Embed Size (px)
Citation preview

An efficient and effective region-based image retrieval frameworkReporter: Francis
2005/5/12

2
Outline
1. Introduction
2. Image content representation
3. Region-based retrieval
4. Relevance feedback
5. Learning region weighting
6. Experiments

3
1.1 Region-based image retrieval
RBIR attempt to overcome the drawback of global features by representing images at object-level. It has three issues:
1. How to compare two images: definition of image similarity measure
2. How to make it scalable: saving time or space
3. How to make it improve retrieval accuracy by interacting with users: the strategy of RF

4
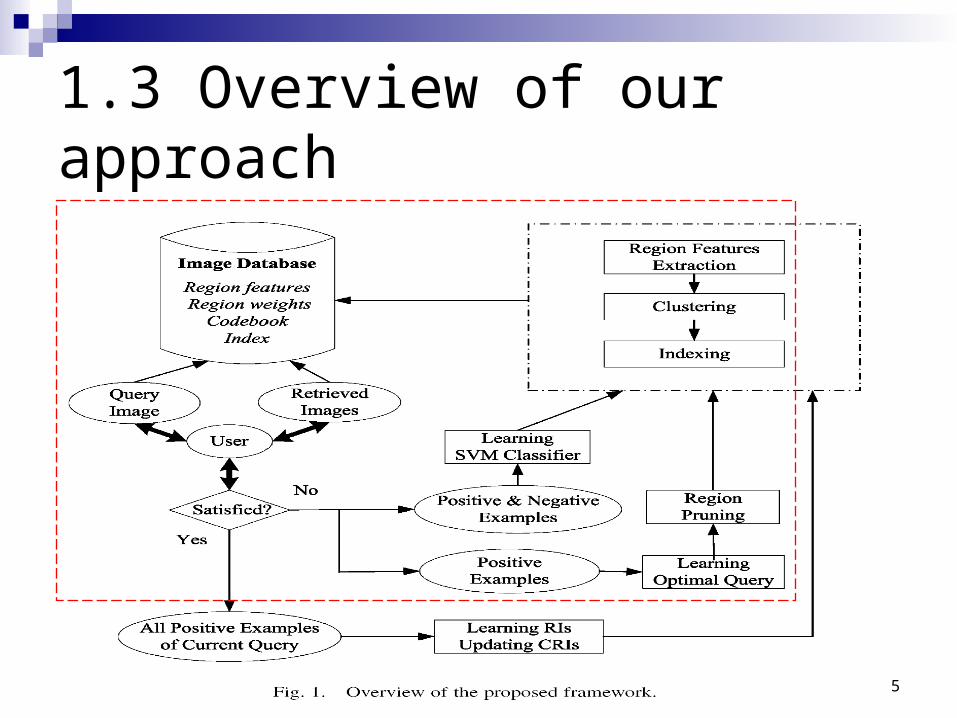
1.2 Our approach
1. The image similarity measure we adopt is the Earth Mover’s Distance (EMD) [26]
2. To be scalable, a region codebook is designed and utilized to save storages.
3. RF strategies: Only using positive feedback: QVM Using both positive and negative feedback:
modified SVM
5
1.3 Overview of our approach

6
2. Image content representation
Images are first segmented into homogeneous regions.(JSEG algorithm[6])
Visually similar regions are clustered to form a region codebook. Images are encoded in two ways:Compact representation that saves storage.Sparse and uniform representation enables ef
fective RF techniques.

7
2.1 Region properties
1. Visual features: we using color moment Simple, robust, effective.
2. Importance weight: Initial weight: the percentage of a region in
an image. (discussed in 5) The sum of importance weights for an image
should be normalized to 1.

8
2.2 Compact and sparse representations

9
3. Region–based retrieval

10
3.1 image similarity measure
Traditional measure: Euclidean distanceNot considering the correlation between two c
odewords. Earth Mover’s Distance (EMD) [26]:
A flexible similarity measure between multidimensional distributions.

11
3.1 image similarity measure

12
3.1 image similarity measure

13
3.2 Indexing using modified inverted file Inverted file (IF) is the most common indexing str
ucture used in information retrieval for simplicity and effectiveness.
For each codeword, a list of images corresponding to the codeword is stored as the IF.
When query a image, the codewords corresponding to the regions of the query are identified, then images that appear in the IF are regarded as candidates for further calculation.

14
3.2 IF’s problem

15
3.3 modified inverted file (MIT)
It contains not only a list of images but also k most similar codewords sorted by their similarity to it (Using EMD).意指 codeword間可以比較
If region’s weight is w, we expand codewords to it. If k is large more expanded codewords and mo
re accuracy results but more comparison time
kw*

16
4. Relevance feedback
Weighted query point movement: Using decaying factor α to reduce the effect of previo
us positive examples.
αis set to be 0 in the first iteration and (1/m) after the second iteration.
βis set to be 1/(n-m+1) and 1/[m(α-1)+n] after second iteration.

17
4. Relevance feedback
SVM with positive and negative example:Modified kernel is

18
5. Learning region weighting
Basis assumption in [14] is that important regions should appear more times in positive images and fewer times in negative images.

19
5.1 Basic definition
The region frequency is:

20
5.1 Basic definition
A region becomes less important for a query if it is similar to many images in the database. We define a measure called inverse image frequency:

21
5.2 Defining region importance
111
The cumulation makes the RI more robust.

22
6. Experiment results

23
6. Experiment results

24
6. Experiment results





























