Embed Size (px)
Citation preview

2018/1/31
1
An Overview of Post-K Development
Yutaka IshikawaRIKEN AICS
9:00– 9:50 31st of January, 2018
28th‐31st, January, 2018HPC Asia 2018, Tokyo, Japan
Outline
FLAGSHIP2020 Project Co-Design and R&D organization CPU Architecture and Post-K System Software Light-Weight OS Kernel: IHK/McKernel
2018/1/31
2
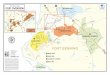
FLAGSHIP2020 Project
20018/1/31
LoginServersLoginServers
MaitenanceServers
MaitenanceServers
I/O NetworkI/O Network
………
……………………… Hierarchical
Storage SystemHierarchical
Storage System
PortalServersPortalServers
Missions• Building the Japanese national flagship supercomputer,
post K, and• Developing wide range of HPC applications, running on
post K, in order to solve social and science issues in Japan
Project organization• Post K Computer development
• RIKEN AICS is in charge of development• Fujitsu is vendor partner.• International collaborations: DOE, JLESC, CEA
• Applications• The government selected
• 9 social & scientific priority issues• 4 exploratory issues
and their R&D organizations.
Current Status• In the middle of “Design and
Implementation” phase.• CPU has been designed and is being
implemented• now evaluated by simulators and
compilers• System software stack has been
designed and is being implemented
3
NOW
(NCSA, ANL, UTK, JSC, BSC, INRIA, RIKEN)
Co-design:
4
Target Applications
Architectural Parameters• #SIMD, SIMD length, #core,
#NUMA node• cache (size and bandwidth)• memory technologies• specialized hardware• Interconnect• I/O network
9 social & scientific priority issues and their organizations
How we are running under the concept
Those are representatives ofalmost all our applications interms of computational methodsand communication patterns todesign architectural features.
2018/1/31
3
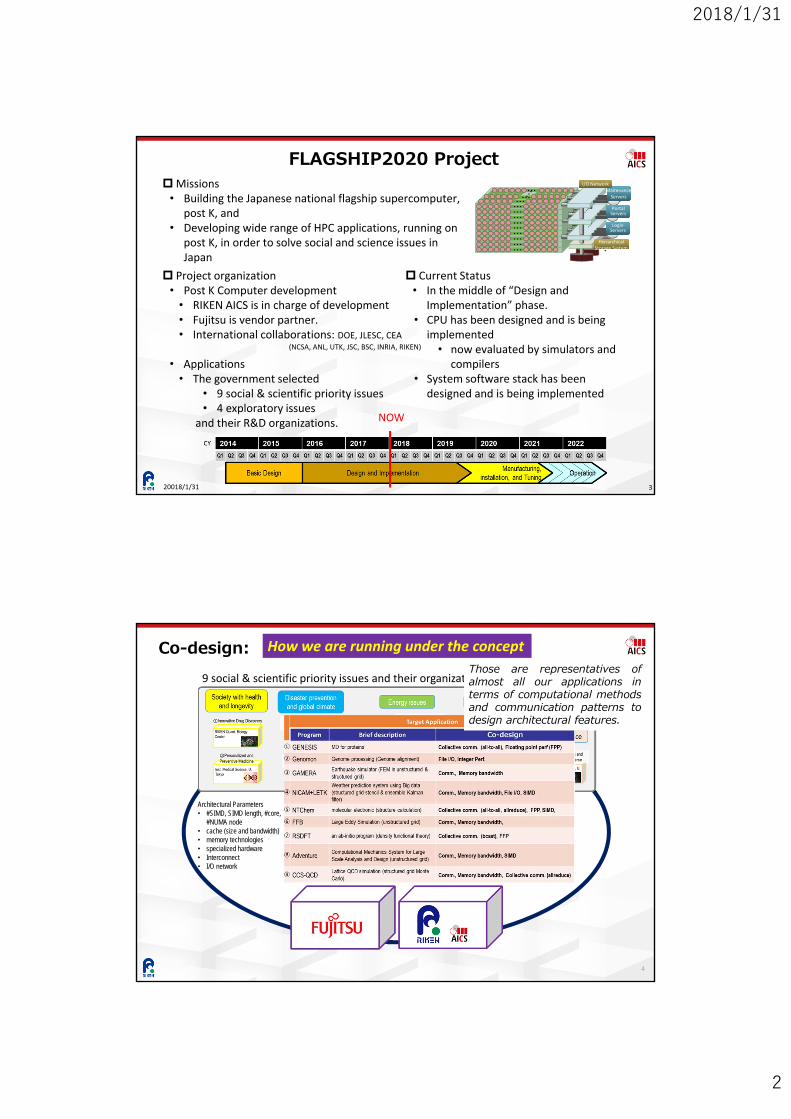
Co-design: How we are running under the concept
5
Architectural Parameters• #SIMD, SIMD length, #core, #NUMA node• cache (size and bandwidth)• memory technologies• specialized hardware• Interconnect• I/O network
Target Applications
Mutual understanding bothcomputer architecture/system software and applications
Looking at performance predicted by the following method
Prediction of node-level performance
Profiling applications, e.g., cache misses and execution unit usages
Prediction Tool
Prediction of scalability(Communication cost)
9 social & scientific priority issues and their organizations
Co-design: How we are running under the concept
6
Architectural Parameters• #SIMD, SIMD length, #core, #NUMA node• cache (size and bandwidth)• memory technologies• specialized hardware• Interconnect• I/O network
Target Applications
Mutual understanding bothcomputer architecture/system software and applications
Looking at performance predicted by the following method
Prediction of node-level performance
Profiling applications, e.g., cache misses and execution unit usages
Prediction Tool
Prediction of scalability(Communication cost)
9 social & scientific priority issues and their organizations
Finding out the best solution with constraints, e.g., power consumption, budget, and space

2018/1/31
4
R&D Organization
7
• DOE‐MEXT• JLESC• CEA
International Collaboration
•
• HPCI Consortium• PC Cluster Consortium• OpenHPC• …
Communities
• Univ. of Tsukuba• Univ. of Tokyo• Univ. of Kyoto
Domestic Collaboration
9 social & scientific priority issues and their organizations
International Collaborations DOE-MEXT
Optimized Memory Management, Efficient MPI for exascale, Dynamic Execution Runtime, Storage Architectures, Metadata and active storage, Storage as a Service, Parallel I/O Libraries, MiniApps for Exascale CoDesign, Performance Models for Proxy Apps, OpenMP/XMP Runtime, Programming Models for Heterogeneity, LLVM for vectorization, Power Monitoring and Control, Power Steering, Resilience API, Shared Fault Data, etc.
JLESC: Joint Laboratory on Extreme Scale Computing (NCSA, ANL, UTK, JSC, BSC, INRIA, RIKEN) Simplified Sustained System performance benchmark , Developer tools for
porting and tuning parallel applications on extreme-scale parallel systems,. HPC libraries for solving dense symmetric eigenvalue problems,.DTF+SZ: Using lossy data compression for direct data transfer in multi-component applications, Process-in-Process: Techniques for Practical Address-Space Sharing
CEA Programming Language, Runtime Environment, Energy-aware batch job
scheduler, Large DFT calculations and QM/MM, Application of High Performance Computing to Earthquake Related Issues of Nuclear Power Plant Facilities, KPIs (Key Performance Indicators)
20018/1/31 8
2018/1/31
5
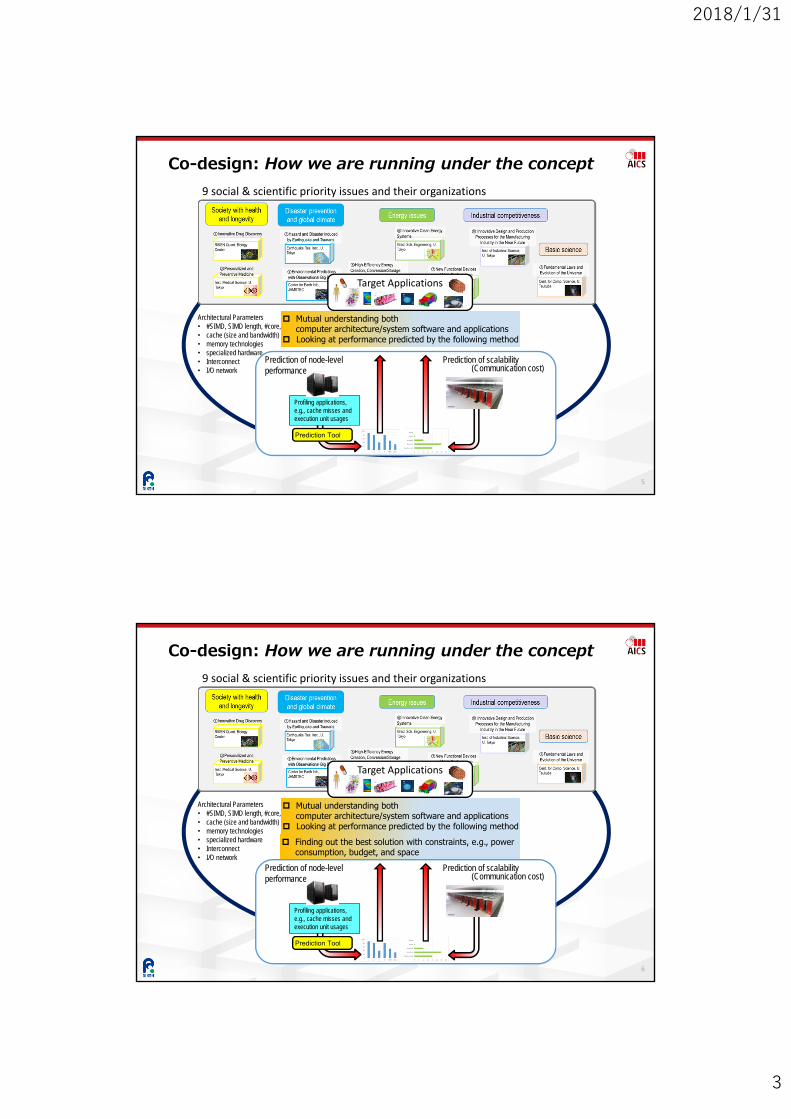
An Overview of Post K Compute Node, Compute + I/O Node Armv8-A SVE + Fujitsu Extension
6D mesh/torus Interconnect 3-level hierarchical storage system Silicon Disk Magnetic Disk Storage for archive
9
LoginServersLoginServers
MaintenanceServers
MaintenanceServersI/O NetworkI/O Network
…
HierarchicalStorage SystemHierarchical
Storage System
PortalServersPortalServers
…
……………
…
……
20018/1/31
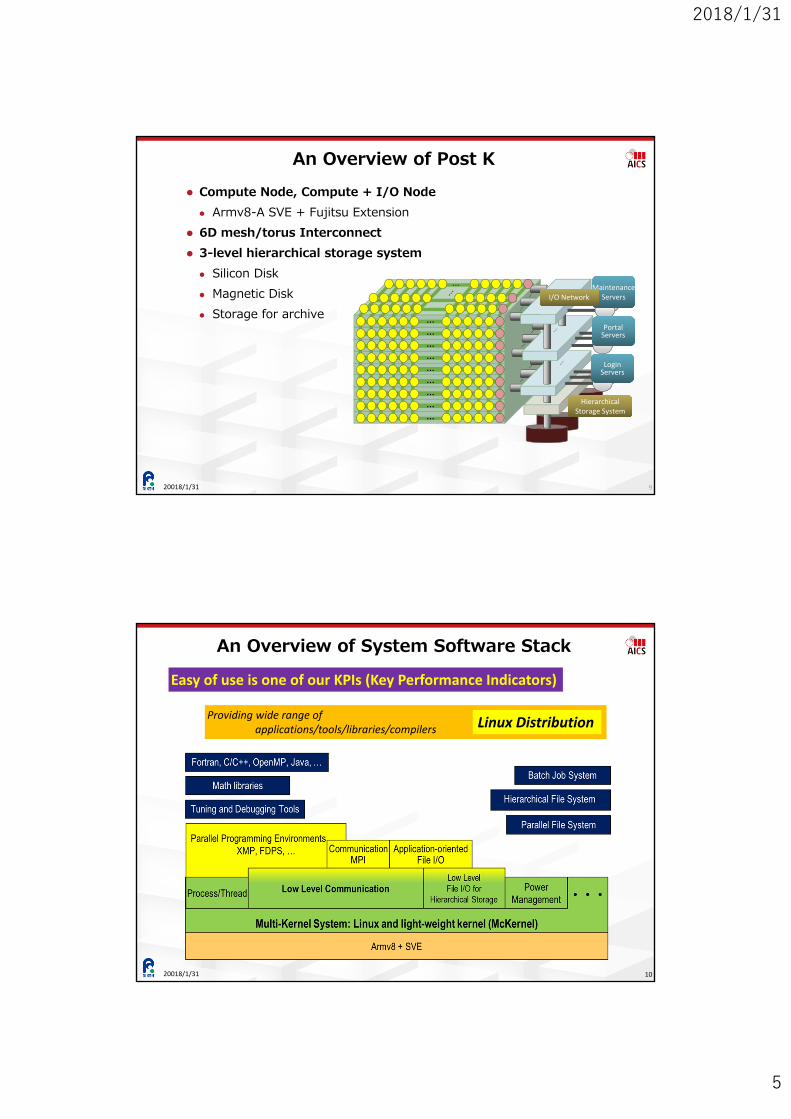
An Overview of System Software Stack
20018/1/31 10
Easy of use is one of our KPIs (Key Performance Indicators)
Providing wide range ofapplications/tools/libraries/compilers Linux Distribution

2018/1/31
6
Partition resources (CPU cores, memory)
Full Linux kernel on some cores System daemons and in-situ non
HPC applications Device drivers
Light-weight kernel(LWK), McKernel on other cores HPC applications
IHK/McKernel developed at RIKEN IHK: Linux kernel module
Allows dynamically partitioning of node resources: CPU cores, physical memory, …
Enables management of LWKs (assign resources, load, boot, destroy, etc..)
Provides inter-kernel communication, messaging and notification
McKernel: Light-weight kernel Is designed for HPC, noiseless, simple Implements only performance sensitive system
calls, e.g., process and memory management, and the rest are offloaded to Linux
Very simplememory
management
Thin LWKProcess/Thread management
General scheduler
Complex Mem. Mngt.
LinuxTCP stack
Dev. Drivers
VFS
File Sys Driers
Memory
… …Interrupt
Systemdaemons
?
HPC Applications
PartitionPartition
In‐situ non HPC application
Linux API (glibc, /sys/, /proc/)
Core Core Core Core Core Core
20018/1/31 11
• IHK/McKernel runs on• Intel Xeon and Xeon phi• Fujitsu FX10 and FX100 (Experiments)
Interface for Heterogeneous Kernels
Executes the same binary of Linux without any recompilation
How to deploy IHK/McKernel
• Linux Kernel with IHK kernel module is resident– daemons for job scheduler and etc. run on Linux
• McKernel is dynamically reloaded (rebooted) by IHK for each application
• No hardware reboot
Finish
App A, requiring LWK-without-scheduler, Is invoked
App B, requiring LWK-with-scheduler,
Is invoked
Finish
App
C,
usin
g fu
ll Li
nux
capa
bilit
y, Is
invo
ked
Finish
20018/1/31 12

2018/1/31
7
FWQ (Fixed Work Quanta) Benchmark
20018/1/31 13
https://asc.llnl.gov/sequoia/benchmarks
GeoFEM (University of Tokyo)
14
ICCG with Additive Schwartz Domain Decomposition - weak scaling Up to 18% improvement
0
2
4
6
8
10
12
14
16
1024 2048 4096 8192 16k 32k 64k 128k
Figu
re of merit (solved problem size
norm
alized to execution tim
e)
Number of physical cores
Linux IHK/McKernel
Acknowledgement: Kengo Nakajima, University of Tokyo, for providing GeoFEM. This result is on Oakforest‐PACS supercomputer, 25 PF in peak, at JCAHPC organized by U. of Tsukuba and U. of Tokyo
Results using the same binary
20018/1/31
Higher is better
Latest results will be presented at IPDPS’18 by Balazs Gerofi, et al.,Performance and Scalability of Lightweight Multi‐Kernel based Operating Systems

2018/1/31
8
CCS-QCD (University of Tsukuba)
15
Lattice quantum chromodynamics code - weak scaling Up to 38% improvement
0
1000
2000
3000
4000
5000
6000
7000
8000
9000
10000
1024 2048 4096 8192 16k 32k 64k 128k
MFlop/sec/node
Number of physical cores
Linux IHK/McKernel
Acknowledgement: Ken’ichi Ishikawa, Hiroshima University, providing CCS‐QCD. This result is on Oakforest‐PACS supercomputer, 25 PF in peak, at JCAHPC organized by U. of Tsukuba and U. of Tokyo
Results using the same binary
20018/1/31
Higher is better
16
miniFE (CORAL benchmark suite) Conjugate gradient - strong scaling Up to 3.5X improvement (Linux falls over.. )
0
2000000
4000000
6000000
8000000
10000000
12000000
1024 2048 4096 8192 16k 32k 64k
Total C
G M
Flops
Number of physical cores
Linux IHK/McKernel 3.5X
Oakforest‐PACS supercomputer, 25 PF in peak, at JCAHPC organized by U. of Tsukuba and U. of Tokyo
Results using the same binary
20017/12/18
Higher is better
2018/1/31
9
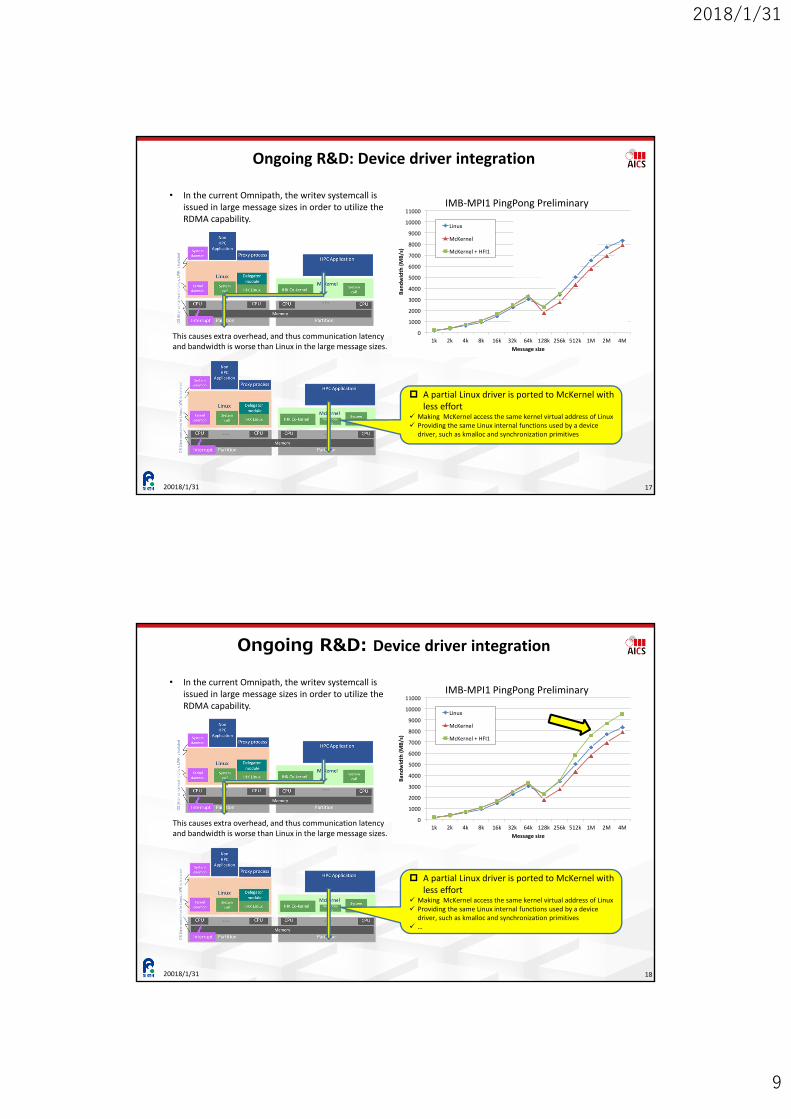
Ongoing R&D: Device driver integration
20018/1/31 17
0
1000
2000
3000
4000
5000
6000
7000
8000
9000
10000
11000
1k 2k 4k 8k 16k 32k 64k 128k 256k 512k 1M 2M 4M
Bandwidth
(MB/s)
Message size
Linux
McKernel
McKernel + HFI1
IMB‐MPI1 PingPong Preliminary• In the current Omnipath, the writev systemcall is
issued in large message sizes in order to utilize the RDMA capability.
This causes extra overhead, and thus communication latency and bandwidth is worse than Linux in the large message sizes.
A partial Linux driver is ported to McKernel with less effort
Making McKernel access the same kernel virtual address of Linux Providing the same Linux internal functions used by a device
driver, such as kmalloc and synchronization primitives
Ongoing R&D: Device driver integration
20018/1/31 18
0
1000
2000
3000
4000
5000
6000
7000
8000
9000
10000
11000
1k 2k 4k 8k 16k 32k 64k 128k 256k 512k 1M 2M 4M
Bandwidth
(MB/s)
Message size
Linux
McKernel
McKernel + HFI1
IMB‐MPI1 PingPong Preliminary• In the current Omnipath, the writev systemcall is
issued in large message sizes in order to utilize the RDMA capability.
This causes extra overhead, and thus communication latency and bandwidth is worse than Linux in the large message sizes.
A partial Linux driver is ported to McKernel with less effort
Making McKernel access the same kernel virtual address of Linux Providing the same Linux internal functions used by a device
driver, such as kmalloc and synchronization primitives …

2018/1/31
10
Concluding Remarks
The system software stack for post-K is being designed and implemented with the leverage of international collaborations, CEA, DOE Labs, and JLESC (NCSA, INRIA, ANL, BSC, JSC, RIKEN)
20018/1/31 19
The software stack developed at RIKEN is open source It also runs on Intel Xeon and Xeon phi