Embed Size (px)
Citation preview

I componenti fondamentali
Architettura dell’informazione

Nella definizione operativa di architettura dell’informazione, che abbiamo deciso di
adottare, tre sono le aree o componenti che costituiscono un sistema informativo:
q Schemi di classificazione : Rappresentano le strutture con cui si categorizzano le informazioni
q Sistemi ricerca rappresentano i sistemi con cui si effettuano le ricerche
q Sistemi di navigazione rappresentano i sistemi in cui ci si muove attraverso le informazioni
q Sistemi di etichettatura: rappresentano i sistemi con cui si rappresentano le informazioni
I componenti di un’architettura dell’informazione
Architettura informativa
Schemi di classificazion Sistemi di navigazioneSistemi di ricerca Sistemi di etichettatura

Schemi di classificazione: strutture o modelli organizzativi
Architettura dell’informazione

q La gerarchia o tassonomia (gerarchico-enumerativa)
Uno schema di classificazione descrive la relazione tra le unità d’informazione presenti. In altri
termini, esprime i percorsi che gli utenti devono compiere per muoversi nello spazio
informativo definito dal sito.
La natura del web permette ai progettisti di applicare diversi modelli di organizzazione:
q Modello a faccette o multidimensionale (analitico-sintetica)
q Social Classification (folksonomy)
I modelli di classificizazione

Modello a faccette o multidimensionale (analitico-sintetica
Tassonomia
(gerarchico enumerativa)

Lo schema di classificazione tassonomica prevede che gli elementi da classificare siano
disposti in un albero gerarchico, vale a dire in un insieme di classi che si ramificano a partire
dalle categorie-padre (classi) che contengono le categorie-figlie (sottoclassi) fino ad
arrivare all’unità di informazione vera e propria.
L’unica vera differenza tra i siti gerarchici è quanto in profondità è collocata l’informazione.
Struttura organizzativa: Tassonomica o gerarchica enumerativa
Partenza
Informazione
Struttura TASSONOMICA a 7 livelli
(6 click da A a B)
A
B
Partenza
Struttura TASSONOMICA a 3 livelli
(3 click da A a B)
Informazione
A
B

Queste forme di organizzazione sono chiamate anche gerarchico-enumerativa. Questa
definizione fa riferimento alle due proprietà peculiari di tale schema:
• il carattere gerarchico, cioè il fatto di essere costituito da classi contenute le une nelle
altre a formare appunto una struttura ad albero;
• il carattere enumerativo, perché in uno schema simile, tutte le classi che compongono
l’albero devono essere enumerate apriori. Quest’ultima proprietà determina
l’impossibilità di aggiungere nuove classi, se non modificando l’intero schema.
Struttura organizzativa: Tassonomica o gerarchica enumerativa
Nel momento che una stessa particella informativa faccia parte di diversi rami lo schema
da gerarchia pura diventa poligerarchia.
Struttura organizzativa: Tassonomica o gerarchica enumerativa
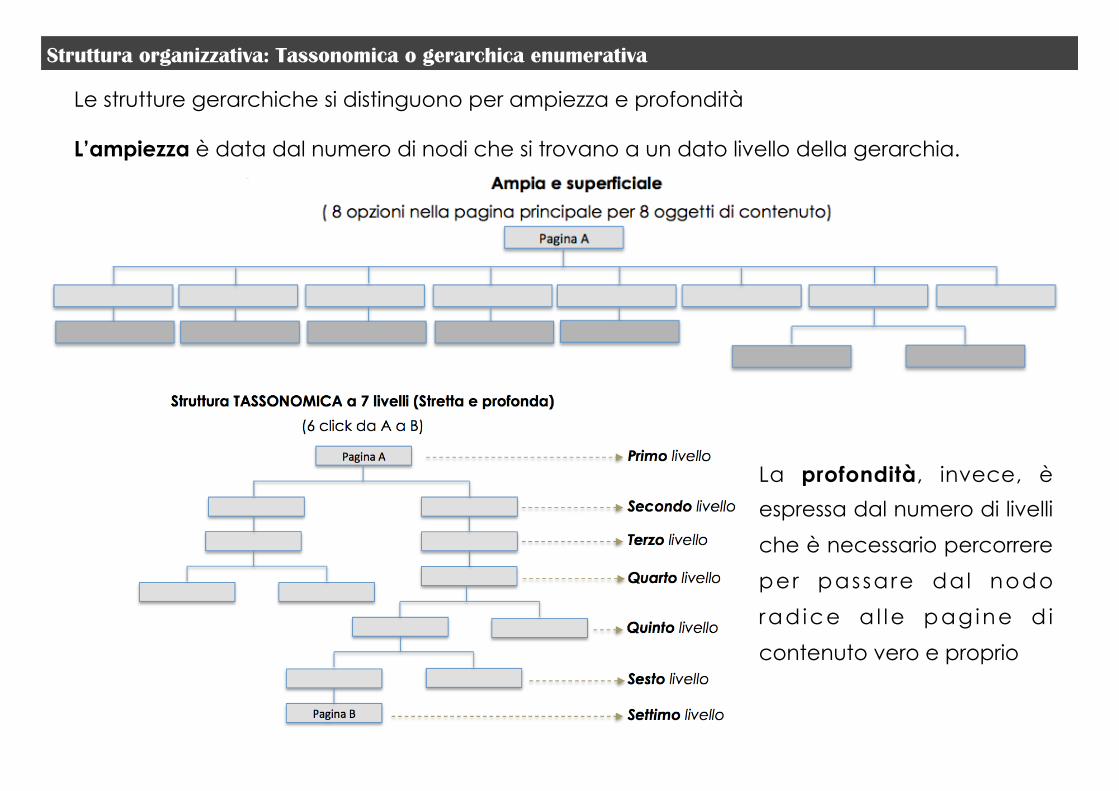
Le strutture gerarchiche si distinguono per ampiezza e profondità
L’ampiezza è data dal numero di nodi che si trovano a un dato livello della gerarchia.
La profondità, invece, è
espressa dal numero di livelli
che è necessario percorrere
per passare dal nodo
rad ice a l le pag ine d i
contenuto vero e proprio

Le ambiguità delle directory
Per descrivere l’ambiguità, esaminiamo le directory o
cataloghi organizzati delle risorse on line:
Dmoz Open Directory , Yahoo! Directory .
Queste utilizzano uno schema gerarchico-numerativo, per
indicizzare le URL dei siti web
A volte, l’impiego delle classificazioni tassonomiche, può produrre delle ambiguità

Yahoo! (e successivamente Dmoz), rappresenta uno dei primi tentativi di classificare i siti
web.
L’idea è quella di creare una tassonomia che può avere valore per tutto il web, in modo
che ogni sito può rientrare in una categoria definita.
La vastità del web, l’eterogeneità delle risorse, hanno resa l’impresa di Yahoo!, sempre più
difficile da realizzare.
Le principali directory

Analizzando il primo livello della classificazione della home page di Yahoo, si può notare
come l’indicizzazione sia avvenuta attraverso una divisione per discipline.
Spicca tra le eccezioni la classe Regional. Il problema di un primo livello realizzato in questo
modo produce una violazione della regola che per ogni nodo della classificazione, produce
categorie non mutuamente esclusive...da ciò un sistema ibrido per cui incoerente.
Esempio:
Se voglio trovare un sito canadese che
vende giochi per computer on line da
dove devo iniziare?
Regional oppure Computer & Internet?
E’ probabile che siano previsti rinvii tra i vari
rami e che quindi ugualmente arrivi alla
classe desiderata.
Ma comunque l’imbarazzo rimane!!!
Classificazione Tassonomica: Ibrida e incoerente

Il problema è che la violazione della regola dell'unicità fundamentum divisionis per ogni
nodo della classificazione, produce categorie non mutuamente esclusive e, quindi, uno
schema organizzativo ibrido (più principi di divisione operano contemporaneamente) che
è, per sua natura, anche incoerente.
Oltre alla categoria Regional è presente:
• la categoria Kids and Teens
(classificazione per tipologia di utente)
• la categoria world
(classificazione per lingua)
• la categoria shopping
(classificazione per attività)
Classificazione Tassonomica: Ibrida e incoerente
Le cose peggiorano se consideriamo la directory Dmoz

Ma sul web allora è necessario impiegare classificazioni in cui la coerenza è una proprietà
irrinunciabile nelle strutture di classificazione?
L’incoerenza degli schemi del web ha seri risvolti negativi sul recupero dell’informazione e
possa così essere di ostacolo nella navigazione?
"il potere di uno schema organizzativo coerente deriva dalla sua capacità di suggerire un semplice
modello mentale che l'utente può facilmente comprendere. Gli utenti riconoscono facilmente
un'organizzazione speci!ca per audience o per argomento e schemi organizzativi coerenti
abbastanza piccoli possono essere applicati a grandi quantità di contenuto senza sacri!carne
l'integrità o sminuirne l'usabilità.
Tuttavia, quando si inizia a miscelare elementi di molteplici schemi, ne consegue spesso confusione
e le soluzioni sono raramente scalabili. Poiché le parti sono mischiate tra loro, non possiamo
formarci un modello mentale".
Rosenfeld e Morville (2002)
Classificazione Ibrida e incoerente: problemi utente

Perché allora i siti web facciano così ampio uso di classificazioni altamente ibride e
incoerenti nonostante le difficoltà che queste possono comportare per l'utente?
Il motivo principale di tale utilizzo può essere fatto risalire alla necessità di
inserire nel top-level della gerarchia (e quindi in homepage) il numero
più alto possibile di "categorie popolari", attuando così una strategia di
"popularity-based classification
Classificazione Tassonomica: popularity-based classification
Lo scopo è quello di consentire all'utente un accesso più veloce a
tali "categorie popolari", intendendo con questa espressione gli
argomenti, i servizi, le azioni, i prodotti, e in generale tutti gli item
classificati, che sono considerati più rilevanti per le tipologie di
utente a cui il sito si rivolge

Categorie di I livello fra loro sovrapponibili.
Essendo Games, un “Categoria popolare” si è
deciso di inserirla come categoria autonoma
Classificazione Tassonomica: popularity-based classification
Fondamentale la ricerca in base ad un
criterio geografico

Modello a faccette o multidimensionale (analitico-sintetica
Modello a faccette
multidimensionale
(analitico-sintetica)

Benché riconosciuta come più potente dei sistemi tradizionali, la classi!cazione a faccette non si è mai imposta come standard in ambito bibliotecario, subendo anzi una sorta di oblio negli ultimi anni. È stato l’avvento dell’architettura dell’informazione per il web a rilanciare questa nozione, intuendone i grandi vantaggi derivanti dalla sua applicazione in ambiente digitale. ambiente digitale.
Luca Rosa)
Classificazione a faccette
Alla verticalità dei sistemi di catalogazione tassonomica e alla loro rigidità, la classificazione a
faccette contrappone un sistema di classi (faccette) orizzontale e aperto, laddove ciascuna
faccetta è descrittiva di una proprietà o faccia dell’oggetto.
La classificazione a faccette o analitico sintetica, non si preoccupa di collocare un oggetto
(item) in una gerarchia, bensì di descriverlo in termini di sue proprietà o caratteristiche
(metadati), dette faccette. Non una singola grande tassonomia, ma tante piccole tassonomie
che rispecchiano altrettanti diversi punti di vista.
I valori di ogni singola faccetta viene detto fuoco o topic

Questo tipo di classificazione ribalta un tipo di logica antropocentrica, nella quale l’oggetto
veniva classificato attraverso il giudizio esterno, dunque soggettivo.
Nel modello a faccette, l’oggetto viene invece analizzato e classificato attraverso le sue
proprietà intrinseche, meno influenzabili dal giudizio soggettivo, a differenza del sistema di
classificazione tassonomica dove ogni elemento è classificato sotto un’unica categoria.
Classificazione a faccette: logica antropocentrica
OGGETTO
da rappresentare
ITEM Faccetta 2
Faccetta 3
Faccetta n
.
.
.
Faccetta 1
• Fuoco 1 opp topic 1 opp faccete II livello 1
• Fuoco 2 opp topic 2 opp faccete II livello 2
• Fuoco 3 opp topic 3 opp faccete II livello 3
• Fuoco 4 opp topic 4 opp faccete II livello 4
• Fuoco n opp topic n opp faccete II livello n
.
.
.

Vitigni
Fasce di prezzi
Tipologie
Regioni del mondo
• Souvignon • Cabernet
• Chardonnay • Merlot
• Pinot noir
• < 10 $
• 10$ < p < 30$
• 30$ < p < 50$
• 50$ < p < 70$
• p >70$
• Rosso • Bianco
• Frizzante • Passito
• Rosato
• Europa • America del nord
• Australia • Africa
• America del sud
Classi = 54 = 625
Con soli 4 faccette e 20 fuochi è possibile
rappresentare ben 625 classi senza doverle
elencarne tutte precedentemente.
Un risparmio di tempo e spazio notevole!!
Classificazione a faccette: Esempio
ITEM

q Il sistema è espandibile (scalarità): è sempre possibile aggiungere una nuova faccetta
descrittiva di un nuovo aspetto dell’oggetto;
Adottare sul Web uno schema a faccette può comportare per il lavoro degli architetti
dell'informazione di un sito sostanziali vantaggi. così sintetizzabili
q La Multidimensionalità: diversamente dai sistemi
tradizionali, ogni oggetto è classificato secondo una
pluralità di attributi;
q La Persistenza: gli attributi/faccette costituiscono proprietà
essenziali e persistenti dell’oggetto; in questo modo l’impatto
(sullo schema di classificazione) di eventuali cambiamenti è
fortemente ridotto o nullo;.
(*)Per scalabilità di un sistema s’intende la sua capacità di adattarsi senza troppi problemi a eventuali aggiunte di componenti
o parziali modifiche nella sua strutture
Classificazione a faccette: Vantaggi lato progettista

q La flessibilità. considerando l’insieme di attributi, ogni oggetto può
essere reperito utilizzando un singolo attributo di ricerca per volta,
oppure una combinazione di attributi.
Non solo, ma gli schemi a faccette sul Web si propongono in una prospettiva di esperienza-
utente
q La ricerca è mirata: La logica a faccette permette di incrociare facilmente più
caratteristiche dello stesso oggetto fornendo risultati più mirati e soddisfacenti per l’utente.
Infatti, ogni oggetto può essere reperito utilizzando un singolo attributo di ricerca (o
faccetta) alla volta, oppure più attributi insieme in combinazione. Il risultato della ricerca si
raffina, diminuisce sensibilmente il numero dei risultati possibili e di conseguenza anche il
tempo impiegato per raggiungere il risultato finale.
q L’utente è più libero: Chi visita il nostro sito non dovrà più sottostare alla
logica che gli viene imposta dalla struttura organizzativa, ma potrà nav-
Classificazione a faccette: Vantaggi lato utente
- igare in base al proprio punto di vista. Il sistema prevede la possibilità di percorsi multipli sulla
base dei diversi bisogni informativi e delle differenti tipologie di utenti
q Migliore gestibilità dello schema: Non è necessario elencare apriori tutte le classi del
sistema..

Le peculiarità elencate in precedenza, rendono particolarmente adeguato la scelta di questo
sistema in ambienti digitali, per un più veloce ed efficiente ritrovamento dell’informazione
Classificazione a faccette: Vantaggi lato utente
Un'interfaccia analitico-sintetica può inoltre risolvere la questione delle categorie popolari:
sotto l'etichetta della faccetta corrispondente non saranno elencati tutti i fuochi, soprattutto
se troppi, ma solo quelli che si prevedono saranno cliccati più frequentemente dagli utenti,
magari ordinandoli proprio per popolarità e non sulla base di un criterio alfabetico. Se l'utente
preferirà vederli tutti, potrà farlo in un secondo tempo.

OSSERVAZIONE: Per quanto concerne la classificazione a faccette negli ambienti legati al web, e anche quelli
legati all’ambiente dell'architettura dell’informazione, si usa definire faccette, un qualsiasi
sistema che adotti una logica di classificazione multidimensionale.
Classificazione a faccette: indicizzazione semantica
• Autore:
• Editore:
• Anno:
• Nr.pagine
• Prezzo:
ITEM
• Argomento:
• Attività:
• Area geografica:
• livello
(1) (2)
La (1) classificazione non è a faccette, i quanto i parametri che vi compaiono riflettono
proprietà formali, descrittivi dell’oggetto che si descrive.
A differenza della (2) classificazione che è a faccette in quanto investono proprietà semantiche
In effetti, per parlare di classificazione a faccette è necessario che il sistema preveda una forma
di indicizzazione semantica (legata al contenuto) di ciò che si vuole classificare.
Per gli oggetti si parla di semantica quando le proprietà non sono ricavabili direttamente
dall’osservazione dell’oggetto

In una struttura di classificazione a faccette, logica multidimensionale è solo uno degli aspetti, di
grande importanza sono: la natura semantica, la tipologia e l’ordine della notazione usata per
le faccette, soprattutto quando la classificazione coinvolge un numero di oggetti elevato.
Tipologie di classificazioni a faccette
q Classificazioni a faccette pure: modelli di classificazione che si rifanno in modo completo alla
teoria della classificazione originaria (Ranganathan), ovvero:
- Accesso mediante più dimensioni semantiche (faccette) all'informazione;
- Ordine conveniente delle faccette;
- Sistema di notazione utile a garantire tale ordine;
q Classificazioni a faccette spurie: modelli di classificazione che si rifanno alla teoria delle
faccette soltanto o principalmente per ciò che riguarda la logica multidimensionale di
accesso all'informazione, mescolano cioè attributi semantici ad altri descrittivi.
q Classificazioni a faccette apparenti: modelli di classificazione a logica multidimensionale che
offrono un accesso all'informazione mediante più parametri o metadati solo o
prevalentemente di tipo descrittivo (proprietà formali dell'oggetto) e non di tipo semantico,

Nel web in genere, gli approcci a faccette sono per lo più del tipo 'spurio mescolano cioè
attributi semantici ad altri descrittivi.
Ma questo non significa che siano scorrette o che non funzionino: è gioco forza che in molti casi
(ad es. nell'e-commerce) io abbia bisogno anche di parametri descrittivi.
Tipologie di classificazioni a faccette spurie: maggioranza nel mondo del web

Faccette
Fuochi
Classificazione a faccette: Esempio
Ogni faccetta corrisponde ad un tipo di
esigenza-competenza-motivazione dell’utente
Le faccette tipo : regione, tipo, vitigno, proposte da
wine.com per classi!care i vini risultano insufficienti
e poco utili per utenti che non hanno conoscenze
enologiche. Peter Meholz [2002]
: classificazione a faccette spurie
leggero e fruttato morbido e poco. tann
Leggero e fresco
Classificazione di aspetti del vino non riconducibili solo a
proprietà fisiche dell'oggetto

Esempio di ricerca avanzata incrociando le varie faccette
Red Wine > France - Bordeaux > $80 and Above (103 results)
Classificazione a faccette: esempio di flessibilità di combinazione delle faccette

Home page
A B C
F1
F2 F3
F4
Fn
Integrazione classificazione enumerativa e classificazione a faccette

Integrazione tra la classificazione enumerativa e classificazione a faccette: EPICONS.COM

Gli schemi a faccette prevedono un
procedimento classificatorio tipicamente
descrittivo, che non può non ricordare molto
da vicino i l metodo di organizzazione
caratteristico dei database relazionali .
il termine database, banca dati o base di dati,
indica un insieme di archivi collegati secondo
un particolare modello logico (relazionale,
gerarchico, reticolare o a oggetti) e in modo
tale da consentire la gestione dei dati stessi
(r icerca o interrogazione, inser imento,
cancellazione ed aggiornamento) da parte di
particolari applicazioni software dedicate
(DBMS)
Infatti, i termini item/faccetta/fuoco possono
essere sostituiti con tabella/attributo/campo.
Definizione di database

Esempio di database
(Entità) (Entità)
(Entità)
(Entità)
(Entità) (Entità)
(Entità)
(Entità)
(Entità)
(Entità)
(Entità)
(Attributi o campi)

Definizione di database
(ITEM) (ITEM)
(ITEM)
(ITEM)
(ITEM) (ITEM)
(ITEM)
(ITEM)
(ITEM)
(ITEM)
(ITEM)
(Fuochi o topic)

categorie
tag
autore
data
…..
Modello orientato ai data base e modello di classificazione a faccette
Classificazione a faccetta Modello orientato ai database
Classificazione a faccetta Modello orientato ai database
In una struttura di classificazione orientata ai database,
benché ci sia la multidimensionalità, essa è costituita
anche da parametri descrittivi
Questa è la differenza che intercorre tra una
classificazione orientata ai database e una classificazione
a faccette: un database descrive un oggetto mediante
più parametri, ma solo se questi parametri sono semantici
esso corrisponde a una classificazione a faccette.
u Classificazione a faccette = solo parametri semantici
u Modello orientato ai database = non necessariamente parametri semantici
OSSERVAZIONE:
il modello orientato ai database, è spesso trattato come uno schema di classificazione a parte
e non come corrispondente di uno a faccette

Insieme dei post
categorie
tag
autore
data
…..
Agli architetti dell’informazioni non si chiede di
diventare esperti di SQL, anche perché esistono
Sistema di Gestione dei Contenuti (CMS), strumento
software installato su un server web studiato per
facilitare la gestione dei contenuti di siti web,
svincolando l'amministratore da conoscenze
tecniche di programmazione Web.
Modello orientato ai data base : CMS

Modello a faccette o multidimensionale (analitico-sintetica
(Social Classification)
Folksonomy

Un tag è un termine associato a un'informazione (un'immagine,
una mappa geografica, un post, un video clip ...), che descrive
l'oggetto rendendo possibile la classificazione e la ricerca di
informazioni basata su parole chiave.
Sono qualcosa di più quindi delle parole chiave, keywords, perchè non vengono
estrapolati automaticamente dal testo, dal titolo o dalla descrizione del contenuto ma
assegnate direttamente o da colui che l'ha pubblicato e che per primo è in grado di
descriverne il significato o da chi fruisce di quel contenuto.
• tag soggettivo - il significato ha senso solo per colui il quale assegna il tag (per esempio
foto di Bali durante il viaggio di nozze con tag “honeymoon”);
• tag oggettivo - il significato ha senso per colui che assegna il tag, ma è condivisibile da
tutti, e conseguentemente all’oggetto viene attribuito lo stesso tag da una moltitudine di
persone (per esempio tag “pesce” per la foto di un pesce).
I tag

Il moltiplicarsi di sistemi di tagging sia nell’ambito della realizzazione di siti web che nel loro
utilizzo quotidiano da parte degli utenti ha portato alla diffusione del concetto di folksonomy.
Il termine è nato durante una discussione svolta il 24 luglio 2004 presso l’Information
Architecture Institute da Thomas Vander Wal
Gene Smith, “architetto” di sistemi informatici, si chiese come si potesse
chiamare il sistema di social classification basato sul tagging, diffuso in
siti come Del.icio.us e Flickr. Eric Scheid rispose intuitivamente “folk
classification” e Thomas Vander Wal si ispirò a questa risposta per il
curioso neologismo “folksonomy”, in cui, egli stesso specifica, il termine
folk è da intendersi come “regular people”, ovvero la massa di utenti
medi del web.
Folksonomy

La diffusione dell’uso dei tag ha poi seguito una crescita esponenziale a partire dal 2003, con il
“decollo” di delicious e successivamente di Flickr, che ha segnato il momento di slancio e di
grande visibilità del “social tagging”, come descritto nell’immagine sulla storia dell’uso dei tag
di Philipp Keller, ricercatore presso Instituto de Investigaciones Filosóficas dell’Università del
Messico, in un suo articolo sulla storia del tagging, presentando un diagramma e una
cronologia degli avvenimenti che hanno coinvolto il tagging.
Cronostoria del TAG
I tag, che in genere vengono scelti direttamente dagli autori/creatori dell'oggetto
dell'indicizzazione in base a criteri del tutto informali, sono stati presto associati al concetto di
web 2.0 e ai cosiddetti servizi di social bookmarking.

Il valore aggiunto delle folkonomie sta proprio nell’aggregazione e nella
condivisione, cioè nella natura sociale del fenomeno (social
classification): la loro forza non è la precisione ma l’ampia adesione
popolare. Anziché sforzarsi di creare sistemi di classificazione che
incontrino modelli mentali degli utenti, si fa in modo che siano gli utenti
stessi – da basso – a far emergere spontaneamente, modelli comuni.
Ecco perché si annovera la folksonomia come una struttura bottom-up
Un altro notevole vantaggio che una classificazione dal basso porta è che collegando le
parole chiave usate da utenti diversi per classificare la medesima risorsa/informazione, si
da vita ad un sistema di correlazioni e rimandi incrociati che favorisce la scoperte di
nuovi contenuti. Da quest’aspetto innovativo e potente, si può instaurare una vera e
propria ecologia dei metadati .
Folksonomy: social classification – modello bottom up

Lo stesso Vander Wal, nel 2005, diede una netta distinzione tra due tipologie di
Folksonomie
I sistemi di classificazione semantica basati su folksonomies possono essere molto diversi
l’uno dall’altro e le applicazioni oggi disponibili suggeriscono l’esistenza di due diversi
approcci all’etnoclassificazione:
1. una ristretta (narrow folksonomy)
2. e una intesa in senso ampio (broad folksonomy).
Folksonomy: tipologie

Iniziamo a parlare della broad folksonomy,
tecnica uti l izzata da Delicious. La broad
folksonomy è il risultato di molte persone che
taggano lo stesso elemento e ogni utente può
taggare l'oggetto in modo diverso, a seconda del
proprio modello mentale, del proprio vocabolario
e della propria lingua. In altri termini l’utente crea
una risorsa e la rende accessibile agli altri.
Gli altri utenti che sono interessati a questa risorsa
le associano a loro volta tag corrispondenti ai
termini che conoscono.
Le persone trovano le informazioni sulla base dei
tag.
Broad folksonomy

• Gruppo "A" (8 persone) hanno applicato i tags "1" e un "2"
all’oggetto, e usano questi per trovare l'oggetto nuovo.
• Gruppo "B" (2 persone) hanno applicato i tags "1" e "2" all'oggetto e
beneficiano per trovare l'oggetto dei tags "1", "2" (creati anche dal
gruppo A) e "del tag 3" (creato dal gruppo “C” e dal gruppo “D”).
• Gruppo "C" (3 persone) hanno applicato i tags "2" e "3" all’oggetto e
beneficiano del tag “2” (creato anche dal gruppo “A” e “B”) e del
tag “3” (creato anche dal gruppo “D”)
• Gruppo "D" applicano all'oggetto un tag "3" e beneficiano di questo
solo (creato anche dal gruppo “C”) per trovare l’oggetto.
• Gruppo "E" (2 persone) applica un tag diverso, "4", per etichettare
l'oggetto e utilizza solo questo termine (creato solo esclusivamente
da lui) per trovare l'oggetto.
• Infine, il gruppo "F" (1 persona) applica anch’esso un tag diverso, "5", "
per l'oggetto e util izza solo questo termine (creato solo
esclusivamente da lui) per trovare l'oggetto..
Da un alto livello si vede un utente (content creator) crea l'oggetto e lo rende accessibile ad altri. Un gruppo
di utenti (rappresentato con le lettere dell'alfabeto) marcano l'oggetto (frecce orientate dal gruppo ai tags)
con i propri tags (costituiti da numeri). Lo stesso gruppo di persone possono usare i tags (frecce orientate dai
tags ai gruppi)
Broad folksonomy: Strategia alla base

• Il tag "2" riceve la maggior parte dei tag con 13 voci,
segue poi il tag "1" ricevendo 10 tag. Sulla base di
queste tendenze (tag più popolari) si potrebbe estrarre
un vocabolario controllato o almeno sapere come
chiamare l’oggetto in modo tale da avere un ampio
spettro di persone (simili a quelli che tag l'oggetto, e
tenere a mente quelle che tag possono essere
rappresentativi di tutta).
La curva caratteristica che tende ad emergere in un sistema di questo tipo, mostra una
distribuzione di tipo power law (coda lunga), Alcune tag tendono ad affermarsi fortemente,
mentre altre sono utilizzate da pochi utenti e spesso solo da uno
• Nella coda, ci sono le persone che hanno taggato
l’oggetto con un solo tag, ma comunque questo
permette ad altre persone con mentalità simile di
trovare l’oggetto, anche se questi tag sono poco
utilizzati.
Broad folksonomy: the long tail

Un classico esempio di broad folksonomy è del.icio.us che è un
servizio per il social bookmarking: ogni iscritto si appunta in uno
spazio personale gli indirizzi di siti e documenti utili trovati durante la
navigazione in rete e assegna a ciascuno di essi uno o più tag,
creando il suo indice analitico di link personali. Anche in questo caso
il sistema mette in comune tutti i collegamenti ipertestuali catalogati
da tutti gli iscritti, moltiplicando gli effetti degli sforzi individuali.
La stessa risorsa (URL) è stata già segnalata
da alti utenti (57) utilizzando i seguenti Tags
Broad folksonomy: delicious

Nelle Narrow folksonomy, ogni oggetto può
essere etichettato solo da una o poche
persone. In genere la persona o il gruppo di
persone che ha la possibilità di etichettare un
oggetto è legata a questa risorsa in qualche
modo. T ipicamente è chi ha creato il
contenuto (in Flickr deve essere il creatore del
contenuto a dare l’autorizzazione a taggare
l’oggetto).
In questa particolare folksonomia, le tag sono
singole per natura, nel senso che possono
essere associate una sola volta ad ogni risorsa,
il che comporta che non vi è una distribuzione
power law.
Narrow folksonomy

• il gruppo "A" utilizza tag "1" per trovare l’oggetto (il tag “1” è
quello creato dal creatore del contenuto).
• Il gruppo "B" utilizza il tag "1" per trovare l'oggetto, ma ha
taggato l'oggetto con tag "2" da utilizzare anche come un
mezzo per trovare l'oggetto.
• Il Gruppo "C" utilizza tag "1", "2" e "3" per trovare l'oggetto.
Notiamo questo gruppo non ha applicato nessun tag.
• Il Gruppo "D" usa i tag "2" e "3" per trovare gli oggetti e anche
esso non aggiunge alcun tag.
• Il Gruppo "E" non è in grado di trovare l'oggetto utilizzando i tag
come il vocabolario che sta usando non corrisponde a uno
qualsiasi dei tag attualmente forniti.
• il Gruppo "F" è la loro etichetta per l'oggetto che solo loro
utilizzano per tornare all'oggetto. Gruppo "F" non ha trovato
l'oggetto con tag esistenti, ma potrebbe aver trovato l'oggetto
con altri mezzi, come un loro amico via e-mail un link o l'oggetto
è stato incluso in un gruppo si abbonano al loro aggregatore di
feed.
Narrow folksonomy: Strategia alla base

Pro e contro della Folksonomy
• L’utilizzo da parte di una grande quantità di utenti, può essere vista come ausilio per la
progettazione di schemi di classificazione classica (informazioni utili per la costruzione di
metadati e vocabolari controllati - Si può instaurare una vera e propria ecologia dei
metadati .);
• Riflette accuratamente il modello mentale degli utenti, rispecchiando il loro linguaggio e i
loro bisogni informativi.
• E’ un sistema di classificazione che permette di recuperare anche informazioni residuali
non altrimenti accessibili. Questo ne fa uno strumento più orientato alla scoperta
dell’informazione anziché indirizzato verso la ricerca mirata. Favorisce quel modello di
ricerca di tipo Berrypicking, integrando fortemente il concetto di serendipity;
• E’ un sistema economico, sia in termini di denaro sia di tempo, poiché il lavoro di
classificazione è svolto dagli utenti.
• Possiede un basso grado di findability, essendo – come detto in precedenza – più
orientate alla ricerca esplorativa, piuttosto che a una mirata.
• Le folksonomy mancano di precisione nelle categorizzazione nel linguaggio, con il rischio
di proliferazione di molte varianti linguistiche per uno stesso concetto;
PRO
CONTRO





























