Embed Size (px)
Citation preview

Alva Erwin Department ofComputing
Raj P. Gopalan, and N.R. AchuthanDepartment of Mathematics and Statistics
Curtin University of Technology Kent St. Bentley Western Australia PAKDD08
Efficient Mining of High Utility Itemsets from Large Datasets
1

OutlineIntroduction
Preliminaries
Method – Compressed Transaction Utility-
Prol
Experiments
Conclusions
2

IntroductionThe goal of frequent itemset mining is to find
items that co-occur in a transaction database above a user given frequency threshold, without considering the quantity or weight such as profit of the items.
Quantity and weight are significant for addressing real world decision problems that require maximizing the utility in an organization.
TwoPhase based on Apriori is suitable for sparse data sets with short patterns, CTU-Mine based on the pattern growth is suitable for dense data.
3
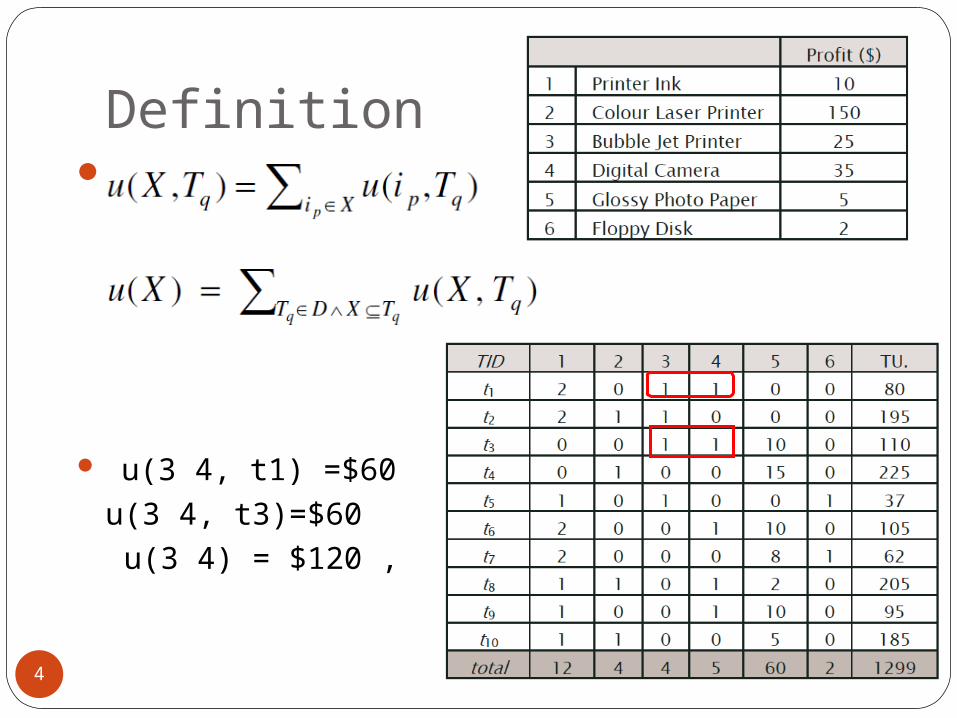
Definition
u(3 4, t1) =$60u(3 4, t3)=$60 u(3 4) = $120 ,
4

DefinitionTransaction Utility :
Transaction weighted Utility:
tu(1) = 80twu(3 4)=$190
TqXDTq
q )tu(T twu(X)
5

Compressed Transaction Utility-Prol
99<min_Utility(129.9)
GlobalItem index
1 2 3 4 5 -
Original item id
5 1 2 4 3 6
Profit 5 10
150
35
25
2
Quantity 60
12
4 5 4 2
TWU 987
964
810
595
422
99
6
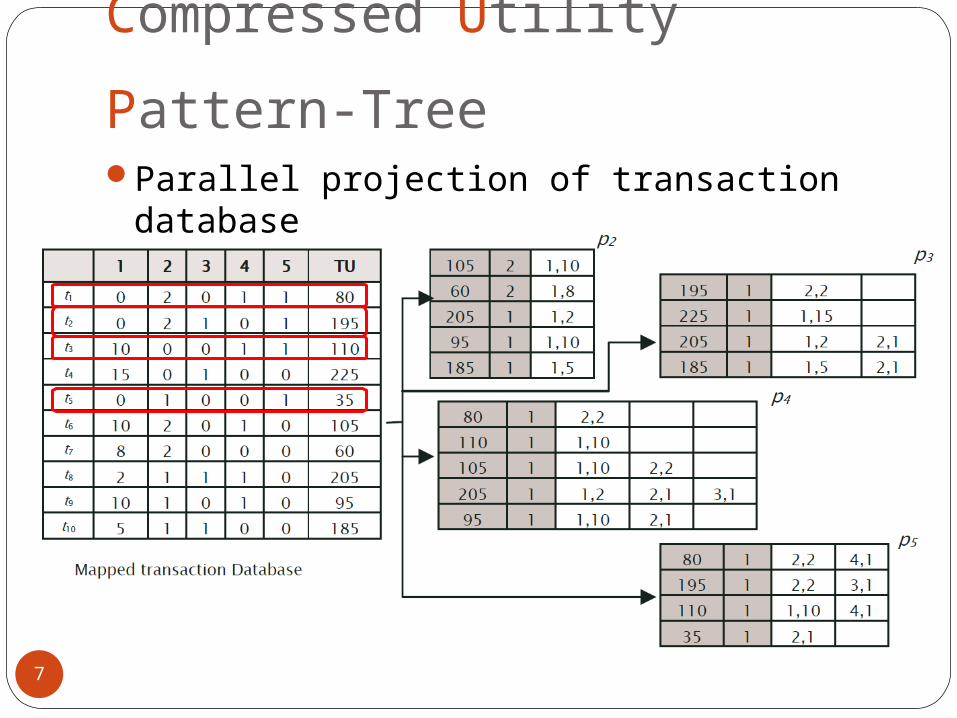
Compressed Utility Pattern-
TreeParallel projection of transaction database
7
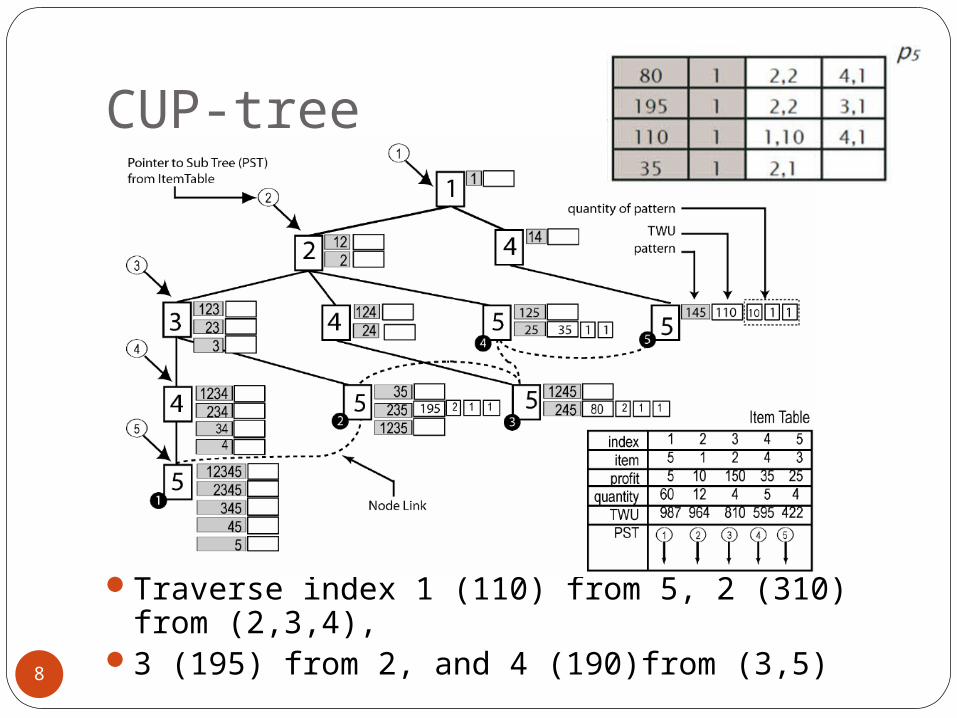
CUP-tree
Traverse index 1 (110) from 5, 2 (310) from (2,3,4),
3 (195) from 2, and 4 (190)from (3,5)8

ProCUP-treeindex 1 (110) from 5, cause
110<min_Utility(129.9)2 (310) from (2,3,4),3 (195) from 2, and 4
(190)from (3,5)
9

ProCUP-tree
oriUtility*itemQuantity + proUtility*proQuantity = Utility
35*2+25*2=120, 150*1+25*1=175, 10*5+25*3=125
High_Utility_Itemset = (3,2) (3,2,1)
GlobalItem index
1 2 3 4 5
Original item id
5 1 2 4 3
ProItem index
-- 1 2 3 --
Profit 5 10 150
35 25
Quantity 60 12 4 5 4
TWU 987
964
810
595
422
10
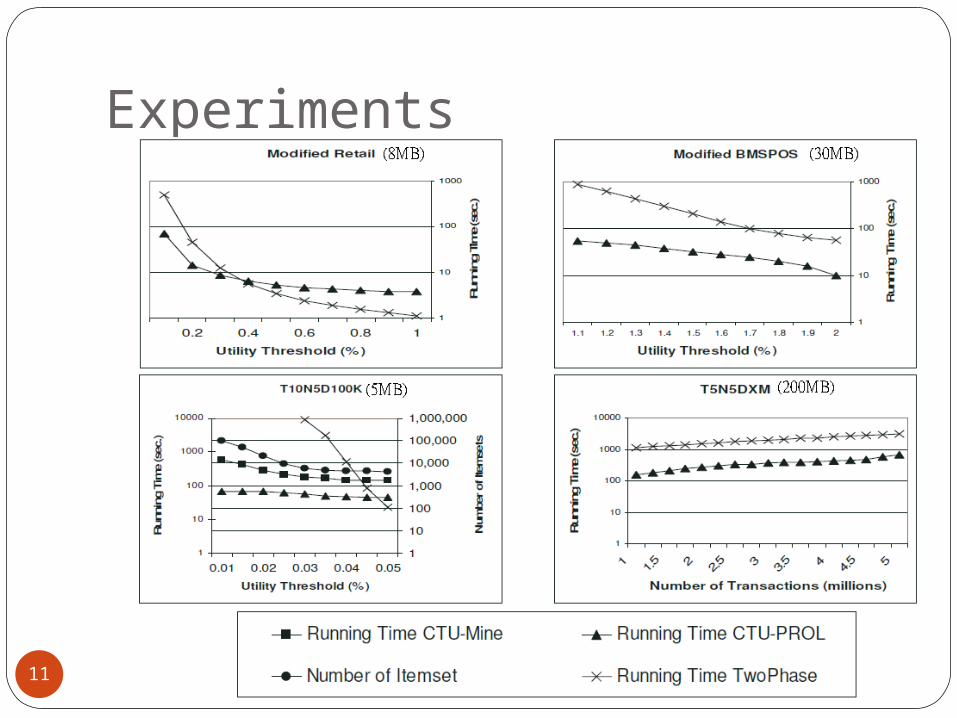
Experiments
11

ConclusionCTU-Pro algorithm to mine the complete set of
high utility itemsets from both sparse and relatively dense datasets with short or longer high utility patterns.
The algorithm adapts to large data by constructing parallel subdivisions on disk that can be mined independently.
12





























