Embed Size (px)
Citation preview

© 2017, Amazon Web Services, Inc. or its Affiliates. All rights reserved.
Amazon Web Services Japan K.K.Yutaka Hoshino, Database Specialist SA
Amazon Aurora(MySQL-compatible edition)
Deep Dive

内容についての注意点
本資料では2017年6⽉1⽇時点のサービス内容および価格についてご説明しています。最新の情報はAWS公式ウェブサイト(http://aws.amazon.com)にてご確認ください。
• 資料作成には⼗分注意しておりますが、資料内の価格とAWS公式ウェブサイト記載の価格に相違があった場合、AWS公式ウェブサイトの価格を優先とさせていただきます。
• 価格は税抜表記となっています。⽇本居住者のお客様が東京リージョンを使⽤する場合、別途消費税をご請求させていただきます。
AWS does not offer binding price quotes. AWS pricing is publicly available and is subject to change in accordance with the AWS Customer Agreement available at http://aws.amazon.com/agreement/. Any pricing information included in this document is provided only as an estimate of usage charges for AWS services based on certain information that you have provided. Monthly charges will be based on your actual use of AWS services, and may vary from the estimates provided.

Amazon Auroraの特徴
ハイパフォーマンス
フルマネージド ⾼可⽤性・⾼耐久性セキュリティにも配慮
MySQL5.6互換スケーラブル

ライセンス料⾦は不要ロックインもない使った分だけ課⾦
vCPU Mem HourlyPrice
db.t2.small 1 2 $0.063db.t2.medium 2 4 $0.125db.r3.large 2 15.25 $0.35db.r3.xlarge 4 30.5 $0.70db.r3.2xlarge 8 61 $1.40db.r3.4xlarge 16 122 $2.80db.r3.8xlarge 32 244 $5.60 • ストレージ: $0.120/GB/月
• IO課金: $0.240/100万リクエスト• 東京リージョンの価格
Amazon Auroraの価格
*NEW*
*NEW*

アーキテクチャ

Auroraのストレージ
SSDを利⽤したシームレスにスケールするストレージ
• 10GBから64TBまでシームレスに⾃動でスケールアップ
• 実際に使った分だけ課⾦
標準で⾼可⽤性を実現• 3AZに6つのデータのコピーを作成
Log structured Storage
SQLTransactions
AZ 1 AZ 2 AZ 3
Caching
Amazon S3

ストレージノードクラスタ• Protection Group毎に6つのストレージノードを使⽤• 各ログレコードはLog Sequence Number(LSN)を持っており不⾜・重複
しているレコードを判別可能• 不⾜している場合はストレージノード間でgossip protocolを利⽤し補完を⾏う

ディスク障害検知と修復• 2つのコピーに障害が起こっても、読み書きに影響は無い• 3つのコピーに障害が発⽣しても読み込みは可能• ⾃動検知、修復
SQLTransaction
AZ 1 AZ 2 AZ 3
Caching
SQLTransactio
n
AZ 1 AZ 2 AZ 3
Caching
読み書き可能読み込み可能

IO traffic in Aurora (ストレージノード)
LOG RECORDS
Primary instance
INCOMING QUEUE
STORAGE NODE
S3 BACKUP
1
2
3
4
5
6
7
8UPDATE QUEUE
ACK
HOTLOG
DATABLOCKS
POINT IN TIMESNAPSHOT
GC
SCRUBCOALESCE
SORTGROUP
PEER-TO-PEER GOSSIPPeerstoragenodes
全てのステップは⾮同期ステップ1と 2だけがフォアグラウンドのレイテンシーに影響インプットキューはMySQLの1/46 (unamplified, per node)レイテンシーにセンシティブな操作に向くディスク領域をバッファーに使ってスパイクに対処
OBSERVATIONS
IO FLOW
① レコードを受信しインメモリのキューに追加② レコードを永続化してACK ③ レコードを整理してギャップを把握④ ピアと通信して⽳埋め⑤ ログレコードを新しいバージョンのデータブロックに
合体⑥ 定期的にログと新しいバージョンのブロックをS3に
転送⑦ 定期的に古いバージョンのガベージコレクションを実
施⑧ 定期的にブロックのCRCを検証

セキュリティデータの暗号化
• AES-256 (ハードウエア⽀援)• ディスクとAmazon S3に置かれている全ブロックを暗号化• AWS KMSを利⽤したキー管理
SSLを利⽤したデータ通信の保護
標準でAmazon VPCを使ったネットワークの分離
ノードへ直接アクセスは不可能
業界標準のセキュリティとデータ保護の認証をサポート
Storage
SQL
Transactions
Caching
Amazon S3
Application

フェイルオーバとリカバリ

フェイルオーバ と リプレース
リードレプリカが存在する場合は1分程でフェイルオーバ可能
• RDS for MySQLよりも⾼速にフェイルオーバ可能• リードレプリカが存在しない場合は10-15分程
Multi-AZ配置として別AZで起動可能• RDS for MySQLと違いリードアクセス可能

⾼速でより予測可能なフェイルオーバー時間
ApprunningFailure detection DNS propagation
Recovery Recovery
DBfailure
MYSQL
Apprunning
Failure detection DNS propagation
Recovery
DBfailure
AURORA WITH MARIADB DRIVER
1 5 - 2 0 s e c
3 - 2 0 s e c

0.00% 5.00%
10.00% 15.00% 20.00% 25.00% 30.00% 35.00%
1 3 5 7 9 11 13 15 17 19 21 23 25 27 29 31 33 35
0 - 5s – 30% of fail-overs
0.00%
10.00%
20.00%
30.00%
40.00%
50.00%
1 3 5 7 9 11 13 15 17 19 21 23 25 27 29 31 33 35
5 - 10s – 40% of fail-overs
0% 10% 20% 30% 40% 50% 60%
1 3 5 7 9 11 13 15 17 19 21 23 25 27 29 31 33 35
10 - 20s – 25% of fail-overs
0%
5%
10%
15%
20%
1 3 5 7 9 11 13 15 17 19 21 23 25 27 29 31 33 35
20 - 30s – 5% of fail-overs
Database fail-over time

Streaming backupとPITR
Amazon Auroraでは各セグメント毎にAmazon S3へ継続的に増分バックアップを取得している
• Backup retention periodでバックアップを残す期間を指定可能
Amazon Auroraが使⽤しているディスクの仕組みによりパフォーマンスへ影響を与えない
PITRで5分前からBackup Retention Periodまでの任意の位置に秒単位で復元可能

Streaming backupSegment snapshot Log records
Recovery point
Segment 1
Segment 2
Segment 3
Time
各セグメントの定期的なSnapshotは並列で⾏われ、redo logはストリームで継続バックアップのためにS3に送られる。パフォーマンスや可⽤性に対する影響は無し
リストアでは、適切なセグメントのSnapshotとログストリームをストレージノードに転送し、並列で⾮同期で適⽤していく

Writer / Readerノードの識別
innodb_read_onlyを参照• SHOW GLOBAL VARIABLES LIKE 'innodb_read_onlyʼ;• OFF: Writer• ON: Reader
アプリケーションやドライバでAuroraノードに対する負荷分散やフェイルオーバーロジックの実装に利⽤可能

SQLによるフェイルオーバのテストSQLによりノード・ディスク・ネットワーク障害をシミュレーション可能
• データベースノードのクラッシュをシミュレート:ALTER SYSTEM CRASH [{INSTANCE | DISPATCHER | NODE}]
• レプリケーション障害をシミュレート:ALTER SYSTEM SIMULATE percentage_of_failure PERCENT
READ REPLICA FAILURE [ TO ALL | TO "replica name" ]FOR INTERVAL quantity [ YEAR | QUARTER | MONTH | WEEK| DAY |
HOUR | MINUTE | SECOND ];
• 他にも– ディスク障害をシミュレート– ディスクコンジェスションをシミュレート

Amazon Aurora Driver

Aurora Driver
MariaDB Connector/J 1.2.0以降に含まれている• https://mariadb.com/kb/en/mariadb/mariadb-connector-j-120-release-
notes/• リリースノートには明確にAuroraの記述は無いがドキュメント中に記載
• https://mariadb.com/kb/en/mariadb/about-mariadb-connector-j/• https://mariadb.com/kb/en/mariadb/failover-and-high-availability-with-
mariadb-connector-j/#specifics-for-amazon-aurora• 2015.09 Amazon Linuxよりrpmを提供
現在の提供機能• Fast failover• Auto node discovery

Aurora Driver
https://mariadb.com/kb/en/mariadb/failover-and-high-availability-with-mariadb-connector-j/

パフォーマンスTips
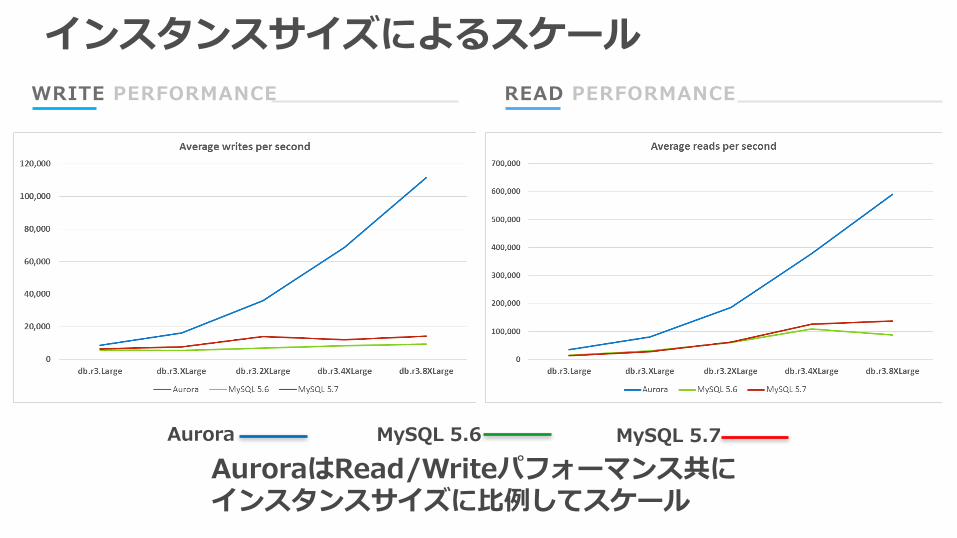
WRITE PERFORMANCE READ PERFORMANCE
インスタンスサイズによるスケール
AuroraはRead/Writeパフォーマンス共にインスタンスサイズに⽐例してスケール
Aurora MySQL 5.6 MySQL 5.7

チューニング指針
Amazon AuroraはMySQLと⽐較してインスタンスリソースを効率的に最⼤限利⽤する設計
• CPUやメモリの利⽤率が⾼めだが、パフォーマンスに影響が出ない限りは過度な⼼配は必要ない
Amazon Auroraは実際のワークロードで性能が発揮できるように開発・チューニングが⾏われている
• 監視項⽬はインスタンスリソースでは無く、実際のパフォーマンステストを元にクエリレイテンシやスループット・buffer poolのcache hitレートに注⽬

チューニング指針
まずはデフォルトのパラメータグループを使⽤• Amazon Auroraはデフォルトの設定でパフォーマンスを
発揮できるようにチューニング済み
適切なインスタンスタイプを選択することが⼤切• それでも性能が出ない場合にパラメータグループの変更
を検討

チューニングTips
1トランザクションで⼤量の更新や削除を⾏ったり、⼤量データのシーケンシャルリードを⾏う場合
• 1トランザクションで⼤量の更新・削除やシーケンシャルリードを⾏う場合Amazon Auroraのアーキテクチャに合わせてクエリを実⾏することで性能を向上させることが可能

チューニングTips
#1> SELECT * FROM Table;
#1> SELECT * FROM Table WHERE id BETWEEN 1 AND 10000;
#2> SELECT * FROM Table WHERE id BETWEEN 10001 AND 20000;
#3> SELECT * FROM Table WHERE id BETWEEN 20001 AND 30000;
#4> .........
• SELECT (Parallel Read Aheadで大幅性能改善)
• DELETE / UPDATE
#1> DELETE * FROM Table WHERE id >= 100000;
#1> DELETE FROM Table WHERE id BETWEEN 10000 AND 20000;
#2> DELETE FROM Table WHERE id BETWEEN 20001 AND 30000;
#3> DELETE FROM Table WHERE id BETWEEN 300001AND 40000;
#4> .........

新しいメトリクス画⾯Throughput
• Select• Commit• DML/DDL
Latency• Select• Commit• DML/DDL
Cache Hit Ratio• Buffer Cache• Result Set
DeadlocksLogin FailuresBlocked Transactions

メトリクススキーマ

メトリクススキーマINFORMATION_SCHEMA.REPLICA_HOST_STATUSmysql.ro_replica_status
mysql> SELECT SERVER_ID, REPLICA_LAG_IN_MILLISECONDS, SESSION_ID FROM INFORMATION_SCHEMA.REPLICA_HOST_STATUS;
+-----------------+-----------------------------------------------------+-----------------------------------------+| SERVER_ID | REPLICA_LAG_IN_MILLISECONDS | SESSION_ID |+-----------------+----------------------------------------------------+-------------------------------------------+| demo-db01 | 18.458999633789062 | 62c35a1c-2f61-11e5-96de-06be620fb7bd || demo-db02 | 0 | MASTER_SESSION_ID || demo-db03 | 19.39299964904785 | 6194b000-2f61-11e5-9bf6-12715c13435b |+-----------------+---------------------------------------+--------------------------------------------------------+

拡張モニタリング
User System Wait IRQ Idle
CPU Utilization
Rx per declared ethnTx per declared ethn
Network
Num processes Num interruptibleNum non-interruptible Num zombie
Processes
Process ID Process name VSS Res Mem % consumed CPU % used CPU time Parent ID
Process List
MemTotalMemFreeBuffers Cached SwapCachedActive Inactive SwapTotalSwapFreeDirty WritebackMapped Slab
MemoryTPS Blk_readBlk_wrtnread_kbread_IOsread_sizewrite_kbwrite_IOswrite_sizeavg_rw_sizeavg_queue_len
Device IO
Free capacity Used % Used
File System
これらのメトリクスを最短1秒間隔で取得可能
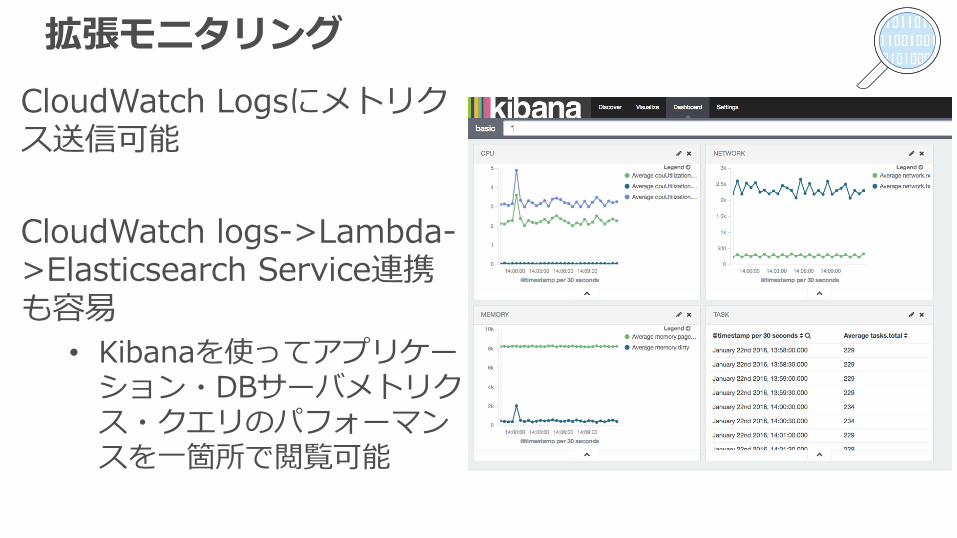
拡張モニタリングCloudWatch Logsにメトリクス送信可能
CloudWatch logs->Lambda->Elasticsearch Service連携も容易
• Kibanaを使ってアプリケーション・DBサーバメトリクス・クエリのパフォーマンスを⼀箇所で閲覧可能

Amazon Auroraへの移⾏

マイグレーション時の注意
Amazon AuroraはInnoDB / ROW_FORMAT=Dynamicのみサポート
• InnoDB以外のストレージエンジンやROW_FORMAT=COMPRESSは⾮対応
マイグレーション時に⾃動でからコンバートされるが、事前に⼿動で対応ストレージエンジンやROW FORMATへの変換を推薦
White paper: http://bit.ly/2qjQzBc

RDS for MySQLからマイグレーションマネージメントコンソールから数クリックでAmazon Auroraへ移⾏可能
• RDS for MySQLのスナップショットからAmazon Auroraへマイグレーション可能
• RDS for MySQLは5.6を使う必要がある

RDS MySQL DBインスタンスからAmazon Aurora Read Replica を作成
RDS MySQLインスタンスからAmazon Auroraにダウンタイムを最⼩限に移⾏する場合、SnapshotからAuroraクラスタを起動し、⼿動でレプリケーションを設定する必要があった
この機能を利⽤することによって、ワンクリックでRDS MySQLのSnapshotからAurora Read Replicaを起動し、レプリケーションの設定まで⾃動で⾏われる

RDS MySQL DBインスタンスからAmazon Aurora Read Replica を作成
RDS MySQL5.6(Master)
Aurora(Writer)
Aurora(Reader)
Application
Write
Read
RDS MySQLのRRを作る感覚でAuroraクラスタへレプリケーション環境を自動で作成

MySQLスナップショットバックアップからの移⾏
Percona Xtrabackupを利⽤して作成したバックアップデータを利⽤してオンプレミス環境やAmazon EC2上のMySQLからAmazon Auroraクラスへ移⾏可能
• mysqldumpと⽐較したテストで約20倍⾼速に移⾏可能
S3にアップロードしたバックアップデータを利⽤• アップロードにはManagement ConsoleやCLI tools、データサイズが⼤
きい場合はAWS Import/Export Snowballを利⽤してS3へ転送する

改善を⾏って来た機能

Reader Endpointの追加Amazon Aurora cluster内のReaderに単⼀のエンドポイントを提供
• ReaderがFailoverした場合は、再接続を⾏うことで新しいReaderに接続が可能• Round Robinで接続
メリット• Load Balancing – クラスタエンドポイントに接続することでDBクラスタ内のリード
レプリカ間でコネクションのロードバランシングが可能
• Higher Availability – 複数のAuroraレプリカをAvailability Zone毎に配置し、リードエンドポイント経由で接続することが可能
• 今までHAproxyなどで分散されていた⽅は置き換えることでシンプルに負荷分散
注意点• DNSベースなのでアプリケーションやドライバ側でIPアドレスのキャッシュ周りの
設定の確認やfailoverのテストを推薦• Readerが1インスタンスもいなくなった場合はWriterへfailbackを⾏う

Reader Endpoint
• クラスタ内のReaderにラウンドロビンで接続
• 常にReaderに接続されるが、Readerが1インスタンスもいなくなった場合はWriterにfailback
• Readerの追加・削除は⾃動で⾏われる
Availability Zone A Availability Zone B
VPC subnet VPC subnet
VPC subnet VPC subnetAurora Reader Aurora Reader
リーダエンドポイント
Read
Aurora Writer

IAM Authentication Integration
Amazon Auroraへログインするための認証にIAMが利⽤可能に(1.10以降)
• IAMのリソース制限を利⽤可能
• パスワードとしてSignature Version 4 を利⽤ (15分間有効の⼀時token)
• SSL接続が必須
• データベースアクセスに必要な認証情報をEC2インスタンスなどに配置しなくても良い
• AWS SDKやAWS CLI Tools対応
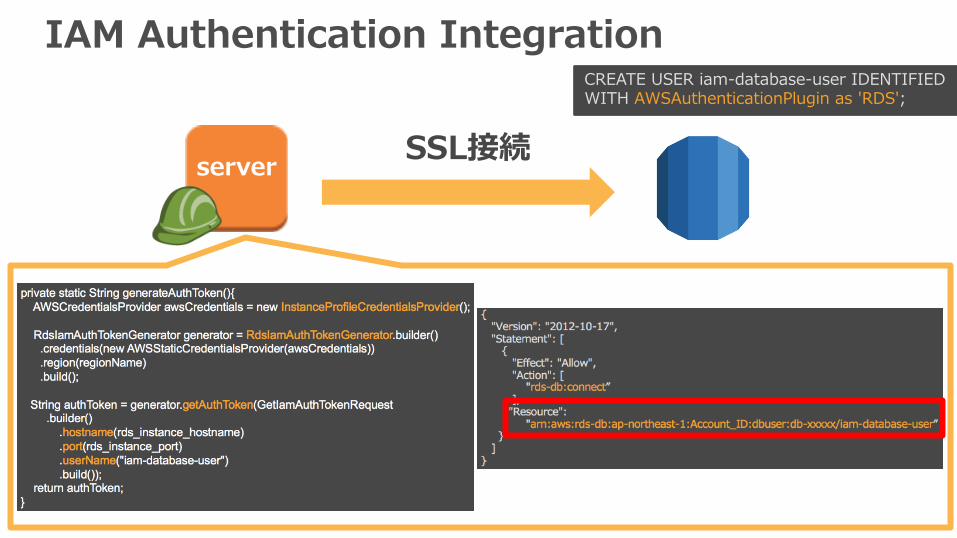
IAM Authentication Integration
SSL接続
CREATE USER iam-database-user IDENTIFIED WITH AWSAuthenticationPlugin as 'RDS';
server

Lambda Function Integration
Amazon Aurora内からAWS Lambdaを呼び出せる• ストアードプロシジャーとして実⾏ (mysql.lambda_async)• ⾮同期でLambdaを実⾏する• IAM Roleで事前にAuroraへ権限を付与しておく
DELIMITER ;; CREATE PROCEDURE SNS_Publish_Message (IN subject VARCHAR(255), IN message TEXT) LANGUAGE SQL BEGIN CALL mysql.lambda_async(’Lambda ARN', CONCAT('{ "subject" : "', subject, '", "message" : "', message, '" }') ); END ;; DELIMITER ;

Load Data From S3
S3バケットに保存されたデータを直接Auroraにインポート可能• テキスト形式(LOAD DATA FROM S3)・XML形式(LOAD XML FROM S3)• LOAD DATA INFILEとほぼ同様のオプションをサポート (圧縮形式のデータ
は現在未サポート)• Manifestによる⼀括ロードにも対応 (Version 1.11以降)
<row column1="value1" column2="value2" /><row column1="value1" column2="value2" />
<row> <column1>value1</column1> <column2>value2</column2>
</row>
<row> <field name="column1">value1</field> <field name="column2">value2</field>
</row>

spatial index
空間インデックスサポート• Amazon Auroraは今までもGEOMETRY型や、
ST_Contains, ST_CrossesやST_Distanceといったspatial queryが利⽤可能
• ⼤きなデータセットに対してスケールするには不⼗分な点や制限があった
• Amazon Auroraではdimensionally ordered space-filling curveを利⽤しスケールし、⾼速かつ正確に情報を取得できる改善を⾏った
• MySQL5.7と⽐較して最⼤2倍のパフォーマンス

Spatial Index BenchmarksSysbench – points and polygons
• r3.8xlarge using Sysbench on <1GB dataset• Write Only: 4000 clients, Select Only: 2000
clients, ST_EQUALS
0
20000
40000
60000
80000
100000
120000
140000
Select-only(reads/sec) Write-only(writes/sec)
Aurora
MySQL5.7
R-Tree MySQL 5.7
Z-index / Aurora(dimensionally ordered space filling curve)

Advanced Auditing
MariaDB server_audit plugin Aurora native audit support
We can sustain over 500K events/sec
Create event string
DDL
DML
Query
DCL
Connect
DDL
DML
Query
DCL
Connect
Write to File
Create event string
Create event string
Create event string
Create event string
Create event string
Latch-free queue
Write to File
Write to File
Write to File
MySQL 5.7 Aurora
Audit Off 95K 615K 6.47x
Audit On 33K 525K 15.9x
Sysbench Select-only Workload on 8xlarge Instance

Zero downtime patch (ZDP)
コネクションを切断すること無くオンラインでパッチを適⽤• 5秒程度スループットの低下が起こるが、アプリケーションとの接続を維持
したままパッチを適⽤可能に (1.10以降)
• ベストエフォート• 既に開かれているSSLコネクション、アクティブなロック、トランザクション
の完了やテンポラリテーブルの削除を待機し、パッチ適⽤可能なウインドウが出来た場合、ゼロダウンタイムパッチとして適⽤
• ゼロダウンタイムパッチで適⽤出来るウインドウがなかった場合、通常のパッチ適⽤プロセスを実⾏
• 以下の条件では通常通りのパッチ適⽤プロセスを実施• バイナリログを有効にしている• SSLを利⽤した接続を⾏っており、ZDPのリトライ回数内に接続が終了しない

Zero downtime patch (ZDP)
Net
wor
king
stat
e
Appl
icat
ion
stat
e
Storage ServiceApp state
Net state
App state
Net stat
e
Befo
re Z
DP
New DB
Engine
Old DB Engine
New DB
Engine
Old DB Engine
With
ZDP
セッションはパッチ適⽤時に切断される
パッチ適⽤中でもセッションは維持される
Storage Service

性能・安定⾯向上に対する新機能

Cached read performanceCatalog concurrency: データ・ディクショナリの同期とキャッシュ破棄の効率化
NUMA aware scheduler: NUMA を考慮したスケジューラへ変更すること、複数CPUが搭載されているインスタンスで性能向上
Read views: read viewを作成する際にラッチフリーなread viewを作成するアルゴリズムに変更
0
100
200
300
400
500
600
700
MySQL 5.6 MySQL 5.7 Aurora 2015 Aurora 2016
1,000 read requests/sec* R3.8xlarge instance, <1GB dataset Sysbench25% Throughput gain

Smart scheduler: IOヘビー・CPUヘビーなワークロードそれぞれに動的に処理スレッドを割り当てるスケジューラに変更
Smart selector: 最も良いパフォーマンスのストレージノードにあるデータを選択することでリードレイテンシーを軽減
Logical read ahead (LRA): btreeの順序に応じて事前にpageを読み込んで置くことで、IO waitを軽減
0
20
40
60
80
100
120
MySQL 5.6 MySQL 5.7 Aurora 2015 Aurora 2016
1,000 requests/sec* R3.8xlarge instance, 1TB dataset Sysbench
10% Throughput gain
Non-cached read performance

§ プライマリーキーでソートされているデータのバッチインサートの速度を改善。インデックス⾛査を⾏う際のカーソル位置をキャッシュ
§ データパターンに応じて動的に機能を有効・無効化
§ ツリーを下⽅向に⾛査する際のラッチロックの競合を軽減
§ 双⽅向で全てのINSERTワークロードで有効• LOAD INFILE, INSERT INTO SELECT,
INSERT INTO REPLACE, Multi-value inserts.
Insert performanceIndex
R4 R5R2 R3R0 R1 R6 R7 R8
Index
Root
Index
R4 R5R2 R3R0 R1 R6 R7 R8
Index
Root
MySQL:全てのINSERTがrootからB-treeをトラバースする
Aurora: indexトラバースを抑制

Faster index build§ MySQL 5.6 はLinuxの先読みを活⽤して
いるため、btreeに連続したブロックアドレスが必要。そのためエントリーをトップダウンで新しいbtreeに挿⼊する際に、分割と多くオンロギングが発⽣
§ Auroraはtree内のポジションを元にブロックをスキャンしてプリフェッチし、リーフブロックを作製してからブランチを作製していく• 分割が発⽣しない
• 各ページは1度のみ参照される
• 1ページに1ログレコード
2-4X better thanMySQL 5.6 or MySQL 5.7
0
2
4
6
8
10
12
r3.large on 10GB dataset
r3.8xlarge on 10GB dataset
r3.8xlarge on 100GB dataset
Hou
rsRDS MySQL 5.6 RDS MySQL 5.7 Aurora 2016

Lab mode
今後提供予定の機能を試すことが可能• DBパラメータグループ aurora_lab_mode 変数で設定可能• 開発中の機能なので本番適⽤ではなく検証⽬的でお使い下さい
• GAクオリティですが、全てのワークロードで性能が発揮出来るか検証を⾏っている段階です
• フィードバックをお待ちしています!
現在ご提供中• Lock compression
• ロックマネージャーが利⽤するメモリを最⼤66%削減• OOMを起こさず、更に多くの⾏ロックを同時に取得することが可能に
• Fast DDL• nullableカラムをテーブルの最後に追加する場合にデータ件数によらず
⾼速に変更が⾏なえます

Fast DDL: Aurora vs. MySQL
§ フルテーブルコピー: 全てのインデックスを再構築 - 数時間から数⽇かかることも
§ DMLクエリ実⾏のために⼀時領域が必要
§ DDLクエリがDMLクエリスループットに影響
§ DMLクエリ実⾏中にテーブル・ロックが発⽣
Index
LeafLeafLeaf Leaf
Index
Root table name operation column-name time-stamp
Table 1Table 2Table 3
add-coladd-coladd-col
column-abccolumn-qprcolumn-xyz
t1t2t3
§ メタデータテーブルにエントリーを追加し、スキーマバージョニングを利⽤
§ 変更を適⽤するために最新のスキーマへブロックをアップグレードする際はmodify-on-write
§ 現在はテーブルの最後にNullableなカラムを追加する場合に対応
MySQL Amazon Aurora
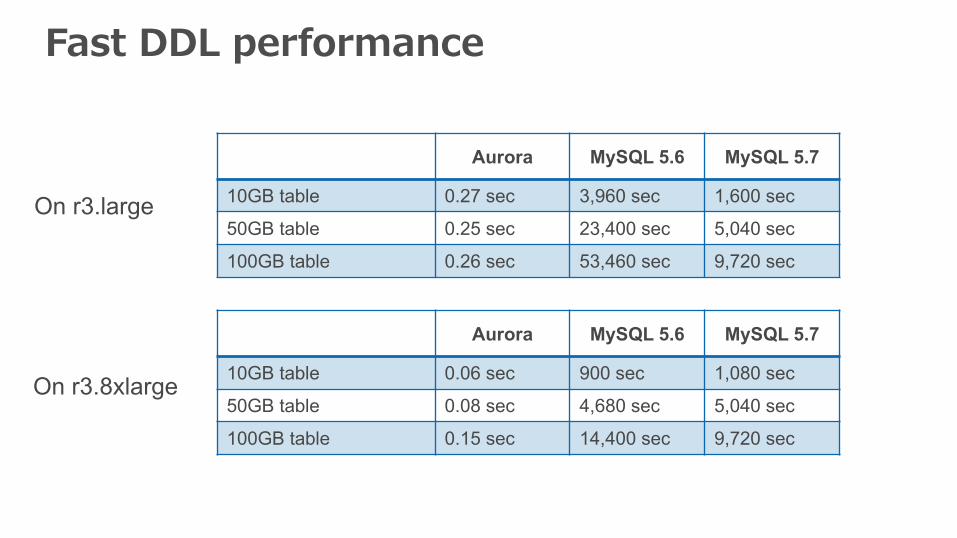
Fast DDL performance
On r3.large
On r3.8xlarge
Aurora MySQL 5.6 MySQL 5.7
10GB table 0.27 sec 3,960 sec 1,600 sec
50GB table 0.25 sec 23,400 sec 5,040 sec
100GB table 0.26 sec 53,460 sec 9,720 sec
Aurora MySQL 5.6 MySQL 5.7
10GB table 0.06 sec 900 sec 1,080 sec
50GB table 0.08 sec 4,680 sec 5,040 sec
100GB table 0.15 sec 14,400 sec 9,720 sec

さらなる改善に向けて

Database backtrack

DBの⼀貫した状態を提供するためにログストリーム中のログを、LSNツリー内のブランチを元に可視・不可視にする§ 最初のt2からt1へのrewindは、紫⾊のログを不可視にする§ 次のt4からt3へDBをrewindする場合、⾚と紫のログを不可視にする
How does it work?
t0 t1 t2
t0 t1
t2
t3 t4
t3
t4
Rewind to t1
Rewind to t3
Invisible Invisible

Database backtrack vs Offline Point in Time Restore (PiTR)Database backtrack Offline PiTR
Database backtrackは現在のデータベースの状態を変更
PITRは現在のDBのバックアップから所望の時点の新しいDBを作成
数テラバイトのテータベースでも数秒で利⽤可能になる
数テラバイトのデータベースをリストアするのに数時間かかる
追加のストレージの料⾦は発⽣しない リストアされた、それぞれのDB毎にストレージ料⾦がかかる
複数回のPITRのイテレーションの実施も現実的
複数回のオフラインPITRは時間を消費する
購⼊したrewind ストレージを元にしたrewind period内の範囲で実⾏可能
オフラインPITRはスナップショットか設定したバックアップウインドウ内で実⾏可能
Cross-region online PiTR は未サポート AuroraはCross-region PITRをサポート

Database cloning

Database cloningストレージコストを増やすことなくデータベースのコピーを作成
• データをコピーするわけではないため、クローンの作成はほぼ即座に完了
• データのコピーはオリジナルボリュームとコピー先のボリュームのデータが異なる場合の書き込み時のみ発⽣
ユースケース• プロダクションデータを使⽤したテスト• データベースの再構成• プロダクションシステムに影響を及ばさずに
分析⽬的で特定の時点でのスナップショットを保存
Production database
Clone Clone
CloneDev/test
applications
Benchmarks
Production applications
Production applications

まとめ

Amazon Aurora
クラウド時代にAmazonが再設計したRDBMS• MySQL5.6と互換があり既存の資産を活かしやすい
⾼いクエリ実⾏並列度・データサイズが⼤きい環境で性能を発揮• Amazon Auroraはコネクション数やテーブル数が多い環境で優位
⾼可⽤性・実環境での性能向上を実現するための多くのチャレンジを継続して⾏っている

Thank you!









![[AWS Black Belt Online Seminar] Amazon Aurora …...MySQL read scaling • レプリケーションにはbinlog / relay logが必要 • レプリケーションはマスターへ負荷がかかる](https://img.dokumen.tips/doc/110x75/5e3cbe8224e691205a51b521/aws-black-belt-online-seminar-amazon-aurora-mysql-read-scaling-a-ffffffbinlog.jpg)



















