Embed Size (px)
Citation preview

� ���
�
Albert-Ludwigs-Universität FreiburgTechnische Fakultät, Institut für Informatik
Anfragetransformationen zum adaptiven Filtern vonXML-Datenströmen
Dissertation zur Erlangung des Dokotorgrades
von
Martin Anton Webergeboren am 29. Juli 1972 in Lahr
Dekan : Prof. Dr. Hans Zappe
Referenten : Prof. Dr. Georg LausenProf. Dr. Pedro José Marrón
Datum der Promotion: 29. Juli 2009


Zusammenfassung
Das Filtern von Datenströmen anhand großer Mengen von Anfragen ist eine Herausforderung,die seit der Verbreitung des World-Wide-Web und der damit einhergehenden Vernetzungzunehmend präsenter wird. Mit der Auszeichnungssprache XML, die eine Beschreibung undDarstellung der Daten in sowohl menschen- als auch maschinenlesbarer Form erlaubt, hatsich eine breit akzeptierte Plattform für den Austausch von Daten etabliert. Damit bedeutetFiltern von Daten in vielen Fällen Filtern von Daten im Format XML.
Die große Stärke von XML ist seine Flexibilität. Durch die Definition geeigneter Schematalassen sich nahezu beliebige Szenarien beschreiben, wobei die konkreten Erfordernisse derAnwendung berücksichtigt werden können. Diese Flexibilität, auf der einen Seite ein großerVorteil von XML, kann sich jedoch auch als gravierender Nachteil erweisen. So existiert füreine konkrete Anwendungsdomäne gegebenenfalls eine Vielzahl verschiedener Schemata, wasim Falle einer Integration von Daten aus verschiedenen Quellen dieser Domäne mit einemerheblichen Aufwand verbunden sein kann. Ein weiteres Problem liegt vor, wenn die Datenvom zugrundeliegenden Schema abweichen, da die Systeme in der Regel auf schemakonformeDaten angewiesen sind.
Mit aXst wird ein System zum Filtern von XML-Datenströmen präsentiert, das Anfragenan die tatsächlich vorliegenden Strukturen der Datenströme anpasst. Damit liefert das Systemauch dann Treffer, wenn die Daten entweder fehlerhaft sind oder von der vom Benutzererwarteten Struktur abweichen. Der Mechanismus zur Anpassung der Anfragen basiert aufTransformationen, welche Anfragen entweder auf Grundlage von Schemata oder aber dentatsächlich vorliegenden Daten umwandelt. Es wird eine Funktion definiert, um die dabeigenerierten Anfragen zu bewerten.
Um den Aufwand der Transformationen, die Performanz des Filterns von Datenströmen,sowie die Qualität der Suchergebnisse zu untersuchen, werden experimentelle Untersuchungeneiner Implementierung der entwickelten Verfahren anhand großer Mengen von Daten undAnfragen vorgenommen.


Abstract
The challenge of efficient data-filtering is present since the great proliferation of the world-wide-web. The generalized markup language XML allows the description of presentation ofdata in human as well as machine readable form and is a widely accepted platform for theexchange of data. So filtering of data often means filtering of XML-data.
The great advantage of XML is its flexibility. XML allows the description of an arbitraryamount of scenarios whereas the concrete requirements of the given task can be considered.The disadvantage of this flexibility is the fact that there are several schemata for a givenscenario, so the integration of multiple resources of that scenario can be difficult. Deficientdata is another problem because most systems are not able to handle such data in a satisfiablemanner.
In this work the system aXst is presented which adapts queries to the currently given data.So aXst is able to present query results even if the data is deficient or the data is not validconsidering a given schema. The central part of aXst is the transformation of queries basedon schemas or based on the currently given data. A function is defined which evaluates thetransformed queries.
An implementation of the system is explored by means of large amounts of automaticallygenerated queries and data-sets. The several variants of the transformation algorithm as wellas its various parameters are considered.


Danksagung
Mein ganz besonderer Dank gilt Prof. Dr. Georg Lausen. Er bot mir die Möglichkeit unddie Unterstützung zur Erstellung dieser Arbeit. Daneben gilt mein Dank Prof. Dr. Pe-dro José Marrón für seine Ideen auf dem Gebiet der Anfragetransformationen und seineHinweise zum Abschluss der Arbeit.
Das angenehme und inspirierende Umfeld am Lehrstuhl für Datenbanken und Informa-tionssysteme in Freiburg erleichterte mir meine Arbeit erheblich. Mein herzlichster Dankgilt daher meinen Kolleginnen und Kollegen, die mich sowohl fachlich als auch persönlichbegleitet haben - ich möchte mich bedanken bei Dr. Lule Ahmedi, Dr. Harald Hiss, Tho-mas Hornung, Dr. Matthias Ihle, Norbert Küchlin, Elisabeth Lott, Prof. Dr. Wolfgang May,Michael Meier, Florian Schmedding, Michael Schmidt, Dr. Kai Simon, Dr. Fang Wei undDr. Cai-Nicholas Ziegler.
Meiner Frau Bernadette und meinem Sohn Joshua danke ich aus tiefstem Herzen für ihrVerständnis, ihre Unterstützung und ihre Geduld.
Gundelfingen, Juli 2009 Martin Weber


Inhaltsverzeichnis
1 Einleitung 11.1 Problemstellungen . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 11.2 Ziele . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 31.3 Gliederung . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 4
2 Verwandte Arbeiten 72.1 Datenintegration . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 7
2.1.1 Bezug zur Arbeit . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 82.2 Verarbeitung von kontinuierlichen Datenströmen . . . . . . . . . . . . . . . . 8
2.2.1 Allgemeine Arbeiten . . . . . . . . . . . . . . . . . . . . . . . . . . . . 92.2.2 Verarbeitung tupelbasierter Streams . . . . . . . . . . . . . . . . . . . 102.2.3 Verarbeitung von XML-Datenströmen . . . . . . . . . . . . . . . . . . 122.2.4 Bezug zur Arbeit . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 16
2.3 Anfragetransformation und -Manipulation . . . . . . . . . . . . . . . . . . . . 172.3.1 Bezug zur Arbeit . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 18
3 Grundlagen 193.1 Integration von Datenquellen . . . . . . . . . . . . . . . . . . . . . . . . . . . 193.2 Selective Information Dissemination . . . . . . . . . . . . . . . . . . . . . . . 213.3 Filtern von XML-Datenströmen . . . . . . . . . . . . . . . . . . . . . . . . . . 253.4 Das Verfahren YFilter - ein NFA-basierter Ansatz . . . . . . . . . . . . . . . . 29
3.4.1 YFilter als Basis von aXst . . . . . . . . . . . . . . . . . . . . . . . . . 33
4 Adaptive Auswertung von XPath 354.1 Transformation von XPath-Subanfragen . . . . . . . . . . . . . . . . . . . . . 364.2 Transformation während der XPath-Auswertung . . . . . . . . . . . . . . . . 384.3 Bewertung der Anfragen und Suchergebnisse . . . . . . . . . . . . . . . . . . . 41
4.3.1 Formale Analyse . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 434.4 A-Priori Anfragetransformationen . . . . . . . . . . . . . . . . . . . . . . . . . 45
4.4.1 Formalisierung . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 454.4.2 Transformationen . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 484.4.3 Komplexität . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 57
ix

Inhaltsverzeichnis
4.4.4 Qualität der Transformationen . . . . . . . . . . . . . . . . . . . . . . 574.5 Anfragetransformationen ohne Schemainformation . . . . . . . . . . . . . . . 57
4.5.1 Generierung aller möglichen Anfragen . . . . . . . . . . . . . . . . . . 574.5.2 Ermittlung von Strukturinformationen aus den Daten . . . . . . . . . 59
5 Identifizieren der zu transformierenden Anfragen 635.1 Daten- und Anfragerepräsentation . . . . . . . . . . . . . . . . . . . . . . . . 63
5.1.1 Pflege der Daten- und Anfragerepräsentation . . . . . . . . . . . . . . 655.2 Identifizieren der Anfragen . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 66
5.2.1 basic-Transformationen . . . . . . . . . . . . . . . . . . . . . . . . . . 665.2.2 extended-Transformationen . . . . . . . . . . . . . . . . . . . . . . . . 66
5.3 Beispiel . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 67
6 Adaptives Filtern mit aXst 716.1 Anfragetransformationen und XML-Streaming . . . . . . . . . . . . . . . . . . 716.2 Architektur von aXst . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 726.3 Verarbeitungsmodi von aXst . . . . . . . . . . . . . . . . . . . . . . . . . . . . 786.4 Die Variante immediate . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 806.5 Anwendung von aXst . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 83
7 Experimente 857.1 Algorithmen . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 857.2 Experimentelle Umgebung . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 86
7.2.1 Praktische Umsetzung . . . . . . . . . . . . . . . . . . . . . . . . . . . 867.3 Performanz der Transformationen . . . . . . . . . . . . . . . . . . . . . . . . . 89
7.3.1 Anzahl der Anfragen . . . . . . . . . . . . . . . . . . . . . . . . . . . . 907.3.2 Eigenschaften der Anfragen . . . . . . . . . . . . . . . . . . . . . . . . 917.3.3 Eigenschaften der Transformationen und Schemata . . . . . . . . . . . 957.3.4 Zeitaufwand für Transformation und Speicherung . . . . . . . . . . . . 997.3.5 Bewertung . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 99
7.4 Qualität der Transformationen . . . . . . . . . . . . . . . . . . . . . . . . . . 1007.4.1 Transformation mit Schema . . . . . . . . . . . . . . . . . . . . . . . . 1017.4.2 Transformation ohne Schema . . . . . . . . . . . . . . . . . . . . . . . 1047.4.3 Abweichung während des Streamings . . . . . . . . . . . . . . . . . . . 1057.4.4 Bewertung . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 106
7.5 Streaming-Performanz . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1077.5.1 Aufwand für den Aufbau der Datenrepräsentation . . . . . . . . . . . 1127.5.2 Bewertung . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 113
7.6 Diskussion . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 113
x

Inhaltsverzeichnis
8 Fazit 1158.1 Zusammenfassung . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1158.2 Beitrag der Arbeit . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1178.3 Ausblick . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 118
Literaturverzeichnis 121
xi

Inhaltsverzeichnis
xii

Kapitel 1
Einleitung
1.1 Problemstellungen
Mit der sprunghaften Verbreitung des World-Wide-Web seit den neunziger Jahren des ver-gangenen Jahrhunderts ging eine zunehmende Durchdringung der verschiedensten Lebens-bereiche durch Informations-Technologie einher. Da viele informationsverarbeitende Systemeihren Nutzen erst im Zuge einer Kommunikation mit anderen Systemen, ihrer Umwelt odereinem Benutzer entfalten können, steigt in gleichem wenn nicht größeren Ausmaß der Bedarfan Vernetzung, Austausch und Integration derselben.
Um eine reibungslose Kommunikation zu gewährleisten müssen sich die Systeme zeitnahaustauschen können und eine effiziente Verarbeitung der anfallenden Daten ist unabdingbar.Ein Sonderfall sind dabei Umgebungen, in denen die Menge der zu verarbeitenden Daten inVerbindung mit dem Bedarf einer möglichst aktuellen Verarbeitung es nicht gestattet, dieDaten zunächst in einer Datenbank abzulegen und dann erst weiter zu verarbeiten.
Eine zentrale Rolle spielt in einem derartigen Umfeld das Filtern von Daten anhand vonProfilen, seien es benutzer- oder systemdefinierte. Die Anzahl dieser Profile kann in der Praxissehr groß sein, d.h. die Daten müssen gegebenenfalls anhand von mehreren Tausend bis zuMillionen von Anfragen gefiltert werden.
Typische Anwendungsfelder, in denen große Mengen von Daten anhand einer Vielzahl vonProfilen gefiltert werden müssen, sind beispielsweise:
• Nachrichtendienste: Benutzer spezifizieren ihr Interesse an einem bestimmten Themen-gebiet in Form von Profilen. Anhand dieser Profile werden aktuelle Nachrichten, dieaus den verschiedensten Quellen eintreffen, verarbeitet und gefiltert. Stimmen Nach-richten mit im System abgelegten Profilen überein, so werden die jeweiligen Benutzermit diesen Nachrichten versorgt.
• Börsendaten: Systeme zur Verarbeitung von Börsendaten zeichnen sich dadurch aus,dass sie mit einem hohen Datenaufkommen zurecht kommen müssen. Daten von ver-schiedenen Marktplätzen kommen an und sind aktuell und zeitnah anhand von Filternan die jeweiligen Ziele weiterzuleiten.
1

Kapitel 1 Einleitung
• Sensordaten: Viele Bereiche in Umwelt und Technik werden heute von Sensoren über-wacht, welche mannigfaltige Parameter ihrer Umgebung aufzeichnen und weiterleiten.Alle diese Daten müssen in irgend einer Form gefiltert und weiterverarbeitet werden.Beispiele für Sensornetzwerke [GHH+02] sind etwa Monitoring des Engergieverbrauchsin Gebäuden, militärische oder zivile Überwachung, Monitoring natürlicher Lebensräu-me zum Verständnis der Dynamik von Ökosystemen, Sammlung von Daten in Lernum-gebungen von Kindern.
• Routingdaten in Netzwerken: Viele Netzwerkprotokolle besonders höherer Schichten ba-sieren heute auf dem Austausch von XML-Nachrichten, man denke dabei etwa an Web-Services bei denen entfernte Methodenaufrufe als SOAP-Nachrichten über ein Netzwerkgeschickt werden. Damit diese Nachrichten schnell ihr Ziel finden, sind effiziente Ver-fahren notwendig, um die häufig sehr umfangreichen Nachrichtenpakete zu verarbeitenund weiterzuleiten.
• Ubiquitous Computing: Der Begriff des Ubiquitous Computing wurde mitgeprägt vonMark Weis (siehe [Wei95]). Er beschreibt die Idee, dass Rechner in Zukunft in einerArt und Weise allgegenwärtig sind, dass wir uns gar nicht mehr darüber bewusst sind,wann, ob und wie wir gerade ein bestimmtes Computersystem benutzen. Rechner undSensoren unterstützen uns in vielfältigen Aspekten unseres Lebens. Um dies zu ermög-lichen, ist es notwendig entsprechende Sensordatenquellen zu verknüpfen und derenpermanenten Austausch zu gewährleisten.
• Monitoring von wissenschaftlichen Daten wie Umwelt [NAS04], Astronomie oder Me-teorologie, von Kontroll-Daten wie im Verkehrswesen [Org03], in Netzwerken oder inder Logistik, von Finanzdaten (z.B. Banktransaktionen) oder dem MPEG-7-Routing.
Wie dem Großteil aller informationsverarbeitenden Systeme ist auch vielen der Systeme ausdiesen Bereichen gemein, dass sie für einen reibungslosen Betrieb auf möglichst perfekte, d.h.fehlerfreie Daten angewiesen sind. Die Systeme basieren auf Beschreibungen von Strukturenund Inhalten der zu verarbeitenden Daten, in der Regel in Form von Schemata. Benutzer,welche ihr Interesse an den Daten in Form von Anfragen oder Profilen ausdrücken, stützensich auf diese Schemata und erwarten, dass die Daten diesen entsprechen. An genau dieserStelle haben viele Systeme eine Achilles-Sehne. Abweichungen vom Schema können aufgrundder verschiedensten Ursachen und in unterschiedlichen Ausprägungen auftreten. So könnenetwa Schemata aktualisiert werden, wobei die betreffenden Änderungen nicht an alle betrof-fenen Systeme und Benutzer weitergegeben werden. Bei der Generierung der Daten könnenSchemata ignoriert werden um zusätzliche Informationen unterzubringen oder fehlende Infor-mationen wegzulassen. Offensichtlich muss an jeder Stelle, an der der Mensch in das Systemeingreift, mit menschlichem Fehlverhalten gerechnet werden. Letztendlich lässt sich diese Lis-te beliebig fortspinnen und in aller Regel sind die Systeme schlecht auf derartige Situationenvorbereitet. Wird das Profil eines Benutzers auf eine Datenquelle angewandt, deren Struktur
2

1.2 Ziele
in irgend einer Form von der durch das Profil ausgedrückten Erwartung abweicht, so wird dasProfil oftmals nicht treffen. Dieser Zustand ist insbesondere dann nicht wünschenswert, wenneine rein strukturelle Abweichung vorliegt, die ein korrektes Ausführen der Anfrage verhin-dert, jedoch tatsächlich Daten vorhanden sind, die von Interesse für den Benutzer sind. DasErkennen derartiger Abweichungen ist oft trivial, die angemessene Reaktion darauf erweistsich jedoch als Herausforderung.
Unsere hochvernetzte Welt verlangt nach Systemen, die Daten aus verschiedenen Quelleneiner bestimmten Domäne bündeln, zu einem einheitlichen Ganzen zusammenfassen und da-mit die Verarbeitung dieser Daten wesentlich vereinfachen. Systeme und Ansätze, die diesbewerkstelligen, lassen sich unter den Stichworten Informations- oder Datenintegration zu-sammenfassen.
Da die einzelnen Quellen in der Regel verschiedene so genannte lokale Schemata haben,ist es im Bereich der Datenintegration notwendig Abbildungen zu definieren, um diese lo-kalen Schemata in ein globales Schema zu überführen. Hinsichtlich der Art der tatsächlichdurchgeführten Integration existieren verschiedene konkurrierende Ansätze. So werden etwabei der physischen Integration die lokalen Daten tatsächlich in das globale Schema überführt,wohingegen bei der logischen Integration die Daten in ihren lokalen Schemata verbleiben underst im Zuge einer Anfrage eine Abbildung stattfindet.
Bei näherer Betrachtung zeigt sich die enge Verwandschaft der Problems der Datenintegra-tion auf der einen und einer fehlertoleranten Verarbeitung von Daten auf der anderen Seite.Daten welche in Bezug auf ein konkretes Schema nicht gültig und damit fehlerhaft sind,erweisen sich jedoch hinsichtlich eines quasi virtuellen bzw. nicht tatsächlich existierendenSchemas als gültig. Somit besteht bei der Verarbeitung fehlerhafter Daten, ebenso wie bei derDatenintegration, das Problem darin, dass die Benutzeranfragen hinsichtlich eines konkretenSchemas formuliert wurden, die tatsächlichen Daten jedoch von diesem Schema abweichen.
1.2 Ziele
In dieser Arbeit soll mit aXst (adaptive XML streaming) erstmalig ein Ansatz zum Filternvon XML-Datenströmen definiert werden, der sowohl eine Integration verschiedenster hetero-gener Datenquellen als auch ein fehlertolerantes Filtern erlaubt. Dabei soll aXst erstmals einperformantes Filtern anhand einer sehr großen Menge von Anfragen mit einer integrativenund fehlertoleranten Verarbeitung der anfallenden Daten kombinieren.
Ein Schwachpunkt vieler gängiger Systeme zur Datenintegration ist die Notwendigkeit dermanuellen Definition von domänspezifischen Transformationsregeln. Dieser Schritt ist auf-wändig, fehleranfällig und für sich dynamisch ändernde Datenstrukturen gänzlich ungeeig-net. Eine wesentliche Herausforderung dieser Arbeit ist aus diesem Grund die Entwicklungeines Ansatzes, der vollständig ohne domänspezifisches Wissen auskommt und damit in seinerAllgemeinheit in jedem Anwendungsgebiet einsatzfähig ist.
Hierbei sollen je nach Anwendungsfall verschiedene Strategien zum Einsatz kommen. Für
3

Kapitel 1 Einleitung
den Fall, dass Schemata der zu verarbeitenden Daten vorliegen und die Schema-Konformitätder Daten gewährleistet ist, sollen diese Schemata auch nutzbringend verwendet werden kön-nen. Stehen jedoch keine Schema bereit bzw. sind die Daten fehlerhaft und entsprechen denSchemata eben nicht, soll ein gezieltes Filtern der Daten auch ohne diese Schemata möglichsein.
Bei der Integration von XML-Daten aus verschiedenen heterogenen Quellen besteht eineoftmals vernachlässigte Hürde in der verschiedenartigen Modellierung von Konzepten in Formvon Elementen, Attributen oder Werten von Attributen. Geeignete Transformationen sollenauch eine Integration derartig verschieden modellierter Quellen erlauben.
Die Verfahren sollen die Möglichkeit zur Spezifikation der gewünschten Genauigkeit undGüte der Suchergebnisse bieten.
1.3 Gliederung
Zur Abgrenzung der von dieser Arbeit hauptsächlich berührten Forschungsgebiete Datenin-tegration, Verarbeitung von Datenströmen und Anfragetransformation werden im nachfol-genden Kapitel 2 verwandte und relevante Arbeiten dieser Bereiche besprochen. In Kapitel 3werden die Grundlagen für die in dieser Arbeit entwickelten Ansätze gelegt. Ein Schwerpunktwerden dabei die grundlegenden Techniken zur Verarbeitung von XML-Datenströmen mit ih-ren Vorläufern aus dem Bereich des Selective Dissemination of Information (SDI) bilden. EineEinführung in Ansätze zur Datenintegration rundet das Kapitel ab.
Der zentrale Aspekt dieser Arbeit ist eine adaptive Anfragetechnik, die durch allgemeineTransformationen eine Anpassung von XPath-Anfragen an tatsächlich vorliegende Struktu-ren ermöglicht. Sie wird in Kapitel 4 behandelt, wobei je nach Einsatzzweck und zur Verfü-gung stehenden Informationen verschiedene Ausprägungen des Verfahrens definiert werden.So operiert die Basis-Version des Transformationsalgorithmus auf rein struktureller Ebeneder Anfragen bzw. Daten wohingegen eine erweiterte Fassung auch Transformationen unterBerücksichtigung inhaltlicher Informationen vorsieht.
Im Hinblick auf die Anwendung der Anfragetransformationen bei der Verarbeitung vonDatenströmen besteht ein wesentlicher Schritt darin, anhand der aktuell verarbeiteten Datenzu bestimmen, ob und welche Anfragen transformiert werden müssen. In Kapitel 5 wirdein Verfahren definiert, welches es anhand verschiedener Datenstrukturen erlaubt die für dieTransformation relevanten Anfragen zu identifizieren.
Auf Basis dieser Transformationsverfahren wird in Kapitel 6 das System aXst definiert.aXst ergänzt ein System zum Filtern von XML-Datenströmen um Komponenten, welche dieeigentlichen Anfragetransformationen vornehmen, sowie eine Überwachung der verarbeitetenDaten leisten um somit erst eine gezielte Transformation bewerkstelligen zu können. Da-neben werden Möglichkeiten zum Caching von Daten vorgestellt, die eine Minimierung desAufwands für die Anfragetransformation ermöglichen, indem der Zeitpunkt der Transforma-tion hinausgezögert wird.
4

1.3 Gliederung
In Kapitel 7 werden die verschiedenen Varianten von aXst in Form einer konkreten Imple-mentierung anhand großer Mengen an zufällig generierten Daten und Anfragen untersucht.Das Hauptaugenmerk liegt hier auf der Performanz der Anfragetransformationen, auf derQualität der Suchergebnisse der generierten Anfragen sowie auf der Performanz der Verar-beitung von Datenströmen. Vergleiche mit einem herkömmlichen System zum Filtern vonXML-Datenströmen zeigen den Einfluss der zusätzlich notwendigen Komponenten von aXstauf die Performanz des Gesamtsystems. Kapitel 8 schließt die Arbeit ab mit einer Zusam-menfassung der erzielten Resultate, dem geleisteten Betrag sowie einem Ausblick auf Mög-lichkeiten zur Weiterentwicklung der hier vorgestellten Ansätze.
5

Kapitel 1 Einleitung
6

Kapitel 2
Verwandte Arbeiten
Die vorliegende Arbeit lässt sich mehreren Forschungsgebieten im Bereich Datenhaltung undInformationssysteme zuordnen. Durch den Ansatz, Anfragen flexibel an aktuell vorliegendeDatenstrukturen anzupassen, bietet sich die Anwendung in einem Umfeld heterogener Da-tenquellen an. Damit lässt sich die Arbeit einerseits dem weiten Feld der Datenintegrationzuordnen. Auf der anderen Seite wird auf Grundlage dieser adaptiven Anfragetechnik einAnsatz entwickelt, der den Aufbau einer Architektur zur robusten Verarbeitung heterogenerXML-Datenströme ermöglicht. Das effiziente Filtern und Verarbeiten kontinuierlicher Datenselbst ist ein breites Forschungsgebiet.
Da sich die vorliegende Arbeit insbesondere mit dem Filtern von XML-Datenströmen be-fasst, wird ein Schwerpunkt des Kapitels auf der Präsentation relevanter Arbeiten diesesBereichs liegen.
Alle Bereiche werden durch intensive Forschungstätigkeit bearbeitet, so dass sie in diesemKapitel nur sehr grob umrissen werden können. In erster Linie soll eine Einordnung dieserArbeit in die jeweiligen Gebiete ermöglicht werden.
2.1 Datenintegration
Wiederhold definiert in [Wie92] erstmals die Architektur eines Mediator-Systems, die alsGrundlage für viele Integrationsarchitekturen dient.
Ziegler und Dittrich geben in [ZD04] einen Überblick über den Stand der Forschung undaktuelle Entwicklungen im Bereich der Datenintegration. Sie machen deutlich, dass es deneinen alle Probleme lösenden Ansatz nicht geben kann. Dazu ist das Problem der Integrationauf zu vielen Ebenen von der Hardware über Betriebssysteme bis hin zu den eigentlichenAnwendungen und ihren Daten bzw. deren Verwendungszweck präsent.
In [GMPQ+97] definieren Garcia-Molina et. al. mit TSIMMIS, dem Standard-IBM Mana-ger of Multiple Information Sources ein System zur Integration von Informationen, welchesim Wesentlichen auf dem Mediator-Konzept basiert und ein Datenmodell basierend auf demeinfachen Object-Exchange-Model (OEM), sowie eine Anfragesprache für verschiedene inte-grierte Datenquellen bietet.
7

Kapitel 2 Verwandte Arbeiten
In [IFF+99] definieren Ives, Florescu, Friedman, Levy und Weld das Problem der Daten-Integration als die Herausforderung, eine einheitliche Anfrageschnittstelle für eine Mengevon Datenquellen zu bieten. Das Integrationsproblem tritt danach vor allem in zweierleiKontexten auf. Auf der einen Seite bieten Organisationen Zugriff auf eine Menge von internenautonomen Quellen und auf der anderen Seite bieten Systeme eine einheitliche Schnittstellefür eine Vielzahl von Quellen im World-Wide-Web.
Einen dem Local As View-Paradigma folgenden Ansatz aus der XML-Welt wird in [MFK01]von Manolescu, Florescu, Kossmann vorgestellt. Dabei wird das globale Schema in Formeiner DTD oder eines XML-Schemas vorausgesetzt. Die in XQuery formulierten Anfragenwerden zunächst anhand des generischen Schemas nach SQL übersetzt und schließlich für dieeinzelnen lokalen Quellen mit Hilfe deren Schemata entsprechend umgeschrieben.
Einen auf Basis von Web-Services beruhenden Ansatz zu Integration präsentieren Abite-boul et. al. in [ABM02].
Die bisher benannten und auch in dieser Arbeit betrachteten Ansätze haben insbesonderegemeinsam, dass sie im Wesentlichen auf der strukturellen Ebene der Daten arbeiten, d.h. eswird versucht, strukturelle Unterschiede zwischen den Schemata der betrachteten Datenquel-len zu behandeln. Der Bereich der semantischen Integration bleibt bei derartigen Ansätzenunberücksichtigt. Gleichwohl dies ein weites Feld ist, welches in den letzten Jahren zuneh-mend Aufmerksamkeit erlangte, liegt eine semantische Betrachtung nicht im Fokus dieserArbeit.
2.1.1 Bezug zur Arbeit
In dieser Arbeit wird ein Ansatz zur Datenintegration präsentiert, der auf Grundlage vonAnfragetransformationen basiert, welche kein konkretes Wissen über die Anwendungsdomä-ne voraussetzen. Der Ansatz lässt sich am ehesten dem Global As View Paradigma zuordnen,wobei die Definition spezifischer Transformationsregeln nicht erforderlich ist. Die allgemeinenTransformationen werden direkt auf der Anfragesprache XPath ausgeführt. Ein Übersetzungin eine andere Sprache ist nicht erforderlich, obgleich für die Definition und Darstellung dereigentlichen Algorithmen eine Repräsentation der Anfragen als Tree-Pattern-Queries vorge-nommen wird. Der Einsatzbereich ist auf verschiedensten Ebenen denkbar, von einer ehersystemnahen Anwendung bis hin zu konkreten Anfragen von Benutzern.
2.2 Verarbeitung von kontinuierlichen Datenströmen
Die Verarbeitung kontinuierlicher Datenströme hat sich im Bereich Datenbanken zu einemweitgehend eigenständigen Forschungszweig entwickelt, in dem sich selbst wiederum verschie-dene Bereiche identifizieren lassen. So gibt es allgemeine Arbeiten, die die Forschungsakti-vitäten in diesem Bereich betrachten, analysieren und auf offene Fragen hinweisen. Es gibtin großem Umfang Arbeiten mit Schwerpunkt auf Anfrageverarbeitung und tupelbasierte
8

2.2 Verarbeitung von kontinuierlichen Datenströmen
Streams. Und schließlich und für die vorliegende Arbeit in besonderem Maße relevant sindArbeiten, die sich auf die Verarbeitung von XML-Datenströmen konzentrieren.
Zum angemessenen Verständnis dieses Spezialgebiets ist es nützlich, einige Begriffe zuklären bzw. gegeneinander abzugrenzen:
Begrifflichkeiten
Continuous Queries unterscheiden sich insofern von herkömmlichen Datenbankanfragen, alsdass sie nicht einmal formuliert und ausgeführt werden, sondern sie werden idealerweisepermanent ausgeführt ([TGNO92]). Wird die Datenbank um neue Inhalte ergänzt undführen diese gemäß einer Continuous Query zu neuen Treffern, so wird die Person oderdas System, welches diese Anfrage formuliert hat, umgehend von diesem Treffer inKenntnis gesetzt.
Publish/Subscribe beschreibt ein Paradigma, in dem Benutzer ein längerfristiges Interesse(die sogenannte Subscription) in einer definierten Art und Weise spezifizieren und einAgent Ereignisse wie z.B. Angebote und Kursschwankungen veröffentlicht. Die Aufgabeeines Publish/Subscribe-Systems ist es dann, an diejenigen Benutzer Nachrichten zuversenden, deren Interessen von den aktuell veröffentlichten befriedigt werden können.
Abgrenzung zwischen Continuous Queries und Event-Condition-Action-Paradigma
Continuous Queries und Event-Condition-Action (ECA) Regeln ähneln sich in man-cherlei Hinsicht. Die Unterschiede zwischen den beiden Konzepten werden in [LPT00]herausgearbeitet. Erstens werden bei ECA-Regeln Update-Ereignisse explizit vom Be-nutzer spezifiziert, wohingegen bei Continuous Queries diese Ereignisse implizit durchdie Trigger-Bedingung gegeben sind und vom System im Zuge der Installationsphaseder Anfrage abgeleitet werden. Zweitens müssen Continuous Queries explizit mit ei-nem Terminierungsstempel versehen werden um zu garantieren, dass Benachrichtigun-gen nur an die richtigen Benutzer verschickt werden, wohingegen ECA-Regeln manuellvom Benutzer aus dem System entfernt werden müssen. Drittens werden ECA-Regelnim Allgemeinen in aktiven Datenbanksystemen oder Produktionsregelsystemen verwen-det, wohingegen Continuous Queries für verteilte ereignisgesteuerte Systeme zur Infor-mationsverteilung konzipiert wurden. Viertens können ECA-Regeln Update-Ereignissenach sich ziehen, die zu kaskadierenden Aufrufen der gleichen Regel führen. Dies istbei Continuous Queries nicht der Fall. Sie sind lediglich dazu da, den Anfrageausdruckauszuwerten, die Benachrichtigungsfunktion auszuführen und einen Veränderungspara-meter zu berechnen. Letztendlich sind sie frei von Seiteneffekten.
2.2.1 Allgemeine Arbeiten
In Models and Issues in Data Stream Systems [BBD+02] motivieren Widom et.al. das For-schungsgebiet der Stream Verarbeitung. Es wird ein Überblick aktueller Forschungsarbeiten
9

Kapitel 2 Verwandte Arbeiten
gegeben und zukünftige Herausforderungen genannt. Es wird das Konzept eines Data StreamManagement System (DSMS) vorgestellt, das in Gestalt des Systems STREAM, des Stand-ford Stream Data Manager implementiert wird. Ein solches DSMS soll sich hinsichtlich zweierwesentlicher Punkte von einem herkömmlichen Datenbankmanagementsystem unterscheiden:Zusätzlich zur Verwaltung traditionell in Relationen abgelegter Daten muss ein DSMS auchvielfältige, kontinuierliche, unbegrenzte und sehr schnelle Datenströme verarbeiten können.Darüber hinaus muss ein solches System langlaufende kontinuierliche Anfragen verarbeitenkönnen. In [MWA+03] und [ABB+03] geben die Autoren einen Einblick über den Fortschrittder Arbeiten an ihrem System.
Babu, Srivastava und Widom präsentieren in [BSW04] so genannte k-Constraints, diessind Parameter, die Aussagen über die Beschaffenheit von Datenströmen zulassen und dieverwendet werden können, um kontinuierliche Anfragen über Datenströme, die Verbünde undAggregationen enthalten, mit geringem Speicherbedarf ausführbar zu machen, bei hinreichendguter Genauigkeit.
Arasu, Cherniack, Galvez, Maier, Maskey, Ryvkina, Stonebraker und Tibbetts präsentierenin [ACG+04] mit Linear Road einen Benchmark für Datenstrommanagementsysteme. DerBenchmark simuliert ein Mautgebühren-System des Kraftfahrzeugverkehrs einer Großstadt.Anhand dieses Benchmarks wird das Streaming Management System STREAM mit einemherkömmlichen Datenbanksystem verglichen.
Eine formale Analyse des Problems der Verarbeitung von Datenströme wird von Law,Wang und Zaniolo in [LWZ04] gegeben. Die Autoren analysieren dabei, inwieweit Anfrage-sprachen und Datenmodelle von den notwendigen Änderungen gegenüber den herkömmlichenModellen betroffen sind. Es wird untersucht, inwieweit traditionelle Modelle, in denen Datenals ungeordnete Mengen von Tupeln betrachtet werden, mit einer physischen und logischenOrdnung angereichert werden können.
In [BSV05] präsentieren Bulut, Singh und Vitenberg eine integrierte und verteilte Index-Architektur zur effizienten Verarbeitung von dynamischen Datenströmen. Ziel ist es, Anfra-gen unterschiedlichster Art zeitnah zu beantworten unter Minimierung von Netzwerk- undRechenressourcen. Es werden zwei Arten von Anfragen betrachtet: so genannte inner product-Anfragen zur statistischen Auswertung von Netzwerkeigenschaften und similarity-Anfragenfür Trendanalysen und Mustererkennung.
2.2.2 Verarbeitung tupelbasierter Streams
In [MF02] stellen Madden und Franklin eine Architektur für die effiziente Verarbeitung vonAnfragen an Sensordatenströme vor. Sie können zeigen, dass mit ihrem System Fjords einegroße Menge von Anfragen an viele Sensoren gestellt werden kann, wobei die Anfragen mitgeringem Verarbeitungsaufwand beantwortet werden können. Das System verarbeitet dabeiherkömmliche SQL-Anfragen.
In [CF02] stellen Chandrasekran und Franklin das auf Telegraph basierende Streaming-
10

2.2 Verarbeitung von kontinuierlichen Datenströmen
System PSoup vor. Seine Besonderheit besteht darin, dass es die Verarbeitung herkömmlicherad-hoc- und kontinuierlicher Anfragen kombiniert, indem Daten und Anfragen symmetrischbetrachtet werden. Dadurch wird es ermöglicht, dass neue Anfragen auf alten Daten sowiealte Anfragen auf neuen Daten ausgeführt werden, was das Verfahren von anderen vergleich-baren Ansätzen unterscheidet. Der Benutzer kommuniziert mit diesem System, indem er eineSQL-Anfrage formuliert, die um die Angabe eines Zeitraums erweitert wird, der entweder re-lativ oder absolut angegeben werden kann. Bei der internen Verarbeitung betrachtet PSoupdie Verarbeitung eines Stroms von Anfragen auf einem Datenstrom als Verbund von zweiStrömen.
Cranor, Johnson, Spataschek und Shkapenyuk präsentieren in [CJSS03] Gigascope, eineDatenbank zur Verarbeitung von Datenströmen für Netzwerk-Anwendungen unter Berück-sichtigung der Analyse von Datenaufkommen, Intrusion Detection, Router Konfiguration,Netzwerk Forschung, Netzwerk Monitoring, Performance Monitoring und Fehlersuche. DasSystem wurde entwickelt mit der Unterstützung des Telekommunikationskonzerns AT&Tund wird dort auch praktisch eingesetzt. Gigascope unterstützt den eigens definierten SQL-Dialekt GSQL. Diese Sprache unterstützt im Wesentlichen Selektion und Verbund-Anfragenüber maximal 2 Datenströme. Der GSQL-Prozessor ist dabei im Kern ein Code-Generator,der die Anfragen in C oder C++ Code übersetzt.
In [MFHH03] stellen Madden, Franklin, Hellerstein und Hong den Ansatz des acquisitionalquery processing (ACQP) zusammen mit einer entsprechenden Implementierung (TinyDB)vor. Ziel des Verfahrens ist es, ein Strom- und Rechenzeit sparendes Verfahren für die Anfra-ge und Verarbeitung von Sensordaten zu entwickeln. Der Schwerpunkt ihres Ansatzes liegtdabei darin, das Wissen der Sensoren darüber auszunutzen, wann und wie oft welche Datenangefordert und an die Anfrage-Prozessoren weitergeleitet werden müssen.
In [FJL+01] wird ein Publish/Subscribe-System als ein System modelliert, das ankommendeStröme von Profilen, so genannten Subscriptions und einen Strom von ankommenden Daten,bzw. Ereignissen verwaltet, wobei beide mit Zeitstempeln versehen werden, um auszudrücken,ob sie noch gültig sind. Das System speichert sowohl Daten als auch Subscriptions für denZeitraum, in dem sie gültig sind und kann damit zweierlei Funktionalität erfüllen: Zunächstwerden neue Subscriptions gegen die derzeit aktuellen Daten ausgewertet und zweitens wer-den bei neuen Daten diejenigen Profile identifiziert, für die diese Daten relevant sind, so dassdiese Daten an die interessierten Parteien gesendet werden können.
Liu, Pu und Tag beschreiben in [LPT00] das Konzept von Continual Queries und dasverteilte ereignisgesteuerte System zur Informationsverteilung OpenCQ, das diese Anfragenunterstützt. Die Anfagen in OpenCQ berücksichtigen dabei vergangene, aktuelle und zukünf-tige Daten. Eine typische Bespielanfrage, entnommen aus der oben zitierten Arbeit, könnteetwa sein: Liefere dem Manager jeden Tag um 18:00 Uhr alle Bank-Aktivitäten des Tages vondenjenigen Kunden, die an diesem Tag mehr als 2.000 Euro abgehoben haben.
In [TB02] stellen Tok und Bressan das Framework AdaptiveCQ für die effiziente Verar-beitung vieler kontinuierlicher Anfragen vor. Die Besonderheit des präsentierten Ansatzes
11

Kapitel 2 Verwandte Arbeiten
besteht darin, dass viele Anfragen Zwischenergebnisse auf einer sehr feingranularen Ebenemiteinander teilen können und dass die Zwischenergebnisse nicht erst auf Platte materiali-siert werden müssen, sondern vielmehr on-the-fly geteilt werden können. Das System basiertauf einer Erweiterung des Eddies-Models. Es werden Verbund-Anfragen und Selektion unter-stützt.
In [GHH+02] betrachten Govindan, Hellerstein, Hong, Madden, Franklin und Shenker einSensornetzwerk als Datenbank. Es werden die Herausforderungen untersucht, die eine solcheSichtweise auf das Netzwerk hat. Insbesondere soll es eine derartige Architektur dem Benutzererlauben, Anfragen direkt an das Netzwerk zu stellen, wobei diese Anfragen einmalig gestelltund ausgeführt oder als kontinuierliche Anfragen betrachtet werden können, die über einenlängeren Zeitraum einen permanenten Strom von Antworten generieren. Der Fokus der Arbeitliegt hier auf zwei Aspekten: zum einen sind so genannten in-network-Implementierungen vonprimitiven Datenbank-Operatoren überall im Netzwerk auf den einzelnen Knoten zu platzie-ren. Zum anderen ist es wünschenswert, dass Datenbankanfragen so genannten approximateErgebnisse erlauben, d.h. die Semantik von Datenbankanfragesprachen ist so zu lockern, dassauch solche Ergebnisse geliefert werden können, die den gestellten Anfragen nur teilweiseentsprechen. Das zugrundeliegende Datenmodell ist das relationale Modell mit Tabellen vonTupeln, die mittels einer SQL-artigen Sprache angefragt werden können. Die hier vorgestellteArchitektur wird umgesetzt in [AH00] mit dem System Eddies, einem Datenfluss-Operator,der im Netzwerk zum Einsatz kommt.
2.2.3 Verarbeitung von XML-Datenströmen
Eine der ersten Arbeiten, die sich explizit mit XPath-basiertem Filtern von XML-Streamsbeschäftigte ist Efficient Filtering of XML Documents for Selective Dissemination of Infor-mation von Mehmet Altinel und Michel J. Franklin [AF00]. Hier führen die Autoren eineFilter-Architektur ein und präsentieren mit XFilter einen auf nichtdeterministischen endli-chen Automaten basierten Ansatz zum effizienten Streaming. Charakteristisch für diesen An-satz ist insbesondere, dass für jede XPath-Anfrage ein separater Automat verwendet wird.In Path Sharing and Predicate Evaluation for High-Performance XML Filtering [DAF+03]wird XFilter zu YFilter weiterwentickelt indem eine Kombination aller Automaten zu einemeinzigen Automaten realisiert wird, wobei Gemeinsamkeiten von Suchanfragen ausgenutztwerden. Außerdem werden verschiedene Ansätze zur Verarbeitung von Prädikaten diskutiert.
Eine performancemäßige Verbesserung gegenüber XFilter erreichten Chan, Felber, Garo-falakis und Rastogi in ihrer Arbeit Efficient Filtering of XML Documents with XPath Ex-pressions [CFGR02] mit XTrie. Auch hier liegt die Zielsetzung darin, einen XML-Streamanhand einer große Menge von XPath-Anfragen zu filtern. Dies wird erreicht durch die Spei-cherung und Verarbeitung der Anfragen in einem Trie-basierten Index, so dass der Matching-Algorithmus folgendermaßen skizziert werden kann: der XML-Strom wird von einem SAX-Parser gelesen, der XML Elemente berichtet. Der Matching-Algorithmus versucht, die so
12

2.2 Verarbeitung von kontinuierlichen Datenströmen
generierten Folgen von Start-Tags, Attributen und Text-Werten auf Pfade im Trie abzu-bilden, indem den Kanten des Tries gefolgt wird. Für jeden Substring, der gefunden wird,wird anhand einer Hilfstabelle verifiziert, ob diese Zeichenkette solche Bedingungen erfüllt,wie vorherige Parent- und Sibling-Zeichenketten, sowie zugeordnete Attribute. Ein XPath-Ausdruck ist ein vollständiger Treffer, wenn alle Substrings mit zugeordneten Bedingungengefunden werden. In [FCGR03] verbessern Felber, Chan, Garofalakis und Rastogi ihr XTrie-Verfahren hinsichtlich des Datendurchsatzes, indem das Verfahren parallelisiert wird. Dazuwird zunächst ein Cluster von parallel arbeitenden XML-Routern implementiert, so dass ei-ne Parallelität auf zweierlei Arten stattfinden kann. Zum einen können die Daten auf dieeinzelnen Rechner des Clusters aufgeteilt werden. Jeder Rechner verwaltet in dem Fall dieGesamtheit der XPath-Anfragen, aber jedes Dokument wird nur von genau einem Rechnerverarbeitet. Zum anderen können die XPath-Anfragen so auf die einzelnen Rechner verteiltwerden, dass jeder verschiedene Ausdruck von genau einem Router verwaltet wird und jedesankommende Dokument von jedem Router gefiltert wird. In der zitierten Arbeit kombinierendie Autoren diese beiden Ansätze in einem hybriden Ansatz, in dem die XML-Router in einerhierarchischen Konfiguration angeordnet werden.
In [CDTW00] stellen die Autoren NiagaraCQ vor, ein verteiltes Datenbanksystem um ver-teilte XML Datenquellen mit Hilfe der Sprache XML-QL [DFF+98] zu verarbeiten. Hauptzieldes Systems soll es sein, es einer sehr großen Anzahl von Benutzern zu ermöglichen, ihre An-fragen beim System zu registrieren. Der gewählte Ansatz besteht darin, die verschiedenenContinuous Queries anhand ihrer jeweiligen Ähnlichkeit untereinander zu gruppieren unddamit bei der Auswertung Rechenzeit zu sparen.
In [LCHT02] wird der mqX-scan-Operator vorgestellt mit dem ein XML-Dokument anhandeiner Menge von Anfragen durch einen einzigen Lesevorgang angefragt werden kann. DieAnfragesprache beruht dabei auf regulären Pfad Ausdrücken.
Chan, Fan, Felber, Garofalakis und Rastogi definieren in [CFF+02] einen Ansatz, eineMenge von Tree-Pattern-Queries zu einer kleineren Menge zu aggregieren, so dass eine gege-bene Größen-Bedingung erfüllt ist und der Verlust an Präzision, die durch die Aggregierungerreicht wird, minimiert wird. Es werden Algorithmen vorgestellt für die Berechnung vonTree-Pattern Containment und Minimierung.
Lakshmanan und Sailaja präsentieren in [LP02] ein Framework zum periodischen Abgleichvon in einer Registry abgelegten Profilen gegen aktuell ankommende XML-Daten. Die Profilewerden in Form einer XPath-ähnlichen Sprache formuliert. Im Vergleich zu anderen Verfah-ren wie dem XFilter-System aus [AF00] besteht eine wesentliche Stärke des MatchMakergenannten Ansatzes darin, nicht nur zu entdecken, ob ein bestimmtes Dokument ein Trefferzu einem Profil ist, sondern es wird auch ganz gezielt das Teildokument identifiziert, welchesden Treffer darstellt.
Ludäscher, Mukhopadhyay und Papakonstantinou stellen in [LMP02] ihre XML StreamMachine (XSM) vor, ein XQuery-Prozessor für die Verarbeitung von XML-Datenströmen.Das System übersetzt dazu die XQuery-Anfragen schrittweise zunächst in ein Netzwerk von
13

Kapitel 2 Verwandte Arbeiten
eventuell mehreren Kellerautomaten mit Ausgabe, diese Automaten werden durch wieder-holte Anwendung eines geeigneten Kompositionsalgorithmus optimiert, indem die Anzahl annotwendigen Tests und Aktionen sowie die Anzahl an Zwischenzuständen verkleinert wird.Zum Abschluss wird die so generierte XSM in ein C-Programm übersetzt.
In [ILW00] präsentieren die Autoren den x-scan-Operator, der zu einem XML-Datenstromeine Menge von Variablenbindungen generiert, entsprechend den Variablen der Pfadaus-drücke, die zu verarbeiten sind. Die verwendete Sprache ist XML-QL.
Fegaras, Levine, Bose und Chaluvadi präsentieren in [FLBC02] ein Framework für dieeffiziente Verarbeitung von Anfragen in einer eigens definierten XML-Algebra auf XML-Datenströmen. Ihre Architektur sieht dabei einen zentralen Server vor, der XML-Datengleichzeitig an viele einzelne Clients verschickt, welche jeweils selbst für die Verarbeitung derDatenströme verantwortlich sind. Dabei können XML-Fragmente aus vielen verschiedenenDokumenten innerhalb eines Stroms versendet werden. Die Klienten verwenden leichtgewich-tige Datenbanken, um die Daten zwischenzuspeichern und auf diesen zwischengespeichertenDaten die in der Algebra definierten Anfragen auszuführen. Zur Synchronisierung zwischenServer und Klienten wird der Datenstrom mit Annotationen versehen.
Peng und Chawathe präsentieren in [PC03] das XSQ-System zur Anfrage von XML-Daten-strömen mittels XPath-Anfragen. Ihr Ansatz basiert auf hierarchisch angeordneten determi-nistischen Kellerautomaten mit Ausgabe, welche um Puffer erweitert werden. Der Ansatzerlaubt mehrere Prädikate, Anfragen an die transitive Hülle (z.B. Anfragen mit descendant-Achse) und Aggregation. Der Datenpuffer ermöglicht die Verarbeitung von Anfragen mitPrädikaten und die Autoren zeigen, dass die Menge an zwischengespeicherten Daten optimalist in dem Sinne, dass nicht mehr Daten gepuffert werden, als von jedem anderen System mitdieser Funktionalität auch gespeichert werden müssten.
In [DF03] identifizieren Diao und Franklin als grundlegende Probleme eines Message Bro-kers das Filtern, die Transformation und das Routing von Nachrichten und stellen in ihrerArbeit einen Ansatz zur Transformation von XML-Nachrichten vor, mit dem Ziel, dem Be-nutzer die Suchergebnisse in angepasster Form zur Verfügung stellen zu können. Ihr Ansatzbasiert dabei im Wesentlichen auf dem YFilter-System und erlaubt Anfragen, die eine Un-termenge von XQuery bilden.
Gupta und Suciu widmen sich in [GS03] der Auswertung einer sehr großen Anzahl anXPath-Anfragen auf einem XML-Datenstrom. Der Schwerpunkt ihrer Arbeit liegt dabei aufXPath-Filtern die viele Prädikate enthalten. Der präsentierte Ansatz XPush Machine basiertauf einer lazy Konstruktion eines einzigen deterministischen Pushdown Automaten. Um eineeffiziente Auswertung von Prädikaten zu gewährleisten, werden nicht nur gemeinsame Merk-male der Struktur-Navigation, sondern insbesondere auch der Prädikate ausgenutzt, wodurchdas Verfahren auch für Anfragen mit einer großen Anzahl an Prädikaten skaliert.
Olteanu, Furche und Bry stellen in [OFB04] eine single-pass Auswertungsstrategie vonXPath-Anfragen gegen potentiell unendlich lange XML-Datenströme vor. Die Strategie ba-siert auf einem Netzwerk von voneinander unabhängigen deterministischen Kellerautomaten
14

2.2 Verarbeitung von kontinuierlichen Datenströmen
mit Ausgabe. Das Verfahren eignet sich insbesondere für Umgebungen in denen wenig Spei-cher und eingeschränkte Rechenkapazität zur Verfügung steht. Ohne vorheriges Umschrei-ben können nur XPath-Anfragen mit Vorwärts-Achsen unterstützt werden. Der wesentlicheSchritt des Ansatzes besteht darin, die Anfragen in Kellerautomaten zu übersetzen. DasVerfahren kann Anfragen tatsächlich beantworten, d.h. die Elemente liefern, die angefragtwerden und nicht nur angeben, ob ein bestimmtes Dokument eine Anfrage wahr macht odernicht.
Koch, Scherzinger, Schweikardt und Stegmaier präsentieren in [KSSS04] mit FluX eineErweiterung der Anfragesprache XQuery. Ziel des Ansatzes ist eine ereignisbasierte Anfrage-verarbeitung unter Berücksichtigung von Hauptspeicher-Beschränkungen. Für eine vorab-Transformation der Anfragen werden Schemainformationen verwendet.
SPEX steht für ”Streamed and progressive evaluation of XPath queries against XML stre-ams” [Olt07]. Es handelt sich dabei also um ein System zur Verarbeitung von XPath-Anfragenan XML-Datenströme. Das Verfahren wird als progressiv bezeichnet, da die Antworten zuden Anfragen so bald wie möglich, d.h. sobald sie verfügbar sind, an die jeweiligen Interessen-ten weitergegeben werden. Zur effizienten Verarbeitung werden die Anfragen in Netzwerkevon Kellerautomaten kompiliert, wodurch eine Verarbeitung in polynomieller Zeit und Platzgewährleistet werden kann.
Behandlung von Vorwärts- und Rückwärts-Achsen
Für eine effiziente, SAX-basierte Verarbeitung von XML-Streams durch XPath-Anfragefilterist es vorteilhaft, dass jedes SAX-Event sofort verarbeitet wird, d.h. insbesondere, dass keineZwischenspeicherung von Dokumenten oder Teilen von Dokumenten stattfindet. Aus diesemGrund verbieten sich XPath-Anfragen, die Rückwärts-Achsen enthalten, da deren Verarbei-tung ein Speichern von Dokumenten verlangt. Die Arbeit XPath: Looking Forward von DanOlteanu, Holger Meuss, Tim Furche und Francois Bry [OMFB02] präsentiert einen elegan-ten Ansatz, der es erlaubt, beliebige XPath-Anfragen, die Rückwärts-Achsen enthalten, inäquivalente XPath-Anfragen umzuwandeln, die ausschließlich Vorwärts-Achsen enthalten.
In [BCG+03] präsentieren Barton, Goyal, Raghavachari, Fontoura und Josifovski einenAnsatz, XPath-Anfragen mit Vorwärts- und Rückwärtsachsen bei einmaligem Lesen desXML-Dokuments verarbeiten zu können. Kern des so genannten XAOS-Algorithmus ist es,alle Rückwärts-Achsen vor der eigentlichen Verarbeitung äquivalenzerhaltend in Vorwärts-Achsen umzuwandeln. Die derartig umformulierten Anfragen werden in eine x-dag genannteRepräsentation umgewandelt, anhand derer schließlich eine ereignisbasierte Verarbeitung desXML-Datenstroms bewerkstelligt werden kann.
Anwendungen
Snoeren, Conley and Gifford stellen in [SCG01] ein System für das Routing von XML-Paketenüber ein Mesh-basiertes Netzwerk vor. Das Netzwerk besteht aus Knoten, die durch XML-
15

Kapitel 2 Verwandte Arbeiten
Router gebildet werden. Jeder Knoten hat dabei eine Menge von Eingabe- und Ausgabever-bindungen. Ausgabeverbindungen haben eine XQuery-Anfrage, die die Daten beschreibt, diean das Ziel des jeweiligen Ausgabelinks zu schicken sind. Um die Latenzzeit zu verkürzenund die Zuverlässigkeit des Netzwerks zu erhöhen, wird ein Protokoll definiert, welches einredundantes Versenden von Nachrichten vorsieht.
Nguyen, Abiteboul, Cobena und Preda präsentieren in [NACP01] ein auf Xyleme [ACV+00]basierendes System zum Monitoring von XML-Daten im Web. Dazu wird ein großes dyna-misches Warehouse aufgebaut, in das regelmäßig Dokumente aufgenommen werden. DieseDokumente werden auf zweierlei Art und Weise gefiltert. Einerseits wird der kontinuierlicheDokumentenfluss in das System hinein überwacht und auf Änderungen hin untersucht, die füreinen Benutzer basierend auf der von ihm gegebenen Spezifikation von Interesse sein könnte.Andererseits werden regelmäßig kontinuierliche Anfragen an das gesamte Warehouse, d.h.an alle gespeicherten Dokumente gestellt. Die Anfragen werden in einer SQL-artigen Syntaxformuliert mit der Möglichkeit XML-spezifische Aspekte zu berücksichtigen.
In [DNGS03] beschäftigen sich Deshpande, Nath, Gibbons und Seshan mit der Anfragevon weit verteilten Sensordatenbanken. Darunter werden Datenbanken aus XML-Daten ver-standen, die von Sensoren generiert werden, die über ein sehr großes Gebiet verteilt sind.Das System enthält eine logische Sicht, die alle Daten als ein einziges großes XML-Dokumentbetrachtet, wobei die Daten tatsächlich jedoch weit verteilt sind. Es wird eine Technik zurAnfrageauswertung vorgestellt, die unter Verwendung von XSLT feststellt, in welchem loka-len Datenbankfragment sich ein Teil des Anfrageergebnisses befindet und wo die fehlendenTeile zu finden sind.
Carzaniga und Wolf definieren in [CW01] das Konzepte des content-based networking, ei-ner inhaltsbasierten Publish/Subscribe Middleware und einer neuen Kommunikations-Infra-struktur. Die grundlegenden Konzepte werden formuliert und mit traditionellen Netzwerk-Architekturen in Beziehung gesetzt.
2.2.4 Bezug zur Arbeit
Diese Arbeit befasst sich mit der Verarbeitung von reinen XML-Datenströmen. Zu dem Be-reich der Verarbeitung tupelbasierter Ströme gibt es insofern einen Berührungspunkt, alsdort oftmals das so genannte Sliding-Window Prinzip zum Einsatz kommt. Dabei handeltes sich um eine Art Schnappschuss der Daten eines gewissen Zeitraums auf den die vor-liegenden Anfragen angewandt werden. Dieses Konzept ist bei den gängigen Techniken zurXML-Verarbeitung unüblich, findet jedoch in der vorliegenden Arbeit in abgewandelter Formin Gestalt eines Caches Anwendung. Dieser dient hier dazu, eine gewisse Datenmenge zu sam-meln bevor der teure Prozess der Anfragetransformation angestoßen wird.
Die Implementierung von YFilter ([AF00]) dient als Grundlage für die Implementierungdes hier entwickelten aXst und damit auch als System zum direkten Performanzvergleich.
Die genannten Ansätze zur Behandlung von Rückwärts-Achsen sind insofern relevant für
16

2.3 Anfragetransformation und -Manipulation
diese Arbeit, als dass sich auch aXst aus Performanzgründen auf die Verarbeitung vonVorwärts-Achsen beschränken muss und aus diesem Grund auf die in diesen Arbeiten prä-sentierten Äquivalenzumformungen angewiesen ist.
2.3 Anfragetransformation und -Manipulation
Das Herzstück von aXst ist der Ansatz zur adaptiven Anfragetransformation. Sie sorgt für dieflexible Anpassung von Anfragen an die aktuell vorliegenden Daten. Auch in diesem Bereichder Anfragetransformation und -Manipulation existiert eine Vielzahl von Arbeiten, so dasshier nur eine Auswahl von mehr oder weniger verwandten Ansätzen vorgestellt werden kann.
Im Bereich der Anfragetransformation wird in [Sch02] ein mit aXst vergleichbarer Ansatzpräsentiert. Es wird dort die konjunktive approximative XML-Anfragesprache ApproXQLdefiniert, die Anfragetransformationen vorsieht, mit dem Ziel ein Embedding für eine in Formeines Baumes repräsentierte Anfrage in ein entsprechendes XML-Dokument zu finden. Umauch dann ein Embedding zu finden, wenn es keine völlige Übereinstimmung zwischen An-frage und Dokument gibt, werden eine Reihe von Änderungsoperationen definiert, um dieAnfrage an das Dokument anzupassen. Dabei werden zweierlei Ansätze verfolgt: ohne dieKenntnis von Schemainformationen werden alle möglichen Ergebnisse berechnet, entspre-chend ihrer Änderungskosten bewertet und die schlechten bzw. teuren Ergebnisse werdenverworfen. Liegt Wissen über die den Daten zugrunde liegenden Schemata vor, kann diesausgenutzt werden, um die besten Anfragen schon vorab abzuschätzen. aXst grenzt sich ins-besondere von ApproXQL insoweit ab, als es direkt auf Transformationen von XPath beruhtund keine eigene Sprache definiert. Darüber hinaus erlaubt aXst die Behandlung von Unter-schieden hinsichtlich der Modellierung von Konzepten in Form von Attributen bzw. in Formvon Elementen. Daneben ist aXst durch die Verwendung einer einheitlichen Repräsentationfür Schemata und Daten flexibel in der Hinsicht, dass es für die Transformationen völligtransparent ist auf welcher Grundlage sie durchgeführt werden.
Amer-Yahia, Cho, Lakshmanan und Srivastava führen in [AYCLS01] Tree Pattern Queriesein. Ziel der Arbeit ist es, diese Anfragen ohne Kenntnis von Integritätsbedingungen zu mini-mieren um damit die Ausführung der Anfragen zu optimieren. Es kann gezeigt werden, dassdies in polynomieller Zeit bewerkstelligt werden kann und dass es für eine gegebene Anfrageeine eindeutige äquivalente minimale Anfrage gibt. In [AYCS02] führen Amer-Yahia, Cho undSrivastava so genannte Relaxations ein, um gegebene Tree Pattern Queries in allgemeinereAnfragen umzuwandeln. Diese Relaxations sind vergleichbar mit den von aXst verwendeten,arbeiten jedoch ausschließlich auf rein struktureller nicht jedoch auf inhaltlicher Ebene. DieVerwendung von Schemainformationen bzw. strukturellen Informationen der anzufragendenDaten ist nicht vorgesehen. Wie in der zitierten Arbeiten, wird der Formalismus der TreePattern Queries auch zur Modellierung der Transformationen von aXst verwendet.
Mit adaptiver Anfrageverarbeitung im Bereich der Verarbeitung von kontinuierlichen Da-tenströmen beschäftigt sich Avnur und Hellerstein in [AH00]. Sie präsentieren dort den
17

Kapitel 2 Verwandte Arbeiten
Anfrageverarbeitungsmechanismus eddy. Dieser erlaubt es, einen Anfrageauswertungsplanpermanent, d.h. auch während der Anfrageausführung, zu manipulieren und anzupassen.Das System eignet sich damit für hochgradig verteilte Datenbanken und Anfragen, die übereinen sehr großen Zeitraum hinweg gültig sind und verarbeitet werden müssen. Es geht dortalso weniger um die Transformation von Anfragen als solche, sondern um die Adaption desAuswertungsplans an das aktuelle Datenaufkommen.
Eine Vielzahl von Arbeiten befasst sich mit der Untersuchung der formalen Eigenschaftenvon XPath. Auch dabei ist oftmals das Ziel, mittels Umschreibetechniken minimale bzw.optimale äquivalente Anfragen zu finden.
Miklau und Suciu untersuchen in [MS04] das Enthaltensein- und das Äquivalenzproblem fürein Kernfragment von XPath, das Verzweigung, Wildcards und Descendant-Beziehungen zwi-schen Knoten umfasst. Die Autoren können zeigen, dass im Falle der Kombination dieser dreiMerkmale das Enthaltensein-Problem coNP-vollständig ist. Es kann jedoch ein Algorithmusgezeigt werden, der für eine signifikante Untermenge von XPath das Enthaltenseinproblemeffizient entscheiden kann.
In [XÖ05] untersuchen Xu und Özsoyoglu das Problem, Rewritings für XPath-Anfragenunter Verwendung von materialisierten Sichten zu finden und darüber hinaus festzustellen,ob es minimale Rewritings gibt. Die Autoren können zeigen, dass das Rewriting-Existenz-Problem coNP-hart ist. Sie geben einen Algorithmus an, der minimale Rewritings erzeugt undder vollständig ist und in polynomieller Zeit läuft für drei relevante Subklassen von XPath.
Kwong und Gertz präsentieren in [KG02] ein Framework für die logische Optimierung vonkomplexen, gegebenenfalls verschachtelten XPath-Ausdrücken unter Verwendung von DTD-Informationen. Es wird die kompakte Repräsentation PEC (path equivalent classes) vorge-stellt, die verwendet wird, um zur Compile-Zeit redundante Pfadausdrücke zu identifizieren,Pfade zu kürzen und die Erfüllbarkeit von XPath-Ausdrücken zu überprüfen. Es wird einVerfahren vorgestellt, mit dem ein XPath-Ausdruck schrittweise in einen optimierten äquiva-lenten Ausdruck umgeschrieben werden kann unter Verwendung verschiedener Eigenschaftenvon PECs.
2.3.1 Bezug zur Arbeit
Das Verfahren ApproXQL verwendet Transformationen, die sich mit den in dieser Arbeitdefinierten vergleichen lassen, wobei auf einer eigens entwickelten Sprache operiert wird undeine Behandlung unterschiedlicher Modellierung von Konzepten in Form von Elementen oderAttributen bzw. Werten von Attributen nicht vorgesehen ist. Letzteres gilt auch für denin [AYCS02] präsentierten Ansatz, dessen Formalismus zur Definition der Transformationenebenso wie hier auf Tree-Pattern-Queries beruht. Viele Arbeiten beschäftigen sich sich mitformalen Eigenschaften oder Aspekten der Komplexität von XPath und definieren zu diesemZwecke Regeln um Anfragen äquivalenzerhaltend zu vereinfachen oder zu optimieren.
18

Kapitel 3
Grundlagen
Das in dieser Arbeit definierte System aXst adressiert mit seinen Anfragetransformationendas Problem einer fehlertoleranten und integrativen Verarbeitung von XML-Datenströmen.Zur Vorbereitung auf die zentralen Kapiteln 4 und 5 werden im Folgenden Grundlagen ausden Bereichen Datenintegration sowie Verarbeitung und Filtern von XML-Datenströmen be-handelt. Filtern und entsprechendes Verteilen von XML-Datenströmen ist eine Spielart desSelective Dissemination of Information und verwendet dort entwickelte Ideen in mehr oderweniger abgewandelter Form. Durch eine einführende Behandlung dieses Gebiets in Abschnitt3.2 wird dem Rechnung getragen. Das System YFilter dient einerseits als Grundlage, ande-rerseits als Referenzimplementierung des hier entwickelten Systems aXst und wird in 3.4vorgestellt.
3.1 Integration von Datenquellen
Datenintegration ist das Problem, Daten verschiedener Quellen zu kombinieren und demBenutzer eine einheitliche Sicht auf diese Daten zu bieten [Hal01] [Hul97] [Ull00].
Seit der Entwicklung der ersten Datenbanksysteme in den 1960er Jahren und deren Verbrei-tung in Wirtschaft, Verwaltung und Forschung besteht ein Bedarf, Daten aus verschiedenenQuellen unter einer einheitlichen Schnittstelle zugänglich zu machen. Dabei wurden Ansätzewie Data Warehouses entwickelt, bei denen die verschiedenen Quellen mehr oder weniger ma-nuell in ein einziges Schema überführt werden. Dieser Ansatz bietet offensichtlich den Vorteileiner effizienten Anfrageverarbeitung, sobald der Integrationsprozess abgeschlossen ist. So-lange die so genannten lokalen Datenquellen jedoch regelmäßig bearbeitet werden, bestehtgrundsätzlich das Problem der Aktualität in der globalen Datenquelle.
Diesem Problem der eher physischen Integration wurde mit der Entwicklung von Ansätzeneiner rein logischen Integration begegnet. Grundsätzlich existiert bei der logischen Integrationeine so genannte globale Sicht bzw. ein globales Schema, welches dem Benutzer präsentiertwird und anhand dem er seine Anfragen definieren kann. Zu beachten ist hierbei, dass dasglobale Schema eine rein virtuelle Sicht darstellt, es gibt keine physischen Daten, welche die-sem Schema entsprechen. Die tatsächlichen integrierten lokalen Datenquellen verfügen überihre eigenen Schemata, so dass die gemäß dem globalen Schema definierten Anfragen in diese
19

Kapitel 3 Grundlagen
Datenbank
lokaleDatenquelle L1mit Schema L1
Datenbank
lokaleDatenquelle L2mit Schema L2
Datenbank
lokaleDatenquelle L3mit Schema L3
Wrapper/Mapping: G↔L1 Wrapper/Mapping: G↔L2 Wrapper/Mapping: G↔L3
globalesSchema G
Virtuelle Datenbank
Abbildung 3.1: Schematische Darstellung einer klassischen Integrations-Architektur
lokalen Schemata umgesetzt werden müssen. Diese Aufgabe übernimmt der Mediator. Derentscheidende Punkt bei diesem Ansatz ist die Definition der Beziehungen zwischen dem glo-balen und den lokalen Schemata. Hierbei lassen sich grundsätzlich die beiden Varianten GlobalAs View und Local As View unterscheiden. Bei Global As View wird das globale Schema alsSicht auf die lokalen Daten definiert. Hinsichtlich der Anfrageverarbeitung ist dieser Ansatzrelativ einfach, da die Anfragen für die lokalen Datenquellen nicht extra umgeschrieben wer-den müssen, sondern direkt ausführbar sind. Der Nachteil dieser Methode besteht jedochdarin, dass das globale Schema für jede zusätzliche lokale Datenquelle bzw. jede lokale Sche-maänderung angepasst werden muss. Dagegen ist bei Local As View das globale Schema völligunabhängig von den Schemata der lokalen Datenquellen. Die Beziehungen zwischen globalemSchema und den lokalen Daten werden gebildet, indem jede lokale Datenquelle als Sicht überdas globale Schema betrachtet wird.
Abbildung 3.1 zeigt in einer schematischen Darstellung die Architektur eines Systems zurDatenintegration. Die Abbildung verdeutlicht, dass für jedes der lokalen Systeme eine Ab-bildung des globalen Schemas auf die lokalen Schemata bzw. umgekehrt erfolgen muss. EinMediator bzw. Wrapper übernimmt die Transformation der Anfragen. Die zu definierendenAbbildungsvorschriften sind in der Regel manuell zu erstellen, bzw. verlangen bei automa-tisierten Ansätzen zumindest eine manuelle Kontrolle. Das Transformationsverfahren aXstkann eine Integration verschiedener heterogener Datenquellen bewerkstelligen, ohne dass der-artige Abbildungen erstellt werden müssen. Es ist darüber hinaus nicht einmal notwendig,dass Schemata der zu integrierenden Datenquellen vorliegen, wiewohl diese verwendet werdenkönnen.
20

3.2 Selective Information Dissemination
3.2 Selective Information Dissemination
Bei dem System aXst handelt es sich insbesondere um ein SDI-System für die Verarbei-tung von Daten in Form von XML-Dateien. In seiner konkret vorliegenden Implementierungerweitert es das System YFilter, grundsätzlich kann es jedoch jedes beliebige System zumFiltern von XML-Daten anhand von XPath ergänzen. Alle diese Systeme lassen sich unterdem Begriff Selective Dissemination of Information (SDI) zusammenfassen, der erstmals in[Sal68] von Salton definiert wurde und basieren in ihren Grundzügen auf den im Rahmendieses Forschungsbereichs entwickelten Ideen.
Der Begriff SDI beschreibt die Problemstellung, dass ein System eine große Menge vonDokumenten, die mit hoher Geschwindigkeit eintreffen, in der Weise verarbeiten muss, dasseine Vielzahl von Nutzern ihr Interesse an diesen Dokumenten in Form von Profilen definierthat und die jeweils aktuellen Dokumente anhand dieser Profile gefiltert werden müssen, sodass Treffer, die zu diesen Profilen gefunden werden, den Benutzern zeitnah zur Verfügunggestellt werden können. SDI-Systeme sollen es Benutzern erlauben, durch Definition von Pro-filen Informationsquellen zu abonnieren, d.h. Anfragen so zu definieren, dass diese permanentgegen aktuelle Daten ausgewertet werden, so dass Benutzer sofort informiert werden können,sobald Daten eintreffen, die für sie von Interesse sein könnten.
Die besondere Herausforderung an ein SDI-System liegt erstens an der hohen Rate, mitder neue Daten ankommen, zweitens an der riesigen Anzahl von Benutzern, die ihre Profileim System hinterlegen und drittens an der Anforderung nach aktueller und rechtzeitigerVerarbeitung neuer Daten.
In ihrer Arbeit [YGM94] definieren Yan und Garcia-Molina erstmalig verschiedene Index-strukturen für die Indexierung von Profilen sowie Algorithmen, die Dokumente effizient gegeneine große Anzahl von Profilen abgleichen. Bei den Profilen handelt es sich hierbei um kon-junktive Anfragen. Es werden Brute-Force Methoden vorgestellt und hinsichtlich ihrer Lauf-zeit und Speicherbedarf-Eigenschaften untersucht und mit effizienteren Ansätzen verglichen.Die Autoren untersuchen Aspekte wie Negation, Disjunktion und Suche mittels Thesauri.
Ein nahe liegender Brute-Force Ansatz für SDI-Systeme besteht darin, dass Profile abge-speichert und in periodischen Abständen im Stapelverfahren abgearbeitet werden, um Än-derungen seit dem letzten Durchlauf zu erkennen. Mit zunehmender Anzahl an Benutzern,Profilen und ankommenden Dokumenten wird diese Art und Weise der Verarbeitung offen-sichtlich ineffizienter.
Aufgrund der Effizienz-Probleme der Brute Force Methode wurden eine Reihe von besserenAnsätzen entwickelt, die im Folgenden skizziert werden sollen.
Abbildung 3.2 zeigt fünf Beispiel-Profile, sowie ein kurzes Dokument. Anhand dieses Bei-spiels werden in den folgenden Abschnitten die einzelnen Verfahren für invertierte Indexeillustriert. Die Abbildungen sowie die Erläuterungen zu den einzelnen Verfahren sind imWesentlichen entnommen aus [YGM94].
21

Kapitel 3 Grundlagen
P1 (a,b)P2 (a,d)P3 (a,d,e)P4 (b,f)P5 (c,d,e,f)
Beispiel Profile: Beispiel Dokument:a c a f b c
Abbildung 3.2: Beispiel-Profile und Beispieldokument
Counting Methode
Das grundsätzliche Problem der Brute Force Methode besteht darin, dass für jedes ankom-mende Dokument alle Profile durchsucht werden müssen. Das Ziel muss also darin bestehen,die Anzahl der zu durchsuchenden Profile zu reduzieren. Die Idee besteht hier darin, eineninvertierten Index für die Profile aufzubauen, d.h. dass für jedes Wort, das in irgendeinemProfil vorkommt, alle Profile gesammelt werden, die dieses Wort enthalten. Die Menge die-ser Worte bildet damit die so genannten invertierte Menge. Die invertierte Menge zu einemWort w wird als invertierte Liste von so genannten Postings gespeichert, wobei jedes Postinglediglich einen Identifikator für die Profile aufführt, die w enthalten. Damit ist ein Profilmit K vielen Worten in K Postings in K verschiedenen Listen enthalten. Wenn also einDokument D verarbeitet wird, müssen nur diejenigen Profile durchsucht werden, die in derinvertierten Liste zu den Wörtern aus D enthalten sind. Auf diese Art und Weise kann schoneine wesentliche Reduktion der Profile erreicht werden, die betrachtet werden müssen, da nurdiejenigen Profile in Frage kommen, von denen bekannt ist, dass zumindest ein Wort davonin D vorkommt.
Der Matching-Prozess funktioniert bei der Counting Methode dann folgendermaßen: Aus-gangspunkt ist die Tatsache, dass ein Profil genau dann in einer invertierten Liste auftaucht,wenn ein Wort zu diesem Profil passt. D.h. es genügt einfach die Anzahl an Vorkommen einesbestimmten Profils in den invertierten Listen zu zählen.
Dieses Verfahren kann mittels Verwendung zweier Arrays sehr effizient implementiert wer-den, ist jedoch auch speicherintensiv, da die Größe dieser Arrays der Anzahl der zu verarbei-tenden Profile entspricht. Dabei enthält das so genannte TOTAL-Array für jedes Profil dieGesamtanzahl an Worten, die das betreffende Profil enthält. Das COUNT-Array enthält fürjedes Profil einen Eintrag, der für jedes Dokument mit 0 initialisiert wird. Für jedes Profil inder invertierten Liste wird dieser Eintrag um 1 erhöht. Ein Profil stellt einen Treffer zu demgerade verarbeiteten Dokument dar, wenn der COUNT-Eintrag gleich dem TOTAL-Eintragist.
22

3.2 Selective Information Dissemination
Key Methoden
Bei der Counting Methode taucht ein bestimmtes Profil mit K Worten in K verschiedeneninvertierten Listen auf. Bei den Key Methoden dagegen taucht dieses Profil im Verzeichnisnur bei einem einzigen Wort, dem so genannten Key-Wort auf. Die verschiedenen Key Verfah-ren unterscheiden sich hinsichtlich der Auswahl dieses Schlüsselworts. Bei der Random KeyMethode wird das Wort zufällig ausgewählt, bei der Ranked Key Methode wird das Profilbei demjenigen Wort gespeichert, welches die geringste Bewertung hat. Dahinter steht dieIdee, dass den häufigen Worten weniger Profile zugeordnet sind und damit im Schnitt proDokument weniger Profile untersucht werden müssen. Da eine Bewertung von Worten nichtimmer möglich ist, ist es in der Regel notwendig, beide Strategien zu berücksichtigen.
Der Matching-Prozess läuft bei Key Verfahren folgendermaßen: Für jedes Dokument wer-den eine Distinct Word Set und eine Occurence Table angelegt. Das Verzeichnis der Wortewird indexiert um für jedes Wort die invertierte Liste zugreifbar zu machen. Das Verfahrenkann so für jedes Profil der invertierten Liste prüfen, ob das Dokument matcht, wobei es dieOccurence Table zur Hilfe nimmt.
Baum Methoden
Häufig kommt es vor, dass Benutzer einer bestimmten Domäne vergleichbare Interessen habenund demzufolge auch die Profile sehr ähnlich sind, bzw. ähnliche Worte enthalten. DieseBeobachtung kann verwendet werden, um Profile in einer kompakteren Form denn als Listenzu speichern. Eine Möglichkeit ist eine Trie-artige Struktur [AHU83].
Wir betrachten dazu ein Profil P mit K Worten, (w1, w2, ..., wK). (w1, ..., wi) sei ein Präfixvon P , 0 ≤ i ≤ K; das korrespondierende Präfix ist (wi+1, ..., wK). Beispielsweise sind (),(a)und (a, b) jeweils Präfixe des Profils (a, b) mit den entsprechenden Postfixen (a, b), (b) und(). Ebenso sei (w1, ..., wj) ein Präfix von (w1, ..., wi), i ≥ j. Ein Präfix identifiziert P , wenni = K oder es gibt kein anderes Profil außer denjenigen, die identisch zu P sind, die also(w1, ..., wi) als Präfix haben. Das kürzeste Präfix welches ein Profil identifiziert ist das sogenannten identifizierende Präfix. Ein Präfix ist das identifizierende Präfix von zwei Profilengenau dann, wenn diese identisch sind. Die identifizierenden Präfixe der Profile sind baumartigorganisiert. Die Wurzel ist auf Ebene 0. Ein Knoten n auf Ebene i entspricht einem Präfixσ = (w1, ..., wi) von identifizierenden Präfixen.
Knoten n hat die folgenden Felder: children ist eine Liste von (v, pn(v)) Paaren, wobei v
ein Wort ist, so dass (w1, ..., wi, v) ein Präfix ist der einem Kind von n entspricht und pn(v)ist ein Zeiger auf dieses Kind; profiles eine Liste von Profilen zu denen σ das identifizierendePräfix ist; length ist die Länge des Postfix’ der Profile, die σ identifiziert und postfix sind dieWörter, die den Postfix der identifizierten Profile bilden.
Betrachtet man den Baum als Indexstruktur, so zeigt sich, dass die Wurzel des Baumes demVerzeichnis entspricht und jeder seiner Teilbäume eine baumartig strukturierte invertierteListe repräsentiert.
23

Kapitel 3 Grundlagen
a e
b
d
c
b
P5
P4
P3P2
P1
a cb
db P10
P41
eP2
P30
P53
0
f
d e f
Abbildung 3.3: Tree Methode
Soll ein Dokument verarbeitet werden, so wird zunächst die Menge der verschiedenenWorte sowie die occurrence table erzeugt. Das Verzeichnis wird für jedes Wort indexiert undin den Speicher der Teilbäume gelesen. Um die treffenden Profile im Teilbaum zu finden,wird Breitensuche angewandt. Dabei wird eine Schlange von Zeigern auf Knoten verwaltet,die während der Suche zu besuchen sind. Die Schlange wird mit der Wurzel des aktuellenTeilbaums initialisiert.
Die folgenden Schritte werden so lange wiederholt, bis diese Schlange leer ist: Man nimmtden ersten Zeiger aus der Schlange und holt sich den Knoten auf den er zeigt. Es wird diechildren-Liste der Wörter überprüft, die im Dokument sind und Zeiger, die Worten entspre-chen, die im Dokument enthalten sind, werden an die Schlange angehängt. Anschließend wirdPostfix daraufhin überprüft, ob alle Wörter im Dokument enthalten sind. Falls ja, sind dieProfile in Profiles Treffer bzgl. des betrachteten Dokuments. Falls Postfix leer ist haben wirebenfalls einen Treffer.
Die Baumstruktur ist insbesondere dann sehr platzsparend, wenn es viele gemeinsamePräfixe unter den Profilen gibt. Eine nahe liegende Heuristik um die Anzahl der gemeinsamenPräfixe zu erhöhen besteht darin, die Wörter in den Profilen zu sortieren. Falls Informationenzur Bewertung verfügbar sind, so bietet es sich ferner an, die Wörter nach umgekehrterBewertung zu sortieren. Dies hat den Vorteil, dass mehr Profile in die Teilbäume von geringerbewerteten Wörtern gesteckt werden, nach welchen auch seltener gesucht wird. Diese Methodewird Ranked Tree Method genannt, die vorhergehende Random Tree Method.
Beispiel Abbildung 3.3 zeigt links die identifizierenden Präfixe für die Profile aus dem ein-führenden Beispiel. Der Knoten mit Label x repräsentiert dabei das Präfix a. Knoten y stehtfür das Präfix (a, b) und identifiziert P1. Rechts sehen wir die interne Struktur des gleichenBaumes. Folgen wir beispielsweise von der Wurzel aus dem a-Zeiger, kommen wir zu Knoten
24

3.3 Filtern von XML-Datenströmen
x, welcher das (a)-Präfix repräsentiert. Folgen wir daraufhin dem b-Zeiger, kommen wir zumKnoten y für das Präfix (a, b). Dieser Knoten hat eine leere children-Liste, eine profiles-Liste,die P1 identifiziert und ein Längen-Feld mit Wert 0, das zeigt, dass das Postfix leer ist.
Der Matching-Prozess lässt sich folgendermaßen skizzieren: Angenommen wir suchen dieProfile im Teilbaum von a. Wir überprüfen die Wurzel dieses Teilbaums, d.h. den Knoten x,wobei wir die Wörter in der children-Liste überprüfen. Da b im Dokument ist, nicht jedochd, wird der Zeiger, welcher b entspricht und auf Knoten y zeigt an die Schlange angehängt.Da kein Postfix überprüft und kein Profil identifiziert werden muss, ist dieser Knoten damiterledigt. Daraufhin wird der nächste Knoten der Schlange entnommen, dieser zeigt auf y.Da y keine Kinder hat wird postfix überprüft. Postfix ist leer, d.h. das Profil P1 matcht dasDokument.
Auch verschiedene Ansätze aus dem Bereich des Streamings von XML-Dokumenten, insbe-sondere das als Basis für aXst verwendete YFilter, machen sich die Idee des Teilens gemein-samer Anfrage-Anteile zunutze, um damit den Anfrageindex effizienter gestalten zu könnenund sind in diesem Sinne Varianten oder Nachfolger der Baum-Methode.
Anforderungen an ein SDI-System
In [YGM94] werden die Anforderungen an ein SDI-System folgendermaßen definiert:
• Es soll eine reichhaltige Klasse von Profilen in Form von Anfragen unterstützen undnicht nur eine vordefinierte Menge von Kategorien anbieten.
• Es soll in der Lage sein, Profile kontinuierlich auszuwerten und Benutzer über rele-vante Dokumente informieren, sobald diese ankommen. Nicht ausreichend ist es, wennBenutzer nur in periodischen Intervallen informiert werden.
• Es soll für eine sehr große Anzahl von Profilen und sehr viele neue Dokumente skalieren.
• Die relevanten Dokumente sollen effizient und zuverlässig an die Interessenten geliefertwerden.
Das in dieser Arbeit definierte System aXst zielt vor allem darauf ab, die erste Anforderungin erhöhtem Maße zu erfüllen. Es wird sich zeigen, inwieweit aXst diesem Anspruch genügenkann.
3.3 Filtern von XML-Datenströmen
Im Zentrum dieser Arbeit steht mit der Definition von aXst (adaptive XML streaming) einSystem, welches es erlaubt, eine Vielzahl heterogener Datenquellen integriert zu verwendenund welches darüber hinaus in der Lage ist, auch bei potentiell fehlerhaften bzw. nicht sche-makonformen Daten gute Ergebnisse zu liefern. Dazu wird die etablierte Architektur eines
25

Kapitel 3 Grundlagen
Daten-Quelle
Daten-Quelle
Daten-Quelle
FilterSystem
Dokumenten Stream
BenutzerProfile
gefilterteDokumente
Abbildung 3.4: Filtern von Datenströmen
Systems zum Filtern von XML-Datenströmen anhand einer großen Anzahl an XPath-Profilenum spezifische Komponenten etwa zur Anfragetransformation und zum Monitoring der Datenerweitert.
Abbildung 3.4 zeigt schematisch ein System zum Filtern von Datenströmen. Die Grafikveranschaulicht, dass es zwei wesentliche Eingaben in das System gibt: auf der einen Seitewerden Dokumentenströme von verschiedenen Datenquellen produziert und von einem Filter-system verarbeitet. Auf der anderen Seite steht eine Vielzahl von Benutzern, die ein Interessean den Dokumenten haben. Dieses Interesse spezifizieren die Benutzer in Form von Benutzer-profilen oder Anfragen, die im Filtersystem abgelegt werden. Das Filtersystem verarbeitet dieankommenden Dokumentenströme anhand der bekannten Anfragen und stellt die gefiltertenDokumente den Benutzern zur Verfügung.
Architektur zum Filtern von Datenströmen
Abbildung 3.5 zeigt die wesentlichen Komponenten einer klassische Architektur zum Fil-tern von Datenströmen. In der Umgebung der eigentlichen Filter-Engine arbeitet ein XPath-Parser, der die in Form von XPath-Anfragen vorliegenden Benutzerprofile verarbeitet undsie der Filter-Engine zur Verfügung stellt. Sie werden in einer Repräsentation der Profileabgelegt, die im Wesentlichen ein Index ist, der eine effiziente Verarbeitung gewährleistensoll.
Die in Abbildung 3.5 gezeigten Architektur bildet die Grundlage für das in dieser Arbeitdefinierte Filtersystem aXst. Die Komponenten dieser grundlegenden Architektur werden inden folgenden Abschnitten erläutert.
XPath Parser
Aufgabe des XPath Parsers ist es, die Benutzerprofile entgegenzunehmen, sie zu parsen undder Filter-Engine zur Verfügung zu stellen. Im einfachsten Fall ist es nur dann möglich, neue
26

3.3 Filtern von XML-Datenströmen
XPath-Parser
Filter-EngineXML Parser
DataDissemination
Events
geparste Profile
Treffer
Benutzer-Profile
gefilterte Daten
XML Dokumente
Filter-EngineProfil-Repräsentation
Index(Automat)
Verarbeitungs-algorithmus
Events
Treffer
Abbildung 3.5: Filtern von Datenströmen
Profile der Filter-Engine hinzuzufügen, wenn diese inaktiv ist, d.h. wenn sie gegenwärtig nichtmit der Verarbeitung von Dokumenten beschäftigt ist.
Verarbeitung von XML-Daten mit einem SAX-Parser
Ein wesentlicher Bestandteil einer effizienten Verarbeitung von Anfragen an XML-Daten-strömen ist, dass mit der Anfrageverarbeitung sofort begonnen werden kann, sobald die ers-ten Daten eintreffen. Die Architektur, welche in obigem Abschnitt vorgestellt wurde, trägtdieser Anforderung Rechnung, indem die Anfrage-Verarbeitung durch einen SAX-Parser vor-angetrieben wird. SAX [Org01] definiert eine Anwendungsschnittstelle, die von Anwendungenimplementiert werden kann, um XML-Daten zu parsen und weiter zu verarbeiten. Dabei hatder Anwendungsentwickler die Möglichkeit, so genannte Listener zu definieren, die auf Er-eignisse wie dem Lesen eines öffnenden oder schließenden Tags reagieren.
Soll beispielsweise eine Anwendung implementiert werden, die an allen Produkt-Elementeneines XML Dokuments interessiert ist, so wird ein Event-Handler implementiert, der aufeinen öffnenden Produkt-Tag reagiert. Liest die Anwendung zur Laufzeit ein XML-Dokumentund es kommt ein solcher öffnender Produkt-Tag, so wird unmittelbar der registrierte Handleraufgerufen und der fragliche Anwendungscode zur Ausführung gebracht.
Das folgende Beispiel illustriert das Funktionsprinzip eines SAX-Parsers:
Beispiel Abbildung 3.6 zeigt auf der linken Seite ein XML-Dokument und auf der rech-ten Seite SAX-Ereignisse, die beim Parsen dieses Dokuments mit Hilfe eines SAX-basiertenParsers generiert werden.
Die Abbildung verdeutlicht wie der SAX-Parser die ursprüngliche Struktur des XML-Dokuments in eine lineare Sequenz von SAX-Ereignissen herunterbricht. Der Parsing-Prozessbeginnt mit dem start-document-Ereignis und wird durch das end-document-Ereignis been-det. Ein start-element-Ereignis liefert neben dem Namen des öffnenden Elements auch In-formationen über enthaltene Attribute. Aus Gründen der Übersichtlichkeit wurden Infor-mationen über Attribute in der obigen Abbildung weggelassen. Jedes end-element- Ereigniskorrespondiert mit einem vorher gelesenen start-element-Ereignis. Es liefert den Namen desschließenden Elements und signalisiert, dass im gelesenen Dokument das betreffende Ele-
27

Kapitel 3 Grundlagen
Start documentstart element: katalogstart element: kategoriestart element: produktstart element: preischaracters: 50end element: preisend element: produktstart element: produkt end element: produktend element: kategoriestart element: kategoriestart element: produktstart element: preischaracters: 25end element: preisend element: produktend element: kategorieend element: katalog
<katalog><kategorie bez='Sport'>
<produkt bez='Schuh'><preis>50</preis>
</produkt><produkt bez='Ball'>
<preis>40</preis></produkt>
</kategorie><kategorie bez='Literatur'>
<produkt bez='HP7'><preis>25</preis>
</produkt></kategorie>
</katalog>
XML-Dokument SAX-Events
Abbildung 3.6: XML-Dokument mit zugehörigen SAX-Events
ment geschlossen wird. Wird zwischen öffnendem und schließendem Tag Text-Informationgelesen, so wird ein character-Ereignis ausgelöst, das den enthaltenen Text liefert. In unse-rem Beispiel-Dokument wird etwa jeweils zwischen den zwei Element-Events zu Preis eincharacter-Ereignis generiert, das den entsprechenden im Dokument an dieser Stelle enthalte-nen Preis liefert.
Das Beispiel verdeutlicht den Vorteil einer SAX-basierten Verarbeitung von XML-Daten.Die Anfrageverarbeitung kann direkt mit dem Parsing-Prozess verzahnt werden, so dass esnicht notwendig ist, zunächst das gesamte Dokument einzulesen und dann erst die Anfrage-verarbeitung zu starten. Dies kann gerade beim Filtern sehr großer Dokumente von Vorteilsein.
Filter Engine
Die zentrale Komponente der Architektur ist die so genannte Filter-Engine. Ihre Aufgabebesteht darin, die geparsten XPath-Profile entgegenzunehmen und sie in eine interne Reprä-sentation zu überführen. Im Zuge der eigentlichen Verarbeitung von Datenströmen erhält siedie Parsing-Ereignisse des XML-Parsers. Die Filter Engine implementiert call-back Funktio-nen über deren Aufruf sie auf diese Events reagiert.
Der Schlüssel für skalierbare Ansätze zum Filtern von Daten anhand großer Mengen vonAnfragen liegt in der Beobachtung, dass Filtern das inverse Problem zur Anfrage von Daten-strömen ist [YGM94]. In herkömmlichen Datenbanksystemen werden riesige Datenmengenpersistent abgelegt. Anfragen werden gemäß dem ACID-Konzept [HR83] streng eine nachder anderen ausgeführt. Demgegenüber wird in einem System zum Filtern von Daten einegroße Anzahl von Anfragen persistent abgespeichert. Der eigentliche Suchprozess wird durchdie Dokumente vorangetrieben die nacheinander verarbeitet werden. In einem traditionellenDatenbanksystem werden Indexe verwendet um eine effiziente Suche zu ermöglichen, die ohneaufwändige sequentielle Scans auskommt. Entsprechend bietet es sich an, in Filtersystemendie Anfragen zu indexieren, um einen selektives Filtern zu ermöglichen.
28

3.4 Das Verfahren YFilter - ein NFA-basierter Ansatz
Zu der Art und Weise, wie derartige Anfrageindexe aufzubauen sind, wurden in den letz-ten Jahren eine Vielzahl verschiedener Ansätze präsentiert von denen eine Auswahl in Ab-schnitt 2.2.3 vorgestellt wird. Vielen dieser Ideen ist gemein, dass die Anfragen in Formvon deterministischen Automaten repräsentiert werden. Intuitiv können so die während desParsing-Prozesses generierten Events dazu verwendet werden, Zustandsübergänge in diesenAutomaten herbeizuführen. Wird wären des Verarbeitungsprozesses ein Endzustand einessolchen Automaten erreicht, so signalisiert dies einen Treffer, der durch den Automaten re-präsentierten Anfrage im aktuell verarbeiteten Dokument. Wesentliche Effizienzsteigerungensowohl hinsichtlich der Größe dieser Automaten als auch der Laufzeit der Suche konntenerreicht werden, indem nicht für jede Anfrage ein separater Automat generiert wird, son-dern indem gemeinsame strukturelle Eigenschaften von Anfragen dazu verwendet werden,den Automaten kompakter zu gestalten.
Daten-Dissemination Komponente
Sobald ein Profil identifiziert wird, das zu dem aktuell gelesenen Dokument passt, muss diesesan den entsprechenden Benutzer bzw. das entsprechende System gesendet werden. Hierbeisind verschiedene Ansätze denkbar. Der einfachste ist sicherlich, dass bei einem Treffer dasvollständige Dokument an jeden Interessenten geschickt wird. Je nach Anwendung und Größeder Dokumente kann es jedoch zweckmäßiger sein, lediglich diejenigen Teildokumente an dieInteressenten zu verteilen, welche auch tatsächlich den Treffer verursacht haben.
3.4 Das Verfahren YFilter - ein NFA-basierter Ansatz
YFilter [DAF+03] ist ein weit entwickelter Ansatz zum effizienten XML-Streaming anhandgroßer Mengen von XPath-Ausdrücken. Es erweist sich vielen vergleichbaren Ansätzen ge-genüber als überlegen, was insbesondere durch eine performante Implementierung empirischgezeigt werden konnte. Das Verfahren kann insofern als Referenz dienen und soll im Folgen-den näher beschrieben werden. Die Implementierung aus [DAF+03] bildet darüber hinaus dieFilter-Komponente des in dieser Arbeit untersuchten Systems aXst.
Die Repräsentation der XPath-Anfragen in Form eines nichtdeterministischen Automatenist die Grundlage von YFilter. Dieser Ansatz ermöglicht es, XML-Daten durch einen einzigenLesevorgang zu filtern. YFilter repräsentiert alle gegebenen Anfragen durch einen einzigenAutomaten, indem ausgenutzt wird, dass verschiedene Anfragen oftmals aus identischen An-teilen bestehen. Auf diese Art und Weise ist es möglich, die passenden Anfragen zum geradeverarbeiteten Dokument mit hoher Effizienz zu identifizieren.
Abbildung 3.7 zeigt auf der linken Seite eine Menge von acht XPath-Anfragen und aufder rechten Seite den dazugehörigen nichtdeterministischen Automaten nach YFilter. DieZustandsübergänge des Automaten sind mit den Knotentests der Anfragen assoziiert. Ei-nem Wildcard-Knotentest entspricht eine mit ’*’ beschriftete Transition, die bei einem be-
29

Kapitel 3 Grundlagen
q1 = /a/b
q2 = /a/c
q3 = /a/b/c
q4 = /a//b/c
q5 = /a/*/c
q6 = /a//c
q7 = /a/*/*/c
q8 = /a/b/c
a
b
c
c
ε
**
*
c
b
c
c
c
{q3,q
8}
{q2}
{q1}
{q4}
{q6}
{q5}
{q7}
XPath-Anfragen zugehöriger nicht-deterministischer Automa (YFilter)
Abbildung 3.7: XPath-Anfrage mit zugehörigem nichtdeterministischen Automaten nachdem Verfahren YFilter
liebigen Element den Automaten in den Nachfolgezustand überführt. Knotentests entlangder child-Achse werden durch einfache Zustandsübergänge repräsentiert, wohingegen diedescendant-or-self-Achsen durch die so genannte leere Transition ε und einen künstlichenZwischenzustand dargestellt wird, welcher eine zusätzliche, mit Wildcard versehene Transi-tion auf sich selbst hat. Diejenigen Zustände des Automaten, welche von mehreren Anfragengeteilt werden, sind in der Abbildung grau. Wird im Zuge der Verarbeitung eines Dokumentsein Endzustand erreicht, so sind die bei diesem Zustand vermerkten Anfragen Treffer zu demjeweiligen Dokument.
Abbildung 3.8 zeigt auf der linken Seite die vier typischen Anfragen, die ’/a’, ’//a’,’/*’ und ’//*’ und wie sie im Automaten repräsentiert werden. Hierbei ist ’a’ ein be-liebiger Knotentest und ’*’ der bekannte Wildcard-Operator. Eine Besonderheit der ver-wendeten Fragmente ist die ε-Transition in einen Zustand mit Schleifen-Transition auf sichselbst. Dies wird benötigt um bei der Kombination von zwei Fragmenten bestehend aus’//’- und ’/’-Schritten, diese auseinanderhalten zu können. Auf der rechten Seite zeigt dieAbbildung nach welchen Regeln mehrere NFA-Fragmente zu einem einzigen NFA-Fragmentverschmolzen werden können. Hierbei zeigt sich, dass durch die beiden Operatoren ’*’ und’//’ Nichtdeterminismus Einzug in das Modell findet. Der descendant-or-self-Operator’//’ bedeutet, dass der assoziierte Knotentest auf jeder beliebigen Ebene ab der aktuellenDokument-Ebene erfüllt werden kann. Falls ein passendes Symbol gelesen wird, wenn sichder Automat im Zustand mit einer Schleife auf sich selbst befindet, führt die Verarbeitungeine Transition in den Nachfolgezustand durch. Zusätzlich muss die Verarbeitung auf weitereEingaben warten.
Die Verarbeitung des Automaten wird durch die von einem SAX-Parser generierten Ereig-
30

3.4 Das Verfahren YFilter - ein NFA-basierter Ansatz
*
*
aε
a
a
b
a/a:
//a:
/*:
//*: *ε
*
b
a
b
a
b
b
b
*
aε
ε*
a
*
aε
*
bε
*
a
ε
b
NFA Fragmente Kombinieren von NFA Fragmenten
Abbildung 3.8: Beispiele für typische NFA-Fragmente und Regeln für die Kombination vonNFA-Fragmenten
nisse gesteuert. Ankommende Dokumente werden geparst und die beim Lesen von ’Start’-Elementen generierten Ereignisse führen zu Transitionen im Automaten. Die geschachtelteStruktur von XML-Dokumenten macht es erforderlich, dass der Automat beim Lesen von’End’-Elementen wieder in denjenigen Zustand versetzt wird, in dem er war, bevor das kor-respondierte ’Start’-Element gelesen wurde. Indem ein Laufzeit-Stack für die Verwaltung deraktuellen Zustände verwendet wird, wird dieses Backtracking zu den vorherigen Zuständenermöglicht. Da in einem NFA zur gleichen Zeit mehrere Zustände aktiv sein können, mussder Laufzeit-Stack in der Lage sein, mehrere aktive Pfade zu verfolgen. Die Verarbeitungeines Dokuments mittels NFA wird angestoßen, indem der Initialzustand als erster aktiverZustand auf den Laufzeit-Stack geschoben wird. Das Lesen eines Element-Namens führt zumAufruf der Behandlungsroutine für ein ’Start’-Element-Ereignis. Entsprechend diesem gelese-nen Element-Namen folgt der NFA den passenden Transitionen aller aktiven Zustände, wobeifür jeden dieser Zustände eine Reihe von Überprüfungen durchgeführt wird: Zunächst wird dieHash-Tabelle des Zustands auf den Element-Namen hin überprüft. Falls der Element-Namevorhanden ist, wird die entsprechende Zustands-ID einer Menge von Ziel-Zuständen hinzuge-fügt. Dann wird die Hash-Tabelle auf das ’*’-Symbol hin geprüft. Existiert es, so wird seineZustands-ID ebenfalls der Menge von Ziel-Zuständen hinzugefügt. Außerdem wird die Typ-Information des Zustands überprüft. Falls es sich um einen ’//-child’-Zustand handelt wirddie Zustands-ID dieses Zustands selbst der Ziel-Menge hinzugefügt. Dies entspricht der Schlei-fe auf den Zustand selbst. Schließlich wird für den Fall, dass die Hash-Tabelle des Zustandseine ε-Transition enthält, der ’//-child’-Zustand der entsprechenden Zustands-ID rekursivverarbeitet, indem die drei vorherigen Überprüfungen durchgeführt werden. Diese Verarbei-tung terminiert auf der nächsten Ebene, da ’//-child’-Knoten selbst keine ε-Transitionenthalten können.
Abbildung 3.9 zeigt unseren aus den vorigen Beispielen bekannten Automaten in Formeiner baumartig organisierten Indexstruktur sowie ein Auszug aus einem XML-Dokument.Die Verarbeitung dieses XML-Dokuments mit Hilfe der Indexstruktur und der beim Lesendes Dokuments generierten Ereignisse wird anhand der Laufzeit-Stacks in der Abbildungveranschaulicht.
31

Kapitel 3 Grundlagen
a
acε*
c
bc
c*
c
c
1
2
3
4
6
9
5
7 8
11
10
12 13
Index
1 11 2
11 2
3 9 7 6
11 2
3 9 7 6
5 10 12 8 11 6
11 2
3 9 7 6
11 2
1
Initial-zustand lies <a> lies <b> lies <c> lies </c> lies </b> lies </a>
Treffer q
1
Treffer q
3 q
8 q
5 q
4 q
6
Laufzeit Stack
XML-Fragment: <a><b><c></c></b></a>{q
1} {q
3,q
8}
{q2}
{q4}
{q6}
{q7}
{q5}
Abbildung 3.9: Beispiel für die Auswertung eines XML-Fragments anhand des YFilter-Index’zur Laufzeit
Die Tatsache, dass der Aufbau eines derartigen NFA ein inkrementeller Prozess ist unddamit neue Anfrage problemlos in einen bestehenden Automaten integriert werden können,eignet sich YFilter in besonderer Weise als Grundlage für einen Ansatz, bei dem Anfragendynamisch erstellt und gegebenenfalls sogar zur Laufzeit verändert werden.
Auswertung von Prädikaten in YFilter Sollen XPath-Anfragen mit wertebasierten Prädi-katen effizient ausgewertet werden, ist es nicht praktikabel die Prädikate direkt im NFA zukodieren, da so der durch das Ausnutzen gemeinsamer Anfrage-Anteile erzielte Performanz-gewinn wieder zunichte gemacht werden würde. In [AF00] werden mit Inline- und SelectionPostponed zwei alternative Ansätze zur effizienteren Evaluierung von Prädikaten mit YFiltervorgestellt. Beim Inline-Ansatz wird die Selektion von zu Prädikaten passenden Elementenschon während der eigentlichen Verarbeitung durchgeführt. Dazu wird jeder Zustand des Au-tomaten um Informationen über die damit assoziierten Prädikate erweitert. Da einem Zustandmehrere Prädikate verschiedener Anfragen zugeordnet sein können werden diese Informatio-nen in Tabellen abgelegt, deren Einträge mittels einer Anfrage-ID und einer Prädikat-IDansprechbar sind. Wird bei der Verarbeitung ein Zustand erreicht, so wird für alle damit as-soziierten Prädikate geprüft, ob sie erfüllt werden. Die Informationen über erfüllte Prädikatewerden gespeichert und wenn ein Endzustand des Automaten erreicht wird, so sind diejenigenAnfragen Treffer, für die alle Prädikate erfüllt wurden. So einfach diese Vorgehensweise imPrinzip ist, so offenbart sie bei näherer Betrachtung doch Mängel. Insbesondere ist zu beach-ten, dass selbst dann, wenn ein Prädikat eines Zwischenzustands nicht erfüllt wurde, dieserZwischenzustand doch weiter betrachtet werden muss, da er Bestandteil von anderen Anfra-gen sein kann, für die das betreffende Prädikat relevant ist. Bei Selection Postponed wird dieAuswertung von Prädikaten auf den Zeitpunkt verschoben, an dem das durch den NFA ge-leistete strukturelle Matching abgeschlossen ist. Dadurch können Prädikate einer Anfrage, diegegebenenfalls mit verschiedenen Elementen assoziiert sind als Konjunktion behandelt undeffizient ausgewertet werden. Die in [AF00] präsentierten experimentellen Resultate belegendie höhere Performanz von Selection Postponed im Vergleich zum Inline-Ansatz.
32

3.4 Das Verfahren YFilter - ein NFA-basierter Ansatz
3.4.1 YFilter als Basis von aXst
Zu YFilter existiert eine stabile, performante und gut dokumentierte Implementierung inJava, welche als Grundlage für die im Rahmen dieser Arbeit entwickelte Implementierungvon aXst verwendet wurde. Insbesondere der dynamische Aspekt von YFilter, der es erlaubt,Anfragen nach dem Beginn des Filterns in den Anfrageindex übernehmen zu können, machtes für aXst nützlich. Diese Dynamik erlaubt es aXst, Anfragen noch während des Filterns vonDaten zu transformieren und die dabei generierten Anfragen dem Automaten hinzuzufügen.
33

Kapitel 3 Grundlagen
34

Kapitel 4
Adaptive Auswertung von XPath
XPath ist eine einfache Anfragesprache für XML. Aufgrund seiner Möglichkeiten innerhalbvon XML-Dokumenten zu navigieren bzw. Knoten von XML-Dokumenten zu adressieren, istes ein wesentlichen Bestandteil mächtiger Anfrage- und Transformationssprachen wie XQueryoder XSLT. XPath-Anfragen sind im Wesentlichen aus einzelnen Subanfragen zusammenge-setzte Pfadausdrücke. Jede dieser Subanfragen besteht aus einem Knotentest und einer Achse,die angibt in welche Richtung im Dokumentbaum navigiert wird. Zusätzliche gegebenenfallsmehrfach verschachtelte Prädikate dienen darüber hinaus der exakten Spezifikation der zuadressierenden Knoten.
Eine XPath-Anfrage liefert dann ein Ergebnis, in der Regel in Form einer Menge vonXML-Knoten oder Elementen, wenn das zu verarbeitende Dokument exakt die durch dieAnfrage erwartete Struktur enthält. Geringfügige Abweichungen zwischen Dokumentstrukturund Anfrage, aus welchen Gründen auch immer sie zustandekommen mögen, führen in derRegel zu einem leeren Anfrageergebnis.
Kern der hier definierten adaptiven Auswertung für XPath ist es, die einzelnen Suban-fragen eines XPath-Ausdrucks gezielten Transformationen zu unterziehen, um so auch dannSuchergebnisse zu generieren, wenn die tatsächlich vorliegenden Daten in ihrer Struktur vonder vom Benutzer erwarteten Struktur abweichen.
Die Art der Anwendung dieser Transformationen ist abhängig von einer Reihe von Fakto-ren. So spielt es eine wichtige Rolle, in welcher Form die anzufragenden Daten vorliegen. Eswird zunächst der allgemeinen Fall betrachtet, in dem die Daten vollständig im Speicher odereiner Datenbank vorhanden sind. Dies erlaubt es, den Transformationsprozess direkt in dieeigentliche Anfrageverarbeitung zu integrieren und bietet darüber hinaus den Vorteil, dassvollständig ohne Schemainformationen operiert werden kann. Im speziellen Fall der Verar-beitung von Datenströmen wird aufgrund der dort vorliegenden besonderen Anforderungendagegen so vorgegangen, dass die Anfragen schon vor der eigentlichen Anfrageverarbeitungtransformiert werden. Hier kann unterschieden werden, ob zur Transformation Schemainfor-mationen genutzt werden können oder nicht. Diese sind hilfreich, indem sie die Anzahl derpotentiell durch Transformation zu generierenden Anfragen stark einschränken können, aufder anderen Seite sind sie für Szenarien ungeeignet, in denen mit Abweichungen der Datenvon eben diesen Schemata zu rechnen ist.
35

Kapitel 4 Adaptive Auswertung von XPath
Unabhängig von der Art und Weise und dem Zeitpunkt ihrer Anwendung ist allen Trans-formationsverfahren gemein, dass zu einer gegebenen Originalanfrage eine Menge von Anfra-gen generiert wird. Die Aufgabe hier ”gute” von ”schlechten” zu unterscheiden obliegt einerFitness-Funktion, die wahlweise die Suchergebnisse der transformierten Anfragen oder dieseAnfragen selbst bewertet.
4.1 Transformation von XPath-Subanfragen
Grundlage der verschiedenen Transformationsverfahren sind die in [LM02] erstmals einge-führten und in [MLW03a] näher untersuchten und verfeinerten Subanfragetransformationen,die auf drei grundsätzlichen Aspekten basiert:
1. Die dem XPath-Modell innewohnenden Eigenschaft, dass Anfragen als eine Reihe vonnacheinander auszuführenden Subanfragen betrachtet werden. Diese Eigenschaft er-möglicht die isolierte Betrachtung jeder einzelnen Subanfrage als eine Funktion, die zueinem Eingabekontext einen Ausgabekontext produziert, welcher wiederum Eingabe-kontext der nächsten Subanfrage ist. Somit muss nicht die Anfrage als Ganzes betrach-tet werden, sondern es können effiziente, isoliert ablaufende Transformationen definiertwerden.
2. Das streng hierarchische Datenmodell von XML. Jedes Element ist Kind-Element ei-nes übergeordneten Elements und enthält seinerseits gegebenenfalls eines oder mehrereKind-Elemente. Die Tatsache, dass jedes wohlgeformte XML-Dokument diesem Modellfolgt, machen sich die Anfragetransformationen zunutze. Wenn sich ein vom Benutzergesuchtes Element an einer anderen als der angenommenen Stelle im Baum befindet,so besteht doch die Erwartung, dass der entsprechende Pfad durch einfache Transfor-mationen aus dem ursprünglichen Pfad generiert werden kann.
3. Einer Fitness-Funktion, die es erlaubt, bessere Antworten von schlechteren zu unter-scheiden. Sie gewährleistet die flexible Anpassung an den gegebenen Anwendungsfall,indem festgelegt werden kann, wie die verschiedenen Transformationen gewichtet sind.
In Konsequenz aus den ersten beiden Punkten können die folgenden Basistransformationendefiniert werden:Definition (Basistransformationen)Auf jede Subanfrage einer gegebenen Anfrage kann jede der folgenden Transformationenangewendet werden:
Keine Transformation: Die Subanfrage wird so ausgeführt, wie sie vom Benutzer ursprüng-lich formuliert wurde.
Generalisierung von Subanfragen: Die Achse einer konkreten Subanfrage wird nach folgen-dem Schema erweitert:
36

4.1 Transformation von XPath-Subanfragen
<a><d>
<c></c>
</d></a>
XML-Dokument Original-Anfrage
/a/b/c
Transformationen
/(n) /a(e) /a(g) /a//c
Abbildung 4.1: Anwendung von Basis-Transformationen
• child :: n ⇒ descendant-or-self :: n
• parent :: n ⇒ ancestor-or-self :: n
Eliminierung von Subanfragen: Die Subanfrage wird aus der ursprünglichen XPath-Anfrageeliminiert.
Abbildung 4.1 zeigt ein XML-Dokument sowie eine einfache XPath-Anfrage. Rechts zeigtdie Abbildung beispielhaft die schrittweise Anwendung der drei Basistransformationen KeineTransformation (n), Generalisierung (g) sowie Eliminierung (e), so dass aus der Originalan-frage /a/b/c die Anfrage /a//c generiert wird.
Die Basistransformationen sind in der Lage strukturelle Abweichungen auf Elementebenezu kompensieren. Voraussetzung für die Wirksamkeit der Transformationen ist, dass die inder Anfrage spezifizierten Knotentests auf entsprechend benannte Elementknoten im Doku-ment treffen. Demgegenüber ist in der Praxis von darüber hinaus gehenden Abweichungenauszugehen.
Von grundlegender Bedeutung ist dabei die Möglichkeit von XML, Konzepte entweder inForm von Elementen, von Attributen oder von Element- bzw. Textinhalt abzulegen. Diesführt zu der Problematik von Anfragen, die etwa Knotentests durchführen, wo angesichtsder tatsächlichen Daten ein Prädikat angebracht wäre, das den Wert eines Attributs abfragt.Oder umgekehrt enthält die Anfrage ein Prädikat mit der Abfrage eines Attributwertes, woeigentlich ein entsprechender Knotentest angebracht wäre.
Wird im Prädikat einer Anfrage der Wert eines Attributs abgefragt, so kann es zweckmäßigsein, diesen Attributwert in einen Knotentest der Anfrage zu transformieren, falls die Strukturdes XML-Dokuments einen Elementtyp dieses Namens vorsieht. Die Downgrade-Transfor-mation leistet diese Umwandlung:
Definition (Downgrade)(1) [@att=’v’] ⇒ child :: v
Abbildung 4.2 zeigt die Anwendung der Downgrade- Transformation. Das Prädikat derAnfrage wird zur Subanfrage child::b transformiert.
37

Kapitel 4 Adaptive Auswertung von XPath
<a><b>
<c></c>
</b></a>
XML-Dokument Original-Anfrage
/a[@*=‘b‘]/c
Transformationen
/(n) /a(d) /a/b(n) /a/b/c
Abbildung 4.2: Anwendung von Downgrade-Transformation
Der inverse Fall wird durch die Upgrade-Transformationen behandelt. Diese wandeln denKnotentest einer Anfrage um in ein Prädikat, welches entweder überprüft, ob es ein Attri-but mit dem Namen des Knotentests gibt oder ob es ein Attribut gibt, dessen Wert demKnotentest entspricht. Diese beiden Tests können von der Upgrade-Transformation in dreiverschieden starken Ausprägungen vorgenommen werden. So wird das neu generierte Prädi-kat entweder direkt der vorhergehenden Subanfrage zugeordnet oder es wird eine neue Sub-anfrage generiert, welche ein beliebiges Kind-Element oder ein beliebiges Nachfolge-Elementadressiert:Definition (Upgrade)
(2) child :: n ⇒ [@∗ = ’n’]child :: n ⇒ [@n]
(3) child :: n ⇒ child :: ∗[@∗ = ’n’]child :: n ⇒ child :: ∗[@n]
(4) child :: n ⇒ descendant-or-self :: ∗[@∗ = ’n’]child :: n ⇒ descendant-or-self :: ∗[@n]
Abbildung 4.3 zeigt die Anwendung der Upgrade- Transformation. Die Subanfrage child::bwird zur Subanfrage mit Prädikat child::*[@*=’b’] transformiert.
Die Basistransformationen und erweiterten Transformationen können völlig isoliert aufeinzelnen Subanfragen angewendet werde. Die im Folgenden definierten Verfahren zu Trans-formation ganzer XPath-Anfragen werden sich darin unterscheiden, ob und welche Informa-tionen sie für die Anfragetransformation verwenden und ob die Transformationen schon voroder erst während der eigentlichen Ausführung der Anfrage durchgeführt werden.
4.2 Transformation während der XPath-Auswertung
In einem Umfeld in dem die anzufragenden XML-Dokumente zum Zeitpunkt der Ausfüh-rung der Anfrage bereits vollständig vorliegen und im Speicher oder einer Datenbank unterUmständen sogar mittels Unterstützung geeigneter Indexstrukturen direkt zugreifbar sind,
38

4.2 Transformation während der XPath-Auswertung
<a><x attr= ‘b‘>
<c></c>
</x></a>
XML-Dokument Original-Anfrage
/a/b/c
Transformationen
/(n) /a(u3) /a/*[@*=‘b‘](n) /a/*[@*=‘b‘]/c
Abbildung 4.3: Anwendung einer Upgrade-Transformation
kann die Anfragetransformation unmittelbar in den Vorgang der Anfrageverarbeitung einge-baut werden. Im Gegensatz zu einer Transformation, die vorab durchgeführt wird, hat diesden Vorteil, dass erstens keine Schemainformationen notwendig sind und zweitens trotzdemkeine überflüssigen Anfragen generiert werden. Nachteilig ist, dass eine derart große Mengean Zwischenergebnissen während der Anfrageverarbeitung zu verwalten ist, dass sich diesesVerfahren für ein effizientes Streamingsystem nicht anbietet.
Nichtsdestotrotz illustriert diese Art der Transformation die Wirkungsweise der Suban-fragetransformationen und bildet den Ausgangspunkt für den in Abschnitt 4.4 eingeführtenTransformations-algorithmus, welcher direkt auf den originalen Anfragen operiert. Im Fol-genden wird diese Variante auch mit on-the-fly bezeichnet.
Grundlage des Verfahrens ist die Auswertung von XPath, welche sich wie folgt formalisierenlässt:
Definition (XPath Anfrage)Eine XPath Anfrage QX ist definiert als:
QX = qo/q1/.../qn
wobei qi eine XPath Subanfrage ist, wie unten definiert, und ’/’ das Trennzeichen für XPathSubanfragen.
Definition (XPath Subanfrage)Eine XPath Subanfrage qi ist ein 3-Tupel
qi = (Ci, wi, Ci+1)
wobei:
• Ci eine Menge von XML-Knoten ist, welche den Eingabekontext bildet.
• wi ein XPath-Ausdruck ist, der auf jeden Knoten des Eingabekontext’ angewendet wird.
• Ci+1 eine Menge von XML-Knoten ist, die sich aus der Anwendung des Ausdrucks wi
auf den Eingabekontext Ci ergeben. Ci+1 ist der sogenannte Ausgabekontext.
39

Kapitel 4 Adaptive Auswertung von XPath
Auf Basis dieser Art der Auswertung von XPath lässt sich die Anwendung der Trans-formationen definieren, wobei die erweiterten Transformationen jeweils separat betrachtetwerden.
Definition (Anwendung der Basistransformationen)Der Auswertungs-Prozess für jede Subanfrage qi wird dann so ausgeführt, dass aus jedemEingabekontext Ci drei Ausgabekontexte folgendermaßen erzeugt werden:
• Cni+1 entsteht durch keine Transformation von qi.
• Cgi+1 entsteht durch Generalisierung von qi.
• Cei+1 entsteht durch Eliminierung von qi.
Für den Ausgabe-Kontext Ci+1 gilt:
Ci+1 = Cni+1 ∪ Cg
i+1 ∪ Cei+1
Definition (Anwendung der erweiterten Transformationen)Kommen die erweiterten Transformationen zur Anwendung so entstehen mit jedem Trans-formationsschritt zwei zusätzliche Mengen, so dass sich der Ausgabekontext insgesamt ausfünf Ausgabekontexten zusammensetzt:
• Cdi+1 entsteht durch Downgrade von qi.
• Cui+1 entsteht durch Upgrade von qi.
Für den Ausgabekontext Ci+1 gilt dann:
Ci+1 = Cni+1 ∪ Cg
i+1 ∪ Cei+1 ∪ Cd
i+1 ∪ Cui+1
Abbildung 4.4 zeigt die grafische Repräsentation der adaptiven Auswertung einer XPath-Anfrage bestehend aus sieben Subanfragen bei Anwendung der Basistransformationen. Auf-grund des Eliminierungs-Schritts, der alle Knoten des Eingabekontext’ in den Ausgabekontextübernimmt, hat man die intuitive Vorstellung, dass sich alle Knoten des Eingabekontext’ alsweiße Knoten im Ausgabekontext wiederfinden. Dies wird in der Abbildung veranschaulicht.Es sei jedoch darauf hingewiesen, dass es im Zuge eines Schritts durchaus der Fall sein kann,dass ein Knoten durch keine Transformation oder Generalisierung erzeugt wird, der bereitsim Eingabekontext des betreffenden Schritts ist. In diesem Fall werden die beiden Knoten ver-schmolzen zu einem Knoten, der dann als durch keine Transformation oder Generalisierunggenerierter Knoten gilt.
40

4.3 Bewertung der Anfragen und Suchergebnisse
q0 q1 q2 q3 q4 q5 q6
C0 C1 C2 C3 C4 C5 C6 C7
������
������
������
������
��������
��������
��������
��������
������
������
��������
��������
Knoten wird ohne Transformation generiert.
Knoten wird duch Generalisierung der Sub−Anfrage generiert.
Knoten wird durch Eliminierung der Sub−Anfrage generiert.
Abbildung 4.4: Beispiel einer adaptiven Auswertung eines XPath-Ausdrucks
4.3 Bewertung der Anfragen und Suchergebnisse
Durch diese Art der Anfragetransformation wird unter Umständen eine Vielzahl von Knotengeneriert, wovon offensichtlich nur einige der Intention der ursprünglichen Anfrage entspre-chen. Es ist also ein Kriterium notwendig, welches die Unterscheidung zwischen ”guten” und”schlechten” Knoten erlaubt. Hierzu wird eine Fitness-Funktion definiert, welche Knoten an-hand derjenigen Transformationen bewertet, die zu ihrer Generierung führten. Insbesonderesoll diese Fitness-Funktion die folgenden Anforderungen erfüllen:
1. Je ähnlicher eine transformierte Anfrage der ursprünglichen Anfrage ist, desto höhersollen die damit generierten Knoten bewertet werden. Demzufolge ist ein Knoten, dervon einer nicht-transformierten Subanfrage generiert wird, höher zu bewerten, als einvon einer generalisierten Subanfrage generierter Knoten. Am geringsten sind Knotenzu bewerten, die durch Eliminierung von Subanfragen generiert werden.
2. Zwischen- und Endergebnisse müssen voneinander unterscheidbar sein, d.h. Endergeb-nisse sind höher als Zwischenergebnisse zu bewerten, woraus folgt, dass die Funktionstreng monoton steigend sein soll in dem Sinne, dass sie im Laufe der Anfrageverarbei-tung später generierte Knoten höher bewertet als früher generierte.
3. Die Funktion sollte einfach sein, damit sie auf jedem Knoten effizient ausgeführt werdenkann.
Grundlage für eine Bewertung, die diesen Kriterien genügt, ist die Festlegung einer Ordnungder einzelnen Transformationen. Jede Transformation ist in unterschiedlichem Maße von der
41

Kapitel 4 Adaptive Auswertung von XPath
originalen Anfrage entfernt. Diese Distanz wird durch die Ordnung wiedergegeben.
Definition (Ordnung der Transformationen)Sei t eine der Transformationen aus n, g, u, d, e, wobei n keine Transformation, g Genera-lisierung, u Upgrade, d Downgrade und e Eliminierung ist. Dann ist O(t) die Ordnung derTransformation t. Für die Basistransformationen gilt:
O(e) = 0
O(g) = 1
O(n) = 2
Für die erweiterten Transformationen gilt:
O(e) = 0
O(u) = 1
O(d) = 1
O(g) = 2
O(n) = 3
Die am weitesten von der ursprünglichen Anfrage entfernte Eliminierung hat damit dieniedrigste Ordnung, die ursprüngliche Anfrage selbst die höchste. Dazwischen liegt die Gene-ralisierung. Downgrade und Upgrade sind im allgemeinen Fall hinsichtlich ihrer Bewertungnicht gegeneinander abzugrenzen, so dass sie die gleiche Ordnung haben. Da sie die Abbil-dung von Konzepten von der Element- auf die Attributebene bzw. umgekehrt vornehmen,haben sie eine niedrigere Ordnung als die Generalisierung.
Durch diese Ordnung wird vorgegeben, wie einzelne Transformationen jeweils zu bewertensind. Da die adaptive Evaluierung einer kompletten XPath-Anfrage aus einer ganzen Folgevon Transformationen besteht, muss darüber hinaus auch festgelegt werden, wie sich mehrereTransformationen einer bestimmten Ordnung zu einer bestimmten Anzahl von Transformatio-nen einer anderen Ordnung verhalten sollen. Dies wird durch die Basis der Fitness-Funktionfestgelegt.
Definition (Basis der Fitness-Funktion)Die Basis b der Fitness-Funktion ist die minimale Anzahl an Transformationen einer be-stimmten Ordnung, die notwendig ist um den Wert einer Transformation der nächst-höherenOrdnung zu erreichen.
Damit lässt sich nun unter Berücksichtigung der eingangs erwähnten Kriterien die folgendeFitness-Funktion definieren.
42

4.3 Bewertung der Anfragen und Suchergebnisse
Definition (Fitness-Funktion)Sei qi die aktuelle Subanfrage, die auszuwerten ist und sei Ci der assoziierte Eingabekontext.Jeder Knoten k ∈ Ci wird erweitert um einen Wert vk, der sich aus der Evaluierung derbisherigen Subanfragen q0, ..., qi−1 ergibt. Wie oben definiert ist Ci+1 = Cn
i+1 ∪Cgi+1 ∪Cu
i+1 ∪Cd
i+1 ∪ Cei+1. Ferner ist bekannt, dass jeder Knoten m ∈ Ci+1 das Ergebnis der Evaluierung
von qi auf einem Knoten k ∈ Ci ist.Dann weist die Evaluierungsfunktion jedem neuen Knoten m ∈ Ci+1 , der aus einem
Knoten k ∈ Ci generiert wurde, folgendermaßen einen Wert vm zu:
• wenn m ∈ Cni+1, dann vm = bO(n) + vk
• wenn m ∈ Cgi+1, dann vm = bO(g) + vk
• wenn m ∈ Cui+1, dann vm = bO(u) + vk
• wenn m ∈ Cdi+1, dann vm = bO(d) + vk
• wenn m ∈ Cei+1, dann vm = bO(e) + vk
Hierbei ist b ein ganzzahliger Wert mit b > 0, der die Basis der Evaluierungsfunktion dar-stellt und O(t) mit t ∈ {n, g, u, d, e} die Ordnung der Transformation t unter Berücksichtigungder Tatsache, dass nur die Basistransformationen oder auch die erweiterten Transformationendurchgeführt werden.
Wird ein Knoten k durch die Anwendung von mehr als einer Strategie generiert, k ∈ Cni+1
und k ∈ Cgi+1, enthält der Kontext Ci+1 nur die Instanz von k mit dem höchsten Wert vk.
Der Wurzel-Knoten wird mit dem Wert 1 initialisiert: vroot = 1.
Indem sie die Ordnung der Transformationen berücksichtigt, gewährleistet die Funktion,dass die Fitness einer Anfrage um so höher ist, je ähnlicher sie der ursprünglichen Anfrageist. Die Funktion ist monoton, da sich die Fitness eines bestimmten Knotens aus der Summeder aktuellen Transformation und der Fitness des Kontext-Knotens ergibt. Die Fitness einesbestimmten Knotens kann zu jedem Zeitpunkt der Anfrage-Evaluierung effizient berechnetwerden.
4.3.1 Formale Analyse
Die Fitness-Funktion definiert eine partielle Ordnung auf allen möglichen Folgen von Trans-formationen, die sich zu einer bestimmten Anfrage ergeben. Es ist klar, dass am Anfang dieserpartiellen Ordnung diejenige Anfrage steht, die durch eine Folge von Eliminierungen entstehtund am Ende der Ordnung die Ursprungsanfrage mit der höchsten Bewertung. Die Wertealler Folgen von Transformationen dazwischen ergeben sich insbesondere durch die Wahl derBasis b. Diese Analyse wurde erstmalig in [MLW03b] vorgestellt.
Abbildung 4.5 zeigt die partielle Ordnung die bei Anwendung aller möglichen Basistrans-formationen auf eine Anfrage der Länge 3 (ql = 3) bei einer Basis von b = 10 entsteht. Wie
43

Kapitel 4 Adaptive Auswertung von XPath
ngg gng ggn
nge neg eng egn gne gen
nee ene een
b2
b2
b2
ggg
gge geg egg
b b b 1 31+ + + =
b 1b 1 22+ + + =
nne nen enn
ngn gnnnng
nnn
gee ege eeg
eee
b2
b2
1 1 202+ + + =
b2
b2
b 2111+ + + =
b2
b2
b2
1 301+ + + =
b 1 1 1 13+ + + =
1 1 1 1 4+ + + =
b b
b 1
1 1
1211
1
1
112
103
+ + +
+ + +
+ + + =
=
=
Abbildung 4.5: Partielle Ordnung für ql = 3 und die Basistransformationen n, g und e
die Fitness-Werte auf der rechten Seite der Abbildung zeigen, erhält jede Ebene durch dieFitness-Funktion einen anderen Wert und zwar so, dass diejenigen Ebenen, die näher an nnn
liegen, höhere Werte haben, als andere Ebenen, die weiter unten in der Ordnung sind.Natürlich ist es im allgemeinen Fall nicht offensichtlich, ob die Annahme korrekt ist, dass
beispielsweise nee > ggg ist, wie es hier der Fall ist. Dies kann jedoch durch die Wahl der Basisb festgelegt werden. Hier sorgt die Wahl von b = 10 dafür, dass selbst für eine Originalanfrageder Länge ql = 10 gelten würde, dass neeeeeeeee > gggggggggg, (110 > 101), was je nachAnwendungsfall die korrekte aber auch eine ungewünschte Ordnung sein kann.
Um hier Folgen von Transformationen niedrigerer Ordnung mehr Gewicht gegenüber ein-zelnen Transformationen höherer Ordnung zu verschaffen, kann b niedriger gewählt werden,was letztendlich zu einer anderen partiellen Ordnung führt. So würde etwa die Wahl vonb = 2 gemäß der Definition von b dafür sorgen, dass nee = ggg, (7 = 7).
Nach Definition ist b die minimale Anzahl an Transformationen einer bestimmten Ord-nung, die notwendig ist, um den Wert einer Transformation der nächsthöheren Ordnung zuerreichen. Es ist offensichtlich, dass diese Forderung durch die Definition der Fitness-Funktiongewährleistet ist:
Der Wert einer Transformation t der Ordnung O(t) ist bO(t). Der Wert der nächsthöherenTransformation ist bO(t)+1 und b ∗ bO(t) = bO(t)+1. Bei der konkreten Transformation einerAnfrage der Länge l bzw. einer entsprechenden adaptiven Auswertung werden l Transfor-mationen durchgeführt. D.h. für die gesamte Anfrage gilt bei b = l und der Annahme, dassbei der Transformationsfolge mit der Transformation der höheren Ordnung die verbleibendenTransformationen von einer niedrigeren Ordnung sind:
b ∗ bO(t) < bO(t)+1 + (b− 1) ∗ bO(t)−1
44

4.4 A-Priori Anfragetransformationen
Die Folge mit der Transformation der höheren Ordnung hat in diesem Fall also insgesamteine höhere Fitness. Kommt jedoch eine weitere Transformation hinzu, so gilt:
(b + 1) ∗ bO(t) = bO(t)+1 + b ∗ bO(t)−1
= (b + 1) ∗ bO(t)
Hier erreicht also die Folge mit der Transformation der niedrigeren Ordnung den Wert derbisher dominanten Folge.
Durch die Wahl von b lässt sich also sehr differenziert die Art und Weise festlegen, in der dieFitness-Funktion eine partielle Ordnung über alle möglichen Folgen von Transformationenlegt.
In der Praxis kann diese Wahl sowohl administrativ für den Anwendungsfall oder aberdurch den Benutzer individuell für seine jeweiligen Anfragen vorgenommen werden.
4.4 A-Priori Anfragetransformationen
Bei der Verarbeitung von Datenströmen macht es zum Zwecke einer effizienten Filterungder Daten Sinn, notwendige Anfragetransformationen schon vor dem eigentlichen Streamingdurchzuführen. Dies hat den Vorteil, dass zum Streaming etablierte Filter-Techniken ein-gesetzt werden können und verlagert den Mehraufwand, der für die Anfragetransformationnotwendig ist, in einen separat durchführbaren Schritt.
Stehen dabei die Schemata der zu verarbeitenden Datenströme zur Verfügung so kön-nen diese nutzbringend zur gezielten Transformation verwendet werden. Die Strukturen derAnfragen können mit den Schemainformationen verglichen und so angepasst werden, dassausschließlich Anfragen generiert werden, die auch potentiell ein Ergebnis erwarten lassen.
Die Grundzüge dieses Verfahrens wurden erstmals in [Web07] präsentiert.
4.4.1 Formalisierung
Zur Definition eines auf Schemainformationen basierenden Transformationsverfahrens wirdein Formalismus verwendet, der es erlaubt, XPath-Anfragen so zu repräsentieren, dass eineAbbildung der Strukturen einer Anfrage auf die Strukturen eines Schemas möglich ist. XPath-Anfragen werden dazu in Form von Tree-Pattern-Queries (TPQ) repräsentiert. Sie erlaubendie baumartige Repräsentation von Anfragen, die aus den Achsen child, descendant, parentund ancestor sowie aus Prädikaten bestehen. XML-Schemata werden ohne Beschränkungder Allgemeinheit in der einfachen Form von DTDs betrachtet. Der für die Definition der An-fragetransformationen notwendige Teil beschränkt sich im Wesentlichen auf die parent-childund ancestor-descendant-Beziehung zwischen Elementen bzw. Element-Typen, so dass diezusätzliche Ausdrucksstärke von XML-Schema im Vergleich zu einfachen DTDs hier keinen
45

Kapitel 4 Adaptive Auswertung von XPath
a
b
e
/a/b/e
a
b
d
//a[/b//d=/c//d]
c
d
$1 $2
$3 $4
$3≈$4
a
*
/a[//*/text()=‚xyz‘]/*[@type=abc]/b[text()=‚A.E.Neumann‘]
*
b
$1
$2 $3
$4
$2.val=„xyz“ &$3.type= abc &$4.val=„A.E.Neumann“
Abbildung 4.6: Beispiel für Tree Pattern Queries
Mehrwert bieten. Andererseits sind die unter Verwendung von DTDs erzielten Erkenntnisseuneingeschränkt auf XML-Schema übertragbar.
XPath-Anfragen als Tree-Pattern-Queries
Tree-Pattern-Queries wurden erstmals in [AYCLS01] eingeführt. Sie erlauben eine Repräsen-tation einer XPath-Anfrage in Form eines Baums.
Definition (Tree-Pattern-Query)Eine Tree Pattern Query (TPQ) ist ein Tripel Q = (V,E, F ), wobei (V,E) ein Baum istmit Knoten V (mit Variablen beschriftet) und mit E = Ec ∪ Ed. Hierbei ist Ec die Mengeder pc-Kanten (parent-child-Kanten) und Ed die Menge der ad-Kanten (ancestor-descendant-Kanten) (den XPath-Achsen entsprechend).Ein Tag $x.tag eines Knotens $x ∈ V ist der Element-Bezeichner des Knotens $x.F ist eine Konjunktion von Tag-Constraints(TCs) und Value-Based-Constraints(VBCs).
• TCs haben die Form $x.tag compop t, wobei $x ein Knoten im Baum und t ein Tag-Name ist. Für den Zeichenketten-Vergleichsoperator gilt: compop ∈ {=, contains}
• VBCs enthalten Selektions-Bedingungen der Form $x.val relop c oder $x.attr relop c,wobei relop ∈ {=, 6=, >,≥, <,≤} .
Beispiel Abbildung 4.6 zeigt drei Beispiele für XPath-Anfragen mit den jeweils entsprechen-den Tree-Pattern-Queries. Um Value-Based-Constraints im Graphen auszudrücken, werdendie Kanten mit Variablenbezeichnern versehen, über die die betreffenden VBCs zugeordnetwerden können. Hierbei ist zu beachten, dass die XPath-Anfragen absolut definiert sind,bzw. relativ zur Wurzel. Auf die Darstellung des Wurzel-Knotens wurde in der Abbildungaus Gründen der Übersichtlichkeit verzichtet.
46

4.4 A-Priori Anfragetransformationen
Formalisierung von Schemata
XML-Schemata werden in der Gestalt von Document Type Definitions (DTDs) betrachtet,wobei die folgende Repräsentation als Graph verwendet wird:
Definition (Element-Typ-Graph)Ein Element-Typ-Graph für eine DTD D ist ein gerichteter Graph G = (V,K). Die Knotenin V sind die Namen der Element-Typen (ET) von D. Eine Kante (ETj , ETi) in K zeigt,dass ETj im Inhaltsmodell von ETi auftritt.
Das Inhaltsmodell beschreibt, welche Elemente als Kind-Element des betreffenden Ele-ments in welcher Kardinalität enthalten sind.
Die Transformationen der adaptiven Anfrage-Technik beruhen zu einem wesentlichen Teilauf parent-child bzw. ancestor-descendant- Beziehungen zwischen XML-Elementen. Eine DTDlegt die zulässigen Beziehungen dieser Art durch eine entsprechende Definition der zugehöri-gen Element-Typen fest. Um diese per Definition explizit oder implizit gegebenen Beziehun-gen für die Anfragetransformation zugänglich zu machen, werden eine Reihe von aus einerDTD ableitbaren Beziehungen verwendet, welche in [BAOG98] erstmalig eingeführt wurden:
Definition (directly-contained-in/directly contains)Element-Typ ETj ist direkt enthalten in (directly-contained-in) Element-Typ ETi wenn eseine Kante (ETj , ETi) in G gibt. Umgekehrt enthält ETi (directly-contains) ETj wenn dieKante existiert. Es werden die abkürzenden Schreibweisen dconti und dcont verwendet.
Die transitive Hülle zur directly contained-in/directly contains-Beziehung lässt sich mitcontained-in/contains definieren:
Definition (contained/contains)Die contained-in Beziehung (contains Beziehung) zwischen Element-Typen ist die transitiveHülle der directly-contained-in Beziehung, bzw. der directly-contains Beziehung. Es werdendie abkürzenden Schreibweisen conti und cont verwendet.
Um die beiden Beziehungen cont und dcont bzw. conti und dconti voneinander abzugrenzen,enthalten die cont und conti Beziehungen nicht die dcont und dconti Beziehungen.
In DTDs bzw. XML-Schema ist es möglich, zu spezifizieren, ob ein Element in einem an-deren Element enthalten sein muss, d.h. ob es obligatorisch ist, oder nicht. Diese Eigenschaftwird durch die obligation-Beziehung ausgedrückt.
Definition (Obligation)Der Element Typ ETi enthält obligatorisch (obligatorily contains) den Element Typ ETj ,wenn jedes Element vom Typ ETi in jedem Dokument ein Element vom Typ ETj enthal-ten muss. Umgekehrt ist ETj obligatorisch in ETj enthalten. Es werden die abkürzendenSchreibweisen obconti und obcont verwendet.
47

Kapitel 4 Adaptive Auswertung von XPath
Document-Typ Definition
<!ELEMENT a(b*,d)><!ELEMENT b(c|e)><!ELEMENT d(e)><!ELEMENT c(#PCDATA)><!ELEMENT e(#PCDATA)>
Element-Typ Graph
a
db
ec
Relationen zwischenElement-Typ
a dcont ba dcont db dcont cb dcont ed dcont e
a cont ca cont e
a obcont da obcont ed obcont e
a excont ba excont db excont ca excont c
Abbildung 4.7: Beziehungen zwischen Element-Typen
Für die später zu definierenden Transformationen wird es relevant sein, ob es von einembestimmten Element-Typ aus einen eindeutigen Pfad zur Wurzel gibt. Diese Eigenschaft kannfolgendermaßen formalisiert werden.
Definition (Exclusivity)Element-Typ ETj ist exklusiv enthalten in Element-Typ ETi wenn jeder Pfad (ej , ..., ek),wobei ej ein Element-Typ ETj und ek die Dokument Wurzel ist, ein Element vom Typ ETi
enthält. Umgekehrt enthält Element-Typ ETi exklusiv den Element-Typ ETj , kurz excontiund excont.
Beispiel Abbildung 4.7 zeigt links eine DTD mit der Definition der Element-Typen a, b, c, d
und e. In der Mitte sieht man die entsprechende Darstellung dieser DTD als Graphen mitden Element-Typen als Knoten. Die Kanten zwischen den Knoten werden definiert durch dieInhaltsmodelle der Element-Typen.
Rechts zeigt die Darstellung verschiedene, durch die DTD definierten Beziehungen zwi-schen den Element-Typen. Zu beachten ist, dass der Element-Typ a als Wurzel alle übrigenElement-Typen exklusiv enthält. Da a das Wurzelelement ist enthält jeder Pfad von einembeliebigen Knoten zur Wurzel auch den Knoten a.
Zu beachten ist hier insbesondere, dass nicht gilt d excont e bzw. b excont e, dass heißt eist nicht exklusiv in d bzw. b enthalten, da es jeweils einen alternativen Pfad zu Wurzel gibt.Im Gegensatz dazu gilt b excont c, d.h. c ist exklusiv in b enthalten, da b auf jedem möglichenPfad von c zur Wurzel liegt.
4.4.2 Transformationen
Zur Transformation einer Anfrage anhand von Schemainformationen werden Regeln definiert,die Subanfragetransformationen durchführen, indem sie die Kanten der entsprechenden TPQauf die durch das Schema gegebenen Beziehungen abbilden. Eine TPQ zu einer gegebenenAnfrage spezifiziert implizit bestimmte erwartete Beziehungen zwischen Element-Typen. Ent-sprechen die tatsächlich durch das Schema gegebenen Beziehungen diesen Erwartungen, kann
48

4.4 A-Priori Anfragetransformationen
die entsprechende Anfrage unverändert bleiben und ausgeführt werden. Verschiedene Fälle,nach denen das Schema diesen Erwartungen nicht entsprechen kann, werden in Form vonRegeln behandelt, welche Transformationen von Anfragen bzw. TPQs durchführen, so dassdie resultierende Anfrage zum Schema passt.
Es kommen dabei die gleichen Subanfragetransformationen zum Einsatz wie bei der inAbschnitt 4.2 präsentierten Variante, bei der die Transformation während der eigentlichenAnfrageverarbeitung stattfindet. Der grundsätzliche Unterschied zwischen beiden Verfahrenbesteht darin, dass hier tatsächlich Anfragen transformiert werden. D.h. es wird ein Verfahrendefiniert, welches eine Anfrage erhält und diese unter Verwendung gewisser Informationen ineine Menge daraus abgeleiteter Anfragen transformiert. Beim anderen Verfahren findet dieTransformation erst während der eigentlichen Anfrageverarbeitung statt. Es wird also eineAnfrage unverändert an die Datenbank gestellt, diese wird auf dieser anhand des speziellenVerfahrens ausgewertet und als Ergebnis wird eine Menge von bewerteten Knoten geliefert.
Da beide Varianten auf den gleichen Subanfragetransformationen basieren, kann hier diegleiche Fitness-Funktion zur Bewertung verwendet werden mit dem Unterschied, dass dortletztendlich Knoten eines Suchergebnisses bewertet werden, hier jedoch Anfragen, welche imZuge der Transformation generiert werden.
Ein weiterer grundsätzlicher Unterschied zwischen den beiden Varianten besteht in der je-weiligen Behandlung von Basis- und erweiterten Transformationen. Wo sich im Falle der mo-difizierten Anfrageverarbeitung die erweiterten Transformationen reibungslos in den Transfor-mationsprozess einbinden lassen, ist dies hier nicht möglich. Hier muss berücksichtigt werden,dass die Basistransformationen zwar auf Grundlage der Schemainformationen definiert wer-den können. Die erweiterten Transformationen jedoch basieren teilweise auf den eigentlichenDaten, so machen sie sich etwa Werte von Attributen zunutze. Da diese Information vorabnicht zur Verfügung steht, können die erweiterten Transformationen lediglich mit Hilfe vonSchemainformationen nicht definiert werden. Es wird dazu letztlich eine Form dieser Trans-formationen definiert, welche voraussetzt, dass ein Inhaltsindex zur Verfügung steht, welcheraus allen bisher verarbeiteten Daten ganz gezielt für die erweiterten Transformationen auf-gebaut wird.
Basistransformationen (basic-Transformationen)
Eine Subanfrage-Transformationen ist als Transformation von Kanten in Tree-Pattern-Queriesdefiniert. Diese Transformationen bilden zusammen mit den definierten Beziehungen zwischenElement-Typen die Grundlage für die später definierten Transformationsregeln:
Definition (Basistransformationen)Gegeben seien Knoten x, y ∈ TPQ q und eine Kante pc(x, y). Dann gibt es die drei Trans-formationen ln, lg, le:
• keine Transformation (ln): pc(x, y) bleibt unverändert;
49

Kapitel 4 Adaptive Auswertung von XPath
• Generalisierung (lg): pc(x, y) wird zu ad(x, y);
• Eliminierung (le): pc(x, y) wird entfernt; die Kante wird ersetzt durch pc(x, z) oderad(x, z), falls pc(y, z) oder ad(y, z) ∈ TPQ q.
Die im Folgenden definierte Transformationsregel wird sukzessive auf die einzelnen durcheine Kante verbundenen Knotenpaare einer Tree-Pattern-Query angewandt. Dabei werdenfür jedes solche Knotenpaar die Beziehungen dcont, cont und excont für die entsprechendenElement-Typen in der betrachteten DTD überprüft und die passenden Basis-Transformationenangewendet.
Transformationsregel Gegeben seien die Knoten x, y, z in der TPQ zur Anfrage q, X =f(x), Y = f(y), Z = f(z) seien die eindeutigen, zu x, y, z korrespondierenden Knoten imGraphen G zum Schema D;es existiere eine Kante pc(x, y) in der TPQ zu q:
Fall dcont(X,Y) cont(X,Y) excont(Z,Y)∗ Transformationen
1 le
2 x ln, le
3 x lg, le
4 x x ln, lg, le
5 x x le
∗∃Z, so dass excont(Z,Y) ∧ (ad(x, z) ∨ pc(x, z)), ad(x, z), pc(x, z) ∈ TPQ zu q .Sind x oder y Wildcards, werden diese Fälle separat behandelt.
Fall Wildcard X ∈ G Y ∈ G Transformationen
6 {x} x ln
7 {y} x ln
8 {x, y} le
Wird mehr als eine Transformation angewendet, wird eine entsprechende Anzahl an Kopiender Ursprungs-Anfrage angelegt und je eine der angegebenen Transformationen angewendet.
Auf die Bedeutung des Eliminierungsschritts, den die Regel in jedem Fall anwendet wirdam Ende dieses Abschnitts eingegangen, dabei werden auch die Besonderheiten der Regeln 5bis 8 näher erläutert. Diese Transformationsregel wird in jedem Transformationsschritt zurAnwendung gebracht:
Transformationsschritt Ein Transformationsschritt ts(t) erzeugt zu einer TPQ t durch An-wendung der Transformationsregel eine Menge von Anfragen T . Dabei erhält jede Anfraget′ ∈ T einen Fitnesswert v(t′), dieser ist die Summe aus v(t) und dem Wert der sich aus
50

4.4 A-Priori Anfragetransformationen
a
b d
c x
e
Graph G
a
f
b
e
Anfrage q: /a/f/b/e
t0a
b
e
t21
a
e
t221
a
b
e
t1
Fall 1: (a,f)
a
b
e
t211
a
e
t22
Fall 3: (a,b)
a
b
t212
a
t222
Fall 3: (b,e) Fall 3: (a,e)
Schritt 1 Schritt 2 Schritt 3 Schritt 3
Abbildung 4.8: Beispiel-Transformation von a/f/b/e
der angewendeten Transformation entsprechend der Definition der Fitness-Funktion ergibt.Außerdem wird jede durch Transformation generierte Kante markiert.
Ein Transformationsschritt generiert damit aus einer TPQ eine Menge von TPQs, wobei dieeinzelnen TPQs dieser Menge entsprechend der durchgeführten Transformationen bewertetwerden. Das eigentliche Verfahren zur Anfragetransformation bringt diesen Transformations-schritt iterativ zur Anwendung. Die dabei generierten Mengen werden in jedem Durchlaufvereinigt und auf die resultierende Menge wird im nächsten Schritt wiederum der Transforma-tionsschritt angewendet. Das Verfahren terminiert, sobald alle Anfragen vollständig markiertsind. Eine vollständig markierte Anfrage signalisiert, dass jede Kante vom Transformations-schritt erfasst wurde.
Transformationsalgorithmus sei q eine XPath-Anfrage mit t := TPQ(q)Eingabe: TPQ t, DTD d
Ausgabe: eine Menge von TPQsInitialisierung: C = {t}, setze für alle Kanten e ∈ t, v(e) = 0,ausgehende Kante von root = 1i ist der mit 0 initialisierte Iterations-SchrittC0 = {t}Ci+1 := ∪(∀t ∈ Ci : ts(t) (bis ∀q′ ∈ Ci+1), q′ vollständig markiert)
Beispiel Gegeben ist ein Schema, repräsentiert durch den in Abbildung 4.8 gezeigten Gra-phen G sowie die XPath-Anfrage q = a/f/b/e, repräsentiert durch die TPQ t0.
Die Abbildung veranschaulicht, wie das Verfahren schrittweise die Transformationsregelauf jede Kante der TPQ anwendet, wobei in jedem Schritt genau eine Kante betrachtetwird. Im Laufe des Verfahrens wird jede Kante dabei genau einmal betrachtet. In Schritt
51

Kapitel 4 Adaptive Auswertung von XPath
1 wird die Kante pc(a, f) von t0 betrachtet. Es kommt Fall 1 zur Anwendung, d.h. mittelsBasis-Transformation le wird die Kante pc(a, f) entfernt. In Schritt 2 wird die Kante pc(a, b)betrachtet; es kommt Fall 3 zur Anwendung, so dass mittels ln t21 und mittels le t22 generiertwird. In Schritt 3 kommt wiederum Fall 3 bei der Betrachtung von pc(b, e) aus t21 zurAnwendung, so dass t211 und t212 erzeugt werden. Die Betrachtung von pc(a, e) aus t22
liefert mit Fall 3 t221 und t222. Es zeigt sich, dass die ursprüngliche Anfrage t0 bzgl. einerDatenquelle, die nach dem durch G repräsentierten Schema gültig wäre, kein Ergebnis liefernwürde. Dagegen könnte beispielsweise die generierte Anfrage t211 ein Ergebnis liefern.
Aus Gründen der Übersichtlichkeit ist das Beispiel bewusst so gewählt, dass die Anfragerelativ zum Knoten a definiert ist und nicht relativ zur Dokument-Wurzel, was die Dar-stellung insoweit vereinfacht, dass auf die Darstellung des virtuellen Dokument-Knotens alseigentlichen Ausgangs-Kontext der einzelnen Anfragen verzichtet werden kann.
Die Bedeutung des Eliminierungsschritts Der Eliminierungsschritt wird von der Transfor-mationsregel in jedem Fall angewendet. Dies ist beispielsweise in Fall 2 auf den ersten Blicküberraschend, denn dort besteht tatsächlich eine dcont-Beziehung zwischen den relevantenElement-Typen und der Sinn der Generierung einer zusätzlichen Anfrage, welche diese Teil-Anfrage eliminiert ist nicht unmittelbar klar. Im Zuge der weiteren Anfragetransformationgewinnt dieser Eliminierungsschritt jedoch an Bedeutung, da er die Generierung weitererrelevanter Anfragen erst ermöglicht. Ein Blick auf das vorangegangene Beispiel verdeutlichtdies. Dort kommt in Schritt 2 für die Kante (a, b) Fall 2 zur Anwendung, d.h. die Transfor-mationen ln und le werden durchgeführt. Durch le wird dabei die Teil-Anfrage a/e generiert,welche in Schritt 3 zu a//e transformiert wird. Wie in obigem Beispiel schon besprochenkann diese Anfrage in einem bezüglich der betrachteten DTD gültigen Dokument ein Ergeb-nis liefern. Letztlich ermöglicht wird diese Anfrage erst durch die Eliminierung in Schritt 2.Durch ihre Anwendung ist sichergestellt, dass alle unter Beachtung der durch die Anfragegegebenen Reihenfolge möglichen Kombinationen von Knotentests auch tatsächlich gegen dieElement-Typen der DTD überprüft werden.
Vernachlässigung der obcont Beziehung Die Bedeutung des Eliminierungsschritts ist letzt-lich auch der Grund für die Tatsache, dass die obcont Beziehung von der Transformationsregelnicht berücksichtigt wird. Intuitiv erscheint es sinnvoll, eine Eliminierung genau dann nichtdurchzuführen, wenn eine obligatorische Beziehung zwischen den relevanten Element-Typenbesteht. Die Konsequenz aus einer derartigen Vorgehensweise wäre jedoch, dass eine derarteliminierte Teil-Anfrage eben nicht mehr für weitere Transformationen zur Verfügung stehenwürde.
Die Behandlung einer obligatorischen Beziehung kann lokal für die aktuell betrachtete Teil-Anfrage sinnvoll sein, für den gesamten Vorgang der Anfragetransformation ist sie es in derRegel nicht und wird deshalb auch nicht durchgeführt.
52

4.4 A-Priori Anfragetransformationen
Behandlung der excont-Beziehung Fall 5 der Transformationsregeln behandelt excont Be-ziehungen zwischen Element-Typen, die durch Anfragen adressiert werden. Derartige Bezie-hungen können ausgenutzt werden, um die Anzahl der generierten Anfragen zu reduzieren,indem überflüssige Anfragen vermieden werden. Fall 5 hebt sich von den anderen Fällen ab,da ein dritter Element-Typ Z und seine Beziehung zu X und Y behandelt wird. Trifft die inder Definition formulierte Beziehung zu, so wird trotz bestehender Beziehung cont(X,Y) keineTransformation lg durchgeführt, wie es im Fall 3 getan wird. Ein Blick auf den Element-TypGraphen in Abbildung 4.7 in Verbindung mit der Beispiel-Anfrage /a/b/c soll diesen Fallillustrieren. Im Zuge einer Transformation dieser Anfrage wird auch die Beziehung zwischenden Element-Typen a und c betrachtet. Da sie in der Beziehung cont(a,c) stehen, würde dabeinach Fall 3 die Transformation lg ausgeführt. Fall 5 wird aber erkennen, dass Element-Typc exklusiv in b enthalten ist, welcher auch durch die Anfrage adressiert wird. Ein Knotenc wird also in einem gültigen Dokument immer in einem Knoten b enthalten sein. Da eineentsprechende Teil-Anfrage b/c auch generiert werden wird, wäre damit eine Teil-Anfragea//c überflüssig.
Behandlung von Wildcards Wildcards werden durch die Fälle 6 bis 8 der Transformati-onsregel behandelt. Bei Wildcards kann nur ein eingeschränkter Nutzen aus Schemainforma-tionen bezogen werden, da entsprechende Anfragen eben beliebige Knoten adressieren. DieTransformationsregel trägt dem Rechnung, indem lediglich betrachtet wird, ob bei Wildcardsder entsprechende Partner-Knoten im Graphen enthalten ist. Ist dies der Fall, wird eine Ge-neralisierung durchgeführt, ansonsten wird die Kante eliminiert. Handelt es sich bei beidenKnoten um Wildcards, wird die Kante eliminiert. Zweck dieser Vereinfachungen ist die Re-duktion der Anzahl an generierten Anfragen. Da von einer Reihe von unmittelbar aufeinanderfolgenden Wildcards der Ursprungs-Anfrage immer mindestens eine Wildcard-Subanfrage ingeneralisierter Form erhalten bleibt, ist der Verlust an Ausdrucksstärke in diesem Fall ver-nachlässigbar. Eventuell an den Wildcard-Knoten vorhandene Prädikate werden in jedemFall am verbleibenden Knoten gesammelt, so dass diese nicht verloren gehen.
Behandlung von Prädikaten Enthält die Originalanfrage Prädikate, so ist die Anwendungbzw. Nicht-Anwendung dieses Prädikats eine zusätzliche Transformation, wobei die Anwen-dung desselben von der Fitness-Funktion den Rang einer Eliminierung erhält. Damit ist ge-währleistet, dass die Originalanfrage mit allen Prädikaten zuverlässig am höchsten bewertetwird.
Verschachtelte Anfragen Indem TPQs als Repräsentation der Anfragen für die Transfor-mationsverfahren verwendet werden, gestaltet sich die Behandlung verschachtelter Anfragenohne zusätzlichen Aufwand. Da der Algorithmus jede Kante einer TPQ genau einmal betrach-tet und gleiches für alle generierten Kanten gilt, ist das Verfahren in der Lage, die in Formvon TPQs so kompakt dargestellten verschachtelten XPath-Anfragen zu transformieren.
53

Kapitel 4 Adaptive Auswertung von XPath
Erweiterte Transformationen (extended-Transformationen)
In Abschnitt 4.2 werden erweiterte Transformationen eingeführt, die Unterschiede zwischender Modellierung von Konzepten als Elemente und der Modellierung von Konzepten in Formvon Attributwerten behandeln. Sollen die Upgrade- und Downgrade-Transformationen aberschon bei einer a-priori-Anfragetransformation eingesetzt werden, so wirkt sich der grundsätz-liche Nachteil, den eine derartige Transformation im Vergleich zu einer on-the-fly-Variantehat, viel stärker aus. Die on-the-fly-Variante hat den großen Vorteil, dass der notwendi-ge Aufwand letztlich einzig von der Ergebnismenge abhängt, welche bei XPath durch dieGröße des anzufragenden Dokuments beschränkt ist. Eine Transformation verursacht dabeinur dann wirklich Aufwand, wenn die dabei generierte Anfrage auch ein Ergebnis liefert,welches dann nämlich den Zwischenkontext vergrößert und damit Einfluss auf die späterenTransformationen hat.
Bei der a-priori-Variante ist dies anders. Hier werden Mengen von Anfragen vorab gene-riert und bewertet, in der Erwartung, dass die gut bewerteten auch tatsächlich Ergebnisseliefern. Die für die Basistransformationen eingesetzten Schemainformationen helfen dabei,diese Vorab-Transformationen möglichst zielgerichtet durchzuführen. Wie die Experimentein Kapitel 7 zeigen werden, erfüllen die Schemainformationen diese unterstützende Aufgabesehr gut.
Für Upgrade und Downgrade Transformationen sind Schemata jedoch nur von geringemNutzen. Sie basieren auf der Abbildung von Attributwerten auf Elemente bzw. von Elementenauf Attributwerte. Um dabei beliebige Elemente bzw. Attribute erreichen zu können, werdenbei der on-the-fly-Variante massiv Wildcards für diese Transformationen verwendet. Umbei der a-priori-Variante die Anzahl an generierten Anfragen im Rahmen zu halten, verbietetes sich hier jedoch, auf jede Subanfrage Transformationen anzuwenden, die eine Vielzahlvon Wildcard-Anfragen generieren. Man hätte damit eine große Menge wenig spezifischerAnfragen, die den Transformationsprozess verlangsamen, eventuell relativ hoch bewertet sindund damit auch zur Ausführung kommen, letztlich aber doch kein Ergebnis liefern, weil dieDaten eben doch nicht zu den durchgeführten Transformationen passen.
Die beiden Transformationen Upgrade und Downgrade werden deshalb bei der a-priori-Variante in etwas abgewandelter und weitaus spezifischerer Form angewandt. Dazu wird einInhaltsindex aller bisher gelesenen Daten dazu verwendet, nur relevante Anfragen zu generie-ren, d.h. Anfragen, die auch potentiell ein Ergebnis aus den aktuell angefragten Daten liefernkönnen. Dieser Inhalts-Index liefert zu Attributwerten Elementnamen bzw. Attributbezeich-ner von entsprechenden XML-Dokumenten. Seine Einträge haben für Attributwerte die Form(attributevalue, element, attribute). Die erweiterten Transformationen greifen somit sowohlauf Schemainformationen als auch auf Inhaltsinformationen bereits gelesener Daten zurück,um relevante Anfragen zu generieren. Der Aufbau eines derartigen Indexes wird in Abschnitt4.5.2 im Detail behandelt.
Auf diese Art und Weise kann zur einem Knotentest n, zu dem es keinen entsprechenden
54

4.4 A-Priori Anfragetransformationen
Elementtyp in der fraglichen DTD gibt, ermittelt werden, ob die bisher gelesenen XML-Dokumente ein Element e enthielten, bei denen n als Wert eines Attributs a oder als Tex-tinhalt auftritt. In dem Fall kann etwa eine ursprüngliche Anfrage child::n in eine Anfragechild::e[@a=’n’] transformiert werden. Eine derartige Anfrage ist spezifischer als eine ent-sprechende Anfrage child::*[@a=’n’], was insbesondere bei einer Anfrage an Datenströmeeinen Effizenzvorteil verspricht. Beim Filtern von Datenströmen wird eine Anfrage in derRegel als Automat repräsentiert. Je spezifischer die Anfrage ist, desto spezifischer ist auchder Automat und desto geringer ist die zu erwartende Anzahl aktiver Zustände bei der Ver-arbeitung eines Dokuments. Umgekehrt wird der eine allgemeine Anfrage repräsentierendeAutomat bei der Verarbeitung eines Dokuments zu einer großen Anzahl aktiver Zuständeführen, die in jedem Verarbeitungsschritt verwaltet werden müssen.
Um strukturelles und inhaltliches Wissen für die Transformationen nutzbar zu machenbenötigen wir Funktionen, die zu Knotentests aus Anfragen diejenigen Elemente liefern dieAttribute mit entsprechenden Werten haben. Diese Funktionen liefern dabei entweder Mengenvon Elementen oder Mengen von Tupeln, bestehend aus einem Element und einem dazuge-hörenden Attribut.
Index-Zugriffsfunktionen Sei n ein Knotentest, e ein Elementbezeichner, ab ein Attribut-bezeichner und av ein Attributwert. Dann greifen die Funktionen cav und cab auf den Indexzu und sind folgendermaßen definiert:
• cav(n) := Cav, Cav ist eine Menge von Tupeln der Form (e, ab, av), wobei e ein Elementist, dessen Attribut ab den Wert av einnimmt mit av = n,
• cab(n) := Cab, Cab ist eine Menge von Tupeln der Form (e, ab), wobei e ein Element ist,das ein Attribut ab hat mit ab = n
Die erweiterten Transformationen entsprechen weitgehend den bereits bekannten Transfor-mationen. Sie unterscheiden sich von ihnen insofern, als dass die jeweils generierten Knoten-tests keine Wildcard-Tests sind, sondern entsprechend den Ergebnissen der Index-Zugriffs-funktionen gesetzt werden.
Definition (Erweiterte Transformationen ohne Wildcards)Gegeben seien Knoten x, y ∈ TPQ q und eine Kante pc(x, y).(e, ab, av) ∈ Cav, (e, ab) ∈ Cab seien jeweils Element-Attribut-Tupel, wobei die Mengen Cav,Cab durch Anwendung der Funktionen cav(y), cab(y) entstanden sind. Dann gibt es die fol-genden Transformationen:
Downgrade:
(1) d1: vbc(x, x.att = ’y’) ⇒ pc(x, y)
Upgrade:
55

Kapitel 4 Adaptive Auswertung von XPath
(2) u21: pc(x, y) ⇒ vbc(x, x.att = ’y’)u22: pc(x, y) ⇒ vbc(x, x.y)
(3) u31: pc(x, y), (e, ab, av), y = av ⇒ pc(x, e) ∧ vbc(e, e.ab = ’y’)u32: pc(x, y), (e, ab), y = ab ⇒ pc(x, e) ∧ vbc(e, e.y)
(4) u41: pc(x, y), (e, ab, av), y = av ⇒ ad(x, e) ∧ vbc(e, e.ab = ’y’)u42: pc(x, y), (e, ab), y = ab ⇒ ad(x, e) ∧ vbc(e, e.y)
Diese Transformationen werden bei der erweiterten Transformationsregeln eingesetzt.
Erweiterte Transformationsregel Gegeben seien die Knoten x, y, z in der TPQ zur Anfrageq;X = f(x), Y = f(y), Z = f(z) seien die eindeutigen, zu x, y, z korrespondierenden Knotenim Graphen G zum Schema D; es existiere eine Kante pc(x, y) in der TPQ zu q;ferner gibt es folgende Tupel beim Zugriff auf den Inhalts-Index gelesener Daten zum SchemaD:(e1, ab, av) ∈ cav(Y ), (e2, ab) ∈ cab(Y ),r1 ∈ cr1(Y ), r2 ∈ cr2(Y )e3 ∈ ct(Y )
Regel Bedingungen Transformationen
X ∈ G, Y ∈ G, pc(x, y) 6∈ G, vbc(x, x.att = ’y’) ∈ G
9 x d1
X ∈ G, (e1, ab, av) ∈ cav(X) X ∈ G, (e1, ab) ∈ cab(X)10 x u21
11 x u22
dcont(X, e1) cont(X, e1)11 x u31
12 x u41
13 x x u31, u41
dcont(X, e2) cont(X, e2)14 x u32
15 x u42
16 x x u32, u42
Die erweiterte Transformationsregel kann die Basisregeln des Transformationsschritts ausdem vorigen Abschnitts erweitern und damit in den Transformationsalgorithmus integriertwerden.
56

4.5 Anfragetransformationen ohne Schemainformation
4.4.3 Komplexität
Die Komplexität des Verfahrens ist abhängig von der Struktur des jeweiligen Schemas. DasVerfahren generiert im schlechtesten Fall größenordnungsmäßig O(tn) Anfragen, wobei t dieAnzahl an möglichen Transformationen und n die Anzahl der Subanfragen ist. Dieser schlech-teste Fall tritt allerdings nur ein, wenn jeder in der Anfrage adressierte Knoten mit jedemanderen Knoten sowohl direkt als auch indirekt über gerichtete Kanten verbunden ist. Intui-tiv bedeutet dies, dass für jeweils zwei in der Anfrage adressierte Element-Typen E1 und E2
gilt, dass E2 sowohl direkt als auch indirekt im Inhaltsmodell von E1 enthalten ist. Darüberhinaus ist zu erwarten, dass n in der Praxis klein sein wird. Die Experimente in Kapitel7 werden mit einer Implementierung dieses Transformationsverfahrens durchgeführt, wobeisowohl die Basis als auch die erweiterte Regel zur Anwendung kommen. Sie werden zeigen,dass durch geeignete Konfiguration des Algorithmus eine effizienten Anfragetransformationerreicht werden kann.
4.4.4 Qualität der Transformationen
Die Qualität der Anfragetransformationen wird in Kapitel 7 untersucht. Es wird sich zeigen,dass das Verfahren sehr robust auch gegen eine große Menge von Veränderungen zwischen vomBenutzer erwarteten Schema und den tatsächlich den Daten zugrunde liegenden Schemataist.
4.5 Anfragetransformationen ohne Schemainformation
Die im vorigen Abschnitt behandelte Variante der Anfragetransformation setzt das Vorhan-densein von Schemainformationen voraus. Sie erlauben damit eine zielgerichtete Generierungvon passenden Anfragen. Weichen jedoch die tatsächlichen Daten vom der Transformationzugrunde liegenden Schema ab, können diese transformierten Anfragen unter Umständen völ-lig wertlos sein. Ferner sind durchaus Situationen denkbar, in denen Schemainformationennicht zur Verfügung stehen und Anfragen einer bestimmten Domäne auf unbekannten Dateneben dieser Domäne ausgeführt werden sollen. Eine mögliche Lösung bietet ein Blick auf dieon-the-fly-Variante des Transformationsverfahrens. Dieses kommt ohne Schemainformatio-nen aus und führt jede mögliche Transformation auf jeder Subanfrage aus. Eine Alternativedazu ist es, die für die Transformation notwendigen strukturellen Daten in einem separatenSchritt aus den Daten selbst zu gewinnen, sie zu sammeln und damit für die Transformationzugänglich zu machen. Beide Varianten werden in den folgenden Abschnitten behandelt.
4.5.1 Generierung aller möglichen Anfragen
Bei der zu Beginn dieses Kapitels eingeführten on-the-fly-Variante werden keine Schema-informationen für die Anfragetransformationen verwendet. Es wird einfach jede mögliche
57

Kapitel 4 Adaptive Auswertung von XPath
3ln 2ln,lg ln,2lg ln,lg,le 2ln,le ln,2le 3lg 2lg,le lg,2le 3le
/a/b/c /a/b//c //a//b/c /a//b /a/b /a //a//b//c //a//b //a //a//b/c //a/b//c /a//c /a/c /b //a//c //b//a/b/c /a//b//c //a/b /b/c /c //b//c //c
//a/c/b//c//b/c
Tabelle 4.1: Alle transformierten Anfragen zu /a/b/c
Transformation während der Anfrageverarbeitung auf jede Subanfrage der Originalanfrageangewendet.
Zur Übertragung dieser Idee auf eine a-priori Variante wird ein Verfahren analog zur a-priori Anfragetransformation mit Schemainformationen definiert, wobei lediglich der Trans-formationsschritt so modifiziert wird, dass statt der Transformationsregel die drei Basis-subanfragetransformationen direkt angewandt werden. Das Verfahren wird in den weiterenBetrachtungen mit all bezeichnet.
Transformationsschritt Ein Transformationsschritt ts(t) erzeugt zu einer TPQ t durch An-wendung der Transformationen ln,lg und le eine Menge von Anfragen T . Dabei erhält jedeAnfrage t′ ∈ T einen Fitnesswert v(t′), dieser ist die Summe aus v(t) und dem Wert dersich aus der angewendeten Transformation entsprechend der Definition der Fitness-Funktionergibt. Außerdem wird jede durch Transformation generierte Kante markiert.
Auf die Anwendung der erweiterten Transformationen muss bei dieser Variante verzichtetwerden, da sie bewusst so definiert wird, dass die Transformationen ohne weitere Informatio-nen durchgeführt werden. Eine sinnvolle Anwendung der erweiterten Transformationen setztjedoch voraus, dass Informationen über Struktur und Inhalt der zu verarbeitenden Datenvorliegen.
Das nachfolgende Beispiel illustriert de Menge der Anfragen, die zu einer Eingabe-Anfrage/a/b/c generiert werden:
Beispiel Subanfrage-Transformationen für die Anfrage /a/b/cTabelle 4.1 zeigt das Ergebnis des Transformations-Algorithmus zur Anfrage /a/b/c, auf
die alle möglichen Basistransformationen durchgeführt werden. Die Anfrage besteht aus dendrei Subanfragen child::a, child::b und child::c, wobei der Kontextknoten der Anfragedie Wurzel ist.
Das Beispiel veranschaulicht zum einen die große Anzahl an Anfragen, die schon für sehreinfache Eingaben generiert werden. Zum anderen verdeutlicht die Gruppierung der Anfragennach durchgeführten Transformationen die Problematik, die sich hier für die Bewertung derAnfragen ergibt. Die Anfragen jeweils einer Spalte werden durch die Fitness-Funktion gleich
58

4.5 Anfragetransformationen ohne Schemainformation
bewertet. Da hier mit zunehmender Komplexität der Anfrage auch die Anzahl an Anfragenzunimmt, die gleich bewertet werden, ergibt sich die Frage der Auswahl der ”richtigen” An-frage. Da diese Frage a-priori nicht zu beantworten ist, müssen also sehr viele Anfragen zurAusführung kommen, was sich letztlich negativ auf die Anfrageperformanz auswirken kann.Der Frage inwieweit dies der Fall ist wird in Kapitel 7 nachgegangen.
Komplexität
Die Anzahl der so generierten und im Anfrageindex abgelegten Anfragen liegt größenordnungs-mäßig bei Anwendung der drei Basistransformationen bei O(3n) wobei n die Anzahl derSubanfragen ist und keine Transformationen auf Prädikaten berücksichtigt werden.
Da dieses Verfahren keinerlei weitere Informationen zur Verfügung hat, müssen alle An-fragen grundsätzlich generiert werden, was schon für kleines n nicht mehr praktikabel ist.Selbstverständlich wird eine Vielzahl dieser Anfragen für den Benutzer nicht relevant sein,was sich in einer entsprechend geringen Fitness ausdrückt. Durch die Wahl geeigneter Schwell-werte schon während der Anfragetransformation kann die Menge der generierten Anfrageneffektiv beschränkt werden.
Die Experimente in Kapitel 7 werden zeigen, inwieweit dies der Fall sein wird, bzw. wie sichim Vergleich dazu die Verwendung von Schema- oder sonstigen Informationen zur Reduktionder Menge an generierten Anfragen auswirkt.
4.5.2 Ermittlung von Strukturinformationen aus den Daten
In Abschnitt 4.4 wurde eine Variante des Transformationsverfahrens definiert, die Anfragena-priori auf Grundlage von Schemainformationen transformiert. Derartige Informationen lie-gen nicht immer vor, bzw. nicht immer kann von validen Daten ausgegangen werden. DasVerfahren aus dem vorigen Abschnitt begegnet dieser Problematik, indem es einfach allemöglichen Transformationen durchführt, was allerdings andere Probleme nach sich zieht.Außerdem ist sowohl bei diesem Verfahren als auch bei der Verwendung von Schemainforma-tionen eine Anwendung der erweiterten Transformationen nicht möglich, da diese Kenntnisüber den Inhalt der zu verarbeitenden Daten voraussetzen. Andererseits liegt eine große Stär-ke des on-the-fly-Verfahrens darin, dass es den Transformationsprozess in die eigentlicheAnfrageverarbeitung verschiebt. Der eigentliche Grund für den Vorteil dieses Verfahrens liegthier darin, dass die Transformationen ”nahe” an den eigentlichen Daten durchgeführt werden.”Nahe” bedeutet hier, dass die Transformationen nur dann einen wirklichen Aufwand nachsich ziehen, wenn die transformierten Anfragen tatsächlich Treffer liefern.
Es bietet sich daher an, das a-priori-Verfahren näher an die Daten zu bringen, indem ausden zu verarbeitenden Daten vorab die für die eigentlichen Transformationen notwendigenInformationen gewonnen werden. Dazu ist offensichtlich ein zusätzlicher, der Anfragetrans-formation vorgelagerter Verarbeitungsschritt erforderlich, welcher die erforderlichen Informa-tionen aus den Daten extrahiert und aufbereitet. Die Integration eines derartigen Schrittes
59

Kapitel 4 Adaptive Auswertung von XPath
<a><b>
<c></c>
</b><d>
<e></e>
</d></a>
XML-Dokument
#a##a#b#a#b#c#a#d##a#d#e
Pfade Relationen zwischenElementen
a dcont ba dcont db dcont cd dcont e
a cont ca cont e
Abbildung 4.9: Extraktion von dcont- und cont-Beziehungen aus einem XML-Dokument
insbesondere in ein System zur Verarbeitung von Datenströmen ist problemlos möglich undwird in Kapitel 6 im Detail behandelt.
Um das a-priori-Verfahren in seiner bisherigen Form unverändert anwenden zu können, wirdein Ansatz definiert, der aus XML-Daten die zugrundeliegenden strukturellen Informationenso extrahiert, dass es für das a-priori-Verfahren völlig transparent ist, ob es auf tatsächlichenSchemainformationen operiert oder nicht. Es erweist sich dabei als nützlich, dass das a-prioriVerfahren seinerseits nur einen kleinen Teil des zur Verfügung stehenden Schemas nutzt.Letztlich reduziert sich dieser Teil im Falle der Basistransformationen auf die dcont und contBeziehungen zwischen Element-Typen. obcont wird nicht verwendet und die excont Beziehungkann aus den bekannten dcont und cont Beziehungen gewonnen werden.
Um dcont und cont Beziehungen aus XML-Daten zu gewinnen, genügt es, jeden vollständi-gen Pfad von der Wurzel zu den einzelnen Elementen zu erfassen und zu jedem dieser Pfadedie dcont und cont Beziehungen zu berechnen. Durch die Kombination dieses Verfahrens mitder Verwendung einer Historie aller bereits verarbeiteten Pfade, lässt sich auf einfache Artund Weise sicherstellen, dass jeder Pfad nur ein einziges Mal verarbeitet wird und damitüberflüssige Berechnungen von dcont und cont nicht erfolgen.
Selbstverständlich würde eine derartige Vorgehensweise keinen allgemeinen Ansatz einesDTD- oder Schema-Minings aus XML-Daten ersetzen. Derartige Verfahren sind wesentlichaufwändiger, würden für diesen Zweck nichtsdestotrotz keinen Mehrwert bieten, da es letztlichnur um dcont und cont Beziehungen geht.
Beispiel Abbildung 4.9 zeigt anhand eines XML-Dokuments die dazugehörigen Pfade unddie daraus gewonnenen dcont und cont Beziehungen. Das XML-Dokument ist gültig bezüglichder DTD in Abbildung 4.7.
Das Beispiel zeigt, dass bei Verwendung einer DTD mehr Beziehungen extrahiert werden
60

4.5 Anfragetransformationen ohne Schemainformation
können. Soweit ausschließlich gültige XML-Dokumente verarbeitet werden ist dies die Regel,da die Dokumente schließlich nur gültige Pfade enthalten und damit keine zusätzlichen Bezie-hungen generieren können. Nichtsdestotrotz werden alle für die aktuellen Transformationenrelevanten Beziehungen generiert. Diejenigen Beziehungen, die nicht generiert werden, sindin den bisher verarbeiteten Daten nicht aufgetreten und daher für die Anfragetransformationauch nicht relevant.
Dagegen werden bei nicht-validen Dokumenten diese Beziehungen ebenfalls erfasst undstehen der Transformation zur Verfügung, was bei der Verwendung von Schemainformationennicht der Fall wäre.
Inhaltsindex
Für die erweiterten Transformationen genügen rein strukturelle Informationen nicht. DieUpgrade-Transformation verwandelt Knotentests von Originalanfragen in Prädikate, die nachentsprechenden Werten von Attributen fragen. Umgekehrt verwandelt die Downgrade-Trans-formation Anfragen an Werte von Attributen in entsprechende Knotentests.
Um diese Transformationen durchführen zu können, sind also Informationen über tatsäch-lich in den XML-Dokumenten vorkommende Werte erforderlich. Aufgrund der Definitionder Transformationsregel ist es jedoch nicht notwendig, sämtlichen Inhalt aller verarbeitetenXML-Dokumente zu speichern. Dies wäre nicht praktikabel und einem System zur Verarbei-tung von Datenströmen nicht angemessen.
Upgrade Die Upgrade Transformation wird durchgeführt, wenn der entsprechende Kno-tentest keine Entsprechung in den Elementen bzw. Element-Typen findet. Für genau dieseKnotentests ist ein Index zu pflegen, der diejenigen Element-Attribut-Paare enthält, in denender entsprechende Knotentest als Wert auftritt.
Downgrade Die Downgrade Transformation wird durchgeführt wenn ein Prädikat einenAttributwert erfragt, der als Element bzw. Element-Typ in den Struktur-Informationen auf-tritt. In diesem Fall wird der entsprechend Attributwert als Knotentest nach außen gezogen.Um diese Operation zu unterstützen ist ein Index zu pflegen, der genau diejenigen Elemen-te enthält, in denen Werte auftreten, die in den zu verarbeitenden Anfragen als Werte vonAttributen abgefragt werden.
Im folgenden Kapitel werden die Bedingungen erläutert unter denen die Upgrade und Dow-ngrade Transformationen durchgeführt werden.
61

Kapitel 4 Adaptive Auswertung von XPath
62

Kapitel 5
Identifizieren der zu transformierendenAnfragen
Im Fokus dieser Arbeit liegt die Transformation von Anfragen, um diese bei der Verarbeitungvon Datenströmen an aktuell auftretende abweichende Strukturen anzupassen. Die Transfor-mation von Anfragen ist eine im Vergleich zum reinen Streaming teure Operation. Da jedeeinzelne Anfrage in einem separaten Schritt transformiert wird, muss es das Ziel sein nurdiejenigen Anfragen zu transformieren, für welche dies notwendig ist. Aus diesem Grundmüssen diejenigen Anfrage gezielt identifiziert werden, die von aktuellen Abweichungen inden verarbeiteten Daten tatsächlich betroffen sind. Um dies bewerkstelligen zu können, wer-den strukturelle und inhaltliche Informationen über die im Index abgelegten Anfragen sowiedie verarbeiteten Daten bzw. deren Schema verwaltet. Diese Informationen werden perma-nent aktualisiert und erlauben es, aus jeder Änderung bzw. Aktualisierung auf betroffene unddamit zu transformierende Anfragen zu schließen.
Im vorliegenden Kapitel werden Repräsentationen von Daten und Anfragen definiert, diefür die Identifizierung von zu transformierenden Anfragen notwendig sind. Auf Grundlagedieser Repräsentationen werden die Verfahren zur Identifikation der für eine Transformationrelevanten Anfragen beschrieben. Ein umfangreiches Beispiel veranschaulicht die Verfahren.
5.1 Daten- und Anfragerepräsentation
Sei D die Datenrepräsentation und A die Anfragerepräsentation. D besteht aus den MengenP und E für die gilt:
• P ist die Menge aller Pfade p
• E ist die Menge aller Element-Attribut-Wert Tupel (e, a, v)
A besteht aus den Mengen Q, T , M , V und I für die gilt:
• Q ist die Menge aller Anfragen q
• T ist die Menge aller Knotentests n
63

Kapitel 5 Identifizieren der zu transformierenden Anfragen
• M ist die Menge aller NotMatchingNodetests nmn
• A ist die Menge aller NodeMatchingAttributeValues nmav
• V ist die Menge aller NodeMatchingPredicateValues nmpv
• I ist die Menge aller Zuordnungen i von Knotentests n zur Menge der Anfragen Q′ ={q1, ..., ql}, die den betreffenden Knotentest enthalten: i = (n, {q1, ..., ql})
Hierbei ist I eine reine Hilfsstruktur, die der effizienten Ermittlung von Anfragen zu Kno-tentests dient. Die Menge M der NotMatchingNodetests wird ausschließlich zur Anfragetrans-formation nicht jedoch zur Identifizierung relevanter Anfragen benötigt. Beide Strukturensind nichtsdestotrotz bei der Aktualisierung der Daten- bzw. Anfragerepräsentation zu pfle-gen.
Um die Elemente der jeweiligen Mengen in ihre Bestandteile zerlegen und damit vergleichenzu können werden folgende Funktionen benötigt.
Knotentests einer Anfrage: Sei q ∈ Q eine XPath-Anfragen; dann ist nt(q) die Menge allerKnotentests dieser Anfrage.
Elemente eines Pfads: Sei p ∈ P ein Pfad; dann ist el(p) die Menge aller Elemente aufdiesem Pfad.
Ein Knotentest einer Anfrage bzw. ein Element eines Pfades wird der Einfachheit halberso interpretiert, dass sie jeweils direkt auf Gleichheit getestet werden können.
Beispiel Abbildung 5.1 auf Seite 68 zeigt die Repräsentation einer DTD in Form einesElement-Typ-Graphen mit der zugehörigen Menge von resultierenden Pfaden sowie eine Men-ge von Anfragen. Im Beispiel ergeben sich die folgenden Mengen:
• P ist die Menge der resultierenden Pfade
• E ist leer, da zu dem Zeitpunkt noch keine Daten verarbeitet wurden
• Q = {q1, q2, q3, q4}
• T = {a, b1, c1, d1, f, d2, g}
• M = {g}
• A ist leer, da zu dem Zeitpunkt noch keine Daten verarbeitet wurden
• V = {d3}
• I = {(a, {q1, q2}), (b1, {q1, q4}), (c1, {q1, q2, q3}), (d1, {q1}), (f, {q3}),(d2, {q4}), (g, {q4})}
Für die Anfrage q1 gilt: nt(q1) = {a, b1, c1, d1}.Für den Pfad p = #a#b2#c1#d1# ist el(p) = {a, b2, c1, d1}.
64

5.1 Daten- und Anfragerepräsentation
5.1.1 Pflege der Daten- und Anfragerepräsentation
Um ein unnötiges wiederholtes Transformieren von Anfragen zu vermeiden, muss die Daten-repräsentation stets auf dem aktuellen Stand gehalten werden, sprich alle bereits gelesenenDaten repräsentieren. Hierbei ist zu beachten, dass neben einer reinen Repräsentation der Da-ten wie den Pfaden und Element-Attribut-Wert Tupeln sowohl reine Informationen über dieAnfragen als auch Informationen über Daten bereit gestellt werden, die in Beziehung zu denAnfragen des Anfrageindex’ stehen und damit bei der Aktualisierung mit diesem abgeglichenwerden müssen.
• Pfade: enthält alle gelesenen Pfade; neue Pfade werden sofort eingefügt;
• Element-Attribut-Wert Tupel: enthält alle entsprechenden Tupel; neue werden soforteingefügt;
• Anfragen: enthält alle Anfragen; Anfragen können hinzugefügt, aktualisiert oder ent-fernt werden;
• Knotentests: enthält die Knotentests aller Anfragen; wird zusammen mit den Anfragengepflegt;
• Zuordnung von Knotentests zu Anfragen: enthält die Zuordnung aller Knotentests zuden Anfragen, welche den entsprechenden Test enthalten; wird zusammen mit den An-fragen gepflegt;
• NodeMatchingAttributeValues: enthält Werte von Attributen, die in den gelesenen Da-ten vorkommen und die Knotentests aus Anfragen entsprechen; jeder gelesene Wertmuss dazu mit den Knotentests der Anfragen abgeglichen werden. Werden entspre-chende Anfragen entfernt, so dass ein Knotentest nicht mehr vorhanden ist, muss einentsprechender Eintrag hier ebenfalls entfernt werden;
• NodeMatchingPredicateValues: enthält Attributwerte, die in Prädikaten von Anfragenauf Gleichheit überprüft werden und die Knotenbezeichnern in den gelesenen Datenentsprechen; jeder gelesene Knotenbezeichner muss mit in Prädikaten von Anfragen ver-wendeten Attributwerten abgeglichen werden; werden entsprechende Anfragen entfernt,so dass ein Attributwert nicht mehr vorhanden ist, muss ein entsprechender Eintrag hierebenfalls entfernt werden;
• NotMatchingNodetests: enthält Knotentests von Anfragen, für die kein entsprechen-der Knoten in den Daten gelesen wurde; solange keine neuen Anfragen aufgenommenwerden, werden hier im Zuge von Aktualisierungen beim Lesen von Daten höchstensEinträge entfernt, wenn zu einem Knotentest ein passender Knoten gelesen wird; neueAnfragen können zu neuen Einträgen führen, wenn entsprechende Knoten noch nichtgelesen wurden.
65

Kapitel 5 Identifizieren der zu transformierenden Anfragen
Darüber hinaus sind noch verschiedene einfache Hilfs-Strukturen erforderlich, wie Listenaller gelesenen Knoten oder Attributwerte.
5.2 Identifizieren der Anfragen
5.2.1 basic-Transformationen
Da die basic-Transformationen ausschließlich auf Ebene von kompletten Subanfragen ar-beiten, sprich diese entweder unverändert belassen, sie entfernen oder lediglich deren Achsegeneralisieren, nicht jedoch auf Attribut-Ebene, sind hier für die Identifizierung betroffenerAnfragen nur Informationen über Pfade bzw. Elemente erforderlich. Letztlich ist ein Pfadaus den gelesenen Daten genau dann relevant für eine konkrete Anfrage, wenn der Pfad einElement enthält, welches potentiell durch einen Knotentest dieser Anfrage adressiert wer-den kann. Das bedeutet, dass es schon genügt, dass ein beliebiges Element des Pfades anbeliebiger Stelle der Anfrage als Knotentest auftaucht. Erst durch die Transformation dieserAnfrage wird potentiell eine Anfrage generiert, welche das betreffende Element adressiert.
Um die bezüglich eines neuen Pfades relevanten Anfragen zu identifizieren, werden dem-zufolge diejenigen Anfragen ausgewählt, welche ein beliebiges Element dieses betreffendenPfades als Knotentest enthalten.
Relevante Anfragen für basic-Transformationen Sei p ein neuer Pfad, der nicht in P
enthalten ist: p /∈ P , el(p) ist die Menge aller Elemente von p, nt(q) ist die Menge allerKnotentests einer Anfrage q, dann gilt für Rb die Menge der bezüglich p relevanten Anfragenfür eine basic-Transformation:
Rb = {q|q ∈ Q,∃e ∈ el(p) ∧ e ∈ nt(q)}
Anfragen mit Wildcards sind nur dann relevant für einen Pfad, wenn mindestens ein Nicht-Wildcard Knotentest die obige Bedingung erfüllt.
Bei jeder Aktualisierung der Datenrepräsentation, d.h. jedem Einfügen eines neuen Pfadesp in P wird die Menge Rb der relevanten Anfragen bestimmt. Die resultierenden Anfragensind zu transformieren, wobei der Zeitpunkt der Transformation von der Konfiguration desCaches abhängt. Auf diesen Cache wird im nachfolgenden Kapitel in Abschnitt 6.2 nähereingegangen.
5.2.2 extended-Transformationen
Die beiden extended-Transformationen Downgrade und Upgrade arbeiten auf der Ebene vonPrädikaten, indem sie Attributwerte aus Prädikaten in Knotentest (Downgrade), oder Kno-tentests in Anfragen an Attributwerte (Upgrade) umwandeln. Da beide mit konkreten Wertenvon Daten arbeiten, genügt eine reine Betrachtung von Pfaden hier nicht, um die für die
66

5.3 Beispiel
Transformationen relevanten Anfragen zu identifizieren. Statt dessen müssen Informationenüber Werte von Attributen mit den dazugehörenden Elementen auf Seiten der Daten verwen-det werden. Auf Seiten der Anfragen müssen die in Prädikaten abgefragten Werte effizientzugreifbar sein, um relevante Anfragen identifizieren zu können.
Der Wert eines Attributs ist dann relevant für eine Anfrage, wenn er einem Knotentestentspricht, der in dieser Anfrage vorkommt.
Relevante Anfragen für Upgrade-Transformationen Sei e ein Element-Attribut-Wert Tu-pel, welches nicht in E enthalten ist: e /∈ E, nt(q) ist die Menge der Knotentests von Anfrageq, v′ ∈ A, dann gilt für Rd die Menge der bezüglich p relevanten Anfragen für eine Upgrade-Transformation:
Ru = {q|q ∈ Q,∃n ∈ nt(q) ∧ n = v′}
Das Element eines Pfades ist dann relevant für eine Anfrage hinsichtlich der Downgrade-Transformation, wenn es dem Wert eines Attributs entspricht, welches in einem Prädikatdieser Anfrage selektiert wird.
Relevante Anfragen für Downgrade-Transformationen Sei p ein neuer Pfad, der nicht inP enthalten ist: p /∈ P , el(p) ist die Menge aller Elemente von p, dann gilt für Ru die Mengeder bezüglich p relevanten Anfragen für eine Downgrade-Transformation:
Rd = {q|q ∈ Q,∃v ∈ V,∃e ∈ el(p) ∧ v = e}
Ebenso wie bei basic muss bei den extended-Transformationen jede Aktualisierung derDatenrepräsentation eine Bestimmung der relevanten Anfragen nach sich ziehen. Bei extendedmüssen dabei zusätzlich zur Menge Rb die Mengen Rd und Ru bestimmt werden. Da dieeigentliche Anfragetransformation völlig unabhängig von den Daten-Aktualisierungen aufGrundlage der kompletten Datenrepräsentation durchgeführt werden, muss eine bestimm-te Anfrage nur ein einziges Mal transformiert werden, auch wenn sie in mehreren Mengenauftritt.
5.3 Beispiel
Das folgende Beispiel verdeutlicht die Art und Weise, wie das im folgenden Kapitel definierteaXst die für die Anfragetransformation relevanten Anfragen identifiziert. Hierbei wird dieSituation angenommen, dass initial eine DTD vorliegt, welche die zu verarbeitenden Datenrepräsentiert. Unter Berücksichtigung dieser DTD werden eine Reihe von Anfragen formuliert,um die Daten zu filtern. Da davon ausgegangen wird, dass die Daten mehr oder weniger stark
67

Kapitel 5 Identifizieren der zu transformierenden Anfragen
Element-Typ Graph
a
b2b1
d2
c1
d3
e1 f
d1
Resultierende Pfade
#a##a#b1##a#b1#c1##a#b1#c1#d1##a#b1#c1#d1#e1##a#b1#c1#d2##a#b1#c1#d3##a#b1#c1#d3#f#a#b2##a#b2#c1##a#b2#c1#d1##a#b2#c1#d1#e1##a#b2#c1#d2##a#b2#c1#d3##a#b2#c1#d3#f
Anfragen
q1: /a/b1/c1/d1
q2: /a//c1[attr = “d3“]
q3: //c1/d3/f
q4: //b1//d2/g
Knotentests
a, b1, c1, d1, f, d2, g
NotMatchingNodetests
g
NodeMatchingPredicateValues
d3
Abbildung 5.1: Datenstruktur und Anfragen
vom vorliegenden Schema abweichen, werden sie mit aXst gefiltert. Das Beispiel zeigt, wieanhand der Verarbeitung eines Beispieldokuments unter Berücksichtigung der verschiedenenTransformationsvarianten relevante Anfragen identifiziert und transformiert werden. Die beider Transformation resultierenden Anfragen können dem Anfrageindex hinzugefügt und fürdas Filtern der aktuellen Daten verwendet werden.
Abbildung 5.1 zeigt die DTD in Gestalt eines Dokument-Typ-Graphen, sowie eine Men-ge von Anfragen. Im Beispiel auf Seite 64 werden die sich daraus ergebenden Mengen derDaten- und Anfragerepräsentation beschrieben. Es ist zu beachten, dass lediglich anhandder DTD und der Anfragen die beiden Repräsentationen schon fast vollständig aufgebautwerden können. Offensichtlich sind lediglich diejenigen Bestandteile leer, welche auf inhalt-lichen Informationen tatsächlich verarbeiteter Daten basieren. Diese sind die Menge E derElement-Attribut-Wert Tupel und die Menge A der NodeMatchingAttributeValues.
Bei der Verarbeitung des XML-Dokuments in Abbildung 5.2 wird vor dem eigentlichenFiltern das Dokument mit der Datenrepräsentation abgeglichen, diese gegebenenfalls aktua-lisiert und relevante Anfragen identifiziert. Dazu werden zunächst die resultierenden Pfade,sowie Element-Attribut-Wert Tupel erfasst. Die Abbildung zeigt in der Mitte oben alle resul-tierenden Pfade, wobei die grau dargestellten bereits in der Datenrepräsentation vorhandensind. In der Mitte unten sind die neuen Element-Attribut-Wert Tupel dargestellt.
Zunächst ist festzuhalten, dass das XML-Dokument an einigen Stellen vom eigentlich zu-grunde liegenden Schema abweicht. So gibt es Elemente c2 und c3 als dritte Ebene unter b1und b2 statt eines Elements c1. d1 hat kein Kind e1. Statt dessen hat d2 ein Kind e2 und d3ein Kind e1. Das Element f ist statt unter d3 unter e1. Insbesondere die Tatsache, dass eineAbweichung auf weit oben in der Dokument-Hierarchie gelegenen Ebene ist (c2 und c3 stattc1), erklärt die relativ große Anzahl an von der gegebenen Repräsentation abweichendenPfaden.
68

5.3 Beispiel
Resultierende Pfade#a##a#b1##a#b1#c2##a#b1#c2#d1##a#b1#c2#d2##a#b1#c2#d3##a#b1#c2#d3#e1##a#b1#c2#d3#e1#f##a#b2##a#b2#c1##a#b2#c1#d2#
NotMatchingNodetestsg
NodeMatchingPredicateValuesd3
XML-Dokument<a>
<b1><c2>
<d1/><d2/><d3>
<e1 attr=“v“><f/>
</e1></d3>
</c2></b1><b2>
<c1><d1 attr=“g“/>
</c1></b2>
</a>
Element-Attribut-Wert(e1,attr,v)(d1,attr,g)
NodeMatchingAttributeValuesg
Abbildung 5.2: XML-Daten und resultierende Datenrepräsentation
Identifizieren der Anfragen für basic
Bei der Variante basic werden diejenigen Anfragen für die eine Transformation erforderlichist, anhand der neuen Pfade in P ermittelt, wobei definitionsgemäß die Menge Rb zu bestim-men ist. Bei Betrachtung des Pfades #a#b1#c1# ergibt sich beispielsweise, dass a sowohl imbetreffenden Pfad als auch in den Anfrage q1 sowie q2 enthalten ist, womit diese Anfragenin der Menge Rb enthalten sind. Da die Elemente b1, d2, d3 und f ebenfalls sowohl in neuenPfaden als auch in Anfragen enthalten sind, ist auch die Anfrage q3 Element der Menge Rb.
Somit sind alle Anfrage zu transformieren. Da diese Transformationen anhand einer ak-tualisierten Datenrepräsentation erfolgen, welche die neuen Pfade berücksichtigt, ergibt sichdabei für die zur Anfrage q1 transformierten Anfrage q1′ =/a/b1//d1, welche bei der Anwen-dung auf die vorliegenden Daten einen Treffer liefert, im Gegensatz zur originalen Anfrage.
Identifizieren der Anfragen für extended
Um die Anfragen zu bestimmen, welche bei Anwendung der Variante extended zu transfor-mieren sind, müssen neben den Pfaden weitere Mengen betrachtet werden. Zunächst wird dieMenge Rb wie oben bestimmt.
Um die Menge der Anfragen zu ermitteln, für welche eine Upgrade-Transformation möglichist, wird die Menge Ru bestimmt. Dabei ist die Menge A der NodeMatchingAttributeValueszu betrachten, wobei hier A = {g}, womit die Anfrage q2 Element von Rd ist. Eine extendedTransformation dieser Anfrage unter Berücksichtigung der aktualisierten Daten- und Anfrage-Repräsentation ergibt die Anfrage q4′ = //b1//d1[attr=”g”].
Zur Ermittlung der für die Downgrade-Transformation relevanten Anfragen wird Rd be-stimmt, wobei die Menge V der NodeMatchingPredicateValues zu betrachten ist. d3 ist Ele-ment dieser Menge, so dass die Anfrage q2 zu transformieren ist. Die Anwendung einerDowngrade-Transformation auf diese Anfrage resultiert in der Anfrage q2′ = /a//d3.
69

Kapitel 5 Identifizieren der zu transformierenden Anfragen
Das Beispiel verdeutlicht, dass bei der Variante extended eine Anfragen gegebenenfalls inmehreren der Mengen Rb, Rd und Ru enthalten ist. Wichtig ist, dass jede Anfrage nichtsde-stotrotz für eine bestimmte Menge an Abweichungen nur ein einziges Mal transformiert wird.Je nach Transformationsvariante werden dabei die entsprechenden Regeln angewandt. DieMenge der Abweichungen ist durch den konfigurierten Zeitpunkt der Transformation festge-legt. So kann entweder sofort, d.h. bei jeder Abweichung transformiert werden, oder nachdemeine Menge von Dokumenten in den Cache geladen wurde.
70

Kapitel 6
Adaptives Filtern mit aXst
Auf Grundlage der in Kapitel 4 definierten Transformations-Techniken und den im vorigenKapitel vorgestellten Verfahren zur Identifizierung relevanter Anfragen wird nun aXst (adap-tive XML-streaming) beschrieben, ein System zum adaptiven Filtern von XML-Datenströmen.Dazu wird eine modulare Architektur definiert, die es erlaubt, ein System zur Verarbeitungvon XML-Datenströmen bzw. eine Data-Dissemination-Komponente um Bausteine zu ergän-zen, die ein adaptives Streaming ermöglichen. Diese Architektur wird in Abschnitt 6.2 diesesKapitels beschrieben. Der modulare Aufbau ist dabei insofern von zentraler Bedeutung, alsdamit aXst in den verschiedensten Anwendungsfällen unter einer Vielzahl von Rahmenbe-dingungen einsetzbar ist, indem die einzelnen Module unabhängig voneinander konfiguriertwerden können. Auf die Art und Weise des Zusammenspiels dieser Module und deren Verar-beitungsmodi wird in Abschnitt 6.3 eingegangen.
6.1 Anfragetransformationen und XML-Streaming
Von entscheidender Bedeutung bei der Kombination eines Verfahrens zur Anfragetransforma-tion mit einem System zur Verarbeitung von Datenströmen wie es in der vorliegenden Arbeitdurchgeführt wird, ist die Art und Weise wie diese Kombination durchgeführt wird. Das we-sentliche Qualitätsmerkmal beim Streaming von Daten ist der erreichbare Datendurchsatzauch bei großen Mengen von Anfragen. Dieser wird nach aktuellem Stand vor allem erreicht,indem die Anfragen vorab in geeigneten Indexstrukturen abgelegt werden, so dass die ei-gentliche Verarbeitung der Datenströme effizient erfolgen kann. Durch die Verwendung einesderartigen Indexes ist es möglich, den notwendigen Aufwand bei der Verarbeitung jedes SAX-Ereignisses auf eine in konstanter Zeit durchführbare Anfrage an den Index zu beschränken,wie es in Kapitel 3 näher beschrieben wurde.
Andererseits wurden in Kapitel 4 zwei grundsätzlich verschiedene Varianten der Anfrage-transformation vorgestellt. Zum einen die Transformation während der eigentlichen Anfrage-verarbeitung und zum anderen die Transformation davor, die sogenannte a-priori Transfor-mation.
Beide Varianten können beim Streaming von XML-Daten angewandt werden, wobei es na-he liegend erscheint, die Anfragetransformationen vor dem Streaming durchzuführen, um so
71

Kapitel 6 Adaptives Filtern mit aXst
die Arbeitsweise der performanten Filtersysteme unbeeinflusst zu lassen. Um dies zu errei-chen, muss das System lediglich um eine zusätzliche Komponente zur Anfragetransformationergänzt werden, welche jede Anfrage den notwendigen Transformationen unterzieht und dieso generierten Anfragen im Anfrageindex ablegt. Nichtsdestotrotz ist es auch denkbar, denTransformationsschritt während bzw. parallel zur Verarbeitung des Datenstroms durchzufüh-ren. Auf die Art und Weise wie diese beiden Varianten in aXst angewendet werden, wird inAbschnitt 6.3 näher eingegangen.
6.2 Architektur von aXst
Die Architektur von aXst ergänzt ein klassisches System zum Filtern vom XML-Datenströmenum zusätzliche Komponenten. Kernstück eines jeden derartigen Systems ist die Filter-Engine,die durch von einem SAX-Parser generierte SAX-Ereignisse gespeist wird. Die Filter-Enginegreift zur effizienten Verarbeitung dieser Ereignisse auf einen Anfrageindex zurück, der eineRepräsentation aller am System abgelegten Anfragen enthält. Der Anfrageindex seinerseitserhält die Anfragen in geparster Form vom Query-Parser. Die in Kapitel 2 vorgestellten An-sätze zum Streaming von XML-Daten setzen alle im Wesentlichen auf diese Architektur. ImKern unterscheiden sich die einzelnen Ansätze hinsichtlich der Gestaltung des Query-Index,wobei sich ein Aufbau als nichtdeterministischen Automaten bewährt hat.
Abbildung 6.1 zeigt schematisch die Architektur von aXst, wobei die Bestandteile der klas-sischen Architektur als transparente Objekte dargestellt sind. Die für aXst spezifischen Mo-dule sind grau hinterlegt. Zentrales Element des Aufbaus ist der Query-Transformer, der dieTransformation der geparsten Anfragen durchführt, die dabei generierten Anfragen bewertetund im Query-Index ablegt. Unterstützt werden kann er dabei von der Datenrepräsentation,wobei dies je nach Art der Transformationen nicht notwendig ist.
Die Datenrepräsentation enthält eine Repräsentation der Schemata der zu verarbeitendenDaten soweit diese Schemata zur Verfügung stehen. Darüber hinaus kann sie eine direkt ausden Datenströmen gewonnene Repräsentation der Datenstrukturen und der für die Trans-formation wesentlichen Inhalts-Informationen enthalten. Die Schemainformationen werdenvon einem Schema-Parser zur Verfügung gestellt, die Daten stellt die Monitor-Komponentebereit. Daneben enthält die Datenrepräsentation Informationen über Anfragen, die keine Ent-sprechung in den bekannten Daten haben. Die Aufgabe der Monitor-Komponente ist es, denDatenstrom auf unbekannte Strukturen zu überwachen und diese bei deren Auftreten in derDaten-Repräsentation abzulegen. Darüber hinaus stößt sie die Transformation von Anfragenan, falls Anfragen von Veränderungen der Datenstrukturen oder relevanten Inhalten betroffensind, bzw. steuert den Cache durch Zugriff auf die Caching-Komponente. Wie die Abbildungzeigt, sind Cache mit Caching-Komponente jeglicher weiteren Verarbeitung vorgeschaltet.Der Cache dient der temporären Speicherung einer begrenzten und konfigurierbaren Mengevon Dokumenten, mit dem Ziel, die Anzahl an durchzuführenden Anfragetransformationenzu verringern.
72

6.2 Architektur von aXst
SAX-Parser Monitor
Query-TransformerQuery2Data
Filter-Engine
Cache
Data-Representation
Query-Index
Caching
Schema-Parser
XML-Documents
XPath-Queries
Query-Parser
aXst-spezifische Komponente
Komponente einer klassischen Architektur
Abbildung 6.1: Architektur von aXst
Dieser modulare Aufbau von aXst ist seine wesentliche Stärke und erlaubt einen Einsatzunter einer Vielzahl von Bedingungen. Um dies zu verdeutlichen wird im Folgenden dasZusammenwirken der einzelnen Module näher betrachtet.
Query-Transformer
Abbildung 6.2 zeigt einen detaillierteren Auszug der aXst-Architektur mit dem Query-Trans-former und seinen Beziehungen zu den anderen Modulen im Zentrum. Die gestrichelten Ver-bindungen repräsentieren dabei optionale Beziehungen zwischen den einzelnen Komponenten,d.h. Beziehungen, die in Abhängigkeit des gewählten Transformations-Modus bestehen.
Aufgabe des Query-Transformers ist die Durchführung der Anfragetransformationen. Dazugreift er auf die vom Query-Parser vorbereiteten Originalanfragen zu, wendet einen Trans-formationsalgorithmus an, bewertet die dabei generierten Anfragen anhand der zugehörigenFitness-Funktion und legt die am besten bewerteten Anfragen im Query-Index ab. Dabei kanneines der drei Transformations-Verfahren basic, extended und all angewandt werden. DieAnzahl der generierten Anfragen, die pro Originalanfrage in den Query-Index übernommenwerden soll, sowie der minimale Fitnesswert, den diese Anfragen in Relation zum maximalmöglichen Fitnesswert mindestens erreichen müssen, können vom Benutzer vorgegeben wer-den.
Hinsichtlich der Ausdrucksmächtigkeit ist zu beachten, dass der Query-Transformer ent-sprechend der Definitionen der Transformationsalgorithmen alle XPath-Anfragen verarbeitenkann, die sich als TPQs repräsentieren lassen. Nichtsdestotrotz unterliegt aXst den Beschrän-kungen der Filter-Komponente, die in der Regel keine Rückwärts-Achsen verarbeiten kann.
Der Query-Index enthält damit einerseits die Originalanfragen direkt vom Query-Parser,
73

Kapitel 6 Adaptives Filtern mit aXst
Monitor
Query-Transformer-Basic /ExtendedTranformation- ALLTransformations
Data-Representation-Schema-Repr.- Data-Repr.- Content-Index- Query-Info
Query-Index-Originalanfragen- durch Transformationgenerierte Anfragen
Query-Parser
bewerteteAnfragen
Zugriff auf geparste Originalanfragen
geparste Originalanfragen
Query2Data
aXst-spezifische Komponente
Komponente eine klassischen Architektur
Abbildung 6.2: Der Query-Transformer
sowie andererseits die im Zuge der Anfragetransformation generierten und bewerteten Anfra-gen vom Query-Transformer. Für den Query-Index bzw. die Filter-Engine ist es transparent,ob es sich um eine originale oder eine generierte Anfrage handelt. Indem jede Anfrage einenVerweis auf ihre Originalanfrage trägt - welcher für eine Originalanfrage auf diese selbst zeigt- kann bei der Ausgabe der Anfrage-Treffer in konstanter Zeit die originale Anfrage berichtetwerden.
Bei Anwendung der Transformationsverfahren basic- oder extended greift der Query--Transformer auf die Datenrepräsentation zu, um die passenden Transformationsregeln an-wenden zu können. Das Verfahren basic benötigt dabei entweder eine Schema- oder eineDaten-Repräsentation. Beide unterscheiden sich lediglich hinsichtlich ihrer Herkunft, so dasses für das Transformations-Verfahren keinen Unterschied macht, welche verwendet wird. DasVerfahren extended benötigt Informationen aus dem Content-Index und der Query-Info Re-präsentation. Die Query-Infos werden durch einen Abgleich von Anfrageindex und Daten-Repräsentation von der Query2Data-Komponente gewonnen.
Der eigentliche Vorgang der Anfragetransformation wird je nach Modus von aXst entwedereinmalig zu Beginn vor dem Streaming durchgeführt oder während dessen durch den Monitorangestoßen.
Data-Representation
Die Datenrepräsentation erfüllt zwei Aufgaben: Zum einen stellt sie dem Query-Transformerfür dessen Anfragetransformationen aufbereitete Informationen über die den Datenströmenzugrunde liegenden Schemata bzw. über die Strukturen und Inhalte der Daten selbst zurVerfügung. Zum anderen ist sie das ”Gedächtnis” aller bisher verarbeiteten Datenströme und
74

6.2 Architektur von aXst
wird in dieser Form von der Monitor-Komponenten dazu verwendet, den aktuellen Daten-strom auf neue für die Anfragetransformation potentiell relevante Strukturen und Inhalte hinzu untersuchen.
Mit Ausnahmen von all ist die Datenrepräsentation für alle Transformationsverfahren not-wendig, wobei die tatsächlich erforderlichen Informationen wiederum vom Verfahren selbstabhängig sind. Die Transformationsregel von basic verwendet ausschließlich die dcont , contund excont Beziehungen, welche sich aus Schemata oder den XML-Daten selbst gewinnenlassen. Die Transformationsregel für extended benötigt darüber hinaus Informationen überdie Inhalte der Daten, d.h. die Werte von XML-Attributen. Zusammenfassend stellt die Da-tenrepräsentation damit folgende Informationen für den Query-Transformer zur Verfügung:
• dcont die Menge der Paare von Elementen, die in einer directly-contains Beziehungstehen
• cont die Menge der Paare von Elementen, die in einer contains Beziehung stehen
• excont die Menge der Paare von Elementen, die in einer exclusively-contains Beziehungstehen
• ea die Menge der Element-Attribut-Paare für die gilt, dass das betreffende AttributTeil des Elements ist
• eav die Menge der Element-Attribut-Wert-Tupel für die gilt, dass der betreffende Wertin dem Attribut des Elements auftritt
Dem Monitor stellt die Datenrepräsentation Informationen bereit, anhand derer dieserentscheiden kann, ob das Filtern der aktuellen Daten unterbrochen werden muss, um An-fragetransformationen durchzuführen. Die grundsätzliche Herausforderung hierbei ist es, nurdiejenigen Daten zu speichern, die für das Transformationsverfahren selbst, sowie die Ent-scheidung, ob es durchzuführen ist, relevant ist. Die dem Monitor bereitgestellten Informa-tionen sind:
• Pfade: die Menge aller Pfade, die in den bisher verarbeiteten XML-Dokumenten auftra-ten, bzw. aller Pfade, die sich aus den zur Verfügung stehenden Schemainformationenerschließen lassen
• Nodetests: die Menge aller Knotentests der Anfragen des Query-Index
• NotMatchingNodetests: die Menge aller Knotentests aus den Anfragen des Query-Index,zu denen es keinen entsprechenden Element-Typ (bzw. kein entsprechendes Element)gibt
• NodeMatchingPredicateValues: die Menge aller Attributwerte, die in Prädikaten vonAnfragen angefragt werden und für die gilt, dass sie einem Knoten in den verarbeitendenDaten entsprechen
75

Kapitel 6 Adaptives Filtern mit aXst
• NodetestInQuery: die Menge aller Zuordnungen von Knotentests zu allen Anfragen indenen der betreffende Knotentest enthalten ist
Die Menge aller Pfade wird je nach Herkunft der Daten durch den Monitor anhand deraktuellen Daten gepflegt oder initial mit Hilfe des Schema-Parsers anhand der zu Verfügungstehenden Schemata gefüllt. Die Nodetests und NodetestInQuery müssen durch eine Kom-ponente gepflegt werden, die Zugriff sowohl auf die Datenrepräsentation, als auch auf denQuery-Index hat. Diese Aufgabe übernimmt die Query2Data-Komponente. Die NotMatchin-gNodetests und die NodeMatchingValues werden vom Monitor während der Verarbeitung derDaten gepflegt. Stehen Schemainformationen zur Verfügung können die NotMatchingNode-tests schon vor der eigentlichen Verarbeitung initialisiert werden.
Query2Data
Die Query2Data-Komponente nutzt Informationen über die Anfragen im Query-Index, um inder Datenrepräsentation des Query-Info-Index die Nodetests und NodetestInQuery zu füllen.Query2Data extrahiert aus jeder in den Query-Index übernommenen Anfrage die enthaltenenKnotentests und trägt sie in Nodetests ein. Zusätzlich wird die Zuordnung von Knotentestszu den Anfragen, in denen sie enthalten sind, in NodetestInQuery eingetragen.
Monitor
Eine zentrale Komponente von aXst ist der Monitor. Er versorgt die Filter-Engine mit denParsing-Events der verarbeiteten Datenströme, wobei er gegebenenfalls auf die zusätzlicheCaching-Komponente zugreift. Er überwacht die Datenströme auf Abweichungen und sorgtfür die Transformation von relevanten Anfragen. Der Monitor steuert damit alle Kompo-nenten von aXst und sorgt für deren geordnetes Zusammenspiel. Lediglich bei der Trans-formations-Variante all, bei der weder die Datenrepräsentation noch der Cache benötigtwird, ist der Monitor nicht notwendig. Die Parsing-Events werden dort direkt vom Parser andie Filter-Engine weitergereicht.
Die Hauptaufgabe der Monitor-Komponente ist es, anhand der aktuell verarbeiteten Datenzu entscheiden, ob Anfragetransformationen notwendig sind. Dazu gleicht sie die verarbeite-ten Daten mit der Daten-Repräsentation ab und protokolliert die aufgetretenen Abweichun-gen. Grundsätzlich führen Abweichungen dazu, dass die Query2Data-Komponente daraufhinangefragt wird, ob Anfragen von diesen Abweichungen betroffen sind und dass diese Anfragengegebenenfalls transformiert und in den Anfrageindex übernommen werden.
Der Zeitpunkt zu dem diese Transformationen durchgeführt werden, kann in aXst kon-figuriert werden. So kann festgelegt werden, dass sofort beim Auftreten einer Abweichungdie Anfragetransformation durchgeführt wird. Es ist aber auch möglich, einen Cache zu ver-wenden, so dass zunächst eine gewisse Anzahl an Dokumenten geparst und vom Monitorverarbeitet werden, bevor eventuell notwendige Transformationen durchgeführt werden. Der
76

6.2 Architektur von aXst
SAX-Parser Monitor
Query-Transformer
Filter-Engine
Cache
Data-Representation
Caching
Laden von Dokumenten in den Cache/Lesen von Dokumenten aus dem Cache
Steuern des Cachings:-Laden von Dokumenten-Lesen von Dokumenten
Überprüfen auf Abweichungen
Query2Data
Anstoßen von Transformationen
Abgleichen von Abweichungenmit Anfragen
aXst-spezifische Komponente
Komponente eine klassischen Architektur
Abbildung 6.3: Monitor und Caching-Komponente
Monitor übernimmt an dieser Stelle die Steuerung des Caches. Er sorgt dafür, dass die korrek-te Anzahl an Dokumenten in den Cache geladen wird und dass die beim Laden des Cachesregistrierten Abweichungen in geeignete Anfragetransformationen umgesetzt werden. Nachderen Durchführung ist es die Aufgabe des Monitors, das Lesen der Dokumente aus demCache und deren Weitergabe an die Filter-Engine anzustoßen.
Abbildung 6.3 zeigt das Zusammenspiel des Monitors mit den übrigen Komponenten vonaXst.
Cache
Die Transformation von Anfragen ist eine teure Operation, die außerdem ein Stoppen derVerarbeitung des Datenstroms notwendig macht. Bei Daten mit unbekannten oder permanentabweichenden Strukturen kann sich der für die Transformation erforderliche Aufwand negativauf die Performanz des Gesamtsystems auswirken. Im Extremfall weist von einer Mengevon zu verarbeitenden Dokumenten jedes Dokument abweichende Strukturen auf, welcheihrerseits wiederum für eine große Menge von Anfragen relevant sind, so dass jede dieserAnfragen gegebenenfalls wiederholt transformiert werden muss.
Durch den Einsatz der Caching-Komponente kann die Durchführung dieser teuren Trans-formationen auf einen späteren Zeitpunkt verschoben werden. Es wird dabei zunächst einevorgegebene und konfigurierbare Anzahl an Dokumenten gelesen, auf Abweichungen hin un-tersucht und im Cache abgelegt. Sobald die Kapazität des Caches erschöpft ist werden dieprotokollierten Abweichungen verwendet, um die betroffenen Anfragen zu transformieren.Der entscheidende Vorteil ergibt sich dabei aus der Tatsache, dass jede betroffene Anfragefür eine bestimmte ”Cache-Ladung” nur ein einziges Mal transformiert werden muss. Dies
77

Kapitel 6 Adaptives Filtern mit aXst
wird dadurch ermöglicht, dass einerseits alle registrierten Abweichungen in die Datenreprä-sentation übernommen werden und damit der Anfragetransformation zur Verfügung stehen,dass andererseits aber auch mit Hilfe der Query2Data-Komponente die von Abweichungenbetroffenen Anfragen ermittelt werden. Wird eine Anfrage im Zuge der Verarbeitung einer”Cache-Ladung” mehrfach ermittelt, so genügt es trotzdem, diese Anfrage nur ein einziges Malzu transformieren, da alle Abweichungen, die registriert wurden, in der DatenrepräsentationEingang gefunden haben und damit der Transformation zur Verfügung stehen.
Die Caching-Komponente selbst ist dabei sehr einfach. Sie besteht aus dem eigentlichenCache, in dem die Dokumente temporär abgelegt werden und einer steuernden Komponente,die dafür sorgt, dass neue Dokumente in den Cache geladen werden, bzw. im Cache abgelegteDokumente ausgelesen werden können. Die Anzahl der im Cache abzulegenden Dokumenteist konfigurierbar, so dass das System an die vorliegenden Gegebenheiten, d.h. die Strukturder zu verarbeitenden Daten angepasst werden kann. Ist die Struktur der Daten beispielsweisesehr stabil, bietet es sich an, den Cache eher klein zu halten um die Dokumente möglichstschnell der Filter-Engine übergeben zu können. Ist andererseits mit häufigen Änderungen derStrukturen zu rechnen, kann der Cache so konfiguriert werden, dass er eine große Anzahl anDokumenten aufnimmt, um den Aufwand für die Anfragetransformationen zu minimieren.
Wie Abbildung 6.3 zeigt, wird der Cache durch den Monitor gesteuert. Dieser teilt demCache mit, wann Dokumente geladen bzw. ausgelesen werden müssen.
Der Einsatz des Caches sorgt für eine Abweichung von dem Paradigma, jedes ankommendeEreignis bei der Verarbeitung eines Dokuments unmittelbar der Filter-Engine zugänglich zumachen, verspricht andererseits aber einen erheblichen Performanzgewinn im Hinblick aufeine in das eigentliche Filtern eingebettete Anfragetransformation.
6.3 Verarbeitungsmodi von aXst
Ziel des modularen Aufbaus von aXst ist die Möglichkeit, die einzelnen Komponenten indi-viduell konfigurieren zu können. Dadurch können die adaptiven Transformationsalgorithmenan das vorliegende Anwendungsszenario angepasst werden. So kann festgelegt werden, welcheArt der Transformationen durchzuführen sind. Je nachdem ob Schemainformationen vorlie-gen oder nicht, kann konfiguriert werden, ob diese verwendet werden sollen oder nicht, bzw.ob eine Datenrepräsentation gepflegt und verwendet werden soll. Schließlich kann es für diePerformanz des Systems von entscheidender Bedeutung sein, zu welchem Zeitpunkt relevanteAnfragen transformiert werden sollen.
Art der Transformationen
Hinsichtlich der Art der Anfragetransformationen unterscheidet aXst die strukturellen Basis-und die erweiterten Transformationen. Stehen für die Basistransformationen unterstützen-de Informationen wie Schemata oder eine Datenrepräsentation zur Verfügung, werden diese
78

6.3 Verarbeitungsmodi von aXst
mit basic bezeichnet. Stehen derartige Informationen nicht zur Verfügung, müssen stets alleTransformationen angewandt werden. Dieser Sonderfall wird mit all bezeichnet. Für die mitextended bezeichneten erweiterten Transformationen ist in jedem Fall eine Datenrepräsen-tation notwendig.
Daneben lässt sich aXst als herkömmliches System zum Filtern von Datenströmen betrei-ben, d.h. es findet weder eine Anfragetransformation statt, noch wird eine Datenrepräsenta-tion gepflegt. In diesem mit no bezeichneten Fall sind alle zusätzlichen und aXst-spezifischenKomponenten deaktiviert.
Schemainformationen
Stehen Schemainformationen der zu verarbeitenden Daten zur Verfügung, können diese fürdie Anfragetransformation verwendet werden. Je nachdem wie exakt die tatsächlichen Datendem jeweiligen Schema entsprechen kann es jedoch auch besser sein, auf dieses zu verzichtenund statt dessen die aus den Daten gewonnene Repräsentation zu verwenden.
Für die Transformationen basic und extended ist in jedem Fall entweder ein Schema odereine Datenrepräsentation erforderlich, wogegen bei der Variante all auf beides verzichtetwird.
Datenrepräsentation
Die Datenrepräsentation wird aus dem Schema und den tatsächlich verarbeiteten Daten ge-wonnen und bildet einfache strukturelle Merkmale, sowie verschiedene Inhalte dieser Datenab. Für die Anfragetransformationen der Variante basic ist es transparent, ob die Datenre-präsentation nur aus Schemainformationen oder auch aus den tatsächlichen Daten gewonnenwird. Für die Variante extended ist insbesondere der inhaltliche Teil der Repräsentationzwingend erforderlich.
Zeitpunkt der Transformation
Der Zeitpunkt zu dem die Anfragetransformationen durchzuführen sind, ist je nach Anwen-dungsfall unterschiedlich zu wählen. Da die Transformation eine teure Operation ist, mussdie Entscheidung über diesen Zeitpunkt sorgfältig gewählt werden. Soll die basic-Varianteauf Grundlage von Schemainformationen gewählt werden und sind keine Abweichungen derDaten von den Schemata zu erwarten, so ist es ausreichend, die Anfragen einmalig und zwarsobald sie in das System übernommen werden, zu transformieren. Diese Variante wird mitinit bezeichnet und wird auch für die Transformations-Variante all angewandt.
Bei der Variante immediate wird die Verarbeitung des Datenstroms sofort unterbrochen,sobald eine Abweichung der Daten von den bekannten Strukturen registriert wird. Die vonder Abweichung betroffenen Anfragen werden transformiert und das Streaming wird an ge-eigneter Stelle fortgesetzt. Der Nachteil dieser Variante besteht darin, dass bei sehr häufigen
79

Kapitel 6 Adaptives Filtern mit aXst
Abweichungen Anfragen wiederholt transformiert werden müssen. In Abschnitt 6.4 wird dieseVariante beschrieben.
Diesem Nachteil wird mit der Variante a priori begegnet. Hier wird zunächst eine gewisseAnzahl von Dokumenten eingelesen und auf Abweichungen hin untersucht. Die registrierenAbweichungen werden gesammelt und die untersuchten Dokumente in einem Cache abgelegt.Sobald der Cache voll ist, werden die von den registrierten Abweichungen betroffenen Anfra-gen transformiert und die Dokumente des Caches werden daraufhin anhand des aktualisiertenAnfrageindex gefiltert.
6.4 Die Variante immediate
Bei der Variante immediate findet kein Caching der Daten statt. Statt dessen wird jedesEvent unmittelbar vom Monitor an die Filter-Engine weitergegeben. Sobald der Monitoreine Abweichung der Daten registriert, werden sofort die betroffenen Anfragen identifiziert,sie werden transformiert und die Verarbeitung des Datenstroms wird fortgesetzt. Ziel diesesVerfahrens ist eine zeitnahe Transformation der Anfragen unter Vermeidung des beim Cachingnotwendigen doppelten Einlesens der Daten.
Zur Transformation wird also die Verarbeitung der Daten unterbrochen und danach wiederaufgenommen. Dabei ergeben sich zwei Herausforderungen: Erstens befindet sich das Anfra-gesystem, also beispielsweise YFilter, in einem bestimmten Zustand, bzw. einer Menge vonZuständen und zweitens verändert sich der Automat durch die zwischenzeitliche Transforma-tion, indem gegebenenfalls neue Anfragen hinzugefügt werden. Die Herausforderung dieserVariante besteht darin, nach der Transformation von Anfragen die Verarbeitung der Datenan der korrekten Stelle wieder aufzunehmen und zwar so, dass sich der Anfrageautomat ineinem korrekten und definierten Zustand befindet.
Hierbei erweist es sich als nützlich, dass bei der Verarbeitung von Datenströmen nurvorwärts-gerichtete Achsen betrachtet werden, d.h. die Anfragen nur Dokument-Teile be-trachten, die in Dokument-Ordnung vor dem aktuellen Kontext-Knoten liegen. Damit sindalle zu einem bestimmten Zeitpunkt bereits geschlossenen Tags bzw. Elemente eines Doku-ments für eine gegebene Anfrage nicht mehr relevant.
Für die Variante immediate bedeutet dies, dass während der Verarbeitung der Daten ineiner zusätzlichen Datenstruktur alle Elemente auf dem direkten Pfad von der Wurzel zumaktuellen Element verwaltet werden. Sobald nach einer durch eine Abweichung der Datenbedingten Transformation von Anfragen der Filter-Vorgang fortgesetzt werden soll, wird dasAnfragesystem zunächst zurückgesetzt, d.h. der Stack zur Verwaltung der Zustände des Au-tomaten wird geleert. Anschließend wird der Filter-Vorgang wieder aufgenommen, indemim nächsten Schritt die Elemente auf dem direkten Pfad von der Wurzel zum aktuellenElement, die zwischengespeichert wurden, wieder eingelesen werden. Sobald das letzte zwi-schengespeicherte Element eingelesen wurde, wird die Verarbeitung an der aktuellen Positionim Dokument wieder aufgenommen.
80

6.4 Die Variante immediate
Bekannte Pfade
#a##a#b##a#b#c#
XML-Dokument
<a><b>
<c></c>
</b><b>
<d></d>
</b></a>
Resultierende Pfade
#a##a#b##a#b#c##a#b##a#b#d#
SAX-Events
Open (a) Open (b) Open (c) Close (c) Close (b) Open (b) Open (d)
a a a
b b
a
b
c
a a
b
a
b
d
Lade SAX-Events
Open (a) Open (b)
Wiederaufnahme
Open (d) Close (d)...
a
b
d
a
b
Event-Stack
Abbildung 6.4: Beispiel zur Variante immediate
Indem der direkte Pfad aller Elemente von der Wurzel bis zum aktuellen Element geladenwird, ist sichergestellt, dass das Anfragesystem mindestens diejenigen Zustände aktiviert,die vor der Unterbrechung aktiviert waren. Da der aktuelle Pfad tatsächlich für die Abwei-chung der Daten und damit die Unterbrechung verantwortlich war, und genau dieser Pfadnochmals eingelesen wird, ist darüber hinaus gewährleistet, dass neue Anfragen, die Ergebniseiner aufgrund dieser Abweichung angestoßenen Transformation sind, ebenfalls zu Ausfüh-rung kommen.
Das Verfahren immediate lässt sich damit wie folgt beschreiben:
Das Verfahren immediate Sei D ein XML-Dokument, das von einem SAX-Parser eingelesenwird, S ein Stapel auf den ein Element e beim öffnenden Tag von e gelegt wird und von demdas entsprechende Element beim schließenden Tag entfernt wird. A sei der Stapel, welcherdie Zustände des Automaten zur Anfrageverarbeitung repräsentiert.
P sei der direkte Pfad der Elemente von der Wurzel von D zum aktuellen Element e′, beidem die Verarbeitung unterbrochen wird.
Die Wiederaufnahme der Verarbeitung geschieht in drei Schritten:
1. A wird zurückgesetzt, aktueller Zustand wird der Start-Zustand;
2. die Elemente aus S werden bis auf das Top-Element e′ Bottom-Up an die Filter-Engineweitergegeben;
3. die Verarbeitung von D wird bei Element e′ fortgesetzt;
Das nachfolgende Beispiel illustriert das Verfahren:
81

Kapitel 6 Adaptives Filtern mit aXst
Beispiel Abbildung 6.4 zeigt die Verarbeitung eines XML-Dokument von aXst in der Va-riante immediate. Links oben zeigt die Abbildung die vor der Verarbeitung des Dokumentsbekannten Pfade der Datenrepräsentation. In der Mitte ist das verarbeitete Dokument mitden resultierenden Pfaden auf der rechten Seite. Dabei ist der Pfad #a#b#d ein unbekannterPfad der für eine Unterbrechung der Verarbeitung sorgt. Im Dokument ist die entsprechen-de Stelle durch den Querstrich gekennzeichnet. Die Abbildung zeigt unten die Folge derbei der Verarbeitung generierten SAX-Events, sowie den für jede Situation aktualisiertenEvent-Stack. Auch in dieser Folge der Ereignisse ist die Stelle, an der der unbekannte Pfadregistriert und damit die Verarbeitung unterbrochen wird, durch einen Strich gekennzeichnet.Nach der Unterbrechung werden zunächst die relevanten Anfragen identifiziert, transformiertund die resultierenden Anfragen in den Index übernommen. Anschließend wird das Anfrage-system zurückgesetzt, gemäß Schritt 1 des obigen Verfahrens. Die Abbildung veranschaulichtan dieser Stelle Schritt 2 und 3. Zunächst werden die SAX-Events aus dem Event-Stack inBottom-Up-Reihenfolge geladen und an das Filtersystem übergeben, anschließend wird dieVerarbeitung des Dokuments an der aktuellen Position mit demjenigen Element fortgesetzt,bei welchem die Abweichung registriert wurde.
Ausdrucksmächtigkeit
Indem die Verarbeitung von Dokumenten bei immediate unterbrochen, die Zustände des Fil-tersystems zurückgesetzt und lediglich der direkte Pfad zum aktuellen Element neu geladenwird, geht ein Stück an Ausdruckskraft verloren. Einerseits arbeiten Filtersysteme grundsätz-lich mit vorwärts gerichteten Achsen, so dass ein ”Gedächtnis” über bereits verarbeitete Teileeines Dokuments nicht notwendig und damit auch nicht vorgesehen ist. Insofern sind alle Ach-sen unkritisch, die den aktuellen bzw. tiefer in der Hierarchie liegende Knoten adressieren unddamit von der gezeigten modifizierten Verarbeitung nicht betroffen. Eine Ausnahme bildenan dieser Stelle die ebenfalls vorwärts gerichteten Varianten der sibling-Achse. Diese adres-sieren auf gleicher Ebene, jedoch in Dokument-Ordnung dem aktuellen Kontext nachfolgendeKnoten.
Informationen über die Zustände derartiger Anfragen gehen aber zwangsläufig verloren,wenn der Zustandsautomat vollständig zurückgesetzt wird und lediglich der direkte Pfadzum aktuellen Dokument neu geladen wird.
Ziel von immediate ist eine zeitnahe Transformation von relevanten Anfragen unter weitge-hender Vermeidung einer wiederholten Verarbeitung von Dokumenten um so den Speicherbe-darf des Cachings zu minimieren. Dies kann durch das gezeigte Verfahren unter einer gewissenEinschränkung der Ausdrucksstärke erreicht werden. Hinsichtlich dieser Einschränkung ist zubemerken, dass derzeit gängige Filtersysteme wie YFilter die sibling-Achse nicht unterstüt-zen, so dass aXst den Anfragen hier keine relevante zusätzliche Einschränkung auferlegt.
Das entscheidende Merkmal, welches immediate von den a priori Varianten unterschei-det, ist die Tatsache, dass relevante Anfragen ohne Verzögerung bei jedem Auftreten einer
82

6.5 Anwendung von aXst
Abweichung identifiziert und transformiert werden. Hierbei ist zu beachten, dass die An-fragetransformation eine relativ teure Operation ist, von der zu erwarten ist, das sie einenstarken Einfluss auf die Gesamtperformanz des Systems haben wird. Die experimentellenUntersuchungen in Kapitel 7 werden zeigen, wie sich dieser Ansatz auswirkt.
6.5 Anwendung von aXst
Eine der Hauptanwendungen von aXst ist die Integration mehrerer verschieden strukturierterDatenquellen zu einem einheitlichen Anfragesystem. Hierbei ist zu beachten, dass für jededieser Datenquellen eine eigene Datenrepräsentation sowie ein eigener Anfrageindex zu ver-walten ist, soweit sich die Datenquellen strukturell und inhaltlich voneinander unterscheiden.Dies versteht sich, da die Stärke von aXst darin besteht, die Anfragen eben ganz spezifischan die jeweiligen Datenquellen anzupassen. Damit wird eine für eine Datenquelle A transfor-mierte Anfrage für eine andere Datenquelle B in der Regel nicht brauchbar sein.
Da die Transformationen vollständig automatisch ablaufen, bedeutet dies für die Integra-tion lediglich einen erhöhten Speicherplatzbedarf. Von zentraler Bedeutung ist letztlich, dassdie spezifischen aXst-Komponenten der Architektur jeweils konkreten Datenquellen zugeord-net sind.
Wird das System zum Zwecke einer fehlertoleranten Verarbeitung eines einzigen Daten-stroms verwendet, so genügt es, jede der aXst-Komponenten in einfacher Form einzusetzen.
83

Kapitel 6 Adaptives Filtern mit aXst
84

Kapitel 7
Experimente
Im vorliegenden Kapitel wird die experimentelle Untersuchung der Transformationsalgorith-men beschrieben. Ein wesentlicher Aspekt wird dabei der Zeitaufwand für die Durchführungder Anfragetransformationen sein. Je nach verwendetem Verfahren werden die Transformatio-nen nur einmalig vor dem eigentlichen Filtern der Daten oder wiederholt und so auch währenddes Filterns durchgeführt. Damit ist eine eingehende Diskussion der verschiedenen Größen,die Einfluss auf die Performanz des Transformationsalgorithmus haben, notwendig. Dem Nut-zer verspricht das System ein Mehr an Anfrageergebnissen unter ungünstigen Bedingungen.Es wird untersucht, inwieweit dieses Versprechen eingelöst wird. Letztendlich steht und fälltdie Akzeptanz eines Systems zur Verarbeitung von Datenströmen mit der Geschwindigkeit, inder es diese Aufgabe bewerkstelligt. Offensichtlich wird für die Anfragetransformationen not-wendige zusätzliche Aufwand einen Einfluss auf die Streamingperformanz haben. Der Frageunter welchen Bedingungen dieser Einfluss wie groß ist, wird eingehend untersucht.
7.1 Algorithmen
Die untersuchten Algorithmen lassen sich hinsichtlich mehrerer Dimensionen unterscheiden.Bezüglich der Art der durchgeführten Transformationen wird sowohl der basic Algorithmsbetrachtet, der nur die Basistransformationen durchführt, als auch der extended Algorithms,der zusätzlich die erweiterten Transformationen anwendet. Hinsichtlich der für die Trans-formation zur Verfügung stehenden Informationen wird einerseits der Fall untersucht, dassSchemainformationen in Form von DTDs zur Verfügung stehen andererseits aber auch derFall, dass Strukturinformationen erst zur Laufzeit gewonnen werden können, bzw. gar nichtverwendet werden. Ein Sonderfall wird dabei das mit all bezeichnete Verfahren sein. Hier-bei werden ohne Kenntnis von Schemainformationen alle möglichen Basistransformationendurchgeführt und zur Anwendung gebracht.
Schließlich wird unterschieden, zu welchem Zeitpunkt die Transformationen zur Anwen-dung kommen, also nur zu Beginn, was zur Folge hat, dass kein Monitor die Daten über-wachen muss, oder permanent was seinen Einsatz zwingend macht. Werden die Transforma-tionen nur zu Beginn und ohne Einsatz des Monitors durchgeführt, so wird dieses Verfah-ren mit a priori (no update) gekennzeichnet, unter Einsatz eines Monitors mit a priori
85

Kapitel 7 Experimente
NITF Auction DBLP
Anzahl von Element-Typen 123 77 36Gesamtanzahl von Attributen 510 16 14Maximal zulässige Verschachtelungstiefe unbegrenzt unbegrenzt unbegrenzt
Tabelle 7.1: Charakteristika der drei verwendeten DTDs
(update), wobei in dem Fall noch angegeben wird, wie viele Dokumente jeweils eingelesenwerden, bzw. in den Cache kommen, bevor transformiert wird. Führt jede vom Monitor re-gistrierte Abweichung sofort zu einer Anfragetransformationen, so handelt es sich um dasVerfahren immediate.
Ein unmittelbarer Vergleich mit anderen Systemen wurde in sofern durchgeführt, als dieVariante no eine direkte Anwendung der YFilter Implementierung ist, d.h. es kommen keineTransformationen der Anfragen zum Einsatz und während des eigentlichen Filterns überwachtkein zusätzlicher Monitor die Daten auf Abweichungen.
7.2 Experimentelle Umgebung
Das System aXst, d.h. sowohl die Transformationsalgorithmen als auch das Streamingsystemwurden im Rahmen dieser Arbeit in Java implementiert. Sämtliche hier besprochenen expe-rimentellen Ergebnisse wurden unter einer Java Virtual Machine (JVM) 1.6.0_06 auf einemRechner mit zwei Pentium XEON Prozessoren mit 3.06 GHz und 6 GB RAM unter SuSELinux 10.0 erzielt. Der JVM wurden jeweils beim Start 1.6 GB Speicher zugewiesen.
Die Implementierung der Streamingalgorithmen basiert grundsätzlich auf der YFilter Im-plementierung in der Version 1.0, wobei insbesondere für die Integration des Monitors An-passungen notwendig waren.
7.2.1 Praktische Umsetzung
Zur rein praktischen Umsetzung der Experimente mussten sowohl Daten als auch Anfragenin großer Menge generiert werden um die Transformationsalgorithmen und die Streaming-und Monitoringverfahren untersuchten zu können. Grundlage dafür waren jeweils die dreirealen DTDs NITF (News Industry Text Format) [Cov99], Xmark-Auction [WK+02] sowiedie DTD der DBLP [Ley01]. Der Schwerpunkt lag hierbei auf der NITF, da sie aufgrundder Anzahl an Elementen und Attributen die höchste Komplexität aufweist. Tabelle 7.1 zeigteinige wesentlichen Charakteristiken dieser drei DTDs. Jede dieser DTDs erlaubt aufgrundvon Schleifen über mehrere Element-Typen eine unbegrenzte Anzahl von verschachteltenEbenen.
Bei der Auswahl der DTDs sowie der Tools zur Generierung von Anfragen und Dokumentenwurde ähnlich vorgegangen wie in [DAF+03]. Ausgehend von den DTDs wurde mithilfe eines
86

7.2 Experimentelle Umgebung
Parameter Wertebereich Beschreibung
Q 1000 bis 500000 Anzahl der AnfragenD 6 bis 10 Maximale Tiefe von XML-Dokumenten und XPath-AnfragenW 0 bis 1 Wahrscheinlichkeit eines Wildcards (’*’) in einem Location StepDS 0 bis 1 Wahrscheinlichkeit der Descendant-Achse (’//’) in einem Location StepDistinct true oder false Sind die Anfragen eindeutigP 0 bis 20 Anzahl von Prädikaten pro AnfrageWP 0 bis 1 Wahrscheinlichkeit eines Prädikats in einem Location StepNP 0 bis 3 Anzahl verschachtelter Pfade pro AnfrageWN 0 bis 1 Wahrscheinlichkeit eines verschachtelten Pfads in einem Location StepRP 2,3,5 Maximale Anzahl von Wiederholungen eines Elements
unter einem einzigen Elter-ElementSMOD 0 bis 20 Maximale Anzahl von Editierschritten
von der Anfrage-DTD zur Daten-DTD
Tabelle 7.2: Parameter für die Generierung von Anfragen und Dokumenten
DTD Parsers ein Anfrage Generator bzw. ein XML Generator dazu verwendet, die XPath-Anfragen und die XML-Dokumente zu generieren. Der Anfrage Generator ist in der Lage,XPath Anfragen entsprechend verschiedener Parameter zu generieren, um etwa die Wahr-scheinlichkeit des Vorkommens von Descendant-Achsen (//), Wildcards (*), Prädikaten oderverschachtelten Anfragen sowie die Länge zu generierender Anfragen zu bestimmen. Tabelle7.2 zeigt die möglichen Parameter mit ihren zulässigen Werten. Die tatsächlich verwendetenWerte werden bei der Diskussion der einzelnen Ergebnisse jeweils angegeben.
Der Anfrage-Generator kann mit Hilfe des Distinct-Parameters so konfiguriert werden,dass keine Anfrage mehrfach generiert wird. Bei der Mehrzahl der durchgeführten Experimen-te wurden nur Mengen von eindeutigen Anfragen verwendet (Distinct=true). In den Fällenin denen der Anfrage-Generator nicht in der Lage war, eindeutige Anfragen in der gewünsch-ten Anzahl herzustellen, ist dies jeweils angegeben. In der Regel handelt es sich dabei umMengen von sehr einfachen Anfragen, d.h. Anfragen ohne Prädikate, Wildcards, Descendant-Achsen oder verschachtelte Pfade, was es dem Generator nicht erlaubt, ausgehend von dengegebenen DTDs eindeutige Anfragen in ausreichender Menge zu erzeugen.
Für die Generierung der XML Dokumente wurde der XML Generator von IBM [DL99] ver-wendet, wobei er mit den beiden Parametern maximale Tiefe (D) und (RP) gesteuert wurde.RP spezifiziert die maximale Anzahl mit der ein bestimmtes Element unter einem bestimm-ten Elter-Element wiederholt werden darf. Attribute von Elementen werden entsprechendder Wahrscheinlichkeit ihres Auftretens generiert. Der Wert eines Elements oder Attributsnimmt einen zufälligen Wert zwischen 1 und der maximalen Anzahl von Werten an, die siejeweils einnehmen können.
Soweit entspricht die Versuchsanordnung im Wesentlichen einem Experiment zu Untersu-chung eines Systems zum reinen Filtern von Daten anhand einer großen Menge von XPath-Anfragen. Um die Spezialitäten der Transformationsalgorithmen zu steuern und ihr Verhalten
87

Kapitel 7 Experimente
Parameter Wertebereich Beschreibung
T no, basic, extended, all TransformationsverfahrenTH 0 bis 100 Schwellwert für Fitness der transformierten AnfragenRC 0 bis alle Anzahl transformierter Anfragen pro Original-AnfrageC 1 bis 300 Anzahl Dokumente im Cache vor Neu-TransformationEX true oder false Verwendung der Beziehung excontTT init(no update), Zeitpunkt der Transformation
a priori(update), immediateDTD true oder false steht DTD zur Anfragetransformation zur Verfügung
Tabelle 7.3: Parameter für den Transformationsalgorithmus und den Monitor
unter verschiedenen Bedingungen untersuchen zu können, sind weitere Parameter und Ein-stellungen notwendig.
Insbesondere muss, um die Effektivität der Transformationen zu untersuchen, die Strukturder Datenströme von den bei der Definition der Anfragen bekannten Strukturen abweichen.Dazu wurden ausgehend von den ursprünglichen DTDs mehr oder weniger stark modifizierteAbleger generiert. Die Art der Modifikation bestand im zufälligen Entfernen bestehender oderEinfügen neuer Elemente, bzw. Verschieben bestehender Elemente in andere Elter-Elemente.Zusätzlich konnten Attribute generiert werden, die an Stelle von entfernten Elementen denbetreffenden Elementnamen aufnehmen konnten. Die Anzahl dieser Modifikationen konntein Zweier-Schritten zwischen 0 und 20 variiert werden. Auf diese Art und Weise konntenMengen von Dokumenten generiert werden, die zu einem fest definierten Ausmaß von dererwarteten Struktur abwichen.
So legt der Parameter T die Art des Transformationsalgorithmus fest, wobei no für keineTransformation steht, d.h. es kommen nur die originalen Anfragen zur Anwendung. basicsteht für die Anwendung der Basistransformationen, extended für die zusätzliche Anwendungder erweiterten Transformationen. In beiden Fällen werden Zusatzinformationen entweder inForm von DTDs oder in Form von gelernten Strukturinformationen verwendet, was durch denParameter DTD gesteuert wird. Das Transformationsverfahren all dagegen verwendet keineZusatzinformationen und wendet alle möglichen Basistransformationen auf jede Subanfrageder Originalanfragen an. Da in aller Regel zu jeder Originalanfrage eine ganze Menge vonAnfragen transformiert werden, bietet das System die Möglichkeit zur Konfiguration, wie vie-le Anfrage übernommen werden sollen und wie stark diese Anfragen von der Originalanfrageabweichen dürfen. Mit dem Parameter RC kann spezifiziert werden, wie viele transformierteAnfragen pro Originalanfrage in den Anfrageindex übernommen werden sollen und wie starkdie Abweichung von der Originalanfrage im Sinne der Fitness-Funktion sein darf. Je nachAnwendungsbereich des Systems und Art der zu verarbeitenden Daten macht der Vorgangder Anfragetransformation nur zu bestimmten Zeitpunkten Sinn. Der Parameter TT erlaubtes, diesen Transformations-Zeitpunkt festzulegen. init bedeutet, dass der Transformations-schritt nur beim Start des Systems, bzw. beim Hinzufügen neuer Anfragen in das laufende
88

7.3 Performanz der Transformationen
System durchgeführt wird. Während des Filterns der Daten findet keine Transformationstatt, was insbesondere bedeutet, dass der Einsatz des Monitors zur Überwachung der Da-tenstrukturen nicht notwendig ist. Dagegen legen die Parameter a priori und immediatefest, dass auch bestehende Anfragen während des eigentlichen Filterns transformiert werdenkönnen, falls der Monitor registriert, das abweichende Datenstrukturen verarbeitet werden.immediate bedeutet dabei, dass die Anfragetransformation sofort durchgeführt wird, wennein Dokument eine Abweichung aufweist. D.h. die laufende Verarbeitung des aktuellen Do-kuments wird sofort unterbrochen und nach der Transformation relevanter Anfragen an derbetreffenden Stelle wieder aufgenommen. Im Gegensatz dazu legt a priori fest, dass zu-nächst eine gewisse Anzahl von Dokumenten vom Monitor einzulesen und auf Abweichungenzu untersuchen sind, bevor es gegebenenfalls zum Transformationsschritt kommt. Hierbeilegt der optionale Parameter C fest, wie viele Dokumente der Monitor einliest, bevor dieseDokumente an die Filter-Komponente weitergegeben werden. Tabelle 7.3 gibt eine Übersichtüber die dabei möglichen Parameter.
Um zu betonen, dass beim Verfahren a priori eine Aktualisierung des Anfrageindex’während der Datenstromverarbeitung stattfindet, wird das Verfahren auch mit update be-zeichnet. Das Verfahren init entsprechend mit no update.
7.3 Performanz der Transformationen
Bei der Untersuchung der Performanz der Transformationsalgorithmen ist insbesondere dieTransformationszeit (TZeit) von Interesse. Dies ist die Zeit die das System benötigt eineMenge von gegebenen Anfragen unter Anwendung eines Transformationsverfahrens in eineMenge neuer Anfragen zu transformieren. Die Transformationszeit beinhaltet dabei nicht dieZeit zum Einlesen der Originalanfragen bzw. die Zeit, die notwendig ist, die transformiertenAnfragen im Index abzuspeichern. Da auch diese Zeit nicht unerheblich sein kann, wird dieZeit zum Abspeichern der Anfragen separat betrachtet.
Bei allen Performanzuntersuchungen wurde davon ausgegangen, dass die vorliegenden An-fragen gemäß der betrachteten DTDs formuliert wurden, d.h. die Anfragen wurden auf Grundder Originalversion einer der drei DTDs NITF, Auction oder DBLP generiert. Grundlage derAnfragetransformationen waren dagegen DTDs, die durch eine festgelegte Anzahl von Modi-fikationsschritten aus den ursprünglichen DTDs generiert wurden.
Hinsichtlich der Transformationsalgorithmen wurden hier ausschließlich die Basistransfor-mationen (Variante basic) untersucht, wobei auch die Variante betrachtet wurde, in derfür die Transformationen keine weiteren Informationen zur Verfügung standen und somitjede Subanfrage allen Transformationen unterzogen werden musste (Variante all). Die er-weiterten Transformationen setzen voraus, dass schon Datenströme verarbeitet wurden unddadurch Inhaltsinformationen gesammelt werden konnten, was bei der vorliegenden Versuchs-anordnung nicht gegeben war. Diese Variante wird im Zuge der Untersuchung der Streaming-performanz von aXst experimentell behandelt.
89

Kapitel 7 Experimente
0
5
10
15
20
25
30
25000 50000 75000 100000 125000 150000Anzahl Anfragen
TZei
t (se
c.)
NITFDBLPAuction
Abbildung 7.1: variables Q
0
5
10
15
20
25
30
35
5 6 7 8 9 10durchschnittliche Länge der Anfragen
TZei
t (se
c.) b
ei 5
0.00
0 A
nfra
gen
NITF
DBLP
Auction
Abbildung 7.2: variables QL, Q=50000
7.3.1 Anzahl der Anfragen
Um eine Vorstellung von der Effizienz der Transformationsalgorithmen zu bekommen, wur-de zunächst untersucht wie schnell das System unterschiedlich große Mengen von Anfragentransformiert. Dazu wurden aus den drei DTDs NITF, Auction und DBLP jeweils Mengenvon 25.000 bis 150.000 eindeutiger Anfragen mit einer maximalen Länge von 7 und einer überalle Anfragen durchschnittlichen Länge von 4,6 Subanfragen generiert. Bei der Erstellung derAnfragen wurden die Parameter W, DS und WP auf 0.1 gesetzt. D.h. die Wahrscheinlichkeitdes Auftretens des Wildcards (’*’), der Descendant-Achse oder eines Prädikats pro Locati-on Step betrug 0.1. Die Anzahl der Prädikate P pro Anfrage wurde auf 10 festgelegt. Diefür die eigentlichen Transformationen verwendeten DTDs wurden jeweils 4 Modifikationenunterzogen. Der Schwellwert für die Fitness der transformierten Anfrage betrug 80 Prozent.
Abbildung 7.1 zeigt die TZeit, die für die unterschiedlich großen Mengen von Anfragenbenötigt wurde. Da jede Anfrage bei der Transformation separat betrachtet wird, d.h. keineInformationen aus bereits durchgeführten Transformationen verwendet werden, ist der lineareZuwachs des Zeitaufwands nicht überraschend. An dieser Stelle sei darauf verwiesen, dass beider Implementierung der Transformationsalgorithmen auch Varianten untersucht wurden,bei denen Informationen über vorangegangene Transformationen von Teilanfragen für einespätere Verwendung vorgehalten wurden, um diese gegebenenfalls abrufen zu können. Aufdiese Art und Weise konnten wiederholte Transformationen ganzer Teilanfragen eingespartwerden. Es zeigte sich jedoch, dass der Aufwand für die Verwaltung dieser Zwischenergebnissediese Einsparung wieder wettmachte, so dass diese Variante keinen echten Performanzgewinnbrachte.
Auffallend sind hier beim Vergleich der Kurven die Unterschiede zwischen den einzelnenDTDs, wobei vor allem der größere Zeitbedarf für NITF hervorsticht. Dieses Phänomen istletztendlich auf die unterschiedlich starke Komplexität der einzelnen DTDs zurückzuführen.Tabelle 7.1 zeigt, dass NITF erheblich mehr verschiedene Element-Typen hat, als Auction undDBLP. Es ist hier zu bemerken, dass bei zunehmender Anzahl an Element-Typen der Anteil
90

7.3 Performanz der Transformationen
an von den Schema-Modifikationen in den Ziel-DTDs betroffenen Anfragen zurückgeht. In denfolgenden Untersuchungen wird sich zeigen, dass mit zunehmender Ähnlichkeit von Quell- undZiel-DTD zum einen die Anzahl der transformierten Anfragen, insbesondere aber die Größeder Zwischenergebnisse während der Transformation zunimmt. Die wachsende Größe dieserZwischenergebnisse wiederum hat einen negativen Einfluss auf die Transformationszeit. Wirkönnen an dieser Stelle festhalten, dass bei dem in Abbildung 7.1 gezeigten Experiment diedurchschnittliche Größe der Zwischenergebnisse bei NITF 7, bei Auction 3 und bei DBLP 2Anfragen betrug. Diese Unterschiede sind wiederum auf den verschieden großen Anteil dervon Schema-Modifikationen betroffenen Anfragen zurückzuführen. Bei NITF ist dieser Anteilam geringsten, was zur Folge hat, dass der Transformationsalgorithmus Anfragen generiert,die sehr ähnlich bzw. sogar identisch mit der Originalanfrage sind. Die Zwischenergebnissesind in diesem Fall größer als bei den anderen DTDs, so dass die Transformation insgesamtaufwändiger ist.
7.3.2 Eigenschaften der Anfragen
Da die Transformationsalgorithmen Anfragen auf struktureller Ebene bearbeiten, ist zu er-warten, dass verschiedene Eigenschaften wie Länge, Wahrscheinlichkeit des Auftretens vonWildcards oder Descendant-Achsen, Prädikate oder Verschachtelung die Performanz derTransformationen beeinflussen.
Länge der Anfragen
Ein wesentliches Merkmal der hier betrachteten Transformationsverfahren ist, dass jedeSubanfrage einem separaten Transformationsschritt unterzogen wird, wobei in jedem dieserSchritte die Anwendbarkeit der Transformationen geprüft wird. Ist diese gegeben, so werdendie entsprechenden Transformationen durchgeführt. Intuitiv ist klar, dass damit potentiellsehr viele Anfragen generiert werden. Zwar soll durch Berücksichtigung der gegebenen Sche-mainformationen die Anzahl dieser Anfragen reduziert werden, aber nichtsdestotrotz bestehteine Gefahr des Verfahrens darin, dass mit zunehmender Länge der Originalanfragen die Grö-ße der Zwischenergebnisse soweit ansteigt, dass eine effiziente Transformation nicht möglichist.
Von zentraler Bedeutung ist daher eine Untersuchung der Transformationszeit bei wachsen-der Länge der Anfragen. Dazu wurden jeweils 50.000 Anfragen mit einer durchschnittlichenund maximalen Länge von 5 bis 10 Subanfragen zu den drei untersuchten DTDs generiert. Dain diesem Fall ausschließlich der Einfluss der Anfragelänge untersucht werden sollte, wurdendie Parameter W, DS, WP und WN auf 0.0 gesetzt, so dass nur einfache Pfad-Anfragen ohneWildcard, Descendant-Achse, Prädikate und verschachtelte Anfragen generiert wurden. DieAnfragen waren in diesem Fall nicht eindeutig, da aufgrund der einfachen Art der Anfrage,keine eindeutigen Anfragen in ausreichender Zahl erzeugt werden konnten.
Um zu gewährleisten, dass zu möglichst jeder Originalanfrage entsprechende Anfragen
91

Kapitel 7 Experimente
generiert werden konnten, wurden als Transformations-DTDs die gleichen wie bei der Gene-rierung der Anfragen gewählt. Ist der Unterschied zwischen Original- und Ziel-DTD zu groß,besteht die Gefahr, dass der Transformationsalgorithmus zu früh abbricht, was sich zwarpositiv auf die Performanz auswirken würde, damit aber das Ergebnis verfälscht hätte. DerSchwellwert für die Fitness der transformierten Anfragen wurde auf 80 Prozent gesetzt.
Abbildung 7.2 zeigt die gemessene Transformationszeit für die drei DTDs für Anfragen biszu einer Länge von 10 Subanfragen. Die Grafik verdeutlicht klar den wesentlichen Einfluss,den die Anfragelänge auf die Transformationszeit hat. Es zeigt sich aber auch, dass der Zeit-aufwand linear mit der Länge der Anfragen zunimmt. Zu beachten ist hier, dass dieser lineareVerlauf durch eine Optimierungsmaßnahme bei der Implementierung möglich wurde. So wirdbei der Anfragetransformation der vorab definierte Schwellwert für die Anfragefitness dazuverwendet, Zwischenergebnisse rechtzeitig zu verwerfen, die nicht mehr zu einem Endergebnismit ausreichender Fitness führen können. Wird diese Optimierung deaktiviert, so sorgen diezunehmend großen Zwischenergebnisse für einen erheblichen Verlust an Performanz.
Art der Anfragen
Um zu ermitteln wie sich Art und Struktur der Anfragen auf die Performanz der Transfor-mationsalgorithmen auswirkt, wurden die wesentlichen strukturellen Merkmale von XPath-Anfragen jeweils isoliert und konnten somit separat betrachtet werden. Die untersuchtenMerkmale waren dabei Knotentests mit Wildcards, Descendant-Achsen, Subanfragen mitPrädikaten sowie verschachtelte Anfragen.
Um über den Einfluss eines dieser Merkmale gezielt Klarheit zu gewinnen, wurden jeweilsmehrere Mengen von 50.000 eindeutigen Anfragen generiert. Dabei wurde die Wahrschein-lichkeit des Auftretens des in Frage stehenden Merkmals bei der Generierung der Anfragenvariiert, wobei für jede der Mengen die Wahrscheinlichkeit konstant war. Die Wahrscheinlich-keit des Auftretens der jeweils anderen aktuell nicht betrachteten Merkmale betrug immer0.0.
Bei der Anfrage-Generierung wurden die drei DTDs NITF, Auction und DBLP verwen-det. Die Anfragetransformation basierte auf modifizierten Varianten, wobei SMOD 10 war.Die durchschnittliche und maximale Länge der jeweils eindeutigen Anfragen betrug 7. DerTransformationsalgorithmus wurde mit den Parametern TH=80 und TC=1 ausgeführt.
Vorab sei bemerkt, dass jede der vier im Folgenden behandelten Untersuchungen die imvorigen Abschnitt besprochene Beobachtung bestätigt, dass die Transformation der Anfragenaus NITF zeitaufwändiger ist als die Transformation der Anfragen aus DBLP und Auction.Auch hier erklärt sich das Phänomen mit dem größeren Kontext bei NITF während desAblaufs des Transformationsalgorithmus.
Variation von D Abbildung 7.3 zeigt die Transformationszeit für jeweils 50.000 Anfragen,wobei die Wahrscheinlichkeit des Auftretens einer Descendant-Achse zwischen 0.1 und 0.8
92

7.3 Performanz der Transformationen
0
1
2
3
4
5
6
0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8
Wahrscheinlichkeit für '//'
TZei
t (se
c.) b
ei 5
0.00
0 A
nfra
gen
NITFDBLPAuction
Abbildung 7.3: variables D, Q=50000
0
1
2
3
4
5
6
0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8Wahrscheinlichkeit '*'
TZei
t (se
c.) b
ei 5
0.00
0 A
nfra
gen
NITFDBLPAuction
Abbildung 7.4: variables W, Q=50000
variiert wurde. In allen drei Fällen zeigt sich eine mit zunehmender Wahrscheinlichkeit vonD sinkende Transformationszeit. Umgekehrt ist die Transformationszeit also um so höher, jegeringer die Wahrscheinlichkeit für das Auftreten einer Descendant-Achse ist. Deren Trans-formation ist nicht so aufwändig wie die von Child-Achsen. Dies ist letztlich offensichtlich,da auf jede Child-Achse maximal drei Transformationen, auf jede Descendant-Achse dagegennur zwei angewendet werden. Insgesamt müssen mit zunehmender Anzahl von Descendant-Achsen weniger Subanfrage-Transformationen durchgeführt werden, was sich in eine geringe-ren Transformationszeit niederschlägt.
Variation von W Abbildung 7.4 zeigt die Transformationszeit für jeweils 50.000 Anfragen,wobei die Wahrscheinlichkeit des Auftretens eines Wildcard-Knotentests ’*’ zwischen 0.1 und0.8 variiert wurde. Wie bei der Variation von D zeigt sich auch hier eine mit zunehmenderAuftretenswahrscheinlichkeit sinkende Transformationszeit, wiewohl diese Tendenz dort aus-geprägter ist. Die Erklärung dafür liegt wiederum im Transformationsalgorithmus und derArt und Weise, wie Subanfragen mit Wildcard-Knotentests behandelt werden. Jede dieserSubanfragen wird nur maximal zwei statt drei Transformationen unterzogen, so dass auchhier insgesamt weniger Transformationen durchgeführt werden müssen, als bei Anfragen mitwenigen derartigen Knotentests. Beim Vergleich des Verlaufs der Kurven insbesondere zuNITF zwischen Abbildung 7.3 und Abbildung 7.4 fällt nichtsdestotrotz auf, dass der Ein-fluss der Descendant-Achse ausgeprägter im Sinne einer geringeren Transformationszeit mitzunehmender Auftretenswahrscheinlichkeit ist als der von Wildcards. Der Grund liegt darin,dass auf Subanfragen mit Wildcard-Knotentest in jedem Fall beide der möglichen Transfor-mationen angewendet werden, unabhängig davon, wie die verwendeten Schemainformationenaussehen. Im Gegensatz zu Subanfragen mit Descendant-Achsen, bei denen die Kenntnis desSchemas dazu führen kann, dass die betreffende Anfrage eben nur eliminiert wird. Auch hierzeigt sich, welcher Nutzen in der Verwendung von Schemainformationen zur Anfragetrans-formation liegt.
93

Kapitel 7 Experimente
0
2
4
6
8
10
12
14
16
18
0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8Wahrscheinlichkeit für Prädikat
TZei
t (se
c.) b
ei 5
0.00
0 A
nfra
gen
NITFDBLPAuction
Abbildung 7.5: variables WP, Q=50000
0
10
20
30
40
50
60
0.0 0.1 0.2 0.3Wahrscheinlichkeit für verschachtelte Anfrage
TZei
t (se
c.) b
ei 5
0.00
0 A
nfra
gen
NITFDBLPAuction
Abbildung 7.6: variables WN, Q=50000
Variation von WP Abbildung 7.5 zeigt die Transformationszeit für jeweils 50.000 Anfragen,wobei die Wahrscheinlichkeit des Auftretens eines Prädikats zwischen 0.1 und 0.8 variiertwurde. Bei diesen Prädikaten handelt es sich ausschließlich um einfache Tests auf Gleich-heit von Attributen und Werten oder Textinhalt von Elementen. Komplexere Prädikate mitverschachtelten Subanfragen werden im folgenden Abschnitt behandelt.
Ein erkennbarer und in diesem Fall sogar sehr ausgeprägter Einfluss von Prädikaten istbei der Transformationszeit für NITF erkennbar. Mit zunehmender Wahrscheinlichkeit vonPrädikaten steigt dort die Transformationszeit deutlich an. Zu beachten ist dabei, wie derTransformationsalgorithmus mit den einfachen hier untersuchten Prädikaten umgeht. DasBerücksichtigen bzw. Weglassen eines Prädikats von der zugehörigen Subanfragen ist letztlicheine weitere Transformation, so dass das Vorhandensein von Prädikaten dazu führt, dassmaximal fünf Transformationen möglich sind. Neben der Eliminierung, der Generalisierungund der unveränderten Anwendung eben noch die Anwendung von Prädikaten bei letzterenbeiden. Die absolute Anzahl potentiell generierbarer Anfragen steigt damit weiter an, wasdie erhöhte Transformationszeit erklärt.
Bei DBLP und Auction ist dieser Einfluss nicht messbar, was zunächst überraschendscheint, sich jedoch durch einen Blick auf die Struktur der DTDs in Tabelle 7.1 erklärt.DBLP und Auction haben absolut nur sehr wenige Attribute. Wo etwa bei NITF jedes Ele-ment in der Regel mehrere Attribute hat, haben bei DBLP und Auction viele Elementekeine Attribute. Damit werden auch keine entsprechenden Subanfragen generiert, die Wertevon Attributen anfragen würden. Insgesamt hat das verwendete Tool zur Generierung derAnfragen bei diesen DTDs nur bei wenigen Elementen die Möglichkeit passende Prädikatezu generieren. Was erklärt, warum die Variation der Prädikate bei diesen DTDs so gut wiekeinen Einfluss auf die Transformationszeit hat.
Variation von WN Abbildung 7.6 zeigt die Transformationszeit für jeweils 50.000 Anfragen,wobei die Wahrscheinlichkeit des Auftretens von verschachtelten Anfragen zwischen 0.0 und0.3 variiert wurde. Die maximale Verschachtelungstiefe betrug 1, wobei die hier gewonnenen
94

7.3 Performanz der Transformationen
Erkenntnisse über den Einfluss verschachtelter Anfragen auf den allgemeinen Fall übertragenwerden können.
Inbesondere bei Betrachtung des Verlaufs der Kurve für NITF fallen zwei Dinge ins Auge.Zunächst ist schon bei einer Wahrscheinlichkeit von 0.1 die notwendige Transformationszeitmit ca. 20 sec. wesentlich höher als bei Anfragen ohne Verschachtelung wie man etwa zumVergleich in Abbildung 7.1 ablesen kann wo für 50.000 Anfragen ca. 10 sec. benötigt wer-den, wenngleich die dort vorhanden Wildcards und Descendant-Achsen für eine geringereTransformationszeit sorgen.
Die Erklärung für diesen starken Anstieg liegt wiederum in der Größe des Kontexts fürdie Zwischenergebnisse. Im konkreten in der Abbildung gezeigten Fall wächst dieser vondurchschnittlich 2 Anfragen bei einer Wahrscheinlichkeit von 0.0 bis zu 32 bei einer Wahr-scheinlichkeit von 0.3. Die Ursache darin, dass bei dieser Art von Anfragen mehr als bei denanderen den optimale Schwellwert überschreiten. Bei verschachtelten Anfragen gibt es prin-zipiell wesentlich mehr Möglichkeiten der Transformation und damit auch mehr Anfragen imKontext während der Transformation und im Endergebnis, was letztlich die höheren Laufzeiterklärt.
Diese Beobachtung verdeutlicht, wie sensibel das Transformationsverfahren auf die ange-messene Konfiguration unter Berücksichtigung der zu verarbeitenden Anfragen reagiert.
7.3.3 Eigenschaften der Transformationen und Schemata
Die in dieser Arbeit definierten Transformationsalgorithmen liegen in verschiedenen Aus-prägungen vor und lassen sich durch verschiedene Parameter auf konkrete Einsatzgebietevorbereiten. Diese Einsatzgebiete sind in der Regel durch das Ausmaß festgelegt in dem dievorliegenden Daten von den erwarteten Strukturen abweichen. Der wechselseitige Einfluss vonTransformationsparametern und Eigenschaften der Schemata ist daher bei der Untersuchungder Transformationsalgorithmen von Interesse.
Transformationsparameter TH
Der Parameter TH erlaubt es einen Schwellwert festzulegen, den die Fitness der transformier-ten Anfragen mindestens erreichen muss, damit sie als Kandidaten für die Aufnahmen in denAnfrageindex in Frage zu kommen. Seine korrekte Konfiguration beeinflusst in starkem Maßesowohl die Qualität der Anfrageergebnisse als auch die Performanz der Transformationen.Eine eher niedrige Einstellung sorgt dafür, dass potentiell mehr Anfragen transformiert wer-den, was einerseits bei starken Abweichungen der Daten vom erwarteten Schema gewünschtsein kann, andererseits aber auch die Geschwindigkeit der Transformation negativ beeinflusst.Dies wird der Fall sein, wenn er niedrig gewählt wird, die Daten jedoch geringe Abweichungenaufweisen.
Es wurde daher untersucht, welche Auswirkungen die Wahl dieses Parameters auf Trans-formationsgeschwindigkeit und Anzahl der transformierten Anfragen hat, wobei einerseits
95
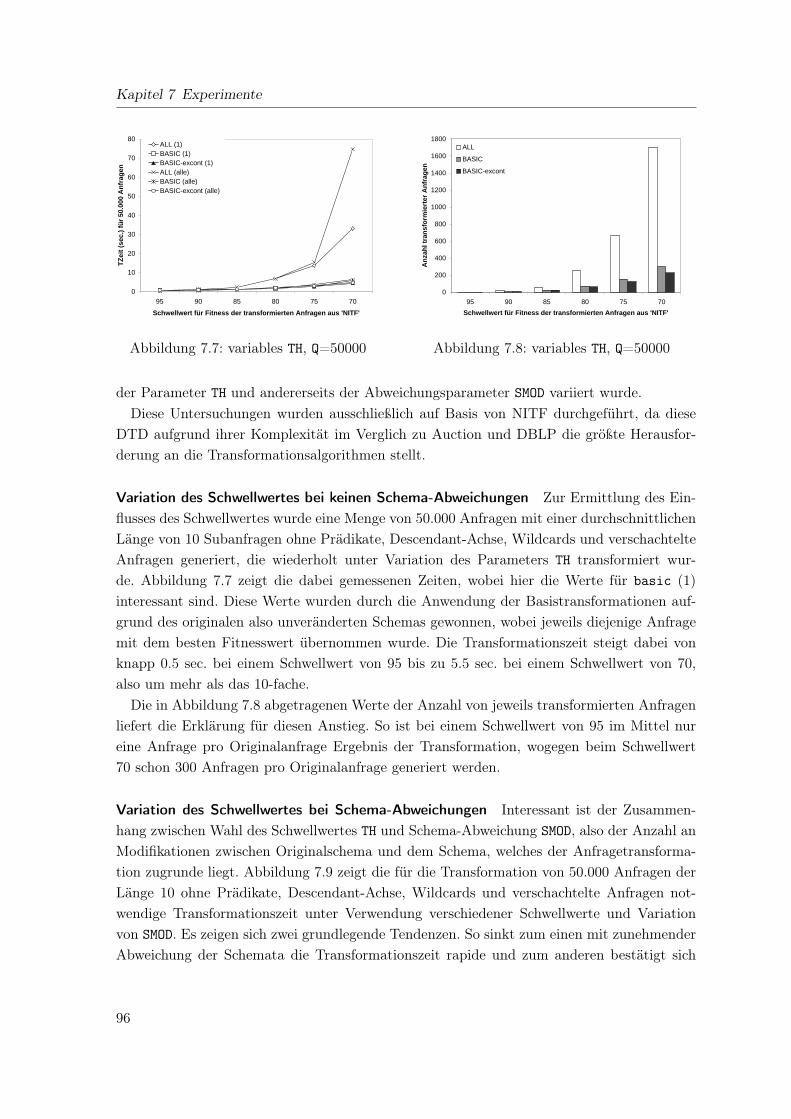
Kapitel 7 Experimente
0
10
20
30
40
50
60
70
80
95 90 85 80 75 70
Schwellwert für Fitness der transformierten Anfragen aus 'NITF'
TZei
t (se
c.) f
ür 5
0.00
0 A
nfra
gen
ALL (1)BASIC (1)BASIC-excont (1)ALL (alle)BASIC (alle)BASIC-excont (alle)
Abbildung 7.7: variables TH, Q=50000
0
200
400
600
800
1000
1200
1400
1600
1800
95 90 85 80 75 70Schwellwert für Fitness der transformierten Anfragen aus 'NITF'
Anz
ahl t
rans
form
iert
er A
nfra
gen
ALL
BASIC
BASIC-excont
Abbildung 7.8: variables TH, Q=50000
der Parameter TH und andererseits der Abweichungsparameter SMOD variiert wurde.Diese Untersuchungen wurden ausschließlich auf Basis von NITF durchgeführt, da diese
DTD aufgrund ihrer Komplexität im Verglich zu Auction und DBLP die größte Herausfor-derung an die Transformationsalgorithmen stellt.
Variation des Schwellwertes bei keinen Schema-Abweichungen Zur Ermittlung des Ein-flusses des Schwellwertes wurde eine Menge von 50.000 Anfragen mit einer durchschnittlichenLänge von 10 Subanfragen ohne Prädikate, Descendant-Achse, Wildcards und verschachtelteAnfragen generiert, die wiederholt unter Variation des Parameters TH transformiert wur-de. Abbildung 7.7 zeigt die dabei gemessenen Zeiten, wobei hier die Werte für basic (1)interessant sind. Diese Werte wurden durch die Anwendung der Basistransformationen auf-grund des originalen also unveränderten Schemas gewonnen, wobei jeweils diejenige Anfragemit dem besten Fitnesswert übernommen wurde. Die Transformationszeit steigt dabei vonknapp 0.5 sec. bei einem Schwellwert von 95 bis zu 5.5 sec. bei einem Schwellwert von 70,also um mehr als das 10-fache.
Die in Abbildung 7.8 abgetragenen Werte der Anzahl von jeweils transformierten Anfragenliefert die Erklärung für diesen Anstieg. So ist bei einem Schwellwert von 95 im Mittel nureine Anfrage pro Originalanfrage Ergebnis der Transformation, wogegen beim Schwellwert70 schon 300 Anfragen pro Originalanfrage generiert werden.
Variation des Schwellwertes bei Schema-Abweichungen Interessant ist der Zusammen-hang zwischen Wahl des Schwellwertes TH und Schema-Abweichung SMOD, also der Anzahl anModifikationen zwischen Originalschema und dem Schema, welches der Anfragetransforma-tion zugrunde liegt. Abbildung 7.9 zeigt die für die Transformation von 50.000 Anfragen derLänge 10 ohne Prädikate, Descendant-Achse, Wildcards und verschachtelte Anfragen not-wendige Transformationszeit unter Verwendung verschiedener Schwellwerte und Variationvon SMOD. Es zeigen sich zwei grundlegende Tendenzen. So sinkt zum einen mit zunehmenderAbweichung der Schemata die Transformationszeit rapide und zum anderen bestätigt sich
96

7.3 Performanz der Transformationen
0
50
100
150
200
250
0 4 8 12 16 20Anzahl von Schema-Abweichungen in 'NITF'
TZei
t (se
c.) f
ür 5
0.00
0 A
nfra
gen
95%90%85%80%75%70%
Abbildung 7.9: variables SMOD, Q=50000
0
50
100
150
200
250
300
350
0 4 8 12 16 20Anzahl von Schema-Abweichungen in 'NITF'
Anz
ahl t
r. A
nfra
gen
pro
Orig
inal
anfr
age
90%85%80%75%70%
Abbildung 7.10: variables SMOD, Q=50000
die Beobachtung aus dem vorigen Abschnitt, dass die Transformationszeit um so höher ist,je niedriger TH ist.
In Abbildung 7.10 ist die Anzahl der jeweils dabei generierten Anfragen abgetragen. Eswird der Zusammenhang deutlich, dass bei einem niedrigen Schwellwert und hoher Über-einstimmung zwischen den Schemata sehr viele Anfragen generiert werden, wohingegen beieiner geringen Übereinstimmung der Schemata ein niedriger Schwellwert notwendig ist, umüberhaupt Transformationsergebnisse zu erhalten. Die Anzahl transformierter Anfragen proOriginalanfragen ist nur ein indirektes Indiz für die erreichte Transformationszeit. Wie be-reits erwähnt ist die Größe der Zwischenergebnisse bzw. des Kontexts während der Anfra-getransformationen maßgeblich für die Transformationszeit. Ein wesentliches Merkmal derTransformationsalgorithmen ist, dass sie schrittweise ablaufen, wobei jeder Schritt auf einenEingabekontext angewandt wird und durch Anwendung von Transformationen einen Ausga-bekontext generieren, der wiederum Eingabekontext für den nächsten Schritt ist. Die Per-formanz des Verfahrens ist also in ganz wesentlichem Maße bestimmt durch die Größe derKontexte, die wiederum stark von der Wahl des Schwellwertes in Zusammenhang mit derSchemaabweichung abhängt. Abbildung 7.11 zeigt die bei den hier besprochenen Anfrage-transformationen ermittelten mittleren Kontextgrößen. Man sieht, dass ein hoher Schwellwertzu kleinen Zwischenergebnissen führt, wohingegen ein niedriger Schwellwert insbesondere beiwenigen Schema-Abweichungen sehr große Zwischenergebnisse nach sich zieht, was die obenbesprochene niedrige Transformationsgeschwindigkeit zur Folge hat.
Zusammenfassend wird hier der sensible Zusammenhang zwischen Schwellwert und Schema-Abweichung bei Betrachtung der Extremfälle deutlich. So wirkt sich bei nur geringen Abwei-chungen die Wahl eines hohen Schwellwertes positiv auf die Transformationszeit aus, wohin-gegen es bei großen Abweichungen offensichtlich notwendig ist, den Schwellwert entsprechendniedrig zu wählen um überhaupt Anfrageergebnisse zu erhalten.
Durch eine angemessene Wahl des Schwellwertes ist es also möglich, die Transformations-zeit so positiv zu beeinflussen, dass eine große Menge von Anfragen in kurzer Zeit verarbeitetwerden können und der Benutzer auch den gewünschten Nutzen in Form zusätzlicher Anfra-
97

Kapitel 7 Experimente
0
50
100
150
200
250
300
350
400
95 90 85 80 75 70Schwellwert für Fitness der transformierten Anfragen
durc
hsch
nittl
iche
Kon
text
größ
e
0 Abweichung4 Abweichungen8 Abweichungen12 Abweichungen16 Abweichungen20 Abweichungen
Abbildung 7.11: variables TH, Q=50000
0
20
40
60
80
100
120
140
25000 50000 75000 100000 125000 150000Anzahl Anfragen
Zeit
(sec
.)
Speichern Transformierte Anfragen
Speichern Originalanfragen
Transformation
Abbildung 7.12: variables Q, TH=90, RC=1
gen hat.
Transformationsparameter EX Durch den Parameter EX kann gesteuert werden, ob derTransformationsalgorithmus Schemainformationen über die Beziehung excont ausnutzt odernicht. Wird diese Information verwendet, kann die Generierung ”überflüssiger” Anfragen ver-mieden werden, d.h. die Zwischenergebnisse und Ergebnisse werden kleiner und es bestehtdie Aussicht auf eine höhere Transformationsgeschwindigkeit. Andererseits ist die Berech-nung der excont Beziehungen aufwändig, so dass es an dieser Stelle auch notwendig ist zuuntersuchen, inwieweit sich das Ausnutzen dieser Information auszahlt.
Zunächst zeigt Abbildung 7.8, dass tatsächlich weniger Anfragen generiert werden, wenn EXangeschaltet ist, wenngleich der Unterschied nicht sehr gravierend ist. Der Gewinn an Trans-formationsgeschwindigkeit wird in Abbildung 7.7 gezeigt. So beträgt der Gewinn bei einemSchwellwert von 70 ca. 1 sec, was einem Vorteil von immerhin 20 Prozent entspricht. Zu be-achten ist allerdings, dass die hier verwendeten Anfragen weder Wildcards noch Descendant-Achsen enthielten, was für die Verwendung von excont-Informationen optimal ist. Sind dieseMerkmale in den Originalanfragen gegeben, so ist mit einem in aller Regel deutlich geringerenGewinn zu rechnen.
Transformationsparameter RC Mit dem Parameter RC kann die Anzahl transformierter An-fragen pro Originalanfrage festgelegt werden, die bei ausreichendem Schwellwert in den An-frageindex übernommen werden. In Abbildung 7.7 werden die ermittelten Zeiten für zweiExtremfälle gezeigt. Es wurden die Zeiten ermittelt wenn alle transformierten Anfragen mitausreichendem Schwellwert bzw. wenn nur diejenige mit der höchsten Fitness übernommenwurde. Der Unterschied liegt in der basic Variante bei ca. 1 sec. also etwas 20 Prozent zu-gunsten des Falles, in dem nur die Top-Anfrage übernommen wurde. Bei der Variante all desTransformationsalgorithmus, bei der insgesamt eine viel höhere Anzahl an Anfragen generiertwird, ist der Unterschied auch absolut sehr gut im Diagramm ersichtlich.
Da die Übernahme der Anfragen in den Index im Prinzip nichts mit der eigentlichen An-
98

7.3 Performanz der Transformationen
fragetransformation zu tun hat ist es zunächst überraschend, dass hier überhaupt ein Unter-schied ermittelt werden kann. Die Ursache liegt darin, dass jede Anfrage, die in den Indexübernommen werden muss zunächst als Objekt erzeugt wird. Dieser Vorgang findet erst nachvollendeter Transformation in Abhängigkeit vom Parameter RC statt. Die Transformationselbst wird auf einem Pool von Objekten ausgeführt, der für jede neue Anfrage wiederver-wendet wird.
Die Erzeugung von Objekten ist teuer und letztlich als Teil der Anfragetransformationnotwendig und damit auch dieser anzurechnen. Damit hat die Wahl Parameter RC einenerkennbaren Einfluss auf die Transformationszeit.
Transformationsalgorithmus all Die Variante all des Algorithmus wendet in jedem Schrittjede Transformation an, ohne Schema- oder sonstige Informationen über die zu verarbeiten-den Daten zu verwenden. In der Konsequenz wird so zu jeder Originalanfrage eine großeMenge an Anfragen transformiert, was eine geringe Transformationsgeschwindigkeit erwar-ten lässt.
Die in Abbildung 7.8 veranschaulichten Zahlen bestätigen diese Erwartung. Wo bei derVariante basic bei einem Schwellwert von 70 immerhin pro Originalanfrage 300 Anfragengeneriert werden sind es bei all mehr als 1700 Anfragen. Der für die Transformation undGenerierung dieser Anfragen notwendigen Zeitaufwand lässt sich in Abbildung 7.7 ablesen.Im Gegensatz zu den ca. 5 sec. die basic benötigt beträgt der Bedarf von all hier über75 sec. Es muss hier also ein erheblicher Mehraufwand dafür betrieben werden, dass keinerleiInformation über die zu verarbeitenden Daten verwendet wird.
7.3.4 Zeitaufwand für Transformation und Speicherung
Das Diagramm in Abbildung 7.12 veranschaulicht den anteiligen Zeitbedarf für Speichernund Transformieren der Anfragen unter Berücksichtigung der Originalanfragen. Die Wertewurden bei der Transformation von Anfragen mit einer durchschnittlichen Länge von 10Subanfragen gewonnen. Hierbei betrug der Schwellwert TH 90 und RC war 1.
Das Diagramm bestätigt die Erwartung, dass der Aufwand für die eigentliche Anfragetrans-formation die Zeit zum Speichern dominiert. Nichtsdestotrotz muss beachtet werden, dass beiWahl eines geringen Schwellwertes TH bzw. eines hohen RC und einer Transformationsvariantewie all, die sehr viele Anfragen generiert, der Aufwand für die eigentliche Speicherung nichtvernachlässigen werden darf.
7.3.5 Bewertung
Die hier erzielten Ergebnisse belegen, dass die Transformationsalgorithmen bei der Variationder verschiedensten strukturellen Eigenschaften sowohl von Anfragen als auch von Daten gutskalieren. Verschiedene Eigenschaften von Anfragen wirken sich dabei in unterschiedlichem
99

Kapitel 7 Experimente
Ausmaß auf die Performanz der Transformationen aus. Es lässt sich feststellen, dass ins-besondere die Länge der Anfragen, sowie das Ausmaß der Verschachtelung und die Anzahlan Prädikaten eine Herausforderung ist. Andererseits sind zunehmend allgemeine Anfragenvöllig unproblematisch.
Es zeigt sich weiterhin, dass eine wesentliche Stärke der Verfahren darin besteht, dass siesehr robust gegenüber dem Grad der Abweichung zwischen dem erwarteten und dem vorhan-denen Schema sind. Tatsächlich steigt die Performanz der Transformationen mit zunehmenderAbweichung der Schemata. Dies war so nicht unbedingt zu erwarten und spricht für einenEinsatz des Verfahrens Umgebungen, in denen mit sehr unvorhersehbaren Datenstrukturenzu rechnen ist.
Letztendlich erweist sich die Verwendung von Schemainformationen als sehr nützlich. Eineungezielte Transformation wie sie bei der Variante all stattfindet ist schon bei einer kleinenMenge von Anfragen nicht mehr praktikabel. Im Vorgriff auf die nachfolgenden Untersu-chungen wäre es hier schon wichtig zu erwähnen, dass die Algorithmen tatsächlich nicht aufSchemainformationen angewiesen sind. Gleichwertige Ergebnisse lassen sich auch mit Struk-turinformationen erzielen, welche aus den vorliegenden Daten gewonnen werden.
7.4 Qualität der Transformationen
Die Qualität der hier vorgestellten Transformationsverfahren wird ermittelt, indem die An-zahl von Treffern bestimmt wird, die bei der Verarbeitung einer Menge von XML-Dokumentengefunden werden. Der feste Bezugspunkt wird dabei immer die Anzahl der Treffer der ori-ginalen Anfragen sein, mit denen die Treffer der transformierten Anfragen direkt verglichenwerden können. Es ist offensichtlich, dass für den Benutzer die bloße Generierung von Ergeb-nissen, die entfernt etwas mit seiner ursprünglichen Anfrage zu tun haben, nur von geringemNutzen ist. Letztendlich entscheidet er durch die Auswahl des Schwellwertes TH wie starkdie Ergebnisse von seiner eigentlichen Intention abweichen können. Indem hier das einfacheKriterium von absoluten Trefferzahlen verwendet wird, ergibt sich jedoch ein klares Bild,mit welchen Suchergebnissen unter den verschiedensten Bedingungen hinsichtlich der Datenals auch hinsichtlich der verschiedenen Transformationsverfahren mit ihren unterschiedlichenParametern gerechnet werden kann.
Bei diesen Untersuchungen wurde so vorgegangen, dass Mengen von 200 XML-Dokumentengeneriert wurden, welche anhand von 10.000 Originalanfragen mit jeweils daraus transformier-ten Anfragen durchsucht wurden. Dieser Vorgehensweise wurde unter verschiedenen Bedin-gungen gefolgt, wobei jeweils die Arten von Anfragen, die Transformationsverfahren, sowiedie Abweichung der Daten vom bekannten Schema variiert wurden. Es wurde sowohl derFall untersucht, dass Schemainformationen für die Transformationen vorliegen, als auch derFall dass diese Informationen anfangs nicht vorliegen, sondern erst im Zuge der Datenstrom-verarbeitung ermittelt werden. Schließlich wurde auch untersucht, wie sich die Verfahrenverhalten, wenn die Schemainformationen für die Anfragetransformation zwar vorliegen, die
100

7.4 Qualität der Transformationen
0
200
400
600
800
1000
1200
4 8 12 16
Anzahl Schemaabweichungen (SMOD)
Anz
ahl T
reffe
r
NO
ALL
BASIC
EXTENDED
Abbildung 7.13: variables SMOD, Q=10000mit D und WC = 0.0
0
200
400
600
800
1000
1200
1400
1600
1800
2000
4 8 12 16
Anzahl Schemaabweichungen (SMOD)
Anz
ahl T
reffe
r
NOALLBASICEXTENDED
Abbildung 7.14: variables SMOD, Q=10000mit D und WC = 0.1
tatsächlich zu verarbeitenden Daten jedoch in unterschiedlichem Maße von diesem abweichen.Es wurden keine verschachtelten Anfragen oder Anfragen mit Prädikaten verwendet. Da dieVerfahren im Wesentlichen auf Pfad-Transformationen basieren, sind derartige Anfragen fürdie Untersuchung der Transformationsqualität nicht von Belang.
Treffer Für eine Anfrage wurde jeweils genau ein Treffer gezählt, wenn sie in einem Do-kument mindestens einen passenden Knoten fand. Mehrfache Vorkommen passender Knotenwurden nicht berücksichtigt. Die Größe der einzelnen XML-Dokumente lag zwischen einemund 200 Elementen bzw. zwischen 50 und 8000 Zeichen. Sowohl die Anfragen als auch dieDokumente wurden aus der originalen bzw. einer modifizierten Version der NITF-DTD gene-riert da sie im Vergleich zu den beiden anderen verwendeten DTDs die höchste Komplexitätaufweist.
Treffer der Originalanfragen und der daraus transformierten Anfragen werden unabhängigvoneinander gezählt.
7.4.1 Transformation mit Schema
Ein wesentliches Anwendungsgebiet unserer Transformationsalgorithmen liegt vor, wenn An-fragen, die unter Berücksichtigung bestimmter Schemainformationen formuliert wurden, aufDaten angewandt werden sollen, die von diesem Schema abweichen, wobei das Schema die-ser Daten jedoch bekannt ist. Diese abweichenden Schemainformationen können also für dieAnfragetransformation unmittelbar verwendet werden.
Die Abbildungen 7.13 und 7.14 zeigen die erzielten Suchergebnisse von 10.000 Anfragen,die auf Mengen von jeweils 200 Dokumenten angewandt wurden. Jede dieser Mengen wurdeanhand von Schemata generiert, deren Abweichung von der Original-Schema durch den Pa-rameter SMOD variiert wurde. Die Anfragen wurden mit Hilfe dieser abgewandelten Schematadurch die Transformationen basic und extended verarbeitet. Ohne Verwendung von Sche-mata wurde das Verfahren all eingesetzt. Zusätzlich wurden die Treffer der Originalanfragen
101

Kapitel 7 Experimente
0
200
400
600
800
1000
1200
1400
1600
70 80 90
Schwellwert der Fitness (TH)
Anz
ahl T
reffe
r
NO
ALL
BASIC
EXTENDED
Abbildung 7.15: variables TH, Q=10000
0
100
200
300
400
500
600
700
800
900
1000
1 10 100
Anzahl transformierter Anfragen pro Originalanfrage (RC)
Anz
ahl T
reffe
r
NO
ALL
BASIC
EXTENDED
Abbildung 7.16: variables RC, Q=10000
ermittelt.Der Schwellwert für die Anfrage-Fitness TH war jeweils 80, es wurden für jede Original-
Anfrage 10 transformierte Anfrage in den Anfrageindex übernommen (RC=10). In beidenFällen wurden weder verschachtelte Anfrage noch Prädikate verwendet. In der linken Abbil-dungen sind die Suchergebnisse von reinen Pfadausdrücken ohne Wildcards und Descendant-Achse dargestellt, die rechte Abbildung zeigt die Ergebnisse von Anfragen mit einer Wahr-scheinlichkeit für D und WC von jeweils 0.1.
Das Diagramm in der linken Abbildung verdeutlicht die Stärke der Transformationen beieinfachen Pfadanfragen. Die Originalanfragen liefern schon bei einer geringen Abweichung desSchemas keine Ergebnisse mehr. Die Verfahren basic und extended liefern auch bei zuneh-mender Abweichung vom originalen Schema noch Anfragen, wenngleich die Anzahl der Treffermit zunehmender Abweichung geringer wird. Offensichtlich ist für größere Abweichungen derParameter TH mit 80 zu hoch angesetzt. Dieses Diagramm verdeutlicht insbesondere den Nut-zen, den die Verwendung von Schemainformationen bietet. Das Verfahren all ist schon beigeringen Abweichungen nicht in der Lage passende Anfragen zu generieren. Dadurch, dassnur eine begrenzte Anzahl von Anfragen pro Originalanfrage zum Zuge kommt, sind dieseAnfragen zwar die am höchsten bewerteten, sie sind damit aber lediglich der Originalanfragesehr ähnlich, was aber nichts über ihre Nähe zu den verarbeiteten Daten aussagt.
Ein etwas undifferenzierteres Bild zeigt das rechte Diagramm in Abbildung 7.14. Auf denersten Blick überraschend mag sein, dass die Originalanfragen praktisch unabhängig von derAbweichung der Daten vom ursprünglichen Schema ihre Treffer liefern. Offensichtlich sorgtdie Art der Anfragen mit der Verwendung von Wildcards und Descendant-Achsen dafür, dasssie wesentlich robuster gegenüber Veränderungen des den Daten zugrunde liegenden Schemassind. Die Treffer der durch basic oder extended generierten Anfragen entwickeln sich mitwachsendem SMOD vergleichbar zu den vorherigen Anfragen. Allerdings zeigt sich auch hier,dass die Anfragen robuster gegen ein großes SMOD sind, sprich mehr Treffer liefern. Klar unter-legen ist in diesem Fall das Verfahren all. Es zeigt sich auch für diese Art der Anfragen, dassdas sehr unspezifische Verfahren mit wachsenden Abweichungen seine Schwächen offenbart.
102

7.4 Qualität der Transformationen
0
5000
10000
15000
20000
25000
30000
35000
40000
45000
0 4 8 12 16
Anzahl Schemaabweichungen (SMOD)
Anz
ahl T
reffe
r
BASIC (DTD)
EXTENDED (DTD)
BASIC (APRIORI)
EXTENDED (APRIORI)
BASIC (IMMEDIATE)
EXTENDED (IMMEDIATE)
Abbildung 7.17: variables SMOD, Q=10000mit D und WC = 0.0
0
5000
10000
15000
20000
25000
30000
35000
40000
45000
50000
0 4 8 12 16
Anzahl Schemaabweichungen (SMOD)
Anz
ahl T
reffe
r
BASIC (DTD)
EXTENDED (DTD)
BASIC (APRIORI)
EXTENDED (APRIORI)
BASIC (IMMEDIATE)
EXTENDED (IMMEDIATE)
Abbildung 7.18: variables SMOD, Q=10000mit D und WC = 0.1
Die Erklärung für den qualitative Unterschied zwischen basic und extended auf der einenSeite und all auf der anderen liefert das Diagramm in Abbildung 7.16. Es zeigt die Anzahl derTreffer von transformierten Anfragen in Abhängigkeit vom Parameter RC bei einem Schwell-wert TH von 80 und konstanten SMOD von 8. Die Verfahren basic und extended können nahezuunabhängig von RC ihre Treffer generieren, wohingegen das Verfahren all diese Qualität nurdann erreicht, wenn pro Originalanfrage eine große Anzahl von Anfragen transformiert wird.Die Verwendung von Schemainformationen erlaubt es den entsprechenden Verfahren zielge-richtet erfolgversprechende Anfragen zu generieren. Das ”blinde” Verfahren all kann dieseTreffer nur liefern, wenn es eine ausreichend große Anzahl an Anfragen transformiert.
Nichtsdestotrotz ist für ein konstantes SMOD und konstantes RC die Transformationsqualitätselbstverständlich für alle Verfahren abhängig vom Schwellwert TH, wie Abbildung 7.15 ver-anschaulicht. Je geringer TH gewählt wird, desto mehr erfolgreiche Anfragen werden generiert.
Vergleich von basic und extended
Zieht man in den bisher vorgestellten Ergebnissen einen Vergleich zwischen den beiden Ver-fahren basic und extended so fällt auf, dass sie sich in allen Fällen hinsichtlich der geliefertenErgebnisse nur wenig voneinander unterscheiden. Hierbei ist zu beachten, dass das extendedVerfahren zusätzliche Transformationen beherrscht, die insbesondere auf inhaltlichen Infor-mationen über die verarbeiteten Daten basieren. Bei der Durchführung der Experimentewurde dies berücksichtigt, indem passende Attribute der Daten zufällig mit entsprechen-den Werten besetzt wurden, so dass ein potentieller Erfolg von extended Transformationengegeben war.
Es zeigte sich jedoch, dass dieser Erfolg sich zwar durchaus einstellte, jedoch nur in sehrgeringem Umfang. Die Ursache liegt in der Fitness-Funktion, welche die erweiterten Trans-formationen zwar berücksichtigt, allerdings nicht so stark wie die Basis-Transformationen,welche Schema-Abweichungen ausgleichen. Ein Erfolg von erweiterten Transformationen isterst dann wirklich messbar, wenn der Unterschied zwischen den verwendeten Schemata darin
103

Kapitel 7 Experimente
0
2000
4000
6000
8000
10000
12000
14000
16000
18000
70 80 90
Schwellwert der Fitness (TH)
Anz
ahl T
reffe
r
BASIC (DTD)
EXTENDED (DTD)
BASIC (XML)
EXTENDED (XML)
BASIC (IMMEDIATE)
EXTENDED(IMMEDIATE)
Abbildung 7.19: variables TH, Q=10000
0
5000
10000
15000
20000
25000
1 10 100Anzahl transformierter Anfragen pro
Originalanfrage (RC)
Anz
ahl T
reffe
r
BASIC (DTD)
EXTENDED (DTD)
BASIC (XML)
EXTENDED (XML)
BASIC (IMMEDIATE)
EXTENDED(IMMEDIATE)
Abbildung 7.20: variables RC, Q=10000
besteht, dass ein Großteil der Konzepte nicht in Elementen sondern in Werten von Attributenoder umgekehrt repräsentiert wird.
Bei den hier durchgeführten Experimenten zeigte sich, dass dieser konzeptuelle Unter-schied so schwach war, dass sich die beiden Verfahren hinsichtlich ihrer Qualität nur geringvoneinander abgrenzten.
7.4.2 Transformation ohne Schema
Der Vergleich der Verfahren all und basic bzw. extended aus dem vorigen Abschnitt ver-deutlicht die Bedeutung von Schemainformationen für die Qualität der Anfrageergebnisse.Im vorliegenden Abschnitt werden wir diesen Verfahren unsere Varianten gegenüberstellen,welche die Schemainformationen erst während der Verarbeitung der Daten aus diesen selbstgewinnen.
Dabei kommen die Varianten a priori und immediate für den Parameter TT zur An-wendung. Beiden stehen keine Schemainformationen für die Anfragetransformation zur Ver-fügung. Dem eigentlichen Filtern ist jeweils ein Monitor vorgeschaltet, der Strukturen derDaten protokolliert und der Anfragetransformation zur Verfügung stellt. Die Abbildungen7.17 und 7.18 zeigen die Ergebnisse bei der Anwendung von 10.000 Anfragen auf 200 Do-kumente, wobei in der linken Abbildung die Ergebnisse für einfache Pfadausdrücke ohneWildcards und Descendant-Achse dargestellt und in der rechten Abbildung die Parameter Dund WC jeweils auf 0.1 gesetzt wurden. TH betrug 80 und RC 10.
Beide Diagramme zeigen nur einen minimalen Unterschied zwischen den einzelnen Verfah-ren, wobei die Verfahren immediate und a priori teilweise eine geringfügig höhere Tref-ferzahl liefern. Die Ursache dafür liegt am Parameter RC in Verbindung mit der Tatsache,dass die betreffenden Verfahren die Strukturen zunächst erlernen und dabei auf die zu ver-arbeitenden Daten angewiesen sind. So ist es möglich, dass aufgrund dieser Daten Anfragengeneriert werden, die eine ausreichende Fitness haben und damit in den Anfrageindex aufge-nommen werden. Ein Verfahren, dass vollständige Kenntnis des Schemas hat, würde gerade
104

7.4 Qualität der Transformationen
0
2000
4000
6000
8000
10000
12000
4 8 12 16
Anzahl Schemaabweichungen (SMOD)
Anz
ahl T
reffe
r
NO
BASIC (no update)
BASIC (update)
BASIC (IMMEDIATE)
ALL
Abbildung 7.21: variables SMOD, Q=10000mit D und WC = 0.0
0
1000
2000
3000
4000
5000
6000
7000
8000
9000
10000
1 10 100 1000Anzahl transformierter Anfragen pro Originalanfrage(
RC)
Anz
ahl T
reffe
r
BASIC (INIT)
BASIC (APRIORI)
BASIC(IMMEDIATE)ALL
Abbildung 7.22: variables RC, Q=10000mit D und WC = 0.0
diese Anfragen jedoch eventuell nicht aufnehmen, da es besser bewertete Anfragen generierenkann und diese bevorzugt. Da der Parameter RC die Anzahl der aufzunehmenden Anfragenlimitiert, kämen die schlechter bewerteten Anfragen hier nicht zum Zuge.
Sowohl immediate als auch a priori verfahren so, dass sie später transformierte Anfragenmit einer höheren Fitness als bereits im Index vorhandene auch dann dem Index hinzufügen,wenn das durch den Parameter RC gesetzte Limit erreicht ist. Damit werden auch bei diesenVerfahren bei passenden Daten alle Anfragen generiert und in den Index aufgenommen, dieauch bei Verwendung von Schemainformationen generiert werden würden. Gegebenenfallswerden aber auch zusätzliche Anfragen transformiert und in den Index aufgenommen.
Das Diagramm in Abbildung 7.20 verdeutlicht in diesem Zusammenhang den Einfluss desParameters RC auf diesen Aspekt. Je höher er gewählt wird, desto mehr gleichen sich dieVerfahren an. Abbildung 7.19 zeigt einen ähnlichen Einfluss des Parameters TH. Der Grunddafür, dass mit zunehmender Höhe des Schwellwertes die beiden Verfahren sich mehr undmehr angleichen, liegt schlicht darin, dass die Menge an potientiellen Anfragen geringer wird,je höher die Schwelle gelegt wird. Damit gibt es bei den Verfahren ohne Schema um so wenigerKandidaten, welche in den Index übernommen werden könnten.
7.4.3 Abweichung während des Streamings
Abschließend wird gezeigt, wie sich die Transformationsverfahren verhalten, wenn das denDaten und den Transformationen zugrundeliegende Schema identisch ist, die Daten jedoch inunterschiedlich starkem Maße von diesem Schema abweichen. Selbstverständlich ist dies fürdie Verfahren, die ohne vorab vorliegende Schemainformationen arbeiten nicht von Belang,da sie ihre für die Transformationen notwendigen Informationen ohnehin erst aus den vorlie-genden Daten gewinnen. Von Interesse wird sein, wie sich das Verfahren basic-init verhält.Es wurde hier eine Variante dieses Verfahrens gewählt, die zwar eine initiale Transformationauf Basis der vorliegenden Informationen durchführt, die jedoch auch einen Monitor einsetzt,um Abweichungen in den Daten zu registrieren und gegebenenfalls neu zu transformieren.
105

Kapitel 7 Experimente
Das Diagramm in 7.21 Abbildung zeigt die Ergebnisse der Verfahren in Abhängigkeitvom Parameter SMOD für TH=80 und RC=10. Es zeigt sich, dass die Verfahren, welche ohneSchemainformationen arbeiten in diesem Fall leicht überlegen sind. Der Grund liegt darin,dass der Parameter RC hier wieder die Anzahl an aufzunehmender Anfragen beschränkt,so dass selbst im Falle von registrierten Abweichungen zwar zusätzliche Transformationendurchgeführt werden, diese jedoch gegebenenfalls nicht zum Zuge kommen, weil bereits imIndex vorhandene Anfragen eine höhere Fitness haben.
Diesem Problem kann natürlich durch die Wahl eines höheren Wertes für RC begegnetwerden, wie das Diagramm in Abbildung 7.22 zeigt. Bei niedrigem Wert sind diejenigen Ver-fahren im Vorteil, die jede registrierte Änderung der Daten sofort in transformierte Anfragenumsetzen. Wird der Wert für RC höher gewählt, gleichen sich die Verfahren wieder an. Nichts-destotrotz muss natürlich beachtet werden, dass die immediate-Verfahren eventuell Anfragengenerieren, die eine eher geringe Fitness aufweisen, die sich also stark von der Ursprungs-anfrage unterscheiden. Für den Benutzer kann dies zur Folge haben, dass er mit zu vielenErgebnissen versorgt wird, die zu weit von seinem Interesse entfernt ist.
Die Wahl des Parameters RC ist also mit Bedacht in Abhängigkeit des eingesetzten Ver-fahrens und der vorliegenden Daten zu wählen.
7.4.4 Bewertung
Die Ergebnisse belegen, dass die Anfragetransformationen in der Lage sind, dem Benutzerauch dann ein Mehr an Treffern zu liefern, wenn es starke Abweichungen zwischen erwartetenund tatsächlichen Strukturen der Daten gibt. Insbesondere bei sehr spezifischen Anfrage,welche wenig Freiheit und damit Abweichungen zulassen, zeigt sich der Vorteil der Verfahren.Ohne explizites Wissen über die auftretenden Abweichungen können die Transformationenpassende und erfolgreiche Anfragen generieren.
Dabei zeigt sich eine weitere Stärke: unabhängig davon ob Schemata als Grundlage für dieTransformationen verwendet werden, oder strukturelle Informationen, die aus den tatsächli-chen Daten gewonnen werden, liefern die Verfahren ihre Treffer. Wie gezeigt werden konnte,eigenen sich die Verfahren damit auch für eine Anwendung bei fehleranfälligen Daten. Geradedieser Punkt verdient besondere Beachtung. Schemata sind oftmals in stark evolutionäre Pro-zesse eingebunden und damit ebenfalls einer ständigen Veränderung und Weiterentwicklungunterworfen, so dass mit verschiedenen Versionen und Varianten gerechnet werden muss.Werden diese Weiterentwicklungen nicht zuverlässig von beteiligten Systemen eingepflegt,genügen schon einfache Änderungen, um die Trefferquote drastisch zu verringern.
Ein alternativer und in beiden Fällen üblicher Ansatz zur Lösung der Problematik wür-de darin bestehen, zunächst durch eine Validierung der Dokumente die Schemakonformitätzu überprüfen und in negativen Falle gegebenenfalls manuelle Transformationen bzw. Repa-raturen der Daten durchzuführen. Beide Schritte werden aXst durch eine vollautomatischeVerarbeitung vermieden.
106

7.5 Streaming-Performanz
7.5 Streaming-Performanz
Von wesentlicher Bedeutung für ein System zum Filtern von Datenströmen ist die Performanz,d.h. in unserem Fall der Datendurchsatz oder die Zeit, die zum Filtern eine bestimmten Mengevon Daten benötigt wird. Dabei ist ein zentraler Aspekt wie ein solches System mit einerwachsenden Menge von zu verarbeitenden Anfragen skaliert. Bei der Untersuchung unsereradaptiven Verfahren wird das Augenmerk darüber hinaus vor allem darauf gerichtet, wie sichder zusätzliche Aufwand zur Überwachung und zur Transformation während des Filterns aufdie Gesamtperformanz auswirken.
Streamingzeit Das hier verwendete Maß Streamingzeit beinhaltet dementsprechend die Ge-samtzeit zum Filtern einer Menge von Dokumenten inklusive der Zeit, die der Monitor zurWartung der Datenrepräsentation benötigt, sowie der Zeit, die zur vom Monitor initiiertenAnfragetransformation während des eigentlichen Filters aufgewendet werden muss. Dadurchkann die Performanz realistisch mit Systemen verglichen werden, die keinen Monitor undkeine parallele Transformation durchführen. Weiterhin enthält die Streamingzeit auch dieZeit zur Ausgabe der Suchergebnisse, wobei diese dadurch minimiert wurde, dass für jedesDokument lediglich die Anzahl der treffenden Anfragen berichtet wurde.
Konkret wurde hier jeweils die Zeit ermittelt, die benötigt wird, um eine Menge von 600XML-Dokumenten mit einer Gesamtgröße von ca. 20 Megabyte der DTD NITF zu filtern.Dementsprechend verfügen die einzelnen Dokumente über eine mittlere Größe von 31.000Zeichen. Jedes der Dokumente bestand durchschnittlich aus 240 XML-Elementen.
Untersucht wurden die Verfahren basic und extended jeweils sowohl mit, als auch ohneMonitor, sowie das Verfahren all und zusätzlich zum Vergleich das Verfahren no, welches nurdie Originalanfragen verarbeitet und keinen Monitor einsetzt. Um die Verfahren mit Monitorausreichend herauszufordern wurde hier die initiale Transformation anhand der originalenDTDs durchgeführt, die zu filternden Daten folgten jedoch abweichenden Varianten, so dassgewährleistet war, dass der Monitor abweichende Daten registriert und damit Anfragetrans-formationen auslöst.
Anzahl der Originalanfragen Bei der Ermittlung der Streamingzeiten in Abhängigkeit vonder Anzahl der Originalanfragen wurden Anfragen ohne Prädikate und verschachtelte An-fragen verwendet, die Parameter WC und D für die Wahrscheinlichkeit von Wildcards undDescendant-Achsen betrugen 0.1. Die Daten wurden aus der DTD NITF mit SMOD=8 gene-riert. Lediglich für die Ermittlung der Zeiten für die Variante no wurde die originale DTDverwendet, da die Anfragen sonst nur wenige Treffer erzielt hätten, was den Vergleich mitden anderen Verfahren erschwert hätte. Die Transformationsparameter TH und RC betrugen90 bzw. 10.
Abbildung 7.23 zeigt den Verlauf der Streamingzeit in Sekunden bei einer wachsendenAnzahl von Originalanfragen für die verschiedenen Transformationsverfahren. Wenig überra-
107

Kapitel 7 Experimente
0
50
100
150
200
250
25000 50000 75000 100000 125000 150000
Anzahl Originalanfragen
Stre
amin
gzei
t (se
c.)
ALLBASIC (no update)EXTENDED (no update)NOBASIC (update)EXTENDED (update)
Abbildung 7.23: variables C; D, WC = 0.1
0
10
20
30
40
50
60
70
80
90
100
p0.0 wd0.0 p0.1 wd0.0 p0.0 wd0.1 p0.1 wd0.1Art der Anfragen
Stre
amin
gzei
t (se
c.)
ALLBASIC (no update)EXTENDED (no update)NOBASIC (update)EXTENDED (update)
Abbildung 7.24: variable WC,P; Q=50.000
schend schlägt no die anderen Verfahren, wobei auch bei zunehmender Anzahl von Anfragender notwendige Zeitaufwand nur sehr moderat ansteigt. Ähnliches gilt für unsere Verfahrenbasic, extended und all. Sie benötigen zwar jeweils mehr Zeit bei gleicher Anzahl von Ori-ginalanfragen, jedoch ist der Anstieg mit zunehmender Anzahl nur unwesentlich stärker alsbei no. Ein anderes Ergebnis wäre hier insoweit auch überraschend, als während dem eigentli-chen Filtern kein zusätzlicher Aufwand im Vergleich zu no zu leisten ist. Die insgesamt jeweilsgrößere Verarbeitungszeit ist einzig und allein der Tatsache geschuldet, dass sich bei diesenVarianten nicht nur die Originalanfragen, sondern auch die initial transformierten Anfragenim Anfrageindex befinden und somit einen Mehraufwand beim Filtern bedeuten. Konkretführten in diesem Fall die beiden Parameter TH=90 in Verbindung mit RC=10 dazu, dasspro Originalanfrage durchschnittlich bei basic, extended eine und bei all vier zusätzlichetransformierte Anfragen zu verarbeiten waren. Dieser Faktor entspricht im Wesentlichen demin der Abbildung erkennbaren Mehraufwand bei diesen Verfahren.
Demgegenüber steht der in der Abbildung erkennbare deutliche Mehraufwand bei Verwen-dung eines Monitors bei den Varianten basic und extended mit update bzw. a priori. Hiermuss einerseits der Monitor den Datenstrom auf unbekannte Strukturen hin überwachen undgegebenenfalls seine Datenstrukturen aktualisieren und darüber hinaus entsprechende Anfra-getransformationen anstoßen.
Dieses nicht unerheblichen Aufwandes zum Trotz kann jedoch auch hier ein wenngleichstärkerer, aber immer noch linearer Zuwachs mit zunehmender Anzahl an Originalanfragenbeobachtet werden.
Art der Originalanfragen Abbildung 7.24 zeigt den Einfluss der Anfrageart auf die Streaming-Performanz. Bei dieser Untersuchung wurden jeweils 50.000 Originalanfragen generiert, wobeifür die Parameter WC, D und P die Werte 0.0 bzw. 0.1 angenommen wurden. Es wird deut-lich, dass mit zunehmender Komplexität der Anfragen die Streamingzeit ansteigt, wobei derAnstieg für die verschiedenen Varianten wiederum unterschiedlich stark ausfällt. So ist derAnstieg bei no nur moderat und bei den beiden Varianten basic und extended mit Monitor
108

7.5 Streaming-Performanz
am ausgeprägtesten. Die Ursache ist selbstverständlich wieder der Monitor selbst, und dieTatsache, dass zusätzliche Transformationen während dem eigentlichen Filtern durchgeführtwerden.
Dass die Verwendung von Prädikaten insgesamt zu einer höheren Laufzeit führt, liegt darinbegründet, dass sie in einem separaten Schritt nach der eigentlichen Pfad-Evaluierung ausge-wertet werden. Hinsichtlich der Parameter WC und D für die Wahrscheinlichkeit des Auftretensvon Wildcards bzw. Descendant-Achsen ist festzustellen, dass ihr Einfluss vielfältig ist. Zumeinen haben sie einen direkten Einfluss auf die Filter-Performanz, da sie einerseits Einflussauf den Aufbau des Automaten haben, andererseits haben sei Einfluss auf die Verarbeitung,da sie zu einer erhöhten Anzahl an parallelen Zuständen während der Verarbeitung führen.In [AF00] wird dieser Einfluss im Detail erklärt und es kann sogar gezeigt werden, dass ihreEinführung zwar zunächst zu einer höheren Laufzeit führt, mit zunehmender Auftretenswahr-scheinlichkeit beider Eigenschaften aber mit einer sinkenden Streamingzeit gerechnet werdenkann.
Transformationsparameter Die beiden Parameter TH und RC haben einen mehr oder we-niger direkten Einfluss auf die Anzahl der Anfragen, die pro Originalanfrage transformiertbzw. in den Anfrageindex übernommen werden. Den sich daraus ergebenden Einfluss auf dieStreamingzeit zeigen die Diagramme in den Abbildungen 7.25 und 7.26.
Der Schwellwert für die Fitness der transformierten Anfragen TH wirkt sich insbesondereauf die Varianten, welche einen Monitor verwenden, sehr stark aus. Er hat zum einen einengroßen Einfluss auf die Transformationsgeschwindigkeit, die um so mehr sinkt, desto nied-riger er gewählt wird - selbstverständlich in Abhängigkeit von der Abweichung der Datenvom erwarteten Schema. Zum anderen führt ein niedriger Schwellwert dazu, dass potentiellmehr Anfragen in den Index übernommen werden, was wiederum die Streaming-Performanzinsgesamt mindert. Dieser letztere Einfluss ist beim Verlauf der Werte für die drei Varian-ten ohne Monitor all, basic (no update) und extended (no update) zu beobachten. Hierfinden während des eigentlichen Streamings keine Transformationen statt und trotzdem istein Anstieg der Verarbeitungszeit mit abnehmendem Schwellwert zu beobachten.
Die maximale Anzahl transformierter Anfragen, die pro Originalanfrage in den Index über-nommen werden können, wird mit dem Parameter RC festgelegt. Sein Einfluss auf die Strea-mingzeit besteht damit ebenso wie bei TH darin, dass er einerseits Einfluss auf die Größe desAnfrageindex hat und andererseits dass bei den beiden Varianten mit Monitor, die währenddes Streamings transformierten Daten auch in den Index übernommen werden müssen. DasDiagramm in Abbildung 7.26 zeigt insbesondere für die Variante all einen extremen Abfallder Verarbeitungsgeschwindigkeit bei zunehmendem Wert für RC. Für dieses Phänomen istdie Tatsache verantwortlich, dass all grundsätzlich eine große Menge von Anfragen generiert.Da das Verfahren keine Schemainformationen verwendet, kann es auch keine Anfragen aus-schließen und übernimmt damit so viele Anfragen wie der Parameter RC es eben gestattet. Imkonkreten Fall erklärt sich die schlechte Laufzeit damit dass zu den 50.000 Originalanfragen
109

Kapitel 7 Experimente
0
50
100
150
200
250
90 80 70
Schwellwert (TH)
Stre
amin
gzei
t (se
c.)
ALLBASIC (no update)EXTENDED (no update)BASIC (update)EXTENDED (update)
Abbildung 7.25: variables TH; Q=50.000
0
50
100
150
200
250
300
350
400
450
1 10 100Anzahl transformierter Anfragen pro Originalanfrage (RC)
Stre
amin
gzei
t (se
c.)
ALL
BASIC (no update)
EXTENDED (no update)
BASIC (update)
EXTENDED (update)
Abbildung 7.26: variables RC; Q=50.000
zusätzlich über 1 Million transformierte Anfragen übernommen wurden.Überraschenderweise ist ein vergleichbarer Anstieg bei den Varianten mit Monitor nicht
zu verzeichnen. Im Gegenteil sind die Zeiten unverändert, unabhängig davon, ob 10 oder100 Anfragen übernommen werden sollen. Der Grund dafür liegt im engen Zusammenhangzwischen der Abweichung der zu filternden Daten vom erwarteten Schema einerseits und denParametern TH und RC andererseits. Im konkreten Fall betrug die Abweichung SMOD 8 undder Schwellwert TH 80. Selbstverständlich ist für einen bestimmten Grad der Abweichungund einen bestimmten Schwellwert die Anzahl an möglichen Anfragen zu einer gegebenenOriginalanfrage begrenzt. Über diese Grenze hinaus sind keine zusätzlichen Anfragen mehrmöglich, so dass ein negativer Einfluss auf die Streaming-Performanz nicht mehr messbar ist,wie dies in dem in Abbildung 7.26 gezeigten Fall jenseits des Wertes 10 für RC auftritt.
Schema-Abweichung Auf den ersten Blick mag es überraschend sein, dass die Anzahl derAbweichungen zwischen dem Originalschema und dem Schema der zu verarbeitenden Dateneinen Einfluss auf die Performanz des Streamings hat. Die in Abbildung 7.27 gezeigten Datenweisen nichtsdestotrotz auf einen Zusammenhang hin, wobei mit zunehmender Abweichungder Schemata die Verarbeitungsgeschwindigkeit ansteigt. Ursächlich sind hier zwei Punkte.Zum einen nimmt die Anzahl der transformierten Anfragen bei zunehmender Abweichung ab,damit enthält der Index auch weniger Anfragen und daraus ergibt sich eine höhere Geschwin-digkeit beim Streaming. Ein Blick auf den Verlauf der Werte für all verrät jedoch, dass diesnur eine Ursache sein kann. all generiert schließlich seine Anfrage völlig unabhängig vonden verwendeten Schemata, lediglich gesteuert durch die Parameter TH und RC, die in diesemFall 80 bzw. 10 betrugen. Für all bedeutete dies hier, dass zu den 50.000 Originalanfrageninsgesamt über 400.000 zusätzliche Anfragen transformiert und in den Index aufgenommenwurden.
Dies führt uns zur zweiten Ursache. Mit zunehmender Abweichung der Schemata generiertinsbesondere das ”blinde” Verfahren all zunehmend Anfragen, die für die zu verarbeitendenDaten überhaupt nicht relevant sind. Dies hat für den Automaten, der zur Ermittlung von
110

7.5 Streaming-Performanz
0
20
40
60
80
100
120
140
160
180
0 8 16
Schema-Abweichung (SMOD)
Stre
amin
gzei
t (se
c.)
ALLBASIC (no update)EXTENDED (no update)BASIC (update)EXTENDED (update)
Abbildung 7.27: variables SMOD; Q=50.000
0
20
40
60
80
100
120
140
160
180
200
50 100 150 200 250 300Anzahl der Dokumente im Cache
Stre
amin
gzei
t (se
c.)
BASIC (DTD)
EXTENDED (DTD)
BASIC (no DTD)
EXTENDED (no DTD)
Abbildung 7.28: variables C; Q=50.000
Treffern verwendet wird, zur Folge, dass sich die Anzahl an parallelen bzw. aktiven Zuständenverringert und damit die Verarbeitung schneller wird.
Die Tatsache, das das gleiche Phänomen auch bei den Varianten mit Schema zu beobachtenist, bedeutet nun aber nicht, dass hier trotz Schemata irrelevante Anfragen generiert werdenwürden. Hier liegt die Ursache darin, dass bei gegebenem Schwellwert TH und zunehmenderAbweichung SMOD ganz einfach weniger Anfragen pro Originalanfrage möglich sind.
Größe des Monitor-Caches Die Stärke der Transformationsvarianten mit Monitor ist, dasssie sich flexibel an die tatsächlich verarbeiteten Daten anpassen. Wie die bisherigen Un-tersuchungen zur Streaming-Performanz gezeigt haben, ist diese Stärke jedoch teuer durcheinen teilweise erheblichen Performanzverlust erkauft, was daran liegt, dass die Verarbeitungimmer wieder unterbrochen werden muss, um Anfragen neu zu transformieren. Durch denParameter C kann gesteuert werden, wieviele Dokumente jeweils zunächst eingelesen undvom Monitor kontrolliert werden, bevor Anfragen transformiert werden. Wird dieser Cachezu klein gewählt, so besteht die Wahrscheinlichkeit, dass ein und dieselbe Anfrage wiederholttransformiert wird, weil sie immer wieder von veränderten Daten betroffen ist. Bei einemgrößeren Cache werden alle diese registrierten Veränderungen quasi gebündelt, so dass dieseAnfrage seltener transformiert werden muss.
Bei den bisherigen Untersuchungen wurde die Größe des Caches bei den Varianten mitMonitor auf 100 Dokumente gesetzt. Abbildung 7.28 zeigt Messwerte, die beim Filtern von600 Dokumenten anhand von 50.000 Anfragen ermittelt wurden, wobei jeweils sie Größe desCaches variiert wurde. Dabei wurden die zwei Verfahren basic und extended verwendet,wobei die initiale Transformation in einem Fall auf Basis einer DTD stattfand und im ande-ren Fall völlig ohne initiale DTD gearbeitet wurde, so dass die strukturellen Informationenzunächst alle gelernt werden mussten.
Für alle Fälle zeigt sich ein nahezu identischer Verlauf. Mit zunehmender Größe des Cachesnimmt die Verarbeitungsgeschwindigkeit deutlich zu, wobei sich das Wachstum mit zuneh-mender Größe abschwächt.
111

Kapitel 7 Experimente
Zu beachten ist hier, dass bei einer Verringerung des Caches die Verarbeitungsgeschwindig-keit exponentiell zunimmt. So wurde das Verfahren auch bei einer Cache-Größe von 1 unter-sucht, d.h. nach jedem einzelnen Dokument entschied der Monitor, ob eine Transformationdurchzuführen war. Gerade zu Beginn der Verarbeitung, wenn der Monitor die Strukturenerst noch lernen muss, führt dies dazu, dass nach fast jedem Dokument ein Großteil der An-fragen transformiert werden muss. So wurden im konkreten Fall bei einer Cache-Größe von1 Streamingzeiten von über 660 Sekunden gemessen.
Sofortige Transformation (immediate)
Auf die Spitze getrieben wird eine Verringerung der Cache-Größe, wenn der Monitor nichterst nach dem Einlesen eines vollständigen Dokuments entscheidet, ob zu transformierenist, sondern sofort, wenn eine unbekannte Struktur gelesen wird. Die Untersuchungen habenjedoch gezeigt, dass hier die Verarbeitungsgeschwindigkeit nochmals wesentlich geringer ist,als bei einer Cache-Größe von 1, so dass von einem sinnvollen Einsatz dieser Variante nichtdie Rede sein kann. So wurden teilweise für die Verarbeitung von 600 Dokumenten anhandvon 50.000 Anfragen über 10.000 Sekunden benötigt.
7.5.1 Aufwand für den Aufbau der Datenrepräsentation
Neben der eigentlichen Anfragetransformation, dem Verwalten der Anfragen und dem Stre-aming muss unser System auch für den Aufbau und die Verwaltung der Datenstrukturen seies aus einer DTD oder aus den gelesenen Daten, Zeit und Platz aufwänden.
Für den Aufbau der Repräsentation aus der DTD NITF werden dabei durchschnittlich 55Sekunden benötigt, wobei 218443 Pfade gespeichert werden. Die Relation dcont enthält 737Einträge und die Relation cont 3308 Einträge. Hierbei ist zu beachten, dass nur Pfade bis zueiner Länge von 10 gespeichert wurden. NITF erlaubt potentiell unendlich tief verschachtelteElemente und damit Pfade. Die Repräsentation zur DTD Auction kann in knapp 200 Milli-sekunden aufgebaut werden und besteht aus 666 Pfaden mit einer maximalen Länge von 10.Die Relation dcont enthält dabei 109 und die Relation cont 561 Einträge. Für den Aufbauder Repräsentation zur DTD DBLP werden knapp 1,5 Sekunden bei 31557 Pfaden benötigt.Die Relation dcont enthält dabei 185 und die Relation cont 221 Einträge.
Steht keine DTD zur Verfügung, so ist der Aufbau der Datenrepräsentation abhängig vonden gelesenen Daten, wobei der Zeitaufwand ein Teil des Gesamtaufwands des Monitors istund sich damit im Wesentlichen in einem zusätzlichen Parsing-Durchlauf manifestiert. Eszeigt sich jedoch, dass insbesondere bei NITF die Anzahl der gespeicherten Pfade mit knapp10.000 bei 600 gelesenen Dokumenten deutlich niedriger ist, als bei der Verwendung einerDTD.
112

7.6 Diskussion
7.5.2 Bewertung
Im direkten Vergleich der Streamingzeit der verschiedenen Varianten von aXst mit einemgängigen System zum Filtern von XML-Datenströmen (in diesem Fall YFilter) zeigt sich derMehraufwand, welcher für die Überwachung des Datenstroms, sowie die Transformation undVerarbeitung der zusätzlichen Anfragen geleistet wird.
Dabei erweist sich der Aufwand für die Verwaltung und Verarbeitung der zusätzlichenAnfragen als gering. Beim Einsatz von aXst zur Integration von Datenquellen mit schonvorab feststehenden Schemata werden die Anfragetransformationen schon vor dem Filterndurchgeführt. Das Filtern der Daten selbst wird damit nur unwesentlich verlangsamt.
Eine permanente Überwachung der Daten auf Abweichungen mit daraus resultierendenpermanenten Transformationen während des eigentlichen Filterns verlangsamt das Strea-ming stärker. Durch die Verwendung eines Caches können die Transformationen jedoch so-weit reduziert werden, dass ein linearer Zusammenhang zwischen Anzahl der Anfragen undStreamingzeit gewährleistet bleibt.
Eine Stärke des Verfahrens ist dabei auch der geringe Aufwand, der für den Aufbau derDatenrepräsentation aus den Daten zu leisten ist. Eine bis zu einer gewissen Dokument-Tiefevollständige Repräsentation aus einer DTD abzuleiten ist sehr aufwändig. Beim Aufbau derRepräsentation aus den Daten selbst wird diese auf den jeweils relevanten Teil beschränkt,was sehr effizient durchführbar ist.
7.6 Diskussion
Aus den durchgeführten Experimenten können eine Reihe wertvoller Erkenntnisse gewonnenwerden. Die wichtigste ist dabei sicher, dass mit Hilfe der Transformationen tatsächlich dieQualität der Suchergebnisse deutlich verbessert werden kann.
Außerdem zahlt sich die Verwendung von strukturellen Informationen für die Anfrage-transformation in jedem Falle aus. Sowohl die eigentliche Anfragetransformation als auchdas Streaming ist schneller und es können bessere oder zumindest genauso gute Ergebnisseerzielt werden, als wenn alle möglichen Transformationen durchgeführt werden. Dabei ist esletztendlich so gut wie unerheblich, ob tatsächlich Schemainformationen für die Transforma-tionen vorliegen, oder ob diese Information erst aus den gelesenen Daten gewonnen werdenmuss. Der Qualität der Suchergebnisse tut dies keinen Abbruch.
Was den Grad der möglichen Abweichungen der tatsächlichen von den erwarteten Datenangeht, so zeigt sich, dass dieser in Verbindung mit verschiedenen Parametern zur Steuerungder Anfragetransformation einen wesentlichen Einfluss sowohl auf die Qualität der Suchergeb-nisse als auch auf die Performanz des Systems hat. So müssen diese Parameter mit Bedacht inAbhängigkeit vom erwarteten Grad dieser Abweichung gewählt werden. Hier eine gute Wahlzu treffen wird im praktischen Einsatz eine Herausforderung sein.
113

Kapitel 7 Experimente
114

Kapitel 8
Fazit
8.1 Zusammenfassung
Die beiden in der vorliegenden Arbeit behandelten Kern-Aspekte sind die Definition, Weiter-entwicklung und Untersuchung einer adaptiven Anfragetechnik für XPath sowie die Definitionund empirische Untersuchung einer Architektur zum integrativen und fehlertoleranten Filternvon XML-Datenströmen auf Grundlage dieser adaptiven Anfragetechnik.
Die hier definierte Anfragetechnik ist adaptiv in dem Sinn, dass Anfragen während bzw. vorder eigentlichen Ausführung der Anfrage an die tatsächlich vorliegenden Datenstrukturen an-gepasst werden. Damit eignet sich diese Anfragetechnik für Situationen, in denen verschiede-ne Datenquellen einer bestimmten Domäne zu einem einheitlichen System zusammengefasstwerden sollen und bietet damit eine elegante und unkomplizierte Möglichkeit zur Integrationheterogener Datenquellen. Die Stärke dieses Verfahrens liegt dabei insbesondere darin, dassdie Integration vollständig automatisiert bewerkstelligt werden kann. Eine manuelle Defini-tion von Transformationsregeln für konkrete Integrations-Szenarien ist nicht erforderlich. InAbschnitt 7.4.1 werden Experimente gezeigt, bei denen sehr starke Abweichungen bestehenzwischen dem Schema, welches dem Benutzer bekannt ist und anhand dessen er seine Anfra-gen formuliert hat und demjenigen, welches den aktuellen Daten tatsächlich zu Grunde liegt.Die Ergebnisse belegen, dass die Anfragetransformationen in derartigen Situationen dafürsorgen, dass auch sehr spezifische Anfragen an die aktuellen Strukturen angepasst werdenkönnen.
Darüber hinaus zeigen die experimentellen Ergebnisse in Abschnitt 7.4.1, dass sogar völligauf die Verwendung von Schemainformationen verzichtet werden kann und trotzdem gleich-wertige Ergebnisse geliefert werden können. Dazu wurden Varianten definiert, die entwedergänzlich ohne ein Wissen über die Strukturen und Inhalte der vorliegenden Daten operierenkönnen, damit jedoch auch gewissen Einschränkungen inbesondere hinsichtlich der Perfor-manz unterliegen. Andererseits konnten Verfahren entwickelt werden, die aus vorliegendenDaten strukturelle und gegebenenfalls inhaltliche Informationen zunächst extrahieren unddiese dann für die eigentliche Transformation verwenden. Diese Option erlaubt den Einsatzin Umgebungen, in denen mit massiven Abweichungen der Daten von den zugrunde liegendenSchemata zu rechnen ist. Der Ansatz erlaubt es, die Anfragen direkt an die tatsächlichen Da-
115

Kapitel 8 Fazit
tenstrukturen anzupassen, unabhängig davon, ob die Daten schemakonform sind oder nicht.In den in Abschnitt 7.4.3 diskutierten Experimenten kann nachgewiesen werden, wie gera-de die Trefferquote von sehr spezifischen Anfragen in derart unvorhersehbaren Umgebungenleidet und wie mit Hilfe einer Überwachung des Datenstroms auf Veränderungen und ent-sprechenden dadurch initiierten Transformationen diese Trefferquote wesentlich verbessertwerden kann.
Eine Vielzahl von Ergebnissen belegt darüber hinaus, dass der Aufwand, welcher für ei-ne gezielte Transformation anhand von Schema- oder strukturellen Informationen betriebenwerden muss, absolut gerechtfertigt ist. Die Experimente zeigen praktisch ausnahmslos denVorteil dieser zielgerichteten Verfahren sowohl hinsichtlich Transformationszeit, Qualität derSuchergebnisse sowie der für das Streaming von Dokumenten notwendigen Zeit gegenüber ei-nem Verfahren, das diese Informationen nicht nutzt. Die große Anzahl von Anfragen, die po-tentiell möglich sind, übersteigt auch dann jedes handhabbare Maß, wenn nur solche gewähltwerden, die der Originalanfrage sehr ähnlich sind. Die Ergebnisse bei den Untersuchungenzur Variation des Schwellwertes bei keinen Schema-Abweichungen in Abschnitt 7.3.2 zeigenbeispielsweise den extremen Anstieg der notwendigen Transformationszeit bei der Varianteall.
Der Vielfalt an Anfragen, welche potentiell durch die Transformationen generiert werdenkönnen, wird mit Hilfe einer Bewertungsfunktion begegnet, welche ”gute” von ”schlechten”Anfragen zu unterscheiden hilft. Die formalen Eigenschaften dieser einfachen Funktion wur-den untersucht und ihre Beziehung zu den Eigenschaften der konkreten Anfragen beleuchtet.Die Experimente belegen die Auswirkungen der Bewertungsfunktion auf die Suchergebnisse.Sie definiert eine Ordnung auf der Menge aller möglichen durch die Transformationen gene-rierbaren Anfragen, so dass durch die Wahl eines Schwellwertes implizit festgelegt werdenkann, welche Anfrageergebnisse noch akzeptabel sind.
Auf Basis der adaptiven Anfragetechnik wurde das Streaming-System aXst entwickelt,welches ein bestehendes System zur Filterung von XML-Datenströmen um die Möglichkeiterweitert, verschiedene Datenquellen einer bestimmten Domäne zu integrieren. Darüber hin-aus bietet die Architektur eine Plattform für die robuste Verarbeitung potentiell fehlerhafterDaten. Durch einen modularen Aufbau dieser Architektur ist es möglich, aXst ganz gezielt fürden in Frage stehenden Einsatzzweck zu konfigurieren. Es kann dabei festgelegt werden, obSchemainformationen zur Transformation verwendet werden sollen, welcher Transformations-algorithmus verwendet werden soll und zu welchem Zeitpunkt die Anfragen jeweils transfor-miert werden sollen.
Anhand realer Schemata wurde die Performanz und Qualität der Algorithmen und desFiltersystems untersucht, wobei dem Einfluss der verschiedensten Parameter nachgegangenwurde. Es konnte gezeigt werden, dass sich bei angemessener Konfigurierung des Systems un-ter Berücksichtigung des konkreten Anwendungs-Falles der zusätzlich notwendige Aufwandin vertretbarem Rahmen bewegt. So zeigen die experimentellen Ergebnisse in Abschnitt 7.3,dass selbst bei komplexen Schemata für die Transformation von 100.000 Anfragen weniger als
116

8.2 Beitrag der Arbeit
20 sec. benötigt werden. Aufgrund der schrittweisen Vorgehensweise des Transformationsal-gorithmus’ nimmt mit zunehmender Länge der Anfragen die notwendige Transformationszeitlediglich linear zu. Die Untersuchungen zur Performanz beim eigentlichen Filtern von Datenin Abschnitt 7.5 zeigen beim direkten Vergleich mit einem reinen Filtersystem, dass der Mehr-aufwand selbst dann vertretbar ist, wenn tatsächlich parallel zum Filtern auch Monitoringder Daten sowie Transformation von Anfragen durchgeführt wird.
8.2 Beitrag der Arbeit
Fehlertolerantes und integratives Verarbeiten von Daten erfordert häufig eine aufwändige Va-lidierung und den Einsatz mehr oder weniger manuell definierter Regeln zur Transformation,um die Daten in ein Format zu bringen, das eine weitere Verarbeitung ermöglicht. Geradebeim Filtern von hohen und kontinuierlichen Datenaufkommen stoßen Ansätze, die in irgendeiner Form ein manuelles Eingreifen erfordern, schnell an ihre Grenzen.
In dieser Arbeit wird erstmalig ein System zum integrativen und fehlertoleranten Filternvon XML-Datenströmen anhand großer Mengen von Anfragen definiert, das vollständig au-tomatisch abläuft.
Das System basiert auf einem Verfahren zur Transformation von XPath-Anfragen. In seinenverschiedenen Varianten erlaubt es dieses, einerseits eine Integration heterogener Datenquel-len durch Transformation von Anfragen in ein gegebenes Zielschema durchzuführen. Ande-rerseits kann die Transformation jedoch gänzlich ohne Schemainformationen auch anhand dertatsächlich vorhandenen Daten durchgeführt werde. Dieser Ansatz erlaubt es, XML-Datenflexibel und unter Berücksichtigung tatsächlicher Abweichungen der Daten von einem Schemaanzufragen. Mit der Verwendung einer einheitlichen Repräsentation für Schemata und Datenist aXst sehr flexibel in der Hinsicht, dass es für die Transformationen völlig transparent istauf welcher Grundlage sie durchgeführt werden. Erstmalig kann damit ein System definiertund experimentell untersucht werden, welches in der Lage ist, gleichermaßen als Plattformfür eine Datenintegration zu dienen und darüber hinaus eine fehlertolerante Verarbeitungvon XML-Daten ermöglicht.
Eine Vielzahl vergleichbarer Ansätze zur Anfragetransformation beschränkt sich auf einerein strukturelle Betrachtung von Anfragen, was den flexiblen Möglichkeiten zur Modellie-rung von XML nicht gerecht wird. Hier werden Anfragetransformationen definiert, die nebeneinem Umschreiben von Anfragen auf rein struktureller Ebene auch in der Lage sind inhalt-liche und strukturelle Teile von Anfragen gegeneinander auszutauschen. Damit kann demUmstand Rechnung getragen werden, dass es die große Flexibilität von XML erlaubt, einbestimmtes Szenario auf die verschiedensten Arten und mit einem unterschiedlichen Grad anGeneralisierung zu modellieren.
Durch Identifizierung von Anfragen, die bezüglich gegebener Daten relevant für eine An-fragetransformation sind, können die durchzuführenden Transformationen auf die tatsächlichnotwendigen beschränkt werden. Dies verschafft dem Verfahren einen großen Vorteil gegen-
117

Kapitel 8 Fazit
über Ansätzen, welche zur Integration erst die eigentlichen Daten verarbeiten müssen. Beieinem derartigen Ansatz müssen die Daten bei jeder Abweichung transformiert werden, auchwenn ein und dieselbe Abweichung wiederholt auftritt. Beim hier vorgestellten Ansatz bestehtdie Gefahr von wiederholten Transformation aufgrund gleicher Abweichungen nicht. Sobaldeine Abweichung einmal aufgetreten ist, hat sie durch entsprechende Transformationen derrelevanten Anfragen Eingang in das System gefunden.
Auf Grundlage der Transformationen und des Verfahrens zur Identifizierung relevanterAnfragen wird das System aXst definiert, welches ein System zum Filtern von XML-Datenanhand von XPath-Anfragen um Komponenten erweitert, die die Anfragetransformationenzur Laufzeit des Systems auf Basis der aktuell verarbeiteten Daten vornehmen können.
aXst als Architektur, die ein System zum Filtern von XML-Daten mit einem Mechanismuszur adaptiven Anfrageverarbeitung zusammenbringt, erweist sich dabei im Vergleich miteinem gängigen Filtersystem als Fortschritt. Es zeigt sich, dass der notwendige Mehraufwandsich durch bessere Anfrage-Ergebnisse bei der Anwendung in unbekanntem Umfeld auszahlt.Eine der wesentlichen Anforderungen an ein SDI-(Selective Dissemination of Information)System ist, dass es eine reichhaltige Klasse von Profilen in Form von Anfragen unterstützt.aXst geht hier einen entscheidenden Schritt weiter und schafft es, die Benutzerprofile soweitzu verallgemeinern, dass sie auch einen sinnvollen Einsatz in Umgebungen erlauben, die demBenutzer bei der Formulierung seines Profils gar nicht gegenwärtig waren.
8.3 Ausblick
Eine intensivere experimentelle Untersuchung verdienen die erweiterten Transformationen.So werden sie in den gezeigten Experimenten zwar durchgehend zur Anwendung gebrachtund gegen die Basistransformationen abgegrenzt, jedoch sind die zufällig generierten Datenmit ihren Abweichungen nicht ausreichend in der Lage, die speziellen Vorzüge dieser Art derTransformationen hervorzubringen.
XPath ist Bestandteil von Sprachen zur Anfrage und Manipulation von XML wie XQueryoder XSLT. Es gibt mittlerweile eine Reihe von Arbeiten, die Techniken zur Anfrage von Da-tenströme mit Hilfe dieser mächtigeren Sprachen erlauben. Ein Ergänzung derartiger Systemeum eine adaptive Komponente würde sich daher anbieten.
Angesichts der Tatsache, dass aXst eine Architektur verschiedener prinzipiell autonomerKomponenten wie der Filter-Engine oder dem Monitor ist, wäre eine Parallelisierung derVerarbeitung dieser Komponenten unter dem Aspekt der Performanz denkbar, wobei diegeeignete Synchronisierung dabei sicher eine Herausforderung wäre.
Eine konsequente Weiterentwicklung von aXst wäre die Integration einer semantischenKomponente, welche über die rein strukturellen Transformationen hinaus auch Umwandlun-gen von Anfragen auf semantischer Ebene erlauben. Durch die Verwendung einer Taxonomiedes fraglichen Themenbereichs könnte eine viel umfassendere Integration von Datenquellenbewerkstelligt werden, als dies derzeit möglich ist.
118

8.3 Ausblick
Durch den Einsatz des Caches durchbricht aXst das gängige Paradigma beim Streamingvon XML, nach dem jedes SAX-Ereignis nur einmalig behandelt wird und dabei sofort vonder Filter-Engine verarbeitet wird. Diesem Paradigma ist die eingeschränkte Ausdrucks-mächtigkeit der hier verwendeten Untermenge von XPath mit dem Verzicht auf eine direkteUmsetzung von rückwärts gerichteten Achsen geschuldet. Mit dem zweimaligen Lesen jedesDokuments bei Verwendung des Caches ergeben sich neue Möglichkeiten für eine direkte Be-handlung derartiger Achsen, so dass ein Filtersystem mit der vollen Ausdrucksmächtigkeitvon XPath realisierbar wäre.
119

Kapitel 8 Fazit
120

Literaturverzeichnis
[ABB+03] Arvind Arasu, Brian Babcock, Shivnath Babu, Mayur Datar, Keith Ito, Ita-ru Nishizawa, Justin Rosenstein, and Jennifer Widom. Stream: The stanfordstream data manager. In Proceedings of the 2003 ACM SIGMOD InternationalConference on Management of Data, page 665, San Diego, USA, June 2003.ACM.
[ABM02] Serge Abiteboul, Omar Benjelloun, and Tova Milo. Web services and dataintegration. In WISE 2002: 3rd International Conference on Web InformationSystems Engineering, pages 3–6, Singapore, December 2002. IEEE ComputerSociety.
[ACG+04] Arvind Arasu, Mitch Cherniack, Eduardo F. Galvez, David Maier, Anurag Mas-key, Esther Ryvkina, Michael Stonebraker, and Richard Tibbetts. Linear road:A stream data management benchmark. In VLDB 2004: Proceedings of theThirtieth International Conference on Very Large Data Bases, pages 480–491,Toronto, Canada, August 2004. Morgan Kaufmann.
[ACV+00] V. Aguilera, S. Cluet, P. Veltri, D. Vodislav, and F. Wattez. Querying xmldocuments in xyleme. 2000.
[AF00] Mehmet Altinel and Michael J. Franklin. Efficient filtering of xml documentsfor selective dissemination of information. In VLDB 2000: Proceedings of 26thInternational Conference on Very Large Data Bases, pages 53–64, Cairo, Egypt,September 2000. Morgan Kaufmann.
[AH00] Ron Avnur and Joseph M. Hellerstein. Eddies: Continuously adaptive queryprocessing. In Proceedings of the 2000 ACM SIGMOD International Conferenceon Management of Data, pages 261–272, Dallas, USA, May 2000. ACM.
[AHU83] Alfred V. Aho, John E. Hopcroft, and Jeffrey D. Ullman. Data Structures andAlgorithms. Addison-Wesley, 1983.
[AYCLS01] Sihem Amer-Yahia, SungRan Cho, Laks V. S. Lakshmanan, and Divesh Sriva-stava. Minimization of tree pattern queries. In Proceedings of the 2001 ACMSIGMOD Conference, Santa Barbara, USA, May 2001.
121

Literaturverzeichnis
[AYCS02] Sihem Amer-Yahia, SungRan Cho, and Divesh Srivastava. Tree pattern rela-xation. In EDBT 2002: Advances in Database Technology - 8th InternationalConference on Extending Database Technology, Prague, Czech Republic, March2002.
[BAOG98] Klemens Böhm, Karl Aberer, M. Tamer Özsu, and Kathrin Gayer. Queryoptimization for structured documents based on knowledge on the documenttype definition. In Proceedings of the IEEE Forum on Reasearch and TechnologyAdvances in Digital Libraries, pages 196–205, Santa Barbara, USA, April 1998.IEEE Computer Society.
[BBD+02] Brian Babcock, Shivnath Babu, Mayur Datar, Rajeev Motwani, and JenniferWidom. Models and issues in data stream systems. In Proceedings of theTwenty-first ACM SIGACT-SIGMOD-SIGART Symposium on Principles ofDatabase Systems, pages 1–16, Madison, USA, June 2002. ACM.
[BCG+03] Charles Barton, Philippe Charles, Deepak Goyal, Mukund Raghavachari, Mar-cus Fontoura, and Vanja Josifovski. Streaming xpath processing with forwardand backward axes. In Proceedings of the 19th International Conference on Da-ta Engineering, pages 455–466, Bangalore, India, March 2003. IEEE ComputerSociety.
[BSV05] Ahmet Bulut, Ambuj K. Singh, and Roman Vitenberg. Distributed data stre-ams indexing using content-based routing paradigm. In IPDPS 2005: 19th In-ternational Parallel and Distributed Processing Symposium, Denver, USA, April2005. IEEE Computer Society.
[BSW04] Shivnath Babu, Utkarsh Srivastava, and Jennifer Widom. Exploiting k-constraints to reduce memory overhead in continuous queries over data stre-ams. TODS 2004: ACM Transactions on Database Systems, 29(3):545–580,March 2004.
[CDTW00] Jianjun Chen, David J. DeWitt, Feng Tian, and Yuan Wang. Niagaracq: Ascalable continuous query system for internet databases. In Proceedings of the2000 ACM SIGMOD International Conference on Management of Data, pages379–390, Dallas, USA, May 2000. ACM.
[CF02] Sirish Chandrasekaran and Michael J. Franklin. Streaming queries over stre-aming data. In VLDB 2002: Proceedings of 28th International Conference onVery Large Data Bases, pages 203–214, Hong Kong, China, August 2002. Mor-gan Kaufmann.
[CFF+02] Chee Yong Chan, Wenfei Fan, Pascal Felber, Minos N. Garofalakis, and RajeevRastogi. Tree pattern aggregation for scalable xml data dissemination. In VLDB
122

Literaturverzeichnis
2002: Proceedings of 28th International Conference on Very Large Data Bases,pages 826–837, Hong Kong, China, August 2002. Morgan Kaufmann.
[CFGR02] Chee Yong Chan, Pascal Felber, Minos N. Garofalakis, and Rajeev Rastogi.Efficient filtering of xml documents with xpath expressions. In Proceedings of the18th International Conference on Data Engineering, San Jose, USA, February2002. IEEE Computer Society.
[CJSS03] Chuck Cranor, Theodore Johnson, Oliver Spataschek, and Vladislav Shkape-nyuk. Gigascope: a stream database for network applications. In SIGMOD2003: Proceedings of the 2003 ACM SIGMOD international conference on Ma-nagement of data, pages 647–651, San Diego, USA, June 2003. ACM.
[Cov99] R. Cover. The sgml/xml web page, http://www.w3.org/tr/xslt. 1999.
[CW01] Antonio Carzaniga and Alexander L. Wolf. Content-based networking: A newcommunication infrastructure. In Developing an Infrastructure for Mobile andWireless Systems, NSF Workshop IMWS 2001, pages 59–68, Scottsdale, USA,October 2001. Springer.
[DAF+03] Yanlei Diao, Mehmet Altinel, Michael J. Franklin, Hao Zhang, and Peter M.Fischer. Path sharing and predicate evaluation for high-performance xml filte-ring. TODS: ACM Transactions on Database Systems, 28(4):467–516, Decem-ber 2003.
[DF03] Yanlei Diao and Michael J. Franklin. Query processing for high-volume xmlmessage brokering. In VLDB 2003: Proceedings of 29th International Confe-rence on Very Large Data Bases, pages 261–272, Berlin, Germany, September2003.
[DFF+98] Alin Deutsch, Mary F. Fernández, Daniela Florescu, Alon Y. Levy, and DanSuciu. Xml-ql. In QL 1998: The Query Languages Workshop (W3C Workshop),Boston, USA, December 1998.
[DL99] A.L. Diaz and D. Lovell. Xml generator,http://www.alphaworks.ibm.com/tech/xmlgenerator, 1999.
[DNGS03] Amol Deshpande, Suman Kumar Nath, Phillip B. Gibbons, and SrinivasanSeshan. Cache-and-query for wide area sensor databases. In Proceedings of the2003 ACM SIGMOD International Conference on Management of Data, pages503–514, San Diego, USA, June 2003. ACM.
[FCGR03] Pascal Felber, Chee Yong Chan, Minos N. Garofalakis, and Rajeev Rastogi.Scalable filtering of xml data for web services. IEEE Internet Computing, 7(1):49–57, 2003.
123

Literaturverzeichnis
[FJL+01] Françoise Fabret, Hans-Arno Jacobsen, François Llirbat, João Pereira, Ken-neth A. Ross, and Dennis Shasha. Filtering algorithms and implementationfor very fast publish/subscribe. In Proceedings of the 2001 ACM SIGMODConference, Santa Barbara, USA, May 2001.
[FLBC02] Leonidas Fegaras, David Levine, Sujoe Bose, and Vamsi Chaluvadi. Query pro-cessing of streamed xml data. In Proceedings of the 2002 ACM CIKM Interna-tional Conference on Information and Knowledge Management, pages 126–133,McLean, USA, November 2002. ACM.
[GHH+02] R. Govindan, J. Hellerstein, W. Hong, S. Madden, M. Franklin, and S. Shenker.The sensor network as a database. USC Technical Report No. 02-771, September2002.
[GMPQ+97] Hector Garcia-Molina, Yannis Papakonstantinou, Dallan Quass, Anand Rajara-man, Yehoshua Sagiv, Jeffrey D. Ullman, Vasilis Vassalos, and Jennifer Widom.The tsimmis approach to mediation: Data models and languages. Journal ofIntelligent Information Systems (JIIS), 8(2):117–132, 1997.
[GS03] Ashish Kumar Gupta and Dan Suciu. Stream processing of xpath queries withpredicates. In Proceedings of the 2003 ACM SIGMOD International Conferenceon Management of Data, pages 419–430, San Diego, USA, June 2003. ACM.
[Hal01] Alon Y. Halevy. Answering queries using views: A survey. The VLDB Journal,10(4):270–294, 2001.
[HR83] Theo Härder and Andreas Reuter. Principles of transaction-oriented databaserecovery. ACM Computing Surveys, 15(4):287–317, 1983.
[Hul97] Richard Hull. Managing semantic heterogeneity in databases: A theoreticalperspective. In Proceedings of the Sixteenth ACM SIGACT-SIGMOD-SIGARTSymposium on Principles of Database Systems, Tucson, USA, May 1997.
[IFF+99] Zachary G. Ives, Daniela Florescu, Marc Friedman, Alon Y. Levy, and Daniel S.Weld. An adaptive query execution system for data integration. In SIGMOD1999: Proceedings ACM SIGMOD International Conference on Management ofData, pages 299–310, Philadelphia, USA, June 1999. ACM Press.
[ILW00] Zachary G. Ives, Alon Y. Levy, and Daniel S. Weld. Efficient evaluation ofregular path expressions on streaming xml data. In Technical Report UW-CSE-2000-05-02, University of Washington., Washington, May 2000.
[KG02] A. Kwong and M. Gertz. Schema-based optimization of xpath expressions. InTechnical report, University of California Davis, 2002.
124

Literaturverzeichnis
[KSSS04] Christoph Koch, Stefanie Scherzinger, Nicole Schweikardt, and Bernhard Steg-maier. Schema-based scheduling of event processors and buffer minimization forqueries on structured data streams. In VLDB 2004: Proceedings of the ThirtiethInternational Conference on Very Large Data Bases, pages 228–239, Toronto,Canada, August 2004. Morgan Kaufmann.
[Lae06] Laemmel. Api-based xml streaming with flwor power and functional updates.In XML Conference, Boston, December 2006.
[LCHT02] Mong-Li Lee, Boon Chin Chua, Wynne Hsu, and Kian-Lee Tan. Efficient evalua-tion of multiple queries on streaming xml data. In Proceedings of the 2002 ACMCIKM International Conference on Information and Knowledge Management,pages 118–125, McLean, USA, November 2002. ACM.
[Ley01] M. Ley. Dblp dtd, http://www.acm.org/sigmod/dblp/db/about/dblp.dtd,2001.
[LM02] Georg Lausen and Pedro José Marrón. Adaptive evaluation techniques for que-rying xml-based e-catalogs. In Ride 2002: Proceedings of the 12th InternationalWorkshop on Research Issues on Data Engineering, pages 19–28, San Jose, USA,February 2002.
[LMP02] Bertram Ludäscher, Pratik Mukhopadhyay, and Yannis Papakonstantinou. Atransducer-based xml query processor. In VLDB 2002: Proceedings of 28thInternational Conference on Very Large Data Bases, pages 227–238, Hong Kong,China, August 2002. Morgan Kaufmann.
[LP02] Laks V. S. Lakshmanan and Sailaja Parthasarathy. On efficient matching ofstreaming xml documents and queries. In EDBT 2002: Advances in DatabaseTechnology - 8th International Conference on Extending Database Technology,Prague, Czech Republic, March 2002.
[LPT00] Ling Liu, Calton Pu, and Wei Tang. Correction to “continual queries for internetscale event-driven information delivery”. IEEE Transactions on Knowledge andData Engineering, 12(5):861, 2000.
[LWZ04] Yan-Nei Law, Haixun Wang, and Carlo Zaniolo. Query languages and datamodels for database sequences and data streams. In VLDB 2004: Proceedingsof the Thirtieth International Conference on Very Large Data Bases, pages 492–503. Morgan Kaufmann, August 2004.
[MF02] Samuel Madden and Michael J. Franklin. Fjording the stream: An architecturefor queries over streaming sensor data. In Proceedings of the 18th International
125

Literaturverzeichnis
Conference on Data Engineering, pages 555–566, San Jose, USA, March 2002.IEEE Computer Society.
[MFHH03] Samuel Madden, Michael J. Franklin, Joseph M. Hellerstein, and Wei Hong. Thedesign of an acquisitional query processor for sensor networks. In Proceedingsof the 2003 ACM SIGMOD International Conference on Management of Data,pages 491–502, San Diego, USA, June 2003. ACM.
[MFK01] Ioana Manolescu, Daniela Florescu, and Donald Kossmann. Answering xmlqueries on heterogeneous data sources. In VLDB 2001: Proceedings of 27thInternational Conference on Very Large Data Bases, pages 241–250, Roma,Italy, September 2001. Morgan Kaufmann.
[MLW03a] Pedro José Marrón, Georg Lausen, and Martin Weber. Catalog integrationmade easy. In Proceedings of the 19th International Conference on Data Engi-neering, pages 677–679, Bangalore, India, March 2003. IEEE Computer Society.
[MLW03b] Pedro José Marrón, Georg Lausen, and Martin Weber. Catalog integrationmade easy. In BTW 2003, Datenbanksysteme für Business, Technologie undWeb, Tagungsband der 10. BTW-Konferenz, pages 98–107, Leipzig, Germany,February 2003. GI.
[MS04] Gerome Miklau and Dan Suciu. Containment and equivalence for a fragmentof xpath. Journal of the ACM, 51(1):2–45, January 2004.
[MWA+03] Rajeev Motwani, Jennifer Widom, Arvind Arasu, Brian Babcock, Shivnath Ba-bu, Mayur Datar, Gurmeet Singh Manku, Chris Olston, Justin Rosenstein, andRohit Varma. Query processing, approximation, and resource management ina data stream management system. In CIDR 2003: First Biennial Conferenceon Innovative Data Systems Research, Asilomar, USA, January 2003.
[NACP01] Benjamin Nguyen, Serge Abiteboul, Gregory Cobena, and Mihai Preda. Moni-toring xml data on the web. In ACM SIGMOD Conference 2001, pages 437–448,Santa Barbara, USA, 2001.
[NAS04] NASA. Jpl sensor webs project, http://sensorwebs.jpl.nasa.gov, 2004.
[OFB04] Dan Olteanu, Tim Furche, and François Bry. An efficient single-pass query eva-luator for xml data streams. In SAC 2004: Proceedings of the 2004 ACM Sym-posium on Applied Computing, pages 627–631, Nicosia, Cyprus, March 2004.ACM.
[Olt07] Dan Olteanu. Spex: Streamed and progressive evaluation of xpath. IEEETransactions on Knowledge and Data Engineering, 19(7):934–949, 2007.
126

Literaturverzeichnis
[OMFB02] Dan Olteanu, Holger Meuss, Tim Furche, and François Bry. Xpath: Loo-king forward. In XML-Based Data Management and Multimedia Engineering -EDBT 2002 Workshops, XMLDM, MDDE, and YRWS, Prague, pages 109–127,Prague, Czech Republic, March 2002. Springer.
[Org01] SAX Project Organisation. Sax: Simple api for xml, http://www.saxproject.org.http://www.saxproject.org, 2001.
[Org03] International Standard Organization. Traffic and travel information (tti) - ttimessages via traffic message coding part 1: Coding protocol for radio datasystem – traffic message channel (rds-tmc) using alert-c, http://www.iso.org,2003.
[PC03] Feng Peng and Sudarshan S. Chawathe. Xpath queries on streaming data. InProceedings of the 2003 ACM SIGMOD International Conference on Manage-ment of Data, pages 431–442, San Diego, USA, June 2003. ACM.
[Sal68] Gerard. Salton. Automatic Information Organization and Retrieval. McGrawHill Text, 1968.
[SCG01] Alex C. Snoeren, Kenneth Conley, and David K. Gifford. Mesh based contentrouting using xml. In SOSP 2001: Proceedings of the 18th ACM Symposiumon Operating System Principles, pages 160–173, Chateau Lake Louise, Canada,October 2001. ACM.
[Sch02] T. Schlieder. Schema-driven evaluation of of approximate tree-pattern queries.In Advances in Database Technology 8th International Conference on ExtendingDatabase Technology, pages 514–532, Heidelberg, March 2002. Springer.
[TB02] Wee Hyong Tok and Stéphane Bressan. Efficient and adaptive processing ofmultiple continuous queries. In EDBT 2002: Advances in Database Technology -8th International Conference on Extending Database Technology, Prague, CzechRepublic, March 2002.
[TGNO92] Douglas B. Terry, David Goldberg, David Nichols, and Brian M. Oki. Conti-nuous queries over append-only databases. In SIGMOD 1992: Proceedings ofthe ACM SIGMOD International Conference on Management of Data, pages321–330. ACM Press, June 1992.
[Ull00] Jeffrey D. Ullman. Information integration using logical views. TheoreticalComputer Science, 239(2):189–210, 2000.
[Web07] Martin Weber. Xpath-transformationen zur integration von xml-datenströmen.In Post-Proceedings of the 19. GI-Workshop on Foundations of Databases
127

Literaturverzeichnis
(Grundlagen von Datenbanken), pages 32–36, Bretten, Germany, May 2007.School of Information Technology, International University.
[Wei95] Mark Weiser. The computer for the 21st century. In Human-computer inter-action: toward the year 2000, pages 933–940, San Francisco, CA, USA, 1995.Morgan Kaufmann Publishers Inc.
[Wie92] Gio Wiederhold. Mediators in the architecture of future information systems.IEEE Computer, 25(3):38–49, 1992.
[WK+02] Albrecht Schmidt 0002, Florian Waas, Martin L. Kersten, Michael J. Carey,Ioana Manolescu, and Ralph Busse. Xmark: A benchmark for xml data mana-gement. In VLDB 2002: Proceedings of 28th International Conference on VeryLarge Data Bases, pages 974–985, Hong Kong, China, August 2002. MorganKaufmann.
[XÖ05] Wanhong Xu and Z. Meral Özsoyoglu. Rewriting xpath queries using materia-lized views. In Proceedings of the 31st International Conference on Very LargeData Bases, pages 121–132, Trondheim, Norway, August 2005. ACM.
[YGM94] Tak W. Yan and Hector Garcia-Molina. Index structures for selective dissemi-nation of information under the boolean model. TODS: ACM Transactions onDatabase Systems, 19(2):332–364, 1994.
[ZD04] Patrick Ziegler and Klaus R. Dittrich. Three decades of data integration -all problems solved? In Building the Information Society, IFIP 18th WorldComputer Congress, Topical Sessions, pages 3–12, Toulouse, France, August2004. Kluwer.
128






















![기존 마크업 언어와 XML XML 필요성과 적용 분야 XML 관련 표준 XML 사용 환경 XML 개발 환경 [ 실습 ] 간단한 XML 문서 작성](https://img.dokumen.tips/doc/110x75/56814021550346895dab7f4b/-xml-xml-xml-.jpg)






