Embed Size (px)
Citation preview

Research ArticleAnticipating Stock Market of the Renowned CompaniesA Knowledge Graph Approach
Yang Liu 1 Qingguo Zeng 2 Joaqu-n Ordieres Mereacute 1 and Huanrui Yang3
1Department of Industrial Engineering Business Administration and Statistics Escuela Tecnica Superior de Ingenieros IndustrialesUniversidad Politecnica de Madrid Madrid 28006 Spain2School of Mathematical Sciences South China Normal University Guangzhou 510631 China3Electrical and Computer Engineering Department Duke University Durham 27708 USA
Correspondence should be addressed to Yang Liu yangliu00alumnosupmes
Received 26 March 2019 Accepted 18 July 2019 Published 7 August 2019
Guest Editor Benjamin M Tabak
Copyright copy 2019 Yang Liu et alThis is an open access article distributed under the Creative Commons Attribution License whichpermits unrestricted use distribution and reproduction in any medium provided the original work is properly cited
An increasing number of the renowned companyrsquos investors are turning attention to stock prediction in the search for new efficientways of hypothesizing about markets through the application of behavioral finance Accordingly research on stock prediction isbecoming a popular direction in academia and industry In this study the goal is to establish a model for predicting stock pricemovement through knowledge graph from the financial news of the renowned companies In contrast to traditional methods ofstock prediction our approach considers the effects of event tuple characteristics on stocks on the basis of knowledge graph anddeep learning The proposed model and other feature selection models were used to perform feature extraction on the websitesof Thomson Reuters and Cable News Network Numerous experiments were conducted to derive evidence of the effectiveness ofknowledge graph embedding for classification tasks in stock prediction A comparison of the average accuracy with which thesame feature combinations were extracted over six stocks indicated that the proposed method achieves better performance thanthat exhibited by an approach that uses only stock data a bag-of-words method and convolutional neural network Our workhighlights the usefulness of knowledge graph in implementing business activities and helping practitioners and managers makebusiness decisions
1 Introduction
Research on stockmarket of company prediction has becomepopular with the introduction of Famarsquos efficient markethypothesis (EMH) [1] but in recent years an increasing num-ber of people have found that stock market of the renownedcompany changes is random complex and unstable giventhat they are affected by many factors Stock market ofcompany changes is affected by cultural aspects that fun-damentally influence investor sentiment traditional cultureoften determines peoplersquos investment psychology which inturn affects the inflow and outflow of stock market capitalCompany-related issues such as the effects of companyoperations on stock prices and market factors [2] Usingthese factors as bases for accurately predicting stock pricemovement gives investors hope that themaximumprofits willbe achievedwith the least stock investment Correspondingly
analyzing stock market movements is both challenging andattractive to researchers and investors Moreover as thedevelopment of knowledge graph in natural language pro-cessing (NLP) researchers in the financial field began payingattention to text mining in financial news As maintained byEMH and artificial intelligence technique the best results areachieved when news information is used to forecast stockmarket movement which can also control financial risk inbusiness activities
In May 2012 Google formally announced its knowledgegraph project which is aimed at improving the search engineseffectiveness and search quality as well as user experiencewith the engine [3] The development of knowledge graphpromoted the extensive use of artificial intelligence technol-ogy in smart search smart question-and-answer tasks andintelligent finance In finance knowledge graph is designed tofind relationships amongst entities such as the management
HindawiComplexityVolume 2019 Article ID 9202457 15 pageshttpsdoiorg10115520199202457
2 Complexity
of companies news events and user preferences Theseentities can be used by investors to achieve efficient financialdata-based decision-making andobtain business insights intopredicting stock market [4] For these reasons the currentresearch focused on how to use knowledge graph to improvethe accuracy of stock price forecasts Knowledge graph isdatabases that implement semantic searches by preservingrelationships amongstmultiple entities Based on event tuplesin knowledge graph [5] we can infer the definition of anevent tuple as (A P O) where A represents an agent Pdenotes a predicate and O represents an object [6] In viewof the objects converted by each event tuple are known whenthey are converted to vectors which loses more semanticinformation Event tuples link relevant elements together andcan be used as an efficient method of improving predictiveaccuracy As a result we propose a learning model of eventtuples which retains their semantic features at themaximum
Knowledge graph embedding is a kind of representationlearning in knowledge graph Currently several algorithms[3] explore the mapping relationship between entities andrelationships in the translation distance model The TransEmodel [7] is a computationally efficient predictive model thatsatisfactorily represents a one-to-one type of relationship Ithas been used as a basis in the development of differenttranslation distance models The TransH model [8] mapsthe head and tail of a vector onto a hyperplane after whichthese two components complete the translation process onthe hyperplane The TransR model [9] which is based on theTransE model consists of entities and relationships that arelocated in different dimensions of space For each relation-ship the model defines a matrix that is used to convert entityvectors into spaceThemodel is also dynamically determinedby an entity relationship The TransD model [10] is animprovement of the TransR model which the former uses asa basis in considering a transformation matrix In comparingthese models solving the head and tail of a news tuple formapping in a single space necessitates the simple mappingof one-to-one entity extraction features This functionality isfound in the TransE model this study is used to establish afeature combination model for news event metagroups
This work selects six globally renowned companiesto forecast their stock price movement namely AppleMicrosoft Samsung Boeing Google and Walmart as appli-cation scenarios According to different data sources betweenThomson Reuters and Cable News Network we reveal theresult of the case studies in some algorithms which illustratesthat the performance of combined feature outperforms thatusing only stock data using a bag-of-words algorithmand using convolutional neural network Although thereare already some examples of the powerful application ofdeep learning in NLP [11] such as speech recognition textclassification and machine translation most of the previousresearch in predicting stock price movement [12] is based onthe semantic information news which ignores the semanticfeatures of structured eventsThe application of deep learningand knowledge graph on the renowned companiesrsquo stocks israrely available Thus our work provides a viable applicationframework for financial markets which can also be extendedto other aspects of the financial filed
For stock market prediction we formulated a knowledgegraph embedding-driven approach that involves four mainphases (Figure 1)The first is data retrieval which begins withsearching keywords such as ldquoApplerdquo or ldquoGooglerdquo over theThomson Reuters or Cable News Network (CNN) as shownin Figure 2 The yellow part is the headline of financial newsand the orange part is the release time of the financial newsA web crawler is then used to obtain financial news from thesites and match them with corresponding stock data com-bining all this information into one corpusThe second phaseinvolves preprocessing which encompasses corpus analysistext normalization word tokenization label tagging andword-to-vector transformation The features derived fromword embeddings and stock data layers are then selected forthe computation of eigenvalues after which a feature vectoris generated using machine learning and knowledge graphembeddingThe third phase ismodel creation in which stockmarket prediction labels (increase or decrease) are assigned tofinancial news to training a classification model Finally thefinance decision relies on the predictive performance of thisframework Specifically a small improvement directly affectsdecision-making which increases the renowned companyrsquosprofits The fourth phase involves model evaluation whereinthe results and the extraction of conclusions of each machinelearning model are analyzed
The remaining part of the paper is organized as fol-lows Section 2 is a review of existing studies on the useof machine learning in stock market prediction Section 3introduces the methodology adopted in this study includingthe data description and feature selection approach Section 4presents the classification results and Section 5 discussesthe results and implications Section 6 concludes with thesummary
2 Literature Review
In Table 1 the application of machine learning techniquesto stock market prediction is an emerging research fieldThe advantage of machine learning models is their ability tofacilitate the processing of large amounts of data A procedurecommon to these models is the concatenation of featuresfromdifferent sources into a feature vector Formostmachinelearningmodels used research is focused on predicting stocktrends (increase or decrease)
Various feature extractions have already been proposedto predict the stock price of the renowned companies In theearly years most of the companyrsquos stock prediction dependson the empirical analysis of the econometric model namelythe feature extracted is the raw data of the companyrsquos stockHowever the previous work ignored the potential impactof unstructured data on company stocks Since the bag-of-words is widely utilized in the task of document classificationthe frequency of word appearance can be used as a feature ofthe classification Hence the bags of words model only cal-culate the frequency of words and do not consider the wordorder or word sparsity in the context which directly impactsthe prediction result Furthermore EMH had found thatthe emotional impulses of the renowned company investorsoften observe abnormal fluctuations in company stocks
Complexity 3
Financial news
DATARETRIEVAL
PRE-PROCESSING
MODEL CREATIONamp PREDICTION
MODELAPPLICATION
Corpus
Stock data Data
Feature News-stock
Machine learningmodel creation
Modelevaluation
Decisionmaking
mappingrepresentation
Featureselection
transformation
Figure 1 Research workflow for machine learning and knowledge graph
Figure 2 Example of collected financial news in CNN
4 Complexity
Table 1 A review of financial expert system ANN NB KNN SVM DT and SVR stand for artificial neural network naive Bayes k nearestneighbors support vector machine decision tree and support vector regression respectively Measure metrics mean squared error (MSE)root mean square error (RMSE) area under the curve (AUC)
Paper Text type Feature extraction Model type Performancemeasure
[13] Professional newspaper Stock data NB Accuracy[14] Professional newspaper Stock data SVM Accuracy
[15] Message board Stock data Regression Correlationcoefficient
[16] PRNewswire Stock data KNN SVM Accuracy F1-score
[17] Aggregate news Stock databag-of-words SVR MSE accuracy
[18] Corporate disclosures Stock databag-of-words Multiple Accuracy recall
precision F1-score
[19] Financial news Stock datasentiment DT Accuracy recall
precision F1-score
[20] Web media Stock databag-of-words SVR Accuracy recall
precision F1-score
[21] Mixed typeStock data
bag-of-wordssentiment
SVR RMSE accuracyprecision
[22] Message board Stock datasentiment SVM Accuracy
[23] Mixed typeStock data
technical indicatorssentiment
ANN SVM DTAccuracy AUCF1-score precision
[24] None Stock data Regression Correlationcoefficient
[25] Media news Stock data Regression Correlationcoefficient
Our financial expert system Financial newsStock data
technical indicatorsbag-of-words
syntax
Multiple Accuracy F1-score
Tetlock [26] adopted the popular news from the Wall StreetJournal to find that news sentiment has predictive power oncompany stocks Chen et al [27] found information comen-tions have a significant influence on the stock return throughsentiment analysis Furthermore the investorsrsquo sentimenttrends after the positive news which results in a buying trendand higher stock market prices while after negative newsstocks are sold result in a decrease of the price Howeversentiment analysis can only be employed in specific textsIf sentiment is implicit rather than direct emotional wordsthen the ability of using sentiment analysis for predicting thestock price of the renowned company is relatively limitedMittermayer and Knolmayer [16] illustrated that news-CATSachieves a performance that is superior to that of otherATC prototypes used to forecast stock price trends Li et al[21] proposed a media-aware quantitative trading strategy byusing sentiment information on web media The simulationtrading return was up to 16611 Nguyen et al [22] proposeda feature topic sentiment to improve the performance of stockmarket prediction Their method achieved an accuracy thatis 983 better than that of the historical price method and303 better than that of the human sentiment method
We utilize the characteristics of syntax analysis as beingproposed in [6 12] namely a structured tuple is extractedfrom an unstructured text based on the semantic structureof each piece of news Knowledge graph can enrich thestructured representation of the news event and effectivelyretain feature vectors for the news event The main featureextraction in the previous studies [28 29] is sentimentanalysis which neglected the event characteristics in thetext Furthermore the existing literature [23 29] had provedthe positive effect of technical indicators on stock marketprediction In summary our research highlights syntax anal-ysis in financial news which also incorporates with otherfeatures extraction (stock data technical indicators and bag-of-words) Because of the variety of considered features thisresearch will deliver an improved prediction of the stockmarket value for renowned companies in at least 36
Previous research [30] was applied with the traditionalmachine learning algorithms especially since the power-ful application ability of deep learning based on machinelearning Deep learning is utilized in several studies forpredicting stock price movement Kraus and Feuerriegel [31]forecasted the stock returns based on financial disclosures
Complexity 5
Table 2 Quotes and renowned company names
Financial newsdataset Stocks Company names Time interval Number of news
headlinesAAAL Apple Inc 3102011- - -3172017 6423
Thomson Reuters MSFT Microsoft Corporation 3092011- - -29112017 6623SSNLF Samsung Electronics Co Ltd 3092011- - -29112017 6900BA The Boeing Company 891998- - -2322017 2999
CNN GOOG Google Inc 2552006- - -2422017 5278WMT Walmart Inc 751997- - -2422017 4913
Table 3 Samples extracted from the dataset
Date News headline News headline event tuple3182012 Chinese writersrsquo group sues Apple state media Chinese writersrsquo group sues Apple
4132012 German court upholds ban on Apple push email German court upholds ban on Apple pushemail
442012 Apple two publishers hold out againstsettlement-report
Apple- two publishers hold out againstsettlement-report
3262012 Apple CEO Cook meets Chinese officials Apple CEO Cook meets Chinese officials
4252012 US STOCKS-Apple results put Nasdaq on track for bestgain of year Apple results Nasdaq on track for best gain
and their result demonstrated that a higher directional ofdeep learning surpasses traditional machine learning Dinget al [5] illustrated that deep learning also can forecaststock market of the renowned company Sim et al [32]proposed that technical indicators transform into images ofthe time series graph which examines the applicability ofdeep learning in the stock market Overall we adopt themultiple models for prediction stock price of the renownedcompany which proves the reliability of our proposed modelas comparing different algorithms This work applies deeplearning incorporated with knowledge graph embeddingfor feature extraction which examines the applicability ofcombined features methods in the renowned company stockprice movement
3 Materials and Methods
We developed a knowledge graph-based approach that con-sists of three steps namely data description data preprocess-ing and feature selection
31 Dataset Description Table 2 shows the custom financialnews corpus built with headlines from two datasets The firstdataset contains news articles published byThomsonReutersincluding those regarding Apple Inc (AAPL) MicrosoftCorporation (MSFT) and Samsung Electronics Co Ltd(SSNLF) The second dataset comprises news reports pub-lished in CNN including reports on the Boeing Company(BA) Google Inc (GOOG) and Walmart Inc (WMT) Italso consists of financial news headlines published at specifictime intervals with each news report accompanied by a titleand a release date Titles are used for event embedding andfeature extraction and release dates are used as a referencein ensuring alignment between corresponding financial news
and trading data from a time series As shown in previouswork [5 31] using a headline to build corpora can helpreduce noise in text mining as headlines concisely representthe content of a text We used only the news headlines fromReuters andCNN for the prediction of stock pricemovement
Daily stock data from index report in each company arecollected by Yahoo Finance in the same period during stockdata and financial news headlines Daily trading data whichare common predictors of stock price [23 33] and technicalindicator features were used in our model There are openingprice closing price high price low price and volume andthree technical indicators
Table 3 shows some examples of filtered financial newsheadlines To illustrate 6423 headlines regarding Apple Incwere extracted and then reduced to 2799 headlines afterfiltering via Reverb [34] Let us take the article ldquoWhat is nextfor Applersquos boardrdquo published on 6 October 2011 as a specificexample The title of the article cannot be transformed intoan event tuple using Reverb Because the sentence is in theinterrogative form there is no event tuple that constitutes arule After the matching of time-wise data and stock data941 headlines were left Daily news and stock data werealigned to create input-output pairs except the days whenno news was released In 9 January 2012 for instance threenews articles were reported but we chose only one headlinefor alignment with stock market data News events possiblyhappen several times within one day but they do not happenevery day unlike stock trading which happens daily excepton nontrading days falling on weekends or holidays
Table 4 shows that the matches found are pairs betweenevent tuples and stock data From this complete dataset weused 80 of the samples in training data and the remaining20 for testing dataThis selection method is the same as theprevious literature [5 24]
6 Complexity
Table 4 Training and testing datasets
Data source Company Training Testing TotalApple 780 161 941
Reuters Microsoft 832 208 1040Samsung 855 214 1069Boeing 528 132 660
CNN Google 1010 252 1262Walmart 798 200 998
Table 5 Number of event characteristic labels for each company
CompaniesLabel Apple Microsoft Samsung Boeing Google Walmart0 502 967 1433 133 661 2061 537 432 379 200 245 2872 661 557 378 152 389 2333 692 707 724 233 683 4384 407 228 193 147 196 180Total 2799 2891 3107 865 2174 1344
Table 6 Features of the prediction model
Feature Feature expression1 Stock price yesterday + yesterdayrsquos trend (in Section 331) 119901119903119894119888119890
119905minus1 119905 119894119899119889119894119888119886119905119900119903119905minus1
2 Same + bag-of-words (in Section 332) 119901119903119894119888119890119905minus1
119905 119894119899119889119894119888119886119905119900119903119905minus1 119905119891 119894119889119891119905minus1
3 Same + some features inferred through a convolutional neural network (in Section 333) 119901119903119894119888119890119905minus1
119905 119894119899119889119894119888119886119905119900119903119905minus1 119888119899119899119905minus14 Same + some features inferred through feature combination (in Section 334) 119901119903119894119888119890
119905minus1 119905 119894119899119889119894119888119886119905119900119903119905minus1 119891 119888119900119898119887119894119899119890
119905minus1
32 Data Preprocessing The following three steps are forpreprocessing which prepares for feature extraction andmodel creation
(1) Tagging the label for each news headline Five possiblelabels are characterized by categorical values as follows 0for an extremely negative label 1 for a negative label 2 tosignify a neutral label 3 for a positive label and 4 to denote anextremely positive label According to the time characteristicsof each news headline an event is manually tagged withthe label for each news headline Table 5 shows the labelingapplied for each company Label 0 means that a companyrsquoscompetitor has happened in this event label 1 means that thecompany lost something label 2 means that it did not causeany impact on the company label 3 means that this eventenabled the company to obtain something and label 4 meansthat the company increased its profits or created more value
(2) Word vector transformation We used the word2vec[35] algorithm to train word embedding and set the numberof dimensions to 300 The word embedding was also trainedusing the Google News dataset which contains 100 billionwords that are characterized by a continuous bag-of-wordsstructure
(3) Technical indicators calculation Three additionaltechnical indicators that are calculated on the basis of dailytrading data were used as follows
(a) Stochastic oscillator (K)This indicator is a momen-tum analysis method created by George C Lane When the
price trend rises the closing price tends to approach thehighest price of the day When the price trend declines theclosing price tends to approach the lowest price of the day[36]
(b) Larry Williamss R indicator This indicator is anoscillation indicator that measures the ratio of the highestprice to the daily closing price It indicates the proportion ofstock price fluctuations in a certain period thereby providinga signal out of the reversal of a stock market trend [37]
(c) Relative strength index (RSI) Buying and sellingintentions in the market are analyzed by comparing theclosing prices in a given period Stocks that have had moreor stronger positive changes have a higher RSI than do thosethat have had more or stronger negative changes Strengthindicators fall between 0 and 100 investors sell if this valueis ge 80 and buy if it is le 20 [23 36]
33 Variable Feature Selection To assess the effectivenessof applying the prediction model on the basis of financialnews we designed four sets of features for predicting stockprice movement (Table 6) Features 3 and 4 are used for eventcharacteristics Each feature is explained in the succeedingsubsections The target output consists of a binary variablefor which a value of 1 indicates that the closing price at day t+ 1 will be higher than that at day t and a value of 0 indicatesthat the closing price at day t + 1will be lower than that at dayt
Complexity 7
Financial news
middot middot middot
News representation Convolutional layer Max pooling Fully connected layer Features
X (I)
Z (I)
Figure 3 Convolutional neural network architecture proposed for feature selection
331 Stock Data Only We considered historical price as theinput for predicting stock price movement and used it asa baseline for comparison with other sets of features Thefeatures used to train the machine learning model that usesonly stock data are 119901119903119894119888119890119905minus1 and 119905 119894119899119889119894119888119886119905119900119903119905minus1 The output isthe indicator of pricemovement (increase or decrease) at eachtransaction date examined
332 Bag of Words The input feature set is based on a bag ofwords for the news and price trend for stock Previous studies[18 38 39] have widely used and confirmed the feasibilityof the bag-of-words algorithm but this method disregardselements such as grammar and word order in the text Inthe present study we first prepared each headline for datapreprocessing and then transformed the preprocessed head-line into a feature vector using the term frequency-inversedocument frequency (TF-IDF) algorithm [40] which assignshighweight to eigenvectorsThe studies [41 42] have stronglyproven the effectiveness of the TF-IDF algorithm in featureextraction from news headlines It estimates the frequency ofa term in one document over the maximum in a collection ofdocuments and assesses the importance of aword in one set ofdocuments Such importance increases proportionally withthe number of word appearances in a documentThe featuresused to train the bag-of-words machine learning model are119901119903119894119888119890119905minus1 119905 119894119899119889119894119888119886119905119900119903119905minus1 and 119905119891 119894119889119891119905minus1 which are the pricemovements (increase or decrease) at each transaction dateexamined
333 Convolutional Neural Network Given the sequence ofwords in a headline the word2vec model [35] can be usedto embed each of these words in a real valued-vector 119909 Inthis work we set the dimension 119899 of each word vector at30 (ie 119909 isin R30) We concatenated the word vectors of allthe words in a headline sequentially to form a matrix 119883 =[119909(1) 119909(2) 119909(3) 119909(4)] [35] as the input to a convolutionalneural network model For a headline with 119873 words the
resultant input matrix has dimensions of 30 times 119873 and thedimension of news representation also is 30
In Figure 3 this convolutional neural network model ismade up of four consecutive layers the first layer is theinput the second layer is convolutional the third layer is amax-pooling and the last layer is a fully connected layerThe convolutional and max-pooling layers were designedusing the text-attentional convolutional neural network [43]which effectively carries out sentiment classification In theconvolutional layer input matrix X convolves with a kernel119908 isin R119899times119896 where n is the size of a word vector (30 inour work) and its dimension is 50 k denotes the size of asliding window (k=3 in this study) The computation can beformulated as follows
119885119894 = 120590 (119908119883119894119894+119896minus1 + 119887) (1)
where 119883119894119894+119896minus1 = [119909119894 119909119894+1 119909119894+119896minus1] is the portion of input119883 falling within the sliding window 119887 denotes the optionaloffset and 120590(sdot) is the sigmoid function
In the next step we used the pooling layer to reduce theconvolutional neural networks parameter space and conse-quently minimize information loss in the pooling processingand capture the most important features The eigenvectorof the filter in the pooling layer is cut into 3 chunks anda maximum value is taken in each chunk we obtained 3eigenvalues Convolutional output vector Z was split into pwindows and only themaximum feature as 3 in each windowwas kept for passage onto the final fully connected layer Thefully connected layer is linear regression and the output layeris the feature classification between 0 and 1
Our convolutional neural network model is intended toextract a feature vector from the fully connected layer todescribe the emotional characteristics of input headlinesFollowing the intuition that a good feature vector shouldlead to the accurate classification of the event characteristicsof headlines we attached a softmax layer after the fully
8 Complexity
The United Kingdom of Great Britain and Northern Ireland commonly known as the United Kingdom or Britain hellip
London is the capital city of England and of the United Kingdom It is the most populous region hellip
Head Relationship TailLondon location country capital United Kingdom
London is the caEngland and of Kingdom It is tpopulous region
Kingdom of GreatNorthern Ireland known as the United
Britain hellip
Figure 4 Text description of the entity
connected layer when the convolutional neural networkmodel was trained The entire model was trained to classifythe five emotional labels that describe event characteristicsand the resultant model will be able to provide a mean-ingful emotional feature vector for each inputted headlineMeanwhile we define the loss function of the convolutionalneural network model as 119864119889 The features used to trainthis machine learning model are 119901119903119894119888119890119905minus1 119905 119894119899119889119894119888119886119905119900119903119905minus1and 119888119899119899119905minus1 which are the price movements (increase ordecrease) at corresponding transaction date
334 Combined Features In the introduction section of thispaper we described various translation models Because theTransE model represents a one-to-one relationship betweentwo entities [7] the relationship amongst many entities mustbe continuously incorporated into texts and knowledge graph[44] This model combines a convolutional neural networkwith textual information extraction which fully exploits thesemantic information in a knowledge graph and text [45 46]In Figure 4 knowledge graph contains rich semantics inentity description texts but it is not fully utilized in featureextraction Most of the existing text representation modelssimply train the text into word vectors through word2vecwhich obtains the text representation by means of averagingetc Hence these ways often lose more semantic informationWe therefore proposed to extract feature vectors from newstexts using a convolutional neural network model combinedwith the TransE model which also fully integrates the twoparts of the feature information
In Figure 5 this architecture used in the feature combina-tion model encompasses two parts namely a convolutionalneural network (Section 333) and the TransE model Thefeature combination sets are the average of each word vectorin an entity and it was obtained using the word2vec modelThe two entity vectors are mapped into the same relationalspace and these entities using a trained low-rank weightmatrix [47]
As assumed in the TransE model relationship vector Rshould satisfy ldquoE + R asymp Trdquo The model can be representedas a parameter set 0 = (119871119903 119877119903 120579) where X E and R
represent a word an entity and a relation respectively Andr are the mapping matrices for entities in the structuralmodel and represents the weights of the convolutional neuralnetwork For instance the sentence is ldquoSamsung sues Apple forinfringementrdquo so ldquoSamsung +Appleasymp suesrdquoThe loss function119864119904 of this structural model is defined as follows
119864119904 = ℎ + 119903 minus 11990522 (2)
where h r and t represent head entity relationship and tailentity in event tuple respectively [47]
And text representation 119864119889 is consistent withSection 333 which denotes
119864119889 = 119891119903 (ℎ119904 119905119889) + 119891119903 (ℎ119889 119905119904) + 119891119903 (ℎ119889 119905119889) (3)
where119891119903(ℎ119889 119905119889) = ℎ119889+119903minus11990511988922 represents the head entity andthe tail entity is in text representation119891119903(ℎ119889 119905119904) = ℎ119889+119903minus11990511990422and 119891119903(ℎ119904 119905119889) = ℎ119904 + 119903minus 11990511988922 represent one of the head entityh and the tail entity t in text representation another one is instructure representation
Moreover we combined two types of representationlearning (convolutional neural network and feature combi-nation) to map news titles these vectors will be into featurevectors The relationship vector R identical to the resultof the feature extraction layer of the convolutional neuralnetwork in the structural model Besides we combined thisloss with the classification loss of the convolutional neuralnetwork using L2 regularization which obtains the overallloss function 119864 for feature selection that is
119864 = 119864119904 + 120572119864119889 + 120573 02 (4)
where 02 is a regular item 120572 and 120573 are hyperparameterswhich measure the loss of text information and the weight ofthe regular items respectively W denotes the convolutionalkernels in the layer and 1198791015840 is a negative sample set of 119879 [7]
1198791015840 = (ℎ1015840 119903 119905) | ℎ1015840 isin 119864 cup (ℎ 119903 1199051015840) | 1199051015840 isin 119864
cup (ℎ 1199031015840 119905) | 1199031015840 isin 119877 (5)
Complexity 9
Output layerClass1 Class2
Machinelearning
Max pooling
convolutional
Input news
Feature vector
Embedding layer
Input news
Event tuple
Word2vec
Word2vec
Fully connection
Stock data
Stock layer
TransE model
Figure 5 Proposed architecture for the feature combination model
where the head entity and tail entity are randomly replaced byan entity or relationship in another tuple In particular if thereplaced tuple is already in T it would not be added to thenegative sample Since both h and t represent two types ofentities there are structure-based representations and text-based representations in interval-based loss functions Thestochastic gradient descent (SGD) is employed to minimizethe above loss function
In this structure we choose the optimal parameters asfollowe the learning rate of SGD 120582 = 0001 the dimension ofthe representation vector of entities and relationships k = 100the word vector dimension of the entity description text n =100 and batch size during training is 1440 Convolution layerwindow size is 119882 isin 1 2 3 This experiment is performedin 1000 iterations of training and the optimal parameters arebased on the testing set
Hence the features used for training the machine learn-ing model are 119901119903119894119888119890119905minus1 119905 119894119899119889119894119888119886119905119900119903119905minus1 and 119891 119888119900119898119887119894119899119890119905minus1which are the price movement (increase or decrease) atcorresponding transaction date
4 Experiments and Results
41 Experimental Setting This section compares the perfor-mance of differentmodels in feature extraction fromfinancialnews expended with full sets of features The evaluationwas intended to obtain evidence that the proposed featurecombination model is superior to other feature selectionmodels in predicting the stock price movement As shownin Table 7 we chose linear models for instance logisticalregression and naive Bayes Others are nonlinear models forinstance the ensemble learning (random forest adaboostand gradient boosting) for the comparison We constantlyadjusted the parameters in the grid search and selected theoptimal parameter value their parameter value has proven towork well on machine learning method [29 48]
We used a computer consisting of an Intel Core i5processor with four cores running at 29 GHz and 8 GBRAM under the MacOS platform We used the Scikit-learnlibrary in Python in the experiments involving traditionalmachine learning algorithms and TensorFlow 14 in the
10 Complexity
Table 7 List of machine learning methods
Method Classification Parameter and their value
Traditionalmachinelearning
Decision tree (DT)Criterion= gini splitter= best max depth=None minsamples split=2 min samples leaf =1 min weight
fraction leaf=00Logistical regression (LR) Random state=1
Naive Bayes (NB) No kernel estimatorStochastic gradient descent (SGD) Loss=hinge penalty=l2
Support vector machine (SVM) Polynomial kernel function with exponent = 1 2 RBFkernel function with gamma = 001
Ensemblelearning
Random forest (RF) Randomly sampled as candidates at each split = log2 +1 max-depth=2 random state=0
AdaBoost (AB) Polynomial kernel function with exponent = 1 2 RBFkernel function with gamma = 001 n- estimators=100
Gradient boosting (GB) N-estimators =100 learning rate =10 max-depth=1random state=0
Table 8 Abbreviations of the results for each algorithm considered
Algorithms Stock data (SD) Bag of words (BOW) Convolutionalneural network
Featurecombinationmodel (FC)
DT DT 1 DT 2 DT 3 DT 4LR LR 1 LR 2 LR 3 LR 4NB NB 1 NB 2 NB 3 NB 4SGD SGD 1 SGD 2 SGD 3 SGD 4SVM SVM 1 SVM 2 SVM 3 SVM 4RF RF 1 RF 2 RF 3 RF 4AB AB 1 AB 2 AB 3 AB 4GB GB 1 GB 2 GB 3 GB 4
experiments involving deep learning and the TransE modelThe abbreviations used for comparing classification perfor-mance are presented in Table 8 During testing 2-fold cross-validation is applied to evaluate the stability of the modelsAnd we compared performance in predicting stock pricemovement for the next day with a test dataset and evaluatedthe performance of the models in terms of accuracy and F1-score [49]
42 Results
421 Thomson Reuters Case Study Thomson Reuters isa multinational mass media and information firm Threerenowned companies on the website were selected for theanalysis The first is Apple Inc which is an American multi-national technology company that designs develops andsells consumer electronics computer software and onlineservices The second company selected is Microsoft which isan American multinational technology company that devel-ops manufactures supports and sells computer softwarepersonal computers and other services The last companychosen is Samsung which is a South Korean multinationalelectronics company We considered data from these threetypical technology companies for our problem
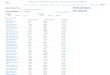
Measurements of average accuracy are shown in Table 9and the results for each renowned company with respectto prediction based on different features are illustrated inFigure 6 We calculated the average of the four feature con-struction approaches for eachmodel for comparison amongstthe three companies The proposed feature combinationmodel generated the best results achieving average accuracylevels of 6163 5918 and 5848 forAppleMicrosoft andSamsung respectively These figures are consistent with therates reported in previous research However many studiesanalyzed only one company or used only one algorithmThe current research probed into three companies on thebasis of information from a common data source to builda prediction model with different feature selection func-tionalities and different algorithms We used stock dataa bag-of-words algorithm a convolutional neural networkand feature combination together with eight algorithms Asindicated in Table 9 the proposed predictionmodel achieved7368 data extraction with the use of LR 4 for Apple and6778 data extraction with the use of SVM 4 for MicrosoftIn particular the LR algorithm used for Apple achievedaccuracy and F1-score of 07326 and 07360 respectivelywhich highlights its powerful capability in a two-class classifi-cation
Complexity 11
Table 9 Results for data extracted fromThomson Reuters
Algorithm Company Stock data(SD)
Bag of words(BOW)
Convolutionalneural network
Feature combinemodel (FC)
AccuracyF1-score
AccuracyF1-score
AccuracyF1-score
AccuracyF1-score
DTApple 0499305079 0488902460 0615005814 0652406486
Microsoft 0486801819 0506505682 0581705915 0658706502Samsung 0470704033 0565405830 0552906820 0568006260
LRApple 0524006727 0505505083 0684506911 0732607368
Microsoft 0475701253 0443004884 0527405333 0546705611Samsung 0494703755 0605406726 0654106343 0805307978
NBApple 0510905123 0477803896 0502704497 0512204030
Microsoft 0484000363 0455704055 0459902889 0500005439Samsung 0529305810 0514406130 0504806578 0511706601
SGDApple 0467201119 0477804404 0497406008 0536602692
Microsoft 0517306819 0485203222 0610304231 0610804193Samsung 0522306541 0476602000 0518706751 0557106548
SVMApple 0502206121 0574705542 0615006129 0622006173
Microsoft 0478401722 0443904566 0523205462 0687506798Samsung 0500803875 0504705508 0513506281 0535206574
RFApple 0524006554 0527806083 0533706232 0620306243
Microsoft 0484002653 0417701687 0532502432 0572105189Samsung 0487203480 0448501194 0476603708 0505205481
ABApple 0534305384 0472202963 0481903333 0620305420
Microsoft 0468702041 0476800461 0614706044 0620206146Samsung 0485703619 0457902368 0601006820 0633806549
GBApple 0531405129 0466702941 0609604748 0634106591
Microsoft 0474302125 0472801007 0455704557 0538502258Samsung 0487204171 0519206599 0533706572 0562206335
Reuters
Aver
age a
ccur
acy
0
01
02
03
04
05
06
07
Different companyApple Microsoft Samsung
SDBOW
CNNFC
Figure 6 Average accuracy of prediction based on different featuresets for each company in Reuters
To assess the effectiveness of our research we comparedthe feature combination model that uses event tuples with
the stock data approach and the bag-of-words algorithmTheresults showed that the average accuracy of the event tuple-basedmodel is better than that of the stock data approach andthe bag-of-words algorithm by 1001 and 1087 respec-tively We also compared feature extraction using the stockdata approach the bag-of-words algorithm and machinelearning The use of deep learning improved predictionaccuracy by 525 and 611 over the levels achieved withstock data and bag of words respectively Therefore we canconclude that using the proposed feature combinationmodeland deep learning in feature extraction helps improve theaccuracy with which stock price movement is predictedThese results also fully prove the effectiveness of embeddinglayer in feature extraction accuracy improvement
422 CNN Case Study CNN is an American basic cableand satellite television news channel owned by the TurnerBroadcasting System Three renowned companies on whichthese website reports were selected for the analysis The firstis Boeing which is an American multinational corporationthat designs manufactures and sells airplanes rotorcraftrockets and satellites worldwide The second company isGoogle which is an American multinational technology
12 Complexity
Table 10 Results for data extracted from CNN
Algorithm Company Stock data(SD)
Bag of words(BOW)
Convolutionalneural network
Featurecombinationmodel (FC)
AccuracyF1-score
AccuracyF1-score
AccuracyF1-score
AccuracyF1-score
DTBoeing 0495003489 0541306258 0541406347 0559105821Google 0485805600 0518203575 0569204631 0549105471Walmart 0499604422 0530004891 0508804815 0572205829
LRBoeing 0492302378 0511304348 0692306923 0759605733Google 0504106105 0623506491 0625006111 0656306516Walmart 0529005468 0541205083 0732007347 0771907720
NBBoeing 0516206503 0548905161 0519706738 0556407619Google 0511206527 0489905191 0558705281 0534404843Walmart 0504403284 0479405302 0520605674 0530006083
SGDBoeing 0489702407 0556404870 0543304727 0571407220Google 0516506769 0542504375 0578906364 0591006327Walmart 0500403804 0520605280 0525005581 0567005922
SVMBoeing 0489703068 0571406275 0538506418 0594007033Google 0507706297 0603206230 0574905532 0578905840Walmart 0511804333 0500005314 0520005000 0561405455
RFBoeing 0490601345 0511303925 0509605405 0527605714Google 0492301777 0603206260 0522305564 0595105763Walmart 0511805373 0530003188 0530004405 0500005446
ABBoeing 0494503404 0519705120 0496105294 0567305872Google 0487603141 0510106667 0589305619 0595106850Walmart 0507305029 0515005359 0549705650 0561905503
GBBoeing 0489903169 0511804364 0440904580 0500005094Google 0491203387 0587005854 0562505243 0603206202Walmart 0500304955 0505005123 0536105109 0549705650
company that specializes in Internet-related services andproducts The third is Walmart an American multinationalretail corporation that operates a chain of hypermarketsdiscount department stores and grocery stores
The results on average accuracy are shown in Table 10and Figure 7These findings are very similar to those derivedin the previous case study and their comparison confirmedthat the proposed feature combinationmodel can outperformother feature selection models in stock price movementprediction With regard to feature selection underlain bythe bag-of-words algorithm the CNN case study generatedmore robust results than did the Reuters case study Theaverage accuracy of the bag-of-words algorithm was lowerthan that of the stock data approach in the Reuters case studyIn the CNN case study the average accuracy levels of theproposed feature combination model were 5794 5879and 5767 for Boeing Google andWalmart respectively Inthe case study on Reuters an average accuracy that exceeds60 was not achieved for any of the companies illustratingthat differences in data source directly affect stock pricemovement
We chose a combination of deep learning and knowledgegraph to build our feature selection model because this
CNN
Aver
age a
ccur
acy
0
01
02
03
04
05
06
07
Different companyBoeing Google Walmart
SDBOW
CNNFC
Figure 7Average accuracy achieved on the basis of news fromCNNand different feature set
combination exhibited superior prediction performance inthe comparison experiments involving other feature selection
Complexity 13
strategies The forecast results based on different featuresare shown in Table 10 We found that deep learning featuresare better than the use of bag-of-words and stock data Thecorrelation of event tuples with the stock market is relativelyhigh in [5 31] but the bag-of-words algorithm was relativelyfragmented and the correlation between event tuples and thestockmarket data was relatively weak Combining event tuplefeatures with deep learning significantly improves forecastresults indicating a close relationship between stock marketmovements and knowledge graph
5 Discussion
51 Research Findings We attempted to compare our predic-tion results with those made in previous studies wherein pre-diction was also based on the financial news of the renownedcompanies However the findings are incomparable becausedifferent studies use different datasets or algorithms andthese methods are difficult to investigate using financial newsheadlines In the current research we refrained from eval-uating performance on one company dataset this decisionthat enabled our knowledge graphmethod to exceed baselinepredictions based only on the price by up to 36 Thisalso proves that feature extraction in deep learning is moreeffective than traditional machines The combination of deeplearning and knowledge graph fully integrates the semanticinformation in financial news which effectively predicts thestock price movement of the renowned company
This work demonstrated the application of deep learningand knowledge graph in finance To the best of our knowl-edge knowledge graph has been rarely applied in stock pre-diction Becauseminimal financial training sets in knowledgegraph are available financial knowledge extraction is themain task for the organizational construction of a knowledgegraph Such extraction is critical for the understanding andprocessing of deep semantics in the event tuple which alsodirectly influences the feature extraction of financial news
52 Implications for Business Activities Theutility of a featurecombination model based on knowledge graph is not limitedto financial analysis Currently knowledge graph data areavailable for medical diagnosis speech recognition precisemarketing and financial risk control [4] Our model couldalso be applied in these areas
Antifraud activities are an important part of financeApplying our model on the basis of knowledge graph oncustomers helps organize all relevant knowledge fragmentsthrough deep semantic analysis and reasoning which canbe verified with a customerrsquos bank information Moreovercustomers typically use keywords to search for productsand knowledge graph can provide relevant information toa customer If a complete knowledge system of users isdescribed and collected a system would better understandand analyze user behaviors
53 Limitations and Future Work A deep learning modeluses supervised learning and needs a dataset with sufficientlabels but our datasets do not work well with deep learningas a small number of financial news articles match stock
data At present knowledge graph embedding inevitablyproduces a loss in news semantics either because of a learningprinciple or the tokenization of knowledge representation forvectorization Thus continuous representation in a knowl-edge graph is still a huge challenge We attempted to applyregression using the above-mentioned algorithms but theresults indicated poor performance More specifically theresults for Apple validated our expectations
The application of large-scale knowledge graph is stillrelatively limited and knowledge graph for smart searchsmart question-and-answer tasks social media and otherareas are in their initial stages with considerable room forimprovement The following advantages of knowledge graphshould be considered (a) the effective organization andexpression of semistructured data (b) knowledge reasoningand (c) the expansion of cognitive ability for incorporatingdeep learning Traditional knowledge elements (entities rela-tionship attributes) extraction technologies and methodshave achieved good results in limited areas but because ofnumerous constraints and poor scalability knowledge graphis not fully functional for financial forecasting because ofnumerous constraints and poor scalability
6 Conclusions
Stock movement prediction of the renowned company is adaunting task because stock prices are affected by many fac-tors This research presented a novel method for integratingknowledge graph embedding with stock market predictionThe contributions of this study can be summarized as followsFirst we developed a novel feature combination model thatconstructs a feature mapping vector for each tuplendashnewspair by simultaneously considering the diversity of entitiesand relationships Second the feature combination modelwas successfully applied to different types of companies anddatasets and exhibited good performance in classificationtasks
Stock market prediction of the renowned companygrounded in knowledge graph is an interesting topic forbusiness activities Given that the study of knowledge graphfor feature set is still in its infancy we expect it to be appliedin a wide range of academic research More companies willalso earn profits and create more opportunities through theuse of knowledge graph in the feature set
Data Availability
The data used in this study can be accessed via httpsgithubcomlinechanyknowledge-graph
Conflicts of Interest
The author declares that there is no conflict of interestregarding the publication of this paper
Acknowledgments
This work is supported by the China Scholarship Council(CSC) throughout the grant number 201508390019 The
14 Complexity
authors also want to thank the research program RFCS fromthe EU which partially supported this research through theresearch project AutoSurveillance with project ID 847202
References
[1] B GMalkiel and E F Fama ldquoEfficient capital markets a reviewof theory and empirical workrdquo The Journal of Finance vol 25no 2 pp 383ndash417 1970
[2] D Galai and R W Masulis ldquoThe option pricing model and therisk factor of stockrdquo Journal of Financial Economics vol 3 no1-2 pp 53ndash81 1976
[3] Q Wang Z Mao B Wang and L Guo ldquoKnowledge graphembedding A survey of approaches and applicationsrdquo IEEETransactions on Knowledge and Data Engineering vol 29 no12 pp 2724ndash2743 2017
[4] H Paulheim and P Cimiano ldquoKnowledge graph refinement Asurvey of approaches and evaluation methodsrdquo Journal of WebSemantics Science Services and Agents on the World Wide Webvol 8 no 3 pp 489ndash508 2016
[5] X Ding Y Zhang T Liu and J Duan ldquoDeep learning for event-driven stock predictionrdquo in Proceedings of the 24th InternationalJoint Conference on Artificial Intelligence IJCAI 2015 pp 2327ndash2333 Argentina July 2015
[6] X Ding Y Zhang T Liu and J Duan ldquoKnowledge-drivenevent embedding for stock predictionrdquo in Proceedings of the26th International Conference on Computational LinguisticsCOLING 2016 pp 2133ndash2142 Japan December 2016
[7] A Bordes N Usunier J Weston and O Yakhnenko ldquoTranslat-ing embeddings for modeling multi-relational datardquo Advancesin NIPS vol 26 pp 2787ndash2795 2013
[8] H Lin Y Liu W Wang Y Yue and Z Lin ldquoLearning entityand relation embeddings for knowledge resolutionrdquo ProcediaComputer Science vol 108 pp 345ndash354 2017
[9] G Ji K Liu S He and J Zhao ldquoKnowledge graph completionwith adaptive sparse transfer matrixrdquo in Proceedings of the 30thAAAI Conference on Artificial Intelligence AAAI 2016 pp 985ndash991 USA February 2016
[10] G Ji S He L Xu K Liu and J Zhao ldquoKnowledge graphembedding via dynamic mapping matrixrdquo in Proceedings ofthe 53rd Annual Meeting of the Association for ComputationalLinguistics and the 7th International Joint Conference on NaturalLanguage Processing (Volume 1 Long Papers) pp 687ndash696Beijing China July 2015
[11] Y LeCun Y Bengio and G Hinton ldquoDeep learningrdquo Naturevol 521 no 7553 pp 436ndash444 2015
[12] Q Li Y Chen J Wang and H Chen ldquoWeb media andstock markets a survey and future directions from a bigdata perspectiverdquo IEEE Transactions on Knowledge and DataEngineering vol 4347 p 1 2017
[13] B Wuthrich V Cho S Leung D Permunetilleke K Sankaranand J Zhang ldquoDaily stock market forecast from textual Webdatardquo in Proceedings of the 1998 IEEE International Confer-ence on Systems Man and Cybernetics (Cat No98CH36218)SMCrsquo98 vol 3 pp 2720ndash2725 October 1998
[14] G Pui Cheong Fung J Xu Yu and W Lam ldquoStock predictionintegrating text mining approach using real-time newsrdquo inProceedings of the 2003 IEEE International Conference on Com-putational Intelligence for Financial Engineering CIFEr 2003vol 2003 pp 395ndash402 China March 2003
[15] W Antweiler and M Z Frank ldquoIs all that talk just noise theinformation content of internet stock message boardsrdquo SSRNElectronic Journal 2001
[16] M-A Mittermayer and G F Knolmayer ldquoNewsCATS A newscategorization and trading systemrdquo in Proceedings of the 6thInternational Conference onDataMining ICDM2006 pp 1002ndash1007 China December 2006
[17] R P Schumaker and H Chen ldquoTextual analysis of stockmarket prediction using breaking financial news theAZFin textsystemrdquo ACM Transactions on Information and Systems pp 1ndash29 2009
[18] S S Groth and J Muntermann ldquoAn intraday market riskmanagement approach based on textual analysisrdquo DecisionSupport Systems vol 50 no 4 pp 680ndash691 2011
[19] T Vu S Chang Q Ha and N Collier ldquoAn experiment in inte-grating sentiment features for tech stock prediction in twitterrdquoin Proceedings of the Workshop on Information Extraction AndEntity Analytics on Social Media Data vol 3 pp 23ndash38 2012
[20] B Wang H Huang and X Wang ldquoA novel text miningapproach to financial time series forecastingrdquo Neurocomputingvol 83 pp 136ndash145 2012
[21] Q Li T Wang P Li L Liu Q Gong and Y Chen ldquoThe effectof news and public mood on stock movementsrdquo InformationSciences vol 278 pp 826ndash840 2014
[22] T H Nguyen K Shirai and J Velcin ldquoSentiment analysis onsocial media for stock movement predictionrdquo Expert Systemswith Applications vol 42 no 24 pp 9603ndash9611 2015
[23] BWengM A Ahmed and FMMegahed ldquoStockmarket one-day ahead movement prediction using disparate data sourcesrdquoExpert Systems with Applications vol 79 pp 153ndash163 2017
[24] J Eberhard J F Lavin and A Montecinos-Pearce ldquoA network-based dynamic analysis in an equity stock marketrdquo Complexityvol 2017 Article ID 3979836 16 pages 2017
[25] Z Zhang Y Zhang D Shen and W Zhang ldquoThe dynamiccross-correlations between mass media news newmedia newsand stock returnsrdquo Complexity vol 2018 11 pages 2018
[26] P C Tetlock ldquoGiving content to investor sentiment The role ofmedia in the stock marketrdquo Journal of Finance vol 62 no 3 pp1139ndash1168 2007
[27] K Chen P Luo L Liu andW Zhang ldquoNews search and stockco-movement Investigating information diffusion in the finan-cial marketrdquo Electronic Commerce Research and Applicationsvol 28 pp 159ndash171 2018
[28] F Z Xing E Cambria and Y Zhang ldquoSentiment-awarevolatility forecastingrdquo Knowledge-Based Systems vol 176 pp68ndash76 2019
[29] A Picasso S Merello Y Ma L Oneto and E CambrialdquoTechnical analysis and sentiment embeddings formarket trendpredictionrdquo Expert Systems with Applications vol 135 pp 60ndash70 2019
[30] A Khadjeh Nassirtoussi S Aghabozorgi T Ying Wah and DC L Ngo ldquoText mining for market prediction a systematicreviewrdquo Expert Systems with Applications vol 41 no 16 pp7653ndash7670 2014
[31] M Kraus and S Feuerriegel ldquoDecision support from financialdisclosures with deep neural networks and transfer learningrdquoDecision Support Systems vol 104 pp 38ndash48 2017
[32] H S Sim H I Kim and J J Ahn ldquoIs deep learning for imagerecognition applicable to stockmarket predictionrdquoComplexityvol 2019 10 pages 2019
Complexity 15
[33] M Jasemi A M Kimiagari and A Memariani ldquoA modernneural network model to do stock market timing on the basisof the ancient investment technique of Japanese candlestickrdquoExpert Systems with Applications vol 38 no 4 pp 3884ndash38902011
[34] A Fader S Soderland and O Etzioni ldquoIdentifying relations foropen information extractionrdquo in Proceedings of the Conferenceon Empirical Methods in Natural Language Processing EMNLP2011 pp 1535ndash1545 Association for Computational LinguisticsUK July 2011
[35] T Mikolov K Chen G Corrado and J Dean ldquoEfficientestimation of word representations in vector spacerdquo pp 1ndash122013 httpsarxivorgabs13013781
[36] X Lin Z Yang and Y Song ldquoIntelligent stock trading systembased on improved technical analysis and Echo State NetworkrdquoExpert Systems with Applications vol 38 no 9 pp 11347ndash113542011
[37] K-J Kim and I Han ldquoGenetic algorithms approach to featurediscretization in artificial neural networks for the prediction ofstock price indexrdquo Expert Systems with Applications vol 19 no2 pp 125ndash132 2000
[38] Y Yu W Duan and Q Cao ldquoThe impact of social andconventional media on firm equity value A sentiment analysisapproachrdquoDecision Support Systems vol 55 no 4 pp 919ndash9262013
[39] MHagenauM Liebmann andDNeumann ldquoAutomated newsreading Stock price prediction based on financial news usingcontext-capturing featuresrdquo Decision Support Systems vol 55no 3 pp 685ndash697 2013
[40] A Aizawa ldquoAn information-theoretic perspective of tf-idfmeasuresrdquo Information Processing amp Management vol 39 no1 pp 45ndash65 2003
[41] A Khadjeh Nassirtoussi S Aghabozorgi T Ying Wah and DC Ngo ldquoText mining of news-headlines for FOREX marketprediction a Multi-layer dimension reduction algorithm withsemantics and sentimentrdquo Expert Systems with Applications vol42 no 1 pp 306ndash324 2015
[42] D Peramunetilleke and R K Wong ldquoCurrency exchange rateforecasting from news headlinesrdquo Australian Computer ScienceCommunications vol 24 no 2 pp 131ndash139 2002
[43] Y Kim ldquoConvolutional neural networks for sentence classifica-tionrdquo 2014 httpsarxivorgabs14085882
[44] ZWang J Zhang J Feng and Z Chen ldquoKnowledge graph andtext jointly embeddingrdquo in Proceedings of the 2014 Conferenceon Empirical Methods in Natural Language Processing EMNLP2014 pp 1591ndash1601 Qatar October 2014
[45] J Xu X Qiu K Chen and X Huang ldquoKnowledge graphrepresentation with jointly structural and textual encodingrdquo inProceedings of the 26th International Joint Conference on Arti-ficial Intelligence IJCAI 2017 pp 1318ndash1324 Australia August2017
[46] R Xie Z Liu J Jia H Luan and M Sun ldquoRepresentationlearning of knowledge graphs with entity descriptionsrdquo in Pro-ceedings of the 30th AAAI Conference on Artificial IntelligenceAAAI rsquo16 pp 2659ndash2665 February 2016
[47] F Tian B Gao E Chen and T Liu ldquoLearning better wordembedding by asymmetric low-rank projection of knowledgegraphrdquo Journal of Computer Science and Technology vol 31 no3 pp 624ndash634 2016
[48] F Z Xing E Cambria and R E Welsch ldquoNatural languagebased financial forecasting a surveyrdquo Artificial IntelligenceReview vol 50 no 1 pp 49ndash73 2018
[49] C Goutte and E Gaussier ldquoA probabilistic interpretation ofprecision recall and F-score with implication for evaluationrdquoin Advances in Information Retrieval D E Losada and J MFernandez-Luna Eds vol 3408 of Lecture Notes in ComputerScience pp 345ndash359 Springer Berlin Germany 2005
Hindawiwwwhindawicom Volume 2018
MathematicsJournal of
Hindawiwwwhindawicom Volume 2018
Mathematical Problems in Engineering
Applied MathematicsJournal of
Hindawiwwwhindawicom Volume 2018
Probability and StatisticsHindawiwwwhindawicom Volume 2018
Journal of
Hindawiwwwhindawicom Volume 2018
Mathematical PhysicsAdvances in
Complex AnalysisJournal of
Hindawiwwwhindawicom Volume 2018
OptimizationJournal of
Hindawiwwwhindawicom Volume 2018
Hindawiwwwhindawicom Volume 2018
Engineering Mathematics
International Journal of
Hindawiwwwhindawicom Volume 2018
Operations ResearchAdvances in
Journal of
Hindawiwwwhindawicom Volume 2018
Function SpacesAbstract and Applied AnalysisHindawiwwwhindawicom Volume 2018
International Journal of Mathematics and Mathematical Sciences
Hindawiwwwhindawicom Volume 2018
Hindawi Publishing Corporation httpwwwhindawicom Volume 2013Hindawiwwwhindawicom
The Scientific World Journal
Volume 2018
Hindawiwwwhindawicom Volume 2018Volume 2018
Numerical AnalysisNumerical AnalysisNumerical AnalysisNumerical AnalysisNumerical AnalysisNumerical AnalysisNumerical AnalysisNumerical AnalysisNumerical AnalysisNumerical AnalysisNumerical AnalysisNumerical AnalysisAdvances inAdvances in Discrete Dynamics in
Nature and SocietyHindawiwwwhindawicom Volume 2018
Hindawiwwwhindawicom
Dierential EquationsInternational Journal of
Volume 2018
Hindawiwwwhindawicom Volume 2018
Decision SciencesAdvances in
Hindawiwwwhindawicom Volume 2018
AnalysisInternational Journal of
Hindawiwwwhindawicom Volume 2018
Stochastic AnalysisInternational Journal of
Submit your manuscripts atwwwhindawicom

2 Complexity
of companies news events and user preferences Theseentities can be used by investors to achieve efficient financialdata-based decision-making andobtain business insights intopredicting stock market [4] For these reasons the currentresearch focused on how to use knowledge graph to improvethe accuracy of stock price forecasts Knowledge graph isdatabases that implement semantic searches by preservingrelationships amongstmultiple entities Based on event tuplesin knowledge graph [5] we can infer the definition of anevent tuple as (A P O) where A represents an agent Pdenotes a predicate and O represents an object [6] In viewof the objects converted by each event tuple are known whenthey are converted to vectors which loses more semanticinformation Event tuples link relevant elements together andcan be used as an efficient method of improving predictiveaccuracy As a result we propose a learning model of eventtuples which retains their semantic features at themaximum
Knowledge graph embedding is a kind of representationlearning in knowledge graph Currently several algorithms[3] explore the mapping relationship between entities andrelationships in the translation distance model The TransEmodel [7] is a computationally efficient predictive model thatsatisfactorily represents a one-to-one type of relationship Ithas been used as a basis in the development of differenttranslation distance models The TransH model [8] mapsthe head and tail of a vector onto a hyperplane after whichthese two components complete the translation process onthe hyperplane The TransR model [9] which is based on theTransE model consists of entities and relationships that arelocated in different dimensions of space For each relation-ship the model defines a matrix that is used to convert entityvectors into spaceThemodel is also dynamically determinedby an entity relationship The TransD model [10] is animprovement of the TransR model which the former uses asa basis in considering a transformation matrix In comparingthese models solving the head and tail of a news tuple formapping in a single space necessitates the simple mappingof one-to-one entity extraction features This functionality isfound in the TransE model this study is used to establish afeature combination model for news event metagroups
This work selects six globally renowned companiesto forecast their stock price movement namely AppleMicrosoft Samsung Boeing Google and Walmart as appli-cation scenarios According to different data sources betweenThomson Reuters and Cable News Network we reveal theresult of the case studies in some algorithms which illustratesthat the performance of combined feature outperforms thatusing only stock data using a bag-of-words algorithmand using convolutional neural network Although thereare already some examples of the powerful application ofdeep learning in NLP [11] such as speech recognition textclassification and machine translation most of the previousresearch in predicting stock price movement [12] is based onthe semantic information news which ignores the semanticfeatures of structured eventsThe application of deep learningand knowledge graph on the renowned companiesrsquo stocks israrely available Thus our work provides a viable applicationframework for financial markets which can also be extendedto other aspects of the financial filed
For stock market prediction we formulated a knowledgegraph embedding-driven approach that involves four mainphases (Figure 1)The first is data retrieval which begins withsearching keywords such as ldquoApplerdquo or ldquoGooglerdquo over theThomson Reuters or Cable News Network (CNN) as shownin Figure 2 The yellow part is the headline of financial newsand the orange part is the release time of the financial newsA web crawler is then used to obtain financial news from thesites and match them with corresponding stock data com-bining all this information into one corpusThe second phaseinvolves preprocessing which encompasses corpus analysistext normalization word tokenization label tagging andword-to-vector transformation The features derived fromword embeddings and stock data layers are then selected forthe computation of eigenvalues after which a feature vectoris generated using machine learning and knowledge graphembeddingThe third phase ismodel creation in which stockmarket prediction labels (increase or decrease) are assigned tofinancial news to training a classification model Finally thefinance decision relies on the predictive performance of thisframework Specifically a small improvement directly affectsdecision-making which increases the renowned companyrsquosprofits The fourth phase involves model evaluation whereinthe results and the extraction of conclusions of each machinelearning model are analyzed
The remaining part of the paper is organized as fol-lows Section 2 is a review of existing studies on the useof machine learning in stock market prediction Section 3introduces the methodology adopted in this study includingthe data description and feature selection approach Section 4presents the classification results and Section 5 discussesthe results and implications Section 6 concludes with thesummary
2 Literature Review
In Table 1 the application of machine learning techniquesto stock market prediction is an emerging research fieldThe advantage of machine learning models is their ability tofacilitate the processing of large amounts of data A procedurecommon to these models is the concatenation of featuresfromdifferent sources into a feature vector Formostmachinelearningmodels used research is focused on predicting stocktrends (increase or decrease)
Various feature extractions have already been proposedto predict the stock price of the renowned companies In theearly years most of the companyrsquos stock prediction dependson the empirical analysis of the econometric model namelythe feature extracted is the raw data of the companyrsquos stockHowever the previous work ignored the potential impactof unstructured data on company stocks Since the bag-of-words is widely utilized in the task of document classificationthe frequency of word appearance can be used as a feature ofthe classification Hence the bags of words model only cal-culate the frequency of words and do not consider the wordorder or word sparsity in the context which directly impactsthe prediction result Furthermore EMH had found thatthe emotional impulses of the renowned company investorsoften observe abnormal fluctuations in company stocks
Complexity 3
Financial news
DATARETRIEVAL
PRE-PROCESSING
MODEL CREATIONamp PREDICTION
MODELAPPLICATION
Corpus
Stock data Data
Feature News-stock
Machine learningmodel creation
Modelevaluation
Decisionmaking
mappingrepresentation
Featureselection
transformation
Figure 1 Research workflow for machine learning and knowledge graph
Figure 2 Example of collected financial news in CNN
4 Complexity
Table 1 A review of financial expert system ANN NB KNN SVM DT and SVR stand for artificial neural network naive Bayes k nearestneighbors support vector machine decision tree and support vector regression respectively Measure metrics mean squared error (MSE)root mean square error (RMSE) area under the curve (AUC)
Paper Text type Feature extraction Model type Performancemeasure
[13] Professional newspaper Stock data NB Accuracy[14] Professional newspaper Stock data SVM Accuracy
[15] Message board Stock data Regression Correlationcoefficient
[16] PRNewswire Stock data KNN SVM Accuracy F1-score
[17] Aggregate news Stock databag-of-words SVR MSE accuracy
[18] Corporate disclosures Stock databag-of-words Multiple Accuracy recall
precision F1-score
[19] Financial news Stock datasentiment DT Accuracy recall
precision F1-score
[20] Web media Stock databag-of-words SVR Accuracy recall
precision F1-score
[21] Mixed typeStock data
bag-of-wordssentiment
SVR RMSE accuracyprecision
[22] Message board Stock datasentiment SVM Accuracy
[23] Mixed typeStock data
technical indicatorssentiment
ANN SVM DTAccuracy AUCF1-score precision
[24] None Stock data Regression Correlationcoefficient
[25] Media news Stock data Regression Correlationcoefficient
Our financial expert system Financial newsStock data
technical indicatorsbag-of-words
syntax
Multiple Accuracy F1-score
Tetlock [26] adopted the popular news from the Wall StreetJournal to find that news sentiment has predictive power oncompany stocks Chen et al [27] found information comen-tions have a significant influence on the stock return throughsentiment analysis Furthermore the investorsrsquo sentimenttrends after the positive news which results in a buying trendand higher stock market prices while after negative newsstocks are sold result in a decrease of the price Howeversentiment analysis can only be employed in specific textsIf sentiment is implicit rather than direct emotional wordsthen the ability of using sentiment analysis for predicting thestock price of the renowned company is relatively limitedMittermayer and Knolmayer [16] illustrated that news-CATSachieves a performance that is superior to that of otherATC prototypes used to forecast stock price trends Li et al[21] proposed a media-aware quantitative trading strategy byusing sentiment information on web media The simulationtrading return was up to 16611 Nguyen et al [22] proposeda feature topic sentiment to improve the performance of stockmarket prediction Their method achieved an accuracy thatis 983 better than that of the historical price method and303 better than that of the human sentiment method
We utilize the characteristics of syntax analysis as beingproposed in [6 12] namely a structured tuple is extractedfrom an unstructured text based on the semantic structureof each piece of news Knowledge graph can enrich thestructured representation of the news event and effectivelyretain feature vectors for the news event The main featureextraction in the previous studies [28 29] is sentimentanalysis which neglected the event characteristics in thetext Furthermore the existing literature [23 29] had provedthe positive effect of technical indicators on stock marketprediction In summary our research highlights syntax anal-ysis in financial news which also incorporates with otherfeatures extraction (stock data technical indicators and bag-of-words) Because of the variety of considered features thisresearch will deliver an improved prediction of the stockmarket value for renowned companies in at least 36
Previous research [30] was applied with the traditionalmachine learning algorithms especially since the power-ful application ability of deep learning based on machinelearning Deep learning is utilized in several studies forpredicting stock price movement Kraus and Feuerriegel [31]forecasted the stock returns based on financial disclosures
Complexity 5
Table 2 Quotes and renowned company names
Financial newsdataset Stocks Company names Time interval Number of news
headlinesAAAL Apple Inc 3102011- - -3172017 6423
Thomson Reuters MSFT Microsoft Corporation 3092011- - -29112017 6623SSNLF Samsung Electronics Co Ltd 3092011- - -29112017 6900BA The Boeing Company 891998- - -2322017 2999
CNN GOOG Google Inc 2552006- - -2422017 5278WMT Walmart Inc 751997- - -2422017 4913
Table 3 Samples extracted from the dataset
Date News headline News headline event tuple3182012 Chinese writersrsquo group sues Apple state media Chinese writersrsquo group sues Apple
4132012 German court upholds ban on Apple push email German court upholds ban on Apple pushemail
442012 Apple two publishers hold out againstsettlement-report
Apple- two publishers hold out againstsettlement-report
3262012 Apple CEO Cook meets Chinese officials Apple CEO Cook meets Chinese officials
4252012 US STOCKS-Apple results put Nasdaq on track for bestgain of year Apple results Nasdaq on track for best gain
and their result demonstrated that a higher directional ofdeep learning surpasses traditional machine learning Dinget al [5] illustrated that deep learning also can forecaststock market of the renowned company Sim et al [32]proposed that technical indicators transform into images ofthe time series graph which examines the applicability ofdeep learning in the stock market Overall we adopt themultiple models for prediction stock price of the renownedcompany which proves the reliability of our proposed modelas comparing different algorithms This work applies deeplearning incorporated with knowledge graph embeddingfor feature extraction which examines the applicability ofcombined features methods in the renowned company stockprice movement
3 Materials and Methods
We developed a knowledge graph-based approach that con-sists of three steps namely data description data preprocess-ing and feature selection
31 Dataset Description Table 2 shows the custom financialnews corpus built with headlines from two datasets The firstdataset contains news articles published byThomsonReutersincluding those regarding Apple Inc (AAPL) MicrosoftCorporation (MSFT) and Samsung Electronics Co Ltd(SSNLF) The second dataset comprises news reports pub-lished in CNN including reports on the Boeing Company(BA) Google Inc (GOOG) and Walmart Inc (WMT) Italso consists of financial news headlines published at specifictime intervals with each news report accompanied by a titleand a release date Titles are used for event embedding andfeature extraction and release dates are used as a referencein ensuring alignment between corresponding financial news
and trading data from a time series As shown in previouswork [5 31] using a headline to build corpora can helpreduce noise in text mining as headlines concisely representthe content of a text We used only the news headlines fromReuters andCNN for the prediction of stock pricemovement
Daily stock data from index report in each company arecollected by Yahoo Finance in the same period during stockdata and financial news headlines Daily trading data whichare common predictors of stock price [23 33] and technicalindicator features were used in our model There are openingprice closing price high price low price and volume andthree technical indicators
Table 3 shows some examples of filtered financial newsheadlines To illustrate 6423 headlines regarding Apple Incwere extracted and then reduced to 2799 headlines afterfiltering via Reverb [34] Let us take the article ldquoWhat is nextfor Applersquos boardrdquo published on 6 October 2011 as a specificexample The title of the article cannot be transformed intoan event tuple using Reverb Because the sentence is in theinterrogative form there is no event tuple that constitutes arule After the matching of time-wise data and stock data941 headlines were left Daily news and stock data werealigned to create input-output pairs except the days whenno news was released In 9 January 2012 for instance threenews articles were reported but we chose only one headlinefor alignment with stock market data News events possiblyhappen several times within one day but they do not happenevery day unlike stock trading which happens daily excepton nontrading days falling on weekends or holidays
Table 4 shows that the matches found are pairs betweenevent tuples and stock data From this complete dataset weused 80 of the samples in training data and the remaining20 for testing dataThis selection method is the same as theprevious literature [5 24]
6 Complexity
Table 4 Training and testing datasets
Data source Company Training Testing TotalApple 780 161 941
Reuters Microsoft 832 208 1040Samsung 855 214 1069Boeing 528 132 660
CNN Google 1010 252 1262Walmart 798 200 998
Table 5 Number of event characteristic labels for each company
CompaniesLabel Apple Microsoft Samsung Boeing Google Walmart0 502 967 1433 133 661 2061 537 432 379 200 245 2872 661 557 378 152 389 2333 692 707 724 233 683 4384 407 228 193 147 196 180Total 2799 2891 3107 865 2174 1344
Table 6 Features of the prediction model
Feature Feature expression1 Stock price yesterday + yesterdayrsquos trend (in Section 331) 119901119903119894119888119890
119905minus1 119905 119894119899119889119894119888119886119905119900119903119905minus1
2 Same + bag-of-words (in Section 332) 119901119903119894119888119890119905minus1
119905 119894119899119889119894119888119886119905119900119903119905minus1 119905119891 119894119889119891119905minus1
3 Same + some features inferred through a convolutional neural network (in Section 333) 119901119903119894119888119890119905minus1
119905 119894119899119889119894119888119886119905119900119903119905minus1 119888119899119899119905minus14 Same + some features inferred through feature combination (in Section 334) 119901119903119894119888119890
119905minus1 119905 119894119899119889119894119888119886119905119900119903119905minus1 119891 119888119900119898119887119894119899119890
119905minus1
32 Data Preprocessing The following three steps are forpreprocessing which prepares for feature extraction andmodel creation
(1) Tagging the label for each news headline Five possiblelabels are characterized by categorical values as follows 0for an extremely negative label 1 for a negative label 2 tosignify a neutral label 3 for a positive label and 4 to denote anextremely positive label According to the time characteristicsof each news headline an event is manually tagged withthe label for each news headline Table 5 shows the labelingapplied for each company Label 0 means that a companyrsquoscompetitor has happened in this event label 1 means that thecompany lost something label 2 means that it did not causeany impact on the company label 3 means that this eventenabled the company to obtain something and label 4 meansthat the company increased its profits or created more value
(2) Word vector transformation We used the word2vec[35] algorithm to train word embedding and set the numberof dimensions to 300 The word embedding was also trainedusing the Google News dataset which contains 100 billionwords that are characterized by a continuous bag-of-wordsstructure
(3) Technical indicators calculation Three additionaltechnical indicators that are calculated on the basis of dailytrading data were used as follows
(a) Stochastic oscillator (K)This indicator is a momen-tum analysis method created by George C Lane When the
price trend rises the closing price tends to approach thehighest price of the day When the price trend declines theclosing price tends to approach the lowest price of the day[36]
(b) Larry Williamss R indicator This indicator is anoscillation indicator that measures the ratio of the highestprice to the daily closing price It indicates the proportion ofstock price fluctuations in a certain period thereby providinga signal out of the reversal of a stock market trend [37]
(c) Relative strength index (RSI) Buying and sellingintentions in the market are analyzed by comparing theclosing prices in a given period Stocks that have had moreor stronger positive changes have a higher RSI than do thosethat have had more or stronger negative changes Strengthindicators fall between 0 and 100 investors sell if this valueis ge 80 and buy if it is le 20 [23 36]
33 Variable Feature Selection To assess the effectivenessof applying the prediction model on the basis of financialnews we designed four sets of features for predicting stockprice movement (Table 6) Features 3 and 4 are used for eventcharacteristics Each feature is explained in the succeedingsubsections The target output consists of a binary variablefor which a value of 1 indicates that the closing price at day t+ 1 will be higher than that at day t and a value of 0 indicatesthat the closing price at day t + 1will be lower than that at dayt
Complexity 7
Financial news
middot middot middot
News representation Convolutional layer Max pooling Fully connected layer Features
X (I)
Z (I)
Figure 3 Convolutional neural network architecture proposed for feature selection
331 Stock Data Only We considered historical price as theinput for predicting stock price movement and used it asa baseline for comparison with other sets of features Thefeatures used to train the machine learning model that usesonly stock data are 119901119903119894119888119890119905minus1 and 119905 119894119899119889119894119888119886119905119900119903119905minus1 The output isthe indicator of pricemovement (increase or decrease) at eachtransaction date examined
332 Bag of Words The input feature set is based on a bag ofwords for the news and price trend for stock Previous studies[18 38 39] have widely used and confirmed the feasibilityof the bag-of-words algorithm but this method disregardselements such as grammar and word order in the text Inthe present study we first prepared each headline for datapreprocessing and then transformed the preprocessed head-line into a feature vector using the term frequency-inversedocument frequency (TF-IDF) algorithm [40] which assignshighweight to eigenvectorsThe studies [41 42] have stronglyproven the effectiveness of the TF-IDF algorithm in featureextraction from news headlines It estimates the frequency ofa term in one document over the maximum in a collection ofdocuments and assesses the importance of aword in one set ofdocuments Such importance increases proportionally withthe number of word appearances in a documentThe featuresused to train the bag-of-words machine learning model are119901119903119894119888119890119905minus1 119905 119894119899119889119894119888119886119905119900119903119905minus1 and 119905119891 119894119889119891119905minus1 which are the pricemovements (increase or decrease) at each transaction dateexamined
333 Convolutional Neural Network Given the sequence ofwords in a headline the word2vec model [35] can be usedto embed each of these words in a real valued-vector 119909 Inthis work we set the dimension 119899 of each word vector at30 (ie 119909 isin R30) We concatenated the word vectors of allthe words in a headline sequentially to form a matrix 119883 =[119909(1) 119909(2) 119909(3) 119909(4)] [35] as the input to a convolutionalneural network model For a headline with 119873 words the
resultant input matrix has dimensions of 30 times 119873 and thedimension of news representation also is 30
In Figure 3 this convolutional neural network model ismade up of four consecutive layers the first layer is theinput the second layer is convolutional the third layer is amax-pooling and the last layer is a fully connected layerThe convolutional and max-pooling layers were designedusing the text-attentional convolutional neural network [43]which effectively carries out sentiment classification In theconvolutional layer input matrix X convolves with a kernel119908 isin R119899times119896 where n is the size of a word vector (30 inour work) and its dimension is 50 k denotes the size of asliding window (k=3 in this study) The computation can beformulated as follows
119885119894 = 120590 (119908119883119894119894+119896minus1 + 119887) (1)
where 119883119894119894+119896minus1 = [119909119894 119909119894+1 119909119894+119896minus1] is the portion of input119883 falling within the sliding window 119887 denotes the optionaloffset and 120590(sdot) is the sigmoid function
In the next step we used the pooling layer to reduce theconvolutional neural networks parameter space and conse-quently minimize information loss in the pooling processingand capture the most important features The eigenvectorof the filter in the pooling layer is cut into 3 chunks anda maximum value is taken in each chunk we obtained 3eigenvalues Convolutional output vector Z was split into pwindows and only themaximum feature as 3 in each windowwas kept for passage onto the final fully connected layer Thefully connected layer is linear regression and the output layeris the feature classification between 0 and 1
Our convolutional neural network model is intended toextract a feature vector from the fully connected layer todescribe the emotional characteristics of input headlinesFollowing the intuition that a good feature vector shouldlead to the accurate classification of the event characteristicsof headlines we attached a softmax layer after the fully
8 Complexity
The United Kingdom of Great Britain and Northern Ireland commonly known as the United Kingdom or Britain hellip
London is the capital city of England and of the United Kingdom It is the most populous region hellip
Head Relationship TailLondon location country capital United Kingdom
London is the caEngland and of Kingdom It is tpopulous region
Kingdom of GreatNorthern Ireland known as the United
Britain hellip
Figure 4 Text description of the entity
connected layer when the convolutional neural networkmodel was trained The entire model was trained to classifythe five emotional labels that describe event characteristicsand the resultant model will be able to provide a mean-ingful emotional feature vector for each inputted headlineMeanwhile we define the loss function of the convolutionalneural network model as 119864119889 The features used to trainthis machine learning model are 119901119903119894119888119890119905minus1 119905 119894119899119889119894119888119886119905119900119903119905minus1and 119888119899119899119905minus1 which are the price movements (increase ordecrease) at corresponding transaction date
334 Combined Features In the introduction section of thispaper we described various translation models Because theTransE model represents a one-to-one relationship betweentwo entities [7] the relationship amongst many entities mustbe continuously incorporated into texts and knowledge graph[44] This model combines a convolutional neural networkwith textual information extraction which fully exploits thesemantic information in a knowledge graph and text [45 46]In Figure 4 knowledge graph contains rich semantics inentity description texts but it is not fully utilized in featureextraction Most of the existing text representation modelssimply train the text into word vectors through word2vecwhich obtains the text representation by means of averagingetc Hence these ways often lose more semantic informationWe therefore proposed to extract feature vectors from newstexts using a convolutional neural network model combinedwith the TransE model which also fully integrates the twoparts of the feature information
In Figure 5 this architecture used in the feature combina-tion model encompasses two parts namely a convolutionalneural network (Section 333) and the TransE model Thefeature combination sets are the average of each word vectorin an entity and it was obtained using the word2vec modelThe two entity vectors are mapped into the same relationalspace and these entities using a trained low-rank weightmatrix [47]
As assumed in the TransE model relationship vector Rshould satisfy ldquoE + R asymp Trdquo The model can be representedas a parameter set 0 = (119871119903 119877119903 120579) where X E and R
represent a word an entity and a relation respectively Andr are the mapping matrices for entities in the structuralmodel and represents the weights of the convolutional neuralnetwork For instance the sentence is ldquoSamsung sues Apple forinfringementrdquo so ldquoSamsung +Appleasymp suesrdquoThe loss function119864119904 of this structural model is defined as follows
119864119904 = ℎ + 119903 minus 11990522 (2)
where h r and t represent head entity relationship and tailentity in event tuple respectively [47]
And text representation 119864119889 is consistent withSection 333 which denotes
119864119889 = 119891119903 (ℎ119904 119905119889) + 119891119903 (ℎ119889 119905119904) + 119891119903 (ℎ119889 119905119889) (3)
where119891119903(ℎ119889 119905119889) = ℎ119889+119903minus11990511988922 represents the head entity andthe tail entity is in text representation119891119903(ℎ119889 119905119904) = ℎ119889+119903minus11990511990422and 119891119903(ℎ119904 119905119889) = ℎ119904 + 119903minus 11990511988922 represent one of the head entityh and the tail entity t in text representation another one is instructure representation
Moreover we combined two types of representationlearning (convolutional neural network and feature combi-nation) to map news titles these vectors will be into featurevectors The relationship vector R identical to the resultof the feature extraction layer of the convolutional neuralnetwork in the structural model Besides we combined thisloss with the classification loss of the convolutional neuralnetwork using L2 regularization which obtains the overallloss function 119864 for feature selection that is
119864 = 119864119904 + 120572119864119889 + 120573 02 (4)
where 02 is a regular item 120572 and 120573 are hyperparameterswhich measure the loss of text information and the weight ofthe regular items respectively W denotes the convolutionalkernels in the layer and 1198791015840 is a negative sample set of 119879 [7]
1198791015840 = (ℎ1015840 119903 119905) | ℎ1015840 isin 119864 cup (ℎ 119903 1199051015840) | 1199051015840 isin 119864
cup (ℎ 1199031015840 119905) | 1199031015840 isin 119877 (5)
Complexity 9
Output layerClass1 Class2
Machinelearning
Max pooling
convolutional
Input news
Feature vector
Embedding layer
Input news
Event tuple
Word2vec
Word2vec
Fully connection
Stock data
Stock layer
TransE model
Figure 5 Proposed architecture for the feature combination model
where the head entity and tail entity are randomly replaced byan entity or relationship in another tuple In particular if thereplaced tuple is already in T it would not be added to thenegative sample Since both h and t represent two types ofentities there are structure-based representations and text-based representations in interval-based loss functions Thestochastic gradient descent (SGD) is employed to minimizethe above loss function
In this structure we choose the optimal parameters asfollowe the learning rate of SGD 120582 = 0001 the dimension ofthe representation vector of entities and relationships k = 100the word vector dimension of the entity description text n =100 and batch size during training is 1440 Convolution layerwindow size is 119882 isin 1 2 3 This experiment is performedin 1000 iterations of training and the optimal parameters arebased on the testing set
Hence the features used for training the machine learn-ing model are 119901119903119894119888119890119905minus1 119905 119894119899119889119894119888119886119905119900119903119905minus1 and 119891 119888119900119898119887119894119899119890119905minus1which are the price movement (increase or decrease) atcorresponding transaction date
4 Experiments and Results
41 Experimental Setting This section compares the perfor-mance of differentmodels in feature extraction fromfinancialnews expended with full sets of features The evaluationwas intended to obtain evidence that the proposed featurecombination model is superior to other feature selectionmodels in predicting the stock price movement As shownin Table 7 we chose linear models for instance logisticalregression and naive Bayes Others are nonlinear models forinstance the ensemble learning (random forest adaboostand gradient boosting) for the comparison We constantlyadjusted the parameters in the grid search and selected theoptimal parameter value their parameter value has proven towork well on machine learning method [29 48]
We used a computer consisting of an Intel Core i5processor with four cores running at 29 GHz and 8 GBRAM under the MacOS platform We used the Scikit-learnlibrary in Python in the experiments involving traditionalmachine learning algorithms and TensorFlow 14 in the
10 Complexity
Table 7 List of machine learning methods
Method Classification Parameter and their value
Traditionalmachinelearning
Decision tree (DT)Criterion= gini splitter= best max depth=None minsamples split=2 min samples leaf =1 min weight
fraction leaf=00Logistical regression (LR) Random state=1
Naive Bayes (NB) No kernel estimatorStochastic gradient descent (SGD) Loss=hinge penalty=l2
Support vector machine (SVM) Polynomial kernel function with exponent = 1 2 RBFkernel function with gamma = 001
Ensemblelearning
Random forest (RF) Randomly sampled as candidates at each split = log2 +1 max-depth=2 random state=0
AdaBoost (AB) Polynomial kernel function with exponent = 1 2 RBFkernel function with gamma = 001 n- estimators=100
Gradient boosting (GB) N-estimators =100 learning rate =10 max-depth=1random state=0
Table 8 Abbreviations of the results for each algorithm considered
Algorithms Stock data (SD) Bag of words (BOW) Convolutionalneural network
Featurecombinationmodel (FC)
DT DT 1 DT 2 DT 3 DT 4LR LR 1 LR 2 LR 3 LR 4NB NB 1 NB 2 NB 3 NB 4SGD SGD 1 SGD 2 SGD 3 SGD 4SVM SVM 1 SVM 2 SVM 3 SVM 4RF RF 1 RF 2 RF 3 RF 4AB AB 1 AB 2 AB 3 AB 4GB GB 1 GB 2 GB 3 GB 4
experiments involving deep learning and the TransE modelThe abbreviations used for comparing classification perfor-mance are presented in Table 8 During testing 2-fold cross-validation is applied to evaluate the stability of the modelsAnd we compared performance in predicting stock pricemovement for the next day with a test dataset and evaluatedthe performance of the models in terms of accuracy and F1-score [49]
42 Results
421 Thomson Reuters Case Study Thomson Reuters isa multinational mass media and information firm Threerenowned companies on the website were selected for theanalysis The first is Apple Inc which is an American multi-national technology company that designs develops andsells consumer electronics computer software and onlineservices The second company selected is Microsoft which isan American multinational technology company that devel-ops manufactures supports and sells computer softwarepersonal computers and other services The last companychosen is Samsung which is a South Korean multinationalelectronics company We considered data from these threetypical technology companies for our problem
Measurements of average accuracy are shown in Table 9and the results for each renowned company with respectto prediction based on different features are illustrated inFigure 6 We calculated the average of the four feature con-struction approaches for eachmodel for comparison amongstthe three companies The proposed feature combinationmodel generated the best results achieving average accuracylevels of 6163 5918 and 5848 forAppleMicrosoft andSamsung respectively These figures are consistent with therates reported in previous research However many studiesanalyzed only one company or used only one algorithmThe current research probed into three companies on thebasis of information from a common data source to builda prediction model with different feature selection func-tionalities and different algorithms We used stock dataa bag-of-words algorithm a convolutional neural networkand feature combination together with eight algorithms Asindicated in Table 9 the proposed predictionmodel achieved7368 data extraction with the use of LR 4 for Apple and6778 data extraction with the use of SVM 4 for MicrosoftIn particular the LR algorithm used for Apple achievedaccuracy and F1-score of 07326 and 07360 respectivelywhich highlights its powerful capability in a two-class classifi-cation
Complexity 11
Table 9 Results for data extracted fromThomson Reuters
Algorithm Company Stock data(SD)
Bag of words(BOW)
Convolutionalneural network
Feature combinemodel (FC)
AccuracyF1-score
AccuracyF1-score
AccuracyF1-score
AccuracyF1-score
DTApple 0499305079 0488902460 0615005814 0652406486
Microsoft 0486801819 0506505682 0581705915 0658706502Samsung 0470704033 0565405830 0552906820 0568006260
LRApple 0524006727 0505505083 0684506911 0732607368
Microsoft 0475701253 0443004884 0527405333 0546705611Samsung 0494703755 0605406726 0654106343 0805307978
NBApple 0510905123 0477803896 0502704497 0512204030
Microsoft 0484000363 0455704055 0459902889 0500005439Samsung 0529305810 0514406130 0504806578 0511706601
SGDApple 0467201119 0477804404 0497406008 0536602692
Microsoft 0517306819 0485203222 0610304231 0610804193Samsung 0522306541 0476602000 0518706751 0557106548
SVMApple 0502206121 0574705542 0615006129 0622006173
Microsoft 0478401722 0443904566 0523205462 0687506798Samsung 0500803875 0504705508 0513506281 0535206574
RFApple 0524006554 0527806083 0533706232 0620306243
Microsoft 0484002653 0417701687 0532502432 0572105189Samsung 0487203480 0448501194 0476603708 0505205481
ABApple 0534305384 0472202963 0481903333 0620305420
Microsoft 0468702041 0476800461 0614706044 0620206146Samsung 0485703619 0457902368 0601006820 0633806549
GBApple 0531405129 0466702941 0609604748 0634106591
Microsoft 0474302125 0472801007 0455704557 0538502258Samsung 0487204171 0519206599 0533706572 0562206335
Reuters
Aver
age a
ccur
acy
0
01
02
03
04
05
06
07
Different companyApple Microsoft Samsung
SDBOW
CNNFC
Figure 6 Average accuracy of prediction based on different featuresets for each company in Reuters
To assess the effectiveness of our research we comparedthe feature combination model that uses event tuples with
the stock data approach and the bag-of-words algorithmTheresults showed that the average accuracy of the event tuple-basedmodel is better than that of the stock data approach andthe bag-of-words algorithm by 1001 and 1087 respec-tively We also compared feature extraction using the stockdata approach the bag-of-words algorithm and machinelearning The use of deep learning improved predictionaccuracy by 525 and 611 over the levels achieved withstock data and bag of words respectively Therefore we canconclude that using the proposed feature combinationmodeland deep learning in feature extraction helps improve theaccuracy with which stock price movement is predictedThese results also fully prove the effectiveness of embeddinglayer in feature extraction accuracy improvement
422 CNN Case Study CNN is an American basic cableand satellite television news channel owned by the TurnerBroadcasting System Three renowned companies on whichthese website reports were selected for the analysis The firstis Boeing which is an American multinational corporationthat designs manufactures and sells airplanes rotorcraftrockets and satellites worldwide The second company isGoogle which is an American multinational technology
12 Complexity
Table 10 Results for data extracted from CNN
Algorithm Company Stock data(SD)
Bag of words(BOW)
Convolutionalneural network
Featurecombinationmodel (FC)
AccuracyF1-score
AccuracyF1-score
AccuracyF1-score
AccuracyF1-score
DTBoeing 0495003489 0541306258 0541406347 0559105821Google 0485805600 0518203575 0569204631 0549105471Walmart 0499604422 0530004891 0508804815 0572205829
LRBoeing 0492302378 0511304348 0692306923 0759605733Google 0504106105 0623506491 0625006111 0656306516Walmart 0529005468 0541205083 0732007347 0771907720
NBBoeing 0516206503 0548905161 0519706738 0556407619Google 0511206527 0489905191 0558705281 0534404843Walmart 0504403284 0479405302 0520605674 0530006083
SGDBoeing 0489702407 0556404870 0543304727 0571407220Google 0516506769 0542504375 0578906364 0591006327Walmart 0500403804 0520605280 0525005581 0567005922
SVMBoeing 0489703068 0571406275 0538506418 0594007033Google 0507706297 0603206230 0574905532 0578905840Walmart 0511804333 0500005314 0520005000 0561405455
RFBoeing 0490601345 0511303925 0509605405 0527605714Google 0492301777 0603206260 0522305564 0595105763Walmart 0511805373 0530003188 0530004405 0500005446
ABBoeing 0494503404 0519705120 0496105294 0567305872Google 0487603141 0510106667 0589305619 0595106850Walmart 0507305029 0515005359 0549705650 0561905503
GBBoeing 0489903169 0511804364 0440904580 0500005094Google 0491203387 0587005854 0562505243 0603206202Walmart 0500304955 0505005123 0536105109 0549705650
company that specializes in Internet-related services andproducts The third is Walmart an American multinationalretail corporation that operates a chain of hypermarketsdiscount department stores and grocery stores
The results on average accuracy are shown in Table 10and Figure 7These findings are very similar to those derivedin the previous case study and their comparison confirmedthat the proposed feature combinationmodel can outperformother feature selection models in stock price movementprediction With regard to feature selection underlain bythe bag-of-words algorithm the CNN case study generatedmore robust results than did the Reuters case study Theaverage accuracy of the bag-of-words algorithm was lowerthan that of the stock data approach in the Reuters case studyIn the CNN case study the average accuracy levels of theproposed feature combination model were 5794 5879and 5767 for Boeing Google andWalmart respectively Inthe case study on Reuters an average accuracy that exceeds60 was not achieved for any of the companies illustratingthat differences in data source directly affect stock pricemovement
We chose a combination of deep learning and knowledgegraph to build our feature selection model because this
CNN
Aver
age a
ccur
acy
0
01
02
03
04
05
06
07
Different companyBoeing Google Walmart
SDBOW
CNNFC
Figure 7Average accuracy achieved on the basis of news fromCNNand different feature set
combination exhibited superior prediction performance inthe comparison experiments involving other feature selection
Complexity 13
strategies The forecast results based on different featuresare shown in Table 10 We found that deep learning featuresare better than the use of bag-of-words and stock data Thecorrelation of event tuples with the stock market is relativelyhigh in [5 31] but the bag-of-words algorithm was relativelyfragmented and the correlation between event tuples and thestockmarket data was relatively weak Combining event tuplefeatures with deep learning significantly improves forecastresults indicating a close relationship between stock marketmovements and knowledge graph
5 Discussion
51 Research Findings We attempted to compare our predic-tion results with those made in previous studies wherein pre-diction was also based on the financial news of the renownedcompanies However the findings are incomparable becausedifferent studies use different datasets or algorithms andthese methods are difficult to investigate using financial newsheadlines In the current research we refrained from eval-uating performance on one company dataset this decisionthat enabled our knowledge graphmethod to exceed baselinepredictions based only on the price by up to 36 Thisalso proves that feature extraction in deep learning is moreeffective than traditional machines The combination of deeplearning and knowledge graph fully integrates the semanticinformation in financial news which effectively predicts thestock price movement of the renowned company
This work demonstrated the application of deep learningand knowledge graph in finance To the best of our knowl-edge knowledge graph has been rarely applied in stock pre-diction Becauseminimal financial training sets in knowledgegraph are available financial knowledge extraction is themain task for the organizational construction of a knowledgegraph Such extraction is critical for the understanding andprocessing of deep semantics in the event tuple which alsodirectly influences the feature extraction of financial news
52 Implications for Business Activities Theutility of a featurecombination model based on knowledge graph is not limitedto financial analysis Currently knowledge graph data areavailable for medical diagnosis speech recognition precisemarketing and financial risk control [4] Our model couldalso be applied in these areas
Antifraud activities are an important part of financeApplying our model on the basis of knowledge graph oncustomers helps organize all relevant knowledge fragmentsthrough deep semantic analysis and reasoning which canbe verified with a customerrsquos bank information Moreovercustomers typically use keywords to search for productsand knowledge graph can provide relevant information toa customer If a complete knowledge system of users isdescribed and collected a system would better understandand analyze user behaviors
53 Limitations and Future Work A deep learning modeluses supervised learning and needs a dataset with sufficientlabels but our datasets do not work well with deep learningas a small number of financial news articles match stock
data At present knowledge graph embedding inevitablyproduces a loss in news semantics either because of a learningprinciple or the tokenization of knowledge representation forvectorization Thus continuous representation in a knowl-edge graph is still a huge challenge We attempted to applyregression using the above-mentioned algorithms but theresults indicated poor performance More specifically theresults for Apple validated our expectations
The application of large-scale knowledge graph is stillrelatively limited and knowledge graph for smart searchsmart question-and-answer tasks social media and otherareas are in their initial stages with considerable room forimprovement The following advantages of knowledge graphshould be considered (a) the effective organization andexpression of semistructured data (b) knowledge reasoningand (c) the expansion of cognitive ability for incorporatingdeep learning Traditional knowledge elements (entities rela-tionship attributes) extraction technologies and methodshave achieved good results in limited areas but because ofnumerous constraints and poor scalability knowledge graphis not fully functional for financial forecasting because ofnumerous constraints and poor scalability
6 Conclusions
Stock movement prediction of the renowned company is adaunting task because stock prices are affected by many fac-tors This research presented a novel method for integratingknowledge graph embedding with stock market predictionThe contributions of this study can be summarized as followsFirst we developed a novel feature combination model thatconstructs a feature mapping vector for each tuplendashnewspair by simultaneously considering the diversity of entitiesand relationships Second the feature combination modelwas successfully applied to different types of companies anddatasets and exhibited good performance in classificationtasks
Stock market prediction of the renowned companygrounded in knowledge graph is an interesting topic forbusiness activities Given that the study of knowledge graphfor feature set is still in its infancy we expect it to be appliedin a wide range of academic research More companies willalso earn profits and create more opportunities through theuse of knowledge graph in the feature set
Data Availability
The data used in this study can be accessed via httpsgithubcomlinechanyknowledge-graph
Conflicts of Interest
The author declares that there is no conflict of interestregarding the publication of this paper
Acknowledgments
This work is supported by the China Scholarship Council(CSC) throughout the grant number 201508390019 The
14 Complexity
authors also want to thank the research program RFCS fromthe EU which partially supported this research through theresearch project AutoSurveillance with project ID 847202
References
[1] B GMalkiel and E F Fama ldquoEfficient capital markets a reviewof theory and empirical workrdquo The Journal of Finance vol 25no 2 pp 383ndash417 1970
[2] D Galai and R W Masulis ldquoThe option pricing model and therisk factor of stockrdquo Journal of Financial Economics vol 3 no1-2 pp 53ndash81 1976
[3] Q Wang Z Mao B Wang and L Guo ldquoKnowledge graphembedding A survey of approaches and applicationsrdquo IEEETransactions on Knowledge and Data Engineering vol 29 no12 pp 2724ndash2743 2017
[4] H Paulheim and P Cimiano ldquoKnowledge graph refinement Asurvey of approaches and evaluation methodsrdquo Journal of WebSemantics Science Services and Agents on the World Wide Webvol 8 no 3 pp 489ndash508 2016
[5] X Ding Y Zhang T Liu and J Duan ldquoDeep learning for event-driven stock predictionrdquo in Proceedings of the 24th InternationalJoint Conference on Artificial Intelligence IJCAI 2015 pp 2327ndash2333 Argentina July 2015
[6] X Ding Y Zhang T Liu and J Duan ldquoKnowledge-drivenevent embedding for stock predictionrdquo in Proceedings of the26th International Conference on Computational LinguisticsCOLING 2016 pp 2133ndash2142 Japan December 2016
[7] A Bordes N Usunier J Weston and O Yakhnenko ldquoTranslat-ing embeddings for modeling multi-relational datardquo Advancesin NIPS vol 26 pp 2787ndash2795 2013
[8] H Lin Y Liu W Wang Y Yue and Z Lin ldquoLearning entityand relation embeddings for knowledge resolutionrdquo ProcediaComputer Science vol 108 pp 345ndash354 2017
[9] G Ji K Liu S He and J Zhao ldquoKnowledge graph completionwith adaptive sparse transfer matrixrdquo in Proceedings of the 30thAAAI Conference on Artificial Intelligence AAAI 2016 pp 985ndash991 USA February 2016
[10] G Ji S He L Xu K Liu and J Zhao ldquoKnowledge graphembedding via dynamic mapping matrixrdquo in Proceedings ofthe 53rd Annual Meeting of the Association for ComputationalLinguistics and the 7th International Joint Conference on NaturalLanguage Processing (Volume 1 Long Papers) pp 687ndash696Beijing China July 2015
[11] Y LeCun Y Bengio and G Hinton ldquoDeep learningrdquo Naturevol 521 no 7553 pp 436ndash444 2015
[12] Q Li Y Chen J Wang and H Chen ldquoWeb media andstock markets a survey and future directions from a bigdata perspectiverdquo IEEE Transactions on Knowledge and DataEngineering vol 4347 p 1 2017
[13] B Wuthrich V Cho S Leung D Permunetilleke K Sankaranand J Zhang ldquoDaily stock market forecast from textual Webdatardquo in Proceedings of the 1998 IEEE International Confer-ence on Systems Man and Cybernetics (Cat No98CH36218)SMCrsquo98 vol 3 pp 2720ndash2725 October 1998
[14] G Pui Cheong Fung J Xu Yu and W Lam ldquoStock predictionintegrating text mining approach using real-time newsrdquo inProceedings of the 2003 IEEE International Conference on Com-putational Intelligence for Financial Engineering CIFEr 2003vol 2003 pp 395ndash402 China March 2003
[15] W Antweiler and M Z Frank ldquoIs all that talk just noise theinformation content of internet stock message boardsrdquo SSRNElectronic Journal 2001
[16] M-A Mittermayer and G F Knolmayer ldquoNewsCATS A newscategorization and trading systemrdquo in Proceedings of the 6thInternational Conference onDataMining ICDM2006 pp 1002ndash1007 China December 2006
[17] R P Schumaker and H Chen ldquoTextual analysis of stockmarket prediction using breaking financial news theAZFin textsystemrdquo ACM Transactions on Information and Systems pp 1ndash29 2009
[18] S S Groth and J Muntermann ldquoAn intraday market riskmanagement approach based on textual analysisrdquo DecisionSupport Systems vol 50 no 4 pp 680ndash691 2011
[19] T Vu S Chang Q Ha and N Collier ldquoAn experiment in inte-grating sentiment features for tech stock prediction in twitterrdquoin Proceedings of the Workshop on Information Extraction AndEntity Analytics on Social Media Data vol 3 pp 23ndash38 2012
[20] B Wang H Huang and X Wang ldquoA novel text miningapproach to financial time series forecastingrdquo Neurocomputingvol 83 pp 136ndash145 2012
[21] Q Li T Wang P Li L Liu Q Gong and Y Chen ldquoThe effectof news and public mood on stock movementsrdquo InformationSciences vol 278 pp 826ndash840 2014
[22] T H Nguyen K Shirai and J Velcin ldquoSentiment analysis onsocial media for stock movement predictionrdquo Expert Systemswith Applications vol 42 no 24 pp 9603ndash9611 2015
[23] BWengM A Ahmed and FMMegahed ldquoStockmarket one-day ahead movement prediction using disparate data sourcesrdquoExpert Systems with Applications vol 79 pp 153ndash163 2017
[24] J Eberhard J F Lavin and A Montecinos-Pearce ldquoA network-based dynamic analysis in an equity stock marketrdquo Complexityvol 2017 Article ID 3979836 16 pages 2017
[25] Z Zhang Y Zhang D Shen and W Zhang ldquoThe dynamiccross-correlations between mass media news newmedia newsand stock returnsrdquo Complexity vol 2018 11 pages 2018
[26] P C Tetlock ldquoGiving content to investor sentiment The role ofmedia in the stock marketrdquo Journal of Finance vol 62 no 3 pp1139ndash1168 2007
[27] K Chen P Luo L Liu andW Zhang ldquoNews search and stockco-movement Investigating information diffusion in the finan-cial marketrdquo Electronic Commerce Research and Applicationsvol 28 pp 159ndash171 2018
[28] F Z Xing E Cambria and Y Zhang ldquoSentiment-awarevolatility forecastingrdquo Knowledge-Based Systems vol 176 pp68ndash76 2019
[29] A Picasso S Merello Y Ma L Oneto and E CambrialdquoTechnical analysis and sentiment embeddings formarket trendpredictionrdquo Expert Systems with Applications vol 135 pp 60ndash70 2019
[30] A Khadjeh Nassirtoussi S Aghabozorgi T Ying Wah and DC L Ngo ldquoText mining for market prediction a systematicreviewrdquo Expert Systems with Applications vol 41 no 16 pp7653ndash7670 2014
[31] M Kraus and S Feuerriegel ldquoDecision support from financialdisclosures with deep neural networks and transfer learningrdquoDecision Support Systems vol 104 pp 38ndash48 2017
[32] H S Sim H I Kim and J J Ahn ldquoIs deep learning for imagerecognition applicable to stockmarket predictionrdquoComplexityvol 2019 10 pages 2019
Complexity 15
[33] M Jasemi A M Kimiagari and A Memariani ldquoA modernneural network model to do stock market timing on the basisof the ancient investment technique of Japanese candlestickrdquoExpert Systems with Applications vol 38 no 4 pp 3884ndash38902011
[34] A Fader S Soderland and O Etzioni ldquoIdentifying relations foropen information extractionrdquo in Proceedings of the Conferenceon Empirical Methods in Natural Language Processing EMNLP2011 pp 1535ndash1545 Association for Computational LinguisticsUK July 2011
[35] T Mikolov K Chen G Corrado and J Dean ldquoEfficientestimation of word representations in vector spacerdquo pp 1ndash122013 httpsarxivorgabs13013781
[36] X Lin Z Yang and Y Song ldquoIntelligent stock trading systembased on improved technical analysis and Echo State NetworkrdquoExpert Systems with Applications vol 38 no 9 pp 11347ndash113542011
[37] K-J Kim and I Han ldquoGenetic algorithms approach to featurediscretization in artificial neural networks for the prediction ofstock price indexrdquo Expert Systems with Applications vol 19 no2 pp 125ndash132 2000
[38] Y Yu W Duan and Q Cao ldquoThe impact of social andconventional media on firm equity value A sentiment analysisapproachrdquoDecision Support Systems vol 55 no 4 pp 919ndash9262013
[39] MHagenauM Liebmann andDNeumann ldquoAutomated newsreading Stock price prediction based on financial news usingcontext-capturing featuresrdquo Decision Support Systems vol 55no 3 pp 685ndash697 2013
[40] A Aizawa ldquoAn information-theoretic perspective of tf-idfmeasuresrdquo Information Processing amp Management vol 39 no1 pp 45ndash65 2003
[41] A Khadjeh Nassirtoussi S Aghabozorgi T Ying Wah and DC Ngo ldquoText mining of news-headlines for FOREX marketprediction a Multi-layer dimension reduction algorithm withsemantics and sentimentrdquo Expert Systems with Applications vol42 no 1 pp 306ndash324 2015
[42] D Peramunetilleke and R K Wong ldquoCurrency exchange rateforecasting from news headlinesrdquo Australian Computer ScienceCommunications vol 24 no 2 pp 131ndash139 2002
[43] Y Kim ldquoConvolutional neural networks for sentence classifica-tionrdquo 2014 httpsarxivorgabs14085882
[44] ZWang J Zhang J Feng and Z Chen ldquoKnowledge graph andtext jointly embeddingrdquo in Proceedings of the 2014 Conferenceon Empirical Methods in Natural Language Processing EMNLP2014 pp 1591ndash1601 Qatar October 2014
[45] J Xu X Qiu K Chen and X Huang ldquoKnowledge graphrepresentation with jointly structural and textual encodingrdquo inProceedings of the 26th International Joint Conference on Arti-ficial Intelligence IJCAI 2017 pp 1318ndash1324 Australia August2017
[46] R Xie Z Liu J Jia H Luan and M Sun ldquoRepresentationlearning of knowledge graphs with entity descriptionsrdquo in Pro-ceedings of the 30th AAAI Conference on Artificial IntelligenceAAAI rsquo16 pp 2659ndash2665 February 2016
[47] F Tian B Gao E Chen and T Liu ldquoLearning better wordembedding by asymmetric low-rank projection of knowledgegraphrdquo Journal of Computer Science and Technology vol 31 no3 pp 624ndash634 2016
[48] F Z Xing E Cambria and R E Welsch ldquoNatural languagebased financial forecasting a surveyrdquo Artificial IntelligenceReview vol 50 no 1 pp 49ndash73 2018
[49] C Goutte and E Gaussier ldquoA probabilistic interpretation ofprecision recall and F-score with implication for evaluationrdquoin Advances in Information Retrieval D E Losada and J MFernandez-Luna Eds vol 3408 of Lecture Notes in ComputerScience pp 345ndash359 Springer Berlin Germany 2005
Hindawiwwwhindawicom Volume 2018
MathematicsJournal of
Hindawiwwwhindawicom Volume 2018
Mathematical Problems in Engineering
Applied MathematicsJournal of
Hindawiwwwhindawicom Volume 2018
Probability and StatisticsHindawiwwwhindawicom Volume 2018
Journal of
Hindawiwwwhindawicom Volume 2018
Mathematical PhysicsAdvances in
Complex AnalysisJournal of
Hindawiwwwhindawicom Volume 2018
OptimizationJournal of
Hindawiwwwhindawicom Volume 2018
Hindawiwwwhindawicom Volume 2018
Engineering Mathematics
International Journal of
Hindawiwwwhindawicom Volume 2018
Operations ResearchAdvances in
Journal of
Hindawiwwwhindawicom Volume 2018
Function SpacesAbstract and Applied AnalysisHindawiwwwhindawicom Volume 2018
International Journal of Mathematics and Mathematical Sciences
Hindawiwwwhindawicom Volume 2018
Hindawi Publishing Corporation httpwwwhindawicom Volume 2013Hindawiwwwhindawicom
The Scientific World Journal
Volume 2018
Hindawiwwwhindawicom Volume 2018Volume 2018
Numerical AnalysisNumerical AnalysisNumerical AnalysisNumerical AnalysisNumerical AnalysisNumerical AnalysisNumerical AnalysisNumerical AnalysisNumerical AnalysisNumerical AnalysisNumerical AnalysisNumerical AnalysisAdvances inAdvances in Discrete Dynamics in
Nature and SocietyHindawiwwwhindawicom Volume 2018
Hindawiwwwhindawicom
Dierential EquationsInternational Journal of
Volume 2018
Hindawiwwwhindawicom Volume 2018
Decision SciencesAdvances in
Hindawiwwwhindawicom Volume 2018
AnalysisInternational Journal of
Hindawiwwwhindawicom Volume 2018
Stochastic AnalysisInternational Journal of
Submit your manuscripts atwwwhindawicom

Complexity 3
Financial news
DATARETRIEVAL
PRE-PROCESSING
MODEL CREATIONamp PREDICTION
MODELAPPLICATION
Corpus
Stock data Data
Feature News-stock
Machine learningmodel creation
Modelevaluation
Decisionmaking
mappingrepresentation
Featureselection
transformation
Figure 1 Research workflow for machine learning and knowledge graph
Figure 2 Example of collected financial news in CNN
4 Complexity
Table 1 A review of financial expert system ANN NB KNN SVM DT and SVR stand for artificial neural network naive Bayes k nearestneighbors support vector machine decision tree and support vector regression respectively Measure metrics mean squared error (MSE)root mean square error (RMSE) area under the curve (AUC)
Paper Text type Feature extraction Model type Performancemeasure
[13] Professional newspaper Stock data NB Accuracy[14] Professional newspaper Stock data SVM Accuracy
[15] Message board Stock data Regression Correlationcoefficient
[16] PRNewswire Stock data KNN SVM Accuracy F1-score
[17] Aggregate news Stock databag-of-words SVR MSE accuracy
[18] Corporate disclosures Stock databag-of-words Multiple Accuracy recall
precision F1-score
[19] Financial news Stock datasentiment DT Accuracy recall
precision F1-score
[20] Web media Stock databag-of-words SVR Accuracy recall
precision F1-score
[21] Mixed typeStock data
bag-of-wordssentiment
SVR RMSE accuracyprecision
[22] Message board Stock datasentiment SVM Accuracy
[23] Mixed typeStock data
technical indicatorssentiment
ANN SVM DTAccuracy AUCF1-score precision
[24] None Stock data Regression Correlationcoefficient
[25] Media news Stock data Regression Correlationcoefficient
Our financial expert system Financial newsStock data
technical indicatorsbag-of-words
syntax
Multiple Accuracy F1-score
Tetlock [26] adopted the popular news from the Wall StreetJournal to find that news sentiment has predictive power oncompany stocks Chen et al [27] found information comen-tions have a significant influence on the stock return throughsentiment analysis Furthermore the investorsrsquo sentimenttrends after the positive news which results in a buying trendand higher stock market prices while after negative newsstocks are sold result in a decrease of the price Howeversentiment analysis can only be employed in specific textsIf sentiment is implicit rather than direct emotional wordsthen the ability of using sentiment analysis for predicting thestock price of the renowned company is relatively limitedMittermayer and Knolmayer [16] illustrated that news-CATSachieves a performance that is superior to that of otherATC prototypes used to forecast stock price trends Li et al[21] proposed a media-aware quantitative trading strategy byusing sentiment information on web media The simulationtrading return was up to 16611 Nguyen et al [22] proposeda feature topic sentiment to improve the performance of stockmarket prediction Their method achieved an accuracy thatis 983 better than that of the historical price method and303 better than that of the human sentiment method
We utilize the characteristics of syntax analysis as beingproposed in [6 12] namely a structured tuple is extractedfrom an unstructured text based on the semantic structureof each piece of news Knowledge graph can enrich thestructured representation of the news event and effectivelyretain feature vectors for the news event The main featureextraction in the previous studies [28 29] is sentimentanalysis which neglected the event characteristics in thetext Furthermore the existing literature [23 29] had provedthe positive effect of technical indicators on stock marketprediction In summary our research highlights syntax anal-ysis in financial news which also incorporates with otherfeatures extraction (stock data technical indicators and bag-of-words) Because of the variety of considered features thisresearch will deliver an improved prediction of the stockmarket value for renowned companies in at least 36
Previous research [30] was applied with the traditionalmachine learning algorithms especially since the power-ful application ability of deep learning based on machinelearning Deep learning is utilized in several studies forpredicting stock price movement Kraus and Feuerriegel [31]forecasted the stock returns based on financial disclosures
Complexity 5
Table 2 Quotes and renowned company names
Financial newsdataset Stocks Company names Time interval Number of news
headlinesAAAL Apple Inc 3102011- - -3172017 6423
Thomson Reuters MSFT Microsoft Corporation 3092011- - -29112017 6623SSNLF Samsung Electronics Co Ltd 3092011- - -29112017 6900BA The Boeing Company 891998- - -2322017 2999
CNN GOOG Google Inc 2552006- - -2422017 5278WMT Walmart Inc 751997- - -2422017 4913
Table 3 Samples extracted from the dataset
Date News headline News headline event tuple3182012 Chinese writersrsquo group sues Apple state media Chinese writersrsquo group sues Apple
4132012 German court upholds ban on Apple push email German court upholds ban on Apple pushemail
442012 Apple two publishers hold out againstsettlement-report
Apple- two publishers hold out againstsettlement-report
3262012 Apple CEO Cook meets Chinese officials Apple CEO Cook meets Chinese officials
4252012 US STOCKS-Apple results put Nasdaq on track for bestgain of year Apple results Nasdaq on track for best gain
and their result demonstrated that a higher directional ofdeep learning surpasses traditional machine learning Dinget al [5] illustrated that deep learning also can forecaststock market of the renowned company Sim et al [32]proposed that technical indicators transform into images ofthe time series graph which examines the applicability ofdeep learning in the stock market Overall we adopt themultiple models for prediction stock price of the renownedcompany which proves the reliability of our proposed modelas comparing different algorithms This work applies deeplearning incorporated with knowledge graph embeddingfor feature extraction which examines the applicability ofcombined features methods in the renowned company stockprice movement
3 Materials and Methods
We developed a knowledge graph-based approach that con-sists of three steps namely data description data preprocess-ing and feature selection
31 Dataset Description Table 2 shows the custom financialnews corpus built with headlines from two datasets The firstdataset contains news articles published byThomsonReutersincluding those regarding Apple Inc (AAPL) MicrosoftCorporation (MSFT) and Samsung Electronics Co Ltd(SSNLF) The second dataset comprises news reports pub-lished in CNN including reports on the Boeing Company(BA) Google Inc (GOOG) and Walmart Inc (WMT) Italso consists of financial news headlines published at specifictime intervals with each news report accompanied by a titleand a release date Titles are used for event embedding andfeature extraction and release dates are used as a referencein ensuring alignment between corresponding financial news
and trading data from a time series As shown in previouswork [5 31] using a headline to build corpora can helpreduce noise in text mining as headlines concisely representthe content of a text We used only the news headlines fromReuters andCNN for the prediction of stock pricemovement
Daily stock data from index report in each company arecollected by Yahoo Finance in the same period during stockdata and financial news headlines Daily trading data whichare common predictors of stock price [23 33] and technicalindicator features were used in our model There are openingprice closing price high price low price and volume andthree technical indicators
Table 3 shows some examples of filtered financial newsheadlines To illustrate 6423 headlines regarding Apple Incwere extracted and then reduced to 2799 headlines afterfiltering via Reverb [34] Let us take the article ldquoWhat is nextfor Applersquos boardrdquo published on 6 October 2011 as a specificexample The title of the article cannot be transformed intoan event tuple using Reverb Because the sentence is in theinterrogative form there is no event tuple that constitutes arule After the matching of time-wise data and stock data941 headlines were left Daily news and stock data werealigned to create input-output pairs except the days whenno news was released In 9 January 2012 for instance threenews articles were reported but we chose only one headlinefor alignment with stock market data News events possiblyhappen several times within one day but they do not happenevery day unlike stock trading which happens daily excepton nontrading days falling on weekends or holidays
Table 4 shows that the matches found are pairs betweenevent tuples and stock data From this complete dataset weused 80 of the samples in training data and the remaining20 for testing dataThis selection method is the same as theprevious literature [5 24]
6 Complexity
Table 4 Training and testing datasets
Data source Company Training Testing TotalApple 780 161 941
Reuters Microsoft 832 208 1040Samsung 855 214 1069Boeing 528 132 660
CNN Google 1010 252 1262Walmart 798 200 998
Table 5 Number of event characteristic labels for each company
CompaniesLabel Apple Microsoft Samsung Boeing Google Walmart0 502 967 1433 133 661 2061 537 432 379 200 245 2872 661 557 378 152 389 2333 692 707 724 233 683 4384 407 228 193 147 196 180Total 2799 2891 3107 865 2174 1344
Table 6 Features of the prediction model
Feature Feature expression1 Stock price yesterday + yesterdayrsquos trend (in Section 331) 119901119903119894119888119890
119905minus1 119905 119894119899119889119894119888119886119905119900119903119905minus1
2 Same + bag-of-words (in Section 332) 119901119903119894119888119890119905minus1
119905 119894119899119889119894119888119886119905119900119903119905minus1 119905119891 119894119889119891119905minus1
3 Same + some features inferred through a convolutional neural network (in Section 333) 119901119903119894119888119890119905minus1
119905 119894119899119889119894119888119886119905119900119903119905minus1 119888119899119899119905minus14 Same + some features inferred through feature combination (in Section 334) 119901119903119894119888119890
119905minus1 119905 119894119899119889119894119888119886119905119900119903119905minus1 119891 119888119900119898119887119894119899119890
119905minus1
32 Data Preprocessing The following three steps are forpreprocessing which prepares for feature extraction andmodel creation
(1) Tagging the label for each news headline Five possiblelabels are characterized by categorical values as follows 0for an extremely negative label 1 for a negative label 2 tosignify a neutral label 3 for a positive label and 4 to denote anextremely positive label According to the time characteristicsof each news headline an event is manually tagged withthe label for each news headline Table 5 shows the labelingapplied for each company Label 0 means that a companyrsquoscompetitor has happened in this event label 1 means that thecompany lost something label 2 means that it did not causeany impact on the company label 3 means that this eventenabled the company to obtain something and label 4 meansthat the company increased its profits or created more value
(2) Word vector transformation We used the word2vec[35] algorithm to train word embedding and set the numberof dimensions to 300 The word embedding was also trainedusing the Google News dataset which contains 100 billionwords that are characterized by a continuous bag-of-wordsstructure
(3) Technical indicators calculation Three additionaltechnical indicators that are calculated on the basis of dailytrading data were used as follows
(a) Stochastic oscillator (K)This indicator is a momen-tum analysis method created by George C Lane When the
price trend rises the closing price tends to approach thehighest price of the day When the price trend declines theclosing price tends to approach the lowest price of the day[36]
(b) Larry Williamss R indicator This indicator is anoscillation indicator that measures the ratio of the highestprice to the daily closing price It indicates the proportion ofstock price fluctuations in a certain period thereby providinga signal out of the reversal of a stock market trend [37]
(c) Relative strength index (RSI) Buying and sellingintentions in the market are analyzed by comparing theclosing prices in a given period Stocks that have had moreor stronger positive changes have a higher RSI than do thosethat have had more or stronger negative changes Strengthindicators fall between 0 and 100 investors sell if this valueis ge 80 and buy if it is le 20 [23 36]
33 Variable Feature Selection To assess the effectivenessof applying the prediction model on the basis of financialnews we designed four sets of features for predicting stockprice movement (Table 6) Features 3 and 4 are used for eventcharacteristics Each feature is explained in the succeedingsubsections The target output consists of a binary variablefor which a value of 1 indicates that the closing price at day t+ 1 will be higher than that at day t and a value of 0 indicatesthat the closing price at day t + 1will be lower than that at dayt
Complexity 7
Financial news
middot middot middot
News representation Convolutional layer Max pooling Fully connected layer Features
X (I)
Z (I)
Figure 3 Convolutional neural network architecture proposed for feature selection
331 Stock Data Only We considered historical price as theinput for predicting stock price movement and used it asa baseline for comparison with other sets of features Thefeatures used to train the machine learning model that usesonly stock data are 119901119903119894119888119890119905minus1 and 119905 119894119899119889119894119888119886119905119900119903119905minus1 The output isthe indicator of pricemovement (increase or decrease) at eachtransaction date examined
332 Bag of Words The input feature set is based on a bag ofwords for the news and price trend for stock Previous studies[18 38 39] have widely used and confirmed the feasibilityof the bag-of-words algorithm but this method disregardselements such as grammar and word order in the text Inthe present study we first prepared each headline for datapreprocessing and then transformed the preprocessed head-line into a feature vector using the term frequency-inversedocument frequency (TF-IDF) algorithm [40] which assignshighweight to eigenvectorsThe studies [41 42] have stronglyproven the effectiveness of the TF-IDF algorithm in featureextraction from news headlines It estimates the frequency ofa term in one document over the maximum in a collection ofdocuments and assesses the importance of aword in one set ofdocuments Such importance increases proportionally withthe number of word appearances in a documentThe featuresused to train the bag-of-words machine learning model are119901119903119894119888119890119905minus1 119905 119894119899119889119894119888119886119905119900119903119905minus1 and 119905119891 119894119889119891119905minus1 which are the pricemovements (increase or decrease) at each transaction dateexamined
333 Convolutional Neural Network Given the sequence ofwords in a headline the word2vec model [35] can be usedto embed each of these words in a real valued-vector 119909 Inthis work we set the dimension 119899 of each word vector at30 (ie 119909 isin R30) We concatenated the word vectors of allthe words in a headline sequentially to form a matrix 119883 =[119909(1) 119909(2) 119909(3) 119909(4)] [35] as the input to a convolutionalneural network model For a headline with 119873 words the
resultant input matrix has dimensions of 30 times 119873 and thedimension of news representation also is 30
In Figure 3 this convolutional neural network model ismade up of four consecutive layers the first layer is theinput the second layer is convolutional the third layer is amax-pooling and the last layer is a fully connected layerThe convolutional and max-pooling layers were designedusing the text-attentional convolutional neural network [43]which effectively carries out sentiment classification In theconvolutional layer input matrix X convolves with a kernel119908 isin R119899times119896 where n is the size of a word vector (30 inour work) and its dimension is 50 k denotes the size of asliding window (k=3 in this study) The computation can beformulated as follows
119885119894 = 120590 (119908119883119894119894+119896minus1 + 119887) (1)
where 119883119894119894+119896minus1 = [119909119894 119909119894+1 119909119894+119896minus1] is the portion of input119883 falling within the sliding window 119887 denotes the optionaloffset and 120590(sdot) is the sigmoid function
In the next step we used the pooling layer to reduce theconvolutional neural networks parameter space and conse-quently minimize information loss in the pooling processingand capture the most important features The eigenvectorof the filter in the pooling layer is cut into 3 chunks anda maximum value is taken in each chunk we obtained 3eigenvalues Convolutional output vector Z was split into pwindows and only themaximum feature as 3 in each windowwas kept for passage onto the final fully connected layer Thefully connected layer is linear regression and the output layeris the feature classification between 0 and 1
Our convolutional neural network model is intended toextract a feature vector from the fully connected layer todescribe the emotional characteristics of input headlinesFollowing the intuition that a good feature vector shouldlead to the accurate classification of the event characteristicsof headlines we attached a softmax layer after the fully
8 Complexity
The United Kingdom of Great Britain and Northern Ireland commonly known as the United Kingdom or Britain hellip
London is the capital city of England and of the United Kingdom It is the most populous region hellip
Head Relationship TailLondon location country capital United Kingdom
London is the caEngland and of Kingdom It is tpopulous region
Kingdom of GreatNorthern Ireland known as the United
Britain hellip
Figure 4 Text description of the entity
connected layer when the convolutional neural networkmodel was trained The entire model was trained to classifythe five emotional labels that describe event characteristicsand the resultant model will be able to provide a mean-ingful emotional feature vector for each inputted headlineMeanwhile we define the loss function of the convolutionalneural network model as 119864119889 The features used to trainthis machine learning model are 119901119903119894119888119890119905minus1 119905 119894119899119889119894119888119886119905119900119903119905minus1and 119888119899119899119905minus1 which are the price movements (increase ordecrease) at corresponding transaction date
334 Combined Features In the introduction section of thispaper we described various translation models Because theTransE model represents a one-to-one relationship betweentwo entities [7] the relationship amongst many entities mustbe continuously incorporated into texts and knowledge graph[44] This model combines a convolutional neural networkwith textual information extraction which fully exploits thesemantic information in a knowledge graph and text [45 46]In Figure 4 knowledge graph contains rich semantics inentity description texts but it is not fully utilized in featureextraction Most of the existing text representation modelssimply train the text into word vectors through word2vecwhich obtains the text representation by means of averagingetc Hence these ways often lose more semantic informationWe therefore proposed to extract feature vectors from newstexts using a convolutional neural network model combinedwith the TransE model which also fully integrates the twoparts of the feature information
In Figure 5 this architecture used in the feature combina-tion model encompasses two parts namely a convolutionalneural network (Section 333) and the TransE model Thefeature combination sets are the average of each word vectorin an entity and it was obtained using the word2vec modelThe two entity vectors are mapped into the same relationalspace and these entities using a trained low-rank weightmatrix [47]
As assumed in the TransE model relationship vector Rshould satisfy ldquoE + R asymp Trdquo The model can be representedas a parameter set 0 = (119871119903 119877119903 120579) where X E and R
represent a word an entity and a relation respectively Andr are the mapping matrices for entities in the structuralmodel and represents the weights of the convolutional neuralnetwork For instance the sentence is ldquoSamsung sues Apple forinfringementrdquo so ldquoSamsung +Appleasymp suesrdquoThe loss function119864119904 of this structural model is defined as follows
119864119904 = ℎ + 119903 minus 11990522 (2)
where h r and t represent head entity relationship and tailentity in event tuple respectively [47]
And text representation 119864119889 is consistent withSection 333 which denotes
119864119889 = 119891119903 (ℎ119904 119905119889) + 119891119903 (ℎ119889 119905119904) + 119891119903 (ℎ119889 119905119889) (3)
where119891119903(ℎ119889 119905119889) = ℎ119889+119903minus11990511988922 represents the head entity andthe tail entity is in text representation119891119903(ℎ119889 119905119904) = ℎ119889+119903minus11990511990422and 119891119903(ℎ119904 119905119889) = ℎ119904 + 119903minus 11990511988922 represent one of the head entityh and the tail entity t in text representation another one is instructure representation
Moreover we combined two types of representationlearning (convolutional neural network and feature combi-nation) to map news titles these vectors will be into featurevectors The relationship vector R identical to the resultof the feature extraction layer of the convolutional neuralnetwork in the structural model Besides we combined thisloss with the classification loss of the convolutional neuralnetwork using L2 regularization which obtains the overallloss function 119864 for feature selection that is
119864 = 119864119904 + 120572119864119889 + 120573 02 (4)
where 02 is a regular item 120572 and 120573 are hyperparameterswhich measure the loss of text information and the weight ofthe regular items respectively W denotes the convolutionalkernels in the layer and 1198791015840 is a negative sample set of 119879 [7]
1198791015840 = (ℎ1015840 119903 119905) | ℎ1015840 isin 119864 cup (ℎ 119903 1199051015840) | 1199051015840 isin 119864
cup (ℎ 1199031015840 119905) | 1199031015840 isin 119877 (5)
Complexity 9
Output layerClass1 Class2
Machinelearning
Max pooling
convolutional
Input news
Feature vector
Embedding layer
Input news
Event tuple
Word2vec
Word2vec
Fully connection
Stock data
Stock layer
TransE model
Figure 5 Proposed architecture for the feature combination model
where the head entity and tail entity are randomly replaced byan entity or relationship in another tuple In particular if thereplaced tuple is already in T it would not be added to thenegative sample Since both h and t represent two types ofentities there are structure-based representations and text-based representations in interval-based loss functions Thestochastic gradient descent (SGD) is employed to minimizethe above loss function
In this structure we choose the optimal parameters asfollowe the learning rate of SGD 120582 = 0001 the dimension ofthe representation vector of entities and relationships k = 100the word vector dimension of the entity description text n =100 and batch size during training is 1440 Convolution layerwindow size is 119882 isin 1 2 3 This experiment is performedin 1000 iterations of training and the optimal parameters arebased on the testing set
Hence the features used for training the machine learn-ing model are 119901119903119894119888119890119905minus1 119905 119894119899119889119894119888119886119905119900119903119905minus1 and 119891 119888119900119898119887119894119899119890119905minus1which are the price movement (increase or decrease) atcorresponding transaction date
4 Experiments and Results
41 Experimental Setting This section compares the perfor-mance of differentmodels in feature extraction fromfinancialnews expended with full sets of features The evaluationwas intended to obtain evidence that the proposed featurecombination model is superior to other feature selectionmodels in predicting the stock price movement As shownin Table 7 we chose linear models for instance logisticalregression and naive Bayes Others are nonlinear models forinstance the ensemble learning (random forest adaboostand gradient boosting) for the comparison We constantlyadjusted the parameters in the grid search and selected theoptimal parameter value their parameter value has proven towork well on machine learning method [29 48]
We used a computer consisting of an Intel Core i5processor with four cores running at 29 GHz and 8 GBRAM under the MacOS platform We used the Scikit-learnlibrary in Python in the experiments involving traditionalmachine learning algorithms and TensorFlow 14 in the
10 Complexity
Table 7 List of machine learning methods
Method Classification Parameter and their value
Traditionalmachinelearning
Decision tree (DT)Criterion= gini splitter= best max depth=None minsamples split=2 min samples leaf =1 min weight
fraction leaf=00Logistical regression (LR) Random state=1
Naive Bayes (NB) No kernel estimatorStochastic gradient descent (SGD) Loss=hinge penalty=l2
Support vector machine (SVM) Polynomial kernel function with exponent = 1 2 RBFkernel function with gamma = 001
Ensemblelearning
Random forest (RF) Randomly sampled as candidates at each split = log2 +1 max-depth=2 random state=0
AdaBoost (AB) Polynomial kernel function with exponent = 1 2 RBFkernel function with gamma = 001 n- estimators=100
Gradient boosting (GB) N-estimators =100 learning rate =10 max-depth=1random state=0
Table 8 Abbreviations of the results for each algorithm considered
Algorithms Stock data (SD) Bag of words (BOW) Convolutionalneural network
Featurecombinationmodel (FC)
DT DT 1 DT 2 DT 3 DT 4LR LR 1 LR 2 LR 3 LR 4NB NB 1 NB 2 NB 3 NB 4SGD SGD 1 SGD 2 SGD 3 SGD 4SVM SVM 1 SVM 2 SVM 3 SVM 4RF RF 1 RF 2 RF 3 RF 4AB AB 1 AB 2 AB 3 AB 4GB GB 1 GB 2 GB 3 GB 4
experiments involving deep learning and the TransE modelThe abbreviations used for comparing classification perfor-mance are presented in Table 8 During testing 2-fold cross-validation is applied to evaluate the stability of the modelsAnd we compared performance in predicting stock pricemovement for the next day with a test dataset and evaluatedthe performance of the models in terms of accuracy and F1-score [49]
42 Results
421 Thomson Reuters Case Study Thomson Reuters isa multinational mass media and information firm Threerenowned companies on the website were selected for theanalysis The first is Apple Inc which is an American multi-national technology company that designs develops andsells consumer electronics computer software and onlineservices The second company selected is Microsoft which isan American multinational technology company that devel-ops manufactures supports and sells computer softwarepersonal computers and other services The last companychosen is Samsung which is a South Korean multinationalelectronics company We considered data from these threetypical technology companies for our problem
Measurements of average accuracy are shown in Table 9and the results for each renowned company with respectto prediction based on different features are illustrated inFigure 6 We calculated the average of the four feature con-struction approaches for eachmodel for comparison amongstthe three companies The proposed feature combinationmodel generated the best results achieving average accuracylevels of 6163 5918 and 5848 forAppleMicrosoft andSamsung respectively These figures are consistent with therates reported in previous research However many studiesanalyzed only one company or used only one algorithmThe current research probed into three companies on thebasis of information from a common data source to builda prediction model with different feature selection func-tionalities and different algorithms We used stock dataa bag-of-words algorithm a convolutional neural networkand feature combination together with eight algorithms Asindicated in Table 9 the proposed predictionmodel achieved7368 data extraction with the use of LR 4 for Apple and6778 data extraction with the use of SVM 4 for MicrosoftIn particular the LR algorithm used for Apple achievedaccuracy and F1-score of 07326 and 07360 respectivelywhich highlights its powerful capability in a two-class classifi-cation
Complexity 11
Table 9 Results for data extracted fromThomson Reuters
Algorithm Company Stock data(SD)
Bag of words(BOW)
Convolutionalneural network
Feature combinemodel (FC)
AccuracyF1-score
AccuracyF1-score
AccuracyF1-score
AccuracyF1-score
DTApple 0499305079 0488902460 0615005814 0652406486
Microsoft 0486801819 0506505682 0581705915 0658706502Samsung 0470704033 0565405830 0552906820 0568006260
LRApple 0524006727 0505505083 0684506911 0732607368
Microsoft 0475701253 0443004884 0527405333 0546705611Samsung 0494703755 0605406726 0654106343 0805307978
NBApple 0510905123 0477803896 0502704497 0512204030
Microsoft 0484000363 0455704055 0459902889 0500005439Samsung 0529305810 0514406130 0504806578 0511706601
SGDApple 0467201119 0477804404 0497406008 0536602692
Microsoft 0517306819 0485203222 0610304231 0610804193Samsung 0522306541 0476602000 0518706751 0557106548
SVMApple 0502206121 0574705542 0615006129 0622006173
Microsoft 0478401722 0443904566 0523205462 0687506798Samsung 0500803875 0504705508 0513506281 0535206574
RFApple 0524006554 0527806083 0533706232 0620306243
Microsoft 0484002653 0417701687 0532502432 0572105189Samsung 0487203480 0448501194 0476603708 0505205481
ABApple 0534305384 0472202963 0481903333 0620305420
Microsoft 0468702041 0476800461 0614706044 0620206146Samsung 0485703619 0457902368 0601006820 0633806549
GBApple 0531405129 0466702941 0609604748 0634106591
Microsoft 0474302125 0472801007 0455704557 0538502258Samsung 0487204171 0519206599 0533706572 0562206335
Reuters
Aver
age a
ccur
acy
0
01
02
03
04
05
06
07
Different companyApple Microsoft Samsung
SDBOW
CNNFC
Figure 6 Average accuracy of prediction based on different featuresets for each company in Reuters
To assess the effectiveness of our research we comparedthe feature combination model that uses event tuples with
the stock data approach and the bag-of-words algorithmTheresults showed that the average accuracy of the event tuple-basedmodel is better than that of the stock data approach andthe bag-of-words algorithm by 1001 and 1087 respec-tively We also compared feature extraction using the stockdata approach the bag-of-words algorithm and machinelearning The use of deep learning improved predictionaccuracy by 525 and 611 over the levels achieved withstock data and bag of words respectively Therefore we canconclude that using the proposed feature combinationmodeland deep learning in feature extraction helps improve theaccuracy with which stock price movement is predictedThese results also fully prove the effectiveness of embeddinglayer in feature extraction accuracy improvement
422 CNN Case Study CNN is an American basic cableand satellite television news channel owned by the TurnerBroadcasting System Three renowned companies on whichthese website reports were selected for the analysis The firstis Boeing which is an American multinational corporationthat designs manufactures and sells airplanes rotorcraftrockets and satellites worldwide The second company isGoogle which is an American multinational technology
12 Complexity
Table 10 Results for data extracted from CNN
Algorithm Company Stock data(SD)
Bag of words(BOW)
Convolutionalneural network
Featurecombinationmodel (FC)
AccuracyF1-score
AccuracyF1-score
AccuracyF1-score
AccuracyF1-score
DTBoeing 0495003489 0541306258 0541406347 0559105821Google 0485805600 0518203575 0569204631 0549105471Walmart 0499604422 0530004891 0508804815 0572205829
LRBoeing 0492302378 0511304348 0692306923 0759605733Google 0504106105 0623506491 0625006111 0656306516Walmart 0529005468 0541205083 0732007347 0771907720
NBBoeing 0516206503 0548905161 0519706738 0556407619Google 0511206527 0489905191 0558705281 0534404843Walmart 0504403284 0479405302 0520605674 0530006083
SGDBoeing 0489702407 0556404870 0543304727 0571407220Google 0516506769 0542504375 0578906364 0591006327Walmart 0500403804 0520605280 0525005581 0567005922
SVMBoeing 0489703068 0571406275 0538506418 0594007033Google 0507706297 0603206230 0574905532 0578905840Walmart 0511804333 0500005314 0520005000 0561405455
RFBoeing 0490601345 0511303925 0509605405 0527605714Google 0492301777 0603206260 0522305564 0595105763Walmart 0511805373 0530003188 0530004405 0500005446
ABBoeing 0494503404 0519705120 0496105294 0567305872Google 0487603141 0510106667 0589305619 0595106850Walmart 0507305029 0515005359 0549705650 0561905503
GBBoeing 0489903169 0511804364 0440904580 0500005094Google 0491203387 0587005854 0562505243 0603206202Walmart 0500304955 0505005123 0536105109 0549705650
company that specializes in Internet-related services andproducts The third is Walmart an American multinationalretail corporation that operates a chain of hypermarketsdiscount department stores and grocery stores
The results on average accuracy are shown in Table 10and Figure 7These findings are very similar to those derivedin the previous case study and their comparison confirmedthat the proposed feature combinationmodel can outperformother feature selection models in stock price movementprediction With regard to feature selection underlain bythe bag-of-words algorithm the CNN case study generatedmore robust results than did the Reuters case study Theaverage accuracy of the bag-of-words algorithm was lowerthan that of the stock data approach in the Reuters case studyIn the CNN case study the average accuracy levels of theproposed feature combination model were 5794 5879and 5767 for Boeing Google andWalmart respectively Inthe case study on Reuters an average accuracy that exceeds60 was not achieved for any of the companies illustratingthat differences in data source directly affect stock pricemovement
We chose a combination of deep learning and knowledgegraph to build our feature selection model because this
CNN
Aver
age a
ccur
acy
0
01
02
03
04
05
06
07
Different companyBoeing Google Walmart
SDBOW
CNNFC
Figure 7Average accuracy achieved on the basis of news fromCNNand different feature set
combination exhibited superior prediction performance inthe comparison experiments involving other feature selection
Complexity 13
strategies The forecast results based on different featuresare shown in Table 10 We found that deep learning featuresare better than the use of bag-of-words and stock data Thecorrelation of event tuples with the stock market is relativelyhigh in [5 31] but the bag-of-words algorithm was relativelyfragmented and the correlation between event tuples and thestockmarket data was relatively weak Combining event tuplefeatures with deep learning significantly improves forecastresults indicating a close relationship between stock marketmovements and knowledge graph
5 Discussion
51 Research Findings We attempted to compare our predic-tion results with those made in previous studies wherein pre-diction was also based on the financial news of the renownedcompanies However the findings are incomparable becausedifferent studies use different datasets or algorithms andthese methods are difficult to investigate using financial newsheadlines In the current research we refrained from eval-uating performance on one company dataset this decisionthat enabled our knowledge graphmethod to exceed baselinepredictions based only on the price by up to 36 Thisalso proves that feature extraction in deep learning is moreeffective than traditional machines The combination of deeplearning and knowledge graph fully integrates the semanticinformation in financial news which effectively predicts thestock price movement of the renowned company
This work demonstrated the application of deep learningand knowledge graph in finance To the best of our knowl-edge knowledge graph has been rarely applied in stock pre-diction Becauseminimal financial training sets in knowledgegraph are available financial knowledge extraction is themain task for the organizational construction of a knowledgegraph Such extraction is critical for the understanding andprocessing of deep semantics in the event tuple which alsodirectly influences the feature extraction of financial news
52 Implications for Business Activities Theutility of a featurecombination model based on knowledge graph is not limitedto financial analysis Currently knowledge graph data areavailable for medical diagnosis speech recognition precisemarketing and financial risk control [4] Our model couldalso be applied in these areas
Antifraud activities are an important part of financeApplying our model on the basis of knowledge graph oncustomers helps organize all relevant knowledge fragmentsthrough deep semantic analysis and reasoning which canbe verified with a customerrsquos bank information Moreovercustomers typically use keywords to search for productsand knowledge graph can provide relevant information toa customer If a complete knowledge system of users isdescribed and collected a system would better understandand analyze user behaviors
53 Limitations and Future Work A deep learning modeluses supervised learning and needs a dataset with sufficientlabels but our datasets do not work well with deep learningas a small number of financial news articles match stock
data At present knowledge graph embedding inevitablyproduces a loss in news semantics either because of a learningprinciple or the tokenization of knowledge representation forvectorization Thus continuous representation in a knowl-edge graph is still a huge challenge We attempted to applyregression using the above-mentioned algorithms but theresults indicated poor performance More specifically theresults for Apple validated our expectations
The application of large-scale knowledge graph is stillrelatively limited and knowledge graph for smart searchsmart question-and-answer tasks social media and otherareas are in their initial stages with considerable room forimprovement The following advantages of knowledge graphshould be considered (a) the effective organization andexpression of semistructured data (b) knowledge reasoningand (c) the expansion of cognitive ability for incorporatingdeep learning Traditional knowledge elements (entities rela-tionship attributes) extraction technologies and methodshave achieved good results in limited areas but because ofnumerous constraints and poor scalability knowledge graphis not fully functional for financial forecasting because ofnumerous constraints and poor scalability
6 Conclusions
Stock movement prediction of the renowned company is adaunting task because stock prices are affected by many fac-tors This research presented a novel method for integratingknowledge graph embedding with stock market predictionThe contributions of this study can be summarized as followsFirst we developed a novel feature combination model thatconstructs a feature mapping vector for each tuplendashnewspair by simultaneously considering the diversity of entitiesand relationships Second the feature combination modelwas successfully applied to different types of companies anddatasets and exhibited good performance in classificationtasks
Stock market prediction of the renowned companygrounded in knowledge graph is an interesting topic forbusiness activities Given that the study of knowledge graphfor feature set is still in its infancy we expect it to be appliedin a wide range of academic research More companies willalso earn profits and create more opportunities through theuse of knowledge graph in the feature set
Data Availability
The data used in this study can be accessed via httpsgithubcomlinechanyknowledge-graph
Conflicts of Interest
The author declares that there is no conflict of interestregarding the publication of this paper
Acknowledgments
This work is supported by the China Scholarship Council(CSC) throughout the grant number 201508390019 The
14 Complexity
authors also want to thank the research program RFCS fromthe EU which partially supported this research through theresearch project AutoSurveillance with project ID 847202
References
[1] B GMalkiel and E F Fama ldquoEfficient capital markets a reviewof theory and empirical workrdquo The Journal of Finance vol 25no 2 pp 383ndash417 1970
[2] D Galai and R W Masulis ldquoThe option pricing model and therisk factor of stockrdquo Journal of Financial Economics vol 3 no1-2 pp 53ndash81 1976
[3] Q Wang Z Mao B Wang and L Guo ldquoKnowledge graphembedding A survey of approaches and applicationsrdquo IEEETransactions on Knowledge and Data Engineering vol 29 no12 pp 2724ndash2743 2017
[4] H Paulheim and P Cimiano ldquoKnowledge graph refinement Asurvey of approaches and evaluation methodsrdquo Journal of WebSemantics Science Services and Agents on the World Wide Webvol 8 no 3 pp 489ndash508 2016
[5] X Ding Y Zhang T Liu and J Duan ldquoDeep learning for event-driven stock predictionrdquo in Proceedings of the 24th InternationalJoint Conference on Artificial Intelligence IJCAI 2015 pp 2327ndash2333 Argentina July 2015
[6] X Ding Y Zhang T Liu and J Duan ldquoKnowledge-drivenevent embedding for stock predictionrdquo in Proceedings of the26th International Conference on Computational LinguisticsCOLING 2016 pp 2133ndash2142 Japan December 2016
[7] A Bordes N Usunier J Weston and O Yakhnenko ldquoTranslat-ing embeddings for modeling multi-relational datardquo Advancesin NIPS vol 26 pp 2787ndash2795 2013
[8] H Lin Y Liu W Wang Y Yue and Z Lin ldquoLearning entityand relation embeddings for knowledge resolutionrdquo ProcediaComputer Science vol 108 pp 345ndash354 2017
[9] G Ji K Liu S He and J Zhao ldquoKnowledge graph completionwith adaptive sparse transfer matrixrdquo in Proceedings of the 30thAAAI Conference on Artificial Intelligence AAAI 2016 pp 985ndash991 USA February 2016
[10] G Ji S He L Xu K Liu and J Zhao ldquoKnowledge graphembedding via dynamic mapping matrixrdquo in Proceedings ofthe 53rd Annual Meeting of the Association for ComputationalLinguistics and the 7th International Joint Conference on NaturalLanguage Processing (Volume 1 Long Papers) pp 687ndash696Beijing China July 2015
[11] Y LeCun Y Bengio and G Hinton ldquoDeep learningrdquo Naturevol 521 no 7553 pp 436ndash444 2015
[12] Q Li Y Chen J Wang and H Chen ldquoWeb media andstock markets a survey and future directions from a bigdata perspectiverdquo IEEE Transactions on Knowledge and DataEngineering vol 4347 p 1 2017
[13] B Wuthrich V Cho S Leung D Permunetilleke K Sankaranand J Zhang ldquoDaily stock market forecast from textual Webdatardquo in Proceedings of the 1998 IEEE International Confer-ence on Systems Man and Cybernetics (Cat No98CH36218)SMCrsquo98 vol 3 pp 2720ndash2725 October 1998
[14] G Pui Cheong Fung J Xu Yu and W Lam ldquoStock predictionintegrating text mining approach using real-time newsrdquo inProceedings of the 2003 IEEE International Conference on Com-putational Intelligence for Financial Engineering CIFEr 2003vol 2003 pp 395ndash402 China March 2003
[15] W Antweiler and M Z Frank ldquoIs all that talk just noise theinformation content of internet stock message boardsrdquo SSRNElectronic Journal 2001
[16] M-A Mittermayer and G F Knolmayer ldquoNewsCATS A newscategorization and trading systemrdquo in Proceedings of the 6thInternational Conference onDataMining ICDM2006 pp 1002ndash1007 China December 2006
[17] R P Schumaker and H Chen ldquoTextual analysis of stockmarket prediction using breaking financial news theAZFin textsystemrdquo ACM Transactions on Information and Systems pp 1ndash29 2009
[18] S S Groth and J Muntermann ldquoAn intraday market riskmanagement approach based on textual analysisrdquo DecisionSupport Systems vol 50 no 4 pp 680ndash691 2011
[19] T Vu S Chang Q Ha and N Collier ldquoAn experiment in inte-grating sentiment features for tech stock prediction in twitterrdquoin Proceedings of the Workshop on Information Extraction AndEntity Analytics on Social Media Data vol 3 pp 23ndash38 2012
[20] B Wang H Huang and X Wang ldquoA novel text miningapproach to financial time series forecastingrdquo Neurocomputingvol 83 pp 136ndash145 2012
[21] Q Li T Wang P Li L Liu Q Gong and Y Chen ldquoThe effectof news and public mood on stock movementsrdquo InformationSciences vol 278 pp 826ndash840 2014
[22] T H Nguyen K Shirai and J Velcin ldquoSentiment analysis onsocial media for stock movement predictionrdquo Expert Systemswith Applications vol 42 no 24 pp 9603ndash9611 2015
[23] BWengM A Ahmed and FMMegahed ldquoStockmarket one-day ahead movement prediction using disparate data sourcesrdquoExpert Systems with Applications vol 79 pp 153ndash163 2017
[24] J Eberhard J F Lavin and A Montecinos-Pearce ldquoA network-based dynamic analysis in an equity stock marketrdquo Complexityvol 2017 Article ID 3979836 16 pages 2017
[25] Z Zhang Y Zhang D Shen and W Zhang ldquoThe dynamiccross-correlations between mass media news newmedia newsand stock returnsrdquo Complexity vol 2018 11 pages 2018
[26] P C Tetlock ldquoGiving content to investor sentiment The role ofmedia in the stock marketrdquo Journal of Finance vol 62 no 3 pp1139ndash1168 2007
[27] K Chen P Luo L Liu andW Zhang ldquoNews search and stockco-movement Investigating information diffusion in the finan-cial marketrdquo Electronic Commerce Research and Applicationsvol 28 pp 159ndash171 2018
[28] F Z Xing E Cambria and Y Zhang ldquoSentiment-awarevolatility forecastingrdquo Knowledge-Based Systems vol 176 pp68ndash76 2019
[29] A Picasso S Merello Y Ma L Oneto and E CambrialdquoTechnical analysis and sentiment embeddings formarket trendpredictionrdquo Expert Systems with Applications vol 135 pp 60ndash70 2019
[30] A Khadjeh Nassirtoussi S Aghabozorgi T Ying Wah and DC L Ngo ldquoText mining for market prediction a systematicreviewrdquo Expert Systems with Applications vol 41 no 16 pp7653ndash7670 2014
[31] M Kraus and S Feuerriegel ldquoDecision support from financialdisclosures with deep neural networks and transfer learningrdquoDecision Support Systems vol 104 pp 38ndash48 2017
[32] H S Sim H I Kim and J J Ahn ldquoIs deep learning for imagerecognition applicable to stockmarket predictionrdquoComplexityvol 2019 10 pages 2019
Complexity 15
[33] M Jasemi A M Kimiagari and A Memariani ldquoA modernneural network model to do stock market timing on the basisof the ancient investment technique of Japanese candlestickrdquoExpert Systems with Applications vol 38 no 4 pp 3884ndash38902011
[34] A Fader S Soderland and O Etzioni ldquoIdentifying relations foropen information extractionrdquo in Proceedings of the Conferenceon Empirical Methods in Natural Language Processing EMNLP2011 pp 1535ndash1545 Association for Computational LinguisticsUK July 2011
[35] T Mikolov K Chen G Corrado and J Dean ldquoEfficientestimation of word representations in vector spacerdquo pp 1ndash122013 httpsarxivorgabs13013781
[36] X Lin Z Yang and Y Song ldquoIntelligent stock trading systembased on improved technical analysis and Echo State NetworkrdquoExpert Systems with Applications vol 38 no 9 pp 11347ndash113542011
[37] K-J Kim and I Han ldquoGenetic algorithms approach to featurediscretization in artificial neural networks for the prediction ofstock price indexrdquo Expert Systems with Applications vol 19 no2 pp 125ndash132 2000
[38] Y Yu W Duan and Q Cao ldquoThe impact of social andconventional media on firm equity value A sentiment analysisapproachrdquoDecision Support Systems vol 55 no 4 pp 919ndash9262013
[39] MHagenauM Liebmann andDNeumann ldquoAutomated newsreading Stock price prediction based on financial news usingcontext-capturing featuresrdquo Decision Support Systems vol 55no 3 pp 685ndash697 2013
[40] A Aizawa ldquoAn information-theoretic perspective of tf-idfmeasuresrdquo Information Processing amp Management vol 39 no1 pp 45ndash65 2003
[41] A Khadjeh Nassirtoussi S Aghabozorgi T Ying Wah and DC Ngo ldquoText mining of news-headlines for FOREX marketprediction a Multi-layer dimension reduction algorithm withsemantics and sentimentrdquo Expert Systems with Applications vol42 no 1 pp 306ndash324 2015
[42] D Peramunetilleke and R K Wong ldquoCurrency exchange rateforecasting from news headlinesrdquo Australian Computer ScienceCommunications vol 24 no 2 pp 131ndash139 2002
[43] Y Kim ldquoConvolutional neural networks for sentence classifica-tionrdquo 2014 httpsarxivorgabs14085882
[44] ZWang J Zhang J Feng and Z Chen ldquoKnowledge graph andtext jointly embeddingrdquo in Proceedings of the 2014 Conferenceon Empirical Methods in Natural Language Processing EMNLP2014 pp 1591ndash1601 Qatar October 2014
[45] J Xu X Qiu K Chen and X Huang ldquoKnowledge graphrepresentation with jointly structural and textual encodingrdquo inProceedings of the 26th International Joint Conference on Arti-ficial Intelligence IJCAI 2017 pp 1318ndash1324 Australia August2017
[46] R Xie Z Liu J Jia H Luan and M Sun ldquoRepresentationlearning of knowledge graphs with entity descriptionsrdquo in Pro-ceedings of the 30th AAAI Conference on Artificial IntelligenceAAAI rsquo16 pp 2659ndash2665 February 2016
[47] F Tian B Gao E Chen and T Liu ldquoLearning better wordembedding by asymmetric low-rank projection of knowledgegraphrdquo Journal of Computer Science and Technology vol 31 no3 pp 624ndash634 2016
[48] F Z Xing E Cambria and R E Welsch ldquoNatural languagebased financial forecasting a surveyrdquo Artificial IntelligenceReview vol 50 no 1 pp 49ndash73 2018
[49] C Goutte and E Gaussier ldquoA probabilistic interpretation ofprecision recall and F-score with implication for evaluationrdquoin Advances in Information Retrieval D E Losada and J MFernandez-Luna Eds vol 3408 of Lecture Notes in ComputerScience pp 345ndash359 Springer Berlin Germany 2005
Hindawiwwwhindawicom Volume 2018
MathematicsJournal of
Hindawiwwwhindawicom Volume 2018
Mathematical Problems in Engineering
Applied MathematicsJournal of
Hindawiwwwhindawicom Volume 2018
Probability and StatisticsHindawiwwwhindawicom Volume 2018
Journal of
Hindawiwwwhindawicom Volume 2018
Mathematical PhysicsAdvances in
Complex AnalysisJournal of
Hindawiwwwhindawicom Volume 2018
OptimizationJournal of
Hindawiwwwhindawicom Volume 2018
Hindawiwwwhindawicom Volume 2018
Engineering Mathematics
International Journal of
Hindawiwwwhindawicom Volume 2018
Operations ResearchAdvances in
Journal of
Hindawiwwwhindawicom Volume 2018
Function SpacesAbstract and Applied AnalysisHindawiwwwhindawicom Volume 2018
International Journal of Mathematics and Mathematical Sciences
Hindawiwwwhindawicom Volume 2018
Hindawi Publishing Corporation httpwwwhindawicom Volume 2013Hindawiwwwhindawicom
The Scientific World Journal
Volume 2018
Hindawiwwwhindawicom Volume 2018Volume 2018
Numerical AnalysisNumerical AnalysisNumerical AnalysisNumerical AnalysisNumerical AnalysisNumerical AnalysisNumerical AnalysisNumerical AnalysisNumerical AnalysisNumerical AnalysisNumerical AnalysisNumerical AnalysisAdvances inAdvances in Discrete Dynamics in
Nature and SocietyHindawiwwwhindawicom Volume 2018
Hindawiwwwhindawicom
Dierential EquationsInternational Journal of
Volume 2018
Hindawiwwwhindawicom Volume 2018
Decision SciencesAdvances in
Hindawiwwwhindawicom Volume 2018
AnalysisInternational Journal of
Hindawiwwwhindawicom Volume 2018
Stochastic AnalysisInternational Journal of
Submit your manuscripts atwwwhindawicom

4 Complexity
Table 1 A review of financial expert system ANN NB KNN SVM DT and SVR stand for artificial neural network naive Bayes k nearestneighbors support vector machine decision tree and support vector regression respectively Measure metrics mean squared error (MSE)root mean square error (RMSE) area under the curve (AUC)
Paper Text type Feature extraction Model type Performancemeasure
[13] Professional newspaper Stock data NB Accuracy[14] Professional newspaper Stock data SVM Accuracy
[15] Message board Stock data Regression Correlationcoefficient
[16] PRNewswire Stock data KNN SVM Accuracy F1-score
[17] Aggregate news Stock databag-of-words SVR MSE accuracy
[18] Corporate disclosures Stock databag-of-words Multiple Accuracy recall
precision F1-score
[19] Financial news Stock datasentiment DT Accuracy recall
precision F1-score
[20] Web media Stock databag-of-words SVR Accuracy recall
precision F1-score
[21] Mixed typeStock data
bag-of-wordssentiment
SVR RMSE accuracyprecision
[22] Message board Stock datasentiment SVM Accuracy
[23] Mixed typeStock data
technical indicatorssentiment
ANN SVM DTAccuracy AUCF1-score precision
[24] None Stock data Regression Correlationcoefficient
[25] Media news Stock data Regression Correlationcoefficient
Our financial expert system Financial newsStock data
technical indicatorsbag-of-words
syntax
Multiple Accuracy F1-score
Tetlock [26] adopted the popular news from the Wall StreetJournal to find that news sentiment has predictive power oncompany stocks Chen et al [27] found information comen-tions have a significant influence on the stock return throughsentiment analysis Furthermore the investorsrsquo sentimenttrends after the positive news which results in a buying trendand higher stock market prices while after negative newsstocks are sold result in a decrease of the price Howeversentiment analysis can only be employed in specific textsIf sentiment is implicit rather than direct emotional wordsthen the ability of using sentiment analysis for predicting thestock price of the renowned company is relatively limitedMittermayer and Knolmayer [16] illustrated that news-CATSachieves a performance that is superior to that of otherATC prototypes used to forecast stock price trends Li et al[21] proposed a media-aware quantitative trading strategy byusing sentiment information on web media The simulationtrading return was up to 16611 Nguyen et al [22] proposeda feature topic sentiment to improve the performance of stockmarket prediction Their method achieved an accuracy thatis 983 better than that of the historical price method and303 better than that of the human sentiment method
We utilize the characteristics of syntax analysis as beingproposed in [6 12] namely a structured tuple is extractedfrom an unstructured text based on the semantic structureof each piece of news Knowledge graph can enrich thestructured representation of the news event and effectivelyretain feature vectors for the news event The main featureextraction in the previous studies [28 29] is sentimentanalysis which neglected the event characteristics in thetext Furthermore the existing literature [23 29] had provedthe positive effect of technical indicators on stock marketprediction In summary our research highlights syntax anal-ysis in financial news which also incorporates with otherfeatures extraction (stock data technical indicators and bag-of-words) Because of the variety of considered features thisresearch will deliver an improved prediction of the stockmarket value for renowned companies in at least 36
Previous research [30] was applied with the traditionalmachine learning algorithms especially since the power-ful application ability of deep learning based on machinelearning Deep learning is utilized in several studies forpredicting stock price movement Kraus and Feuerriegel [31]forecasted the stock returns based on financial disclosures
Complexity 5
Table 2 Quotes and renowned company names
Financial newsdataset Stocks Company names Time interval Number of news
headlinesAAAL Apple Inc 3102011- - -3172017 6423
Thomson Reuters MSFT Microsoft Corporation 3092011- - -29112017 6623SSNLF Samsung Electronics Co Ltd 3092011- - -29112017 6900BA The Boeing Company 891998- - -2322017 2999
CNN GOOG Google Inc 2552006- - -2422017 5278WMT Walmart Inc 751997- - -2422017 4913
Table 3 Samples extracted from the dataset
Date News headline News headline event tuple3182012 Chinese writersrsquo group sues Apple state media Chinese writersrsquo group sues Apple
4132012 German court upholds ban on Apple push email German court upholds ban on Apple pushemail
442012 Apple two publishers hold out againstsettlement-report
Apple- two publishers hold out againstsettlement-report
3262012 Apple CEO Cook meets Chinese officials Apple CEO Cook meets Chinese officials
4252012 US STOCKS-Apple results put Nasdaq on track for bestgain of year Apple results Nasdaq on track for best gain
and their result demonstrated that a higher directional ofdeep learning surpasses traditional machine learning Dinget al [5] illustrated that deep learning also can forecaststock market of the renowned company Sim et al [32]proposed that technical indicators transform into images ofthe time series graph which examines the applicability ofdeep learning in the stock market Overall we adopt themultiple models for prediction stock price of the renownedcompany which proves the reliability of our proposed modelas comparing different algorithms This work applies deeplearning incorporated with knowledge graph embeddingfor feature extraction which examines the applicability ofcombined features methods in the renowned company stockprice movement
3 Materials and Methods
We developed a knowledge graph-based approach that con-sists of three steps namely data description data preprocess-ing and feature selection
31 Dataset Description Table 2 shows the custom financialnews corpus built with headlines from two datasets The firstdataset contains news articles published byThomsonReutersincluding those regarding Apple Inc (AAPL) MicrosoftCorporation (MSFT) and Samsung Electronics Co Ltd(SSNLF) The second dataset comprises news reports pub-lished in CNN including reports on the Boeing Company(BA) Google Inc (GOOG) and Walmart Inc (WMT) Italso consists of financial news headlines published at specifictime intervals with each news report accompanied by a titleand a release date Titles are used for event embedding andfeature extraction and release dates are used as a referencein ensuring alignment between corresponding financial news
and trading data from a time series As shown in previouswork [5 31] using a headline to build corpora can helpreduce noise in text mining as headlines concisely representthe content of a text We used only the news headlines fromReuters andCNN for the prediction of stock pricemovement
Daily stock data from index report in each company arecollected by Yahoo Finance in the same period during stockdata and financial news headlines Daily trading data whichare common predictors of stock price [23 33] and technicalindicator features were used in our model There are openingprice closing price high price low price and volume andthree technical indicators
Table 3 shows some examples of filtered financial newsheadlines To illustrate 6423 headlines regarding Apple Incwere extracted and then reduced to 2799 headlines afterfiltering via Reverb [34] Let us take the article ldquoWhat is nextfor Applersquos boardrdquo published on 6 October 2011 as a specificexample The title of the article cannot be transformed intoan event tuple using Reverb Because the sentence is in theinterrogative form there is no event tuple that constitutes arule After the matching of time-wise data and stock data941 headlines were left Daily news and stock data werealigned to create input-output pairs except the days whenno news was released In 9 January 2012 for instance threenews articles were reported but we chose only one headlinefor alignment with stock market data News events possiblyhappen several times within one day but they do not happenevery day unlike stock trading which happens daily excepton nontrading days falling on weekends or holidays
Table 4 shows that the matches found are pairs betweenevent tuples and stock data From this complete dataset weused 80 of the samples in training data and the remaining20 for testing dataThis selection method is the same as theprevious literature [5 24]
6 Complexity
Table 4 Training and testing datasets
Data source Company Training Testing TotalApple 780 161 941
Reuters Microsoft 832 208 1040Samsung 855 214 1069Boeing 528 132 660
CNN Google 1010 252 1262Walmart 798 200 998
Table 5 Number of event characteristic labels for each company
CompaniesLabel Apple Microsoft Samsung Boeing Google Walmart0 502 967 1433 133 661 2061 537 432 379 200 245 2872 661 557 378 152 389 2333 692 707 724 233 683 4384 407 228 193 147 196 180Total 2799 2891 3107 865 2174 1344
Table 6 Features of the prediction model
Feature Feature expression1 Stock price yesterday + yesterdayrsquos trend (in Section 331) 119901119903119894119888119890
119905minus1 119905 119894119899119889119894119888119886119905119900119903119905minus1
2 Same + bag-of-words (in Section 332) 119901119903119894119888119890119905minus1
119905 119894119899119889119894119888119886119905119900119903119905minus1 119905119891 119894119889119891119905minus1
3 Same + some features inferred through a convolutional neural network (in Section 333) 119901119903119894119888119890119905minus1
119905 119894119899119889119894119888119886119905119900119903119905minus1 119888119899119899119905minus14 Same + some features inferred through feature combination (in Section 334) 119901119903119894119888119890
119905minus1 119905 119894119899119889119894119888119886119905119900119903119905minus1 119891 119888119900119898119887119894119899119890
119905minus1
32 Data Preprocessing The following three steps are forpreprocessing which prepares for feature extraction andmodel creation
(1) Tagging the label for each news headline Five possiblelabels are characterized by categorical values as follows 0for an extremely negative label 1 for a negative label 2 tosignify a neutral label 3 for a positive label and 4 to denote anextremely positive label According to the time characteristicsof each news headline an event is manually tagged withthe label for each news headline Table 5 shows the labelingapplied for each company Label 0 means that a companyrsquoscompetitor has happened in this event label 1 means that thecompany lost something label 2 means that it did not causeany impact on the company label 3 means that this eventenabled the company to obtain something and label 4 meansthat the company increased its profits or created more value
(2) Word vector transformation We used the word2vec[35] algorithm to train word embedding and set the numberof dimensions to 300 The word embedding was also trainedusing the Google News dataset which contains 100 billionwords that are characterized by a continuous bag-of-wordsstructure
(3) Technical indicators calculation Three additionaltechnical indicators that are calculated on the basis of dailytrading data were used as follows
(a) Stochastic oscillator (K)This indicator is a momen-tum analysis method created by George C Lane When the
price trend rises the closing price tends to approach thehighest price of the day When the price trend declines theclosing price tends to approach the lowest price of the day[36]
(b) Larry Williamss R indicator This indicator is anoscillation indicator that measures the ratio of the highestprice to the daily closing price It indicates the proportion ofstock price fluctuations in a certain period thereby providinga signal out of the reversal of a stock market trend [37]
(c) Relative strength index (RSI) Buying and sellingintentions in the market are analyzed by comparing theclosing prices in a given period Stocks that have had moreor stronger positive changes have a higher RSI than do thosethat have had more or stronger negative changes Strengthindicators fall between 0 and 100 investors sell if this valueis ge 80 and buy if it is le 20 [23 36]
33 Variable Feature Selection To assess the effectivenessof applying the prediction model on the basis of financialnews we designed four sets of features for predicting stockprice movement (Table 6) Features 3 and 4 are used for eventcharacteristics Each feature is explained in the succeedingsubsections The target output consists of a binary variablefor which a value of 1 indicates that the closing price at day t+ 1 will be higher than that at day t and a value of 0 indicatesthat the closing price at day t + 1will be lower than that at dayt
Complexity 7
Financial news
middot middot middot
News representation Convolutional layer Max pooling Fully connected layer Features
X (I)
Z (I)
Figure 3 Convolutional neural network architecture proposed for feature selection
331 Stock Data Only We considered historical price as theinput for predicting stock price movement and used it asa baseline for comparison with other sets of features Thefeatures used to train the machine learning model that usesonly stock data are 119901119903119894119888119890119905minus1 and 119905 119894119899119889119894119888119886119905119900119903119905minus1 The output isthe indicator of pricemovement (increase or decrease) at eachtransaction date examined
332 Bag of Words The input feature set is based on a bag ofwords for the news and price trend for stock Previous studies[18 38 39] have widely used and confirmed the feasibilityof the bag-of-words algorithm but this method disregardselements such as grammar and word order in the text Inthe present study we first prepared each headline for datapreprocessing and then transformed the preprocessed head-line into a feature vector using the term frequency-inversedocument frequency (TF-IDF) algorithm [40] which assignshighweight to eigenvectorsThe studies [41 42] have stronglyproven the effectiveness of the TF-IDF algorithm in featureextraction from news headlines It estimates the frequency ofa term in one document over the maximum in a collection ofdocuments and assesses the importance of aword in one set ofdocuments Such importance increases proportionally withthe number of word appearances in a documentThe featuresused to train the bag-of-words machine learning model are119901119903119894119888119890119905minus1 119905 119894119899119889119894119888119886119905119900119903119905minus1 and 119905119891 119894119889119891119905minus1 which are the pricemovements (increase or decrease) at each transaction dateexamined
333 Convolutional Neural Network Given the sequence ofwords in a headline the word2vec model [35] can be usedto embed each of these words in a real valued-vector 119909 Inthis work we set the dimension 119899 of each word vector at30 (ie 119909 isin R30) We concatenated the word vectors of allthe words in a headline sequentially to form a matrix 119883 =[119909(1) 119909(2) 119909(3) 119909(4)] [35] as the input to a convolutionalneural network model For a headline with 119873 words the
resultant input matrix has dimensions of 30 times 119873 and thedimension of news representation also is 30
In Figure 3 this convolutional neural network model ismade up of four consecutive layers the first layer is theinput the second layer is convolutional the third layer is amax-pooling and the last layer is a fully connected layerThe convolutional and max-pooling layers were designedusing the text-attentional convolutional neural network [43]which effectively carries out sentiment classification In theconvolutional layer input matrix X convolves with a kernel119908 isin R119899times119896 where n is the size of a word vector (30 inour work) and its dimension is 50 k denotes the size of asliding window (k=3 in this study) The computation can beformulated as follows
119885119894 = 120590 (119908119883119894119894+119896minus1 + 119887) (1)
where 119883119894119894+119896minus1 = [119909119894 119909119894+1 119909119894+119896minus1] is the portion of input119883 falling within the sliding window 119887 denotes the optionaloffset and 120590(sdot) is the sigmoid function
In the next step we used the pooling layer to reduce theconvolutional neural networks parameter space and conse-quently minimize information loss in the pooling processingand capture the most important features The eigenvectorof the filter in the pooling layer is cut into 3 chunks anda maximum value is taken in each chunk we obtained 3eigenvalues Convolutional output vector Z was split into pwindows and only themaximum feature as 3 in each windowwas kept for passage onto the final fully connected layer Thefully connected layer is linear regression and the output layeris the feature classification between 0 and 1
Our convolutional neural network model is intended toextract a feature vector from the fully connected layer todescribe the emotional characteristics of input headlinesFollowing the intuition that a good feature vector shouldlead to the accurate classification of the event characteristicsof headlines we attached a softmax layer after the fully
8 Complexity
The United Kingdom of Great Britain and Northern Ireland commonly known as the United Kingdom or Britain hellip
London is the capital city of England and of the United Kingdom It is the most populous region hellip
Head Relationship TailLondon location country capital United Kingdom
London is the caEngland and of Kingdom It is tpopulous region
Kingdom of GreatNorthern Ireland known as the United
Britain hellip
Figure 4 Text description of the entity
connected layer when the convolutional neural networkmodel was trained The entire model was trained to classifythe five emotional labels that describe event characteristicsand the resultant model will be able to provide a mean-ingful emotional feature vector for each inputted headlineMeanwhile we define the loss function of the convolutionalneural network model as 119864119889 The features used to trainthis machine learning model are 119901119903119894119888119890119905minus1 119905 119894119899119889119894119888119886119905119900119903119905minus1and 119888119899119899119905minus1 which are the price movements (increase ordecrease) at corresponding transaction date
334 Combined Features In the introduction section of thispaper we described various translation models Because theTransE model represents a one-to-one relationship betweentwo entities [7] the relationship amongst many entities mustbe continuously incorporated into texts and knowledge graph[44] This model combines a convolutional neural networkwith textual information extraction which fully exploits thesemantic information in a knowledge graph and text [45 46]In Figure 4 knowledge graph contains rich semantics inentity description texts but it is not fully utilized in featureextraction Most of the existing text representation modelssimply train the text into word vectors through word2vecwhich obtains the text representation by means of averagingetc Hence these ways often lose more semantic informationWe therefore proposed to extract feature vectors from newstexts using a convolutional neural network model combinedwith the TransE model which also fully integrates the twoparts of the feature information
In Figure 5 this architecture used in the feature combina-tion model encompasses two parts namely a convolutionalneural network (Section 333) and the TransE model Thefeature combination sets are the average of each word vectorin an entity and it was obtained using the word2vec modelThe two entity vectors are mapped into the same relationalspace and these entities using a trained low-rank weightmatrix [47]
As assumed in the TransE model relationship vector Rshould satisfy ldquoE + R asymp Trdquo The model can be representedas a parameter set 0 = (119871119903 119877119903 120579) where X E and R
represent a word an entity and a relation respectively Andr are the mapping matrices for entities in the structuralmodel and represents the weights of the convolutional neuralnetwork For instance the sentence is ldquoSamsung sues Apple forinfringementrdquo so ldquoSamsung +Appleasymp suesrdquoThe loss function119864119904 of this structural model is defined as follows
119864119904 = ℎ + 119903 minus 11990522 (2)
where h r and t represent head entity relationship and tailentity in event tuple respectively [47]
And text representation 119864119889 is consistent withSection 333 which denotes
119864119889 = 119891119903 (ℎ119904 119905119889) + 119891119903 (ℎ119889 119905119904) + 119891119903 (ℎ119889 119905119889) (3)
where119891119903(ℎ119889 119905119889) = ℎ119889+119903minus11990511988922 represents the head entity andthe tail entity is in text representation119891119903(ℎ119889 119905119904) = ℎ119889+119903minus11990511990422and 119891119903(ℎ119904 119905119889) = ℎ119904 + 119903minus 11990511988922 represent one of the head entityh and the tail entity t in text representation another one is instructure representation
Moreover we combined two types of representationlearning (convolutional neural network and feature combi-nation) to map news titles these vectors will be into featurevectors The relationship vector R identical to the resultof the feature extraction layer of the convolutional neuralnetwork in the structural model Besides we combined thisloss with the classification loss of the convolutional neuralnetwork using L2 regularization which obtains the overallloss function 119864 for feature selection that is
119864 = 119864119904 + 120572119864119889 + 120573 02 (4)
where 02 is a regular item 120572 and 120573 are hyperparameterswhich measure the loss of text information and the weight ofthe regular items respectively W denotes the convolutionalkernels in the layer and 1198791015840 is a negative sample set of 119879 [7]
1198791015840 = (ℎ1015840 119903 119905) | ℎ1015840 isin 119864 cup (ℎ 119903 1199051015840) | 1199051015840 isin 119864
cup (ℎ 1199031015840 119905) | 1199031015840 isin 119877 (5)
Complexity 9
Output layerClass1 Class2
Machinelearning
Max pooling
convolutional
Input news
Feature vector
Embedding layer
Input news
Event tuple
Word2vec
Word2vec
Fully connection
Stock data
Stock layer
TransE model
Figure 5 Proposed architecture for the feature combination model
where the head entity and tail entity are randomly replaced byan entity or relationship in another tuple In particular if thereplaced tuple is already in T it would not be added to thenegative sample Since both h and t represent two types ofentities there are structure-based representations and text-based representations in interval-based loss functions Thestochastic gradient descent (SGD) is employed to minimizethe above loss function
In this structure we choose the optimal parameters asfollowe the learning rate of SGD 120582 = 0001 the dimension ofthe representation vector of entities and relationships k = 100the word vector dimension of the entity description text n =100 and batch size during training is 1440 Convolution layerwindow size is 119882 isin 1 2 3 This experiment is performedin 1000 iterations of training and the optimal parameters arebased on the testing set
Hence the features used for training the machine learn-ing model are 119901119903119894119888119890119905minus1 119905 119894119899119889119894119888119886119905119900119903119905minus1 and 119891 119888119900119898119887119894119899119890119905minus1which are the price movement (increase or decrease) atcorresponding transaction date
4 Experiments and Results
41 Experimental Setting This section compares the perfor-mance of differentmodels in feature extraction fromfinancialnews expended with full sets of features The evaluationwas intended to obtain evidence that the proposed featurecombination model is superior to other feature selectionmodels in predicting the stock price movement As shownin Table 7 we chose linear models for instance logisticalregression and naive Bayes Others are nonlinear models forinstance the ensemble learning (random forest adaboostand gradient boosting) for the comparison We constantlyadjusted the parameters in the grid search and selected theoptimal parameter value their parameter value has proven towork well on machine learning method [29 48]
We used a computer consisting of an Intel Core i5processor with four cores running at 29 GHz and 8 GBRAM under the MacOS platform We used the Scikit-learnlibrary in Python in the experiments involving traditionalmachine learning algorithms and TensorFlow 14 in the
10 Complexity
Table 7 List of machine learning methods
Method Classification Parameter and their value
Traditionalmachinelearning
Decision tree (DT)Criterion= gini splitter= best max depth=None minsamples split=2 min samples leaf =1 min weight
fraction leaf=00Logistical regression (LR) Random state=1
Naive Bayes (NB) No kernel estimatorStochastic gradient descent (SGD) Loss=hinge penalty=l2
Support vector machine (SVM) Polynomial kernel function with exponent = 1 2 RBFkernel function with gamma = 001
Ensemblelearning
Random forest (RF) Randomly sampled as candidates at each split = log2 +1 max-depth=2 random state=0
AdaBoost (AB) Polynomial kernel function with exponent = 1 2 RBFkernel function with gamma = 001 n- estimators=100
Gradient boosting (GB) N-estimators =100 learning rate =10 max-depth=1random state=0
Table 8 Abbreviations of the results for each algorithm considered
Algorithms Stock data (SD) Bag of words (BOW) Convolutionalneural network
Featurecombinationmodel (FC)
DT DT 1 DT 2 DT 3 DT 4LR LR 1 LR 2 LR 3 LR 4NB NB 1 NB 2 NB 3 NB 4SGD SGD 1 SGD 2 SGD 3 SGD 4SVM SVM 1 SVM 2 SVM 3 SVM 4RF RF 1 RF 2 RF 3 RF 4AB AB 1 AB 2 AB 3 AB 4GB GB 1 GB 2 GB 3 GB 4
experiments involving deep learning and the TransE modelThe abbreviations used for comparing classification perfor-mance are presented in Table 8 During testing 2-fold cross-validation is applied to evaluate the stability of the modelsAnd we compared performance in predicting stock pricemovement for the next day with a test dataset and evaluatedthe performance of the models in terms of accuracy and F1-score [49]
42 Results
421 Thomson Reuters Case Study Thomson Reuters isa multinational mass media and information firm Threerenowned companies on the website were selected for theanalysis The first is Apple Inc which is an American multi-national technology company that designs develops andsells consumer electronics computer software and onlineservices The second company selected is Microsoft which isan American multinational technology company that devel-ops manufactures supports and sells computer softwarepersonal computers and other services The last companychosen is Samsung which is a South Korean multinationalelectronics company We considered data from these threetypical technology companies for our problem
Measurements of average accuracy are shown in Table 9and the results for each renowned company with respectto prediction based on different features are illustrated inFigure 6 We calculated the average of the four feature con-struction approaches for eachmodel for comparison amongstthe three companies The proposed feature combinationmodel generated the best results achieving average accuracylevels of 6163 5918 and 5848 forAppleMicrosoft andSamsung respectively These figures are consistent with therates reported in previous research However many studiesanalyzed only one company or used only one algorithmThe current research probed into three companies on thebasis of information from a common data source to builda prediction model with different feature selection func-tionalities and different algorithms We used stock dataa bag-of-words algorithm a convolutional neural networkand feature combination together with eight algorithms Asindicated in Table 9 the proposed predictionmodel achieved7368 data extraction with the use of LR 4 for Apple and6778 data extraction with the use of SVM 4 for MicrosoftIn particular the LR algorithm used for Apple achievedaccuracy and F1-score of 07326 and 07360 respectivelywhich highlights its powerful capability in a two-class classifi-cation
Complexity 11
Table 9 Results for data extracted fromThomson Reuters
Algorithm Company Stock data(SD)
Bag of words(BOW)
Convolutionalneural network
Feature combinemodel (FC)
AccuracyF1-score
AccuracyF1-score
AccuracyF1-score
AccuracyF1-score
DTApple 0499305079 0488902460 0615005814 0652406486
Microsoft 0486801819 0506505682 0581705915 0658706502Samsung 0470704033 0565405830 0552906820 0568006260
LRApple 0524006727 0505505083 0684506911 0732607368
Microsoft 0475701253 0443004884 0527405333 0546705611Samsung 0494703755 0605406726 0654106343 0805307978
NBApple 0510905123 0477803896 0502704497 0512204030
Microsoft 0484000363 0455704055 0459902889 0500005439Samsung 0529305810 0514406130 0504806578 0511706601
SGDApple 0467201119 0477804404 0497406008 0536602692
Microsoft 0517306819 0485203222 0610304231 0610804193Samsung 0522306541 0476602000 0518706751 0557106548
SVMApple 0502206121 0574705542 0615006129 0622006173
Microsoft 0478401722 0443904566 0523205462 0687506798Samsung 0500803875 0504705508 0513506281 0535206574
RFApple 0524006554 0527806083 0533706232 0620306243
Microsoft 0484002653 0417701687 0532502432 0572105189Samsung 0487203480 0448501194 0476603708 0505205481
ABApple 0534305384 0472202963 0481903333 0620305420
Microsoft 0468702041 0476800461 0614706044 0620206146Samsung 0485703619 0457902368 0601006820 0633806549
GBApple 0531405129 0466702941 0609604748 0634106591
Microsoft 0474302125 0472801007 0455704557 0538502258Samsung 0487204171 0519206599 0533706572 0562206335
Reuters
Aver
age a
ccur
acy
0
01
02
03
04
05
06
07
Different companyApple Microsoft Samsung
SDBOW
CNNFC
Figure 6 Average accuracy of prediction based on different featuresets for each company in Reuters
To assess the effectiveness of our research we comparedthe feature combination model that uses event tuples with
the stock data approach and the bag-of-words algorithmTheresults showed that the average accuracy of the event tuple-basedmodel is better than that of the stock data approach andthe bag-of-words algorithm by 1001 and 1087 respec-tively We also compared feature extraction using the stockdata approach the bag-of-words algorithm and machinelearning The use of deep learning improved predictionaccuracy by 525 and 611 over the levels achieved withstock data and bag of words respectively Therefore we canconclude that using the proposed feature combinationmodeland deep learning in feature extraction helps improve theaccuracy with which stock price movement is predictedThese results also fully prove the effectiveness of embeddinglayer in feature extraction accuracy improvement
422 CNN Case Study CNN is an American basic cableand satellite television news channel owned by the TurnerBroadcasting System Three renowned companies on whichthese website reports were selected for the analysis The firstis Boeing which is an American multinational corporationthat designs manufactures and sells airplanes rotorcraftrockets and satellites worldwide The second company isGoogle which is an American multinational technology
12 Complexity
Table 10 Results for data extracted from CNN
Algorithm Company Stock data(SD)
Bag of words(BOW)
Convolutionalneural network
Featurecombinationmodel (FC)
AccuracyF1-score
AccuracyF1-score
AccuracyF1-score
AccuracyF1-score
DTBoeing 0495003489 0541306258 0541406347 0559105821Google 0485805600 0518203575 0569204631 0549105471Walmart 0499604422 0530004891 0508804815 0572205829
LRBoeing 0492302378 0511304348 0692306923 0759605733Google 0504106105 0623506491 0625006111 0656306516Walmart 0529005468 0541205083 0732007347 0771907720
NBBoeing 0516206503 0548905161 0519706738 0556407619Google 0511206527 0489905191 0558705281 0534404843Walmart 0504403284 0479405302 0520605674 0530006083
SGDBoeing 0489702407 0556404870 0543304727 0571407220Google 0516506769 0542504375 0578906364 0591006327Walmart 0500403804 0520605280 0525005581 0567005922
SVMBoeing 0489703068 0571406275 0538506418 0594007033Google 0507706297 0603206230 0574905532 0578905840Walmart 0511804333 0500005314 0520005000 0561405455
RFBoeing 0490601345 0511303925 0509605405 0527605714Google 0492301777 0603206260 0522305564 0595105763Walmart 0511805373 0530003188 0530004405 0500005446
ABBoeing 0494503404 0519705120 0496105294 0567305872Google 0487603141 0510106667 0589305619 0595106850Walmart 0507305029 0515005359 0549705650 0561905503
GBBoeing 0489903169 0511804364 0440904580 0500005094Google 0491203387 0587005854 0562505243 0603206202Walmart 0500304955 0505005123 0536105109 0549705650
company that specializes in Internet-related services andproducts The third is Walmart an American multinationalretail corporation that operates a chain of hypermarketsdiscount department stores and grocery stores
The results on average accuracy are shown in Table 10and Figure 7These findings are very similar to those derivedin the previous case study and their comparison confirmedthat the proposed feature combinationmodel can outperformother feature selection models in stock price movementprediction With regard to feature selection underlain bythe bag-of-words algorithm the CNN case study generatedmore robust results than did the Reuters case study Theaverage accuracy of the bag-of-words algorithm was lowerthan that of the stock data approach in the Reuters case studyIn the CNN case study the average accuracy levels of theproposed feature combination model were 5794 5879and 5767 for Boeing Google andWalmart respectively Inthe case study on Reuters an average accuracy that exceeds60 was not achieved for any of the companies illustratingthat differences in data source directly affect stock pricemovement
We chose a combination of deep learning and knowledgegraph to build our feature selection model because this
CNN
Aver
age a
ccur
acy
0
01
02
03
04
05
06
07
Different companyBoeing Google Walmart
SDBOW
CNNFC
Figure 7Average accuracy achieved on the basis of news fromCNNand different feature set
combination exhibited superior prediction performance inthe comparison experiments involving other feature selection
Complexity 13
strategies The forecast results based on different featuresare shown in Table 10 We found that deep learning featuresare better than the use of bag-of-words and stock data Thecorrelation of event tuples with the stock market is relativelyhigh in [5 31] but the bag-of-words algorithm was relativelyfragmented and the correlation between event tuples and thestockmarket data was relatively weak Combining event tuplefeatures with deep learning significantly improves forecastresults indicating a close relationship between stock marketmovements and knowledge graph
5 Discussion
51 Research Findings We attempted to compare our predic-tion results with those made in previous studies wherein pre-diction was also based on the financial news of the renownedcompanies However the findings are incomparable becausedifferent studies use different datasets or algorithms andthese methods are difficult to investigate using financial newsheadlines In the current research we refrained from eval-uating performance on one company dataset this decisionthat enabled our knowledge graphmethod to exceed baselinepredictions based only on the price by up to 36 Thisalso proves that feature extraction in deep learning is moreeffective than traditional machines The combination of deeplearning and knowledge graph fully integrates the semanticinformation in financial news which effectively predicts thestock price movement of the renowned company
This work demonstrated the application of deep learningand knowledge graph in finance To the best of our knowl-edge knowledge graph has been rarely applied in stock pre-diction Becauseminimal financial training sets in knowledgegraph are available financial knowledge extraction is themain task for the organizational construction of a knowledgegraph Such extraction is critical for the understanding andprocessing of deep semantics in the event tuple which alsodirectly influences the feature extraction of financial news
52 Implications for Business Activities Theutility of a featurecombination model based on knowledge graph is not limitedto financial analysis Currently knowledge graph data areavailable for medical diagnosis speech recognition precisemarketing and financial risk control [4] Our model couldalso be applied in these areas
Antifraud activities are an important part of financeApplying our model on the basis of knowledge graph oncustomers helps organize all relevant knowledge fragmentsthrough deep semantic analysis and reasoning which canbe verified with a customerrsquos bank information Moreovercustomers typically use keywords to search for productsand knowledge graph can provide relevant information toa customer If a complete knowledge system of users isdescribed and collected a system would better understandand analyze user behaviors
53 Limitations and Future Work A deep learning modeluses supervised learning and needs a dataset with sufficientlabels but our datasets do not work well with deep learningas a small number of financial news articles match stock
data At present knowledge graph embedding inevitablyproduces a loss in news semantics either because of a learningprinciple or the tokenization of knowledge representation forvectorization Thus continuous representation in a knowl-edge graph is still a huge challenge We attempted to applyregression using the above-mentioned algorithms but theresults indicated poor performance More specifically theresults for Apple validated our expectations
The application of large-scale knowledge graph is stillrelatively limited and knowledge graph for smart searchsmart question-and-answer tasks social media and otherareas are in their initial stages with considerable room forimprovement The following advantages of knowledge graphshould be considered (a) the effective organization andexpression of semistructured data (b) knowledge reasoningand (c) the expansion of cognitive ability for incorporatingdeep learning Traditional knowledge elements (entities rela-tionship attributes) extraction technologies and methodshave achieved good results in limited areas but because ofnumerous constraints and poor scalability knowledge graphis not fully functional for financial forecasting because ofnumerous constraints and poor scalability
6 Conclusions
Stock movement prediction of the renowned company is adaunting task because stock prices are affected by many fac-tors This research presented a novel method for integratingknowledge graph embedding with stock market predictionThe contributions of this study can be summarized as followsFirst we developed a novel feature combination model thatconstructs a feature mapping vector for each tuplendashnewspair by simultaneously considering the diversity of entitiesand relationships Second the feature combination modelwas successfully applied to different types of companies anddatasets and exhibited good performance in classificationtasks
Stock market prediction of the renowned companygrounded in knowledge graph is an interesting topic forbusiness activities Given that the study of knowledge graphfor feature set is still in its infancy we expect it to be appliedin a wide range of academic research More companies willalso earn profits and create more opportunities through theuse of knowledge graph in the feature set
Data Availability
The data used in this study can be accessed via httpsgithubcomlinechanyknowledge-graph
Conflicts of Interest
The author declares that there is no conflict of interestregarding the publication of this paper
Acknowledgments
This work is supported by the China Scholarship Council(CSC) throughout the grant number 201508390019 The
14 Complexity
authors also want to thank the research program RFCS fromthe EU which partially supported this research through theresearch project AutoSurveillance with project ID 847202
References
[1] B GMalkiel and E F Fama ldquoEfficient capital markets a reviewof theory and empirical workrdquo The Journal of Finance vol 25no 2 pp 383ndash417 1970
[2] D Galai and R W Masulis ldquoThe option pricing model and therisk factor of stockrdquo Journal of Financial Economics vol 3 no1-2 pp 53ndash81 1976
[3] Q Wang Z Mao B Wang and L Guo ldquoKnowledge graphembedding A survey of approaches and applicationsrdquo IEEETransactions on Knowledge and Data Engineering vol 29 no12 pp 2724ndash2743 2017
[4] H Paulheim and P Cimiano ldquoKnowledge graph refinement Asurvey of approaches and evaluation methodsrdquo Journal of WebSemantics Science Services and Agents on the World Wide Webvol 8 no 3 pp 489ndash508 2016
[5] X Ding Y Zhang T Liu and J Duan ldquoDeep learning for event-driven stock predictionrdquo in Proceedings of the 24th InternationalJoint Conference on Artificial Intelligence IJCAI 2015 pp 2327ndash2333 Argentina July 2015
[6] X Ding Y Zhang T Liu and J Duan ldquoKnowledge-drivenevent embedding for stock predictionrdquo in Proceedings of the26th International Conference on Computational LinguisticsCOLING 2016 pp 2133ndash2142 Japan December 2016
[7] A Bordes N Usunier J Weston and O Yakhnenko ldquoTranslat-ing embeddings for modeling multi-relational datardquo Advancesin NIPS vol 26 pp 2787ndash2795 2013
[8] H Lin Y Liu W Wang Y Yue and Z Lin ldquoLearning entityand relation embeddings for knowledge resolutionrdquo ProcediaComputer Science vol 108 pp 345ndash354 2017
[9] G Ji K Liu S He and J Zhao ldquoKnowledge graph completionwith adaptive sparse transfer matrixrdquo in Proceedings of the 30thAAAI Conference on Artificial Intelligence AAAI 2016 pp 985ndash991 USA February 2016
[10] G Ji S He L Xu K Liu and J Zhao ldquoKnowledge graphembedding via dynamic mapping matrixrdquo in Proceedings ofthe 53rd Annual Meeting of the Association for ComputationalLinguistics and the 7th International Joint Conference on NaturalLanguage Processing (Volume 1 Long Papers) pp 687ndash696Beijing China July 2015
[11] Y LeCun Y Bengio and G Hinton ldquoDeep learningrdquo Naturevol 521 no 7553 pp 436ndash444 2015
[12] Q Li Y Chen J Wang and H Chen ldquoWeb media andstock markets a survey and future directions from a bigdata perspectiverdquo IEEE Transactions on Knowledge and DataEngineering vol 4347 p 1 2017
[13] B Wuthrich V Cho S Leung D Permunetilleke K Sankaranand J Zhang ldquoDaily stock market forecast from textual Webdatardquo in Proceedings of the 1998 IEEE International Confer-ence on Systems Man and Cybernetics (Cat No98CH36218)SMCrsquo98 vol 3 pp 2720ndash2725 October 1998
[14] G Pui Cheong Fung J Xu Yu and W Lam ldquoStock predictionintegrating text mining approach using real-time newsrdquo inProceedings of the 2003 IEEE International Conference on Com-putational Intelligence for Financial Engineering CIFEr 2003vol 2003 pp 395ndash402 China March 2003
[15] W Antweiler and M Z Frank ldquoIs all that talk just noise theinformation content of internet stock message boardsrdquo SSRNElectronic Journal 2001
[16] M-A Mittermayer and G F Knolmayer ldquoNewsCATS A newscategorization and trading systemrdquo in Proceedings of the 6thInternational Conference onDataMining ICDM2006 pp 1002ndash1007 China December 2006
[17] R P Schumaker and H Chen ldquoTextual analysis of stockmarket prediction using breaking financial news theAZFin textsystemrdquo ACM Transactions on Information and Systems pp 1ndash29 2009
[18] S S Groth and J Muntermann ldquoAn intraday market riskmanagement approach based on textual analysisrdquo DecisionSupport Systems vol 50 no 4 pp 680ndash691 2011
[19] T Vu S Chang Q Ha and N Collier ldquoAn experiment in inte-grating sentiment features for tech stock prediction in twitterrdquoin Proceedings of the Workshop on Information Extraction AndEntity Analytics on Social Media Data vol 3 pp 23ndash38 2012
[20] B Wang H Huang and X Wang ldquoA novel text miningapproach to financial time series forecastingrdquo Neurocomputingvol 83 pp 136ndash145 2012
[21] Q Li T Wang P Li L Liu Q Gong and Y Chen ldquoThe effectof news and public mood on stock movementsrdquo InformationSciences vol 278 pp 826ndash840 2014
[22] T H Nguyen K Shirai and J Velcin ldquoSentiment analysis onsocial media for stock movement predictionrdquo Expert Systemswith Applications vol 42 no 24 pp 9603ndash9611 2015
[23] BWengM A Ahmed and FMMegahed ldquoStockmarket one-day ahead movement prediction using disparate data sourcesrdquoExpert Systems with Applications vol 79 pp 153ndash163 2017
[24] J Eberhard J F Lavin and A Montecinos-Pearce ldquoA network-based dynamic analysis in an equity stock marketrdquo Complexityvol 2017 Article ID 3979836 16 pages 2017
[25] Z Zhang Y Zhang D Shen and W Zhang ldquoThe dynamiccross-correlations between mass media news newmedia newsand stock returnsrdquo Complexity vol 2018 11 pages 2018
[26] P C Tetlock ldquoGiving content to investor sentiment The role ofmedia in the stock marketrdquo Journal of Finance vol 62 no 3 pp1139ndash1168 2007
[27] K Chen P Luo L Liu andW Zhang ldquoNews search and stockco-movement Investigating information diffusion in the finan-cial marketrdquo Electronic Commerce Research and Applicationsvol 28 pp 159ndash171 2018
[28] F Z Xing E Cambria and Y Zhang ldquoSentiment-awarevolatility forecastingrdquo Knowledge-Based Systems vol 176 pp68ndash76 2019
[29] A Picasso S Merello Y Ma L Oneto and E CambrialdquoTechnical analysis and sentiment embeddings formarket trendpredictionrdquo Expert Systems with Applications vol 135 pp 60ndash70 2019
[30] A Khadjeh Nassirtoussi S Aghabozorgi T Ying Wah and DC L Ngo ldquoText mining for market prediction a systematicreviewrdquo Expert Systems with Applications vol 41 no 16 pp7653ndash7670 2014
[31] M Kraus and S Feuerriegel ldquoDecision support from financialdisclosures with deep neural networks and transfer learningrdquoDecision Support Systems vol 104 pp 38ndash48 2017
[32] H S Sim H I Kim and J J Ahn ldquoIs deep learning for imagerecognition applicable to stockmarket predictionrdquoComplexityvol 2019 10 pages 2019
Complexity 15
[33] M Jasemi A M Kimiagari and A Memariani ldquoA modernneural network model to do stock market timing on the basisof the ancient investment technique of Japanese candlestickrdquoExpert Systems with Applications vol 38 no 4 pp 3884ndash38902011
[34] A Fader S Soderland and O Etzioni ldquoIdentifying relations foropen information extractionrdquo in Proceedings of the Conferenceon Empirical Methods in Natural Language Processing EMNLP2011 pp 1535ndash1545 Association for Computational LinguisticsUK July 2011
[35] T Mikolov K Chen G Corrado and J Dean ldquoEfficientestimation of word representations in vector spacerdquo pp 1ndash122013 httpsarxivorgabs13013781
[36] X Lin Z Yang and Y Song ldquoIntelligent stock trading systembased on improved technical analysis and Echo State NetworkrdquoExpert Systems with Applications vol 38 no 9 pp 11347ndash113542011
[37] K-J Kim and I Han ldquoGenetic algorithms approach to featurediscretization in artificial neural networks for the prediction ofstock price indexrdquo Expert Systems with Applications vol 19 no2 pp 125ndash132 2000
[38] Y Yu W Duan and Q Cao ldquoThe impact of social andconventional media on firm equity value A sentiment analysisapproachrdquoDecision Support Systems vol 55 no 4 pp 919ndash9262013
[39] MHagenauM Liebmann andDNeumann ldquoAutomated newsreading Stock price prediction based on financial news usingcontext-capturing featuresrdquo Decision Support Systems vol 55no 3 pp 685ndash697 2013
[40] A Aizawa ldquoAn information-theoretic perspective of tf-idfmeasuresrdquo Information Processing amp Management vol 39 no1 pp 45ndash65 2003
[41] A Khadjeh Nassirtoussi S Aghabozorgi T Ying Wah and DC Ngo ldquoText mining of news-headlines for FOREX marketprediction a Multi-layer dimension reduction algorithm withsemantics and sentimentrdquo Expert Systems with Applications vol42 no 1 pp 306ndash324 2015
[42] D Peramunetilleke and R K Wong ldquoCurrency exchange rateforecasting from news headlinesrdquo Australian Computer ScienceCommunications vol 24 no 2 pp 131ndash139 2002
[43] Y Kim ldquoConvolutional neural networks for sentence classifica-tionrdquo 2014 httpsarxivorgabs14085882
[44] ZWang J Zhang J Feng and Z Chen ldquoKnowledge graph andtext jointly embeddingrdquo in Proceedings of the 2014 Conferenceon Empirical Methods in Natural Language Processing EMNLP2014 pp 1591ndash1601 Qatar October 2014
[45] J Xu X Qiu K Chen and X Huang ldquoKnowledge graphrepresentation with jointly structural and textual encodingrdquo inProceedings of the 26th International Joint Conference on Arti-ficial Intelligence IJCAI 2017 pp 1318ndash1324 Australia August2017
[46] R Xie Z Liu J Jia H Luan and M Sun ldquoRepresentationlearning of knowledge graphs with entity descriptionsrdquo in Pro-ceedings of the 30th AAAI Conference on Artificial IntelligenceAAAI rsquo16 pp 2659ndash2665 February 2016
[47] F Tian B Gao E Chen and T Liu ldquoLearning better wordembedding by asymmetric low-rank projection of knowledgegraphrdquo Journal of Computer Science and Technology vol 31 no3 pp 624ndash634 2016
[48] F Z Xing E Cambria and R E Welsch ldquoNatural languagebased financial forecasting a surveyrdquo Artificial IntelligenceReview vol 50 no 1 pp 49ndash73 2018
[49] C Goutte and E Gaussier ldquoA probabilistic interpretation ofprecision recall and F-score with implication for evaluationrdquoin Advances in Information Retrieval D E Losada and J MFernandez-Luna Eds vol 3408 of Lecture Notes in ComputerScience pp 345ndash359 Springer Berlin Germany 2005
Hindawiwwwhindawicom Volume 2018
MathematicsJournal of
Hindawiwwwhindawicom Volume 2018
Mathematical Problems in Engineering
Applied MathematicsJournal of
Hindawiwwwhindawicom Volume 2018
Probability and StatisticsHindawiwwwhindawicom Volume 2018
Journal of
Hindawiwwwhindawicom Volume 2018
Mathematical PhysicsAdvances in
Complex AnalysisJournal of
Hindawiwwwhindawicom Volume 2018
OptimizationJournal of
Hindawiwwwhindawicom Volume 2018
Hindawiwwwhindawicom Volume 2018
Engineering Mathematics
International Journal of
Hindawiwwwhindawicom Volume 2018
Operations ResearchAdvances in
Journal of
Hindawiwwwhindawicom Volume 2018
Function SpacesAbstract and Applied AnalysisHindawiwwwhindawicom Volume 2018
International Journal of Mathematics and Mathematical Sciences
Hindawiwwwhindawicom Volume 2018
Hindawi Publishing Corporation httpwwwhindawicom Volume 2013Hindawiwwwhindawicom
The Scientific World Journal
Volume 2018
Hindawiwwwhindawicom Volume 2018Volume 2018
Numerical AnalysisNumerical AnalysisNumerical AnalysisNumerical AnalysisNumerical AnalysisNumerical AnalysisNumerical AnalysisNumerical AnalysisNumerical AnalysisNumerical AnalysisNumerical AnalysisNumerical AnalysisAdvances inAdvances in Discrete Dynamics in
Nature and SocietyHindawiwwwhindawicom Volume 2018
Hindawiwwwhindawicom
Dierential EquationsInternational Journal of
Volume 2018
Hindawiwwwhindawicom Volume 2018
Decision SciencesAdvances in
Hindawiwwwhindawicom Volume 2018
AnalysisInternational Journal of
Hindawiwwwhindawicom Volume 2018
Stochastic AnalysisInternational Journal of
Submit your manuscripts atwwwhindawicom

Complexity 5
Table 2 Quotes and renowned company names
Financial newsdataset Stocks Company names Time interval Number of news
headlinesAAAL Apple Inc 3102011- - -3172017 6423
Thomson Reuters MSFT Microsoft Corporation 3092011- - -29112017 6623SSNLF Samsung Electronics Co Ltd 3092011- - -29112017 6900BA The Boeing Company 891998- - -2322017 2999
CNN GOOG Google Inc 2552006- - -2422017 5278WMT Walmart Inc 751997- - -2422017 4913
Table 3 Samples extracted from the dataset
Date News headline News headline event tuple3182012 Chinese writersrsquo group sues Apple state media Chinese writersrsquo group sues Apple
4132012 German court upholds ban on Apple push email German court upholds ban on Apple pushemail
442012 Apple two publishers hold out againstsettlement-report
Apple- two publishers hold out againstsettlement-report
3262012 Apple CEO Cook meets Chinese officials Apple CEO Cook meets Chinese officials
4252012 US STOCKS-Apple results put Nasdaq on track for bestgain of year Apple results Nasdaq on track for best gain
and their result demonstrated that a higher directional ofdeep learning surpasses traditional machine learning Dinget al [5] illustrated that deep learning also can forecaststock market of the renowned company Sim et al [32]proposed that technical indicators transform into images ofthe time series graph which examines the applicability ofdeep learning in the stock market Overall we adopt themultiple models for prediction stock price of the renownedcompany which proves the reliability of our proposed modelas comparing different algorithms This work applies deeplearning incorporated with knowledge graph embeddingfor feature extraction which examines the applicability ofcombined features methods in the renowned company stockprice movement
3 Materials and Methods
We developed a knowledge graph-based approach that con-sists of three steps namely data description data preprocess-ing and feature selection
31 Dataset Description Table 2 shows the custom financialnews corpus built with headlines from two datasets The firstdataset contains news articles published byThomsonReutersincluding those regarding Apple Inc (AAPL) MicrosoftCorporation (MSFT) and Samsung Electronics Co Ltd(SSNLF) The second dataset comprises news reports pub-lished in CNN including reports on the Boeing Company(BA) Google Inc (GOOG) and Walmart Inc (WMT) Italso consists of financial news headlines published at specifictime intervals with each news report accompanied by a titleand a release date Titles are used for event embedding andfeature extraction and release dates are used as a referencein ensuring alignment between corresponding financial news
and trading data from a time series As shown in previouswork [5 31] using a headline to build corpora can helpreduce noise in text mining as headlines concisely representthe content of a text We used only the news headlines fromReuters andCNN for the prediction of stock pricemovement
Daily stock data from index report in each company arecollected by Yahoo Finance in the same period during stockdata and financial news headlines Daily trading data whichare common predictors of stock price [23 33] and technicalindicator features were used in our model There are openingprice closing price high price low price and volume andthree technical indicators
Table 3 shows some examples of filtered financial newsheadlines To illustrate 6423 headlines regarding Apple Incwere extracted and then reduced to 2799 headlines afterfiltering via Reverb [34] Let us take the article ldquoWhat is nextfor Applersquos boardrdquo published on 6 October 2011 as a specificexample The title of the article cannot be transformed intoan event tuple using Reverb Because the sentence is in theinterrogative form there is no event tuple that constitutes arule After the matching of time-wise data and stock data941 headlines were left Daily news and stock data werealigned to create input-output pairs except the days whenno news was released In 9 January 2012 for instance threenews articles were reported but we chose only one headlinefor alignment with stock market data News events possiblyhappen several times within one day but they do not happenevery day unlike stock trading which happens daily excepton nontrading days falling on weekends or holidays
Table 4 shows that the matches found are pairs betweenevent tuples and stock data From this complete dataset weused 80 of the samples in training data and the remaining20 for testing dataThis selection method is the same as theprevious literature [5 24]
6 Complexity
Table 4 Training and testing datasets
Data source Company Training Testing TotalApple 780 161 941
Reuters Microsoft 832 208 1040Samsung 855 214 1069Boeing 528 132 660
CNN Google 1010 252 1262Walmart 798 200 998
Table 5 Number of event characteristic labels for each company
CompaniesLabel Apple Microsoft Samsung Boeing Google Walmart0 502 967 1433 133 661 2061 537 432 379 200 245 2872 661 557 378 152 389 2333 692 707 724 233 683 4384 407 228 193 147 196 180Total 2799 2891 3107 865 2174 1344
Table 6 Features of the prediction model
Feature Feature expression1 Stock price yesterday + yesterdayrsquos trend (in Section 331) 119901119903119894119888119890
119905minus1 119905 119894119899119889119894119888119886119905119900119903119905minus1
2 Same + bag-of-words (in Section 332) 119901119903119894119888119890119905minus1
119905 119894119899119889119894119888119886119905119900119903119905minus1 119905119891 119894119889119891119905minus1
3 Same + some features inferred through a convolutional neural network (in Section 333) 119901119903119894119888119890119905minus1
119905 119894119899119889119894119888119886119905119900119903119905minus1 119888119899119899119905minus14 Same + some features inferred through feature combination (in Section 334) 119901119903119894119888119890
119905minus1 119905 119894119899119889119894119888119886119905119900119903119905minus1 119891 119888119900119898119887119894119899119890
119905minus1
32 Data Preprocessing The following three steps are forpreprocessing which prepares for feature extraction andmodel creation
(1) Tagging the label for each news headline Five possiblelabels are characterized by categorical values as follows 0for an extremely negative label 1 for a negative label 2 tosignify a neutral label 3 for a positive label and 4 to denote anextremely positive label According to the time characteristicsof each news headline an event is manually tagged withthe label for each news headline Table 5 shows the labelingapplied for each company Label 0 means that a companyrsquoscompetitor has happened in this event label 1 means that thecompany lost something label 2 means that it did not causeany impact on the company label 3 means that this eventenabled the company to obtain something and label 4 meansthat the company increased its profits or created more value
(2) Word vector transformation We used the word2vec[35] algorithm to train word embedding and set the numberof dimensions to 300 The word embedding was also trainedusing the Google News dataset which contains 100 billionwords that are characterized by a continuous bag-of-wordsstructure
(3) Technical indicators calculation Three additionaltechnical indicators that are calculated on the basis of dailytrading data were used as follows
(a) Stochastic oscillator (K)This indicator is a momen-tum analysis method created by George C Lane When the
price trend rises the closing price tends to approach thehighest price of the day When the price trend declines theclosing price tends to approach the lowest price of the day[36]
(b) Larry Williamss R indicator This indicator is anoscillation indicator that measures the ratio of the highestprice to the daily closing price It indicates the proportion ofstock price fluctuations in a certain period thereby providinga signal out of the reversal of a stock market trend [37]
(c) Relative strength index (RSI) Buying and sellingintentions in the market are analyzed by comparing theclosing prices in a given period Stocks that have had moreor stronger positive changes have a higher RSI than do thosethat have had more or stronger negative changes Strengthindicators fall between 0 and 100 investors sell if this valueis ge 80 and buy if it is le 20 [23 36]
33 Variable Feature Selection To assess the effectivenessof applying the prediction model on the basis of financialnews we designed four sets of features for predicting stockprice movement (Table 6) Features 3 and 4 are used for eventcharacteristics Each feature is explained in the succeedingsubsections The target output consists of a binary variablefor which a value of 1 indicates that the closing price at day t+ 1 will be higher than that at day t and a value of 0 indicatesthat the closing price at day t + 1will be lower than that at dayt
Complexity 7
Financial news
middot middot middot
News representation Convolutional layer Max pooling Fully connected layer Features
X (I)
Z (I)
Figure 3 Convolutional neural network architecture proposed for feature selection
331 Stock Data Only We considered historical price as theinput for predicting stock price movement and used it asa baseline for comparison with other sets of features Thefeatures used to train the machine learning model that usesonly stock data are 119901119903119894119888119890119905minus1 and 119905 119894119899119889119894119888119886119905119900119903119905minus1 The output isthe indicator of pricemovement (increase or decrease) at eachtransaction date examined
332 Bag of Words The input feature set is based on a bag ofwords for the news and price trend for stock Previous studies[18 38 39] have widely used and confirmed the feasibilityof the bag-of-words algorithm but this method disregardselements such as grammar and word order in the text Inthe present study we first prepared each headline for datapreprocessing and then transformed the preprocessed head-line into a feature vector using the term frequency-inversedocument frequency (TF-IDF) algorithm [40] which assignshighweight to eigenvectorsThe studies [41 42] have stronglyproven the effectiveness of the TF-IDF algorithm in featureextraction from news headlines It estimates the frequency ofa term in one document over the maximum in a collection ofdocuments and assesses the importance of aword in one set ofdocuments Such importance increases proportionally withthe number of word appearances in a documentThe featuresused to train the bag-of-words machine learning model are119901119903119894119888119890119905minus1 119905 119894119899119889119894119888119886119905119900119903119905minus1 and 119905119891 119894119889119891119905minus1 which are the pricemovements (increase or decrease) at each transaction dateexamined
333 Convolutional Neural Network Given the sequence ofwords in a headline the word2vec model [35] can be usedto embed each of these words in a real valued-vector 119909 Inthis work we set the dimension 119899 of each word vector at30 (ie 119909 isin R30) We concatenated the word vectors of allthe words in a headline sequentially to form a matrix 119883 =[119909(1) 119909(2) 119909(3) 119909(4)] [35] as the input to a convolutionalneural network model For a headline with 119873 words the
resultant input matrix has dimensions of 30 times 119873 and thedimension of news representation also is 30
In Figure 3 this convolutional neural network model ismade up of four consecutive layers the first layer is theinput the second layer is convolutional the third layer is amax-pooling and the last layer is a fully connected layerThe convolutional and max-pooling layers were designedusing the text-attentional convolutional neural network [43]which effectively carries out sentiment classification In theconvolutional layer input matrix X convolves with a kernel119908 isin R119899times119896 where n is the size of a word vector (30 inour work) and its dimension is 50 k denotes the size of asliding window (k=3 in this study) The computation can beformulated as follows
119885119894 = 120590 (119908119883119894119894+119896minus1 + 119887) (1)
where 119883119894119894+119896minus1 = [119909119894 119909119894+1 119909119894+119896minus1] is the portion of input119883 falling within the sliding window 119887 denotes the optionaloffset and 120590(sdot) is the sigmoid function
In the next step we used the pooling layer to reduce theconvolutional neural networks parameter space and conse-quently minimize information loss in the pooling processingand capture the most important features The eigenvectorof the filter in the pooling layer is cut into 3 chunks anda maximum value is taken in each chunk we obtained 3eigenvalues Convolutional output vector Z was split into pwindows and only themaximum feature as 3 in each windowwas kept for passage onto the final fully connected layer Thefully connected layer is linear regression and the output layeris the feature classification between 0 and 1
Our convolutional neural network model is intended toextract a feature vector from the fully connected layer todescribe the emotional characteristics of input headlinesFollowing the intuition that a good feature vector shouldlead to the accurate classification of the event characteristicsof headlines we attached a softmax layer after the fully
8 Complexity
The United Kingdom of Great Britain and Northern Ireland commonly known as the United Kingdom or Britain hellip
London is the capital city of England and of the United Kingdom It is the most populous region hellip
Head Relationship TailLondon location country capital United Kingdom
London is the caEngland and of Kingdom It is tpopulous region
Kingdom of GreatNorthern Ireland known as the United
Britain hellip
Figure 4 Text description of the entity
connected layer when the convolutional neural networkmodel was trained The entire model was trained to classifythe five emotional labels that describe event characteristicsand the resultant model will be able to provide a mean-ingful emotional feature vector for each inputted headlineMeanwhile we define the loss function of the convolutionalneural network model as 119864119889 The features used to trainthis machine learning model are 119901119903119894119888119890119905minus1 119905 119894119899119889119894119888119886119905119900119903119905minus1and 119888119899119899119905minus1 which are the price movements (increase ordecrease) at corresponding transaction date
334 Combined Features In the introduction section of thispaper we described various translation models Because theTransE model represents a one-to-one relationship betweentwo entities [7] the relationship amongst many entities mustbe continuously incorporated into texts and knowledge graph[44] This model combines a convolutional neural networkwith textual information extraction which fully exploits thesemantic information in a knowledge graph and text [45 46]In Figure 4 knowledge graph contains rich semantics inentity description texts but it is not fully utilized in featureextraction Most of the existing text representation modelssimply train the text into word vectors through word2vecwhich obtains the text representation by means of averagingetc Hence these ways often lose more semantic informationWe therefore proposed to extract feature vectors from newstexts using a convolutional neural network model combinedwith the TransE model which also fully integrates the twoparts of the feature information
In Figure 5 this architecture used in the feature combina-tion model encompasses two parts namely a convolutionalneural network (Section 333) and the TransE model Thefeature combination sets are the average of each word vectorin an entity and it was obtained using the word2vec modelThe two entity vectors are mapped into the same relationalspace and these entities using a trained low-rank weightmatrix [47]
As assumed in the TransE model relationship vector Rshould satisfy ldquoE + R asymp Trdquo The model can be representedas a parameter set 0 = (119871119903 119877119903 120579) where X E and R
represent a word an entity and a relation respectively Andr are the mapping matrices for entities in the structuralmodel and represents the weights of the convolutional neuralnetwork For instance the sentence is ldquoSamsung sues Apple forinfringementrdquo so ldquoSamsung +Appleasymp suesrdquoThe loss function119864119904 of this structural model is defined as follows
119864119904 = ℎ + 119903 minus 11990522 (2)
where h r and t represent head entity relationship and tailentity in event tuple respectively [47]
And text representation 119864119889 is consistent withSection 333 which denotes
119864119889 = 119891119903 (ℎ119904 119905119889) + 119891119903 (ℎ119889 119905119904) + 119891119903 (ℎ119889 119905119889) (3)
where119891119903(ℎ119889 119905119889) = ℎ119889+119903minus11990511988922 represents the head entity andthe tail entity is in text representation119891119903(ℎ119889 119905119904) = ℎ119889+119903minus11990511990422and 119891119903(ℎ119904 119905119889) = ℎ119904 + 119903minus 11990511988922 represent one of the head entityh and the tail entity t in text representation another one is instructure representation
Moreover we combined two types of representationlearning (convolutional neural network and feature combi-nation) to map news titles these vectors will be into featurevectors The relationship vector R identical to the resultof the feature extraction layer of the convolutional neuralnetwork in the structural model Besides we combined thisloss with the classification loss of the convolutional neuralnetwork using L2 regularization which obtains the overallloss function 119864 for feature selection that is
119864 = 119864119904 + 120572119864119889 + 120573 02 (4)
where 02 is a regular item 120572 and 120573 are hyperparameterswhich measure the loss of text information and the weight ofthe regular items respectively W denotes the convolutionalkernels in the layer and 1198791015840 is a negative sample set of 119879 [7]
1198791015840 = (ℎ1015840 119903 119905) | ℎ1015840 isin 119864 cup (ℎ 119903 1199051015840) | 1199051015840 isin 119864
cup (ℎ 1199031015840 119905) | 1199031015840 isin 119877 (5)
Complexity 9
Output layerClass1 Class2
Machinelearning
Max pooling
convolutional
Input news
Feature vector
Embedding layer
Input news
Event tuple
Word2vec
Word2vec
Fully connection
Stock data
Stock layer
TransE model
Figure 5 Proposed architecture for the feature combination model
where the head entity and tail entity are randomly replaced byan entity or relationship in another tuple In particular if thereplaced tuple is already in T it would not be added to thenegative sample Since both h and t represent two types ofentities there are structure-based representations and text-based representations in interval-based loss functions Thestochastic gradient descent (SGD) is employed to minimizethe above loss function
In this structure we choose the optimal parameters asfollowe the learning rate of SGD 120582 = 0001 the dimension ofthe representation vector of entities and relationships k = 100the word vector dimension of the entity description text n =100 and batch size during training is 1440 Convolution layerwindow size is 119882 isin 1 2 3 This experiment is performedin 1000 iterations of training and the optimal parameters arebased on the testing set
Hence the features used for training the machine learn-ing model are 119901119903119894119888119890119905minus1 119905 119894119899119889119894119888119886119905119900119903119905minus1 and 119891 119888119900119898119887119894119899119890119905minus1which are the price movement (increase or decrease) atcorresponding transaction date
4 Experiments and Results
41 Experimental Setting This section compares the perfor-mance of differentmodels in feature extraction fromfinancialnews expended with full sets of features The evaluationwas intended to obtain evidence that the proposed featurecombination model is superior to other feature selectionmodels in predicting the stock price movement As shownin Table 7 we chose linear models for instance logisticalregression and naive Bayes Others are nonlinear models forinstance the ensemble learning (random forest adaboostand gradient boosting) for the comparison We constantlyadjusted the parameters in the grid search and selected theoptimal parameter value their parameter value has proven towork well on machine learning method [29 48]
We used a computer consisting of an Intel Core i5processor with four cores running at 29 GHz and 8 GBRAM under the MacOS platform We used the Scikit-learnlibrary in Python in the experiments involving traditionalmachine learning algorithms and TensorFlow 14 in the
10 Complexity
Table 7 List of machine learning methods
Method Classification Parameter and their value
Traditionalmachinelearning
Decision tree (DT)Criterion= gini splitter= best max depth=None minsamples split=2 min samples leaf =1 min weight
fraction leaf=00Logistical regression (LR) Random state=1
Naive Bayes (NB) No kernel estimatorStochastic gradient descent (SGD) Loss=hinge penalty=l2
Support vector machine (SVM) Polynomial kernel function with exponent = 1 2 RBFkernel function with gamma = 001
Ensemblelearning
Random forest (RF) Randomly sampled as candidates at each split = log2 +1 max-depth=2 random state=0
AdaBoost (AB) Polynomial kernel function with exponent = 1 2 RBFkernel function with gamma = 001 n- estimators=100
Gradient boosting (GB) N-estimators =100 learning rate =10 max-depth=1random state=0
Table 8 Abbreviations of the results for each algorithm considered
Algorithms Stock data (SD) Bag of words (BOW) Convolutionalneural network
Featurecombinationmodel (FC)
DT DT 1 DT 2 DT 3 DT 4LR LR 1 LR 2 LR 3 LR 4NB NB 1 NB 2 NB 3 NB 4SGD SGD 1 SGD 2 SGD 3 SGD 4SVM SVM 1 SVM 2 SVM 3 SVM 4RF RF 1 RF 2 RF 3 RF 4AB AB 1 AB 2 AB 3 AB 4GB GB 1 GB 2 GB 3 GB 4
experiments involving deep learning and the TransE modelThe abbreviations used for comparing classification perfor-mance are presented in Table 8 During testing 2-fold cross-validation is applied to evaluate the stability of the modelsAnd we compared performance in predicting stock pricemovement for the next day with a test dataset and evaluatedthe performance of the models in terms of accuracy and F1-score [49]
42 Results
421 Thomson Reuters Case Study Thomson Reuters isa multinational mass media and information firm Threerenowned companies on the website were selected for theanalysis The first is Apple Inc which is an American multi-national technology company that designs develops andsells consumer electronics computer software and onlineservices The second company selected is Microsoft which isan American multinational technology company that devel-ops manufactures supports and sells computer softwarepersonal computers and other services The last companychosen is Samsung which is a South Korean multinationalelectronics company We considered data from these threetypical technology companies for our problem
Measurements of average accuracy are shown in Table 9and the results for each renowned company with respectto prediction based on different features are illustrated inFigure 6 We calculated the average of the four feature con-struction approaches for eachmodel for comparison amongstthe three companies The proposed feature combinationmodel generated the best results achieving average accuracylevels of 6163 5918 and 5848 forAppleMicrosoft andSamsung respectively These figures are consistent with therates reported in previous research However many studiesanalyzed only one company or used only one algorithmThe current research probed into three companies on thebasis of information from a common data source to builda prediction model with different feature selection func-tionalities and different algorithms We used stock dataa bag-of-words algorithm a convolutional neural networkand feature combination together with eight algorithms Asindicated in Table 9 the proposed predictionmodel achieved7368 data extraction with the use of LR 4 for Apple and6778 data extraction with the use of SVM 4 for MicrosoftIn particular the LR algorithm used for Apple achievedaccuracy and F1-score of 07326 and 07360 respectivelywhich highlights its powerful capability in a two-class classifi-cation
Complexity 11
Table 9 Results for data extracted fromThomson Reuters
Algorithm Company Stock data(SD)
Bag of words(BOW)
Convolutionalneural network
Feature combinemodel (FC)
AccuracyF1-score
AccuracyF1-score
AccuracyF1-score
AccuracyF1-score
DTApple 0499305079 0488902460 0615005814 0652406486
Microsoft 0486801819 0506505682 0581705915 0658706502Samsung 0470704033 0565405830 0552906820 0568006260
LRApple 0524006727 0505505083 0684506911 0732607368
Microsoft 0475701253 0443004884 0527405333 0546705611Samsung 0494703755 0605406726 0654106343 0805307978
NBApple 0510905123 0477803896 0502704497 0512204030
Microsoft 0484000363 0455704055 0459902889 0500005439Samsung 0529305810 0514406130 0504806578 0511706601
SGDApple 0467201119 0477804404 0497406008 0536602692
Microsoft 0517306819 0485203222 0610304231 0610804193Samsung 0522306541 0476602000 0518706751 0557106548
SVMApple 0502206121 0574705542 0615006129 0622006173
Microsoft 0478401722 0443904566 0523205462 0687506798Samsung 0500803875 0504705508 0513506281 0535206574
RFApple 0524006554 0527806083 0533706232 0620306243
Microsoft 0484002653 0417701687 0532502432 0572105189Samsung 0487203480 0448501194 0476603708 0505205481
ABApple 0534305384 0472202963 0481903333 0620305420
Microsoft 0468702041 0476800461 0614706044 0620206146Samsung 0485703619 0457902368 0601006820 0633806549
GBApple 0531405129 0466702941 0609604748 0634106591
Microsoft 0474302125 0472801007 0455704557 0538502258Samsung 0487204171 0519206599 0533706572 0562206335
Reuters
Aver
age a
ccur
acy
0
01
02
03
04
05
06
07
Different companyApple Microsoft Samsung
SDBOW
CNNFC
Figure 6 Average accuracy of prediction based on different featuresets for each company in Reuters
To assess the effectiveness of our research we comparedthe feature combination model that uses event tuples with
the stock data approach and the bag-of-words algorithmTheresults showed that the average accuracy of the event tuple-basedmodel is better than that of the stock data approach andthe bag-of-words algorithm by 1001 and 1087 respec-tively We also compared feature extraction using the stockdata approach the bag-of-words algorithm and machinelearning The use of deep learning improved predictionaccuracy by 525 and 611 over the levels achieved withstock data and bag of words respectively Therefore we canconclude that using the proposed feature combinationmodeland deep learning in feature extraction helps improve theaccuracy with which stock price movement is predictedThese results also fully prove the effectiveness of embeddinglayer in feature extraction accuracy improvement
422 CNN Case Study CNN is an American basic cableand satellite television news channel owned by the TurnerBroadcasting System Three renowned companies on whichthese website reports were selected for the analysis The firstis Boeing which is an American multinational corporationthat designs manufactures and sells airplanes rotorcraftrockets and satellites worldwide The second company isGoogle which is an American multinational technology
12 Complexity
Table 10 Results for data extracted from CNN
Algorithm Company Stock data(SD)
Bag of words(BOW)
Convolutionalneural network
Featurecombinationmodel (FC)
AccuracyF1-score
AccuracyF1-score
AccuracyF1-score
AccuracyF1-score
DTBoeing 0495003489 0541306258 0541406347 0559105821Google 0485805600 0518203575 0569204631 0549105471Walmart 0499604422 0530004891 0508804815 0572205829
LRBoeing 0492302378 0511304348 0692306923 0759605733Google 0504106105 0623506491 0625006111 0656306516Walmart 0529005468 0541205083 0732007347 0771907720
NBBoeing 0516206503 0548905161 0519706738 0556407619Google 0511206527 0489905191 0558705281 0534404843Walmart 0504403284 0479405302 0520605674 0530006083
SGDBoeing 0489702407 0556404870 0543304727 0571407220Google 0516506769 0542504375 0578906364 0591006327Walmart 0500403804 0520605280 0525005581 0567005922
SVMBoeing 0489703068 0571406275 0538506418 0594007033Google 0507706297 0603206230 0574905532 0578905840Walmart 0511804333 0500005314 0520005000 0561405455
RFBoeing 0490601345 0511303925 0509605405 0527605714Google 0492301777 0603206260 0522305564 0595105763Walmart 0511805373 0530003188 0530004405 0500005446
ABBoeing 0494503404 0519705120 0496105294 0567305872Google 0487603141 0510106667 0589305619 0595106850Walmart 0507305029 0515005359 0549705650 0561905503
GBBoeing 0489903169 0511804364 0440904580 0500005094Google 0491203387 0587005854 0562505243 0603206202Walmart 0500304955 0505005123 0536105109 0549705650
company that specializes in Internet-related services andproducts The third is Walmart an American multinationalretail corporation that operates a chain of hypermarketsdiscount department stores and grocery stores
The results on average accuracy are shown in Table 10and Figure 7These findings are very similar to those derivedin the previous case study and their comparison confirmedthat the proposed feature combinationmodel can outperformother feature selection models in stock price movementprediction With regard to feature selection underlain bythe bag-of-words algorithm the CNN case study generatedmore robust results than did the Reuters case study Theaverage accuracy of the bag-of-words algorithm was lowerthan that of the stock data approach in the Reuters case studyIn the CNN case study the average accuracy levels of theproposed feature combination model were 5794 5879and 5767 for Boeing Google andWalmart respectively Inthe case study on Reuters an average accuracy that exceeds60 was not achieved for any of the companies illustratingthat differences in data source directly affect stock pricemovement
We chose a combination of deep learning and knowledgegraph to build our feature selection model because this
CNN
Aver
age a
ccur
acy
0
01
02
03
04
05
06
07
Different companyBoeing Google Walmart
SDBOW
CNNFC
Figure 7Average accuracy achieved on the basis of news fromCNNand different feature set
combination exhibited superior prediction performance inthe comparison experiments involving other feature selection
Complexity 13
strategies The forecast results based on different featuresare shown in Table 10 We found that deep learning featuresare better than the use of bag-of-words and stock data Thecorrelation of event tuples with the stock market is relativelyhigh in [5 31] but the bag-of-words algorithm was relativelyfragmented and the correlation between event tuples and thestockmarket data was relatively weak Combining event tuplefeatures with deep learning significantly improves forecastresults indicating a close relationship between stock marketmovements and knowledge graph
5 Discussion
51 Research Findings We attempted to compare our predic-tion results with those made in previous studies wherein pre-diction was also based on the financial news of the renownedcompanies However the findings are incomparable becausedifferent studies use different datasets or algorithms andthese methods are difficult to investigate using financial newsheadlines In the current research we refrained from eval-uating performance on one company dataset this decisionthat enabled our knowledge graphmethod to exceed baselinepredictions based only on the price by up to 36 Thisalso proves that feature extraction in deep learning is moreeffective than traditional machines The combination of deeplearning and knowledge graph fully integrates the semanticinformation in financial news which effectively predicts thestock price movement of the renowned company
This work demonstrated the application of deep learningand knowledge graph in finance To the best of our knowl-edge knowledge graph has been rarely applied in stock pre-diction Becauseminimal financial training sets in knowledgegraph are available financial knowledge extraction is themain task for the organizational construction of a knowledgegraph Such extraction is critical for the understanding andprocessing of deep semantics in the event tuple which alsodirectly influences the feature extraction of financial news
52 Implications for Business Activities Theutility of a featurecombination model based on knowledge graph is not limitedto financial analysis Currently knowledge graph data areavailable for medical diagnosis speech recognition precisemarketing and financial risk control [4] Our model couldalso be applied in these areas
Antifraud activities are an important part of financeApplying our model on the basis of knowledge graph oncustomers helps organize all relevant knowledge fragmentsthrough deep semantic analysis and reasoning which canbe verified with a customerrsquos bank information Moreovercustomers typically use keywords to search for productsand knowledge graph can provide relevant information toa customer If a complete knowledge system of users isdescribed and collected a system would better understandand analyze user behaviors
53 Limitations and Future Work A deep learning modeluses supervised learning and needs a dataset with sufficientlabels but our datasets do not work well with deep learningas a small number of financial news articles match stock
data At present knowledge graph embedding inevitablyproduces a loss in news semantics either because of a learningprinciple or the tokenization of knowledge representation forvectorization Thus continuous representation in a knowl-edge graph is still a huge challenge We attempted to applyregression using the above-mentioned algorithms but theresults indicated poor performance More specifically theresults for Apple validated our expectations
The application of large-scale knowledge graph is stillrelatively limited and knowledge graph for smart searchsmart question-and-answer tasks social media and otherareas are in their initial stages with considerable room forimprovement The following advantages of knowledge graphshould be considered (a) the effective organization andexpression of semistructured data (b) knowledge reasoningand (c) the expansion of cognitive ability for incorporatingdeep learning Traditional knowledge elements (entities rela-tionship attributes) extraction technologies and methodshave achieved good results in limited areas but because ofnumerous constraints and poor scalability knowledge graphis not fully functional for financial forecasting because ofnumerous constraints and poor scalability
6 Conclusions
Stock movement prediction of the renowned company is adaunting task because stock prices are affected by many fac-tors This research presented a novel method for integratingknowledge graph embedding with stock market predictionThe contributions of this study can be summarized as followsFirst we developed a novel feature combination model thatconstructs a feature mapping vector for each tuplendashnewspair by simultaneously considering the diversity of entitiesand relationships Second the feature combination modelwas successfully applied to different types of companies anddatasets and exhibited good performance in classificationtasks
Stock market prediction of the renowned companygrounded in knowledge graph is an interesting topic forbusiness activities Given that the study of knowledge graphfor feature set is still in its infancy we expect it to be appliedin a wide range of academic research More companies willalso earn profits and create more opportunities through theuse of knowledge graph in the feature set
Data Availability
The data used in this study can be accessed via httpsgithubcomlinechanyknowledge-graph
Conflicts of Interest
The author declares that there is no conflict of interestregarding the publication of this paper
Acknowledgments
This work is supported by the China Scholarship Council(CSC) throughout the grant number 201508390019 The
14 Complexity
authors also want to thank the research program RFCS fromthe EU which partially supported this research through theresearch project AutoSurveillance with project ID 847202
References
[1] B GMalkiel and E F Fama ldquoEfficient capital markets a reviewof theory and empirical workrdquo The Journal of Finance vol 25no 2 pp 383ndash417 1970
[2] D Galai and R W Masulis ldquoThe option pricing model and therisk factor of stockrdquo Journal of Financial Economics vol 3 no1-2 pp 53ndash81 1976
[3] Q Wang Z Mao B Wang and L Guo ldquoKnowledge graphembedding A survey of approaches and applicationsrdquo IEEETransactions on Knowledge and Data Engineering vol 29 no12 pp 2724ndash2743 2017
[4] H Paulheim and P Cimiano ldquoKnowledge graph refinement Asurvey of approaches and evaluation methodsrdquo Journal of WebSemantics Science Services and Agents on the World Wide Webvol 8 no 3 pp 489ndash508 2016
[5] X Ding Y Zhang T Liu and J Duan ldquoDeep learning for event-driven stock predictionrdquo in Proceedings of the 24th InternationalJoint Conference on Artificial Intelligence IJCAI 2015 pp 2327ndash2333 Argentina July 2015
[6] X Ding Y Zhang T Liu and J Duan ldquoKnowledge-drivenevent embedding for stock predictionrdquo in Proceedings of the26th International Conference on Computational LinguisticsCOLING 2016 pp 2133ndash2142 Japan December 2016
[7] A Bordes N Usunier J Weston and O Yakhnenko ldquoTranslat-ing embeddings for modeling multi-relational datardquo Advancesin NIPS vol 26 pp 2787ndash2795 2013
[8] H Lin Y Liu W Wang Y Yue and Z Lin ldquoLearning entityand relation embeddings for knowledge resolutionrdquo ProcediaComputer Science vol 108 pp 345ndash354 2017
[9] G Ji K Liu S He and J Zhao ldquoKnowledge graph completionwith adaptive sparse transfer matrixrdquo in Proceedings of the 30thAAAI Conference on Artificial Intelligence AAAI 2016 pp 985ndash991 USA February 2016
[10] G Ji S He L Xu K Liu and J Zhao ldquoKnowledge graphembedding via dynamic mapping matrixrdquo in Proceedings ofthe 53rd Annual Meeting of the Association for ComputationalLinguistics and the 7th International Joint Conference on NaturalLanguage Processing (Volume 1 Long Papers) pp 687ndash696Beijing China July 2015
[11] Y LeCun Y Bengio and G Hinton ldquoDeep learningrdquo Naturevol 521 no 7553 pp 436ndash444 2015
[12] Q Li Y Chen J Wang and H Chen ldquoWeb media andstock markets a survey and future directions from a bigdata perspectiverdquo IEEE Transactions on Knowledge and DataEngineering vol 4347 p 1 2017
[13] B Wuthrich V Cho S Leung D Permunetilleke K Sankaranand J Zhang ldquoDaily stock market forecast from textual Webdatardquo in Proceedings of the 1998 IEEE International Confer-ence on Systems Man and Cybernetics (Cat No98CH36218)SMCrsquo98 vol 3 pp 2720ndash2725 October 1998
[14] G Pui Cheong Fung J Xu Yu and W Lam ldquoStock predictionintegrating text mining approach using real-time newsrdquo inProceedings of the 2003 IEEE International Conference on Com-putational Intelligence for Financial Engineering CIFEr 2003vol 2003 pp 395ndash402 China March 2003
[15] W Antweiler and M Z Frank ldquoIs all that talk just noise theinformation content of internet stock message boardsrdquo SSRNElectronic Journal 2001
[16] M-A Mittermayer and G F Knolmayer ldquoNewsCATS A newscategorization and trading systemrdquo in Proceedings of the 6thInternational Conference onDataMining ICDM2006 pp 1002ndash1007 China December 2006
[17] R P Schumaker and H Chen ldquoTextual analysis of stockmarket prediction using breaking financial news theAZFin textsystemrdquo ACM Transactions on Information and Systems pp 1ndash29 2009
[18] S S Groth and J Muntermann ldquoAn intraday market riskmanagement approach based on textual analysisrdquo DecisionSupport Systems vol 50 no 4 pp 680ndash691 2011
[19] T Vu S Chang Q Ha and N Collier ldquoAn experiment in inte-grating sentiment features for tech stock prediction in twitterrdquoin Proceedings of the Workshop on Information Extraction AndEntity Analytics on Social Media Data vol 3 pp 23ndash38 2012
[20] B Wang H Huang and X Wang ldquoA novel text miningapproach to financial time series forecastingrdquo Neurocomputingvol 83 pp 136ndash145 2012
[21] Q Li T Wang P Li L Liu Q Gong and Y Chen ldquoThe effectof news and public mood on stock movementsrdquo InformationSciences vol 278 pp 826ndash840 2014
[22] T H Nguyen K Shirai and J Velcin ldquoSentiment analysis onsocial media for stock movement predictionrdquo Expert Systemswith Applications vol 42 no 24 pp 9603ndash9611 2015
[23] BWengM A Ahmed and FMMegahed ldquoStockmarket one-day ahead movement prediction using disparate data sourcesrdquoExpert Systems with Applications vol 79 pp 153ndash163 2017
[24] J Eberhard J F Lavin and A Montecinos-Pearce ldquoA network-based dynamic analysis in an equity stock marketrdquo Complexityvol 2017 Article ID 3979836 16 pages 2017
[25] Z Zhang Y Zhang D Shen and W Zhang ldquoThe dynamiccross-correlations between mass media news newmedia newsand stock returnsrdquo Complexity vol 2018 11 pages 2018
[26] P C Tetlock ldquoGiving content to investor sentiment The role ofmedia in the stock marketrdquo Journal of Finance vol 62 no 3 pp1139ndash1168 2007
[27] K Chen P Luo L Liu andW Zhang ldquoNews search and stockco-movement Investigating information diffusion in the finan-cial marketrdquo Electronic Commerce Research and Applicationsvol 28 pp 159ndash171 2018
[28] F Z Xing E Cambria and Y Zhang ldquoSentiment-awarevolatility forecastingrdquo Knowledge-Based Systems vol 176 pp68ndash76 2019
[29] A Picasso S Merello Y Ma L Oneto and E CambrialdquoTechnical analysis and sentiment embeddings formarket trendpredictionrdquo Expert Systems with Applications vol 135 pp 60ndash70 2019
[30] A Khadjeh Nassirtoussi S Aghabozorgi T Ying Wah and DC L Ngo ldquoText mining for market prediction a systematicreviewrdquo Expert Systems with Applications vol 41 no 16 pp7653ndash7670 2014
[31] M Kraus and S Feuerriegel ldquoDecision support from financialdisclosures with deep neural networks and transfer learningrdquoDecision Support Systems vol 104 pp 38ndash48 2017
[32] H S Sim H I Kim and J J Ahn ldquoIs deep learning for imagerecognition applicable to stockmarket predictionrdquoComplexityvol 2019 10 pages 2019
Complexity 15
[33] M Jasemi A M Kimiagari and A Memariani ldquoA modernneural network model to do stock market timing on the basisof the ancient investment technique of Japanese candlestickrdquoExpert Systems with Applications vol 38 no 4 pp 3884ndash38902011
[34] A Fader S Soderland and O Etzioni ldquoIdentifying relations foropen information extractionrdquo in Proceedings of the Conferenceon Empirical Methods in Natural Language Processing EMNLP2011 pp 1535ndash1545 Association for Computational LinguisticsUK July 2011
[35] T Mikolov K Chen G Corrado and J Dean ldquoEfficientestimation of word representations in vector spacerdquo pp 1ndash122013 httpsarxivorgabs13013781
[36] X Lin Z Yang and Y Song ldquoIntelligent stock trading systembased on improved technical analysis and Echo State NetworkrdquoExpert Systems with Applications vol 38 no 9 pp 11347ndash113542011
[37] K-J Kim and I Han ldquoGenetic algorithms approach to featurediscretization in artificial neural networks for the prediction ofstock price indexrdquo Expert Systems with Applications vol 19 no2 pp 125ndash132 2000
[38] Y Yu W Duan and Q Cao ldquoThe impact of social andconventional media on firm equity value A sentiment analysisapproachrdquoDecision Support Systems vol 55 no 4 pp 919ndash9262013
[39] MHagenauM Liebmann andDNeumann ldquoAutomated newsreading Stock price prediction based on financial news usingcontext-capturing featuresrdquo Decision Support Systems vol 55no 3 pp 685ndash697 2013
[40] A Aizawa ldquoAn information-theoretic perspective of tf-idfmeasuresrdquo Information Processing amp Management vol 39 no1 pp 45ndash65 2003
[41] A Khadjeh Nassirtoussi S Aghabozorgi T Ying Wah and DC Ngo ldquoText mining of news-headlines for FOREX marketprediction a Multi-layer dimension reduction algorithm withsemantics and sentimentrdquo Expert Systems with Applications vol42 no 1 pp 306ndash324 2015
[42] D Peramunetilleke and R K Wong ldquoCurrency exchange rateforecasting from news headlinesrdquo Australian Computer ScienceCommunications vol 24 no 2 pp 131ndash139 2002
[43] Y Kim ldquoConvolutional neural networks for sentence classifica-tionrdquo 2014 httpsarxivorgabs14085882
[44] ZWang J Zhang J Feng and Z Chen ldquoKnowledge graph andtext jointly embeddingrdquo in Proceedings of the 2014 Conferenceon Empirical Methods in Natural Language Processing EMNLP2014 pp 1591ndash1601 Qatar October 2014
[45] J Xu X Qiu K Chen and X Huang ldquoKnowledge graphrepresentation with jointly structural and textual encodingrdquo inProceedings of the 26th International Joint Conference on Arti-ficial Intelligence IJCAI 2017 pp 1318ndash1324 Australia August2017
[46] R Xie Z Liu J Jia H Luan and M Sun ldquoRepresentationlearning of knowledge graphs with entity descriptionsrdquo in Pro-ceedings of the 30th AAAI Conference on Artificial IntelligenceAAAI rsquo16 pp 2659ndash2665 February 2016
[47] F Tian B Gao E Chen and T Liu ldquoLearning better wordembedding by asymmetric low-rank projection of knowledgegraphrdquo Journal of Computer Science and Technology vol 31 no3 pp 624ndash634 2016
[48] F Z Xing E Cambria and R E Welsch ldquoNatural languagebased financial forecasting a surveyrdquo Artificial IntelligenceReview vol 50 no 1 pp 49ndash73 2018
[49] C Goutte and E Gaussier ldquoA probabilistic interpretation ofprecision recall and F-score with implication for evaluationrdquoin Advances in Information Retrieval D E Losada and J MFernandez-Luna Eds vol 3408 of Lecture Notes in ComputerScience pp 345ndash359 Springer Berlin Germany 2005
Hindawiwwwhindawicom Volume 2018
MathematicsJournal of
Hindawiwwwhindawicom Volume 2018
Mathematical Problems in Engineering
Applied MathematicsJournal of
Hindawiwwwhindawicom Volume 2018
Probability and StatisticsHindawiwwwhindawicom Volume 2018
Journal of
Hindawiwwwhindawicom Volume 2018
Mathematical PhysicsAdvances in
Complex AnalysisJournal of
Hindawiwwwhindawicom Volume 2018
OptimizationJournal of
Hindawiwwwhindawicom Volume 2018
Hindawiwwwhindawicom Volume 2018
Engineering Mathematics
International Journal of
Hindawiwwwhindawicom Volume 2018
Operations ResearchAdvances in
Journal of
Hindawiwwwhindawicom Volume 2018
Function SpacesAbstract and Applied AnalysisHindawiwwwhindawicom Volume 2018
International Journal of Mathematics and Mathematical Sciences
Hindawiwwwhindawicom Volume 2018
Hindawi Publishing Corporation httpwwwhindawicom Volume 2013Hindawiwwwhindawicom
The Scientific World Journal
Volume 2018
Hindawiwwwhindawicom Volume 2018Volume 2018
Numerical AnalysisNumerical AnalysisNumerical AnalysisNumerical AnalysisNumerical AnalysisNumerical AnalysisNumerical AnalysisNumerical AnalysisNumerical AnalysisNumerical AnalysisNumerical AnalysisNumerical AnalysisAdvances inAdvances in Discrete Dynamics in
Nature and SocietyHindawiwwwhindawicom Volume 2018
Hindawiwwwhindawicom
Dierential EquationsInternational Journal of
Volume 2018
Hindawiwwwhindawicom Volume 2018
Decision SciencesAdvances in
Hindawiwwwhindawicom Volume 2018
AnalysisInternational Journal of
Hindawiwwwhindawicom Volume 2018
Stochastic AnalysisInternational Journal of
Submit your manuscripts atwwwhindawicom

6 Complexity
Table 4 Training and testing datasets
Data source Company Training Testing TotalApple 780 161 941
Reuters Microsoft 832 208 1040Samsung 855 214 1069Boeing 528 132 660
CNN Google 1010 252 1262Walmart 798 200 998
Table 5 Number of event characteristic labels for each company
CompaniesLabel Apple Microsoft Samsung Boeing Google Walmart0 502 967 1433 133 661 2061 537 432 379 200 245 2872 661 557 378 152 389 2333 692 707 724 233 683 4384 407 228 193 147 196 180Total 2799 2891 3107 865 2174 1344
Table 6 Features of the prediction model
Feature Feature expression1 Stock price yesterday + yesterdayrsquos trend (in Section 331) 119901119903119894119888119890
119905minus1 119905 119894119899119889119894119888119886119905119900119903119905minus1
2 Same + bag-of-words (in Section 332) 119901119903119894119888119890119905minus1
119905 119894119899119889119894119888119886119905119900119903119905minus1 119905119891 119894119889119891119905minus1
3 Same + some features inferred through a convolutional neural network (in Section 333) 119901119903119894119888119890119905minus1
119905 119894119899119889119894119888119886119905119900119903119905minus1 119888119899119899119905minus14 Same + some features inferred through feature combination (in Section 334) 119901119903119894119888119890
119905minus1 119905 119894119899119889119894119888119886119905119900119903119905minus1 119891 119888119900119898119887119894119899119890
119905minus1
32 Data Preprocessing The following three steps are forpreprocessing which prepares for feature extraction andmodel creation
(1) Tagging the label for each news headline Five possiblelabels are characterized by categorical values as follows 0for an extremely negative label 1 for a negative label 2 tosignify a neutral label 3 for a positive label and 4 to denote anextremely positive label According to the time characteristicsof each news headline an event is manually tagged withthe label for each news headline Table 5 shows the labelingapplied for each company Label 0 means that a companyrsquoscompetitor has happened in this event label 1 means that thecompany lost something label 2 means that it did not causeany impact on the company label 3 means that this eventenabled the company to obtain something and label 4 meansthat the company increased its profits or created more value
(2) Word vector transformation We used the word2vec[35] algorithm to train word embedding and set the numberof dimensions to 300 The word embedding was also trainedusing the Google News dataset which contains 100 billionwords that are characterized by a continuous bag-of-wordsstructure
(3) Technical indicators calculation Three additionaltechnical indicators that are calculated on the basis of dailytrading data were used as follows
(a) Stochastic oscillator (K)This indicator is a momen-tum analysis method created by George C Lane When the
price trend rises the closing price tends to approach thehighest price of the day When the price trend declines theclosing price tends to approach the lowest price of the day[36]
(b) Larry Williamss R indicator This indicator is anoscillation indicator that measures the ratio of the highestprice to the daily closing price It indicates the proportion ofstock price fluctuations in a certain period thereby providinga signal out of the reversal of a stock market trend [37]
(c) Relative strength index (RSI) Buying and sellingintentions in the market are analyzed by comparing theclosing prices in a given period Stocks that have had moreor stronger positive changes have a higher RSI than do thosethat have had more or stronger negative changes Strengthindicators fall between 0 and 100 investors sell if this valueis ge 80 and buy if it is le 20 [23 36]
33 Variable Feature Selection To assess the effectivenessof applying the prediction model on the basis of financialnews we designed four sets of features for predicting stockprice movement (Table 6) Features 3 and 4 are used for eventcharacteristics Each feature is explained in the succeedingsubsections The target output consists of a binary variablefor which a value of 1 indicates that the closing price at day t+ 1 will be higher than that at day t and a value of 0 indicatesthat the closing price at day t + 1will be lower than that at dayt
Complexity 7
Financial news
middot middot middot
News representation Convolutional layer Max pooling Fully connected layer Features
X (I)
Z (I)
Figure 3 Convolutional neural network architecture proposed for feature selection
331 Stock Data Only We considered historical price as theinput for predicting stock price movement and used it asa baseline for comparison with other sets of features Thefeatures used to train the machine learning model that usesonly stock data are 119901119903119894119888119890119905minus1 and 119905 119894119899119889119894119888119886119905119900119903119905minus1 The output isthe indicator of pricemovement (increase or decrease) at eachtransaction date examined
332 Bag of Words The input feature set is based on a bag ofwords for the news and price trend for stock Previous studies[18 38 39] have widely used and confirmed the feasibilityof the bag-of-words algorithm but this method disregardselements such as grammar and word order in the text Inthe present study we first prepared each headline for datapreprocessing and then transformed the preprocessed head-line into a feature vector using the term frequency-inversedocument frequency (TF-IDF) algorithm [40] which assignshighweight to eigenvectorsThe studies [41 42] have stronglyproven the effectiveness of the TF-IDF algorithm in featureextraction from news headlines It estimates the frequency ofa term in one document over the maximum in a collection ofdocuments and assesses the importance of aword in one set ofdocuments Such importance increases proportionally withthe number of word appearances in a documentThe featuresused to train the bag-of-words machine learning model are119901119903119894119888119890119905minus1 119905 119894119899119889119894119888119886119905119900119903119905minus1 and 119905119891 119894119889119891119905minus1 which are the pricemovements (increase or decrease) at each transaction dateexamined
333 Convolutional Neural Network Given the sequence ofwords in a headline the word2vec model [35] can be usedto embed each of these words in a real valued-vector 119909 Inthis work we set the dimension 119899 of each word vector at30 (ie 119909 isin R30) We concatenated the word vectors of allthe words in a headline sequentially to form a matrix 119883 =[119909(1) 119909(2) 119909(3) 119909(4)] [35] as the input to a convolutionalneural network model For a headline with 119873 words the
resultant input matrix has dimensions of 30 times 119873 and thedimension of news representation also is 30
In Figure 3 this convolutional neural network model ismade up of four consecutive layers the first layer is theinput the second layer is convolutional the third layer is amax-pooling and the last layer is a fully connected layerThe convolutional and max-pooling layers were designedusing the text-attentional convolutional neural network [43]which effectively carries out sentiment classification In theconvolutional layer input matrix X convolves with a kernel119908 isin R119899times119896 where n is the size of a word vector (30 inour work) and its dimension is 50 k denotes the size of asliding window (k=3 in this study) The computation can beformulated as follows
119885119894 = 120590 (119908119883119894119894+119896minus1 + 119887) (1)
where 119883119894119894+119896minus1 = [119909119894 119909119894+1 119909119894+119896minus1] is the portion of input119883 falling within the sliding window 119887 denotes the optionaloffset and 120590(sdot) is the sigmoid function
In the next step we used the pooling layer to reduce theconvolutional neural networks parameter space and conse-quently minimize information loss in the pooling processingand capture the most important features The eigenvectorof the filter in the pooling layer is cut into 3 chunks anda maximum value is taken in each chunk we obtained 3eigenvalues Convolutional output vector Z was split into pwindows and only themaximum feature as 3 in each windowwas kept for passage onto the final fully connected layer Thefully connected layer is linear regression and the output layeris the feature classification between 0 and 1
Our convolutional neural network model is intended toextract a feature vector from the fully connected layer todescribe the emotional characteristics of input headlinesFollowing the intuition that a good feature vector shouldlead to the accurate classification of the event characteristicsof headlines we attached a softmax layer after the fully
8 Complexity
The United Kingdom of Great Britain and Northern Ireland commonly known as the United Kingdom or Britain hellip
London is the capital city of England and of the United Kingdom It is the most populous region hellip
Head Relationship TailLondon location country capital United Kingdom
London is the caEngland and of Kingdom It is tpopulous region
Kingdom of GreatNorthern Ireland known as the United
Britain hellip
Figure 4 Text description of the entity
connected layer when the convolutional neural networkmodel was trained The entire model was trained to classifythe five emotional labels that describe event characteristicsand the resultant model will be able to provide a mean-ingful emotional feature vector for each inputted headlineMeanwhile we define the loss function of the convolutionalneural network model as 119864119889 The features used to trainthis machine learning model are 119901119903119894119888119890119905minus1 119905 119894119899119889119894119888119886119905119900119903119905minus1and 119888119899119899119905minus1 which are the price movements (increase ordecrease) at corresponding transaction date
334 Combined Features In the introduction section of thispaper we described various translation models Because theTransE model represents a one-to-one relationship betweentwo entities [7] the relationship amongst many entities mustbe continuously incorporated into texts and knowledge graph[44] This model combines a convolutional neural networkwith textual information extraction which fully exploits thesemantic information in a knowledge graph and text [45 46]In Figure 4 knowledge graph contains rich semantics inentity description texts but it is not fully utilized in featureextraction Most of the existing text representation modelssimply train the text into word vectors through word2vecwhich obtains the text representation by means of averagingetc Hence these ways often lose more semantic informationWe therefore proposed to extract feature vectors from newstexts using a convolutional neural network model combinedwith the TransE model which also fully integrates the twoparts of the feature information
In Figure 5 this architecture used in the feature combina-tion model encompasses two parts namely a convolutionalneural network (Section 333) and the TransE model Thefeature combination sets are the average of each word vectorin an entity and it was obtained using the word2vec modelThe two entity vectors are mapped into the same relationalspace and these entities using a trained low-rank weightmatrix [47]
As assumed in the TransE model relationship vector Rshould satisfy ldquoE + R asymp Trdquo The model can be representedas a parameter set 0 = (119871119903 119877119903 120579) where X E and R
represent a word an entity and a relation respectively Andr are the mapping matrices for entities in the structuralmodel and represents the weights of the convolutional neuralnetwork For instance the sentence is ldquoSamsung sues Apple forinfringementrdquo so ldquoSamsung +Appleasymp suesrdquoThe loss function119864119904 of this structural model is defined as follows
119864119904 = ℎ + 119903 minus 11990522 (2)
where h r and t represent head entity relationship and tailentity in event tuple respectively [47]
And text representation 119864119889 is consistent withSection 333 which denotes
119864119889 = 119891119903 (ℎ119904 119905119889) + 119891119903 (ℎ119889 119905119904) + 119891119903 (ℎ119889 119905119889) (3)
where119891119903(ℎ119889 119905119889) = ℎ119889+119903minus11990511988922 represents the head entity andthe tail entity is in text representation119891119903(ℎ119889 119905119904) = ℎ119889+119903minus11990511990422and 119891119903(ℎ119904 119905119889) = ℎ119904 + 119903minus 11990511988922 represent one of the head entityh and the tail entity t in text representation another one is instructure representation
Moreover we combined two types of representationlearning (convolutional neural network and feature combi-nation) to map news titles these vectors will be into featurevectors The relationship vector R identical to the resultof the feature extraction layer of the convolutional neuralnetwork in the structural model Besides we combined thisloss with the classification loss of the convolutional neuralnetwork using L2 regularization which obtains the overallloss function 119864 for feature selection that is
119864 = 119864119904 + 120572119864119889 + 120573 02 (4)
where 02 is a regular item 120572 and 120573 are hyperparameterswhich measure the loss of text information and the weight ofthe regular items respectively W denotes the convolutionalkernels in the layer and 1198791015840 is a negative sample set of 119879 [7]
1198791015840 = (ℎ1015840 119903 119905) | ℎ1015840 isin 119864 cup (ℎ 119903 1199051015840) | 1199051015840 isin 119864
cup (ℎ 1199031015840 119905) | 1199031015840 isin 119877 (5)
Complexity 9
Output layerClass1 Class2
Machinelearning
Max pooling
convolutional
Input news
Feature vector
Embedding layer
Input news
Event tuple
Word2vec
Word2vec
Fully connection
Stock data
Stock layer
TransE model
Figure 5 Proposed architecture for the feature combination model
where the head entity and tail entity are randomly replaced byan entity or relationship in another tuple In particular if thereplaced tuple is already in T it would not be added to thenegative sample Since both h and t represent two types ofentities there are structure-based representations and text-based representations in interval-based loss functions Thestochastic gradient descent (SGD) is employed to minimizethe above loss function
In this structure we choose the optimal parameters asfollowe the learning rate of SGD 120582 = 0001 the dimension ofthe representation vector of entities and relationships k = 100the word vector dimension of the entity description text n =100 and batch size during training is 1440 Convolution layerwindow size is 119882 isin 1 2 3 This experiment is performedin 1000 iterations of training and the optimal parameters arebased on the testing set
Hence the features used for training the machine learn-ing model are 119901119903119894119888119890119905minus1 119905 119894119899119889119894119888119886119905119900119903119905minus1 and 119891 119888119900119898119887119894119899119890119905minus1which are the price movement (increase or decrease) atcorresponding transaction date
4 Experiments and Results
41 Experimental Setting This section compares the perfor-mance of differentmodels in feature extraction fromfinancialnews expended with full sets of features The evaluationwas intended to obtain evidence that the proposed featurecombination model is superior to other feature selectionmodels in predicting the stock price movement As shownin Table 7 we chose linear models for instance logisticalregression and naive Bayes Others are nonlinear models forinstance the ensemble learning (random forest adaboostand gradient boosting) for the comparison We constantlyadjusted the parameters in the grid search and selected theoptimal parameter value their parameter value has proven towork well on machine learning method [29 48]
We used a computer consisting of an Intel Core i5processor with four cores running at 29 GHz and 8 GBRAM under the MacOS platform We used the Scikit-learnlibrary in Python in the experiments involving traditionalmachine learning algorithms and TensorFlow 14 in the
10 Complexity
Table 7 List of machine learning methods
Method Classification Parameter and their value
Traditionalmachinelearning
Decision tree (DT)Criterion= gini splitter= best max depth=None minsamples split=2 min samples leaf =1 min weight
fraction leaf=00Logistical regression (LR) Random state=1
Naive Bayes (NB) No kernel estimatorStochastic gradient descent (SGD) Loss=hinge penalty=l2
Support vector machine (SVM) Polynomial kernel function with exponent = 1 2 RBFkernel function with gamma = 001
Ensemblelearning
Random forest (RF) Randomly sampled as candidates at each split = log2 +1 max-depth=2 random state=0
AdaBoost (AB) Polynomial kernel function with exponent = 1 2 RBFkernel function with gamma = 001 n- estimators=100
Gradient boosting (GB) N-estimators =100 learning rate =10 max-depth=1random state=0
Table 8 Abbreviations of the results for each algorithm considered
Algorithms Stock data (SD) Bag of words (BOW) Convolutionalneural network
Featurecombinationmodel (FC)
DT DT 1 DT 2 DT 3 DT 4LR LR 1 LR 2 LR 3 LR 4NB NB 1 NB 2 NB 3 NB 4SGD SGD 1 SGD 2 SGD 3 SGD 4SVM SVM 1 SVM 2 SVM 3 SVM 4RF RF 1 RF 2 RF 3 RF 4AB AB 1 AB 2 AB 3 AB 4GB GB 1 GB 2 GB 3 GB 4
experiments involving deep learning and the TransE modelThe abbreviations used for comparing classification perfor-mance are presented in Table 8 During testing 2-fold cross-validation is applied to evaluate the stability of the modelsAnd we compared performance in predicting stock pricemovement for the next day with a test dataset and evaluatedthe performance of the models in terms of accuracy and F1-score [49]
42 Results
421 Thomson Reuters Case Study Thomson Reuters isa multinational mass media and information firm Threerenowned companies on the website were selected for theanalysis The first is Apple Inc which is an American multi-national technology company that designs develops andsells consumer electronics computer software and onlineservices The second company selected is Microsoft which isan American multinational technology company that devel-ops manufactures supports and sells computer softwarepersonal computers and other services The last companychosen is Samsung which is a South Korean multinationalelectronics company We considered data from these threetypical technology companies for our problem
Measurements of average accuracy are shown in Table 9and the results for each renowned company with respectto prediction based on different features are illustrated inFigure 6 We calculated the average of the four feature con-struction approaches for eachmodel for comparison amongstthe three companies The proposed feature combinationmodel generated the best results achieving average accuracylevels of 6163 5918 and 5848 forAppleMicrosoft andSamsung respectively These figures are consistent with therates reported in previous research However many studiesanalyzed only one company or used only one algorithmThe current research probed into three companies on thebasis of information from a common data source to builda prediction model with different feature selection func-tionalities and different algorithms We used stock dataa bag-of-words algorithm a convolutional neural networkand feature combination together with eight algorithms Asindicated in Table 9 the proposed predictionmodel achieved7368 data extraction with the use of LR 4 for Apple and6778 data extraction with the use of SVM 4 for MicrosoftIn particular the LR algorithm used for Apple achievedaccuracy and F1-score of 07326 and 07360 respectivelywhich highlights its powerful capability in a two-class classifi-cation
Complexity 11
Table 9 Results for data extracted fromThomson Reuters
Algorithm Company Stock data(SD)
Bag of words(BOW)
Convolutionalneural network
Feature combinemodel (FC)
AccuracyF1-score
AccuracyF1-score
AccuracyF1-score
AccuracyF1-score
DTApple 0499305079 0488902460 0615005814 0652406486
Microsoft 0486801819 0506505682 0581705915 0658706502Samsung 0470704033 0565405830 0552906820 0568006260
LRApple 0524006727 0505505083 0684506911 0732607368
Microsoft 0475701253 0443004884 0527405333 0546705611Samsung 0494703755 0605406726 0654106343 0805307978
NBApple 0510905123 0477803896 0502704497 0512204030
Microsoft 0484000363 0455704055 0459902889 0500005439Samsung 0529305810 0514406130 0504806578 0511706601
SGDApple 0467201119 0477804404 0497406008 0536602692
Microsoft 0517306819 0485203222 0610304231 0610804193Samsung 0522306541 0476602000 0518706751 0557106548
SVMApple 0502206121 0574705542 0615006129 0622006173
Microsoft 0478401722 0443904566 0523205462 0687506798Samsung 0500803875 0504705508 0513506281 0535206574
RFApple 0524006554 0527806083 0533706232 0620306243
Microsoft 0484002653 0417701687 0532502432 0572105189Samsung 0487203480 0448501194 0476603708 0505205481
ABApple 0534305384 0472202963 0481903333 0620305420
Microsoft 0468702041 0476800461 0614706044 0620206146Samsung 0485703619 0457902368 0601006820 0633806549
GBApple 0531405129 0466702941 0609604748 0634106591
Microsoft 0474302125 0472801007 0455704557 0538502258Samsung 0487204171 0519206599 0533706572 0562206335
Reuters
Aver
age a
ccur
acy
0
01
02
03
04
05
06
07
Different companyApple Microsoft Samsung
SDBOW
CNNFC
Figure 6 Average accuracy of prediction based on different featuresets for each company in Reuters
To assess the effectiveness of our research we comparedthe feature combination model that uses event tuples with
the stock data approach and the bag-of-words algorithmTheresults showed that the average accuracy of the event tuple-basedmodel is better than that of the stock data approach andthe bag-of-words algorithm by 1001 and 1087 respec-tively We also compared feature extraction using the stockdata approach the bag-of-words algorithm and machinelearning The use of deep learning improved predictionaccuracy by 525 and 611 over the levels achieved withstock data and bag of words respectively Therefore we canconclude that using the proposed feature combinationmodeland deep learning in feature extraction helps improve theaccuracy with which stock price movement is predictedThese results also fully prove the effectiveness of embeddinglayer in feature extraction accuracy improvement
422 CNN Case Study CNN is an American basic cableand satellite television news channel owned by the TurnerBroadcasting System Three renowned companies on whichthese website reports were selected for the analysis The firstis Boeing which is an American multinational corporationthat designs manufactures and sells airplanes rotorcraftrockets and satellites worldwide The second company isGoogle which is an American multinational technology
12 Complexity
Table 10 Results for data extracted from CNN
Algorithm Company Stock data(SD)
Bag of words(BOW)
Convolutionalneural network
Featurecombinationmodel (FC)
AccuracyF1-score
AccuracyF1-score
AccuracyF1-score
AccuracyF1-score
DTBoeing 0495003489 0541306258 0541406347 0559105821Google 0485805600 0518203575 0569204631 0549105471Walmart 0499604422 0530004891 0508804815 0572205829
LRBoeing 0492302378 0511304348 0692306923 0759605733Google 0504106105 0623506491 0625006111 0656306516Walmart 0529005468 0541205083 0732007347 0771907720
NBBoeing 0516206503 0548905161 0519706738 0556407619Google 0511206527 0489905191 0558705281 0534404843Walmart 0504403284 0479405302 0520605674 0530006083
SGDBoeing 0489702407 0556404870 0543304727 0571407220Google 0516506769 0542504375 0578906364 0591006327Walmart 0500403804 0520605280 0525005581 0567005922
SVMBoeing 0489703068 0571406275 0538506418 0594007033Google 0507706297 0603206230 0574905532 0578905840Walmart 0511804333 0500005314 0520005000 0561405455
RFBoeing 0490601345 0511303925 0509605405 0527605714Google 0492301777 0603206260 0522305564 0595105763Walmart 0511805373 0530003188 0530004405 0500005446
ABBoeing 0494503404 0519705120 0496105294 0567305872Google 0487603141 0510106667 0589305619 0595106850Walmart 0507305029 0515005359 0549705650 0561905503
GBBoeing 0489903169 0511804364 0440904580 0500005094Google 0491203387 0587005854 0562505243 0603206202Walmart 0500304955 0505005123 0536105109 0549705650
company that specializes in Internet-related services andproducts The third is Walmart an American multinationalretail corporation that operates a chain of hypermarketsdiscount department stores and grocery stores
The results on average accuracy are shown in Table 10and Figure 7These findings are very similar to those derivedin the previous case study and their comparison confirmedthat the proposed feature combinationmodel can outperformother feature selection models in stock price movementprediction With regard to feature selection underlain bythe bag-of-words algorithm the CNN case study generatedmore robust results than did the Reuters case study Theaverage accuracy of the bag-of-words algorithm was lowerthan that of the stock data approach in the Reuters case studyIn the CNN case study the average accuracy levels of theproposed feature combination model were 5794 5879and 5767 for Boeing Google andWalmart respectively Inthe case study on Reuters an average accuracy that exceeds60 was not achieved for any of the companies illustratingthat differences in data source directly affect stock pricemovement
We chose a combination of deep learning and knowledgegraph to build our feature selection model because this
CNN
Aver
age a
ccur
acy
0
01
02
03
04
05
06
07
Different companyBoeing Google Walmart
SDBOW
CNNFC
Figure 7Average accuracy achieved on the basis of news fromCNNand different feature set
combination exhibited superior prediction performance inthe comparison experiments involving other feature selection
Complexity 13
strategies The forecast results based on different featuresare shown in Table 10 We found that deep learning featuresare better than the use of bag-of-words and stock data Thecorrelation of event tuples with the stock market is relativelyhigh in [5 31] but the bag-of-words algorithm was relativelyfragmented and the correlation between event tuples and thestockmarket data was relatively weak Combining event tuplefeatures with deep learning significantly improves forecastresults indicating a close relationship between stock marketmovements and knowledge graph
5 Discussion
51 Research Findings We attempted to compare our predic-tion results with those made in previous studies wherein pre-diction was also based on the financial news of the renownedcompanies However the findings are incomparable becausedifferent studies use different datasets or algorithms andthese methods are difficult to investigate using financial newsheadlines In the current research we refrained from eval-uating performance on one company dataset this decisionthat enabled our knowledge graphmethod to exceed baselinepredictions based only on the price by up to 36 Thisalso proves that feature extraction in deep learning is moreeffective than traditional machines The combination of deeplearning and knowledge graph fully integrates the semanticinformation in financial news which effectively predicts thestock price movement of the renowned company
This work demonstrated the application of deep learningand knowledge graph in finance To the best of our knowl-edge knowledge graph has been rarely applied in stock pre-diction Becauseminimal financial training sets in knowledgegraph are available financial knowledge extraction is themain task for the organizational construction of a knowledgegraph Such extraction is critical for the understanding andprocessing of deep semantics in the event tuple which alsodirectly influences the feature extraction of financial news
52 Implications for Business Activities Theutility of a featurecombination model based on knowledge graph is not limitedto financial analysis Currently knowledge graph data areavailable for medical diagnosis speech recognition precisemarketing and financial risk control [4] Our model couldalso be applied in these areas
Antifraud activities are an important part of financeApplying our model on the basis of knowledge graph oncustomers helps organize all relevant knowledge fragmentsthrough deep semantic analysis and reasoning which canbe verified with a customerrsquos bank information Moreovercustomers typically use keywords to search for productsand knowledge graph can provide relevant information toa customer If a complete knowledge system of users isdescribed and collected a system would better understandand analyze user behaviors
53 Limitations and Future Work A deep learning modeluses supervised learning and needs a dataset with sufficientlabels but our datasets do not work well with deep learningas a small number of financial news articles match stock
data At present knowledge graph embedding inevitablyproduces a loss in news semantics either because of a learningprinciple or the tokenization of knowledge representation forvectorization Thus continuous representation in a knowl-edge graph is still a huge challenge We attempted to applyregression using the above-mentioned algorithms but theresults indicated poor performance More specifically theresults for Apple validated our expectations
The application of large-scale knowledge graph is stillrelatively limited and knowledge graph for smart searchsmart question-and-answer tasks social media and otherareas are in their initial stages with considerable room forimprovement The following advantages of knowledge graphshould be considered (a) the effective organization andexpression of semistructured data (b) knowledge reasoningand (c) the expansion of cognitive ability for incorporatingdeep learning Traditional knowledge elements (entities rela-tionship attributes) extraction technologies and methodshave achieved good results in limited areas but because ofnumerous constraints and poor scalability knowledge graphis not fully functional for financial forecasting because ofnumerous constraints and poor scalability
6 Conclusions
Stock movement prediction of the renowned company is adaunting task because stock prices are affected by many fac-tors This research presented a novel method for integratingknowledge graph embedding with stock market predictionThe contributions of this study can be summarized as followsFirst we developed a novel feature combination model thatconstructs a feature mapping vector for each tuplendashnewspair by simultaneously considering the diversity of entitiesand relationships Second the feature combination modelwas successfully applied to different types of companies anddatasets and exhibited good performance in classificationtasks
Stock market prediction of the renowned companygrounded in knowledge graph is an interesting topic forbusiness activities Given that the study of knowledge graphfor feature set is still in its infancy we expect it to be appliedin a wide range of academic research More companies willalso earn profits and create more opportunities through theuse of knowledge graph in the feature set
Data Availability
The data used in this study can be accessed via httpsgithubcomlinechanyknowledge-graph
Conflicts of Interest
The author declares that there is no conflict of interestregarding the publication of this paper
Acknowledgments
This work is supported by the China Scholarship Council(CSC) throughout the grant number 201508390019 The
14 Complexity
authors also want to thank the research program RFCS fromthe EU which partially supported this research through theresearch project AutoSurveillance with project ID 847202
References
[1] B GMalkiel and E F Fama ldquoEfficient capital markets a reviewof theory and empirical workrdquo The Journal of Finance vol 25no 2 pp 383ndash417 1970
[2] D Galai and R W Masulis ldquoThe option pricing model and therisk factor of stockrdquo Journal of Financial Economics vol 3 no1-2 pp 53ndash81 1976
[3] Q Wang Z Mao B Wang and L Guo ldquoKnowledge graphembedding A survey of approaches and applicationsrdquo IEEETransactions on Knowledge and Data Engineering vol 29 no12 pp 2724ndash2743 2017
[4] H Paulheim and P Cimiano ldquoKnowledge graph refinement Asurvey of approaches and evaluation methodsrdquo Journal of WebSemantics Science Services and Agents on the World Wide Webvol 8 no 3 pp 489ndash508 2016
[5] X Ding Y Zhang T Liu and J Duan ldquoDeep learning for event-driven stock predictionrdquo in Proceedings of the 24th InternationalJoint Conference on Artificial Intelligence IJCAI 2015 pp 2327ndash2333 Argentina July 2015
[6] X Ding Y Zhang T Liu and J Duan ldquoKnowledge-drivenevent embedding for stock predictionrdquo in Proceedings of the26th International Conference on Computational LinguisticsCOLING 2016 pp 2133ndash2142 Japan December 2016
[7] A Bordes N Usunier J Weston and O Yakhnenko ldquoTranslat-ing embeddings for modeling multi-relational datardquo Advancesin NIPS vol 26 pp 2787ndash2795 2013
[8] H Lin Y Liu W Wang Y Yue and Z Lin ldquoLearning entityand relation embeddings for knowledge resolutionrdquo ProcediaComputer Science vol 108 pp 345ndash354 2017
[9] G Ji K Liu S He and J Zhao ldquoKnowledge graph completionwith adaptive sparse transfer matrixrdquo in Proceedings of the 30thAAAI Conference on Artificial Intelligence AAAI 2016 pp 985ndash991 USA February 2016
[10] G Ji S He L Xu K Liu and J Zhao ldquoKnowledge graphembedding via dynamic mapping matrixrdquo in Proceedings ofthe 53rd Annual Meeting of the Association for ComputationalLinguistics and the 7th International Joint Conference on NaturalLanguage Processing (Volume 1 Long Papers) pp 687ndash696Beijing China July 2015
[11] Y LeCun Y Bengio and G Hinton ldquoDeep learningrdquo Naturevol 521 no 7553 pp 436ndash444 2015
[12] Q Li Y Chen J Wang and H Chen ldquoWeb media andstock markets a survey and future directions from a bigdata perspectiverdquo IEEE Transactions on Knowledge and DataEngineering vol 4347 p 1 2017
[13] B Wuthrich V Cho S Leung D Permunetilleke K Sankaranand J Zhang ldquoDaily stock market forecast from textual Webdatardquo in Proceedings of the 1998 IEEE International Confer-ence on Systems Man and Cybernetics (Cat No98CH36218)SMCrsquo98 vol 3 pp 2720ndash2725 October 1998
[14] G Pui Cheong Fung J Xu Yu and W Lam ldquoStock predictionintegrating text mining approach using real-time newsrdquo inProceedings of the 2003 IEEE International Conference on Com-putational Intelligence for Financial Engineering CIFEr 2003vol 2003 pp 395ndash402 China March 2003
[15] W Antweiler and M Z Frank ldquoIs all that talk just noise theinformation content of internet stock message boardsrdquo SSRNElectronic Journal 2001
[16] M-A Mittermayer and G F Knolmayer ldquoNewsCATS A newscategorization and trading systemrdquo in Proceedings of the 6thInternational Conference onDataMining ICDM2006 pp 1002ndash1007 China December 2006
[17] R P Schumaker and H Chen ldquoTextual analysis of stockmarket prediction using breaking financial news theAZFin textsystemrdquo ACM Transactions on Information and Systems pp 1ndash29 2009
[18] S S Groth and J Muntermann ldquoAn intraday market riskmanagement approach based on textual analysisrdquo DecisionSupport Systems vol 50 no 4 pp 680ndash691 2011
[19] T Vu S Chang Q Ha and N Collier ldquoAn experiment in inte-grating sentiment features for tech stock prediction in twitterrdquoin Proceedings of the Workshop on Information Extraction AndEntity Analytics on Social Media Data vol 3 pp 23ndash38 2012
[20] B Wang H Huang and X Wang ldquoA novel text miningapproach to financial time series forecastingrdquo Neurocomputingvol 83 pp 136ndash145 2012
[21] Q Li T Wang P Li L Liu Q Gong and Y Chen ldquoThe effectof news and public mood on stock movementsrdquo InformationSciences vol 278 pp 826ndash840 2014
[22] T H Nguyen K Shirai and J Velcin ldquoSentiment analysis onsocial media for stock movement predictionrdquo Expert Systemswith Applications vol 42 no 24 pp 9603ndash9611 2015
[23] BWengM A Ahmed and FMMegahed ldquoStockmarket one-day ahead movement prediction using disparate data sourcesrdquoExpert Systems with Applications vol 79 pp 153ndash163 2017
[24] J Eberhard J F Lavin and A Montecinos-Pearce ldquoA network-based dynamic analysis in an equity stock marketrdquo Complexityvol 2017 Article ID 3979836 16 pages 2017
[25] Z Zhang Y Zhang D Shen and W Zhang ldquoThe dynamiccross-correlations between mass media news newmedia newsand stock returnsrdquo Complexity vol 2018 11 pages 2018
[26] P C Tetlock ldquoGiving content to investor sentiment The role ofmedia in the stock marketrdquo Journal of Finance vol 62 no 3 pp1139ndash1168 2007
[27] K Chen P Luo L Liu andW Zhang ldquoNews search and stockco-movement Investigating information diffusion in the finan-cial marketrdquo Electronic Commerce Research and Applicationsvol 28 pp 159ndash171 2018
[28] F Z Xing E Cambria and Y Zhang ldquoSentiment-awarevolatility forecastingrdquo Knowledge-Based Systems vol 176 pp68ndash76 2019
[29] A Picasso S Merello Y Ma L Oneto and E CambrialdquoTechnical analysis and sentiment embeddings formarket trendpredictionrdquo Expert Systems with Applications vol 135 pp 60ndash70 2019
[30] A Khadjeh Nassirtoussi S Aghabozorgi T Ying Wah and DC L Ngo ldquoText mining for market prediction a systematicreviewrdquo Expert Systems with Applications vol 41 no 16 pp7653ndash7670 2014
[31] M Kraus and S Feuerriegel ldquoDecision support from financialdisclosures with deep neural networks and transfer learningrdquoDecision Support Systems vol 104 pp 38ndash48 2017
[32] H S Sim H I Kim and J J Ahn ldquoIs deep learning for imagerecognition applicable to stockmarket predictionrdquoComplexityvol 2019 10 pages 2019
Complexity 15
[33] M Jasemi A M Kimiagari and A Memariani ldquoA modernneural network model to do stock market timing on the basisof the ancient investment technique of Japanese candlestickrdquoExpert Systems with Applications vol 38 no 4 pp 3884ndash38902011
[34] A Fader S Soderland and O Etzioni ldquoIdentifying relations foropen information extractionrdquo in Proceedings of the Conferenceon Empirical Methods in Natural Language Processing EMNLP2011 pp 1535ndash1545 Association for Computational LinguisticsUK July 2011
[35] T Mikolov K Chen G Corrado and J Dean ldquoEfficientestimation of word representations in vector spacerdquo pp 1ndash122013 httpsarxivorgabs13013781
[36] X Lin Z Yang and Y Song ldquoIntelligent stock trading systembased on improved technical analysis and Echo State NetworkrdquoExpert Systems with Applications vol 38 no 9 pp 11347ndash113542011
[37] K-J Kim and I Han ldquoGenetic algorithms approach to featurediscretization in artificial neural networks for the prediction ofstock price indexrdquo Expert Systems with Applications vol 19 no2 pp 125ndash132 2000
[38] Y Yu W Duan and Q Cao ldquoThe impact of social andconventional media on firm equity value A sentiment analysisapproachrdquoDecision Support Systems vol 55 no 4 pp 919ndash9262013
[39] MHagenauM Liebmann andDNeumann ldquoAutomated newsreading Stock price prediction based on financial news usingcontext-capturing featuresrdquo Decision Support Systems vol 55no 3 pp 685ndash697 2013
[40] A Aizawa ldquoAn information-theoretic perspective of tf-idfmeasuresrdquo Information Processing amp Management vol 39 no1 pp 45ndash65 2003
[41] A Khadjeh Nassirtoussi S Aghabozorgi T Ying Wah and DC Ngo ldquoText mining of news-headlines for FOREX marketprediction a Multi-layer dimension reduction algorithm withsemantics and sentimentrdquo Expert Systems with Applications vol42 no 1 pp 306ndash324 2015
[42] D Peramunetilleke and R K Wong ldquoCurrency exchange rateforecasting from news headlinesrdquo Australian Computer ScienceCommunications vol 24 no 2 pp 131ndash139 2002
[43] Y Kim ldquoConvolutional neural networks for sentence classifica-tionrdquo 2014 httpsarxivorgabs14085882
[44] ZWang J Zhang J Feng and Z Chen ldquoKnowledge graph andtext jointly embeddingrdquo in Proceedings of the 2014 Conferenceon Empirical Methods in Natural Language Processing EMNLP2014 pp 1591ndash1601 Qatar October 2014
[45] J Xu X Qiu K Chen and X Huang ldquoKnowledge graphrepresentation with jointly structural and textual encodingrdquo inProceedings of the 26th International Joint Conference on Arti-ficial Intelligence IJCAI 2017 pp 1318ndash1324 Australia August2017
[46] R Xie Z Liu J Jia H Luan and M Sun ldquoRepresentationlearning of knowledge graphs with entity descriptionsrdquo in Pro-ceedings of the 30th AAAI Conference on Artificial IntelligenceAAAI rsquo16 pp 2659ndash2665 February 2016
[47] F Tian B Gao E Chen and T Liu ldquoLearning better wordembedding by asymmetric low-rank projection of knowledgegraphrdquo Journal of Computer Science and Technology vol 31 no3 pp 624ndash634 2016
[48] F Z Xing E Cambria and R E Welsch ldquoNatural languagebased financial forecasting a surveyrdquo Artificial IntelligenceReview vol 50 no 1 pp 49ndash73 2018
[49] C Goutte and E Gaussier ldquoA probabilistic interpretation ofprecision recall and F-score with implication for evaluationrdquoin Advances in Information Retrieval D E Losada and J MFernandez-Luna Eds vol 3408 of Lecture Notes in ComputerScience pp 345ndash359 Springer Berlin Germany 2005
Hindawiwwwhindawicom Volume 2018
MathematicsJournal of
Hindawiwwwhindawicom Volume 2018
Mathematical Problems in Engineering
Applied MathematicsJournal of
Hindawiwwwhindawicom Volume 2018
Probability and StatisticsHindawiwwwhindawicom Volume 2018
Journal of
Hindawiwwwhindawicom Volume 2018
Mathematical PhysicsAdvances in
Complex AnalysisJournal of
Hindawiwwwhindawicom Volume 2018
OptimizationJournal of
Hindawiwwwhindawicom Volume 2018
Hindawiwwwhindawicom Volume 2018
Engineering Mathematics
International Journal of
Hindawiwwwhindawicom Volume 2018
Operations ResearchAdvances in
Journal of
Hindawiwwwhindawicom Volume 2018
Function SpacesAbstract and Applied AnalysisHindawiwwwhindawicom Volume 2018
International Journal of Mathematics and Mathematical Sciences
Hindawiwwwhindawicom Volume 2018
Hindawi Publishing Corporation httpwwwhindawicom Volume 2013Hindawiwwwhindawicom
The Scientific World Journal
Volume 2018
Hindawiwwwhindawicom Volume 2018Volume 2018
Numerical AnalysisNumerical AnalysisNumerical AnalysisNumerical AnalysisNumerical AnalysisNumerical AnalysisNumerical AnalysisNumerical AnalysisNumerical AnalysisNumerical AnalysisNumerical AnalysisNumerical AnalysisAdvances inAdvances in Discrete Dynamics in
Nature and SocietyHindawiwwwhindawicom Volume 2018
Hindawiwwwhindawicom
Dierential EquationsInternational Journal of
Volume 2018
Hindawiwwwhindawicom Volume 2018
Decision SciencesAdvances in
Hindawiwwwhindawicom Volume 2018
AnalysisInternational Journal of
Hindawiwwwhindawicom Volume 2018
Stochastic AnalysisInternational Journal of
Submit your manuscripts atwwwhindawicom

Complexity 7
Financial news
middot middot middot
News representation Convolutional layer Max pooling Fully connected layer Features
X (I)
Z (I)
Figure 3 Convolutional neural network architecture proposed for feature selection
331 Stock Data Only We considered historical price as theinput for predicting stock price movement and used it asa baseline for comparison with other sets of features Thefeatures used to train the machine learning model that usesonly stock data are 119901119903119894119888119890119905minus1 and 119905 119894119899119889119894119888119886119905119900119903119905minus1 The output isthe indicator of pricemovement (increase or decrease) at eachtransaction date examined
332 Bag of Words The input feature set is based on a bag ofwords for the news and price trend for stock Previous studies[18 38 39] have widely used and confirmed the feasibilityof the bag-of-words algorithm but this method disregardselements such as grammar and word order in the text Inthe present study we first prepared each headline for datapreprocessing and then transformed the preprocessed head-line into a feature vector using the term frequency-inversedocument frequency (TF-IDF) algorithm [40] which assignshighweight to eigenvectorsThe studies [41 42] have stronglyproven the effectiveness of the TF-IDF algorithm in featureextraction from news headlines It estimates the frequency ofa term in one document over the maximum in a collection ofdocuments and assesses the importance of aword in one set ofdocuments Such importance increases proportionally withthe number of word appearances in a documentThe featuresused to train the bag-of-words machine learning model are119901119903119894119888119890119905minus1 119905 119894119899119889119894119888119886119905119900119903119905minus1 and 119905119891 119894119889119891119905minus1 which are the pricemovements (increase or decrease) at each transaction dateexamined
333 Convolutional Neural Network Given the sequence ofwords in a headline the word2vec model [35] can be usedto embed each of these words in a real valued-vector 119909 Inthis work we set the dimension 119899 of each word vector at30 (ie 119909 isin R30) We concatenated the word vectors of allthe words in a headline sequentially to form a matrix 119883 =[119909(1) 119909(2) 119909(3) 119909(4)] [35] as the input to a convolutionalneural network model For a headline with 119873 words the
resultant input matrix has dimensions of 30 times 119873 and thedimension of news representation also is 30
In Figure 3 this convolutional neural network model ismade up of four consecutive layers the first layer is theinput the second layer is convolutional the third layer is amax-pooling and the last layer is a fully connected layerThe convolutional and max-pooling layers were designedusing the text-attentional convolutional neural network [43]which effectively carries out sentiment classification In theconvolutional layer input matrix X convolves with a kernel119908 isin R119899times119896 where n is the size of a word vector (30 inour work) and its dimension is 50 k denotes the size of asliding window (k=3 in this study) The computation can beformulated as follows
119885119894 = 120590 (119908119883119894119894+119896minus1 + 119887) (1)
where 119883119894119894+119896minus1 = [119909119894 119909119894+1 119909119894+119896minus1] is the portion of input119883 falling within the sliding window 119887 denotes the optionaloffset and 120590(sdot) is the sigmoid function
In the next step we used the pooling layer to reduce theconvolutional neural networks parameter space and conse-quently minimize information loss in the pooling processingand capture the most important features The eigenvectorof the filter in the pooling layer is cut into 3 chunks anda maximum value is taken in each chunk we obtained 3eigenvalues Convolutional output vector Z was split into pwindows and only themaximum feature as 3 in each windowwas kept for passage onto the final fully connected layer Thefully connected layer is linear regression and the output layeris the feature classification between 0 and 1
Our convolutional neural network model is intended toextract a feature vector from the fully connected layer todescribe the emotional characteristics of input headlinesFollowing the intuition that a good feature vector shouldlead to the accurate classification of the event characteristicsof headlines we attached a softmax layer after the fully
8 Complexity
The United Kingdom of Great Britain and Northern Ireland commonly known as the United Kingdom or Britain hellip
London is the capital city of England and of the United Kingdom It is the most populous region hellip
Head Relationship TailLondon location country capital United Kingdom
London is the caEngland and of Kingdom It is tpopulous region
Kingdom of GreatNorthern Ireland known as the United
Britain hellip
Figure 4 Text description of the entity
connected layer when the convolutional neural networkmodel was trained The entire model was trained to classifythe five emotional labels that describe event characteristicsand the resultant model will be able to provide a mean-ingful emotional feature vector for each inputted headlineMeanwhile we define the loss function of the convolutionalneural network model as 119864119889 The features used to trainthis machine learning model are 119901119903119894119888119890119905minus1 119905 119894119899119889119894119888119886119905119900119903119905minus1and 119888119899119899119905minus1 which are the price movements (increase ordecrease) at corresponding transaction date
334 Combined Features In the introduction section of thispaper we described various translation models Because theTransE model represents a one-to-one relationship betweentwo entities [7] the relationship amongst many entities mustbe continuously incorporated into texts and knowledge graph[44] This model combines a convolutional neural networkwith textual information extraction which fully exploits thesemantic information in a knowledge graph and text [45 46]In Figure 4 knowledge graph contains rich semantics inentity description texts but it is not fully utilized in featureextraction Most of the existing text representation modelssimply train the text into word vectors through word2vecwhich obtains the text representation by means of averagingetc Hence these ways often lose more semantic informationWe therefore proposed to extract feature vectors from newstexts using a convolutional neural network model combinedwith the TransE model which also fully integrates the twoparts of the feature information
In Figure 5 this architecture used in the feature combina-tion model encompasses two parts namely a convolutionalneural network (Section 333) and the TransE model Thefeature combination sets are the average of each word vectorin an entity and it was obtained using the word2vec modelThe two entity vectors are mapped into the same relationalspace and these entities using a trained low-rank weightmatrix [47]
As assumed in the TransE model relationship vector Rshould satisfy ldquoE + R asymp Trdquo The model can be representedas a parameter set 0 = (119871119903 119877119903 120579) where X E and R
represent a word an entity and a relation respectively Andr are the mapping matrices for entities in the structuralmodel and represents the weights of the convolutional neuralnetwork For instance the sentence is ldquoSamsung sues Apple forinfringementrdquo so ldquoSamsung +Appleasymp suesrdquoThe loss function119864119904 of this structural model is defined as follows
119864119904 = ℎ + 119903 minus 11990522 (2)
where h r and t represent head entity relationship and tailentity in event tuple respectively [47]
And text representation 119864119889 is consistent withSection 333 which denotes
119864119889 = 119891119903 (ℎ119904 119905119889) + 119891119903 (ℎ119889 119905119904) + 119891119903 (ℎ119889 119905119889) (3)
where119891119903(ℎ119889 119905119889) = ℎ119889+119903minus11990511988922 represents the head entity andthe tail entity is in text representation119891119903(ℎ119889 119905119904) = ℎ119889+119903minus11990511990422and 119891119903(ℎ119904 119905119889) = ℎ119904 + 119903minus 11990511988922 represent one of the head entityh and the tail entity t in text representation another one is instructure representation
Moreover we combined two types of representationlearning (convolutional neural network and feature combi-nation) to map news titles these vectors will be into featurevectors The relationship vector R identical to the resultof the feature extraction layer of the convolutional neuralnetwork in the structural model Besides we combined thisloss with the classification loss of the convolutional neuralnetwork using L2 regularization which obtains the overallloss function 119864 for feature selection that is
119864 = 119864119904 + 120572119864119889 + 120573 02 (4)
where 02 is a regular item 120572 and 120573 are hyperparameterswhich measure the loss of text information and the weight ofthe regular items respectively W denotes the convolutionalkernels in the layer and 1198791015840 is a negative sample set of 119879 [7]
1198791015840 = (ℎ1015840 119903 119905) | ℎ1015840 isin 119864 cup (ℎ 119903 1199051015840) | 1199051015840 isin 119864
cup (ℎ 1199031015840 119905) | 1199031015840 isin 119877 (5)
Complexity 9
Output layerClass1 Class2
Machinelearning
Max pooling
convolutional
Input news
Feature vector
Embedding layer
Input news
Event tuple
Word2vec
Word2vec
Fully connection
Stock data
Stock layer
TransE model
Figure 5 Proposed architecture for the feature combination model
where the head entity and tail entity are randomly replaced byan entity or relationship in another tuple In particular if thereplaced tuple is already in T it would not be added to thenegative sample Since both h and t represent two types ofentities there are structure-based representations and text-based representations in interval-based loss functions Thestochastic gradient descent (SGD) is employed to minimizethe above loss function
In this structure we choose the optimal parameters asfollowe the learning rate of SGD 120582 = 0001 the dimension ofthe representation vector of entities and relationships k = 100the word vector dimension of the entity description text n =100 and batch size during training is 1440 Convolution layerwindow size is 119882 isin 1 2 3 This experiment is performedin 1000 iterations of training and the optimal parameters arebased on the testing set
Hence the features used for training the machine learn-ing model are 119901119903119894119888119890119905minus1 119905 119894119899119889119894119888119886119905119900119903119905minus1 and 119891 119888119900119898119887119894119899119890119905minus1which are the price movement (increase or decrease) atcorresponding transaction date
4 Experiments and Results
41 Experimental Setting This section compares the perfor-mance of differentmodels in feature extraction fromfinancialnews expended with full sets of features The evaluationwas intended to obtain evidence that the proposed featurecombination model is superior to other feature selectionmodels in predicting the stock price movement As shownin Table 7 we chose linear models for instance logisticalregression and naive Bayes Others are nonlinear models forinstance the ensemble learning (random forest adaboostand gradient boosting) for the comparison We constantlyadjusted the parameters in the grid search and selected theoptimal parameter value their parameter value has proven towork well on machine learning method [29 48]
We used a computer consisting of an Intel Core i5processor with four cores running at 29 GHz and 8 GBRAM under the MacOS platform We used the Scikit-learnlibrary in Python in the experiments involving traditionalmachine learning algorithms and TensorFlow 14 in the
10 Complexity
Table 7 List of machine learning methods
Method Classification Parameter and their value
Traditionalmachinelearning
Decision tree (DT)Criterion= gini splitter= best max depth=None minsamples split=2 min samples leaf =1 min weight
fraction leaf=00Logistical regression (LR) Random state=1
Naive Bayes (NB) No kernel estimatorStochastic gradient descent (SGD) Loss=hinge penalty=l2
Support vector machine (SVM) Polynomial kernel function with exponent = 1 2 RBFkernel function with gamma = 001
Ensemblelearning
Random forest (RF) Randomly sampled as candidates at each split = log2 +1 max-depth=2 random state=0
AdaBoost (AB) Polynomial kernel function with exponent = 1 2 RBFkernel function with gamma = 001 n- estimators=100
Gradient boosting (GB) N-estimators =100 learning rate =10 max-depth=1random state=0
Table 8 Abbreviations of the results for each algorithm considered
Algorithms Stock data (SD) Bag of words (BOW) Convolutionalneural network
Featurecombinationmodel (FC)
DT DT 1 DT 2 DT 3 DT 4LR LR 1 LR 2 LR 3 LR 4NB NB 1 NB 2 NB 3 NB 4SGD SGD 1 SGD 2 SGD 3 SGD 4SVM SVM 1 SVM 2 SVM 3 SVM 4RF RF 1 RF 2 RF 3 RF 4AB AB 1 AB 2 AB 3 AB 4GB GB 1 GB 2 GB 3 GB 4
experiments involving deep learning and the TransE modelThe abbreviations used for comparing classification perfor-mance are presented in Table 8 During testing 2-fold cross-validation is applied to evaluate the stability of the modelsAnd we compared performance in predicting stock pricemovement for the next day with a test dataset and evaluatedthe performance of the models in terms of accuracy and F1-score [49]
42 Results
421 Thomson Reuters Case Study Thomson Reuters isa multinational mass media and information firm Threerenowned companies on the website were selected for theanalysis The first is Apple Inc which is an American multi-national technology company that designs develops andsells consumer electronics computer software and onlineservices The second company selected is Microsoft which isan American multinational technology company that devel-ops manufactures supports and sells computer softwarepersonal computers and other services The last companychosen is Samsung which is a South Korean multinationalelectronics company We considered data from these threetypical technology companies for our problem
Measurements of average accuracy are shown in Table 9and the results for each renowned company with respectto prediction based on different features are illustrated inFigure 6 We calculated the average of the four feature con-struction approaches for eachmodel for comparison amongstthe three companies The proposed feature combinationmodel generated the best results achieving average accuracylevels of 6163 5918 and 5848 forAppleMicrosoft andSamsung respectively These figures are consistent with therates reported in previous research However many studiesanalyzed only one company or used only one algorithmThe current research probed into three companies on thebasis of information from a common data source to builda prediction model with different feature selection func-tionalities and different algorithms We used stock dataa bag-of-words algorithm a convolutional neural networkand feature combination together with eight algorithms Asindicated in Table 9 the proposed predictionmodel achieved7368 data extraction with the use of LR 4 for Apple and6778 data extraction with the use of SVM 4 for MicrosoftIn particular the LR algorithm used for Apple achievedaccuracy and F1-score of 07326 and 07360 respectivelywhich highlights its powerful capability in a two-class classifi-cation
Complexity 11
Table 9 Results for data extracted fromThomson Reuters
Algorithm Company Stock data(SD)
Bag of words(BOW)
Convolutionalneural network
Feature combinemodel (FC)
AccuracyF1-score
AccuracyF1-score
AccuracyF1-score
AccuracyF1-score
DTApple 0499305079 0488902460 0615005814 0652406486
Microsoft 0486801819 0506505682 0581705915 0658706502Samsung 0470704033 0565405830 0552906820 0568006260
LRApple 0524006727 0505505083 0684506911 0732607368
Microsoft 0475701253 0443004884 0527405333 0546705611Samsung 0494703755 0605406726 0654106343 0805307978
NBApple 0510905123 0477803896 0502704497 0512204030
Microsoft 0484000363 0455704055 0459902889 0500005439Samsung 0529305810 0514406130 0504806578 0511706601
SGDApple 0467201119 0477804404 0497406008 0536602692
Microsoft 0517306819 0485203222 0610304231 0610804193Samsung 0522306541 0476602000 0518706751 0557106548
SVMApple 0502206121 0574705542 0615006129 0622006173
Microsoft 0478401722 0443904566 0523205462 0687506798Samsung 0500803875 0504705508 0513506281 0535206574
RFApple 0524006554 0527806083 0533706232 0620306243
Microsoft 0484002653 0417701687 0532502432 0572105189Samsung 0487203480 0448501194 0476603708 0505205481
ABApple 0534305384 0472202963 0481903333 0620305420
Microsoft 0468702041 0476800461 0614706044 0620206146Samsung 0485703619 0457902368 0601006820 0633806549
GBApple 0531405129 0466702941 0609604748 0634106591
Microsoft 0474302125 0472801007 0455704557 0538502258Samsung 0487204171 0519206599 0533706572 0562206335
Reuters
Aver
age a
ccur
acy
0
01
02
03
04
05
06
07
Different companyApple Microsoft Samsung
SDBOW
CNNFC
Figure 6 Average accuracy of prediction based on different featuresets for each company in Reuters
To assess the effectiveness of our research we comparedthe feature combination model that uses event tuples with
the stock data approach and the bag-of-words algorithmTheresults showed that the average accuracy of the event tuple-basedmodel is better than that of the stock data approach andthe bag-of-words algorithm by 1001 and 1087 respec-tively We also compared feature extraction using the stockdata approach the bag-of-words algorithm and machinelearning The use of deep learning improved predictionaccuracy by 525 and 611 over the levels achieved withstock data and bag of words respectively Therefore we canconclude that using the proposed feature combinationmodeland deep learning in feature extraction helps improve theaccuracy with which stock price movement is predictedThese results also fully prove the effectiveness of embeddinglayer in feature extraction accuracy improvement
422 CNN Case Study CNN is an American basic cableand satellite television news channel owned by the TurnerBroadcasting System Three renowned companies on whichthese website reports were selected for the analysis The firstis Boeing which is an American multinational corporationthat designs manufactures and sells airplanes rotorcraftrockets and satellites worldwide The second company isGoogle which is an American multinational technology
12 Complexity
Table 10 Results for data extracted from CNN
Algorithm Company Stock data(SD)
Bag of words(BOW)
Convolutionalneural network
Featurecombinationmodel (FC)
AccuracyF1-score
AccuracyF1-score
AccuracyF1-score
AccuracyF1-score
DTBoeing 0495003489 0541306258 0541406347 0559105821Google 0485805600 0518203575 0569204631 0549105471Walmart 0499604422 0530004891 0508804815 0572205829
LRBoeing 0492302378 0511304348 0692306923 0759605733Google 0504106105 0623506491 0625006111 0656306516Walmart 0529005468 0541205083 0732007347 0771907720
NBBoeing 0516206503 0548905161 0519706738 0556407619Google 0511206527 0489905191 0558705281 0534404843Walmart 0504403284 0479405302 0520605674 0530006083
SGDBoeing 0489702407 0556404870 0543304727 0571407220Google 0516506769 0542504375 0578906364 0591006327Walmart 0500403804 0520605280 0525005581 0567005922
SVMBoeing 0489703068 0571406275 0538506418 0594007033Google 0507706297 0603206230 0574905532 0578905840Walmart 0511804333 0500005314 0520005000 0561405455
RFBoeing 0490601345 0511303925 0509605405 0527605714Google 0492301777 0603206260 0522305564 0595105763Walmart 0511805373 0530003188 0530004405 0500005446
ABBoeing 0494503404 0519705120 0496105294 0567305872Google 0487603141 0510106667 0589305619 0595106850Walmart 0507305029 0515005359 0549705650 0561905503
GBBoeing 0489903169 0511804364 0440904580 0500005094Google 0491203387 0587005854 0562505243 0603206202Walmart 0500304955 0505005123 0536105109 0549705650
company that specializes in Internet-related services andproducts The third is Walmart an American multinationalretail corporation that operates a chain of hypermarketsdiscount department stores and grocery stores
The results on average accuracy are shown in Table 10and Figure 7These findings are very similar to those derivedin the previous case study and their comparison confirmedthat the proposed feature combinationmodel can outperformother feature selection models in stock price movementprediction With regard to feature selection underlain bythe bag-of-words algorithm the CNN case study generatedmore robust results than did the Reuters case study Theaverage accuracy of the bag-of-words algorithm was lowerthan that of the stock data approach in the Reuters case studyIn the CNN case study the average accuracy levels of theproposed feature combination model were 5794 5879and 5767 for Boeing Google andWalmart respectively Inthe case study on Reuters an average accuracy that exceeds60 was not achieved for any of the companies illustratingthat differences in data source directly affect stock pricemovement
We chose a combination of deep learning and knowledgegraph to build our feature selection model because this
CNN
Aver
age a
ccur
acy
0
01
02
03
04
05
06
07
Different companyBoeing Google Walmart
SDBOW
CNNFC
Figure 7Average accuracy achieved on the basis of news fromCNNand different feature set
combination exhibited superior prediction performance inthe comparison experiments involving other feature selection
Complexity 13
strategies The forecast results based on different featuresare shown in Table 10 We found that deep learning featuresare better than the use of bag-of-words and stock data Thecorrelation of event tuples with the stock market is relativelyhigh in [5 31] but the bag-of-words algorithm was relativelyfragmented and the correlation between event tuples and thestockmarket data was relatively weak Combining event tuplefeatures with deep learning significantly improves forecastresults indicating a close relationship between stock marketmovements and knowledge graph
5 Discussion
51 Research Findings We attempted to compare our predic-tion results with those made in previous studies wherein pre-diction was also based on the financial news of the renownedcompanies However the findings are incomparable becausedifferent studies use different datasets or algorithms andthese methods are difficult to investigate using financial newsheadlines In the current research we refrained from eval-uating performance on one company dataset this decisionthat enabled our knowledge graphmethod to exceed baselinepredictions based only on the price by up to 36 Thisalso proves that feature extraction in deep learning is moreeffective than traditional machines The combination of deeplearning and knowledge graph fully integrates the semanticinformation in financial news which effectively predicts thestock price movement of the renowned company
This work demonstrated the application of deep learningand knowledge graph in finance To the best of our knowl-edge knowledge graph has been rarely applied in stock pre-diction Becauseminimal financial training sets in knowledgegraph are available financial knowledge extraction is themain task for the organizational construction of a knowledgegraph Such extraction is critical for the understanding andprocessing of deep semantics in the event tuple which alsodirectly influences the feature extraction of financial news
52 Implications for Business Activities Theutility of a featurecombination model based on knowledge graph is not limitedto financial analysis Currently knowledge graph data areavailable for medical diagnosis speech recognition precisemarketing and financial risk control [4] Our model couldalso be applied in these areas
Antifraud activities are an important part of financeApplying our model on the basis of knowledge graph oncustomers helps organize all relevant knowledge fragmentsthrough deep semantic analysis and reasoning which canbe verified with a customerrsquos bank information Moreovercustomers typically use keywords to search for productsand knowledge graph can provide relevant information toa customer If a complete knowledge system of users isdescribed and collected a system would better understandand analyze user behaviors
53 Limitations and Future Work A deep learning modeluses supervised learning and needs a dataset with sufficientlabels but our datasets do not work well with deep learningas a small number of financial news articles match stock
data At present knowledge graph embedding inevitablyproduces a loss in news semantics either because of a learningprinciple or the tokenization of knowledge representation forvectorization Thus continuous representation in a knowl-edge graph is still a huge challenge We attempted to applyregression using the above-mentioned algorithms but theresults indicated poor performance More specifically theresults for Apple validated our expectations
The application of large-scale knowledge graph is stillrelatively limited and knowledge graph for smart searchsmart question-and-answer tasks social media and otherareas are in their initial stages with considerable room forimprovement The following advantages of knowledge graphshould be considered (a) the effective organization andexpression of semistructured data (b) knowledge reasoningand (c) the expansion of cognitive ability for incorporatingdeep learning Traditional knowledge elements (entities rela-tionship attributes) extraction technologies and methodshave achieved good results in limited areas but because ofnumerous constraints and poor scalability knowledge graphis not fully functional for financial forecasting because ofnumerous constraints and poor scalability
6 Conclusions
Stock movement prediction of the renowned company is adaunting task because stock prices are affected by many fac-tors This research presented a novel method for integratingknowledge graph embedding with stock market predictionThe contributions of this study can be summarized as followsFirst we developed a novel feature combination model thatconstructs a feature mapping vector for each tuplendashnewspair by simultaneously considering the diversity of entitiesand relationships Second the feature combination modelwas successfully applied to different types of companies anddatasets and exhibited good performance in classificationtasks
Stock market prediction of the renowned companygrounded in knowledge graph is an interesting topic forbusiness activities Given that the study of knowledge graphfor feature set is still in its infancy we expect it to be appliedin a wide range of academic research More companies willalso earn profits and create more opportunities through theuse of knowledge graph in the feature set
Data Availability
The data used in this study can be accessed via httpsgithubcomlinechanyknowledge-graph
Conflicts of Interest
The author declares that there is no conflict of interestregarding the publication of this paper
Acknowledgments
This work is supported by the China Scholarship Council(CSC) throughout the grant number 201508390019 The
14 Complexity
authors also want to thank the research program RFCS fromthe EU which partially supported this research through theresearch project AutoSurveillance with project ID 847202
References
[1] B GMalkiel and E F Fama ldquoEfficient capital markets a reviewof theory and empirical workrdquo The Journal of Finance vol 25no 2 pp 383ndash417 1970
[2] D Galai and R W Masulis ldquoThe option pricing model and therisk factor of stockrdquo Journal of Financial Economics vol 3 no1-2 pp 53ndash81 1976
[3] Q Wang Z Mao B Wang and L Guo ldquoKnowledge graphembedding A survey of approaches and applicationsrdquo IEEETransactions on Knowledge and Data Engineering vol 29 no12 pp 2724ndash2743 2017
[4] H Paulheim and P Cimiano ldquoKnowledge graph refinement Asurvey of approaches and evaluation methodsrdquo Journal of WebSemantics Science Services and Agents on the World Wide Webvol 8 no 3 pp 489ndash508 2016
[5] X Ding Y Zhang T Liu and J Duan ldquoDeep learning for event-driven stock predictionrdquo in Proceedings of the 24th InternationalJoint Conference on Artificial Intelligence IJCAI 2015 pp 2327ndash2333 Argentina July 2015
[6] X Ding Y Zhang T Liu and J Duan ldquoKnowledge-drivenevent embedding for stock predictionrdquo in Proceedings of the26th International Conference on Computational LinguisticsCOLING 2016 pp 2133ndash2142 Japan December 2016
[7] A Bordes N Usunier J Weston and O Yakhnenko ldquoTranslat-ing embeddings for modeling multi-relational datardquo Advancesin NIPS vol 26 pp 2787ndash2795 2013
[8] H Lin Y Liu W Wang Y Yue and Z Lin ldquoLearning entityand relation embeddings for knowledge resolutionrdquo ProcediaComputer Science vol 108 pp 345ndash354 2017
[9] G Ji K Liu S He and J Zhao ldquoKnowledge graph completionwith adaptive sparse transfer matrixrdquo in Proceedings of the 30thAAAI Conference on Artificial Intelligence AAAI 2016 pp 985ndash991 USA February 2016
[10] G Ji S He L Xu K Liu and J Zhao ldquoKnowledge graphembedding via dynamic mapping matrixrdquo in Proceedings ofthe 53rd Annual Meeting of the Association for ComputationalLinguistics and the 7th International Joint Conference on NaturalLanguage Processing (Volume 1 Long Papers) pp 687ndash696Beijing China July 2015
[11] Y LeCun Y Bengio and G Hinton ldquoDeep learningrdquo Naturevol 521 no 7553 pp 436ndash444 2015
[12] Q Li Y Chen J Wang and H Chen ldquoWeb media andstock markets a survey and future directions from a bigdata perspectiverdquo IEEE Transactions on Knowledge and DataEngineering vol 4347 p 1 2017
[13] B Wuthrich V Cho S Leung D Permunetilleke K Sankaranand J Zhang ldquoDaily stock market forecast from textual Webdatardquo in Proceedings of the 1998 IEEE International Confer-ence on Systems Man and Cybernetics (Cat No98CH36218)SMCrsquo98 vol 3 pp 2720ndash2725 October 1998
[14] G Pui Cheong Fung J Xu Yu and W Lam ldquoStock predictionintegrating text mining approach using real-time newsrdquo inProceedings of the 2003 IEEE International Conference on Com-putational Intelligence for Financial Engineering CIFEr 2003vol 2003 pp 395ndash402 China March 2003
[15] W Antweiler and M Z Frank ldquoIs all that talk just noise theinformation content of internet stock message boardsrdquo SSRNElectronic Journal 2001
[16] M-A Mittermayer and G F Knolmayer ldquoNewsCATS A newscategorization and trading systemrdquo in Proceedings of the 6thInternational Conference onDataMining ICDM2006 pp 1002ndash1007 China December 2006
[17] R P Schumaker and H Chen ldquoTextual analysis of stockmarket prediction using breaking financial news theAZFin textsystemrdquo ACM Transactions on Information and Systems pp 1ndash29 2009
[18] S S Groth and J Muntermann ldquoAn intraday market riskmanagement approach based on textual analysisrdquo DecisionSupport Systems vol 50 no 4 pp 680ndash691 2011
[19] T Vu S Chang Q Ha and N Collier ldquoAn experiment in inte-grating sentiment features for tech stock prediction in twitterrdquoin Proceedings of the Workshop on Information Extraction AndEntity Analytics on Social Media Data vol 3 pp 23ndash38 2012
[20] B Wang H Huang and X Wang ldquoA novel text miningapproach to financial time series forecastingrdquo Neurocomputingvol 83 pp 136ndash145 2012
[21] Q Li T Wang P Li L Liu Q Gong and Y Chen ldquoThe effectof news and public mood on stock movementsrdquo InformationSciences vol 278 pp 826ndash840 2014
[22] T H Nguyen K Shirai and J Velcin ldquoSentiment analysis onsocial media for stock movement predictionrdquo Expert Systemswith Applications vol 42 no 24 pp 9603ndash9611 2015
[23] BWengM A Ahmed and FMMegahed ldquoStockmarket one-day ahead movement prediction using disparate data sourcesrdquoExpert Systems with Applications vol 79 pp 153ndash163 2017
[24] J Eberhard J F Lavin and A Montecinos-Pearce ldquoA network-based dynamic analysis in an equity stock marketrdquo Complexityvol 2017 Article ID 3979836 16 pages 2017
[25] Z Zhang Y Zhang D Shen and W Zhang ldquoThe dynamiccross-correlations between mass media news newmedia newsand stock returnsrdquo Complexity vol 2018 11 pages 2018
[26] P C Tetlock ldquoGiving content to investor sentiment The role ofmedia in the stock marketrdquo Journal of Finance vol 62 no 3 pp1139ndash1168 2007
[27] K Chen P Luo L Liu andW Zhang ldquoNews search and stockco-movement Investigating information diffusion in the finan-cial marketrdquo Electronic Commerce Research and Applicationsvol 28 pp 159ndash171 2018
[28] F Z Xing E Cambria and Y Zhang ldquoSentiment-awarevolatility forecastingrdquo Knowledge-Based Systems vol 176 pp68ndash76 2019
[29] A Picasso S Merello Y Ma L Oneto and E CambrialdquoTechnical analysis and sentiment embeddings formarket trendpredictionrdquo Expert Systems with Applications vol 135 pp 60ndash70 2019
[30] A Khadjeh Nassirtoussi S Aghabozorgi T Ying Wah and DC L Ngo ldquoText mining for market prediction a systematicreviewrdquo Expert Systems with Applications vol 41 no 16 pp7653ndash7670 2014
[31] M Kraus and S Feuerriegel ldquoDecision support from financialdisclosures with deep neural networks and transfer learningrdquoDecision Support Systems vol 104 pp 38ndash48 2017
[32] H S Sim H I Kim and J J Ahn ldquoIs deep learning for imagerecognition applicable to stockmarket predictionrdquoComplexityvol 2019 10 pages 2019
Complexity 15
[33] M Jasemi A M Kimiagari and A Memariani ldquoA modernneural network model to do stock market timing on the basisof the ancient investment technique of Japanese candlestickrdquoExpert Systems with Applications vol 38 no 4 pp 3884ndash38902011
[34] A Fader S Soderland and O Etzioni ldquoIdentifying relations foropen information extractionrdquo in Proceedings of the Conferenceon Empirical Methods in Natural Language Processing EMNLP2011 pp 1535ndash1545 Association for Computational LinguisticsUK July 2011
[35] T Mikolov K Chen G Corrado and J Dean ldquoEfficientestimation of word representations in vector spacerdquo pp 1ndash122013 httpsarxivorgabs13013781
[36] X Lin Z Yang and Y Song ldquoIntelligent stock trading systembased on improved technical analysis and Echo State NetworkrdquoExpert Systems with Applications vol 38 no 9 pp 11347ndash113542011
[37] K-J Kim and I Han ldquoGenetic algorithms approach to featurediscretization in artificial neural networks for the prediction ofstock price indexrdquo Expert Systems with Applications vol 19 no2 pp 125ndash132 2000
[38] Y Yu W Duan and Q Cao ldquoThe impact of social andconventional media on firm equity value A sentiment analysisapproachrdquoDecision Support Systems vol 55 no 4 pp 919ndash9262013
[39] MHagenauM Liebmann andDNeumann ldquoAutomated newsreading Stock price prediction based on financial news usingcontext-capturing featuresrdquo Decision Support Systems vol 55no 3 pp 685ndash697 2013
[40] A Aizawa ldquoAn information-theoretic perspective of tf-idfmeasuresrdquo Information Processing amp Management vol 39 no1 pp 45ndash65 2003
[41] A Khadjeh Nassirtoussi S Aghabozorgi T Ying Wah and DC Ngo ldquoText mining of news-headlines for FOREX marketprediction a Multi-layer dimension reduction algorithm withsemantics and sentimentrdquo Expert Systems with Applications vol42 no 1 pp 306ndash324 2015
[42] D Peramunetilleke and R K Wong ldquoCurrency exchange rateforecasting from news headlinesrdquo Australian Computer ScienceCommunications vol 24 no 2 pp 131ndash139 2002
[43] Y Kim ldquoConvolutional neural networks for sentence classifica-tionrdquo 2014 httpsarxivorgabs14085882
[44] ZWang J Zhang J Feng and Z Chen ldquoKnowledge graph andtext jointly embeddingrdquo in Proceedings of the 2014 Conferenceon Empirical Methods in Natural Language Processing EMNLP2014 pp 1591ndash1601 Qatar October 2014
[45] J Xu X Qiu K Chen and X Huang ldquoKnowledge graphrepresentation with jointly structural and textual encodingrdquo inProceedings of the 26th International Joint Conference on Arti-ficial Intelligence IJCAI 2017 pp 1318ndash1324 Australia August2017
[46] R Xie Z Liu J Jia H Luan and M Sun ldquoRepresentationlearning of knowledge graphs with entity descriptionsrdquo in Pro-ceedings of the 30th AAAI Conference on Artificial IntelligenceAAAI rsquo16 pp 2659ndash2665 February 2016
[47] F Tian B Gao E Chen and T Liu ldquoLearning better wordembedding by asymmetric low-rank projection of knowledgegraphrdquo Journal of Computer Science and Technology vol 31 no3 pp 624ndash634 2016
[48] F Z Xing E Cambria and R E Welsch ldquoNatural languagebased financial forecasting a surveyrdquo Artificial IntelligenceReview vol 50 no 1 pp 49ndash73 2018
[49] C Goutte and E Gaussier ldquoA probabilistic interpretation ofprecision recall and F-score with implication for evaluationrdquoin Advances in Information Retrieval D E Losada and J MFernandez-Luna Eds vol 3408 of Lecture Notes in ComputerScience pp 345ndash359 Springer Berlin Germany 2005
Hindawiwwwhindawicom Volume 2018
MathematicsJournal of
Hindawiwwwhindawicom Volume 2018
Mathematical Problems in Engineering
Applied MathematicsJournal of
Hindawiwwwhindawicom Volume 2018
Probability and StatisticsHindawiwwwhindawicom Volume 2018
Journal of
Hindawiwwwhindawicom Volume 2018
Mathematical PhysicsAdvances in
Complex AnalysisJournal of
Hindawiwwwhindawicom Volume 2018
OptimizationJournal of
Hindawiwwwhindawicom Volume 2018
Hindawiwwwhindawicom Volume 2018
Engineering Mathematics
International Journal of
Hindawiwwwhindawicom Volume 2018
Operations ResearchAdvances in
Journal of
Hindawiwwwhindawicom Volume 2018
Function SpacesAbstract and Applied AnalysisHindawiwwwhindawicom Volume 2018
International Journal of Mathematics and Mathematical Sciences
Hindawiwwwhindawicom Volume 2018
Hindawi Publishing Corporation httpwwwhindawicom Volume 2013Hindawiwwwhindawicom
The Scientific World Journal
Volume 2018
Hindawiwwwhindawicom Volume 2018Volume 2018
Numerical AnalysisNumerical AnalysisNumerical AnalysisNumerical AnalysisNumerical AnalysisNumerical AnalysisNumerical AnalysisNumerical AnalysisNumerical AnalysisNumerical AnalysisNumerical AnalysisNumerical AnalysisAdvances inAdvances in Discrete Dynamics in
Nature and SocietyHindawiwwwhindawicom Volume 2018
Hindawiwwwhindawicom
Dierential EquationsInternational Journal of
Volume 2018
Hindawiwwwhindawicom Volume 2018
Decision SciencesAdvances in
Hindawiwwwhindawicom Volume 2018
AnalysisInternational Journal of
Hindawiwwwhindawicom Volume 2018
Stochastic AnalysisInternational Journal of
Submit your manuscripts atwwwhindawicom

8 Complexity
The United Kingdom of Great Britain and Northern Ireland commonly known as the United Kingdom or Britain hellip
London is the capital city of England and of the United Kingdom It is the most populous region hellip
Head Relationship TailLondon location country capital United Kingdom
London is the caEngland and of Kingdom It is tpopulous region
Kingdom of GreatNorthern Ireland known as the United
Britain hellip
Figure 4 Text description of the entity
connected layer when the convolutional neural networkmodel was trained The entire model was trained to classifythe five emotional labels that describe event characteristicsand the resultant model will be able to provide a mean-ingful emotional feature vector for each inputted headlineMeanwhile we define the loss function of the convolutionalneural network model as 119864119889 The features used to trainthis machine learning model are 119901119903119894119888119890119905minus1 119905 119894119899119889119894119888119886119905119900119903119905minus1and 119888119899119899119905minus1 which are the price movements (increase ordecrease) at corresponding transaction date
334 Combined Features In the introduction section of thispaper we described various translation models Because theTransE model represents a one-to-one relationship betweentwo entities [7] the relationship amongst many entities mustbe continuously incorporated into texts and knowledge graph[44] This model combines a convolutional neural networkwith textual information extraction which fully exploits thesemantic information in a knowledge graph and text [45 46]In Figure 4 knowledge graph contains rich semantics inentity description texts but it is not fully utilized in featureextraction Most of the existing text representation modelssimply train the text into word vectors through word2vecwhich obtains the text representation by means of averagingetc Hence these ways often lose more semantic informationWe therefore proposed to extract feature vectors from newstexts using a convolutional neural network model combinedwith the TransE model which also fully integrates the twoparts of the feature information
In Figure 5 this architecture used in the feature combina-tion model encompasses two parts namely a convolutionalneural network (Section 333) and the TransE model Thefeature combination sets are the average of each word vectorin an entity and it was obtained using the word2vec modelThe two entity vectors are mapped into the same relationalspace and these entities using a trained low-rank weightmatrix [47]
As assumed in the TransE model relationship vector Rshould satisfy ldquoE + R asymp Trdquo The model can be representedas a parameter set 0 = (119871119903 119877119903 120579) where X E and R
represent a word an entity and a relation respectively Andr are the mapping matrices for entities in the structuralmodel and represents the weights of the convolutional neuralnetwork For instance the sentence is ldquoSamsung sues Apple forinfringementrdquo so ldquoSamsung +Appleasymp suesrdquoThe loss function119864119904 of this structural model is defined as follows
119864119904 = ℎ + 119903 minus 11990522 (2)
where h r and t represent head entity relationship and tailentity in event tuple respectively [47]
And text representation 119864119889 is consistent withSection 333 which denotes
119864119889 = 119891119903 (ℎ119904 119905119889) + 119891119903 (ℎ119889 119905119904) + 119891119903 (ℎ119889 119905119889) (3)
where119891119903(ℎ119889 119905119889) = ℎ119889+119903minus11990511988922 represents the head entity andthe tail entity is in text representation119891119903(ℎ119889 119905119904) = ℎ119889+119903minus11990511990422and 119891119903(ℎ119904 119905119889) = ℎ119904 + 119903minus 11990511988922 represent one of the head entityh and the tail entity t in text representation another one is instructure representation
Moreover we combined two types of representationlearning (convolutional neural network and feature combi-nation) to map news titles these vectors will be into featurevectors The relationship vector R identical to the resultof the feature extraction layer of the convolutional neuralnetwork in the structural model Besides we combined thisloss with the classification loss of the convolutional neuralnetwork using L2 regularization which obtains the overallloss function 119864 for feature selection that is
119864 = 119864119904 + 120572119864119889 + 120573 02 (4)
where 02 is a regular item 120572 and 120573 are hyperparameterswhich measure the loss of text information and the weight ofthe regular items respectively W denotes the convolutionalkernels in the layer and 1198791015840 is a negative sample set of 119879 [7]
1198791015840 = (ℎ1015840 119903 119905) | ℎ1015840 isin 119864 cup (ℎ 119903 1199051015840) | 1199051015840 isin 119864
cup (ℎ 1199031015840 119905) | 1199031015840 isin 119877 (5)
Complexity 9
Output layerClass1 Class2
Machinelearning
Max pooling
convolutional
Input news
Feature vector
Embedding layer
Input news
Event tuple
Word2vec
Word2vec
Fully connection
Stock data
Stock layer
TransE model
Figure 5 Proposed architecture for the feature combination model
where the head entity and tail entity are randomly replaced byan entity or relationship in another tuple In particular if thereplaced tuple is already in T it would not be added to thenegative sample Since both h and t represent two types ofentities there are structure-based representations and text-based representations in interval-based loss functions Thestochastic gradient descent (SGD) is employed to minimizethe above loss function
In this structure we choose the optimal parameters asfollowe the learning rate of SGD 120582 = 0001 the dimension ofthe representation vector of entities and relationships k = 100the word vector dimension of the entity description text n =100 and batch size during training is 1440 Convolution layerwindow size is 119882 isin 1 2 3 This experiment is performedin 1000 iterations of training and the optimal parameters arebased on the testing set
Hence the features used for training the machine learn-ing model are 119901119903119894119888119890119905minus1 119905 119894119899119889119894119888119886119905119900119903119905minus1 and 119891 119888119900119898119887119894119899119890119905minus1which are the price movement (increase or decrease) atcorresponding transaction date
4 Experiments and Results
41 Experimental Setting This section compares the perfor-mance of differentmodels in feature extraction fromfinancialnews expended with full sets of features The evaluationwas intended to obtain evidence that the proposed featurecombination model is superior to other feature selectionmodels in predicting the stock price movement As shownin Table 7 we chose linear models for instance logisticalregression and naive Bayes Others are nonlinear models forinstance the ensemble learning (random forest adaboostand gradient boosting) for the comparison We constantlyadjusted the parameters in the grid search and selected theoptimal parameter value their parameter value has proven towork well on machine learning method [29 48]
We used a computer consisting of an Intel Core i5processor with four cores running at 29 GHz and 8 GBRAM under the MacOS platform We used the Scikit-learnlibrary in Python in the experiments involving traditionalmachine learning algorithms and TensorFlow 14 in the
10 Complexity
Table 7 List of machine learning methods
Method Classification Parameter and their value
Traditionalmachinelearning
Decision tree (DT)Criterion= gini splitter= best max depth=None minsamples split=2 min samples leaf =1 min weight
fraction leaf=00Logistical regression (LR) Random state=1
Naive Bayes (NB) No kernel estimatorStochastic gradient descent (SGD) Loss=hinge penalty=l2
Support vector machine (SVM) Polynomial kernel function with exponent = 1 2 RBFkernel function with gamma = 001
Ensemblelearning
Random forest (RF) Randomly sampled as candidates at each split = log2 +1 max-depth=2 random state=0
AdaBoost (AB) Polynomial kernel function with exponent = 1 2 RBFkernel function with gamma = 001 n- estimators=100
Gradient boosting (GB) N-estimators =100 learning rate =10 max-depth=1random state=0
Table 8 Abbreviations of the results for each algorithm considered
Algorithms Stock data (SD) Bag of words (BOW) Convolutionalneural network
Featurecombinationmodel (FC)
DT DT 1 DT 2 DT 3 DT 4LR LR 1 LR 2 LR 3 LR 4NB NB 1 NB 2 NB 3 NB 4SGD SGD 1 SGD 2 SGD 3 SGD 4SVM SVM 1 SVM 2 SVM 3 SVM 4RF RF 1 RF 2 RF 3 RF 4AB AB 1 AB 2 AB 3 AB 4GB GB 1 GB 2 GB 3 GB 4
experiments involving deep learning and the TransE modelThe abbreviations used for comparing classification perfor-mance are presented in Table 8 During testing 2-fold cross-validation is applied to evaluate the stability of the modelsAnd we compared performance in predicting stock pricemovement for the next day with a test dataset and evaluatedthe performance of the models in terms of accuracy and F1-score [49]
42 Results
421 Thomson Reuters Case Study Thomson Reuters isa multinational mass media and information firm Threerenowned companies on the website were selected for theanalysis The first is Apple Inc which is an American multi-national technology company that designs develops andsells consumer electronics computer software and onlineservices The second company selected is Microsoft which isan American multinational technology company that devel-ops manufactures supports and sells computer softwarepersonal computers and other services The last companychosen is Samsung which is a South Korean multinationalelectronics company We considered data from these threetypical technology companies for our problem
Measurements of average accuracy are shown in Table 9and the results for each renowned company with respectto prediction based on different features are illustrated inFigure 6 We calculated the average of the four feature con-struction approaches for eachmodel for comparison amongstthe three companies The proposed feature combinationmodel generated the best results achieving average accuracylevels of 6163 5918 and 5848 forAppleMicrosoft andSamsung respectively These figures are consistent with therates reported in previous research However many studiesanalyzed only one company or used only one algorithmThe current research probed into three companies on thebasis of information from a common data source to builda prediction model with different feature selection func-tionalities and different algorithms We used stock dataa bag-of-words algorithm a convolutional neural networkand feature combination together with eight algorithms Asindicated in Table 9 the proposed predictionmodel achieved7368 data extraction with the use of LR 4 for Apple and6778 data extraction with the use of SVM 4 for MicrosoftIn particular the LR algorithm used for Apple achievedaccuracy and F1-score of 07326 and 07360 respectivelywhich highlights its powerful capability in a two-class classifi-cation
Complexity 11
Table 9 Results for data extracted fromThomson Reuters
Algorithm Company Stock data(SD)
Bag of words(BOW)
Convolutionalneural network
Feature combinemodel (FC)
AccuracyF1-score
AccuracyF1-score
AccuracyF1-score
AccuracyF1-score
DTApple 0499305079 0488902460 0615005814 0652406486
Microsoft 0486801819 0506505682 0581705915 0658706502Samsung 0470704033 0565405830 0552906820 0568006260
LRApple 0524006727 0505505083 0684506911 0732607368
Microsoft 0475701253 0443004884 0527405333 0546705611Samsung 0494703755 0605406726 0654106343 0805307978
NBApple 0510905123 0477803896 0502704497 0512204030
Microsoft 0484000363 0455704055 0459902889 0500005439Samsung 0529305810 0514406130 0504806578 0511706601
SGDApple 0467201119 0477804404 0497406008 0536602692
Microsoft 0517306819 0485203222 0610304231 0610804193Samsung 0522306541 0476602000 0518706751 0557106548
SVMApple 0502206121 0574705542 0615006129 0622006173
Microsoft 0478401722 0443904566 0523205462 0687506798Samsung 0500803875 0504705508 0513506281 0535206574
RFApple 0524006554 0527806083 0533706232 0620306243
Microsoft 0484002653 0417701687 0532502432 0572105189Samsung 0487203480 0448501194 0476603708 0505205481
ABApple 0534305384 0472202963 0481903333 0620305420
Microsoft 0468702041 0476800461 0614706044 0620206146Samsung 0485703619 0457902368 0601006820 0633806549
GBApple 0531405129 0466702941 0609604748 0634106591
Microsoft 0474302125 0472801007 0455704557 0538502258Samsung 0487204171 0519206599 0533706572 0562206335
Reuters
Aver
age a
ccur
acy
0
01
02
03
04
05
06
07
Different companyApple Microsoft Samsung
SDBOW
CNNFC
Figure 6 Average accuracy of prediction based on different featuresets for each company in Reuters
To assess the effectiveness of our research we comparedthe feature combination model that uses event tuples with
the stock data approach and the bag-of-words algorithmTheresults showed that the average accuracy of the event tuple-basedmodel is better than that of the stock data approach andthe bag-of-words algorithm by 1001 and 1087 respec-tively We also compared feature extraction using the stockdata approach the bag-of-words algorithm and machinelearning The use of deep learning improved predictionaccuracy by 525 and 611 over the levels achieved withstock data and bag of words respectively Therefore we canconclude that using the proposed feature combinationmodeland deep learning in feature extraction helps improve theaccuracy with which stock price movement is predictedThese results also fully prove the effectiveness of embeddinglayer in feature extraction accuracy improvement
422 CNN Case Study CNN is an American basic cableand satellite television news channel owned by the TurnerBroadcasting System Three renowned companies on whichthese website reports were selected for the analysis The firstis Boeing which is an American multinational corporationthat designs manufactures and sells airplanes rotorcraftrockets and satellites worldwide The second company isGoogle which is an American multinational technology
12 Complexity
Table 10 Results for data extracted from CNN
Algorithm Company Stock data(SD)
Bag of words(BOW)
Convolutionalneural network
Featurecombinationmodel (FC)
AccuracyF1-score
AccuracyF1-score
AccuracyF1-score
AccuracyF1-score
DTBoeing 0495003489 0541306258 0541406347 0559105821Google 0485805600 0518203575 0569204631 0549105471Walmart 0499604422 0530004891 0508804815 0572205829
LRBoeing 0492302378 0511304348 0692306923 0759605733Google 0504106105 0623506491 0625006111 0656306516Walmart 0529005468 0541205083 0732007347 0771907720
NBBoeing 0516206503 0548905161 0519706738 0556407619Google 0511206527 0489905191 0558705281 0534404843Walmart 0504403284 0479405302 0520605674 0530006083
SGDBoeing 0489702407 0556404870 0543304727 0571407220Google 0516506769 0542504375 0578906364 0591006327Walmart 0500403804 0520605280 0525005581 0567005922
SVMBoeing 0489703068 0571406275 0538506418 0594007033Google 0507706297 0603206230 0574905532 0578905840Walmart 0511804333 0500005314 0520005000 0561405455
RFBoeing 0490601345 0511303925 0509605405 0527605714Google 0492301777 0603206260 0522305564 0595105763Walmart 0511805373 0530003188 0530004405 0500005446
ABBoeing 0494503404 0519705120 0496105294 0567305872Google 0487603141 0510106667 0589305619 0595106850Walmart 0507305029 0515005359 0549705650 0561905503
GBBoeing 0489903169 0511804364 0440904580 0500005094Google 0491203387 0587005854 0562505243 0603206202Walmart 0500304955 0505005123 0536105109 0549705650
company that specializes in Internet-related services andproducts The third is Walmart an American multinationalretail corporation that operates a chain of hypermarketsdiscount department stores and grocery stores
The results on average accuracy are shown in Table 10and Figure 7These findings are very similar to those derivedin the previous case study and their comparison confirmedthat the proposed feature combinationmodel can outperformother feature selection models in stock price movementprediction With regard to feature selection underlain bythe bag-of-words algorithm the CNN case study generatedmore robust results than did the Reuters case study Theaverage accuracy of the bag-of-words algorithm was lowerthan that of the stock data approach in the Reuters case studyIn the CNN case study the average accuracy levels of theproposed feature combination model were 5794 5879and 5767 for Boeing Google andWalmart respectively Inthe case study on Reuters an average accuracy that exceeds60 was not achieved for any of the companies illustratingthat differences in data source directly affect stock pricemovement
We chose a combination of deep learning and knowledgegraph to build our feature selection model because this
CNN
Aver
age a
ccur
acy
0
01
02
03
04
05
06
07
Different companyBoeing Google Walmart
SDBOW
CNNFC
Figure 7Average accuracy achieved on the basis of news fromCNNand different feature set
combination exhibited superior prediction performance inthe comparison experiments involving other feature selection
Complexity 13
strategies The forecast results based on different featuresare shown in Table 10 We found that deep learning featuresare better than the use of bag-of-words and stock data Thecorrelation of event tuples with the stock market is relativelyhigh in [5 31] but the bag-of-words algorithm was relativelyfragmented and the correlation between event tuples and thestockmarket data was relatively weak Combining event tuplefeatures with deep learning significantly improves forecastresults indicating a close relationship between stock marketmovements and knowledge graph
5 Discussion
51 Research Findings We attempted to compare our predic-tion results with those made in previous studies wherein pre-diction was also based on the financial news of the renownedcompanies However the findings are incomparable becausedifferent studies use different datasets or algorithms andthese methods are difficult to investigate using financial newsheadlines In the current research we refrained from eval-uating performance on one company dataset this decisionthat enabled our knowledge graphmethod to exceed baselinepredictions based only on the price by up to 36 Thisalso proves that feature extraction in deep learning is moreeffective than traditional machines The combination of deeplearning and knowledge graph fully integrates the semanticinformation in financial news which effectively predicts thestock price movement of the renowned company
This work demonstrated the application of deep learningand knowledge graph in finance To the best of our knowl-edge knowledge graph has been rarely applied in stock pre-diction Becauseminimal financial training sets in knowledgegraph are available financial knowledge extraction is themain task for the organizational construction of a knowledgegraph Such extraction is critical for the understanding andprocessing of deep semantics in the event tuple which alsodirectly influences the feature extraction of financial news
52 Implications for Business Activities Theutility of a featurecombination model based on knowledge graph is not limitedto financial analysis Currently knowledge graph data areavailable for medical diagnosis speech recognition precisemarketing and financial risk control [4] Our model couldalso be applied in these areas
Antifraud activities are an important part of financeApplying our model on the basis of knowledge graph oncustomers helps organize all relevant knowledge fragmentsthrough deep semantic analysis and reasoning which canbe verified with a customerrsquos bank information Moreovercustomers typically use keywords to search for productsand knowledge graph can provide relevant information toa customer If a complete knowledge system of users isdescribed and collected a system would better understandand analyze user behaviors
53 Limitations and Future Work A deep learning modeluses supervised learning and needs a dataset with sufficientlabels but our datasets do not work well with deep learningas a small number of financial news articles match stock
data At present knowledge graph embedding inevitablyproduces a loss in news semantics either because of a learningprinciple or the tokenization of knowledge representation forvectorization Thus continuous representation in a knowl-edge graph is still a huge challenge We attempted to applyregression using the above-mentioned algorithms but theresults indicated poor performance More specifically theresults for Apple validated our expectations
The application of large-scale knowledge graph is stillrelatively limited and knowledge graph for smart searchsmart question-and-answer tasks social media and otherareas are in their initial stages with considerable room forimprovement The following advantages of knowledge graphshould be considered (a) the effective organization andexpression of semistructured data (b) knowledge reasoningand (c) the expansion of cognitive ability for incorporatingdeep learning Traditional knowledge elements (entities rela-tionship attributes) extraction technologies and methodshave achieved good results in limited areas but because ofnumerous constraints and poor scalability knowledge graphis not fully functional for financial forecasting because ofnumerous constraints and poor scalability
6 Conclusions
Stock movement prediction of the renowned company is adaunting task because stock prices are affected by many fac-tors This research presented a novel method for integratingknowledge graph embedding with stock market predictionThe contributions of this study can be summarized as followsFirst we developed a novel feature combination model thatconstructs a feature mapping vector for each tuplendashnewspair by simultaneously considering the diversity of entitiesand relationships Second the feature combination modelwas successfully applied to different types of companies anddatasets and exhibited good performance in classificationtasks
Stock market prediction of the renowned companygrounded in knowledge graph is an interesting topic forbusiness activities Given that the study of knowledge graphfor feature set is still in its infancy we expect it to be appliedin a wide range of academic research More companies willalso earn profits and create more opportunities through theuse of knowledge graph in the feature set
Data Availability
The data used in this study can be accessed via httpsgithubcomlinechanyknowledge-graph
Conflicts of Interest
The author declares that there is no conflict of interestregarding the publication of this paper
Acknowledgments
This work is supported by the China Scholarship Council(CSC) throughout the grant number 201508390019 The
14 Complexity
authors also want to thank the research program RFCS fromthe EU which partially supported this research through theresearch project AutoSurveillance with project ID 847202
References
[1] B GMalkiel and E F Fama ldquoEfficient capital markets a reviewof theory and empirical workrdquo The Journal of Finance vol 25no 2 pp 383ndash417 1970
[2] D Galai and R W Masulis ldquoThe option pricing model and therisk factor of stockrdquo Journal of Financial Economics vol 3 no1-2 pp 53ndash81 1976
[3] Q Wang Z Mao B Wang and L Guo ldquoKnowledge graphembedding A survey of approaches and applicationsrdquo IEEETransactions on Knowledge and Data Engineering vol 29 no12 pp 2724ndash2743 2017
[4] H Paulheim and P Cimiano ldquoKnowledge graph refinement Asurvey of approaches and evaluation methodsrdquo Journal of WebSemantics Science Services and Agents on the World Wide Webvol 8 no 3 pp 489ndash508 2016
[5] X Ding Y Zhang T Liu and J Duan ldquoDeep learning for event-driven stock predictionrdquo in Proceedings of the 24th InternationalJoint Conference on Artificial Intelligence IJCAI 2015 pp 2327ndash2333 Argentina July 2015
[6] X Ding Y Zhang T Liu and J Duan ldquoKnowledge-drivenevent embedding for stock predictionrdquo in Proceedings of the26th International Conference on Computational LinguisticsCOLING 2016 pp 2133ndash2142 Japan December 2016
[7] A Bordes N Usunier J Weston and O Yakhnenko ldquoTranslat-ing embeddings for modeling multi-relational datardquo Advancesin NIPS vol 26 pp 2787ndash2795 2013
[8] H Lin Y Liu W Wang Y Yue and Z Lin ldquoLearning entityand relation embeddings for knowledge resolutionrdquo ProcediaComputer Science vol 108 pp 345ndash354 2017
[9] G Ji K Liu S He and J Zhao ldquoKnowledge graph completionwith adaptive sparse transfer matrixrdquo in Proceedings of the 30thAAAI Conference on Artificial Intelligence AAAI 2016 pp 985ndash991 USA February 2016
[10] G Ji S He L Xu K Liu and J Zhao ldquoKnowledge graphembedding via dynamic mapping matrixrdquo in Proceedings ofthe 53rd Annual Meeting of the Association for ComputationalLinguistics and the 7th International Joint Conference on NaturalLanguage Processing (Volume 1 Long Papers) pp 687ndash696Beijing China July 2015
[11] Y LeCun Y Bengio and G Hinton ldquoDeep learningrdquo Naturevol 521 no 7553 pp 436ndash444 2015
[12] Q Li Y Chen J Wang and H Chen ldquoWeb media andstock markets a survey and future directions from a bigdata perspectiverdquo IEEE Transactions on Knowledge and DataEngineering vol 4347 p 1 2017
[13] B Wuthrich V Cho S Leung D Permunetilleke K Sankaranand J Zhang ldquoDaily stock market forecast from textual Webdatardquo in Proceedings of the 1998 IEEE International Confer-ence on Systems Man and Cybernetics (Cat No98CH36218)SMCrsquo98 vol 3 pp 2720ndash2725 October 1998
[14] G Pui Cheong Fung J Xu Yu and W Lam ldquoStock predictionintegrating text mining approach using real-time newsrdquo inProceedings of the 2003 IEEE International Conference on Com-putational Intelligence for Financial Engineering CIFEr 2003vol 2003 pp 395ndash402 China March 2003
[15] W Antweiler and M Z Frank ldquoIs all that talk just noise theinformation content of internet stock message boardsrdquo SSRNElectronic Journal 2001
[16] M-A Mittermayer and G F Knolmayer ldquoNewsCATS A newscategorization and trading systemrdquo in Proceedings of the 6thInternational Conference onDataMining ICDM2006 pp 1002ndash1007 China December 2006
[17] R P Schumaker and H Chen ldquoTextual analysis of stockmarket prediction using breaking financial news theAZFin textsystemrdquo ACM Transactions on Information and Systems pp 1ndash29 2009
[18] S S Groth and J Muntermann ldquoAn intraday market riskmanagement approach based on textual analysisrdquo DecisionSupport Systems vol 50 no 4 pp 680ndash691 2011
[19] T Vu S Chang Q Ha and N Collier ldquoAn experiment in inte-grating sentiment features for tech stock prediction in twitterrdquoin Proceedings of the Workshop on Information Extraction AndEntity Analytics on Social Media Data vol 3 pp 23ndash38 2012
[20] B Wang H Huang and X Wang ldquoA novel text miningapproach to financial time series forecastingrdquo Neurocomputingvol 83 pp 136ndash145 2012
[21] Q Li T Wang P Li L Liu Q Gong and Y Chen ldquoThe effectof news and public mood on stock movementsrdquo InformationSciences vol 278 pp 826ndash840 2014
[22] T H Nguyen K Shirai and J Velcin ldquoSentiment analysis onsocial media for stock movement predictionrdquo Expert Systemswith Applications vol 42 no 24 pp 9603ndash9611 2015
[23] BWengM A Ahmed and FMMegahed ldquoStockmarket one-day ahead movement prediction using disparate data sourcesrdquoExpert Systems with Applications vol 79 pp 153ndash163 2017
[24] J Eberhard J F Lavin and A Montecinos-Pearce ldquoA network-based dynamic analysis in an equity stock marketrdquo Complexityvol 2017 Article ID 3979836 16 pages 2017
[25] Z Zhang Y Zhang D Shen and W Zhang ldquoThe dynamiccross-correlations between mass media news newmedia newsand stock returnsrdquo Complexity vol 2018 11 pages 2018
[26] P C Tetlock ldquoGiving content to investor sentiment The role ofmedia in the stock marketrdquo Journal of Finance vol 62 no 3 pp1139ndash1168 2007
[27] K Chen P Luo L Liu andW Zhang ldquoNews search and stockco-movement Investigating information diffusion in the finan-cial marketrdquo Electronic Commerce Research and Applicationsvol 28 pp 159ndash171 2018
[28] F Z Xing E Cambria and Y Zhang ldquoSentiment-awarevolatility forecastingrdquo Knowledge-Based Systems vol 176 pp68ndash76 2019
[29] A Picasso S Merello Y Ma L Oneto and E CambrialdquoTechnical analysis and sentiment embeddings formarket trendpredictionrdquo Expert Systems with Applications vol 135 pp 60ndash70 2019
[30] A Khadjeh Nassirtoussi S Aghabozorgi T Ying Wah and DC L Ngo ldquoText mining for market prediction a systematicreviewrdquo Expert Systems with Applications vol 41 no 16 pp7653ndash7670 2014
[31] M Kraus and S Feuerriegel ldquoDecision support from financialdisclosures with deep neural networks and transfer learningrdquoDecision Support Systems vol 104 pp 38ndash48 2017
[32] H S Sim H I Kim and J J Ahn ldquoIs deep learning for imagerecognition applicable to stockmarket predictionrdquoComplexityvol 2019 10 pages 2019
Complexity 15
[33] M Jasemi A M Kimiagari and A Memariani ldquoA modernneural network model to do stock market timing on the basisof the ancient investment technique of Japanese candlestickrdquoExpert Systems with Applications vol 38 no 4 pp 3884ndash38902011
[34] A Fader S Soderland and O Etzioni ldquoIdentifying relations foropen information extractionrdquo in Proceedings of the Conferenceon Empirical Methods in Natural Language Processing EMNLP2011 pp 1535ndash1545 Association for Computational LinguisticsUK July 2011
[35] T Mikolov K Chen G Corrado and J Dean ldquoEfficientestimation of word representations in vector spacerdquo pp 1ndash122013 httpsarxivorgabs13013781
[36] X Lin Z Yang and Y Song ldquoIntelligent stock trading systembased on improved technical analysis and Echo State NetworkrdquoExpert Systems with Applications vol 38 no 9 pp 11347ndash113542011
[37] K-J Kim and I Han ldquoGenetic algorithms approach to featurediscretization in artificial neural networks for the prediction ofstock price indexrdquo Expert Systems with Applications vol 19 no2 pp 125ndash132 2000
[38] Y Yu W Duan and Q Cao ldquoThe impact of social andconventional media on firm equity value A sentiment analysisapproachrdquoDecision Support Systems vol 55 no 4 pp 919ndash9262013
[39] MHagenauM Liebmann andDNeumann ldquoAutomated newsreading Stock price prediction based on financial news usingcontext-capturing featuresrdquo Decision Support Systems vol 55no 3 pp 685ndash697 2013
[40] A Aizawa ldquoAn information-theoretic perspective of tf-idfmeasuresrdquo Information Processing amp Management vol 39 no1 pp 45ndash65 2003
[41] A Khadjeh Nassirtoussi S Aghabozorgi T Ying Wah and DC Ngo ldquoText mining of news-headlines for FOREX marketprediction a Multi-layer dimension reduction algorithm withsemantics and sentimentrdquo Expert Systems with Applications vol42 no 1 pp 306ndash324 2015
[42] D Peramunetilleke and R K Wong ldquoCurrency exchange rateforecasting from news headlinesrdquo Australian Computer ScienceCommunications vol 24 no 2 pp 131ndash139 2002
[43] Y Kim ldquoConvolutional neural networks for sentence classifica-tionrdquo 2014 httpsarxivorgabs14085882
[44] ZWang J Zhang J Feng and Z Chen ldquoKnowledge graph andtext jointly embeddingrdquo in Proceedings of the 2014 Conferenceon Empirical Methods in Natural Language Processing EMNLP2014 pp 1591ndash1601 Qatar October 2014
[45] J Xu X Qiu K Chen and X Huang ldquoKnowledge graphrepresentation with jointly structural and textual encodingrdquo inProceedings of the 26th International Joint Conference on Arti-ficial Intelligence IJCAI 2017 pp 1318ndash1324 Australia August2017
[46] R Xie Z Liu J Jia H Luan and M Sun ldquoRepresentationlearning of knowledge graphs with entity descriptionsrdquo in Pro-ceedings of the 30th AAAI Conference on Artificial IntelligenceAAAI rsquo16 pp 2659ndash2665 February 2016
[47] F Tian B Gao E Chen and T Liu ldquoLearning better wordembedding by asymmetric low-rank projection of knowledgegraphrdquo Journal of Computer Science and Technology vol 31 no3 pp 624ndash634 2016
[48] F Z Xing E Cambria and R E Welsch ldquoNatural languagebased financial forecasting a surveyrdquo Artificial IntelligenceReview vol 50 no 1 pp 49ndash73 2018
[49] C Goutte and E Gaussier ldquoA probabilistic interpretation ofprecision recall and F-score with implication for evaluationrdquoin Advances in Information Retrieval D E Losada and J MFernandez-Luna Eds vol 3408 of Lecture Notes in ComputerScience pp 345ndash359 Springer Berlin Germany 2005
Hindawiwwwhindawicom Volume 2018
MathematicsJournal of
Hindawiwwwhindawicom Volume 2018
Mathematical Problems in Engineering
Applied MathematicsJournal of
Hindawiwwwhindawicom Volume 2018
Probability and StatisticsHindawiwwwhindawicom Volume 2018
Journal of
Hindawiwwwhindawicom Volume 2018
Mathematical PhysicsAdvances in
Complex AnalysisJournal of
Hindawiwwwhindawicom Volume 2018
OptimizationJournal of
Hindawiwwwhindawicom Volume 2018
Hindawiwwwhindawicom Volume 2018
Engineering Mathematics
International Journal of
Hindawiwwwhindawicom Volume 2018
Operations ResearchAdvances in
Journal of
Hindawiwwwhindawicom Volume 2018
Function SpacesAbstract and Applied AnalysisHindawiwwwhindawicom Volume 2018
International Journal of Mathematics and Mathematical Sciences
Hindawiwwwhindawicom Volume 2018
Hindawi Publishing Corporation httpwwwhindawicom Volume 2013Hindawiwwwhindawicom
The Scientific World Journal
Volume 2018
Hindawiwwwhindawicom Volume 2018Volume 2018
Numerical AnalysisNumerical AnalysisNumerical AnalysisNumerical AnalysisNumerical AnalysisNumerical AnalysisNumerical AnalysisNumerical AnalysisNumerical AnalysisNumerical AnalysisNumerical AnalysisNumerical AnalysisAdvances inAdvances in Discrete Dynamics in
Nature and SocietyHindawiwwwhindawicom Volume 2018
Hindawiwwwhindawicom
Dierential EquationsInternational Journal of
Volume 2018
Hindawiwwwhindawicom Volume 2018
Decision SciencesAdvances in
Hindawiwwwhindawicom Volume 2018
AnalysisInternational Journal of
Hindawiwwwhindawicom Volume 2018
Stochastic AnalysisInternational Journal of
Submit your manuscripts atwwwhindawicom

Complexity 9
Output layerClass1 Class2
Machinelearning
Max pooling
convolutional
Input news
Feature vector
Embedding layer
Input news
Event tuple
Word2vec
Word2vec
Fully connection
Stock data
Stock layer
TransE model
Figure 5 Proposed architecture for the feature combination model
where the head entity and tail entity are randomly replaced byan entity or relationship in another tuple In particular if thereplaced tuple is already in T it would not be added to thenegative sample Since both h and t represent two types ofentities there are structure-based representations and text-based representations in interval-based loss functions Thestochastic gradient descent (SGD) is employed to minimizethe above loss function
In this structure we choose the optimal parameters asfollowe the learning rate of SGD 120582 = 0001 the dimension ofthe representation vector of entities and relationships k = 100the word vector dimension of the entity description text n =100 and batch size during training is 1440 Convolution layerwindow size is 119882 isin 1 2 3 This experiment is performedin 1000 iterations of training and the optimal parameters arebased on the testing set
Hence the features used for training the machine learn-ing model are 119901119903119894119888119890119905minus1 119905 119894119899119889119894119888119886119905119900119903119905minus1 and 119891 119888119900119898119887119894119899119890119905minus1which are the price movement (increase or decrease) atcorresponding transaction date
4 Experiments and Results
41 Experimental Setting This section compares the perfor-mance of differentmodels in feature extraction fromfinancialnews expended with full sets of features The evaluationwas intended to obtain evidence that the proposed featurecombination model is superior to other feature selectionmodels in predicting the stock price movement As shownin Table 7 we chose linear models for instance logisticalregression and naive Bayes Others are nonlinear models forinstance the ensemble learning (random forest adaboostand gradient boosting) for the comparison We constantlyadjusted the parameters in the grid search and selected theoptimal parameter value their parameter value has proven towork well on machine learning method [29 48]
We used a computer consisting of an Intel Core i5processor with four cores running at 29 GHz and 8 GBRAM under the MacOS platform We used the Scikit-learnlibrary in Python in the experiments involving traditionalmachine learning algorithms and TensorFlow 14 in the
10 Complexity
Table 7 List of machine learning methods
Method Classification Parameter and their value
Traditionalmachinelearning
Decision tree (DT)Criterion= gini splitter= best max depth=None minsamples split=2 min samples leaf =1 min weight
fraction leaf=00Logistical regression (LR) Random state=1
Naive Bayes (NB) No kernel estimatorStochastic gradient descent (SGD) Loss=hinge penalty=l2
Support vector machine (SVM) Polynomial kernel function with exponent = 1 2 RBFkernel function with gamma = 001
Ensemblelearning
Random forest (RF) Randomly sampled as candidates at each split = log2 +1 max-depth=2 random state=0
AdaBoost (AB) Polynomial kernel function with exponent = 1 2 RBFkernel function with gamma = 001 n- estimators=100
Gradient boosting (GB) N-estimators =100 learning rate =10 max-depth=1random state=0
Table 8 Abbreviations of the results for each algorithm considered
Algorithms Stock data (SD) Bag of words (BOW) Convolutionalneural network
Featurecombinationmodel (FC)
DT DT 1 DT 2 DT 3 DT 4LR LR 1 LR 2 LR 3 LR 4NB NB 1 NB 2 NB 3 NB 4SGD SGD 1 SGD 2 SGD 3 SGD 4SVM SVM 1 SVM 2 SVM 3 SVM 4RF RF 1 RF 2 RF 3 RF 4AB AB 1 AB 2 AB 3 AB 4GB GB 1 GB 2 GB 3 GB 4
experiments involving deep learning and the TransE modelThe abbreviations used for comparing classification perfor-mance are presented in Table 8 During testing 2-fold cross-validation is applied to evaluate the stability of the modelsAnd we compared performance in predicting stock pricemovement for the next day with a test dataset and evaluatedthe performance of the models in terms of accuracy and F1-score [49]
42 Results
421 Thomson Reuters Case Study Thomson Reuters isa multinational mass media and information firm Threerenowned companies on the website were selected for theanalysis The first is Apple Inc which is an American multi-national technology company that designs develops andsells consumer electronics computer software and onlineservices The second company selected is Microsoft which isan American multinational technology company that devel-ops manufactures supports and sells computer softwarepersonal computers and other services The last companychosen is Samsung which is a South Korean multinationalelectronics company We considered data from these threetypical technology companies for our problem
Measurements of average accuracy are shown in Table 9and the results for each renowned company with respectto prediction based on different features are illustrated inFigure 6 We calculated the average of the four feature con-struction approaches for eachmodel for comparison amongstthe three companies The proposed feature combinationmodel generated the best results achieving average accuracylevels of 6163 5918 and 5848 forAppleMicrosoft andSamsung respectively These figures are consistent with therates reported in previous research However many studiesanalyzed only one company or used only one algorithmThe current research probed into three companies on thebasis of information from a common data source to builda prediction model with different feature selection func-tionalities and different algorithms We used stock dataa bag-of-words algorithm a convolutional neural networkand feature combination together with eight algorithms Asindicated in Table 9 the proposed predictionmodel achieved7368 data extraction with the use of LR 4 for Apple and6778 data extraction with the use of SVM 4 for MicrosoftIn particular the LR algorithm used for Apple achievedaccuracy and F1-score of 07326 and 07360 respectivelywhich highlights its powerful capability in a two-class classifi-cation
Complexity 11
Table 9 Results for data extracted fromThomson Reuters
Algorithm Company Stock data(SD)
Bag of words(BOW)
Convolutionalneural network
Feature combinemodel (FC)
AccuracyF1-score
AccuracyF1-score
AccuracyF1-score
AccuracyF1-score
DTApple 0499305079 0488902460 0615005814 0652406486
Microsoft 0486801819 0506505682 0581705915 0658706502Samsung 0470704033 0565405830 0552906820 0568006260
LRApple 0524006727 0505505083 0684506911 0732607368
Microsoft 0475701253 0443004884 0527405333 0546705611Samsung 0494703755 0605406726 0654106343 0805307978
NBApple 0510905123 0477803896 0502704497 0512204030
Microsoft 0484000363 0455704055 0459902889 0500005439Samsung 0529305810 0514406130 0504806578 0511706601
SGDApple 0467201119 0477804404 0497406008 0536602692
Microsoft 0517306819 0485203222 0610304231 0610804193Samsung 0522306541 0476602000 0518706751 0557106548
SVMApple 0502206121 0574705542 0615006129 0622006173
Microsoft 0478401722 0443904566 0523205462 0687506798Samsung 0500803875 0504705508 0513506281 0535206574
RFApple 0524006554 0527806083 0533706232 0620306243
Microsoft 0484002653 0417701687 0532502432 0572105189Samsung 0487203480 0448501194 0476603708 0505205481
ABApple 0534305384 0472202963 0481903333 0620305420
Microsoft 0468702041 0476800461 0614706044 0620206146Samsung 0485703619 0457902368 0601006820 0633806549
GBApple 0531405129 0466702941 0609604748 0634106591
Microsoft 0474302125 0472801007 0455704557 0538502258Samsung 0487204171 0519206599 0533706572 0562206335
Reuters
Aver
age a
ccur
acy
0
01
02
03
04
05
06
07
Different companyApple Microsoft Samsung
SDBOW
CNNFC
Figure 6 Average accuracy of prediction based on different featuresets for each company in Reuters
To assess the effectiveness of our research we comparedthe feature combination model that uses event tuples with
the stock data approach and the bag-of-words algorithmTheresults showed that the average accuracy of the event tuple-basedmodel is better than that of the stock data approach andthe bag-of-words algorithm by 1001 and 1087 respec-tively We also compared feature extraction using the stockdata approach the bag-of-words algorithm and machinelearning The use of deep learning improved predictionaccuracy by 525 and 611 over the levels achieved withstock data and bag of words respectively Therefore we canconclude that using the proposed feature combinationmodeland deep learning in feature extraction helps improve theaccuracy with which stock price movement is predictedThese results also fully prove the effectiveness of embeddinglayer in feature extraction accuracy improvement
422 CNN Case Study CNN is an American basic cableand satellite television news channel owned by the TurnerBroadcasting System Three renowned companies on whichthese website reports were selected for the analysis The firstis Boeing which is an American multinational corporationthat designs manufactures and sells airplanes rotorcraftrockets and satellites worldwide The second company isGoogle which is an American multinational technology
12 Complexity
Table 10 Results for data extracted from CNN
Algorithm Company Stock data(SD)
Bag of words(BOW)
Convolutionalneural network
Featurecombinationmodel (FC)
AccuracyF1-score
AccuracyF1-score
AccuracyF1-score
AccuracyF1-score
DTBoeing 0495003489 0541306258 0541406347 0559105821Google 0485805600 0518203575 0569204631 0549105471Walmart 0499604422 0530004891 0508804815 0572205829
LRBoeing 0492302378 0511304348 0692306923 0759605733Google 0504106105 0623506491 0625006111 0656306516Walmart 0529005468 0541205083 0732007347 0771907720
NBBoeing 0516206503 0548905161 0519706738 0556407619Google 0511206527 0489905191 0558705281 0534404843Walmart 0504403284 0479405302 0520605674 0530006083
SGDBoeing 0489702407 0556404870 0543304727 0571407220Google 0516506769 0542504375 0578906364 0591006327Walmart 0500403804 0520605280 0525005581 0567005922
SVMBoeing 0489703068 0571406275 0538506418 0594007033Google 0507706297 0603206230 0574905532 0578905840Walmart 0511804333 0500005314 0520005000 0561405455
RFBoeing 0490601345 0511303925 0509605405 0527605714Google 0492301777 0603206260 0522305564 0595105763Walmart 0511805373 0530003188 0530004405 0500005446
ABBoeing 0494503404 0519705120 0496105294 0567305872Google 0487603141 0510106667 0589305619 0595106850Walmart 0507305029 0515005359 0549705650 0561905503
GBBoeing 0489903169 0511804364 0440904580 0500005094Google 0491203387 0587005854 0562505243 0603206202Walmart 0500304955 0505005123 0536105109 0549705650
company that specializes in Internet-related services andproducts The third is Walmart an American multinationalretail corporation that operates a chain of hypermarketsdiscount department stores and grocery stores
The results on average accuracy are shown in Table 10and Figure 7These findings are very similar to those derivedin the previous case study and their comparison confirmedthat the proposed feature combinationmodel can outperformother feature selection models in stock price movementprediction With regard to feature selection underlain bythe bag-of-words algorithm the CNN case study generatedmore robust results than did the Reuters case study Theaverage accuracy of the bag-of-words algorithm was lowerthan that of the stock data approach in the Reuters case studyIn the CNN case study the average accuracy levels of theproposed feature combination model were 5794 5879and 5767 for Boeing Google andWalmart respectively Inthe case study on Reuters an average accuracy that exceeds60 was not achieved for any of the companies illustratingthat differences in data source directly affect stock pricemovement
We chose a combination of deep learning and knowledgegraph to build our feature selection model because this
CNN
Aver
age a
ccur
acy
0
01
02
03
04
05
06
07
Different companyBoeing Google Walmart
SDBOW
CNNFC
Figure 7Average accuracy achieved on the basis of news fromCNNand different feature set
combination exhibited superior prediction performance inthe comparison experiments involving other feature selection
Complexity 13
strategies The forecast results based on different featuresare shown in Table 10 We found that deep learning featuresare better than the use of bag-of-words and stock data Thecorrelation of event tuples with the stock market is relativelyhigh in [5 31] but the bag-of-words algorithm was relativelyfragmented and the correlation between event tuples and thestockmarket data was relatively weak Combining event tuplefeatures with deep learning significantly improves forecastresults indicating a close relationship between stock marketmovements and knowledge graph
5 Discussion
51 Research Findings We attempted to compare our predic-tion results with those made in previous studies wherein pre-diction was also based on the financial news of the renownedcompanies However the findings are incomparable becausedifferent studies use different datasets or algorithms andthese methods are difficult to investigate using financial newsheadlines In the current research we refrained from eval-uating performance on one company dataset this decisionthat enabled our knowledge graphmethod to exceed baselinepredictions based only on the price by up to 36 Thisalso proves that feature extraction in deep learning is moreeffective than traditional machines The combination of deeplearning and knowledge graph fully integrates the semanticinformation in financial news which effectively predicts thestock price movement of the renowned company
This work demonstrated the application of deep learningand knowledge graph in finance To the best of our knowl-edge knowledge graph has been rarely applied in stock pre-diction Becauseminimal financial training sets in knowledgegraph are available financial knowledge extraction is themain task for the organizational construction of a knowledgegraph Such extraction is critical for the understanding andprocessing of deep semantics in the event tuple which alsodirectly influences the feature extraction of financial news
52 Implications for Business Activities Theutility of a featurecombination model based on knowledge graph is not limitedto financial analysis Currently knowledge graph data areavailable for medical diagnosis speech recognition precisemarketing and financial risk control [4] Our model couldalso be applied in these areas
Antifraud activities are an important part of financeApplying our model on the basis of knowledge graph oncustomers helps organize all relevant knowledge fragmentsthrough deep semantic analysis and reasoning which canbe verified with a customerrsquos bank information Moreovercustomers typically use keywords to search for productsand knowledge graph can provide relevant information toa customer If a complete knowledge system of users isdescribed and collected a system would better understandand analyze user behaviors
53 Limitations and Future Work A deep learning modeluses supervised learning and needs a dataset with sufficientlabels but our datasets do not work well with deep learningas a small number of financial news articles match stock
data At present knowledge graph embedding inevitablyproduces a loss in news semantics either because of a learningprinciple or the tokenization of knowledge representation forvectorization Thus continuous representation in a knowl-edge graph is still a huge challenge We attempted to applyregression using the above-mentioned algorithms but theresults indicated poor performance More specifically theresults for Apple validated our expectations
The application of large-scale knowledge graph is stillrelatively limited and knowledge graph for smart searchsmart question-and-answer tasks social media and otherareas are in their initial stages with considerable room forimprovement The following advantages of knowledge graphshould be considered (a) the effective organization andexpression of semistructured data (b) knowledge reasoningand (c) the expansion of cognitive ability for incorporatingdeep learning Traditional knowledge elements (entities rela-tionship attributes) extraction technologies and methodshave achieved good results in limited areas but because ofnumerous constraints and poor scalability knowledge graphis not fully functional for financial forecasting because ofnumerous constraints and poor scalability
6 Conclusions
Stock movement prediction of the renowned company is adaunting task because stock prices are affected by many fac-tors This research presented a novel method for integratingknowledge graph embedding with stock market predictionThe contributions of this study can be summarized as followsFirst we developed a novel feature combination model thatconstructs a feature mapping vector for each tuplendashnewspair by simultaneously considering the diversity of entitiesand relationships Second the feature combination modelwas successfully applied to different types of companies anddatasets and exhibited good performance in classificationtasks
Stock market prediction of the renowned companygrounded in knowledge graph is an interesting topic forbusiness activities Given that the study of knowledge graphfor feature set is still in its infancy we expect it to be appliedin a wide range of academic research More companies willalso earn profits and create more opportunities through theuse of knowledge graph in the feature set
Data Availability
The data used in this study can be accessed via httpsgithubcomlinechanyknowledge-graph
Conflicts of Interest
The author declares that there is no conflict of interestregarding the publication of this paper
Acknowledgments
This work is supported by the China Scholarship Council(CSC) throughout the grant number 201508390019 The
14 Complexity
authors also want to thank the research program RFCS fromthe EU which partially supported this research through theresearch project AutoSurveillance with project ID 847202
References
[1] B GMalkiel and E F Fama ldquoEfficient capital markets a reviewof theory and empirical workrdquo The Journal of Finance vol 25no 2 pp 383ndash417 1970
[2] D Galai and R W Masulis ldquoThe option pricing model and therisk factor of stockrdquo Journal of Financial Economics vol 3 no1-2 pp 53ndash81 1976
[3] Q Wang Z Mao B Wang and L Guo ldquoKnowledge graphembedding A survey of approaches and applicationsrdquo IEEETransactions on Knowledge and Data Engineering vol 29 no12 pp 2724ndash2743 2017
[4] H Paulheim and P Cimiano ldquoKnowledge graph refinement Asurvey of approaches and evaluation methodsrdquo Journal of WebSemantics Science Services and Agents on the World Wide Webvol 8 no 3 pp 489ndash508 2016
[5] X Ding Y Zhang T Liu and J Duan ldquoDeep learning for event-driven stock predictionrdquo in Proceedings of the 24th InternationalJoint Conference on Artificial Intelligence IJCAI 2015 pp 2327ndash2333 Argentina July 2015
[6] X Ding Y Zhang T Liu and J Duan ldquoKnowledge-drivenevent embedding for stock predictionrdquo in Proceedings of the26th International Conference on Computational LinguisticsCOLING 2016 pp 2133ndash2142 Japan December 2016
[7] A Bordes N Usunier J Weston and O Yakhnenko ldquoTranslat-ing embeddings for modeling multi-relational datardquo Advancesin NIPS vol 26 pp 2787ndash2795 2013
[8] H Lin Y Liu W Wang Y Yue and Z Lin ldquoLearning entityand relation embeddings for knowledge resolutionrdquo ProcediaComputer Science vol 108 pp 345ndash354 2017
[9] G Ji K Liu S He and J Zhao ldquoKnowledge graph completionwith adaptive sparse transfer matrixrdquo in Proceedings of the 30thAAAI Conference on Artificial Intelligence AAAI 2016 pp 985ndash991 USA February 2016
[10] G Ji S He L Xu K Liu and J Zhao ldquoKnowledge graphembedding via dynamic mapping matrixrdquo in Proceedings ofthe 53rd Annual Meeting of the Association for ComputationalLinguistics and the 7th International Joint Conference on NaturalLanguage Processing (Volume 1 Long Papers) pp 687ndash696Beijing China July 2015
[11] Y LeCun Y Bengio and G Hinton ldquoDeep learningrdquo Naturevol 521 no 7553 pp 436ndash444 2015
[12] Q Li Y Chen J Wang and H Chen ldquoWeb media andstock markets a survey and future directions from a bigdata perspectiverdquo IEEE Transactions on Knowledge and DataEngineering vol 4347 p 1 2017
[13] B Wuthrich V Cho S Leung D Permunetilleke K Sankaranand J Zhang ldquoDaily stock market forecast from textual Webdatardquo in Proceedings of the 1998 IEEE International Confer-ence on Systems Man and Cybernetics (Cat No98CH36218)SMCrsquo98 vol 3 pp 2720ndash2725 October 1998
[14] G Pui Cheong Fung J Xu Yu and W Lam ldquoStock predictionintegrating text mining approach using real-time newsrdquo inProceedings of the 2003 IEEE International Conference on Com-putational Intelligence for Financial Engineering CIFEr 2003vol 2003 pp 395ndash402 China March 2003
[15] W Antweiler and M Z Frank ldquoIs all that talk just noise theinformation content of internet stock message boardsrdquo SSRNElectronic Journal 2001
[16] M-A Mittermayer and G F Knolmayer ldquoNewsCATS A newscategorization and trading systemrdquo in Proceedings of the 6thInternational Conference onDataMining ICDM2006 pp 1002ndash1007 China December 2006
[17] R P Schumaker and H Chen ldquoTextual analysis of stockmarket prediction using breaking financial news theAZFin textsystemrdquo ACM Transactions on Information and Systems pp 1ndash29 2009
[18] S S Groth and J Muntermann ldquoAn intraday market riskmanagement approach based on textual analysisrdquo DecisionSupport Systems vol 50 no 4 pp 680ndash691 2011
[19] T Vu S Chang Q Ha and N Collier ldquoAn experiment in inte-grating sentiment features for tech stock prediction in twitterrdquoin Proceedings of the Workshop on Information Extraction AndEntity Analytics on Social Media Data vol 3 pp 23ndash38 2012
[20] B Wang H Huang and X Wang ldquoA novel text miningapproach to financial time series forecastingrdquo Neurocomputingvol 83 pp 136ndash145 2012
[21] Q Li T Wang P Li L Liu Q Gong and Y Chen ldquoThe effectof news and public mood on stock movementsrdquo InformationSciences vol 278 pp 826ndash840 2014
[22] T H Nguyen K Shirai and J Velcin ldquoSentiment analysis onsocial media for stock movement predictionrdquo Expert Systemswith Applications vol 42 no 24 pp 9603ndash9611 2015
[23] BWengM A Ahmed and FMMegahed ldquoStockmarket one-day ahead movement prediction using disparate data sourcesrdquoExpert Systems with Applications vol 79 pp 153ndash163 2017
[24] J Eberhard J F Lavin and A Montecinos-Pearce ldquoA network-based dynamic analysis in an equity stock marketrdquo Complexityvol 2017 Article ID 3979836 16 pages 2017
[25] Z Zhang Y Zhang D Shen and W Zhang ldquoThe dynamiccross-correlations between mass media news newmedia newsand stock returnsrdquo Complexity vol 2018 11 pages 2018
[26] P C Tetlock ldquoGiving content to investor sentiment The role ofmedia in the stock marketrdquo Journal of Finance vol 62 no 3 pp1139ndash1168 2007
[27] K Chen P Luo L Liu andW Zhang ldquoNews search and stockco-movement Investigating information diffusion in the finan-cial marketrdquo Electronic Commerce Research and Applicationsvol 28 pp 159ndash171 2018
[28] F Z Xing E Cambria and Y Zhang ldquoSentiment-awarevolatility forecastingrdquo Knowledge-Based Systems vol 176 pp68ndash76 2019
[29] A Picasso S Merello Y Ma L Oneto and E CambrialdquoTechnical analysis and sentiment embeddings formarket trendpredictionrdquo Expert Systems with Applications vol 135 pp 60ndash70 2019
[30] A Khadjeh Nassirtoussi S Aghabozorgi T Ying Wah and DC L Ngo ldquoText mining for market prediction a systematicreviewrdquo Expert Systems with Applications vol 41 no 16 pp7653ndash7670 2014
[31] M Kraus and S Feuerriegel ldquoDecision support from financialdisclosures with deep neural networks and transfer learningrdquoDecision Support Systems vol 104 pp 38ndash48 2017
[32] H S Sim H I Kim and J J Ahn ldquoIs deep learning for imagerecognition applicable to stockmarket predictionrdquoComplexityvol 2019 10 pages 2019
Complexity 15
[33] M Jasemi A M Kimiagari and A Memariani ldquoA modernneural network model to do stock market timing on the basisof the ancient investment technique of Japanese candlestickrdquoExpert Systems with Applications vol 38 no 4 pp 3884ndash38902011
[34] A Fader S Soderland and O Etzioni ldquoIdentifying relations foropen information extractionrdquo in Proceedings of the Conferenceon Empirical Methods in Natural Language Processing EMNLP2011 pp 1535ndash1545 Association for Computational LinguisticsUK July 2011
[35] T Mikolov K Chen G Corrado and J Dean ldquoEfficientestimation of word representations in vector spacerdquo pp 1ndash122013 httpsarxivorgabs13013781
[36] X Lin Z Yang and Y Song ldquoIntelligent stock trading systembased on improved technical analysis and Echo State NetworkrdquoExpert Systems with Applications vol 38 no 9 pp 11347ndash113542011
[37] K-J Kim and I Han ldquoGenetic algorithms approach to featurediscretization in artificial neural networks for the prediction ofstock price indexrdquo Expert Systems with Applications vol 19 no2 pp 125ndash132 2000
[38] Y Yu W Duan and Q Cao ldquoThe impact of social andconventional media on firm equity value A sentiment analysisapproachrdquoDecision Support Systems vol 55 no 4 pp 919ndash9262013
[39] MHagenauM Liebmann andDNeumann ldquoAutomated newsreading Stock price prediction based on financial news usingcontext-capturing featuresrdquo Decision Support Systems vol 55no 3 pp 685ndash697 2013
[40] A Aizawa ldquoAn information-theoretic perspective of tf-idfmeasuresrdquo Information Processing amp Management vol 39 no1 pp 45ndash65 2003
[41] A Khadjeh Nassirtoussi S Aghabozorgi T Ying Wah and DC Ngo ldquoText mining of news-headlines for FOREX marketprediction a Multi-layer dimension reduction algorithm withsemantics and sentimentrdquo Expert Systems with Applications vol42 no 1 pp 306ndash324 2015
[42] D Peramunetilleke and R K Wong ldquoCurrency exchange rateforecasting from news headlinesrdquo Australian Computer ScienceCommunications vol 24 no 2 pp 131ndash139 2002
[43] Y Kim ldquoConvolutional neural networks for sentence classifica-tionrdquo 2014 httpsarxivorgabs14085882
[44] ZWang J Zhang J Feng and Z Chen ldquoKnowledge graph andtext jointly embeddingrdquo in Proceedings of the 2014 Conferenceon Empirical Methods in Natural Language Processing EMNLP2014 pp 1591ndash1601 Qatar October 2014
[45] J Xu X Qiu K Chen and X Huang ldquoKnowledge graphrepresentation with jointly structural and textual encodingrdquo inProceedings of the 26th International Joint Conference on Arti-ficial Intelligence IJCAI 2017 pp 1318ndash1324 Australia August2017
[46] R Xie Z Liu J Jia H Luan and M Sun ldquoRepresentationlearning of knowledge graphs with entity descriptionsrdquo in Pro-ceedings of the 30th AAAI Conference on Artificial IntelligenceAAAI rsquo16 pp 2659ndash2665 February 2016
[47] F Tian B Gao E Chen and T Liu ldquoLearning better wordembedding by asymmetric low-rank projection of knowledgegraphrdquo Journal of Computer Science and Technology vol 31 no3 pp 624ndash634 2016
[48] F Z Xing E Cambria and R E Welsch ldquoNatural languagebased financial forecasting a surveyrdquo Artificial IntelligenceReview vol 50 no 1 pp 49ndash73 2018
[49] C Goutte and E Gaussier ldquoA probabilistic interpretation ofprecision recall and F-score with implication for evaluationrdquoin Advances in Information Retrieval D E Losada and J MFernandez-Luna Eds vol 3408 of Lecture Notes in ComputerScience pp 345ndash359 Springer Berlin Germany 2005
Hindawiwwwhindawicom Volume 2018
MathematicsJournal of
Hindawiwwwhindawicom Volume 2018
Mathematical Problems in Engineering
Applied MathematicsJournal of
Hindawiwwwhindawicom Volume 2018
Probability and StatisticsHindawiwwwhindawicom Volume 2018
Journal of
Hindawiwwwhindawicom Volume 2018
Mathematical PhysicsAdvances in
Complex AnalysisJournal of
Hindawiwwwhindawicom Volume 2018
OptimizationJournal of
Hindawiwwwhindawicom Volume 2018
Hindawiwwwhindawicom Volume 2018
Engineering Mathematics
International Journal of
Hindawiwwwhindawicom Volume 2018
Operations ResearchAdvances in
Journal of
Hindawiwwwhindawicom Volume 2018
Function SpacesAbstract and Applied AnalysisHindawiwwwhindawicom Volume 2018
International Journal of Mathematics and Mathematical Sciences
Hindawiwwwhindawicom Volume 2018
Hindawi Publishing Corporation httpwwwhindawicom Volume 2013Hindawiwwwhindawicom
The Scientific World Journal
Volume 2018
Hindawiwwwhindawicom Volume 2018Volume 2018
Numerical AnalysisNumerical AnalysisNumerical AnalysisNumerical AnalysisNumerical AnalysisNumerical AnalysisNumerical AnalysisNumerical AnalysisNumerical AnalysisNumerical AnalysisNumerical AnalysisNumerical AnalysisAdvances inAdvances in Discrete Dynamics in
Nature and SocietyHindawiwwwhindawicom Volume 2018
Hindawiwwwhindawicom
Dierential EquationsInternational Journal of
Volume 2018
Hindawiwwwhindawicom Volume 2018
Decision SciencesAdvances in
Hindawiwwwhindawicom Volume 2018
AnalysisInternational Journal of
Hindawiwwwhindawicom Volume 2018
Stochastic AnalysisInternational Journal of
Submit your manuscripts atwwwhindawicom

10 Complexity
Table 7 List of machine learning methods
Method Classification Parameter and their value
Traditionalmachinelearning
Decision tree (DT)Criterion= gini splitter= best max depth=None minsamples split=2 min samples leaf =1 min weight
fraction leaf=00Logistical regression (LR) Random state=1
Naive Bayes (NB) No kernel estimatorStochastic gradient descent (SGD) Loss=hinge penalty=l2
Support vector machine (SVM) Polynomial kernel function with exponent = 1 2 RBFkernel function with gamma = 001
Ensemblelearning
Random forest (RF) Randomly sampled as candidates at each split = log2 +1 max-depth=2 random state=0
AdaBoost (AB) Polynomial kernel function with exponent = 1 2 RBFkernel function with gamma = 001 n- estimators=100
Gradient boosting (GB) N-estimators =100 learning rate =10 max-depth=1random state=0
Table 8 Abbreviations of the results for each algorithm considered
Algorithms Stock data (SD) Bag of words (BOW) Convolutionalneural network
Featurecombinationmodel (FC)
DT DT 1 DT 2 DT 3 DT 4LR LR 1 LR 2 LR 3 LR 4NB NB 1 NB 2 NB 3 NB 4SGD SGD 1 SGD 2 SGD 3 SGD 4SVM SVM 1 SVM 2 SVM 3 SVM 4RF RF 1 RF 2 RF 3 RF 4AB AB 1 AB 2 AB 3 AB 4GB GB 1 GB 2 GB 3 GB 4
experiments involving deep learning and the TransE modelThe abbreviations used for comparing classification perfor-mance are presented in Table 8 During testing 2-fold cross-validation is applied to evaluate the stability of the modelsAnd we compared performance in predicting stock pricemovement for the next day with a test dataset and evaluatedthe performance of the models in terms of accuracy and F1-score [49]
42 Results
421 Thomson Reuters Case Study Thomson Reuters isa multinational mass media and information firm Threerenowned companies on the website were selected for theanalysis The first is Apple Inc which is an American multi-national technology company that designs develops andsells consumer electronics computer software and onlineservices The second company selected is Microsoft which isan American multinational technology company that devel-ops manufactures supports and sells computer softwarepersonal computers and other services The last companychosen is Samsung which is a South Korean multinationalelectronics company We considered data from these threetypical technology companies for our problem
Measurements of average accuracy are shown in Table 9and the results for each renowned company with respectto prediction based on different features are illustrated inFigure 6 We calculated the average of the four feature con-struction approaches for eachmodel for comparison amongstthe three companies The proposed feature combinationmodel generated the best results achieving average accuracylevels of 6163 5918 and 5848 forAppleMicrosoft andSamsung respectively These figures are consistent with therates reported in previous research However many studiesanalyzed only one company or used only one algorithmThe current research probed into three companies on thebasis of information from a common data source to builda prediction model with different feature selection func-tionalities and different algorithms We used stock dataa bag-of-words algorithm a convolutional neural networkand feature combination together with eight algorithms Asindicated in Table 9 the proposed predictionmodel achieved7368 data extraction with the use of LR 4 for Apple and6778 data extraction with the use of SVM 4 for MicrosoftIn particular the LR algorithm used for Apple achievedaccuracy and F1-score of 07326 and 07360 respectivelywhich highlights its powerful capability in a two-class classifi-cation
Complexity 11
Table 9 Results for data extracted fromThomson Reuters
Algorithm Company Stock data(SD)
Bag of words(BOW)
Convolutionalneural network
Feature combinemodel (FC)
AccuracyF1-score
AccuracyF1-score
AccuracyF1-score
AccuracyF1-score
DTApple 0499305079 0488902460 0615005814 0652406486
Microsoft 0486801819 0506505682 0581705915 0658706502Samsung 0470704033 0565405830 0552906820 0568006260
LRApple 0524006727 0505505083 0684506911 0732607368
Microsoft 0475701253 0443004884 0527405333 0546705611Samsung 0494703755 0605406726 0654106343 0805307978
NBApple 0510905123 0477803896 0502704497 0512204030
Microsoft 0484000363 0455704055 0459902889 0500005439Samsung 0529305810 0514406130 0504806578 0511706601
SGDApple 0467201119 0477804404 0497406008 0536602692
Microsoft 0517306819 0485203222 0610304231 0610804193Samsung 0522306541 0476602000 0518706751 0557106548
SVMApple 0502206121 0574705542 0615006129 0622006173
Microsoft 0478401722 0443904566 0523205462 0687506798Samsung 0500803875 0504705508 0513506281 0535206574
RFApple 0524006554 0527806083 0533706232 0620306243
Microsoft 0484002653 0417701687 0532502432 0572105189Samsung 0487203480 0448501194 0476603708 0505205481
ABApple 0534305384 0472202963 0481903333 0620305420
Microsoft 0468702041 0476800461 0614706044 0620206146Samsung 0485703619 0457902368 0601006820 0633806549
GBApple 0531405129 0466702941 0609604748 0634106591
Microsoft 0474302125 0472801007 0455704557 0538502258Samsung 0487204171 0519206599 0533706572 0562206335
Reuters
Aver
age a
ccur
acy
0
01
02
03
04
05
06
07
Different companyApple Microsoft Samsung
SDBOW
CNNFC
Figure 6 Average accuracy of prediction based on different featuresets for each company in Reuters
To assess the effectiveness of our research we comparedthe feature combination model that uses event tuples with
the stock data approach and the bag-of-words algorithmTheresults showed that the average accuracy of the event tuple-basedmodel is better than that of the stock data approach andthe bag-of-words algorithm by 1001 and 1087 respec-tively We also compared feature extraction using the stockdata approach the bag-of-words algorithm and machinelearning The use of deep learning improved predictionaccuracy by 525 and 611 over the levels achieved withstock data and bag of words respectively Therefore we canconclude that using the proposed feature combinationmodeland deep learning in feature extraction helps improve theaccuracy with which stock price movement is predictedThese results also fully prove the effectiveness of embeddinglayer in feature extraction accuracy improvement
422 CNN Case Study CNN is an American basic cableand satellite television news channel owned by the TurnerBroadcasting System Three renowned companies on whichthese website reports were selected for the analysis The firstis Boeing which is an American multinational corporationthat designs manufactures and sells airplanes rotorcraftrockets and satellites worldwide The second company isGoogle which is an American multinational technology
12 Complexity
Table 10 Results for data extracted from CNN
Algorithm Company Stock data(SD)
Bag of words(BOW)
Convolutionalneural network
Featurecombinationmodel (FC)
AccuracyF1-score
AccuracyF1-score
AccuracyF1-score
AccuracyF1-score
DTBoeing 0495003489 0541306258 0541406347 0559105821Google 0485805600 0518203575 0569204631 0549105471Walmart 0499604422 0530004891 0508804815 0572205829
LRBoeing 0492302378 0511304348 0692306923 0759605733Google 0504106105 0623506491 0625006111 0656306516Walmart 0529005468 0541205083 0732007347 0771907720
NBBoeing 0516206503 0548905161 0519706738 0556407619Google 0511206527 0489905191 0558705281 0534404843Walmart 0504403284 0479405302 0520605674 0530006083
SGDBoeing 0489702407 0556404870 0543304727 0571407220Google 0516506769 0542504375 0578906364 0591006327Walmart 0500403804 0520605280 0525005581 0567005922
SVMBoeing 0489703068 0571406275 0538506418 0594007033Google 0507706297 0603206230 0574905532 0578905840Walmart 0511804333 0500005314 0520005000 0561405455
RFBoeing 0490601345 0511303925 0509605405 0527605714Google 0492301777 0603206260 0522305564 0595105763Walmart 0511805373 0530003188 0530004405 0500005446
ABBoeing 0494503404 0519705120 0496105294 0567305872Google 0487603141 0510106667 0589305619 0595106850Walmart 0507305029 0515005359 0549705650 0561905503
GBBoeing 0489903169 0511804364 0440904580 0500005094Google 0491203387 0587005854 0562505243 0603206202Walmart 0500304955 0505005123 0536105109 0549705650
company that specializes in Internet-related services andproducts The third is Walmart an American multinationalretail corporation that operates a chain of hypermarketsdiscount department stores and grocery stores
The results on average accuracy are shown in Table 10and Figure 7These findings are very similar to those derivedin the previous case study and their comparison confirmedthat the proposed feature combinationmodel can outperformother feature selection models in stock price movementprediction With regard to feature selection underlain bythe bag-of-words algorithm the CNN case study generatedmore robust results than did the Reuters case study Theaverage accuracy of the bag-of-words algorithm was lowerthan that of the stock data approach in the Reuters case studyIn the CNN case study the average accuracy levels of theproposed feature combination model were 5794 5879and 5767 for Boeing Google andWalmart respectively Inthe case study on Reuters an average accuracy that exceeds60 was not achieved for any of the companies illustratingthat differences in data source directly affect stock pricemovement
We chose a combination of deep learning and knowledgegraph to build our feature selection model because this
CNN
Aver
age a
ccur
acy
0
01
02
03
04
05
06
07
Different companyBoeing Google Walmart
SDBOW
CNNFC
Figure 7Average accuracy achieved on the basis of news fromCNNand different feature set
combination exhibited superior prediction performance inthe comparison experiments involving other feature selection
Complexity 13
strategies The forecast results based on different featuresare shown in Table 10 We found that deep learning featuresare better than the use of bag-of-words and stock data Thecorrelation of event tuples with the stock market is relativelyhigh in [5 31] but the bag-of-words algorithm was relativelyfragmented and the correlation between event tuples and thestockmarket data was relatively weak Combining event tuplefeatures with deep learning significantly improves forecastresults indicating a close relationship between stock marketmovements and knowledge graph
5 Discussion
51 Research Findings We attempted to compare our predic-tion results with those made in previous studies wherein pre-diction was also based on the financial news of the renownedcompanies However the findings are incomparable becausedifferent studies use different datasets or algorithms andthese methods are difficult to investigate using financial newsheadlines In the current research we refrained from eval-uating performance on one company dataset this decisionthat enabled our knowledge graphmethod to exceed baselinepredictions based only on the price by up to 36 Thisalso proves that feature extraction in deep learning is moreeffective than traditional machines The combination of deeplearning and knowledge graph fully integrates the semanticinformation in financial news which effectively predicts thestock price movement of the renowned company
This work demonstrated the application of deep learningand knowledge graph in finance To the best of our knowl-edge knowledge graph has been rarely applied in stock pre-diction Becauseminimal financial training sets in knowledgegraph are available financial knowledge extraction is themain task for the organizational construction of a knowledgegraph Such extraction is critical for the understanding andprocessing of deep semantics in the event tuple which alsodirectly influences the feature extraction of financial news
52 Implications for Business Activities Theutility of a featurecombination model based on knowledge graph is not limitedto financial analysis Currently knowledge graph data areavailable for medical diagnosis speech recognition precisemarketing and financial risk control [4] Our model couldalso be applied in these areas
Antifraud activities are an important part of financeApplying our model on the basis of knowledge graph oncustomers helps organize all relevant knowledge fragmentsthrough deep semantic analysis and reasoning which canbe verified with a customerrsquos bank information Moreovercustomers typically use keywords to search for productsand knowledge graph can provide relevant information toa customer If a complete knowledge system of users isdescribed and collected a system would better understandand analyze user behaviors
53 Limitations and Future Work A deep learning modeluses supervised learning and needs a dataset with sufficientlabels but our datasets do not work well with deep learningas a small number of financial news articles match stock
data At present knowledge graph embedding inevitablyproduces a loss in news semantics either because of a learningprinciple or the tokenization of knowledge representation forvectorization Thus continuous representation in a knowl-edge graph is still a huge challenge We attempted to applyregression using the above-mentioned algorithms but theresults indicated poor performance More specifically theresults for Apple validated our expectations
The application of large-scale knowledge graph is stillrelatively limited and knowledge graph for smart searchsmart question-and-answer tasks social media and otherareas are in their initial stages with considerable room forimprovement The following advantages of knowledge graphshould be considered (a) the effective organization andexpression of semistructured data (b) knowledge reasoningand (c) the expansion of cognitive ability for incorporatingdeep learning Traditional knowledge elements (entities rela-tionship attributes) extraction technologies and methodshave achieved good results in limited areas but because ofnumerous constraints and poor scalability knowledge graphis not fully functional for financial forecasting because ofnumerous constraints and poor scalability
6 Conclusions
Stock movement prediction of the renowned company is adaunting task because stock prices are affected by many fac-tors This research presented a novel method for integratingknowledge graph embedding with stock market predictionThe contributions of this study can be summarized as followsFirst we developed a novel feature combination model thatconstructs a feature mapping vector for each tuplendashnewspair by simultaneously considering the diversity of entitiesand relationships Second the feature combination modelwas successfully applied to different types of companies anddatasets and exhibited good performance in classificationtasks
Stock market prediction of the renowned companygrounded in knowledge graph is an interesting topic forbusiness activities Given that the study of knowledge graphfor feature set is still in its infancy we expect it to be appliedin a wide range of academic research More companies willalso earn profits and create more opportunities through theuse of knowledge graph in the feature set
Data Availability
The data used in this study can be accessed via httpsgithubcomlinechanyknowledge-graph
Conflicts of Interest
The author declares that there is no conflict of interestregarding the publication of this paper
Acknowledgments
This work is supported by the China Scholarship Council(CSC) throughout the grant number 201508390019 The
14 Complexity
authors also want to thank the research program RFCS fromthe EU which partially supported this research through theresearch project AutoSurveillance with project ID 847202
References
[1] B GMalkiel and E F Fama ldquoEfficient capital markets a reviewof theory and empirical workrdquo The Journal of Finance vol 25no 2 pp 383ndash417 1970
[2] D Galai and R W Masulis ldquoThe option pricing model and therisk factor of stockrdquo Journal of Financial Economics vol 3 no1-2 pp 53ndash81 1976
[3] Q Wang Z Mao B Wang and L Guo ldquoKnowledge graphembedding A survey of approaches and applicationsrdquo IEEETransactions on Knowledge and Data Engineering vol 29 no12 pp 2724ndash2743 2017
[4] H Paulheim and P Cimiano ldquoKnowledge graph refinement Asurvey of approaches and evaluation methodsrdquo Journal of WebSemantics Science Services and Agents on the World Wide Webvol 8 no 3 pp 489ndash508 2016
[5] X Ding Y Zhang T Liu and J Duan ldquoDeep learning for event-driven stock predictionrdquo in Proceedings of the 24th InternationalJoint Conference on Artificial Intelligence IJCAI 2015 pp 2327ndash2333 Argentina July 2015
[6] X Ding Y Zhang T Liu and J Duan ldquoKnowledge-drivenevent embedding for stock predictionrdquo in Proceedings of the26th International Conference on Computational LinguisticsCOLING 2016 pp 2133ndash2142 Japan December 2016
[7] A Bordes N Usunier J Weston and O Yakhnenko ldquoTranslat-ing embeddings for modeling multi-relational datardquo Advancesin NIPS vol 26 pp 2787ndash2795 2013
[8] H Lin Y Liu W Wang Y Yue and Z Lin ldquoLearning entityand relation embeddings for knowledge resolutionrdquo ProcediaComputer Science vol 108 pp 345ndash354 2017
[9] G Ji K Liu S He and J Zhao ldquoKnowledge graph completionwith adaptive sparse transfer matrixrdquo in Proceedings of the 30thAAAI Conference on Artificial Intelligence AAAI 2016 pp 985ndash991 USA February 2016
[10] G Ji S He L Xu K Liu and J Zhao ldquoKnowledge graphembedding via dynamic mapping matrixrdquo in Proceedings ofthe 53rd Annual Meeting of the Association for ComputationalLinguistics and the 7th International Joint Conference on NaturalLanguage Processing (Volume 1 Long Papers) pp 687ndash696Beijing China July 2015
[11] Y LeCun Y Bengio and G Hinton ldquoDeep learningrdquo Naturevol 521 no 7553 pp 436ndash444 2015
[12] Q Li Y Chen J Wang and H Chen ldquoWeb media andstock markets a survey and future directions from a bigdata perspectiverdquo IEEE Transactions on Knowledge and DataEngineering vol 4347 p 1 2017
[13] B Wuthrich V Cho S Leung D Permunetilleke K Sankaranand J Zhang ldquoDaily stock market forecast from textual Webdatardquo in Proceedings of the 1998 IEEE International Confer-ence on Systems Man and Cybernetics (Cat No98CH36218)SMCrsquo98 vol 3 pp 2720ndash2725 October 1998
[14] G Pui Cheong Fung J Xu Yu and W Lam ldquoStock predictionintegrating text mining approach using real-time newsrdquo inProceedings of the 2003 IEEE International Conference on Com-putational Intelligence for Financial Engineering CIFEr 2003vol 2003 pp 395ndash402 China March 2003
[15] W Antweiler and M Z Frank ldquoIs all that talk just noise theinformation content of internet stock message boardsrdquo SSRNElectronic Journal 2001
[16] M-A Mittermayer and G F Knolmayer ldquoNewsCATS A newscategorization and trading systemrdquo in Proceedings of the 6thInternational Conference onDataMining ICDM2006 pp 1002ndash1007 China December 2006
[17] R P Schumaker and H Chen ldquoTextual analysis of stockmarket prediction using breaking financial news theAZFin textsystemrdquo ACM Transactions on Information and Systems pp 1ndash29 2009
[18] S S Groth and J Muntermann ldquoAn intraday market riskmanagement approach based on textual analysisrdquo DecisionSupport Systems vol 50 no 4 pp 680ndash691 2011
[19] T Vu S Chang Q Ha and N Collier ldquoAn experiment in inte-grating sentiment features for tech stock prediction in twitterrdquoin Proceedings of the Workshop on Information Extraction AndEntity Analytics on Social Media Data vol 3 pp 23ndash38 2012
[20] B Wang H Huang and X Wang ldquoA novel text miningapproach to financial time series forecastingrdquo Neurocomputingvol 83 pp 136ndash145 2012
[21] Q Li T Wang P Li L Liu Q Gong and Y Chen ldquoThe effectof news and public mood on stock movementsrdquo InformationSciences vol 278 pp 826ndash840 2014
[22] T H Nguyen K Shirai and J Velcin ldquoSentiment analysis onsocial media for stock movement predictionrdquo Expert Systemswith Applications vol 42 no 24 pp 9603ndash9611 2015
[23] BWengM A Ahmed and FMMegahed ldquoStockmarket one-day ahead movement prediction using disparate data sourcesrdquoExpert Systems with Applications vol 79 pp 153ndash163 2017
[24] J Eberhard J F Lavin and A Montecinos-Pearce ldquoA network-based dynamic analysis in an equity stock marketrdquo Complexityvol 2017 Article ID 3979836 16 pages 2017
[25] Z Zhang Y Zhang D Shen and W Zhang ldquoThe dynamiccross-correlations between mass media news newmedia newsand stock returnsrdquo Complexity vol 2018 11 pages 2018
[26] P C Tetlock ldquoGiving content to investor sentiment The role ofmedia in the stock marketrdquo Journal of Finance vol 62 no 3 pp1139ndash1168 2007
[27] K Chen P Luo L Liu andW Zhang ldquoNews search and stockco-movement Investigating information diffusion in the finan-cial marketrdquo Electronic Commerce Research and Applicationsvol 28 pp 159ndash171 2018
[28] F Z Xing E Cambria and Y Zhang ldquoSentiment-awarevolatility forecastingrdquo Knowledge-Based Systems vol 176 pp68ndash76 2019
[29] A Picasso S Merello Y Ma L Oneto and E CambrialdquoTechnical analysis and sentiment embeddings formarket trendpredictionrdquo Expert Systems with Applications vol 135 pp 60ndash70 2019
[30] A Khadjeh Nassirtoussi S Aghabozorgi T Ying Wah and DC L Ngo ldquoText mining for market prediction a systematicreviewrdquo Expert Systems with Applications vol 41 no 16 pp7653ndash7670 2014
[31] M Kraus and S Feuerriegel ldquoDecision support from financialdisclosures with deep neural networks and transfer learningrdquoDecision Support Systems vol 104 pp 38ndash48 2017
[32] H S Sim H I Kim and J J Ahn ldquoIs deep learning for imagerecognition applicable to stockmarket predictionrdquoComplexityvol 2019 10 pages 2019
Complexity 15
[33] M Jasemi A M Kimiagari and A Memariani ldquoA modernneural network model to do stock market timing on the basisof the ancient investment technique of Japanese candlestickrdquoExpert Systems with Applications vol 38 no 4 pp 3884ndash38902011
[34] A Fader S Soderland and O Etzioni ldquoIdentifying relations foropen information extractionrdquo in Proceedings of the Conferenceon Empirical Methods in Natural Language Processing EMNLP2011 pp 1535ndash1545 Association for Computational LinguisticsUK July 2011
[35] T Mikolov K Chen G Corrado and J Dean ldquoEfficientestimation of word representations in vector spacerdquo pp 1ndash122013 httpsarxivorgabs13013781
[36] X Lin Z Yang and Y Song ldquoIntelligent stock trading systembased on improved technical analysis and Echo State NetworkrdquoExpert Systems with Applications vol 38 no 9 pp 11347ndash113542011
[37] K-J Kim and I Han ldquoGenetic algorithms approach to featurediscretization in artificial neural networks for the prediction ofstock price indexrdquo Expert Systems with Applications vol 19 no2 pp 125ndash132 2000
[38] Y Yu W Duan and Q Cao ldquoThe impact of social andconventional media on firm equity value A sentiment analysisapproachrdquoDecision Support Systems vol 55 no 4 pp 919ndash9262013
[39] MHagenauM Liebmann andDNeumann ldquoAutomated newsreading Stock price prediction based on financial news usingcontext-capturing featuresrdquo Decision Support Systems vol 55no 3 pp 685ndash697 2013
[40] A Aizawa ldquoAn information-theoretic perspective of tf-idfmeasuresrdquo Information Processing amp Management vol 39 no1 pp 45ndash65 2003
[41] A Khadjeh Nassirtoussi S Aghabozorgi T Ying Wah and DC Ngo ldquoText mining of news-headlines for FOREX marketprediction a Multi-layer dimension reduction algorithm withsemantics and sentimentrdquo Expert Systems with Applications vol42 no 1 pp 306ndash324 2015
[42] D Peramunetilleke and R K Wong ldquoCurrency exchange rateforecasting from news headlinesrdquo Australian Computer ScienceCommunications vol 24 no 2 pp 131ndash139 2002
[43] Y Kim ldquoConvolutional neural networks for sentence classifica-tionrdquo 2014 httpsarxivorgabs14085882
[44] ZWang J Zhang J Feng and Z Chen ldquoKnowledge graph andtext jointly embeddingrdquo in Proceedings of the 2014 Conferenceon Empirical Methods in Natural Language Processing EMNLP2014 pp 1591ndash1601 Qatar October 2014
[45] J Xu X Qiu K Chen and X Huang ldquoKnowledge graphrepresentation with jointly structural and textual encodingrdquo inProceedings of the 26th International Joint Conference on Arti-ficial Intelligence IJCAI 2017 pp 1318ndash1324 Australia August2017
[46] R Xie Z Liu J Jia H Luan and M Sun ldquoRepresentationlearning of knowledge graphs with entity descriptionsrdquo in Pro-ceedings of the 30th AAAI Conference on Artificial IntelligenceAAAI rsquo16 pp 2659ndash2665 February 2016
[47] F Tian B Gao E Chen and T Liu ldquoLearning better wordembedding by asymmetric low-rank projection of knowledgegraphrdquo Journal of Computer Science and Technology vol 31 no3 pp 624ndash634 2016
[48] F Z Xing E Cambria and R E Welsch ldquoNatural languagebased financial forecasting a surveyrdquo Artificial IntelligenceReview vol 50 no 1 pp 49ndash73 2018
[49] C Goutte and E Gaussier ldquoA probabilistic interpretation ofprecision recall and F-score with implication for evaluationrdquoin Advances in Information Retrieval D E Losada and J MFernandez-Luna Eds vol 3408 of Lecture Notes in ComputerScience pp 345ndash359 Springer Berlin Germany 2005
Hindawiwwwhindawicom Volume 2018
MathematicsJournal of
Hindawiwwwhindawicom Volume 2018
Mathematical Problems in Engineering
Applied MathematicsJournal of
Hindawiwwwhindawicom Volume 2018
Probability and StatisticsHindawiwwwhindawicom Volume 2018
Journal of
Hindawiwwwhindawicom Volume 2018
Mathematical PhysicsAdvances in
Complex AnalysisJournal of
Hindawiwwwhindawicom Volume 2018
OptimizationJournal of
Hindawiwwwhindawicom Volume 2018
Hindawiwwwhindawicom Volume 2018
Engineering Mathematics
International Journal of
Hindawiwwwhindawicom Volume 2018
Operations ResearchAdvances in
Journal of
Hindawiwwwhindawicom Volume 2018
Function SpacesAbstract and Applied AnalysisHindawiwwwhindawicom Volume 2018
International Journal of Mathematics and Mathematical Sciences
Hindawiwwwhindawicom Volume 2018
Hindawi Publishing Corporation httpwwwhindawicom Volume 2013Hindawiwwwhindawicom
The Scientific World Journal
Volume 2018
Hindawiwwwhindawicom Volume 2018Volume 2018
Numerical AnalysisNumerical AnalysisNumerical AnalysisNumerical AnalysisNumerical AnalysisNumerical AnalysisNumerical AnalysisNumerical AnalysisNumerical AnalysisNumerical AnalysisNumerical AnalysisNumerical AnalysisAdvances inAdvances in Discrete Dynamics in
Nature and SocietyHindawiwwwhindawicom Volume 2018
Hindawiwwwhindawicom
Dierential EquationsInternational Journal of
Volume 2018
Hindawiwwwhindawicom Volume 2018
Decision SciencesAdvances in
Hindawiwwwhindawicom Volume 2018
AnalysisInternational Journal of
Hindawiwwwhindawicom Volume 2018
Stochastic AnalysisInternational Journal of
Submit your manuscripts atwwwhindawicom

Complexity 11
Table 9 Results for data extracted fromThomson Reuters
Algorithm Company Stock data(SD)
Bag of words(BOW)
Convolutionalneural network
Feature combinemodel (FC)
AccuracyF1-score
AccuracyF1-score
AccuracyF1-score
AccuracyF1-score
DTApple 0499305079 0488902460 0615005814 0652406486
Microsoft 0486801819 0506505682 0581705915 0658706502Samsung 0470704033 0565405830 0552906820 0568006260
LRApple 0524006727 0505505083 0684506911 0732607368
Microsoft 0475701253 0443004884 0527405333 0546705611Samsung 0494703755 0605406726 0654106343 0805307978
NBApple 0510905123 0477803896 0502704497 0512204030
Microsoft 0484000363 0455704055 0459902889 0500005439Samsung 0529305810 0514406130 0504806578 0511706601
SGDApple 0467201119 0477804404 0497406008 0536602692
Microsoft 0517306819 0485203222 0610304231 0610804193Samsung 0522306541 0476602000 0518706751 0557106548
SVMApple 0502206121 0574705542 0615006129 0622006173
Microsoft 0478401722 0443904566 0523205462 0687506798Samsung 0500803875 0504705508 0513506281 0535206574
RFApple 0524006554 0527806083 0533706232 0620306243
Microsoft 0484002653 0417701687 0532502432 0572105189Samsung 0487203480 0448501194 0476603708 0505205481
ABApple 0534305384 0472202963 0481903333 0620305420
Microsoft 0468702041 0476800461 0614706044 0620206146Samsung 0485703619 0457902368 0601006820 0633806549
GBApple 0531405129 0466702941 0609604748 0634106591
Microsoft 0474302125 0472801007 0455704557 0538502258Samsung 0487204171 0519206599 0533706572 0562206335
Reuters
Aver
age a
ccur
acy
0
01
02
03
04
05
06
07
Different companyApple Microsoft Samsung
SDBOW
CNNFC
Figure 6 Average accuracy of prediction based on different featuresets for each company in Reuters
To assess the effectiveness of our research we comparedthe feature combination model that uses event tuples with
the stock data approach and the bag-of-words algorithmTheresults showed that the average accuracy of the event tuple-basedmodel is better than that of the stock data approach andthe bag-of-words algorithm by 1001 and 1087 respec-tively We also compared feature extraction using the stockdata approach the bag-of-words algorithm and machinelearning The use of deep learning improved predictionaccuracy by 525 and 611 over the levels achieved withstock data and bag of words respectively Therefore we canconclude that using the proposed feature combinationmodeland deep learning in feature extraction helps improve theaccuracy with which stock price movement is predictedThese results also fully prove the effectiveness of embeddinglayer in feature extraction accuracy improvement
422 CNN Case Study CNN is an American basic cableand satellite television news channel owned by the TurnerBroadcasting System Three renowned companies on whichthese website reports were selected for the analysis The firstis Boeing which is an American multinational corporationthat designs manufactures and sells airplanes rotorcraftrockets and satellites worldwide The second company isGoogle which is an American multinational technology
12 Complexity
Table 10 Results for data extracted from CNN
Algorithm Company Stock data(SD)
Bag of words(BOW)
Convolutionalneural network
Featurecombinationmodel (FC)
AccuracyF1-score
AccuracyF1-score
AccuracyF1-score
AccuracyF1-score
DTBoeing 0495003489 0541306258 0541406347 0559105821Google 0485805600 0518203575 0569204631 0549105471Walmart 0499604422 0530004891 0508804815 0572205829
LRBoeing 0492302378 0511304348 0692306923 0759605733Google 0504106105 0623506491 0625006111 0656306516Walmart 0529005468 0541205083 0732007347 0771907720
NBBoeing 0516206503 0548905161 0519706738 0556407619Google 0511206527 0489905191 0558705281 0534404843Walmart 0504403284 0479405302 0520605674 0530006083
SGDBoeing 0489702407 0556404870 0543304727 0571407220Google 0516506769 0542504375 0578906364 0591006327Walmart 0500403804 0520605280 0525005581 0567005922
SVMBoeing 0489703068 0571406275 0538506418 0594007033Google 0507706297 0603206230 0574905532 0578905840Walmart 0511804333 0500005314 0520005000 0561405455
RFBoeing 0490601345 0511303925 0509605405 0527605714Google 0492301777 0603206260 0522305564 0595105763Walmart 0511805373 0530003188 0530004405 0500005446
ABBoeing 0494503404 0519705120 0496105294 0567305872Google 0487603141 0510106667 0589305619 0595106850Walmart 0507305029 0515005359 0549705650 0561905503
GBBoeing 0489903169 0511804364 0440904580 0500005094Google 0491203387 0587005854 0562505243 0603206202Walmart 0500304955 0505005123 0536105109 0549705650
company that specializes in Internet-related services andproducts The third is Walmart an American multinationalretail corporation that operates a chain of hypermarketsdiscount department stores and grocery stores
The results on average accuracy are shown in Table 10and Figure 7These findings are very similar to those derivedin the previous case study and their comparison confirmedthat the proposed feature combinationmodel can outperformother feature selection models in stock price movementprediction With regard to feature selection underlain bythe bag-of-words algorithm the CNN case study generatedmore robust results than did the Reuters case study Theaverage accuracy of the bag-of-words algorithm was lowerthan that of the stock data approach in the Reuters case studyIn the CNN case study the average accuracy levels of theproposed feature combination model were 5794 5879and 5767 for Boeing Google andWalmart respectively Inthe case study on Reuters an average accuracy that exceeds60 was not achieved for any of the companies illustratingthat differences in data source directly affect stock pricemovement
We chose a combination of deep learning and knowledgegraph to build our feature selection model because this
CNN
Aver
age a
ccur
acy
0
01
02
03
04
05
06
07
Different companyBoeing Google Walmart
SDBOW
CNNFC
Figure 7Average accuracy achieved on the basis of news fromCNNand different feature set
combination exhibited superior prediction performance inthe comparison experiments involving other feature selection
Complexity 13
strategies The forecast results based on different featuresare shown in Table 10 We found that deep learning featuresare better than the use of bag-of-words and stock data Thecorrelation of event tuples with the stock market is relativelyhigh in [5 31] but the bag-of-words algorithm was relativelyfragmented and the correlation between event tuples and thestockmarket data was relatively weak Combining event tuplefeatures with deep learning significantly improves forecastresults indicating a close relationship between stock marketmovements and knowledge graph
5 Discussion
51 Research Findings We attempted to compare our predic-tion results with those made in previous studies wherein pre-diction was also based on the financial news of the renownedcompanies However the findings are incomparable becausedifferent studies use different datasets or algorithms andthese methods are difficult to investigate using financial newsheadlines In the current research we refrained from eval-uating performance on one company dataset this decisionthat enabled our knowledge graphmethod to exceed baselinepredictions based only on the price by up to 36 Thisalso proves that feature extraction in deep learning is moreeffective than traditional machines The combination of deeplearning and knowledge graph fully integrates the semanticinformation in financial news which effectively predicts thestock price movement of the renowned company
This work demonstrated the application of deep learningand knowledge graph in finance To the best of our knowl-edge knowledge graph has been rarely applied in stock pre-diction Becauseminimal financial training sets in knowledgegraph are available financial knowledge extraction is themain task for the organizational construction of a knowledgegraph Such extraction is critical for the understanding andprocessing of deep semantics in the event tuple which alsodirectly influences the feature extraction of financial news
52 Implications for Business Activities Theutility of a featurecombination model based on knowledge graph is not limitedto financial analysis Currently knowledge graph data areavailable for medical diagnosis speech recognition precisemarketing and financial risk control [4] Our model couldalso be applied in these areas
Antifraud activities are an important part of financeApplying our model on the basis of knowledge graph oncustomers helps organize all relevant knowledge fragmentsthrough deep semantic analysis and reasoning which canbe verified with a customerrsquos bank information Moreovercustomers typically use keywords to search for productsand knowledge graph can provide relevant information toa customer If a complete knowledge system of users isdescribed and collected a system would better understandand analyze user behaviors
53 Limitations and Future Work A deep learning modeluses supervised learning and needs a dataset with sufficientlabels but our datasets do not work well with deep learningas a small number of financial news articles match stock
data At present knowledge graph embedding inevitablyproduces a loss in news semantics either because of a learningprinciple or the tokenization of knowledge representation forvectorization Thus continuous representation in a knowl-edge graph is still a huge challenge We attempted to applyregression using the above-mentioned algorithms but theresults indicated poor performance More specifically theresults for Apple validated our expectations
The application of large-scale knowledge graph is stillrelatively limited and knowledge graph for smart searchsmart question-and-answer tasks social media and otherareas are in their initial stages with considerable room forimprovement The following advantages of knowledge graphshould be considered (a) the effective organization andexpression of semistructured data (b) knowledge reasoningand (c) the expansion of cognitive ability for incorporatingdeep learning Traditional knowledge elements (entities rela-tionship attributes) extraction technologies and methodshave achieved good results in limited areas but because ofnumerous constraints and poor scalability knowledge graphis not fully functional for financial forecasting because ofnumerous constraints and poor scalability
6 Conclusions
Stock movement prediction of the renowned company is adaunting task because stock prices are affected by many fac-tors This research presented a novel method for integratingknowledge graph embedding with stock market predictionThe contributions of this study can be summarized as followsFirst we developed a novel feature combination model thatconstructs a feature mapping vector for each tuplendashnewspair by simultaneously considering the diversity of entitiesand relationships Second the feature combination modelwas successfully applied to different types of companies anddatasets and exhibited good performance in classificationtasks
Stock market prediction of the renowned companygrounded in knowledge graph is an interesting topic forbusiness activities Given that the study of knowledge graphfor feature set is still in its infancy we expect it to be appliedin a wide range of academic research More companies willalso earn profits and create more opportunities through theuse of knowledge graph in the feature set
Data Availability
The data used in this study can be accessed via httpsgithubcomlinechanyknowledge-graph
Conflicts of Interest
The author declares that there is no conflict of interestregarding the publication of this paper
Acknowledgments
This work is supported by the China Scholarship Council(CSC) throughout the grant number 201508390019 The
14 Complexity
authors also want to thank the research program RFCS fromthe EU which partially supported this research through theresearch project AutoSurveillance with project ID 847202
References
[1] B GMalkiel and E F Fama ldquoEfficient capital markets a reviewof theory and empirical workrdquo The Journal of Finance vol 25no 2 pp 383ndash417 1970
[2] D Galai and R W Masulis ldquoThe option pricing model and therisk factor of stockrdquo Journal of Financial Economics vol 3 no1-2 pp 53ndash81 1976
[3] Q Wang Z Mao B Wang and L Guo ldquoKnowledge graphembedding A survey of approaches and applicationsrdquo IEEETransactions on Knowledge and Data Engineering vol 29 no12 pp 2724ndash2743 2017
[4] H Paulheim and P Cimiano ldquoKnowledge graph refinement Asurvey of approaches and evaluation methodsrdquo Journal of WebSemantics Science Services and Agents on the World Wide Webvol 8 no 3 pp 489ndash508 2016
[5] X Ding Y Zhang T Liu and J Duan ldquoDeep learning for event-driven stock predictionrdquo in Proceedings of the 24th InternationalJoint Conference on Artificial Intelligence IJCAI 2015 pp 2327ndash2333 Argentina July 2015
[6] X Ding Y Zhang T Liu and J Duan ldquoKnowledge-drivenevent embedding for stock predictionrdquo in Proceedings of the26th International Conference on Computational LinguisticsCOLING 2016 pp 2133ndash2142 Japan December 2016
[7] A Bordes N Usunier J Weston and O Yakhnenko ldquoTranslat-ing embeddings for modeling multi-relational datardquo Advancesin NIPS vol 26 pp 2787ndash2795 2013
[8] H Lin Y Liu W Wang Y Yue and Z Lin ldquoLearning entityand relation embeddings for knowledge resolutionrdquo ProcediaComputer Science vol 108 pp 345ndash354 2017
[9] G Ji K Liu S He and J Zhao ldquoKnowledge graph completionwith adaptive sparse transfer matrixrdquo in Proceedings of the 30thAAAI Conference on Artificial Intelligence AAAI 2016 pp 985ndash991 USA February 2016
[10] G Ji S He L Xu K Liu and J Zhao ldquoKnowledge graphembedding via dynamic mapping matrixrdquo in Proceedings ofthe 53rd Annual Meeting of the Association for ComputationalLinguistics and the 7th International Joint Conference on NaturalLanguage Processing (Volume 1 Long Papers) pp 687ndash696Beijing China July 2015
[11] Y LeCun Y Bengio and G Hinton ldquoDeep learningrdquo Naturevol 521 no 7553 pp 436ndash444 2015
[12] Q Li Y Chen J Wang and H Chen ldquoWeb media andstock markets a survey and future directions from a bigdata perspectiverdquo IEEE Transactions on Knowledge and DataEngineering vol 4347 p 1 2017
[13] B Wuthrich V Cho S Leung D Permunetilleke K Sankaranand J Zhang ldquoDaily stock market forecast from textual Webdatardquo in Proceedings of the 1998 IEEE International Confer-ence on Systems Man and Cybernetics (Cat No98CH36218)SMCrsquo98 vol 3 pp 2720ndash2725 October 1998
[14] G Pui Cheong Fung J Xu Yu and W Lam ldquoStock predictionintegrating text mining approach using real-time newsrdquo inProceedings of the 2003 IEEE International Conference on Com-putational Intelligence for Financial Engineering CIFEr 2003vol 2003 pp 395ndash402 China March 2003
[15] W Antweiler and M Z Frank ldquoIs all that talk just noise theinformation content of internet stock message boardsrdquo SSRNElectronic Journal 2001
[16] M-A Mittermayer and G F Knolmayer ldquoNewsCATS A newscategorization and trading systemrdquo in Proceedings of the 6thInternational Conference onDataMining ICDM2006 pp 1002ndash1007 China December 2006
[17] R P Schumaker and H Chen ldquoTextual analysis of stockmarket prediction using breaking financial news theAZFin textsystemrdquo ACM Transactions on Information and Systems pp 1ndash29 2009
[18] S S Groth and J Muntermann ldquoAn intraday market riskmanagement approach based on textual analysisrdquo DecisionSupport Systems vol 50 no 4 pp 680ndash691 2011
[19] T Vu S Chang Q Ha and N Collier ldquoAn experiment in inte-grating sentiment features for tech stock prediction in twitterrdquoin Proceedings of the Workshop on Information Extraction AndEntity Analytics on Social Media Data vol 3 pp 23ndash38 2012
[20] B Wang H Huang and X Wang ldquoA novel text miningapproach to financial time series forecastingrdquo Neurocomputingvol 83 pp 136ndash145 2012
[21] Q Li T Wang P Li L Liu Q Gong and Y Chen ldquoThe effectof news and public mood on stock movementsrdquo InformationSciences vol 278 pp 826ndash840 2014
[22] T H Nguyen K Shirai and J Velcin ldquoSentiment analysis onsocial media for stock movement predictionrdquo Expert Systemswith Applications vol 42 no 24 pp 9603ndash9611 2015
[23] BWengM A Ahmed and FMMegahed ldquoStockmarket one-day ahead movement prediction using disparate data sourcesrdquoExpert Systems with Applications vol 79 pp 153ndash163 2017
[24] J Eberhard J F Lavin and A Montecinos-Pearce ldquoA network-based dynamic analysis in an equity stock marketrdquo Complexityvol 2017 Article ID 3979836 16 pages 2017
[25] Z Zhang Y Zhang D Shen and W Zhang ldquoThe dynamiccross-correlations between mass media news newmedia newsand stock returnsrdquo Complexity vol 2018 11 pages 2018
[26] P C Tetlock ldquoGiving content to investor sentiment The role ofmedia in the stock marketrdquo Journal of Finance vol 62 no 3 pp1139ndash1168 2007
[27] K Chen P Luo L Liu andW Zhang ldquoNews search and stockco-movement Investigating information diffusion in the finan-cial marketrdquo Electronic Commerce Research and Applicationsvol 28 pp 159ndash171 2018
[28] F Z Xing E Cambria and Y Zhang ldquoSentiment-awarevolatility forecastingrdquo Knowledge-Based Systems vol 176 pp68ndash76 2019
[29] A Picasso S Merello Y Ma L Oneto and E CambrialdquoTechnical analysis and sentiment embeddings formarket trendpredictionrdquo Expert Systems with Applications vol 135 pp 60ndash70 2019
[30] A Khadjeh Nassirtoussi S Aghabozorgi T Ying Wah and DC L Ngo ldquoText mining for market prediction a systematicreviewrdquo Expert Systems with Applications vol 41 no 16 pp7653ndash7670 2014
[31] M Kraus and S Feuerriegel ldquoDecision support from financialdisclosures with deep neural networks and transfer learningrdquoDecision Support Systems vol 104 pp 38ndash48 2017
[32] H S Sim H I Kim and J J Ahn ldquoIs deep learning for imagerecognition applicable to stockmarket predictionrdquoComplexityvol 2019 10 pages 2019
Complexity 15
[33] M Jasemi A M Kimiagari and A Memariani ldquoA modernneural network model to do stock market timing on the basisof the ancient investment technique of Japanese candlestickrdquoExpert Systems with Applications vol 38 no 4 pp 3884ndash38902011
[34] A Fader S Soderland and O Etzioni ldquoIdentifying relations foropen information extractionrdquo in Proceedings of the Conferenceon Empirical Methods in Natural Language Processing EMNLP2011 pp 1535ndash1545 Association for Computational LinguisticsUK July 2011
[35] T Mikolov K Chen G Corrado and J Dean ldquoEfficientestimation of word representations in vector spacerdquo pp 1ndash122013 httpsarxivorgabs13013781
[36] X Lin Z Yang and Y Song ldquoIntelligent stock trading systembased on improved technical analysis and Echo State NetworkrdquoExpert Systems with Applications vol 38 no 9 pp 11347ndash113542011
[37] K-J Kim and I Han ldquoGenetic algorithms approach to featurediscretization in artificial neural networks for the prediction ofstock price indexrdquo Expert Systems with Applications vol 19 no2 pp 125ndash132 2000
[38] Y Yu W Duan and Q Cao ldquoThe impact of social andconventional media on firm equity value A sentiment analysisapproachrdquoDecision Support Systems vol 55 no 4 pp 919ndash9262013
[39] MHagenauM Liebmann andDNeumann ldquoAutomated newsreading Stock price prediction based on financial news usingcontext-capturing featuresrdquo Decision Support Systems vol 55no 3 pp 685ndash697 2013
[40] A Aizawa ldquoAn information-theoretic perspective of tf-idfmeasuresrdquo Information Processing amp Management vol 39 no1 pp 45ndash65 2003
[41] A Khadjeh Nassirtoussi S Aghabozorgi T Ying Wah and DC Ngo ldquoText mining of news-headlines for FOREX marketprediction a Multi-layer dimension reduction algorithm withsemantics and sentimentrdquo Expert Systems with Applications vol42 no 1 pp 306ndash324 2015
[42] D Peramunetilleke and R K Wong ldquoCurrency exchange rateforecasting from news headlinesrdquo Australian Computer ScienceCommunications vol 24 no 2 pp 131ndash139 2002
[43] Y Kim ldquoConvolutional neural networks for sentence classifica-tionrdquo 2014 httpsarxivorgabs14085882
[44] ZWang J Zhang J Feng and Z Chen ldquoKnowledge graph andtext jointly embeddingrdquo in Proceedings of the 2014 Conferenceon Empirical Methods in Natural Language Processing EMNLP2014 pp 1591ndash1601 Qatar October 2014
[45] J Xu X Qiu K Chen and X Huang ldquoKnowledge graphrepresentation with jointly structural and textual encodingrdquo inProceedings of the 26th International Joint Conference on Arti-ficial Intelligence IJCAI 2017 pp 1318ndash1324 Australia August2017
[46] R Xie Z Liu J Jia H Luan and M Sun ldquoRepresentationlearning of knowledge graphs with entity descriptionsrdquo in Pro-ceedings of the 30th AAAI Conference on Artificial IntelligenceAAAI rsquo16 pp 2659ndash2665 February 2016
[47] F Tian B Gao E Chen and T Liu ldquoLearning better wordembedding by asymmetric low-rank projection of knowledgegraphrdquo Journal of Computer Science and Technology vol 31 no3 pp 624ndash634 2016
[48] F Z Xing E Cambria and R E Welsch ldquoNatural languagebased financial forecasting a surveyrdquo Artificial IntelligenceReview vol 50 no 1 pp 49ndash73 2018
[49] C Goutte and E Gaussier ldquoA probabilistic interpretation ofprecision recall and F-score with implication for evaluationrdquoin Advances in Information Retrieval D E Losada and J MFernandez-Luna Eds vol 3408 of Lecture Notes in ComputerScience pp 345ndash359 Springer Berlin Germany 2005
Hindawiwwwhindawicom Volume 2018
MathematicsJournal of
Hindawiwwwhindawicom Volume 2018
Mathematical Problems in Engineering
Applied MathematicsJournal of
Hindawiwwwhindawicom Volume 2018
Probability and StatisticsHindawiwwwhindawicom Volume 2018
Journal of
Hindawiwwwhindawicom Volume 2018
Mathematical PhysicsAdvances in
Complex AnalysisJournal of
Hindawiwwwhindawicom Volume 2018
OptimizationJournal of
Hindawiwwwhindawicom Volume 2018
Hindawiwwwhindawicom Volume 2018
Engineering Mathematics
International Journal of
Hindawiwwwhindawicom Volume 2018
Operations ResearchAdvances in
Journal of
Hindawiwwwhindawicom Volume 2018
Function SpacesAbstract and Applied AnalysisHindawiwwwhindawicom Volume 2018
International Journal of Mathematics and Mathematical Sciences
Hindawiwwwhindawicom Volume 2018
Hindawi Publishing Corporation httpwwwhindawicom Volume 2013Hindawiwwwhindawicom
The Scientific World Journal
Volume 2018
Hindawiwwwhindawicom Volume 2018Volume 2018
Numerical AnalysisNumerical AnalysisNumerical AnalysisNumerical AnalysisNumerical AnalysisNumerical AnalysisNumerical AnalysisNumerical AnalysisNumerical AnalysisNumerical AnalysisNumerical AnalysisNumerical AnalysisAdvances inAdvances in Discrete Dynamics in
Nature and SocietyHindawiwwwhindawicom Volume 2018
Hindawiwwwhindawicom
Dierential EquationsInternational Journal of
Volume 2018
Hindawiwwwhindawicom Volume 2018
Decision SciencesAdvances in
Hindawiwwwhindawicom Volume 2018
AnalysisInternational Journal of
Hindawiwwwhindawicom Volume 2018
Stochastic AnalysisInternational Journal of
Submit your manuscripts atwwwhindawicom

12 Complexity
Table 10 Results for data extracted from CNN
Algorithm Company Stock data(SD)
Bag of words(BOW)
Convolutionalneural network
Featurecombinationmodel (FC)
AccuracyF1-score
AccuracyF1-score
AccuracyF1-score
AccuracyF1-score
DTBoeing 0495003489 0541306258 0541406347 0559105821Google 0485805600 0518203575 0569204631 0549105471Walmart 0499604422 0530004891 0508804815 0572205829
LRBoeing 0492302378 0511304348 0692306923 0759605733Google 0504106105 0623506491 0625006111 0656306516Walmart 0529005468 0541205083 0732007347 0771907720
NBBoeing 0516206503 0548905161 0519706738 0556407619Google 0511206527 0489905191 0558705281 0534404843Walmart 0504403284 0479405302 0520605674 0530006083
SGDBoeing 0489702407 0556404870 0543304727 0571407220Google 0516506769 0542504375 0578906364 0591006327Walmart 0500403804 0520605280 0525005581 0567005922
SVMBoeing 0489703068 0571406275 0538506418 0594007033Google 0507706297 0603206230 0574905532 0578905840Walmart 0511804333 0500005314 0520005000 0561405455
RFBoeing 0490601345 0511303925 0509605405 0527605714Google 0492301777 0603206260 0522305564 0595105763Walmart 0511805373 0530003188 0530004405 0500005446
ABBoeing 0494503404 0519705120 0496105294 0567305872Google 0487603141 0510106667 0589305619 0595106850Walmart 0507305029 0515005359 0549705650 0561905503
GBBoeing 0489903169 0511804364 0440904580 0500005094Google 0491203387 0587005854 0562505243 0603206202Walmart 0500304955 0505005123 0536105109 0549705650
company that specializes in Internet-related services andproducts The third is Walmart an American multinationalretail corporation that operates a chain of hypermarketsdiscount department stores and grocery stores
The results on average accuracy are shown in Table 10and Figure 7These findings are very similar to those derivedin the previous case study and their comparison confirmedthat the proposed feature combinationmodel can outperformother feature selection models in stock price movementprediction With regard to feature selection underlain bythe bag-of-words algorithm the CNN case study generatedmore robust results than did the Reuters case study Theaverage accuracy of the bag-of-words algorithm was lowerthan that of the stock data approach in the Reuters case studyIn the CNN case study the average accuracy levels of theproposed feature combination model were 5794 5879and 5767 for Boeing Google andWalmart respectively Inthe case study on Reuters an average accuracy that exceeds60 was not achieved for any of the companies illustratingthat differences in data source directly affect stock pricemovement
We chose a combination of deep learning and knowledgegraph to build our feature selection model because this
CNN
Aver
age a
ccur
acy
0
01
02
03
04
05
06
07
Different companyBoeing Google Walmart
SDBOW
CNNFC
Figure 7Average accuracy achieved on the basis of news fromCNNand different feature set
combination exhibited superior prediction performance inthe comparison experiments involving other feature selection
Complexity 13
strategies The forecast results based on different featuresare shown in Table 10 We found that deep learning featuresare better than the use of bag-of-words and stock data Thecorrelation of event tuples with the stock market is relativelyhigh in [5 31] but the bag-of-words algorithm was relativelyfragmented and the correlation between event tuples and thestockmarket data was relatively weak Combining event tuplefeatures with deep learning significantly improves forecastresults indicating a close relationship between stock marketmovements and knowledge graph
5 Discussion
51 Research Findings We attempted to compare our predic-tion results with those made in previous studies wherein pre-diction was also based on the financial news of the renownedcompanies However the findings are incomparable becausedifferent studies use different datasets or algorithms andthese methods are difficult to investigate using financial newsheadlines In the current research we refrained from eval-uating performance on one company dataset this decisionthat enabled our knowledge graphmethod to exceed baselinepredictions based only on the price by up to 36 Thisalso proves that feature extraction in deep learning is moreeffective than traditional machines The combination of deeplearning and knowledge graph fully integrates the semanticinformation in financial news which effectively predicts thestock price movement of the renowned company
This work demonstrated the application of deep learningand knowledge graph in finance To the best of our knowl-edge knowledge graph has been rarely applied in stock pre-diction Becauseminimal financial training sets in knowledgegraph are available financial knowledge extraction is themain task for the organizational construction of a knowledgegraph Such extraction is critical for the understanding andprocessing of deep semantics in the event tuple which alsodirectly influences the feature extraction of financial news
52 Implications for Business Activities Theutility of a featurecombination model based on knowledge graph is not limitedto financial analysis Currently knowledge graph data areavailable for medical diagnosis speech recognition precisemarketing and financial risk control [4] Our model couldalso be applied in these areas
Antifraud activities are an important part of financeApplying our model on the basis of knowledge graph oncustomers helps organize all relevant knowledge fragmentsthrough deep semantic analysis and reasoning which canbe verified with a customerrsquos bank information Moreovercustomers typically use keywords to search for productsand knowledge graph can provide relevant information toa customer If a complete knowledge system of users isdescribed and collected a system would better understandand analyze user behaviors
53 Limitations and Future Work A deep learning modeluses supervised learning and needs a dataset with sufficientlabels but our datasets do not work well with deep learningas a small number of financial news articles match stock
data At present knowledge graph embedding inevitablyproduces a loss in news semantics either because of a learningprinciple or the tokenization of knowledge representation forvectorization Thus continuous representation in a knowl-edge graph is still a huge challenge We attempted to applyregression using the above-mentioned algorithms but theresults indicated poor performance More specifically theresults for Apple validated our expectations
The application of large-scale knowledge graph is stillrelatively limited and knowledge graph for smart searchsmart question-and-answer tasks social media and otherareas are in their initial stages with considerable room forimprovement The following advantages of knowledge graphshould be considered (a) the effective organization andexpression of semistructured data (b) knowledge reasoningand (c) the expansion of cognitive ability for incorporatingdeep learning Traditional knowledge elements (entities rela-tionship attributes) extraction technologies and methodshave achieved good results in limited areas but because ofnumerous constraints and poor scalability knowledge graphis not fully functional for financial forecasting because ofnumerous constraints and poor scalability
6 Conclusions
Stock movement prediction of the renowned company is adaunting task because stock prices are affected by many fac-tors This research presented a novel method for integratingknowledge graph embedding with stock market predictionThe contributions of this study can be summarized as followsFirst we developed a novel feature combination model thatconstructs a feature mapping vector for each tuplendashnewspair by simultaneously considering the diversity of entitiesand relationships Second the feature combination modelwas successfully applied to different types of companies anddatasets and exhibited good performance in classificationtasks
Stock market prediction of the renowned companygrounded in knowledge graph is an interesting topic forbusiness activities Given that the study of knowledge graphfor feature set is still in its infancy we expect it to be appliedin a wide range of academic research More companies willalso earn profits and create more opportunities through theuse of knowledge graph in the feature set
Data Availability
The data used in this study can be accessed via httpsgithubcomlinechanyknowledge-graph
Conflicts of Interest
The author declares that there is no conflict of interestregarding the publication of this paper
Acknowledgments
This work is supported by the China Scholarship Council(CSC) throughout the grant number 201508390019 The
14 Complexity
authors also want to thank the research program RFCS fromthe EU which partially supported this research through theresearch project AutoSurveillance with project ID 847202
References
[1] B GMalkiel and E F Fama ldquoEfficient capital markets a reviewof theory and empirical workrdquo The Journal of Finance vol 25no 2 pp 383ndash417 1970
[2] D Galai and R W Masulis ldquoThe option pricing model and therisk factor of stockrdquo Journal of Financial Economics vol 3 no1-2 pp 53ndash81 1976
[3] Q Wang Z Mao B Wang and L Guo ldquoKnowledge graphembedding A survey of approaches and applicationsrdquo IEEETransactions on Knowledge and Data Engineering vol 29 no12 pp 2724ndash2743 2017
[4] H Paulheim and P Cimiano ldquoKnowledge graph refinement Asurvey of approaches and evaluation methodsrdquo Journal of WebSemantics Science Services and Agents on the World Wide Webvol 8 no 3 pp 489ndash508 2016
[5] X Ding Y Zhang T Liu and J Duan ldquoDeep learning for event-driven stock predictionrdquo in Proceedings of the 24th InternationalJoint Conference on Artificial Intelligence IJCAI 2015 pp 2327ndash2333 Argentina July 2015
[6] X Ding Y Zhang T Liu and J Duan ldquoKnowledge-drivenevent embedding for stock predictionrdquo in Proceedings of the26th International Conference on Computational LinguisticsCOLING 2016 pp 2133ndash2142 Japan December 2016
[7] A Bordes N Usunier J Weston and O Yakhnenko ldquoTranslat-ing embeddings for modeling multi-relational datardquo Advancesin NIPS vol 26 pp 2787ndash2795 2013
[8] H Lin Y Liu W Wang Y Yue and Z Lin ldquoLearning entityand relation embeddings for knowledge resolutionrdquo ProcediaComputer Science vol 108 pp 345ndash354 2017
[9] G Ji K Liu S He and J Zhao ldquoKnowledge graph completionwith adaptive sparse transfer matrixrdquo in Proceedings of the 30thAAAI Conference on Artificial Intelligence AAAI 2016 pp 985ndash991 USA February 2016
[10] G Ji S He L Xu K Liu and J Zhao ldquoKnowledge graphembedding via dynamic mapping matrixrdquo in Proceedings ofthe 53rd Annual Meeting of the Association for ComputationalLinguistics and the 7th International Joint Conference on NaturalLanguage Processing (Volume 1 Long Papers) pp 687ndash696Beijing China July 2015
[11] Y LeCun Y Bengio and G Hinton ldquoDeep learningrdquo Naturevol 521 no 7553 pp 436ndash444 2015
[12] Q Li Y Chen J Wang and H Chen ldquoWeb media andstock markets a survey and future directions from a bigdata perspectiverdquo IEEE Transactions on Knowledge and DataEngineering vol 4347 p 1 2017
[13] B Wuthrich V Cho S Leung D Permunetilleke K Sankaranand J Zhang ldquoDaily stock market forecast from textual Webdatardquo in Proceedings of the 1998 IEEE International Confer-ence on Systems Man and Cybernetics (Cat No98CH36218)SMCrsquo98 vol 3 pp 2720ndash2725 October 1998
[14] G Pui Cheong Fung J Xu Yu and W Lam ldquoStock predictionintegrating text mining approach using real-time newsrdquo inProceedings of the 2003 IEEE International Conference on Com-putational Intelligence for Financial Engineering CIFEr 2003vol 2003 pp 395ndash402 China March 2003
[15] W Antweiler and M Z Frank ldquoIs all that talk just noise theinformation content of internet stock message boardsrdquo SSRNElectronic Journal 2001
[16] M-A Mittermayer and G F Knolmayer ldquoNewsCATS A newscategorization and trading systemrdquo in Proceedings of the 6thInternational Conference onDataMining ICDM2006 pp 1002ndash1007 China December 2006
[17] R P Schumaker and H Chen ldquoTextual analysis of stockmarket prediction using breaking financial news theAZFin textsystemrdquo ACM Transactions on Information and Systems pp 1ndash29 2009
[18] S S Groth and J Muntermann ldquoAn intraday market riskmanagement approach based on textual analysisrdquo DecisionSupport Systems vol 50 no 4 pp 680ndash691 2011
[19] T Vu S Chang Q Ha and N Collier ldquoAn experiment in inte-grating sentiment features for tech stock prediction in twitterrdquoin Proceedings of the Workshop on Information Extraction AndEntity Analytics on Social Media Data vol 3 pp 23ndash38 2012
[20] B Wang H Huang and X Wang ldquoA novel text miningapproach to financial time series forecastingrdquo Neurocomputingvol 83 pp 136ndash145 2012
[21] Q Li T Wang P Li L Liu Q Gong and Y Chen ldquoThe effectof news and public mood on stock movementsrdquo InformationSciences vol 278 pp 826ndash840 2014
[22] T H Nguyen K Shirai and J Velcin ldquoSentiment analysis onsocial media for stock movement predictionrdquo Expert Systemswith Applications vol 42 no 24 pp 9603ndash9611 2015
[23] BWengM A Ahmed and FMMegahed ldquoStockmarket one-day ahead movement prediction using disparate data sourcesrdquoExpert Systems with Applications vol 79 pp 153ndash163 2017
[24] J Eberhard J F Lavin and A Montecinos-Pearce ldquoA network-based dynamic analysis in an equity stock marketrdquo Complexityvol 2017 Article ID 3979836 16 pages 2017
[25] Z Zhang Y Zhang D Shen and W Zhang ldquoThe dynamiccross-correlations between mass media news newmedia newsand stock returnsrdquo Complexity vol 2018 11 pages 2018
[26] P C Tetlock ldquoGiving content to investor sentiment The role ofmedia in the stock marketrdquo Journal of Finance vol 62 no 3 pp1139ndash1168 2007
[27] K Chen P Luo L Liu andW Zhang ldquoNews search and stockco-movement Investigating information diffusion in the finan-cial marketrdquo Electronic Commerce Research and Applicationsvol 28 pp 159ndash171 2018
[28] F Z Xing E Cambria and Y Zhang ldquoSentiment-awarevolatility forecastingrdquo Knowledge-Based Systems vol 176 pp68ndash76 2019
[29] A Picasso S Merello Y Ma L Oneto and E CambrialdquoTechnical analysis and sentiment embeddings formarket trendpredictionrdquo Expert Systems with Applications vol 135 pp 60ndash70 2019
[30] A Khadjeh Nassirtoussi S Aghabozorgi T Ying Wah and DC L Ngo ldquoText mining for market prediction a systematicreviewrdquo Expert Systems with Applications vol 41 no 16 pp7653ndash7670 2014
[31] M Kraus and S Feuerriegel ldquoDecision support from financialdisclosures with deep neural networks and transfer learningrdquoDecision Support Systems vol 104 pp 38ndash48 2017
[32] H S Sim H I Kim and J J Ahn ldquoIs deep learning for imagerecognition applicable to stockmarket predictionrdquoComplexityvol 2019 10 pages 2019
Complexity 15
[33] M Jasemi A M Kimiagari and A Memariani ldquoA modernneural network model to do stock market timing on the basisof the ancient investment technique of Japanese candlestickrdquoExpert Systems with Applications vol 38 no 4 pp 3884ndash38902011
[34] A Fader S Soderland and O Etzioni ldquoIdentifying relations foropen information extractionrdquo in Proceedings of the Conferenceon Empirical Methods in Natural Language Processing EMNLP2011 pp 1535ndash1545 Association for Computational LinguisticsUK July 2011
[35] T Mikolov K Chen G Corrado and J Dean ldquoEfficientestimation of word representations in vector spacerdquo pp 1ndash122013 httpsarxivorgabs13013781
[36] X Lin Z Yang and Y Song ldquoIntelligent stock trading systembased on improved technical analysis and Echo State NetworkrdquoExpert Systems with Applications vol 38 no 9 pp 11347ndash113542011
[37] K-J Kim and I Han ldquoGenetic algorithms approach to featurediscretization in artificial neural networks for the prediction ofstock price indexrdquo Expert Systems with Applications vol 19 no2 pp 125ndash132 2000
[38] Y Yu W Duan and Q Cao ldquoThe impact of social andconventional media on firm equity value A sentiment analysisapproachrdquoDecision Support Systems vol 55 no 4 pp 919ndash9262013
[39] MHagenauM Liebmann andDNeumann ldquoAutomated newsreading Stock price prediction based on financial news usingcontext-capturing featuresrdquo Decision Support Systems vol 55no 3 pp 685ndash697 2013
[40] A Aizawa ldquoAn information-theoretic perspective of tf-idfmeasuresrdquo Information Processing amp Management vol 39 no1 pp 45ndash65 2003
[41] A Khadjeh Nassirtoussi S Aghabozorgi T Ying Wah and DC Ngo ldquoText mining of news-headlines for FOREX marketprediction a Multi-layer dimension reduction algorithm withsemantics and sentimentrdquo Expert Systems with Applications vol42 no 1 pp 306ndash324 2015
[42] D Peramunetilleke and R K Wong ldquoCurrency exchange rateforecasting from news headlinesrdquo Australian Computer ScienceCommunications vol 24 no 2 pp 131ndash139 2002
[43] Y Kim ldquoConvolutional neural networks for sentence classifica-tionrdquo 2014 httpsarxivorgabs14085882
[44] ZWang J Zhang J Feng and Z Chen ldquoKnowledge graph andtext jointly embeddingrdquo in Proceedings of the 2014 Conferenceon Empirical Methods in Natural Language Processing EMNLP2014 pp 1591ndash1601 Qatar October 2014
[45] J Xu X Qiu K Chen and X Huang ldquoKnowledge graphrepresentation with jointly structural and textual encodingrdquo inProceedings of the 26th International Joint Conference on Arti-ficial Intelligence IJCAI 2017 pp 1318ndash1324 Australia August2017
[46] R Xie Z Liu J Jia H Luan and M Sun ldquoRepresentationlearning of knowledge graphs with entity descriptionsrdquo in Pro-ceedings of the 30th AAAI Conference on Artificial IntelligenceAAAI rsquo16 pp 2659ndash2665 February 2016
[47] F Tian B Gao E Chen and T Liu ldquoLearning better wordembedding by asymmetric low-rank projection of knowledgegraphrdquo Journal of Computer Science and Technology vol 31 no3 pp 624ndash634 2016
[48] F Z Xing E Cambria and R E Welsch ldquoNatural languagebased financial forecasting a surveyrdquo Artificial IntelligenceReview vol 50 no 1 pp 49ndash73 2018
[49] C Goutte and E Gaussier ldquoA probabilistic interpretation ofprecision recall and F-score with implication for evaluationrdquoin Advances in Information Retrieval D E Losada and J MFernandez-Luna Eds vol 3408 of Lecture Notes in ComputerScience pp 345ndash359 Springer Berlin Germany 2005
Hindawiwwwhindawicom Volume 2018
MathematicsJournal of
Hindawiwwwhindawicom Volume 2018
Mathematical Problems in Engineering
Applied MathematicsJournal of
Hindawiwwwhindawicom Volume 2018
Probability and StatisticsHindawiwwwhindawicom Volume 2018
Journal of
Hindawiwwwhindawicom Volume 2018
Mathematical PhysicsAdvances in
Complex AnalysisJournal of
Hindawiwwwhindawicom Volume 2018
OptimizationJournal of
Hindawiwwwhindawicom Volume 2018
Hindawiwwwhindawicom Volume 2018
Engineering Mathematics
International Journal of
Hindawiwwwhindawicom Volume 2018
Operations ResearchAdvances in
Journal of
Hindawiwwwhindawicom Volume 2018
Function SpacesAbstract and Applied AnalysisHindawiwwwhindawicom Volume 2018
International Journal of Mathematics and Mathematical Sciences
Hindawiwwwhindawicom Volume 2018
Hindawi Publishing Corporation httpwwwhindawicom Volume 2013Hindawiwwwhindawicom
The Scientific World Journal
Volume 2018
Hindawiwwwhindawicom Volume 2018Volume 2018
Numerical AnalysisNumerical AnalysisNumerical AnalysisNumerical AnalysisNumerical AnalysisNumerical AnalysisNumerical AnalysisNumerical AnalysisNumerical AnalysisNumerical AnalysisNumerical AnalysisNumerical AnalysisAdvances inAdvances in Discrete Dynamics in
Nature and SocietyHindawiwwwhindawicom Volume 2018
Hindawiwwwhindawicom
Dierential EquationsInternational Journal of
Volume 2018
Hindawiwwwhindawicom Volume 2018
Decision SciencesAdvances in
Hindawiwwwhindawicom Volume 2018
AnalysisInternational Journal of
Hindawiwwwhindawicom Volume 2018
Stochastic AnalysisInternational Journal of
Submit your manuscripts atwwwhindawicom

Complexity 13
strategies The forecast results based on different featuresare shown in Table 10 We found that deep learning featuresare better than the use of bag-of-words and stock data Thecorrelation of event tuples with the stock market is relativelyhigh in [5 31] but the bag-of-words algorithm was relativelyfragmented and the correlation between event tuples and thestockmarket data was relatively weak Combining event tuplefeatures with deep learning significantly improves forecastresults indicating a close relationship between stock marketmovements and knowledge graph
5 Discussion
51 Research Findings We attempted to compare our predic-tion results with those made in previous studies wherein pre-diction was also based on the financial news of the renownedcompanies However the findings are incomparable becausedifferent studies use different datasets or algorithms andthese methods are difficult to investigate using financial newsheadlines In the current research we refrained from eval-uating performance on one company dataset this decisionthat enabled our knowledge graphmethod to exceed baselinepredictions based only on the price by up to 36 Thisalso proves that feature extraction in deep learning is moreeffective than traditional machines The combination of deeplearning and knowledge graph fully integrates the semanticinformation in financial news which effectively predicts thestock price movement of the renowned company
This work demonstrated the application of deep learningand knowledge graph in finance To the best of our knowl-edge knowledge graph has been rarely applied in stock pre-diction Becauseminimal financial training sets in knowledgegraph are available financial knowledge extraction is themain task for the organizational construction of a knowledgegraph Such extraction is critical for the understanding andprocessing of deep semantics in the event tuple which alsodirectly influences the feature extraction of financial news
52 Implications for Business Activities Theutility of a featurecombination model based on knowledge graph is not limitedto financial analysis Currently knowledge graph data areavailable for medical diagnosis speech recognition precisemarketing and financial risk control [4] Our model couldalso be applied in these areas
Antifraud activities are an important part of financeApplying our model on the basis of knowledge graph oncustomers helps organize all relevant knowledge fragmentsthrough deep semantic analysis and reasoning which canbe verified with a customerrsquos bank information Moreovercustomers typically use keywords to search for productsand knowledge graph can provide relevant information toa customer If a complete knowledge system of users isdescribed and collected a system would better understandand analyze user behaviors
53 Limitations and Future Work A deep learning modeluses supervised learning and needs a dataset with sufficientlabels but our datasets do not work well with deep learningas a small number of financial news articles match stock
data At present knowledge graph embedding inevitablyproduces a loss in news semantics either because of a learningprinciple or the tokenization of knowledge representation forvectorization Thus continuous representation in a knowl-edge graph is still a huge challenge We attempted to applyregression using the above-mentioned algorithms but theresults indicated poor performance More specifically theresults for Apple validated our expectations
The application of large-scale knowledge graph is stillrelatively limited and knowledge graph for smart searchsmart question-and-answer tasks social media and otherareas are in their initial stages with considerable room forimprovement The following advantages of knowledge graphshould be considered (a) the effective organization andexpression of semistructured data (b) knowledge reasoningand (c) the expansion of cognitive ability for incorporatingdeep learning Traditional knowledge elements (entities rela-tionship attributes) extraction technologies and methodshave achieved good results in limited areas but because ofnumerous constraints and poor scalability knowledge graphis not fully functional for financial forecasting because ofnumerous constraints and poor scalability
6 Conclusions
Stock movement prediction of the renowned company is adaunting task because stock prices are affected by many fac-tors This research presented a novel method for integratingknowledge graph embedding with stock market predictionThe contributions of this study can be summarized as followsFirst we developed a novel feature combination model thatconstructs a feature mapping vector for each tuplendashnewspair by simultaneously considering the diversity of entitiesand relationships Second the feature combination modelwas successfully applied to different types of companies anddatasets and exhibited good performance in classificationtasks
Stock market prediction of the renowned companygrounded in knowledge graph is an interesting topic forbusiness activities Given that the study of knowledge graphfor feature set is still in its infancy we expect it to be appliedin a wide range of academic research More companies willalso earn profits and create more opportunities through theuse of knowledge graph in the feature set
Data Availability
The data used in this study can be accessed via httpsgithubcomlinechanyknowledge-graph
Conflicts of Interest
The author declares that there is no conflict of interestregarding the publication of this paper
Acknowledgments
This work is supported by the China Scholarship Council(CSC) throughout the grant number 201508390019 The
14 Complexity
authors also want to thank the research program RFCS fromthe EU which partially supported this research through theresearch project AutoSurveillance with project ID 847202
References
[1] B GMalkiel and E F Fama ldquoEfficient capital markets a reviewof theory and empirical workrdquo The Journal of Finance vol 25no 2 pp 383ndash417 1970
[2] D Galai and R W Masulis ldquoThe option pricing model and therisk factor of stockrdquo Journal of Financial Economics vol 3 no1-2 pp 53ndash81 1976
[3] Q Wang Z Mao B Wang and L Guo ldquoKnowledge graphembedding A survey of approaches and applicationsrdquo IEEETransactions on Knowledge and Data Engineering vol 29 no12 pp 2724ndash2743 2017
[4] H Paulheim and P Cimiano ldquoKnowledge graph refinement Asurvey of approaches and evaluation methodsrdquo Journal of WebSemantics Science Services and Agents on the World Wide Webvol 8 no 3 pp 489ndash508 2016
[5] X Ding Y Zhang T Liu and J Duan ldquoDeep learning for event-driven stock predictionrdquo in Proceedings of the 24th InternationalJoint Conference on Artificial Intelligence IJCAI 2015 pp 2327ndash2333 Argentina July 2015
[6] X Ding Y Zhang T Liu and J Duan ldquoKnowledge-drivenevent embedding for stock predictionrdquo in Proceedings of the26th International Conference on Computational LinguisticsCOLING 2016 pp 2133ndash2142 Japan December 2016
[7] A Bordes N Usunier J Weston and O Yakhnenko ldquoTranslat-ing embeddings for modeling multi-relational datardquo Advancesin NIPS vol 26 pp 2787ndash2795 2013
[8] H Lin Y Liu W Wang Y Yue and Z Lin ldquoLearning entityand relation embeddings for knowledge resolutionrdquo ProcediaComputer Science vol 108 pp 345ndash354 2017
[9] G Ji K Liu S He and J Zhao ldquoKnowledge graph completionwith adaptive sparse transfer matrixrdquo in Proceedings of the 30thAAAI Conference on Artificial Intelligence AAAI 2016 pp 985ndash991 USA February 2016
[10] G Ji S He L Xu K Liu and J Zhao ldquoKnowledge graphembedding via dynamic mapping matrixrdquo in Proceedings ofthe 53rd Annual Meeting of the Association for ComputationalLinguistics and the 7th International Joint Conference on NaturalLanguage Processing (Volume 1 Long Papers) pp 687ndash696Beijing China July 2015
[11] Y LeCun Y Bengio and G Hinton ldquoDeep learningrdquo Naturevol 521 no 7553 pp 436ndash444 2015
[12] Q Li Y Chen J Wang and H Chen ldquoWeb media andstock markets a survey and future directions from a bigdata perspectiverdquo IEEE Transactions on Knowledge and DataEngineering vol 4347 p 1 2017
[13] B Wuthrich V Cho S Leung D Permunetilleke K Sankaranand J Zhang ldquoDaily stock market forecast from textual Webdatardquo in Proceedings of the 1998 IEEE International Confer-ence on Systems Man and Cybernetics (Cat No98CH36218)SMCrsquo98 vol 3 pp 2720ndash2725 October 1998
[14] G Pui Cheong Fung J Xu Yu and W Lam ldquoStock predictionintegrating text mining approach using real-time newsrdquo inProceedings of the 2003 IEEE International Conference on Com-putational Intelligence for Financial Engineering CIFEr 2003vol 2003 pp 395ndash402 China March 2003
[15] W Antweiler and M Z Frank ldquoIs all that talk just noise theinformation content of internet stock message boardsrdquo SSRNElectronic Journal 2001
[16] M-A Mittermayer and G F Knolmayer ldquoNewsCATS A newscategorization and trading systemrdquo in Proceedings of the 6thInternational Conference onDataMining ICDM2006 pp 1002ndash1007 China December 2006
[17] R P Schumaker and H Chen ldquoTextual analysis of stockmarket prediction using breaking financial news theAZFin textsystemrdquo ACM Transactions on Information and Systems pp 1ndash29 2009
[18] S S Groth and J Muntermann ldquoAn intraday market riskmanagement approach based on textual analysisrdquo DecisionSupport Systems vol 50 no 4 pp 680ndash691 2011
[19] T Vu S Chang Q Ha and N Collier ldquoAn experiment in inte-grating sentiment features for tech stock prediction in twitterrdquoin Proceedings of the Workshop on Information Extraction AndEntity Analytics on Social Media Data vol 3 pp 23ndash38 2012
[20] B Wang H Huang and X Wang ldquoA novel text miningapproach to financial time series forecastingrdquo Neurocomputingvol 83 pp 136ndash145 2012
[21] Q Li T Wang P Li L Liu Q Gong and Y Chen ldquoThe effectof news and public mood on stock movementsrdquo InformationSciences vol 278 pp 826ndash840 2014
[22] T H Nguyen K Shirai and J Velcin ldquoSentiment analysis onsocial media for stock movement predictionrdquo Expert Systemswith Applications vol 42 no 24 pp 9603ndash9611 2015
[23] BWengM A Ahmed and FMMegahed ldquoStockmarket one-day ahead movement prediction using disparate data sourcesrdquoExpert Systems with Applications vol 79 pp 153ndash163 2017
[24] J Eberhard J F Lavin and A Montecinos-Pearce ldquoA network-based dynamic analysis in an equity stock marketrdquo Complexityvol 2017 Article ID 3979836 16 pages 2017
[25] Z Zhang Y Zhang D Shen and W Zhang ldquoThe dynamiccross-correlations between mass media news newmedia newsand stock returnsrdquo Complexity vol 2018 11 pages 2018
[26] P C Tetlock ldquoGiving content to investor sentiment The role ofmedia in the stock marketrdquo Journal of Finance vol 62 no 3 pp1139ndash1168 2007
[27] K Chen P Luo L Liu andW Zhang ldquoNews search and stockco-movement Investigating information diffusion in the finan-cial marketrdquo Electronic Commerce Research and Applicationsvol 28 pp 159ndash171 2018
[28] F Z Xing E Cambria and Y Zhang ldquoSentiment-awarevolatility forecastingrdquo Knowledge-Based Systems vol 176 pp68ndash76 2019
[29] A Picasso S Merello Y Ma L Oneto and E CambrialdquoTechnical analysis and sentiment embeddings formarket trendpredictionrdquo Expert Systems with Applications vol 135 pp 60ndash70 2019
[30] A Khadjeh Nassirtoussi S Aghabozorgi T Ying Wah and DC L Ngo ldquoText mining for market prediction a systematicreviewrdquo Expert Systems with Applications vol 41 no 16 pp7653ndash7670 2014
[31] M Kraus and S Feuerriegel ldquoDecision support from financialdisclosures with deep neural networks and transfer learningrdquoDecision Support Systems vol 104 pp 38ndash48 2017
[32] H S Sim H I Kim and J J Ahn ldquoIs deep learning for imagerecognition applicable to stockmarket predictionrdquoComplexityvol 2019 10 pages 2019
Complexity 15
[33] M Jasemi A M Kimiagari and A Memariani ldquoA modernneural network model to do stock market timing on the basisof the ancient investment technique of Japanese candlestickrdquoExpert Systems with Applications vol 38 no 4 pp 3884ndash38902011
[34] A Fader S Soderland and O Etzioni ldquoIdentifying relations foropen information extractionrdquo in Proceedings of the Conferenceon Empirical Methods in Natural Language Processing EMNLP2011 pp 1535ndash1545 Association for Computational LinguisticsUK July 2011
[35] T Mikolov K Chen G Corrado and J Dean ldquoEfficientestimation of word representations in vector spacerdquo pp 1ndash122013 httpsarxivorgabs13013781
[36] X Lin Z Yang and Y Song ldquoIntelligent stock trading systembased on improved technical analysis and Echo State NetworkrdquoExpert Systems with Applications vol 38 no 9 pp 11347ndash113542011
[37] K-J Kim and I Han ldquoGenetic algorithms approach to featurediscretization in artificial neural networks for the prediction ofstock price indexrdquo Expert Systems with Applications vol 19 no2 pp 125ndash132 2000
[38] Y Yu W Duan and Q Cao ldquoThe impact of social andconventional media on firm equity value A sentiment analysisapproachrdquoDecision Support Systems vol 55 no 4 pp 919ndash9262013
[39] MHagenauM Liebmann andDNeumann ldquoAutomated newsreading Stock price prediction based on financial news usingcontext-capturing featuresrdquo Decision Support Systems vol 55no 3 pp 685ndash697 2013
[40] A Aizawa ldquoAn information-theoretic perspective of tf-idfmeasuresrdquo Information Processing amp Management vol 39 no1 pp 45ndash65 2003
[41] A Khadjeh Nassirtoussi S Aghabozorgi T Ying Wah and DC Ngo ldquoText mining of news-headlines for FOREX marketprediction a Multi-layer dimension reduction algorithm withsemantics and sentimentrdquo Expert Systems with Applications vol42 no 1 pp 306ndash324 2015
[42] D Peramunetilleke and R K Wong ldquoCurrency exchange rateforecasting from news headlinesrdquo Australian Computer ScienceCommunications vol 24 no 2 pp 131ndash139 2002
[43] Y Kim ldquoConvolutional neural networks for sentence classifica-tionrdquo 2014 httpsarxivorgabs14085882
[44] ZWang J Zhang J Feng and Z Chen ldquoKnowledge graph andtext jointly embeddingrdquo in Proceedings of the 2014 Conferenceon Empirical Methods in Natural Language Processing EMNLP2014 pp 1591ndash1601 Qatar October 2014
[45] J Xu X Qiu K Chen and X Huang ldquoKnowledge graphrepresentation with jointly structural and textual encodingrdquo inProceedings of the 26th International Joint Conference on Arti-ficial Intelligence IJCAI 2017 pp 1318ndash1324 Australia August2017
[46] R Xie Z Liu J Jia H Luan and M Sun ldquoRepresentationlearning of knowledge graphs with entity descriptionsrdquo in Pro-ceedings of the 30th AAAI Conference on Artificial IntelligenceAAAI rsquo16 pp 2659ndash2665 February 2016
[47] F Tian B Gao E Chen and T Liu ldquoLearning better wordembedding by asymmetric low-rank projection of knowledgegraphrdquo Journal of Computer Science and Technology vol 31 no3 pp 624ndash634 2016
[48] F Z Xing E Cambria and R E Welsch ldquoNatural languagebased financial forecasting a surveyrdquo Artificial IntelligenceReview vol 50 no 1 pp 49ndash73 2018
[49] C Goutte and E Gaussier ldquoA probabilistic interpretation ofprecision recall and F-score with implication for evaluationrdquoin Advances in Information Retrieval D E Losada and J MFernandez-Luna Eds vol 3408 of Lecture Notes in ComputerScience pp 345ndash359 Springer Berlin Germany 2005
Hindawiwwwhindawicom Volume 2018
MathematicsJournal of
Hindawiwwwhindawicom Volume 2018
Mathematical Problems in Engineering
Applied MathematicsJournal of
Hindawiwwwhindawicom Volume 2018
Probability and StatisticsHindawiwwwhindawicom Volume 2018
Journal of
Hindawiwwwhindawicom Volume 2018
Mathematical PhysicsAdvances in
Complex AnalysisJournal of
Hindawiwwwhindawicom Volume 2018
OptimizationJournal of
Hindawiwwwhindawicom Volume 2018
Hindawiwwwhindawicom Volume 2018
Engineering Mathematics
International Journal of
Hindawiwwwhindawicom Volume 2018
Operations ResearchAdvances in
Journal of
Hindawiwwwhindawicom Volume 2018
Function SpacesAbstract and Applied AnalysisHindawiwwwhindawicom Volume 2018
International Journal of Mathematics and Mathematical Sciences
Hindawiwwwhindawicom Volume 2018
Hindawi Publishing Corporation httpwwwhindawicom Volume 2013Hindawiwwwhindawicom
The Scientific World Journal
Volume 2018
Hindawiwwwhindawicom Volume 2018Volume 2018
Numerical AnalysisNumerical AnalysisNumerical AnalysisNumerical AnalysisNumerical AnalysisNumerical AnalysisNumerical AnalysisNumerical AnalysisNumerical AnalysisNumerical AnalysisNumerical AnalysisNumerical AnalysisAdvances inAdvances in Discrete Dynamics in
Nature and SocietyHindawiwwwhindawicom Volume 2018
Hindawiwwwhindawicom
Dierential EquationsInternational Journal of
Volume 2018
Hindawiwwwhindawicom Volume 2018
Decision SciencesAdvances in
Hindawiwwwhindawicom Volume 2018
AnalysisInternational Journal of
Hindawiwwwhindawicom Volume 2018
Stochastic AnalysisInternational Journal of
Submit your manuscripts atwwwhindawicom

14 Complexity
authors also want to thank the research program RFCS fromthe EU which partially supported this research through theresearch project AutoSurveillance with project ID 847202
References
[1] B GMalkiel and E F Fama ldquoEfficient capital markets a reviewof theory and empirical workrdquo The Journal of Finance vol 25no 2 pp 383ndash417 1970
[2] D Galai and R W Masulis ldquoThe option pricing model and therisk factor of stockrdquo Journal of Financial Economics vol 3 no1-2 pp 53ndash81 1976
[3] Q Wang Z Mao B Wang and L Guo ldquoKnowledge graphembedding A survey of approaches and applicationsrdquo IEEETransactions on Knowledge and Data Engineering vol 29 no12 pp 2724ndash2743 2017
[4] H Paulheim and P Cimiano ldquoKnowledge graph refinement Asurvey of approaches and evaluation methodsrdquo Journal of WebSemantics Science Services and Agents on the World Wide Webvol 8 no 3 pp 489ndash508 2016
[5] X Ding Y Zhang T Liu and J Duan ldquoDeep learning for event-driven stock predictionrdquo in Proceedings of the 24th InternationalJoint Conference on Artificial Intelligence IJCAI 2015 pp 2327ndash2333 Argentina July 2015
[6] X Ding Y Zhang T Liu and J Duan ldquoKnowledge-drivenevent embedding for stock predictionrdquo in Proceedings of the26th International Conference on Computational LinguisticsCOLING 2016 pp 2133ndash2142 Japan December 2016
[7] A Bordes N Usunier J Weston and O Yakhnenko ldquoTranslat-ing embeddings for modeling multi-relational datardquo Advancesin NIPS vol 26 pp 2787ndash2795 2013
[8] H Lin Y Liu W Wang Y Yue and Z Lin ldquoLearning entityand relation embeddings for knowledge resolutionrdquo ProcediaComputer Science vol 108 pp 345ndash354 2017
[9] G Ji K Liu S He and J Zhao ldquoKnowledge graph completionwith adaptive sparse transfer matrixrdquo in Proceedings of the 30thAAAI Conference on Artificial Intelligence AAAI 2016 pp 985ndash991 USA February 2016
[10] G Ji S He L Xu K Liu and J Zhao ldquoKnowledge graphembedding via dynamic mapping matrixrdquo in Proceedings ofthe 53rd Annual Meeting of the Association for ComputationalLinguistics and the 7th International Joint Conference on NaturalLanguage Processing (Volume 1 Long Papers) pp 687ndash696Beijing China July 2015
[11] Y LeCun Y Bengio and G Hinton ldquoDeep learningrdquo Naturevol 521 no 7553 pp 436ndash444 2015
[12] Q Li Y Chen J Wang and H Chen ldquoWeb media andstock markets a survey and future directions from a bigdata perspectiverdquo IEEE Transactions on Knowledge and DataEngineering vol 4347 p 1 2017
[13] B Wuthrich V Cho S Leung D Permunetilleke K Sankaranand J Zhang ldquoDaily stock market forecast from textual Webdatardquo in Proceedings of the 1998 IEEE International Confer-ence on Systems Man and Cybernetics (Cat No98CH36218)SMCrsquo98 vol 3 pp 2720ndash2725 October 1998
[14] G Pui Cheong Fung J Xu Yu and W Lam ldquoStock predictionintegrating text mining approach using real-time newsrdquo inProceedings of the 2003 IEEE International Conference on Com-putational Intelligence for Financial Engineering CIFEr 2003vol 2003 pp 395ndash402 China March 2003
[15] W Antweiler and M Z Frank ldquoIs all that talk just noise theinformation content of internet stock message boardsrdquo SSRNElectronic Journal 2001
[16] M-A Mittermayer and G F Knolmayer ldquoNewsCATS A newscategorization and trading systemrdquo in Proceedings of the 6thInternational Conference onDataMining ICDM2006 pp 1002ndash1007 China December 2006
[17] R P Schumaker and H Chen ldquoTextual analysis of stockmarket prediction using breaking financial news theAZFin textsystemrdquo ACM Transactions on Information and Systems pp 1ndash29 2009
[18] S S Groth and J Muntermann ldquoAn intraday market riskmanagement approach based on textual analysisrdquo DecisionSupport Systems vol 50 no 4 pp 680ndash691 2011
[19] T Vu S Chang Q Ha and N Collier ldquoAn experiment in inte-grating sentiment features for tech stock prediction in twitterrdquoin Proceedings of the Workshop on Information Extraction AndEntity Analytics on Social Media Data vol 3 pp 23ndash38 2012
[20] B Wang H Huang and X Wang ldquoA novel text miningapproach to financial time series forecastingrdquo Neurocomputingvol 83 pp 136ndash145 2012
[21] Q Li T Wang P Li L Liu Q Gong and Y Chen ldquoThe effectof news and public mood on stock movementsrdquo InformationSciences vol 278 pp 826ndash840 2014
[22] T H Nguyen K Shirai and J Velcin ldquoSentiment analysis onsocial media for stock movement predictionrdquo Expert Systemswith Applications vol 42 no 24 pp 9603ndash9611 2015
[23] BWengM A Ahmed and FMMegahed ldquoStockmarket one-day ahead movement prediction using disparate data sourcesrdquoExpert Systems with Applications vol 79 pp 153ndash163 2017
[24] J Eberhard J F Lavin and A Montecinos-Pearce ldquoA network-based dynamic analysis in an equity stock marketrdquo Complexityvol 2017 Article ID 3979836 16 pages 2017
[25] Z Zhang Y Zhang D Shen and W Zhang ldquoThe dynamiccross-correlations between mass media news newmedia newsand stock returnsrdquo Complexity vol 2018 11 pages 2018
[26] P C Tetlock ldquoGiving content to investor sentiment The role ofmedia in the stock marketrdquo Journal of Finance vol 62 no 3 pp1139ndash1168 2007
[27] K Chen P Luo L Liu andW Zhang ldquoNews search and stockco-movement Investigating information diffusion in the finan-cial marketrdquo Electronic Commerce Research and Applicationsvol 28 pp 159ndash171 2018
[28] F Z Xing E Cambria and Y Zhang ldquoSentiment-awarevolatility forecastingrdquo Knowledge-Based Systems vol 176 pp68ndash76 2019
[29] A Picasso S Merello Y Ma L Oneto and E CambrialdquoTechnical analysis and sentiment embeddings formarket trendpredictionrdquo Expert Systems with Applications vol 135 pp 60ndash70 2019
[30] A Khadjeh Nassirtoussi S Aghabozorgi T Ying Wah and DC L Ngo ldquoText mining for market prediction a systematicreviewrdquo Expert Systems with Applications vol 41 no 16 pp7653ndash7670 2014
[31] M Kraus and S Feuerriegel ldquoDecision support from financialdisclosures with deep neural networks and transfer learningrdquoDecision Support Systems vol 104 pp 38ndash48 2017
[32] H S Sim H I Kim and J J Ahn ldquoIs deep learning for imagerecognition applicable to stockmarket predictionrdquoComplexityvol 2019 10 pages 2019
Complexity 15
[33] M Jasemi A M Kimiagari and A Memariani ldquoA modernneural network model to do stock market timing on the basisof the ancient investment technique of Japanese candlestickrdquoExpert Systems with Applications vol 38 no 4 pp 3884ndash38902011
[34] A Fader S Soderland and O Etzioni ldquoIdentifying relations foropen information extractionrdquo in Proceedings of the Conferenceon Empirical Methods in Natural Language Processing EMNLP2011 pp 1535ndash1545 Association for Computational LinguisticsUK July 2011
[35] T Mikolov K Chen G Corrado and J Dean ldquoEfficientestimation of word representations in vector spacerdquo pp 1ndash122013 httpsarxivorgabs13013781
[36] X Lin Z Yang and Y Song ldquoIntelligent stock trading systembased on improved technical analysis and Echo State NetworkrdquoExpert Systems with Applications vol 38 no 9 pp 11347ndash113542011
[37] K-J Kim and I Han ldquoGenetic algorithms approach to featurediscretization in artificial neural networks for the prediction ofstock price indexrdquo Expert Systems with Applications vol 19 no2 pp 125ndash132 2000
[38] Y Yu W Duan and Q Cao ldquoThe impact of social andconventional media on firm equity value A sentiment analysisapproachrdquoDecision Support Systems vol 55 no 4 pp 919ndash9262013
[39] MHagenauM Liebmann andDNeumann ldquoAutomated newsreading Stock price prediction based on financial news usingcontext-capturing featuresrdquo Decision Support Systems vol 55no 3 pp 685ndash697 2013
[40] A Aizawa ldquoAn information-theoretic perspective of tf-idfmeasuresrdquo Information Processing amp Management vol 39 no1 pp 45ndash65 2003
[41] A Khadjeh Nassirtoussi S Aghabozorgi T Ying Wah and DC Ngo ldquoText mining of news-headlines for FOREX marketprediction a Multi-layer dimension reduction algorithm withsemantics and sentimentrdquo Expert Systems with Applications vol42 no 1 pp 306ndash324 2015
[42] D Peramunetilleke and R K Wong ldquoCurrency exchange rateforecasting from news headlinesrdquo Australian Computer ScienceCommunications vol 24 no 2 pp 131ndash139 2002
[43] Y Kim ldquoConvolutional neural networks for sentence classifica-tionrdquo 2014 httpsarxivorgabs14085882
[44] ZWang J Zhang J Feng and Z Chen ldquoKnowledge graph andtext jointly embeddingrdquo in Proceedings of the 2014 Conferenceon Empirical Methods in Natural Language Processing EMNLP2014 pp 1591ndash1601 Qatar October 2014
[45] J Xu X Qiu K Chen and X Huang ldquoKnowledge graphrepresentation with jointly structural and textual encodingrdquo inProceedings of the 26th International Joint Conference on Arti-ficial Intelligence IJCAI 2017 pp 1318ndash1324 Australia August2017
[46] R Xie Z Liu J Jia H Luan and M Sun ldquoRepresentationlearning of knowledge graphs with entity descriptionsrdquo in Pro-ceedings of the 30th AAAI Conference on Artificial IntelligenceAAAI rsquo16 pp 2659ndash2665 February 2016
[47] F Tian B Gao E Chen and T Liu ldquoLearning better wordembedding by asymmetric low-rank projection of knowledgegraphrdquo Journal of Computer Science and Technology vol 31 no3 pp 624ndash634 2016
[48] F Z Xing E Cambria and R E Welsch ldquoNatural languagebased financial forecasting a surveyrdquo Artificial IntelligenceReview vol 50 no 1 pp 49ndash73 2018
[49] C Goutte and E Gaussier ldquoA probabilistic interpretation ofprecision recall and F-score with implication for evaluationrdquoin Advances in Information Retrieval D E Losada and J MFernandez-Luna Eds vol 3408 of Lecture Notes in ComputerScience pp 345ndash359 Springer Berlin Germany 2005
Hindawiwwwhindawicom Volume 2018
MathematicsJournal of
Hindawiwwwhindawicom Volume 2018
Mathematical Problems in Engineering
Applied MathematicsJournal of
Hindawiwwwhindawicom Volume 2018
Probability and StatisticsHindawiwwwhindawicom Volume 2018
Journal of
Hindawiwwwhindawicom Volume 2018
Mathematical PhysicsAdvances in
Complex AnalysisJournal of
Hindawiwwwhindawicom Volume 2018
OptimizationJournal of
Hindawiwwwhindawicom Volume 2018
Hindawiwwwhindawicom Volume 2018
Engineering Mathematics
International Journal of
Hindawiwwwhindawicom Volume 2018
Operations ResearchAdvances in
Journal of
Hindawiwwwhindawicom Volume 2018
Function SpacesAbstract and Applied AnalysisHindawiwwwhindawicom Volume 2018
International Journal of Mathematics and Mathematical Sciences
Hindawiwwwhindawicom Volume 2018
Hindawi Publishing Corporation httpwwwhindawicom Volume 2013Hindawiwwwhindawicom
The Scientific World Journal
Volume 2018
Hindawiwwwhindawicom Volume 2018Volume 2018
Numerical AnalysisNumerical AnalysisNumerical AnalysisNumerical AnalysisNumerical AnalysisNumerical AnalysisNumerical AnalysisNumerical AnalysisNumerical AnalysisNumerical AnalysisNumerical AnalysisNumerical AnalysisAdvances inAdvances in Discrete Dynamics in
Nature and SocietyHindawiwwwhindawicom Volume 2018
Hindawiwwwhindawicom
Dierential EquationsInternational Journal of
Volume 2018
Hindawiwwwhindawicom Volume 2018
Decision SciencesAdvances in
Hindawiwwwhindawicom Volume 2018
AnalysisInternational Journal of
Hindawiwwwhindawicom Volume 2018
Stochastic AnalysisInternational Journal of
Submit your manuscripts atwwwhindawicom

Complexity 15
[33] M Jasemi A M Kimiagari and A Memariani ldquoA modernneural network model to do stock market timing on the basisof the ancient investment technique of Japanese candlestickrdquoExpert Systems with Applications vol 38 no 4 pp 3884ndash38902011
[34] A Fader S Soderland and O Etzioni ldquoIdentifying relations foropen information extractionrdquo in Proceedings of the Conferenceon Empirical Methods in Natural Language Processing EMNLP2011 pp 1535ndash1545 Association for Computational LinguisticsUK July 2011
[35] T Mikolov K Chen G Corrado and J Dean ldquoEfficientestimation of word representations in vector spacerdquo pp 1ndash122013 httpsarxivorgabs13013781
[36] X Lin Z Yang and Y Song ldquoIntelligent stock trading systembased on improved technical analysis and Echo State NetworkrdquoExpert Systems with Applications vol 38 no 9 pp 11347ndash113542011
[37] K-J Kim and I Han ldquoGenetic algorithms approach to featurediscretization in artificial neural networks for the prediction ofstock price indexrdquo Expert Systems with Applications vol 19 no2 pp 125ndash132 2000
[38] Y Yu W Duan and Q Cao ldquoThe impact of social andconventional media on firm equity value A sentiment analysisapproachrdquoDecision Support Systems vol 55 no 4 pp 919ndash9262013
[39] MHagenauM Liebmann andDNeumann ldquoAutomated newsreading Stock price prediction based on financial news usingcontext-capturing featuresrdquo Decision Support Systems vol 55no 3 pp 685ndash697 2013
[40] A Aizawa ldquoAn information-theoretic perspective of tf-idfmeasuresrdquo Information Processing amp Management vol 39 no1 pp 45ndash65 2003
[41] A Khadjeh Nassirtoussi S Aghabozorgi T Ying Wah and DC Ngo ldquoText mining of news-headlines for FOREX marketprediction a Multi-layer dimension reduction algorithm withsemantics and sentimentrdquo Expert Systems with Applications vol42 no 1 pp 306ndash324 2015
[42] D Peramunetilleke and R K Wong ldquoCurrency exchange rateforecasting from news headlinesrdquo Australian Computer ScienceCommunications vol 24 no 2 pp 131ndash139 2002
[43] Y Kim ldquoConvolutional neural networks for sentence classifica-tionrdquo 2014 httpsarxivorgabs14085882
[44] ZWang J Zhang J Feng and Z Chen ldquoKnowledge graph andtext jointly embeddingrdquo in Proceedings of the 2014 Conferenceon Empirical Methods in Natural Language Processing EMNLP2014 pp 1591ndash1601 Qatar October 2014
[45] J Xu X Qiu K Chen and X Huang ldquoKnowledge graphrepresentation with jointly structural and textual encodingrdquo inProceedings of the 26th International Joint Conference on Arti-ficial Intelligence IJCAI 2017 pp 1318ndash1324 Australia August2017
[46] R Xie Z Liu J Jia H Luan and M Sun ldquoRepresentationlearning of knowledge graphs with entity descriptionsrdquo in Pro-ceedings of the 30th AAAI Conference on Artificial IntelligenceAAAI rsquo16 pp 2659ndash2665 February 2016
[47] F Tian B Gao E Chen and T Liu ldquoLearning better wordembedding by asymmetric low-rank projection of knowledgegraphrdquo Journal of Computer Science and Technology vol 31 no3 pp 624ndash634 2016
[48] F Z Xing E Cambria and R E Welsch ldquoNatural languagebased financial forecasting a surveyrdquo Artificial IntelligenceReview vol 50 no 1 pp 49ndash73 2018
[49] C Goutte and E Gaussier ldquoA probabilistic interpretation ofprecision recall and F-score with implication for evaluationrdquoin Advances in Information Retrieval D E Losada and J MFernandez-Luna Eds vol 3408 of Lecture Notes in ComputerScience pp 345ndash359 Springer Berlin Germany 2005
Hindawiwwwhindawicom Volume 2018
MathematicsJournal of
Hindawiwwwhindawicom Volume 2018
Mathematical Problems in Engineering
Applied MathematicsJournal of
Hindawiwwwhindawicom Volume 2018
Probability and StatisticsHindawiwwwhindawicom Volume 2018
Journal of
Hindawiwwwhindawicom Volume 2018
Mathematical PhysicsAdvances in
Complex AnalysisJournal of
Hindawiwwwhindawicom Volume 2018
OptimizationJournal of
Hindawiwwwhindawicom Volume 2018
Hindawiwwwhindawicom Volume 2018
Engineering Mathematics
International Journal of
Hindawiwwwhindawicom Volume 2018
Operations ResearchAdvances in
Journal of
Hindawiwwwhindawicom Volume 2018
Function SpacesAbstract and Applied AnalysisHindawiwwwhindawicom Volume 2018
International Journal of Mathematics and Mathematical Sciences
Hindawiwwwhindawicom Volume 2018
Hindawi Publishing Corporation httpwwwhindawicom Volume 2013Hindawiwwwhindawicom
The Scientific World Journal
Volume 2018
Hindawiwwwhindawicom Volume 2018Volume 2018
Numerical AnalysisNumerical AnalysisNumerical AnalysisNumerical AnalysisNumerical AnalysisNumerical AnalysisNumerical AnalysisNumerical AnalysisNumerical AnalysisNumerical AnalysisNumerical AnalysisNumerical AnalysisAdvances inAdvances in Discrete Dynamics in
Nature and SocietyHindawiwwwhindawicom Volume 2018
Hindawiwwwhindawicom
Dierential EquationsInternational Journal of
Volume 2018
Hindawiwwwhindawicom Volume 2018
Decision SciencesAdvances in
Hindawiwwwhindawicom Volume 2018
AnalysisInternational Journal of
Hindawiwwwhindawicom Volume 2018
Stochastic AnalysisInternational Journal of
Submit your manuscripts atwwwhindawicom

Hindawiwwwhindawicom Volume 2018
MathematicsJournal of
Hindawiwwwhindawicom Volume 2018
Mathematical Problems in Engineering
Applied MathematicsJournal of
Hindawiwwwhindawicom Volume 2018
Probability and StatisticsHindawiwwwhindawicom Volume 2018
Journal of
Hindawiwwwhindawicom Volume 2018
Mathematical PhysicsAdvances in
Complex AnalysisJournal of
Hindawiwwwhindawicom Volume 2018
OptimizationJournal of
Hindawiwwwhindawicom Volume 2018
Hindawiwwwhindawicom Volume 2018
Engineering Mathematics
International Journal of
Hindawiwwwhindawicom Volume 2018
Operations ResearchAdvances in
Journal of
Hindawiwwwhindawicom Volume 2018
Function SpacesAbstract and Applied AnalysisHindawiwwwhindawicom Volume 2018
International Journal of Mathematics and Mathematical Sciences
Hindawiwwwhindawicom Volume 2018
Hindawi Publishing Corporation httpwwwhindawicom Volume 2013Hindawiwwwhindawicom
The Scientific World Journal
Volume 2018
Hindawiwwwhindawicom Volume 2018Volume 2018
Numerical AnalysisNumerical AnalysisNumerical AnalysisNumerical AnalysisNumerical AnalysisNumerical AnalysisNumerical AnalysisNumerical AnalysisNumerical AnalysisNumerical AnalysisNumerical AnalysisNumerical AnalysisAdvances inAdvances in Discrete Dynamics in
Nature and SocietyHindawiwwwhindawicom Volume 2018
Hindawiwwwhindawicom
Dierential EquationsInternational Journal of
Volume 2018
Hindawiwwwhindawicom Volume 2018
Decision SciencesAdvances in
Hindawiwwwhindawicom Volume 2018
AnalysisInternational Journal of
Hindawiwwwhindawicom Volume 2018
Stochastic AnalysisInternational Journal of
Submit your manuscripts atwwwhindawicom