Embed Size (px)
Citation preview

Eur. J. Biochem. 147,217-224 (1985) 0 FEBS 1985
Amino acid sequence of the non-collagenous globular domain (NC1) of the g l (IV) chain of basement membrane collagen as derived from complementary DNA Ilse OBERBAUMER, Maryvonne LAURENT, Ulla SCHWARZ, Yoshiki SAKURAI, Yoshihiko YAMADA, Gabriel VOGELI, Tilman VOSS, Bernhard SIEBOLD, Robert W. GLANVILLE and Klaus KUHN
Max-Planck-Institut fur Biochemie, Abteilung Bindegewebsforschung, Martinsried bei Miinchen
(Received November 19, 1984) - EJB 84 1239
NCI, the C-terminal non-collagenous globular domain of collagen IV, represents one of the two end regions responsible for the assembly and cross-linking of the extracellular network of basement membrane collagen. Several cDNA clones for the NCI domain of the ctl(IV) collagen chain of mouse have been isolated by using synthetic oligonucleotides as screening probes for mouse libraries. The oligonucleotides were synthesized according to known stretches of the corresponding protein sequence. Sequencing of the overlapping cDNA clones allowed the complete amino acid sequence of the NCl domain to be deduced as well as the C-terminal 165 amino acid residues of the triple helix. It consists of 229 amino acid residues which comprise two homologous regions with a high content of cysteine. These DNA and protein sequences are compared to the corresponding sequences of other collagens and discussed with respect to their structural and biological significance.
The main collagenous component of basement membranes is collagen IV. The triple helical molecule is 400 nm long and carries a globular domain at its carboxy-terminal [l -31. It contains two ctl (IV) chains and one a2(IV) chain, each consist- ing of approximately 1700 amino acid residues [4, 51. The triple-helical part of these chains is frequently interrupted by non-helical regions [6, 71, in contrast to interstitial collagen chains. In basement membranes, collagen IV forms a macro- molecular network in which the 30-rim-long N-terminal re- gion (7s domain) of four molecules are linked together. Each of these molecules becomes connected at the opposite end, via the C-terminal globule (NCI domain), to the NCI domain of yet another molecule. The network is stabilized by the formation of intermolecular cross-links at both ends [8, 91. This organization differs from the assembly of the interstitial collagens I, I1 and 111, whose 300-nm-long molecules are aligned in parallel but in a D-staggered array (D = 67 nm)
While the amino acid sequence of large parts of the triple- helical region of the al(1V) chain from human [7] and mouse [6] is known, the C-terminal globular domain proved to be difficult to characterize, probably because of its hydrophobic character. Since the NCI domain is important for the assembly of the molecules, we decided to determine its amino acid sequence via the corresponding cDNA. Appropriate for such investigations is poly(A)+ RNA from tissues and cell lines which are known to produce basement membranes and type IV collagen, in particular the EHS mouse tumor [l I], the PYS-2 cell line [I , 121 and F9 cells induced with retionic acid and dibutyryl cAMP [13, 141. In vitro translation assays in a reticulocyte system with sucrose-gradient-enriched poly(A) +-
RNA from the EHS tumor and the PYS-2 cells showed that
Ahbrevintions. Poly(A)+RNA, poly(A)-containing RNA; SSC, standard saline citrate = 0.15 M sodium chloride, 0.015 M sodium citrate; HPLC, high-performance liquid chromatography; bp, base pairs; kb, lo3 base pairs; SDS, sodium dodecyl sulfate.
1101.
both sources contain very little translatable mRNA for the chains of type IV collagen, the amount being estimated to be less than 0.1 % (M. Laurent, I. Oberbaumer, unpublished). However, induced F9 cells have been reported to contain higher levels of these mRNAs [I 51.
Here we will present our data on three cDNA clones, two from an EHS library and one from an F9 library, which cover the C-terminal area of the triple helix, the globular domain of the a1 (IV) chain as well as part of the 3' untranslated region.
MATERIALS AND METHODS
RNA isolation
RNA containing collagen IV mRNA was isolated from three different sources; from the mouse EHS tumor [l I], the PYS-2 cell line [12] and F9 cells, treated with retinoic acid and dibutyryl cAMP [13]. Total RNA from the tumor and the PYS-2 cells was isolated with 8M guanidinium chloride (BRL) according to standard procedures [16] while 4 M guanidinium thiocyanate for the induced F9 cells was used according to the method of Chirgwin et al. [17]. Poly(A)+RNA from PYS-2 and F9 ceIls was prepared by two passages over oligo(dT)-cellulose (PL-Biochemicals or Collaborative Research) while poly(A) 'RNA from the mouse tumor [one passage over oligo(dT) cellulose] was further purified by centrifugation through a sucrose gradient (10 - 37%). Total RNA from calvaria (chicken) was a gift from P. K. Muller (Max-Planck-Institut fur Biochemie).
Synthesis of cDNA libraries
The gradient-purified poly(A)+RNA (> 18 S) of the mouse tumor as well as poly(A)+RNA from induced F9 cells were used to construct cDNA libraries according to standard procedures with minor changes [18]. In brief, both libraries were constructed by starting first-strand synthesis by priming

21 8
with oligo(dT), tailing the obtained cDNA with dC. The second-strand synthesis was primed with oligo(dG) and finally the double-stranded cDNA, tailed with dC, inserted into the vector pBR322 cut with PstI and tailed with dG. The F9 as well as the EHS libraries were established in Escherichia coli C600.4.
Northern hybridization
Poly(A)+RNA from PYS-2 cells (6-7 pg/lane) was loaded on a methylmercury agarose gel (1%) together with total RNA from chick calvaria and DNA molecular mass markers (Biolabs). After electrophoresis, methylmercury was removed from the gel by shaking in 0.1 M ammonium acetate (30 min) followed by two 15-min periods in 0.5 x SSC (SSC = 0.15 M sodium chloride, 0.015 M sodium citrate). The gel was dried down onto a dialysis membrane overnight and afterwards submerged in water in order to peel it off the membrane 1191. Prehybridization (1 h) and hybridization (16 h) were performed in 4 - 5 ml of 5 x SSC, 1 YO sarkosyl (Ciba- Geigy) at 65 "C, using 3 x I O6 cpm (50 ng) of nick-translated clone p5 as a hybridization probe. The gel was washed twice in 3 x SSC, 0.5% sarkosyl (25 ml), once in 3 x SSC (25 ml) and once in 3 x SSC (100 ml) for 30 min each, at the same temperature as before, then sealed in a plastic bag and exposed overnight at - 70°C with intensifying screens. Staining with ethidium bromide was done only after hybridization to avoid artefacts due to drying.
Oligonucleotide synthesis
Mixture I. The amino acid sequence Asp-Gln-Gly-Asp- Gln was selected from the triple helix, 11 2 residues away from its C-terminaI[6]. The mixture of 24 different oligonucleotides, each 14 nucleotides in length, was purchased from PL Bio- chemicals.
Mixture II. The amino acid sequence Phe-Cys-Asn-Ile- Asn-Asn-Val was taken from the cyanogen bromide peptide CB2 (Table 1). The 20-residue oligonucleotides were synthe- sized in a 380 A DNA synthesizer from Applied Biosystems according to the phosphoramidite method [20] with 1 pg of the starting nucleotides. Because of the high number (96) of different sequences, synthesis was performed in four batches (a, b, c, d) of 32 and 16 different oligonucleotides, respectively.
Mixture IZI. The amino acid sequence Asn-Ile-Asn-Asn- Val was also taken from the CB2 peptide (Table 1). A mixture of 24 different oligonucleotides each 14 residues long, was synthesized as described above.
Screening of the libraries
About 100000 colonies of the (amplified) EHS library and 20000 colonies of the F9 library were plated on nitrocellulose filters (Schleicher & Schiill) at high density. After lysing the bacteria, the baked filters were prehybridized in 10- 15 ml of 5 x SSC, 10 x Denhardt's solution, 0.1 % SDS and 10 pg/ml salmon sperm DNA at 40°C (14mer oligonucleotides) or 50°C (20mer oligonucleotides) for at least 4 h. For hybridiz- ation, about 30-50 x lo6 cpm (10-15 pmol) labeled oligo- nucleotides were added to the filters, the bags heated to 65 "C for 10 min and kept at the corresponding prehybridization temperatures for 16 h. Filters were washed three times for 30 min in 25 - 30 m15 x SSC, 0.1 % SDS and a fourth time in I00 ml at the same temperature. The EHS library was screened with primer mixtures derived both from triple-helical (I) and
globular sequences (II), while the F9 library was screened with a shortened oligonucleotide mixture (111) (1 4mer) from the same globular sequence. Of the more than 100 positive clones, about 30 were further characterized by restriction mapping and Southern analysis which finally led to the selection of two clones from the EHS library (p5, p9) and one from the F9 library (pFAC) which were sequenced.
Subcloning and sequencing
The inserts of clones p5 and p9 were excised with PstI from pBR322 and subcloned into the PstI site of pUC9 [21]. The subclones were established in E. coli JM83 and the recombinant plasmids isolated by the method of Birnboim and Doly [22]. For sequencing [23], the unique restriction sites in the poly-linker of pUC9 were used [24]. The complementary strands were sequenced after isolating the corresponding fragments from 5% acrylamide gels. DNA restriction fragments of clone pFAC were isolated by electrophoresis on acrylamide gels.
Subclones of pFAC were established in the vectors MI3 tg 130 and MI3 tg 131 [25] (Amersham) as indicated in Fig. 2. The SacIIXhoI fragment was inserted into both vectors be- tween the Sac1 and SaII site (mF0/30, mF0/31), the other fragments were only subcloned into M13 tg 131, namely the SacI/BamHI piece (mFl), the BamHI/Sau3AI segment (mF2) and the Sau3AI/PstI fragment (mF3). The fragments were isolated from 5% acrylamide gels and ligated to the appro- priately cut vectors according to standard procedures. The restriction enzymes were from either Boehringer or Biolabs. The clones were sequenced according to the method of Sanger et al. [26]. Clone mF3 was used to prepare a partially double- stranded hybridization probe as described in [27].
Protein chemical in vest iga t ion
The NCI domain was isolated using a two-step collagenase treatment of human placenta similar to the method described recently [28]. The tissue was washed with 0.4 M sodium acetate and 0.5 M formic acid and after ex- haustive dialysis against 30 mM Tris/HCI buffer containing 2 mM CaCl, digested with collagenase (1000 Ujkg wet tissue of type IV clostridium peptidase, Millipore Corp.) at 25°C for 24 h. To inactivate the collagenase, EDTA (final concentration 5 mM) was added to the supernatant and the protein precipitated with 2.2 M sodium chloride. The pre- cipitate was dissolved in 2 M urea, 30 mM Ti-is/HCl, 0.2 M sodium chloride, pH 8, exhaustively dialyzed against the same buffer and the acidic non-collagenous material removed by DEAE-cellulose. The second collagenase treatment (0.2 U/ mg protein) was performed at 37°C for 10 h. Subsequently, the solution was dialyzed against 0.1 M acetic acid and con- centrated with a rotary evaporator to avoid lyophilization.
To separate monomeric and dimeric NCI domains, the second collagenase digest was chromatographed on a column (2.5 x 140 cm) of Sephacryl S-300 equilibrated with 0.1 M am- monium formate pH 3. Fractions containing the monomers were desalted, freeze-dried and applied (0.03 - 5 mg) to a re- versed-phase high-pressure liquid chromatography column (Vydac TP/C18, 10 pm particle size, 250 x 9 mm, supplied by Chrompak, Middleburg, Holland). The column was equilibrated at 55°C with 0.1 YO trifluoroacetic acid at a flow rate of 4 ml/min and the sample was eluted with a 0-70Yo linear gradient of isopropanol in 45 min.

219
triple helix globulor domain l? dl I IV) ~-&-,i - - humon
mOuSe [ known pmlein sequence +--t - i I j k A A A n 8 R I A I I
+I I 1
I clone p9 I clone p5 I -
For reduction of the disulfide bridges, al(1V)NCl was dissolved (10 mg/ml) in 6 M guanidium/HCl, 0.1 M Tris/HCl, 0.01 M EDTA pH 8.3 and treated with a 50-fold excess of dithioerythritol at 37 "C for 1 h. The reaction was stopped by adding a 1.1-fold excess of sodium iodoacetate (1 h, 37°C). In order to reduce oxidized methionine before cyanogen cleavage, the ctl(1V)NCI fragment was dissolved in 5% acetic acid ( 5 mg/ml) and incubated at 37°C for 18 h with 20% mercaptoethanol. The reaction mixture was dialyzed against 0.1 M acetic acid and lyophilized. The protein was im- mediately dissolved in 70% formic acid (10 mg/ml) and treated with cyanogen bromide according to [7].
The cyanogen bromide peptides were fractionated by gel permeation chromatography on two TSK SW 2000 columns (Tyota, Soda Co., Japan) connected in tandem, using 0.05% trifluoroacetic acid and a flow rate of 50 pl/min. Further purification of the fractions collected from TSK columns was achieved using reversed-phase HPLC under the same conditions as described for the separation of al(1V)NCI and m2(IV)NCI.
Amino acid sequences were determined using a liquid- phase sequencer (model 890B or 890C, Beckman). The protein quadrol program (Beckman 06275) was used as described 171.
RESULTS
Characterization of the clones
We constructed a cDNA library from sucrose-gradient- purified poly(A)+RNA of the mouse tumor and later one from poly(A)+RNA of induced F9 cells. These libraries were screened with the synthetic oligonucleotide mixtures I, 11 and I11 deduced from known protein sequences as described in Materials and Methods. Fig. 1 shows the relative positions of the three selected cDNA clones with respect to each other and to the protein, as well as the location of the synthetic oligonucleotides used for screening. Clones p5 plus p9 cover a region of about 1000 bp starting in the triple-helical region of the protein and reaching almost to the end of the globular domain. Clone pFAC starts further 5' in the triple-helical region and contains the entire sequence for the globular domain as well as approximately 750 bp of the untranslated 3' region. Although this clone includes p5 and p9, we mainly used it to sequence those regions that were not present in the other two cIones as the short clones, p5 and p9, when sub- cloned into pUC9 [21] were more amenable to sequencing. The subclones in the MI3 vector were prepared only after large parts of the sequence were determined and appropriate restriction sites had been found.
The restriction maps of the three clones together with the sequencing strategies are depicted in Fig. 2. Only those restriction sites are given which were actually used for restric- tion analysis and sequencing of the clones. There are five unique restriction sites in a stretch of about 2000 bp, S a d , PstI, BamHI, SmaI and XhoI, which might be helpful for the identification of similar clones.
Characterization of a1 ( I V ) mRNA
The ability of the selected clones specifically to hybridize to type-IV-collagen mRNA was tested by Northern analysis. As depicted in Fig. 3, the nick-translated insert from clone p5 hybridized only to PYS-2 RNA and not to RNA from chick calvaria, which contain type-I-collagen mRNA but no type- IV-collagen mRNA.
I t I I
I clone pFAC
mixture I mixture I I . 111 Fig. 1. Scheme of the position of the clones p5, p9 andpFAC as well as of the synthetic oligonucleotides, mixtures I , I I and III , with respect to the crl ( I V ) polypeptide chain and its mRNA
clone p5 - v L 3 W . l - ZOObp clone p9 c-
cc)
Fig. 2. Restriction map andsequencing strategy-for the a1 (IV)-specific cDNA clones p5, p9 and pFAC. Arrows indicate the direction of multiple sequencing. mFO-3 are subclones of pFAC in the vectors MI3 tg 130 and M13 tg 131
A B
1 6.7 k b l 5 . 4 k b
C P A C P A Fig. 3. Hybridization analysis of'poly(A) + RNA from PYS-2 cells ( P ) and total chick RNA ( C ) separated on a 1% methylmercury agarose gel. Lambda DNA cut with Hind111 was used as a molecular mass marker. (A) Dried gel stained with ethidiurn bromide; (B) dried gel hybridized with clone p5, labeled by nick translation
The PYS-2 RNA contains two mRNA species which hy- bridize to the clone, the major mRNA being 6.7 kb and the minor one 5.4 kb long. Other groups report sizes of 6.8 kb up to 7.8 kb for the mRNA of the al(1V) chain [16, 291, possibly

220
1 TAACTATGAT GCTCGCCTCT GCCACCGTCA CMCATGGTG CTACTCCCCC CCTTGTCCTC
61 TTCTCCCTCC CATTGTATTT GTAACAGCAA TGAACCCTAG AAGTATATCC TGTGTACCTC
121 ACTGTCCACT ATGAAAACCA TAAAGTGCCT TATAGGGATT CGCGTAACTA ACACACCCCG
181 CTTCGTTGGC CTCTGTTTGC TGAAGGAGAA GGACAGGCAG CGGAGAGCTT TCCATAATGG
241 CACATACCAA ATGGCGCTCC TGATCC AGATGAATTGCATTTTGC AATCCAGTGC 301 ACTGATGTCT GGGGCGAGAA CTCCATAAGA AACCCAAAGG TGCTAGGGGC GTGAGGCGCT
361 CTCCACACAG CCCACAGCCC GCTTCATCCT GTCACCCCAG ATGTGAGTGC TGTCCAACCC
421 ACTGTCCAGT GTTTCCACAT CAGGTCCCTC GAGGGGCTAT GCAGAGAACA GTCAAGGGAA
481 CTGGTTTCTT CCACTTTCTA CATGGAACTC CATCGTTTCA GCCCCAAACA CAAACTTATG
541 CCCTGTGTGG TACTATGCAG CTGCTTTTGT GGAAGTCATG GCTTTCCTGT GGAA
Fig. 4. Nucleotide sequence of the non-coding sequence of clone pFAC. The canonical polyadenylation signal is marked. The d representing deoxy and the hyphens representing phosphodiester bonds have been omitted
Table 1. Sequence of CNBr peptides of human a1 ( IV)NCl The peptides are numbered according to their position in the cDNA-derived sequence (Fig. 6). The N-terminal amino acid residues in brackets belong to the triple helix
Peptide Sequence
CBI ( G P P G T P ) S V D H G F L V T R H S Q T I D D ~
Q C P H G T K I L Y H G Y S L L Y V Q G N E R A X
G Q D L G T A G
CB2 P F L F C N I N N V C N F A X R N D Y
CB5
CB7
A P I T G E N I R P F I S R C A V C E A X A
A V X S X T X Q I P
CB8 I i T S A G A E G S G Q A L
due to different molecular mass standards and/or different gel types. The minor mRNA has not been described previously. The same two bands are seen after hybridization with clone p5 in Northern blots of poly(A)+RNA from induced F9 cells and the EHS tumor, with similar relative intensities (data not shown). At least two mRNAs have been described for the human a2(I) and al(1) and the chick a2(I) chains, which were shown to differ only in the length of the 3' untranslated region [30, 311. Similar heterogeneity seems to occur for the mRNAs of al(IV), since the sequence of the untranslated region contained in clone' pFAC (Fig. 4) shows the canonical polyadenylation signal d(A-A-T-A-A-A) 266 bp after the end of the coding region. If this site was actually used, a messenger of about 5.4 kb could be expected, as the minimal size of an mRNA coding for the approximately 1700 amino acid re- sidues of the al(1V) chain would be 5.1 kb. From the size difference of the two mRNAs and the position of the poly- adenylation signal, an untranslated sequence of about 1.6 kb can be expected for the 6.7-kb mRNA, half of which is contained in the clone pFAC.
The untranslated region in Fig. 4 reveals only short open reading frames, the longest ones starting at position 6 (41 amino acids) and position 131 (46 amino acids).
Triple-helical sequences
The nucleotide sequence representing the C-terminal 165 amino acids of the triple helix of al(1V) mouse and the amino acid sequence derived from it are given in Fig. 5. The sequence
was obtained from clone p5 and the subclone mFO of clone pFAC (cf. Fig. 2). It correlates well with the known peptide sequence of the al(1V) chain of mouse [6]. Two gaps (positions 1 - 15 and 80- 140), which were not elucidated at the protein level, are now closed by the DNA sequence. In four positions, the cDNA-derived sequence does not agree with the peptide sequence of the mouse al(1V) chain. It is, however, identical with the human al(1V) chain [7], which shows a homology of 93% to the mouse sequence, similar to the interspecies homology observed for the interstitial collagens [32].
Characterization o j the NCI domain
Fig. 6 gives the nucleotide sequence of the al(1V)NCI domain. It has been elucidated using the clones p9 and pFAC as indicated in Fig. 2. The amino acid sequence deduced from it correlates well with the partial peptide sequences of the ctl(1V)NCl chain from human obtained by Edman degrada- tion of al(1V)NCI. The corresponding CNBr peptides are listed in Table 1. According to the cDNA sequence, ten CNBr fragments are to be expected. Four of them are dipeptides or tripeptides and were not isolated (CB3, CB4, CB6 and CB10). Of the larger CNBr peptides, only peptide CB9 from the C-terminal area was not found. The homology (96%) between the mouse sequence and the human CNBr peptides is even higher than for the triple-helical sequences.
The globular domain contains 229 residues and has a calculated relative molecular mass of 27800 (25800 + 2000 for sugars). This value agrees with the relative molecular

221
1 1
61 21
121 41
1 a1 61
241 81
301 101
361 121
421 141
4 8 1 161
GCTCCGGGGGTTCCAGGCCCTAAGGGAGACCCAGGATTCC~GGCATGCCGGGCATTGGC A P G V P G P K G D P G F Q G M P G I G
GGCTCTCCAGGGATCACAGGTTCAAAGGGAGGGAGATATGGGACTGCCCGGAGTTCCAGGATTT G S P G I T G S K G D M G L P G V P G F
+ *
CAAGGTCAGAAAGGGCTTCCTGGTCTGCAGGGAGTGAAGGGAGACCAGGGAGACC~GGT Q G Q K G L P G L Q G V K G D Q G D Q G
+ +
GTACCCGGCCCTAAAGGTCTCCAAGGTCCCCCTGGGCCCCCAGGTCCCTACGATGTCATC V P G P K G L Q G P P G P P G P Y D V I * + * * +
RAAGGAGAACCAGGGCTCCCTGGTCCTGAGGGTCCCCCTGGTCTTRRAGGACTCCAGGGA K G E P G L P G P E G P P G L K G L Q G
+
CCACCAGGTCCAAAAGGACAGCAAGGTGTGACAGGCTCAGTGGGCTTGCCTGGACCTCCA P P G P K G Q Q G V T G S V G L P G P P + + + GGTGTCCCTGGGTTCGATGGTGCTCCTGGCCAGAAGGGAGAGACAGGACCCTTTGGACCA G V P G F D G A P G Q K G E T G P F G P
+
CCTGGTCCAAGAGGGTTTCCTGGCCCGCCGGGCCCCGATGGGCTGCCAGGATCCATGGGG P G P R G F P G P P G P D G L P G S M G
60 20
120 40
180 60
240 80
300 100
360 120
420 140
480 160
f
CCCCCAGGTACCCCA 495 P P G T P _ 165
Fig. 5. Nucleotide sequence of the triple-helical portion ojclones p5 andpFAC and the amino acid sequence deduced from it. The thin line marks the sequences that had been previously determined by protein sequencing (mouse) [6]. Asteriks (*)mark differences between DNA and protein sequences. The amino acid sequence of this area in the ctl(1V) chain from human has been completely elucidated [7]. Crosses (+) indicate differences between the mouse and the human sequence. The d representing deoxy and the hyphens representing both phosphodiester and aminoacyl bonds have been omitted
1 1
61 21
121 41
181 81
241 81
301 101
361 121
421 141
481 161
541 181
601 201
661 221
TCTGTGGACCATGGCTTCCTTGTGACCAGGCACAGTCAGACAACAGATGATGACCCACTGTGT S V D H G F L V T R H S Q T T D D P L C
CCCCCAGGGACCAAAATTCTTTACCATGGATACTCTCTGCTCTATGTTCAAGGCRACGAG P P G T K I L Y H G Y S L L Y V Q G N E
CGTGCCCACGGGCAGGACTTGGGTACGGCTGGCAGCTGCCTGCGT~GTTCAGCACCATG R A H G Q D L G T A G S C L R K F S T O
CCCTTTCTCTTCTGCAACATCAACAACGTCTGCAACTTCGCCTCCAGG~CGACTACTCT P F L F C N I N N V C N F A S R N D Y S
TACTGGCTGTCCACGCCAGAGCCCATGCCCATGTCCATGGCACCCATCTCTGGGGACAAC Y W L S T P E P @ P @ S @ A P I S A D N
ATCCGGCCCTTCATTAGCAGGTGTGCGGTTTGTGAAGCACCGGCCATGGTGATGGCGGTA I R P F I S R C A V C E A P A @ V @ A V -
CACAGTCAGACCATTCAGATTCCGCAGTGCCCTAACGGTTGGTCCTCACTGTGGATCGGC H S Q T I Q I P Q C P N G W S S L W I G
T A T T C C T T C G T G A T G C A C A C C A G C G C T G G T G C T G A A G G T T G C C C T C G C A T C C Y S F V O H T S A G A E G S G Q A L A S
CCCGGGTCCTGTCTGGPJ\GAGTTTAGAAGCGCCCCATTCAT~GAGTGCCACGGCAGAGGA
- -
P G S C L E E F R S A P F I E C H G R G
ACGTGCAATTACTACGC~TGCTTACAGCTTTTGGCTCGCCACCATAGAGAGAAGCGAG T C N Y Y A N A Y S F W L A T I E R S E
ATGTTCI~AGAAGCCCACGCCGTCCACCTTG~GGCAGGGGAGCTGCGCACACACGTCAGC O F K K P T P S T L K A G E L R T H V S
CGCTGCCAAGTGTGCATGAGAAGAACATAA 690 R C Q V C @ R R T * 229
60 20
120 40
180 60
240 80
300 100
360 120
420 140
480 160
540 180
600 200
660 220
Fig. 6. Nucleotide sequence of the globular domain NCI of mouse al ( I V ) as determined by sequencing of clonesp.5, p 9 andpFAC. The underlined stretches are identical with the sequences of CNBr peptides isolated from the NC1 domain of human placenta collagen IV (Table 1). Methionine residues are encircled. Missing symbolism as in Fig. 5

222
PRO 111
NCl(A) 7 5 S R N D Y S Y W L S T P E P M P M S M A P - - - NCl(B) 186 A - B A K d A i I a R E N F K K I T P S
NCl(A) 96 I S G D N I R P F I S R C A V C - - - NCl(B) L K A G E LQT H ; L J O / v l M R R
-
PRO 111 L K S G - E Y W I D P N Q G C K M
-
210
Fig. I . Internal repeats in the sequence of the NCI domain of the ctI(IV) chain [positions 2- 111, N C I ( A ) , and 112-225. NCl ( B ) ] and comparison of these regions with the sequence stretch 75- 107 (numbered according to Yamada et al. [3SJ) of the carboxypropeptide of the ct l ( I I I ) chain (PRO I I I ) . The analysis was carried out with the program ALIGN [34], using the following conditions: mutation scoring matrix (250 accepted point mutations) + 2, penalty for break = 12. The alignment of the internal repeats of the NCI domain yielded a score of 17.5 (SD) above the mean score from 100 random sequences. The significance for the homology between PRO 111 and NCl(A) and NCI(B) is 3.71 and 4.29 (SD), respectively. Identical amino acid residues are boxed
masses which have been determined to be 25 000 - 28 000 by equilibrium ultracentrifugation, SDS electrophoresis and gel chromatography and which includes the molecular mass of about 2000 Da for the carbohydrate moiety present in the NCI domain [8, 281. The sequence reveals a relatively high number (12). of cysteine residues. Based on biosynthetic and biochemical studies of collagen IV, there is no evidence for interchain disulfide bridges between the globular ct chain segments of a triple-helical molecule [3, 331. The cysteine re- sidues appear to be mainly involved in intrachain bridges. However, studies of the hexameric globular domain isolated after collagenase digestion of cross-linked collagen IV indicate the presence of intermolecular disulfide bridges, connecting the NCI domains of two different collagen IV molecules [28, 331.
The NCI domain consists of two homologous regions (positions 2 - 11 1 and 11 2 - 225) each containing six cysteine residues at similar positions. The two halves have identical amino acids in 35% of the positions (Fig. 7). If the positions with similar amino acids are also counted, this number goes up to 56%. Identical amino acids are nearly always found before and after cysteine residues. For a more quantitative analysis of the homology of the two repeating units, we used the alignment program of Barker et al. 1341 with a mutation scoring matrix taking into account the frequency of amino acid substitutions between homologous globular proteins. The alignment yields a highly significant score of 17.5 (SD) above the mean score from 100 random sequences. We therefore assume that the C-terminal globule is formed of two building blocks of similar spacial structure, which may have arisen by duplication of a gene unit.
In order to see whether the carboxy-terminal globular NCI domain of collagen IV has some common structural features with the carboxy-terminal globular propeptide of the in- terstitial collagens I, I1 and 111, we compared the sequence of al(II1) carboxypropeptide from chick with the al(1V)NCI domain of mouse. The analysis revealed a homology of one area of the carboxypropeptide (positions 75 - 107, according to the numbering in [35]) with a distinct region of each of the two repeating units of the NC1 domain (Fig. 7), including 4 of the 12 cysteine residues. The sequence of the cdrboxy- propeptides of al(I), ct2(1) and al(II1) are very homologous to one another and it is striking that the area found homolo- gous to the NCI domain belongs to one of the most highly conserved regions of the carboxypropeptides.
Comparison of cDNA sequences of different collagen genes
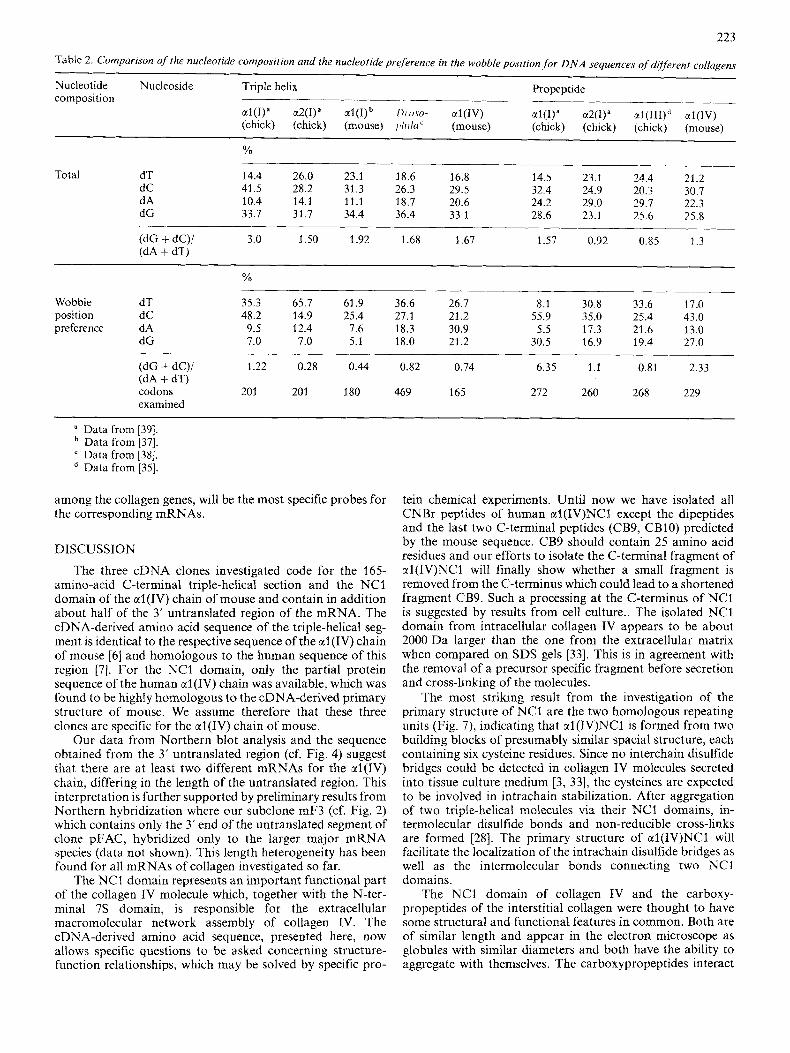
The codon usage in collagen genes, especially in those parts coding for triple-helical sequences, has been studied in detail for the interstitial collagens [36, 371. As glycine, proline and alanine are the most frequent amino acids in the triple helix, the codon usage for these amino acids indicates similarities and differences between the different collagen genes. While in the interstitial collagen genes the codon d(G-G-T) for glycine is highly preferred, followed by d(G-G-C), the most abundant codon for glycine in the estab- lished portion of the ctl (IV) triple-helical sequence is d(G-G-A), followed by d(G-G-T) (cf. Fig. 5 and Table 2). d(G-G-G) is found in 17% of the codons whereas it is used less than 5%, mostly less than 2%, for the interstitial collagens. Also the codons for proline show a similar prefer- ence for A and T in the third position, again in contrast to those of the interstitial collagens. A comparison of the codons for alanine is meaningless, as there are only two in the sequenced triple-helical region of the ctl (IV) chain. These dif- ferent codon usages are also reflected in Table 2, which gives the overall base composition and preferred nucleotide in the wobble position coding for the triple-helical region of several interstitial collagens as well as of Drosophila collagen [38]. With respect to these data, the ctl(1V) chain is more similar to Drosophila collagen, which is believed to be a basement membrane collagen also, than to those of the chick and mouse collagen I chains. The segment coding for the NCI domain of ctl(1V) (cf. Fig. 6) shows a higher degree of similarity in base composition and nucleotide preference in the wobble position to the one for the al(1) carboxypropeptide than to those for the ctl(II1) and a2(I) propeptides, with G and C being the preferred nucleotides. For the C-terminal globule of Drosophilu collagen no sequences are yet available.
The untranslated sequence of the al(1V) mRNAs differs in several respects from those of all known collagen mRNAs. With an estimated 1.6 kb it is the longest found so far. The sequenced portion (cf. Fig. 4) is not (dA + dT)-rich and all four nucleotides are used in about equal proportions [(dG + dC)/ (dA + dT = I)], while the chick al(1) and a2(1) untranslated sequences have (dG + dC)/(dA + dT) ratios of 0.3 and 0.4, respectively [39]. There are also no pronounced homopolymer tracts or repeating units which seem to be characteristic for the corresponding sequence of the ctl(I1) gene [40]. Perhaps these untranslated sequences, which are highly divergent
223
Table 2. Comparison of the nucleotide composition and the nuclrotide preference in the wobbZeposition,for DNA sequences of dijjkrent collagens
Nucleotide Nucleoside Triple helix Propeptide
al(1)" a2(1)" al(I)b /)/-o.w- a 1 ( 1 ~ ) al(1)" a2(I)" al(III)d a l ( I V ) (chick) (chick) (mouse) p / d i C (mouse) (chick) (chick) (chick) (mouse)
Yo
composition ___~
-_____ 16.8 14.5 23.1 24.4 21.2
dC 41.5 28.2 31.3 26.3 29.5 32.4 24.9 20.3 30.7 dA 10.4 14.1 11.1 18.7 20.6 24.2 29.0 29.7 22.3 dG 33.7 31.7 34.4 36.4 33.1 28.6 23.1 25.6 25.8
(dG + dC)/ 3.0 1.50 1.92 1.68 1.67 1.57 0.92 0.85 1.3 (dA + dT)
Total dT 14.4 26.0 23.1 18.6
___
% .__
Wobble dT 35.3 65.7 61.9 36.6 26.7 8.1 30.8 33.6 17.0 position dC 48.2 14.9 25.4 27.1 21.2 55.9 35.0 25.4 43.0 preference dA 9.5 12.4 7.6 18.3 30.9 5.5 17.3 21.6 13.0
dG 7.0 7.0 5.1 18.0 21.2 30.5 16.9 19.4 27.0
(dG + dC)/ 1.22 0.28 0.44 0.82 0.74 6.35 1 .I 0.81 2.33 (dA + dT) codons 201 20 1 180 469 165 272 260 268 229 examined
a Data from [39]. Data from [37]. Data from [38]. Data from [35].
among the collagen genes, will be the most specific probes for the corresponding rnRNAs.
DISCUSSION
The three cDNA clones investigated code for the 165- amino-acid C-terminal triple-helical section and the NC1 domain of the al(1V) chain of mouse and contain in addition about half of the 3' untranslated region of the mRNA. The cDNA-derived amino acid sequence of the triple-helical seg- ment is identical to the respective sequence of the al(1V) chain of mouse [6] and homologous to the human sequence of this region [7]. For the NCI domain, only the partial protein sequence of the human al(1V) chain was available, which was found to be highly homologous to the cDNA-derived primary structure of mouse. We assume therefore that these three clones are specific for the crl(IV) chain of mouse.
Our data from Northern blot analysis and the sequence obtained from the 3' untranslated region (cf. Fig. 4) suggest that there are at least two different mRNAs for the crl(IV) chain, differing in the length of the untranslated region. This interpretation is further supported by preliminary results from Northern hybridization where our subclone mF3 (cf. Fig. 2) which contains only the 3' end of the untranslated segment of clone pFAC, hybridized only to the larger major mRNA species (data not shown). This length heterogeneity has been found for all mRNAs of collagen investigated so far.
The NCI domain represents an important functional part of the collagen IV molecule which, together with the N-ter- minal 7s domain, is responsible for the extracellular macromolecular network assembly of collagen IV. The cDNA-derived amino acid sequence, presented here, now allows specific questions to be asked concerning structure- function relationships, which may be solved by specific pro-
tein chemical experiments. Until now we have isolated all CNBr peptides of human crl(1V)NCl except the dipeptides and the last two C-terminal peptides (CB9, CB10) predicted by the mouse sequence. CB9 should contain 25 amino acid residues and our efforts to isolate the C-terminal fragment of al(1V)NCl will finally show whether a small fragment is removed from the C-terminus which could lead to a shortened fragment CB9. Such a processing at the C-terminus of NC1 is suggested by results from cell culture.. The isolated NCI domain from intracellular collagen IV appears to be about 2000 Da larger than the one from the extracellular matrix when compared on SDS gels 1331. This is in agreement with the removal of a precursor specific fragment before secretion and cross-linking of the molecules.
The most striking result from the investigation of the primary structure of NC1 are the two homologous repeating units (Fig. 7), indicating that al(1V)NCl is formed from two building blocks of presumably similar spacial structure, each containing six cysteine residues. Since no interchain disulfide bridges could be detected in collagen IV molecules secreted into tissue culture medium [3, 331, the cysteines are expected to be involved in intrachain stabilization. After aggregation of two triple-helical molecules via their NCI domains, in- termolecular disulfide bonds and non-reducible cross-links are formed [28]. The primary structure of al(1V)NCl will facilitate the localization of the intrachain disulfide bridges as well as the intermolecular bonds connecting two NCI domains.
The NCI domain of collagen IV and the carboxy- propeptides of the interstitial collagen were thought to have some structural and functional features in common. Both are of similar length and appear in the electron microscope as globules with similar diameters and both have the ability to aggregate with themselves. The carboxypropeptides interact

224
in order to align three a chains and to enable the formation of the triple-helical molecule [41]. They are subsequently split off before fiber formation. The NC1 domain may also be involved in aligning the three a chains before triple-helix formation, but is retained in the molecule and plays in addi- tion an important role in the formation of the collagen IV network. The comparison of the sequence of the al(1V)NCl and of the al(I11) carboxypropeptide did not reveal an overall homology of these two globular domains. There is, for ex- ample, no indication for repeating units in the crl(II1) carboxypropeptide. Only a short stretch of 33 amino acids of the carboxypropeptide showed a significant homology to a distinct region of each of the two repeating units of ctl(1V)NCl. It is striking that this stretch belongs to one of the most highly conserved regions of the homologous carboxypropeptide of al(I), a2(1), al(II1) [35] and al(I1) [40]. A more detailed picture of the evolutionary and functional aspects of this region will have to await the genomic structure (introns and exons) of the al(1V)-collagen-specific gene.
The collagen IV molecule contains, in addition to two a1 chains, one a2 chain. The picture will be incomplete without more information about a2(IV)NCl. First sequence data of some cyanogen bromide peptides of the a2(IV)NCl domain indicate a homology to the al(IV) chain in this region. The investigation of the primary structure of the a2(IV)NC1 domain will also be facilitated by cDNA and genomic cIones for this gene.
We thank Drs J. Engels (Hoechst AG), D. Oesterhelt (Max- Planck-Institut fur Biochemie) and G. Zon (Bureau of Biologics, Food and Drug Administration) for synthesizing the oligo- nucleotides, and R. Deutzmann for stimulating discussions. We are very grateful for the computer analysis by H. Hofmann. This study was supported by a grant from the Fritz Thyssen Stiftung.
REFERENCES 1.
2.
3.
4. 5.
6.
7.
8.
9.
10.
11.
Oberbaumer, I., Wiedemann, H., Timpl, R. & Kiihn, K. (1982)
Bachinger, H. P., Fessler, L. I. & Fessler, J. H. (1982) J . Biol.
Fessler, L. 1. & Fessler, J. H. (1982) J . Biol. Chem. 257, 9804-
Dixit, S. N. & Kang, A. H. (1979) Biochemistry 18, 5686-5692. Triieb, B., Grobli, B., Spiess, M., Odermatt, B. F. & Winterhalter,
Schuppan, D., Glanville, R. W. & Tirnpl, R. (1982) Eur. J . Bio-
Babel, W. & Glanville, R. W. (1984) Ear. J. Biochern. 143,
Timpl, R., Wiedemann, H., van Delden, V., Furthmayr, H. & Kiihn, K. (1981) Eur. J . Biochem. 120,203-211.
Kiihn, K., Wiedemann, H., Timpl, R., Risteli, J., Dieringer, H., Voss, T. & Glanville, R. W. (1981) FEBS Lett. 125, 123- 128.
Kiihn, K. (1982) in Immunochemistry of the extracellular matrix (Furthmayr, H., ed.) vol. 1, pp. 1 -29, CRC Press, Boca Raton, FL.
Orkin, R. W., Gehron, P., McGoodwin, E. B., Martin, G. R., Valentine, T. & Swarm, R. (1977) J . Exp. Med. 145,204-220.
EMBO J . I , 805-810.
Chem. 257,9796-9803.
9810.
K. H. (1982) J . Bid. Chem. 257,5239-5245.
chem. 123, 505-512.
545 - 556.
12. Lehman, J. M., Speers, W. C., Swartzendruber, D. E. & Pierce,
13. Strickland, S., Smith, K. K. & Marotti, K. R. (1980) Cell 21,
14. Prehm, P., Dessau, W. & Timpl, R. (1982) Connect. Tissue Res.
15. Kurkinen, M., Barlow, D. P., Helfman, D. M., Williams, J. G. & Hogan, B. L. M. (1983) Nuc/eic Acids Res. 11,6166-6208.
16. Adams, S. L., Sobel, M. E., Howard, B. H., Olden, K., Yamada, K. M., de Crombrugghe, B. & Pastan, I. (1977) Proc. Nut1 Acad. Sci. USA 74,3399 - 3402.
17. Chirgwin, J. M., Przybyla, A. E., MacDonald, R. J. & Rutter, W. J. (1979) Biochemisrry 18, 5294-5299.
18 Land, H., Grez, M., Hauser, H., Lindenmaier, W. & Schutz, G. (1981) Nucleic Acids Res. 9, 2251 -2266.
19. Tsao, S. G. S., Brunk, C. F. & Pearlman, R. E. (1983) Anal.
G. B. (1974) J . Cell Physiol. 84, 13-28.
347 -355.
10,275-285.
Biochem. 131, 365-372. 20. Beancage, S. L. & Caruthers, M. H. (1981) Tetrahedron Lett. 220,
1859 - 1862. 21. Viera. J . &Messing, J. (1982) Gene 19, 259-268. 22. Birnboim, H. C. & Doly, J. (1979) Nucleic Acids Res. 7, 1513-
23. Maxam, A. & Gilbert, W. (1980) Methods Enzymol. 65,
24. Riither, U., Koenen, M., Otto, K. & Miiller-Hill, B. (1981) Nucleic
25. Kieny, M. P., Lathe, R. & Lecocq, J. P. (1983) Gene 26,91-99. 26. Sanger, F., Coulson, A. R., Barrell, B. G., Smith, A. J. H. & Roe,
B. A. (1980) J . Mol. Biol. 143, 161 -178. 27. Hu, N.-T. & Messing, J. (1982) Gene 17, 271 -277. 28. Weber, S., Engel, J., Wiedemann, H., Glanville, R. W. & Timpl;
R. (1984) Eur. J . Biochern. 139,401 -410. 29. Santos, C. I. S., Villa, L. L., Sonohara, S. & Brentani, R. R.
(1984) Nucleic Acids Res. 12, 2035-2046. 30. Myers, J. C., Dickson, L. A., de Wet, W. J., Bernard, M. P., Chu,
M.-L., di Liberto, M., Pepe, G., Sangiorgi, F. 0. & Ramirez, F. (1983) J . Biol. Chem. 258, 10128-10135.
31. Aho, S., Tate, V. & Boedtker, H. (1983) Nucleic Acids Res. 11,
32. Bernard, M. P., Chu, M.-L., Myers, J. C., Ramirez, F. & Eikenberry, E. F. (1983) Biochemistry 22, 5213-5223.
33. Timpl, R., Oberbaumer, I., von der Mark, H., Bode, W., Wick, G., Weber, S. & Engel, J. (1985) Anal. N. Y. Acad. Sci., in the press.
34. Barker, W. C., Hunt, L. T., Orcutt, B. C., George, D. G., Veh, L. S., Chen, H. R., Blomquist, M. C., Johnson, G. C. & Dayhoff, M. 0. (1983) in Atlas ofprotein sequence andstructure, protein sequence database, vol. 7, National Biomedical Re- search Foundation, Washington, DC.
35. Yamada, Y. , Kiihn, K. & Crombrugghe, B. (1983) Nucleic Acids Res. 11,2733-2744,
36. Boedtker, H., Fuller, F. & Tate, V. (1983) Int. Rev. Connect. Tzssue Rex 10, 1 - 62.
37. Monson, J. M. & McCarthy, B. J. (1981) DNA 1, 59-69. 38. Monson, J. M., Natzle, J., Friedman, J. & McCarthy, B. J . (1982)
39. Fuller, F. & Boedtker, H. (1981) Biochemistry 20, 996- 1006. 40. Sandell, L. J., Prentice, H. L., Kravis, D. & Upholt, W. B. (1984)
41. Fessler, L. I., Timpl, R. & Fessler, J. H. (1981) J . Biol. Chem. 256,
1522.
499 - 560
Acids Res. 9,4087-4097.
5443 - 5450.
Proc. Natl Acad. Sci. USA 79, 1761 - 1765.
J . Biol. Chem. 259,7826 - 7834.
2531 -2537.
I. Oberbaumer, U. Schwarz, T. Voss, B. Siebold, W. Glanville and K. Kiihn, Max-Planck-Institut fur Biochemie, D-8033 Martinsried, Federal Republic of Germany M. Laurent, Unite de Recherches Gtrontologiques (Unite 118 de I’ Institut National de la Sante et de la Recherche Medicale), 29 Rue Wilhelm, F-75016 Paris, France Y. Sakurai and Y. Yamada, Laboratory of Developmental Biology and Anomalies, National Institutes of Health, 9000 Rockville Pike, Bethesda, Maryland, USA 20205 G. Vogeli, Laboratory of Molecular and Developmental Biology, National Eye Institute, National Institutes of Health, 9000 Rockville Pike, Bethesda, Maryland, USA 20205