Embed Size (px)
Citation preview

1
Architecture Net, Simple Neural Net

2
Materi
1. Perceptron
2. ADALINE
3. MADALINE

3
Perceptron
Perceptron lebih powerful dari Hebb
Pembelajaran perceptron mampu menemukan konvergensi terhadap bobot yang benar
Fungsi aktivasi :
Update bobot
= learning rate
4
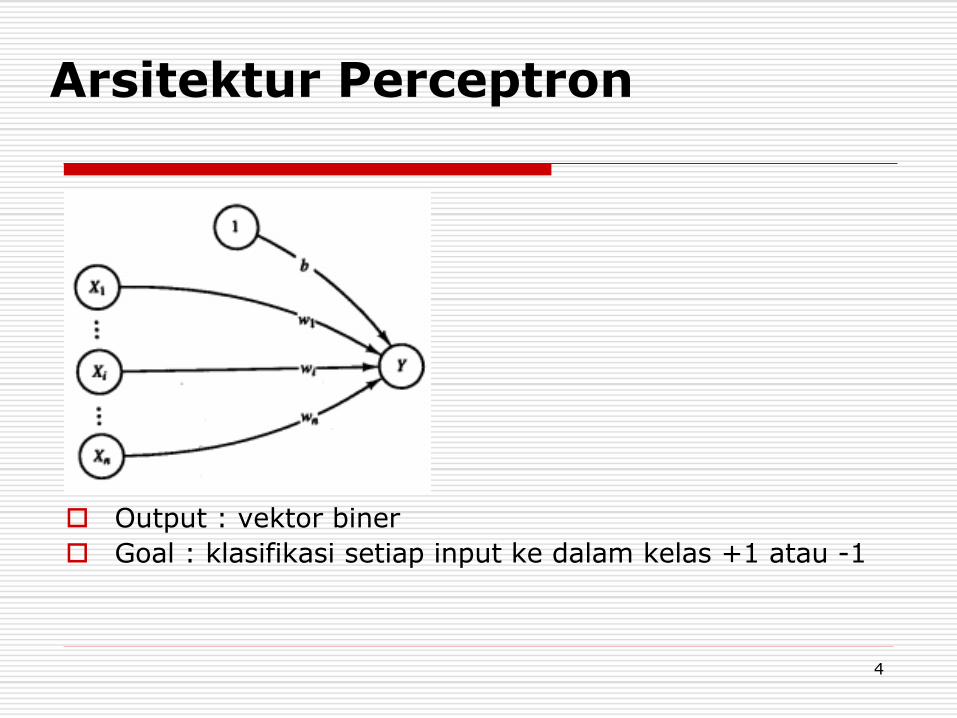
Arsitektur Perceptron
Output : vektor biner
Goal : klasifikasi setiap input ke dalam kelas +1 atau -1

5
Algoritma Perceptron
Inisialisasi bobot dan bias (w=b=0) dan 0 < <= 1 (=1)
Ulangi sampai sesuai kondisi kriteria berhenti Untuk setiap pasangan s:t, lakukan
Set aktivasi input xi = si
Hitung
Update bobot dan bias jika terjadi kesalahan
Evaluasi kriteria berhenti Jika bobot tidak berubah maka berhenti, jika tidak maka
lanjutkan

6
Fungsi AND (biner input & bipolar target)
Inisialisasi: = 1, w=b=0, = 0.2
Epoch = 1
Epoch = 2

7
Fungsi AND (bipolar input & target)
Inisialisasi: = 1, w=b==0
Epoch = 1
Epoch = 2

Latihan
8
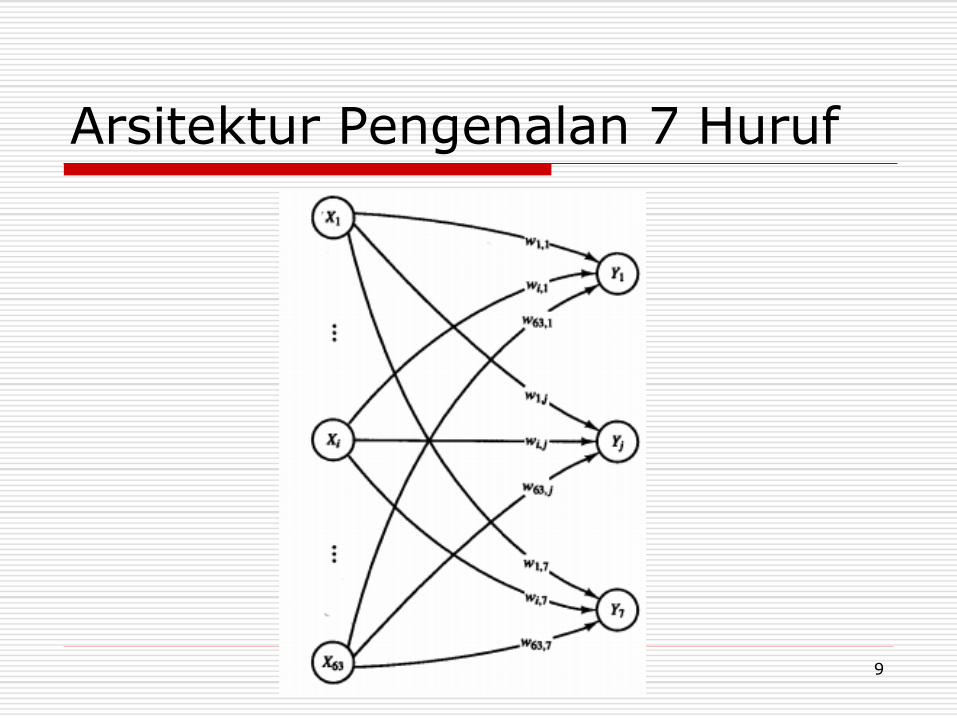
Arsitektur Pengenalan 7 Huruf
9

ADALINE (Adaptive Linear Neuron)
Biasanya menggunakan bipolar dan bias
Random bobot awal dengan bilangan kecil
Dilatih menggunakan aturan delta/LMS dengan meminimalkan MSE antara fungsi aktivasi dan target
Fungsi aktivasi : identitas / linier
Update bobot
= learning rate
10
11
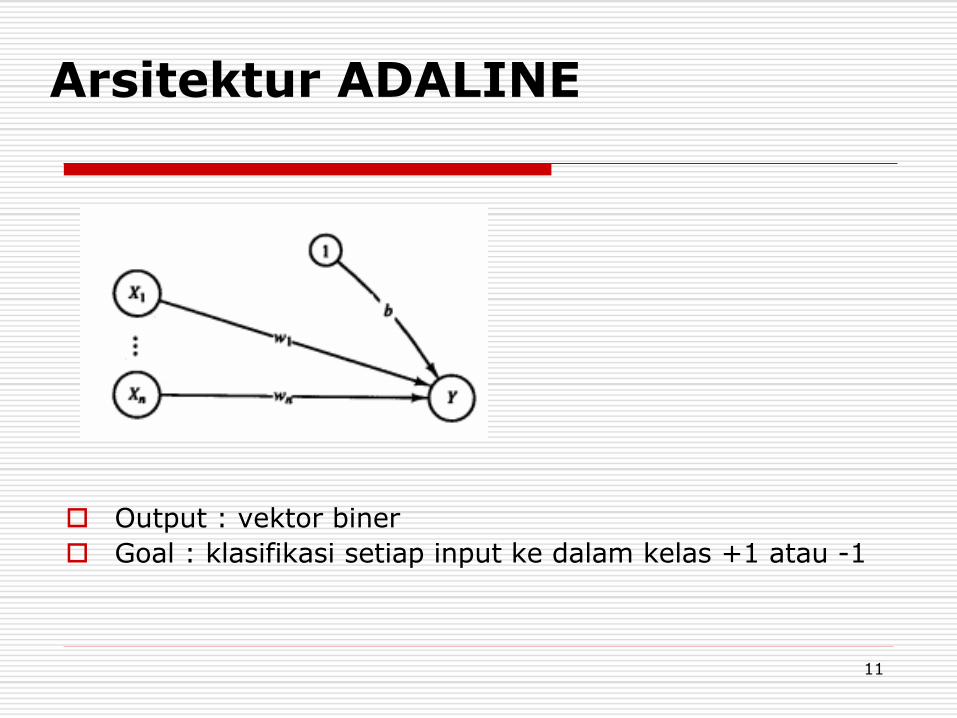
Arsitektur ADALINE
Output : vektor biner
Goal : klasifikasi setiap input ke dalam kelas +1 atau -1

12
Algoritma Training ADALINE
Inisialisasi bobot Biasanya digunakan nilai random yang kecil
Inisialisasi learning rate () Biasanya digunakan nilai yang relatif kecil, yaitu 0.1
Jika nilai terlalu besar, proses learning tidak mencapai konvergen
Jika nilai terlalu kecil, proses learning akan berjalan sangat lambat
Secara praktis, nilai learning rate ditentukan antara 0.1 ≤ n ≤ 1.0, dimana n adalah jumlah input unit
Ulangi sampai sesuai kondisi kriteria berhenti Untuk setiap pasangan s:t, lakukan
Set aktivasi input xi = si
Hitung
Update bobot dan bias
Evaluasi kriteria berhenti Jika bobot tidak berubah maka berhenti, jika tidak maka
lanjutkan

13
Algoritma Testing ADALINE
Inisialisasi bobot Dapatkan bobot dari proses learning
Untuk setiap bipolar input pada vektor x Set aktivasi dari input unit ke x
Hitung nilai jaringan dari input ke output
Terapkan fungsi aktivasi

14
Fungsi AND (biner input & bipolar target)
ADALINE didesain untuk menemukan bobot yang bertujuan meminimalkan total error
net input to output target

MADALINE (Many Adaptive Linear Neuron)
Konsep ADALINE yang menggunakan jaringan multilayer
Arsitektur MADALINE tergantung pada kombinasi ADALINE yang digunakan MADALINE dengan 1 hidden layer (terdiri dari 2
hidden unit ADALINE) dan 1 output unit ADALINE
Fungsi aktivasi untuk hidden dan output layer:
15
16
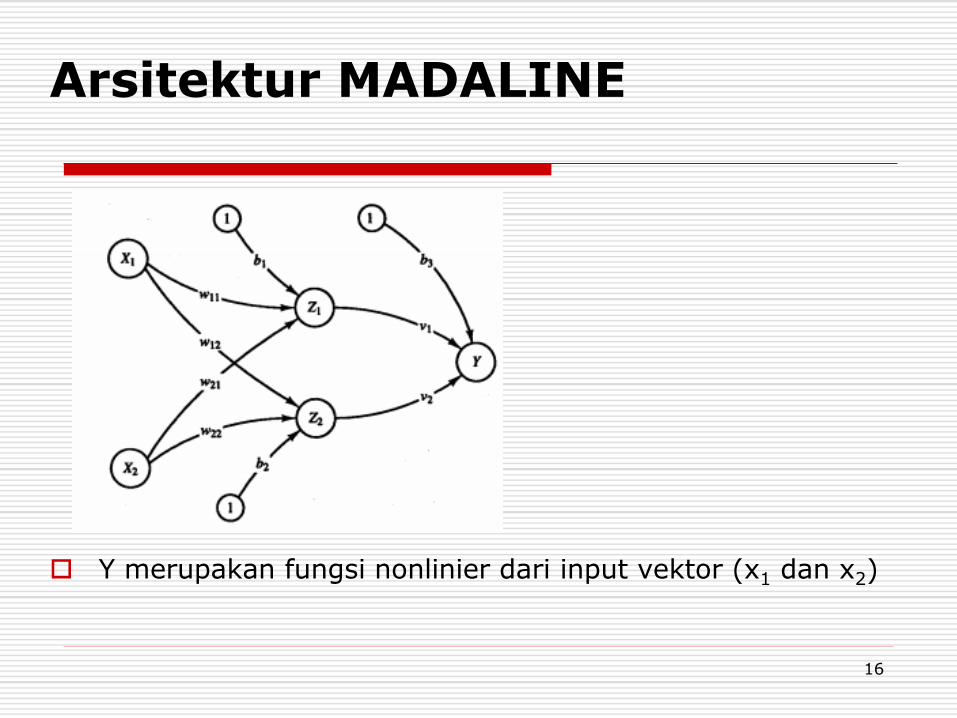
Arsitektur MADALINE
Y merupakan fungsi nonlinier dari input vektor (x1 dan x2)

17
Algoritma Training MADALINE MRI (Widrow dan Hoff)
Inisialisasi bobot
v1 =1
2, 𝑣2 =
1
2, 𝑏3 =
1
2
Bobot yang lain menggunakan bilangan random yang kecil
nilai learning rate ditentukan antara 0.1 ≤ n ≤ 1.0
Untuk setiap bipolar input pada vektor x Set aktivasi dari input unit ke x
Hitung masukan jaringan ke setiap hidden unit
Tentukan output dari setiap hidden unit
zin1 = 𝑏1 + 𝑥1𝑤11 + 𝑥2𝑤21
zin2 = 𝑏2 + 𝑥1𝑤12 + 𝑥2𝑤21
𝑧1 = 𝑓(𝑧𝑖𝑛𝑖)
𝑧2 = 𝑓(𝑧𝑖𝑛𝑖)

18
Untuk setiap bipolar input pada vektor x Tentukan keluaran dari jaringan
Hitung error dan update bobot, jika t=y maka bobot tidak di-update
Jika t=1, update bobot pada Zj
Jika t=-1, update bobot pada semua unit Zk yang punya input positif
yin
= b3 + z1 v1 + z2 v2
y = f yin
bJ(new) = bJ(old) + ∝ (1 – zinJ)
wiJ new = wiJ old + ∝ 1 – zinJ xi
bk(new) = bk(old) + ∝ (−1 – zink)
wik(new) = wik(old) + ∝ −1 – zink xi
Algoritma Training MADALINE MRI (Widrow dan Hoff)

19
Algoritma Training MADALINE MRII (Widrow, Winter dan Baxter)
Inisialisasi bobot
v1 =1
2, 𝑣2 =
1
2, 𝑏3 =
1
2
Bobot yang lain menggunakan bilangan random yang kecil
nilai learning rate ditentukan antara 0.1 ≤ n ≤ 1.0
Untuk setiap bipolar input pada vektor x Set aktivasi dari input unit ke x
Hitung masukan jaringan ke setiap hidden unit
Tentukan output dari setiap hidden unit
zin1 = 𝑏1 + 𝑥1𝑤11 + 𝑥2𝑤21
zin2 = 𝑏2 + 𝑥1𝑤12 + 𝑥2𝑤21
𝑧1 = 𝑓(𝑧𝑖𝑛𝑖)
𝑧2 = 𝑓(𝑧𝑖𝑛𝑖)

20
Untuk setiap bipolar input pada vektor x
Tentukan keluaran dari jaringan
Hitung error dan update bobot, jika t≠y maka laukan update bobot untuk setiap hidden unit dengan input mendekati 0 Ubah keluaran unit (dari +1 menjadi –1, atau sebaliknya)
Hitung kembali respon dari jaringan. Jika kesalahan berkurang: Sesuaikan bobot pada unit ini (gunakan nilai keluaran yang baru sebagai target dan lakukan aturan Delta)
yin
= b3 + z1 v1 + z2 v2
y = f yin
Algoritma Training MADALINE MRII (Widrow, Winter dan Baxter
bJ(new) = bJ(old) + ∝ (1 – zinJ)
wiJ new = wiJ old + ∝ 1 – zinJ xi
bk(new) = bk(old) + ∝ (−1 – zink)
wik(new) = wik(old) + ∝ −1 – zink xi

21
Algoritma Testing MADALINE
Inisialisasi bobot Dapatkan bobot dari proses learning
Untuk setiap bipolar input pada vektor x Set aktivasi dari input unit ke x
Hitung nilai jaringan dari input ke output
Terapkan fungsi aktivasi

Contoh Aplikasi fungsi Xor
Inisialisasi Bobot dg random, learning rate = 0.5
22

Contoh Aplikasi fungsi Xor
23
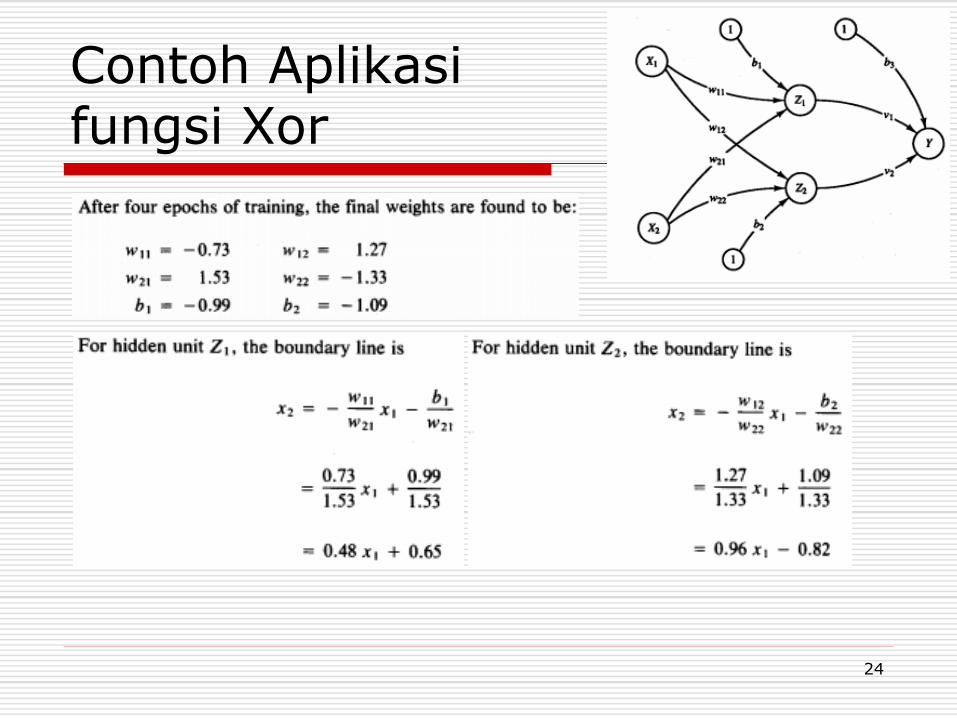
Contoh Aplikasi fungsi Xor
24















![PIP/CA - Programa Interdisciplinar de Pós-Graduação ...osorio.wait4.org/oldsite/sadi/sadifso-02.pdf• Adaline, Madaline, Perceptron [Widrow 62, Rosenblatt 59]](https://img.dokumen.tips/doc/110x75/5b5051d47f8b9a206e8e4bf2/pipca-programa-interdisciplinar-de-pos-graduacao-adaline-madaline.jpg)



![Introdução e Principais Conceitos - feis.unesp.br · A rede neural MADALINE (Multi-ADALINE) ([9]) é constituída por vários elementos ADALINE. Contudo, o processo de treinamento](https://img.dokumen.tips/doc/110x75/5b5051d47f8b9a206e8e4bdf/introducao-e-principais-conceitos-feisunespbr-a-rede-neural-madaline-multi-adaline.jpg)

![Fundamentos de Inteligência Artificial [5COP099]€¦ · Uma Adaline de v arias camadas e chamada Madaline; E de arquitetura feedforward; Soluciona problemas de regress~ao; 4 de](https://img.dokumen.tips/doc/110x75/5b5051d47f8b9a206e8e4c16/fundamentos-de-inteligencia-artificial-5cop099-uma-adaline-de-v-arias-camadas.jpg)

![T HE input-output function realized by a neural net-isl-widrow/papers/j1990sensitivityof.pdf · THE MADALINE ARCHITECTURE The Adaline (adaptive linear element) [3], [5] (also known](https://img.dokumen.tips/doc/110x75/5ec52020613ab73b287ddf76/t-he-input-output-function-realized-by-a-neural-net-isl-widrowpapersj1990sensitivityofpdf.jpg)





