Embed Size (px)
Citation preview

IEEE TRANSACTIONS ON LEARNING TECHNOLOGIES, TLT-2012-07-0092 1
An effective recommendation framework for personal learning environment using learner
preference tree and GAM. Salehi, I. Nakai Kamalabadi, and M.B. Gaznavi Goushchi
Abstract— Personalized recommendations are used to support activity of learners in the personal learning environments and this technology can deliver suitable learning resources to learners. This paper models dynamic and multi-preference of learners using multi-dimensional attributes of resource and learner’ rating by data mining technology to alleviate the sparsity and cold start problems and increase the diversity of recommendation list. The presented approach has two main modules: explicit attribute-based recommender and implicit attribute-based recommender. In the first module, learner preference tree (LPT) is introduced to model interests of learner based on explicit multi-dimensional attributes of resource and historical rating of accessed resources. Then, recommendations are generated by nearest neighborhood collaborative filtering (NNCF). In the second module, weights of implicit or latent attributes of resource for learners are considered as chromosomes in the genetic algorithm, and then this algorithm optimizes the weights according to historical rating. Then, recommendations are generated by NNCF using the optimized weight vectors of implicit attributes. The experimental results show that the proposed method outperforms current algorithms on accuracy measures and can alleviate cold-start and sparsity problems and also generate a more diverse recommendation list.
Index Terms—Collaborative filtering, learning environment, sparsity, personalized recommender, genetic algorithm, explicit attribute, implicit attribute.
—————————— ——————————
1 INTRODUCTIONEB-based education has undergone rapid develop-ment in recent years. With growth of many online learning systems, a huge amount of e-learning re-
sources have been generated which are highly heteroge-neous and in various media formats [1]. The task of deliv-ering personalized learning resource is often framed in terms of a recommendation task in which a system rec-ommends items to an active user [2]. To address infor-mation overload and personalization problems in e-learning environments, recommender systems have been proposed by many researchers. This research also pro-poses an effective recommendation framework for per-sonal learning environment based on attributes of learn-ers and resources. Using this approach, tutors can im-prove the performance of the teaching process and learn-ers can find their suitable online resources.
1.1 MotivationWith the explosion of e-learning resources and digital-
ization a lot of conventional learning resources, it is diffi-cult for learners to discover the most appropriate re-sources according to keyword searching method. On the other hand, several researches have addressed the need
for personalization in the web-based learning environ-ment. Researchers utilize recommendation techniques to resolve information overload in the new learning envi-ronment. By this means, there are still several challenging problems.
The first important problem relates to the sparsity and cold start problems in the e-learning environment. The sparsity problem occurs when rating data are insufficient for identifying similar users (neighbors). In practice rec-ommender systems are used to evaluate very large data sets and since each user only rates a small amount of items, the number of ratings given by the users is very small in comparison with the total number of (user; item) pairs in the system. Cold-start refers to the situation in which an item cannot be recommended unless it has been rated by a substantial number of users. This problem is particularly detrimental to users. Likewise, a new user has to rate a sufficient number of items before the rec-ommendation algorithm be able to provide reliable and accurate recommendations [3]. In the e-learning environ-ment, since various learners have different knowledge and different preferences, the common used items (re-sources) between them are few and therefore the similari-ty value between users will be unreliable. This leads to the sparsity and also the cold start problem.
The second important problem refers to the overspe-cialized recommendation results that occur when recom-mended items are very similar to each other and the rec-ommendation list isn’t diverse. The goal of recommenda-tion diversification is to identify a list of items that are dissimilar, but nonetheless relevant to the user’s interests.
xxxx-xxxx/0x/$xx.00 © 200x IEEE
———————————————— M. Salehi is with the Department of Industrial Engineering, K. N. Toosi University of Technology, Tehran, Iran. E-mail: m_salehi61@ yahoo.com I. Nakai Kamalabadi is with the the Department of Industrial Engineering, Tarbiat Modares University, Tehran, Iran. E-mail: nakhai@ modares.ac.ir. M.B. Gaznavi Goushchi is with the Electrical Department, Shahed Univer-sity, Tehran, Iran, E-mail: ghaznavi@ shahed.ac.ir
Manuscript received (insert date of submission if desired). Please note that all acknowledgments should be placed at the end of the paper, before the bibliography.
w
Digital Object Indentifier 10.1109/TLT.2013.28 1939-1382/13/$31.00 © 2013 IEEE
This article has been accepted for publication in a future issue of this journal, but has not been fully edited. Content may change prior to final publication.

2 IEEE TRANSACTIONS ON LEARNING TECHNOLOGIES, TLT-2012-07-0092
To the best of our knowledge, the diversity of the recom-mended list is defined by how much each item in the list differs from the others in terms of their attribute values [4]. On the other hand, to find similarity between items and user in the usual attribute-based recommendation algorithms, an exact matching between their attributes is necessary. This approach first leads to the low accuracy when there is not adequate attribute information about user and items and second makes the other well-known problem in recommender systems, over specialization.
The third vital challenge relates to how to gather at-tributes information and use them for modeling multi-preference of a learner in the resource recommendation. Because the selection of all suitable attributes for a learner and resource is an almost impossible mission. In addition, it is approximately impossible to collect the correspond-ing data; because some attributes could not be described and coded formally.
Such challenges are potent motivators to find suitable recommendation techniques capable of discovering learn-ing resource to the users.
1.2. ContributionIn response to the aforementioned problems, in this
study, a new hybrid recommender system (RS) applicable for e-learning environments is proposed. We can consider two groups of attributes for learning resources including explicit attributes and implicit (latent) attributes. Explicit attributes are known such as subject, publisher for learn-ing resources and can be extracted by experts, but implicit attributes that are latent can be inferred by historical rat-ing of learners. Some researches combined attributes (fea-ture) of users or items with historical rating for recom-mendation. Burke [5] reviewed several hybrid recom-mender methods developed to combine the external (we called explicit) features and historical rating data for higher predication accuracy. According to the experiment results reported, it is believed that both features and the historical ratings have great values to estimate the predi-cation function for recommendation. Therefore, the con-tribution of this study can be summarized as follows:
1. Establishment a new recommendation approach based on explicit and implicit of attributes of learning resources.
2. Implication of learner preference tree to model multi-preference of learners based on multi-dimensional explicit attributes of resource and rat-ing of learner simultaneously to alleviate the spar-sity and cold start problems and also improve the diversity of recommendation list.
3. Introduction of implicit attributes and optimiza-tion the weight of these attributes by genetic algo-rithm for each user and item to improve the accu-racy of recommendation when the information about explicit attributes is low.
2 LITERATURE REVIEWIn the recent years, most innovations in the education-
al system area have been introduction of new web-based
technologies to train learners in any time and any place. The creation of the technology for personalized lifelong learning has been recognized as a grand challenge prob-lem by peak research bodies [6]. Goal of technology en-hanced learning (TEL) is designing, developing and test-ing sociotechnical innovations that will support and en-hance learning practices of both individuals and organisa-tions.
Similar to other fields where there is a massive in-crease in product variety, in TEL there is also a need for better findability of (mainly digital) learning resources. For instance, in recent years numerous repositories with digital learning resources such as MERLOT (http:// ww.merlot.org) that has more than 40,000 learning re-sources and about 110,000 registered users, have been set up [7]. In this proliferation of online learning resources available, and considering the various opportunities for interacting with such resources in both formal and non-formal settings, it is necessary to creat a technology to help user groups identify suitable learning resources from a potentially overwhelming variety of choices. As a con-sequence, the concept of recommender systems has al-ready appeared in TEL.
Recommender systems address information overload and make a personal learning environment (PLE) for us-ers. PLEs solutions should provide facilities for empower-ing learners in using this kind of technology. Using this approach, we can improve a personal learning path ac-cording to pedagogical issues and available resource. In the TEL domain a number of recommender systems have been introduced in order to propose learning resources to users. Such systems could potentially play an important educational role, considering the variety of learning re-sources that are published online and the benefits of col-laboration between tutors and learners [8].
The recommender systems support a number of rele-vant user tasks within some particular application con-tent. Generally speaking, most of recommendation goals and user tasks in the other area such as e-commerce are valid in the case of TEL recommender systems as well. However, recommendation in a TEL context has many particularities that are based on the richness of the peda-gogical theories and models [9].
Most of recommendation systems are designed either based on content-based filtering or collaborative filtering (CF). Content-based filtering technique suggests items similar to the ones that each user liked in the past taking into account the object content analysis that the user has evaluated in the past [10]. On the other hand, based on the assumption that users with similar past behaviors have similar interests, a collaborative filtering system rec-ommends items that are liked by other users with similar interests. Both types of systems have inherent strengths and weaknesses. Table 1 presents an overview of the rec-ommendation strategies in TEL context. We briefly ex-plain some of important researches here:
Content based filtering: This strategy uses the features of items for recommendation. As Table 1 indicates these features may be used by case based reasoning (CBR) or data mining techniques for recommendation. CBR As-
This article has been accepted for publication in a future issue of this journal, but has not been fully edited. Content may change prior to final publication.

SALEHI ET AL.: TITLE 3
sumes that if a user likes a certain item, s/he will proba-bly also like similar items. This approach recommends new but similar items. However data mining techniques recommend items based on the matching of their attrib-utes to the user profile. CBR mechanisms have to evaluate all the cases in the case base to retrieve those most similar case(s) which makes their efficiency strongly and nega-tively related to the size of the applicable case base [11]. The performances of CBR mechanisms are closely related to the case representation and indexing approach, so their superior performances are unstable and cannot be guar-anteed. Semantic and multi-criteria recommender sys-tems also consider attributes of items. Semantic recom-mender systems instead of using syntactic matching tech-niques use inference techniques borrowed from the se-mantic web. This approach reasons about the semantics of items and user preferences to discover complex associa-tions between them [12]. Rating systems can model a us-er’s utility for a given item with the user’s ratings for each individual criterion [13]. Since more people will lurk in a virtual community than will participate; they usually do not spend time to rate based on each individual criterion in multi-criteria recommenders. Khribi et al. [14] used learners' recent navigation histories and similarities and dissimilarities among the contents of the learning re-sources for online automatic recommendations.
In fact, the existing metrics in content based filtering only detect similarity between items that share the same attributes. Indeed, the basic process performed by a con-tent-based recommender consists in matching up the at-tributes of a user profile in which preferences and inter-ests are stored, with the attributes of a content object (item), in order to recommend to the user new interesting items [10]. This causes overspecialized recommendations that only include items very similar to those the user al-
ready knows. To avoid the overspecialization of content-based methods, researchers proposed new personaliza-tion strategies, such as collaborative filtering and hybrid approaches mixing both techniques. Collaborative filtering: CF is regarded as one of im-portant and useful strategies in recommender systems [15]. CF approaches used in e-learning environments fo-cus on the correlations among users having similar inter-ests and can be divided in to three categories that have been shown in Table 1. Neighbor-based CF finds similar items or users based on rating data and predicts rating using weighted average of similar users or items. Model-based techniques predict rating of a user by learning of complex patterns based on the training data (rating ma-trix). In the demographics approach users with similar attributes are matched, then this method recommends items that are preferred by similar users. The collaborative e-learning field is strongly growing [16, 17], converting this area in an important receiver of appli-cations and generating numerous research papers. One of the first attempts to develop a collaborative filter-ing system for learning resources has been the Altered Vista system [18]. Proposed system collects user-provided evaluations of learning resources, and then propagates them in the form of word-of-mouth recommendations about the qualities of the resources. Lemire et al. [19] pro-posed RACOFI (Rule-Applying Collaborative Filtering) Composer system. RACOFI combines two recommenda-tion approaches by integrating a collaborative filtering engine, that works with ratings that users provide for learning resources, with an inference rule engine that is mining association rules between the learning resources and using them for recommendation. The QSIA (Ques-tions Sharing and Interactive Assignments) for learning resources sharing, assessing and recommendation has
TABLE 1
OVERVIEW OF THE RECOMMENDATION STRATEGIES
This article has been accepted for publication in a future issue of this journal, but has not been fully edited. Content may change prior to final publication.

4 IEEE TRANSACTIONS ON LEARNING TECHNOLOGIES, TLT-2012-07-0092
been developed by Rafaeli et al. [20]. A typical neighborhood-based set of CF algorithms have been tried in order to support learning object recommen-dation by Manouselis et al. [21]. Thier research considers multidimensional ratings that users provide on learning resources. According the results of this study it seems that the performance of the same algorithms is changing, depending on the context where testing takes place.
Since in the e-learning environment learning resources are in a variety of multimedia formats including text, hy-pertext, image, video, audio and slides, it is difficult to calculate content similarity of two items [1]. In this sense, since CF is completely independent of the intrinsic prop-erties of the items being rated or recommended, we can use users’ preference information that is a good indica-tion for recommendation in e-learning systems [22]. Re-gardless of its success in many application domains, col-laborative filtering has two serious drawbacks.
First, its applicability and quality is limited by the so-called sparsity problem, which occurs when the available data are insufficient for identifying similar users. There-fore, many researches were run to alleviate the sparsity problem using data mining techniques. For example, Romero et al. [23] developed a specific Web mining tool for discovering suitable rules in recommender engine. Their objective was to recommend to a student the most appropriate links/WebPages to visit next.
Second, it requires knowing many user profiles in or-der to elaborate accurate recommendations for a given user. Therefore, in some e-learning environments that number of learners is low; recommendation results have not adequate accuracy.
Hybrids: Combining several recommendation strate-gies can be expected to provide better results than either strategy alone [24]. Most hybrids work by combining sev-eral input data sources or several recommendation strate-gies. Table 1 lists some techniques that are used for hy-brid recommendation.
Li et al. [25] discovered content-related item sets by CF then applied the item sets to sequential pattern mining and generated sequential pattern recommendations to learners. Nadolski et al. [26] created a simulation envi-ronment for different combination of recommendation algorithms in hybrid recommender system in order to compare them against each other regarding their impact on learners in informal learning networks. Tang and McCalla proposed an evolving e-learning system, open into new learning resources that may be found online, which includes a hybrid recommendationservice [27]. Learning Object Recommendation Model (LORM) was proposed by Tsai et al. [28] that also follows a hybrid rec-ommendation algorithmic approach and that describes resources upon multiple attributes, but has not yet re-ported to be implemented in an actual system.
An appropriate recommendation technique must be chosen according to pedagogical reasons. These pedagog-ical reasons are derived from specific demands of lifelong learning [29]. Therefore, some recommendation tech-niques are more suitable for specific demands of lifelong learning than others. One way to implement pedagogical
decisions into a recommender system is to use a variety of recommendation techniques in a recommendation strate-gy. This paper uses two recommendation techniques based on explicit and implicit attributes of learners and resources.
3 EXPLICIT AND IMPLICIT ATTRIBUTESThe most important task of recommendation system is
modeling of user’s preferences and computing the appro-priateness degree of items for a target user. There are vari-ous preference elicitation methods employed in current decision support systems. Since the traditional methods are too time-consuming and tedious, the computer aided deci-sion support systems have appeared to simplify the task by making the assumption of additive preferential independ-ence.
In order to improve the accuracy of preferences elicited as well as save decision maker’s effort, another research branch on preference elicitation has aimed at releasing all assumptions on preference structure by matching new us-er’s preferences to other users’ preference models. The Col-laborative Filtering is also based on the similar idea, but the preferences matched are item ratings provided by different users [34]. Currently, CF method uses a rating matrix that is the result of interaction between users and items. Each cell of this matrix can be illustrated as a triple data set
which represents user’s historical prefer-ences, where is a user preference. These algorithms as-sume that user ratings on items are determined by the at-tributes of user and item corporately. In other words, If two items have similar attributes, the users would like to rate them similarly. On the other hand, if two users have simi-lar attributes, they are more likely to choose the same items. In this research, we use this reasonable assumption for recommendation process.
Since ratings depend on needs and attributes of learners and also attributes of resources, the rating prediction func-tion could be denoted as , M is a prediction model learned from the historical rating data H;
and are attributes weight of the learner i and resource j, respectively. Based on this view, the objective of recommender system prob-lem is to find a fit relationship between spaces attributes of learners and resources to generate appropriate recommen-dation. Unfortunately, in most cases we cannot use the mentioned model. Because the selection of all suitable at-tributes for a learner and resource is an almost impossible mission. Even if the attribute set is chosen, it is approxi-mately impossible to collect the corresponding data be-cause some data are involved the privacy of people or some attributes could not be described and coded formally. It leads the low accuracy of prediction only based on the limited observed attributes [35]. However, we can use the historical rating data in a user-item matrix for discovering some of valuable attributes of learner and learning resource that are called implicit at-tributes reflected characteristics of learning resource and learner. The predication models built based on the ob-
This article has been accepted for publication in a future issue of this journal, but has not been fully edited. Content may change prior to final publication.

SALEHI ET AL.: TITLE 5
served attributes plus latent (implicit) attributes should have relative higher prediction accuracy. In this resesrch, matrix factorization (MF) is used for implicit attribute ex-traction. However, genetic algorithm is used to generate the initial sloution of matrix factorization.
Let and denote implicit attributes space for users and items respectively. Let the vector
and represent user i and item j implicit attributes weight respectively. The prediction function could be denoted as
),,,,( Ij
Iiji IUIUM the historical rating data could be con-
verted to )},,,,{( ji
IIji RIUIUH
ji. This research uses near-
est neighborhood as a prediction model and also uses ge-netic algorithm to discover implicit attributes.
4 METHODOLOGYThe proposed framework shown in Fig. 1 is composed
of two main modules. In the explicit attribute-based mod-ule, using server usage logs of learners and rating, LPT is built for each learner. Then, according to the defined simi-larity between LPTs ratings are predicted. In the implicit attribute-based module, the weights of implicit attributes for each learner are calculated using genetic algorithm and MF. The proposed genetic algorithm can calculate the in-terest of learner for each attribute of learning resources.
4.1. Explicit attribute based moduleIdea of using LPT to model explicit interest of a learner
is useful, because this approach can reflect learners’ com-plete spectrum of interests and can take into account re-sources’ multi-dimensional attributes and learners’ rating information simultaneously. This approach traces learner preferences and can adapt recommendation results based
on changes in learner behavior. This tracing is performed based on changes in the rating of learner on multi-dimensional attributes of resources.
4.1.1. Interest learner modelingWe can consider some attributes for each learning re-
source for example subject that has some values such as literature and mathematics. In addition, since rating of learner’s accessed resources that have certain explicit at-tributes indicates the importance of these attributes for the learner; it can be considered as base for weighting of ex-plicit attributes for the learner. Therefore, the resource at-tributes’ description model can be defined as a vector
),(),...,,(),,( 12111 mAWAAWAAWAC where tA denotes the t-th dimensional attribute’s name of resource, tAW denotes the relevant weight value, mAWAWAW ...21 and
. Based on this description model, the attributes of a cer-tain resource jR can be defined as ),...,,( 21 mj AKKAKAR
where tKA denotes the t-th dimension attribute’s keyword of resource jR .To clarify explicit-based module, we use a running example in this section. In this research, we con-sider:
)].15.0,(),2.0,(),25.0,(),4.0,[(Pr PublisherlevelEducationsubjectSecondarysubjectimaryC After registering each resource in the system, system
developer must determine its attribute’s keywords such as: )./,,,(6 eTUPhDstatsticMathematicR
This research introduces a multidimensional attribute-based framework for recommendation that involves explic-it attributes of resource in the recommendation process, but selection of appropriate attributes may vary in the different systems. Relevant attributes of learning resources includ-ing type of object; author; owner; terms of distribution; format; and pedagogical attributes, such as teaching or interaction style could be selected. In this research, accord-ing to the simplicity and usefulness, we selected four at-tributes including: primary subject, secondary subject, edu-cation level (Bachelor Degree (B.D.), Master Degree (M.D.), PhD Degree (PhD.D.)) and publisher of resource. The most important attributes of a learning resource for interest modeling of learners are primary subject and secondary subject; therefore in this research we use a weighting ap-proach that allocates more weight for primary subject and secondary subject and less weight for other attributes.
LPT is introduced to combine multi-dimensional attrib-utes of accessed resources and learner’s rating information for making an information model of learner’s preference. Learner preference tree has (m+1)-level (start from 0) in which m denotes number of attributes of resource. In this tree, the leaf node which represents an accessed resource of the learner is defined as leafLPT ={RID, RR}, where RID denotes accessed resource ID of the learner, RR denotes the rating of learner to the resource (rating is considered be-tween 1 to 5). The non-leaf node can be defined as
leafnonLPT = {KA, RR, level}, where KA is the keyword of the level-th attribute of resource and level denotes the layer number of this node. A typical LPT that has four levels (correspond with four attributes of resources) is shown in Fig. 2. In this tree, each accessed resource corresponds to a
Fig. 1.System framework of the proposed resource RS.
This article has been accepted for publication in a future issue of this journal, but has not been fully edited. Content may change prior to final publication.

6 IEEE TRANSACTIONS ON LEARNING TECHNOLOGIES, TLT-2012-07-0092
unique path from root to the relevant leaf node, and the keywords of all nodes located in this path correspond to the relevant keywords of the resource’s attributes. The cor-responding route of 6R has been highlighted with red col-or.
As we can see in Fig. 2, the RR of non-leaf node k is de-fined as the mean of RR values of all leaf nodes which be-long to k’s sub-tree. For example for information technolo-gy node in the first level we have: 2/)13(2 . Using this definition, tree can transfer preferences of the learner from accessed resources to the highest level of attributes and indicate the importance of each attribute for the learner.
System updates LPTs using the following strategy: 1) Search the keywords of the latest accessed resource
attributes in the LPT from the up to the bottom. If the keyword of i-th attribute cannot be matched, the m−i+1 nodes with latter m−i+1 attribute’ keywords of the resource will be created.
2) Add a leaf node for the latest accessed resource in level m+1 at the proper position
3) Calculate RR of the new node’s all predecessors. If leaner aU visit ),.,,(3 UTDByprobabilitMathematicR
, to update the tree in Fig. 2, search “Mathematic” keyword in the first level, since there is this keyword in the first level of tree, it is matched, then search “probability” keyword in
the second level. As you can see, we do not have a match event in this level; therefore, we add the remaining nodes with their attribute’ keywords in the next levels. 3R is also added to level m+1 and then the RR of mathematic key-word is updated (change from 3 to 4).
4.1.2. Rating predictionAs a logical assumption, two learners with similar at-
tribute keywords in their LPTs can be considered as similar neighbors. Based on this assumption, we can solve sparsity problem. To define similarity degree, two rules are imple-mented:
(1) The more similar attributes of learner and learner ’s accessed resources, the larger similarity between them. (2) The more similar the rating data of learner and
learner , the larger similarity between them. Therefore, similarity degree between two learners can
be calculated based on the Attributes Intersection Subtree (AIS) between two relevant LPTs. AIS between learner and bU , ),( ba UUAIS , is defined as the maximum connected
intersection between aLPT and bLPT with same node’s keyword. We generated AIS between and as Fig. 3 shows. AIS is generated as follows: The traversing process is started on the most left nodes of aLPT and bLPT . If attrib-utes’ keywords of two trees be same, then two trees are matched in this level. At this time, a new node will be add-ed into the proper position in AIS. Then, the traversing process is continued from the most left node of immediate successors. If attributes’ keywords of two trees be different, process is continued from right node, and if we reach to the bottom of tree, then we backtrack to the last matching node between two LPTs and continue process from the right node. This process is continued until all nodes are trav-ersed.
Fig. 3 shows how we can obtain ),( ba UUAIS . To predict rating for learners; we calculate explicit attribute based similarity (EAB) between two learners that reflects the similarity between learners based on explicit attributes. Therefore, inspired from cosines similarity [38], this simi-larity can be defined by Equation (1).
Fig. 2. Learner preference tree sample
Fig. 3.Attributes Intersection Subtree (AIS) sample
This article has been accepted for publication in a future issue of this journal, but has not been fully edited. Content may change prior to final publication.

SALEHI ET AL.: TITLE 7
Where )(. aleveli URR indicates rating of user aU in level i of aLPT , corresponding with level i in AIS. We used this
similarity for our example between and . The result has been shown in above.
The predicated rating of learning resource i by aU us-ing explicit attribute based method, i
UEBA aP . , is obtained by
the rating of neighborhood, )( aEBA UN , that have rated i before. The computation formula is as the follows:
)(
)(. ),(
)(),(
aEBA
aEBAjj
aa
UNjjaEBA
UNjU
iUjaEBA
Ui
UEBA UUsim
RRUUsim
RP
(2)
Where aUR and jUR denote rating average of learning
resources rated by active learner aU and jU respectively
and ),( baEAB UUsim is the similarity between active learn-
er aU and jU that is a member of )( aEAB UN . However, if a learner does not have enough similar learners, tradi-tional algorithms will generate a lot of dissimilar learners which will definitely decrease the prediction accuracy of active learner. Thus, in order to enhance efficiency of cal-culation, neighborhood set should be preliminarily fil-tered via setting a similarity matching threshold τ. The two learners are effective similar neighbor only if the sim-ilarity between them is at least τ. Therefore, the top k learners, which have the largest k similarity between itself and aU and meanwhile satisfy the effective requirement,
are defined as aU ’s neighbors. After rating prediction, we rank resources according to their ratings and recommend top-N resources to active learner. In the our example, if we consider bU and cU (we assume
3,80.3,380.0),( 7cc UUcaEAB RRUUsim ) as neighbors
of aU , predicted rating for 7R will be
92.238.0411.0
)8.33(38.0)667.23(411.0167.37. aUEBAP
4.2. Implicit attribute based moduleThe time complexity of executing collaborative filter-
ing algorithm grows linearly with the number of items and the number of users. Therefore, growing number of users and resources tremendously for learning environ-ments, recommendation algorithms will suffer serious scalability problems, with computational resources going beyond practical or acceptable levels [38]. In general, GAs are believed to be effective on NP-complete global opti-
mization problems, and they can provide good near-optimal solutions in reasonable time. Therefore, this re-search uses a genetic algorithm for optimization of im-plicit attributes weight.
4.2.1. Implicit Attribute optimizationIn the attribute space, different people may place dif-
ferent emphases on the interrelated attributes. The goal of GA is to find the relationship between the overall rating and the underlying attributes rating for each learner. More specifically, given the ratings data of a learner, GA computes his/her preference model in terms of implicit attributes weight. Truly, we use genetic algorithm as a supervised learning task whose fitness function is the Mean Absolute Error (MAE) of the RS.
Coding strategy: Chromosome scheme that has been shown in the Fig. 4 represents the implicit attributes weights for users and items where ),...,,(
21IiK
IIIi wwwU
ii and
),...,,(21
IIIIj jKjj
eeeI indicate the implicit attributes weight
vector for user i and item j respectively that K is number of attributes and , . Each chromo-some has N+M rows correspond with N users and M items and also has columns correspond with K implicit attributes. Each attribute weight is coded in the form of a binary string. Since the value of weight is con-tinuous and also between 0 to 1, in order to express them with 1/1000th precision, 10 binary bits are used for each attribute weight because . Therefore, the length of chromosome will be . These 10 bit binary numbers are transformed into decimal float-ing numbers, ranging from 0 to 1 by applying the follow-ing equation (3):
(3)
Where x is the decimal number of the binary code for each attribute weight. For example, the binary code for
1210x
x
)(2
.)(2
.
),( ..
)(..)(.
)().(.),(
ba
ba
ULPTi bleveliiULPTi alevelii
UUAISi blevelialevelii
baEABURRAWURRAW
URRURRAWUUsim (1)
411.05.22.05.225.075.24.042.0425.05.34.0
5.242.05.2425.075.25.34.0),(222222baEAB UUsim
Fig. 4. Representation of Implicit attributes weight vectors in a chromo-some
This article has been accepted for publication in a future issue of this journal, but has not been fully edited. Content may change prior to final publication.

8 IEEE TRANSACTIONS ON LEARNING TECHNOLOGIES, TLT-2012-07-0092
the weight of the 1-th feature of user 1 in Fig. 4 is20)(111000010 . The decimal value of it is 10(900) and it is
interpreted as
880.08797653.0
1290010x
. Fitness function: Two matrixes,
and that indicate implicit attributes weight vectors for N users and M items respectively be-come the optimizing targets. Their initial solution could be some random values. The fitness function will be the MAE of the RS (indeed we only use the training rating since we are trying to find two optimal latent attributes weight matrixes) for particular matrixes, and . The MAE is obtained by comparing the real ratings with the predicted ratings made based on two matrixes. In order to calculate the MAE of the RS for particular matrixes, and that have been generated in one of generations of GA, we use the following equation (4):
N
i
jijk
K
kik Rewfitness
1
M
1j 1
i
.
(4)
Where jiR is real rating of item j by user i, and
are the weight of attribute k for user i and item j respec-tively and is the number of rated items by user i. It must be noted, since we only use the training rating in the learning stage of model, some of rated items by each user are selected as training set and the remaining rated items are considered as test set. When the fitness is lower, the rating prediction accuracy would be higher.
Selection: A probabilistic selection is performed based upon the individual’s fitness such that the better individ-uals have an increased chance of being selected. There-fore, the selection probability for each string is calculated by:
(5)
Where cfitness denotes the value of fitness function for chromosome c, PS is number of individuals in the popula-tion or population size and Cp denotes the selection probability for chromosome c. Since the sum of fitness in a population is constant, an individual with lower fitness (higher prediction accuracy) has larger probability to be chosen. We find that the universal sampling method scheme yields a good individual to be selected for the reproduction of the next population.
Crossover and Mutation: This study performs the crossover using a uniform crossover routine. The uniform crossover uses a fixed mixing ratio between two parents. Single-point and two point crossover methods may bias the search with the irrelevant position of the attributes. However, the uniform crossover method is considered better at preserving the schema and can generate any schema from the two parents. A single point mutation technique is used in order to introduce diversity.
4.2.2. Rating prediction After implicit attributes weight optimization, similari-
ty between learners using implicit attribute based (IAB) method can be calculated by the following formula that is a cosine similarity [36]:
(6)
To clarify our approach and run our example, we as-sume that Table 2 indicates the optimized implicit attrib-utes weight by GA for and . Therefore, the implicit attribute based similarity between and is as follows:
The predicated rating of learning resource i by aU us-
ing the implicit attribute based method is that is obtained by the rating of neighborhood, , that have rated i before. The computation formula is as fol-lows:
)(
)(. ),(
)(),(
aIBA
aIBA
jj
aa
UNjjaEBA
UNjU
iUjaIBA
UiUIBA UUsim
RRUUsim
RP (7)
Where and denote rating average of learning re-sources rated by active learner aU and jU respectively and
),( jaIBA UUsim is the similarity between active learner aU
and jU that is a member of . In this module, neighbors are determined similar to explicit based attrib-ute module. After rating prediction, we rank resources according to their rating and recommend top-N resources to active learner.
In the our example, similar to explicit attribute based method if we consider bU and cU (we assume
530.0),( caIAB UUsim ) as neighbors of aU , predicted rat-ing for 7R will be
19.340.0803.0
)8.33(40.0)667.23(803.0167.37. aUIBAP
4.3. RecommendationWe proposed two methods for learning resource rec-
ommendation: Explicit Attribute Based Collaborative Fil-tering (EAB-CF) and Implicit Attribute Based Collabora-tive Filtering (IAB-CF).To improve the quality of recom-mendations, we hybrid two methods by the weighted combination method. A linear combination of EAB-CF and IAB-CF is used for recommendation (EB-IB-CF). Therefore, for rating prediction the following formula is used:
iUEBA
iUIBA
iU aaa
PPP .. ).1(. (8) Where i
UaP denotes final predicted rate for learning re-
PS
C 1C
cc
fitness
fitness1p
This article has been accepted for publication in a future issue of this journal, but has not been fully edited. Content may change prior to final publication.

SALEHI ET AL.: TITLE 9
source i by aU . For our example, we have (we assume ):
11.3.3.0.7.0 7.
7.
7aaa UEBAUIBAU PPP
Finally top N-learning resources with the higher pre-dicted rate are considered as recommendation results.
5 EXPERIMENTSWe have conducted a set of experiments to set parame-
ters and examine the effectiveness of our proposed rec-ommendation approach in terms of recommendation ac-curacy and quality.
5.1. Simulation environment and data setFinding appropriate datasets for experimentation can
be a challenging task in TEL, as there are various sources of data that have not been identified and documented exhaustively. This research uses a real-world dataset in its experiment. MACE1 dataset that is a pan-European initia-tive to interconnect and disseminate digital information about architecture is used for experiments. This dataset is issued from MACE project that was done from September 2006 to September 2010. MACE enables architecture stu-dents to search through and find learning resources that are appropriate for their context. This dataset contains 1148 learners and 12000 resources. These objects hold to-gether about 47.000 tags, 12.000 classifications terms and 19.000 competency values. Tags were assigned by logged in users and the classification and competency terms by domain experts.
Most user actions with the MACE portal were logged, including search activities, using facetted search, social tags, geographical locations, classifications and/or com-petencies, access of learning resources, download of re-sources, social tagging, including add tag, add comment and add rating, and access of user pages. The time of each user activity is recorded. In addition to explicit rating feedback, access time, downloads, tags and comments can provide useful implicit indications that can be used to gain knowledge about user interests.
Data sets that can be used by the new proposed algo-rithms must include some features about learners, their action type and learning resources and also some features about the context of learning and results [37]. Learners must can login, search appropriate learning resources and also rate them. Our approach doesn’t use special infor-mation of learners, but it uses available attributes of learning materials. Presented framework in this research can use different attributes for learning resources based
1 - Metadata for Architectural Contents in Europe
on the simplicity and usefulness. Therefore, according to our data set the relevant attributes of learning resources including type of object; author; owner; terms of distribu-tion; format; and pedagogical attributes, such as teaching or interaction style could be used. It must be noted, some datasets haven’t explicit relevance indicators in the form of ratings that are relevant for research on recommenda-tion algorithms for learning.
5.2. Evaluation metricsIn this paper, the evaluation metrics of recommenda-
tion algorithms are divided into to three categories: Decision support accuracy metrics assume the predic-
tion process as a binary operation either items are pre-dicted (good) or not (bad). The precision and recall are the most popular metrics in this category. When referring to recommender systems, the recall and precision can be defined as follows:
fptptpRecall
(9)
fntptp
ecisionPr
(10)
Where tp stands for true positive, fp stands for false posi-tive, and fn stands for false negative. The threshold for de-termining true positive is set to 3.5 meaning that if an item is rated 3.5 or higher, it is considered to be accepted by the user.
Since increasing the size of the recommendation set leads to an increase in recall but at the same time a de-crease in precision, we can use measure [38] that is a well-known combination metric with the following for-mula:
callecisioncallecision
FRePr
Re.Pr.21
(11)
The other metrics that we use are predictive accuracy metrics. These statistical metrics measure how close the recommender system's predicted ratings are to the true user ratings. In this category, mean absolute error (MAE) is used with following formulas:
S
PRMAE
Si
iii
1
(12)
Where iP is the predicted rating for resource i, iR is the learner given rating for resource i, and S is the total number of the pair rating iP and iR .
Since most of recommendation algorithms have been developed based on accuracy measures, recommendation list produced by them contain similar items. Going to Amazon.com for a book by Isaac Asimov, for example, will give you a recommendation list full of all of his other books. In this case, the Item-Item collaborative filtering algorithm can trap users in a ‘similarity hole’, only giving exceptionally similar recommendations. Since accuracy metrics are designed to judge the accuracy of individual item predictions, they cannot see this problem.
TABLE 2
THE OPTIMIZED IMPLICIT ATTRIBUTES WEIGHT FOR AND
This article has been accepted for publication in a future issue of this journal, but has not been fully edited. Content may change prior to final publication.

10 IEEE TRANSACTIONS ON LEARNING TECHNOLOGIES, TLT-2012-07-0092
The recommendation list should be judged for its use-fulness as a complete entity, not just as a collection of in-dividual items. Therefore, in this research we introduced a new measure to compute similarity between recom-mended items in the recommendation list. Less similarity between items in the recommendation list, more diversity between them. An Intra-List Similarity Metric (ISM) [39] is defined as follows:
2#
),(
)( ,
List
RRf
ListISMlistR
jjilistR
i
i j
(13)
Where
m
RRmatRRf jiji
),(),(
(14)
Where function indicates number of matched at-tributes (similar attributes) between resource and and as it was said before is number of explicit attrib-utes for resources. Higher similarity denotes lower diver-sity. This measure is used to evaluate the quality of rec-ommendations.
5.3.Performance evaluationIn this section, the proposed recommendation ap-
proaches are compared with content-based recommenda-tion algorithm [36], collaborative-based recommendation algorithm [40] and hybrid recommendation algorithm [41]. Content-based recommendation algorithm extends the state of the art in recommender system by using mul-tiple TF-IDF vectors to keep track of user interest in dif-ferent domains. This approach uses the feature of re-sources in the recommendation process. Collaborative-based recommendation algorithm doesn’t use multi-dimensional attributes of resources. This algorithm that is based on the memory-based CF extends the state of the art in two ways. First, it uses the enhanced Pearson Corre-lation Coefficient (PCC) algorithm by adding one parame-ter which overcomes the potential decrease of accuracy when computing the similarity of users or items. Second, it uses an effective missing data prediction algorithm, in which information of both users and items is taken into account. While both content-based and collaborative fil-tering methods have their own advantages, individually they fail to provide good recommendations in many situ-ations. Hybrid recommendation algorithm that is used in this research applies an effective framework for combin-ing content and collaboration. It uses a content-based predictor to enhance existing user data, and then pro-vides personalized suggestions through collaborative filtering.
In order to increase the number of records in test set as much as possible so as to eliminate the effect of accidental factor, the top 60% access records of each learner in or-dered dataset are used as training set and the remnant 40% access records are used as test set..
In relevant input parameters, l denotes the number of
recommendation resources; p denotes the number of par-ticipated users which are selected from the dataset to build simulation dataset. We select only users that have rated at least 30 items in the dataset. , denote number of neighborhoods in the explicit and implicit at-tribute based recommendation module respectively. The value range of , , l and p are set in Table 3.
5.3.1. Parameters setting Firstly, we will analyze how some parameters affect
the recommendation performance of proposed algo-rithms. Goal of the following experiments is to determine the values of these parameters (as different dataset may correspond to different optimal value of these parame-ters). For the GA search, we examine the impacts of vari-ous combinations of crossover rate and mutation rate on the precision of implicit attribute based approach. Ac-cording to the experiments, crossover rate=0.8 and cross-over rate =0.15 give good results for our problem.
To be able to compare the effect of changing the initial size of population on the genetic algorithm efficiency and results, while l=20, p=200, =15 and K=8 an experi-ment was set up. Generation numbers are chosen from 0 (initial generated data without running the algorithm) to 800 generations with the step size of 50 generations. The algorithm has been run 50 times for each population size and each generation value. Fig. 5(a) shows the results. The figure only compares the average of best found solu-tions (in population). Results show that a higher popula-tion size provides a higher diversity and as a result con-verging to better solutions happens sooner than smaller population sizes. On the other hand, a higher population size needs more time for the algorithm to run. In this ex-periment, the population size of 20 lost diversity before reaching an acceptable solution. However, a population size of 200 does not provide much benefit over the popu-lation size of 100. We therefore will use a population size of 100 in four experiments. The genetic algorithm stops when there is an individual in the population with a fit-ness value lower than a constant . We use = 1.5. We have used this value according to the optimal values found in our experiments.
Fig. 5(b) shows the results obtained for the implicit at-tribute based approach with different number of implicit attributes while l=20, p=200 and =15. It can be seen that the performance improves steadily with the number of attributes increasing. To have a good efficiency in the computation, we set K=8.
TABLE 3ATTRIBUTES INTERSECTION SUBTREE (AIS) SAMPLE
This article has been accepted for publication in a future issue of this journal, but has not been fully edited. Content may change prior to final publication.

SALEHI ET AL.: TITLE 11
Fig. 5(c) shows the impacts of α on the of EB-IB-CF while l=20, p=200, =15 and K=8. It indicates that taking into consideration a combination of EAB-CF and IAB-CF to predict rating will play a positive role in the recommendation process, but α does not acknowledge ‘the larger the better’ rule. The best preci-sion can be obtained with α = 0.7.
5.3.2. Performance comparisonFig. 6(a) compares the proposed recommendation al-
gorithms with three traditional algorithms according to the number of similar neighbors while l=20, K=8 and p=250. With the increasing the number of similar neigh-bors, 1F of each algorithm is increasing except content-based algorithm. When this number reaches to a certain extent, with increasing of it, the precision of each algo-rithm is decreasing. The reason is that with increasing number of neighbors to a certain extent, several dissimilar users may be denoted as similar users by collaborative-based algorithm; therefore, the corresponding recom-mendation accuracy will decrease. For hybrid algorithm
that also considers content-based mechanism, there is less performance degradation. However, our proposed meth-ods will set a threshold in the similar users calculation process to guarantee the quality of them. Meanwhile the resource’s attributes are taken into account based on tra-ditional collaborative-based mechanism. Therefore, they can find effective similar users more accurately, and then only lead to a little performance degradation.
Fig. 6(b) compares algorithms with respect of the number of recommendation resources while
=15, K=8 and p=250. With the increasing of l, the 1F of each algorithm is decreasing. Moreover EB-IB-CF al-ways produces better performance than any other algo-rithm, especially when l is small. It is because that as the proposed method can make good use of the advantages of content-based and collaborative-based recommenda-tion mechanism while integrate three kinds of infor-mation: multi-dimensional attributes of resource, users’ rating and implicit attributes, hence the actual preference and interests of users can be reflected accurately.
Statistical performance analysis: To evaluate our pro-posed method, we implemented some statistical tests and compare EAB-CF and EB-IB-CF algorithms with the best results of traditional algorithms (Result of the hybrid al-gorithm) using the original educational data on MSE.
The results have been shown in Table 4 and Table 5, along with indications of statistical significance. The P-value indicates the strength of significance as measured by a large-sample paired hypothesis test. With the excep-tion of one data point (for l =10) in Table 4, there was no statistical difference between EAB-CF and the hybrid al-gorithm. But as Table 5 indicates EB-IB-CF performs sig-nificantly better than the hybrid algorithm.
Fig. 5a) Performance of IAB-CF with respect of Population Size
Fig. 5b) Performance of IAB-CF with respect of K
Fig. 5c) Effect of on F1 of EB-IB-CF
Fig. 6a) Comparison of different algorithms with respect of number of neighbors
Fig. 6b) Comparison of different algorithms with respect of number of recommendation
This article has been accepted for publication in a future issue of this journal, but has not been fully edited. Content may change prior to final publication.
12 IEEE TRANSACTIONS ON LEARNING TECHNOLOGIES, TLT-2012-07-0092
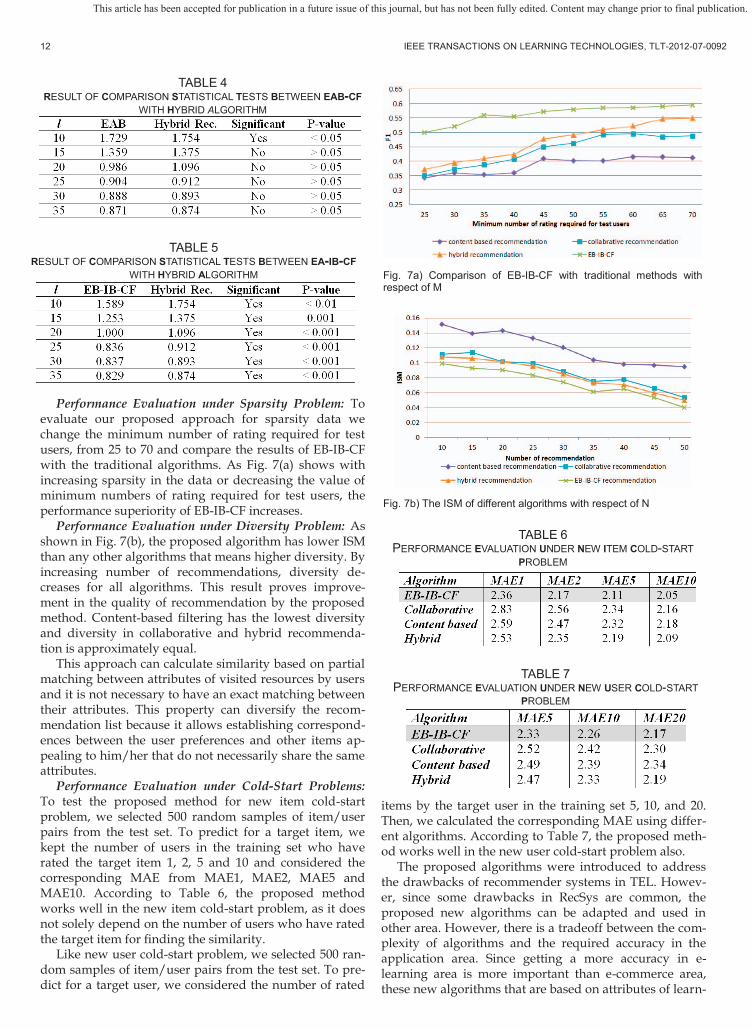
Performance Evaluation under Sparsity Problem: To evaluate our proposed approach for sparsity data we change the minimum number of rating required for test users, from 25 to 70 and compare the results of EB-IB-CF with the traditional algorithms. As Fig. 7(a) shows with increasing sparsity in the data or decreasing the value of minimum numbers of rating required for test users, the performance superiority of EB-IB-CF increases.
Performance Evaluation under Diversity Problem: As shown in Fig. 7(b), the proposed algorithm has lower ISM than any other algorithms that means higher diversity. By increasing number of recommendations, diversity de-creases for all algorithms. This result proves improve-ment in the quality of recommendation by the proposed method. Content-based filtering has the lowest diversity and diversity in collaborative and hybrid recommenda-tion is approximately equal.
This approach can calculate similarity based on partial matching between attributes of visited resources by users and it is not necessary to have an exact matching between their attributes. This property can diversify the recom-mendation list because it allows establishing correspond-ences between the user preferences and other items ap-pealing to him/her that do not necessarily share the same attributes.
Performance Evaluation under Cold-Start Problems: To test the proposed method for new item cold-start problem, we selected 500 random samples of item/user pairs from the test set. To predict for a target item, we kept the number of users in the training set who have rated the target item 1, 2, 5 and 10 and considered the corresponding MAE from MAE1, MAE2, MAE5 and MAE10. According to Table 6, the proposed method works well in the new item cold-start problem, as it does not solely depend on the number of users who have rated the target item for finding the similarity.
Like new user cold-start problem, we selected 500 ran-dom samples of item/user pairs from the test set. To pre-dict for a target user, we considered the number of rated
items by the target user in the training set 5, 10, and 20. Then, we calculated the corresponding MAE using differ-ent algorithms. According to Table 7, the proposed meth-od works well in the new user cold-start problem also.
The proposed algorithms were introduced to address the drawbacks of recommender systems in TEL. Howev-er, since some drawbacks in RecSys are common, the proposed new algorithms can be adapted and used in other area. However, there is a tradeoff between the com-plexity of algorithms and the required accuracy in the application area. Since getting a more accuracy in e-learning area is more important than e-commerce area, these new algorithms that are based on attributes of learn-
TABLE 6PERFORMANCE EVALUATION UNDER NEW ITEM COLD-START
PROBLEM
TABLE 4RESULT OF COMPARISON STATISTICAL TESTS BETWEEN EAB-CF
WITH HYBRID ALGORITHM
TABLE 5RESULT OF COMPARISON STATISTICAL TESTS BETWEEN EA-IB-CF
WITH HYBRID ALGORITHM
Fig. 7a) Comparison of EB-IB-CF with traditional methods with respect of M
Fig. 7b) The ISM of different algorithms with respect of N
TABLE 7PERFORMANCE EVALUATION UNDER NEW USER COLD-START
PROBLEM
This article has been accepted for publication in a future issue of this journal, but has not been fully edited. Content may change prior to final publication.

SALEHI ET AL.: TITLE 13
ing resources and learners are more suitable for learning environment.
6 CONCLUSIONOne of the most important applications of recommenda-tion systems in e-learning environment is personalization and recommendation of learning resources. To address the sparsity and cold start problems and have a more di-verse recommendation list for each learner, this paper presents a novel personalized recommendation frame-work that utilizes explicit and implicit attributes of re-sources in the unified model. The explicit attribute based recommender that uses LPTs for modeling the multi-preference of learners can alleviate the sparsity and cold start problems and also generate a more diverse recom-mendation list than traditional recommender systems. In addition, the implicit attribute based recommender that uses GAs for weight optimization of implicit attributes can increase the accuracy of recommendations. In addi-tion, our approach considers the knowledge concept in recommendation process implicitly. We can infer knowledge level from the preferences because learner preference tree is formed based on rating and behavior of the learner. Since a learner gives more rate to resources that are in her/his knowledge scope (primary subject and secondary subject), and also in her/his knowledge level (education type), system traces this rating and automati-cally recommends appropriate resources based on user knowledge. If a learner gives a more rate to a special re-source in the certain scope and level of knowledge, it means this resource can improve her/his knowledge bet-ter than other resources. For example, if a leaner has knowledge in the applied mathematical area and wants to improve her/his knowledge and reads more resources in the route of improving knowledge, s/he will give more rate to applied mathematical resources rather than pure mathematical resources, therefore system traces this be-havior and automatically recommends appropriate re-sources. However, there are some limitations that can determine some possible directions for further researches: First, many systems need to react immediately to online requirements and make recommendations for all users regardless of ratings history on visited resources, which demands a high scalability of a CF system. Second, there are some access rules of learners that this research doesn’t use them. For example: The learning processes (resource access processes) usually have some time-dependency relationship and are repeatability and periodicity. Therefore, the time-dependency relationship between learning resources in a learning process can re-flect learner’s resource access latent pattern and prefer-ence. Therefore, for further research, we can implement some techniques to increase the scalability of systems. For ex-ample clustering algorithms are good choices that can cluster users based on their behaviors and address the scalability problem by seeking users for recommendation within smaller and highly similar clusters instead of the
entire database. In addition, we can mine learner’s historical access rec-ords for discovering the resource access sequential pat-terns. Then, using these sequential patterns, we can pre-dict the most probable resource that a learner will access in near feature to further improve the quality of recom-mendations and solve the new user problem. In addition, using of real-coded genetic algorithms can be investigated for further researches.
REFERENCES[1] W. Chen, Z. Niu, X. Zhao, and Y. Li, “A hybrid recommenda-
tion algorithm adapted in e-learning environments,”World Wide Web, DOI 10.1007/s11280-012-0187-z, 16 september.
[2] B. Mobasher, “Data Mining for Personalization,” In: P. Brusilovsky, A. Kobsa and W. Nejdl, (eds.) The Adaptive Web: Methods and Strategies of Web Personalization, pp.1–46, 2007.
[3] A.I. Schein, A. Popescul and L.H. Ungar, “Methods and Metrics for Cold-Start Recommendations,". Proc. of the 25th Annual In-ternational ACM SIGIR Conference on Research and Development in Information Retrieval, pp. 253-260, 2002.
[4] S. McNee, J. Riedl, and J.A. Konstan. “Being Accurate Is Not Enough: How Accuracy Metrics Have Hurt Recommender Sys-tems,” Proceeding CHI EA '06 CHI '06 Extended Abstracts on Hu-man Factors in Computing Systems, pp. 1097-1101, 2006
[5] R. Burke, “Hybrid: Recommender systems: Survey and experi-ments,” Journal of User Modeling and User-Adapted Interaction, vol. 12, no. 4, pp. 331–370, 2002.
[6] J. kay, “Lifelong Learner Modeling for Lifelong Personalized Pervasive Learning,” IEEE Transaction on Learning Technology, vol. 1, no. 4, pp. 215-228, 2008.
[7] A. Tzikopoulos, N. Manouselis, R. Vuorikari, "An Overview of Learning Object Repositories", in P. Northrup (Ed.) Learning Objects for Instruction: Design and Evaluation, Hershey, PA: Idea Group Publishing, pp. 29-55, 2007.
[8] V. Kumar, J. Nesbit, K. Han, “Rating Learning Object Quality with Distributed Bayesian Belief Networks: The Why and the How”, in Proc. of the Fifth IEEE International Conference on Ad-vanced Learning Technologies (ICALT'05), pp. 685-687, 2005.
[9] N. Manouselis, H. Drachsler, R. Vuorikari, H. Hummel,R. Ko-per,“Recommender Systems in Technology Enhanced Learn-ing,”In P. B. Kantor, F. Ricci, L. Rokach, B. Shapira (Eds.), Rec-ommender Systems Handbook, pp. 387-415, 2011.
[10] P. Lops, M. de Gemmis and G. Semeraro, “Content-based Rec-ommender Systems: State of the Art and Trends,”Recommender Systems Handbook, pp. 73-105, 2011.
[11] P.-C. Chang and C.-Y. Lai, “A hybrid system Knowledge-Based Systems, combining self-organizing maps with case-based rea-soning in wholesaler's new-release book forecasting,”Expert Systems with Applications, vol. 29, no. 1, pp. 183-192, 2005.
[12] Y. Blanco-Fernandez, et al., “A flexible semantic inference methodology to reason about user preferences in knowledge-based recommender systems,”Knowledge-Based Systems, vol. 21, no. 4, pp. 305–320, 2008.
[13] G. Adomavicius, N. Manouselis and Y. Kwon, “Multi-Criteria Recommender Systems,”Recommender Systems Handbook, pp. 769-803, 2011.
[14] M.K. Khribi, M. Jemni and O. Nasraoui, “Automatic recom-mendations for e-learning personalization based on web usage mining techniques and information retrieval,”Educational Tech-nology and Society, vol. 12, no. 4, pp. 30–42, 2009.
[15] J. Bobadilla, F. Serradilla and J. Bernal, “A new collaborative filtering metric that improves the behavior of recommender systems,”Knowl Based System, vol. 23, no. 6, pp. 520–528, 2010.
[16] E. García, C. Romero, S. Ventura and C. Castro, “An architec-ture for making recommendations to courseware authors using
This article has been accepted for publication in a future issue of this journal, but has not been fully edited. Content may change prior to final publication.

14 IEEE TRANSACTIONS ON LEARNING TECHNOLOGIES, TLT-2012-07-0092
association rule mining and collaborative filtering,” User Model-ing and User-Adapted Interaction, vol. 19, no. 1, pp. 99–132, 2009.
[17] E. García, C. Romero, S. Ventura and C.d. Castroa, “A collabo-rative educational association rule mining tool,”The Internet and Higher Education, vol. 14, no. 2, pp. 77-88, 2011.
[18] A. Walker, M. Recker, K. Lawless, D. Wiley, “Collaborative information filtering: A review and an educational applica-tion”, International Journal of Artificial Intelligence and Education, pp. 14, 1-26, 2004.
[19] D. Lemire, H. Boley, S. McGrath, M. Ball, “Collaborative Filter-ing and Inference Rules for Context-Aware Learning Object Recommendation”, International Journal of Interactive Technology and Smart Education, vol. 2, no. 3, pp. 179-188, 2005.
[20] S. Rafaeli, Y. Dan-Gur, M. Barak, “Social Recommender Sys-tems: Recommendations in Support of E-Learning”, Internation-al Journal of Distance Education Technologies, vol. 3, no. 2, pp. 29-45, 2005.
[21] N. Manouselis, R. Vuorikari, & F. Van Assche, “Simulated analysis of MAUT collaborative filtering for learning object rec-ommendation”, In Proceedings of the 1st Workshop on Social In-formation Retrieval for Technology Enhanced Learning. pp. 27-35, 2007.
[22] L. Yu, Q. Li, H. Xie and Y. Cai, “Exploring folksonomy and cooking procedures to boost cooking recipe recommendation,” In proceedings of APWeb, pp. 119–130, 2011.
[23] C. Romero, S. Ventura, A. Zafra and P. de Bra, “Applying Web usage mining for personalizing hyperlinks in Web-based adap-tive educational systems,”Computers and Education, vol. 53, no. 3, pp. 828–840, 2009.
[24] M.S. Chen, J. Han and P.S. Yu, “Data mining: an overview from a database perspective,” IEEE Transactions on Knowledge and da-ta Engineering, vol. 8, no. 6, pp. 866–883, 1996.
[25] Y. Li, Z. Niu, W.Chen and W. Zhang, “Combining Collabora-tive Filtering and Sequential Pattern Mining for Recommenda-tion in E-Learning Environment,” Lecture Notes in Computer Sci-ence, vol. 7048, pp. 305-313, 2011.
[26] R. J. Nadolski, B. Van den Berg, A. J. Berlanga, H. Drachsler, H. G. Hummel, R. Koper, P. B. Sloep, “Simulating light-weight personalised recommender systems in learning networks: A case for pedagogy-oriented and rating-based hybrid recom-mendation strategies,” Journal of Artificial Societies and Social Simulation, vol. 12, no. 1, 2009, 4.
[27] Tang T.Y., McCalla G.I., “Smart Recommendation for an Evolv-ing E-Learning System: Architecture and Experiment”, Interna-tional Journal on E-Learning, vol. 4, no. 1, pp. 105-129, 2005.
[28] K. H. Tsai, T. K. Chiu, M. C. Lee, T. I. Wang, “A learning objects recommendation model based on the preference and ontologi-cal approaches,” In Advanced Learning Technologies, Sixth Inter-national Conference on, pp. 36-40, 2006, IEEE.
[29] R. Gluga, J. Kay and T. Lever, “Modeling Long Term Learning of Generic Skills,”Intelligent Tutoring Systems, vol. 1, pp. 85-94, 2010.
[30] K.I. Ghauth and N.A. Abdullah, “Learning materials recom-mendation using good learners’ ratings and content-based fil-tering,” Educational Technology Research and Development, vol. 58, no. 6, pp. 711-727, 2010.
[31] M. Salehi, I. Nakhai Kamalabadi and M. B. Ghaznavi Ghoush-chi, “Personalized recommendation of learning material using sequential pattern mining and attribute based collaborative fil-tering,” Education and Information Technologies, DOI 10.1007/s10639-012-9245-5, pp. 1-23, December 2012.
[32] M. Salehi, I. Nakhai Kamalabadi, “Hybrid recommendation approach for learning material based on sequential pattern of the accessed material and the learner’s preference tree,” Knowledge-Based Systems. vol. 48, pp. 57-69, 2013.
[33] M. Salehi, M. Pourzaferani and S. A. Razavi, “Hybrid attribute-based recommender system for learning material using genetic algorithm and a multidimensional information model,” Egyp-tian Informatics Journal, vol. 14, no. 1, pp. 67–78, 2013.
[34] L. Chen, P. Pu, Survey of preference elicitation methods. Rap-port technique, 2004, (http://ceur-ws.org/Vol-307/paper04.pdf).
[35] J. Zhong and X. Li, “Unified collaborative filtering model based on combination of latent features,” Expert Systems with Applica-tions, vol. 37, no. 8, pp. 5666–5672, 2010.
[36] G. Adomavicius and A. Tuzhilin, “Toward the Next Generation of Recommender Systems: A Survey of the State-of-the-Art and Possible Extensions,” IEEE Transactions on Knowledge and Data Engineering, vol. 17, no. 6, pp. 734–749, 2005.
[37] K. Verbert, N. Manouselis, H. Drachsler, E. Duval, “Dataset-Driven Research to Support Learning and Knowledge Analyt-ics,” Educational Technology & Society, vol. 15. no. 3, pp. 133–148, 2012.
[38] Y.Y. Shih, and D.R. Liu, “Product recommendation approaches: Collaborative filtering via customer lifetime value and custom-er demands,” Expert Systems with Applications, vol. 35, no. (1–2), pp. 350–360, 2008.
[39] J.L. Herlocker, J.A. Konstan, L.G. Terveen, and J.T. Riedl, “Evaluating collaborative filtering recommender systems,” ACM Transactions on Information Systems (TOIS), vol. 22, no. 1, pp. 5–53, 2004.
[40] H. Ma, I., King and M.R. Lyu, “Effective missing data predic-tion for collaborative filtering,” In: Proceedings of the 30th Inter-national ACM SIGIR Conference on Information Retrieval, pp. 39-46, 2007.
[41] P. Baudisch, “Joining Collaborative and Content-Based Filter-ing,” In Proceedings of the Conference on Human Factors in Compu-ting Systems, 1999.
Mojtaba Salehi received his B.Sc. degree from Shahid Bahonar Universityin 2004, and the M.Sc. degree from Tehran Universityin 2006 and his PhD degree from Tarbiat Modares University in 2013. Heis currently working as an Assistant Professor of K.N. Toosi University of Technology (KNUT). During 2012, he was a researcher in department of
mathematics & computer science at the TU/e, Netherlands. His re-search areas of interest include soft computing, data mining, recom-mender systems and applied multivariate analysis.
Isa Nakhai Kamalabadi received his B.Sc. degree from Shahid Beshti University in 1979, the M.Sc. degree from Tarbiat Modares University and the Ph.D. in industrial engineering from University of Toronto in 1995. He is currently working as an Associate Professor in Tarbiat Modares University. His research interests include: optimization, opera-
tional research, information technology, scheduling & sequencing andSCM.
M. B. Ghaznavi-Ghoushchi (M’07) received the B.Sc. degree from the Shiraz University, Shiraz, Iran, in 1993, the M.Sc. and Ph.D. degrees both from the Tarbiat Modares Uni-versity, Tehran, Iran, in 1997, and 2003 re-spectively. During 2003-2004, he was a re-searcher in TMU Institute of Information Technology. He is currently an Assistant Pro-fessor with Shahed University, Tehran, Iran.
His interests include VLSI Design, Low-Power and Energy-Efficient circuit and systems, Computer Aided Design Automation for Mixed-Signal and UML-based designs for SOC and Mixed-Signal.
This article has been accepted for publication in a future issue of this journal, but has not been fully edited. Content may change prior to final publication.










![Matching Users Preference Under Target Revenue …arXiv:1901.10721v1 [cs.IT] 30 Jan 2019 1 Matching Users Preference Under Target Revenue Constraints in Optimal Data Recommendation](https://img.dokumen.tips/doc/110x75/5f3b2ff206c5cc3193329239/matching-users-preference-under-target-revenue-arxiv190110721v1-csit-30-jan.jpg)


















