Embed Size (px)
Citation preview

An Interconnect-Centric Design Flow for Nanometer Technologies
Professor Jason CongProfessor Jason Cong<<[email protected][email protected]>>
UCLA Computer Science DepartmentUCLA Computer Science DepartmentLos Angeles, CA 90095Los Angeles, CA 90095
http://http://cadlabcadlab..cscs..uclaucla..eduedu/~/~congcong
VLSI-TSA'99 Jason Cong 2
Gate Delays vs. Interconnect Delays
Source: National Technology Roadmap of Semiconductors (1997)

VLSI-TSA'99 Jason Cong 3
Interconnect-Centric Design Methodology
deviceinterconnect
device interconnect
ProgramsData/Objects
Programs Data/Objects
nn Proposed transitionProposed transition
nn Analogy Analogy
device/function centric interconnect/communication centric
VLSI-TSA'99 Jason Cong 4
Interconnect-Centric Design Flow
nn Key steps in an interconnectKey steps in an interconnect--centric design flow:centric design flow:uu Interconnect PlanningInterconnect Planning
uu Interconnect SynthesisInterconnect Synthesis
uu Interconnect LayoutInterconnect Layout
nn Other supporting tools to enable an interconnectOther supporting tools to enable an interconnect--centric design flowcentric design flowuu Interconnect performance estimationInterconnect performance estimation
uu Interconnect performance verificationInterconnect performance verification

VLSI-TSA'99 Jason Cong 5
Outline of the Talk
nn Interconnect SynthesisInterconnect Synthesis
nn Interconnect Performance EstimationInterconnect Performance Estimation
nn Interconnect PlanningInterconnect Planning
VLSI-TSA'99 Jason Cong 6
Interconnect Synthesis
Constraints:
• Delay
• Skew
• Signal integrity
...
Spacing
SizingTopology
Optimized interconnect designs:
nn Automatic solutions guided by accurate interconnect Automatic solutions guided by accurate interconnect modelsmodels
Buffer insertion

Example: Single-Net Optimal Wire Sizing (OWS) [Cong-Leung, ICCAD’93]
nn Given:Given: A set of possible wire widths { WA set of possible wire widths { W11, W, W22, …, , …, WWrr }}
nn Find:Find: An optimal wire width assignment to minimize An optimal wire width assignment to minimize distributed RC delaydistributed RC delay
WiresizingOptimization
VLSI-TSA'99 Jason Cong 8
Example: Global Interconnect Sizing and Spacing (GISS) [Cong et al, ICCAD’97]
nn Given:Given:uu Initial layout of multiple nets Initial layout of multiple nets uu Critical sinks and their Critical sinks and their criticalitiescriticalitiesuu Capacitance model and design rulesCapacitance model and design rules
nn Output:Output:uu Sizing and spacing of every net to minimize RC Sizing and spacing of every net to minimize RC
delays with consideration of coupling cap.delays with consideration of coupling cap.
Spacing
Sizing

Capacitance Model
nn 2.5D capacitance model 2.5D capacitance model [[CongCong et al, DAC’97]et al, DAC’97]uu Consider: CConsider: Caa (area), (area), CCff (fringing) and (fringing) and CCxx (coupling) (coupling) uu Build capacitance table from 3D field solver (Build capacitance table from 3D field solver (FastCapFastCap))uu Table lookup by interpolation and extrapolationTable lookup by interpolation and extrapolation
cfCa
Cx
VLSI-TSA'99 Jason Cong 10
Main Approaches to GISS
nn Heuristic: Optimize one net at a time: bottomHeuristic: Optimize one net at a time: bottom--up dynamic programming (optimal for one net)up dynamic programming (optimal for one net)
nn Better approach: Compute upper and lower Better approach: Compute upper and lower bounds of opt. wire widths/bounds of opt. wire widths/spacings spacings of all netsof all netsuu Extended local refinement (ELR) using generalized Extended local refinement (ELR) using generalized
CHCH--posynomial posynomial formulationformulationuu Or iterative bound refinement (BR)Or iterative bound refinement (BR)uu In practice, lower and upper bounds meet most of In practice, lower and upper bounds meet most of
time => optimal solution.time => optimal solution.

VLSI-TSA'99 Jason Cong 11
GISS Optimization Results
Center spacing Average Delays( ns)
MIN OWS GISS/S GISS/M
2 x pitch 1.51 1.26 (-17%) 0.82 (-46%) 0.76 (-50%)
3 x pitch 1.33 0.73 (-45%) 0.56 (-58%) 0.50 (-62%)
4 x pitch 1.28 0.46 (-64%) 0.45 (-65%) 0.40 (-69%)
5 x pitch 1.25 0.38 (-70%) 0.37 (-70%) 0.35 (-72%)
nn 1616--bit 10mm bus structure equally spaced, with 5 bit 10mm bus structure equally spaced, with 5 different centerdifferent center spacingsspacings from 2x to 5x min. pitch from 2x to 5x min. pitch
nn pitch = min. width + min.spacingpitch = min. width + min.spacing
nn For nonFor non--equal net weights, GISS/M shall have more equal net weights, GISS/M shall have more advantage than GISS/Sadvantage than GISS/S
VLSI-TSA'99 Jason Cong 12
UCLA TRIO Package (Tree, Repeater, Interconnect Optimization)
nn Synthesis/optimization capabilitiesSynthesis/optimization capabilitiesuu Interconnect topology optimizationInterconnect topology optimizationuu Optimal buffer insertionOptimal buffer insertionuu WiresizingWiresizing optimizationoptimizationuu Global interconnect sizing and spacingGlobal interconnect sizing and spacinguu Simultaneous driver, buffer, and interconnect sizingSimultaneous driver, buffer, and interconnect sizinguu Simultaneous topology generation with buffer insertion and Simultaneous topology generation with buffer insertion and
wiresizingwiresizinguu ......
nn Efficient polynomialEfficient polynomial--time optimal/neartime optimal/near--optimal algorithmsoptimal algorithmsnn Interconnect performance can be improved by up to 7x !Interconnect performance can be improved by up to 7x !nn Available on the web: Available on the web: http://http://cadlabcadlab..cscs..uclaucla..eduedu/~trio/~trio
Demo at DAC’99Demo at DAC’99
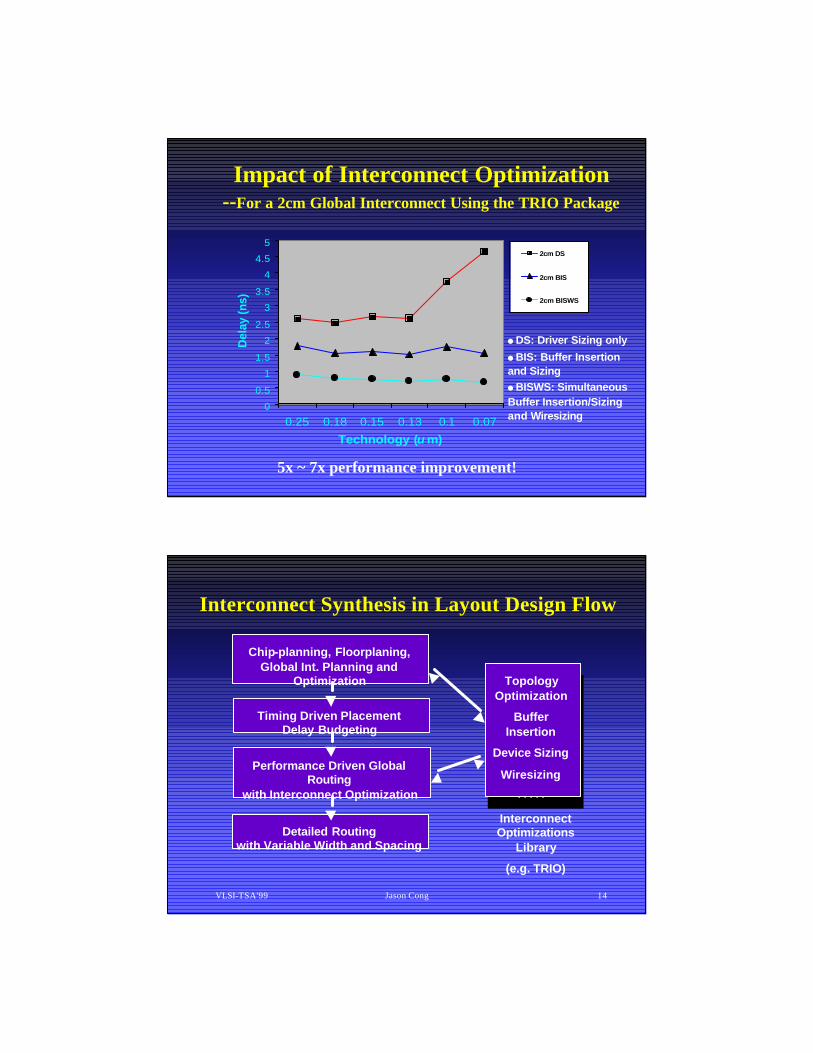
Impact of Interconnect Optimization--For a 2cm Global Interconnect Using the TRIO Package
0
0.5
1
1.5
2
2.5
3
3.5
4
4.5
5
0.25 0.18 0.15 0.13 0.1 0.07
Technology (u m)
Del
ay (n
s)2cm DS
2cm BIS
2cm BISWS
l DS: Driver Sizing only
l BIS: Buffer Insertion and Sizingl BISWS: Simultaneous Buffer Insertion/Sizing and Wiresizing
5x ~ 7x performance improvement!
VLSI-TSA'99 Jason Cong 14
Interconnect Synthesis in Layout Design Flow
Chip-planning, Floorplaning,Global Int. Planning and
Optimization
Timing Driven PlacementDelay Budgeting
Performance Driven Global Routing
with Interconnect Optimization
Detailed Routingwith Variable Width and Spacing
TopologyOptimization
Buffer Insertion
Device Sizing
Wiresizing
. . . . .
TopologyOptimization
Buffer Insertion
Device Sizing
Wiresizing
. . . . .
InterconnectOptimizations
Library
(e.g. TRIO)

VLSI-TSA'99 Jason Cong 15
Outline of the Talk
nn Interconnect SynthesisInterconnect Synthesis
nn Interconnect Performance EstimationInterconnect Performance Estimation
nn Interconnect PlanningInterconnect Planning
Interconnect Performance Estimation
nn Problem: Estimate the optimized interconnect Problem: Estimate the optimized interconnect delay, area, etc., without actually running the delay, area, etc., without actually running the optimization algorithms (such as TRIO)!optimization algorithms (such as TRIO)!
G
Input
G0
Csn
Cs2
Cs1
Sn
S1
S2

Needs for Interconnect Performance Estimation Models
nn Efficiency Efficiency uu need to explore many microneed to explore many micro--architectures/architectures/floorplans floorplans
=> require to process > 1 million nets/second=> require to process > 1 million nets/second
uu cannot afford actual synthesis/optimization (1cannot afford actual synthesis/optimization (1--100 nets/second)100 nets/second)
nn AbstractionAbstraction to hide detailed design informationto hide detailed design informationuu granularity of wire segmentationgranularity of wire segmentation
uu number of wire widths, buffer sizes, ...number of wire widths, buffer sizes, ...
nn Explicit relationExplicit relation to enable optimal design decision at high to enable optimal design decision at high levelslevels
nn Result:Result: very efficient (constantvery efficient (constant --time) estimation models time) estimation models for various interconnect optimization operationsfor various interconnect optimization operations
Example: Delay/Area Estimation under OWS
nn ClosedClosed--formform delay estimation formuladelay estimation formula
llcrcRcRlWl
lWl
ClRT fadfdLdows ⋅
++= +
)(2
)(),,(
2
1
22
1
αα
αα
where
arc41
1 =αLd
a
CRrc
21
2 =α,
W(x) is Lambert’s W function defined as we xw =
nn ClosedClosed--formform area estimation formulaarea estimation formula
lcR
ClcrClRAad
LfLdows ⋅+=
2)2(),,(

VLSI-TSA'99 Jason Cong 19
Delay Comparison of OWS model vs. TRIO
0
0.2
0.4
0.6
0.8
1
1.2
1.4
1.6
0 4000 8000 12000 16000 20000
length(um)
ns
Model TRIO
nn OWS delay model consistently matches TRIO.OWS delay model consistently matches TRIO.nn 0.10um technology from NTRS’97. Driver is 100x min. To run 0.10um technology from NTRS’97. Driver is 100x min. To run
TRIO, 40 discrete wire widths are used with the max width set TRIO, 40 discrete wire widths are used with the max width set to be 40x min width.to be 40x min width.
VLSI-TSA'99 Jason Cong 20
Average Width (Area) Comparison
00.20.40.60.8
11.21.41.61.8
2
0 4000 8000 12000 16000 20000
length(um)
width(um)Model TRIO
nn Area estimation model for OWS almost exactly matches TRIO.Area estimation model for OWS almost exactly matches TRIO.

Example:Delay Estimation Model for BIWS
nn Problem: estimate interconnect delay with optimal buffer Problem: estimate interconnect delay with optimal buffer insertion and wire sizing (BIWS)insertion and wire sizing (BIWS)
nn Critical lengthCritical length for BIWSfor BIWS::uu threshold length over which buffer insertion provides additionalthreshold length over which buffer insertion provides additional
delay reduction over optimal wiredelay reduction over optimal wire--sizing (OWS)sizing (OWS)
nn Critical length for BIWS can be computed efficientlyCritical length for BIWS can be computed efficiently
Critical Lengths of Un-Buffered Wires
Technology (um) 0.25 0.18 0.15 0.13 0.10 0.07b=10x 4.12 3.80 3.97 3.61 2.92 2.08b=50x 6.40 5.81 6.01 5.51 4.45 3.30
b=100x 7.47 6.83 7.04 6.39 5.30 3.91b=200x 8.65 7.92 8.14 7.43 6.35 4.49b=500x 9.98 9.10 9.30 8.57 7.13 5.21
unit: mm
Without wire sizing [Otten ISPD’98, Otten-Brayton DAC’98]
Min. WS 2.52 2.23 2.14 1.94 1.50 1.43
With optimal wire sizing [Cong-Pan, IWLS’98/ASP-DAC’99]

Example: Delay Estimation Model for BIWS (Cont’d)
gbiwsbiws tlT +⋅τ=
biwsτ is the slope, and can be obtained from optimal wire sizing for critical length
nn Linear delay estimation model for BIWS:Linear delay estimation model for BIWS:
Comparison of BIWS Model vs. TRIO
Delay Modeling
0
0.2
0.4
0.6
0.8
1
0 4000 8000 12000 16000 20000
length(um)
ns
Model TRIO
n Rd0 = rg /10, CL = cg x 10 , buffer type is 100 x min.
n For expt., max. wire width is 20x min. width, wire is segmented in every 100um.

VLSI-TSA'99 Jason Cong 25
Outline of the Talk
nn Interconnect SynthesisInterconnect Synthesis
nn Interconnect Performance EstimationInterconnect Performance Estimation
nn Interconnect PlanningInterconnect Planning
VLSI-TSA'99 Jason Cong 26
Interconnect Planning
nn Interconnect architecture planning (preInterconnect architecture planning (pre --design)design)uu Decide within freedom of fabrication technology:Decide within freedom of fabrication technology:
FF number of routing layersnumber of routing layersFF metal and isolation material at each layermetal and isolation material at each layerFF thickness of each metal and isolation layer thickness of each metal and isolation layer FF nominal width and spacing on each layernominal width and spacing on each layerFF vertical interconnection schemes (via structure?) ...vertical interconnection schemes (via structure?) ...
nn Interconnect planning with RTLInterconnect planning with RTL--floorplanfloorplan
nn Interconnect planning with physicalInterconnect planning with physical--level floorplanlevel floorplan

VLSI-TSA'99 Jason Cong 27
Interconnect Planning (cont’d)
nn Interconnect architecture planning (preInterconnect architecture planning (pre --design)design)
nn Interconnect planning with RTLInterconnect planning with RTL--floorplanfloorplanuu Define global and local interconnectsDefine global and local interconnects
uu Estimate overall interconnect distributionEstimate overall interconnect distributionuu Guide RTLGuide RTL--level and logiclevel and logic--level synthesis/optimizationlevel synthesis/optimization
FF ReRe--partition of design hierarchypartition of design hierarchyFF Logic replicationLogic replicationFF Retiming and pipeliningRetiming and pipeliningFF …...…...
nn Interconnect planning with physicalInterconnect planning with physical--level floorplanlevel floorplan
VLSI-TSA'99 Jason Cong 28
Interconnect Planning (cont’d)
nn Interconnect architecture planning (preInterconnect architecture planning (pre --design)design)
nn Interconnect planning with RTLInterconnect planning with RTL--floorplanfloorplan
nn Interconnect planning with physicalInterconnect planning with physical--level level floorplanfloorplanFF Interconnect topologiesInterconnect topologies
FF Wire orderingWire ordering
FF Wire width and spacingWire width and spacing
FF Number of buffers and their locationsNumber of buffers and their locations
FF …………

VLSI-TSA'99 Jason Cong 29
Example: Optimal Wire-Width Planning
n Given: u Certain technologyu Wire length distribution per layer
n Find:u A small set of “globally optimal” widths per layeru Performance/Area optimization
n Motivation u Simplify interconnect optimizationu Simply detailed routing, layout extraction, ...
Overall Flow
For each metal layer iAssign length range lmin and lmax;Find a small set of optimal widths W to minimize
Φ( , , ) ( ) ( , )min max
min
maxr rW l l l f W l dl
l
l
= ⋅∫ λ
h f(W, l): the objective function to be minimized by the design for wire length l, using Whλ (l): the weight function for wire length l
Method: Analytical or numerical

Objective in Our Study
(performance only)
(performance-driven and area-saving)
or
f W l A W l T W l
A area T delay
j k( , ) ( , ) ( , )
: :
r r r= ⋅
f W l T W l( , ) ( , )r r
=
f W l A W l T W l( , ) ( , ) ( , )r r r
= ⋅ 4
Recommendation for Future Tech.
nn 22--width design under objective function of ATwidth design under objective function of AT44
nn Wiring hierarchy for both performance and density !Wiring hierarchy for both performance and density !
Technology (um) 0.25 0.18 0.13 0.10 0.07Tier1 Range (mm) 0-2.50 0-1.80 0-1.30 0-1.00 0-0.70
W (um) 0.25 0.18 0.13 0.10 0.07Tier2 Range(mm) 2.50-6.50 1.80-5.85 1.30-3.27 1.00-2.84 0.70-2.30
W1(um) 0.25 0.18 0.13 0.10 0.08W2(um) 0.50 0.36 0.26 0.20 0.16
Tier3 Range(mm) 6.50-17.3 5.85-19.0 3.27-8.23 2.84-8.04 2.30-7.57W1(um) 0.65 0.47 0.24 0.22 0.23W2(um) 1.30 0.94 0.48 0.44 0.46
Tier4 Range(mm) - - 8.23-20.7 8.04-22.8 7.57-24.9W1(um) - - 0.98 1.00 1.06W2(um) - - 1.96 2.00 2.12
Strawman [Otten-Brayton, DAC’98]
1.0um
2.0um

Two Simple Wire Sizing Schemes
0
0.5
1
1.5
2
2.5
0 4000 8000 12000 16000 20000
length(um)
ns
Tier1-1WS
Tier1-2WS
Tier1-OWS
Tier4-1WS
Tier4-OWS
nn 11--WS and 2WS and 2--WS have less than 10% difference from OWS for WS have less than 10% difference from OWS for length <4mm in Tier1length <4mm in Tier1
nn Both 1Both 1--WS and 2WS and 2--WS work well in Tier4 up to chip sizeWS work well in Tier4 up to chip size
A Performance-Driven, Area-Saving Metric
0.01
0.1
1
100 0.5 1 1.5 2 2.5 3 3.5 4
width(um)
metr
ic
T AT^4 AT^3
AT^2 AT
Optimal widthfor delay T
Opt. width for AT4. Only increase delay by 10%, save area by 60%!
- 0.10um tech;- Top layer pair;- Length range 8 -23 mm;
- Assume uniformdistribution;
- Metric: integral of T, AT, AT2, …, AT4
- Driver/load 100xmin gate

Experimental Settingn For each metal pair (tier), assume certain wire length
rangen Assume the max length in tier1 is 10,000x feature size,
and top tier is Ledge (chip dimension) [Fisher+’98]
n Intermediate tier length range follows a geometric sequence
n Representative driver size for each metal layer (10x, 40x, 100x, and 250x for tiers 1-4)
1 2.84 8.04 22.8 mm
A Rather Surprising Result:2 Widths /Per Layer are Sufficient! [DAC’99]
n Assumptions: 0.10 um process, layers 7&8 ( 8.04 -- 22.8 mm), under AT4 metric, limited driver size variation size per layer
n 2-width design superior than 1-widthu delay reduction up to 12.4%u area saving up to 48% !
n 2-width design comparable to many-width u Avg. delay less than 5% and Max. delay less than 7%u Area difference less than 4.7%
avg-d max-erravg-w avg-d max-err avg-w avg-d max-err avg-w 1-width 0.245 28% 1.98 0.177 16% 1.83 0.143 6% 1.63 2-width 0.215 7% 1.08 0.167 5.90% 1.23 0.14 4% 1.41m-width 0.204 0% 1.03 0.159 0% 1.19 0.136 0% 1.38
pitch-sp=2um pitch-sp=2.9um pitch-sp=3.8umscheme

VLSI-TSA'99 Jason Cong 37
Summary
nn Paradigm shiftParadigm shiftuu Device/functionDevice/function--centric centric
=> interconnect/communication=> interconnect/communication--centriccentric
nn Key components in an interconnectKey components in an interconnect--centric centric design flowdesign flowuu Interconnect planningInterconnect planninguu Interconnect synthesisInterconnect synthesisuu Interconnect layoutInterconnect layout
nn Also need estimation, simulation, and verification tools Also need estimation, simulation, and verification tools at each stage for interconnect performance and signal at each stage for interconnect performance and signal integrityintegrity
VLSI-TSA'99 Jason Cong 38
Acknowledgements
nn Thanks for the supports fromThanks for the supports fromuu Semiconductor Research Corporation (SRC)Semiconductor Research Corporation (SRC)uu National Science Foundation (NSF)National Science Foundation (NSF)uu Defense Advanced Research Project Agency Defense Advanced Research Project Agency
(DARPA)(DARPA)uu Intel CorporationIntel Corporation
nn More information:More information:uu http://http://cadlabcadlab..cscs..uclaucla..eduedu/~/~concongg

“Logic Volume” within critical lengths
Technology (um) 0.25 0.18 0.15 0.13 0.10 0.07
2-NAND (um2) 7.80 4.04 3.00 2.18 1.28 0.64
b=10x 0.55 0.89 1.31 1.49 1.66 1.69b=50x 1.31 2.09 3.01 3.48 3.87 4.25b=100x 1.79 2.88 4.13 4.68 5.48 5.97b=200x 2.4 3.88 5.52 6.33 7.87 7.88b=500x 3.19 5.12 7.21 8.42 9.93 10.6
- Defined as the number of min 2-input NAND gates that can be packed within the area of lc/2 * lc/2
unit: million
VLSI-TSA'99 Jason Cong 40
Another Examp: Buffer Block Planning
nn Problem: automatically generates buffer blocks Problem: automatically generates buffer blocks during physicalduring physical--levellevel floorplanfloorplan
nn Motivation: Motivation: uu Avoid buffer over hard IPAvoid buffer over hard IP--blocks blocks uu Power/ground network sharing among buffersPower/ground network sharing among buffersuu More regular layout, etc.More regular layout, etc.
Logic BlocksBuffer Blocks

VLSI-TSA'99 Jason Cong 41
Experimental Result: Number of BB
nn RDMRDM: a buffer is randomly assigned to a feasible location: a buffer is randomly assigned to a feasible locationnn BBPBBP: buffers are clustered appropriately : buffers are clustered appropriately nn RESRES: Restricted (delay: Restricted (delay--minimal) buffer insertion pointminimal) buffer insertion pointnn FRFR: feasible buffer region for delay constraints: feasible buffer region for delay constraintsnn Our buffer block planning (BOur buffer block planning (B --P) algorithm can reduce the P) algorithm can reduce the
number of buffer blocks to 1/10~1/20 of those from RDMnumber of buffer blocks to 1/10~1/20 of those from RDM
Circuit R D M / R E S R D M / F R B B P / R E S B B P / F R
Apte 222 248 53 29X e r o x 460 515 83 44
H p 323 329 67 33A m i 3 3 338 376 97 42A m i 4 9 435 479 90 44playout 763 824 101 47
VLSI-TSA'99 Jason Cong 42
Interconnect Layout
nn Need a multiNeed a multi--layer generallayer general--area routerarea routeruu gridlessgridless
uu flexible (variable widths within the same segment, variable flexible (variable widths within the same segment, variable spacingsspacings for each pair of nets)for each pair of nets)
uu efficientefficient
nn Will leverage our current research on Will leverage our current research on gridless gridless routingroutinguu Use of implicit graph representationUse of implicit graph representationuu Use of computational geometry techniquesUse of computational geometry techniquesuu Highly scalable and flexibleHighly scalable and flexible





























