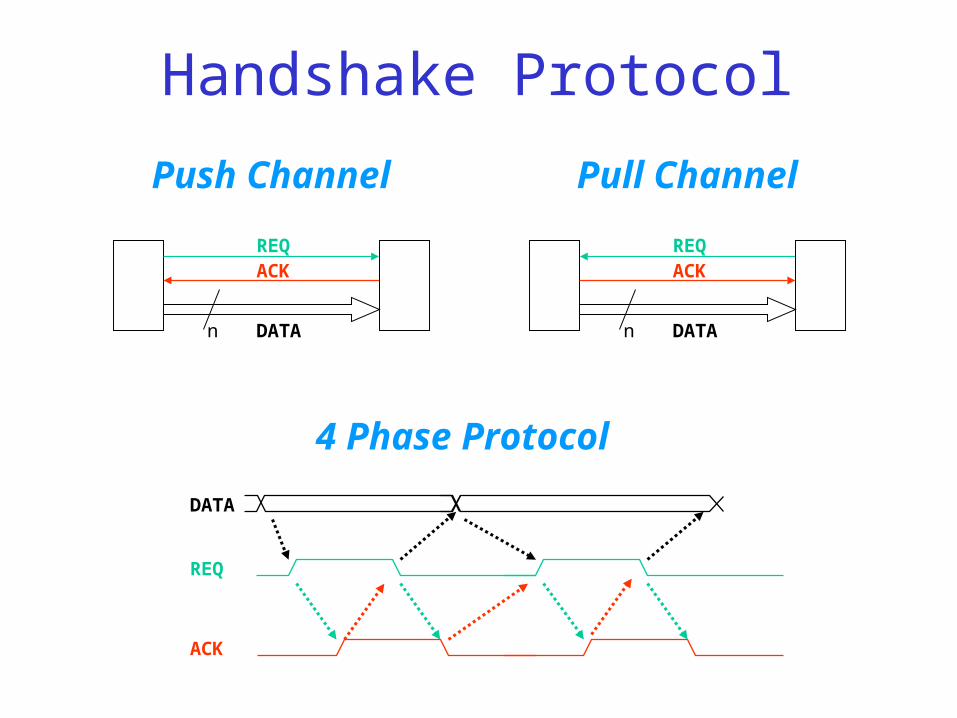
REQACK
DATAn
REQ
ACK
DATA
4 Phase Protocol
Handshake Protocol
Push Channel
REQACK
DATAn
Pull Channel

ARMOR PipestagesIn
stru
ctio
n C
ach
e
Fet
ch
Dec
od
e
Ren
ame
Dat
e C
ach
e
Wri
te B
ack
Exe
cute
Ret
ire
PC[15:0]
Inst[15:0]
VInst[15:0]
Op[3:0]
LDst[3:0]
LSrc[3:0]
Imm[11:0]
Op[3:0]
PDst[3:0]
SrcVal1[15:0]
SrcVal2[15:0]
Imm[11:0]
DataIn[15:0]
PDst[3:0]
Addr[15:0]
ReadWrite#
ALU0PDst[3:0]
ALU0Res[15:0]
ALU1PDst[3:0]
ALU1Res[15:0]
MemPDst[3:0]
DataOut[15:0]
LDst[3:0]
Val15:0]Op[3:0]
PDst[3:0]
SrcVal1[15:0]
SrcVal2[15:0]
Imm[11:0]
BranchDecision
Out Of Order Engine

Instruction Fetch Unit (IFU)• Function:
– Fetch instruction pointed to by the PC register from the instruction cache.
– Execute the jump instruction.– Calculate branch addresses, speculatively fetch
branch target instructions and stall pipeline pending branch decision.
+PC+2
branch offset
branch instructionnext instruction
to instruction cache
to ID
branch decision

Instruction Decoder (ID)• Function:
– Tag instructions by type (REGREG, REGIMM, MEM, BRANCH).
– Queue up to 4 issue-pending instructions, thus allowing continuous instruction fetching in case instruction issue stalls.
VInst
head
tail

ROB
RRF
RAT
RS0 RS1
ALU0 ALU1DATA
CACHE
BranchDecision to IFU
Inst from ID
branchesnon-mem inst
mem instnon-branch inst
Register Alias Table (RAT)

Register Alias Table (RAT)• Function:
– Register Renaming – map logical sources/ destinations to physical registers (ROB/RRF entries):
• Allocate physical destination (PDst) pointers during instruction issue
• Reset pointers during retirement (CAM-match logic)
– Monitor data-readiness of physical sources/destinations:
• Reset ready-bit during
instruction issue• Set ready-bit during writeback
(CAM-match logic)
R0
R1
R2R3
R4
R5
R6R7
PDst Ready

ROB
RRF
RAT
RS0 RS1
ALU0 ALU1DATA
CACHE
BranchDecision to IFU
Inst from ID
branchesnon-mem inst
mem instnon-branch inst
ReOrder Buffer (ROB)

ReOrder Buffer (ROB)• Structure:
Circular buffer of 24 entries (PDsts), each one
holding all relevant data for a single instruction: – Op Code and Op Type– LDst– PSrc1 – pointer, value and status– PSrc2 – pointer, value and status (if needed)– Immediate (if needed)– Writeback Result – Dispatched, Valid bits
Large register file:
24 entries * 71 bits/entry = 1704 bits

• Function:– Hold all instructions currently in the execution
window (issueretirement).– Determine data-readiness of each instruction by
CAM-matching WB buses vs. entry’s PSrc pointers.
– Dispatch data-ready instructions out-of-order to approriate RS (to be explained…☺).
– Retire PDsts of executed instruction in-order to Real Register File (RRF).

• Dispatch Algorithm:– 3 independent iterators, scanning the ROB from
tail to head:• BranchRS Iterator – searches for the oldest branch
instruction yet to be dispatched.• MemRS Iterator – searches for the oldest memory
instruction yet to be dispatched.• RegOpRS Iterator – searches for the oldest data-ready
non-branch/memory instruction yet to be dispatched.
– Iterators’ independence does not cause conflicts no need for arbitration !
– Problem: unbalanced dispatching can clog one ALU and starve the other, leading to diminished performance.

• Dispatch Algorithm (cont.):– Solution: the ROB maintains a load-balance
counter, ranging from -4 to 3:• incremented upon branch issue and memory dispatch• decremented upon memory issue and branch dispatch
– The RegOpRS Iterator dispatches data-ready instructions according to the following rules:
LoadBalancer < 0 LoadBalancer > -1
RS0, RS1 available dispatch to RS0; continue dispatch to RS1; continue
RS0 availableRS1 busy
dispatch to RS0; return to Tail if no branch ops are ready, dispatch to RS0; return to Tail
RS0 busyRS1 available
if no memory ops are ready, dispatch to RS1; return to Tail
dispatch to RS1; return to Tail
RS0, RS1 busy return to Tail return to Tail

ROB
RRF
RAT
RS0 RS1
ALU0 ALU1DATA
CACHE
BranchDecision to IFU
Inst from ID
branchesnon-mem inst
mem instnon-branch inst
Reservation Stations (RS)

PDst Src1 Src2 V
ImmOp Src1 Src2
Src1 Src2
Src1 Src2
Imm
ImmOp
Op
PDst
PDst
PDst V
V
VRS0
RS1
Branch Op
Non Branch/Mem Op
Mem Op
Non Branch/Mem Op
Reservation Stations (RS)• Function:
– Buffer data-ready instructions for both ALUs, so as to minimize (or even eliminate!) execution idle time
– Sort instructions according to type/priority for each ALU:
• ALU0 – branch ops vs. non-branch/memory ops• ALU1 – memory ops vs. non-branch/memory ops
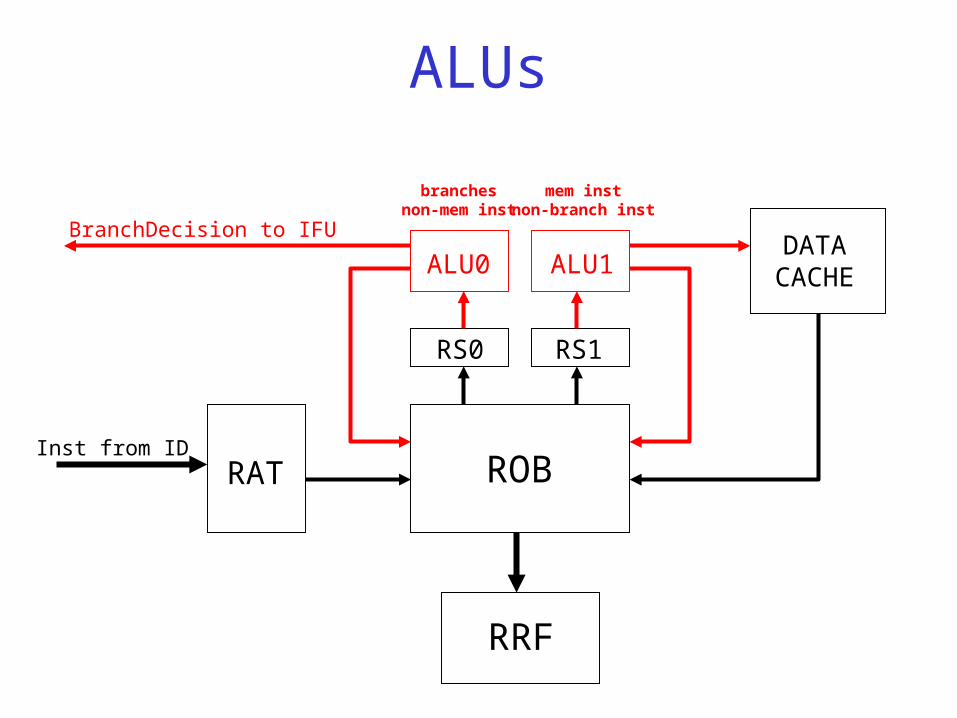
ROB
RRF
RAT
RS0 RS1
ALU0 ALU1DATA
CACHE
BranchDecision to IFU
Inst from ID
branchesnon-mem inst
mem instnon-branch inst
ALUs

ALUs• Function:
– Continuously execute instructions from respective RS and drive their associated PDsts and results on the WB busses.
– Prioritize instructions: • branch ops have precedence over other ops on ALU0
result (branch decision) is driven to IFU• memory ops have precedence over other ops on ALU1
result (address) is driven to DCache
ROB
RRF
RAT
RS0 RS1
ALU0 ALU1DATA
CACHE
BranchDecision to IFU
Inst from ID
branchesnon-mem inst
mem instnon-branch inst
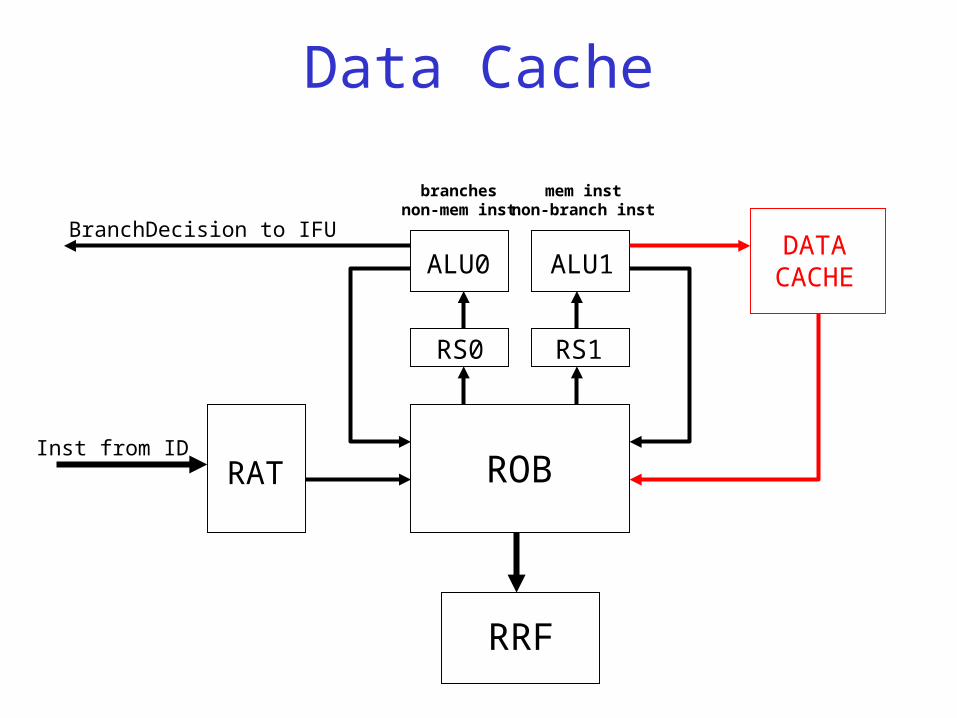
Data Cache

• Function:– Read/write memory operands in-order (according
to address, RdWr# signal from ALU1) and drive their PDsts (and results, for LW ops) on the WB busses.
– Queue up to 4 pending memory access instructions, thus allowing ALU1 to execute successive LW/SW ops without stalling.
Data Cache

Timeline• ASAP (beaurocracy…)
– Install Balsa 3.3, including netlist technology, on Lion server
– Increase Linux user quotas– Install Exceed terminal server in lab so that we
can remotely connect to Lion server
• 4/3/04 (final report, first semester):– Asynchronous simulation of a complete data-path
flow through the pipeline: mov R0, 1
add R0, 1

Balsa Initial Flow
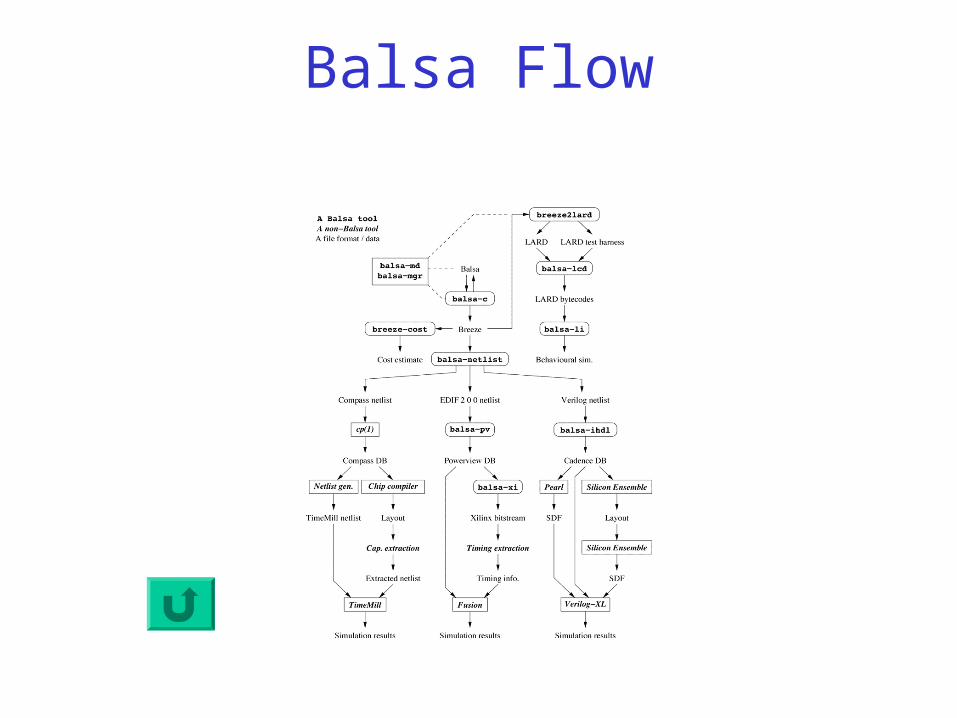
Balsa Flow



























![[Aero] Armor 8 - Armor in the Desert.pdf](https://img.dokumen.tips/doc/110x75/577c7fd01a28abe054a62ea0/aero-armor-8-armor-in-the-desertpdf.jpg)

