Embed Size (px)
DESCRIPTION
An Introduction to Support Vector Machine Classification. Bioinformatics Lecture 7/2/2003. by Pierre Dönnes. Outline. What do we mean with classification, why is it useful Machine learning- basic concept Support Vector Machines (SVM) Linear SVM – basic terminology and some formulas - PowerPoint PPT Presentation
Citation preview

An Introduction to Support Vector Machine Classification
Bioinformatics Lecture 7/2/2003
by
Pierre Dönnes

Outline
• What do we mean with classification, why is it useful
• Machine learning- basic concept• Support Vector Machines (SVM)
– Linear SVM – basic terminology and some formulas
– Non-linear SVM – the Kernel trick
• An example: Predicting protein subcellular location with SVM
• Performance measurments

Tennis example 2
Humidity
Temperature
= play tennis
= do not play tennis

Linear Support Vector Machines
x1
x2
=+1
=-1
Data: <xi,yi>, i=1,..,l
xi Rd
yi {-1,+1}

=-1=+1
Data: <xi,yi>, i=1,..,l
xi Rd
yi {-1,+1}
All hyperplanes in Rd are parameterize by a vector (w) and a constant b. Can be expressed as w•x+b=0 (remember the equation for a hyperplane from algebra!)
Our aim is to find such a hyperplane f(x)=sign(w•x+b), that correctly classify our data.
f(x)
Linear SVM 2

d+
d-
DefinitionsDefine the hyperplane H such that:xi•w+b +1 when yi =+1
xi•w+b -1 when yi =-1
d+ = the shortest distance to the closest poitive point
d- = the shortest distance to the closest negative point
The margin of a separating hyperplane is d+ + d-.
H
H1 and H2 are the planes:H1: xi•w+b = +1
H2: xi•w+b = -1The points on the planes H1 and H2 are the Support Vectors
H1
H2

Maximizing the margin
d+
d-
We want a classifier with as big margin as possible.
Recall the distance from a point(x0,y0) to a line:
Ax+By+c = 0 is|A x0 +B y0 +c|/sqrt(A2+B2)The distance between H and H1 is:|w•x+b|/||w||=1/||w||
The distance between H1 and H2 is: 2/||w||
In order to maximize the margin, we need to minimize ||w||. With the condition that there are no datapoints between H1 and H2:xi•w+b +1 when yi =+1
xi•w+b -1 when yi =-1 Can be combined into yi(xi•w) 1
H1
H2
H

The Lagrangian trickReformulate the optimization problem:A ”trick” often used in optimization is to do an Lagrangian formulation of the problem.The constraints will be replace by constraints on the Lagrangian multipliers and the training data will only occur as dot products.
Gives us the task:Max Ld = i – ½ijxi•xj,Subject to: w = iyixi
iyi = 0What we need to see: xiand xj (input vectors) appear only in the formof dot product – we will soon see why that is important.

Problems with linear SVM
=-1=+1
What if the decison function is not a linear?

Non-linear SVM 1The Kernel trick
=-1=+1
Imagine a function that maps the data into another space: =Rd
=-1=+1
Remember the function we want to optimize: Ld = i – ½ijxi•xj,
xi and xj as a dot product. We will have (xi) • (xj) in the non-linear case. If there is a ”kernel function” K such as K(xi,xj) = (xi) • (xj), wedo not need to know explicitly. One example:
Rd

Non-linear svm2The function we end up optimizing is:Max Ld = i – ½ijK(xi•xj), Subject to:
w = iyixi
iyi = 0
Another kernel example: The polynomial kernelK(xi,xj) = (xi•xj + 1)p, where p is a tunable parameter.Evaluating K only require one addition and one exponentiationmore than the original dot product.

Solving the optimization problem
• In many cases any general purpose optimization package that solves linearly constrained equations will do. – Newtons’ method– Conjugate gradient descent
• Other methods involves nonlinear programming techniques.

Overtraining/overfitting
=-1=+1
An example: A botanist really knowing trees.Everytime he sees a new tree, he claims it is not a tree.
A well known problem with machine learning methods is overtraining.This means that we have learned the training data very well, but we can not classify unseen examples correctly.

Overtraining/overfitting 2
It can be shown that: The portion, n, of unseen data that will be missclassified is bound by:
n No of support vectors / number of training examples
A measure of the risk of overtraining with SVM (there are also othermeasures).
Ockham´s razor principle: Simpler system are better than more complex ones.In SVM case: fewer support vectors mean a simpler representation of the hyperplane.
Example: Understanding a certain cancer if it can be described by one gene is easier than if we have to describe it with 5000.

A practical example, protein localization
• Proteins are synthesized in the cytosol.
• Transported into different subcellular locations where they carry out their functions.
• Aim: To predict in what location a certain protein will end up!!!
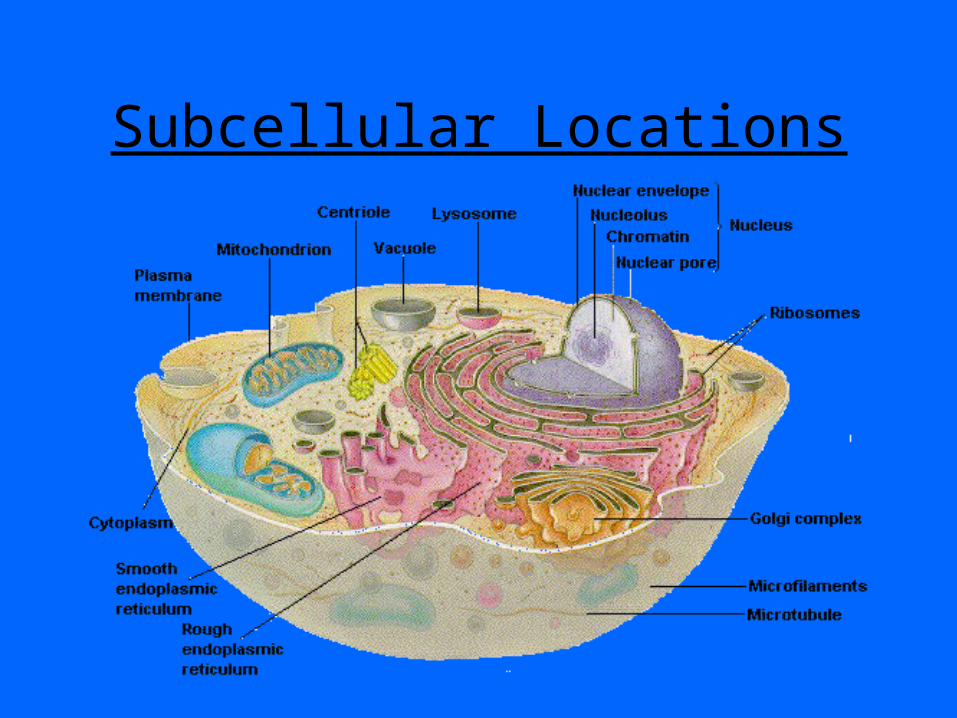
Subcellular Locations

Method• Hypothesis: The amino acid composition of
proteins from different compartments should differ.
• Extract proteins with know subcellular location from SWISSPROT.
• Calculate the amino acid composition of the proteins.
• Try to differentiate between: cytosol, extracellular, mitochondria and nuclear by using SVM

Input encodingPrediction of nuclear proteins: Label the known nuclear proteins as +1 and all others as –1. The input vector xi represents the amino acid composition.Eg xi =(4.2,6.7,12,….,0.5) A , C , D,….., Y)
Nuclear
All others
SVM Model

Cross-validationCross validation: Split the data into n sets, train on n-1 set, test on the set leftout of training.
Nuclear
All others
1
2
3
1
2
3
Test set1
1
Training set
2
3
2
3

Performance measurments
Model
=+1
=-1
Predictions
+1
-1
Test data TP
FP
TN
FN
SP = TP /(TP+FP), the fraction of predicted +1 that actually are +1.SE = TP /(TP+FN), the fraction of the +1 that actually are predicted as +1.
In this case: SP=5/(5+1) =0.83 SE = 5/(5+2) = 0.71

Results
• We definetely get some predictive power out of our models.
• Seems to be a difference in composition of proteins from different subcellular locations.
• Another questions: What about nuclear proteins. Is there a difference between DNA-binding proteins and others???

Conclusions
• We have (hopefully) learned some basic concepts and terminology of SVM.
• We know about the risk of overtraining and how to put a measure on the risk of bad generalization.
• SVMs can be useful for example in predicting subcellular location of proteins.

You can’t input anything into a learning machine!!!
Image classification of tanks. Autofire when an enemy tank is spotted.Input data: Photos of own and enemy tanks.Worked really good with the training set used.In reality it failed completely.
Reason: All enemy tank photos taken in the morning. All own tanks in dawn.The classifier could recognize dusk from dawn!!!!

Referenceshttp://www.kernel-machines.org/
AN INTRODUCTION TO SUPPORT VECTOR MACHINES(and other kernel-based learning methods)N. Cristianini and J. Shawe-TaylorCambridge University Press2000 ISBN: 0 521 78019 5
http://www.support-vector.net/
Papers by Vapnik
C.J.C. Burges: A tutorial on Support Vector Machines. Data Mining and Knowledge Discovery 2:121-167, 1998.





























