Embed Size (px)
DESCRIPTION
ESA2008@Universitat Karlsruhe, Sep 15, 2008. An Online Algorithm for Finding the Longest Previous Factors. Daisuke Okanohara University of Tokyo. Kunihiko Sadakane Kyushu University. Problem: Finding the longest previous factors (matching). Input : A text T[0…n-1] - PowerPoint PPT Presentation
Citation preview

An Online Algorithm for Finding the Longest
Previous Factors
Daisuke OkanoharaUniversity of Tokyo
ESA2008@Universitat Karlsruhe, Sep 15, 2008
Kunihiko Sadakane
Kyushu University

Problem: Finding the longest previous factors (matching)
• Input : A text T[0…n-1]• At all position k, report the longest substri
ng T[k-len+1…k] that also occurs in previous positions (history)T[pos…pos+len-1] = T[k-len+1…k]– c.f. LZ77, LZ-factorization
a b r a c a d a b r a (pos, len) = (0, 4)
a b r a c a d a b r a (pos, len) = (5, 2)d

Applications
• Data Compression– LZ77, Prediction by Partial Matching
• Pattern Analysis– Log analysis
• Data Mining

Previous approach
• Sequential search on the fly – O(n2) time for a text of length n
• Offline- Index approach– Read an whole text beforehand, and build an i
ndex (suffix array/trees) for it. – Search the match using the index
[Chen 07] [Chen 08] [Crochemore 08] [Kolpakov 01] [Larsson 99]
– 6n bytes, and O(n log n) time [Chen 08]Suffix Arrays with Range Minimum Query

New Problem: Online finding the longest previous factors
• Report match information just after reading each character– A case where we don’t know the length
of data beforehand, e.g. streaming data
• Previous approaches cannot deal with this problem

Our approach for new problem
• Online construction of enhanced prefix arrays– Update an index just after reading each
character– Although many methods used in LZ77
cannot report the longest match, our method can.
• Succinct data structures– Keep all information very compactly; using
about the same space for an original text

Prefix arrays
• Keep NOT suffix arrays (SA), but prefix arrays (PA)– because when a character is added at the last of a
text, SA may cause (n) changes, but PA not– In PA, prefixes are sorted in the reverse-
lexicographic orderT=aaaa
0 $1 a$2 aa$3 aaa$4 aaaa$
0 $4 aaaaz$3 aaaz$2 aaz$1 az$5 z$
SA for T SA for Tnew
0 $1 $a 2 $aa3 $aaa4 $aaaa
PA for T
0 $1 $a2 $aa3 $aaa4 $aaaa5 $aaaaz
PA for Tnew
Tnew=aaaaz

Our idea
• Weiner’s suffix tree construction algorithm– Insert the suffixes from the shortest ones– Modify it to the insert prefixes form the shortest ones– Similar idea is used for the incremental construction o
f compressed suffix arrays [Chan, et. al 2007], [Lippert 2005]
• We extend this work to the succinct version– Our algorithm reports matching information as a by-pro
duct of construction– Do not require tree representation, we just use array i
nformation

Preliminary: Dynamic Rank/Select Dictionary (DRSD)• For an text T[0…n-1], DRSD supports:
– rank(T, c, i): return the number of c in T[0…i]– select(T, c, i): return the position of i-th c in T– insert(T, c, i): insert c at T[i]– delete(T, i): delete T[i]
• These operations can be supported in time (O(logn) time if < logn),
bits spacewhere is the alphabet size [Lee, et. al. 07],

Preliminary: Range Minimum Query (RMQ)
• Given an array E[0…n-1] of elements from totally ordered set, rmq(E, l, r) returns the index of the smallest element in E[l…r]– i.e. rmq(E, l, r) = argmink∈[l, r]E[k]– return the leftmost such element in the tie
• In the static case, RMQ can be supported in O(1) time using 2n+o(n) bits space [Fischer, 2007]
• In the dynamic case, RMQ/insert/delete can be supported in O(Tlogn) time using O(n) bits if the lookup cost (E[i]) is O(T)

Data structures
• Keep the following data structures for T[0…k]– Assume T[0]=$, $ is the unique smallest character
• B[0…k]: (Prefix-) BW-transformed Text– B[i] = T[PA[i]+1] and B[i] = $ if PA[i]=k
• H[0…k]: Height Array– will be explained in the next slide
• C[0…-1] : Cumulative Array– C[c] = the total number of characters c’ s.t. c’ < c in T
• s: The position for the next prefix to be inserted

i PA
prefix B H
0 0 $ a 0
1 1 $a b 1
2 4 $abaa b 1
3 3 $aba a 3
4 8 $abaababa $ 3
5 6 $abaaba b 0
6 2 $ab a 2
7 5 $abaab a 2
8 7 $abaabab a 0
T = $abaababa

i PA prefix B H
0 0 $ a 0
1 1 $a b 1
2 4 $abaa b 1
3 3 $aba a 3
4 8 $abaababa $ 3
5 6 $abaaba b 0
6 2 $ab a 2
7 5 $abaab a 2
8 7 $abaabab a 0
T = $abaababa PA stores the end position of each prefix(we will omit this)Prefix stores prefixes sorted in the reverse-lexicographic order(Neither PA nor prefix are stored explicitly)We can examine PA[i] by using SAlookup operation using O(log2n) timeas in FM-index [Ferragina 00]

i prefix B H
0 $ a 0
1 $a b 1
2 $abaa b 1
3 $aba a 3
4 $abaababa $ 3
5 $abaaba b 0
6 $ab a 2
7 $abaab a 2
8 $abaabab a 0
T = $abaababaB stores the next character for each prefix(Burrows Wheeler’s transform for prefix arrays)

i prefix B H
0 $ a 0
1 $a b 1
2 $abaa b 1
3 $aba a 3
4 $abaababa $ 3
5 $abaaba b 0
6 $ab a 2
7 $abaab a 2
8 $abaabab a 0
T = $abaababaH stores the length of the longest common suffix between adjacent prefixes

i prefix B H
0 $ a 0
1 $a b 1
2 $abaa b 1
3 $aba a 3
4 $abaababa $ 3
5 $abaaba b 0
6 $ab a 2
7 $abaab a 2
8 $abaabab a 0
T = $abaababa
s = 4s denotes the position where $ in B, and the longest prefix is placed.

i prefix B H
0 $ a 0
1 $a b 1
2 $abaa b 1
3 $aba a 3
4 $abaababa $ 3
5 $abaaba b 0
6 $ab a 2
7 $abaab a 2
8 $abaabab a 0
T = $abaababa
C[$] =0C[a] = 1
C[b] = 6
C[c] = the number of characters c’ that is smaller than c in T(=B)

i prefix B H
0 $ a 0
1 $a b 1
2 $abaa b 1
3 $aba a 3
4 $abaababa $ 3
5 $abaaba b 0
6 $ab a 2
7 $abaab a 2
8 $abaabab a 0
T = $abaababaaThe next character `a’ comes !

i prefix B H
0 $ a 0
1 $a b 1
2 $abaa b 1
3 $aba a 3
4 $abaababa $ 3
5 $abaaba b 0
6 $ab a 2
7 $abaab a 2
8 $abaabab a 0
T = $abaababaa
Replace $ in B[s] with a(because $ is placed in the position of the longest prefix)
a

i prefix B H
0 $ a 0
1 $a b 1
2 $abaa b 1
3 $aba a 3
4 $abaababa a 3
5 $abaaba b 0
6 $ab a 2
7 $abaab a 2
8 $abaabab a 0
T = $abaababaa
Count the number of a in B[0…s-1] = rank(B, a, s-1) = 2
Find the position for the new prefix $abaababaa

i prefix B H
0 $ a 0
1 $a b 1
2 $abaa b 1
$abaababaa $
3 $aba a 3
4 $abaababa a 3
5 $abaaba b 0
6 $ab a 2
7 $abaab a 2
8 $abaabab a 0
T = $abaababaa
Insert $abaababaaat 3rd position in aC[a]+rank(B, a, s-1) =3 s := C[a]+rank(B, a, s-1), insert(B, s, $)

i prefix B H
0 $ a 0
1 $a b 1
2 $abaa b
$abaababaa $
3 $aba a 3
4 $abaababa a 3
5 $abaaba b 0
6 $ab a 2
7 $abaab a 2
8 $abaabab a 0
T = $abaababaa
Update H
This is actually the length of the longest match in the history

i prefix B H
0 $ a 0
1 $a b 1
2 $abaa b 1
3 $aba a 3
4 $abaababa $ 3
5 $abaaba b 0
6 $ab a 2
7 $abaab a 2
8 $abaabab a 0
T = $abaababa
Recall that in the previous step, $abaa and $aba are placed in the prefixes whose B is `a’
These positions can be found by using rank and select c. f. succ(T, `c’, s) = select(T, c, rank(T, s, c))

i prefix B H
0 $ a 0
1 $a b 1
2 $abaa b 1
3 $aba a 3
4 $abaababa $ 3
5 $abaaba b 0
6 $ab a 2
7 $abaab a 2
8 $abaabab a 0
T = $abaababa
RMQ ( H, 4, 6) = 5, H[5] = 0
ThereforeRMQ ( H, 4, 6) + 1 is the new value for the next H entry

i prefix B H
0 $ a 0
1 $a b 1
2 $abaa b 1
3 $aba a 3
4 $abaababa $ 3
5 $abaaba b 0
6 $ab a 2
7 $abaab a 2
8 $abaabab a 0
T = $abaababa
RMQ ( H, 3, 3) = 3, H[3] = 3
ThereforeRMQ ( H, 3, 3) + 1 is the new value for the nextH entry

i prefix B H
0 $ a 0
1 $a b 1
2 $abaa b 4
$abaababaa $ 1
3 $aba a 3
4 $abaababa a 3
5 $abaaba b 0
6 $ab a 2
7 $abaab a 2
8 $abaabab a 0
T = $abaababaa
rmq(H, 3, 3) + 1
rmq(H, 4, 6) + 1

i prefix B H
0 $ a 0
1 $a b 1
2 $abaa b 4
$abaababaa $ 1
3 $aba a 3
4 $abaababa a 3
5 $abaaba b 0
6 $ab a 2
7 $abaab a 2
8 $abaabab a 0
T = $abaababaa
Report max(4, 1) = 4 as the length of thelongest factorand report the positionof $abaa as SAlookup[2]- len = 0
Report (pos=0, len=4)as the max. matching

Overall algorithm
All operations are rank, select, RMQ

Overall Analysis
• H is stored in 2n bits [Sadakane , Soda 02]– naïve representation requires O(n log n) bits– requires one SA lookup operation to decode
• B is stored in nlog+ o(nlog) bits – by using dynamic rank/select dictionary
• The bottleneck of our algorithm is rmq(H, I, r) which requires O(log3n) time– SAlookup requires O(log2n) time

Overall Analysis (cont.)
• We can solve the online longest previous factor problem in O(log3n) time for each character, using nlog2+ o(nlog) + O(n) bits of space– where is the alphabet size, and n is the leng
th of a text

Simulating window buffer
• If the working space is limited, we often discards the history from the oldest ones
• We can simulate this by using the almost the same operations as in the insertion operation
• We actually do not discard a character but ignore it– If we actually discard an oldest character , it may cause
(n) changes in B and H– The effect of discarded character is remained (prefixes
are sorted according to the discarded characters)– But this does not cause the problem if we only report th
e matching information up to the history size

Experiments
• In experiment, we used a simpler data structure (algorithm is same)– B and H is store in the balanced binary tree– Each leaf stores the small block of B and H– We call this implementation as OS
• Compare OS with other offline algorithms– Require to read the whole text beforehand– CPSa, CPSd: SA+LCP with stack [Chen, et. al. 07]– CPS6n: SA with RMQ [Chen, et. al. 08]– kk-lz: mreps, specialized for σ=4 [Kolpakov 01]

Peak memory usage in bytes per input symbol
• The space of OS is smallest in many real data especially when the values in H is small

Runtime in milliseconds for searching the longest previous
factors
• OS is about 2 ~ 10 times slower than the fastest ones due to the dynamic operations

Conclusion
• Solve online longest matching problem by using enhanced prefix arrays– Simple and easy to implement– Require about 3 ~ 6 times space of the input te
xt– Actually this is a by-product of construction of co
mpressed suffix trees c.f. Weiner’s algorithm• Simple; and much room for improvements
– by using better rank/select/rmq implementation

Future work
• Construction of compressed suffix trees– Update the parenthesis tree efficiently– Actually, the time complexity for this is
smaller
• Practical improvements– Currently, dynamic succinct data structure
is not efficient due to cache misses, and memory fragmentation
– Approximated version of longest matching problem; enough for many application
Thank you for you attention !

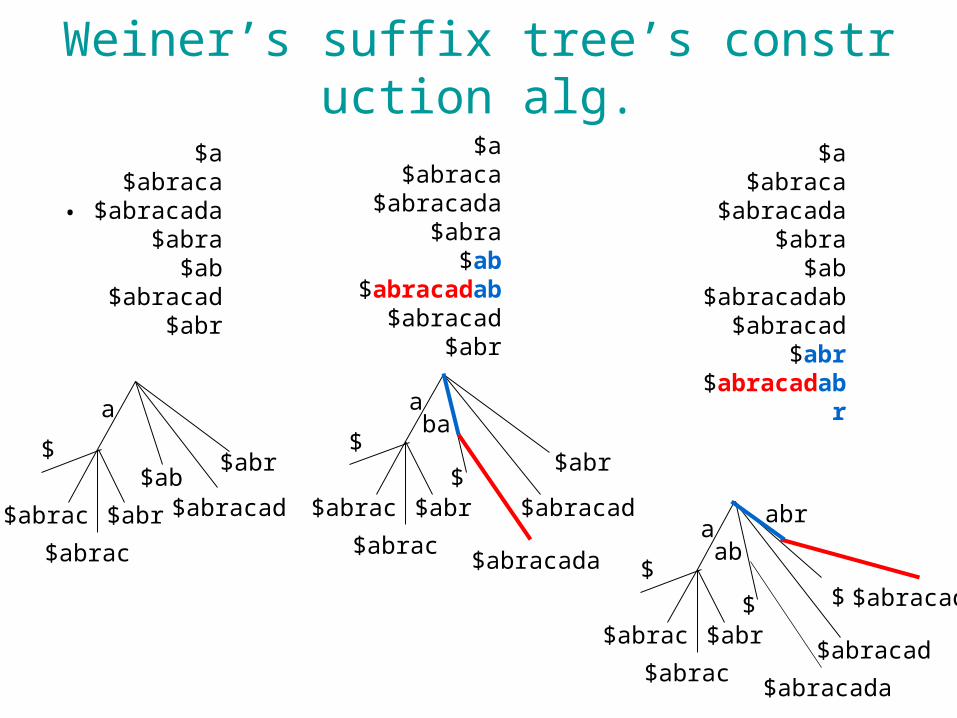
Weiner’s suffix tree’s construction alg.
. $a
$abraca$abracada
$abra$ab
$abracad$abr
a
$abrac
$ab$abracad
$abr
$abrac
$abr
$
a
$abrac$
$abracad
$abr
$abrac
$abr
$ba
$abracadaa
$abrac$
$abracad
$
$abrac
$abr
$ab
$abracada
$a$abraca
$abracada$abra
$ab$abracadab
$abracad$abr
abr
$abracad
$a$abraca
$abracada$abra
$ab$abracadab
$abracad$abr
$abracadabr





























